
Effect of Data Augmentation Using Deep Learning on Predictive Models for Geopolymer Compressive Strength



Abstract
:1. Introduction
2. Literature Review
2.1. Machine Learning Models for Prediction
2.2. Data Augmentation
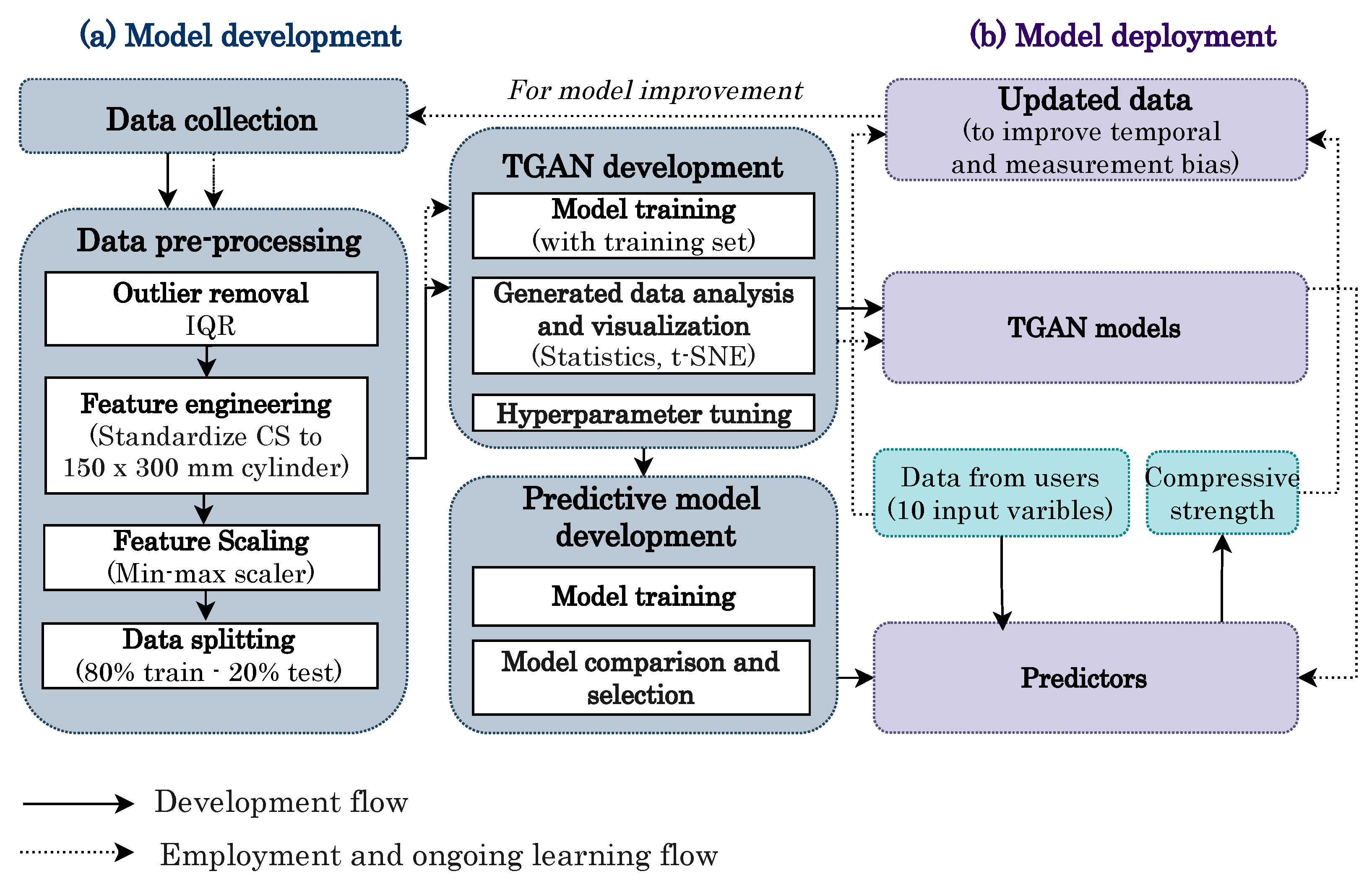
3. Methodology
3.1. Tabular Generative Adversarial Networks
3.2. Machine Learning Predictive Models
3.3. LightGBM
3.4. Support Vector Machine (SVM)
3.5. Cascade forward Neural Networks (CFNNs)
3.6. Study Framework
4. Results and Discussion
4.1. Data Collection and Preparation
4.2. Performance of Models before Data Augmentation
4.3. Synthetic Dataset
4.4. Performance of Models after Data Augmentation
4.5. Discussion and Limitations
5. Conclusions and Future Works
- TGAN proves capable of generating mixture and compressive strength data for geopolymer concrete. The synthetic data significantly improves the performance of ML models, as evident from the increased R2 values and reduced error indices such as MAE, RMSE, MAPE, RSR, and WMAPE. The CFNN model exhibited the most improvement, followed by LightGBM and SVM.
- The enhanced performance of the models indicates that the heterogeneity in the type or quality of precursors in the collected data does not significantly affect the data generation ability and performance of ML models.
- Due to the presence of numerous outliers and skewed characteristics of the data, the SVM model was greatly impacted in both the original and synthetic datasets.
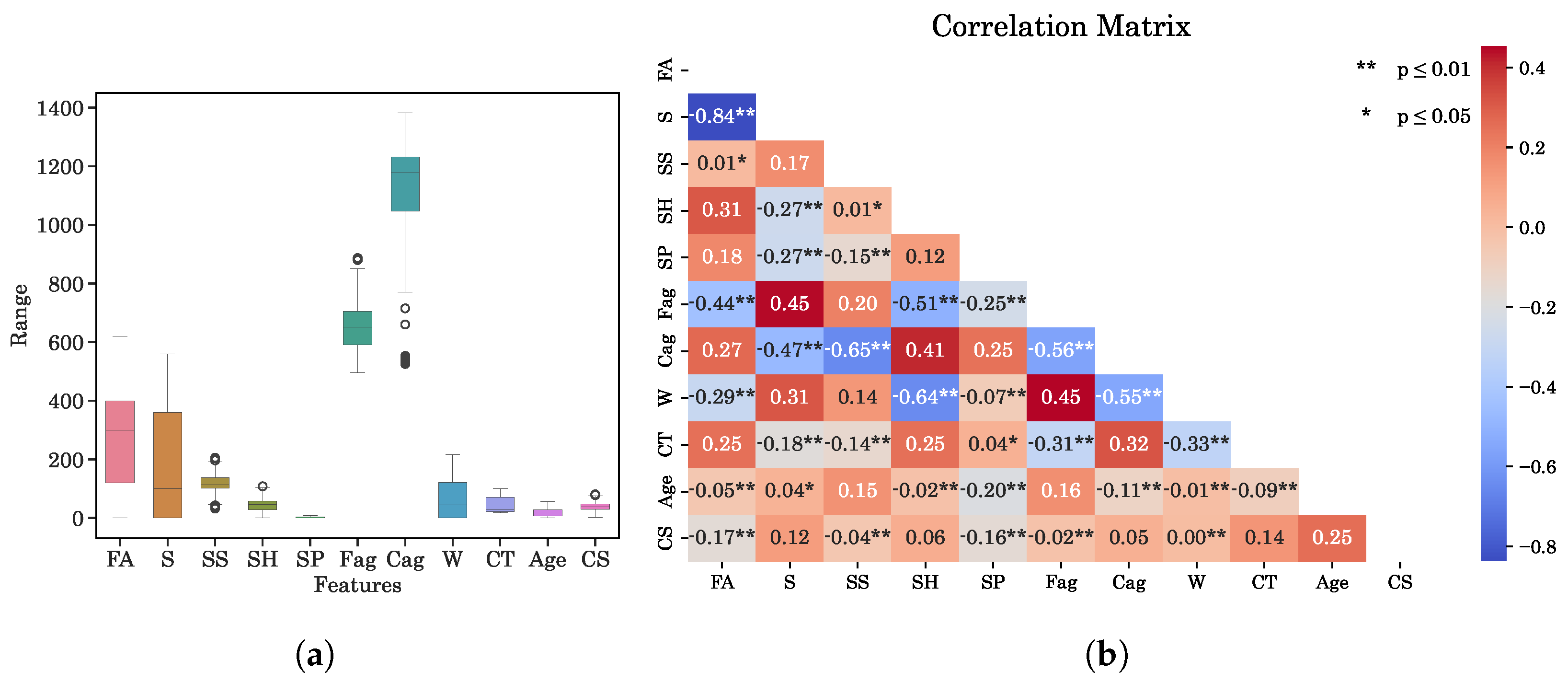
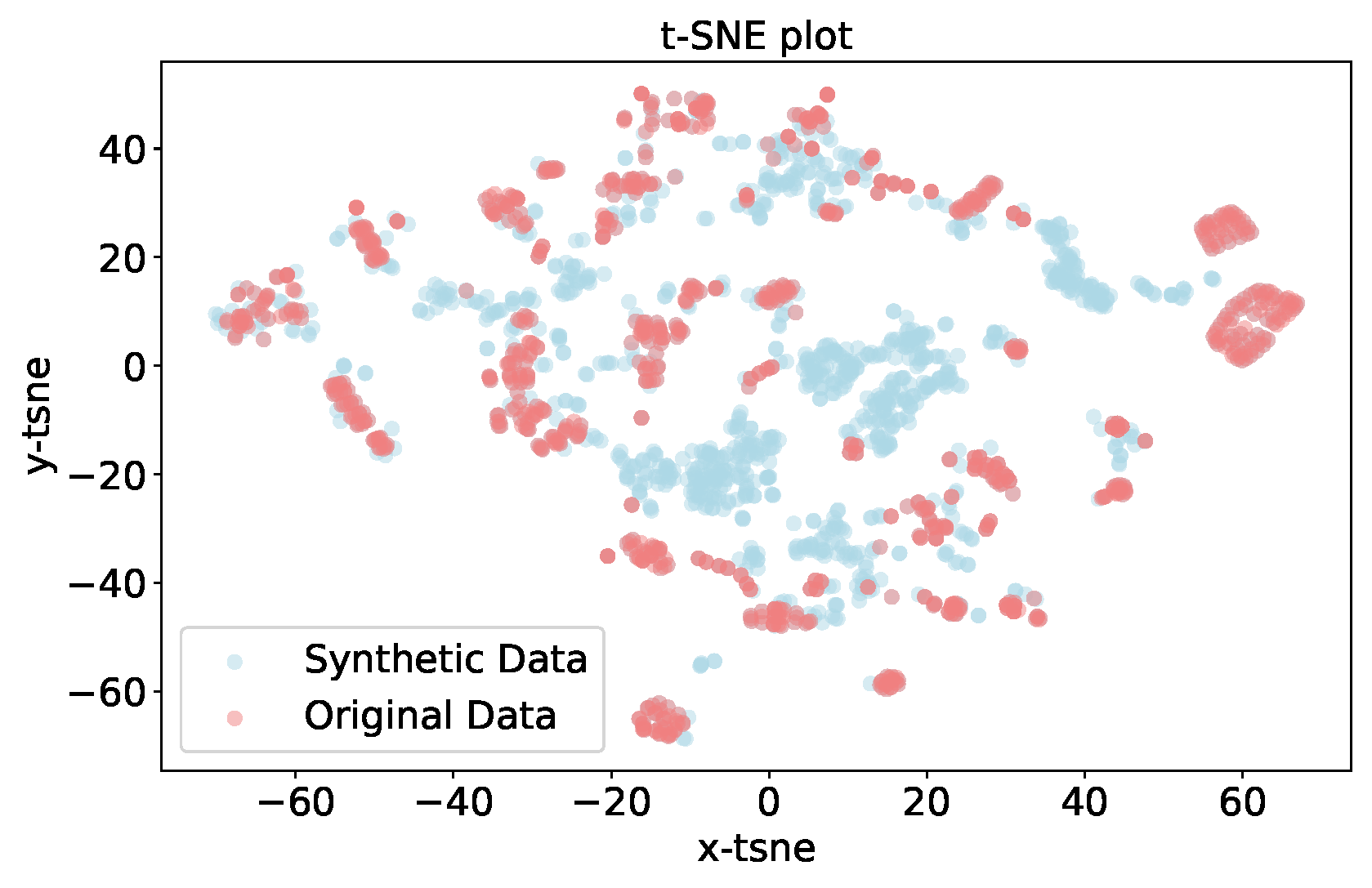
- The generated data statistics demonstrate that the characteristics of the data are quite similar to the original data. This indicates that the TGAN model generated reliable data. However, it is important to note that using such data merely improves accuracy without enhancing the generalization capabilities of the models.
- In addition, this study demonstrates limitations concerning the generalizability of the model, the scope of inputs, the absence of validation with actual experimental data, and regional bias within the dataset.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Habert, G.; Miller, S.A.; John, V.M.; Provis, J.L.; Favier, A.; Horvath, A.; Scrivener, K.L. Environmental impacts and decarbonization strategies in the cement and concrete industries. Nat. Rev. Earth Environ. 2020, 1, 559–573. [Google Scholar] [CrossRef]
- Nwankwo, C.O.; Bamigboye, G.O.; Davies, I.E.; Michaels, T.A. High volume Portland cement replacement: A review. Constr. Build. Mater. 2020, 260, 120445. [Google Scholar] [CrossRef]
- Scrivener, K.L.; John, V.M.; Gartner, E.M. Eco-efficient cements: Potential economically viable solutions for a low-CO2 cement-based materials industry. Cem. Concr. Res. 2018, 114, 2–26. [Google Scholar] [CrossRef]
- Zhuang, X.Y.; Chen, L.; Komarneni, S.; Zhou, C.H.; Tong, D.S.; Yang, H.M.; Yu, W.H.; Wang, H. Fly ash-based geopolymer: Clean production, properties and applications. J. Clean. Prod. 2016, 125, 253–267. [Google Scholar] [CrossRef]
- Zakka, W.P.; Lim, N.H.A.S.; Khun, M.C. A scientometric review of geopolymer concrete. J. Clean. Prod. 2021, 280, 124353. [Google Scholar] [CrossRef]
- Dwibedy, S.; Panigrahi, S.K. Factors affecting the structural performance of geopolymer concrete beam composites. Constr. Build. Mater. 2023, 409, 134129. [Google Scholar] [CrossRef]
- Li, N.; Shi, C.; Zhang, Z.; Wang, H.; Liu, Y. A review on mixture design methods for geopolymer concrete. Compos. Part B Eng. 2019, 178, 107490. [Google Scholar] [CrossRef]
- Gupta, T.; Rao, M.C. Prediction of compressive strength of geopolymer concrete using machine learning techniques. Struct. Concr. 2022, 23, 3073–3090. [Google Scholar] [CrossRef]
- Li, Z.; Yoon, J.; Zhang, R.; Rajabipour, F.; Srubar III, W.V.; Dabo, I.; Radlińska, A. Machine learning in concrete science: Applications, challenges, and best practices. npj Comput. Mater. 2022, 8, 127. [Google Scholar] [CrossRef]
- Yasuno, T.; Nakajima, M.; Sekiguchi, T.; Noda, K.; Aoyanagi, K.; Kato, S. Synthetic image augmentation for damage region segmentation using conditional GAN with structure edge. arXiv 2020, arXiv:2005.08628. [Google Scholar]
- Chen, N.; Zhao, S.; Gao, Z.; Wang, D.; Liu, P.; Oeser, M.; Hou, Y.; Wang, L. Virtual mix design: Prediction of compressive strength of concrete with industrial wastes using deep data augmentation. Constr. Build. Mater. 2022, 323, 126580. [Google Scholar] [CrossRef]
- Liu, K.H.; Xie, T.Y.; Cai, Z.K.; Chen, G.M.; Zhao, X.Y. Data-driven prediction and optimization of axial compressive strength for FRP-reinforced CFST columns using synthetic data augmentation. Eng. Struct. 2024, 300, 117225. [Google Scholar] [CrossRef]
- Marani, A.; Jamali, A.; Nehdi, M.L. Predicting ultra-high-performance concrete compressive strength using tabular generative adversarial networks. Materials 2020, 13, 4757. [Google Scholar] [CrossRef] [PubMed]
- Sharma, U.; Gupta, N.; Verma, M. Prediction of the compressive strength of Flyash and GGBS incorporated geopolymer concrete using artificial neural network. Asian J. Civ. Eng. 2023, 24, 2837–2850. [Google Scholar] [CrossRef]
- Gupta, P.; Gupta, N.; Goyal, S. Predicting compressive strength of calcined clay, fly ash-based geopolymer composite using supervised learning algorithm. Adv. Appl. Math. Sci. 2022, 21, 4151–4161. [Google Scholar]
- Jafari, A.; Toufigh, V. Developing a comprehensive prediction model for the compressive strength of slag-based alkali-activated concrete. J. Sustain. Cem.-Based Mater. 2024, 13, 256–273. [Google Scholar] [CrossRef]
- Kumar, P.; Pratap, B.; Sharma, S.; Kumar, I. Compressive strength prediction of fly ash and blast furnace slag-based geopolymer concrete using convolutional neural network. Asian J. Civ. Eng. 2024, 25, 1561–1569. [Google Scholar] [CrossRef]
- Huynh, A.T.; Nguyen, Q.D.; Xuan, Q.L.; Magee, B.; Chung, T.; Tran, K.T.; Nguyen, K.T. A machine learning-assisted numerical predictor for compressive strength of geopolymer concrete based on experimental data and sensitivity analysis. Appl. Sci. 2020, 10, 7726. [Google Scholar] [CrossRef]
- Wang, Q.; Ahmad, W.; Ahmad, A.; Aslam, F.; Mohamed, A.; Vatin, N.I. Application of soft computing techniques to predict the strength of geopolymer composites. Polymers 2022, 14, 1074. [Google Scholar] [CrossRef]
- Tran, V.Q. Data-driven approach for investigating and predicting of compressive strength of fly ash–slag geopolymer concrete. Struct. Concr. 2023, 24, 7419–7444. [Google Scholar] [CrossRef]
- Ahmed, H.U.; Mohammed, A.S.; Mohammed, A.A. Proposing several model techniques including ANN and M5P-tree to predict the compressive strength of geopolymer concretes incorporated with nano-silica. Environ. Sci. Pollut. Res. 2022, 29, 71232–71256. [Google Scholar] [CrossRef] [PubMed]
- Nazar, S.; Yang, J.; Amin, M.N.; Khan, K.; Ashraf, M.; Aslam, F.; Javed, M.F.; Eldin, S.M. Machine learning interpretable-prediction models to evaluate the slump and strength of fly ash-based geopolymer. J. Mater. Res. Technol. 2023, 24, 100–124. [Google Scholar] [CrossRef]
- Ahmed, H.U.; Mostafa, R.R.; Mohammed, A.; Sihag, P.; Qadir, A. Support vector regression (SVR) and grey wolf optimization (GWO) to predict the compressive strength of GGBFS-based geopolymer concrete. Neural Comput. Appl. 2023, 35, 2909–2926. [Google Scholar] [CrossRef]
- Kumar, A.; Arora, H.C.; Kapoor, N.R.; Kumar, K. Prognosis of compressive strength of fly-ash-based geopolymer-modified sustainable concrete with ML algorithms. Struct. Concr. 2023, 24, 3990–4014. [Google Scholar] [CrossRef]
- Ahmed, H.U.; Mohammed, A.A.; Mohammed, A. Soft computing models to predict the compressive strength of GGBS/FA-geopolymer concrete. PLoS ONE 2022, 17, e0265846. [Google Scholar] [CrossRef] [PubMed]
- Gunasekara, C.; Lokuge, W.; Keskic, M.; Raj, N.; Law, D.; Setunge, S. Design of alkali-activated slag-fly ash concrete mixtures using machine learning. Mater. J. 2020, 117, 263–278. [Google Scholar]
- Gogineni, A.; Panday, I.K.; Kumar, P.; Paswan, R.k. Predictive modelling of concrete compressive strength incorporating GGBS and alkali using a machine-learning approach. Asian J. Civ. Eng. 2024, 25, 699–709. [Google Scholar] [CrossRef]
- Nukah, P.D.; Abbey, S.J.; Booth, C.A.; Oti, J. Evaluation of the structural performance of low carbon concrete. Sustainability 2022, 14, 16765. [Google Scholar] [CrossRef]
- Kina, C.; Tanyildizi, H.; Turk, K. Forecasting the compressive strength of GGBFS-based geopolymer concrete via ensemble predictive models. Constr. Build. Mater. 2023, 405, 133299. [Google Scholar] [CrossRef]
- Parhi, S.K.; Panigrahi, S.K. Alkali–silica reaction expansion prediction in concrete using hybrid metaheuristic optimized machine learning algorithms. Asian J. Civ. Eng. 2024, 25, 1091–1113. [Google Scholar] [CrossRef]
- Dunphy, K.; Fekri, M.N.; Grolinger, K.; Sadhu, A. Data augmentation for deep-learning-based multiclass structural damage detection using limited information. Sensors 2022, 22, 6193. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Jia, J.F.; Chen, X.Z.; Bai, Y.L.; Li, Y.L.; Wang, Z.H. An interpretable ensemble learning method to predict the compressive strength of concrete. Structures 2022, 46, 201–213. [Google Scholar] [CrossRef]
- Çalışkan, A.; Demirhan, S.; Tekin, R. Comparison of different machine learning methods for estimating compressive strength of mortars. Constr. Build. Mater. 2022, 335, 127490. [Google Scholar] [CrossRef]
- Hasanipanah, M.; Jamei, M.; Mohammed, A.S.; Amar, M.N.; Hocine, O.; Khedher, K.M. Intelligent prediction of rock mass deformation modulus through three optimized cascaded forward neural network models. Earth Sci. Inform. 2022, 15, 1659–1669. [Google Scholar] [CrossRef]
- Mijwel, M.M. Artificial neural networks advantages and disadvantages. Mesopotamian J. Big Data 2021, 2021, 29–31. [Google Scholar] [CrossRef]
- Sun, L.; Koopialipoor, M.; Jahed Armaghani, D.; Tarinejad, R.; Tahir, M. Applying a meta-heuristic algorithm to predict and optimize compressive strength of concrete samples. Eng. Comput. 2021, 37, 1133–1145. [Google Scholar] [CrossRef]
- Liang, M.; Chang, Z.; Wan, Z.; Gan, Y.; Schlangen, E.; Šavija, B. Interpretable Ensemble-Machine-Learning models for predicting creep behavior of concrete. Cem. Concr. Compos. 2022, 125, 104295. [Google Scholar] [CrossRef]
- Ling, H.; Qian, C.; Kang, W.; Liang, C.; Chen, H. Combination of Support Vector Machine and K-Fold cross validation to predict compressive strength of concrete in marine environment. Constr. Build. Mater. 2019, 206, 355–363. [Google Scholar] [CrossRef]
- Pwasong, A.; Sathasivam, S. A new hybrid quadratic regression and cascade forward backpropagation neural network. Neurocomputing 2016, 182, 197–209. [Google Scholar] [CrossRef]
- Joseph, B.; Mathew, G. Influence of aggregate content on the behavior of fly ash based geopolymer concrete. Sci. Iran. 2012, 19, 1188–1194. [Google Scholar] [CrossRef]
- Nath, P.; Sarker, P.K. Effect of GGBFS on setting, workability and early strength properties of fly ash geopolymer concrete cured in ambient condition. Constr. Build. Mater. 2014, 66, 163–171. [Google Scholar] [CrossRef]
- Vora, P.R.; Dave, U.V. Parametric studies on compressive strength of geopolymer concrete. Procedia Eng. 2013, 51, 210–219. [Google Scholar] [CrossRef]
- Demie, S.; Nuruddin, M.F.; Shafiq, N. Effects of micro-structure characteristics of interfacial transition zone on the compressive strength of self-compacting geopolymer concrete. Constr. Build. Mater. 2013, 41, 91–98. [Google Scholar] [CrossRef]
- Lee, N.; Lee, H.K. Setting and mechanical properties of alkali-activated fly ash/slag concrete manufactured at room temperature. Constr. Build. Mater. 2013, 47, 1201–1209. [Google Scholar] [CrossRef]
- Nuaklong, P.; Sata, V.; Chindaprasirt, P. Influence of recycled aggregate on fly ash geopolymer concrete properties. J. Clean. Prod. 2016, 112, 2300–2307. [Google Scholar] [CrossRef]
- Rajarajeswari, A.; Dhinakaran, G. Compressive strength of GGBFS based GPC under thermal curing. Constr. Build. Mater. 2016, 126, 552–559. [Google Scholar] [CrossRef]
- Su, H.; Xu, J.; Ren, W. Mechanical properties of geopolymer concrete exposed to dynamic compression under elevated temperatures. Ceram. Int. 2016, 42, 3888–3898. [Google Scholar] [CrossRef]
- Tennakoon, C.; Shayan, A.; Sanjayan, J.G.; Xu, A. Chloride ingress and steel corrosion in geopolymer concrete based on long term tests. Mater. Des. 2017, 116, 287–299. [Google Scholar] [CrossRef]
- Wardhono, A.; Gunasekara, C.; Law, D.W.; Setunge, S. Comparison of long term performance between alkali activated slag and fly ash geopolymer concretes. Constr. Build. Mater. 2017, 143, 272–279. [Google Scholar] [CrossRef]
- Reddy, M.S.; Dinakar, P.; Rao, B.H. Mix design development of fly ash and ground granulated blast furnace slag based geopolymer concrete. J. Build. Eng. 2018, 20, 712–722. [Google Scholar] [CrossRef]
- Nguyen, K.T.; Le, T.A.; Lee, K. Evaluation of the mechanical properties of sea sand-based geopolymer concrete and the corrosion of embedded steel bar. Constr. Build. Mater. 2018, 169, 462–472. [Google Scholar] [CrossRef]
- Li, N.; Shi, C.; Zhang, Z.; Zhu, D.; Hwang, H.J.; Zhu, Y.; Sun, T. A mixture proportioning method for the development of performance-based alkali-activated slag-based concrete. Cem. Concr. Compos. 2018, 93, 163–174. [Google Scholar] [CrossRef]
- Nagaraj, V.K.; Venkatesh Babu, D.L. Assessing the performance of molarity and alkaline activator ratio on engineering properties of self-compacting alkaline activated concrete at ambient temperature. J. Build. Eng. 2018, 20, 137–155. [Google Scholar]
- Morsy, A.M.; Ragheb, A.M.; Shalan, A.H.; Mohamed, O.H. Mechanical characteristics of GGBFS/FA-based geopolymer concrete and its environmental impact. Pract. Period. Struct. Des. Constr. 2022, 27, 04022017. [Google Scholar] [CrossRef]
- Gunasekera, C.; Setunge, S.; Law, D.W. Correlations between mechanical properties of low-calcium fly ash geopolymer concretes. J. Mater. Civ. Eng. 2017, 29, 04017111. [Google Scholar] [CrossRef]
- Sukmak, P.; Horpibulsuk, S.; Shen, S.L. Strength development in clay–fly ash geopolymer. Constr. Build. Mater. 2013, 40, 566–574. [Google Scholar] [CrossRef]
- Somna, K.; Jaturapitakkul, C.; Kajitvichyanukul, P.; Chindaprasirt, P. NaOH-activated ground fly ash geopolymer cured at ambient temperature. Fuel 2011, 90, 2118–2124. [Google Scholar] [CrossRef]
- Suksiripattanapong, C.; Horpibulsuk, S.; Chanprasert, P.; Sukmak, P.; Arulrajah, A. Compressive strength development in fly ash geopolymer masonry units manufactured from water treatment sludge. Constr. Build. Mater. 2015, 82, 20–30. [Google Scholar] [CrossRef]
- Talaat, A.; Emad, A.; Tarek, A.; Masbouba, M.; Essam, A.; Kohail, M. Factors affecting the results of concrete compression testing: A review. Ain Shams Eng. J. 2021, 12, 205–221. [Google Scholar] [CrossRef]
- Taffese, W.Z.; Abegaz, K.A. Prediction of compaction and strength properties of amended soil using machine learning. Buildings 2022, 12, 613. [Google Scholar] [CrossRef]
- Benavoli, A.; Corani, G.; Mangili, F. Should we really use post-hoc tests based on mean-ranks? J. Mach. Learn. Res. 2016, 17, 152–161. [Google Scholar]
- Chowdhary, C.L.; Mittal, M.; P, K.; Pattanaik, P.A.; Marszalek, Z. An efficient segmentation and classification system in medical images using intuitionist possibilistic fuzzy C-mean clustering and fuzzy SVM algorithm. Sensors 2020, 20, 3903. [Google Scholar] [CrossRef] [PubMed]
- Rahmati, M.; Toufigh, V. Evaluation of geopolymer concrete at high temperatures: An experimental study using machine learning. J. Clean. Prod. 2022, 372, 133608. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Refs. | ML Technology | Dataset | Inputs |
|---|---|---|---|
| [24] | LR, EL, SVMR, GPR, optimized EL, optimized SVMR, optimized GPR | 275 | Fly ash, coarse aggregate, fine aggregate, Na2SiO3, NaOH, SiO2, molarity of NaOH and Na2O |
| [19] | DT, AdaBoost, RF | 363 | Water/solids ratio, molarity of NaOH, gravel 4/10 mm, gravel 10/20 mm, Na2SiO3, NaOH, fly ash, GGBS, fag |
| [20] | RF, GB, AdaBoost, DT, lightGBM, XGB, kNN, MVR, GPR, CatB | 158 | Fly ash, superplasticizer, extra water added, Na2SiO3, NaOH, coarse aggregate, fine aggregate, slag, specimen age, rest period, curing temperature, molarity, alkali/binder, and Na2SiO3/NaOH |
| [14] | ANN, MLR, MNLR | 289 | Fly ash, slag, rest period, curing temperature, age, NaOH/Na2SiO3, superplasticizer, extra water, molarity of NaOH, alkali/binder, coarse aggregate, fine aggregate |
| [15] | SVM, DT, RFR | 75 | Molarity of NaOH, curing temperature, age, % of Na2SiO3, NaOH, fly ash, coarse aggregate, fine aggregate, Na2SiO3, NaOH |
| [25] | ANN, M5P, LR, MLR | 220 | Alkali/binder, fly ash, Si/Al of fly ash, GGBS, Si/Ca of GGBS, coarse aggregate, fine aggregate, Na2SiO3, NaOH, Na2SiO3/NaOH, molarity of NaOH |
| [26] | ANN, MARS | 208 | Water/solid ratio, alkali/binder, Na-Silicate/NaOH, fly ash/slag ratio, NaOH molarity |
| [27] | RF, GBR, AdaBoost | 321 | GGBS, Na2SiO3 + NaOH (total alkali), coarse aggregate, fine aggregate, water, water/binder, age |
| [23] | LR, GA, PSO, SVR, GWO, Differential Evolution | 268 | Water, curing temperature, water/binder, GGBFS/ binder, coarse aggregate, fine aggregate, superplasticizer |
| [28] | ANN | 81 | GGBS, silica fume |
| [16] | ANN, BLR | 625 | Na2O:SiO2, Na2O:H2O, GGBFS:H2O, molarity of NaOH, Na2SiO3/NaOH, AS/GGBS, GGBS/water |
| [29] | DT, Bagging, LightGBM | 351 | Specimen age, molarity of NaOH, natural zeolite, silica fume, GGBFS |
| [22] | ANFIS, ANNs, GEP | 245 | Chemical composition of fly ash, mixing procedures, curing regime, activator content, fine aggregate, coarse aggregate, water, activator/fly ash, and molarity of NaOH |
| Algorithms | Advantages | Disadvantages |
|---|---|---|
| LightGBM [33] |
|
|
| SVM [34] |
|
|
| CFNN [35,36] |
|
|
| Feature Name | Symbol | Unit | Mean | STD | Min | Max | Skewness |
|---|---|---|---|---|---|---|---|
| Fly ash | FA | kg/m3 | 246.72 | 159.99 | 0.00 | 620.00 | −0.3385 |
| GGBS | GGBS | kg/m3 | 176.27 | 177.38 | 0.00 | 560.00 | 0.4777 |
| Sodium silicate | SS | kg/m3 | 117.56 | 36.08 | 32.00 | 205.50 | 0.2317 |
| Sodium hydroxide | SH | kg/m3 | 44.78 | 22.51 | 0.00 | 108.00 | 0.1219 |
| Superplasticizer | SP | kg/m3 | 1.52 | 2.57 | 0.00 | 9.00 | 1.3455 |
| Fine aggregate | fag | kg/m3 | 656.26 | 81.65 | 495.00 | 887.00 | 0.3134 |
| Coarse aggregate | cag | kg/m3 | 1082.58 | 239.87 | 525.40 | 1381.35 | −1.3052 |
| Added water | w | kg/m3 | 64.72 | 62.10 | 0.00 | 216.00 | 0.4727 |
| Curing temperature | CT | °C | 48.16 | 28.21 | 19 | 100 | 0.4981 |
| Curing period | CP | days | 21.76 | 14.99 | 1 | 56 | 0.6225 |
| Compressive strength | CS | MPa | 38.45 | 14.95 | 1.25 | 80.51 | 0.1296 |
| Model | Dataset | R2 | MEA | RMSE | MAPE | RSR | WMAPE |
|---|---|---|---|---|---|---|---|
| LightGBM | Train | 0.819 | 4.357 | 6.287 | 17.50% | 0.409 | 11.067% |
| Test | 0.805 | 5.593 | 7.24 | 20.10% | 0.600 | 14.921% | |
| SVM | Train | 0.893 | 3.945 | 5.277 | 26.00% | 0.333 | 11.276% |
| Test | 0.783 | 4.918 | 7.309 | 22.00% | 0.496 | 13.749% | |
| CFNN | Train | 0.902 | 2.973 | 3.348 | 6.00% | 0.227 | 3.444% |
| Test | 0.842 | 3.940 | 6.442 | 18.00% | 0.411 | 10.758% |
| Symbol | Unit | Mean | STD | Min | Max | Skewness | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Original | Synthetic | Original | Synthetic | Original | Synthetic | Original | Synthetic | Original | Synthetic | ||
| FA | kg/m3 | 246.72 | 238.01 | 159.99 | 150.28 | 0.00 | 0.00 | 620.00 | 546.91 | −0.34 | −0.20 |
| GGBS | kg/m3 | 176.27 | 188.92 | 177.38 | 172.51 | 0.00 | 0.00 | 560.00 | 560.00 | 0.48 | 0.40 |
| SS | kg/m3 | 117.56 | 119.44 | 36.08 | 36.01 | 32.00 | 33.11 | 205.50 | 203.66 | 0.23 | 0.23 |
| SH | kg/m3 | 44.78 | 48.60 | 22.51 | 23.93 | 0.00 | 3.26 | 108.00 | 108.00 | 0.12 | 0.09 |
| SP | kg/m3 | 1.52 | 1.69 | 2.57 | 2.54 | 0.00 | 0.00 | 9.00 | 8.33 | 1.35 | 1.13 |
| fag | kg/m3 | 656.26 | 656.37 | 81.65 | 80.66 | 495.00 | 496.07 | 887.00 | 859.69 | 0.31 | 0.18 |
| cag | kg/m3 | 1082.58 | 1063.82 | 239.87 | 246.23 | 525.40 | 528.40 | 1381.35 | 1351.08 | −1.31 | −1.08 |
| w | kg/m3 | 64.72 | 70.93 | 62.10 | 60.39 | 0.00 | 0.00 | 216.00 | 212.41 | 0.47 | 0.29 |
| CT | °C | 48.16 | 49.90 | 28.21 | 28.09 | 19.00 | 19.00 | 100 | 100.00 | 0.50 | 0.41 |
| CP | days | 21.76 | 22.54 | 14.99 | 14.44 | 1.00 | 1.00 | 56 | 56.00 | 0.62 | 0.63 |
| CS | MPa | 38.45 | 35.05 | 14.95 | 16.48 | 1.25 | 0.00 | 80.51 | 80.51 | 0.13 | 0.12 |
| Model | Dataset | R2 | MAE | RMSE | MAPE | RSR | WMAPE |
|---|---|---|---|---|---|---|---|
| LightGBM | Train | 0.913 | 3.004 | 4.676 | 10.00% | 0.282 | 7.679% |
| Test | 0.877 | 3.366 | 4.657 | 10.32% | 0.413 | 9.413% | |
| SVM | Train | 0.922 | 2.373 | 4.256 | 12.00% | 0.281 | 4.323% |
| Test | 0.863 | 2.897 | 4.61 | 21.00% | 0.399 | 5.757% | |
| CFNN | Train | 0.956 | 1.037 | 2.982 | 18.10% | 0.181 | 2.717% |
| Test | 0.942 | 1.546 | 3.836 | 22.83% | 0.194 | 3.265% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, H.A.T.; Pham, D.H.; Ahn, Y. Effect of Data Augmentation Using Deep Learning on Predictive Models for Geopolymer Compressive Strength. Appl. Sci. 2024, 14, 3601. https://doi.org/10.3390/app14093601
Nguyen HAT, Pham DH, Ahn Y. Effect of Data Augmentation Using Deep Learning on Predictive Models for Geopolymer Compressive Strength. Applied Sciences. 2024; 14(9):3601. https://doi.org/10.3390/app14093601
Chicago/Turabian StyleNguyen, Ho Anh Thu, Duy Hoang Pham, and Yonghan Ahn. 2024. "Effect of Data Augmentation Using Deep Learning on Predictive Models for Geopolymer Compressive Strength" Applied Sciences 14, no. 9: 3601. https://doi.org/10.3390/app14093601
APA StyleNguyen, H. A. T., Pham, D. H., & Ahn, Y. (2024). Effect of Data Augmentation Using Deep Learning on Predictive Models for Geopolymer Compressive Strength. Applied Sciences, 14(9), 3601. https://doi.org/10.3390/app14093601