

Integrated AI System for Real-Time Sports Broadcasting: Player Behavior, Game Event Recognition, and Generative AI Commentary in Basketball Games


Abstract
1. Introduction
2. Related Works
2.1. Playground Detection
2.2. Athletic Recognition and Tracking
3. Proposed Method
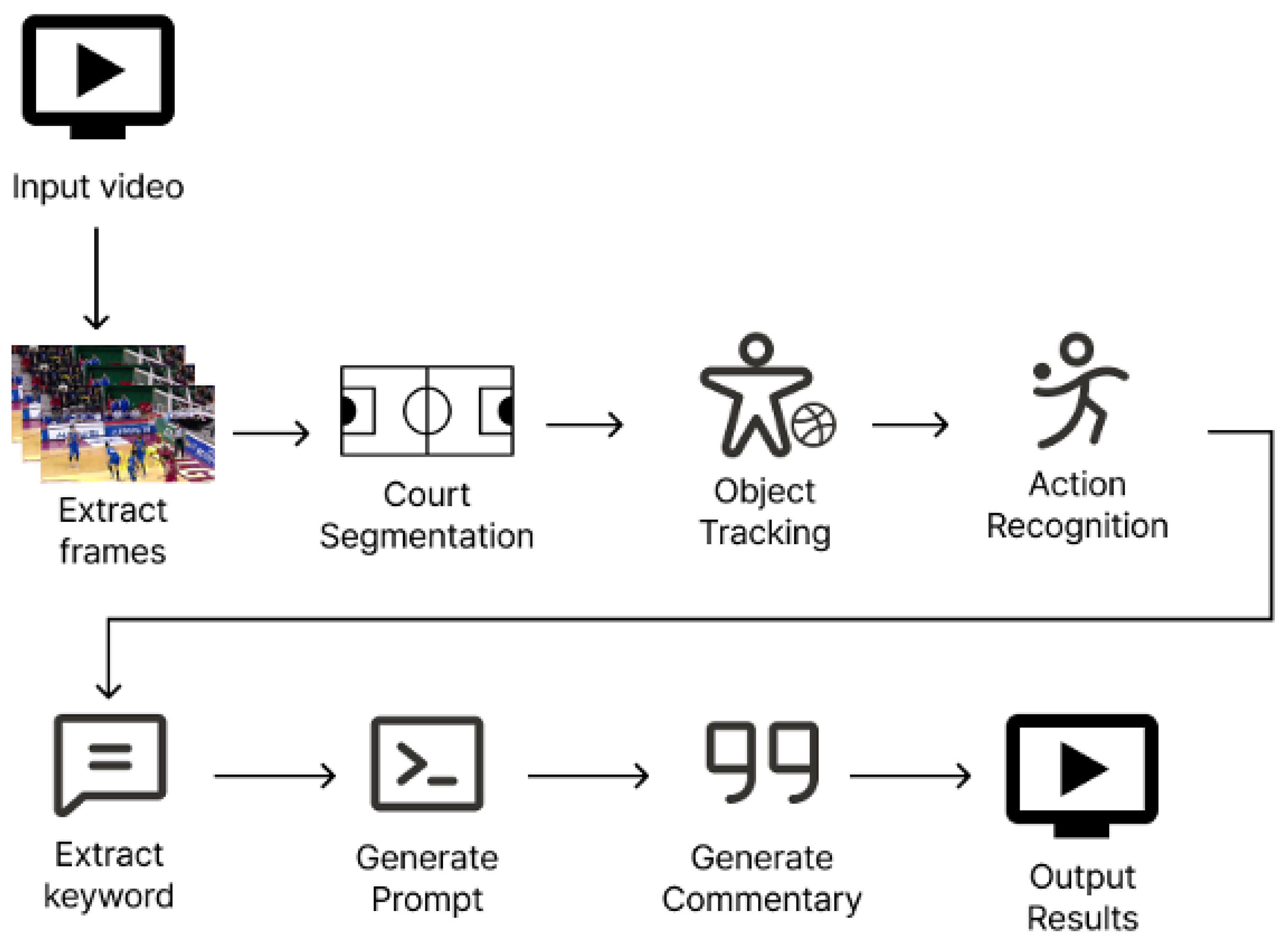
3.1. Overall Architecture
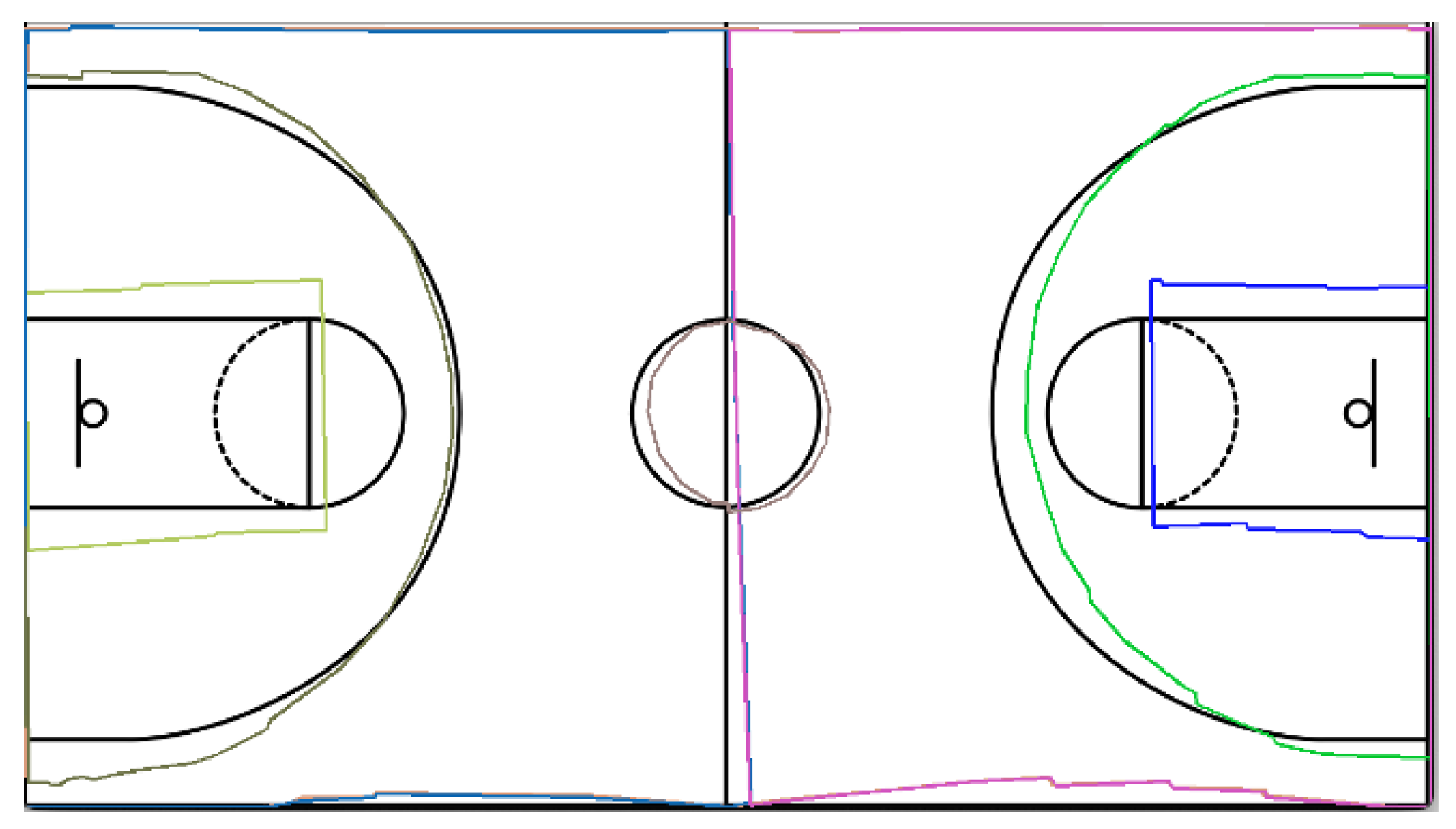
3.2. Court Calibration
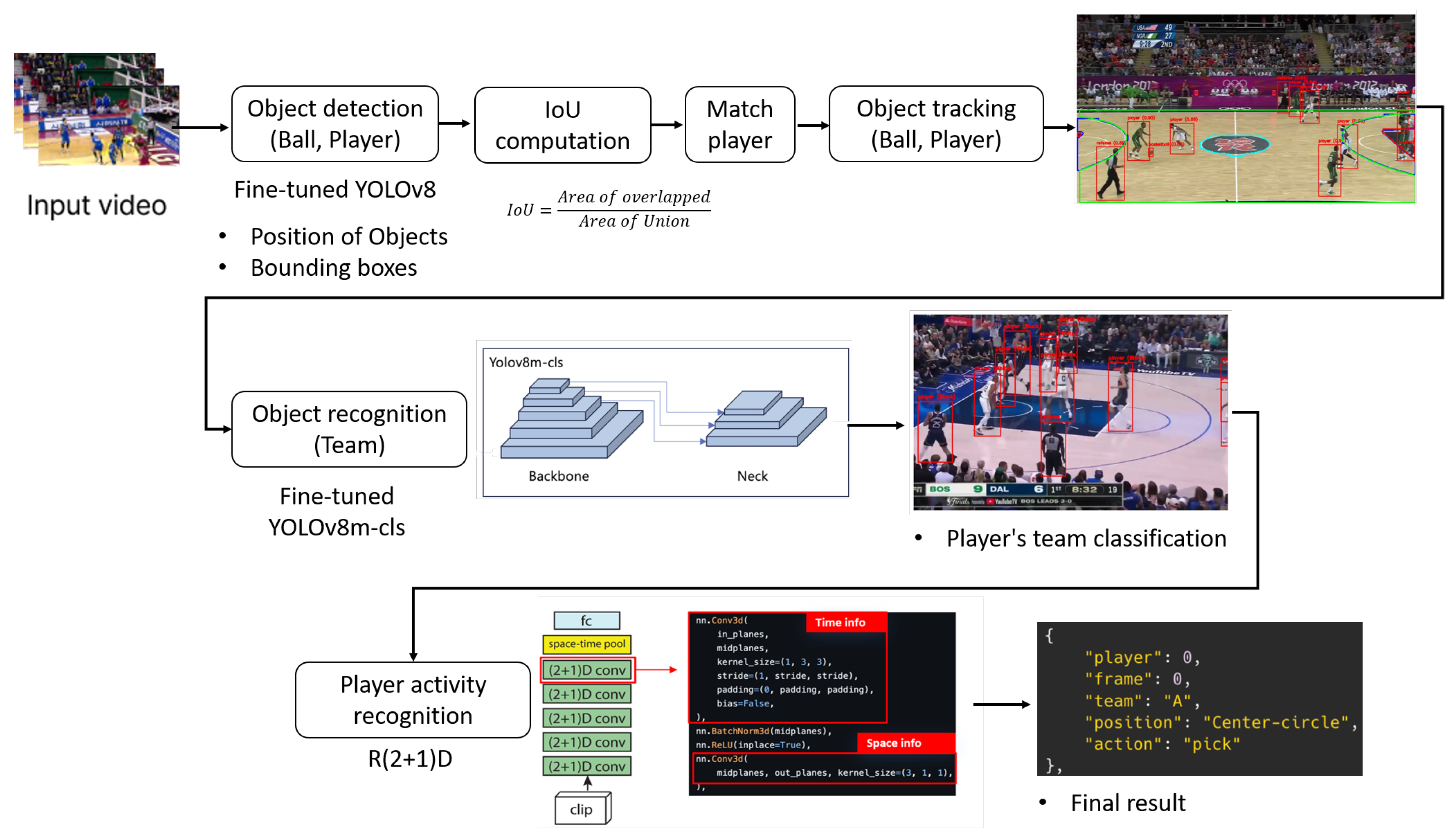
3.3. Player and Ball Tracking
3.4. Sports Activity Recognition
3.5. Commentary Generation
4. Experimental Result
4.1. Implementation
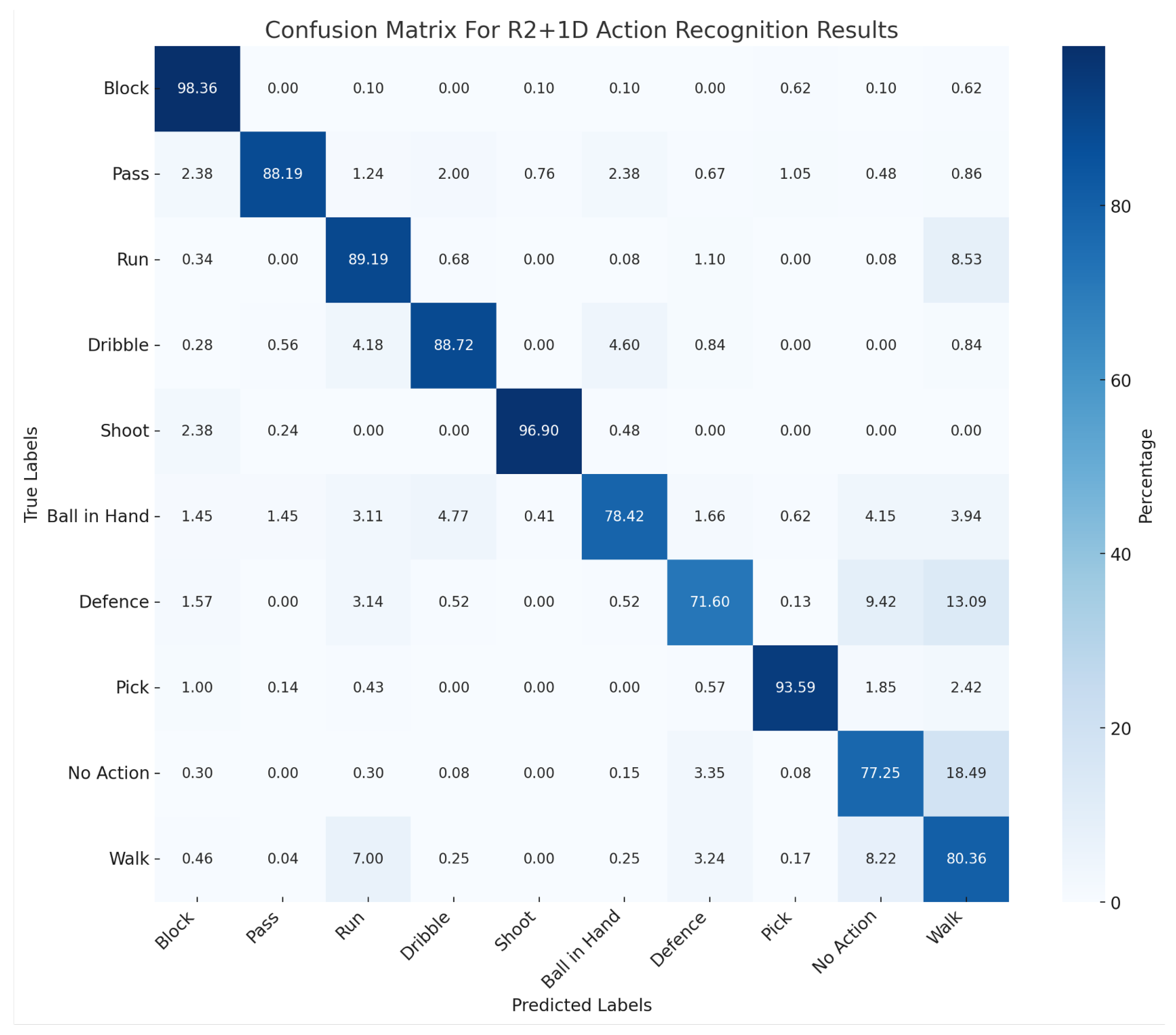
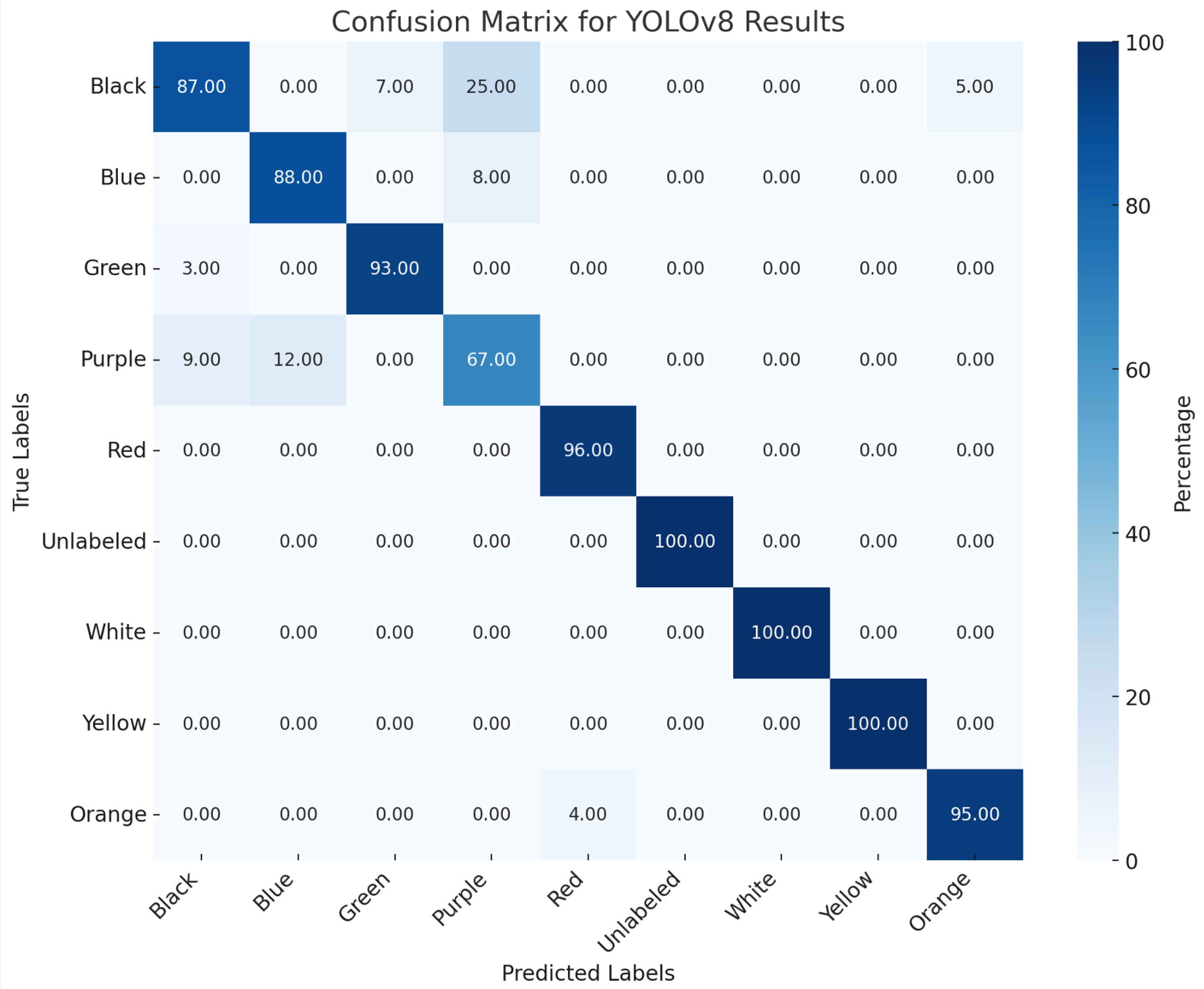
4.2. Experimental Result
5. Discussion
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- NCSOFT PR Center—News Detail. 2024. Available online: https://about.ncsoft.com/news/article/prosody-control-ai-20201210 (accessed on 1 December 2024).
- Park, G.M.; Hyun, H.I.; Kwon, H.Y. Multimodal Learning Model Based on Video–Audio–Chat Feature Fusion for Detecting E-Sports Highlights. Appl. Soft Comput. 2022, 126, 109285. [Google Scholar] [CrossRef]
- Kang, S.K.; Lee, J.H. An E-Sports Video Highlight Generator Using Win-Loss Probability Model. In Proceedings of the 35th Annual ACM Symposium on Applied Computing, Brno, Czech Republic, 30 March–3April 2020; pp. 915–922. [Google Scholar]
- Fu, C.Y.; Lee, J.; Bansal, M.; Berg, A.C. Video Highlight Prediction Using Audience Chat Reactions. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Copenhagen, Denmark, 9–11 September 2017; pp. 972–978. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Terven, J.; Cordova-Esparza, D. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. arXiv 2023, arXiv:2304.00501. [Google Scholar] [CrossRef]
- Wen, P.C.; Cheng, W.C.; Wang, Y.S.; Chu, H.K.; Tang, N.C.; Liao, H.Y.M. Court Reconstruction for Camera Calibration in Broadcast Basketball Videos. IEEE Trans. Vis. Comput. Graph. 2016, 22, 1517–1526. [Google Scholar] [CrossRef] [PubMed]
- Sha, L.; Hobbs, J.; Felsen, P.; Wei, X.; Lucey, P.; Ganguly, S. End-to-End Camera Calibration for Broadcast Videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13627–13636. [Google Scholar]
- Theiner, J.; Ewerth, R. TVCALIB: Camera Calibration for Sports Field Registration in Soccer. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023; pp. 1166–1175. [Google Scholar]
- Ige, A.O.; Noor, M.H.M. A Survey on Unsupervised Learning for Wearable Sensor-Based Activity Recognition. Appl. Soft Comput. 2022, 127, 109363. [Google Scholar] [CrossRef]
- Van Kasteren, T.; Noulas, A.; Englebienne, G.; Kröse, B. Accurate Activity Recognition in a Home Setting. In Proceedings of the 10th International Conference on Ubiquitous Computing, Seoul, Republic of Korea, 21–24 September 2008; pp. 1–9. [Google Scholar]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. UTD-MHAD: A Multimodal Dataset for Human Action Recognition Utilizing a Depth Camera and a Wearable Inertial Sensor. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Quebec, QC, Canada, 27–30 September 2015; pp. 168–172. [Google Scholar]
- Gao, W.; Zhang, L.; Teng, Q.; He, J.; Wu, H. DanHAR: Dual Attention Network for Multimodal Human Activity Recognition Using Wearable Sensors. Appl. Soft Comput. 2021, 111, 107728. [Google Scholar] [CrossRef]
- Khan, M.A.; Sharif, M.; Akram, T.; Raza, M.; Saba, T.; Rehman, A. Hand-Crafted and Deep Convolutional Neural Network Features Fusion and Selection Strategy: An Application to Intelligent Human Action Recognition. Appl. Soft Comput. 2020, 87, 105986. [Google Scholar] [CrossRef]
- Khan, Z.N.; Ahmad, J. Attention Induced Multi-Head Convolutional Neural Network for Human Activity Recognition. Appl. Soft Comput. 2021, 110, 107671. [Google Scholar] [CrossRef]
- Burić, M.; Pobar, M.; Ivašić-Kos, M. Adapting YOLO Network for Ball and Player Detection. In Proceedings of the 8th International Conference on Pattern Recognition Applications and Methods, Prague, Czech Republic, 19–21 February 2019; Volume 1, pp. 845–851. [Google Scholar]
- Khobdeh, S.B.; Yamaghani, M.R.; Sareshkeh, S.K. Basketball Action Recognition Based on the Combination of YOLO and a Deep Fuzzy LSTM Network. J. Supercomput. 2024, 80, 3528–3553. [Google Scholar] [CrossRef]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A Closer Look at Spatiotemporal Convolutions for Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- ZY-VEVVI. Court Segmentation Dataset. 2025. Available online: https://universe.roboflow.com/zy-vevvi/court-segmentation/dataset/4 (accessed on 14 January 2025).
- Annotations, A. AI Sports Analytics System Dataset—Training Split. 2025. Available online: https://universe.roboflow.com/asas-annotations/ai-sports-analytics-system/dataset/7/images?split=train (accessed on 14 January 2025).
- Test-0v7fp. NBA Uniform Color Classification Dataset. 2025. Available online: https://universe.roboflow.com/test-0v7fp/nba-uniform-color-classify/dataset/4 (accessed on 14 January 2025).
- Francia, S. SpaceJam—A Dataset for AI Training. 2025. Available online: https://github.com/simonefrancia/SpaceJam (accessed on 14 January 2025).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Partial IoU Ranges | IoUpart (Mean, %) |
|---|---|
| Full Court | 97.0 |
| Left Semicircle | 96.0 |
| Left Box | 94.0 |
| Left Court | 95.0 |
| Right Court | 95.0 |
| Mid Circle | 95.0 |
| Right Semicircle | 94.0 |
| Right Box | 95.0 |
| Average | 95.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, S.; Kim, H.; Park, H.; Choi, A. Integrated AI System for Real-Time Sports Broadcasting: Player Behavior, Game Event Recognition, and Generative AI Commentary in Basketball Games. Appl. Sci. 2025, 15, 1543. https://doi.org/10.3390/app15031543
Jung S, Kim H, Park H, Choi A. Integrated AI System for Real-Time Sports Broadcasting: Player Behavior, Game Event Recognition, and Generative AI Commentary in Basketball Games. Applied Sciences. 2025; 15(3):1543. https://doi.org/10.3390/app15031543
Chicago/Turabian StyleJung, Sunghoon, Hanmoe Kim, Hyunseo Park, and Ahyoung Choi. 2025. "Integrated AI System for Real-Time Sports Broadcasting: Player Behavior, Game Event Recognition, and Generative AI Commentary in Basketball Games" Applied Sciences 15, no. 3: 1543. https://doi.org/10.3390/app15031543
APA StyleJung, S., Kim, H., Park, H., & Choi, A. (2025). Integrated AI System for Real-Time Sports Broadcasting: Player Behavior, Game Event Recognition, and Generative AI Commentary in Basketball Games. Applied Sciences, 15(3), 1543. https://doi.org/10.3390/app15031543