Abstract
Association rule mining utilizing metaheuristic algorithms is a prominent area of study in the field of data mining. However, when working with extensive data, conventional metaheuristic algorithms exhibit limited search efficiency and face challenges in deriving high-quality rules in multi-objective association rule mining. In order to tackle this issue, a novel approach called the adaptive Weibull distribution sparrow search algorithm is introduced. This algorithm leverages the adaptive Weibull distribution to improve the traditional sparrow search algorithm’s capability to escape local optima and enhance convergence during different iterations. Secondly, an enhancement search strategy and a multidirectional learning strategy are introduced to expand the search range of the population. This paper empirically evaluates the proposed method under real datasets and compares it with other leading methods by using three association rule metrics, namely, support, confidence, and lift, as the fitness function. The experimental results show that the quality of the obtained association rules is significantly improved when dealing with datasets of different sizes.
1. Introduction
Association rule mining (ARM) was originally utilized to suggest a solution to the shopping basket issue and has grown to be one of the major fields of data mining [1]. Association rules are implicit formulae, such as , where X and Y are considered the predecessor and successor of association rules, and X and Y represent separate sets of entries in the database. ARM assists decision makers in numerous businesses to make proper judgments to increase their competitiveness by finding possible dependencies between items in the transactional database and is presently employed in various domains, such as traffic accidents [2], education [3], and medicine [4]. The Apriori method is the most generally used association rule mining technique [5]. However, it regularly searches the whole database and creates a huge number of candidate itemsets, which leads to a considerable amount of I/O overheads. The FP-Growth minimizes the number of scans of the database by compressing the data into the shape of a tree but creates a high number of unordered tree nodes, which causes the complexity of the data structure to rise [6]. The optimization of classic association rule mining algorithms is near the bottleneck, the mining efficiency is too low in the face of larger-dimensional data, and it has to preset the support and confidence criteria in advance, so it is less applicable in diverse circumstances. In recent years, the major strategy to overcome this challenge has been to propose metaheuristic algorithms [7,8]. This family of algorithms has been extensively employed in numerous study fields and is a typical way of tackling combinatorial and hyperparametric optimization issues [9]. Using this class of algorithms to handle association rule mining has more reasonable time and resource overheads. However, when facing multiple high-dimensional datasets, it is also a new challenge to obtain more comprehensive association rules in a complex solution space [10].
Metaheuristic algorithms are frequently motivated by various natural occurrences and human social behaviors [11], such as genetic algorithms [12], slime mold algorithms [13], ant lion algorithms [14], etc. Such algorithms are one of the efficient techniques for tackling the association rule mining issue [8]. In [15,16], the particle swarm and genetic algorithm were used for association rule mining; this strategy does not need one to provide a minimum support or confidence criterion, which improves the applicability of the scenario. Sharmila et al.’s use of fuzzy logic and the whale optimization algorithm for association rule mining in [17] reduced the number of scans of the database and the memory required for computation. The use of metaheuristic algorithms effectively improves the mining efficiency of association rule problems and saves resource overheads. Researchers have started focusing on enhancing the quality of mining rules based on the optimization goals of association rules. These objectives may be categorized into single-objective and multi-objective algorithms [18]. Typical single-objective algorithms are GAR [19] and GENAR [20], but in order to pursue the accuracy and diversity of the rules in more scenarios, the association rules are a multi-objective problem. For example, in [21] weighted combinations of multiple performance indicators developed fitness functions that fulfilled the demands of the decision makers, but for the setting of the weights it was difficult to determine the appropriate value, and it was difficult to equalize between different indica tors. In [22], the Pareto optimal method was used to optimize confidence, comprehensibility, and interest simultaneously. This method does not need to set the objective weights; it will obtain a series of Pareto optimal solutions. The set of these solutions makes up the Pareto frontiers that show solutions with trade-offs under multiple objectives, providing a range of choices for the decision maker [23].
More and more researchers and scholars consider association rule mining as a multi-objective problem to evaluate the mined association rules with multiple objective functions. However, many studies omit to consider how to further enhance the value of the set objective function, and it is a challenge for the optimization ability of heuristic algorithms to simultaneously consider multiple objective functions for association rule mining under large-scale datasets. To address this problem, this paper proposes the adaptive Weibull distributed sparrow search algorithm (AWSSA) to enhance the performance of heuristic algorithms. In order to verify the performance of the improved algorithm, we first conducted experiments on 10 standard functions. The purpose of this was to evaluate the optimization ability of the AWSSA. Finally, in order to test the actual performance of the AWSSA in multi-objective association rule mining, five different-sized datasets were selected, and experimental simulations were conducted with the objectives of support, confidence, and enhancement, which aimed to evaluate the quality of the rules generated by the AWSSA under different-sized datasets.
The main contributions of this paper are as follows: (1) We propose an adaptive Weibull distribution sparrow search algorithm that improves the optimization and convergence ability of the sparrow search algorithm by combining three strategies, namely, adaptive Weibull distribution, augmented search, and multidirectional learning. (2) By applying the improved algorithm to multi-objective association rule mining, there is a significant improvement in the value of the objective function, which further improves the quality of the mined rules and provides more accurate and excellent solutions for decision makers.
2. Related Work
Traditional association rule mining algorithm: The earliest algorithm to solve the association rule mining problem was Apriori [5]. In the AprioriTid algorithm [24], proposed later, the TID set is used in the process of each calculation to replace the frequent itemset, reducing the number of scans of the transaction database and thus reducing the overheads on computer memory. Subsequently, based on the Apriori algorithm, many new improved versions have been proposed, such as the DHP [25] and DIC [26] algorithms, but it is still difficult to change the nature of the original Apriori because it will be scanned many times on the transaction database, resulting in a large amount of resource overheads. Han et al. proposed the FP-Growth algorithm [6]. Compared with the Apriori algorithm, it no longer needs to generate candidate frequent itemsets and uses a tree structure for storing compressed dataset information, called FP-tree, only needing to scan the transaction database twice, thus greatly reducing the demand for computing resources. Aiming at the traditional association rule mining algorithm optimization has been a bottleneck; it is difficult to improve on the basis of the original algorithm. Research scholars have tried to introduce heuristic algorithms into the association rule mining problem.
Association rule mining based on heuristic algorithms: The use of genetic algorithms for association rule mining [19], compared with the traditional algorithms, greatly enhances mining efficiency. However, this method only starts from a single-objective perspective and lacks comprehensive consideration. Ye Z et al. [27] combined different intelligent optimization algorithms based on the whale optimization algorithm into a hybrid whale algorithm and linearly weighted the support, confidence, and accuracy factors into a new adaptive function in order to pursue a new optimization function that is based on the whale optimization algorithm. A new fitness function in pursuit of better rule quality: Linear weighting of different objective functions is a simple and effective way, but it is difficult to determine the appropriate value for the setting of weights, which requires a certain amount of a priori knowledge of the decision maker. Different datasets have different emphasis, which leads to the difficulty of striking a balance between the different indicators, and the weights set by human beings have a certain degree of subjectivity. So, Beiranvand et al. [22] used the Pareto optimal method to measure multi-objective association rules. Heraguemi proposed a MOB-ARM algorithm [28] that uses four quality measures: support, confidence, comprehensibility, and interest, aiming to mine more useful and understandable rules. Minaei-Bidgoli used a multi-objective version of a genetic algorithm for association rule mining [29], targeting support, comprehensibility, and interest, all three. On this basis, we propose an improved sparrow search algorithm for multi-objective association rule mining, aiming to enhance the heuristic algorithm’s ability to find the best and improve the value of the objective function obtained.
3. Methods
3.1. Sparrow Search Algorithm
The sparrow search algorithm (SSA) [30] was proposed in 2020 and was inspired by the predation and scouting warning behavior of sparrows in nature. Sparrow populations are categorized into discoverers, followers, and scouts according to different classes. Discoverers are dominant in the sparrow population as they have a better position in the search space and usually provide information about the location of food for the population, whereas the follower always monitors the finder: when the finder finds food, the follower will immediately follow. And the scout is observing the situation around the food. Once there is a danger, the monitor will immediately issue an alarm. When the alarm signal reaches a certain threshold, the whole population will move under the leadership of the finder. The discoverers update strategy is as in Equation (1):
represents the position of the sparrow in the j-dimension at generation t, a is a random number between , Q is a normally distributed random number, L is a unit matrix. is the warning threshold, is the safety threshold. When , it means that the sparrow did not find the predator, and the individual sparrow carries out a wide range of searching behaviors. When it is larger than , the discoverer needs to lead the population to fly to a safe place to forage. The follower update strategy is as in Equation (2):
where is the current discoverer’s optimal position, is the globally worst position, and is a matrix where the elements are random values from 1 to −1.
Scouts are randomly generated from the population, which is about 10 to 20 percent of the total population, and the scout position update formula is as follows:
where is a normal random number obeying a mean of 0 and a variance of 1, K is a random number in the range , and is a normal number preventing the denominator from being zero.
3.2. Adaptive Weibull Distributed Sparrow Search Algorithm
3.2.1. Adaptive Weibull Distribution Strategy
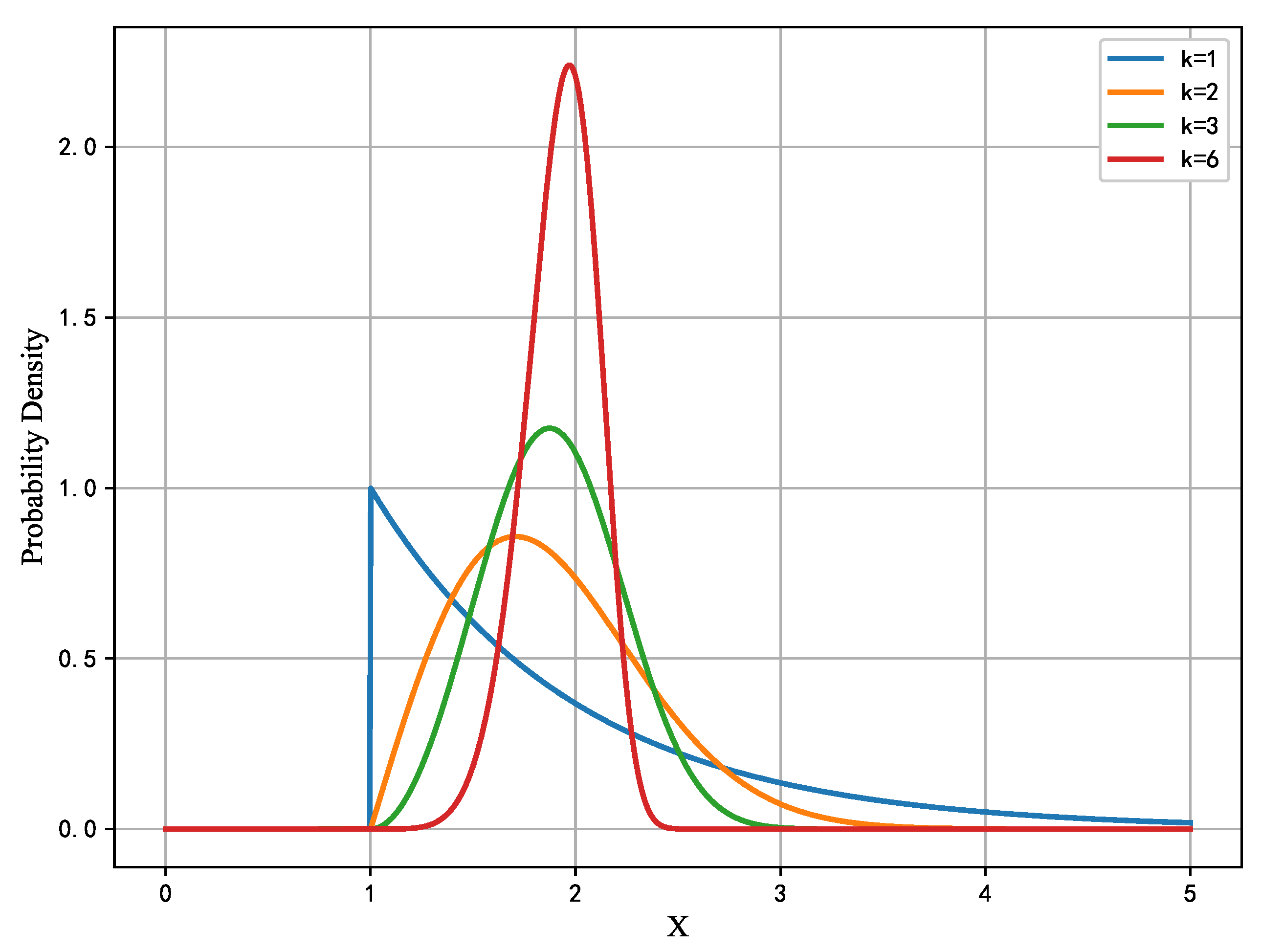
The original SSA utilizes normal distribution to update the population position, but this does not take into consideration that the sparrow population’s individuals in various iteration stages of the algorithm need to leap out of the present location of the varied requirements. In order to further enhance the optimization abilities of the sparrow search algorithm, this study brings forth a form of adaptive Weibull distribution [31] variation to increase the chance of the program leaping out of the local optimum. The Weibull distribution probability density function is as follows:
where x is the value of the random variable, is the scale parameter, and k is the shape parameter. Figure 1 illustrates the probability density function picture of the Weibull distribution, from which it can be observed that the distribution is exponential when k is equal to 1, and the distribution is right-skewed when k is more than 1.
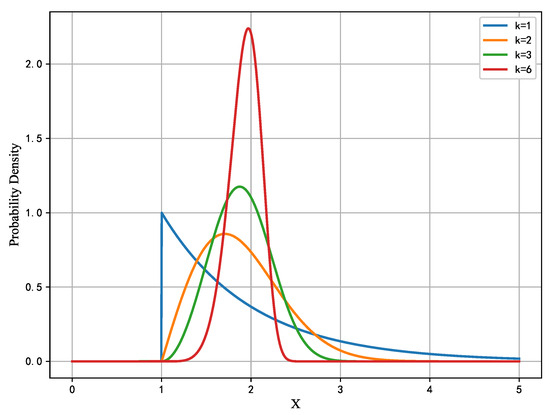
Figure 1.
Image of the probability density function of the Weibull distribution.
Sparrow populations exhibit different behavioral traits during different predation processes, so this study aims to make the sparrow search algorithm a better balance between exploration and exploitation. Specifically, we anticipate that the algorithm favors a vast search space in the early iterations, which has greater potential to leap out of the local optimum solution and enhance the likelihood of discovering a superior solution. In the latter rounds, it tends to be more towards a steady development state in order to converge to the ideal solution quicker. Based on this goal, in this research, we leveraged the Weibull distribution feature, as given in Equation (5), to develop a new shape parameter called a mutation factor, with the number of iterations t as the independent variable and k as the dependent variable. In the early stages of the method, the value of k is small, and the random variable value x produced by Weibull has a wider range interval. And when the iteration goes to a later stage, the value of k steadily grows, the peak of the Weibull distribution gets steeper, and the variability subsequently reduces, meaning that the values of the random variable will be more centrally distributed around . Therefore, the variability factor we construct allows the algorithm to have a greater chance to enter the exploration state in the early iterations, and as the iteration proceeds to the later stages, the variability factor allows the sparrow individuals to develop near the optimal solution, thus accelerating the algorithm’s convergence.
3.2.2. Enhanced Search Strategy
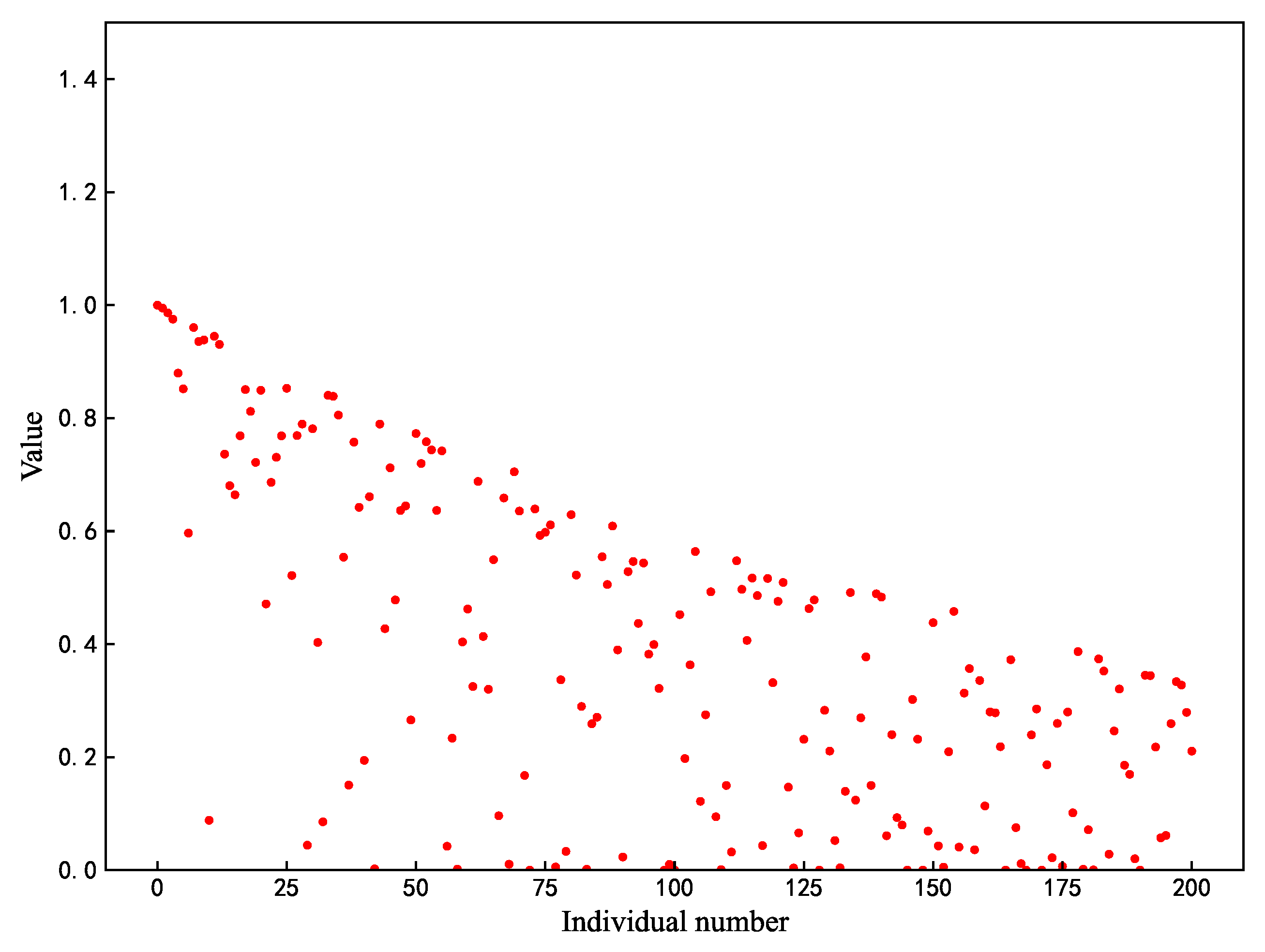
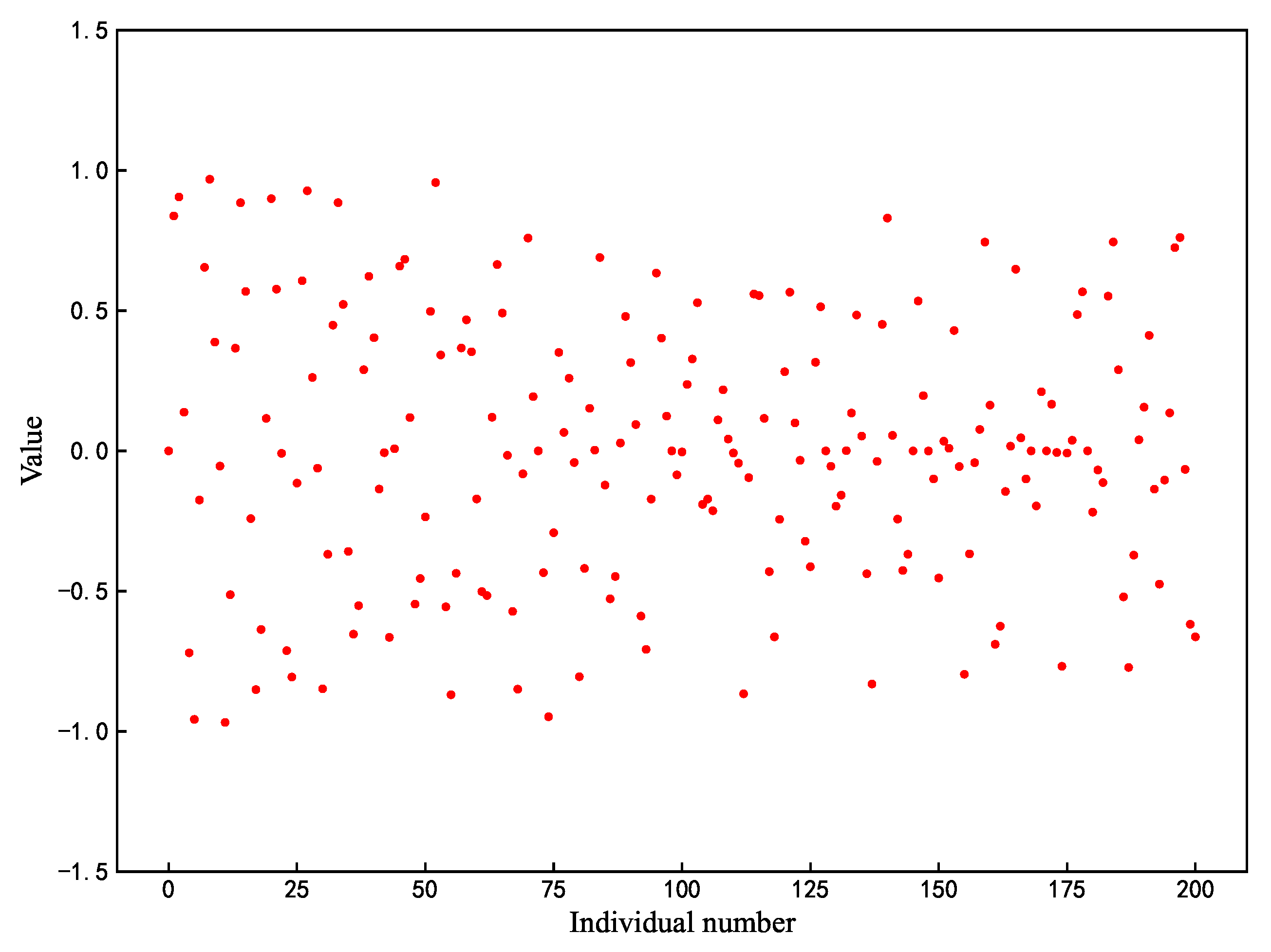
Among the three roles of the sparrow algorithm, when , the position update strategy of the discoverer is shown in Equation (1). Where the image of the function f(x) = is shown in Figure 2, it can be seen that the range of values of the function is gradually narrowed down from at the beginning to between , which means that the finder can easily fall into stagnation, and all the values are in the range of , which renders the finder unable to search extensively. In this paper, based on the original formula, a new position-updating strategy is proposed by combining the oscillatory property of the sinusoidal function as in Equation (6):
where represents random numbers of . The improved individual position update process is shown in Figure 3, where the search becomes broader and goes in the opposite direction compared to Figure 2.
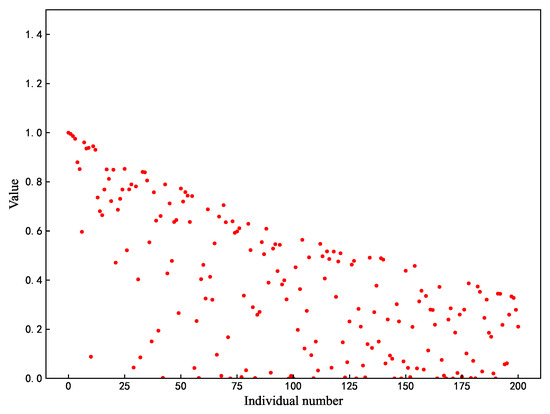
Figure 2.
Original search strategy.
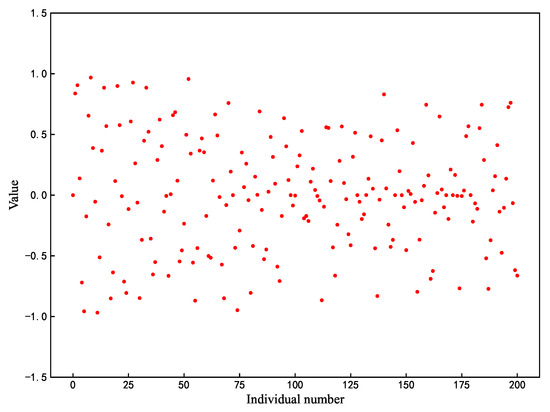
Figure 3.
Enhanced Search Strategy.
3.2.3. Multidirectional Learning Strategy
In Equation (3), when , the scout is aware of the danger. If the scout itself is in the current optimal position, it will choose to move to the neighborhood of itself, and if it is not optimal, it will move to the neighborhood of the current optimal position, which reduces the diversity of the population and increases the risk of local optimality in the previous period. In order to overcome this issue, we introduced a multi-directional learning strategy [32] to improve the scout’s learning process, increase the algorithm’s exploration ability in the search space. As shown in Equation (8) , , and are the fitness of sparrows at three different points and different weights; , , are calculated for this purpose. The sparrows with better adaptations occupy a larger proportion, and the comprehensive consideration of the position information of the three sparrows is more conducive for the follower to have a greater chance of exploring the unknown region. The new updated measurements are as in Equation (7):
After using the above three improvement strategies, the position-update strategy for individual sparrows is as follows (Algorithm 1):
| Algorithm 1 Adaptive Weibull Distributed Sparrow Search Algorithm. |
|
3.3. Algorithm Performance Testing
3.3.1. Selection of Test Functions
In order to verify the optimization performance of the AWSSA, 10 groups of benchmark test functions of different categories were selected for an optimization comparison test, among which F1∼F7 were unimodal test functions and F8∼F10 were multimodal test functions. The information about the functions is shown in Table 1.

Table 1.
Test functions.
3.3.2. AWSSA Compared with Other Algorithms
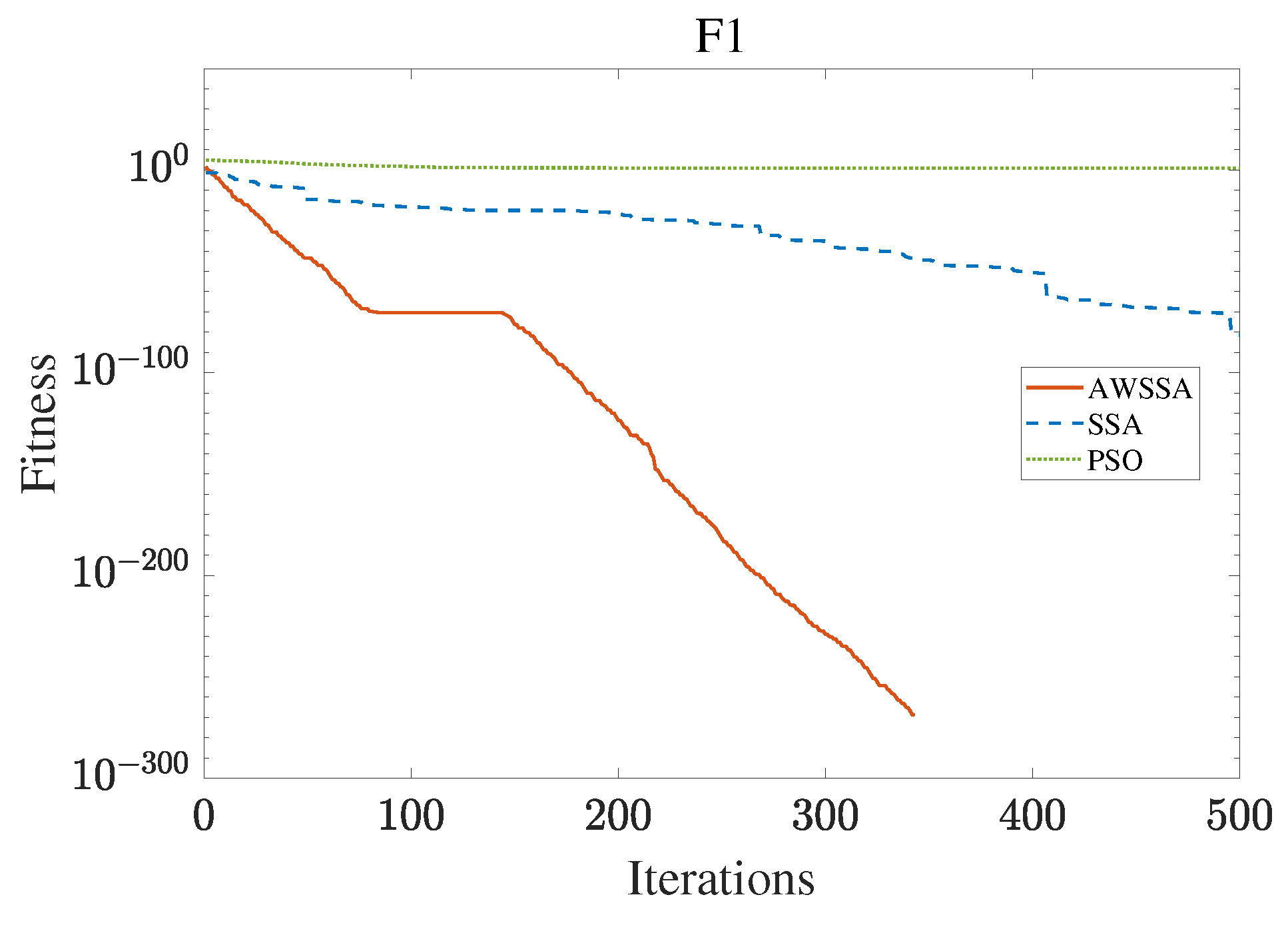
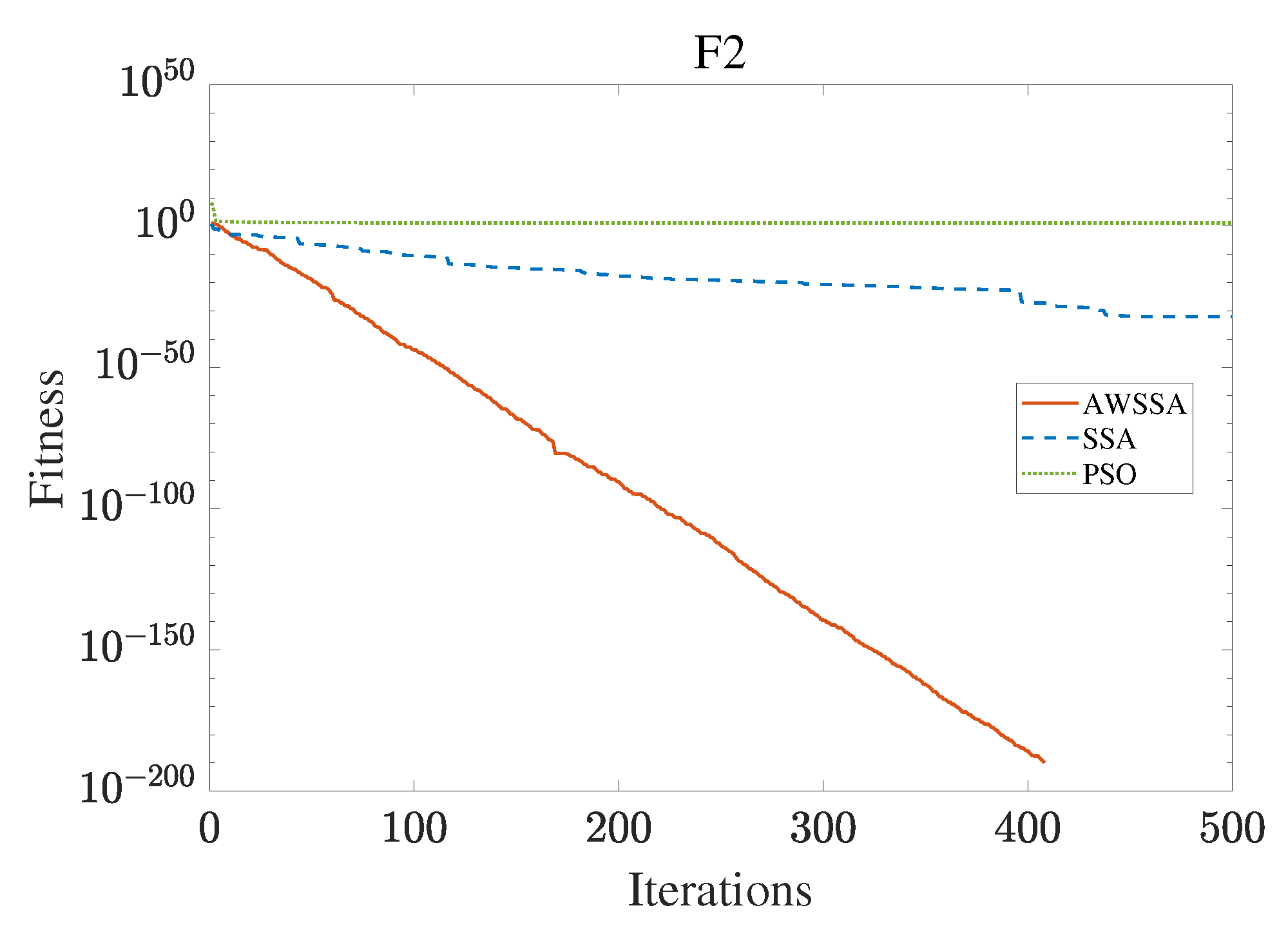
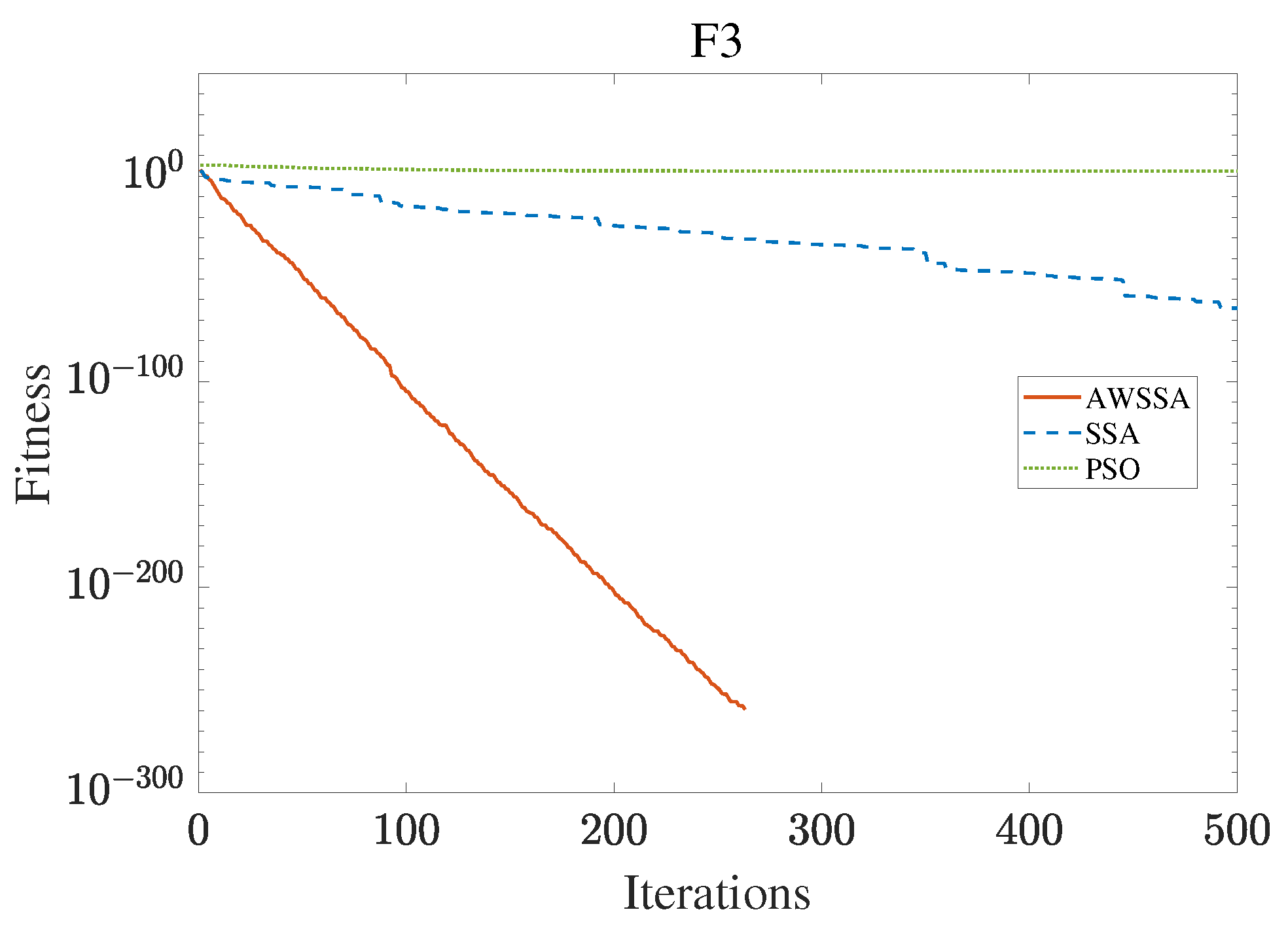
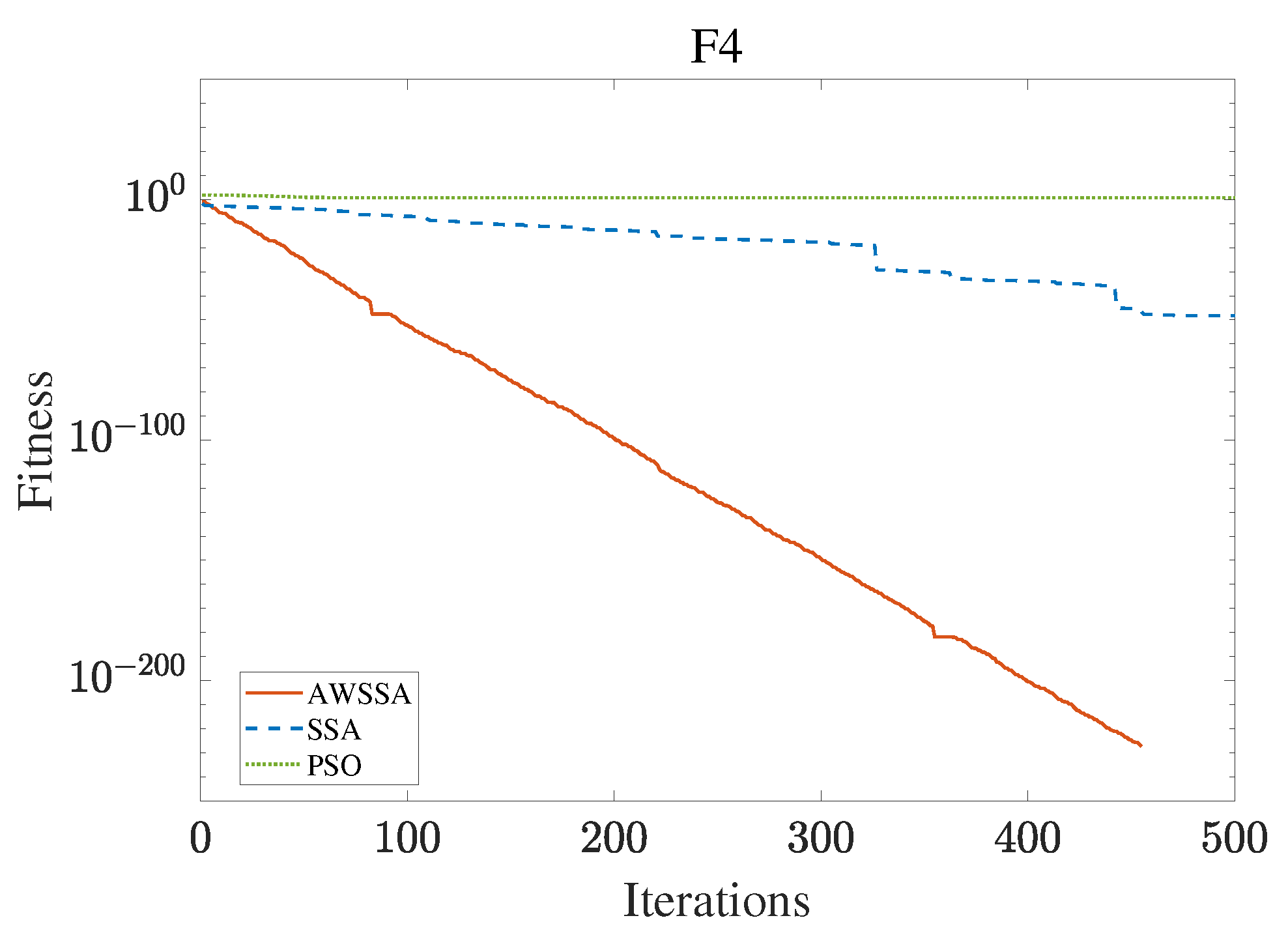
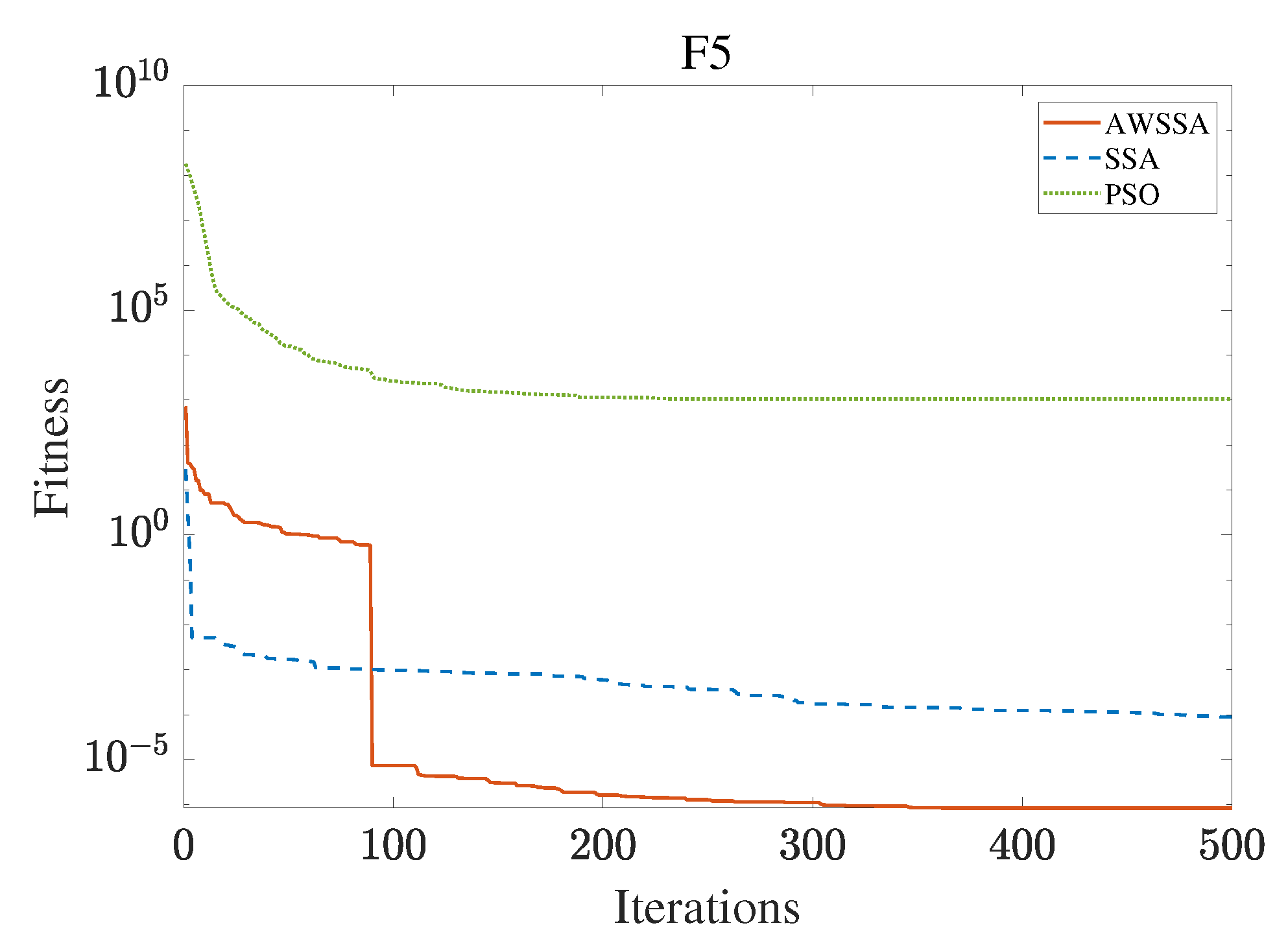
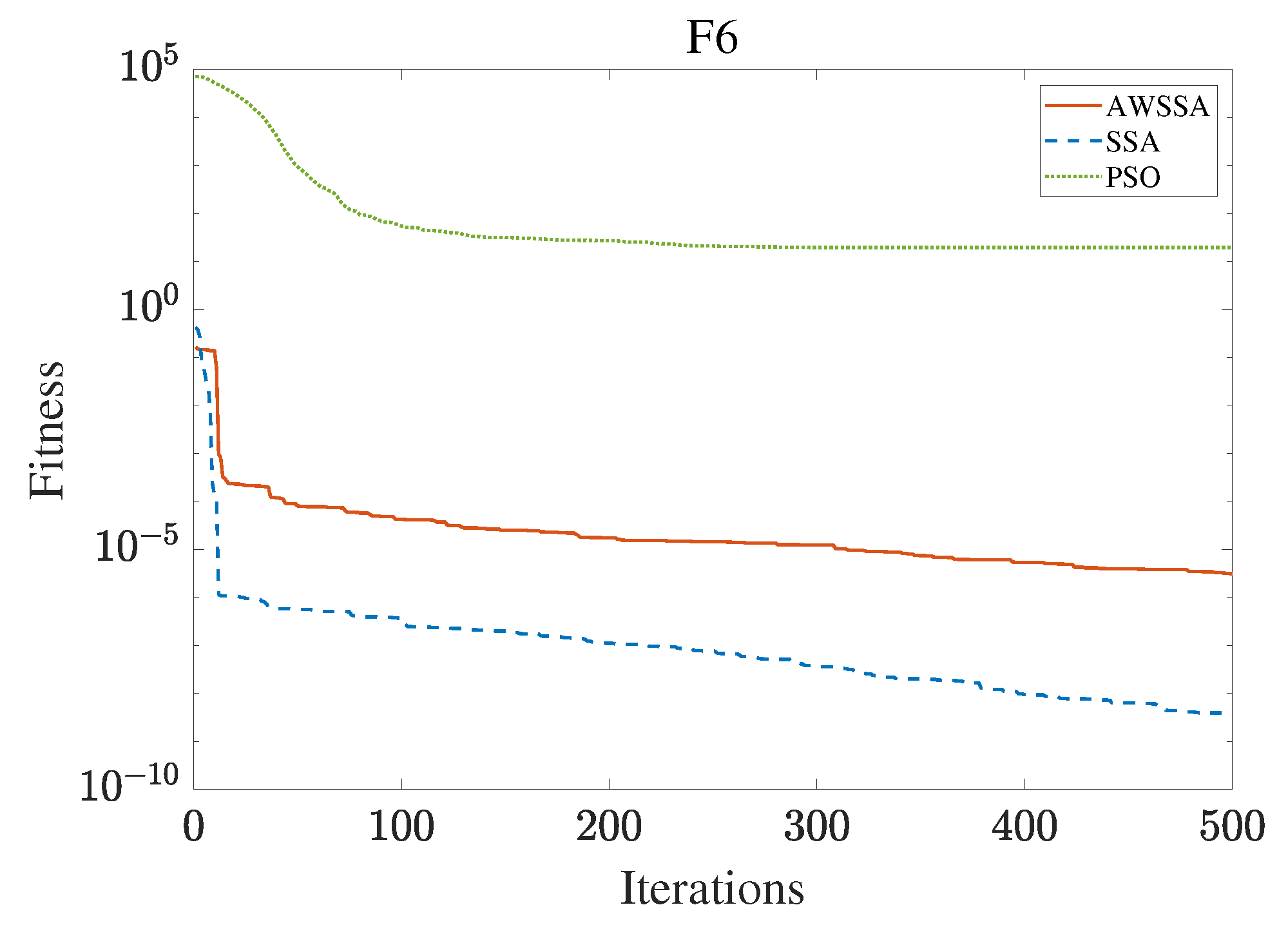
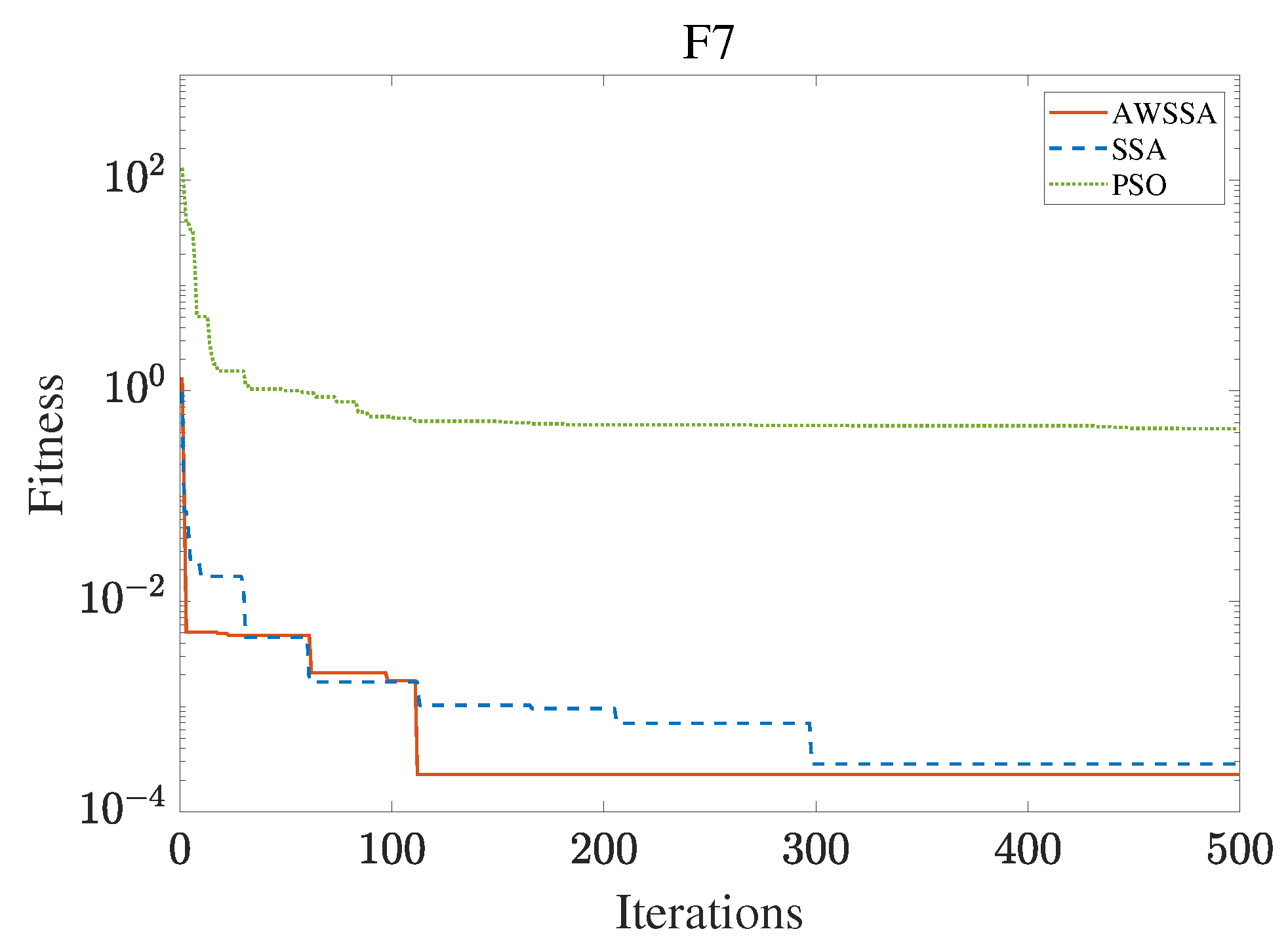
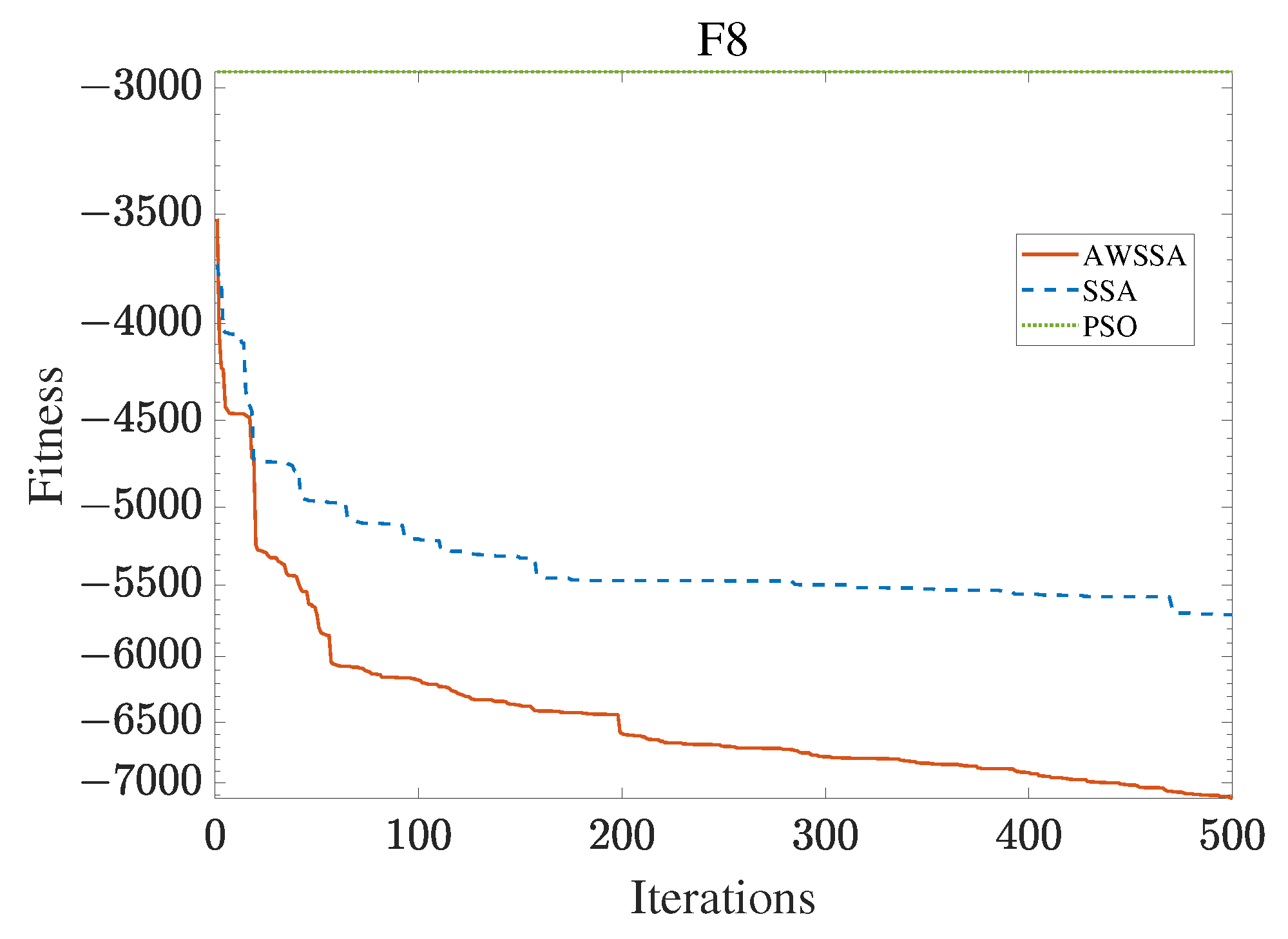
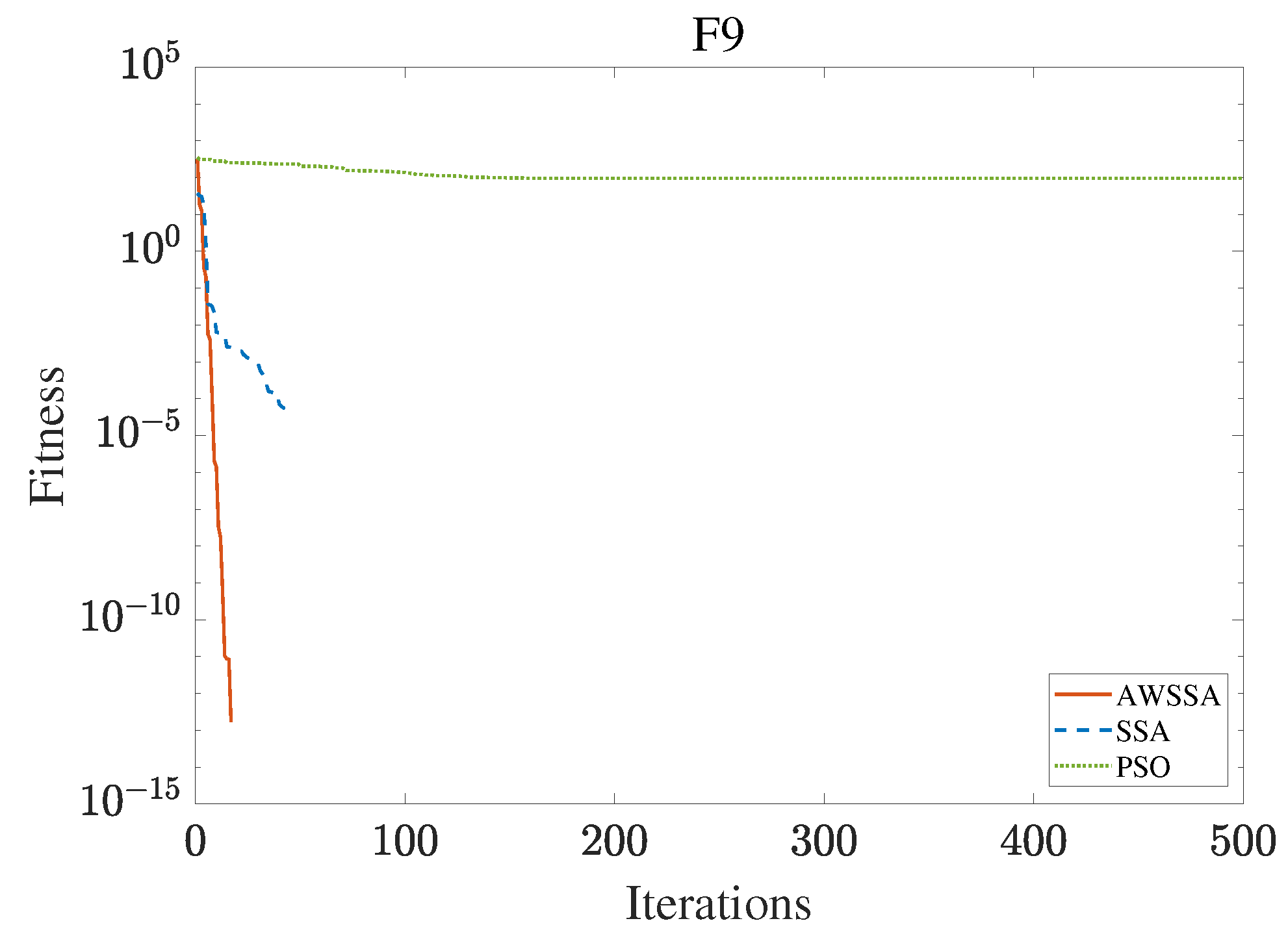
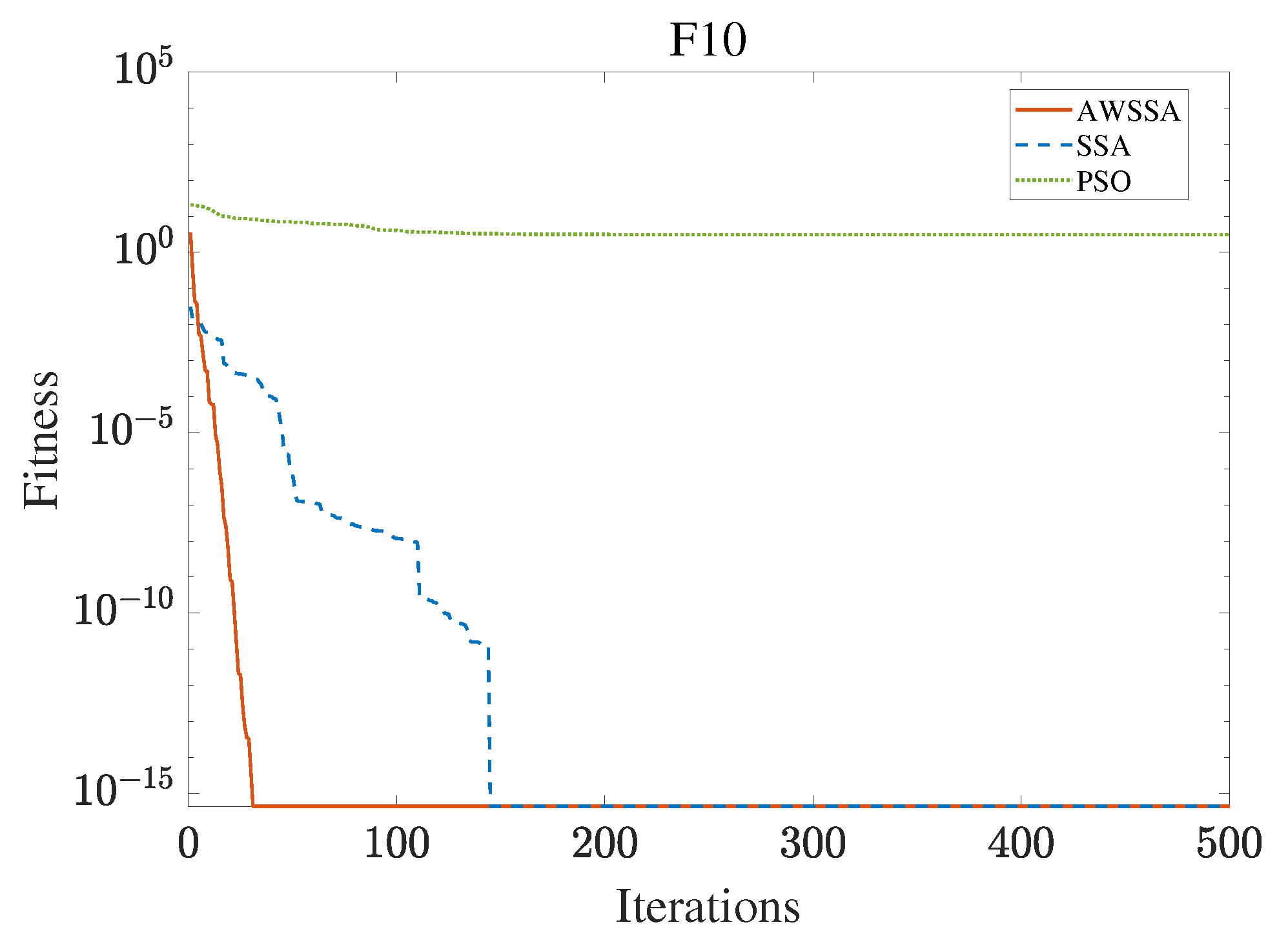
The AWSSA, the SSA, and the PSO algorithm were compared for functional optimization. The population size was set to 30, the maximum number of iterations was 500, and the algorithm parameter settings are shown in Table 2. The three algorithms were run on the test function 30 times, and the average value was taken as a reference. Table 3 lists the detailed experimental results. It can be seen from Table 3 that in the unimodal function, the AWSSA achieved optimal results in F1∼F4, which was dozens of orders of magnitude ahead of the other algorithms. It was only slightly lower than the SSA on the F5 and F6 functions. On the other hand, it can be observed that the AWSSA was far better than the SSA for the multimodal function F8, although the average values and standard deviations obtained by the AWSSA and the SSA were the same on F9 and F10. The information evident from the convergence curves depicted in Figure 4, Figure 5, Figure 6, Figure 7, Figure 8, Figure 9, Figure 10, Figure 11, Figure 12 and Figure 13 is that the convergence speed of the AWSSA was better than that of the other algorithms. From the above results, it can be seen that the improvement strategy in this article has a certain effect on improving the convergence ability and optimization ability of the original algorithm.
Table 2.
Parameters setting of comparison algorithm.
Table 3.
Test Function Results.
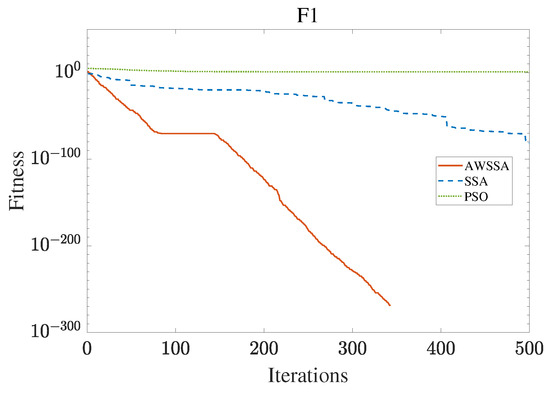
Figure 4.
F1 convergence curve.
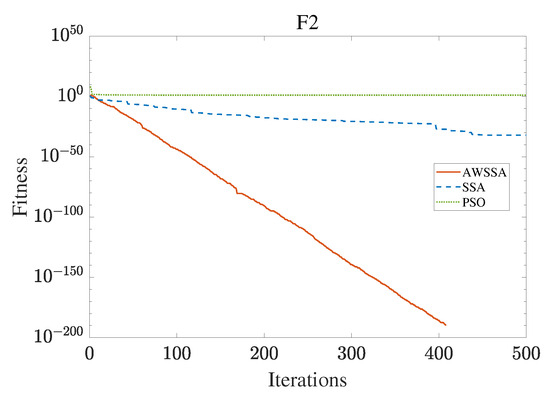
Figure 5.
F2 convergence curve.
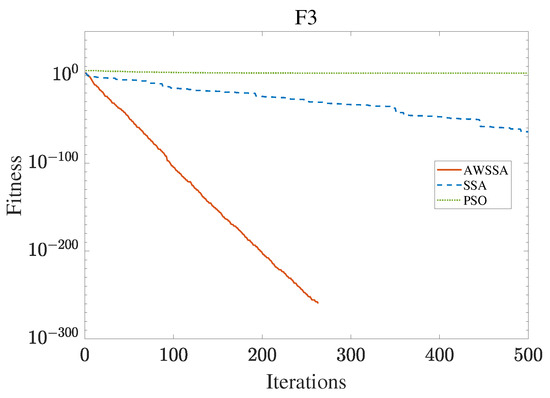
Figure 6.
F3 convergence curve.
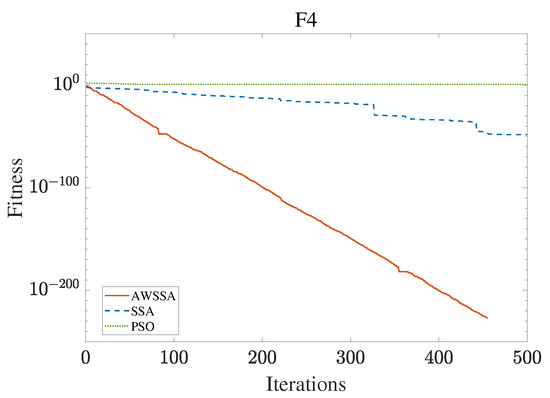
Figure 7.
F4 convergence curve.

Figure 8.
F5 convergence curve.
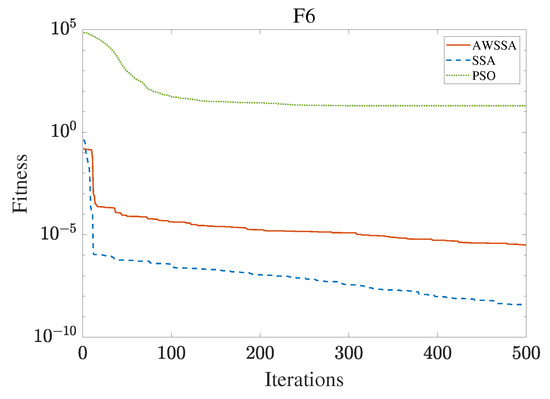
Figure 9.
F6 convergence curve.
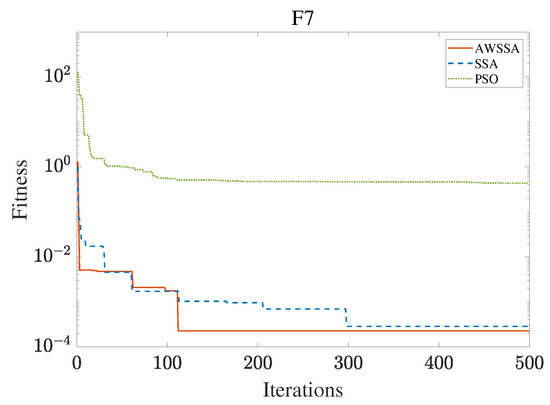
Figure 10.
F7 convergence curve.
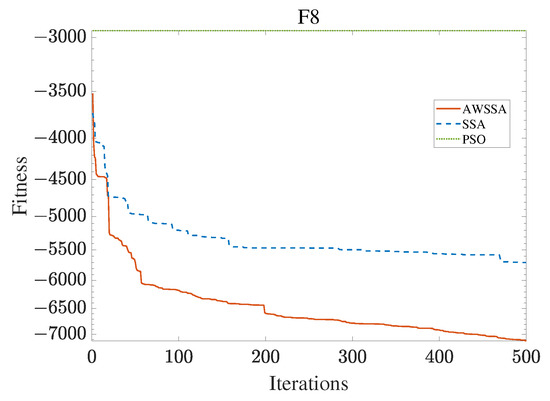
Figure 11.
F8 convergence curve.
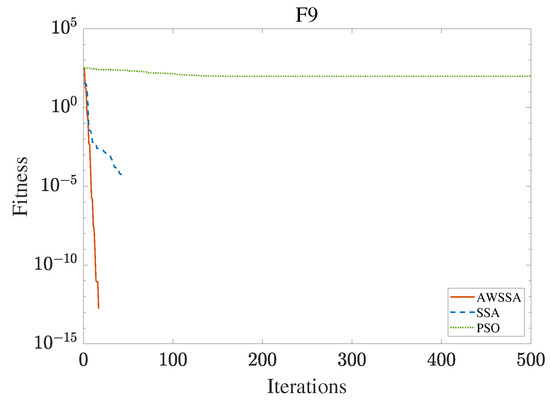
Figure 12.
F9 convergence curve.
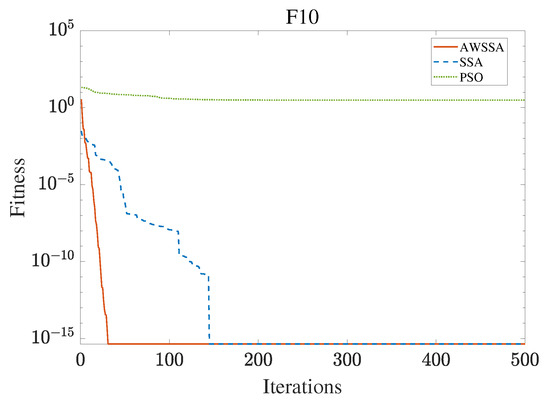
Figure 13.
F10 convergence curve.
In the next section, we describe in detail the application of the AWSSA to multi-objective association rule mining, including the selection of coding rules and fitness functions, as well as its comparison with other algorithms.
4. Solving Multi-Objective Association Rule Mining with the AWSSA
4.1. ARM Rule Representation
In the field of ARM, rules are usually represented in two ways [33]: the Michigan approach and the Pittsburgh approach. The former represents a rule as a single individual and the latter represents a rule as a set. In this paper, we chose to adopt the Michigan method. In the Michigan method, a rule is represented as a vector of integers of length 2N. The first half of this vector is used to represent the presence or absence of each item in the rule and the second half is used to represent the presence or absence of each item in the result. In the first half, if the value is greater than zero, it means that the corresponding item exists in the rule, while in the second half, if the value is greater than zero, it means that the item is in the first item of the rule and, vice versa, it means that the item belongs to the latter item, and thus it is more convenient to compute. For example, in Table 4, the rule is represented as →.
Table 4.
Example of individual.
4.2. Fitness Function Selection
In this paper, the quality of association rules is considered in terms of support, confidence, and Lift [34] for discovering rules with high generality, more reliability, and strong association. Support is defined as follows:
where is the total number of transactions, and represents the number of transactions containing both A and B. Support can be thought of as the frequency of occurrence of a rule in the transaction set, which is used to characterize the degree of prevalence of a rule. If the support is too low, it means that the resulting rule is quite rare, which may not be meaningful to the decision maker. The second objective function is the confidence, which is usually used to measure the credibility of a rule to help determine the strength of the association rule, i.e., the likelihood that itemset B will occur under the condition that itemset A occurs. Rules with high confidence are usually more reliable because their occurrence in the data is well-founded. The confidence level is defined as follows:
In ARM, sometimes there are misleading associations that appear to be related on the surface but are actually caused by chance events, and lift can help us determine the authenticity of such associations. The lift tells us whether the itemsets included in the rule are more related than if they had appeared separately, and it helps to identify non-independent relationships between the itemsets; a lift of less than 1 indicates that A plays no role in the likelihood of B’s occurrence, whereas a larger lift indicates that A is more related to B.
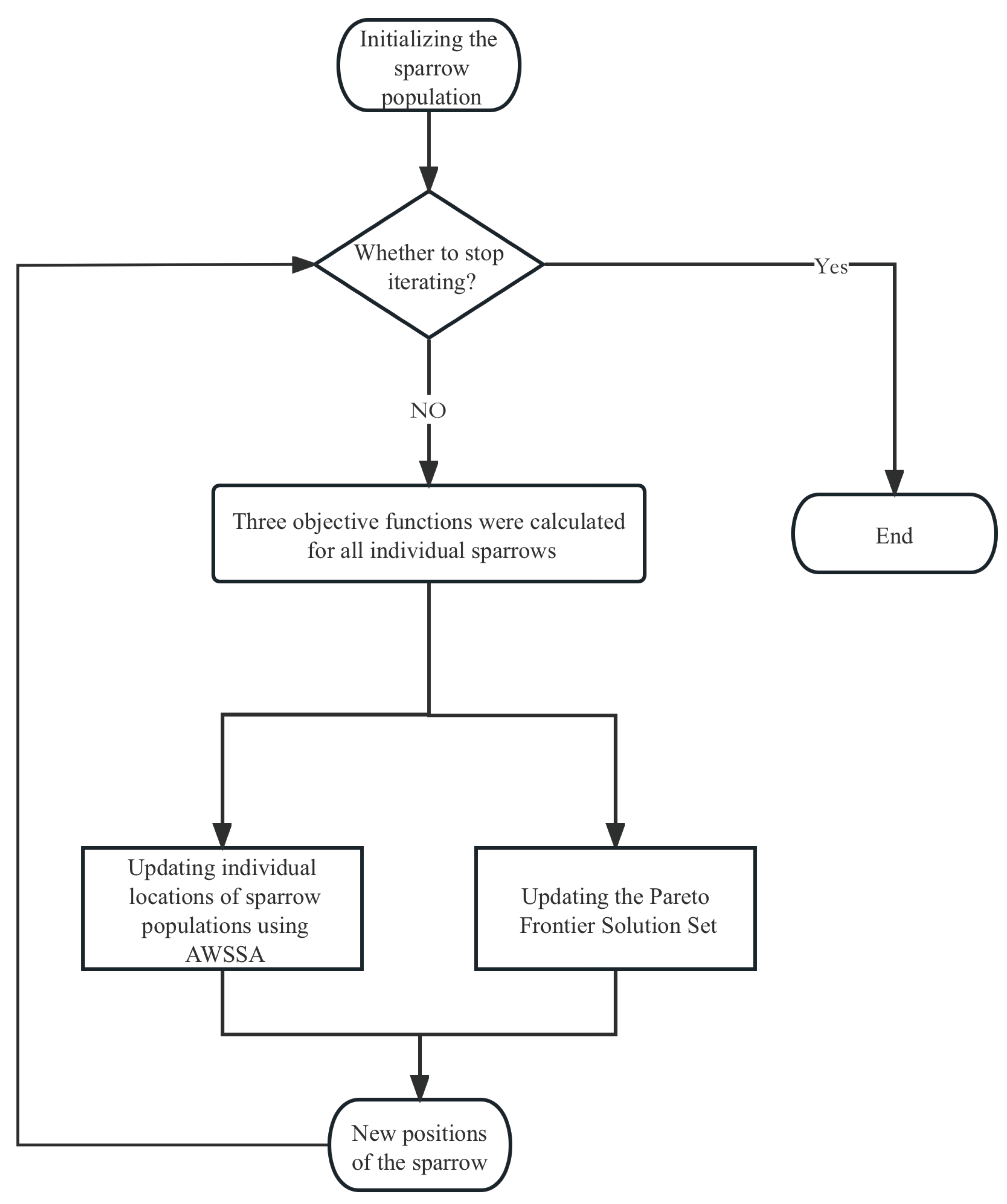
The workflow of the AWSSA in MOARM is shown in Figure 14.
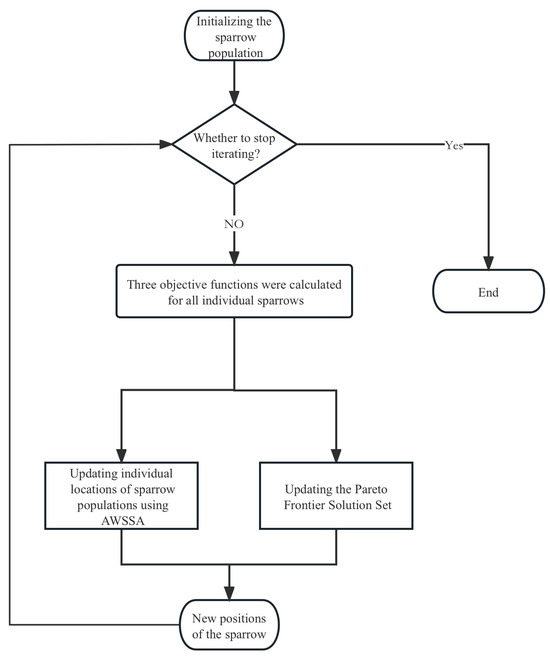
Figure 14.
Flowchart of the proposed multi-objective AWSSA.
4.3. Implementation
We compared the AWSSA with four additional advanced metaheuristic algorithms in association rule issues. The name of the algorithm is listed in Table 2, along with the parameter settings. Five real datasets from UCI [35] were used. Table 5 is a description of the different datasets, where all the datasets have been discretized. From the Table, it can be seen that the number of transactions as well as the number of items in the five datasets were different; the number of transactions is also known as the number of records, and the size of the selected datasets tends to increase to better observe the performance of the algorithms on datasets of different magnitudes. The other four algorithms were the WOA [36], the SSA [30], the SMA [13], and the PSO [37]. The SMA algorithm was proposed in the same year as the SSA, which is a relatively new algorithm, so it was chosen for comparison. As for the PSO algorithm and the WOA, they have been maturely applied in many fields, the original papers have high citations, and their excellent performance has been certified by various industries, so we thought that it was necessary to choose excellent algorithms to compare with the AWSSA. All in all, our selection mainly considered relatively novel algorithms and algorithms that had been highly recognized in many fields. For each calculation, the number of populations and iterations were 30 and 100, respectively. We let each algorithm repeat the experiment five times on the dataset, and the average value obtained was used as a reference basis. The experimental results recorded not only the values of the three objective functions for each rule in the solution set of the Pareto front, but also the size of the Pareto front, i.e., the number of rules obtained.
Table 5.
Datasets selected for experiments.
4.4. Simulation Result Analysis
Analyzing the experimental results based on Table 6, it can be observed that the AWSSA did not show significant superiority over the other algorithms on smaller datasets, such as the Iris dataset. In these cases, it achieved only a moderate level in terms of three different objective function values. The problem complexity of the smaller datasets was relatively low, resulting in insignificant performance differences between the five algorithms. The AWSSA performed much better in all three objective function values when the number of transactions and the number of dimensions of the dataset increased. It performed especially better in terms of lift, where it was much better than the other algorithms. In addition, the AWSSA also maintained a high level of support and confidence. This suggests that the AWSSA has a very proficient capacity for identifying optimization.
Table 6.
Average objective function value of Pareto front.
In Table 7, further analysis shows that the AWSSA found a good number of rules on multiple datasets. In contrast, although the SMA algorithm could also find multiple rules, the average objective function values of these rules were relatively low, i.e., the rules were of poor quality. This phenomenon stemmed from the fact that the SMAs fell into local optima in the early stages, where the populations were rapidly clustered together and lacked the ability to break away from the local optima, resulting in a large number of poor-quality solutions in the Pareto-optimal set. The AWSSAs had a strong potential to break away from the local optima, thanks to the Weibull distribution strategy adopted and had excellent exploration capabilities under the augmented search and multidirectional learning strategies. As a result, the AWSSA was able to find a large number of rules while keeping their quality high. This further validates that the AWSSA strikes a good balance between exploration and exploitation.
Table 7.
Average number of rules composing the Pareto front.
5. Discussion and Conclusions
In this paper, we propose an improved sparrow search algorithm by considering problems such as the poor optimization-seeking ability of current heuristic algorithms in multi-objective association rule mining. The method employs an adaptive Weibull distribution to enhance the ability of the algorithm to jump out of the local optimum in different iteration periods. An enhancement search strategy and a multidirectional learning strategy are introduced, to expand the search range of population individuals. The main conclusions of this paper can be summarized in two aspects: (1) Firstly, comparing with SSA in 10 standard function tests, its optimization searching accuracy is improved by tens of orders of magnitude in most of the functions; at the same time, the standard deviation performs much better and, on the other hand, the convergence speed is also improved, which proves the effectiveness of the improved strategy in this paper. (2) Applying the improved algorithm to multi-objective association rule mining was the final research purpose of this paper. On five different sizes of datasets, the AWSSA took the lead in multiple objective function values, especially on two large-scale datasets, Abalone and Wine. The lift was improved by about 1.5 times compared with SSA, and the confidence was also improved by about 5 percent. On the other hand, while maintaining the high quality of association rules obtained, the AWSSA did not mine the largest number of rules, but combined with the performance on function values, the AWSSA was significantly more comprehensive.
This study confirms that the AWSSA has excellent performance in multi-objective association rule mining. However, considering the limitations of the application scenarios in this paper, they need to be applied to more fields in future work, such as cluster analysis and other directions to verify the performance of the AWSSA. Meanwhile, considering the complexity of the algorithm, a parallel version of this paper’s algorithm could be proposed in the next step, and parallelization could accelerate the search process and reduce the overall computation time, especially when coping with larger datasets in practical applications.
Author Contributions
Conceptualization, L.H. and D.W.; methodology, L.H.; software, L.H.; validation, L.H. and D.W.; formal analysis, L.H. and D.W.; investigation, L.H. and D.W.; resources, D.W.; data curation, L.H. and D.W.; writing—original draft preparation, L.H.; writing—review and editing, L.H. and D.W.; visualization, L.H. and D.W.; supervision, L.H. and D.W.; project administration, L.H. and D.W.; funding acquisition, D.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported in part by the National Science Foundation of China under Grant 62362030.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: https://archive.ics.uci.edu/.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Shu, X.; Ye, Y. Knowledge discovery: Methods from data mining and machine learning. Soc. Sci. Res. 2023, 110, 102817. [Google Scholar] [CrossRef] [PubMed]
- Das, S.; Tamakloe, R.; Zubaidi, H.; Obaid, I.; Alnedawi, A. Fatal pedestrian crashes at intersections: Trend mining using association rules. Accid. Anal. Prev. 2021, 160, 106306. [Google Scholar] [CrossRef] [PubMed]
- Dol, S.M.; Jawandhiya, P.M. Classification technique and its combination with clustering and association rule mining in educational data mining—A survey. Eng. Appl. Artif. Intell. 2023, 122, 106071. [Google Scholar] [CrossRef]
- Sariyer, G.; Öcal Taşar, C. Highlighting the rules between diagnosis types and laboratory diagnostic tests for patients of an emergency department: Use of association rule mining. Health Inform. J. 2020, 26, 1177–1193. [Google Scholar] [CrossRef] [PubMed]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Data Bases, Santiago de Chile, Chile, 12–15 September 1994; Volume 1215, pp. 487–499. [Google Scholar]
- Borgelt, C. Keeping things simple: Finding frequent item sets by recursive elimination. In Proceedings of the 1st International Workshop on Open Source Data Mining: Frequent Pattern Mining Implementations, Chicago, IL, USA, 21 August 2005; pp. 66–70. [Google Scholar]
- Telikani, A.; Gandomi, A.H.; Shahbahrami, A. A survey of evolutionary computation for association rule mining. Inf. Sci. 2020, 524, 318–352. [Google Scholar] [CrossRef]
- Ventura, S.; Luna, J.M.; Ventura, S.; Luna, J.M. Scalability in pattern mining. In Pattern Mining with Evolutionary Algorithms; Springer: Berlin/Heidelberg, Germany, 2016; pp. 177–190. [Google Scholar]
- Abualigah, L.; Elaziz, M.A.; Khasawneh, A.M.; Alshinwan, M.; Ibrahim, R.A.; Al-Qaness, M.A.; Mirjalili, S.; Sumari, P.; Gandomi, A.H. Meta-heuristic optimization algorithms for solving real-world mechanical engineering design problems: A comprehensive survey, applications, comparative analysis, and results. Neural Comput. Appl. 2022, 34, 4081–4110. [Google Scholar] [CrossRef]
- Badhon, B.; Kabir, M.M.J.; Xu, S.; Kabir, M. A survey on association rule mining based on evolutionary algorithms. Int. J. Comput. Appl. 2021, 43, 775–785. [Google Scholar] [CrossRef]
- SS, V.C.; HS, A. Nature inspired meta heuristic algorithms for optimization problems. Computing 2022, 104, 251–269. [Google Scholar] [CrossRef]
- Holland, J.H. Genetic algorithms. Sci. Am. 1992, 267, 66–73. [Google Scholar] [CrossRef]
- Li, S.; Chen, H.; Wang, M.; Heidari, A.A.; Mirjalili, S. Slime mould algorithm: A new method for stochastic optimization. Future Gener. Comput. Syst. 2020, 111, 300–323. [Google Scholar] [CrossRef]
- Mirjalili, S. The ant lion optimizer. Adv. Eng. Softw. 2015, 83, 80–98. [Google Scholar] [CrossRef]
- Sarath, K.; Ravi, V. Association rule mining using binary particle swarm optimization. Eng. Appl. Artif. Intell. 2013, 26, 1832–1840. [Google Scholar] [CrossRef]
- Yan, X.; Zhang, C.; Zhang, S. Genetic algorithm-based strategy for identifying association rules without specifying actual minimum support. Expert Syst. Appl. 2009, 36, 3066–3076. [Google Scholar] [CrossRef]
- Sharmila, S.; Vijayarani, S. Association rule mining using fuzzy logic and whale optimization algorithm. Soft Comput. 2021, 25, 1431–1446. [Google Scholar] [CrossRef]
- Varol Altay, E.; Alatas, B. Performance analysis of multi-objective artificial intelligence optimization algorithms in numerical association rule mining. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 3449–3469. [Google Scholar] [CrossRef]
- Mata, J.; Alvarez, J.L.; Riquelme, J.C. An evolutionary algorithm to discover numeric association rules. In Proceedings of the 2002 ACM Symposium on Applied Computing, Madrid, Spain, 11–14 March 2002; pp. 590–594. [Google Scholar]
- Mata, J.; Alvarez, J.L.; Riquelme, J.C. Mining numeric association rules with genetic algorithms. In Artificial Neural Nets and Genetic Algorithms: Proceedings of the International Conference in Prague, Czech Republic, 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 264–267. [Google Scholar]
- Baró, G.B.; Martínez-Trinidad, J.F.; Rosas, R.M.V.; Ochoa, J.A.C.; González, A.Y.R.; Cortés, M.S. L A pso-based algorithm for mining association rules using a guided exploration strategy. Pattern Recognit. Lett. 2020, 138, 8–15. [Google Scholar] [CrossRef]
- Beiranv, V.; Mobasher-Kashani, M.; Bakar, A.A. Multi-objective pso algorithm for mining numerical association rules without a priori discretization. Expert Syst. Appl. 2014, 41, 4259–4273. [Google Scholar] [CrossRef]
- Petchrompo, S.; Coit, D.W.; Brintrup, A.; Wannakrairot, A.; Parlikad, A.K. A review of pareto pruning methods for multi-objective optimization. Comput. Ind. Eng. 2022, 167, 108022. [Google Scholar] [CrossRef]
- Li, Z.C.; He, P.L.; Lei, M. A high efficient aprioritid algorithm for mining association rule. In Proceedings of the 2005 International Conference on Machine Learning and Cybernetics, Guangzhou, China, 18–21 August 2005; Volume 3, pp. 1812–1815. [Google Scholar]
- Park, J.S.; Chen, M.S.; Yu, P.S. An effective hash-based algorithm for mining association rules. ACM Sigmod Rec. 1995, 24, 175–186. [Google Scholar] [CrossRef]
- Brin, S.; Motwani, R.; Ullman, J.D.; Tsur, S. Dynamic itemset counting and implication rules for market basket data. In Proceedings of the 1997 ACM SIGMOD International Conference on Management of Data, Tucson, AZ, USA, 11–15 May 1997; pp. 255–264. [Google Scholar]
- Ye, Z.; Cai, W.; Wang, M.; Zhang, A.; Zhou, W.; Deng, N.; Wei, Z.; Zhu, D. Association rule mining based on hybrid whale optimization algorithm. Int. J. Data Warehous. Min. 2022, 18, 1–22. [Google Scholar] [CrossRef]
- Heraguemi, K.E.; Kamel, N.; Drias, H. Multi-objective bat algorithm for mining numerical association rules. Int. J. Bio-Inspired Comput. 2018, 11, 239–248. [Google Scholar] [CrossRef]
- Minaei-Bidgoli, B.; Barmaki, R.; Nasiri, M. Mining numerical association rules via multi-objective genetic algorithms. Inf. Sci. 2013, 233, 15–24. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control. Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Rinne, H. The Weibull Distribution: A Handbook; Chapman and Hall/CRC: New York, NY, USA, 2008. [Google Scholar]
- Chai, Y.; Sun, X.; Ren, S. A chaotic sparrow search algorithm incorporating multidirectional learning. J. Comput. Eng. Appl. 2023, 59, 81–91. [Google Scholar] [CrossRef]
- Freitas, A.A. A survey of evolutionary algorithms for data mining and knowledge discovery. In Advances in Evolutionary Computing: Theory and Applications; Springer: Berlin/Heidelberg, Germany, 2003; pp. 819–845. [Google Scholar]
- Luna, J.M.; Ondra, M.; Fardoun, H.M.; Ventura, S. Optimization of quality measures in association rule mining: An empirical study. Int. J. Comput. Intell. Syst. 2018, 12, 59–78. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UC Irvine Machine Learning Repository. 2017. Available online: http://archive.ics.uci.edu/ml (accessed on 1 March 2023).
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).