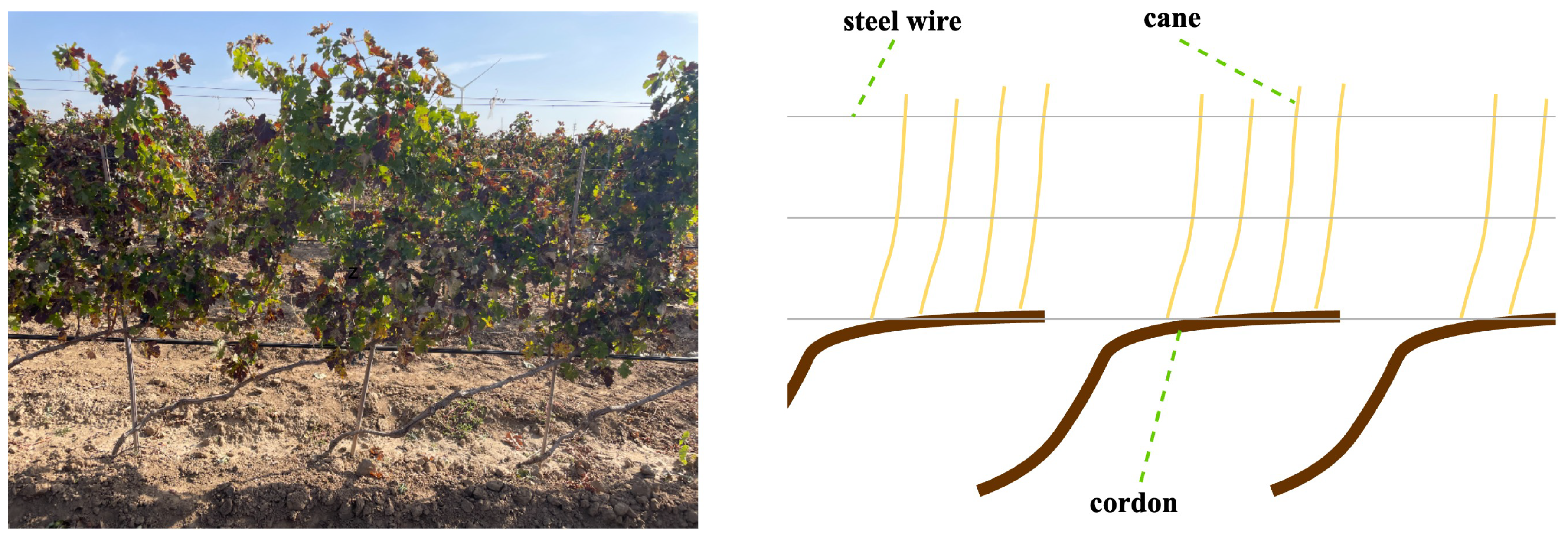
According to the International Organization of Vine and Wine (OIV), the top three wine-producing countries in 2023 were France, Italy and Spain, with production reaching 45.8 million liters, 43.9 million liters and 30.7 million liters. Wine production is high and wine grapes are cultivated on a large area. In order to ensure neat budding in the spring and high-quality grape berries, grapevines planted in northern regions need to be pruned in the winter, cutting off excess buds on the branches before burying in soil to resist the cold [
1]. The mainstream pruning methods currently on the market include manual pruning and machine pruning; manual pruning is effective, but the labor demand is large, with high pruning costs; machine pruning [
2] depends on the bundled branches of the cordon; the efficiency is higher, but the effect of pruning is poor, there is a tendency to miss, there are pruning errors, etc., which results in the quality of wine grapes being greatly reduced. For the pruning of high-quality wine grapes, such as Cabernet Sauvignon wine grapes, which is the object of research in this paper, this paper proposes an intelligent pruning system based on images, which can be pruned in the appropriate position according to the pruning rules, reducing labor costs while ensuring high pruning efficiency and good pruning results.
Up to now, there have been studies aimed at recognizing fruits and stems of various fruit trees. Zhang et al. [
3] fed both pseudo-color and depth images into a convolutional neural network R-CNN to detect branches of apple fruit trees, which was used to automatically shake the branches to harvest apple fruits. Chen et al. [
4] used U-Net and DeepLabv3 and a conditional generative adversarial network, Pix2Pix, to recognize occluded apple trees growing in a V-shape. Ma et al. [
5] used a deep learning method (SPGNet) to segment a 3D point cloud model of date palm trees and estimated the number of date palm branches using the DBSCAN clustering algorithm. Li et al. [
6] used Deeplabv3 to segment the RGB image of lychee nests using a skeleton extraction operation and a noise-based nonparametric density spatial clustering method to identify fruiting branches belonging to the same lychee cluster. Yang et al. [
7] used Mask R-CNN and branch segment merging algorithms to detect citrus fruits and branches in the presence of foliage occlusion and mapped color images onto depth images to obtain the diameters of fruits and branches. Feng et al. [
8] used the lightweight target-detection network YOLOv7-tiny on citrus in video technique, which can measure the citrus yield in an orchard. Cong et al. [
9] introduced RGB-D images and used MSEU R-CNN to segment citrus canopies to obtain the growth information of the canopies, which provided a method for spraying robots. In the study by Sun et al. [
10], in order to pick citrus fruits at the time of obtaining picking points on branches, a candidate region was first generated and then a multilevel feature fusion point was proposed to determine the picking points in the candidate region. In the study by Cuevas-Velasquez et al. [
11], in order to prune a rose bush for its 3D reconstruction, a full convolutional neural network was used to obtain the skeleton and branching structure of the plant after segmentation of the branches. In the study by Turgut et al. [
12], in order to collect the phenotypic traits of a plant population, RoseSegnet, a deep learning network based on a 3D point cloud, was proposed for segmentation of the organs of the rose plant. Koirala et al. [
13] developed a new architecture called “Mango YOLO” based on the features of YOLOv3 [
14] and YOLOv2 (tiny) [
15]. Roy et al. [
16] used Dense-YOLOv4 to detect mangoes at different growth stages under occlusion, and also used DenseNet with a backbone to optimize feature transmission and a Path Aggregation Network (PANet) with an improved pathway to retain fine-grained localization information. Zhou et al. [
17] used YOLOv4 [
18], YOLOv5, YOLOV6 [
19], YOLOX [
20] and YOLOv7 [
21] to compare the effects of picking when studying dragon fruit harvesting and chose YOLOv7 as the method for dragon fruit detection. Chen et al. [
22] used an improved Mask R-CNN based on a YOLACT model and a SOLO model to segment grape images and count the number of grape berries. Morellos et al. [
23] used the lightweight deep learning model MobileNet V2 as a backbone network for U-net to detect diseases in grapevines. Marani et al. [
24] used VGG19 to segment the grape nests in color images and the mutually exclusive classes were separated into two classes. Segmentation was carried out to minimize the cross-entropy loss of mutually exclusive classes to select the optimal threshold for grapevine nests. Multiple data forms such as RGB images and depth images and also point clouds combined with deep learning methods have been widely used for fruit and stem recognition.
After identifying the fruit and stem, it is necessary to combine pruning rules to determine the pruning point. Currently, there are many studies on fruit picking that can determine the picking point on the resulting branch. Zhong et al. [
25] used the YOLACT model to determine the regions of lychee fruits and main fruiting branches as lychee clusters and the midpoint of the mask of the main fruiting branches in lychee clusters was used as the harvesting point. Sun et al. [
10] aimed to obtain picking points on branches during citrus fruit picking. They first used generated candidate regions and then proposed a multi-level feature fusion point to determine the picking points in the candidate regions. However, both of these harvesting methods determine the stem and harvesting point to be picked based on the position of the fruit, which is a relatively large and easily segmented object from the background and are not suitable for grape branch pruning. Tong et al. [
26] used Cascade Mask R-CNN to detect branches of apple trees and combined it with the Zhang–Suen thinning algorithm to obtain skeletons and connection points with trunk diameter information. In addition, You [
27] and others used the topology and geometric priors of an upright fruit branch (UFO) tree to generate such labeled skeletons in order to reconstruct a three-dimensional model of a cherry tree. A skeleton thinning algorithm was applied to the point cloud and the number of manually labeled skeleton segments was used as an accuracy measure, achieving an accuracy of 70%. For the growth characteristics of winter wine grape branches and planting characteristics, i.e., simple tree shape, no foliage shade, etc., you can refer to the above literature for the treatment of branch thinning.
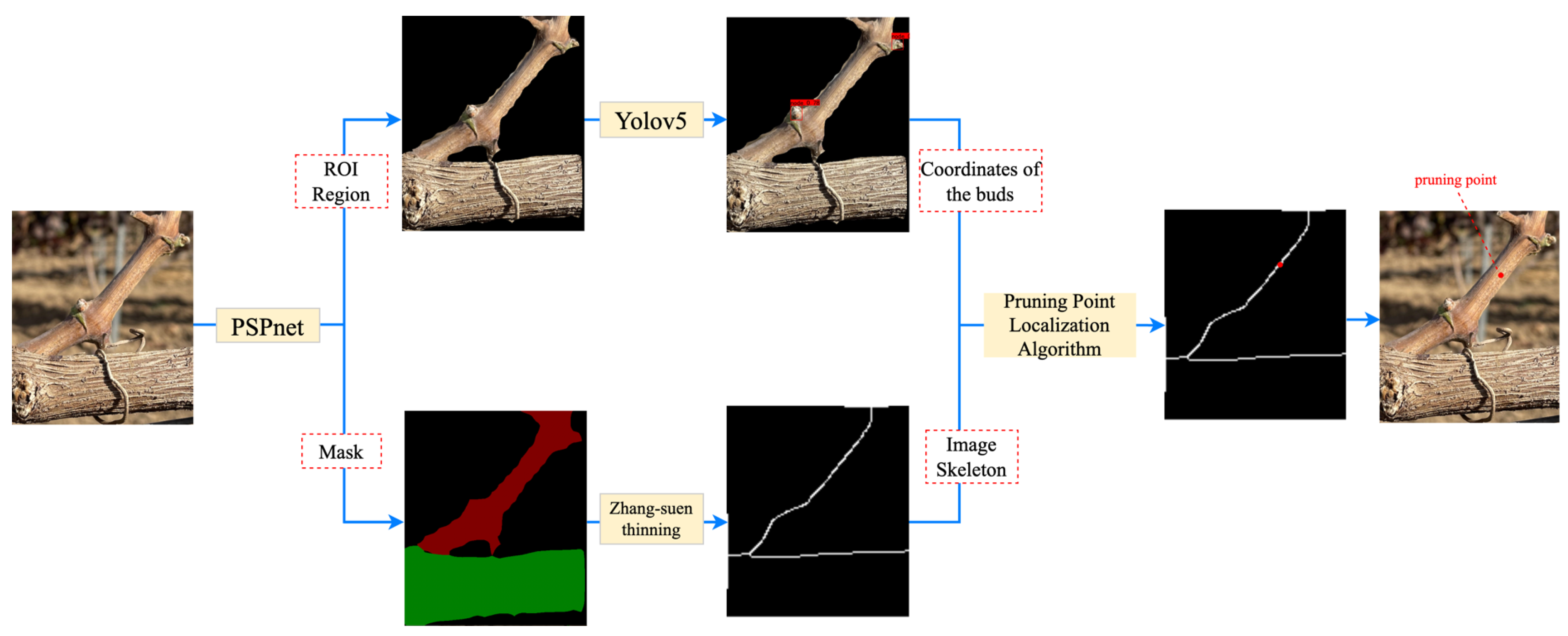
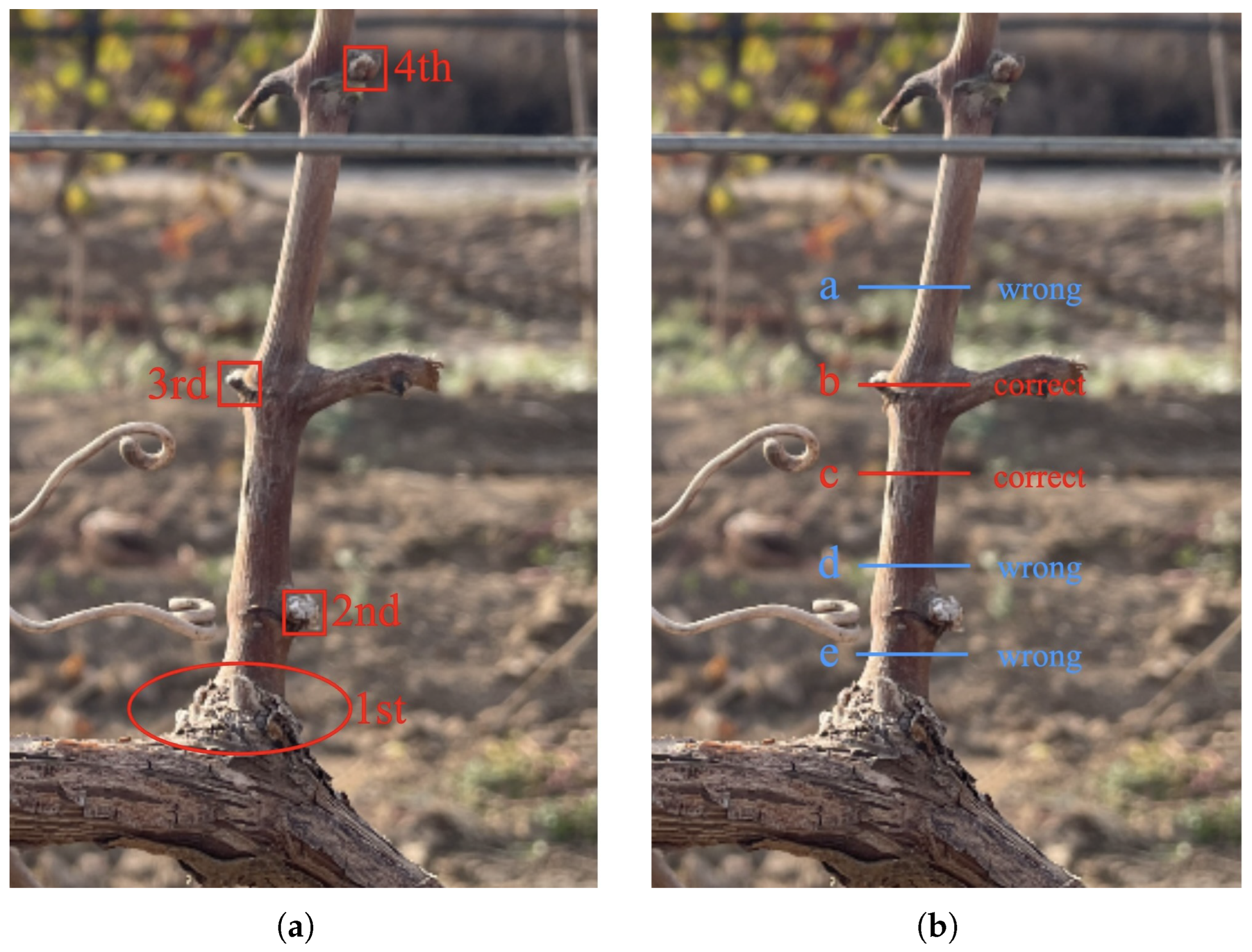
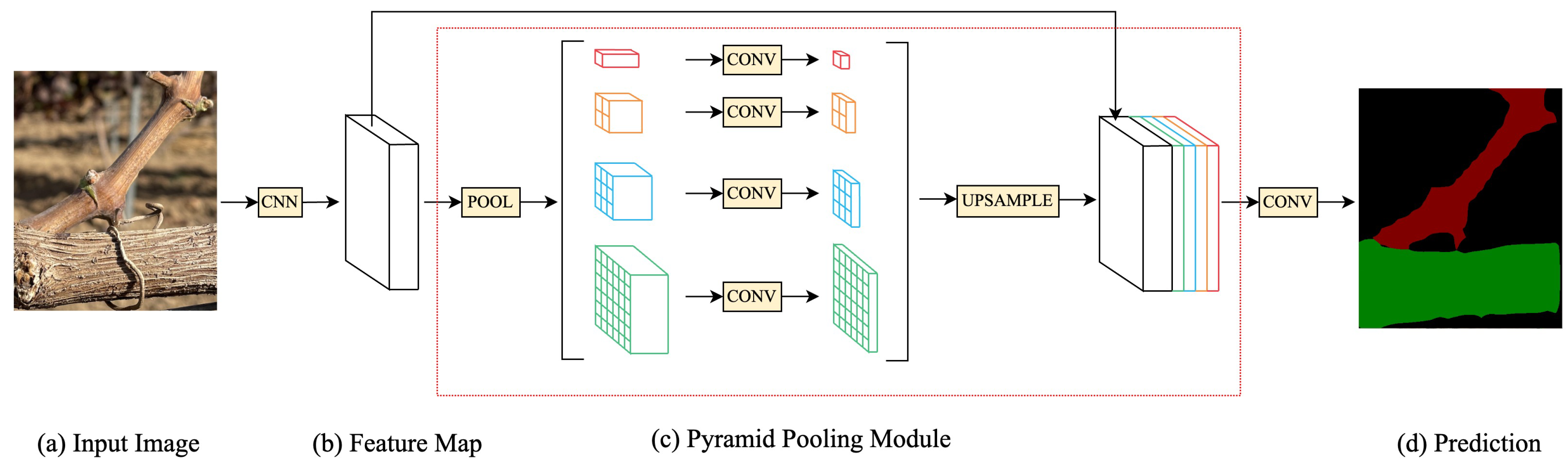
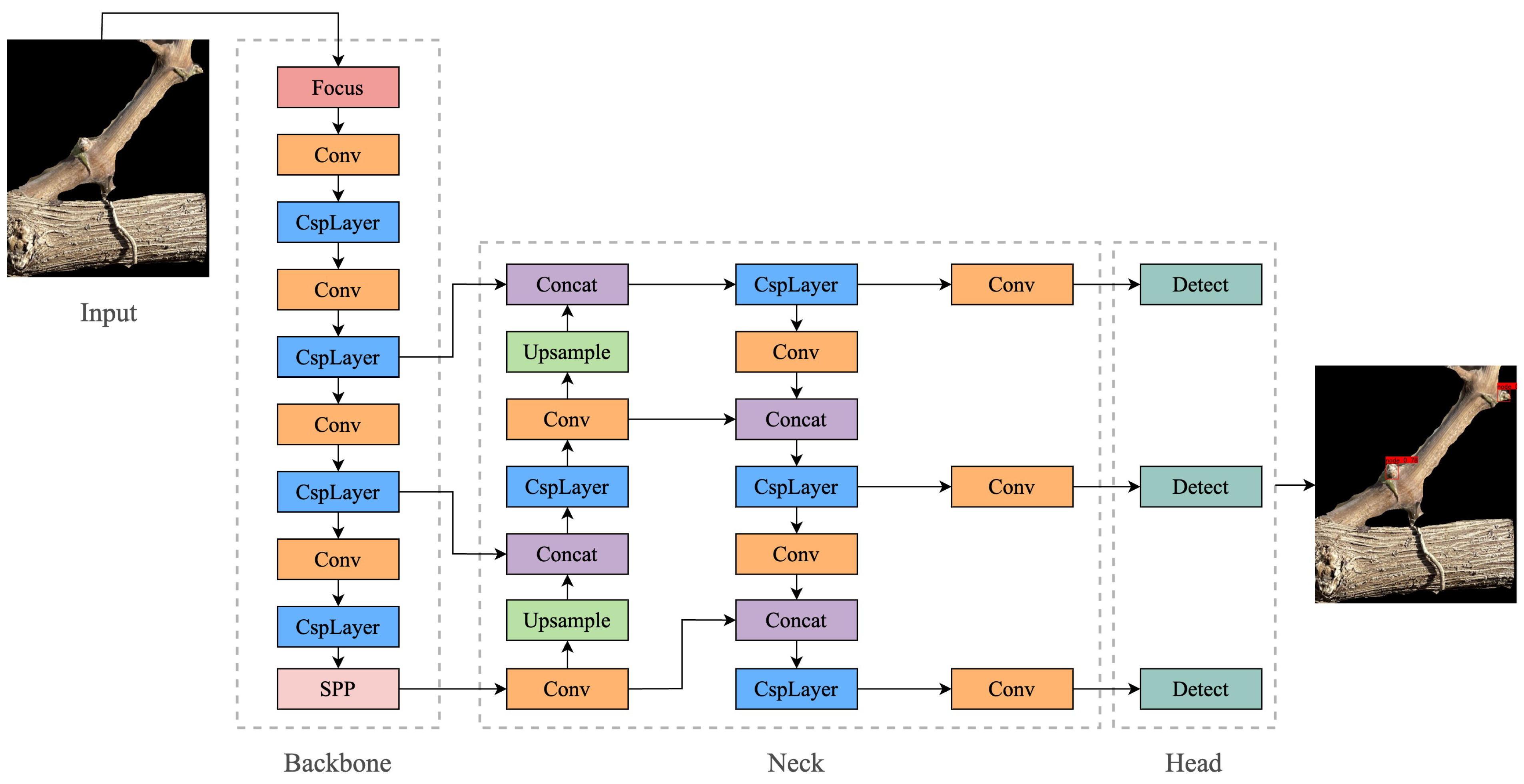
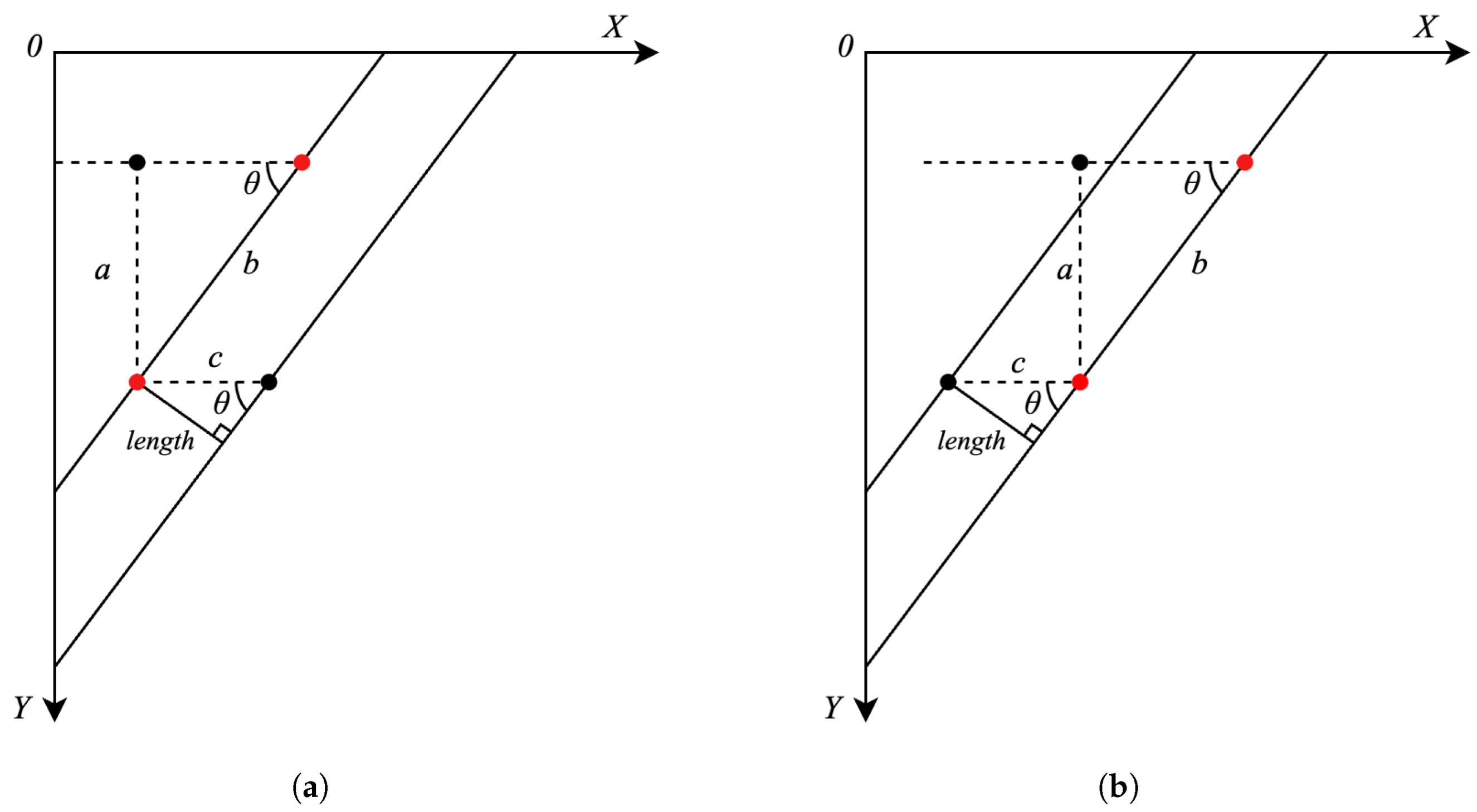
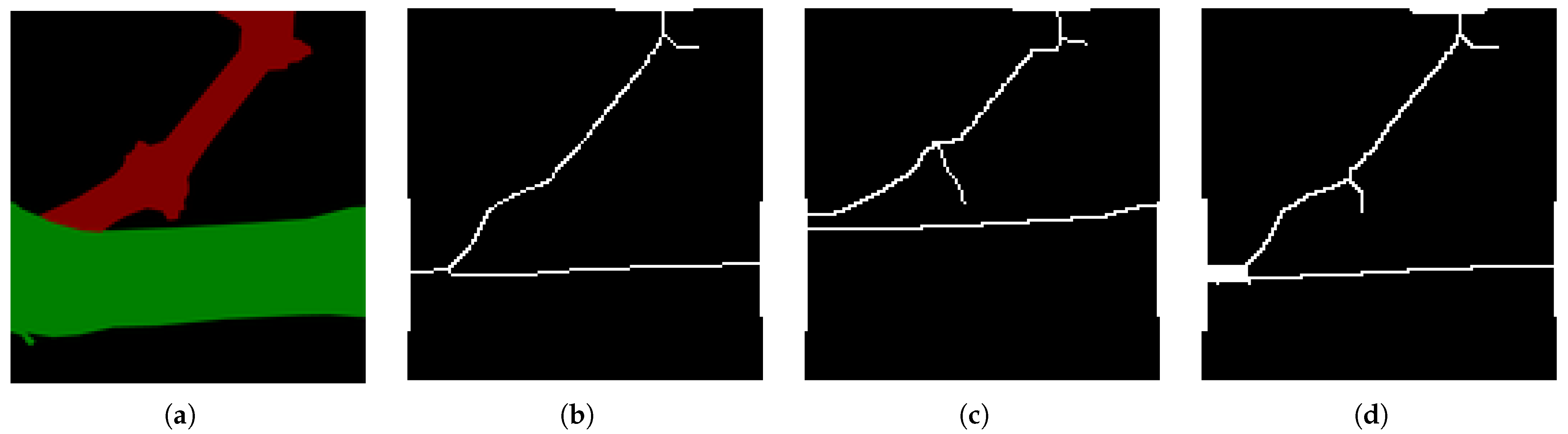
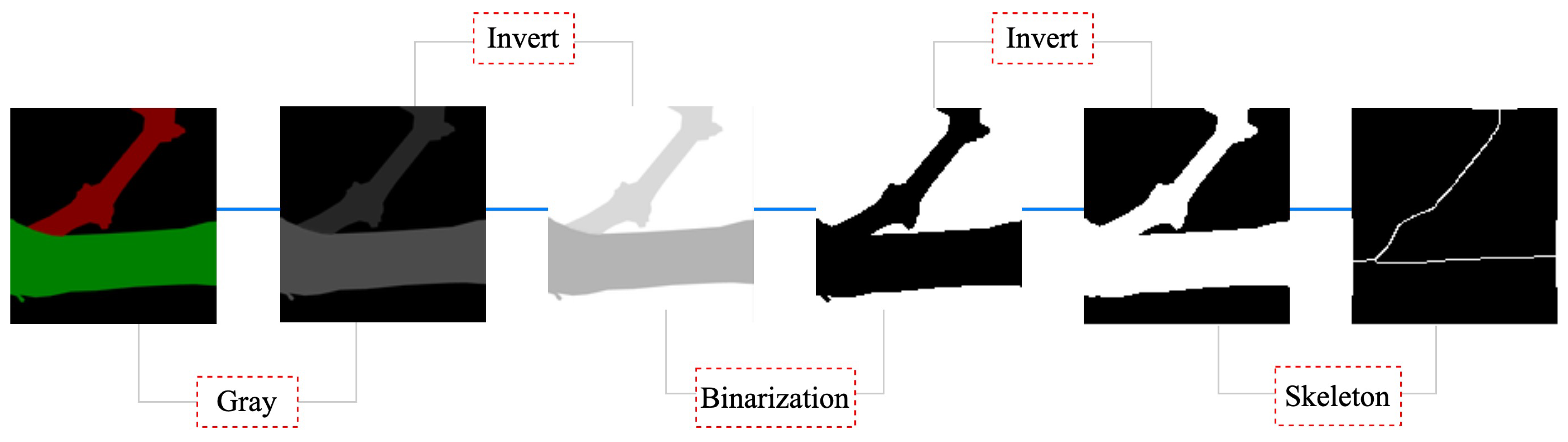
According to the pruning rule, the buds of the object to be recognized in this experiment have the characteristics of small size and similar color to the branches; if we directly use the semantic segmentation algorithm or the target-detection algorithm to detect the branches and the buds at the same time, the features of the buds are not obvious and the branches, which are the main structure, are more easily captured by the model, so the following research objectives are adopted in this experiment: the specific research objectives of this paper are (1) to use semantic segmentation algorithms to segment grape branches, the main stem and the background; (2) to use target-detection algorithms on the segmented image to determine the location of the buds on the branches; (3) to carry out skeleton thinning on the segmented branches; and (4) to determine the location of the clipping point by combining the pruning rules and depth information.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}