

Emotion Recognition beyond Pixels: Leveraging Facial Point Landmark Meshes



Abstract
Featured Application
Abstract
1. Introduction
2. Materials and Methods
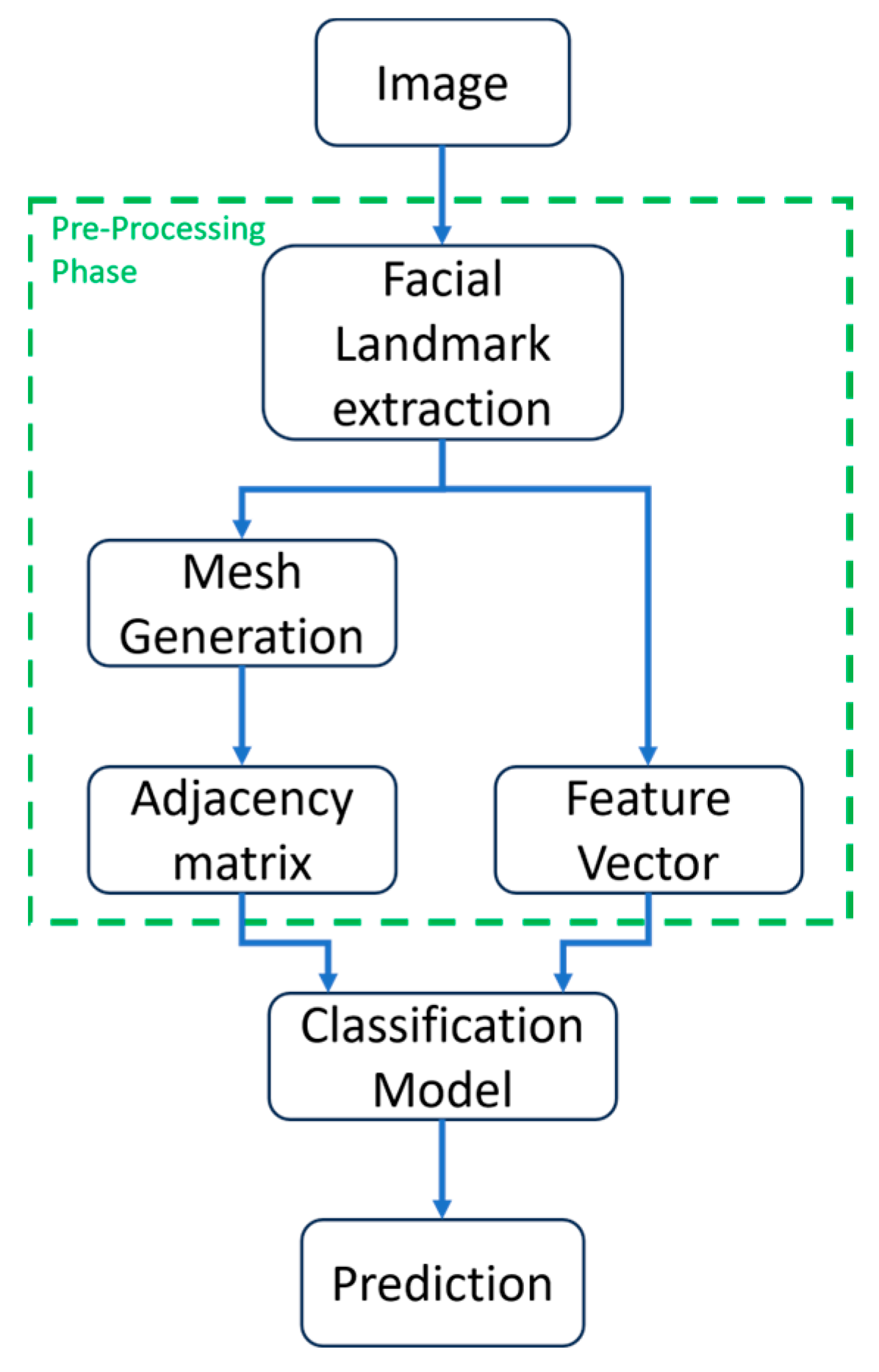
2.1. System Methodology
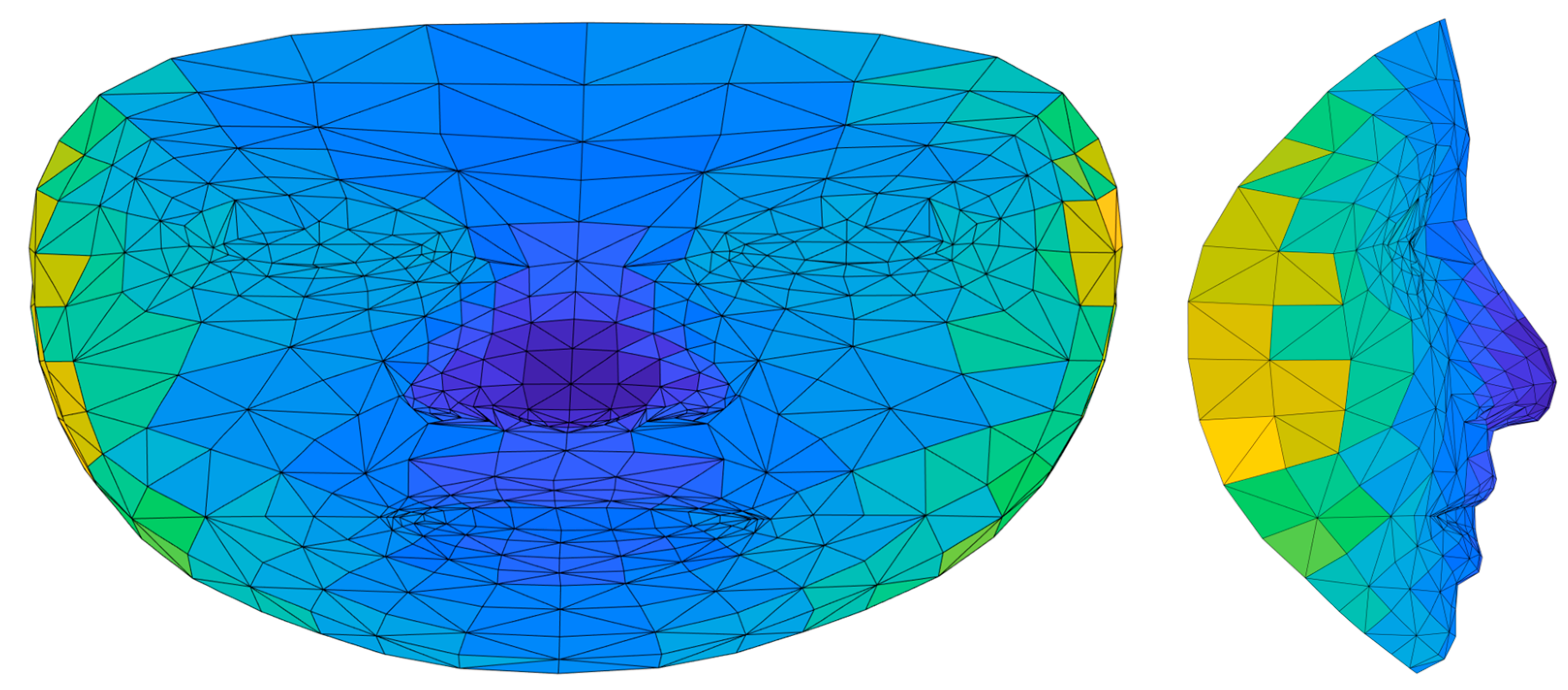
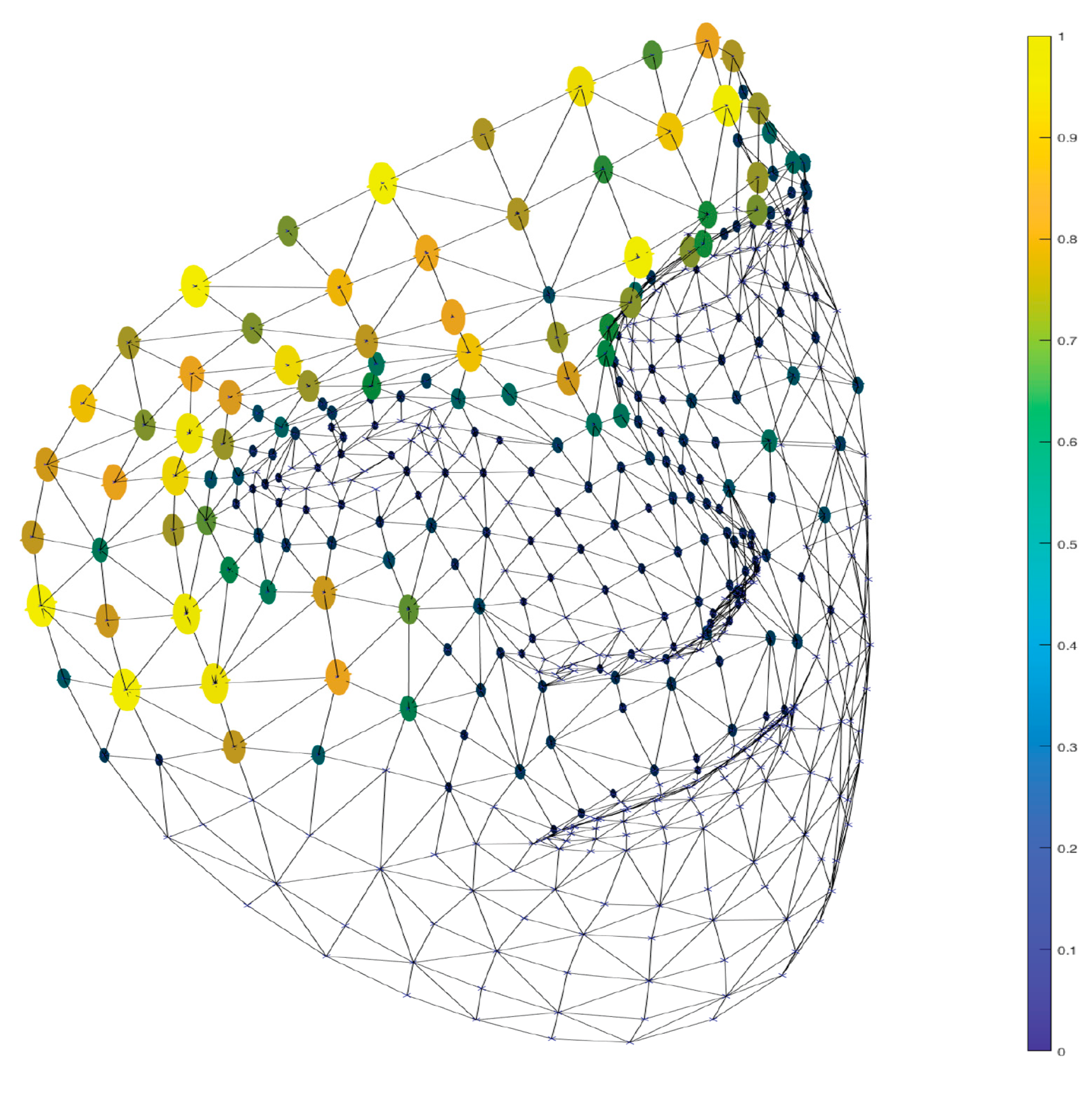
2.2. Pre-Processing Stage
2.3. Feature Extraction
2.4. Classification Model
2.4.1. Network Architecture
2.4.2. Weighted Loss
2.4.3. Training Options
2.5. Performance Measures
2.6. Database Description
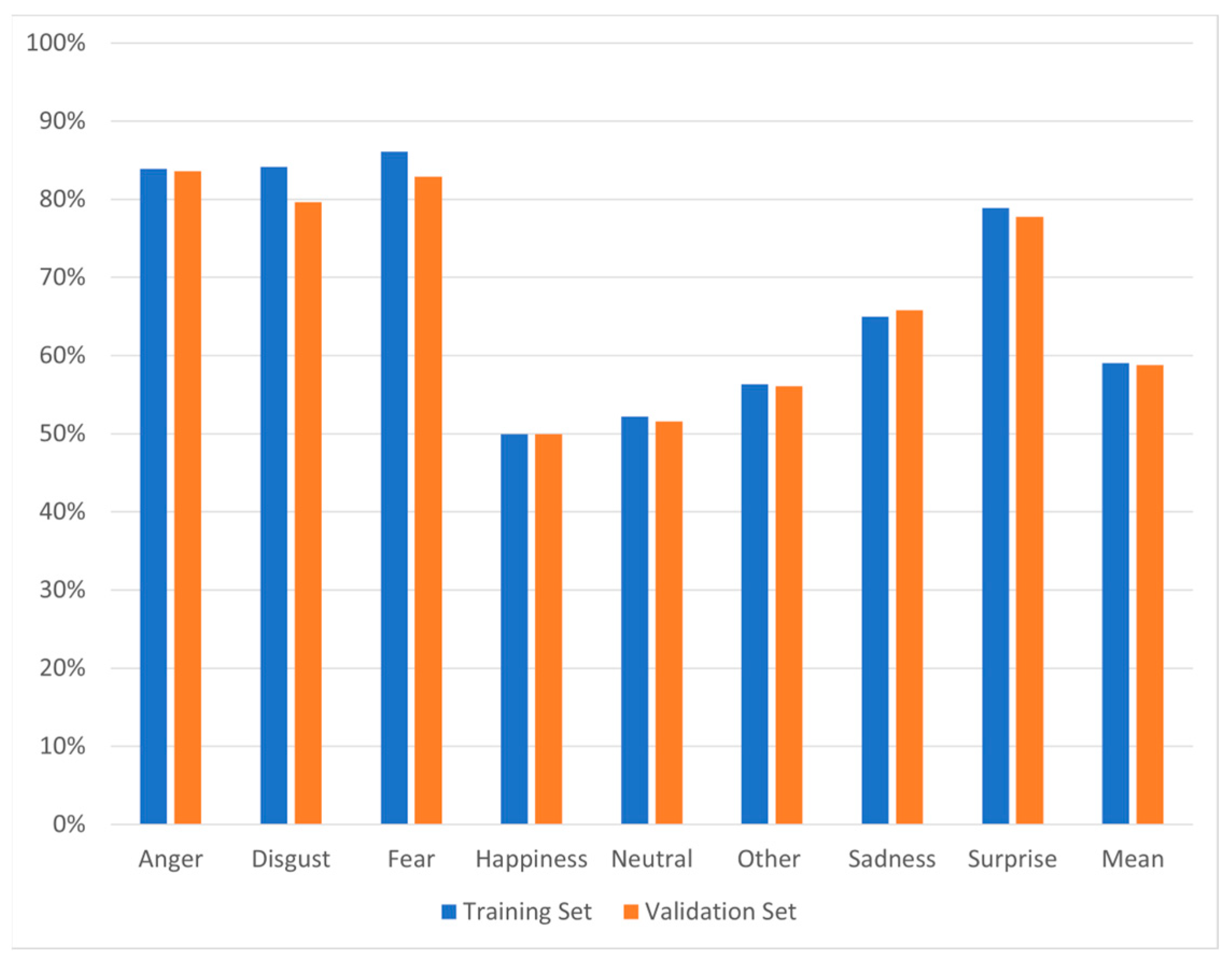
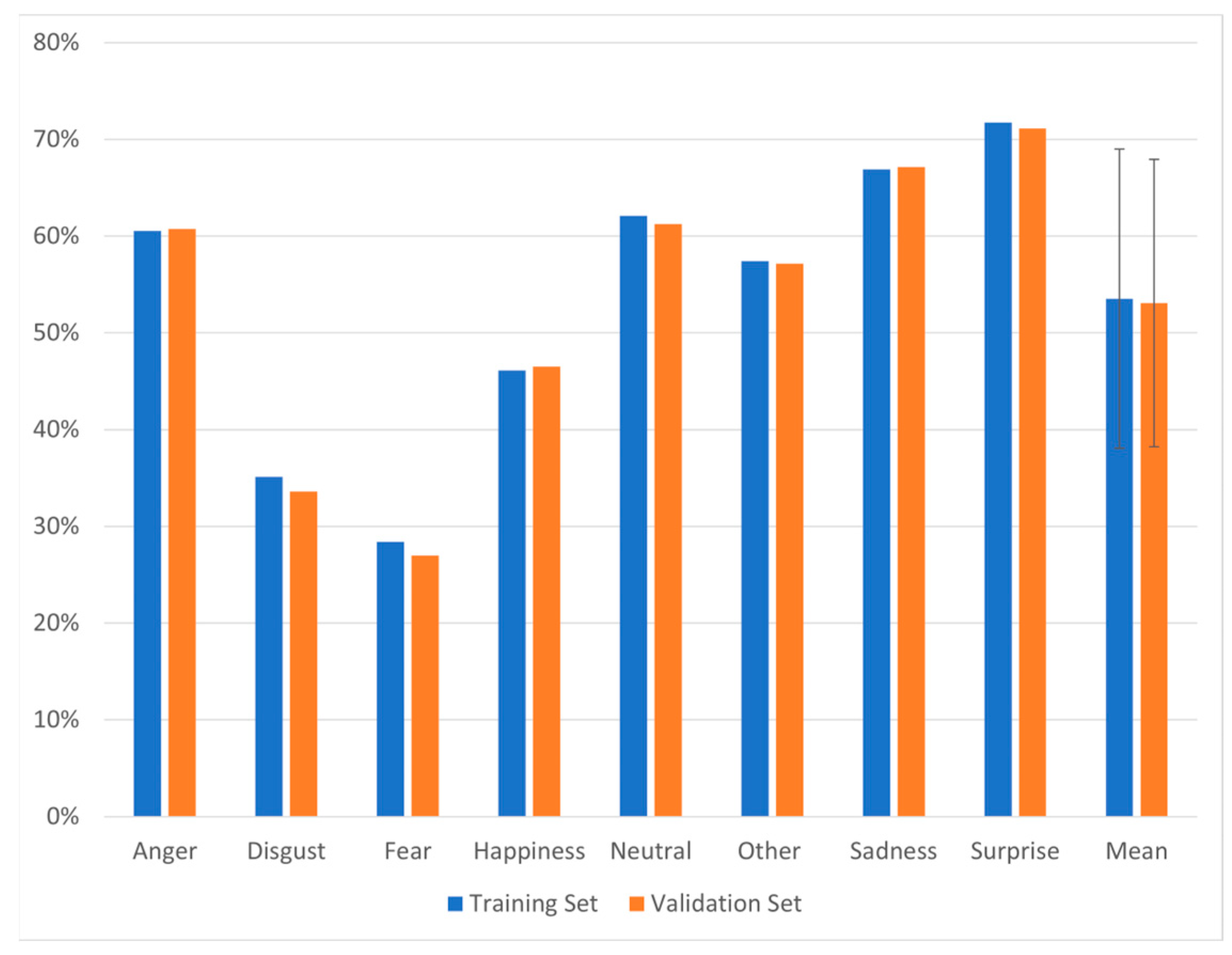
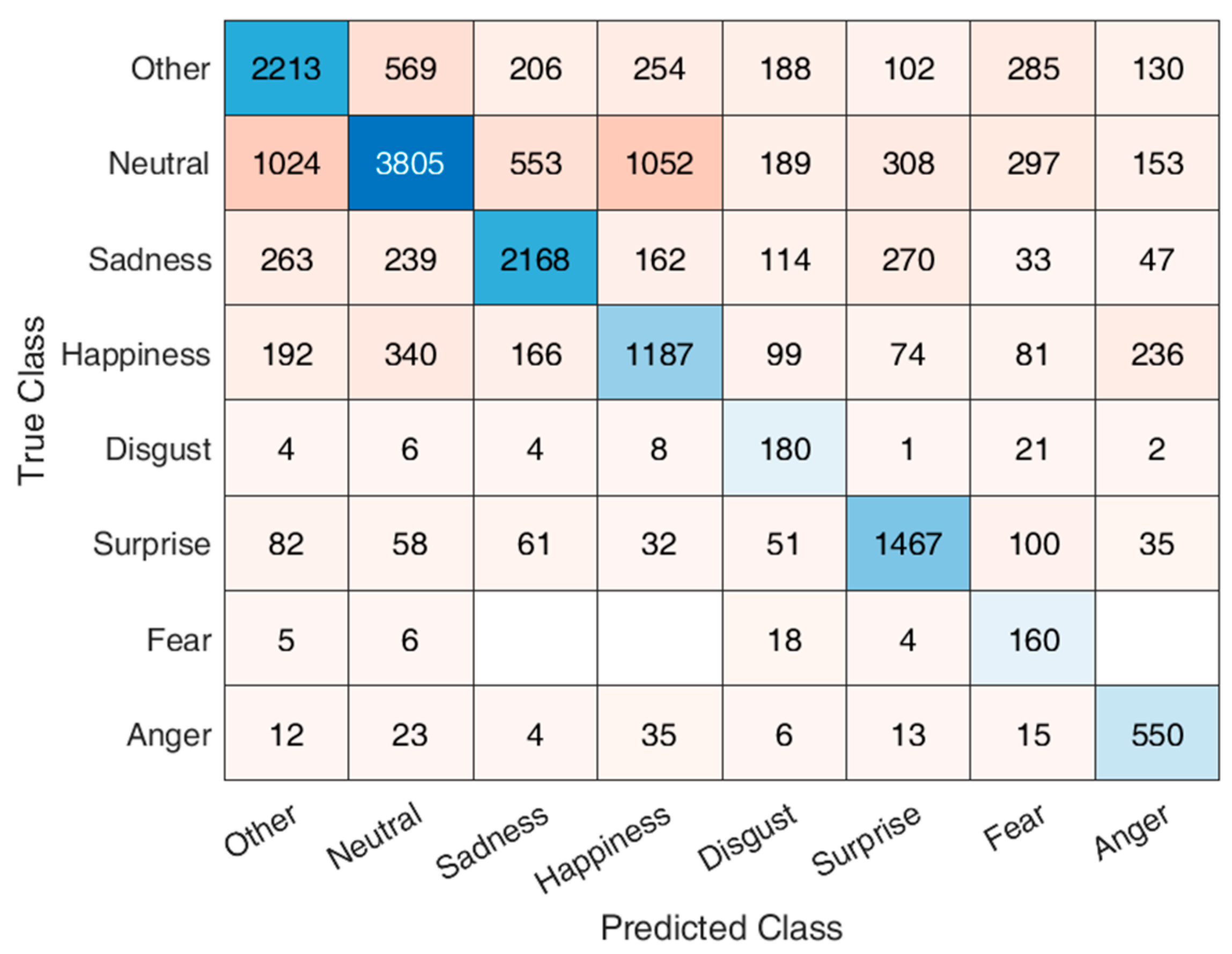
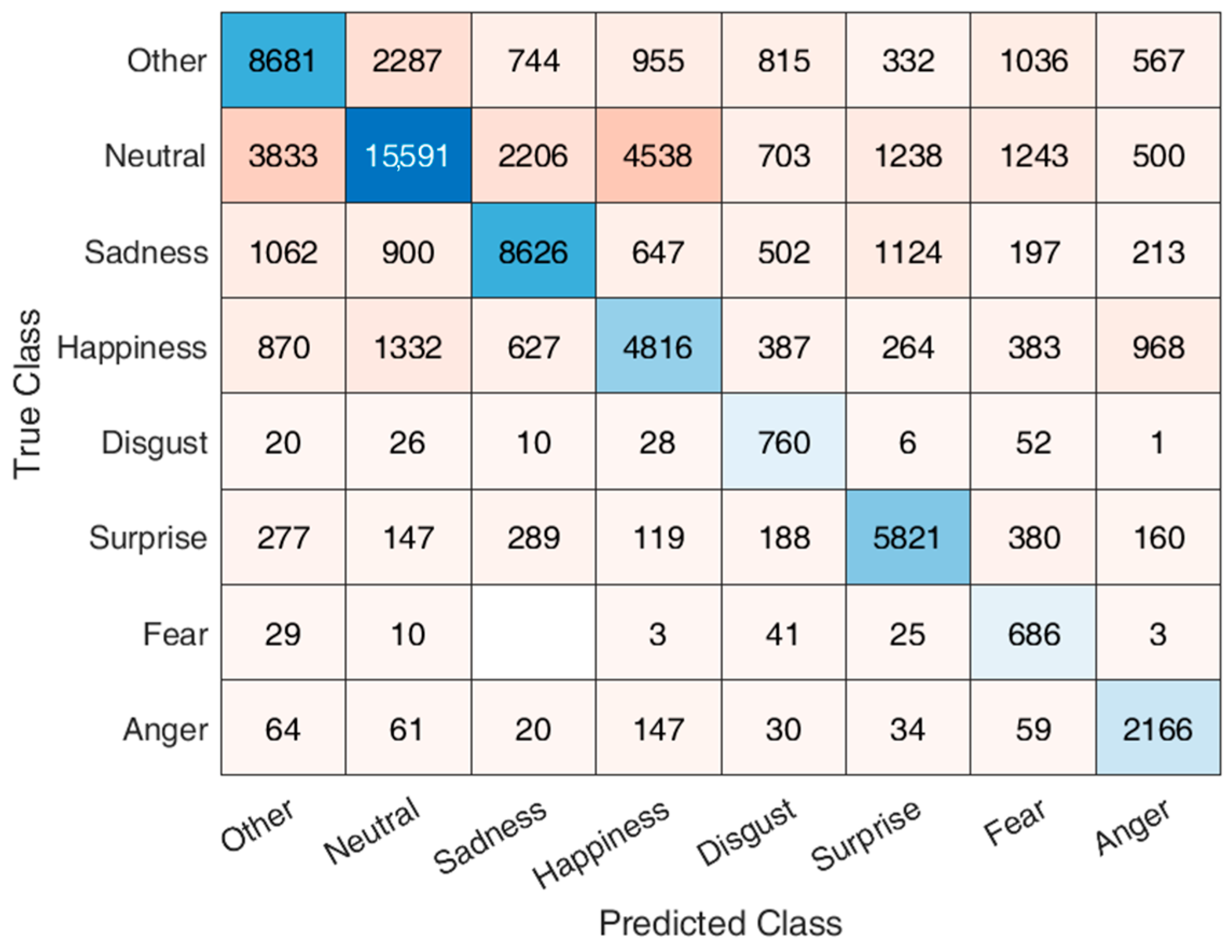
3. Results
3.1. Dataset Distribution
3.2. Model Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dorsey, E.R.; Venkataraman, V.; Grana, M.J.; Bull, M.T.; George, B.P.; Boyd, C.M.; Beck, C.A.; Rajan, B.; Seidmann, A.; Biglan, K.M. Randomized Controlled Clinical Trial of “Virtual House Calls” for Parkinson Disease. JAMA Neurol. 2013, 70, 565–570. [Google Scholar] [CrossRef] [PubMed]
- Campbell, S. From Face-to-Face to FaceTime. IEEE Pulse 2020, 11, 7–11. [Google Scholar] [CrossRef] [PubMed]
- Holder-Pearson, L.; Chase, J.G. Socio-Economic Inequity: Diabetes in New Zealand. Front. Med. 2022, 9, 756223. [Google Scholar] [CrossRef] [PubMed]
- Tebartz van Elst, L.; Fangmeier, T.; Schaller, U.M.; Hennig, O.; Kieser, M.; Koelkebeck, K.; Kuepper, C.; Roessner, V.; Wildgruber, D.; Dziobek, I. FASTER and SCOTT&EVA Trainings for Adults with High-Functioning Autism Spectrum Disorder (ASD): Study Protocol for a Randomized Controlled Trial. Trials 2021, 22, 261. [Google Scholar] [PubMed]
- Rylaarsdam, L.; Guemez-Gamboa, A. Genetic Causes and Modifiers of Autism Spectrum Disorder. Front. Cell. Neurosci. 2019, 13, 385. [Google Scholar] [CrossRef] [PubMed]
- Grifantini, K. Detecting Faces, Saving Lives. IEEE Pulse 2020, 11, 2–7. [Google Scholar] [CrossRef]
- Sandler, A.D.; Brazdziunas, D.; Cooley, W.C.; de Pijem, L.G.; Hirsch, D.; Kastner, T.A.; Kummer, M.E.; Quint, R.D.; Ruppert, E.S. The Pediatrician’s Role in the Diagnosis and Management of Autistic Spectrum Disorder in Children. Pediatrics 2001, 107, 1221–1226. [Google Scholar]
- Golan, O.; Ashwin, E.; Granader, Y.; McClintock, S.; Day, K.; Leggett, V.; Baron-Cohen, S. Enhancing Emotion Recognition in Children with Autism Spectrum Conditions: An Intervention Using Animated Vehicles with Real Emotional Faces. J. Autism Dev. Disord. 2010, 40, 269–279. [Google Scholar] [CrossRef] [PubMed]
- Yuan, S.N.V.; Ip, H.H.S. Using Virtual Reality to Train Emotional and Social Skills in Children with Autism Spectrum Disorder. Lond. J. Prim. Care 2018, 10, 110–112. [Google Scholar] [CrossRef] [PubMed]
- Ravindran, V.; Osgood, M.; Sazawal, V.; Solorzano, R.; Turnacioglu, S. Virtual Reality Support for Joint Attention Using the Floreo Joint Attention Module: Usability and Feasibility Pilot Study. JMIR Pediatr. Parent. 2019, 2, e14429. [Google Scholar] [CrossRef] [PubMed]
- Scherer, K.R. What Are Emotions? And How Can They Be Measured? Soc. Sci. Inf. 2005, 44, 695–729. [Google Scholar] [CrossRef]
- Lang, P.J.; Bradley, M.M. Emotion and the Motivational Brain. Biol. Psychol. 2010, 84, 437–450. [Google Scholar] [CrossRef]
- Vuilleumier, P. How Brains Beware: Neural Mechanisms of Emotional Attention. Trends Cogn. Sci. 2005, 9, 585–594. [Google Scholar] [CrossRef] [PubMed]
- Mancini, C.; Falciati, L.; Maioli, C.; Mirabella, G. Happy Facial Expressions Impair Inhibitory Control with Respect to Fearful Facial Expressions but Only When Task-Relevant. Emotion 2022, 22, 142. [Google Scholar] [CrossRef] [PubMed]
- Mirabella, G.; Grassi, M.; Mezzarobba, S.; Bernardis, P. Angry and Happy Expressions Affect Forward Gait Initiation Only When Task Relevant. Emotion 2023, 23, 387. [Google Scholar] [CrossRef] [PubMed]
- Tautkute, I.; Trzcinski, T.; Bielski, A. I Know How You Feel: Emotion Recognition with Facial Landmarks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1878–1880. [Google Scholar]
- Mehrabian, A. Communication without Words. In Communication Theory; Mortensen, C.D., Ed.; Routledge: London, UK, 2017; pp. 193–200. ISBN 978-1-315-08091-8. [Google Scholar]
- De Gelder, B. Why Bodies? Twelve Reasons for Including Bodily Expressions in Affective Neuroscience. Philos. Trans. R. Soc. B Biol. Sci. 2009, 364, 3475–3484. [Google Scholar] [CrossRef] [PubMed]
- De Gelder, B.; Van den Stock, J.; Meeren, H.K.; Sinke, C.B.; Kret, M.E.; Tamietto, M. Standing up for the Body. Recent Progress in Uncovering the Networks Involved in the Perception of Bodies and Bodily Expressions. Neurosci. Biobehav. Rev. 2010, 34, 513–527. [Google Scholar] [CrossRef] [PubMed]
- Arabian, H.; Battistel, A.; Chase, J.G.; Moeller, K. Attention-Guided Network Model for Image-Based Emotion Recognition. Appl. Sci. 2023, 13, 10179. [Google Scholar] [CrossRef]
- Sepas-Moghaddam, A.; Etemad, A.; Pereira, F.; Correia, P.L. Facial Emotion Recognition Using Light Field Images with Deep Attention-Based Bidirectional LSTM. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 3367–3371. [Google Scholar]
- Khaireddin, Y.; Chen, Z. Facial Emotion Recognition: State of the Art Performance on FER2013. arXiv 2021, arXiv:2105.03588. [Google Scholar]
- Mehendale, N. Facial Emotion Recognition Using Convolutional Neural Networks (FERC). SN Appl. Sci. 2020, 2, 446. [Google Scholar] [CrossRef]
- Zhao, X.; Liang, X.; Liu, L.; Li, T.; Han, Y.; Vasconcelos, N.; Yan, S. Peak-Piloted Deep Network for Facial Expression Recognition. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 425–442. [Google Scholar]
- Li, Y.; Lu, G.; Li, J.; Zhang, Z.; Zhang, D. Facial Expression Recognition in the Wild Using Multi-Level Features and Attention Mechanisms. IEEE Trans. Affect. Comput. 2020, 14, 451–462. [Google Scholar] [CrossRef]
- Tarnowski, P.; Kołodziej, M.; Majkowski, A.; Rak, R.J. Emotion Recognition Using Facial Expressions. Procedia Comput. Sci. 2017, 108, 1175–1184. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. Facial Action Coding System. Environ. Psychol. Nonverbal Behav. 1978. [Google Scholar] [CrossRef]
- Goeleven, E.; De Raedt, R.; Leyman, L.; Verschuere, B. The Karolinska Directed Emotional Faces: A Validation Study. Cogn. Emot. 2008, 22, 1094–1118. [Google Scholar] [CrossRef]
- Li, D.; Wang, Z.; Gao, Q.; Song, Y.; Yu, X.; Wang, C. Facial Expression Recognition Based on Electroencephalogram and Facial Landmark Localization. Technol. Health Care 2019, 27, 373–387. [Google Scholar] [CrossRef] [PubMed]
- Siam, A.I.; Soliman, N.F.; Algarni, A.D.; El-Samie, A.; Fathi, E.; Sedik, A. Deploying Machine Learning Techniques for Human Emotion Detection. Comput. Intell. Neurosci. 2022, 2022, 8032673. [Google Scholar] [CrossRef] [PubMed]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Derrow-Pinion, A.; She, J.; Wong, D.; Lange, O.; Hester, T.; Perez, L.; Nunkesser, M.; Lee, S.; Guo, X.; Wiltshire, B. Eta Prediction with Graph Neural Networks in Google Maps. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Gold Coast, Australia, 1–5 November 2021; pp. 3767–3776. [Google Scholar]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph Neural Networks: A Review of Methods and Applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Zafeiriou, S.; Kollias, D.; Nicolaou, M.A.; Papaioannou, A.; Zhao, G.; Kotsia, I. Aff-Wild: Valence and Arousal ‘In-the-Wild’ challenge. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 34–41. [Google Scholar]
- Kollias, D.; Tzirakis, P.; Nicolaou, M.A.; Papaioannou, A.; Zhao, G.; Schuller, B.; Kotsia, I.; Zafeiriou, S. Deep Affect Prediction In-the-Wild: Aff-Wild Database and Challenge, Deep Architectures, and Beyond. Int. J. Comput. Vis. 2019, 127, 907–929. [Google Scholar] [CrossRef]
- Kollias, D.; Sharmanska, V.; Zafeiriou, S. Face Behavior a La Carte: Expressions, Affect and Action Units in a Single Network. arXiv 2019, arXiv:1910.11111. [Google Scholar]
- Kollias, D.; Zafeiriou, S. Expression, Affect, Action Unit Recognition: Aff-Wild2, Multi-Task Learning and Arcface. arXiv 2019, arXiv:1910.04855. [Google Scholar]
- Kollias, D.; Zafeiriou, S. Affect Analysis In-the-Wild: Valence-Arousal, Expressions, Action Units and a Unified Framework. arXiv 2021, arXiv:2103.15792. [Google Scholar]
- Kollias, D.; Sharmanska, V.; Zafeiriou, S. Distribution Matching for Heterogeneous Multi-Task Learning: A Large-Scale Face Study. arXiv 2021, arXiv:2105.03790. [Google Scholar]
- Kollias, D.; Schulc, A.; Hajiyev, E.; Zafeiriou, S. Analysing Affective Behavior in the First Abaw 2020 Competition. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 637–643. [Google Scholar]
- Kollias, D.; Zafeiriou, S. Analysing Affective Behavior in the Second Abaw2 Competition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3652–3660. [Google Scholar]
- Kollias, D. Abaw: Valence-Arousal Estimation, Expression Recognition, Action Unit Detection & Multi-Task Learning Challenges. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2328–2336. [Google Scholar]
- Kollias, D. ABAW: Learning from Synthetic Data & Multi-Task Learning Challenges. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 157–172. [Google Scholar]
- Kollias, D.; Tzirakis, P.; Baird, A.; Cowen, A.; Zafeiriou, S. Abaw: Valence-Arousal Estimation, Expression Recognition, Action Unit Detection & Emotional Reaction Intensity Estimation Challenges. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5888–5897. [Google Scholar]
- Lugaresi, C.; Tang, J.; Nash, H.; McClanahan, C.; Uboweja, E.; Hays, M.; Zhang, F.; Chang, C.-L.; Yong, M.; Lee, J. Mediapipe: A Framework for Perceiving and Processing Reality. In Proceedings of the Third Workshop on Computer Vision for AR/VR at IEEE Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; Volume 2019. [Google Scholar]
- Yu, J.; Cai, Z.; Li, R.; Zhao, G.; Xie, G.; Zhu, J.; Zhu, W.; Ling, Q.; Wang, L.; Wang, C. Exploring Large-Scale Unlabeled Faces to Enhance Facial Expression Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5802–5809. [Google Scholar]
- Xue, F.; Sun, Y.; Yang, Y. Exploring Expression-Related Self-Supervised Learning for Affective Behaviour Analysis. arXiv 2023, arXiv:2303.10511. [Google Scholar]
- Savchenko, A.V. Emotieffnet Facial Features in Uni-Task Emotion Recognition in Video at Abaw-5 Competition. arXiv 2023, arXiv:2303.09162. [Google Scholar]
- Zhang, Z.; An, L.; Cui, Z.; Dong, T. Facial Affect Recognition Based on Transformer Encoder and Audiovisual Fusion for the ABAW5 Challenge. arXiv 2023, arXiv:2303.09158. [Google Scholar]
- Zhou, W.; Lu, J.; Xiong, Z.; Wang, W. Leveraging TCN and Transformer for Effective Visual-Audio Fusion in Continuous Emotion Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5755–5762. [Google Scholar]
- Zhu, R.; Guo, Y.; Xue, J.-H. Adjusting the Imbalance Ratio by the Dimensionality of Imbalanced Data. Pattern Recognit. Lett. 2020, 133, 217–223. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Emotion Class | Selected | Training | Validation |
|---|---|---|---|
| Anger | 3239 | 2581 | 658 |
| Disgust | 1129 | 903 | 226 |
| Fear | 990 | 797 | 193 |
| Happiness | 12,022 | 9647 | 2375 |
| Neutral | 37,233 | 29,852 | 7381 |
| Other | 19,364 | 15,417 | 3947 |
| Sadness | 16,567 | 13,271 | 3296 |
| Surprise | 9267 | 7381 | 1886 |
| Total | 99,811 | 79,849 | 19,962 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arabian, H.; Abdulbaki Alshirbaji, T.; Chase, J.G.; Moeller, K. Emotion Recognition beyond Pixels: Leveraging Facial Point Landmark Meshes. Appl. Sci. 2024, 14, 3358. https://doi.org/10.3390/app14083358
Arabian H, Abdulbaki Alshirbaji T, Chase JG, Moeller K. Emotion Recognition beyond Pixels: Leveraging Facial Point Landmark Meshes. Applied Sciences. 2024; 14(8):3358. https://doi.org/10.3390/app14083358
Chicago/Turabian StyleArabian, Herag, Tamer Abdulbaki Alshirbaji, J. Geoffrey Chase, and Knut Moeller. 2024. "Emotion Recognition beyond Pixels: Leveraging Facial Point Landmark Meshes" Applied Sciences 14, no. 8: 3358. https://doi.org/10.3390/app14083358
APA StyleArabian, H., Abdulbaki Alshirbaji, T., Chase, J. G., & Moeller, K. (2024). Emotion Recognition beyond Pixels: Leveraging Facial Point Landmark Meshes. Applied Sciences, 14(8), 3358. https://doi.org/10.3390/app14083358