1. Introduction
Surface Electromyography (sEMG) allows for non-invasive detection of electrical activity generated by muscle fibers on the surface of the skin. These signals reflect muscle activity and provide information about limb movement [
1]. Gesture recognition is one of the most crucial perceptual channels in human–computer interaction. It finds extensive applications in virtual reality, intelligent sign language translation for the deaf and mute [
2], rehabilitation therapy and assessment [
3,
4], and bionic prosthetics [
5], among other scenarios, showing vast potential across various applications. In the field of gesture recognition, surface electromyography signals serve as a common signal source, capturing muscle activity from electrical signals on the skin’s surface [
6]. sEMG signals offer numerous advantages, including non-invasiveness, ease of acquisition, and suitability for dynamic gesture recognition. Consequently, sEMG has garnered significant attention from scholars and is widely applied in contexts where high-precision gesture recognition is demanded. Gesture recognition based on surface electromyography features high accuracy, ease of wear, and non-invasiveness, making it a focal point of research in the field.
Traditional gesture recognition frameworks based on sEMG consist of data preprocessing, feature extraction, feature selection, and gesture classification. Among these stages, feature extraction and gesture classification are two critical phases within the framework of sEMG-based gesture recognition. Common feature extraction methods encompass time-domain features [
7], frequency-domain features [
8], and time–frequency-domain features [
9]. For instance, time-domain features often include metrics such as Mean Absolute Value (MAV), Root Mean Square (RMS), Mean Absolute Value Slope (MAV Slope), Waveform Length (WL), Slope Sign Changes (SSCs), Zero Crossing (ZC), and EMG Histogram (HIST), with EMG histogram being an extension of zero crossing. Following the feature extraction methods, traditional classification techniques are employed for gesture classification. Different classifiers have been introduced, such as k-Nearest Neighbors (KNN) [
10], random forest [
11], Linear Discriminant Analysis (LDA) [
12], Support Vector Machine (SVM) [
13], and Hidden Markov Models (HMMs) [
14]. Khomami and Shamekhi [
15] employed a KNN classifier using 25 features of sEMG and accelerometer signals to classify Persian sign language symbols, achieving an average accuracy of 96.13%. Altimemy et al. [
16] classified 15 hand movements for individuals with intact limbs and 12 hand movements for amputees using linear discriminant analysis (LDA) and SVM with AutoRegressive (AR) features. Given that EMG signals represent sequential data, hidden Markov models are suitable for modeling the latent information in EMG signals. Yun et al. [
17] used an HMM classifier to create an sEMG-based sign language recognition system. Despite the significant potential of sEMG technology, traditional gesture recognition methods still face several challenges. sEMG signals are usually of high dimensionality and complexity, involving multi-channel and high-sampling-rate data, which poses challenges for feature extraction and dimensionality management. Moreover, sEMG signals are susceptible to interference from muscle fatigue, electrode displacement, and environmental noise, which affects the stability and accuracy of the model. Finally, existing gesture recognition methods usually rely on complex feature engineering, which may limit the performance of the model.
In recent years, deep learning has gained substantial popularity and made groundbreaking advances in various domains, such as image processing [
18] and speech recognition [
19]. More recently, the use of deep learning for sEMG-based gesture recognition has started to capture researchers’ attention. They have begun exploring the application of deep neural networks (DNNs) for gesture recognition. DNNs offer powerful feature learning and classification capabilities, eliminating the need for manual feature engineering and enabling the automatic learning of gesture feature representations, consequently significantly enhancing gesture recognition accuracy. Among various deep learning techniques used for sEMG-based gesture recognition, the Convolutional Neural Network (CNN) architecture stands out as one of the most widely employed. Researchers have categorized these into two primary types based on different evaluation methods. For example, Atzori et al. [
5] conducted sEMG classification tasks on four publicly available datasets using a deep convolutional neural network (CNN) architecture comprising two convolutional layers. Their work demonstrated a performance improvement of 2–5% compared to existing machine learning classifiers such as KNN, SVM, random forests, and LDA [
20]. Jia et al. [
21] proposed a deep learning model that combines Convolutional Autoencoders (CAEs) and CNNs for classification of sEMG datasets consisting of ten hand gestures. The results indicated high levels of performance and robustness. Zhai et al. [
22] fed the spectral representations of sEMG into a CNN for gesture recognition, but they achieved only 78.7% accuracy on the second sub-database of the NinaPro dataset. Furthermore, due to the temporal characteristics of sEMG, Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) architectures have been applied to hand-related problems based on surface electromyography. In [
23], Koch et al. employed a ConvLSTM cascaded with an LSTM architecture for gesture sequence classification. In [
24], a two-level network composed of a fully connected network and stacked RNNs was implemented to classify high-density (HD) and sparse sEMG signals. Amor et al. [
25] collected sEMG signals using the Myo armband for sign language recognition and applied an RNN architecture to extract features from sequential data for analysis of sign language gestures.
Despite the promising outcomes in sEMG signal analysis, the broader application of existing methods is impeded by their complexity, computational demands, and extended training times. Current models predominantly focus on augmenting feature information from temporal and frequency domains [
26], neglecting inter-channel correlations [
27]. This oversight leads to increased model parameters and complexity due to excessive feature extraction, necessitating higher levels of computational resources.
Addressing this challenge requires methodologies capable of both extracting valuable inter-channel feature information and efficiently filtering and compressing redundant features. This paper introduces a novel deep learning-based approach for gesture recognition. The methodology presented in this paper was inspired by the work of Jia et al. [
28], particularly the multimodal squeeze-and-excite feature fusion module in the SEN-DAL model. Given the unequal contributions of electroencephalogram (EEG) and electro-oculogram (EOG) data in different sleep stages, it is necessary to assign varying levels of importance to them. Hence, by modeling the interdependencies among channels through squeeze-and-excite (SE), SEN-DAL recalibrates the response contributions of channel features. Building upon the aforementioned process, this paper considers how to design modules to extract inter-channel feature information, thereby establishing the correlation between channel features and actions. Importance is assigned to different channel features based on their contributions during different action processes, thereby filtering and compressing the model’s features. The model incorporates a channel feature selection unit to comprehensively address the interplay between distinct feature channels. It excels at amplifying the importance of valuable features, suppressing redundant attributes, and employs partial convolution to efficiently capture essential feature channel information while economizing on parameter count. This not only enhances algorithm robustness but also fosters generalization. Our innovative approach not only offers a fresh vantage point in sEMG signal processing and analysis but also ushers in new horizons for the application of deep learning in the realm of biomedical signal processing. Experimental results unequivocally underscore the effectiveness of our method and provide profound insights for the advancement of sEMG gesture recognition.
The structure of this paper is outlined as follows. First, we briefly introduce the importance of gesture recognition and its application areas to outline the research theme. Next, we provide an overview of existing gesture recognition methods and point out the existing issues. Then, we present the details of the method proposed in this paper. Subsequently, we describe the experimental results, including accuracy, recall, and other metrics, followed by a comparative analysis of the experimental results. Finally, we summarize the research achievements of this paper and provide insights into future research directions. The main contributions of this paper are summarized as follows:
We introduce a channel selection mechanism empowered by gating unit mechanisms to selectively filter channel feature vectors. This innovation compresses and selects key features within high-dimensional feature vectors of the model, reducing its complexity and laying a foundation for further enhancements.
We implement a combination of partial convolution and channel selection units. Through the collaborative operation of these modules, our approach not only extracts inter-channel features but also efficiently filters intrinsic redundant features in feature maps while maintaining recognition accuracy. Consequently, it significantly reduces the model’s parameter count, marking progress in model efficiency and resource optimization.
Our model is evaluated across various publicly available databases to demonstrate its effectiveness and robustness. Through comprehensive analysis and comparison with state-of-the-art deep learning methods, we show that our model achieves higher accuracy with fewer trainable parameters across different databases while maintaining exceptional recognition stability. These results provide strong evidence of the efficacy of our proposed model.
2. Methods
2.1. Patch Embedding
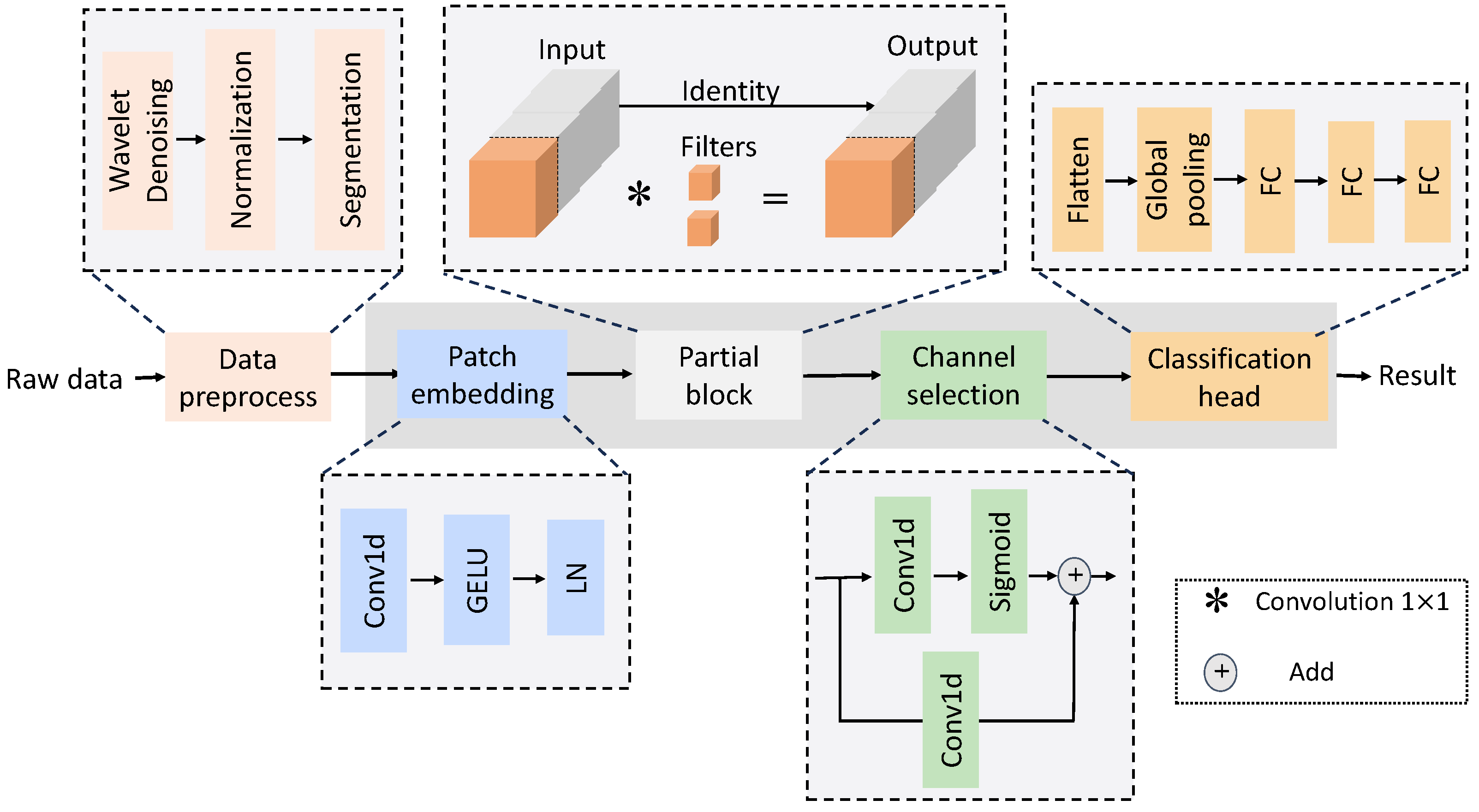
We utilize patch embedding to segment sEMG signals and employ one-dimensional convolutional layers to extract local features based on the temporal aspects of the sEMG signals, as depicted in
Figure 1. Patch embedding plays a crucial role in transforming these segments into a representation suitable for neural networks. Furthermore, patch embedding subdivides sEMG signal segments into smaller patches, thereby reducing the parameter count at the input layer and making the network more lightweight. This enhancement enables the network to capture local contextual sEMG information more effectively. Additionally, patch embedding adds scalability to the network, enabling it to process sEMG segments of varying sizes without requiring modifications to the network structure. This significantly enhances its versatility.
The employed one-dimensional convolutional layer comprises 128 filters with dimensions of 10 × 1 and a stride of 6. Convolutional neural networks (CNNs) are neural networks equipped with a “receptive field” to extract local features. In one-dimensional CNNs, the convolutional kernel convolves along the temporal dimension to extract local features from the time-based sEMG signal. Gaussian Error Linear Units (GELUs) are then employed as the activation function for the nonlinear transformation of the extracted features. Additionally, due to the strong correlation between adjacent time steps in the sEMG signal, Layer Normalization (LN) is applied to normalize the output.
2.2. Partial Block
In the realm of signal processing, precisely recognizing and utilizing essential features is a paramount challenge, especially in applications like sEMG-based gesture recognition. Our innovative approach tackles this challenge by introducing feature importance learning, a pivotal component that dynamically identifies and prioritizes the most critical features within the sEMG signal. The feature importance learning process revolves around our feature importance network, a tailored neural network meticulously designed for this task. This network boasts a 1D convolutional layer that diligently evaluates the significance of each feature. By harnessing this layer, it quantifies the importance of features and generates importance scores. These scores, constituting a multidimensional importance distribution, undergo normalization via the softmax function. This ensures that they accurately reflect the relative importance of each feature in the input channels.
where
represents the input signal data within the partial block in
Figure 1, which has is processed through patch embedding. The term
denotes the importance scores of feature vectors, referred to as filters in
Figure 1. Complementing our feature importance extraction is the partial conv module, a lightweight local convolutional layer that optimizes the signal processing pipeline. The partial conv module plays an indispensable role in feature processing and the reduction of computational overhead. The architecture of the partial conv module consists of a standard convolutional layer augmented by a GELU activation function and a partial convolution layer.
where
x represents the processed output signal in
Figure 1. The symbol ⊙ denotes the dot product operation. This combination enables the efficient processing of input channels while preserving the vital components of the signal. This is achieved by selectively applying convolution to a fraction of the input channels, a crucial element for efficient feature extraction.
Our unique methodology seamlessly intertwines feature importance learning and the partial conv module, leveraging the strengths of both components for optimized signal processing. The process begins with the feature importance network, which calculates importance scores for individual features. These scores serve as guidance for the selective feature weighting, emphasizing those features deemed most crucial. Following the feature importance-based weighting, the data are handed over to the partial conv module. This component, working in tandem with the importance scores, performs the processing. It partitions the input data into two segments, with one segment being selectively weighted based on the feature importance scores. By focusing computation on the most critical features, we substantially reduce redundancy and computational overhead.
Our approach marries feature importance learning with the lightweight partial conv module, presenting a powerful solution for efficient sEMG signal processing. This approach not only adapts to the dynamic importance of features in various gestures but also significantly streamlines computational complexity. It stands as an ideal choice for real-time applications by reducing computational load and enhancing the effectiveness of gesture recognition systems while preserving high accuracy.
2.3. Channel Selection Block
The channel selection block is at the core of this mechanism, playing a pivotal role in the process. During the forward propagation phase, it dynamically evaluates the significance of each input channel by computing gating signals denoted as
g. These gating signals are generated based on the input data features, as seen in the following equation:
where
g represents the gating signal,
is the sigmoid activation function, and
and
stand for the weight and bias of the gate convolution, respectively.
The gating signals are instrumental in determining which channel features should progress to the subsequent processing layer, selectively allowing certain feature channels to pass through while deliberately suppressing others. This selective activation is described by the following equation:
Equation (
4) demonstrates that the input features (
x) are selectively modified by the gating signals (
g) to produce
, which represents the channel features after activation or suppression.
The convolution module complements this process by handling feature processing. It employs a convolutional layer specialized in processing input data features. Notably, it differs from standard convolutional layers in that the output of the convolution module is selectively influenced by the gating signals. This means that only those channel features deemed essential by the model are permitted to pass through the convolution module, while others are intentionally suppressed. This selective processing can be expressed as follows:
where
represents the channel features after selective convolution processing.
Moreover, the unique strength of the channel selection mechanism lies in its adaptability. By autonomously learning and assigning importance to individual input channels, the model becomes adept at dynamically enabling or inhibiting specific channels as needed. This adaptability proves invaluable in effectively managing a wide range of tasks, as the relevance of different channels can fluctuate depending on the specific requirements of each task. In models that incorporate the channel selection mechanism, input data undergo processing, resulting in an output tensor. The output tensor exclusively comprises features from channels the model deems crucial, with features from less important channels consciously suppressed. This reduction in computational redundancy significantly simplifies the model, making it a robust and efficient solution for various gesture recognition tasks. The channel selection mechanism’s adaptability and efficiency make it a valuable addition to the field of sEMG signal processing, where streamlined models capable of accommodating diverse gestures and tasks are in high demand.
2.4. Classification Head
In the final classification stage, we begin by flattening the preceding input features and pass them through a global average pooling layer, followed by three fully connected (FC) layers. The first FC layer consists of 128 neurons, corresponding to the features extracted from the two previously mentioned blocks. Subsequently, the feature vector is fed into a classification network comprising two fully connected layers, each consisting of 512 neurons. In both of these blocks, nonlinear GELU activations and layer normalization are applied after each FC layer. Within the classifier, we also apply a 20% dropout after the first and second fully connected layers to mitigate overfitting. This randomized dropout of neurons reduces the chances of common adaptation among parameters, subsequently decreasing interdependencies among neurons, thus mitigating the risk of overfitting.
4. Experiment and Results
4.1. Evaluation of the Proposed Network
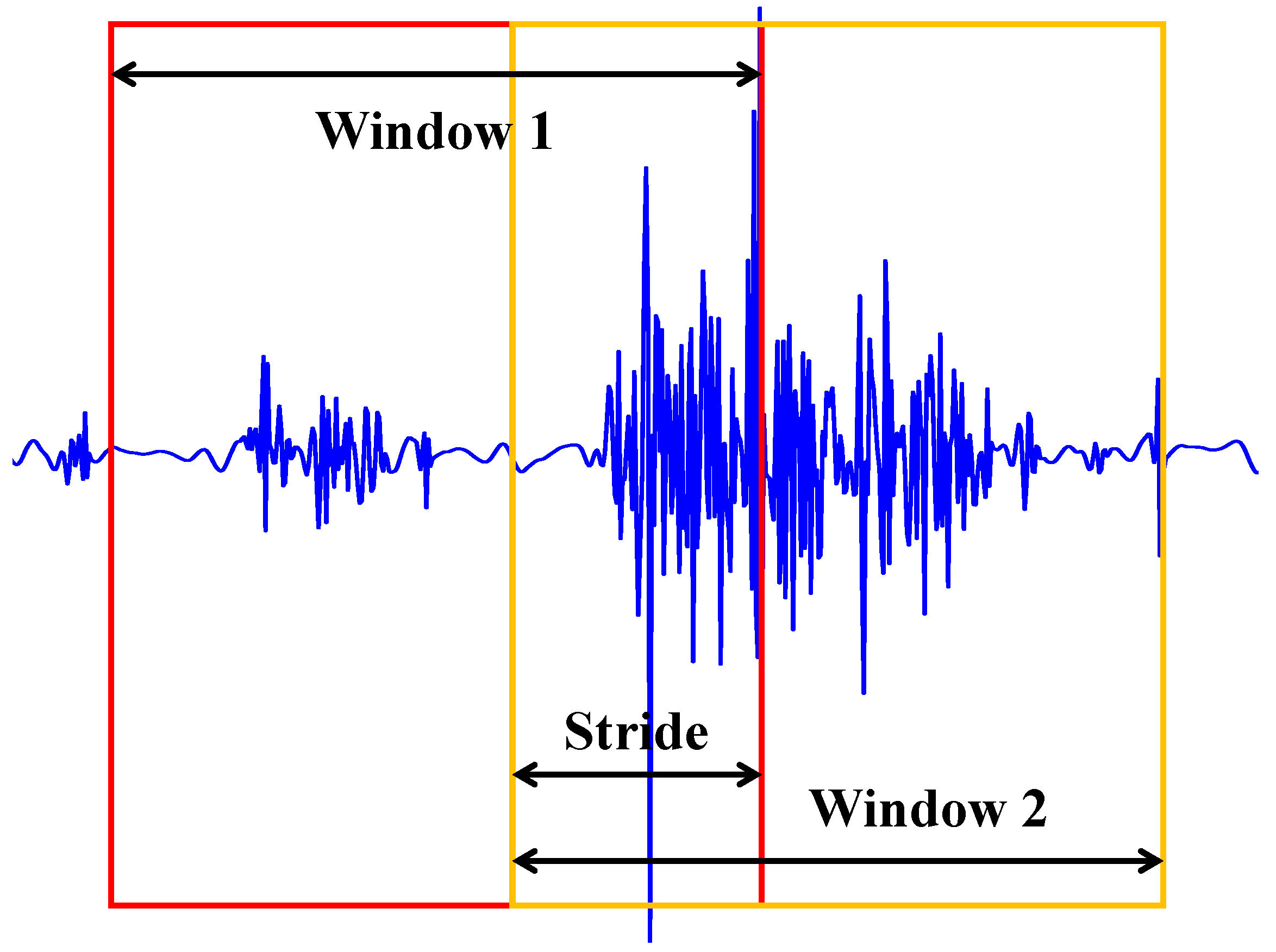
Our proposed method’s classification accuracy and F1-score on the Ninapro DB4 and DB5 and the BioPatRec DB1, DB2, and DB3 datasets are presented in
Table 3. To comprehensively assess the model’s performance, we conducted tests with window sizes of 50 ms, 150 ms, and 250 ms. For Ninapro DB4, the classification accuracy and F1-score were 83.0% and 83.1%, respectively, with a window size of 250 ms. In the case of Ninapro DB5, a window size of 250 ms resulted in a classification accuracy of 87.6% and an F1-score of 87.4%. For BioPatRec DB1, DB2, and DB3, the best results were obtained with a window size of 250 ms, with identical classification accuracies and F1-scores of 91.4%, 91.3%, and 91.3%, respectively. This consistency demonstrates the stability of the model.
Our experimental results suggest that larger window sizes generally lead to higher accuracy but introduce increased latency. Striking a balance between accuracy and latency is crucial. The results indicate that a window size of 150 ms represents a favorable choice, offering performance close to the 250 ms window with minimal performance loss while reducing real-time recognition latency, and it outperforms the 50 ms window in terms of accuracy.
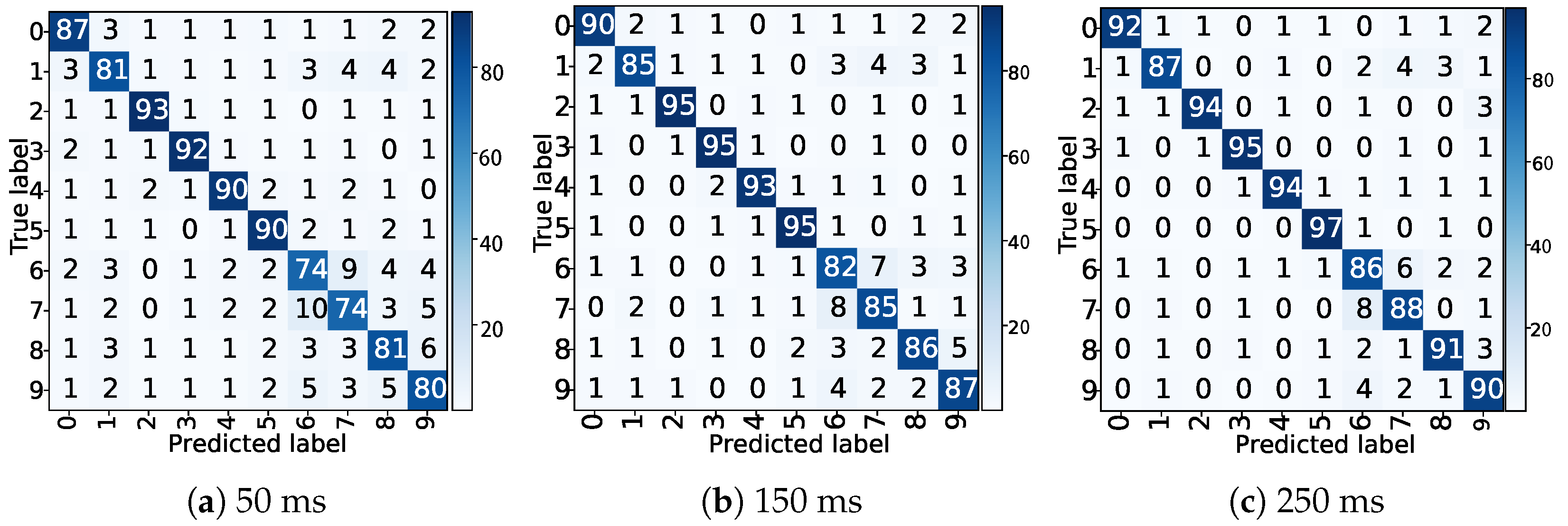
Figure 3 illustrates the confusion matrices for BioPatRec DB1 at 50 ms, 150 ms, and 250 ms. It is apparent from the figures that the model can correctly predict most classes, achieving single-class recognition accuracies of 94%, 95%, and 96% for the three different window sizes, respectively.
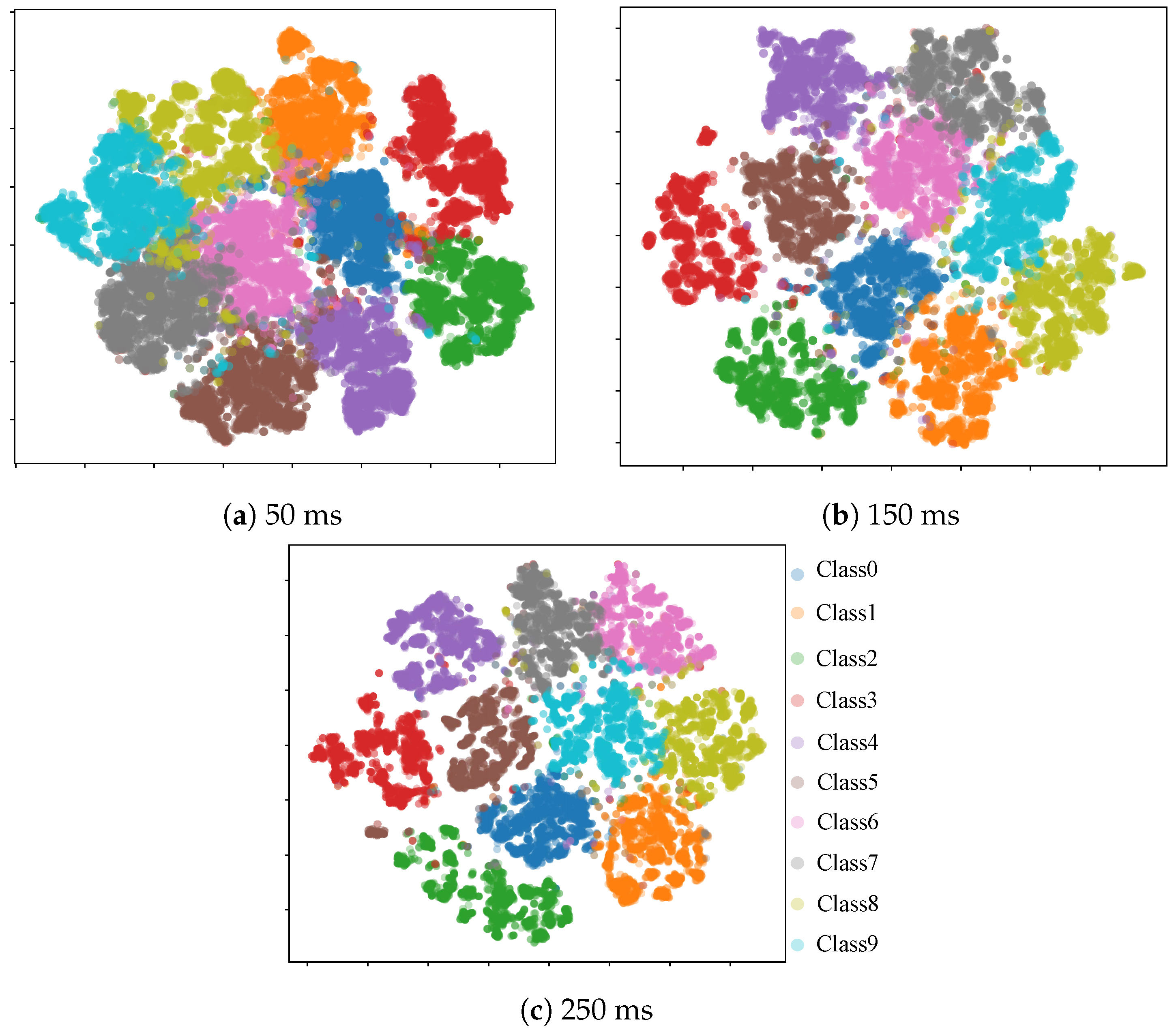
To further analyze the performance of the model and attempt to visualize it, the machine learning method t-SNE (t-distributed Stochastic Neighbor Embedding) [
35] was employed to perform dimensionality reduction analysis on the model’s output. This was done to measure the Euclidean distance between different categories and samples of the same category, thereby facilitating an analysis of the model’s performance. t-SNE is a nonlinear dimensionality reduction technique designed to map high-dimensional data into two or three-dimensional space for visualization. By applying t-SNE for nonlinear dimensionality reduction and data visualization techniques, we conducted an in-depth visual analysis of the model’s classification performance. It effectively projected complex high-dimensional feature information into a two-dimensional space. As illustrated in
Figure 4, as the window segment length increased from 50 ms to 250 ms, the model’s performance in recognizing different hand gesture actions progressively improved. This improvement was evident in the increased clustering of similar gestures and the more pronounced distinction between different gestures. Notably, when the window lengths were set at 150 ms and 250 ms, there was no significant difference in the model’s performance in classifying various hand gestures. This finding suggests that within a certain range of window lengths, further increasing the length has a limited effect in terms of enhancing the model’s classification capabilities.
4.2. Ablation Studies of the Proposed Network
In this section, to demonstrate the effectiveness of our proposed feature extraction method with partial convolutional fusion, we conduct ablation experiments. Additionally, we perform ablation experiments on the channel selection unit to demonstrate its capability in reducing computational complexity and compressing the channel features. We compare the recognition accuracy of partial convolution with feature importance learning. These comparisons were performed continuously with three different window sizes (50 ms, 150 ms, and 250 ms) on the Ninapro DB4 and DB5 and BioPatRec DB1, DB2, and DB3 datasets while maintaining constant experimental settings. The results are shown in
Table 4.
As shown in
Table 4, the use of partial convolution consistently enhances accuracy across all datasets. Across the five datasets and three different window sizes, the average improvement in classification accuracy due to partial convolution is 3%, 2%, 2.23%, 1.03%, and 3.93%, respectively. This highlights the important role of partial convolution, as it is effective in extracting valuable features from the sEMG signals, thus improving the training efficiency. In addition, the introduction of the channel selection unit can significantly reduce the number of parameters with minimal impact on accuracy.
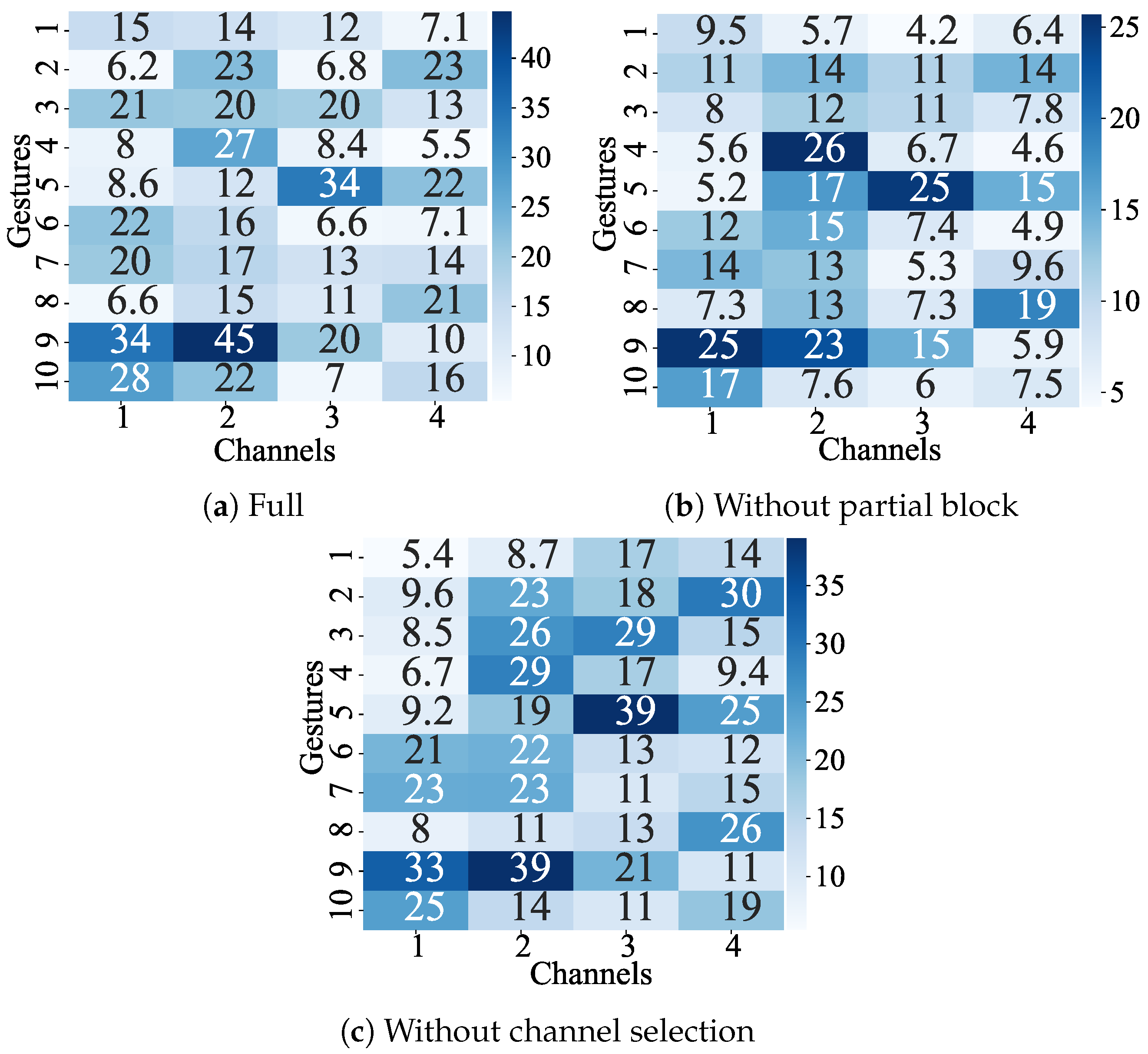
To validate the effectiveness of the proposed model in channel selection, a comprehensive analysis was conducted using Shapley Additive exPlanations (SHAP), which is python package shap 0.44.1, as illustrated in
Figure 5. Initially, SHAP was employed to delve into the correlation between each sEMG channel and the final gesture action. Specifically, we compared the model integrating both a partial block and a channel selection block with the models lacking either of these blocks in terms of the correlation scores between channel features and gesture action outcomes.
Figure 5a,c reveal that the introduction of the channel selection block did not alter the model’s classification performance, nor did it significantly change the focus on respective channel features. However, the incorporation of this block led to a nearly 50% reduction in the model’s parameter count, substantially decreasing its size and thereby highlighting the significant role of the channel selection block in filtering and focusing on relevant channel features. Concurrently,
Figure 5a,b demonstrate the impact of the presence or absence of the partial block on the model’s performance in channel feature extraction, as well as a more dispersed representation of related channel features.
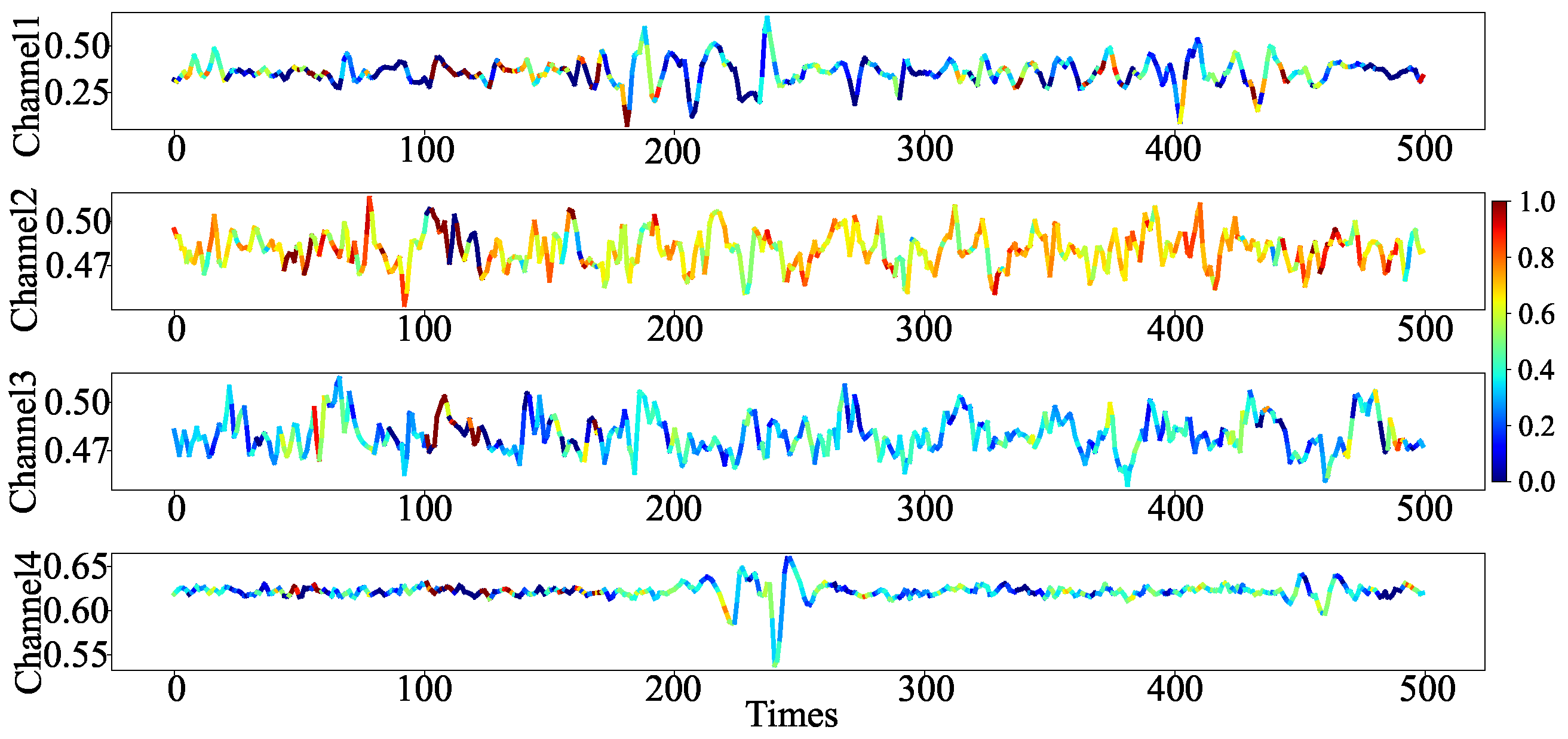
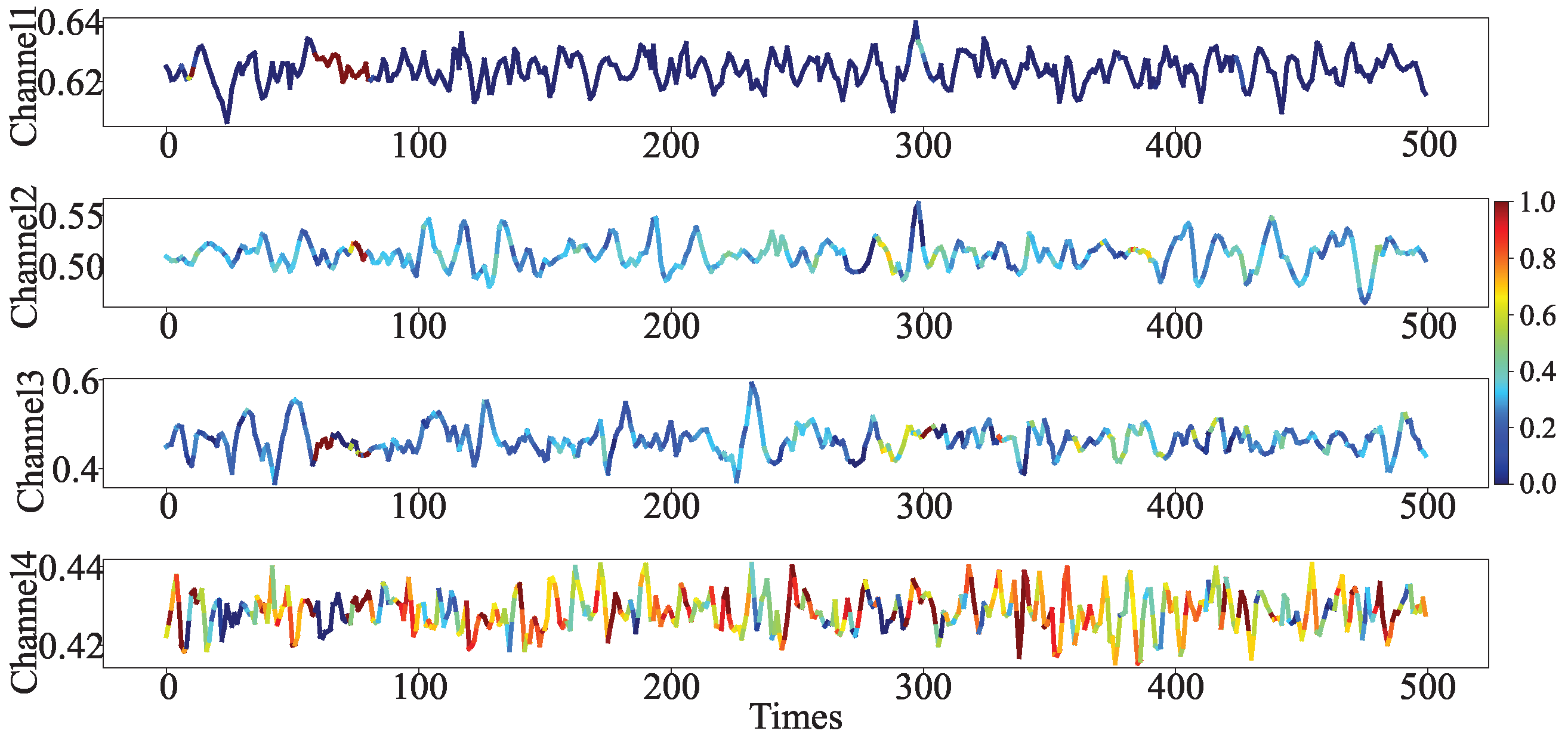
To further showcase the model’s focus on channel features, a segment of the sEMG signal corresponding to the agree gesture and fine grip gesture in the BioPatRec DB1 dataset were selected as a case study, as shown in
Figure 6 and
Figure 7. The red highlight areas in
Figure 6 and
Figure 7 align with the model’s focus on channel features for the corresponding action, further substantiating the precision and practicality of our model in terms of channel feature attention.
4.3. Comparison with the Current Gesture Recognition Methods
In this section, we conduct a performance comparison with existing research methods on five publicly available datasets, namely Multi-view CNN [
26], HVPN [
36], Attention sEMG [
37], EMGHandNet [
38], TDCT [
39], and SE-CNN [
40]. The SE-CNN [
40] method utilizes a strategy that integrates squeeze-and-excite (SE) modules within a CNN framework to suppress irrelevant features while enhancing important ones. This approach integrates SE, CNN, and attention mechanisms to recognize features. EMGHandNet [
38] is built upon a hybrid architecture of CNN and Bi-LSTM for the learning of inter-channel and temporal features. Spatial and short-term temporal relationships are encoded by convolutional layers, while long-term temporal relationships are learned by the Bi-LSTM layer. The proposed framework is capable of extracting cross-channel and temporal features, where one-dimensional convolution encodes cross-channel and short-term temporal information, while Bi-LSTM encodes long-term temporal information in both forward and backward directions. In contrast, Attention sEMG [
37] and TDCT [
39] are variants based on attention mechanisms to extract global feature information, facilitating the learning of global long-term features for gesture classification. Attention sEMG utilizes a feed-forward simple attention mechanism to extract representation features in the time domain from multiple channels, while TDCT enhances the extraction of local temporal and channel correlation features in sEMG by replacing the linear transformation in the multi-head self-attention mechanism with temporal depth convolution. This modification boosts feature-learning capabilities and decreases parameter size. Both Multi-view CNN [
26] and HVPN [
36] employ similar approaches by integrating multiple sets of feature information. They extract feature information from various perspectives and integrate it using different network architectures. In multi-view learning, each perspective has specific viewpoint features, and all perspectives can access common viewpoint features. These models learn feature information from multi-channel sEMG signals from both local and global perspectives. The key aspect of these models lies in their rich feature information, which may, however, introduce feature redundancy.
Due to variations in the window sizes used by different models, for the sake of fairness, we unify the comparison based on each model’s best classification results, as shown in
Table 5.
From
Table 5, it is evident that our proposed model delivers strong performance across multiple datasets, achieving an average classification accuracy of 88.98% across the five datasets. For the NinaPro DB4 dataset, our model achieved an accuracy of 83.3%—slightly lower than EMGHandNet’s 89.5%. However, it is important to note that our model maintains a significantly lower parameter count, with only 0.20 million parameters compared to EMGHandNet’s 6.4 million. This underscores the effectiveness of our approach.
For the Ninapro DB5 dataset, our model achieved a classification accuracy of 87.6%, coming close to the best results. In contrast, Multi-View CNN exhibits notable instability and significant performance variations across different datasets, with an average classification accuracy of 73.4% across the five datasets, trailing our model by 15.4%. Our model leverages compact convolution to learn temporal dependencies and dynamically model correlations between different channels, enabling strong generalization across diverse datasets.
Similar to the Ninapro DB5 results, for the BioPatRec DB2 dataset, our model maintained excellent classification performance, outperforming EMGHandNet by a substantial margin of 7.4%. For the BioPatRec DB1 and BioPatRec DB3 datasets, our model achieved remarkable classification accuracies of 91.4% and 91.3%, respectively, significantly surpassing Multi-View CNN. While our model may not achieve the absolute highest accuracy on certain databases, it consistently ranks second overall, comparable to the average accuracy of all other models, and this is accomplished with an impressively minimal parameter count.
4.4. Computational Complexity Analysis
In this section, we compare the computational complexity of the model proposed in this study with popular sEMG-based hand gesture recognition methods to highlight the advantages of our approach in managing complexity. Drawing on the previously mentioned dataset, we selected the widely used NinaPro dataset as a benchmark and compared models with window lengths of up to 300 ms. Given the lack of a unified standard for window lengths in prior research, we opted for a comparison using a 250 ms window length.
In
Table 6, we present the recognition performance and parameter size of current popular gesture recognition models on the NinaPro DB4 and DB5 datasets. Compared to the existing optimal model, EMGHandNet, which boasts an accuracy of 89.5%, our proposed model is slightly behind by 6.5% in accuracy. However, in terms of parameter size, our model accounts for only 3.8% of EMGHandNet. This significant difference demonstrates that our model substantially reduces parameter size while maintaining relatively high accuracy, thereby greatly saving on the resource consumption of the model. Apart from the optimal model, compared to other models, our model exhibits clear advantages in both accuracy and parameter size.
In comparison to the HVPN and Multi-View CNN models, which employ a multi-feature approach on the NinaPro DB5 dataset, our proposed model exhibits a slight decrease in accuracy—approximately 1.7% lower than that of the Multi-View CNN model. However, our model achieves this performance with only 5% of its parameter scale. Unlike methods focusing on the fusion of multiple features, our approach, centered on channel feature selection and compression, appears to be better-suited for relevant recognition tasks. Despite a minor performance loss compared to the optimal model, the reductions in parameter scale and computational complexity contribute to an overall enhancement of our model’s performance. Additionally, when contrasted with attention mechanism-based models such as Attention sEMG and TDCT, our model outperforms them both in terms of accuracy and parameter count. This suggests that in recognition tasks, improving model performance through local feature attention and the selection of key features, as opposed to a global focus on sEMG signal features, may be pivotal.
5. Conclusions
In this paper, we introduce a PCS-EMGNet based on a channel selection mechanism powered by gating units mechanisms to tackle the enduring challenges within the domain of sEMG gesture recognition. By recognizing the imperative for more precise and computationally efficient methodologies, our proposed model significantly enhances feature extraction capabilities, yielding a model that is both more generalizable and robust. The empirical validation of our model on diverse datasets, including NinaPro DB4, NinaPro DB5, BioPatRec DB1, BioPatRec DB2, and BioPatRec DB3, demonstrated an impressive average classification accuracy of 88.34%, with a notable increase in accuracy and a substantial reduction in computational requirements compared to existing methods. Our findings indicate that our model not only achieves superior performance in terms of accuracy but also in computational efficiency, marking a significant advancement in the practical application of sEMG gesture recognition technologies.
Furthermore, by incorporating a novel partial convolution module alongside a channel feature selection unit, our approach effectively capitalizes on the redundancy within feature maps. This methodical application of convolution to select portions of input channels drastically reduces the model’s parameter count, thereby streamlining the computational process. This innovation is poised to set a new benchmark for resource efficiency in the field of sEMG gesture recognition.
Gesture recognition through sEMG signals is rapidly gaining traction for its non-invasive nature, ease of acquisition, and high signal stability, making it an exemplary choice for dynamic gesture recognition applications. However, the field continues to grapple with challenges stemming from the diversity and complexity of gestures, as well as vulnerability to signal interference. Current gesture recognition techniques are often limited by their low accuracy and high computational demands. In response to these challenges, future research will focus on optimizing model architectures, advancing feature extraction methods, and broadening the scope of this technology’s applications to tackle a wider array of real-world issues, thereby enhancing the accessibility and efficacy of sEMG-based gesture recognition systems.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}