1. Introduction
sEMG signals constitute bioelectric signals that record sequential muscle contraction processes within skeletal muscles, encompassing crucial information regarding muscle contraction modes and intensities; they can serve as a straightforward, reliable information source for the purpose of gesture recognition. In recent years, sEMG signals have found widespread applications in diverse fields, notably in human–computer interaction [
1,
2] and prosthetic limb control [
3,
4,
5]. Gesture recognition based on sEMG signals presents itself as a multi-classification problem within the domain of pattern recognition; currently, two primary methodologies are employed to address this challenge: traditional machine-learning methods and deep-learning methods. Traditional machine-learning approaches typically involve the extraction of features from sEMG signals in the time domain, frequency domain, or time–frequency domain. Following dimensionality reduction in these features [
6,
7], conventional classification methods, such as support vector machines (SVMs) [
8,
9,
10,
11], random forest (RF) [
12,
13], linear discriminant analysis (LDA) [
14,
15,
16], and others, are subsequently applied for effective gesture recognition.
Deep-learning methods have a strong ability to learn features from data and images; they have been confirmed to perform well in pattern recognition, so in recent years, various deep-learning structures and methods have been gradually applied for gesture recognition based on sEMG signals. For instance, in Ref. [
17], a convolutional neural network (CNN) was employed for electromyography gesture recognition, yielding superior accuracy compared to the traditional SVM. Atzori et al. [
18] utilized the LeNet model for recognition, achieving a recognition accuracy equivalent to traditional classification methods in 53 gesture recognition tasks. Geng et al. [
19] introduced an eight-layer CNN for gesture recognition. Soroushmojdehi et al. [
20] proposed a topic transfer learning method for gesture recognition on the NinaPro DB2 dataset, elevating the recognition accuracy from 81.43% to 82.87%. Zhai et al. [
21] utilized a CNN for gesture recognition on the NinaPro DB2 dataset, achieving a correct recognition rate of 78.7%. Cheng et al. [
22] proposed a deep CNN model for gesture recognition, with the highest recognition accuracy reaching 82.54% on the NinaPro DB1 dataset. Wei et al. [
23] employed a multi-stream CNN fusion network for gesture recognition, achieving a recognition accuracy of 85%.
Attention mechanisms in deep learning have proven instrumental in enhancing system focus on key information within signals, thereby improving classification accuracy and decoding. They have been used in gesture recognition problems based on sEMG signals. For instance, Hao et al. [
24] integrated attention mechanism modules into a neural network’s input layer for electromyography gesture recognition based on the CapgMyo and CSLHDEMG datasets, resulting in accuracy improvements of 4.44% and 2.71%, respectively. Wang et al. [
25] enhanced the LSTM-CNN network by introducing the attention mechanism CBAM, leading to a notable 5.3% increase in recognition accuracy. Fan et al. [
26] proposed the CSAC-Net network model, leveraging attention mechanisms to focus on crucial information in the channel space, achieving a gesture recognition accuracy of 82.50%. Rahimian et al. [
27] employed the attention mechanism and temporal convolution in the TC-HGR architecture, achieving a gesture recognition accuracy of 81.65%. Hu et al. [
28] proposed a hybrid CNN-RNN network structure based on the attention mechanism, achieving an average gesture recognition accuracy of 84.80% based on the NinaPro DB1 dataset.
Additionally, multi-scale modules in deep learning use convolution kernels and pooling operations of various sizes concurrently to facilitate feature extraction across different scales. This multi-scale design allows for the capture of information from diverse-sized areas in the image, thereby enhancing the model’s perceptual capabilities. This approach has found application in electromyography gesture recognition as well. For example, Han et al. [
29] introduced a novel CNN incorporating multi-scale kernels and feature fusion (MKFF-CNN), and it was applied to gesture recognition based on sEMG signals, resulting in a significant 6.54% increase in recognition accuracy compared to a single-scale convolutional subnetwork. Shen et al. [
30] proposed an sEMG signal gesture classification model based on a multi-scale module, achieving a recognition accuracy of 79.43% on NinaPro DB5. Jiang et al. [
31] introduced an RIE model based on inception multi-scale fusion convolution and the ECA mechanism, which achieved an average accuracy of 88.27% on NinaPro DB1, surpassing the traditional CNN by 7.89%.
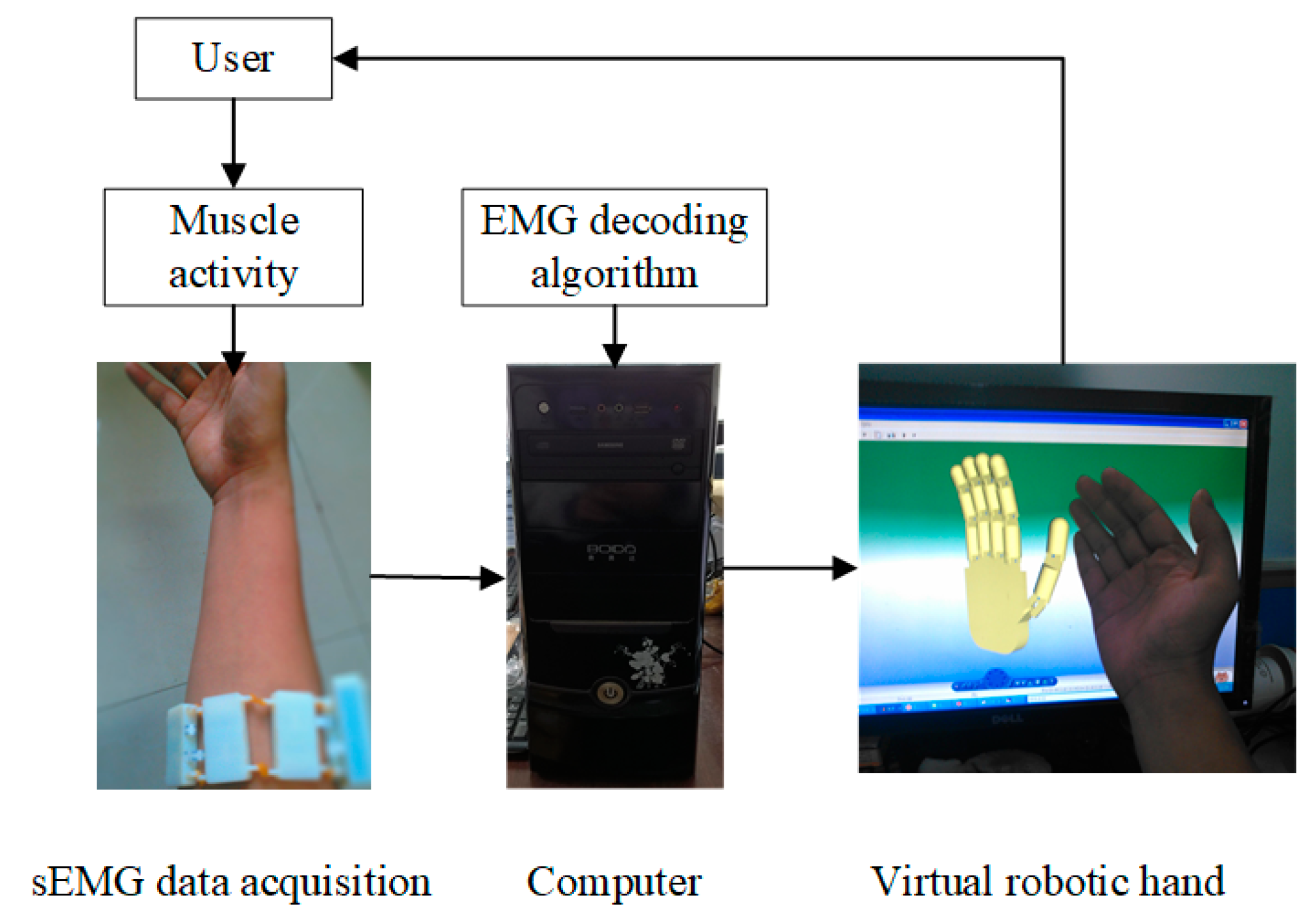
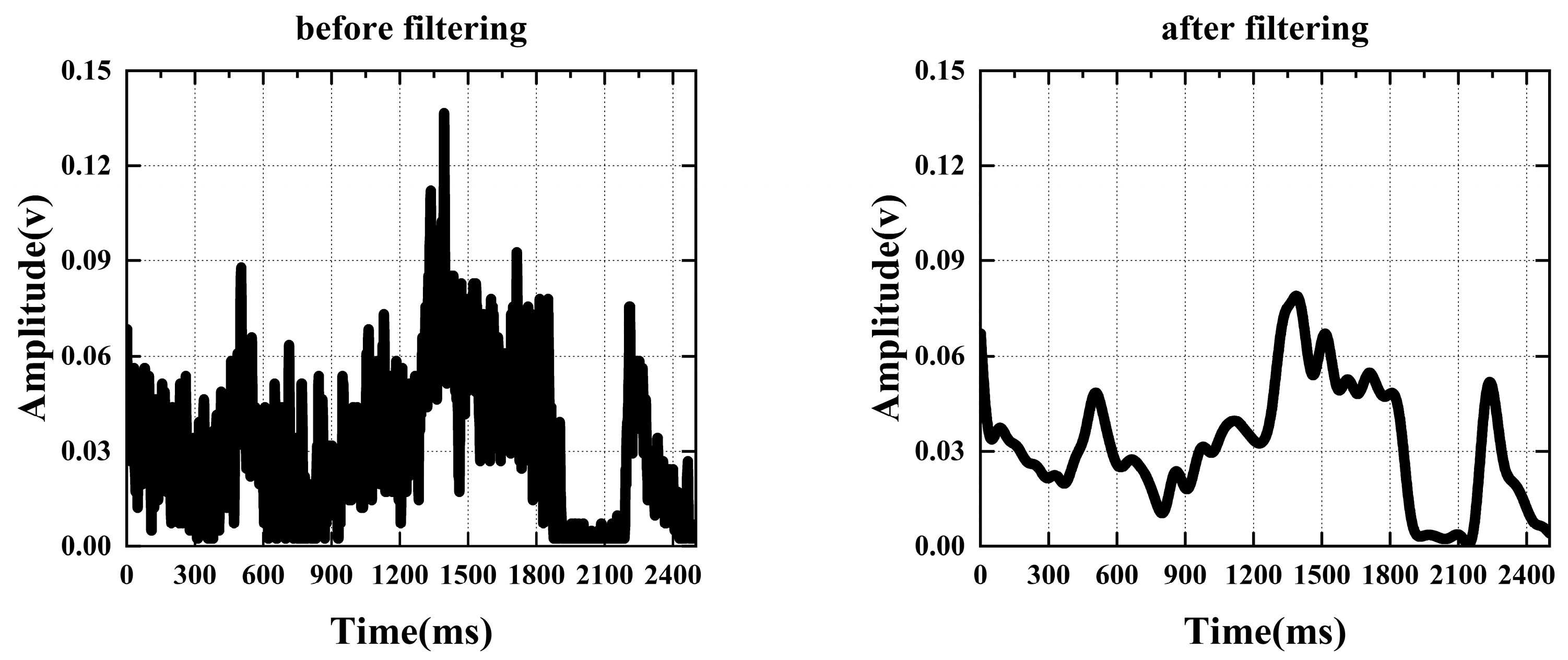
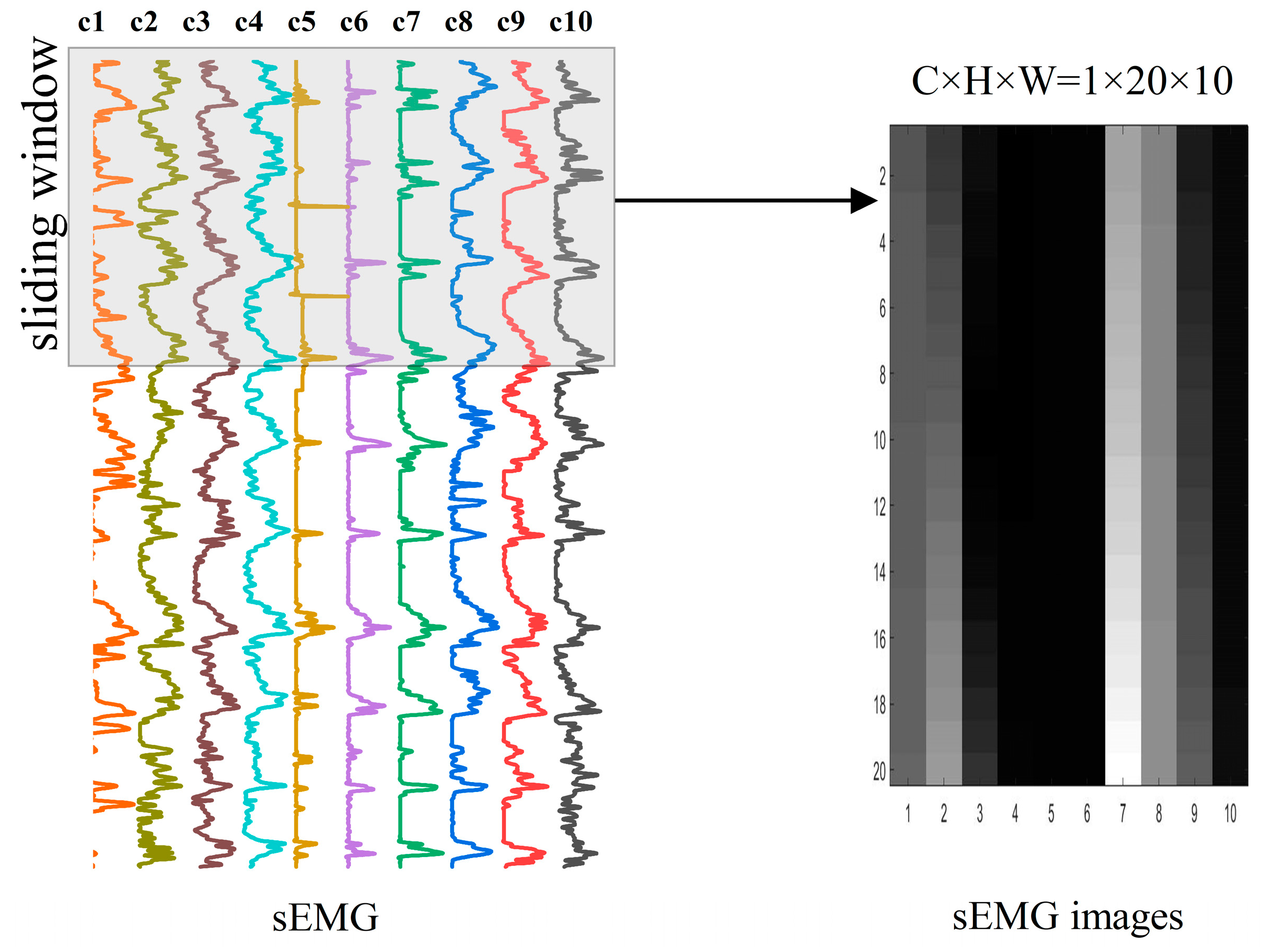
There is multi-dimensional information in sEMG signals, such as the time domain, frequency domain, or time–frequency domain, so deep-learning methods for gesture recognition based on sEMG signals include two predominant approaches. The first involves feature extraction from the original sEMG signals, the subsequent conversion of features into maps, and finally the inputting of these maps into the deep-learning model. In this approach, manual feature extraction is required. The second involves the direct conversion of the original sEMG signals into an electromyography image, enabling the deep-learning model to autonomously learn sophisticated features in the gesture recognition process. This approach can avoid the step of manually extracting features and simplify the recognition process.
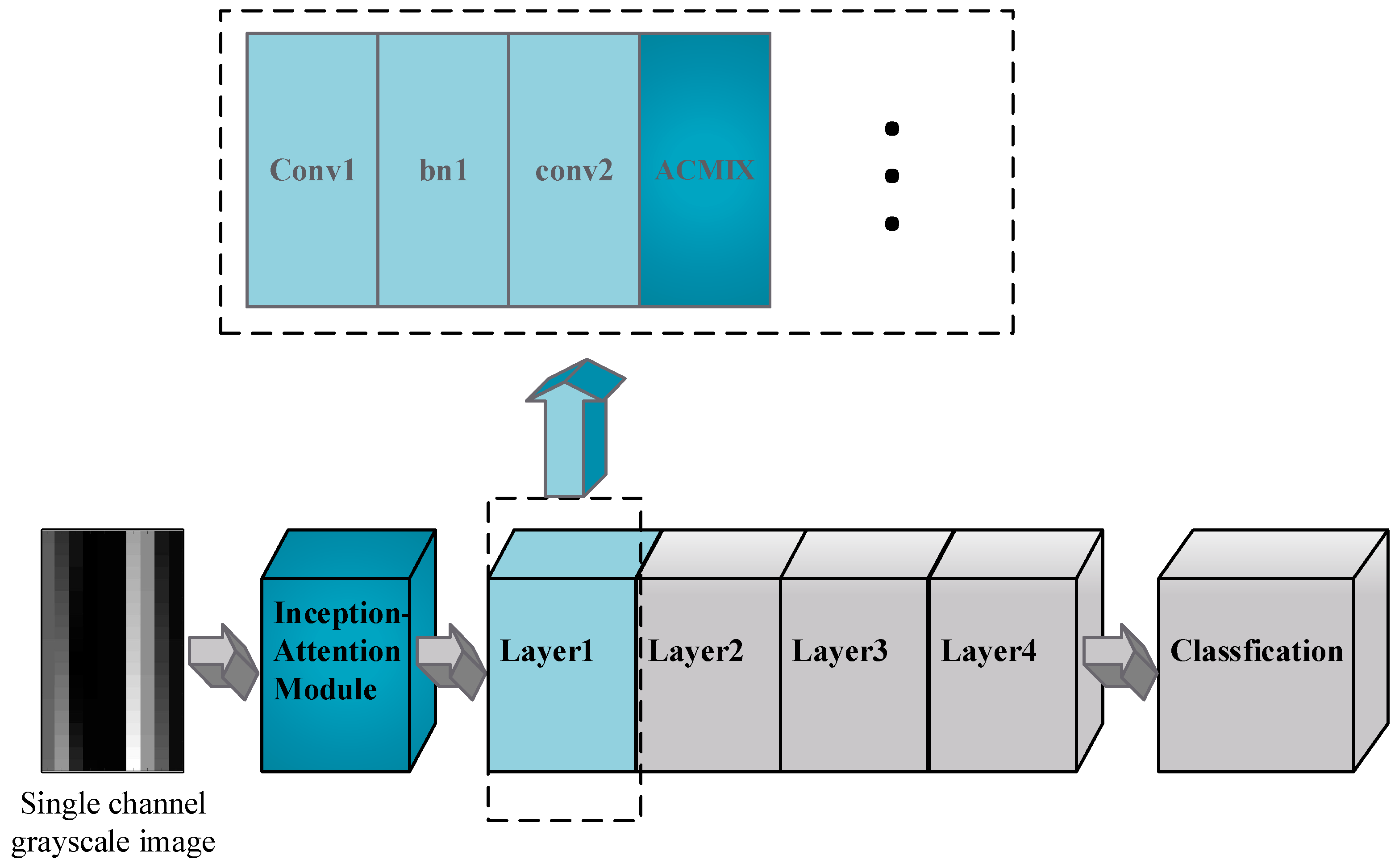
Hence, this study integrates both the attention mechanism and a multi-scale structure into the ResNet50 model in order to enhance the model’s proficiency in capturing various receptive field image features and critical area information within sEMG signals. Simultaneously, features in sEMG signals can be autonomously learned, with no manually feature extracting required.
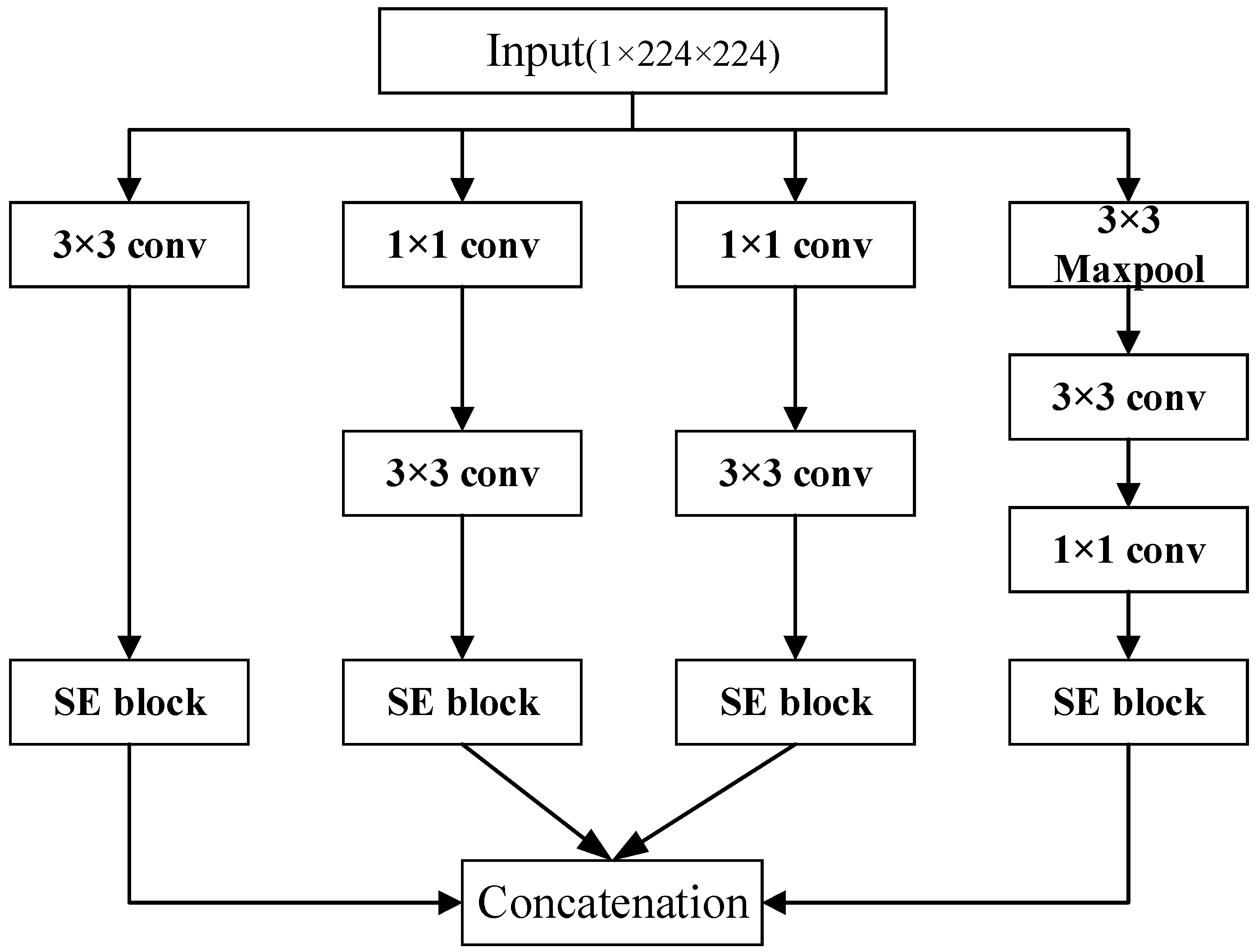
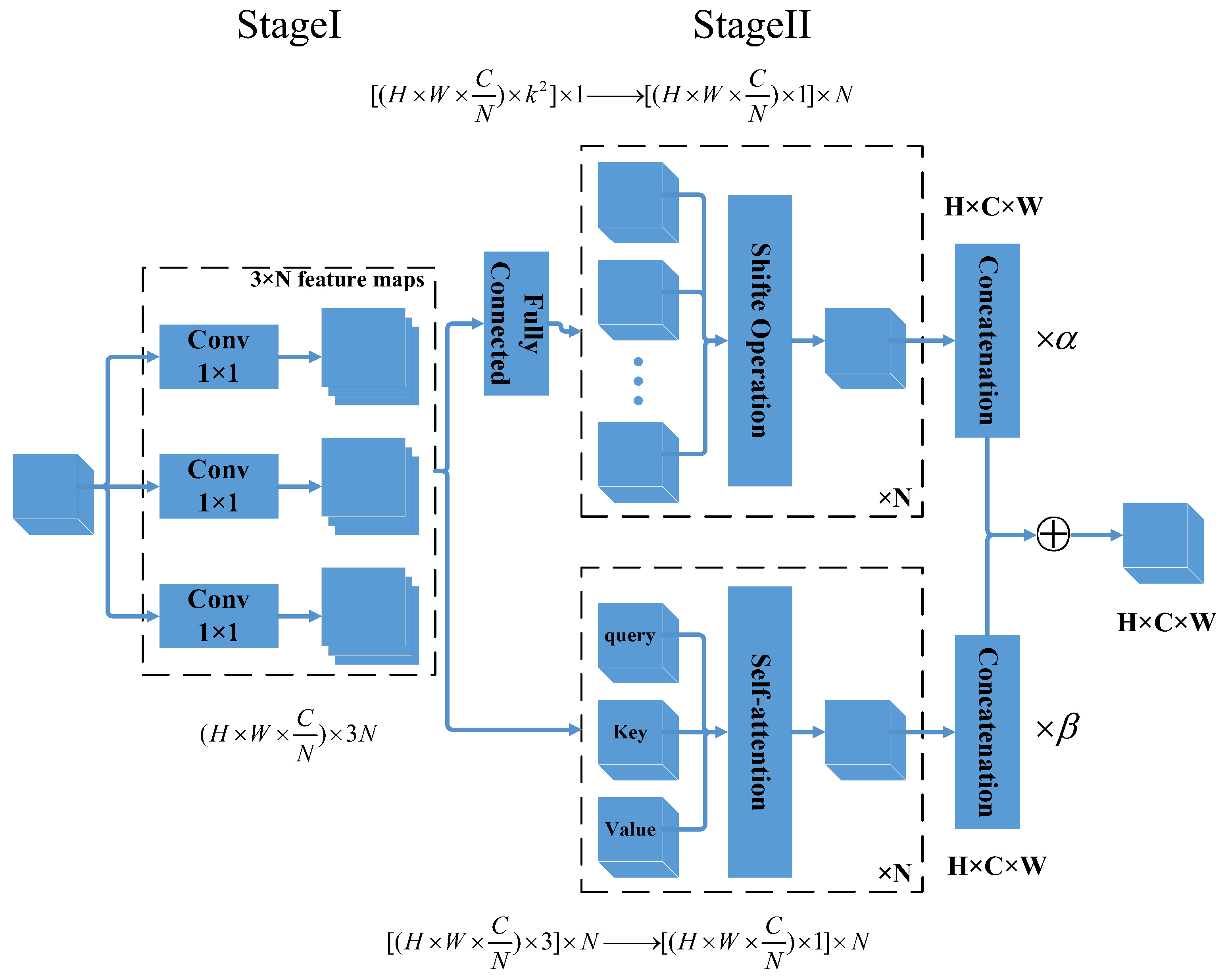
This study integrates the attention mechanism with a multi-scale structure into a deep-learning model, proposing the InRes-ACNet model based on ResNet50. Initially, to tackle challenges associated with the potential loss of channel information during feature extraction from sEMG signals, we introduce a multi-scale inception–attention module. This module aims to enhance the model’s ability to extract features related to channel information. Furthermore, we incorporate the ACmix module into the ResNet50 model, providing a synergistic blend of the self-attention mechanism and convolution operations. This integration seeks to enhance the model’s feature extraction capabilities. The simultaneous use of both the inception–attention and ACmix modules is intended to improve the model’s proficiency in gesture recognition based on sEMG images. Additionally, the model’s inputs are the original grayscale images of the sEMG signal. This approach eliminates the need for manual feature extraction during sEMG signal preprocessing, thereby streamlining the gesture recognition process.
The rest of this paper is organized as follows:
Section 2 describes the preprocessing of original sEMG signals and the generation of sEMG grayscale image datasets.
Section 3 introduces the proposed InRes-ACNet model.
Section 4 verifies the effectiveness of the InRes-ACNet model through experiments and conducts grasping mode prediction for the electromyography manipulator.
Section 5 summarizes the results of this paper’s work.
4. Model Training and Experimental Results
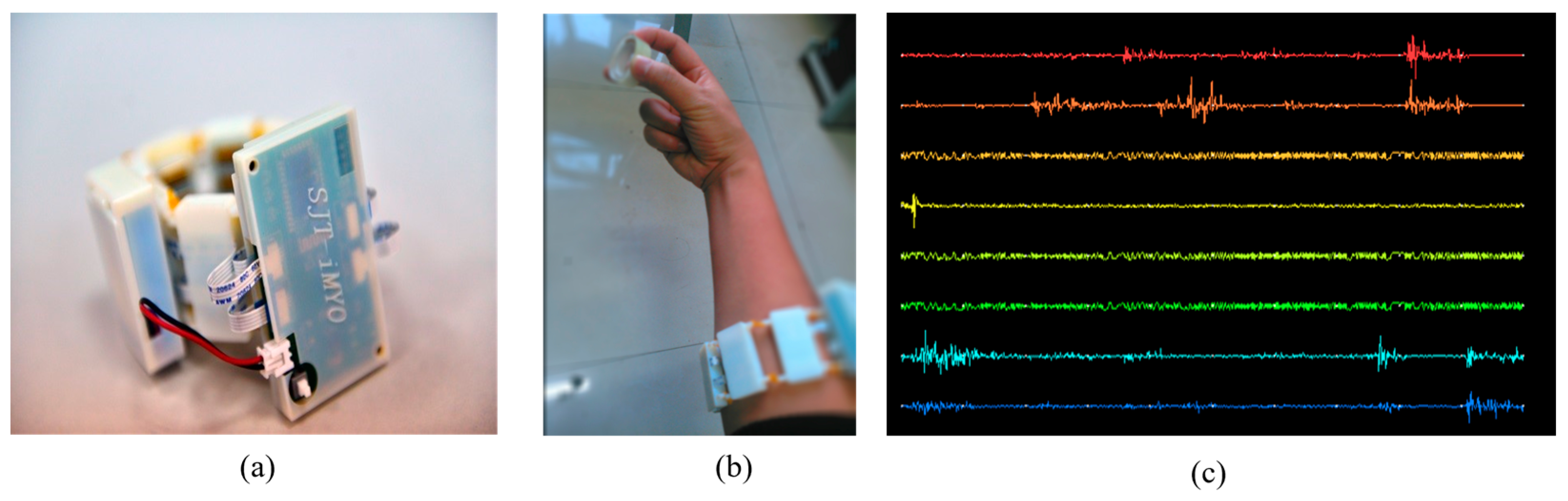
Two kinds of experiments were conducted: the first experiment was based on the publicly available dataset NinaPro DB1 and NinaPro DB5; the second experiment was based on sEMG signals collected by 8-channel wireless sEMG armband.
4.1. Experiment Based on Publicly Available Dataset
The NinaProDB1 dataset encompasses 52 hand gestures, classified into three categories for training: (A) 12 finger gestures; (B) 8 gestures of uniform opening and closure with equal length, along with 9 wrist gestures; (C) 23 basic grasp gestures. A total of 10 healthy volunteers (7 males and 3 females, aged 22 to 30 years old, without any medical history and of similar physique) participated in the collection of sEMG signals from forearm muscles using an ELONXI electromyography system equipped with 18 dry electrodes, including 2 for grounding. The sampling frequency was set to 100 Hz. Each participant performed the 52 hand gestures 10 times, with each gesture lasting 10 s. A 3-s rest was allowed between gestures, and subjects could rest for 10 min between different sessions.
The NinaProDB5 datasets encompass 52 hand gestures, classified into three categories for training: (A) finger gestures; (B) gestures characterized by uniform opening and closure of equal length, along with wrist gestures; (C) basic grasp gestures. Ten healthy volunteers participated in the collection of sEMG signals, utilizing a 16-channel sampling system. The sampling frequency was set at 200 Hz. Each participant was required to perform the 52 hand gestures in the experiment, repeating each gesture 6 times, with each repetition lasting 5 s. Participants were allowed a 3-s rest period between different hand gestures.
In the experiment, the sEMG data from the second and sixth repetitions of each gesture constituted the test sets, while the remaining data formed the training and validation sets. The distribution among the training, validation, and test sets was approximately in a 6:2:2 ratio. We employed data augmentation techniques, such as random and center cropping, to enhance the diversity of the training data. Each recognition model was trained individually, and the corresponding trained model was then utilized for each individual. The batch size for training was set at 64, with the Adam optimizer (adaptive moment estimation method) selected. The learning rate was established at 0.001, and a dropout rate of 0.4 was applied to improve the model’s generalization capability.
4.1.1. Ablation Experiment
We conducted comparative experiments using four distinct network architectures: the ResNet50 model, the ACResNet model (which integrates ACmix into ResNet50), the InResNet model (introducing inception–attention into ResNet50), and the InRes-ACNet model. We employed the cross-entropy loss function for forward propagation, a standard approach in addressing multi-classification problems, as illustrated in Equations (5) and (6).
where
is the average loss rate;
is the loss rate of the
th sample;
is the total number of samples;
is the number of classes; The value of
can be 0 or 1, it is 1 if the true class of the
th sample is to class
, 0 otherwise;
is the predicted probability that the observed sample
belongs to class
.
The results of the ablation experiments are presented in
Table 1. The ResNet50 model demonstrated an accuracy of 82.71% in the sEMG gesture recognition test, attributed to its robust feature extraction capabilities embedded in the deep convolutional structure. The ACResNet model achieved an increased accuracy rate of 85.98%, owing to the incorporation of the ACmix module, which facilitated more precise information integration, thereby enhancing the model’s ability to comprehend and characterize image content.
The InResNet model demonstrated a slight improvement in accuracy to 86.31%. This enhancement is attributed to the integration of the inception–attention module, which enables the model to capture multi-scale feature information. The InRes-ACNet model, combining the inception and ACmix modules, achieved a notable accuracy of 87.82% in sEMG gesture recognition, significantly surpassing other individually enhanced models. Compared with the ResNet50, the recognition accuracy of the ACResNet and InResNet models increased by 3.24% and 3.6%, respectively. The InRes-ACNet model’s accuracy improved by 5.11%, with only a 0.23 M increase in the number of parameters. As indicated by the parameter values in
Table 1, the InRes-ACNet model effectively extracts both local details and global information of sEMG signals, thanks to its improved module structure, while maintaining parameter efficiency, thus significantly enhancing model performance.
In experiments, it was demonstrated that both the inception–attention module and the ACmix module individually enhance the model’s recognition performance. The InRes-ACNet model, which integrates these two modules simultaneously, exhibits a superior classification performance in sEMG gesture recognition tasks.
4.1.2. Comparative Analysis of Identification Performance of Different Model
This experiment utilized the NinaPro DB1 dataset, covering 17 different gestures. The InRes-ACNet model, as proposed in this study, was employed for sEMG gesture recognition. The experimental results were compared with mainstream recognition methods reported by other researchers, as illustrated in
Table 2. The results indicated that traditional sEMG gesture recognition methods, such as SVM and the random forest algorithm, yielded relatively low gesture recognition rates of 69.45% and 75.36%, respectively. The adoption of deep-learning methods, specifically the convolutional neural network variant MyoCNN and VGGNet models, significantly enhanced the recognition performance, with rates of 78.25% and 81.12%, respectively. Furthermore, the accuracy of the MSCNet model increased to 83.24% through the extraction of multi-scale features. The InRes-ACNet model proposed in this study, integrating a multi-scale module, the ResNet50 architecture, and the ACmix module, achieved a recognition rate of 86.46%, demonstrating considerable promise in gesture recognition. This outcome further substantiates the efficacy of the attention mechanism and multi-scale feature fusion strategy in enhancing the performance of sEMG gesture recognition tasks.
4.1.3. Individual Variability Analysis
The primary objective of this research is to assess the model’s performance when applied to various datasets, with a particular focus on evaluating its recognition performance across different gestures of different individuals. The experiment involved four datasets: NinaPro DB1 E1, NinaPro DB1 E2, NinaPro DB5 E1, and NinaPro DB5 E2.
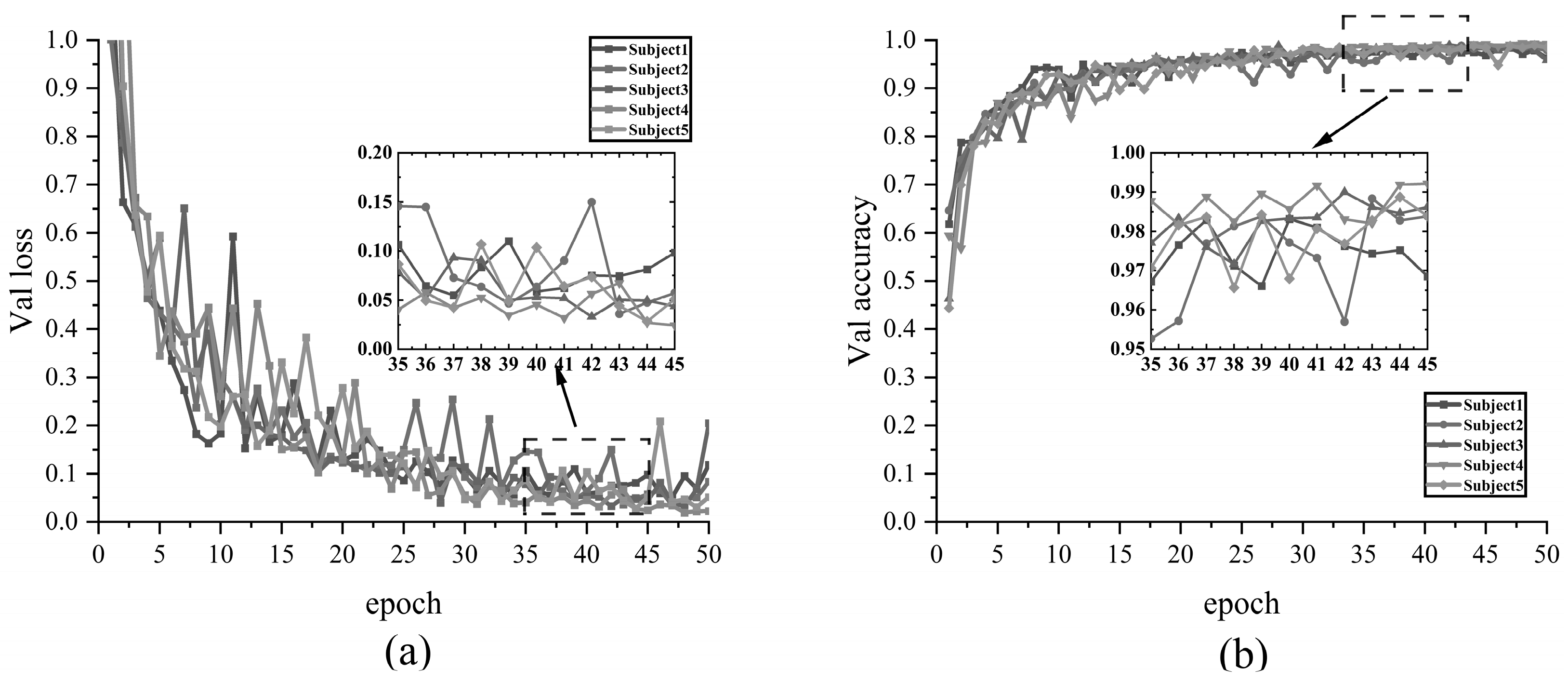
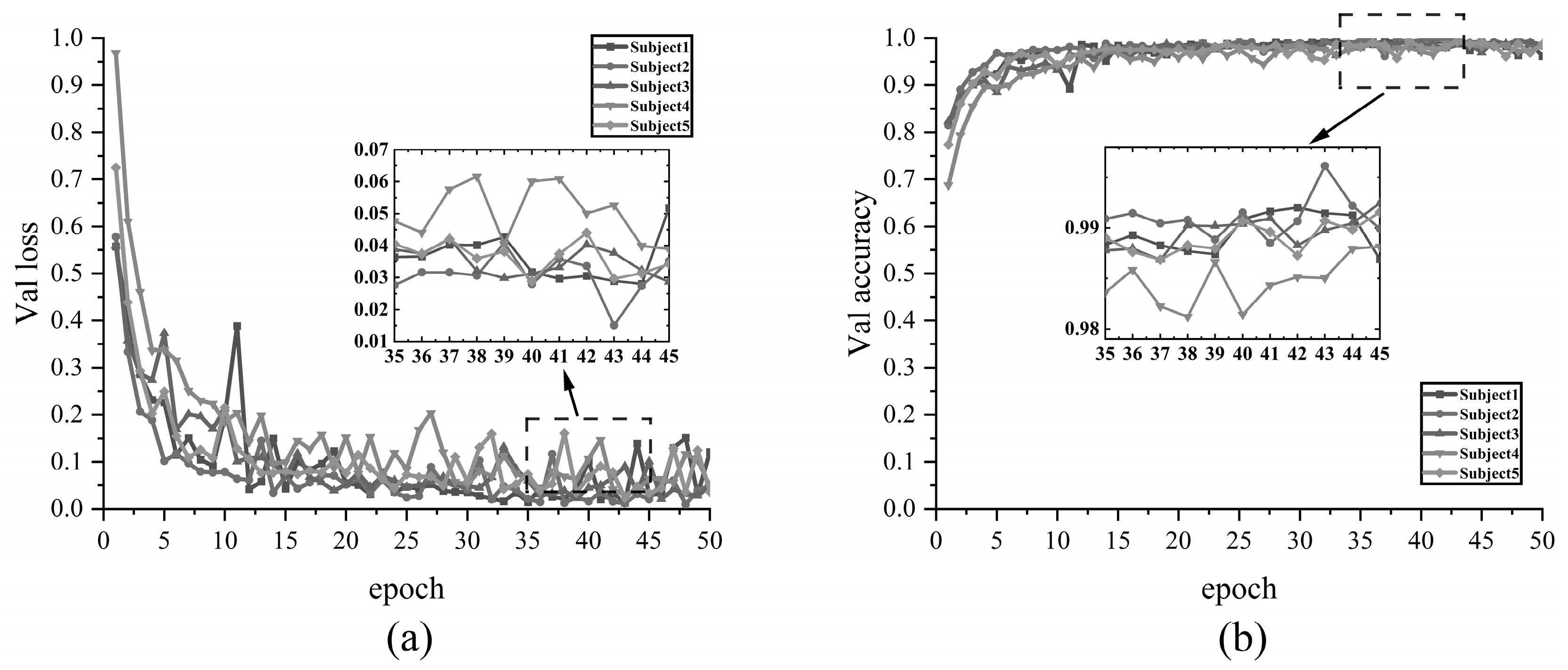
Figure 9 illustrates the validation effect of using the InRes-ACNet model on the NinaPro DB1 E1 dataset, which encompasses 12 different gestures. It presents the validation loss values and recognition accuracy for five subjects across 50 validation cycles (epochs). In the initial stages of validation, the loss values for all subjects decreased rapidly, while the accuracy rates increased significantly, nearing their peak levels. This indicates that the model exhibits a fast convergence rate and robust learning capabilities. Throughout the validation process, despite minor fluctuations, the loss and accuracy curves generally remained stable, demonstrating the recognition stability of the InRes-ACNet model.
Figure 10 illustrates the validation effect of employing the InRes-ACNet model on the NinaPro DB1 E2 dataset, encompassing 17 different gestures. It presents the validation loss values and recognition accuracy for five subjects across 50 validation cycles (epochs). At the initial stage of validation, the loss value decreased rapidly, while the accuracy rate ascended to 95%, indicating the model’s rapid learning capability and convergence speed. Despite minor fluctuations in loss values and accuracy between the 40th and 50th epochs, the model demonstrated stability and high accuracy throughout the entire gesture recognition process.
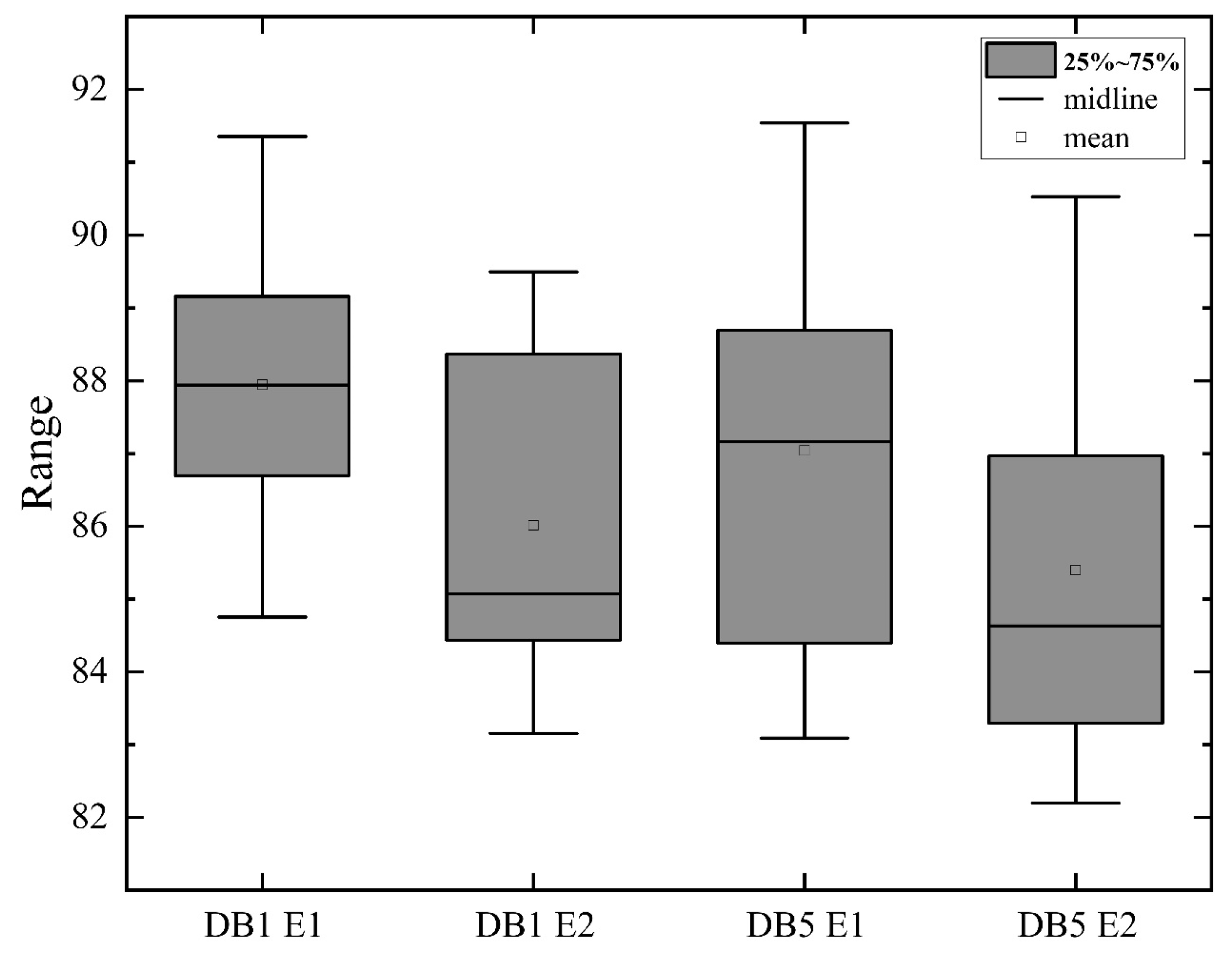
The variability experiment results for the datasets NinaPro DB1 E1, NinaPro DB1 E2, NinaPro DB5 E1, and NinaPro DB5 E2 are presented in
Table 3, with the boxplot of recognition accuracy for these four datasets depicted in
Figure 11. This boxplot illustrates the distribution of recognition accuracy for each dataset, including statistical measures such as the quartile, median, and mean. The NinaPro DB1 E1 and E2 datasets cover 12 and 17 gestures, respectively. As indicated in
Table 3, the average recognition accuracy for these datasets was 87.94% and 86.00%, respectively, with individual variances of 8.04% and 6.25%. The boxplot reveals that the median recognition accuracy closely aligns with the mean, showing a relatively balanced distribution without extreme outliers or significant skewness. For the NinaPro DB5 E1 and E2 datasets, which cover 12 and 17 gestures respectively, the average recognition accuracy was noted as 87.04% and 85.39%, respectively, with individual differences of 8.45% and 8.16%. The boxplot indicates that, despite the quartiles’ wide range, the median remains close to the mean, suggesting that the model maintains a consistent performance even in more complex gesture recognition tasks. Overall, the results demonstrate the model’s consistent performance across different datasets in gesture recognition tasks.
Overall, the InRes-ACNet model achieves a high accuracy rate in various gesture recognition tasks, demonstrating its effectiveness in capturing and utilizing key features in sEMG images. While recognition accuracy rates varied across datasets, the model’s performance underlines its effectiveness and reliability in sEMG gesture recognition. This further validates the InRes-ACNet model’s generalization capability across diverse datasets.
4.2. Experiment Based on sEMG Signals from 8-Channel Wireless Armband
This paper presents the integration of the inception–attention module and the ACmix module to develop the InRes-ACNet model as a gesture recognition framework. Initially, a multi-scale inception–attention module is constructed and integrated into the ResNet50 model. Subsequently, the self-attention mechanism, the ACmix module, is incorporated into ResNet50, resulting in the formulation of the InRes-ACNet gesture prediction model. For online prediction, the InRes-ACNet model is employed for gesture recognition tasks.
Experimenters donned an sEMG armband and executed eight types of gestures on a manipulator grasping mode control platform (
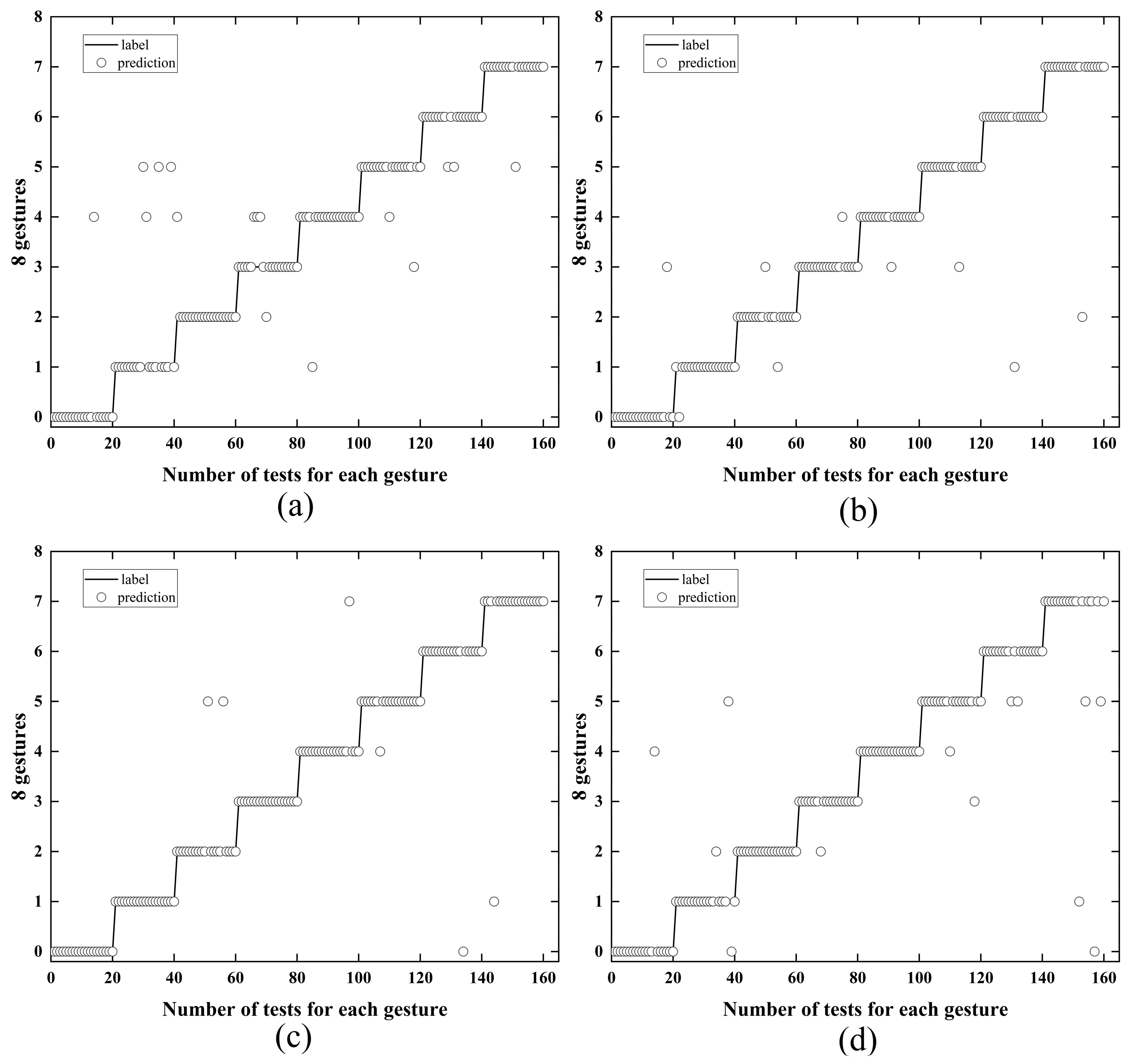
Figure 12). For each gesture, 480 muscle signal segments were extracted and transformed into 480 sEMG grayscale images, yielding a dataset size of 3840 for each experimenter. To assess the model’s robustness, ten diverse experimenters, including seven males and three females, were selected. Each experimenter replicated the specified actions to capture muscle electrical signals. The dataset from each experimenter was utilized to train the model, allocating 60% of the data for training, 20% for validation, and 20% for testing. For the test database, twenty groups of data corresponding to different gestures were randomly selected, totaling 160 data groups, and multiple rounds of testing were conducted on the outcomes. A subset of the test results is displayed in
Figure 13.
The test results from four experimenters, as depicted in
Figure 13, demonstrate that the InRes-ACNet model delivers commendable recognition performance in gesture recognition tasks. Given that the test data are randomly selected, this underscores the robustness of the InRes-ACNet. By integrating both the attention mechanism and a multi-scale structure, the InRes-ACNet showcases a high recognition accuracy and stability in human gesture recognition challenges.
The average recognition accuracy across ten experimenters is 88.37%. To elaborate on the results obtained from our model, we have selected four illustrative examples. These examples depict the gesture tests conducted by four experimenters.
Figure 13a presents the gesture predictions for Experimenter 1, with an average recognition accuracy of 84.63%. Notably, there are a considerable number of deviations from the target category, such as the circle, indicating that the predicted gestures significantly diverge from the actual gestures. This is especially true for Gesture 2 (spherical grasping), which deviates markedly from its actual form. The figure illustrates that each gesture is prone to misidentification, such as Gesture 5 (two-finger pinch) and Gesture 6 (side pinch).
Figure 13b displays the gesture predictions for Experimenter 2, achieving an average recognition accuracy of 90.63%. Most of the predicted category tags align closely with the actual category line, indicating more precise gesture recognition.
Figure 13c reveals the gesture predictions for Experimenter 3, with an average recognition accuracy of 92.96%. The minimal deviation from the actual category (i.e., circles) suggests highly accurate gesture recognition results.
Figure 13d showcases the gesture predictions for Experimenter 4, with an average recognition accuracy of 87.32%. Despite the recognition errors, particularly for Gesture 8 (thumb extension grip), the findings indicate variability in recognition accuracy across different experiments.
This variability may stem from several factors, such as inconsistent muscle strength exerted by experimenters during gesture performance or discrepancies in movement standards. Despite these variations, the gesture recognition model maintains a high accuracy and stability, underscoring the InRes-ACNet model’s robust capability in gesture recognition tasks, particularly in natural grasp, cylindrical grasp, and tip pinch.
For comparative purposes, the ResNet50 model was also employed in gesture prediction tasks. Utilizing the same ten experimenters as in the previous InRes-ACNet model tests, the gesture prediction results are summarized in
Table 4. The InResNet50 model achieves an average recognition accuracy of 85.63%, while the InRes-ACNet model attains an average recognition accuracy of 88.37%, highlighting the superior performance of the InRes-ACNet model in gesture prediction tasks.
5. Conclusions
In this study, by incorporating an attention mechanism and multi-scale module into the ResNet50 model, we propose the InRes-ACNet model for gesture recognition based on surface electromyography (sEMG) signals. Initially, the study constructs the inception–attention module based on the multi-scale inception module, which is then integrated into the ResNet50 model to enhance its multi-scale feature extraction capabilities. Subsequently, the self-attention mechanism, the ACmix module, is incorporated into ResNet50, enabling the model to maintain a lower parameter count while improving its feature extraction performance. Ultimately, employing the InRes-ACNet model on the NinaPro DB1 and NinaPro DB5 datasets for gesture recognition yielded accuracy rates of 87.94% and 87.04%, respectively. Additionally, the InRes-ACNet model was applied to the prediction of grasping modes in an electromyography manipulator, achieving an average recognition accuracy of 88.37%. These results confirm the effectiveness of the InRes-ACNet model for gesture recognition tasks based on sEMG signals.
Our research enhances gesture recognition performance by incorporating multi-scale modules and attention mechanisms, alongside utilizing the grayscale images of the original sEMG signals. Nevertheless, the InRes-ACNet model, integrating the inception–attention module, ACmix module, and ResNet50, entails a considerable number of parameters. This complexity results in extensive computations and slower training speeds. Variations in the dataset sizes, attributable to the differing collection times and frequencies for each gesture, also affect the duration of each training step. Given the non-stationary and random characteristics of sEMG signals, coupled with significant variations among individuals, the model’s generalization capacity in real-time recognition is constrained. Direct application of model training tailored to specific individuals to others may lead to a suboptimal recognition performance.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}