Application of Deep Convolutional Neural Networks and Smartphone Sensors for Indoor Localization




Abstract
:
1. Introduction
- A scene recognition model based on deep convolutional neural network is trained for indoor scene recognition in varying light conditions. The model is used to identify different floors and refines indoor localization accuracy. Tensorflow 1.12.0 is used to build and train the model. The accuracy of CNN is compared with support vector machines.
- An indoor localization approach is presented which utilizes the magnetic data from smartphone magnetic sensor to localize a pedestrian.
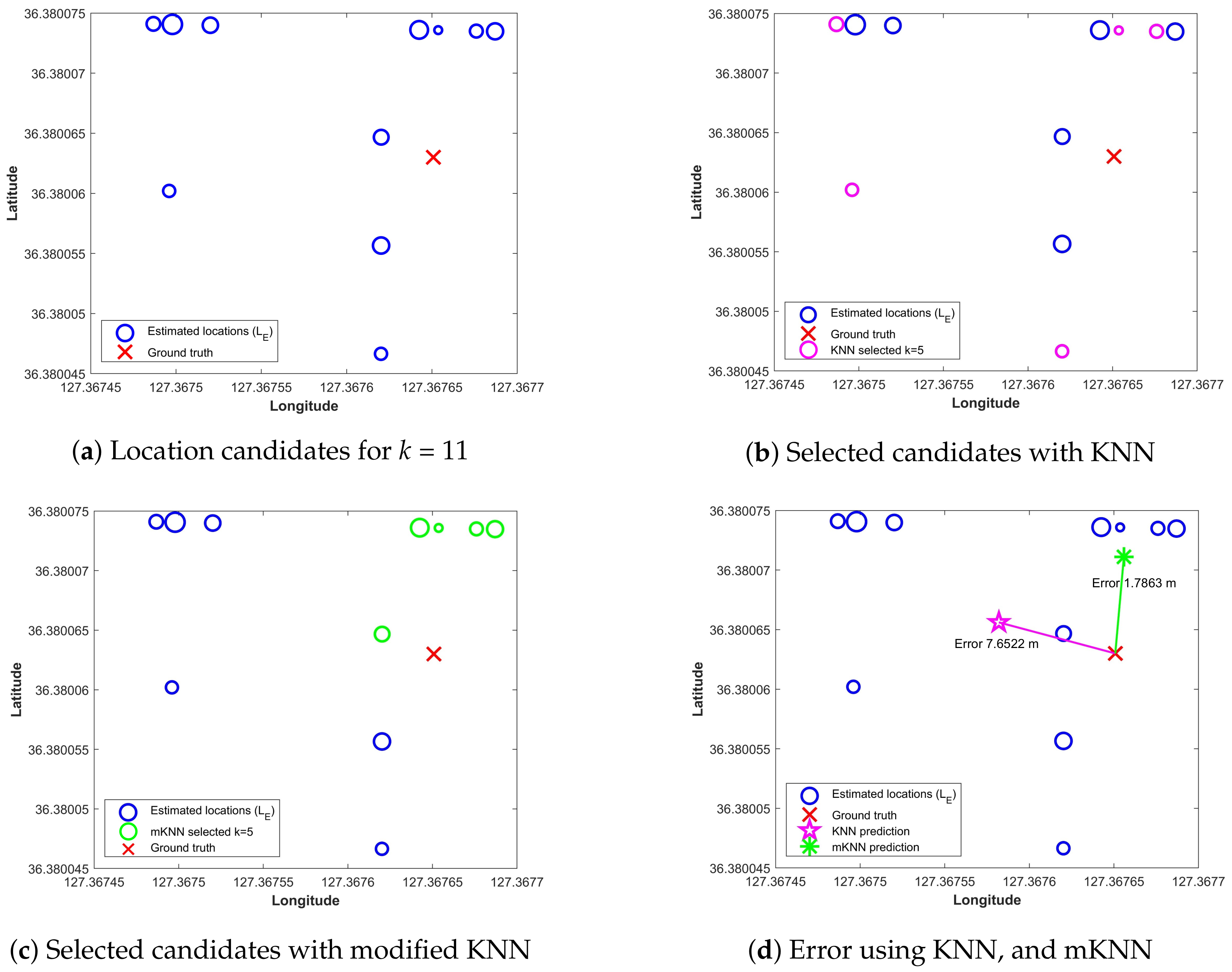
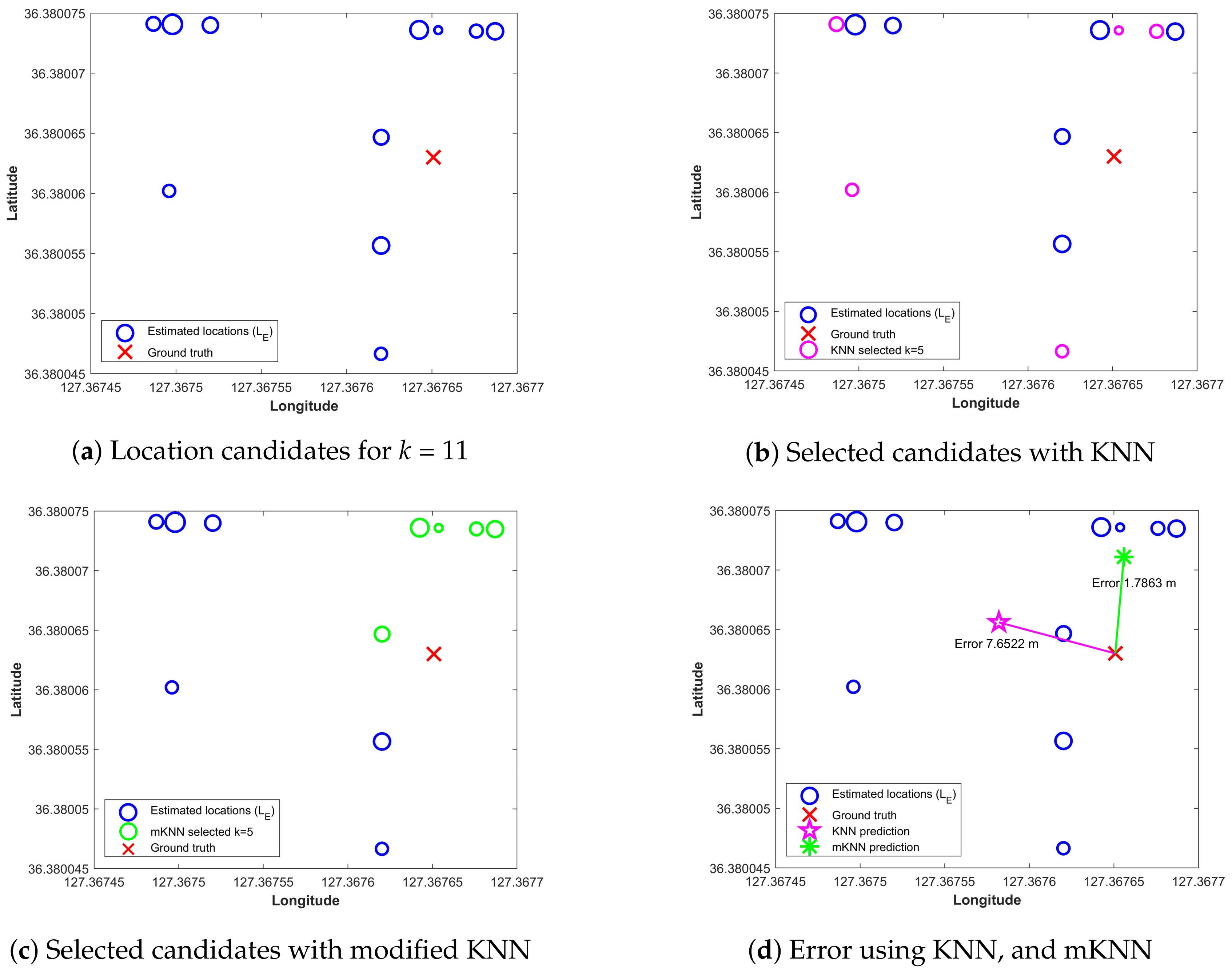
- Spatial proximity is considered to modify K nearest neighbor (KNN) which removes the distant neighbors and refines the current location of the pedestrian using the magnetic data.
- The proposed approach is tested on different smartphones and results are compared against other localization techniques to evaluate the impact of device dependence.
2. Related Work
3. Materials and Methods
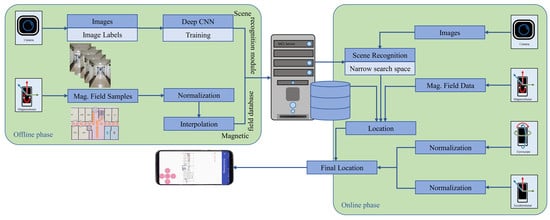
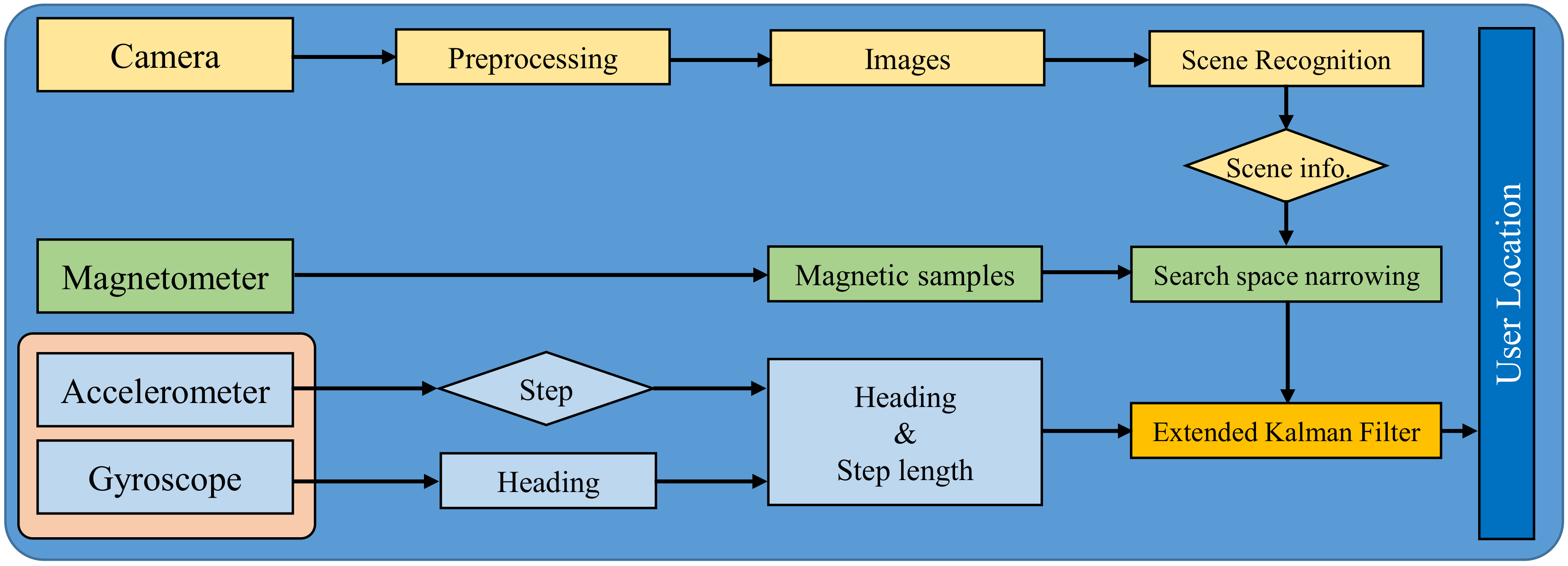
3.1. Overview of Proposed Approach
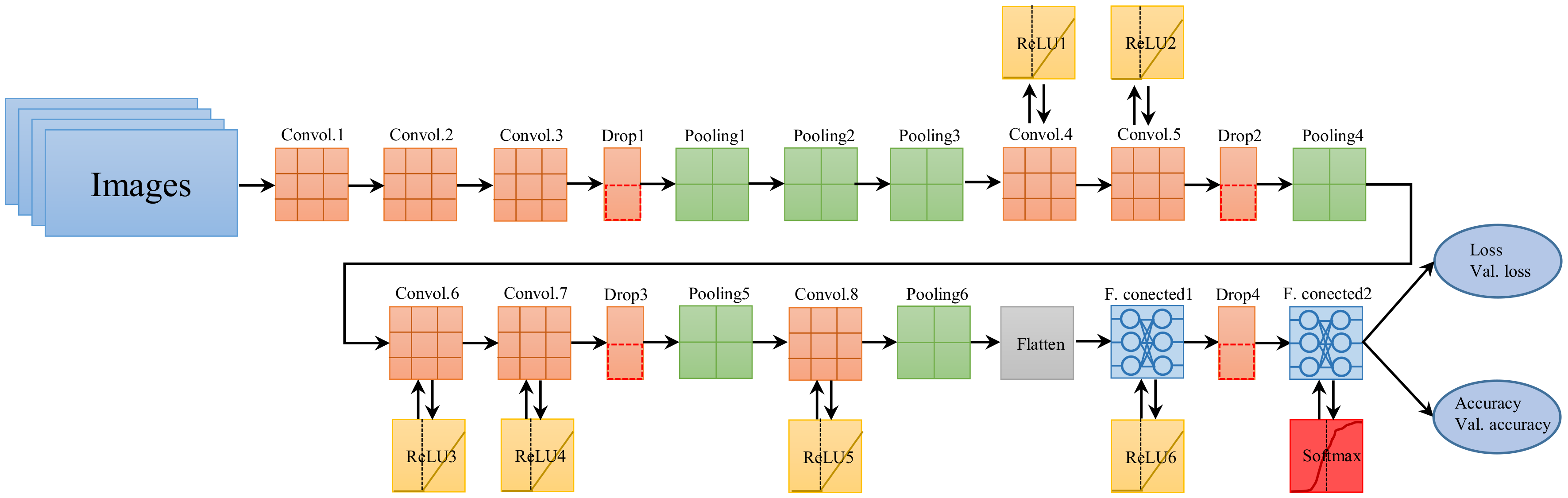
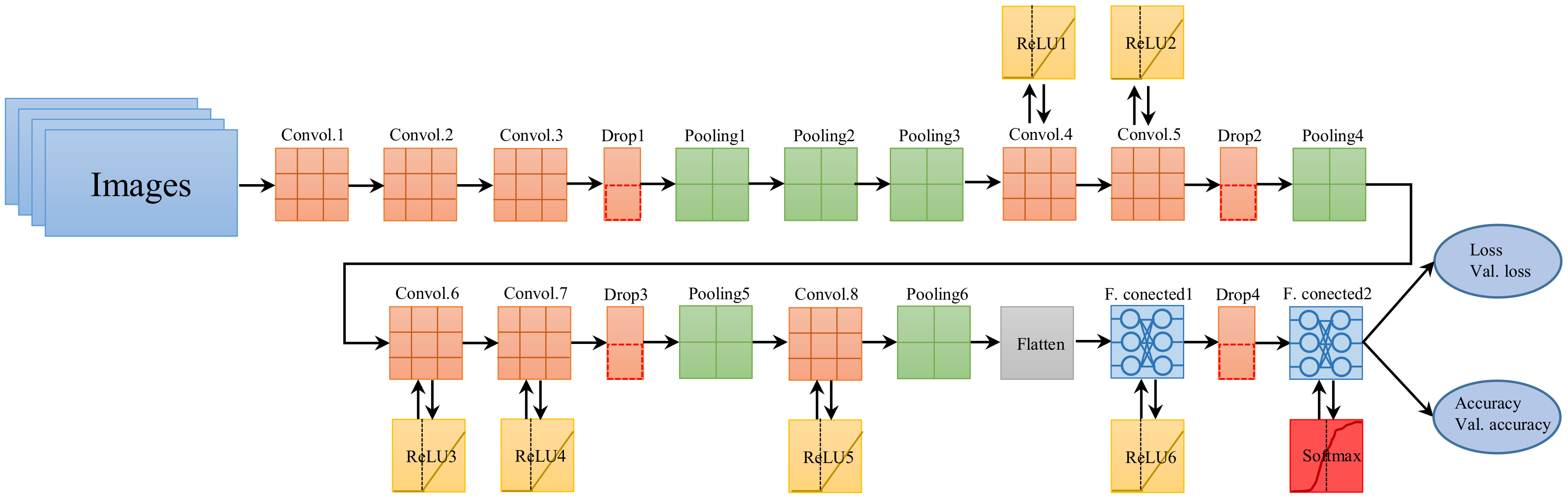
3.2. Deep Convolutional Neural Network
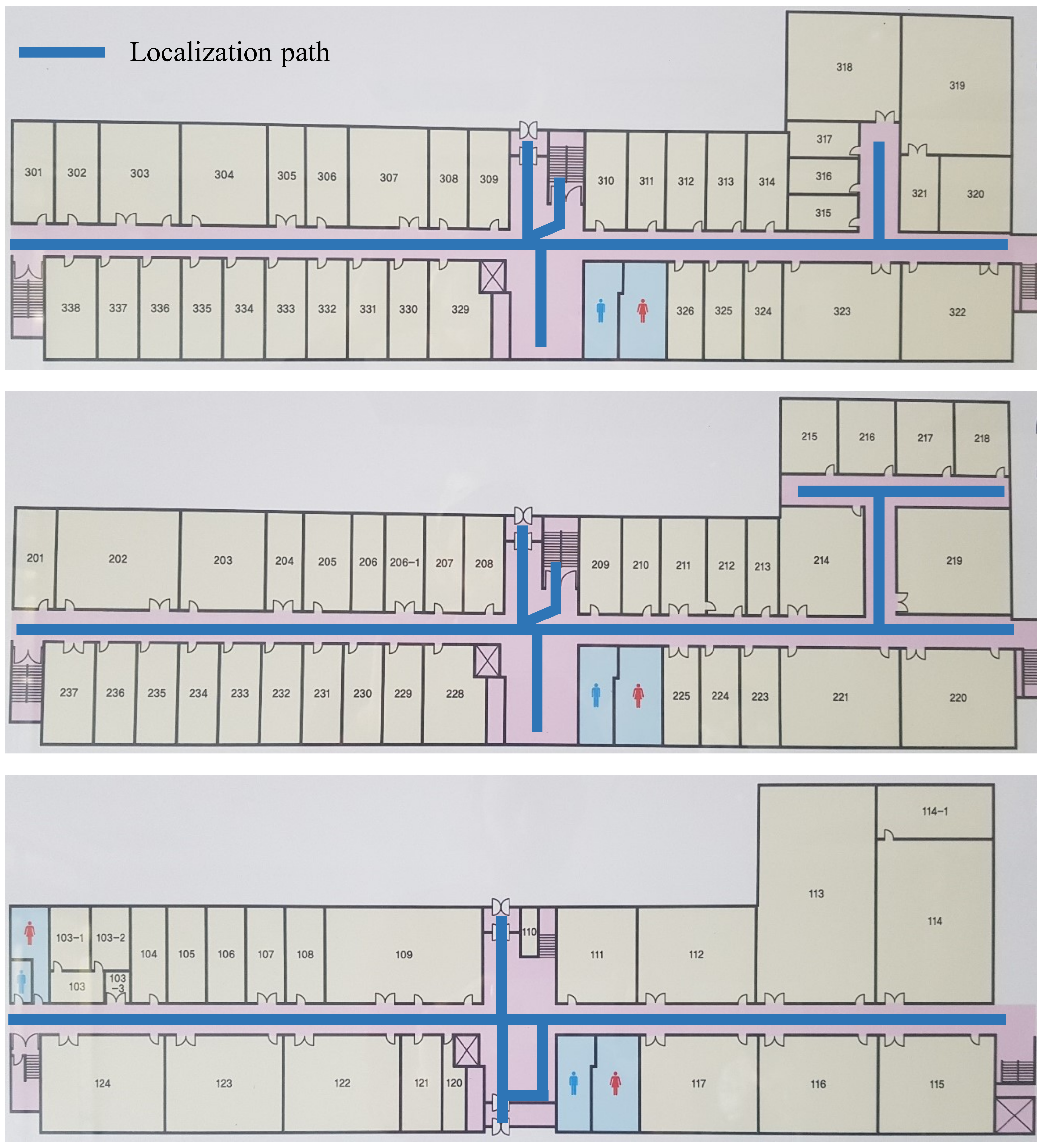
3.3. Data Collection
3.4. Location Estimation
3.4.1. Scene Recognition
3.4.2. Magnetic Localization
| Algorithm 1: Find user location |
| Input: Recognized scene information () & magnetic samples () Output: User’s estimated location () 1: identify floor using 2: load magnetic database 3: set , and // Set the search space for database 4: for do 5: for do 6: 7: end for 8: // denotes number of neighbors 9: for do 10: 11: end for 12: 13: 14: end for |
3.5. Evaulation
4. Experiment and Results
4.1. Experiment Setup
4.2. CNN Classifier Performance
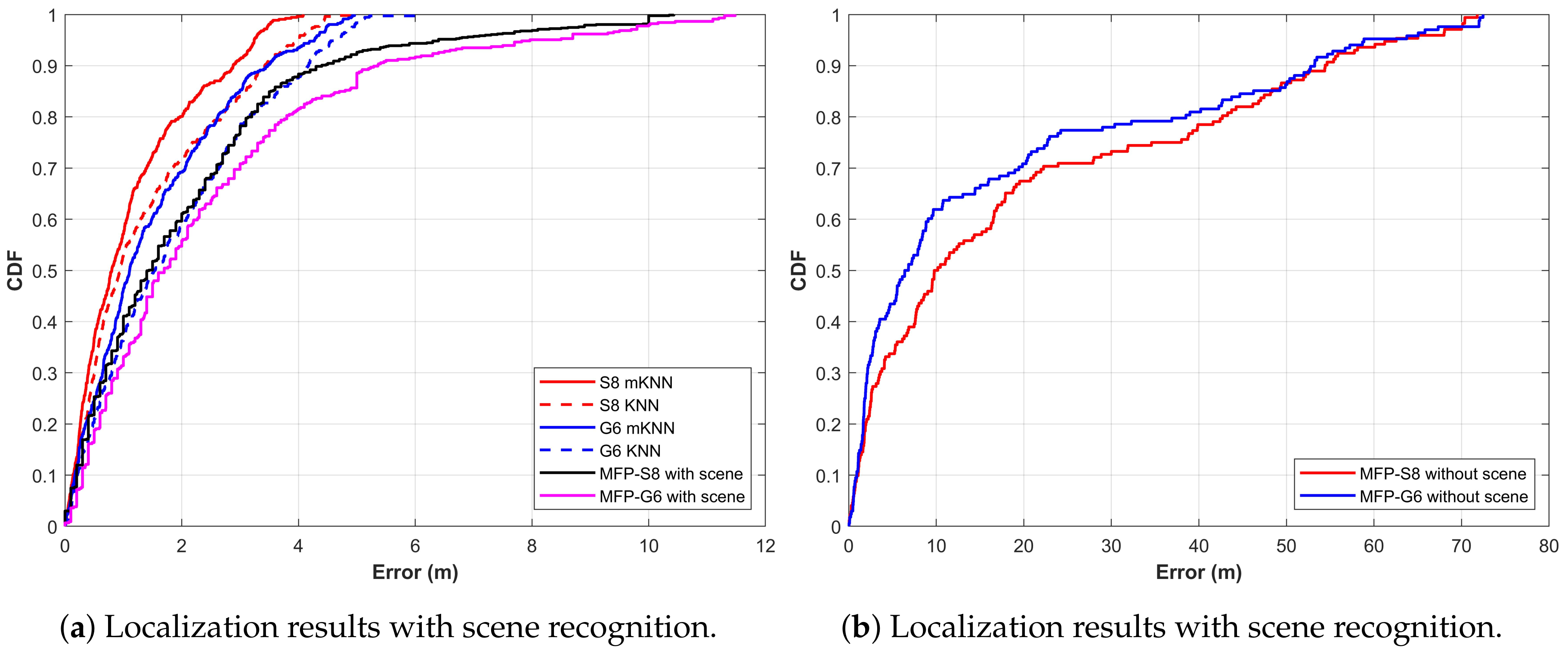
4.3. Performance of Indoor Localization
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yuan, Y.; Mou, L.; Lu, X. Scene recognition by manifold regularized deep learning architecture. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2222–2233. [Google Scholar] [CrossRef] [PubMed]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN architecture for weakly supervised place recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5297–5307. [Google Scholar]
- Herranz, L.; Jiang, S.; Li, X. Scene recognition with CNNs: Objects, scales and dataset bias. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 571–579. [Google Scholar]
- Shang, J.; Hu, X.; Gu, F.; Wang, D.; Yu, S. Improvement schemes for indoor mobile location estimation: A survey. Math. Probl. Eng. 2015, 2015, 32. [Google Scholar] [CrossRef]
- Ashraf, I.; Hur, S.; Park, Y. BLocate: A building identification scheme in GPS denied environments using smartphone sensors. Sensors 2018, 18, 3862. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Subbu, K.P.; Luo, J.; Wu, J. GROPING: Geomagnetism and crowdsensing powered indoor navigation. IEEE Trans. Mob. Comput. 2015, 14, 387–400. [Google Scholar] [CrossRef]
- Ashraf, I.; Hur, S.; Park, Y. Floor identification using magnetic field data with smartphone sensors. Sensors 2019, 19, 2538. [Google Scholar] [CrossRef]
- Shu, Y.; Bo, C.; Shen, G.; Zhao, C.; Li, L.; Zhao, F. Magicol: Indoor localization using pervasive magnetic field and opportunistic WiFi sensing. IEEE J. Sel. Areas Commun. 2015, 33, 1443–1457. [Google Scholar] [CrossRef]
- Ashraf, I.; Hur, S.; Park, Y. MDIRECT-Magnetic field strength and peDestrIan dead RECkoning based indoor localizaTion. In Proceedings of the 2018 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Nantes, France, 24–27 September 2018; pp. 24–27. [Google Scholar]
- Ashraf, I.; Hur, S.; Shafiq, M.; Kumari, S.; Park, Y. GUIDE: Smartphone sensors based pedestrian indoor localization with heterogeneous devices. Int. J. Commun. Syst. 2019, 19, 4062. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Arandjelović, R.; Zisserman, A. DisLocation: Scalable descriptor distinctiveness for location recognition. In Asian Conference on Computer Vision; Springer: Berlin, Germany, 2014; pp. 188–204. [Google Scholar]
- Sattler, T.; Leibe, B.; Kobbelt, L. Fast image-based localization using direct 2d-to-3d matching. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 667–674. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Sünderhauf, N.; Shirazi, S.; Jacobson, A.; Dayoub, F.; Pepperell, E.; Upcroft, B.; Milford, M. Place recognition with convnet landmarks: Viewpoint-robust, condition-robust, training-free. In Proceedings of the Robotics: Science and Systems XII, Berkeley, CA, USA, 13–17 July 2015. [Google Scholar]
- Uddin, M.T.; Uddiny, M.A. Human activity recognition from wearable sensors using extremely randomized trees. In Proceedings of the 2015 International Conference on Electrical Engineering and Information Communication Technology (ICEEICT), Jahangirnagar, Bengal, 21–23 May 2015; pp. 1–6. [Google Scholar]
- Jalal, A.; Kim, J.T.; Kim, T.S. Human activity recognition using the labeled depth body parts information of depth silhouettes. In Proceedings of the 6th International Symposium on Sustainable Healthy Buildings, Seoul, Korea, 10–13 August 2012; Volume 27. [Google Scholar]
- Jalal, A.; Uddin, M.Z.; Kim, J.T.; Kim, T.S. Daily Human Activity Recognition Using Depth Silhouettes and\mathcal {R} Transformation for Smart Home. In International Conference on Smart Homes and Health Telematics; Springer: Berlin, Germany, 2011; pp. 25–32. [Google Scholar]
- Ahad, M.A.R.; Kobashi, S.; Tavares, J.M.R. Advancements of image processing and vision in healthcare. J. Healthc. Eng. 2018, 2018, 3. [Google Scholar] [CrossRef]
- Jalal, A.; Sarif, N.; Kim, J.T.; Kim, T.S. Human activity recognition via recognized body parts of human depth silhouettes for residents monitoring services at smart home. Indoor Built Environ. 2013, 22, 271–279. [Google Scholar] [CrossRef]
- Jalal, A.; Quaid, M.A.K.; Hasan, A.S. Wearable Sensor-Based Human Behavior Understanding and Recognition in Daily Life for Smart Environments. In Proceedings of the 2018 International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 17–19 December 2018; pp. 105–110. [Google Scholar]
- Jalal, A.; Uddin, I. Security architecture for third generation (3G) using GMHS cellular network. In Proceedings of the 2007 International Conference on Emerging Technologies, Islamabad, Pakistan, 12–13 November 2007; pp. 74–79. [Google Scholar]
- Kendall, A.; Grimes, M.; Cipolla, R. Posenet: A convolutional network for real-time 6-dof camera relocalization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2938–2946. [Google Scholar]
- Boutell, M.; Luo, J. Bayesian fusion of camera metadata cues in semantic scene classification. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; Volume 2. [Google Scholar]
- Wang, Y.; Jodoin, P.M.; Porikli, F.; Konrad, J.; Benezeth, Y.; Ishwar, P. CDnet 2014: An expanded change detection benchmark dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2014; pp. 387–394. [Google Scholar]
- Procházka, A.; Kolinova, M.; Fiala, J.; Hampl, P.; Hlavaty, K. Satellite image processing and air pollution detection. In Proceedings of the 2000 IEEE International Conference on Acoustics, Speech, and Signal Processing, Istanbul, Turkey, 5–9 June 2000; Volume 4, pp. 2282–2285. [Google Scholar]
- Siagian, C.; Itti, L. Rapid biologically-inspired scene classification using features shared with visual attention. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 300–312. [Google Scholar] [CrossRef] [PubMed]
- Chen, I.K.; Chi, C.Y.; Hsu, S.L.; Chen, L.G. A real-time system for object detection and location reminding with rgb-d camera. In Proceedings of the 2014 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 10–13 January 2014; pp. 412–413. [Google Scholar]
- Jalal, A.; Kim, Y.; Kim, D. Ridge body parts features for human pose estimation and recognition from RGB-D video data. In Proceedings of the Fifth International Conference on Computing, Communications and Networking Technologies (ICCCNT), Hefei, China, 11–13 July 2014; pp. 1–6. [Google Scholar]
- Kamal, S.; Jalal, A.; Kim, D. Depth images-based human detection, tracking and activity recognition using spatiotemporal features and modified HMM. J. Electr. Eng. Technol. 2016, 11, 1921–1926. [Google Scholar] [CrossRef]
- Jalal, A.; Kim, J.T.; Kim, T.S. Development of a life logging system via depth imaging-based human activity recognition for smart homes. In Proceedings of the International Symposium on Sustainable Healthy Buildings, Seoul, Korea, 10 February 2012; Volume 19. [Google Scholar]
- Fonseca, L.M.G.; Namikawa, L.M.; Castejon, E.F. Digital image processing in remote sensing. In Proceedings of the 2009 Tutorials of the XXII Brazilian Symposium on Computer Graphics and Image Processing, Rio de Janeiro, Brazil, 11–14 October 2009; pp. 59–71. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed]
- Han, M.; Li, S.; Wan, X.; Liu, G. Scene recognition with convolutional residual features via deep forest. In Proceedings of the 2018 IEEE 3rd International Conference on Image, Vision and Computing (ICIVC), Chongqing, China, 27–29 June 2018; pp. 178–182. [Google Scholar]
- Lacerda, A.; Nascimento, E.R. A Robust Indoor Scene Recognition Method Based on Sparse Representation. In Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications: 22nd Iberoamerican Congress, CIARP 2017, Valparaíso, Chile, 7–10 November 2017; Springer: Berlin, Germany, 2018; Volume 10657, p. 408. [Google Scholar]
- Li, L.; Hu, P.; Peng, C.; Shen, G.; Zhao, F. Epsilon: A visible light based positioning system. In Proceedings of the 11th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 14), Seattle, WA, USA, 2–4 April 2014; pp. 331–343. [Google Scholar]
- Subbu, K.P.; Gozick, B.; Dantu, R. LocateMe: Magnetic-fields-based indoor localization using smartphones. ACM Trans. Intell. Syst. Technol. (TIST) 2013, 4, 73. [Google Scholar] [CrossRef]
- Ashraf, I.; Hur, S.; Park, Y. mPILOT-magnetic field strength based pedestrian indoor localization. Sensors 2018, 18, 2283. [Google Scholar] [CrossRef] [PubMed]
- Sánchez, J.; Perronnin, F.; Mensink, T.; Verbeek, J. Image classification with the fisher vector: Theory and practice. Int. J. Comput. Vis. 2013, 105, 222–245. [Google Scholar] [CrossRef]
- Koskela, M.; Laaksonen, J. Convolutional network features for scene recognition. In Proceedings of the 22nd ACM International Conference on Multimedia; ACM: New York, NY, USA, 2014; pp. 1169–1172. [Google Scholar]
- Zhang, Y.; Ma, L.; Tan, X. Smart phone camera image localization method for narrow corridors based on epipolar geometry. In Proceedings of the 2016 International Wireless Communications and Mobile Computing Conference (IWCMC), Paphos, Cyprus, 5–9 September 2016; pp. 660–664. [Google Scholar]
- Hu, Z.; Huang, G.; Hu, Y.; Yang, Z. WI-VI fingerprint: WiFi and vision integrated fingerprint for smartphone-based indoor self-localization. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 4402–4406. [Google Scholar]
- Farooq, A.; Jalal, A.; Kamal, S. Dense RGB-D map-based human tracking and activity recognition using skin joints features and self-organizing map. KSII Trans. Int. Inf. Syst. (TIIS) 2015, 9, 1856–1869. [Google Scholar]
- Kamal, S.; Jalal, A. A hybrid feature extraction approach for human detection, tracking and activity recognition using depth sensors. Arab. J. Sci. Eng. 2016, 41, 1043–1051. [Google Scholar] [CrossRef]
- Jalal, A.; Kim, S. Global security using human face understanding under vision ubiquitous architecture system. World Acad. Sci. Eng. Technol. 2006, 13, 7–11. [Google Scholar]
- Yoshimoto, H.; Date, N.; Yonemoto, S. Vision-based real-time motion capture system using multiple cameras. In Proceedings of the IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems, MFI2003, Crete, Greece, 30 July–1 August 2003; pp. 247–251. [Google Scholar]
- Huang, Q.; Yang, J.; Qiao, Y. Person re-identification across multi-camera system based on local descriptors. In Proceedings of the 2012 Sixth International Conference on Distributed Smart Cameras (ICDSC), Hong Kong, China, 30 October–2 November 2012; pp. 1–6. [Google Scholar]
- Jalal, A.; Shahzad, A. Multiple facial feature detection using vertex-modeling structure. In Proceedings of the IEEE Conference on Interactive Computer Aided Learning, Villach, Austria, 26–28 September 2007; Volume 2628. [Google Scholar]
- Xu, H.; Yang, Z.; Zhou, Z.; Shangguan, L.; Yi, K.; Liu, Y. Enhancing wifi-based localization with visual clues. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Osaka, Japan, 7–11 September 2015; pp. 963–974. [Google Scholar]
- Hu, X.; Shang, J.; Gu, F.; Han, Q. Improving Wi-Fi indoor positioning via AP sets similarity and semi-supervised affinity propagation clustering. Int. J. Distrib. Sens. Netw. 2015, 11, 109642. [Google Scholar] [CrossRef]
- Wang, X.; Gao, L.; Mao, S.; Pandey, S. CSI-based fingerprinting for indoor localization: A deep learning approach. IEEE Trans. Veh. Technol. 2017, 66, 763–776. [Google Scholar] [CrossRef]
- Nowicki, M.; Wietrzykowski, J. Low-effort place recognition with WiFi fingerprints using deep learning. In International Conference Automation; Springer: Berlin, Germany, 2017; pp. 575–584. [Google Scholar]
- Dong, J.; Xiao, Y.; Noreikis, M.; Ou, Z.; Ylä-Jääski, A. imoon: Using smartphones for image-based indoor navigation. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems, Seoul, Korea, 1–4 November 2015; pp. 85–97. [Google Scholar]
- Gu, F.; Niu, J.; Duan, L. Waipo: A fusion-based collaborative indoor localization system on smartphones. IEEE/ACM Trans. Netw. 2017, 25, 2267–2280. [Google Scholar] [CrossRef]
- Sun, L.; Zheng, Z.; He, T.; Li, F. Multifloor Wi-Fi localization system with floor identification. Int. J. Distrib. Sens. Netw. 2015, 11, 131523. [Google Scholar] [CrossRef]
- Bitew, M.A.; Hsiao, R.S.; Lin, H.P.; Lin, D.B. Hybrid indoor human localization system for addressing the issue of RSS variation in fingerprinting. Int. J. Distrib. Sens. Netw. 2015, 11, 831423. [Google Scholar] [CrossRef]
- Bensky, A. Wireless Positioning Technologies and Applications; Artech House: Norwood, MA, USA, 2016. [Google Scholar]
- Zafari, F.; Gkelias, A.; Leung, K. A survey of indoor localization systems and technologies. arXiv 2017, arXiv:1709.01015. [Google Scholar] [CrossRef]
- Stats, S.C.G. Mobile OS Market Share. 2019. Available online: http://gs.statcounter.com/os-market-share/mobile/worldwide (accessed on 5 June 2019).
- Lee, N.; Han, D. Magnetic indoor positioning system using deep neural network. In Proceedings of the 2017 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Sapporo, Japan, 18–21 September 2017; pp. 1–8. [Google Scholar]
- Liu, M.; Chen, R.; Li, D.; Chen, Y.; Guo, G.; Cao, Z.; Pan, Y. Scene recognition for indoor localization using a multi-sensor fusion approach. Sensors 2017, 17, 2847. [Google Scholar] [CrossRef]
- Zhu, Y.; Ouyang, Q.; Mao, Y. A deep convolutional neural network approach to single-particle recognition in cryo-electron microscopy. BMC Bioinform. 2017, 18, 348. [Google Scholar] [CrossRef]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin, Germany, 2006. [Google Scholar]
- Piyathilaka, L.; Kodagoda, S. Gaussian mixture based HMM for human daily activity recognition using 3D skeleton features. In Proceedings of the 2013 IEEE 8th Conference on Industrial Electronics and Applications (ICIEA), Melbourne, Australia, 19–21 June 2013; pp. 567–572. [Google Scholar]
- Jalal, A.; Kamal, S.; Kim, D. A depth video sensor-based life-logging human activity recognition system for elderly care in smart indoor environments. Sensors 2014, 14, 11735–11759. [Google Scholar] [CrossRef]
- Jalal, A.; Kim, Y.H.; Kim, Y.J.; Kamal, S.; Kim, D. Robust human activity recognition from depth video using spatiotemporal multi-fused features. Pattern Recognit. 2017, 61, 295–308. [Google Scholar] [CrossRef]
- Jalal, A.; Kamal, S.; Kim, D. Shape and motion features approach for activity tracking and recognition from kinect video camera. In Proceedings of the 2015 IEEE 29th International Conference on Advanced Information Networking and Applications Workshops, Gwangju, Korea, 24–27 March 2015; pp. 445–450. [Google Scholar]
- Jalal, A.; Kim, Y. Dense depth maps-based human pose tracking and recognition in dynamic scenes using ridge data. In Proceedings of the 2014 11th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Seoul, Korea, 26–29 August 2014; pp. 119–124. [Google Scholar]
- Jalal, A.; Kamal, S.; Kim, D. Individual detection-tracking-recognition using depth activity images. In Proceedings of the 2015 12th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Goyang City, Korea, 28–30 October 2015; pp. 450–455. [Google Scholar]
- Wu, H.; Pan, W.; Xiong, X.; Xu, S. Human activity recognition based on the combined svm&hmm. In Proceedings of the 2014 IEEE International Conference on Information and Automation (ICIA), Hailar, China, 28–30 July 2014; pp. 219–224. [Google Scholar]
- Weinberg, H. Using the ADXL202 in pedometer and personal navigation applications. Analog Devices AN-602 Appl. Note 2002, 2, 1–6. [Google Scholar]
- Jalal, A.; Quaid, M.A.; Sidduqi, M. A Triaxial acceleration-based human motion detection for ambient smart home system. In Proceedings of the 2019 16th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 8–12 January 2019; pp. 353–358. [Google Scholar]
- Jalal, A.; Maria, M.; Sidduqi, M. Robust spatio-temporal features for human interaction recognition via artificial neural network. In Proceedings of the IEEE Conference on International Conference on Frontiers of Information Technology, Paris, France, 17–19 December 2018. [Google Scholar]
- Jalal, A.; Uddin, M.Z.; Kim, J.T.; Kim, T.S. Recognition of human home activities via depth silhouettes and R transformation for Smart Homes. Indoor Built Environ. 2012, 21, 184–190. [Google Scholar] [CrossRef]
- Jalal, A.; Rasheed, Y.A. Collaboration achievement along with performance maintenance in video streaming. In Proceedings of the IEEE Conference on Interactive Computer Aided Learning, Villach, Austria, 26–28 September 2007; Volume 2628, p. 18. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Ashraf, I.; Hur, S.; Park, Y. MagIO: Magnetic Field Strength Based Indoor-Outdoor Detection with a Commercial Smartphone. Micromachines 2018, 9, 534. [Google Scholar] [CrossRef]
- Broadcom. Online. 2018. Available online: https://www.broadcom.com/products/wireless/wireless-lan-infrastructure/bcm4360 (accessed on 5 June 2019).
- STMicroelectronics. LSM6DSL Fact Sheet. 2018. Available online: https://www.st.com/resource/en/datasheet/lsm6dsl.pdf (accessed on 5 June 2019).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | CNN Accuracy | SVM Accuracy |
|---|---|---|
| 0 | 0.942 | 0.890 |
| 1 | 0.925 | 0.880 |
| 2 | 0.920 | 0.800 |
| 3 | 0.912 | 0.880 |
| 4 | 0.887 | 0.740 |
| 5 | 0.854 | 0.710 |
| 6 | 0.953 | 0.910 |
| 7 | 0.924 | 0.880 |
| 8 | 0.957 | 0.899 |
| 9 | 0.870 | 0.760 |
| 10 | 0.901 | 0.843 |
| 11 | 0.890 | 0.820 |
| 12 | 0.882 | 0.810 |
| 13 | 0.928 | 0.846 |
| 14 | 0.913 | 0.808 |
| Average 0.9104 | 0.8317 |
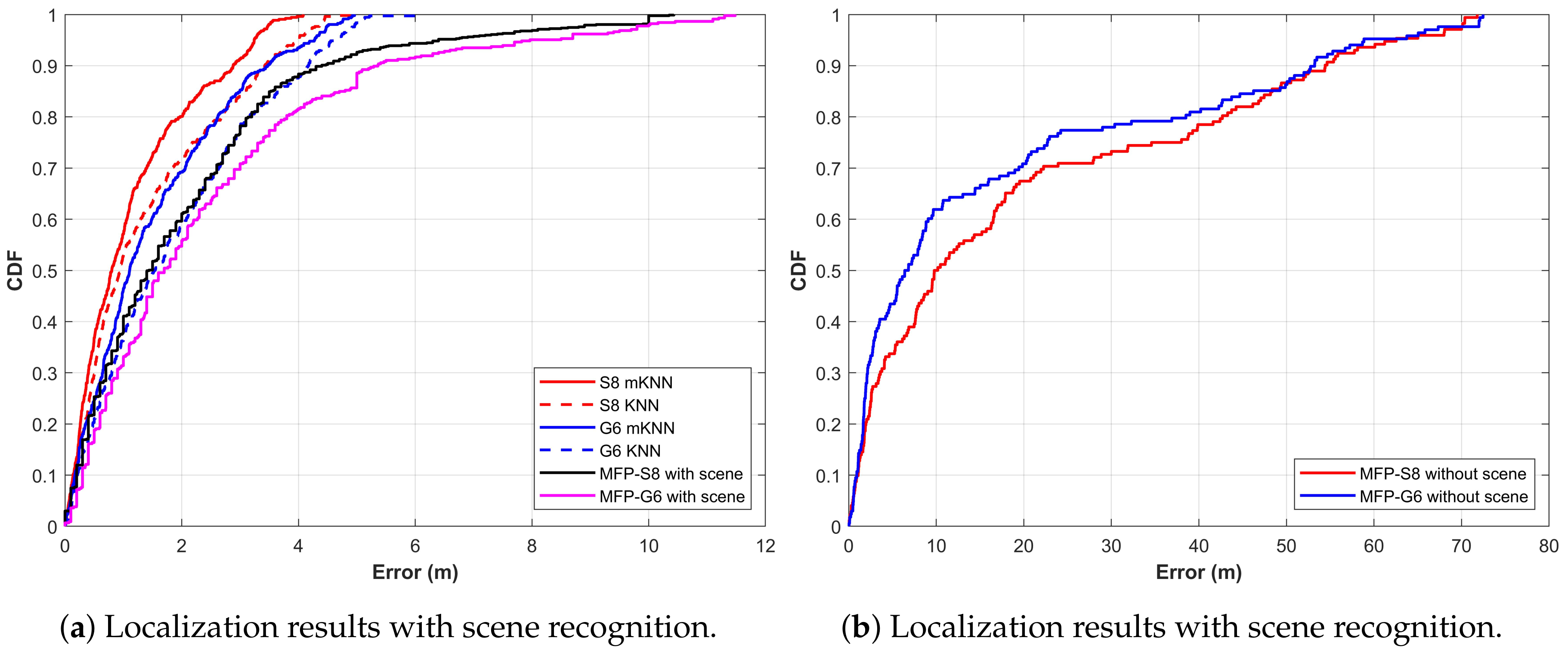
| Method & Device | Mean Error | Standard Deviation | 50% Accuracy | 75% Accuracy |
|---|---|---|---|---|
| KNN-G6 | 1.86 | 1.44 | 1.53 | 2.88 |
| mKNN-G6 | 1.46 | 1.23 | 1.08 | 2.22 |
| KNN-S8 | 1.40 | 1.24 | 1.02 | 2.18 |
| mKNN-S8 | 1.15 | 1.01 | 0.89 | 1.68 |
| MFP-S8 with scene | 2.04 | 1.44 | 1.50 | 2.9 |
| MFP-G6 with scene | 2.47 | 2.41 | 1.70 | 3.35 |
| MFP-S8 without scene | 14.05 | 17.45 | 5.74 | 2.28 |
| MFP-G6 without scene | 19.74 | 21.02 | 9.77 | 34.55 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ashraf, I.; Hur, S.; Park, Y. Application of Deep Convolutional Neural Networks and Smartphone Sensors for Indoor Localization. Appl. Sci. 2019, 9, 2337. https://doi.org/10.3390/app9112337
Ashraf I, Hur S, Park Y. Application of Deep Convolutional Neural Networks and Smartphone Sensors for Indoor Localization. Applied Sciences. 2019; 9(11):2337. https://doi.org/10.3390/app9112337
Chicago/Turabian StyleAshraf, Imran, Soojung Hur, and Yongwan Park. 2019. "Application of Deep Convolutional Neural Networks and Smartphone Sensors for Indoor Localization" Applied Sciences 9, no. 11: 2337. https://doi.org/10.3390/app9112337
APA StyleAshraf, I., Hur, S., & Park, Y. (2019). Application of Deep Convolutional Neural Networks and Smartphone Sensors for Indoor Localization. Applied Sciences, 9(11), 2337. https://doi.org/10.3390/app9112337