
Enhancing Robustness within the Collaborative Federated Learning Framework: A Novel Grouping Algorithm for Edge Clients


Abstract
:1. Introduction
2. Related Works
3. Proposed Collaborative FL Framework
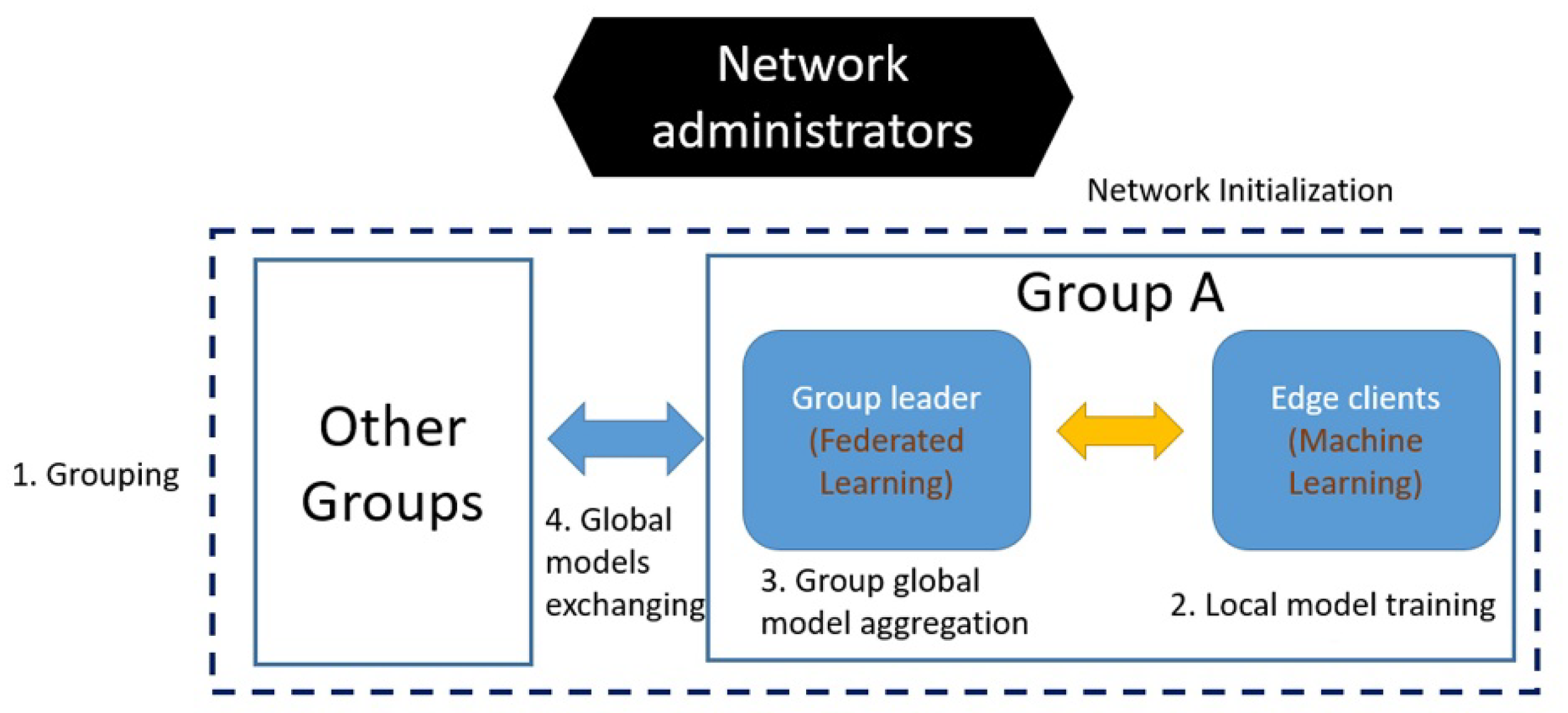
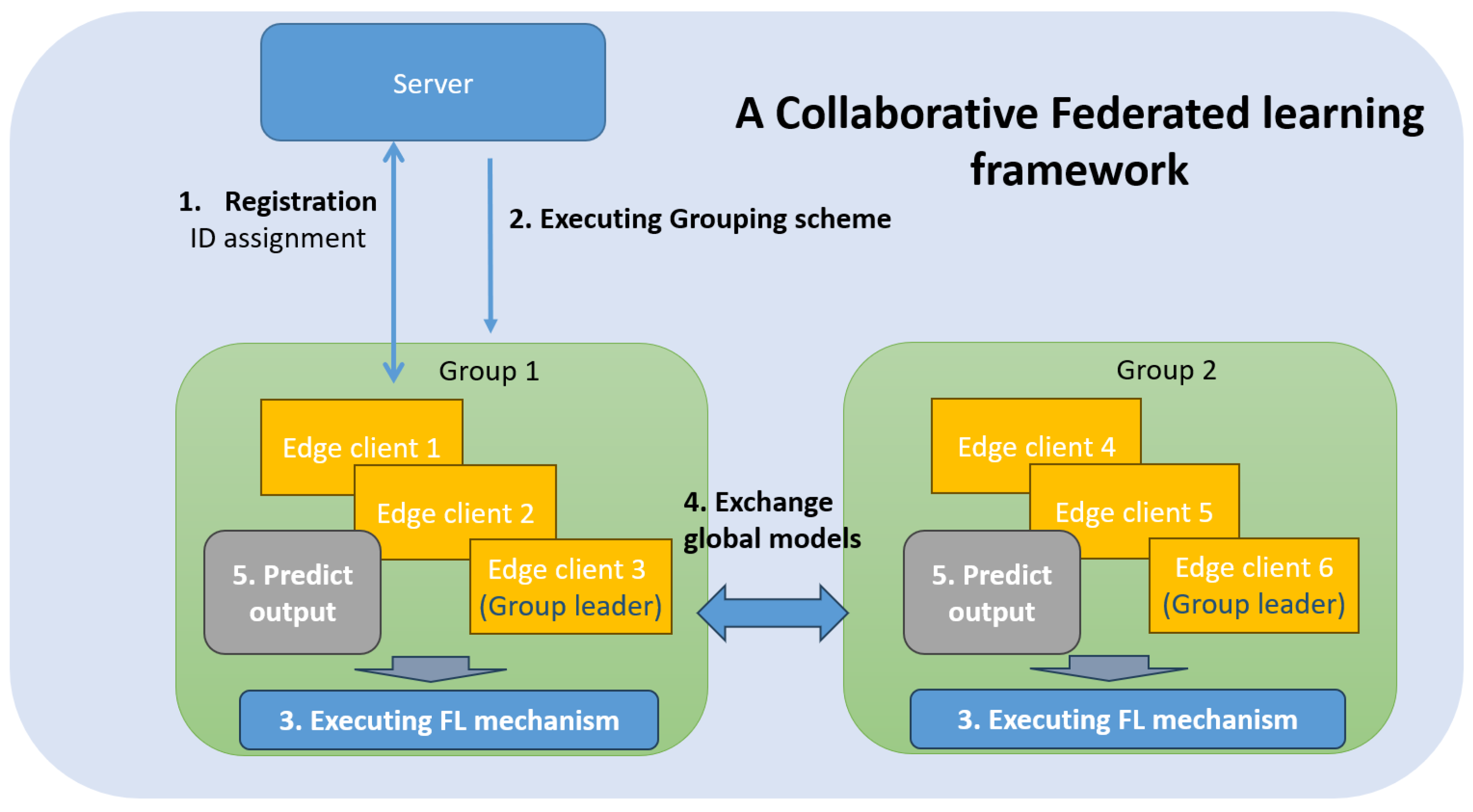
3.1. Network Architecture
3.2. Adversary Model
- The adversary is not allowed to join the initial registration process but is able to forge a malicious model with a randomly selected ID. Hence, the adversary can deviate the global model of a specified group in an unexpected direction. Once this event occurs, we also can say this group is compromised by the adversary. We call this compromised group the malicious one.
- Inside each group, the adversary can overhear the messages in transit between the clients and local group leader and remove them.
- The adversary cannot decrypt the encrypted messages in transit between the clients and the central server in time. Hence, the privacy of clients’ IDs will not be jeopardized.
3.3. Basic Workflow
3.4. ID Assignment
3.5. Proposed Grouping Scheme
3.5.1. Distinguishing between Edge Clients
3.5.2. The Number of Normal and Malicious Groups
The Impact of a False Positive Rate of Classifying Edge Clients
The Impact of Prediction Accuracy of Global Models
3.5.3. Grouping Edge Clients
| Algorithm 1 Grouping scheme |
| Input: C, N, λ, 4σ, pn, pm Output: Groups, Nn, and Nm, Initialization: Cn, Cm, No /* Classifying the edge clients and Counting the number of nn_est, nm_est*/ For Ci in C do If the Ci’s IDs, Idn_i, is in the range of λ 4σ Then Ci is classified into the set of Cn Else Ci is classified into the set of Cm End if End for Obtain nn_est, nm_est through the distinguishing principle /* Computing k, Nn, and Nm */ If nn_est nm_est Then k is equal to Nn = max If If Else if nn_est nm_est Then k = End if /*Grouping all clients*/ While at least one of the normal groups is not filled with normal clients For Ci in C do If Ci Cn Then Ci → Nn_j, until this group is filled Then continue assigning Ci to next group, until all groups are filled with normal edge clients Else if Ci Cm Then Ci → Nm_j, until this group is filled Then continue assigning Ci to next group, until all groups are filled with malicious edge clients End if End for End while |
3.6. Dynamic Joining of Nodes
4. Numerical Experiments
- The first numerical experiment demonstrates that our collaborative FL framework ensures the number of malicious groups remains less than that of normal ones, even if the number of malicious groups increases.
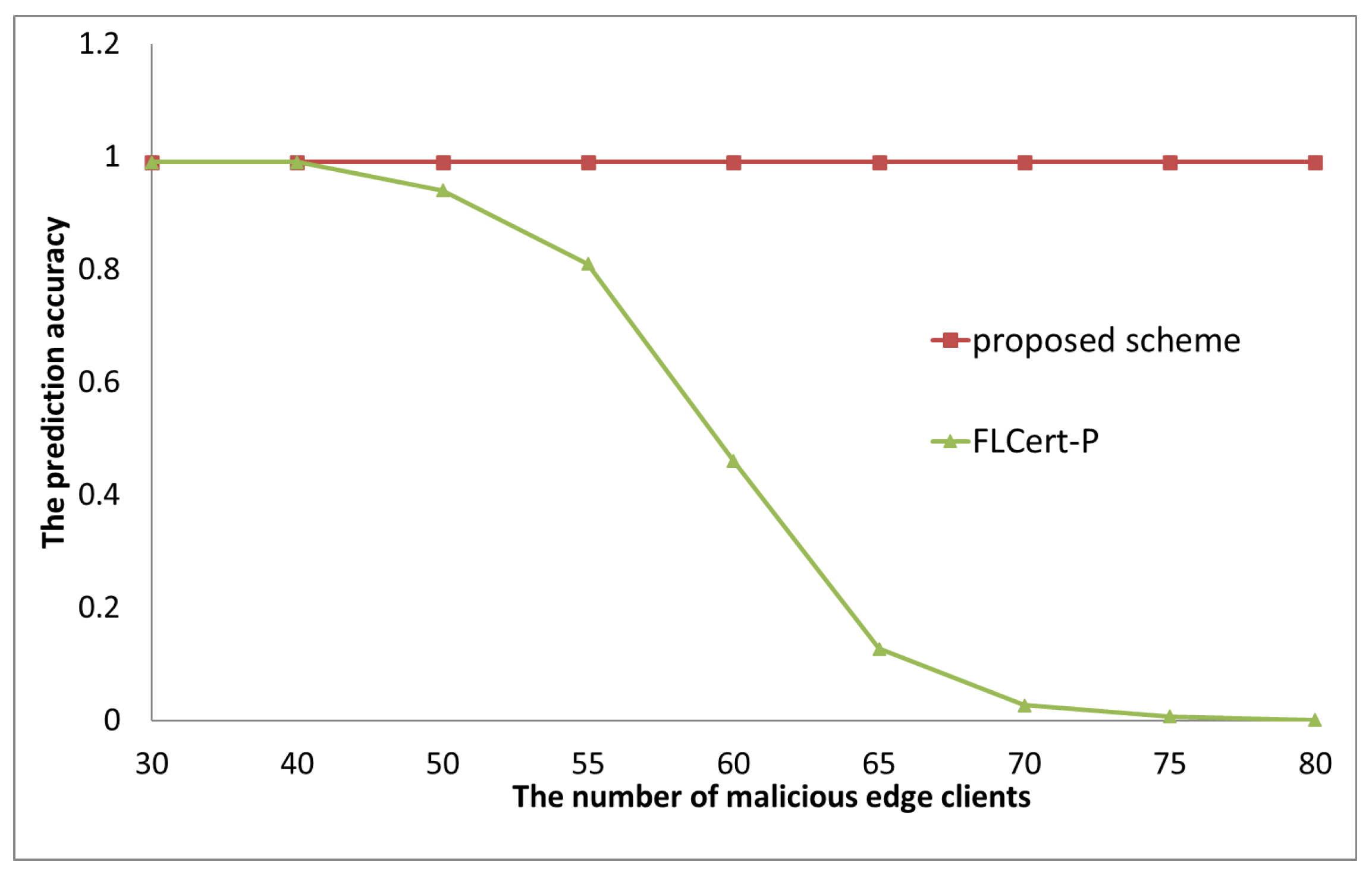
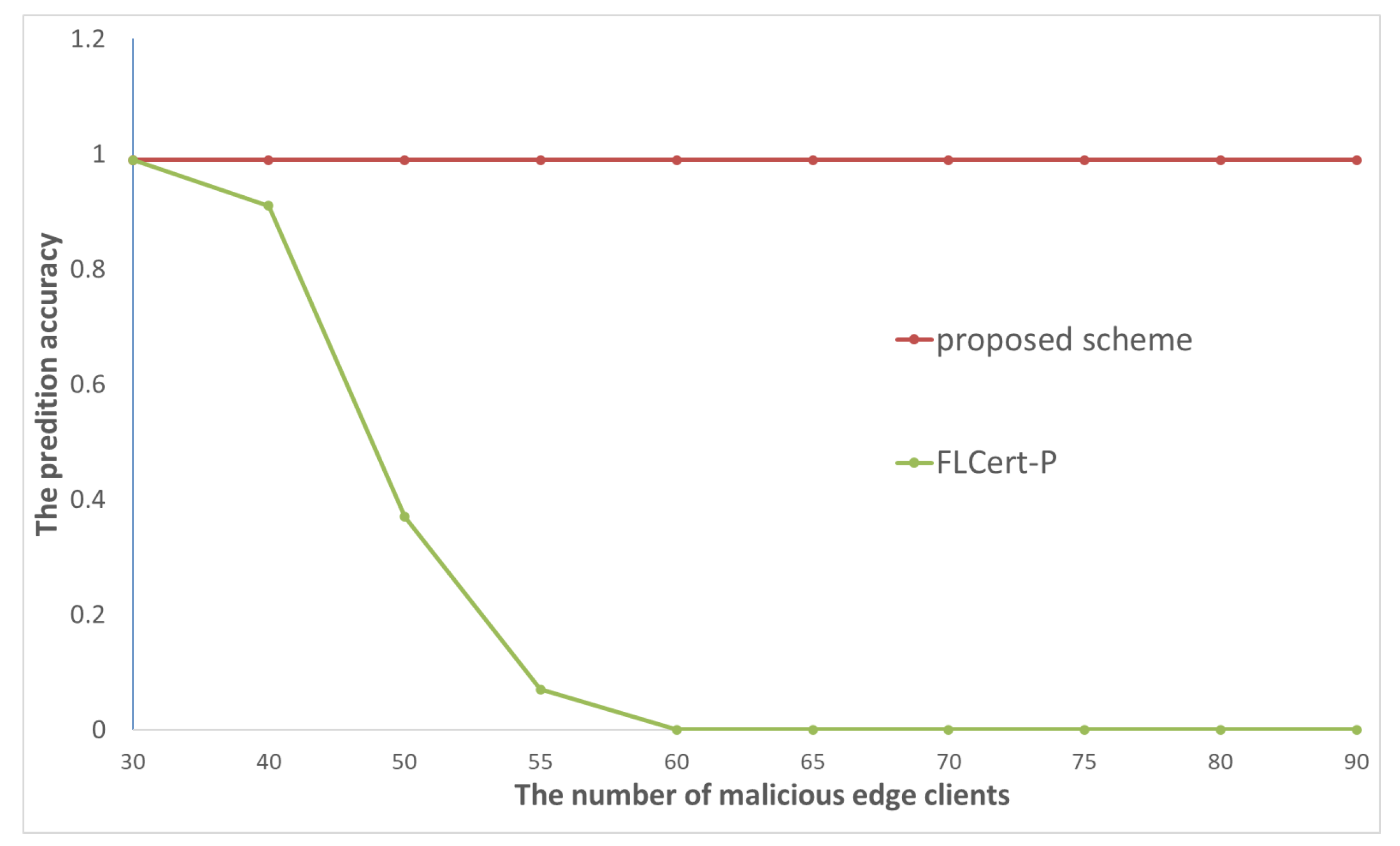
- The second experiment verifies that the overall prediction accuracy of our collaborative FL framework maintains a high value compared to FLcert-P, despite an increase in the number of malicious groups.
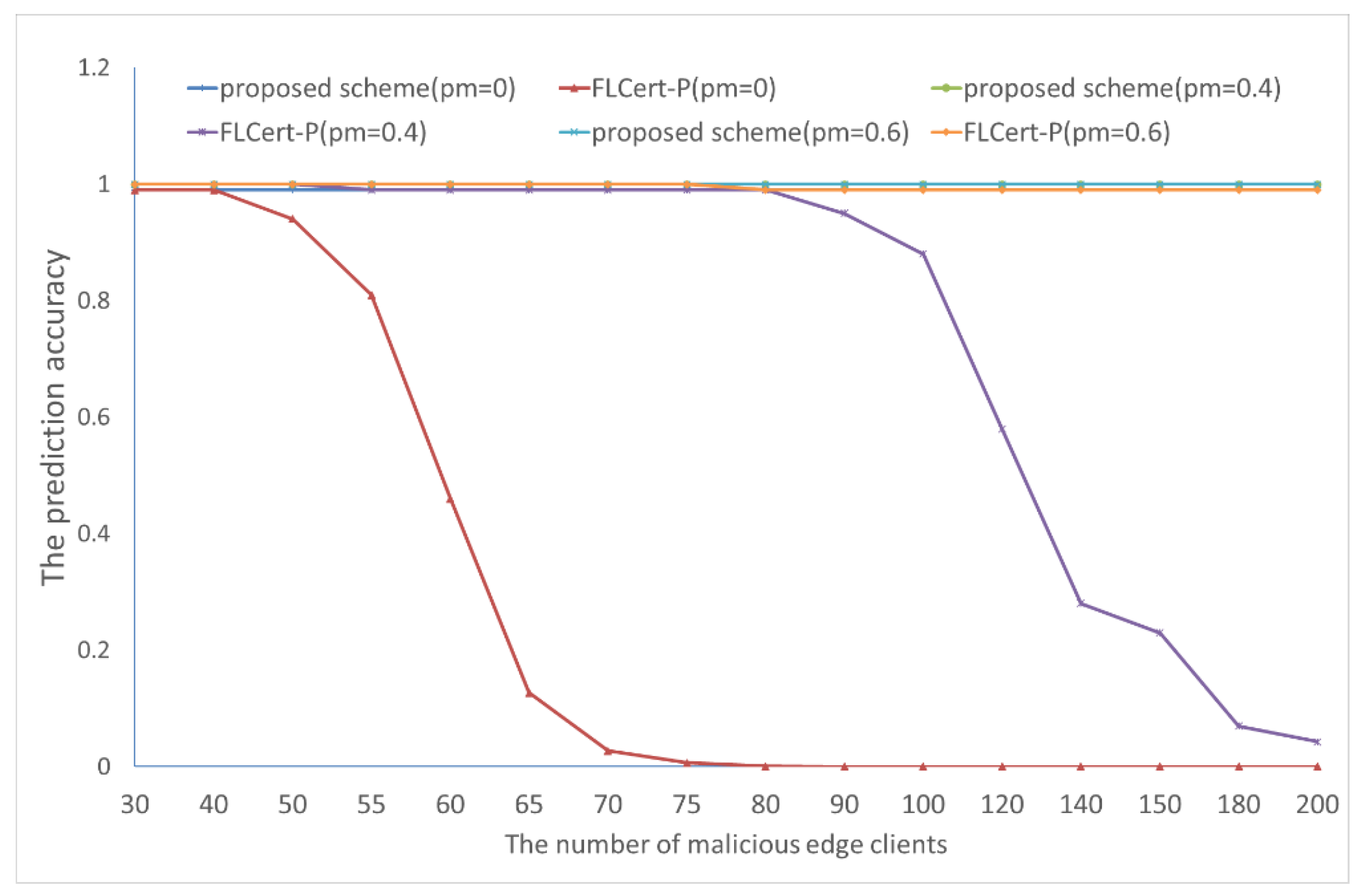
- The third experiment further proves that our collaborative FL framework performs well, regardless of the prediction accuracies of the malicious groups’ global models.
- The final experiment confirms that our proposed collaborative FL framework maintains high prediction accuracy even if the prediction accuracies of some normal groups’ global models are low.
4.1. Numerical Experiment 1
4.2. Numerical Experiment 2
4.3. Numerical Experiment 3
4.4. Numerical Experiment 4
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Symbols | Definitions |
| C | The set of the edge clients |
| Cn_i | The ith normal edge client |
| Ci | The ith edge client |
| Cm_j | The jth malicious client |
| N | The total number of groups |
| Nm | The number of malicious groups |
| Nm_j | The jth malicious group |
| Nn | The number of normal groups |
| Nn_j | The jth normal group |
| n | The number of total clients |
| nn | The number of normal clients |
| nm | The number of malicious clients |
| nf | The number of malicious clients whose IDs fall in valid range |
| kn | The number of client members in a normal group |
| km | The number of client members in a malicious group |
| k | The number of client member in a group |
| Npe | The expected number of positive answers |
| Nne | The expected number of negative answers |
| pn | The prediction accuracy of the global model in a normal group |
| pm | The prediction accuracy of the global model in a malicious group |
| No | The number offset between normal and malicious groups |
| λ | The mean of normal distribution |
| σ | The standard deviation of normal distribution |
References
- Kone, J.; McMahan, H.B.; Yu, X.F.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated Learning: Strategies for Improving Communication Efficiency. In Proceedings of the NeurIPS Workshop Private Multi-Party Machine Learning 2016, Barcelona, Spain, 9 December 2016. [Google Scholar] [CrossRef]
- Qolomany, B.; Ahmad, K.; Al-Fuqaha, A.; Qadir, J. Particle Swarm Optimized Federated Learning for Industrial IoT and Smart City Services. In Proceedings of the GLOBECOM 2020–2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020. [Google Scholar] [CrossRef]
- Xing, J.; Jiang, Z.X.; Yin, H. Jupiter: A Modern Federated Learning Platform for Regional Medical Care. In Proceedings of the 2020 IEEE International Conference on Joint Cloud Computing, Oxford, UK, 3–6 August 2020. [Google Scholar] [CrossRef]
- Hu, Y.; Cao, N.; Guo, W.; Chen, M.; Rong, Y.; Lu, H. FedDeep: A Federated Deep Learning Network for Edge Assisted Multi-Urban PM2.5 Forecasting. Appl. Sci. 2024, 14, 1979. [Google Scholar] [CrossRef]
- Saputra, Y.M.; Hoang, D.T.; Nguyen, D.N.; Dutkiewicz, E.; Mueck, M.D.; Srikanteswara, S. Energy Demand Prediction with Federated Learning for Electric Vehicle Networks. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019. [Google Scholar] [CrossRef]
- Yu, Z.; Hu, J.; Min, G.; Zhao, Z.; Miao, W.; Hossain, M.S. Mobility-Aware Proactive Edge Caching for Connected Vehicles Using Federated Learning. IEEE Trans. Intell. Transp. Syst. 2021, 22, 5341. [Google Scholar] [CrossRef]
- Li, H.; Li, C.; Wang, J.; Yang, A.; Ma, Z.; Zhang, Z.; Hua, D. Review on security of federated learning and its application in healthcare. Future Gener. Comput. Syst. 2023, 144, 271–290. [Google Scholar] [CrossRef]
- Rahman, S.A.; Tout, H.; Talhi, C.; Mourad, A. Internet of Things Intrusion Detection: Centralized, on-Device, or Federated Learning? IEEE Netw. 2020, 34, 310. [Google Scholar] [CrossRef]
- Cao, X.; Zhang, Z.; Jia, J.; Gong, N.Z. FLCert: Provably Secure Federated Learning Against Poisoning Attacks. IEEE Trans. Inf. Forensics Secur. 2022, 17, 3691. [Google Scholar] [CrossRef]
- Liu, C.K.; Chiang, C.H. A Collaboration Federated Learning Framework with a Grouping Scheme against Poisoning Attacks. In Proceedings of the International Symposium on Computer, Consumer and Control, Taichung, Taiwan, 30 June–3 July 2023. [Google Scholar] [CrossRef]
- Ghimire, B.; Rawat, D.B. Recent Advances on Federated Learning for Cybersecurity and Cybersecurity for Federated Learning for Internet of Things. IEEE Internet Thing J. 2022, 9, 8229. [Google Scholar] [CrossRef]
- Taheri, R.; Shojafar, M.; Alazab, M.; Tafazolli, R. Fed-IIoT: A Robust Federated Malware Detection Architecture in Industrial IoT. IEEE Trans. Ind. Informat. 2021, 17, 8442. [Google Scholar] [CrossRef]
- Sun, Y.; Ochiai, H.; Esaki, H. Intrusion Detection with Segmented Federated Learning for Large-Scale Multiple LANs. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar] [CrossRef]
- Lin, K.-Y.; Huang, W.-R. Using Federated Learning on Malware Classification. In Proceedings of the 22nd International Conference on Advanced Communication Technology, Phoenix Park, Republic of Korea, 16–19 February 2020. [Google Scholar] [CrossRef]
- Fu, A.; Zhang, X.; Xiong, N.; Gao, Y.; Wang, H.; Zhang, J. VFL: A Verifiable Federated Learning with Privacy-Preserving for Big Data in Industrial IoT. IEEE Trans. Ind. Informat. 2022, 18, 3316. [Google Scholar] [CrossRef]
- Ioannou, I.; Nagaradjane, P.; Angin, P.; Balasubramanian, P.; Kavitha, K.J.; Murugan, P.; Vassiliou, V. GEMLIDS-MIOT: A Green Effective Machine Learning Intrusion Detection System based on Federated Learning for Medical IoT network security hardening. Comput. Commun. 2024, 218, 209–239. [Google Scholar] [CrossRef]
- Khoa, T.V.; Saputra, Y.M.; Hoang, D.T.; Trung, N.L.; Nguyen, D.; Ha, N.V.; Dutkiewicz, E. Collaborative Learning Model for Cyberattack Detection Systems in IoT Industry 4.0. In Proceedings of the IEEE Wireless Communications and Networking, Seoul, Republic of Korea, 25–28 May 2020. [Google Scholar] [CrossRef]
- Huong, T.T.; Bac, T.P.; Long, D.M.; Luong, T.D.; Dan, N.M.; Quang, L.A.; Cong, L.T.; Thang, B.D.; Tran, K.P. Detecting cyberattacks using anomaly detection in industrial control systems: A Federated Learning approach. Comput. Ind. 2021, 132, 103509. [Google Scholar] [CrossRef]
- Mahindru, A.; Arora, H. DNNdroid: Android Malware Detection Framework Based on Federated Learning and Edge Computing. In Proceedings of the Advancements in Smart Computing and Information Security 2022, Rajkot, India, 24–26 November 2022. [Google Scholar] [CrossRef]
- Mahindru, A.; Sharma, S.K.; Mittal, M. YarowskyDroid: Semi-supervised based Android malware detection using federation learning. In Proceedings of the 2023 International Conference on Advancement in Computation & Computer Technologies (InCACCT), Gharuan, India, 5–6 May 2023; pp. 380–385. [Google Scholar] [CrossRef]
- Gálvez, R.; Moonsamy, V.; Diaz, C. Less is More: A privacy-respecting Android malware classifier using Federated Learning. Proc. Priv. Enhancing Technol. 2021, 4, 96–116. [Google Scholar] [CrossRef]
- Jiang, C.; Yin, K.; Xia, C.; Huang, W. FedHGCDroid: An Adaptive Multi-Dimensional Federated Learning for Privacy-Preserving Android Malware Classification. Entropy 2022, 24, 919. [Google Scholar] [CrossRef] [PubMed]
- Lamport, L.; Shostak, R.; Pease, M. The Byzantine Generals Problem. ACM Trans. Prog. Lang. Sys. 1982, 4, 382. [Google Scholar] [CrossRef]
- Blanchard, P.; Mhamdi, E.M.E.; Guerraoui, R.; Stainer, J. Machine learning with adversaries: Byzantine tolerant gradient descent. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar] [CrossRef]
- Zhang, Z.; Cao, X.; Jia, J.; Gong, N.Z. FLDetector: Defending Federated Learning Against Model Poisoning Attacks via Detecting Malicious Clients. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 14–18 August 2022. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Items | Specifications |
|---|---|
| Operation system | Windows 10 (Microsoft, Redmond, DC, USA) |
| Programming language | C++ |
| CPU | 11th Gen Intel(R) Core(TM) i9-11900F @ 2.50 GHz (Intel, Santa Clara, CA, USA) |
| Memory | 32 G |
| Graphics card | Nvidia Geforce RTX 2060 (NVIDIA, Santa Clara, CA, USA) |
| Nm | FLcert-P (Worst Case) | Proposed Scheme | |
|---|---|---|---|
| nm | |||
| 30 | 30 | 8 | |
| 40 | 40 | 10 | |
| 50 | 50 | 13 | |
| 60 | 50 | 15 | |
| 70 | 50 | 18 | |
| 90 | 50 | 20 | |
| 110 | 50 | 20 | |
| 150 | 50 | 20 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, Z.-Y.; Liu, I.-H.; Li, C.-F.; Liu, C.-K.; Chiang, C.-H. Enhancing Robustness within the Collaborative Federated Learning Framework: A Novel Grouping Algorithm for Edge Clients. Appl. Sci. 2024, 14, 3255. https://doi.org/10.3390/app14083255
Su Z-Y, Liu I-H, Li C-F, Liu C-K, Chiang C-H. Enhancing Robustness within the Collaborative Federated Learning Framework: A Novel Grouping Algorithm for Edge Clients. Applied Sciences. 2024; 14(8):3255. https://doi.org/10.3390/app14083255
Chicago/Turabian StyleSu, Zhi-Yuan, I-Hsien Liu, Chu-Fen Li, Chuan-Kang Liu, and Chi-Hui Chiang. 2024. "Enhancing Robustness within the Collaborative Federated Learning Framework: A Novel Grouping Algorithm for Edge Clients" Applied Sciences 14, no. 8: 3255. https://doi.org/10.3390/app14083255
APA StyleSu, Z.-Y., Liu, I.-H., Li, C.-F., Liu, C.-K., & Chiang, C.-H. (2024). Enhancing Robustness within the Collaborative Federated Learning Framework: A Novel Grouping Algorithm for Edge Clients. Applied Sciences, 14(8), 3255. https://doi.org/10.3390/app14083255