Video Searching and Fingerprint Detection by Using the Image Query and PlaceNet-Based Shot Boundary Detection Method


Abstract
:1. Introduction
- Introducing a new deep-learning-based SBD method. The method has three stages: candidate segment selection, places semantic-based segment, and segment verification. The Network is places-centric instead of object-centric.
- Developing a novel image-query-based video searching/fingerprint detection system.
2. Overview of Related Works
2.1. VCD Approaches
2.2. SBD Approaches
3. Materials and Methods
3.1. PlaceNet-Based SBD Method
3.1.1. Candidate Segment Selection
3.1.2. Shot Detection Network
Dataset Construction
- We add computer-generated images, such as cartoons and 3D model images, to each category.
- We merge the categories that have common features into one category. For example, the categories of “forest_broadleaf”, “forest_needleleaf”, “forest_path”, and “forest_road” can be merged into the category “forest”.
Network Architecture
3.1.3. Shot Boundary Verification
3.2. Image-Query-Based Video Searching
- Robustness. It should have invariability to common video distortions.
- Discriminability. The features of different video contents should be distinctively different.
- Compactness. The feature size should be large enough to retain the robustness.
- Complexity. The computing complexity should be simple enough.
4. Experimental Results and Analyses
4.1. Evaluation Methods
4.2. Experiment on Shot Boundary Detection
4.2.1. Open Video Scene Detection (OVSD) Dataset
4.2.2. BBC Planet Earth Dataset
4.2.3. TRECVID 2001 Dataset
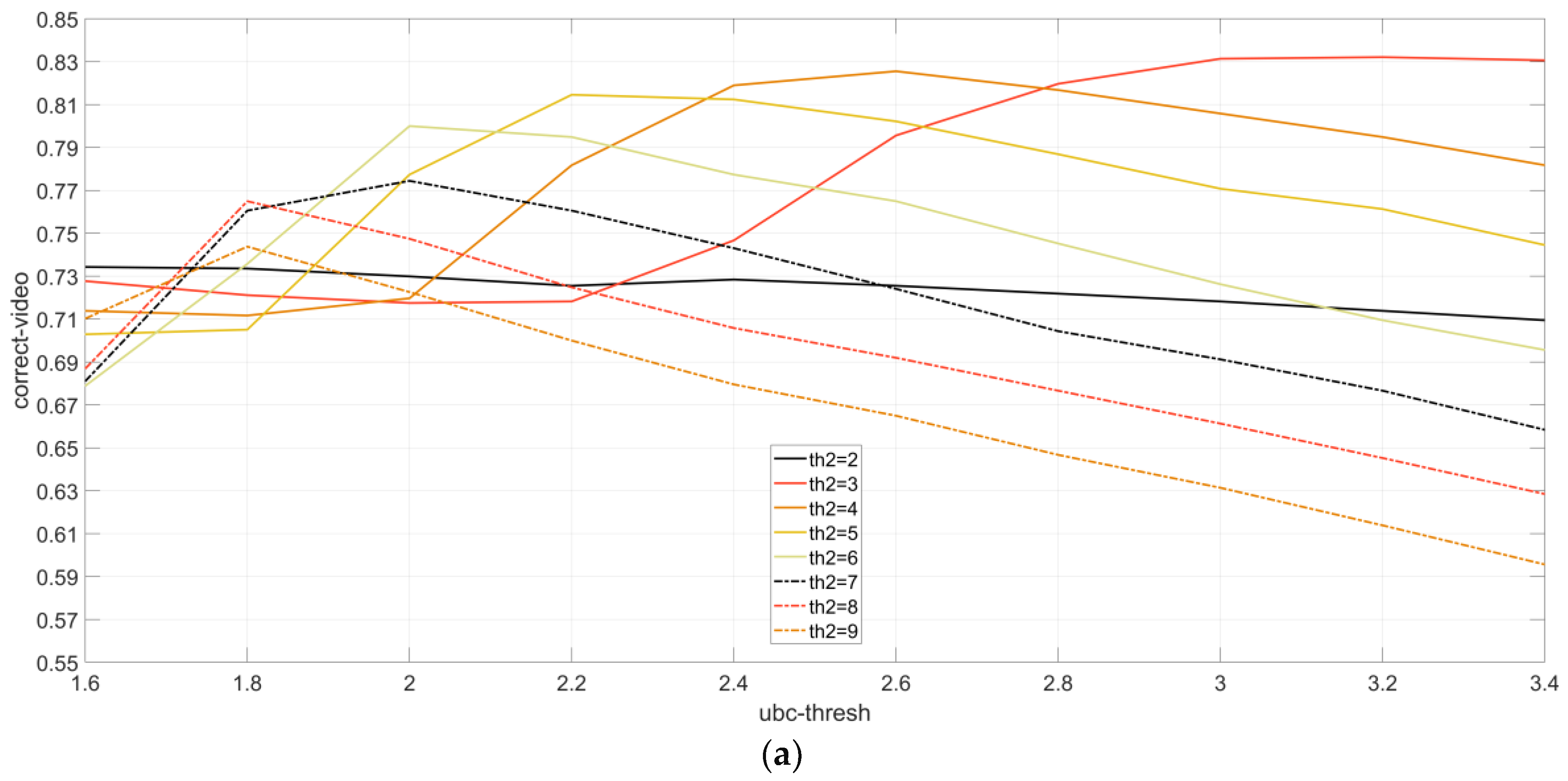
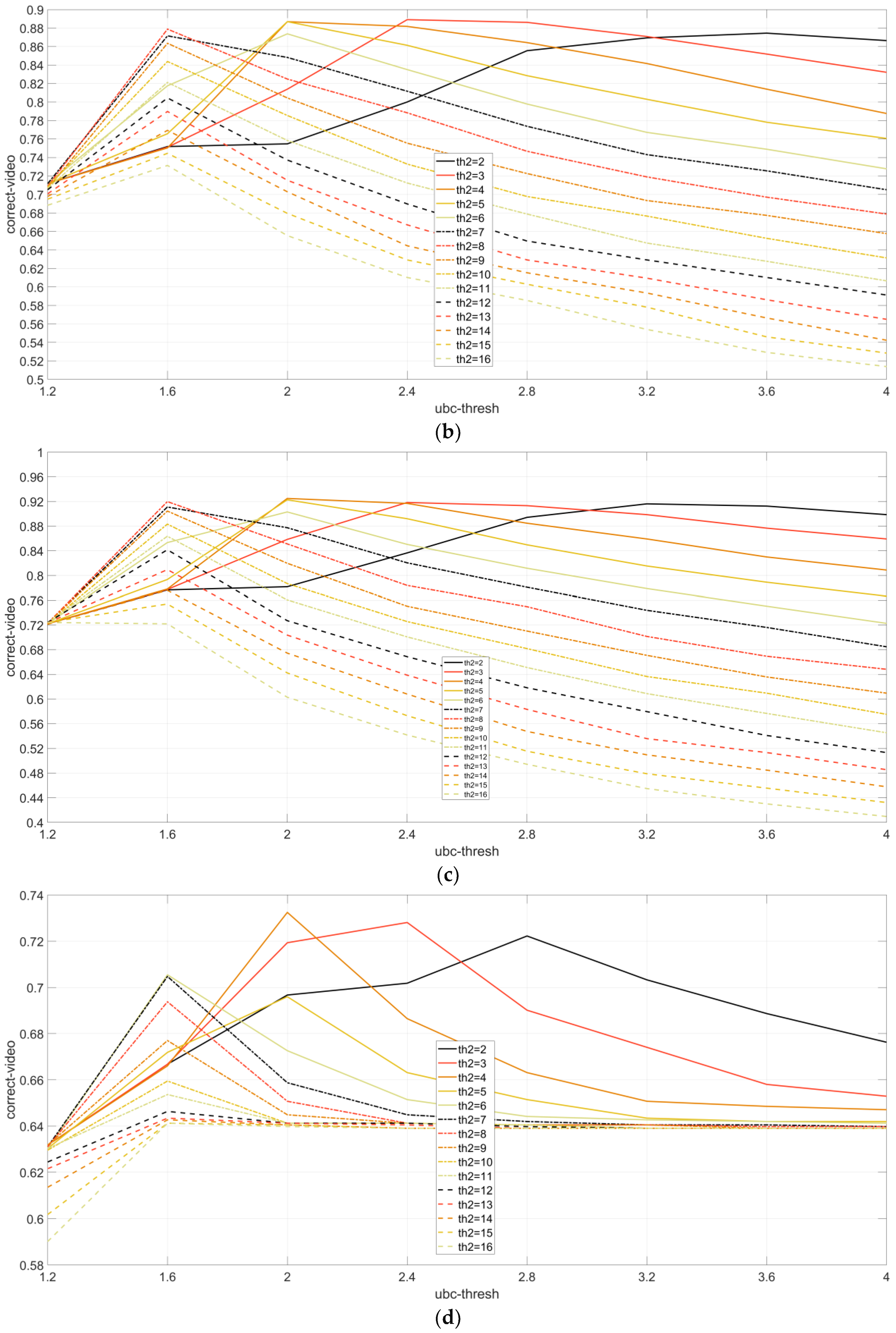
4.3. Experiment on Image-Query-Based Video Searching
4.3.1. ReTRiEVED Dataset
4.3.2. CNN2h Dataset
4.3.3. Experiment on Our Video Searching and Fingerprint Detection Dataset
Results of Image-Query-Based Video Searching Experiments without Transformations
Results of Image-Query-Based Video Searching Experiments with Transformations
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Awad, G.; Over, P.; Kraaij, W. Content-based video copy detection benchmarking at TRECVID. ACM Trans. Inf. Syst. 2014, 32, 14. [Google Scholar] [CrossRef] [Green Version]
- Ng, P.C.; Henikoff, S. SIFT: Predicting amino acid changes that affect protein function. Nucleic Acids Res. 2003, 31, 3812–3814. [Google Scholar] [CrossRef] [PubMed]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Computer Vision—ECCV 2006, Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Huang, J.; Kumar, S.R.; Mitra, M.; Zhu, W.J.; Zabih, R. Image indexing using color correlograms. In Proceedings of the 1997 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 7–19 June 1997; pp. 762–768. [Google Scholar] [Green Version]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Canny, J. A computational approach to edge detection. In Readings in Computer Vision; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1987; pp. 184–203. [Google Scholar]
- Hays, J.; Efros, A.A. August. Scene completion using millions of photographs. ACM Trans. Graph. 2007, 26, 4. [Google Scholar] [CrossRef]
- Shensa, M.J. The discrete wavelet transform: Wedding the trous and Mallat algorithms. IEEE Trans. Signal Process. 1992, 40, 2464–2482. [Google Scholar] [CrossRef]
- Ahmed, N.; Natarajan, T.; Rao, K.R. Discrete cosine transform. IEEE Trans. Comput. 1974, 100, 90–93. [Google Scholar] [CrossRef]
- Tekalp, A.M. Digital Video Processing; Prentice Hall Press: Upper Saddle River, NJ, USA, 2015. [Google Scholar]
- TREC Video Retrieval Evaluation: TRECVID. Available online: https://trecvid.nist.gov/ (accessed on 15 September 2018).
- Matthijs, D.; Adrien, G.; Herve, J.; Marcin, M.; Cordelia, S. INRIA-IMEDIA TRECVID 2008: Video Copy Detection. 2008. Available online: http://www-nlpir.nist.gov/projects/tvpubs/tv8.papers/inria-lear.pdf (accessed on 15 June 2018).
- Liu, Z.; Liu, T.; Shahraray, B. ATT Research at TRECVID 2009 Content-Based Copy Detection. 2009. Available online: http://www-nlpir.nist.gov/projects/tvpubs/tv9.papers/att.pdf (accessed on 15 September 2018).
- Maguelonne, H.; Vishwa, G.; Langis, G.; Gilles, B.; Samuel, F.; Patrick, C. CRIMs Content-Based Copy Detection System for TRECVID. Available online: http://www-nlpir.nist.gov/projects/tvpubs/tv9.papers/crim.pdf (accessed on 22 September 2018).
- Li, Y.N.; Mou, L.T.; Jiang, M.L.; Su, C.; Fang, X.Y.; Qian, M.R.; Tian, Y.; Wang, Y.; Huang, T.; Gao, W. PKU-INM @ TRECVid 2010: Copy Detection with Visual-Audio Feature Fusion and Sequential Pyramid Matching. 2010. Available online: http://www-nlpir.nist.gov/projects/tvpubs/tv10.papers/pku-idm-ccd.pdf (accessed on 15 September 2018).
- Gupta, V.; Varcheie, P.D.Z.; Gagnon, L.; Boulianne, G. CRIM AT TRECVID 2011: CONTENT-BASED COPY DETECTION USING NEAREST NEIGHBOR MAPPING. 2011. Available online: http://www-nlpir.nist.gov/projects/tvpubs/tv11.papers/crim.ccd.pdf (accessed on 22 September 2018).
- Wu, C.; Zhu, J.; Zhang, J. A content-based video copy detection method with randomly projected binary features. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 21–26. [Google Scholar]
- Zhao, W.L.; Ngo, C.W. Flip-invariant SIFT for copy and object detection. IEEE Trans. Image Process. 2013, 22, 980–991. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Choi, J.Y.; Han, S.; Ro, Y.M. Adaptive weighted fusion with new spatial and temporal fingerprints for improved video copy detection. Signal Process. Image Commun. 2014, 297, 788–806. [Google Scholar] [CrossRef]
- Lu, Z.M.; Li, B.; Ji, Q.G.; Tan, Z.F.; Zhang, Y. Robust video identification approach based on local non-negative matrix factorization. AEU Int. J. Electron. Commun. 2015, 69, 82–89. [Google Scholar] [CrossRef]
- Mao, J.; Xiao, G.; Sheng, W.; Hu, Y.; Qu, Z. A method for video authenticity based on the fingerprint of scene frame. Neurocomputing 2016, 173, 2022–2032. [Google Scholar] [CrossRef]
- Guzman-Zavaleta, Z.J.; Feregrino-Uribe, C.; Morales-Sandoval, M.; Menendez-Ortiz, A. A robust and low-cost video fingerprint extraction method for copy detection. Multimed. Tools Appl. 2017, 76, 24143–24163. [Google Scholar] [CrossRef]
- Araujo, A.; Girod, B. Large-scale video retrieval using image queries. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 1406–1420. [Google Scholar] [CrossRef]
- Kordopatis-Zilos, G.; Papadopoulos, S.; Patras, I.; Kompatsiaris, Y. Near-duplicate video retrieval by aggregating intermediate CNN layers. In MMM 2017: MultiMedia Modeling, Proceedings of the International Conference on Multimedia Modeling, Reykjavík, Iceland, 4–6 January2017; Springer: Cham, Switzerland, 2017; pp. 251–263. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th Annual Conference on Neural Information Processing Systems 25 (NIPS2012), Lake Tahoe, Nevada, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Kikukawa, T.; Kawafuchi, S. Development of an automatic summary editing system for the audio-visual resources. Trans. Inst. Electron. Inf. Commun. Eng. 1992, 75, 204–212. [Google Scholar]
- Zhang, H.; Kankanhalli, A.; Smoliar, S.W. Automatic partitioning of full-motion video. Multimed. Syst. 1993, 1, 10–28. [Google Scholar] [CrossRef]
- Shahraray, B. Scene change detection and content-based sampling of video sequences. In IST/SPIE’s Symposium on Electronic Imaging: Science Technology; International Society for Optics and Photonics: San Jose, CA, USA, 1995; pp. 2–13. [Google Scholar]
- Küçüktunç, O.; Güdükbay, U.; Ulusoy, Ö. Fuzzy color histogram-based video segmentation. Comput. Vis. Image Underst. 2010, 114, 125–134. [Google Scholar] [CrossRef] [Green Version]
- Janwe, N.J.; Bhoyar, K.K. Video shot boundary detection based on JND color histogram. In Proceedings of the 2013 IEEE Second International Conference on Image Information Processing (ICIIP), Shimla, India, 9–11 December 2013; pp. 476–480. [Google Scholar]
- Li, Z.; Liu, X.; Zhang, S. Shot Boundary Detection based on Multilevel Difference of Color Histograms. In Proceedings of the 2016 First International Conference on Multimedia and Image Processing (ICMIP), Bandar Seri Begawan, Brunei, 1–3 June 2016; pp. 15–22. [Google Scholar]
- Zheng, J.; Zou, F.; Shi, M. An efficient algorithm for video shot boundary detection. In Proceedings of the 2004 IEEE International Symposium on Intelligent Multimedia, Video and Speech Processing, Hong Kong, China, 20–22 October 2004; pp. 266–269. [Google Scholar]
- Adjeroh, D.; Lee, M.C.; Banda, N.; Kandaswamy, U. Adaptive edge-oriented shot boundary detection. EURASIP J. Image Video Process. 2009, 2009, 859371. [Google Scholar] [CrossRef]
- Cooper, M.; Foote, J.; Adcock, J.; Casi, S. Shot boundary detection via similarity analysis. In Proceedings of the National Institute of Standards and Technology (NIST) TREC Video Retrieval Evaluation (TRECVID) Workshop, Palo Alto, CA, USA, 31 October 2003; pp. 79–84. [Google Scholar]
- Priya, G.L.; Domnic, S. Edge Strength Extraction using Orthogonal Vectors for Shot Boundary Detection. Procedia Technol. 2012, 6, 247–254. [Google Scholar] [CrossRef]
- Porter, S.; Mirmehdi, M.; Thomas, B. Temporal video segmentation and classification of edit effects. Image Vis. Comput. 2003, 21, 1097–1106. [Google Scholar] [CrossRef] [Green Version]
- Bouthemy, P.; Gelgon, M.; Ganansia, F. A unified approach to shot change detection and camera motion characterization. IEEE Trans. Circuits Syst. Video Technol. 1999, 9, 1030–1044. [Google Scholar] [CrossRef] [Green Version]
- Miadowicz, J.Z. Story Tracking in Video News Broadcasts. Ph.D. Thesis, University of Kansas, Lawrence, KS, USA, 2004. [Google Scholar]
- Bendraou, Y. Video Shot Boundary Detection and Key-Frame Extraction Using Mathematical Models; Image Processing; Université du Littoral Côte d’Opale: Dunkirk, France, 2017. [Google Scholar]
- Ngo, C.W.; Pong, T.C.; Chin, R.T. Video partitioning by temporal slice coherency. IEEE Trans. Circuits Syst. Video Technol. 2001, 11, 941–953. [Google Scholar]
- Dadashi, R.; Kanan, H.R. AVCD-FRA: A novel solution to automatic video cut detection using fuzzy-rulebased approach. Comput. Vis. Image Underst. 2013, 117, 807–817. [Google Scholar] [CrossRef]
- Bhaumik, H.; Chakraborty, M.; Bhattacharyya, S.; Chakraborty, S. Detection of Gradual Transition in Videos: Approaches and Applications. In Intelligent Analysis of Multimedia Information; IGI Global: Hershey, PA, USA, 2017; pp. 282–318. [Google Scholar]
- Xu, J.; Song, L.; Xie, R. Shot boundary detection using convolutional neural networks. In Proceedings of the 2016 Visual Communications and Image Processing (VCIP), Chengdu, China, 27–30 November 2016; pp. 1–4. [Google Scholar]
- Baraldi, L.; Grana, C.; Cucchiara, R. A deep siamese network for scene detection in broadcast videos. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1199–1202. [Google Scholar]
- Hassanien, A.; Elgharib, M.; Selim, A.; Hefeeda, M.; Matusik, W. Large-scale, fast and accurate shot boundary detection through spatio-temporal convolutional neural networks. arXiv. 2017. Available online: http://research.ibm.com/haifa/projects/imt/video/Video_DataSetTable (accessed on 22 September 2018).
- Liang, R.; Zhu, Q.; Wei, H.; Liao, S. A Video Shot Boundary Detection Approach Based on CNN Feature. In Proceedings of the 2017 IEEE International Symposium on Multimedia (ISM), Taichung, Taiwan, 11–13 December 2017; pp. 489–494. [Google Scholar]
- Selesnick, I.W.; Baraniuk, R.G.; Kingsbury, N.C. The dual-tree complex wavelet transforms. IEEE Signal Process. Mag. 2005, 22, 123–151. [Google Scholar] [CrossRef]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed]
- Places. Available online: http://places2.csail.mit.edu/demo.html (accessed on 22 September 2018).
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Computer Vision—ECCV 2014, Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Association for the Advancement of Artificial Intelligence (AAAI), San Francisco, CA, USA, 4–9 February 2017; Volume 4, p. 12. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Berg, A.C. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Vedaldi, A.; Fulkerson, B. VLFeat: An open and portable library of computer vision algorithms. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1469–1472. [Google Scholar]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary robust invariant scalable keypoints. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar]
- Alahi, A.; Ortiz, R.; Vandergheynst, P. Freak: Fast retina keypoint. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 510–517. [Google Scholar]
- Tola, E.; Lepetit, V.; Fua, P. Daisy: An efficient dense descriptor applied to wide-baseline stereo. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 815–830. [Google Scholar] [CrossRef] [PubMed]
- Matas, J.; Chum, O.; Urban, M.; Pajdla, T. Robust wide baseline stereo from maximally stable extremal regions. Image Vis. Comput. 2004, 22, 761–767. [Google Scholar] [CrossRef]
- Levi, G.; Hassner, T. LATCH: Learned arrangements of three patch codes. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–9. [Google Scholar]
- Alcantarilla, P.F.; Bartoli, A.; Davison, A.J. KAZE features. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 214–227. [Google Scholar]
- Morel, J.M.; Yu, G. ASIFT: A new framework for fully affine invariant image comparison. SIAM J. Imaging Sci. 2009, 2, 438–469. [Google Scholar] [CrossRef]
- Lin, W.Y.; Cheng, M.-M.; Lu, J.; Yang, H.; Do, M.N.; Torr, P. Bilateral functions for global motion modeling. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 341–356. [Google Scholar]
- Bian, J.; Lin, W.Y.; Matsushita, Y.; Yeung, S.K.; Nguyen, T.D.; Cheng, M.M. GMS: Grid-based motion statistics for fast, ultra-robust feature correspondence. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2828–2837. [Google Scholar]
- Filmora. Available online: https://filmora.wondershare.com/ (accessed on 22 September 2018).
- Ground Truth Download. Available online: https://www-nlpir.nist.gov/projects/trecvid/trecvid.data.html#tv01 (accessed on 22 July 2018).
- Smeaton, A.F.; Over, P.; Taban, R. The TREC-2001 Video Track Report. In Proceedings of the Tenth Text REtrieval Conference (TREC), Gaithersburg, MD, USA, 13–16 November 2001. [Google Scholar]
- Li, S.; Lee, M.C. Effective detection of various wipe transitions. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 663–673. [Google Scholar] [CrossRef]
- Cooper, M.; Liu, T.; Rieffel, E. Video segmentation via temporal pattern classification. IEEE Trans. Multimed. 2007, 9, 610–618. [Google Scholar] [CrossRef]
- Li, Y.; Lu, Z.; Niu, X. Fast video shot boundary detection framework employing pre-processing techniques. IET Image Process. 2009, 3, 121–134. [Google Scholar] [CrossRef]
- Lu, Z.; Shi, Y. Fast video shot boundary detection based on SVD and pattern matching. IEEE Trans. Image Process. 2013, 22, 5136–5145. [Google Scholar] [CrossRef] [PubMed]
- Tong, W.; Song, L.; Yang, X.; Qu, H.; Xie, R. CNN-based shot boundary detection and video annotation. In Proceedings of the 2015 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Ghent, Belgium, 17–19 June 2015; pp. 1–5. [Google Scholar]
- Paudyal, P.; Battisti, F.; Carli, M. A study on the effects of quality of service parameters on perceived video quality. In Proceedings of the 5th European Workshop on Visual Information Processing, EUVIP 2014, Paris, France, 10–12 December 2014; Available online: http://vqa.como.polimi.it/sequences.htm (accessed on 22 September 2018).
- Roopalakshmi, R.; Reddy, G.R.M. A framework for estimating geometric distortions in video copies based on visual-audio fingerprints. Signal Image Video Process. 2015, 9, 201–210. [Google Scholar] [CrossRef]
- Lei, Y.; Luo, W.; Wang, Y.; Huang, J. Video sequence matching based on the invariance of color correlation. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1332–1343. [Google Scholar] [CrossRef]
- Dataset: CNN2h—Video Search Using Image Queries. Available online: http://purl.stanford.edu/pj408hq3574 (accessed on 22 September 2018).





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Description | Robustness | Frailty | |
|---|---|---|---|---|
| Color-based | Color histogram [5] | Color histogram for the intensity image in RGB (Red, Green, Blue) color space or in HSV (Hue, Saturation, Value) color space | Signal processing, Flip, Scaling | Color change, Post-production, or edition |
| LBP [6] | Local Binary Pattern (LBP), Texture Spectrum model by computing neighborhood pixels | Signal processing | Color change, Post-production, or edition | |
| Gradient-based | HOG [7] | Histogram of Oriented Gradients (HOG) counts the occurrences of gradient orientation in localized portions of an image | Signal processing | Geometrical transformations |
| Edge [8] | Edge of oriented gradients | Scaling, compression | Color change, Post-production, or edition | |
| GIST [9] | A set of spectral dimensions (naturalness, openness, roughness, expansion, ruggedness) that represent the spatial structure of a scene | Scaling, compression | Post-production or edition, cropping | |
| Transform-coefficients-based | DWT [10] | Discrete Wavelet Transform (DWT) coefficients by using a mean value, an STD (Standard deviation) value, and SVD (Singular Value Decomposition) | Compression, Flip | Post-production or edition, blur |
| DCT [11] | Discrete Cosine Transform (DCT) coefficients | Scaling | Post-production or edition | |
| Motion-based [12] | Object motion and camera motion operated by a block matching consecutive frame blocks algorithm | Signal processing | Desynchronization | |
| Local descriptors | Descriptors can search for abrupt changes in pixel intensity values | Most geometrical transformations | Luminance change | |
| Presenters/Year | Methods | Characteristics | Based Types |
|---|---|---|---|
| INRIA-LEAR [14]/08 | The method uses the SIFT features representing the uniform sampled query frames, uses K-means to generate the visual vocabulary, and uses hamming encoding to generate the candidate set of video segments. | Using keyframe classifiers for video processing to increase the performance. Computationally expensive. | Keyframes |
| AT&T team [15]/09 | The method uses SBD to segment query videos and reference videos at the same time. The first frame of the shot is taken as a keyframe. | Using preprocessing to remove and reduce bad effects of transitions. | SBD |
| CRIM team [16]/09 | The method segments the video files into shots, uses SIFT for feature representation, the L1 distance is used for quantization, and Latent Dirichlet Allocation (LDA) is applied to discrete discriminants over matches. | The Bag of Words (BOW) model is used to eliminate the features that are not representative enough. | SBD |
| PKU-IDM team [17]/10 | The method uses four detectors: two visual local features (SIFT and SURF), one global feature DCT, and one audio feature: Mel-frequency cepstrum coefficients (MFCCs). | A fusion of features: audio and video. | Keyframes |
| Gupta [18]/11 | The method maps each video frame of the test to the closest query video frame firstly, and then moves the query over the test to find the test segment with the highest number of matching frames. | A fusion model reduces the false alarm rate. | Keyframes |
| Wu [19]/12 | The method uses two global features: a pyramid histogram of oriented gradients (PHOG) and GIST; their binary features are quantitated by using the pairwise Euclidean distance. | Uses a sparse random projection method to encode the features | Keyframes |
| Zhao [20]/13 | The method F-SIFT starts by estimating the dominant curl of a local patch and then geometrically normalizes the patch by flipping before the computation of SIFT. | Flip-invariant and can save on computational cost. | Keyframes |
| Kim [21]/14 | The method fuses models of spatial modalities and temporal modalities. The spatial fingerprint consists of DCT coefficients signs in local areas in a keyframe and the temporal fingerprint computes the temporal variances in local areas in consecutive keyframes. | A video shots features and adaptive modality fusion. | SBD |
| Lu [22]/15 | The method is based on local non-negative matrix factorization (LNMF), which is used for shot detection. The VCD has two-stage processing and the Hausdorff distance is used. | The robustness needs to be enhanced. | SBD |
| Mao [23]/16 | The method uses five scene frames from a video for video authenticity. | Can save storage space. | Keyframes |
| Guzman-Zavaleta [24]/17 | The method uses a combination of features: ORB, R&F (Resize and Flip), and a Spectrogram Saliency Map (SSM). The feature of a keyframe requires approximately 3 KB, which has a low-cost extraction. | Low-cost extraction of features and the synergy of lightweight video fingerprints. | Keyframes |
| Araujo [25]/17 | The method uses the frame fisher vector and scene fisher vector for video segments. | The query image is compared directly against video clips in the database. | SBD |
| Kordopatis-Zilos [26]/17 | The method extracts the Convolutional Neural Network (CNN) features from AlexNet [27], VGGNet [28], and GoogleNet [29] first, and then uses the vector aggregation method to make codebooks. | Deep learning based features. | Keyframes |
| Type | Presenters | Methods | Characteristics |
|---|---|---|---|
| Pixel-based | Kikukawa [30] | The method uses the sum of the absolute differences of the total pixel with a threshold to locate the cut shot. | Easy and fast, but cannot give a satisfactorily result. |
| Zhang [31] | The method uses the preprocessing method of average filtering before detecting shots. | False detection is the main problem. | |
| Shahraray [32] | The method divides the frame into regions, matches the regions between the current frame and its next frame, then chooses the best matches. | Real-time processing. | |
| Histogram-based | Küçüktunç [33] | The method uses fuzzy logic to generate a color histogram for SBD in the L*ab color space. | Robust to illumination changes and quantization errors, so it performs better than conventional color histogram methods. |
| Janwe [34] | The method uses the just-noticeable difference (JND) to map the RGB color space into three orthogonal axes JR, JG, and JB, and the sliding window-based adaptive threshold is used. | Highly depends on the size of the sliding window and parameter values. | |
| Li [35] | The method uses a three-stage approach: the candidate shots are detected by two thresholds based on the sliding window at first; then, the local maximum difference of the color histogram is used to eliminate disturbances; finally, the HSV color space and Euclidean distance are employed. | Can deal with a gradual change and a cut change in the same way. | |
| Edge-based | Zheng [36] | The method uses the Robert edge detector for gradual shot detecting; the fixed threshold is to determine the total number of edges that appear. | Fast but the performance for gradual transition detection is not good. |
| Adjeroh [37] | The method uses locally adaptive edge maps for feature extraction and uses three-level adaptive thresholds for video sequencing and shot detection. | Fast, uses an adaptive threshold, and is slightly superior to the color-based and histogram-based methods. | |
| Transform-based | Cooper [38] | The method computes the self-similarity between the features of each frame and uses the DCT to generate low-order coefficients of each frame color channel for a similarity matrix. | Competitive with seemingly simpler approaches, such as histogram differences |
| Priya [39] | The method uses the Walsh–Hadamard operation to extract the edge strength frames. | Simple but the performance should be improved. | |
| Motion-based | Porter [40] | The method uses camera and object motion to detect transitions and uses the average inter-frame correlation coefficient and block-based motion estimation to track image blocks. | High computational cost and has dissolve detection as a weakness. |
| Bounthemy [41] | The method estimates the dominant motion in an image represented by a two-dimensional (2D) affine model. | Applicable to MPEG videos. | |
| Statistical-based | Ribnick [42] | The method uses the mean, standard deviation, and skew of the color moments. | Simple but has dissolve detection as a weakness. |
| Bendraou [43] | The method uses SVD updating and pattern matching for gradual transitions. | Reduces the process and has good performance in both cut and gradual transition detection | |
| Temporal Slice Coherency | Ngo [44] | The method constructs a spatial-temporal slice of the video and analyzes its temporal coherency. Slice coherency is defined as the common rhythm shared by all frames within a shot. | Capable of detecting various wipe patterns. |
| Fuzzy-rule-based | Dadashi [45] | The method calculates a localized fuzzy color histogram for each frame and constructs a feature vector using fuzzy color histogram distances in a temporal window. Finally, it uses a fuzzy inference system to classify the transitions. | Threshold-independent and has a weakness against gradual transition types. |
| Two-phased | Bhaumik [46] | The first phase detects candidate dissolves by identifying parabolic patterns in the mean fuzzy entropy of the frames. The second phase uses a filter to eliminate candidates based on thresholds set for each of the four stages of filtration. | Has good performance for detecting dissolve transitions, uses lots of sub-stages, and is threshold-dependent. |
| Deep learning based | Xu [47] | The method implements three steps and uses CNN to extract the features of frames. The final decision is based on the cosine distance. | Suitable for the detection of both cut and gradual transitions boundaries; is threshold-dependent. |
| Baraldi [48] | The method uses Siamese networks to exploit the visual and textual features from the transcript at first and then uses the clustering algorithm to segment the video. | Uses CNN-based features and can achieve good results. | |
| Hassanien [49] | The method uses a support vector machine (SVM) to merge the outputs of a three-dimensional (3D) CNN with the same labeling and uses a histogram-driven temporal differential measurement to reduce false alarms of gradual transitions. | Exploits big data to achieve high detection performance. | |
| Liang [50] | The method extracts the features using the AlexNet and ResNet-152 model. The method uses local frame similarity and dual-threshold sliding window similarity. | Threshold-dependent. |
| Method | Processing | Length/Time | Frame Difference Plot |
|---|---|---|---|
| C-RGB | Using MATLAB’s IMHIST function | 512/12.5 s |  |
| C-HSV | Change to HSV space, each of them has eight bins | 512/16.9 s |  |
| LBP-SVD | Computing the Local Binary Pattern (LBP) then using singular value decomposition (SVD) | 58/14.2 s |  |
| GIST | LMgist function | 512/82.6 s |  |
| HOG-SVD | Computing HOG then using SVD | 31/13.6 s |  |
| DWT | 2D DWT, then using the mean, STD, and SV | 32/13.2 s |  |
| DTCWT | 2D DTCWT, then using the mean, STD, and SVD values | 52/17.5 s |  |
| DCT | Block processing DCT using the DC value | 64/15.4 s |  |
| EDGE | Edge processing, then using the mean value of a block | 64/16.6 s |  |
| Video Segment | Types | Length | Cuts | Gradual Transitions | Ratio |
|---|---|---|---|---|---|
| Scent of a Woman (Tango dance) | Movie | 03′53″ | 34 | 12 | 3:1 |
| The Sound of Music | Movie | 01′47″ | 12 | 1 | 12:1 |
| Forrest Gump (Start) | Movie | 01′44″ | 10 | 1 | 10:1 |
| Run Devil Run | Music | 03′28″ | 95 | 24 | 4:1 |
| Donkey and Puss in Boots | Cartoon | 02′06″ | 32 | 8 | 4:1 |
| LANEIGE | Advertisement | 32″ | 12 | 6 | 2:1 |
| MISSHA | Advertisement | 30″ | 10 | 2 | 5:1 |
| Men’s Basketball | News | 04′09″ | 6 | 43 | 1:7 |
| Edward Snowden | News | 04′28″ | 54 | 13 | 4:1 |
| Proposed Year | Architecture | Default Input Size | Top-5 Error % ILSVRC 12 | Work Contribution |
|---|---|---|---|---|
| 2012 | AlexNet | 227 | 15.3 | Use of rectified linear units (ReLU), the dropout technique, and overlapping max pooling |
| 2013 | ZF Net | 224 | 14.8 | Accurate tuning of the hyper-parameters |
| 2014 | VGG16/VGG19 | 224 | 6.67 | Uses multiple 3 × 3 convolutional layers to represent complex features |
| 2014 | GoogleNet/Inception | 224/299 | 7.3 | Use of 1 × 1 convolutional blocks (NiN), use of a width increase |
| 2015 | ResNet50/101/152 | 224 | 3.6 | Feeding the output of two successive convolutional layers AND also bypassing the input to the next layers |
| 2016 | InceptionResNet-v2 | 299 | 4.7 | Training with residual connections accelerates the training of Inception networks |
| Validation Set of Places Data | Test Set of Places Data | |||
|---|---|---|---|---|
| Top-1 acc | Top-5 acc | Top-1 acc | Top-5 acc | |
| Places-GoogleNet | 37.25% | 65.81% | 37.04% | 65.63% |
| Places-ResNet-50 | 45.32% | 74.28% | 45.18% | 74.21% |
| ID-Features | Feature Detector | Feature Descriptor | ID-Features | Feature Detector | Feature Descriptor |
|---|---|---|---|---|---|
| 1-SIFT | VL_SIFT | VL_SIFT | 7-DAISY [62] | OPENCV_SURF | OPENCV_DAISY |
| 2-SURF | OPENCV_SURF | OPENCV_SURF | 8-LATCH [63] | OPENCV_BRISK | OPENCV_LATCH |
| 3-BRISK [59] | OPENCV_BRISK | OPENCV_BRISK | 9-KAZE [64] | OPENCV_KAZE | OPENCV_KAZE |
| 4-FREAK [60] | OPENCV_BRISK | OPENCV_FREAK | 10-ASIFT [65] | VL_SIFT | VL_SIFT |
| 5-MSER [61] | OPENCV_MSER | OPENCV_SURF | 11-BF [66] | VL_SIFT | VL_SIFT |
| 6-ORB | OPENCV_ORB | OPENCV_ORB | 12-GMS [67] | OPENCV_ORB | OPENCV_ORB |
| Name | Duration (hh:mm:ss) | Number of Frames | Number of Shots | Video Size |
|---|---|---|---|---|
| Big Buck Bunny | 00:08:08 | 11,726 | 130 | 1920 × 1080 |
| Cosmos Laundromat | 00:09:59 | 14,394 | 94 | 1920 × 804 |
| Elephants Dream | 00:09:22 | 13,490 | 130 | 1024 × 576 |
| Tears of Steel | 00:09:48 | 14,111 | 136 | 1920 × 800 |
| Sintel | 00:12:24 | 17,858 | 198 | 1024 × 436 |
| Valkaama | 01:33:05 | 139,133 | 713 | 1280 × 720 |
| Video information | Shot Plot |
|---|---|
| Name: “Big Buck Bunny.mp4”; Manual OVSD: 130; Manual: 91; Proposed: 99; Filmora: 90; Frames: 11,726 |  |
| Name: “Cosmos Laundromat.mp4”; Manual: 94; Proposed: 104; Filmora: 124; Frames: 14,394 |  |
| Name: “Leon.mp4”; Manual: 26; Proposed: 28; Filmora: 24; Frames: 3920 |  |
| Name: “Gangnam Style.mp4”; Manual: 108; Proposed: 74; Filmora: 70; Frames: 3771 |  |
| Name | Shots | Detected | Correct | False | Miss | Precision | Recall |
|---|---|---|---|---|---|---|---|
| Big Buck Bunny | 91* | 99 | 85 | 14 | 6 | 0.86 | 0.93 |
| Cosmos Laundromat | 94 | 104 | 85 | 19 | 9 | 0.82 | 0.90 |
| Elephants Dream | 130 | 146 | 113 | 33 | 17 | 0.77 | 0.87 |
| Tears of Steel | 136 | 156 | 125 | 31 | 11 | 0.80 | 0.92 |
| Sintel | 198 | 221 | 174 | 47 | 24 | 0.79 | 0.88 |
| Valkaama | 85 | 93 | 79 | 14 | 6 | 0.85 | 0.93 |
| Total | 734 | 819 | 661 | 158 | 73 | 0.81 | 0.90 |
| Id-Name | Total Shots | Shots in 10 Min | Detected Shots | Correct Shots | False Shots | Miss Shots | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|---|---|---|
| 01_From_Pole_to_Pole | 445 | 71 | 86 | 66 | 20 | 5 | 0.767 | 0.929 | 0.8402 |
| 02_Mountains | 383 | 111 | 117 | 103 | 14 | 8 | 0.963 | 0.928 | 0.9452 |
| 03_Ice Worlds | 421 | 84 | 98 | 77 | 11 | 7 | 0.786 | 0.917 | 0.8464 |
| 04_Great Plains | 472 | 86 | 94 | 78 | 16 | 8 | 0.830 | 0.907 | 0.8668 |
| 05_Jungles | 460 | 63 | 77 | 57 | 20 | 6 | 0.740 | 0.905 | 0.8142 |
| 06_Seasonal_Forests | 526 | 88 | 108 | 74 | 34 | 14 | 0.685 | 0.841 | 0.7550 |
| 07_Fresh_Water | 531 | 99 | 104 | 90 | 14 | 9 | 0.865 | 0.909 | 0.8864 |
| 08_Ocean_Deep | 410 | 65 | 76 | 57 | 19 | 8 | 0.750 | 0.877 | 0.8086 |
| 09_Shallow_Seas | 366 | 65 | 68 | 58 | 10 | 7 | 0.853 | 0.892 | 0.8720 |
| 10_Caves | 374 | 71 | 72 | 67 | 15 | 4 | 0.931 | 0.944 | 0.9374 |
| 11_Deserts | 467 | 72 | 71 | 65 | 6 | 7 | 0.915 | 0.903 | 0.9090 |
| Total | 4855 | 875 | 971 | 792 | 179 | 83 | 0.816 | 0.905 | 0.8580 |
| Id-Name | Total Frames | Total Shots | Cut Shots | Gradual Shots | Cut Precision | Cut Recall | Cut F1-Score | Gradual Precision | Gradual Recall | Gradual F1-Score | Total F1-Score |
|---|---|---|---|---|---|---|---|---|---|---|---|
| anni005 | 11,364 | 65 | 38 | 27 | 0.94 | 0.96 | 0.95 | 0.87 | 0.86 | 0.87 | 0.91 |
| anni009 | 12,307 | 103 | 38 | 65 | 0.92 | 0.86 | 0.89 | 0.92 | 0.82 | 0.87 | 0.87 |
| BOR03 | 48,451 | 242 | 231 | 11 | 0.87 | 0.95 | 0.91 | 0.80 | 0.82 | 0.81 | 0.91 |
| BOR08 | 50,569 | 531 | 380 | 151 | 0.88 | 0.92 | 0.90 | 0.90 | 0.84 | 0.87 | 0.89 |
| NAD53 | 25,783 | 159 | 83 | 76 | 0.86 | 0.93 | 0.89 | 0.88 | 0.86 | 0.84 | 0.88 |
| NAD57 | 12,781 | 67 | 44 | 23 | 0.96 | 0.95 | 0.94 | 0.88 | 0.87 | 0.86 | 0.93 |
| Total | 161,255 | 1167 | 814 | 353 | 0.88 | 0.93 | 0.90 | 0.89 | 0.84 | 0.86 | 0.91 |
| Id-Name | Correlation Based [71] | Kernel-Correlation [72] | Edge-Oriented [37] | Proposed Method | ||||
|---|---|---|---|---|---|---|---|---|
| Cut Precision | Cut Recall | Cut Precision | Cut Recall | Cut Precision | Cut Recall | Cut Precision | Cut Recall | |
| anni005 | 0.87 | 0.89 | 0.71 | 0.64 | 0.87 | 0.91 | 0.94 | 0.96 |
| anni009 | 0.86 | 0.94 | 0.81 | 0.78 | 0.87 | 0.93 | 0.92 | 0.86 |
| BOR08 | 0.85 | 0.88 | 0.60 | 0.83 | 0.86 | 0.91 | 0.88 | 0.92 |
| NAD53 | 0.79 | 0.94 | 0.69 | 0.84 | 0.81 | 0.97 | 0.86 | 0.93 |
| Id-Name | Pre-Processing [73] | SVD [74] | CNN [75] | Proposed Method | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cut-Pr | Cut-Rc | Gra-Pr | Gra-Rc | Cut-Pr | Cut-Rc | Gra-Pr | Gra-Rc | Cut-Pr | Cut-Rc | Gra-Pr | Gra-Rc | Cut-Pr | Cut-Rc | Gra-Pr | Gra-Rc | |
| anni005 | 0.95 | 0.95 | 0.75 | 0.96 | 0.88 | 0.97 | 0.67 | 0.80 | 1 | 0.90 | 0.89 | 0.86 | 0.94 | 0.96 | 0.87 | 0.86 |
| anni009 | 0.88 | 0.74 | 0.92 | 0.69 | 0.88 | 0.74 | 0.68 | 0.80 | 1 | 0.82 | 0.94 | 0.73 | 0.92 | 0.86 | 0.92 | 0.82 |
| Attacks | Parameters | ||||||
|---|---|---|---|---|---|---|---|
| Delay (ms) | 100 | 300 | 500 | 800 | 1000 | / | / |
| Jitter (ms) | 1 | 2 | 3 | 4 | 5 | / | / |
| Packet Loss Rate (%) | 0.1 | 0.4 | 1 | 3 | 5 | 8 | 10 |
| Throughput (Mbps) | 0.5 | 1 | 2 | 3 | 5 | / | / |
| Method | Attacks | |||
|---|---|---|---|---|
| Delay | Jitter | Packet Loss Rate | Throughput | |
| SIFT | 1 | 1 | 1 | 0.9610 |
| CST–SURF | 0.1740 | 0.3737 | 0.2889 | 0.2121 |
| CC | 0.8932 | 0.9777 | 0.9730 | 0.9335 |
| {Th; CC; ORB} | 0.9996 | 0.9930 | 0.9940 | 0.9495 |
| ID_VT | Video Transformations | Parameters |
|---|---|---|
| VT1 | Flip | Horizontal flip |
| VT2 | Contrast change | 10% |
| VT3 | Noise Addition | Gaussian: mean = 0; variance = 0.01 |
| VT4 | Brightness change | 10% |
| VT5 | Cropping | 10% of the frame border |
| VT6 | Rotation | +5° |
| VT7 | Geometric projection | θ = 1°, projective 2d = ([cos(θ), −sin(θ), 0.001; sin(θ), cos(θ), 0.001; 0, 0, 1]); |
| VT8 | Picture in picture | Original video resized to 90% at the front, background image randomly used |
| VT9 | Picture fusion | original video and background images are added, background alpha value = 0.4 |
| VT10 | patterns insertion | Patterns are random images and occupy 2.25% of the area of the Original video |
| ID_AT | Attack Types | Sample Attacked Image | ID_AT | Attack Types | Sample Attacked Image |
|---|---|---|---|---|---|
| AT1 | VT1 |  | AT6 | VT5→VT6→VT3 |  |
| AT2 | VT2→VT3 |  | AT7 | VT7 |  |
| AT3 | VT1→VT2→VT3 |  | AT8 | VT7→VT4→VT5 |  |
| AT4 | VT4→VT5 |  | AT9 | V10→VT8 |  |
| AT5 | VT1→VT4→VT5 |  | AT10 | VT9→V10 |  |
| Parameters | Value |
|---|---|
| Image resize for feature extraction | 128 × 128; 256 × 256 |
| Select frames in a shot | three frames (first frame, middle frame, last frame); step skip frames (step skip by a quarter of the frame rate) |
| Using different features | SIFT; Speed Up Robust Features (SURF) |
| UBCMATCH threshold1 | [1.2, 1.4, 1.6, 1.8, 2.0, 2.2, 2.4, 2.6, 2.8, 3.0, 3.2, 3.4] |
| Matched numbers threshold2 | [2, 3, 4, 5, 6, 7, 8, 9] |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, D.; Kim, J. Video Searching and Fingerprint Detection by Using the Image Query and PlaceNet-Based Shot Boundary Detection Method. Appl. Sci. 2018, 8, 1735. https://doi.org/10.3390/app8101735
Jiang D, Kim J. Video Searching and Fingerprint Detection by Using the Image Query and PlaceNet-Based Shot Boundary Detection Method. Applied Sciences. 2018; 8(10):1735. https://doi.org/10.3390/app8101735
Chicago/Turabian StyleJiang, DaYou, and Jongweon Kim. 2018. "Video Searching and Fingerprint Detection by Using the Image Query and PlaceNet-Based Shot Boundary Detection Method" Applied Sciences 8, no. 10: 1735. https://doi.org/10.3390/app8101735
APA StyleJiang, D., & Kim, J. (2018). Video Searching and Fingerprint Detection by Using the Image Query and PlaceNet-Based Shot Boundary Detection Method. Applied Sciences, 8(10), 1735. https://doi.org/10.3390/app8101735