Video Interpolation-Based Multi-Source Data Fusion Method for Laser Processing Melt Pool



Abstract
:1. Introduction
2. Experiments and Data Preprocessing
2.1. Laser Cladding Experimental Platform and Experimental Design
2.2. Data Preprocessing
- (1)
- Data Cleaning: In this study, the data cleaning process consisted of two main stages. For visible-light data, the specular reflection part was removed using a manually designed IR mask. The design of the IR mask is shown in Figure 2, marking the cladding nozzle area as True and the rest as False. For infrared temperature distribution data, a threshold segmentation algorithm was first applied, with a threshold set to 90, to retain the temperature data of the melt pool area and droplet splash. Then, an 8-connected region analysis method was used to ensure that the melt pool area and the cladding head area were not connected in the image and were both complete. Finally, the temperature distribution of the cladding head was removed, and the temperature distribution of the melt pool was retained.
- (2)
- Data Registration: This study employed affine transformation to process images obtained from the infrared thermal camera to achieve registration between the visible-light and the infrared thermal camera processing areas. The affine transformation formula is as follows:where represents the coordinates of a certain pixel in the original infrared image, represents the corresponding coordinates after affine transformation, and denotes the parameters in the affine transformation matrix.
- (3)
- ROI Extraction: After the affine transformation was completed, we proceeded with ROI extraction. Since the center of the transformed infrared image still corresponds to the cladding area, to ensure that the ROI regions of the visible-light and infrared images correspond to the same cladding area, the position of the laser light source is taken as the center of the ROI region. Based on the temperature distribution of the melt pool area, the resolution of the infrared image ROI region is set to 200 × 200 to maintain the characteristics of the temperature distribution of the melt pool and its surroundings, reducing feature loss. Considering the difference in spatial resolution between the high-speed camera and the infrared thermal camera, to ensure consistency in the spatial resolution of the multi-source data during image fusion and to retain as much image information as possible, the infrared data are upsampled to align spatially with the visible-light video data. The resolution of the visible-light image ROI region is also set to 200 × 200. To address potential data distortion during the upsampling process, this study included distortion compensation in the image fusion module to ensure the authenticity of the fused images.
- (4)
- Data Augmentation: The number of infrared data collected in the experiment was relatively small, only 347 images, while the number of visible-light data was larger, approximately 694 images. This study enhanced the infrared data to meet the data requirements for network model training and to enhance the model’s generalization ability for different processing conditions. Considering that the scanning directions in the experiment were along the X- and Y-axes, data diversity was increased through image rotation and flipping operations. Specific operations include flipping along the X-axis, the Y-axis, and in both directions, generating 7 new images from each image. After data augmentation, the number of infrared images increased to 2776, and the number of visible-light images increased to 5552. It should be noted that the optimal cladding quality is achieved within the laser cladding process window determined in the experiment, which can obtain a steady-state melt pool morphology. This enables the proposed multi-source data fusion method to have sufficient generalizability in the application of steady-state melt pool morphology in various laser processing processes. However, it must be acknowledged that the practicality under extreme conditions, such as large melt pool fluctuations, ultra-high-speed processing, and a high power density, still needs to be assessed.
3. A Method for Multi-Source Data Fusion Based on Video Frame Interpolation
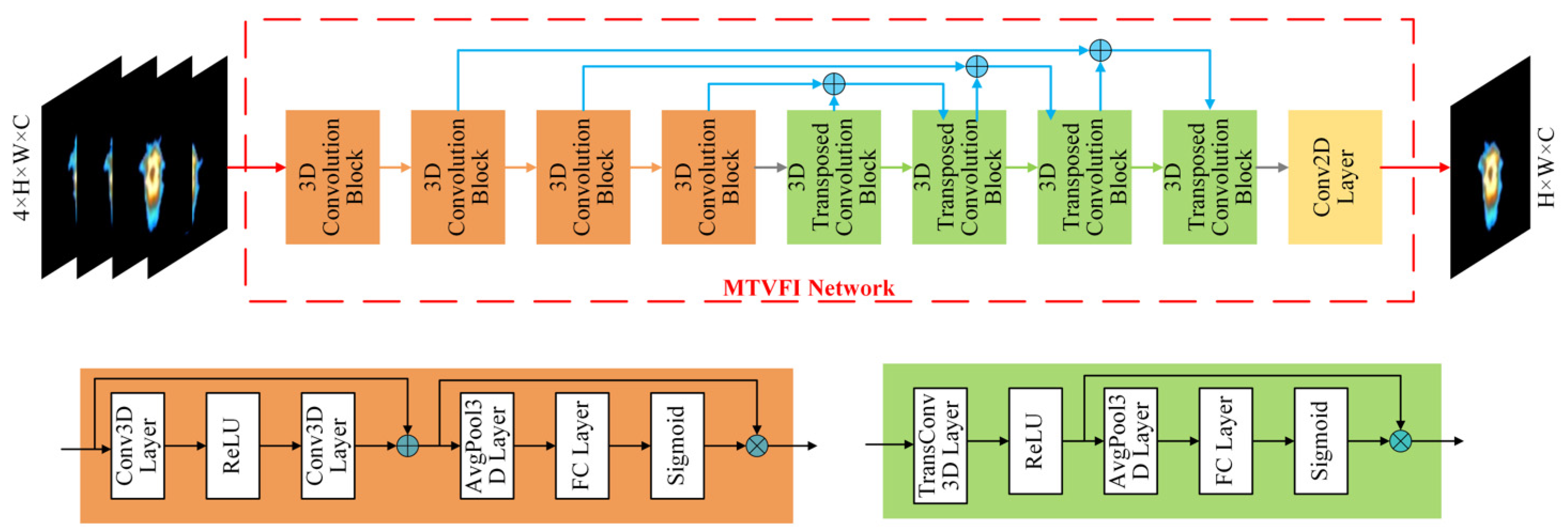
3.1. Infrared Video Frame Interpolation Network Model
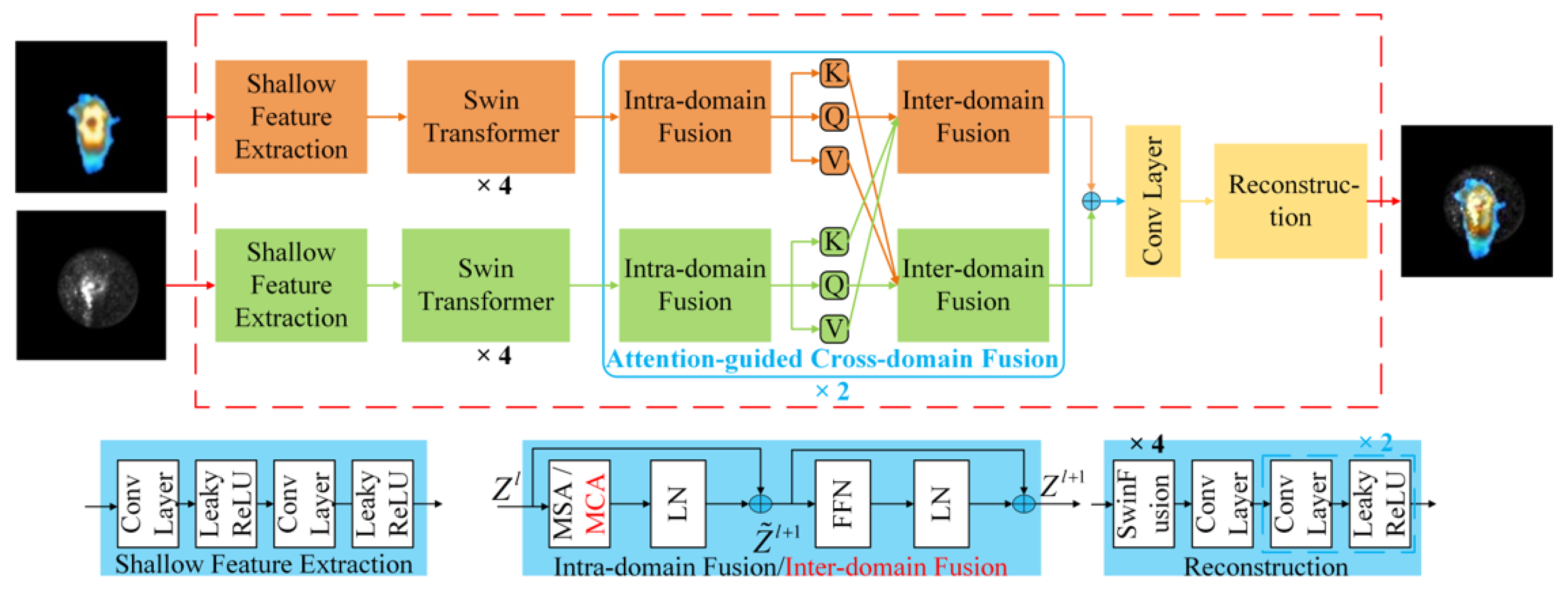
3.2. Infrared and Visible Image Fusion Network Model
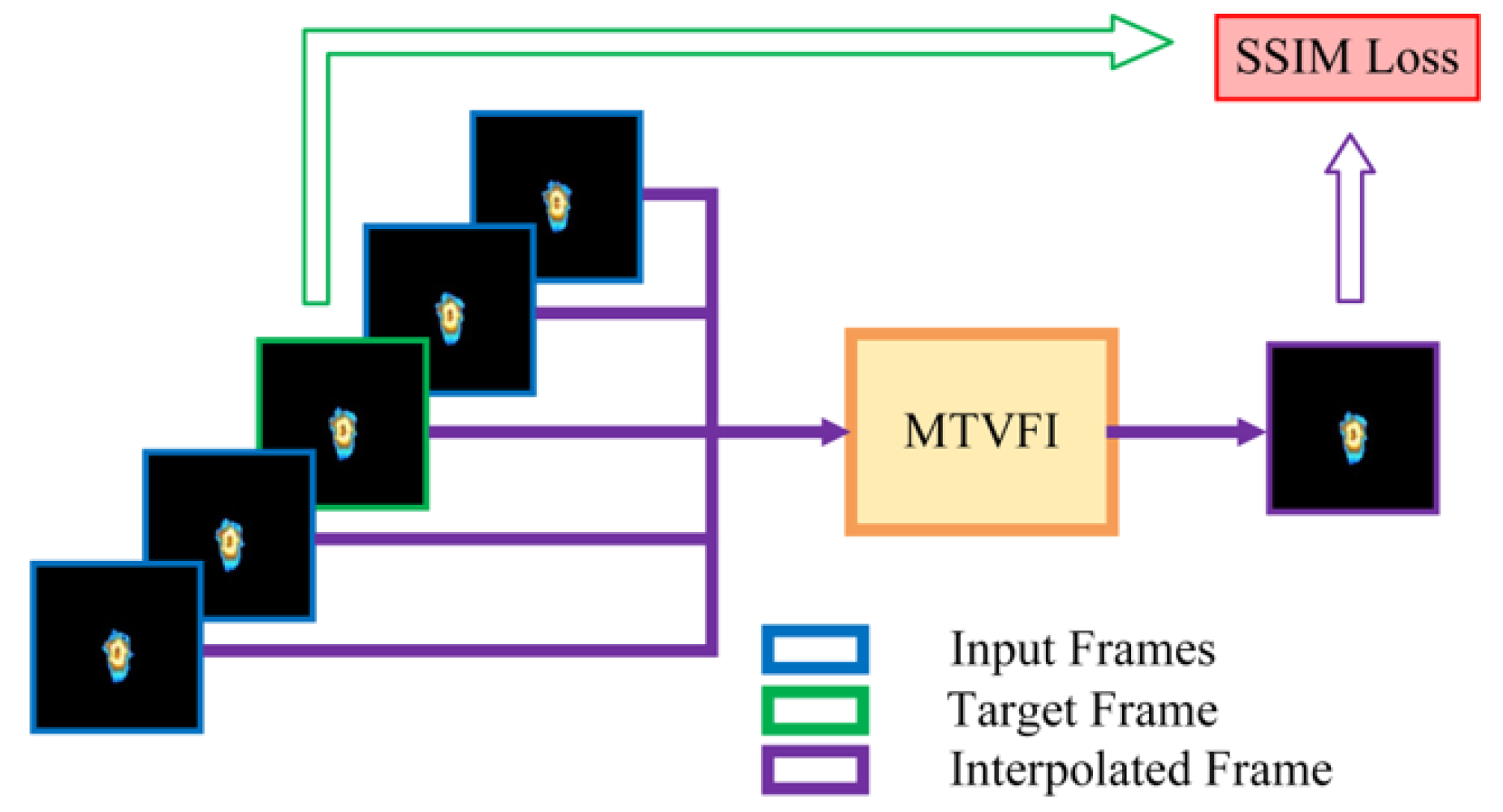
3.3. Self-Supervised Training Strategy Based on Transfer Learning
4. Results and Discussion
4.1. Video Frame Interpolation Module Evaluation
4.1.1. MTVFI Model Evaluation
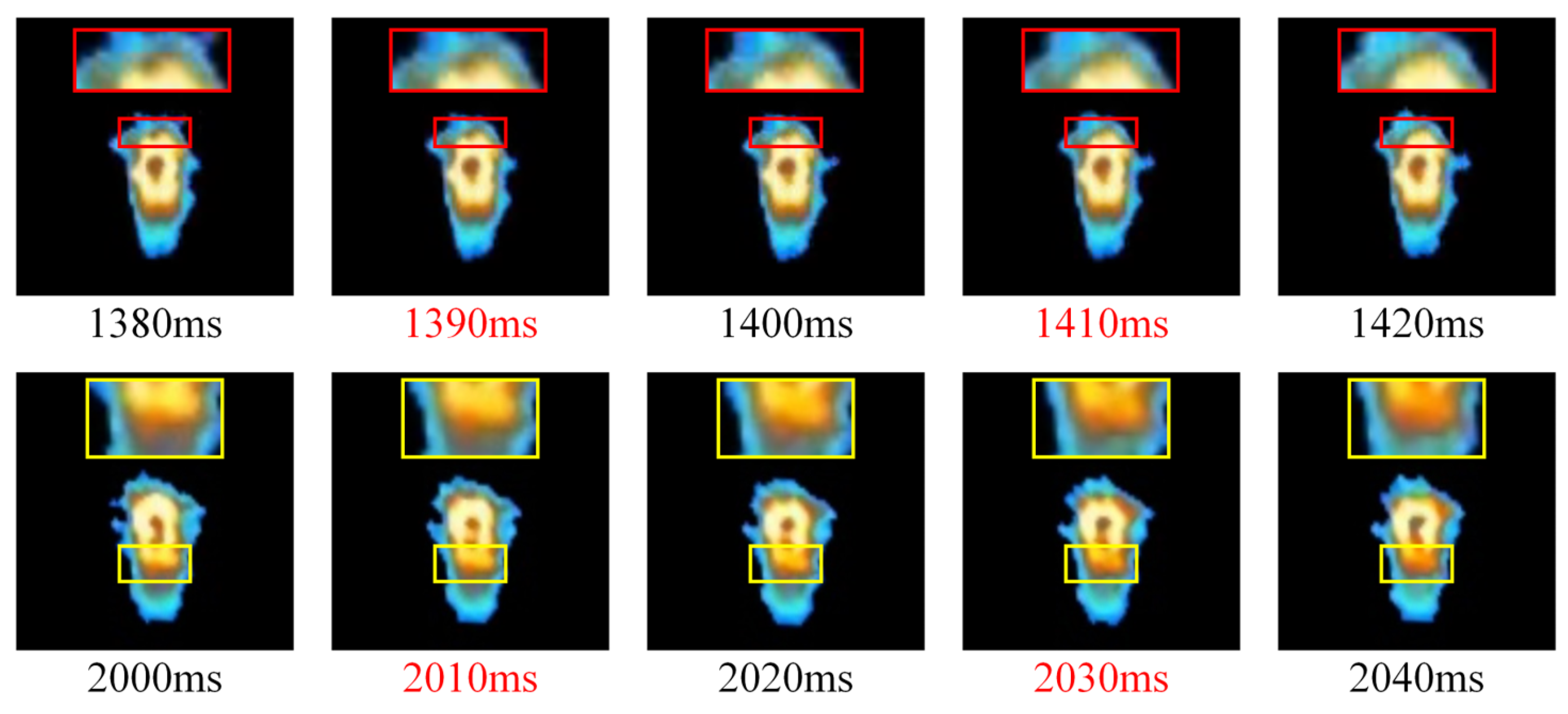
4.1.2. The Effectiveness of the Video Frame Interpolation Module
4.1.3. Analysis of Training Strategies Based on Pre-Training
4.1.4. High-Dynamic Analysis of Melt Pool Temperature Distribution
4.2. Data Fusion Method Evaluation
4.2.1. Dynamic Analysis of Melt Pool
4.2.2. Performance of Image Fusion Module
4.2.3. Multi-Source Data Fusion for High-Dynamic Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, J.C.; Zhu, R.; Liu, Y.J.; Zhang, L.C. Understanding melt pool characteristics in laser powder bed fusion: An overview of single- and multi-track melt pools for process optimization. Adv. Powder Mater. 2023, 2, 100137. [Google Scholar] [CrossRef]
- Yu, M.; Zhu, L.; Yang, Z.; Xu, L.; Ning, J.; Chang, B. A novel data-driven framework for enhancing the consistency of deposition contours and mechanical properties in metal additive manufacturing. Comput. Ind. 2024, 163, 104154. [Google Scholar] [CrossRef]
- Guo, S.R.; Liu, Y.Y.; Cui, L.J.; Cui, Y.H.; Li, X.L.; Chen, Y.Q.; Zheng, B. In-situ capture of melt pool signature in high-speed laser cladding using fully convolutional network. Opt. Lasers Eng. 2024, 176, 108113. [Google Scholar] [CrossRef]
- Tang, Z.J.; Liu, W.W.; Zhang, N.; Wang, Y.W.; Zhang, H.C. Real-time prediction of penetration depths of laser surface melting based on coaxial visual monitoring. Opt. Lasers Eng. 2020, 128, 106034. [Google Scholar] [CrossRef]
- Peng, X.; Kong, L.B. Defect extraction method for additive manufactured parts with improved learning-based image super-resolution and the Canny algorithm. Appl. Opt. 2022, 61, 8500–8507. [Google Scholar] [CrossRef] [PubMed]
- Grishin, M.Y.; Sdvizhenskii, P.A.; Asyutin, R.D.; Tretyakov, R.S.; Stavertiy, A.Y.; Pershin, S.M.; Liu, D.S.; Ledne, V.N. Combining thermal imaging and spectral pyrometry for express temperature mapping in additive manufacturing. Appl. Opt. 2023, 62, 335–341. [Google Scholar] [CrossRef]
- Chen, L.; Bi, G.; Yao, X.; Tan, C.; Su, J.; Ng, N.P.H.; Chew, Y.; Liu, K.; Moon, S.K. Multisensor fusion-based digital twin for localized quality prediction in robotic laser-directed energy deposition. Robot. Comput.-Integr. Manuf. 2023, 84, 102581. [Google Scholar] [CrossRef]
- Gaikwad, A.; Williams, R.J.; de Winton, H.; Bevans, B.D.; Smoqi, Z.; Rao, P.; Hooper, P.A. Multi phenomena melt pool sensor data fusion for enhanced process monitoring of laser powder bed fusion additive manufacturing. Mater. Des. 2022, 221, 110919. [Google Scholar] [CrossRef]
- Meriaudeau, F.; Truchetet, F. Control and optimization of the laser cladding process using matrix cameras and image processing. J. Laser Appl. 1996, 8, 317–324. [Google Scholar] [CrossRef]
- Tang, L.; Feng, L.; Axelsson, T.; Toerngren, M.; Wilkman, D. A deep learning based sensor fusion method to diagnose tightening errors. J. Manuf. Syst. 2023, 71, 59–69. [Google Scholar] [CrossRef]
- Guo, Z.; Zhang, Y.; Xiao, H.; Jayan, H.; Majeed, U.; Ashiagbor, K.; Jiang, S.; Zou, X. Multi-sensor fusion and deep learning for batch monitoring and real-time warning of apple spoilage. Food Control 2025, 172, 111174. [Google Scholar] [CrossRef]
- Shin, S.; Kwon, M.; Kim, S.; So, H. Prediction of Equivalence Ratio in Combustion Flame Using Chemiluminescence Emission and Deep Neural Network. Int. J. Energy Res. 2023, 2023, 3889951. [Google Scholar] [CrossRef]
- Thottempudi, P.; Jambek, A.B.B.; Kumar, V.; Acharya, B.; Moreira, F. Resilient object detection for autonomous vehicles: Integrating deep learning and sensor fusion in adverse conditions. Eng. Appl. Artif. Intell. 2025, 151, 110563. [Google Scholar] [CrossRef]
- Yu, R.; Tan, X.; He, S.; Huang, Y.; Wang, L.; Peng, Y.; Wang, K. Monitoring of robot trajectory deviation based on multimodal fusion perception in WAAM process. Measurement 2024, 224, 113933. [Google Scholar] [CrossRef]
- Zheng, L.; Zhang, Q.; Cao, H.; Wu, W.; Ma, H.; Ding, X.; Yang, J.; Duan, X.; Fan, S. Melt pool boundary extraction and its width prediction from infrared images in selective laser melting. Mater. Des. 2019, 183, 108110. [Google Scholar] [CrossRef]
- Dong, J.; Ota, K.; Dong, M.X. Video Frame Interpolation: A Comprehensive Survey. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 1–31. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Häusser, P.; Hazirbas, C.; Golkov, V.; van der Smagt, P.; Cremers, D.; Brox, T. FlowNet: Learning Optical Flow with Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 2758–2766. [Google Scholar]
- Kalluri, T.; Pathak, D.; Chandraker, M.; Du, T. FLAVR: Flow-Agnostic Video Representations for Fast Frame Interpolation. In Proceedings of the 23rd IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–7 January 2023; pp. 2070–2081. [Google Scholar]
- Choi, M.; Kim, H.; Han, B.; Xu, N.; Lee, K.M. Channel Attention Is All You Need for Video Frame Interpolation. In Proceedings of the 34th AAAI Conference on Artificial Intelligence/32nd Innovative Applications of Artificial Intelligence Conference/10th AAAI Symposium on Educational Advances in Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 10663–10671. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J.; Soc, I.C. Deformable ConvNets v2: More Deformable, Better Results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 9300–9308. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A Closer Look at Spatiotemporal Convolutions for Action Recognition. arXiv 2018, arXiv:1711.11248. [Google Scholar]
- Han, D.; Li, L.; Guo, X.; Ma, J. Multi-exposure image fusion via deep perceptual enhancement. Inf. Fusion 2022, 79, 248–262. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J.; Durrani, T. NestFuse: An Infrared and Visible Image Fusion Architecture Based on Nest Connection and Spatial/Channel Attention Models. IEEE Trans. Instrum. Meas. 2020, 69, 9645–9656. [Google Scholar] [CrossRef]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.-P. DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-Domain Long-Range Learning for General Image Fusion via Swin Transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV), Electr Network, Montreal, QC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar]
- Ma, J.; Ma, Y.; Li, C. Infrared and visible image fusion methods and applications: A survey. Inf. Fusion 2019, 45, 153–178. [Google Scholar] [CrossRef]
- Haghighat, M.B.A.; Aghagolzadeh, A.; Seyedarabi, H. A non-reference image fusion metric based on mutual information of image features. Comput. Electr. Eng. 2011, 37, 744–756. [Google Scholar] [CrossRef]
- Xydeas, C.S.; Petrovic, V. Objective image fusion performance measure. Electron. Lett. 2000, 36, 308–309. [Google Scholar] [CrossRef]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multi-scale structural similarity for image quality assessment. In Proceedings of the 37th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 9–12 November 2003; pp. 1398–1402. [Google Scholar]
- Petrovic, V.; Xydeas, C. Objective image fusion performance characterisation. In Proceedings of the 10th IEEE International Conference on Computer Vision (ICCV 2005), Beijing, China, 17–20 October 2005; pp. 1866–1871. [Google Scholar]
- Ma, J.; Liang, P.; Yu, W.; Chen, C.; Guo, X.; Wu, J.; Jiang, J. Infrared and visible image fusion via detail preserving adversarial learning. Inf. Fusion 2020, 54, 85–98. [Google Scholar] [CrossRef]
- Zheng, Y.; Essock, E.A.; Hansen, B.C.; Haun, A.M. A new metric based on extended spatial frequency and its application to DWT based fusion algorithms. Inf. Fusion 2007, 8, 177–192. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Types | Melt Pool Temperature Distribution | Visible-Light Melt Pool Morphology |
|---|---|---|---|
| Dataset 1 | Training Set | 2220 | 2220 |
| Validation Set | 278 | 278 | |
| Test Set | 278 | 278 | |
| Dataset 2 | Training Set | 4440 | 4440 |
| Validation Set | 556 | 556 | |
| Test Set | 556 | 556 | |
| Dataset 3 | Training Set | 2220 | 4440 |
| Validation Set | 278 | 556 | |
| Test Set | 278 | 556 | |
| Dataset 4 | Training Set | 1110 | / |
| Validation Set | 139 | / | |
| Test Set | 139 | / |
| Model | PSNR | SSIM |
|---|---|---|
| Super-SloMo | 36.917 | 0.982 |
| IFRNet | 39.114 | 0.991 |
| MTVFI (our model) | 38.908 | 0.992 |
| Model | PSNR | SSIM |
|---|---|---|
| PreTrain-MTVFI | 38.908 | 0.992 |
| MTVFI | 32.490 | 0.966 |
| Model | PSNR | FMI | Qabf | MS-SSIM | Nabf | AG | SD | SF |
|---|---|---|---|---|---|---|---|---|
| U2Fusion | 73.08 | 0.950 | 0.342 | 0.963 | 0.065 | 0.651 | 17.85 | 5.150 |
| EMFusion | 73.92 | 0.948 | 0.435 | 0.952 | 0.123 | 0.659 | 17.87 | 4.997 |
| SwinFusion | 71.68 | 0.951 | 0.639 | 0.983 | 0.035 | 0.902 | 23.76 | 6.460 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, H.; Zhang, Y.; Li, H.; Long, Y. Video Interpolation-Based Multi-Source Data Fusion Method for Laser Processing Melt Pool. Appl. Sci. 2025, 15, 4850. https://doi.org/10.3390/app15094850
Ren H, Zhang Y, Li H, Long Y. Video Interpolation-Based Multi-Source Data Fusion Method for Laser Processing Melt Pool. Applied Sciences. 2025; 15(9):4850. https://doi.org/10.3390/app15094850
Chicago/Turabian StyleRen, Hang, Yuhui Zhang, Huaping Li, and Yu Long. 2025. "Video Interpolation-Based Multi-Source Data Fusion Method for Laser Processing Melt Pool" Applied Sciences 15, no. 9: 4850. https://doi.org/10.3390/app15094850
APA StyleRen, H., Zhang, Y., Li, H., & Long, Y. (2025). Video Interpolation-Based Multi-Source Data Fusion Method for Laser Processing Melt Pool. Applied Sciences, 15(9), 4850. https://doi.org/10.3390/app15094850