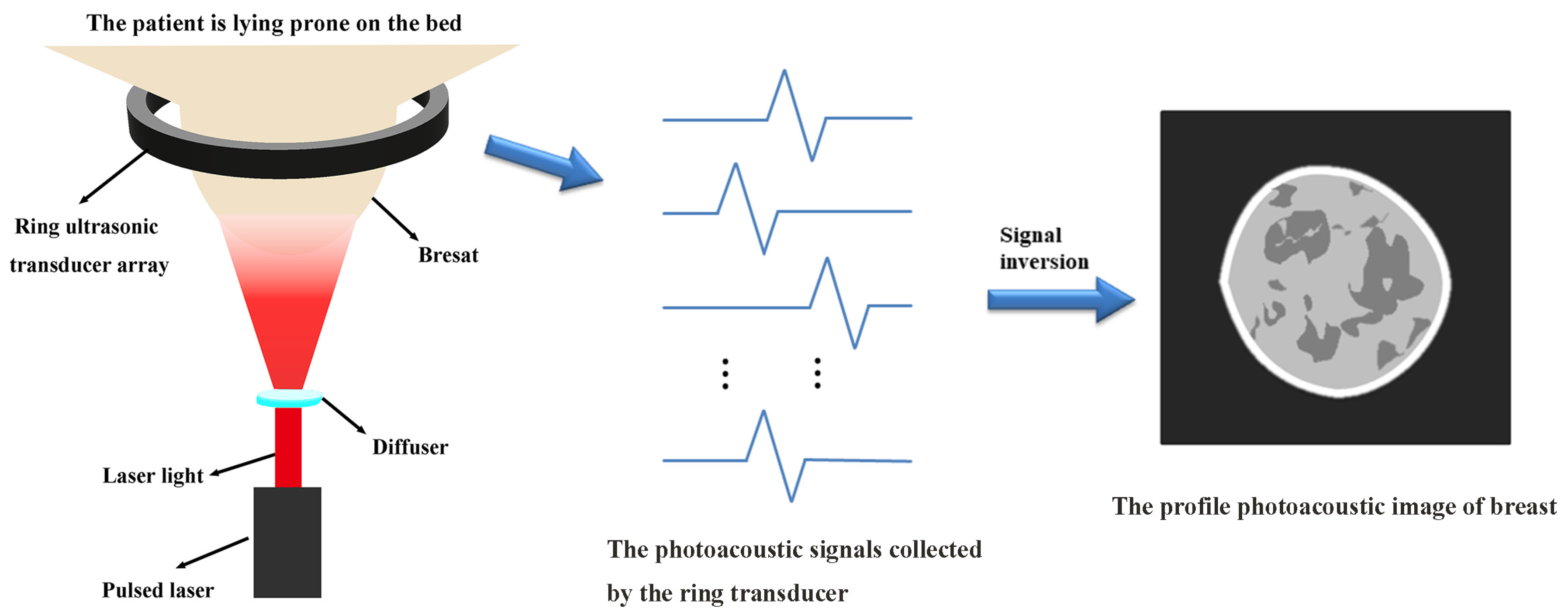
2.1. The Influence of Inaccurate Sound Speed Fields on PAI
Assuming that biological tissue is a homogeneous medium, the basic equation of PAI can be expressed as follows [
17]:
In Equation (1),
is the photoacoustic pressure received by the ultrasonic transducer at position
at time
t.
v is the homogeneous sound speed.
is the coefficient of thermal expansion.
C is the specific heat capacity.
represents the light absorption coefficient distribution function.
represents the time distribution function of the incident laser. Due to the short duration of the laser pulse,
can be replaced by an excitation pulse
approximation [
17]. Using the Green function to solve
, the general relationship between photoacoustic pressure and the light absorption coefficient is obtained as follows [
17]:
The temporal integral function of
is introduced as follows:
Equation (2) is brought into Equation (3). The constant terms of the two formulas cancel, and the time derivative term
in Equation (2) cancels the time integral term
in Equation (3), so Equation (4) is obtained, as follows:
where
represents the spherical Radon transform of the
; therefore, the photoacoustic image can be obtained by inverting the spherical Radon transform [
18]. However, Equation (4) is only suitable for PAI under homogeneous sound speed fields.
When the presence of an inhomogeneous sound speed field is taken into account in PAI, the speed field causes photoacoustic signals to refract during propagation [
19]. The sound speed at any position in this sound speed field can be set to
. The TOF of the photoacoustic signal is obtained by calculating the line integral of the reciprocal of the sound speed along the approximate propagation path as follows:
where
is the distance from the sound source position
r to the ultrasonic transducer
. Equation (5) is brought into Equation (2). The relationship between the photoacoustic pressure
obtained under the inhomogeneous sound speed field and
can be expressed as follows:
Equations (5) and (6) are brought into Equation (3) as follows:
where
is called the generalized Radon transformation of the
A(
r) in the inhomogeneous sound speed field. The image reconstruction process can be achieved by performing the inverse Radon transform on Equation (7) [
18].
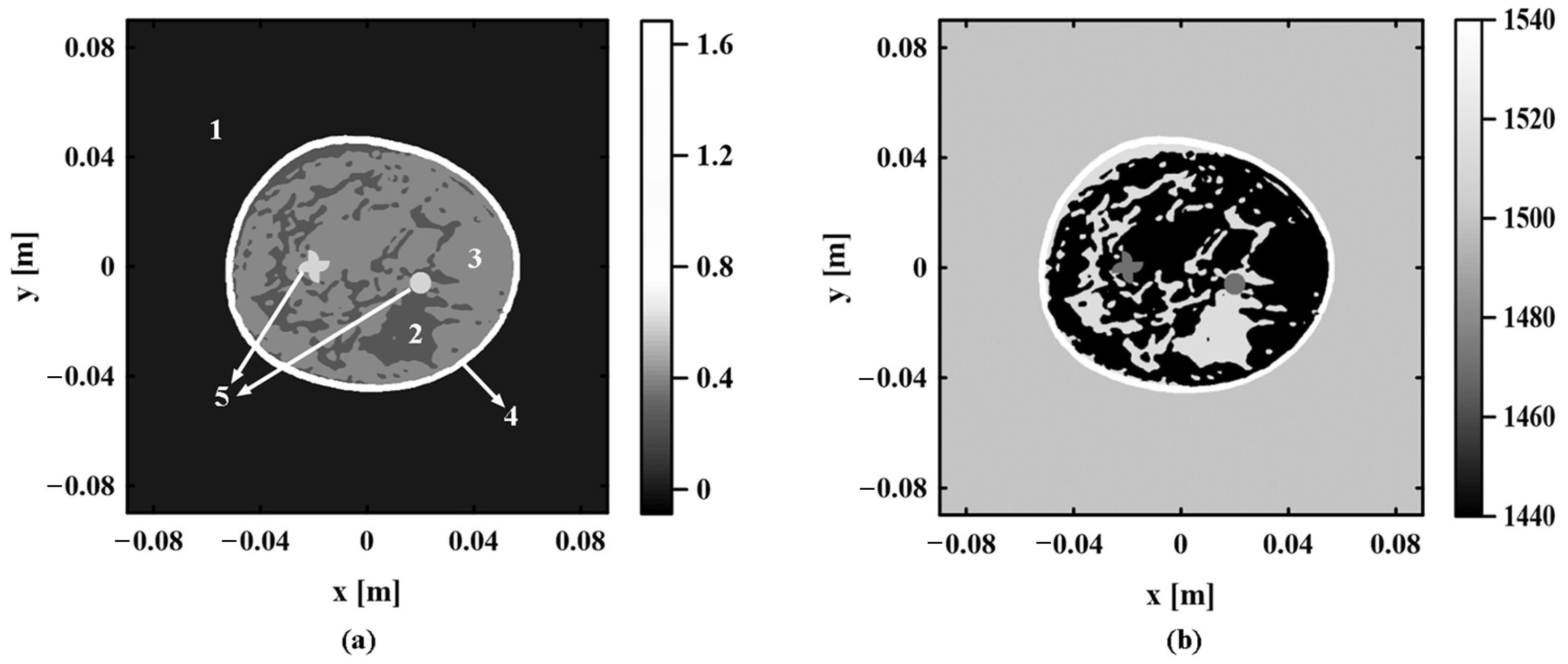
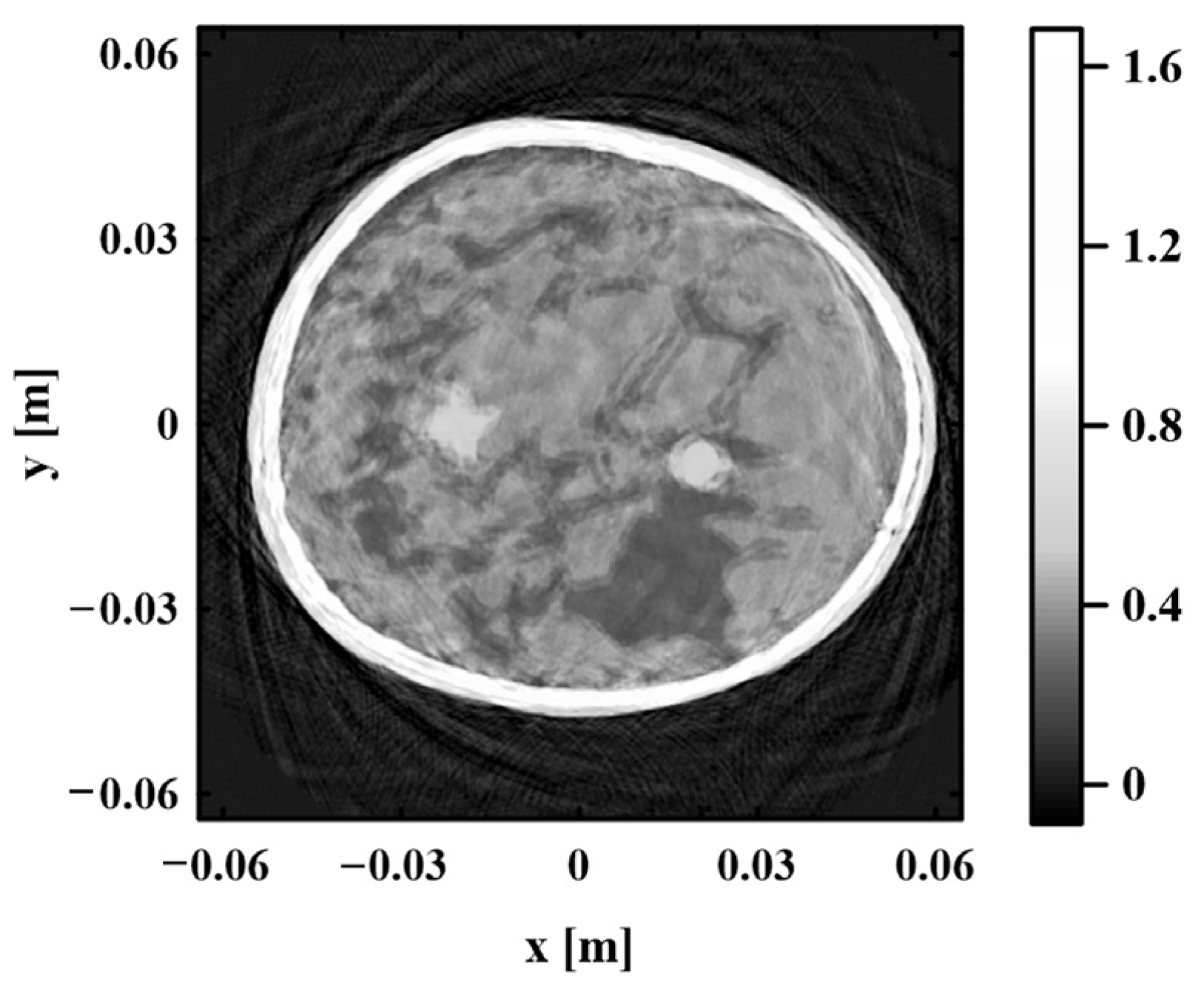
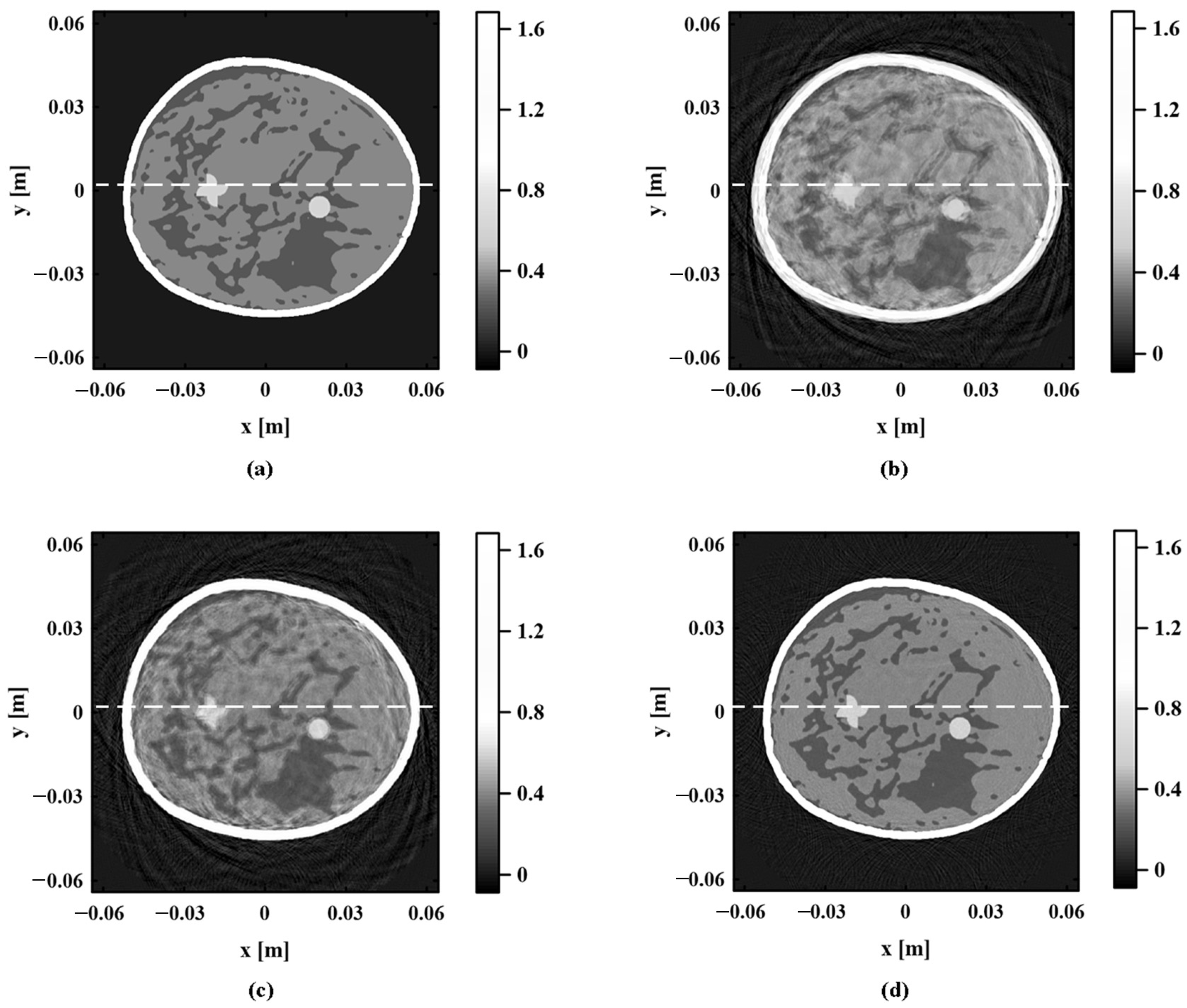
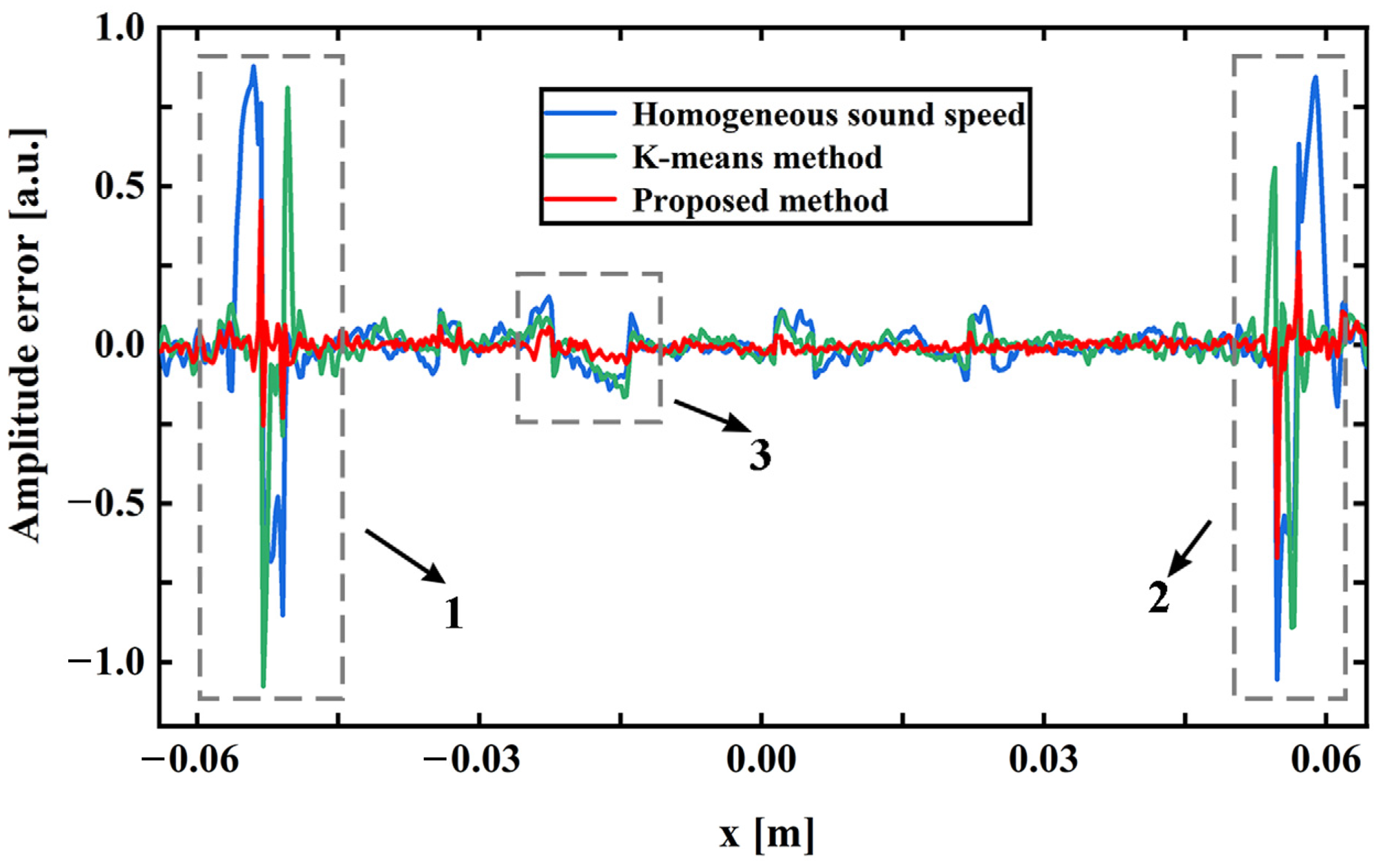
In the process of image reconstruction, the TOF is related to the propagation path of photoacoustic signal and depends on the sound speed distribution of biological tissue. If the inhomogeneous sound speed field is quite different from the real sound speed distribution in the reconstruction process, the TOF of photoacoustic signals will inevitably have serious errors. As shown in Equation (7), the change in TOF further leads to the failure of the photoacoustic signal to achieve focus at the target position, which makes the photoacoustic image appear as an artifact. The inaccuracy of the inhomogeneous sound speed field can seriously affect the quality of the photoacoustic image.
2.2. “K-Means + Gaussian Mixture Model” Clustering
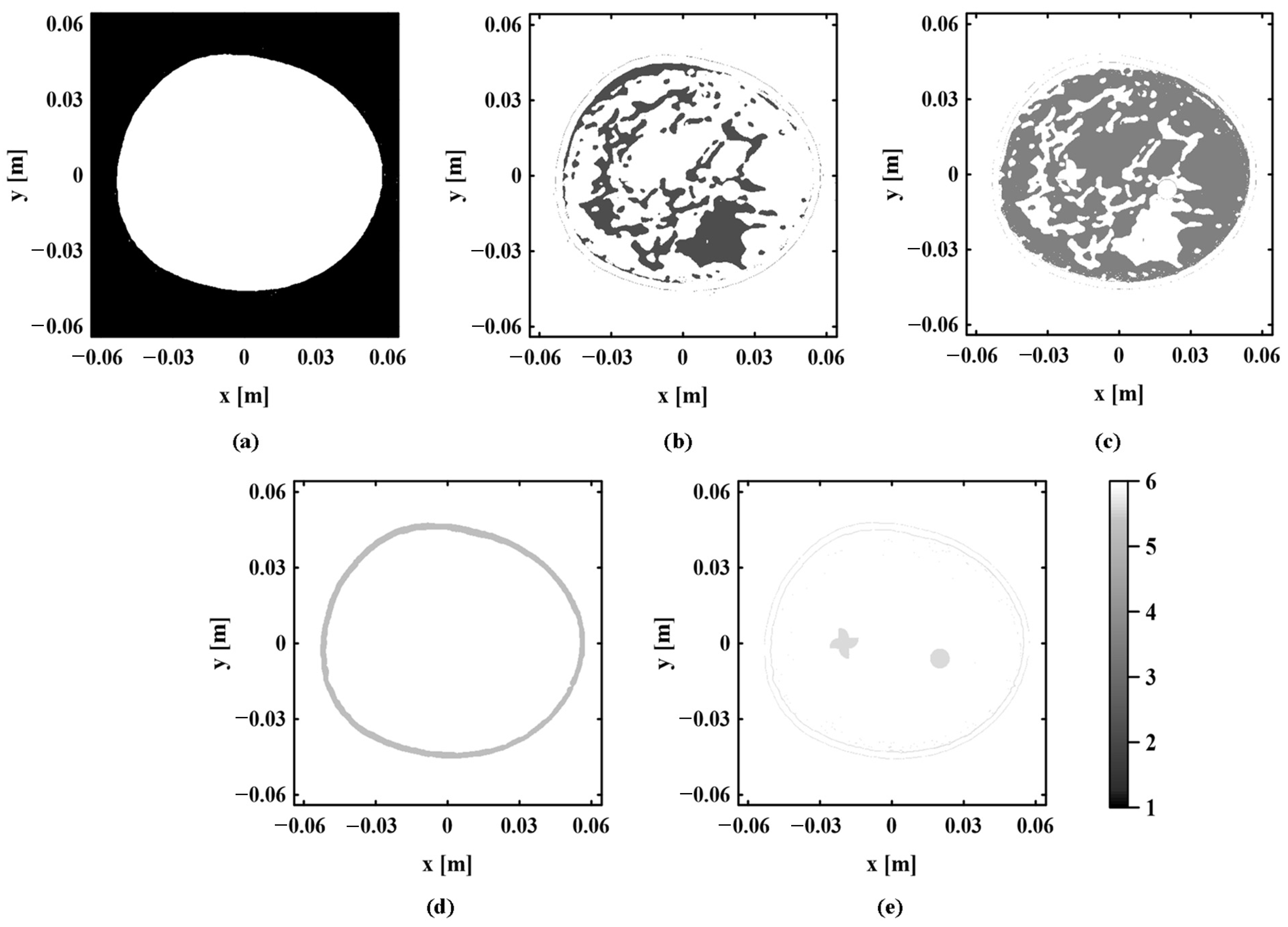
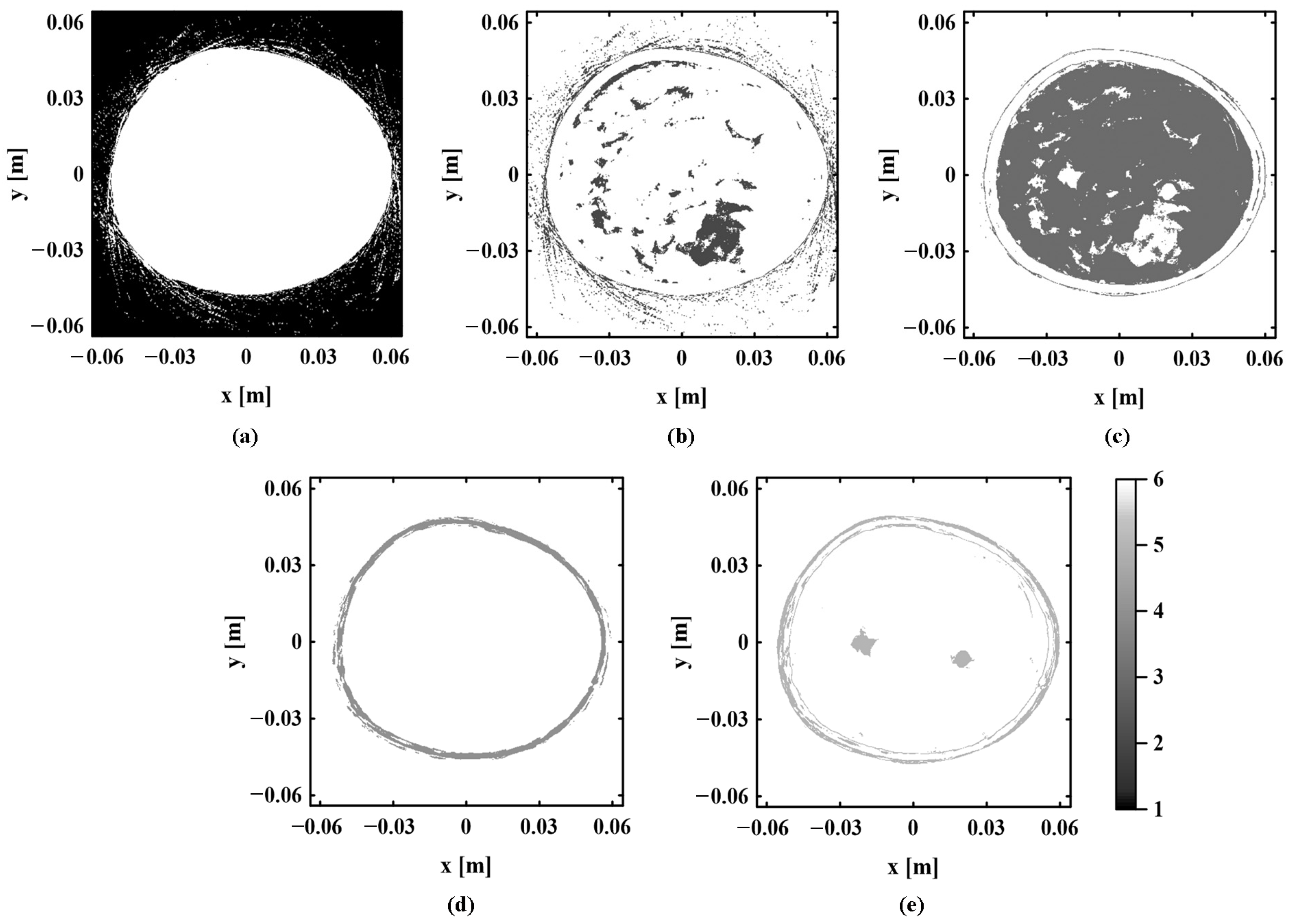
In PAI, the sound speed field is one of the important parameters that directly affect the accuracy and quality of imaging. It is necessary to accurately estimate the inhomogeneous sound speed field of biological tissues. Since identical tissues in biological tissues have similar properties, data clustering can be carried out according to the similarity between the photoacoustic pressure data to extract the regional location information about various tissues. The application of clustering regards the same tissue region of homogeneous sound speed as a whole. This reduces the number of sound speeds to be estimated in the inhomogeneous sound speed field and provides convenience for the further accurate estimation of sound speed distribution.
The internal structure of biological tissue is reflected through the photoacoustic pressure value of each pixel in a photoacoustic image. The photoacoustic pressure data are matrix data of
. The sequence form is expressed as
. The proposed method combining K-means and GMM is used to cluster the data. Compared with K-means or GMM, this hybrid clustering displays a significant improvement in clustering performance [
20]. It can obtain more accurate regional location information. K-means is one of the most common clustering analysis algorithms, and its convergence speed is fast. The application of K-means to pre-process photoacoustic pressure data can provide relatively accurate initial parameters for GMM and improve computational efficiency. K-means belongs to hard clustering. It takes distance as the similarity index and calculates the distance between each data and the center of each cluster. Each datum is divided into the closest cluster.
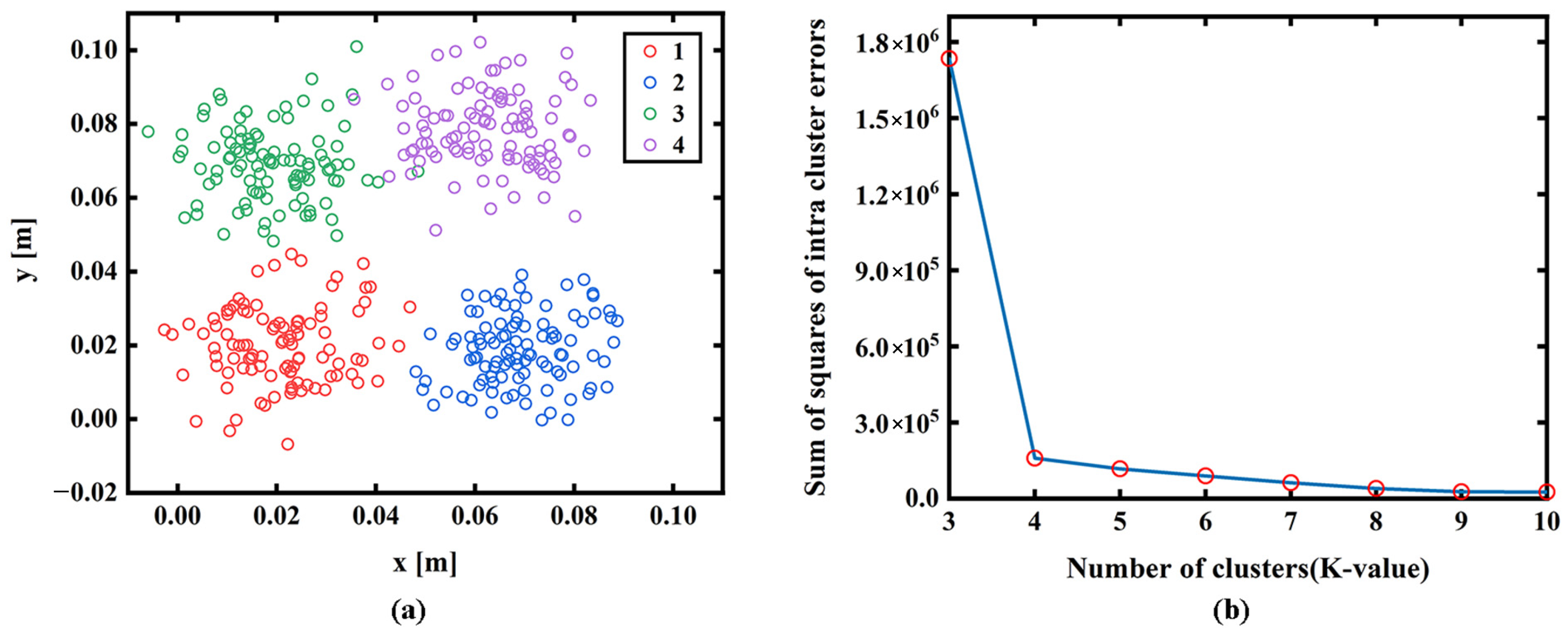
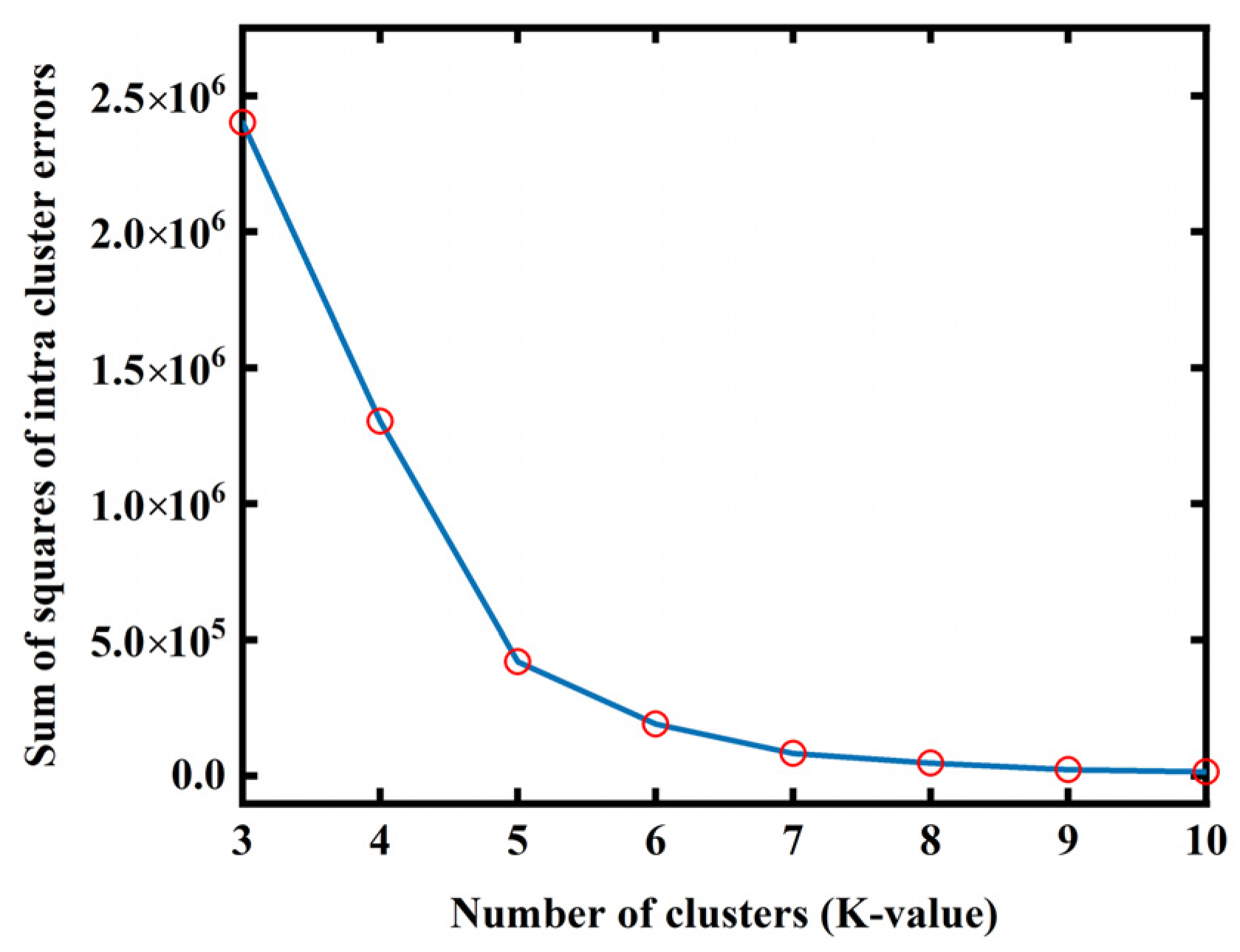
K-means needs to pre-specify the number of clusters,
K, namely, the number of categories of the tissue. The elbow method is usually used to select the appropriate
K value by comparing the sum of squared errors (SSE) of the clustering results corresponding to different clustering values. Four groups of randomly generated data in
Figure 2a are taken as examples to explain the method as follows:
where
K is the number of clusters,
M represents the number of data contained in the kth cluster,
represents the
ith data point in the kth cluster and
is the mean of all data in the
kth cluster. The SSE value is used to evaluate the clustering result, which gradually decreases with the increase in clustering degree. As shown in
Figure 2b, the SSE will decrease sharply when
K reaches the most suitable clustering value and then plateau with increasing
K values. The fitting map of SSE and
K is the shape of an elbow, and the corresponding
K value of the elbow is the best cluster number of the sample data. In addition, the elbow method can also provide the initial center point of each cluster for K-means to improve the accuracy of the clustering result.
The photoacoustic pressure data are trained several times by the elbow method. The most suitable clustering value
K and the corresponding initial center are selected. They are brought into the K-means to obtain preliminary clustering results. Because K-means can only fit the data by spherical clusters, for biological tissues with complex distribution, the clustering result obtained by this algorithm can only roughly describe the regional distribution of various tissues. To obtain a more accurate tissue distribution, the GMM is selected to further iteratively optimize the rough clustering result. The GMM belongs to soft clustering. It makes clustering by calculating the posterior probability that the data belong to each Gaussian distribution [
21]. Compared with hard clustering, this algorithm can divide the category of tissue boundary region more flexibly. The GMM can fit data through arbitrary ellipsoidal clusters, which are more suitable for dealing with the regional division of complex biological tissues.
However, the GMM is very sensitive to the setting of initial parameters, and the number of clusters needs to be set in advance. The clustering result of K-means can provide it with the initial values of these parameters, avoiding the influence of the randomness of the initial parameters on the GMM. The GMM is a parametric probabilistic model. This model is given as follows:
where
stands for the probability density function of the kth Gaussian distribution.
is the weight coefficient, which represents the proportion of each type of tissue.
is the mean value, which corresponds to the central position of the distribution of each tissue.
is the variance, which describes the distribution of data around the mean value. When the GMM is applied to fit the photoacoustic pressure data, the data need to be allocated to
K Gaussian distributions, and each Gaussian distribution corresponds to the distribution information of a class of tissues. The initial parameters are set based on the clustering result of K-means. The cluster center point of the
kth cluster can be set directly to the initial mean value of the
kth Gaussian distribution. The initial weight coefficient of the
kth Gaussian distribution is obtained according to the proportion of the number of data
M in the
kth cluster to the total data. The initial mean and the number of data
M are brought into Equation (10). The initial variance parameter of the
kth Gaussian distribution can be obtained.
After the initial parameters of the GMM are obtained, the expectation–maximization (EM) algorithm is used to iteratively optimize these parameters to obtain a set of optimal model parameters. The posteriori probability is estimated by the current model parameters in E-step of the EM algorithm, namely, the probability that the data
belong to the kth Gaussian distribution as follows [
20]:
The updated model parameters are calculated through the M-step of the EM algorithm as follows:
In Equation (14),
N represents the total number of photoacoustic pressure data. From Equations (12)–(14), a set of more accurate model parameters can be obtained. The GMM described by the set of model parameters is closer to the real distribution of biological tissues. These parameters are used to calculate the log-likelihood function of the GMM as follows:
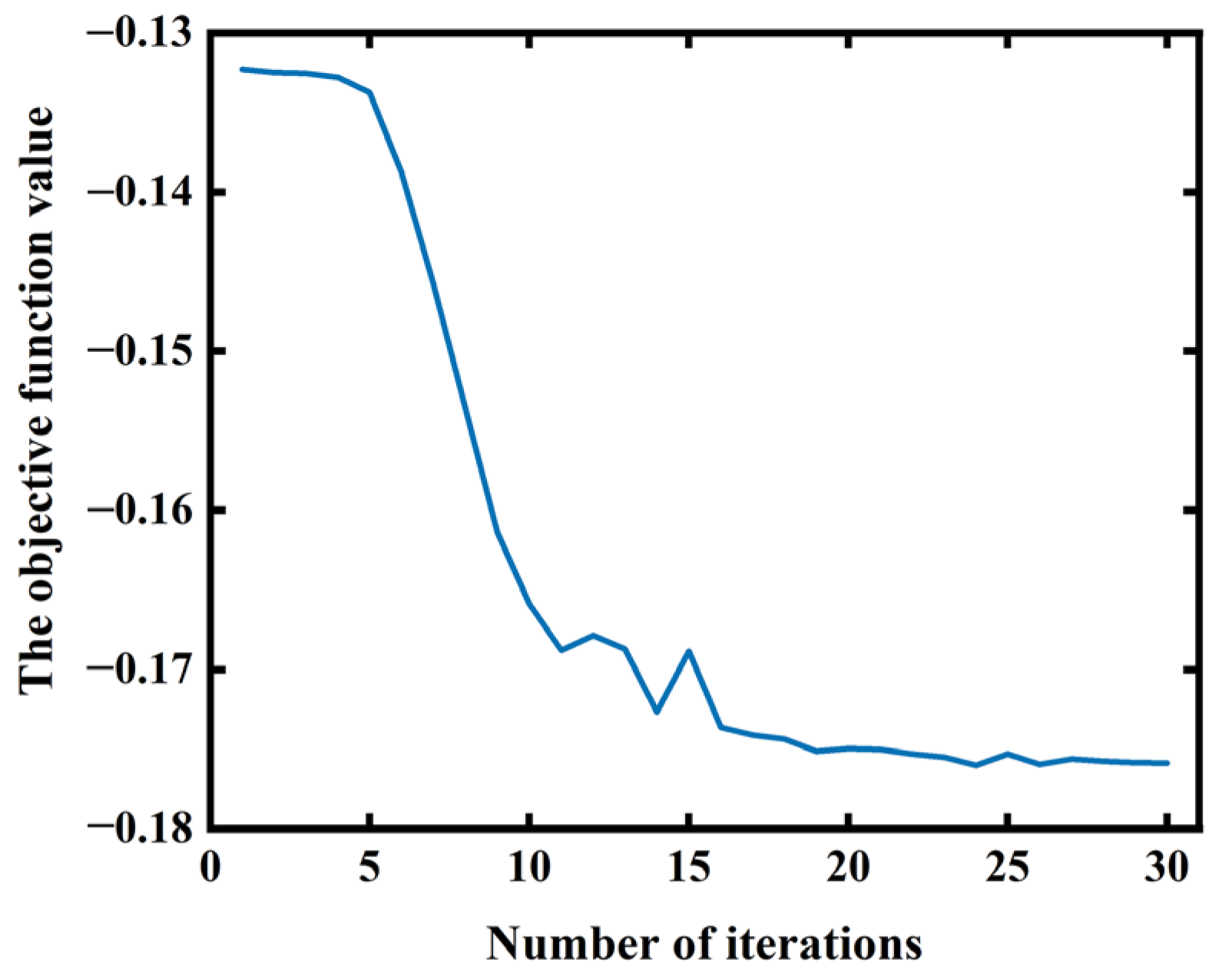
If the log-likelihood function does not converge, the model parameters need to return to E-step again for iterative updates. When the log-likelihood function of the model reaches the convergence state, the fitting effect of the GMM to the data also reaches its best. The current model parameter is the optimal model parameter. Each photoacoustic pressure datum is assigned to the Gaussian distribution with the largest probability according to the posteriori probability, and the clustering result can be obtained.
2.3. Root Mean Square Propagation Algorithm
“K-means + GMM” fits the photoacoustic pressure data into K Gaussian distributions; namely, the regional distribution information about K tissues is obtained. To further improve the accuracy of the sound speed field, it is necessary to search for more accurate sound speeds for each tissue based on regional distribution information. The clinical data information about biological tissues is usually selected for sound speed assignment in the reported methods. However, this method relies heavily on clinical data. Moreover, there are differences in tissue sound speeds among different individuals. The selection of sound speed based on clinical data may still be inaccurate. To avoid these problems, the RMSprop algorithm is used in this paper to realize the automatic optimization of the sound speed field. The RMSprop algorithm is an improved algorithm based on the gradient descent (GD) method, which continues the optimization strategy of the GD method. The fixed step length of the GD method is improved to the adaptive step length to improve the stability of the algorithm.
To highlight the improvement purpose of the RMSprop algorithm, the GD method is first introduced. The GD method is an optimization algorithm used to solve the extreme value problem of function [
22]. It iteratively optimizes the independent variables of function by calculating the negative gradient direction of the objective function. It is hoped that the optimal solution of the corresponding independent variables can be obtained when the objective function converges. It is known that the purpose of correcting the inhomogeneous sound speed field is to improve the quality of photoacoustic images and make it closer to the real distribution of biological tissue. When the GD method is applied to solve the optimal sound speed, the function evaluating the quality of photoacoustic images can be set as the objective function. The sound speed of each tissue is the
K parameter of the objective function. This method can identify the best search direction of the sound speed field and realize the automatic update of the sound speed of each tissue.
In the GD method, the initial sound speed vector and objective function are first set as follows:
For the convenience of calculation, the sound speed of each tissue in the inhomogeneous sound speed field is formed into a sound speed vector in a fixed order. Equation (16) is the initial sound speed vector formed by the initial sound speed field. In Equation (17),
represents the gradient value of the pixel at the (
m,
n) position.
represents the photoacoustic pressure value of the pixel at the (
m,
n) position in the photoacoustic image. As shown in Equation (18),
represents the photoacoustic pressure gradient values at each tissue boundary extracted from the
data.
represents the number of tissue boundary gradient values in
. The objective function
F can be obtained by calculating the negative average of all the gradient values in
.
It is known that there are differences in photoacoustic pressure values in different tissue areas and the photoacoustic pressure values of the same type of tissue are very similar. When Equation (17) is applied to calculate the gradient, the gradient value of the pixels in the internal region of the tissue tends to be 0 due to the similarity of the tissues. The gradient value of the pixel in the tissue boundary region is determined by the photoacoustic pressure difference value of the tissue on both sides of the boundary. Its gradient value is larger relative to the gradient value inside the tissue. The photoacoustic pressure gradient value of each tissue boundary can be extracted by setting a threshold value. When the imaging effect is better, the photoacoustic pressure value in the tissue boundary area shows a “cliff-like” change. The gradient amplitude value of the boundary area extracted by the threshold is larger and the boundary is more accurate. When the imaging effect is poor, the photoacoustic pressure value in the tissue boundary region shows a gentle “stepped” change due to the possible blurring and artifacts in the image. This makes the gradient amplitude value lower in the border area. The above analysis shows that the gradient values of each tissue boundary in a photoacoustic image can reflect the quality of the image. When Equation (18) is applied to calculate the value of the objective function, the better the quality of the photoacoustic image, the smaller the value of the objective function.
Taking the
sth iteration as an example, the gradient vector of the objective function at the sound speed vector
is calculated. The gradient vector contains K derivatives. When the derivative of each type of tissue is calculated, only the sound speed of this tissue is changed and the sound speeds of other tissues remain unchanged,
is obtained. The value of the objective function before and after changing
is calculated to obtain the D-value
. The derivative of the kth tissue region is
. The gradient vector for this iteration is as follows:
The negative direction of the gradient vector is the direction with the fastest descent at
. Along this search direction, the sound speeds of various tissues are updated as follows:
where
Vs+1 represents the updated sound speed vector and
λ is the predefined constant step length.
The distribution size of different tissues in real biological tissues may be very different. When calculating the derivative of each tissue, the objective function is more sensitive to changes in the sound speed of the tissue with large regional distribution. This causes its derivative to differ from that of other tissues. In this case, if the fixed step length is applied to update the sound speed value, it may lead to large differences in the updated amplitude of the sound speed values of various tissues. The sound speed of tissue with large regional distribution may converge faster and even incorrectly compensate for sound speed errors in other tissues. It not only interferes with the updates to the sound speed of other tissues and seriously affects the stability of the convergence process, but also may trap the sound speed field into a local optimum. To solve this problem, the RMSprop algorithm is introduced to realize the improvement in the constant step length in the GD method. The RMSprop algorithm adaptively adjusts the step length of the sound speed of each tissue according to the weighted average of the square of the historical derivatives of the corresponding tissue [
23]. If the derivative of the tissue is larger, the RMSprop algorithm will automatically reduce its step length. If the derivative of the tissue is smaller, its step length will automatically increase accordingly. The step length of adaptive adjustment can balance the amplitude of the sound speed update, which makes the convergence process more stable, and the accuracy of the sound speed field can be improved.
The RMSprop algorithm uses the idea of the exponential weighted moving average (EWMA) method to calculate the exponential mean of the latest
h iterations of the derivative squared of various tissues, as shown in the following:
In Equation (21),
is the exponential mean of the derivative squared of the
kth tissue in the
sth iteration.
is the exponential mean of the derivative squared of the
kth tissue in the (
s−1)th iteration.
represents the derivative squared of the
kth tissue in the
sth iteration.
α represents the hyperparameter.
h is the number of historical derivatives required to calculate the average value of the index. Based on the idea of the EWMA method, Equation (21) weights the derivative squared of the latest
h iterations to control the contribution of the historical derivative squared to the exponential mean. The closer the derivative squared is to the current iteration, the greater the weight it multiplies. According to the weight size, the data information about derivative squared is extracted. The exponential mean obtained from Equation (21) provides reference data for the adaptive adjustment of step length.
In addition, the exponential mean calculated by the RMSprop algorithm in the early iteration may be inaccurate. To solve this problem, Equation (23) is applied to correct the deviation of the exponential mean to improve the accuracy of the early exponential mean.
In Equation (23),
is the corrected value of the exponential mean of the
kth tissue in the
sth iteration. The corrected value of the exponential mean of each tissue is calculated by Equation (23), which can provide the weight vector
for adaptively adjusting the step length of the sound speed of each tissue.
The global step length is set to
, and its initial value is
. To avoid the sound speed parameter producing a small range of oscillation in the later stage of iteration, the global step length slowly decays with iteration.
where
η is the attenuation coefficient of global step length. Along the direction of the negative gradient vector, various tissues use the corresponding step length to calculate the updated sound speed as follows:
where the ⊙ symbol is the Hadamard product, which refers to the new vector obtained by multiplying the elements at the corresponding positions of two vectors.
The RMSprop algorithm can balance the updated amplitude of sound speed by adaptively adjusting the step length of the sound speed of each tissue. It alleviates the interaction between various tissues in the process of updating sound speed. If a tissue with a large proportion reaches the convergence state, the small range change of its sound speed value may still have an impact on other tissues. To solve this problem, the sound speed values of several successive iterations after this tissue convergence can be selected to create an average, and the average value is taken as the optimal solution of this tissue’s sound speed. The sound speed value of this tissue is fixed as the optimal solution in the subsequent iterations to ensure the stability of the convergence process for other tissues.
In summary, the proposed algorithm optimizes the inhomogeneous sound speed field iteratively through two steps. “K-means + GMM” is used to update the regional location information about various tissues, and the RMSprop algorithm is applied to update the sound speed value of each tissue. When the sound speed values of various tissues begin to converge, the objective function values reach saturation. The final inhomogeneous sound speed field and photoacoustic image can be obtained.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














