1. Introduction
Machine learning, which is one of the fields of artificial intelligence and is a technology to implement functions such as human learning ability by computer, has been studied in various concessions mainly used in the field of signal processing and image processing [
1,
2,
3], such as speech recognition [
4,
5], natural language processing [
6,
7,
8], and medical treatment [
9,
10]. Since the performance using machine learning shows good results, it will play an important role in the 4th industrial revolution as is well known in Alpha machine learning [
11]. Reinforced learning is the training of machine learning models to make a sequence of decisions so that a robot learns to achieve a goal in an uncertain, potentially complex environment by selecting the action to be performed according to the environment without an accurate system model. When learning data is not provided, some actions are taken to compensate the system for learning. Reinforcement learning, which includes actor critic [
12,
13,
14] structure and q learning [
15,
16,
17,
18,
19,
20,
21], has many applications such as scheduling, chess, and robot control based on image processing, path planning [
22,
23,
24,
25,
26,
27,
28,
29] and etc. Most of the existing studies using reinforcement learning exclusively the performance in simulation or games. In multi-robot control, reinforcement learning and genetic algorithms have some drawbacks that have to be compensated for. In contrast to the control of multiple motors in a single robot arm, reinforcement learning of the multiple robots for solving one task or multiple tasks is relatively inactive.
This paper deals with information and strategy around reinforcement learning for multi-robot navigation algorithm [
30,
31,
32,
33] where each robot can be considered as a dynamic obstacle [
34,
35] or cooperative robot depending on the situation. That is, each robot in the system can perform independent actions and simultaneously collaborate with each other depending on the given mission. After the selected action, the relationship with the target is evaluated, and rewards or penalty is given to each robot to learn.
The robot learns the next action based on the learned data when it selects the next action, and after several learning, it moves to the closest target. By interacting with the environment, robots exhibit new and complex behaviors rather than existing behaviors. The existing analytical methods suffer from adaptation to complex and dynamic systems and environments. By using Deep q learning [
36,
37,
38] and CNN [
39,
40,
41], reinforcement learning is performed on the basis of image, and the same data as the actual multi-robot is used to compare it with the existing algorithms.
In the proposed algorithm, the global image information in the multi-robot provides the robots with higher autonomy comparing with conventional robots. In this paper, we propose a noble method for a robot to move quickly to the target point by using reinforcement learning for path planning of a multi-robot system. In this case, reinforcement learning is a Deep q learning that can be used in a real mobile robot environment by sharing q parameters for each robot. In various 2D environments such as static and dynamic environment, the proposed algorithm spends less searching time than other path planning algorithms.
2. Reinforcement Learning
Reinforcement learning is the training of machine learning models to make a sequence of decisions through trial and error in a dynamic environment. The robots learn to achieve a goal in an uncertain, potentially complex environment through programming the object by reward or penalty.
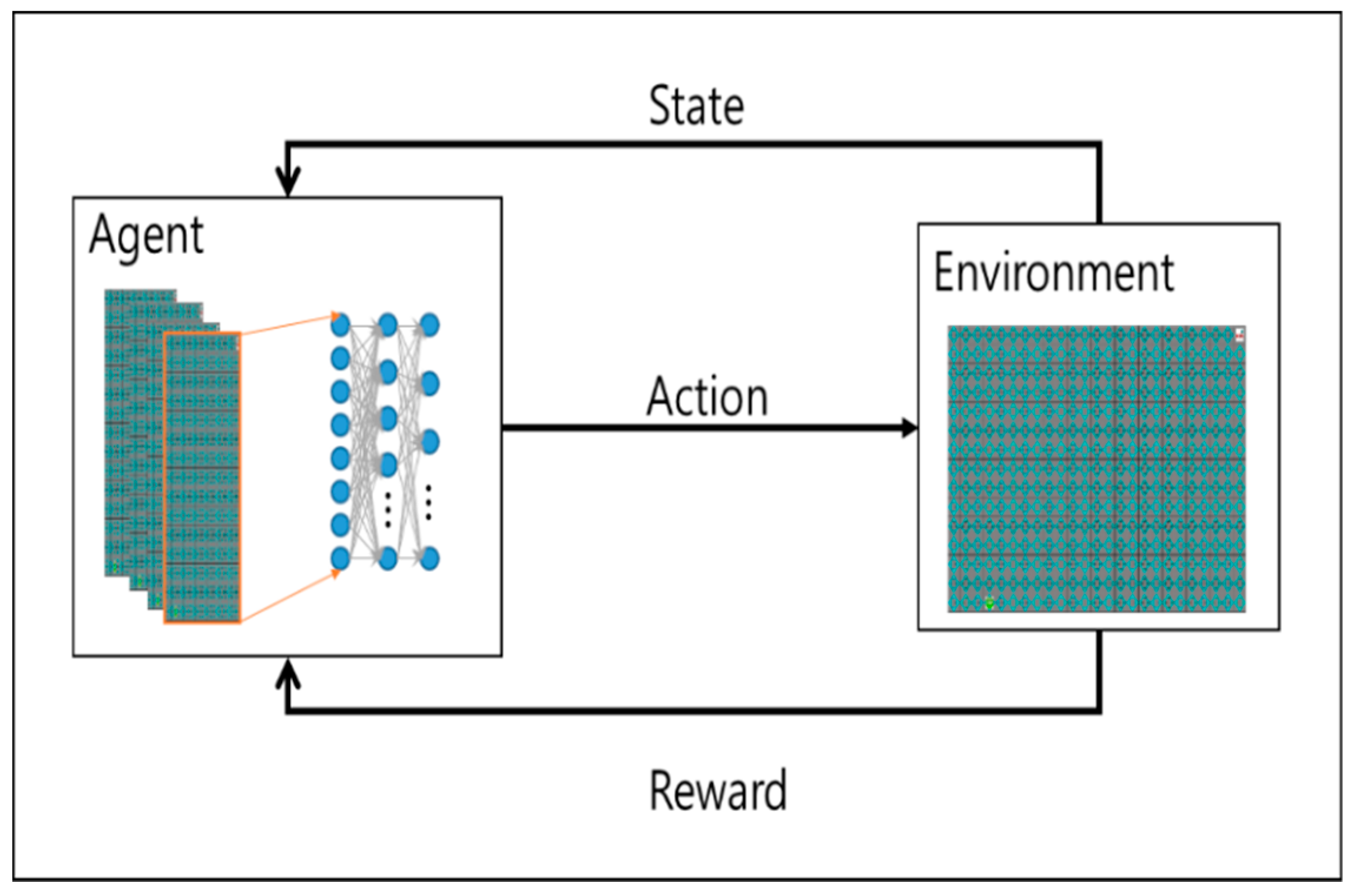
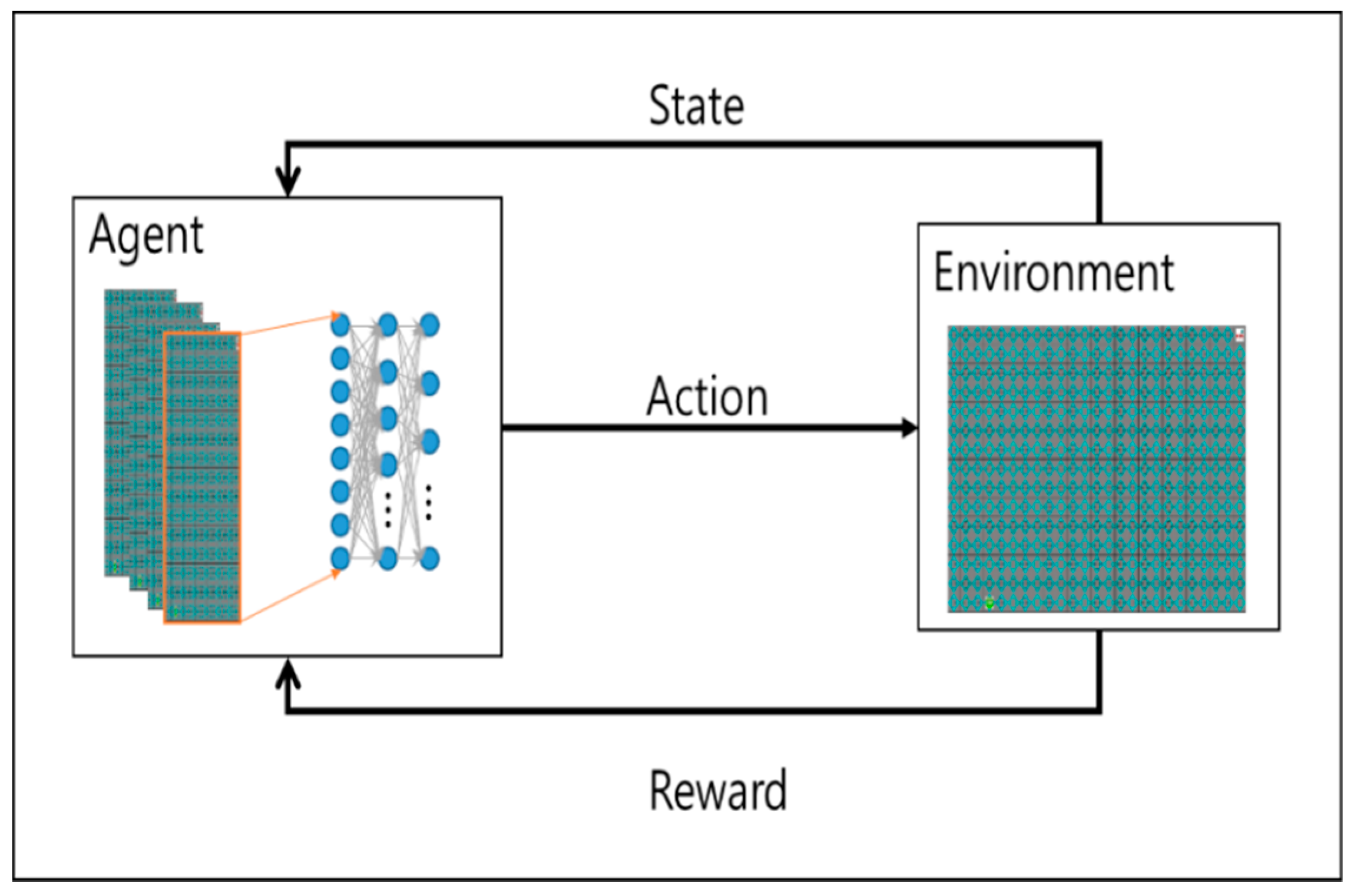
Figure 1 shows a general reinforcement learning, a robot which selects the action a as output recognizes the environment and receives the state, s, of the environment. The state of the behavior is changed, and the state transition is delivered to the individual as a reinforcement signal called a reinforcement signal. The behavior of the individual robot is selected in such a way as to increase the sum of the enhancement signal values over a long period of time.
One of the most distinguishable differences of reinforcement learning from supervised learning is that it does not use the representation of the link between input and output. After choosing an action, it is rewarded and knows the following situation. Another difference is that the online features of reinforcement learning are important since the computation of the system takes place at the same time as learning. One of the reinforcement learning features, Deep q learning, is characterized by the temporal difference method, which allows learning directly by experience and does not need to wait until the final result to calculate the value of each state like dynamic programming.
When a robot is moving in a discrete, restrictive environment, it chooses one of a set of definite behaviors at every time interval and assumes that it is in Markov state; the state changes to the probability s of different.
At every time interval t, a robot can get status s from the environment and then take action at. It receives a stochastic prize r, which depends on the state and behavior of the expected prize Rst to find the optimal policy that an entity wants to achieve.
The discount factor means that the rewards received at t time intervals are less affected than the rewards currently received. The operational value function Va is calculated using the policy function π and the policy value function Vp as shown in Equation (3). The state value function for the expected prize when starting from state s and following the policy is expressed by the following equation.
It is proved that there is at least one optimal policy as follows. The goal of Q-learning is to set an optimal policy without initial conditions. For the policy, define the Q value as follows.
Q(st, at) is the newly calculated Q(st−1, at−1), and Q(st−1, at−1) corresponding to the next state by the current Q(st−1, at−1) value and the current Q(st−1, at−1).
3. Proposed Algorithm
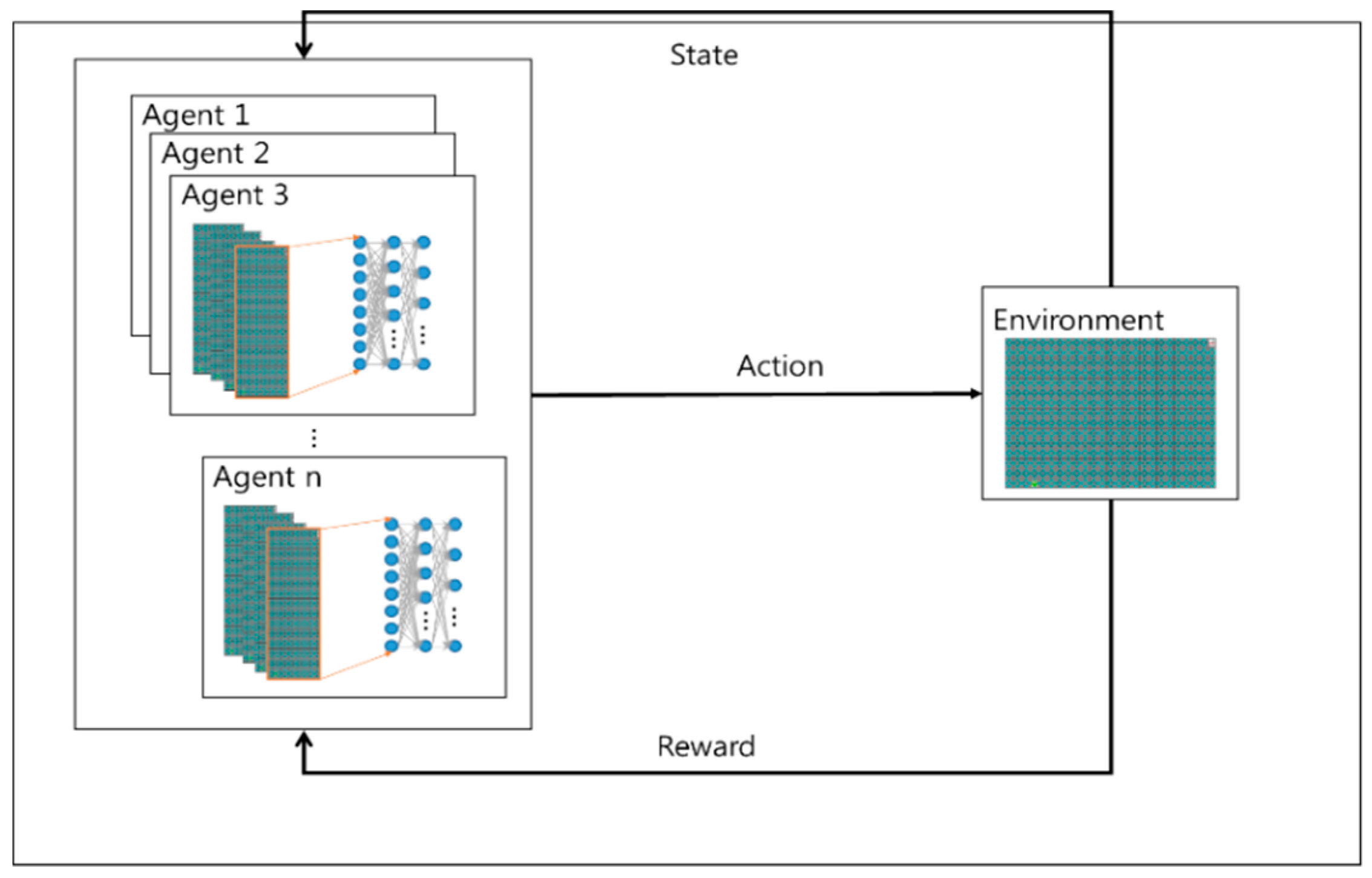
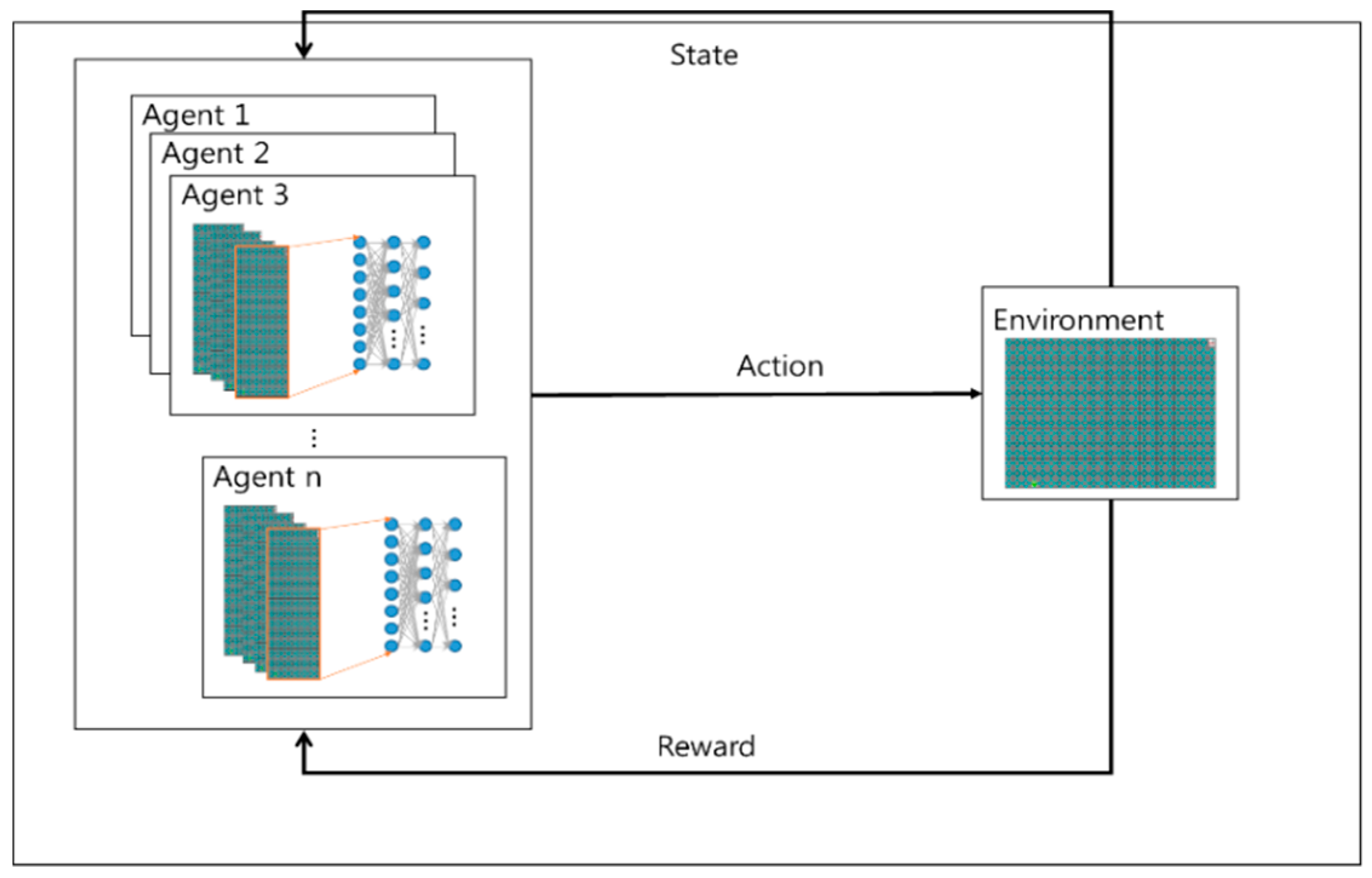
Figure 2 is the form of the proposed. The proposed algorithm uses empirical representation technique. The learning experience that occurs at each time step through multiple episodes to be stored in the dataset is called memory regeneration. The learning data samples are used for updating with a certain probability in the reconstructed memory each time. Data efficiency can be improved by reusing experience data and reducing correlations between samples.
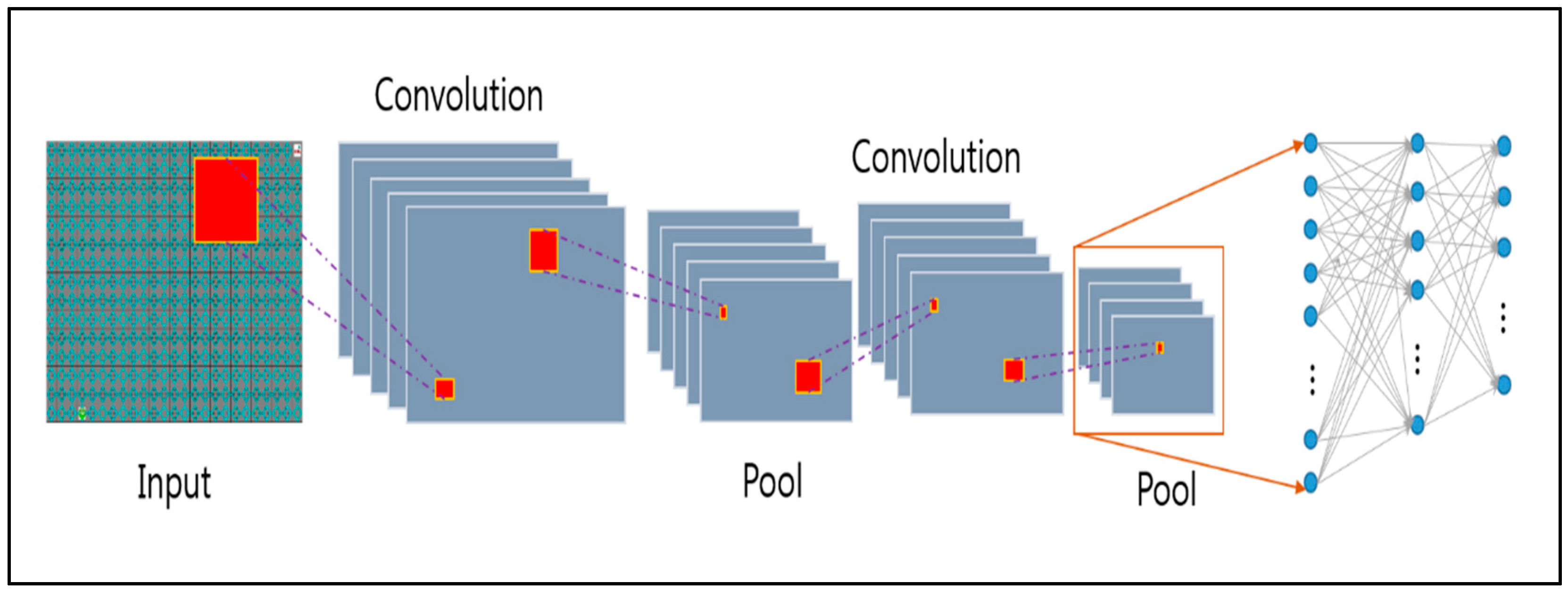
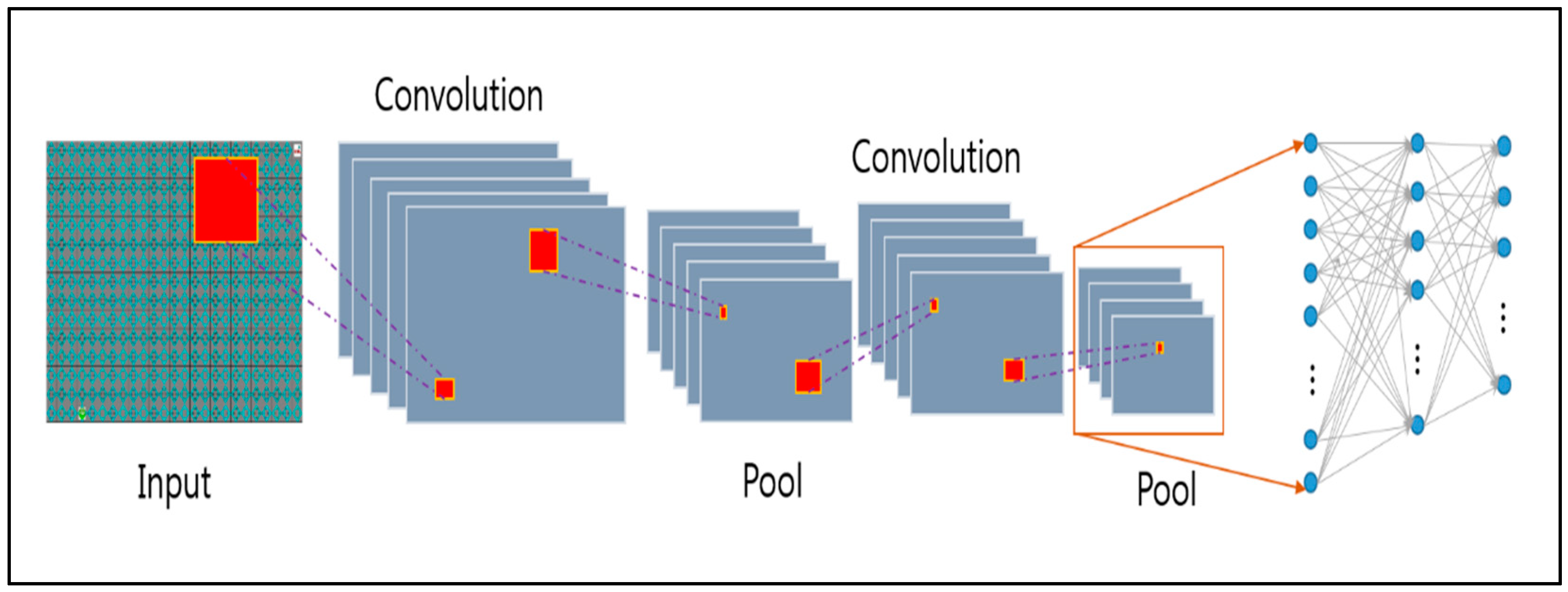
Without treating each pixel independently, we use the CNN algorithm to understand the information in the images. The transformation layer transmits the feature information of the image to the neural network by considering the area of the image and maintaining the relationship between the objects on the screen. CNN extracts only feature information from image information. The reconstructed memory to store the experience basically stores the agent’s experience and uses it randomly when learning neural networks. Through this process, which prevents learning about immediate behavior in the environment, the experience is sustained and updated. In addition, the goal value is used to calculate the loss of all actions during learning.
The proposed algorithm uses empirical data according to the roles assigned individually. In learning how to set goal value by dividing several situations, different expectation value for each role before starting to learn is set. For example, assuming that the path planning should take less time than the A* algorithm in any case and that it is a success factor for each episode, the proposed algorithm designates an arbitrary position and number of obstacles in the map of a given size and use the A*. This time is used as a compensation function of Deep q algorithm.
The agent learns so that the compensation value always increases. If the searching time increases more than the A* algorithm, the compensation value decreases and learning is performed so that the search time does not increase.
Figure 3 shows the learning part of the overall system, which consists of preprocessing part for finding outlier in video using CNN and post-processing part for learning data using singular point.
In the preprocessing part, the features of the image are searched using input images, and these features are collected and learned. In this case, the Q value is learned for each robot assigned to each role, but the CNN value has the same input with a different expected value. Therefore, the Q value is shared when learning, and used for the learning machine. In order to optimize the updating of Q value, it is necessary to define an objective function as defined as error of target value and prediction value of Q value. Equation (5) describes an objective function.
The basic information for obtaining a loss function is a transition <s, a, r, s’>. Therefore, first, the Q-network forward pass is performed using the state as an input to obtain an action-value value for all actions. After obtaining the environment return value <r, s’> for the action a, the action-value value for all action a’ is obtained again using the state s’. Then, we get all the information to get the loss function, which updates the weight parameter so that the Q-value updates for the selected action converges; that is, as close as possible to the target value and the prediction value. Algorithm 1 is a function of compensation, which greatly increases compensation if the distance to the current target point is reduced before, and decreases the compensation if the distance becomes longer and closer.
| Algorithm 1 Reward Function |
if distancet−1 > distancet
then reward = 0.2
else
then reward = −0.2
if action == 0
then reward = reward + 0.1
else if action == 1 or action == 2
then reward = reward − 0.1
else if action == 3 or action == 4
then reward = reward − 0.2
if collision
then reward = −10
else if goal
then reward = 100
return reward |
The two Q networks, such as target Q network and Q network, which is used mandatorily, are employed in the algorithm. Both networks are exactly the same with different weight parameters. In order to smooth convergence in DQN, the target network is updated not continuously, but periodically.
The adaptive learning rate method, RMSProp method, was used as the optimizer and the learning rate was adjusted according to the parameter gradient. This means that, in a situation where the training set is continuously changing, unlike the case of a certain training set, it is necessary to continuously change certain parameters.
The algorithm is simply stated as follows.
When entering the state st, randomly selects a behavior a that maximizes Q (st, a; θt).
Obtain state sn+1 and a complement rt by action a.
Enter state st+1 and find Max Q (st+1, a; θ).
Update the variable θt with the correct answer.
4. Experiment
4.1. Experiment Environment
Experiments were conducted on Intel Core i5-6500 3.20GHz, GPU GTX 1060 6GB, RAM 8GB, OS Ubuntu 16.04 and Window 7 Python and C++.
On a regular PC, we built a simulator using C++ and Python in a Linux environment. The robot has four random positions and its arrival position is always in the upper right corner. In a static and dynamic obstacle environment in the simulator, the number and location of obstacles are chosen randomly. Under each environment, the proposed algorithm is compared with A* and algorithm D* algorithm, respectively.
The simulation was conducted under the environment without considering the physical engine of the robot, assuming that the robot made ideal movements.
4.2. Learning Environment
The experiment result compares the proposed algorithm with the existing A* algorithm. The proposed algorithm learns based on the search time of the A* algorithm and assumes learning success when it reaches the target position more quickly than the A* algorithm.
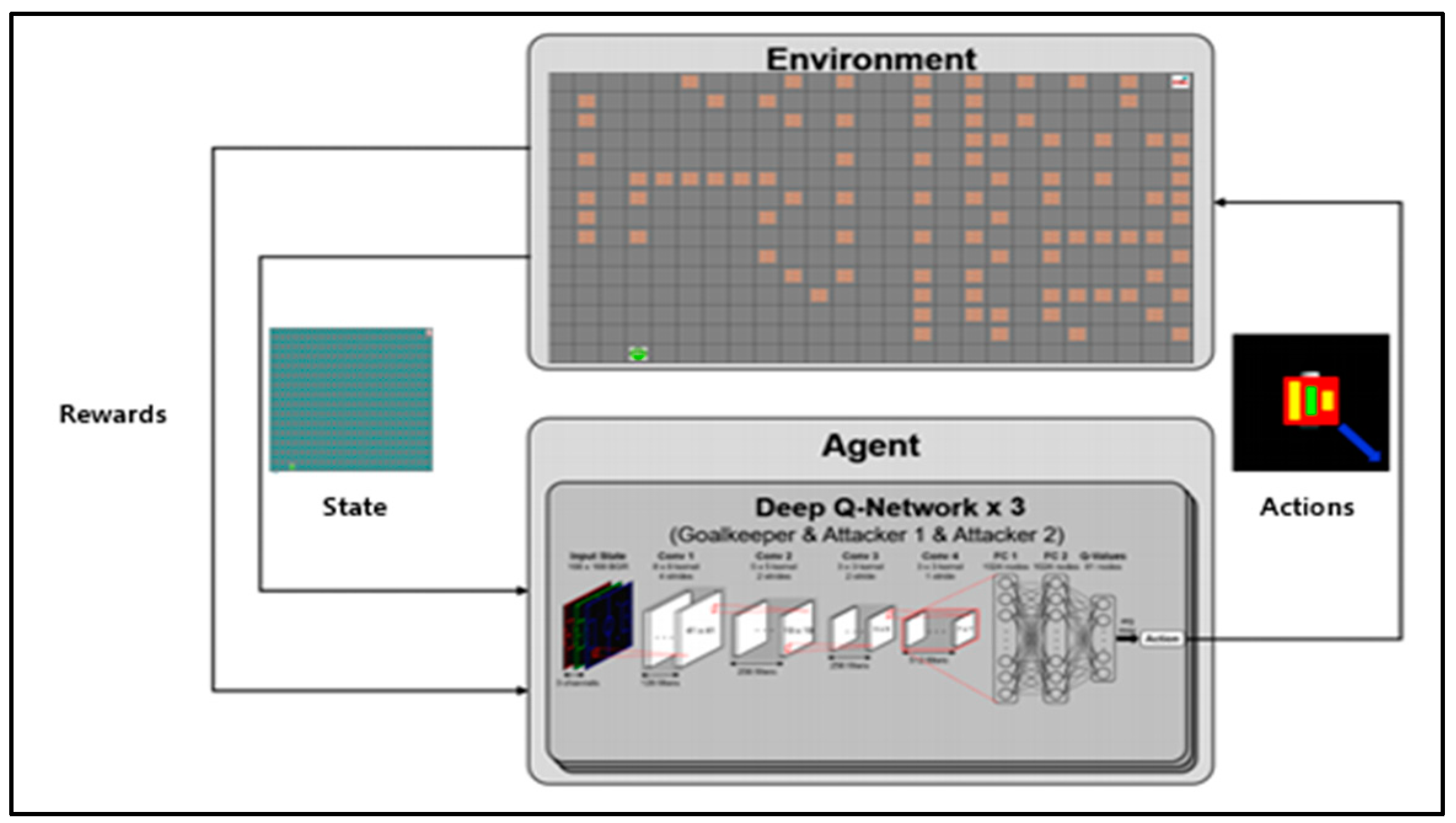
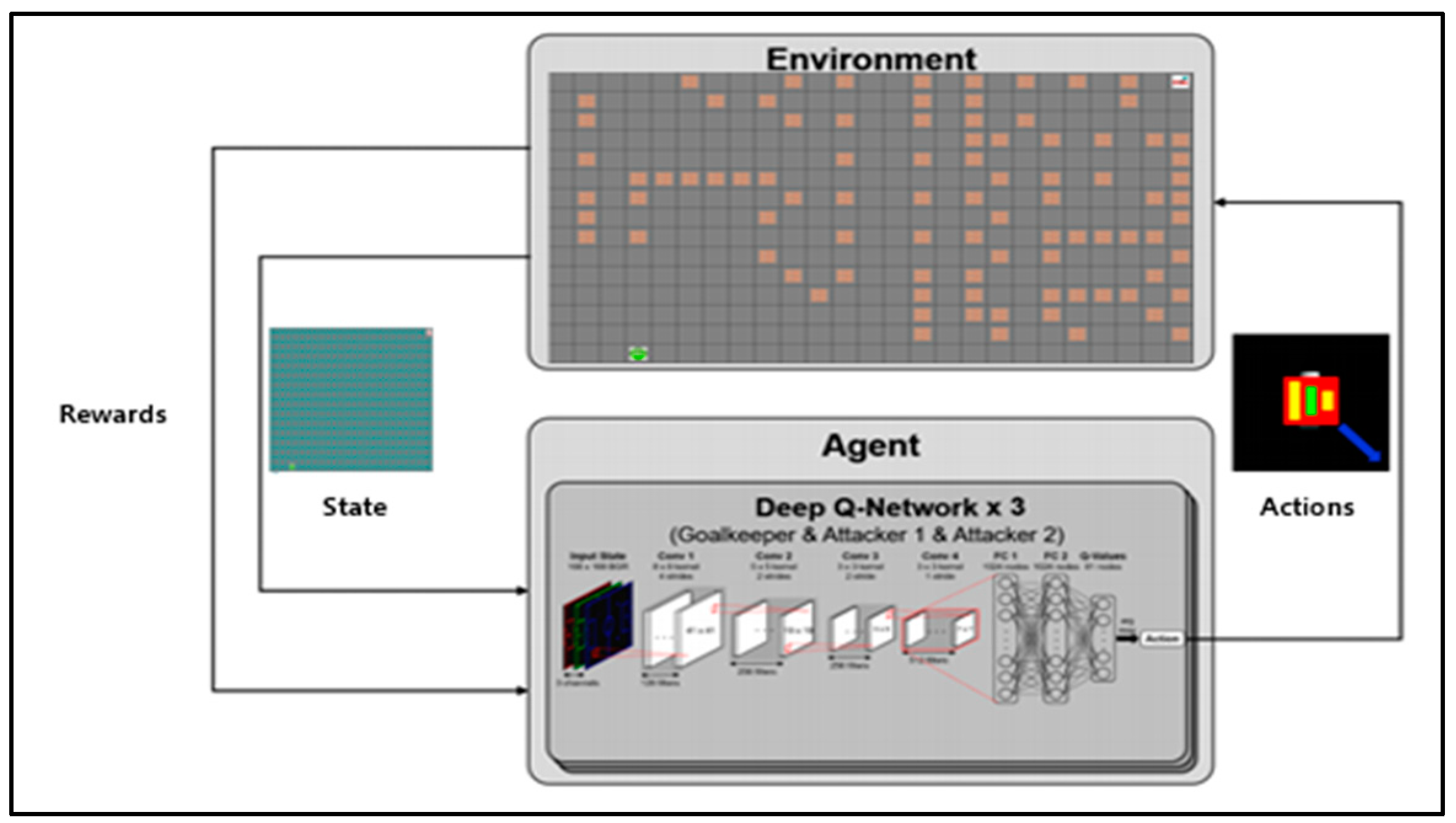
Figure 4 shows the simulation configuration diagram of the proposed algorithm. The environmental information image used by CNN is 2560 × 2000 and is designed with 3 × 3 filters with a total of 19 layers (16conv. and 3 FC layers) in the form of VGGNet [
42].
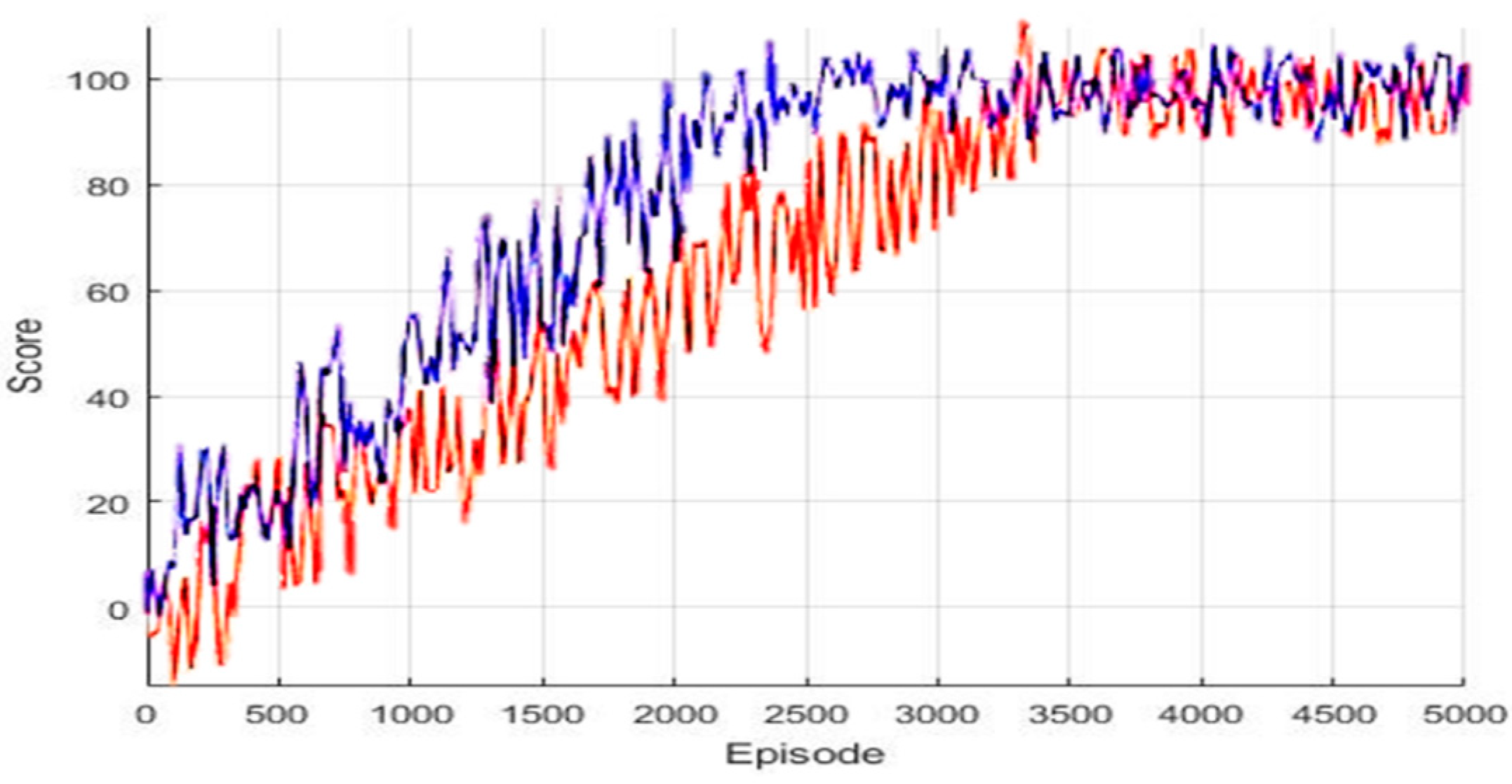
Figure 5 shows the score of the Q parameter when learning by episode. In the graph, the red line depicts the score of the proposed algorithm and the blue line is the score when learning Q parameters per mobile robot. The experiment result confirms that the score of the proposed algorithm is slightly slower at the beginning of learning but reaches the final goal score.
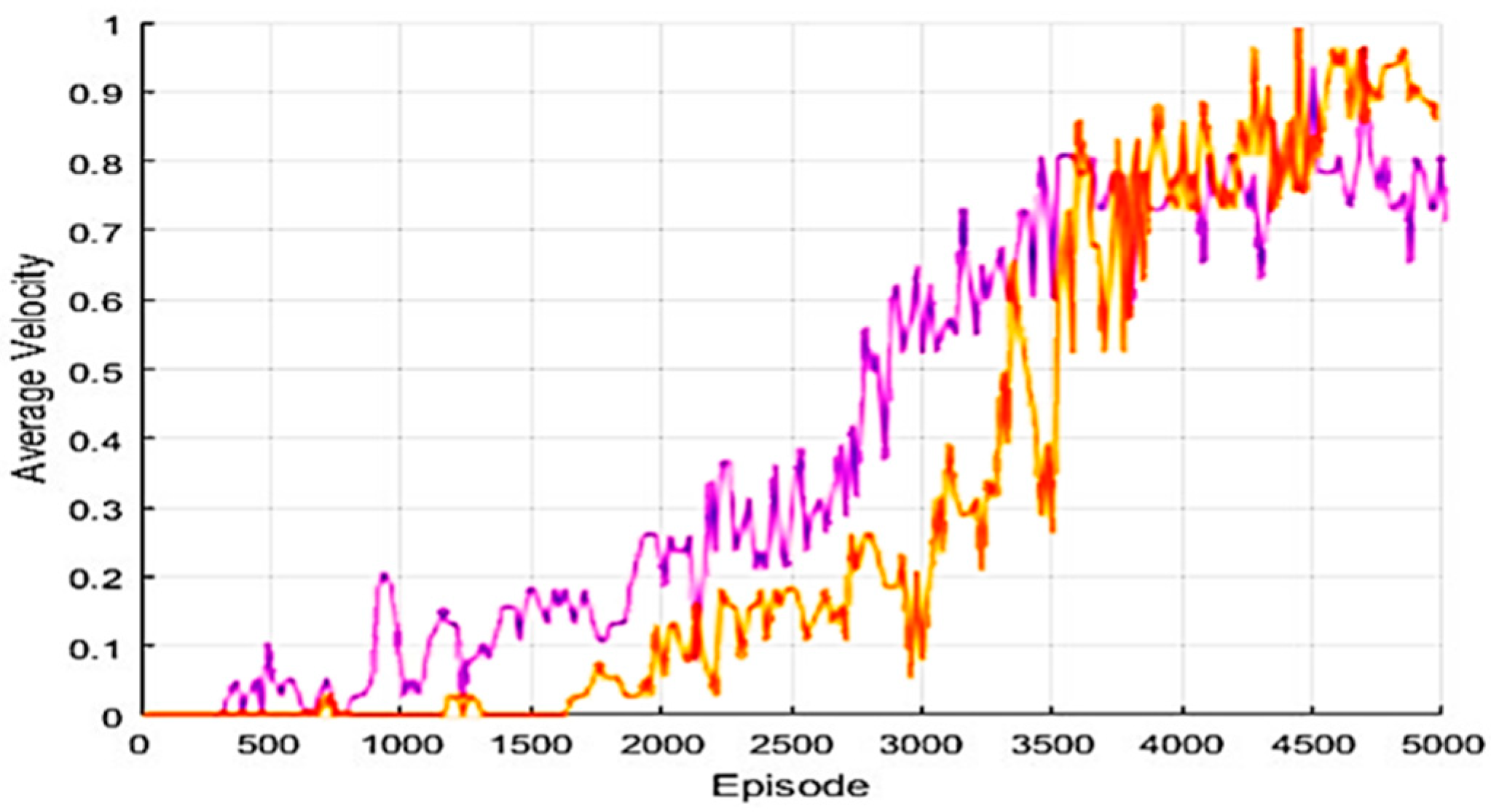
The proposed algorithm, as in
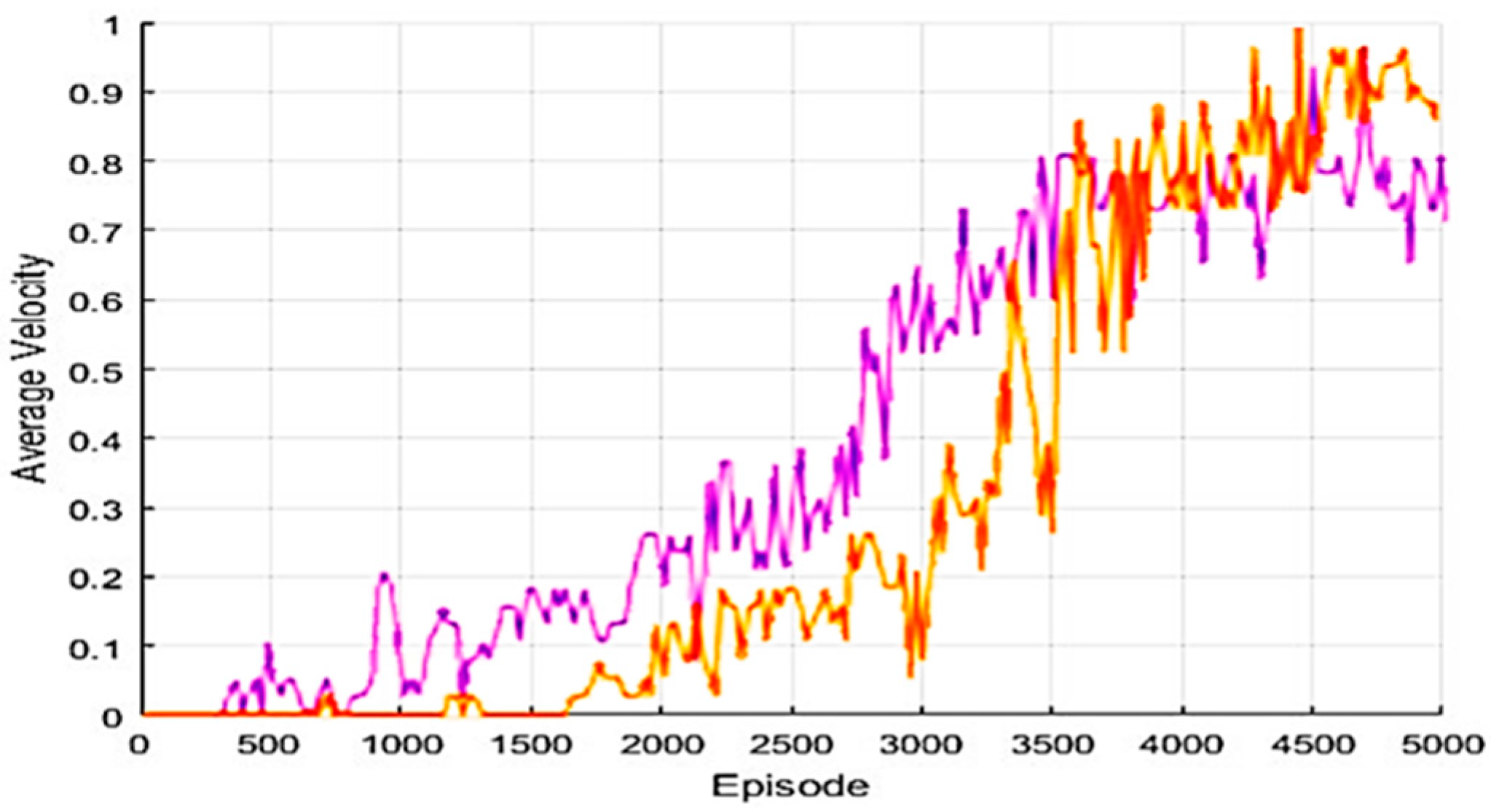
Figure 6, which shows the target arrival speed of the episode-based algorithm, has slower learning progression speed than the Q parameter of each model with a similar target position.
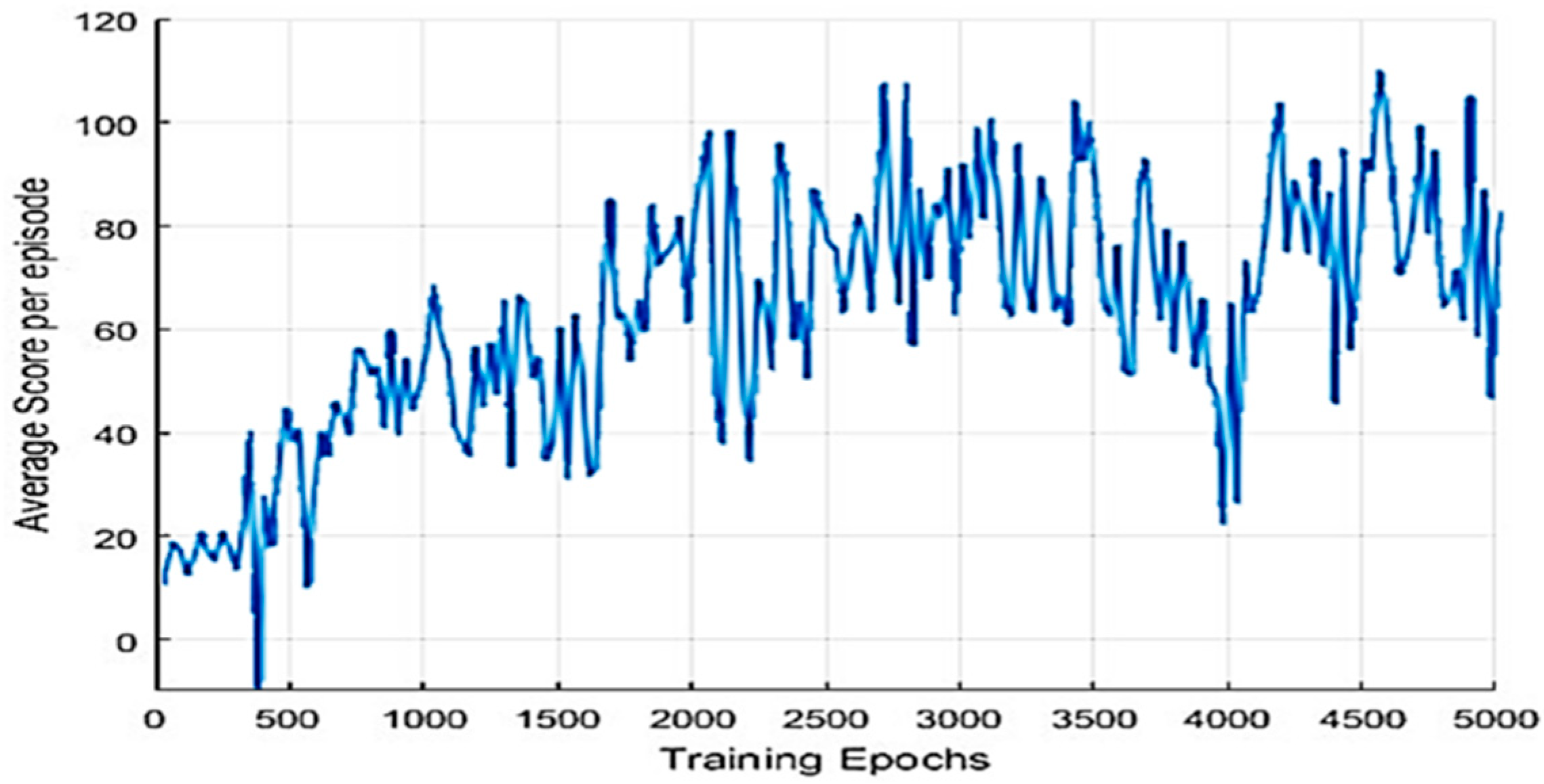
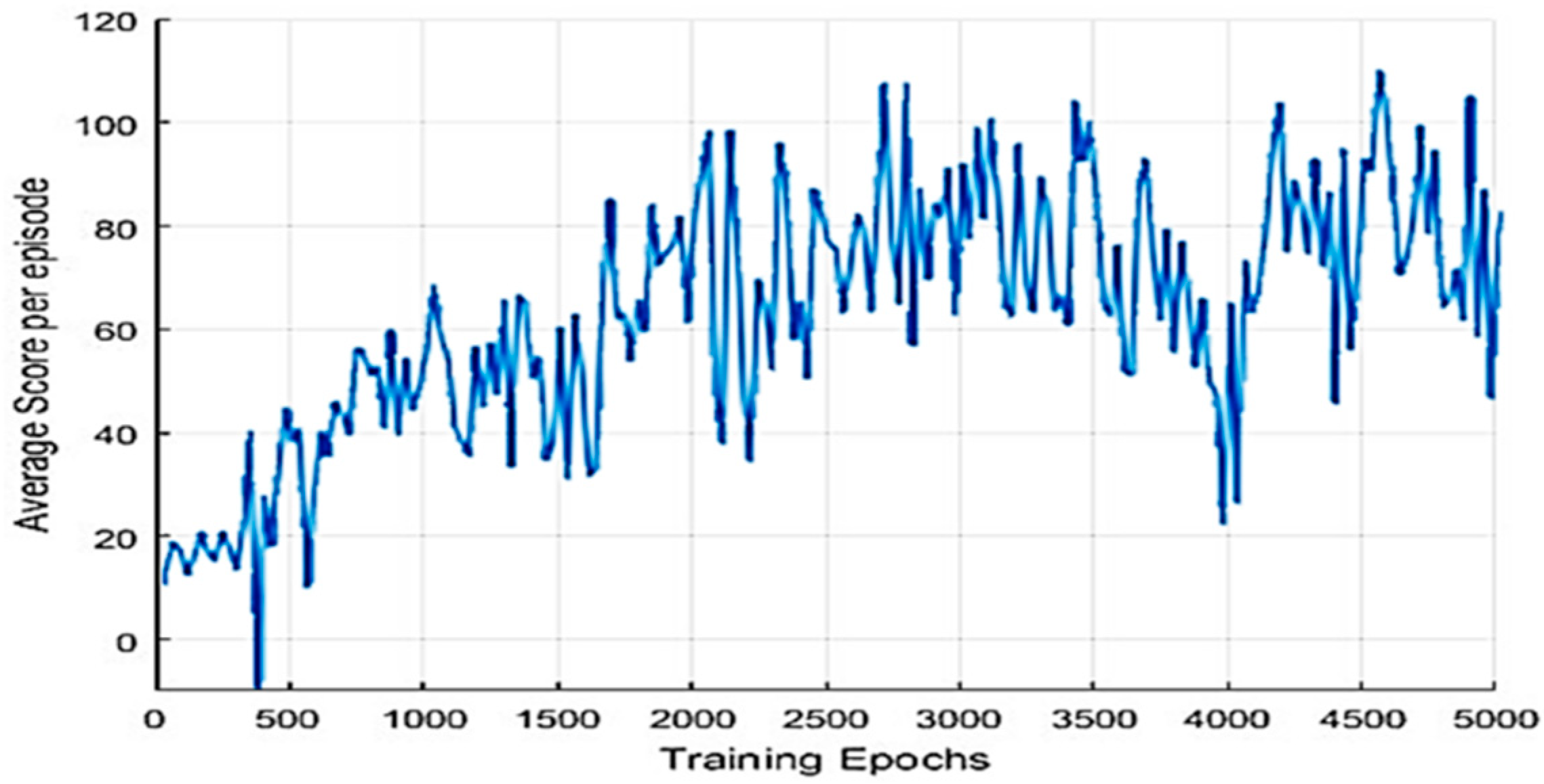
Figure 7 depicts that the average score of each generation increases gradually as learning progresses. As the learning progresses, it gradually gets better results.
4.3. Experimental Results in a Static Environment
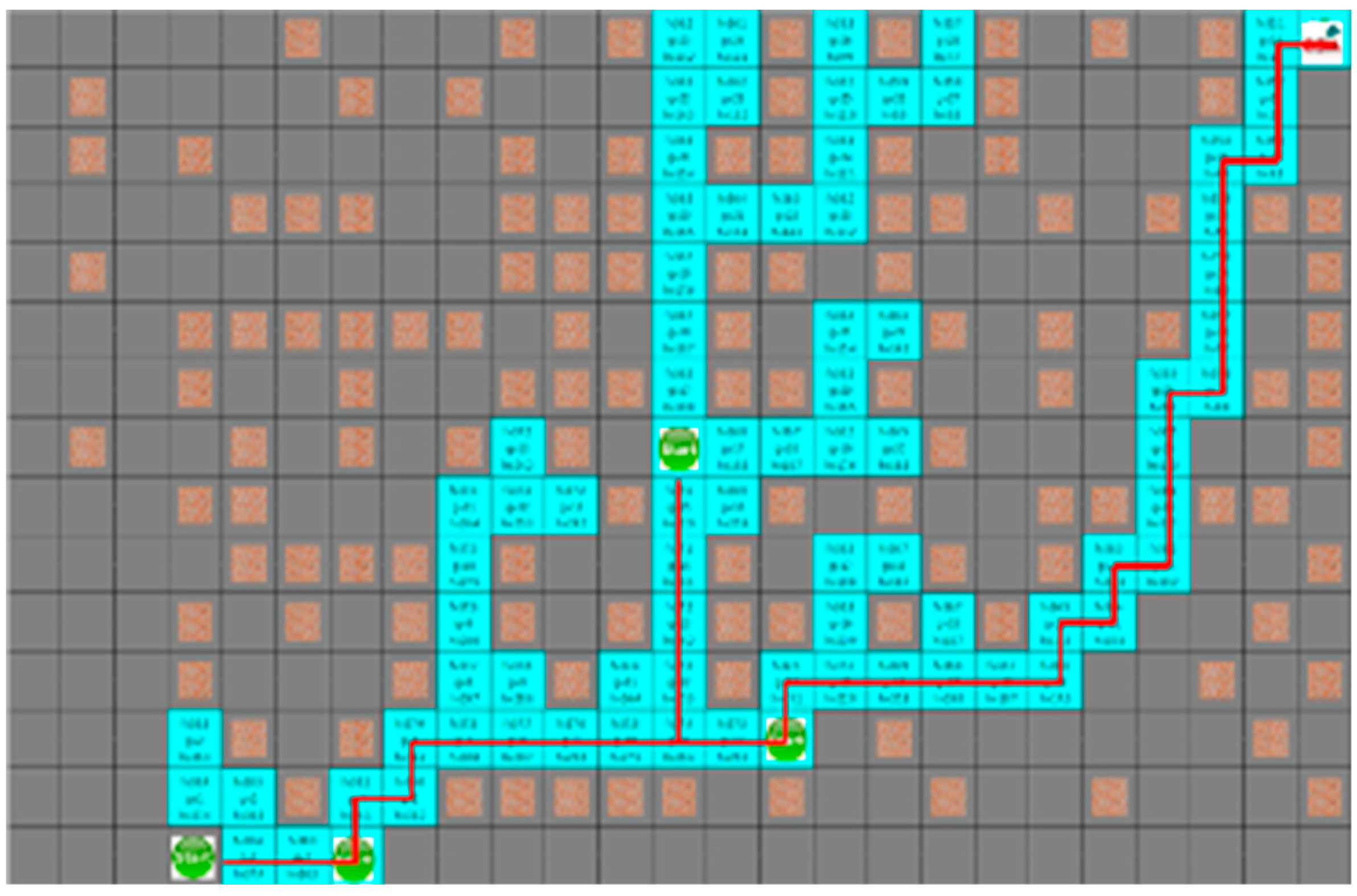
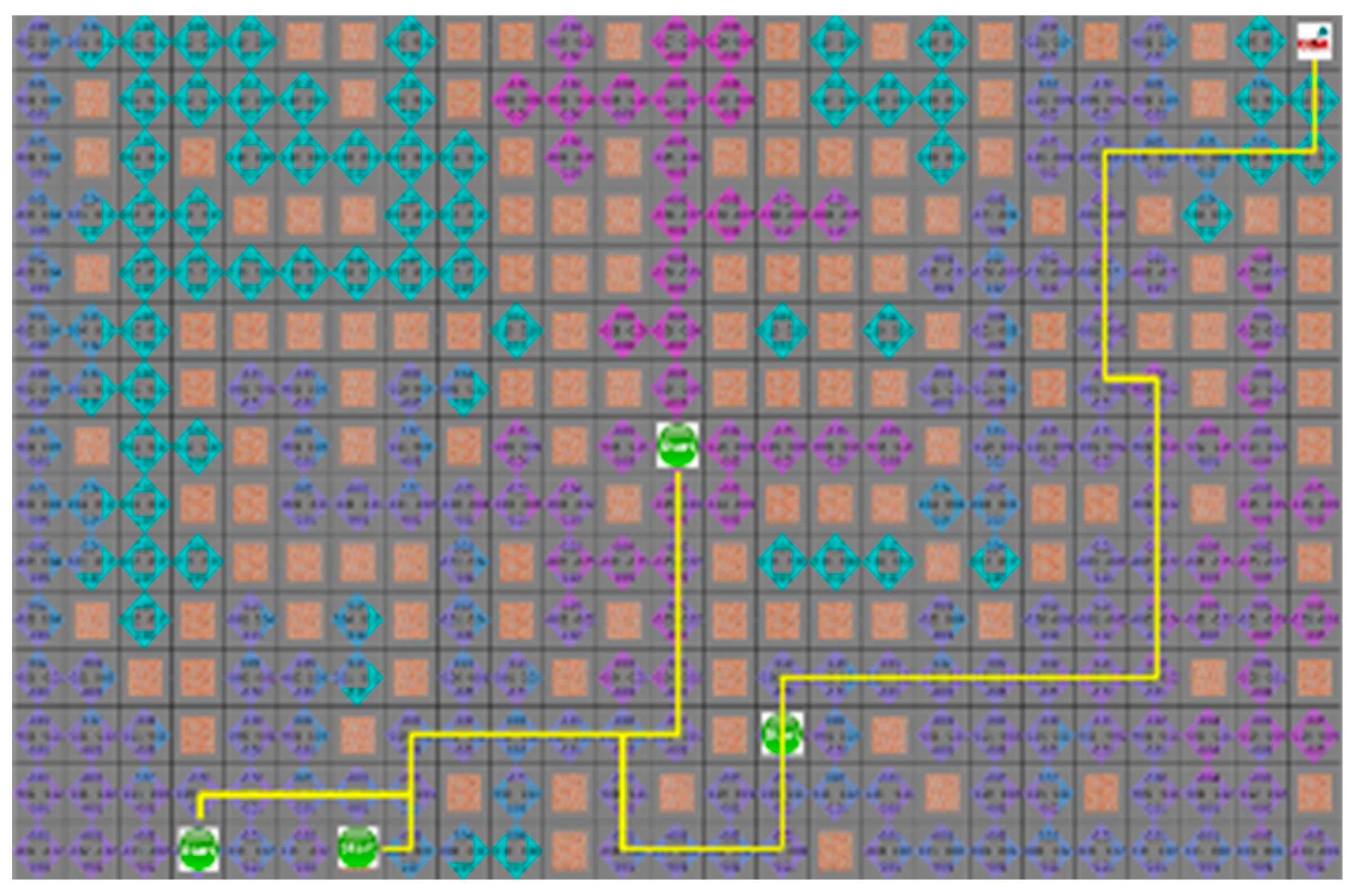
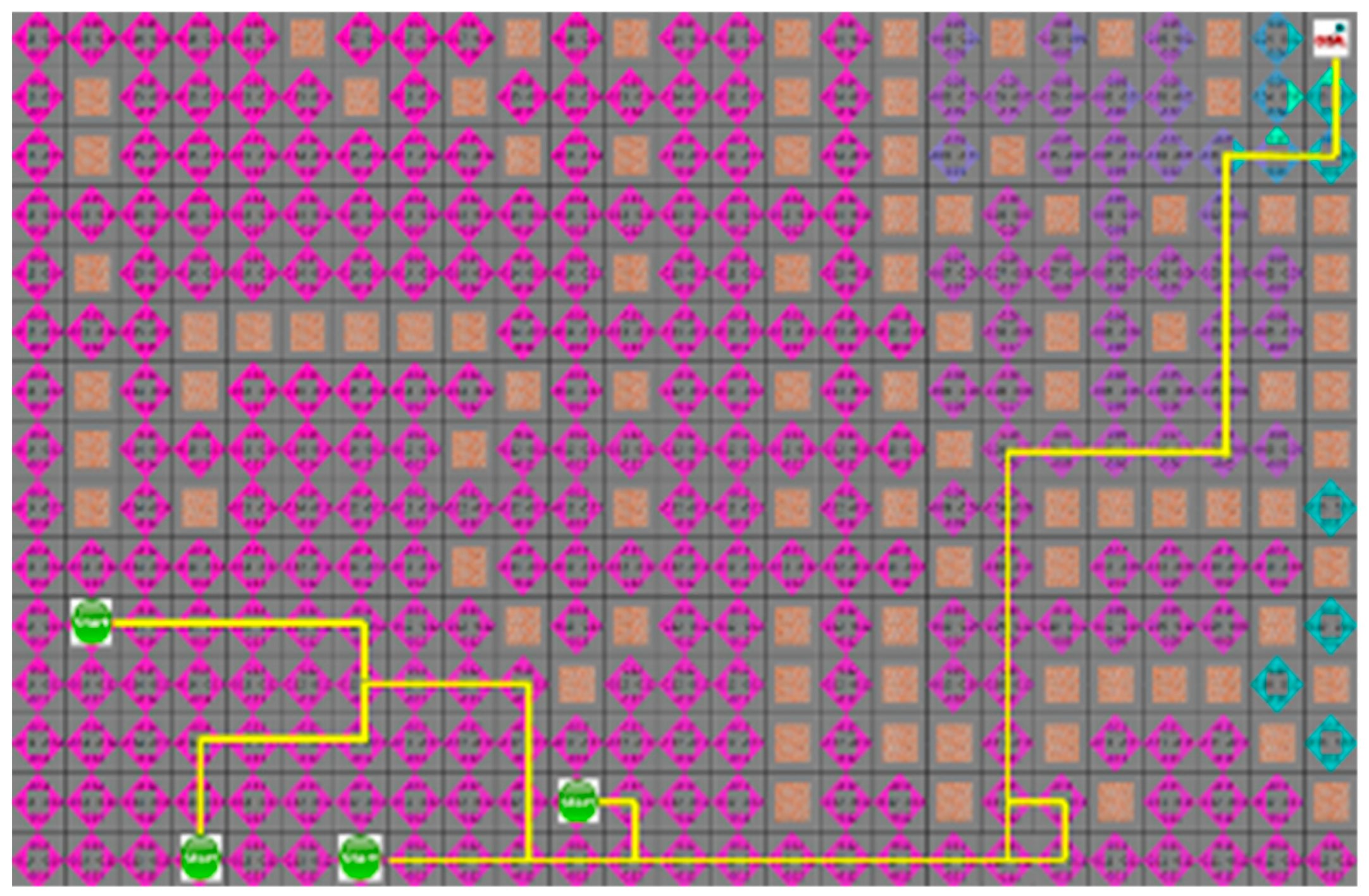
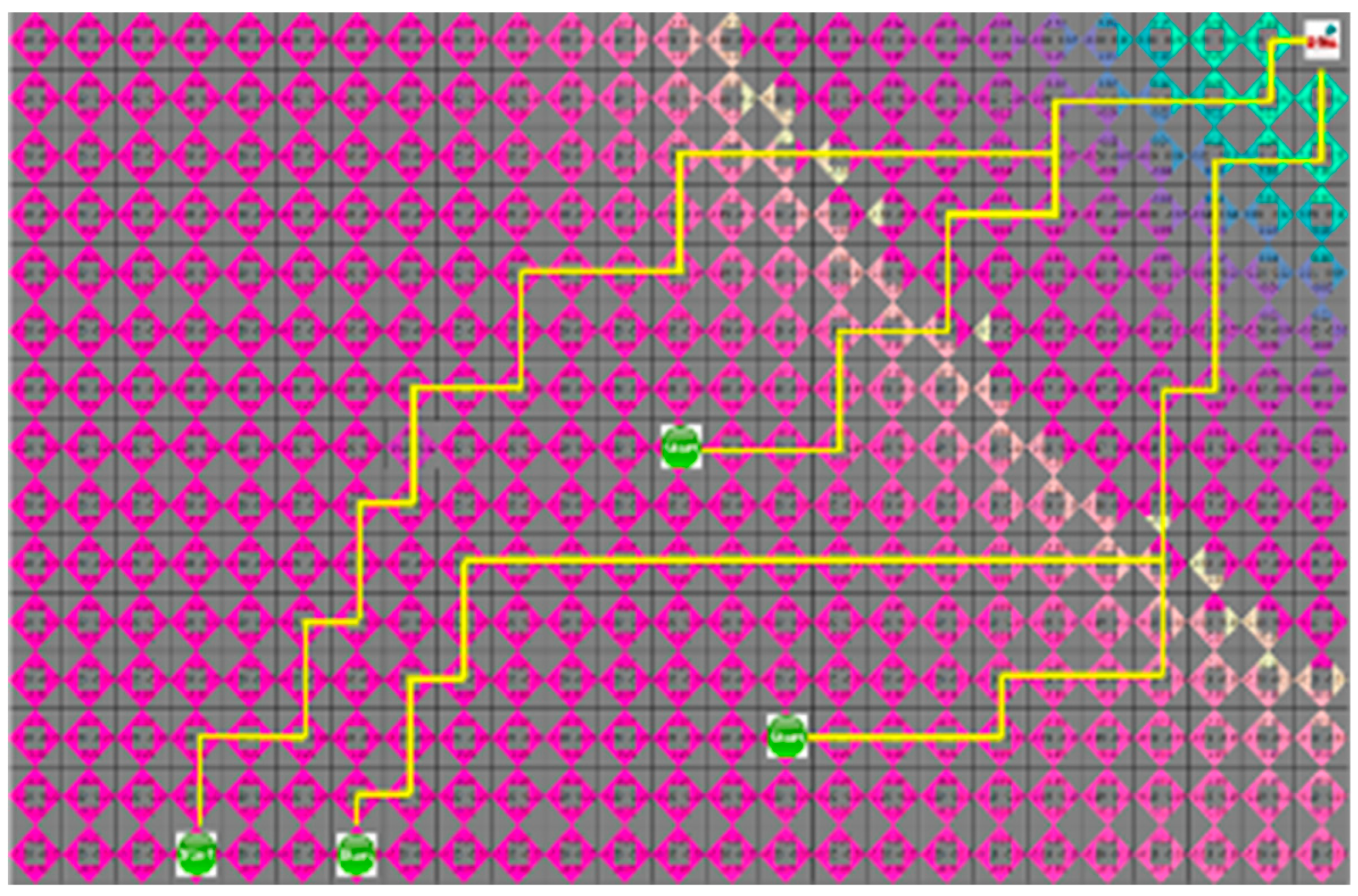
In
Section 4.3, the proposed algorithm is compared with the A* algorithm. Because the A* algorithm always finds the shortest path, it can see how quickly the proposed algorithm can find the shortest path. The proposed algorithm and the A* algorithm were tested by four robots to find a path with an arbitrary numbers of obstacles in random initial positions. The test was repeated 100 times on the generated map, which is changed 5000 times to obtain the route visited by the robot and the shortest path for each robot to reach the target point. In the first case, the search area and the time to reach the target point of the proposed algorithm is smaller than the A* algorithm, but the actual travel distance of the robot is increased, as shown in
Figure 8 and
Figure 9.
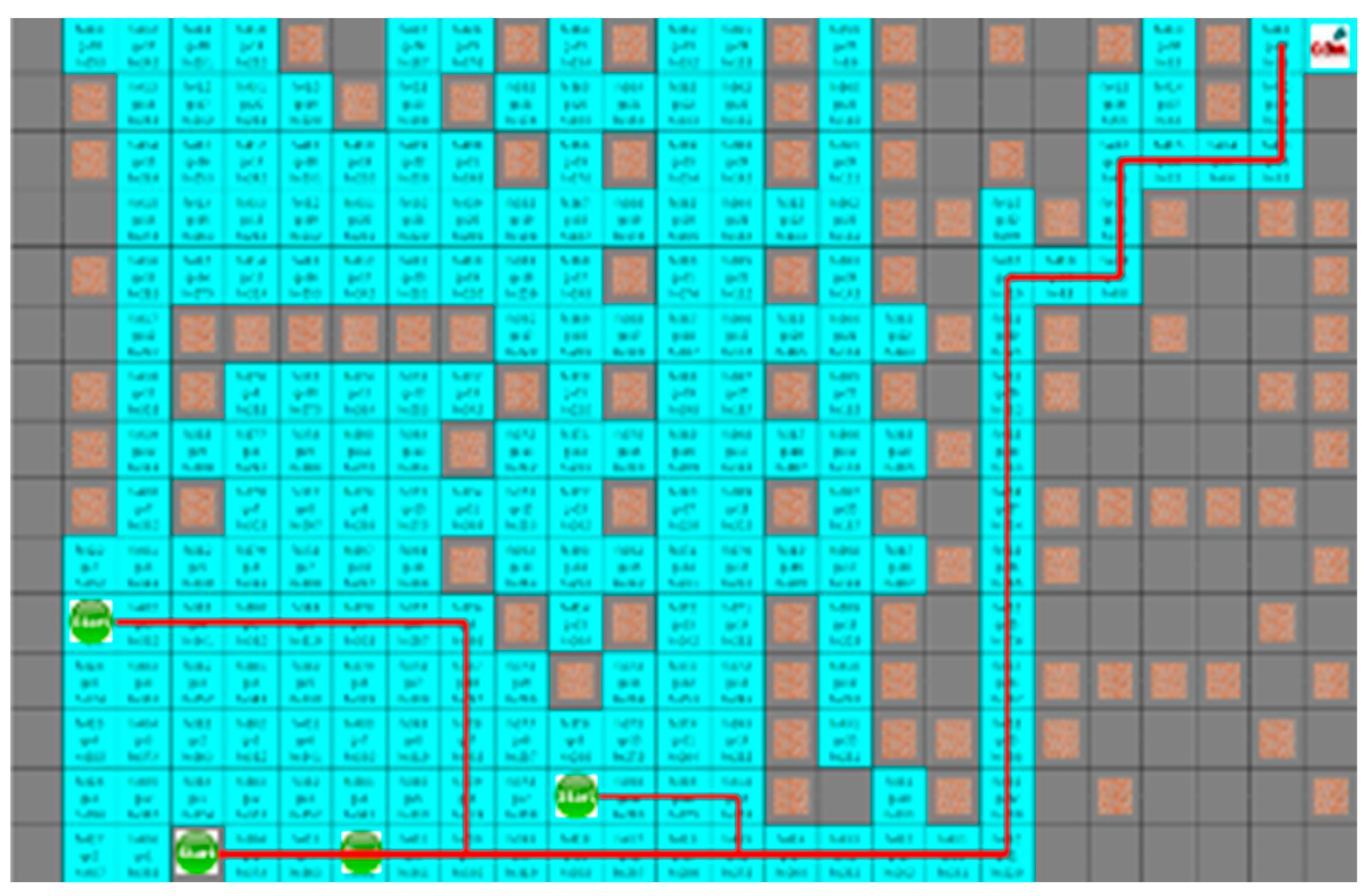
Figure 8 and
Figure 9 depict the results of the A* algorithm and the proposed algorithm, respectively. The average search range of A* algorithm is 222 node visitation. The shortest paths of robots 1 to 4 were 35, 38, 43, and 28 steps, respectively, and the proposed algorithm, where each robot path are 41, 39, 44, and 31 steps, had 137 visited nodes.
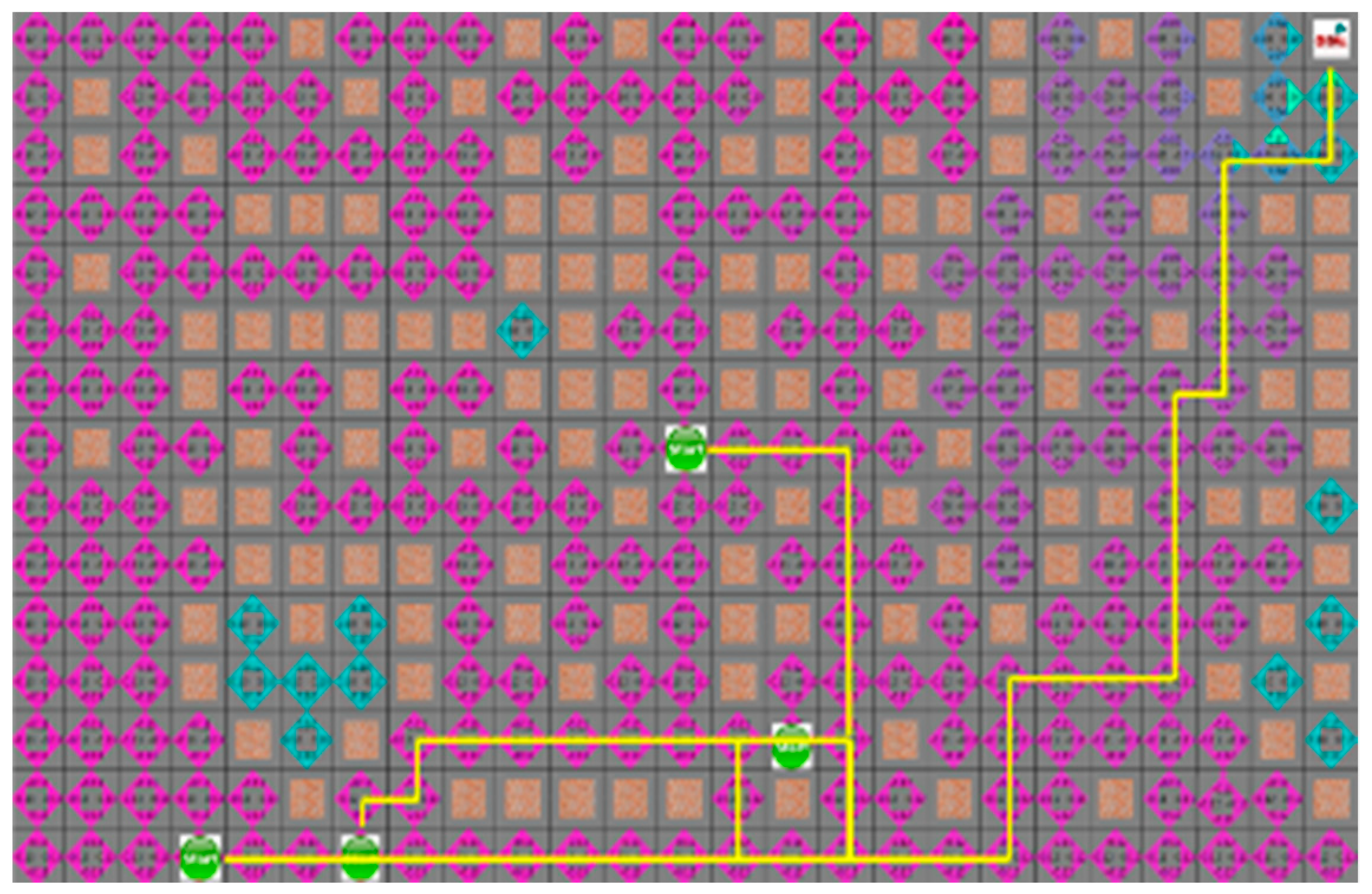
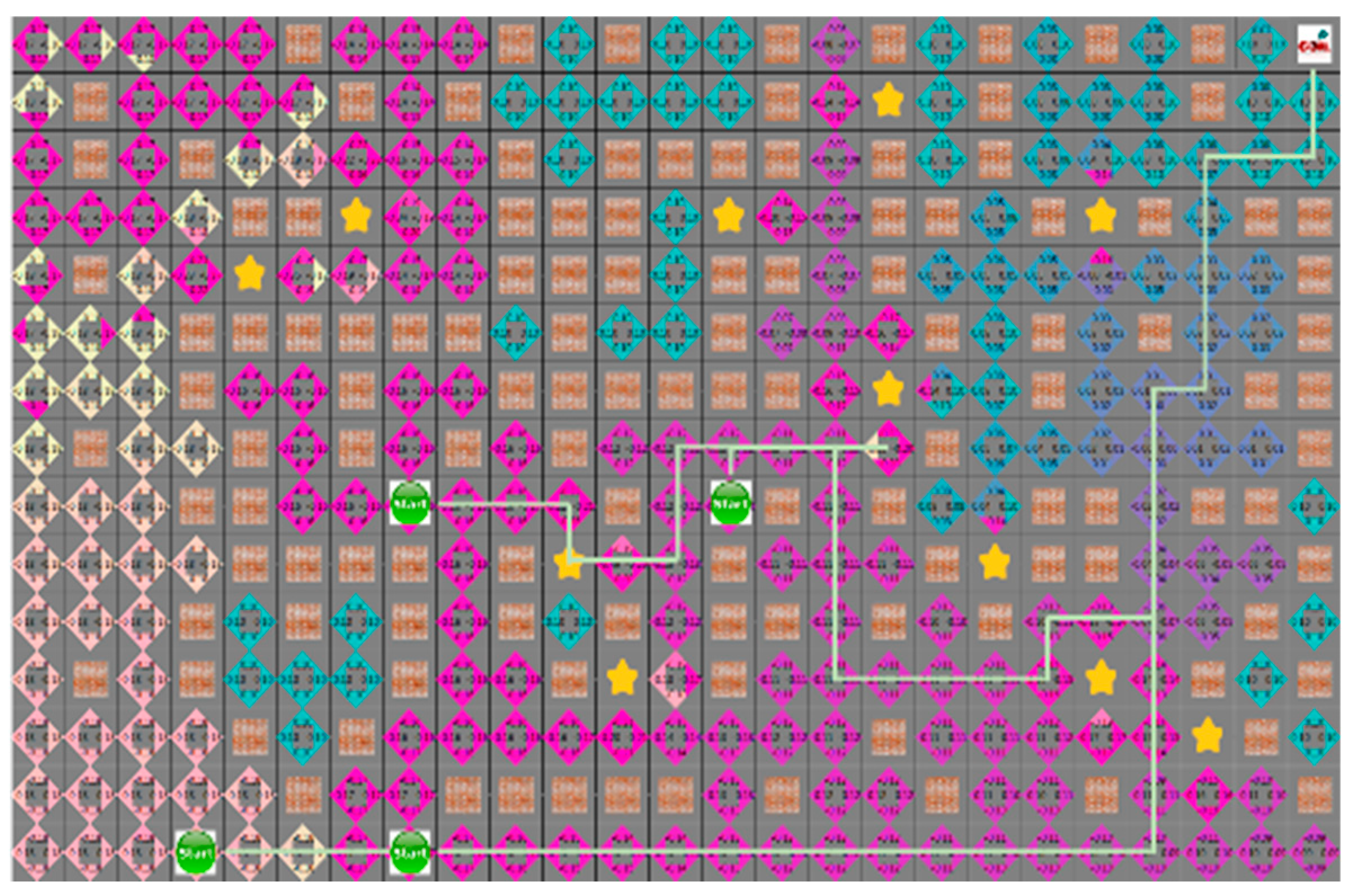
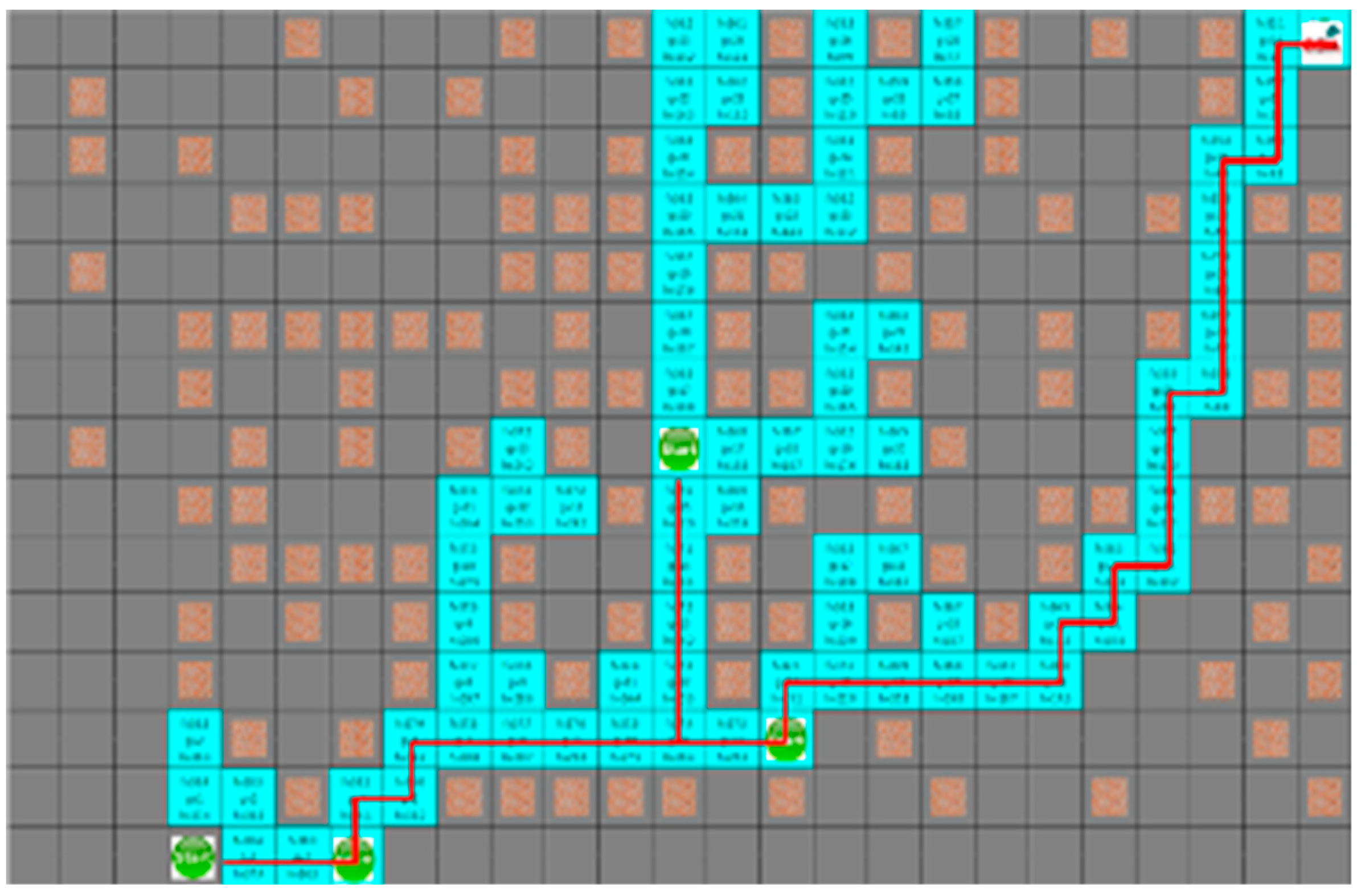
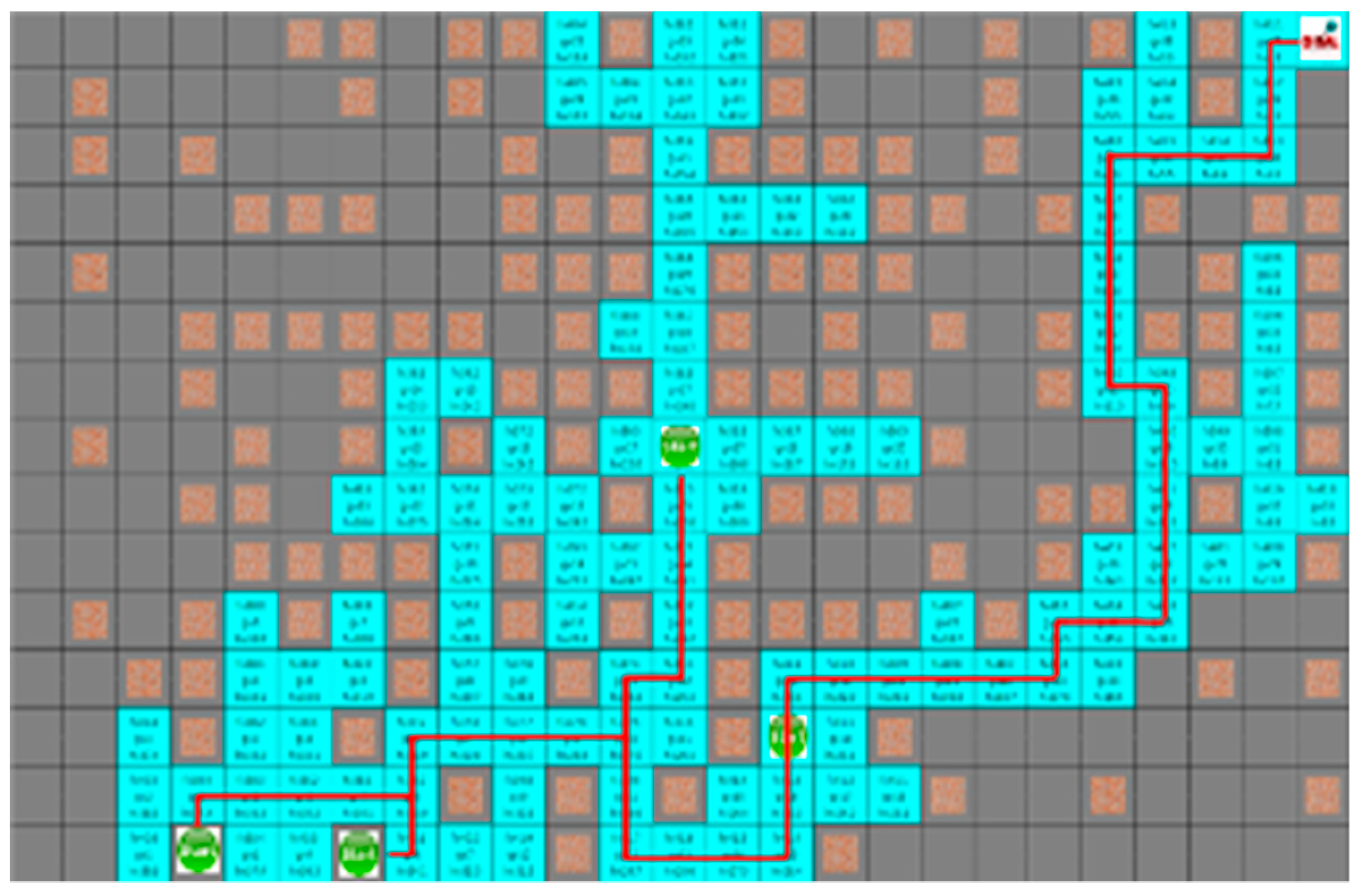
As shown in
Figure 10 and
Figure 11, which are the result of the A* algorithm and the proposed algorithm, respectively for the second case, the search range of the proposed algorithm is similar to that of the A* algorithm. The average search range of A* algorithm is 80 node visitation. The shortest paths of robots 1 to 4 were 33, 29, 28, and 21 steps, and the proposed algorithm had 65 visited nodes, where each robot pathare 34, 36, 32, and 25 steps, respectively.
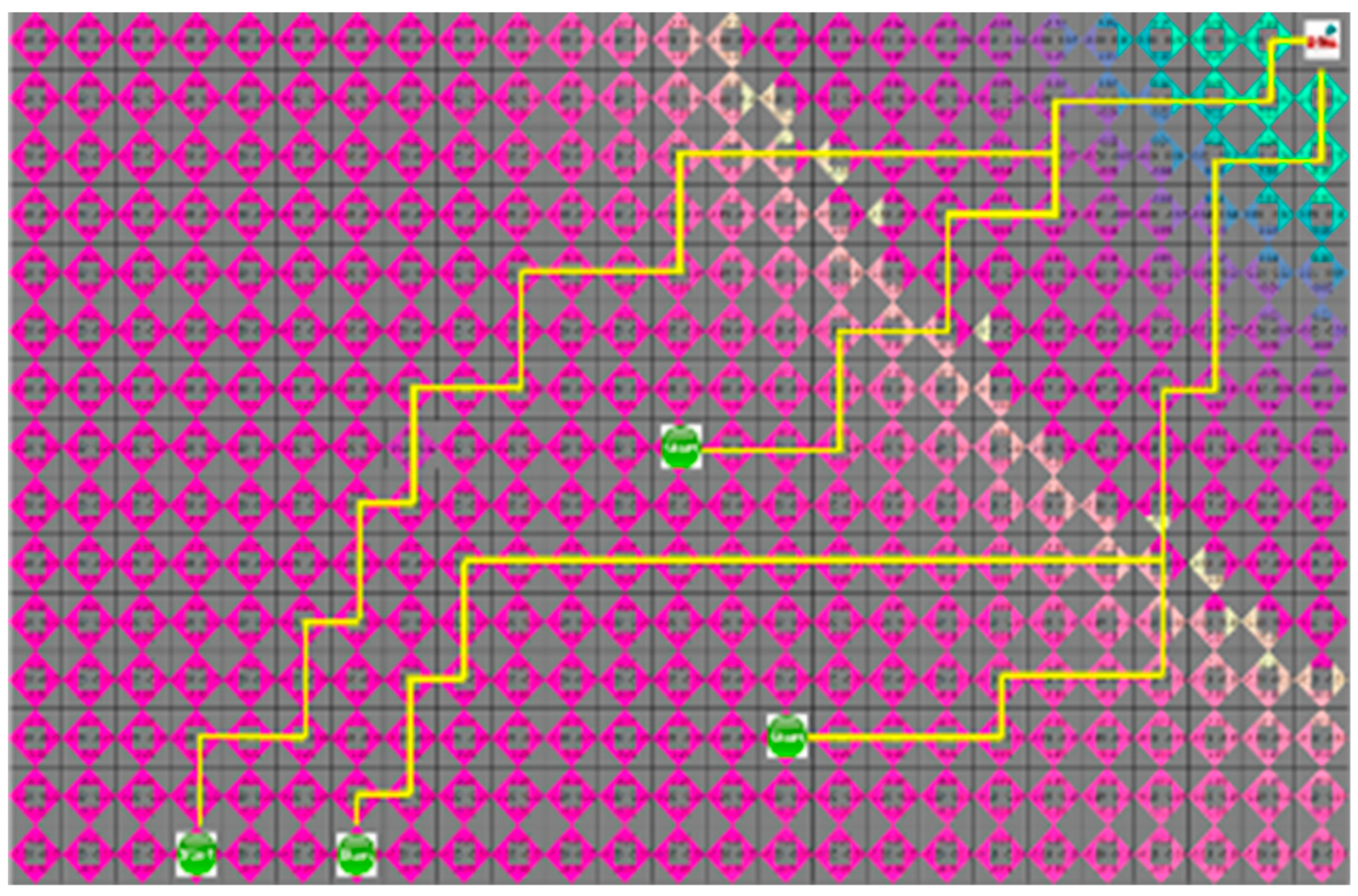
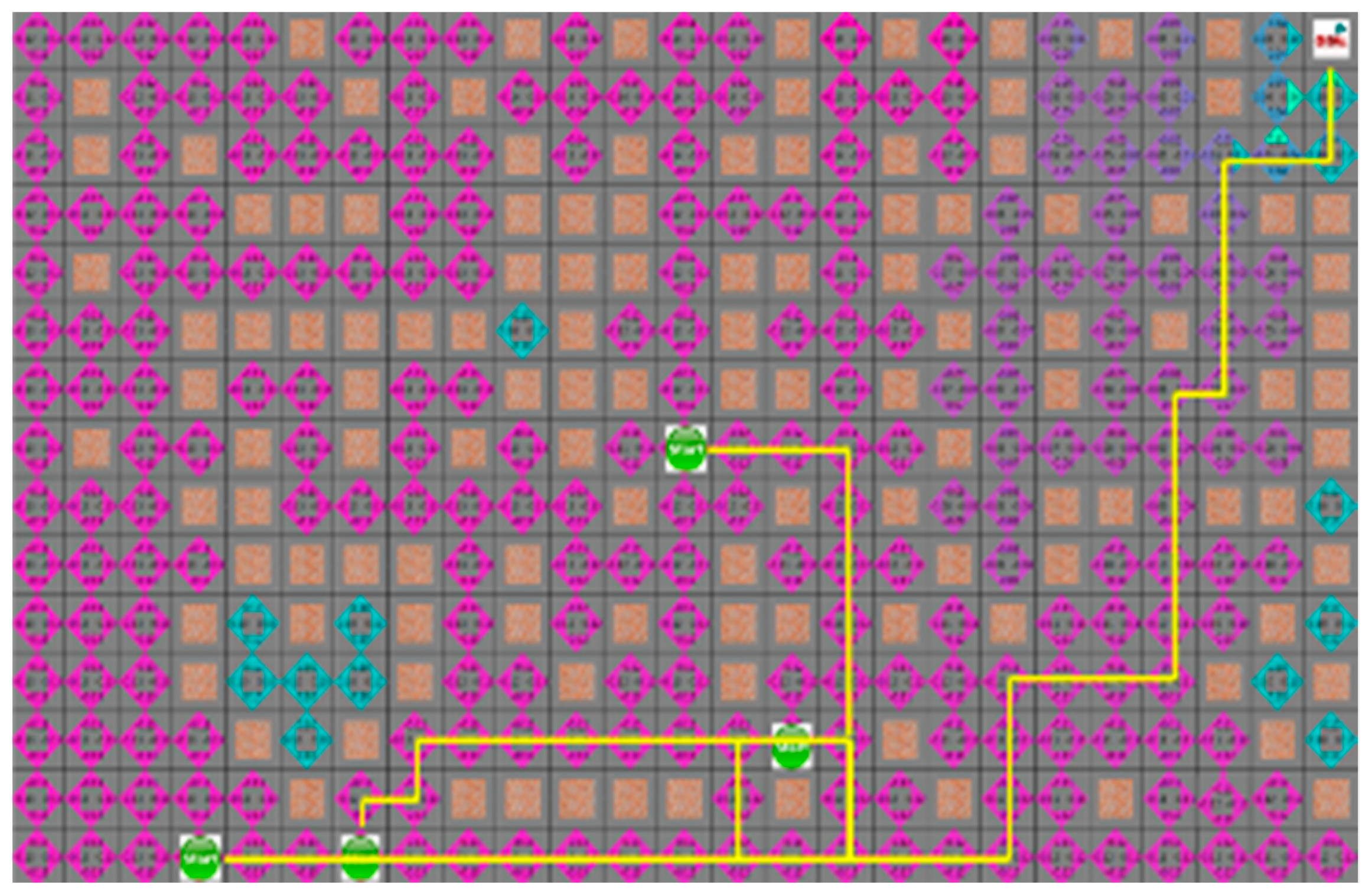
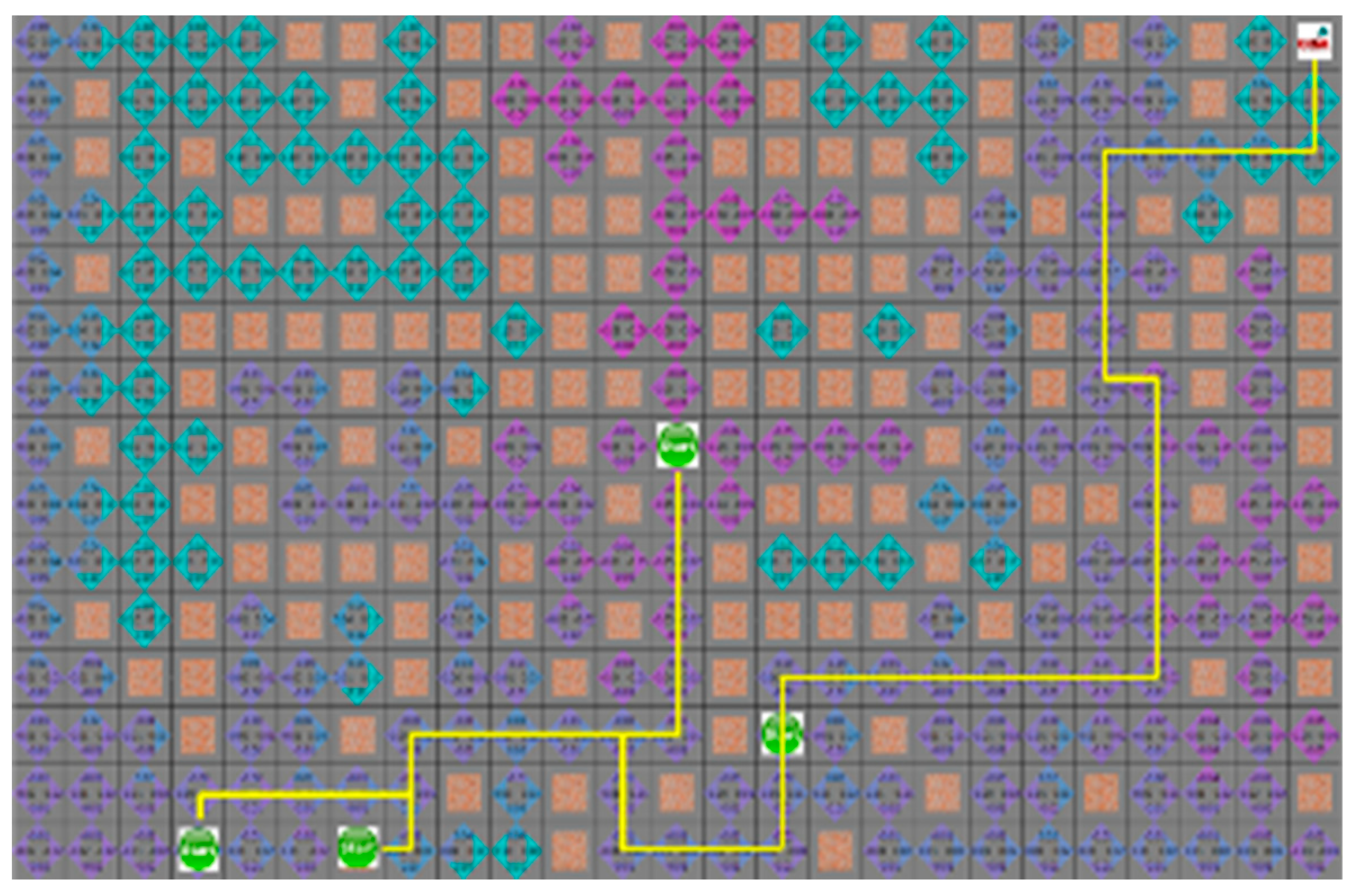
In the third case without obstacles in environment, as shown in
Figure 12 and
Figure 13, the search range of two algorithms is the same, and the movement path of the robot is similar. The average search range of the A* algorithm was 66 node visitation. The shortest paths of robots 1 to 4 were 33, 29, 28, 21, and 66 steps; the proposed algorithm had 66 visited nodes, and each robot path was 34, 31, 28, and 22 steps, respectively.
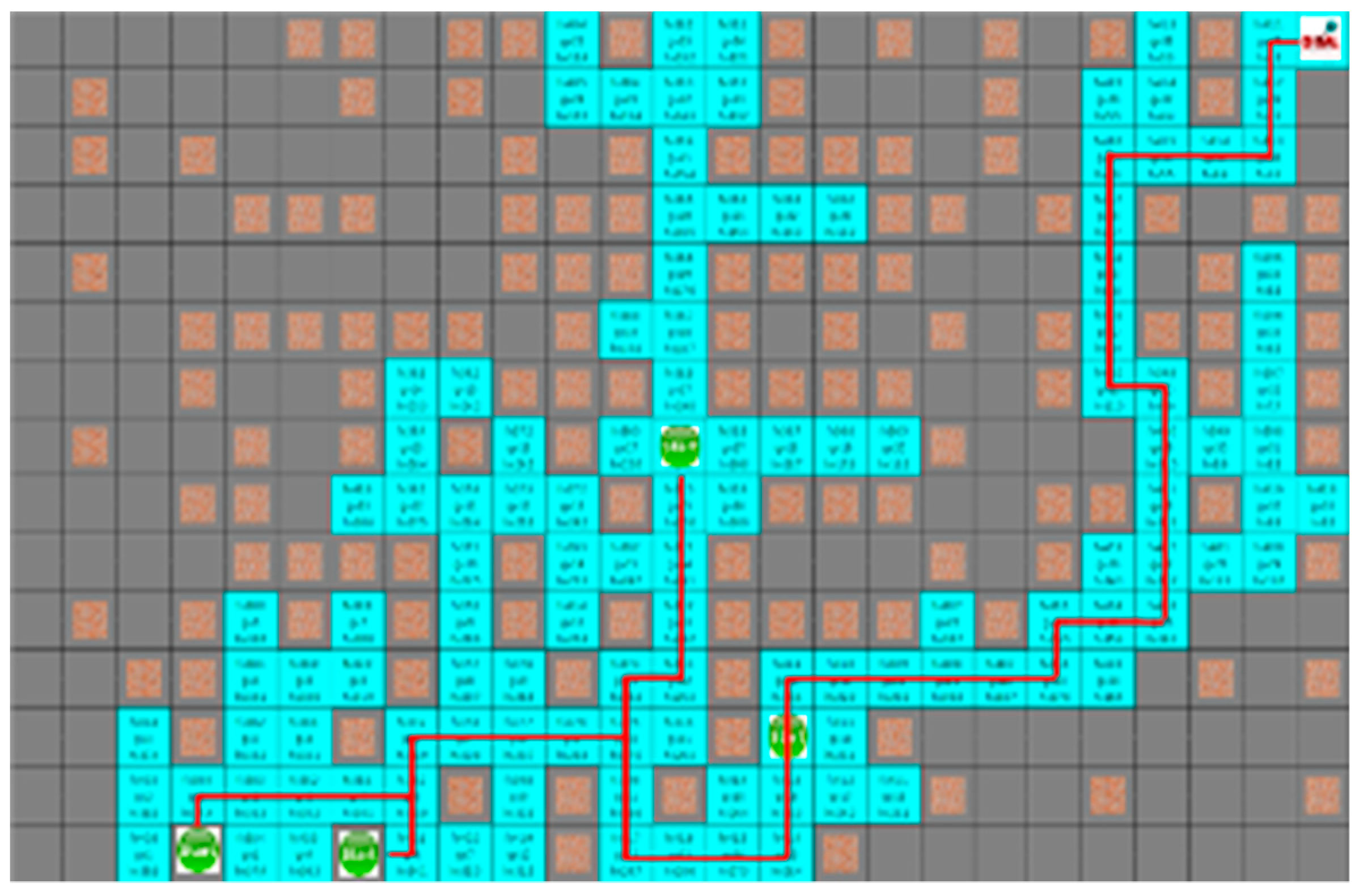
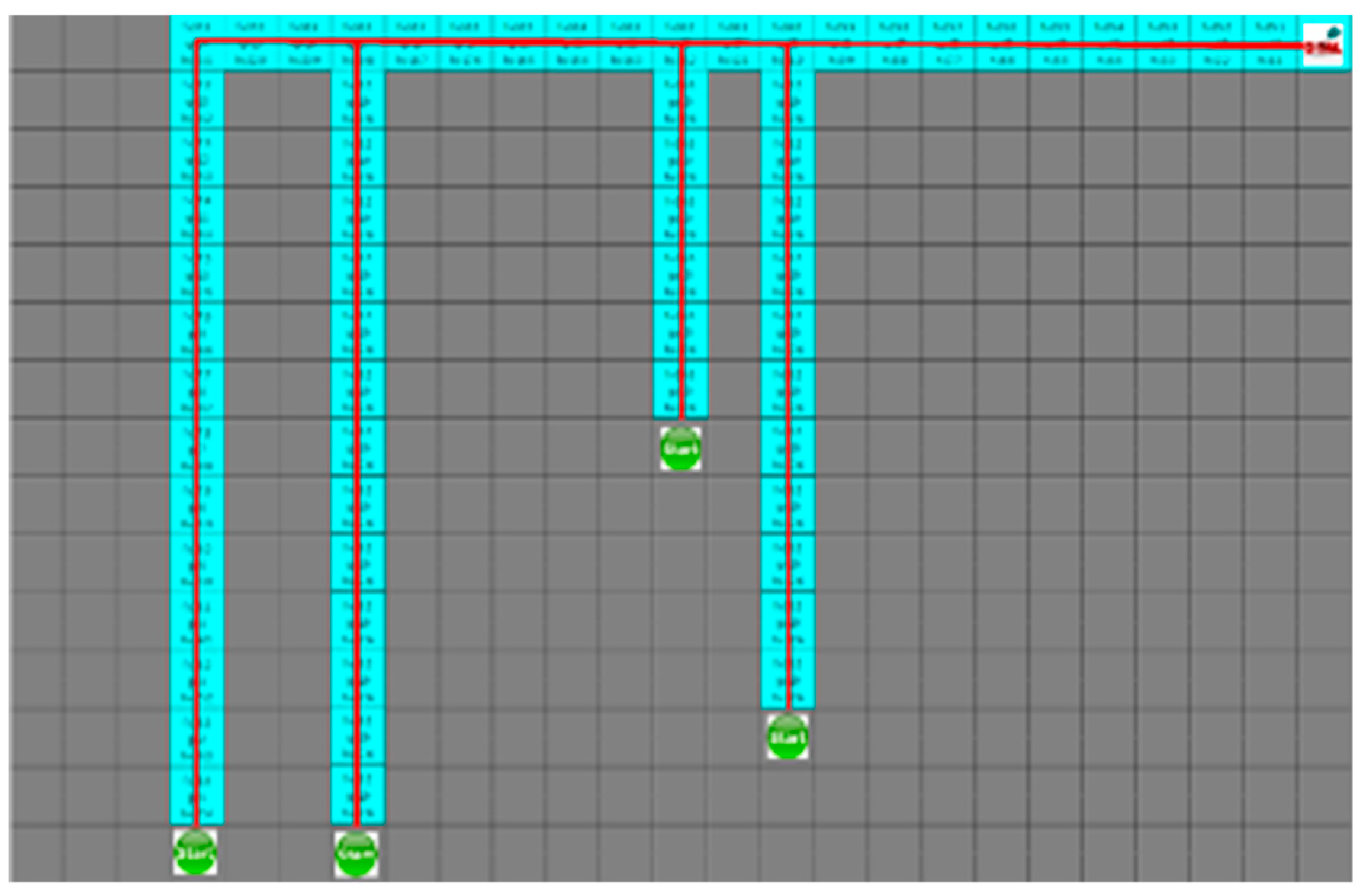
In the fourth case, the search range of both algorithms is similar, and the movement path of the robot is the same.
Figure 14 and
Figure 15 show the results of the A* algorithm and the proposed algorithm, respectively. In the average search range of A* algorithm, robot visited 121 nodes, and the shortest paths of robots 1 to 4 were 40, 38, 36, and 23 steps respectively. And the proposed algorithm had 100 visited nodes, and the shortest path of each robot is 40, 39, 36, and 23 steps, respectively.
Table 1 shows the search range of the proposed algorithm and A* algorithm for each situation. The search range is one of the most important factors on effective robot navigation to the target point. As shown in
Table 1, the proposed algorithm has a smaller search range than the A* algorithm.
Table 2 shows the generated path for each robot according to the situation for both proposed and A* algorithm. The proposed algorithm results in no less number of steps than A* in an average generation. In general, A* algorithm is not always searching for the optimal path because it always searches the optimal path in a static environment. However, the proposed algorithm generates the path faster than A*.
Table 3 shows the frequency of occurrence of each situation when a total of 5000 experiments were conducted. Although the search area is small, the situation 1 where the robot generation path is long shows about 58% of occurrence, and the situation 2 where the search area and travel distance are similar is about 34%. According to the simulation result, the search range of the proposed method is always smaller and the robot generation path is the same or similar to the robot path generated by the A* algorithm with a probability of about 34.76%.
4.4. Experimental Results in a Dynamic Environment
Experiments based on the proposed algorithm in a dynamic environment is performed to compare the learning results of the D* algorithm. D* [
43] and its variants have been widely used for mobile robot navigation because of its adaptation on dynamic environment. During the navigation of the robot, new information is used for a robot to replan a new shortest path from its current coordinates repeatedly. Under the 5000 different dynamic environments consisting of the smallized static environment as done in
Section 4.3, and dynamic obstacles with random initial positions, the simulation was performed around 100 times per environment.
For the D* algorithm, if an obstacle is locates on the robot path, the path will be checked again after the path of movement. In the same situation, different paths may occur depending on the circumstances of the moving obstacle.
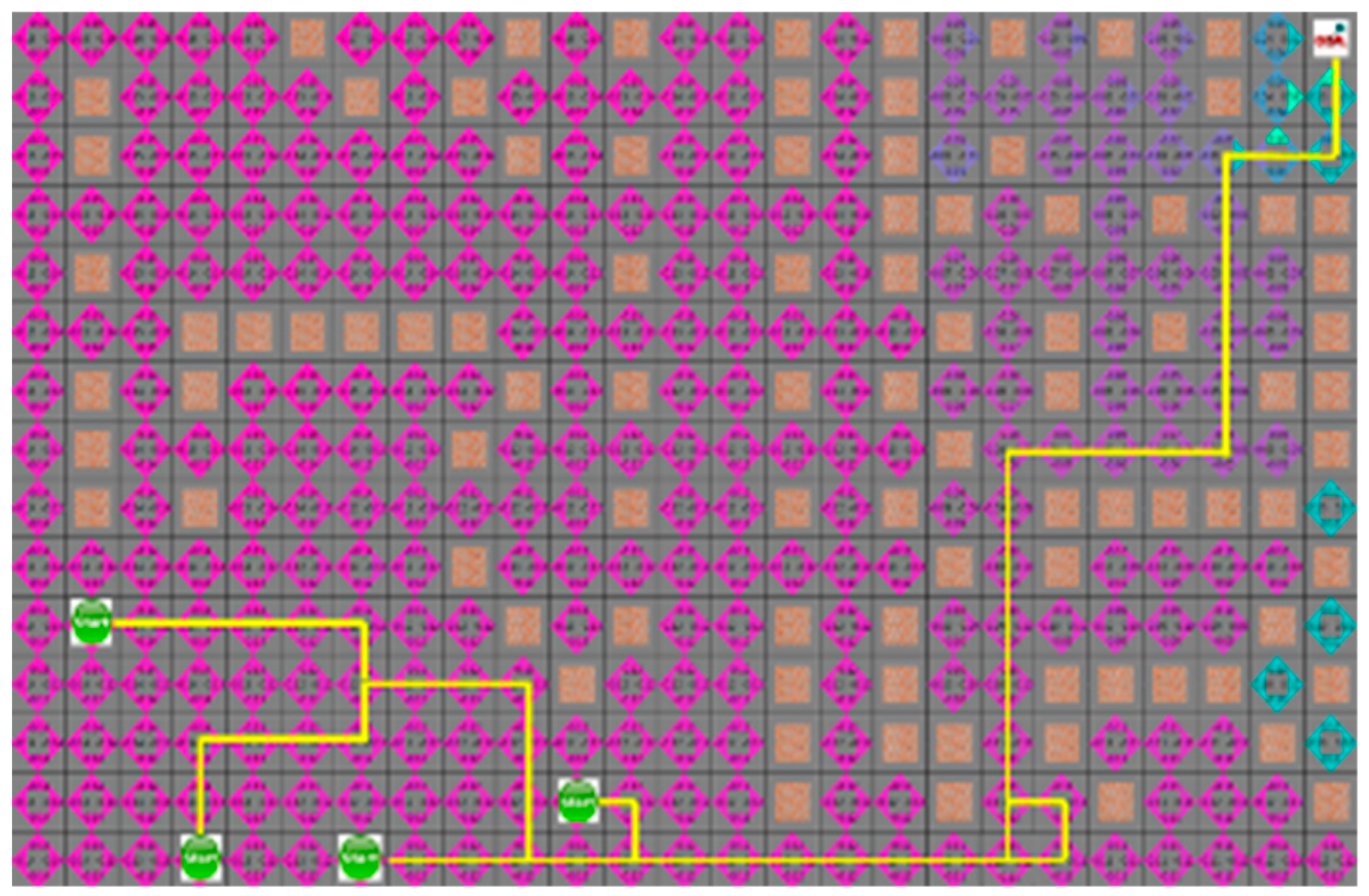
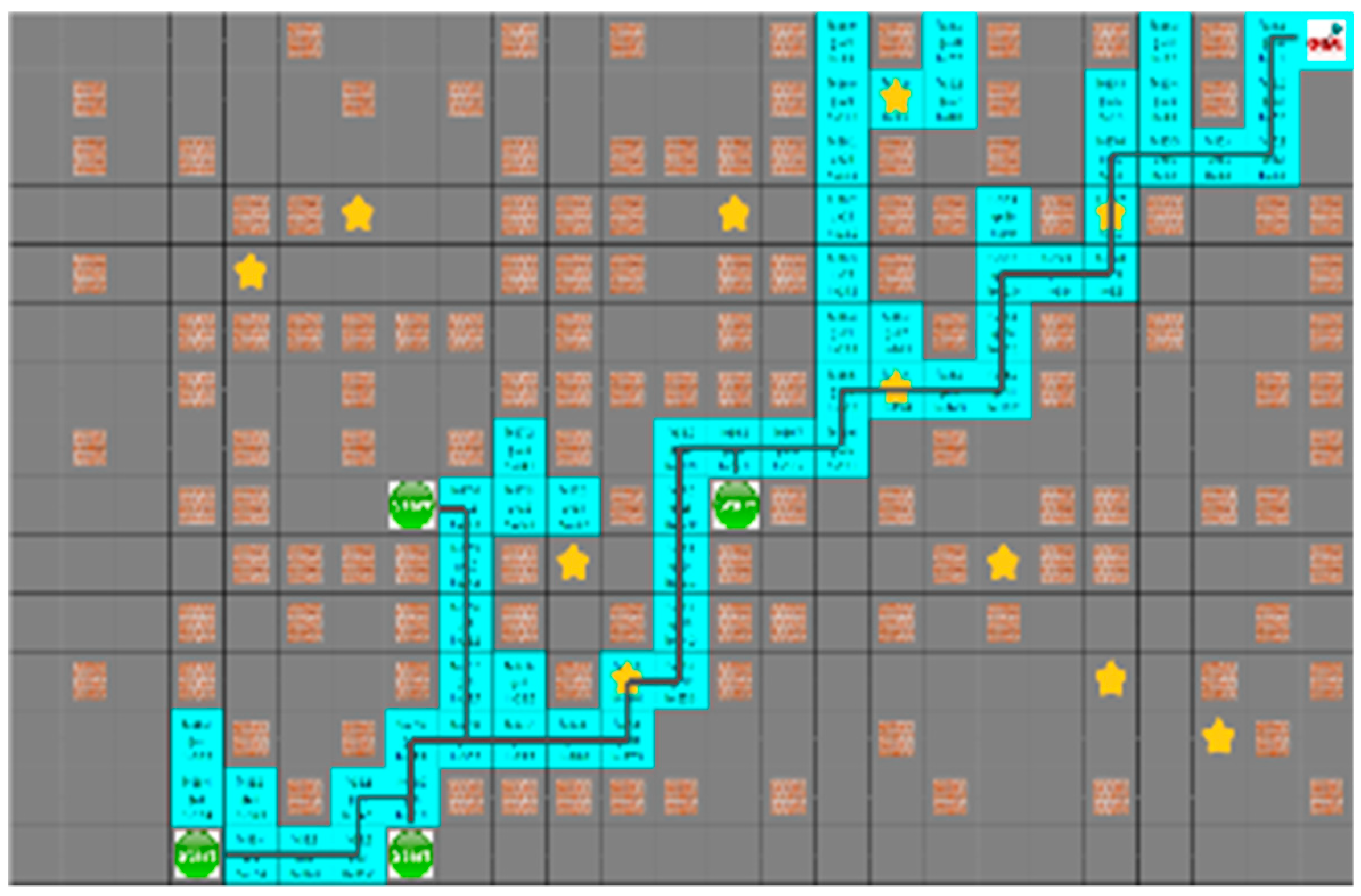
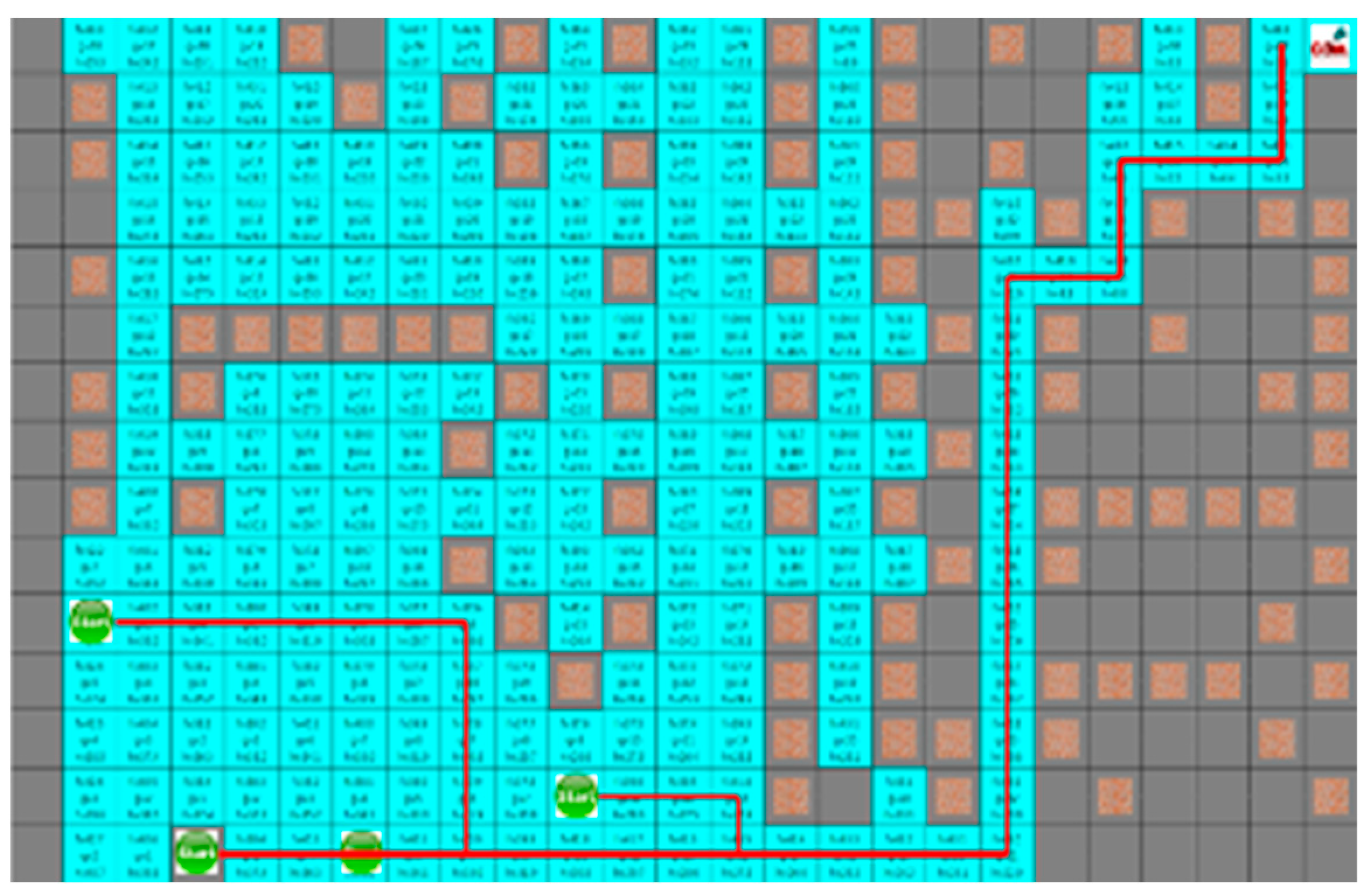
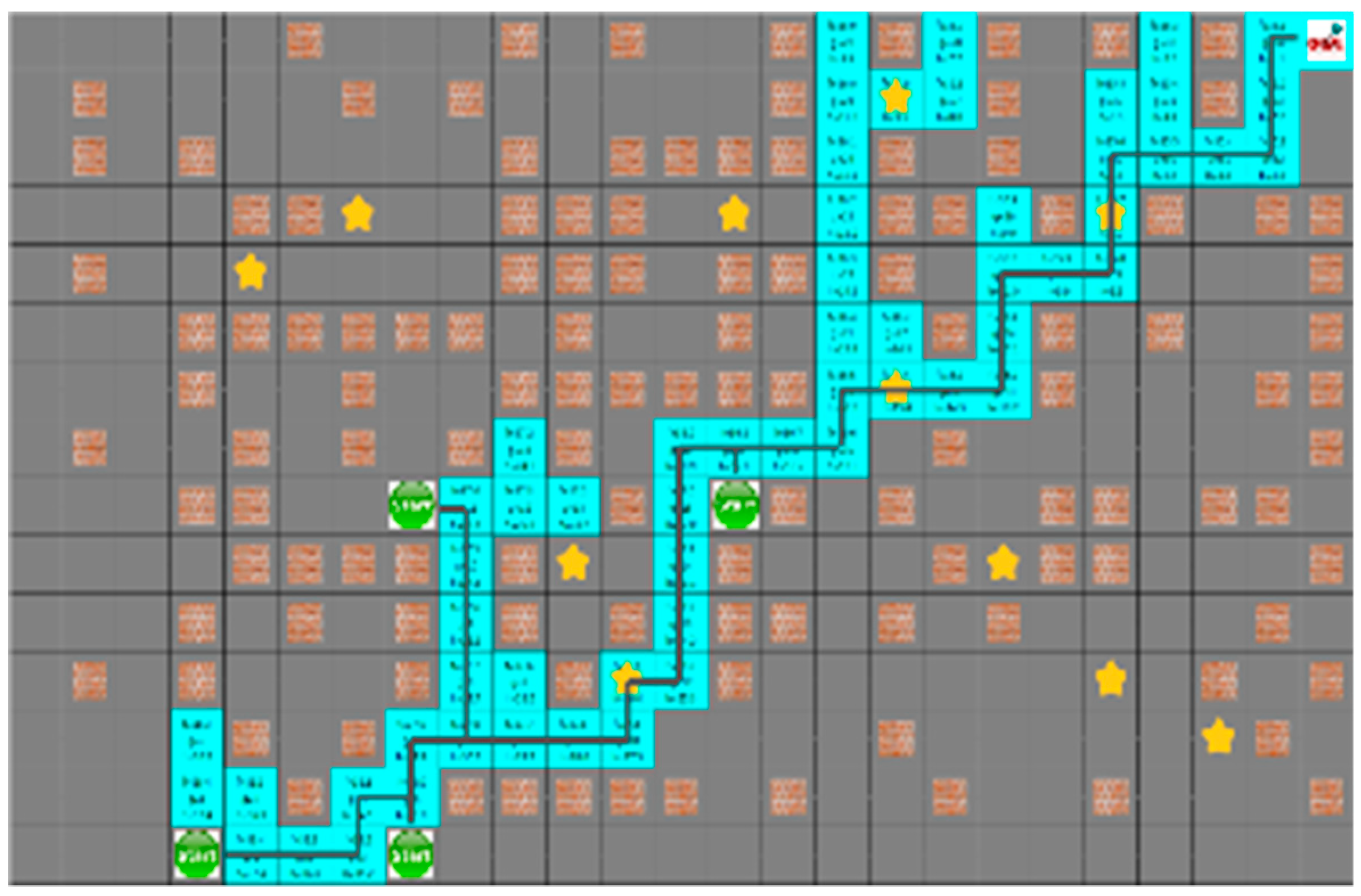
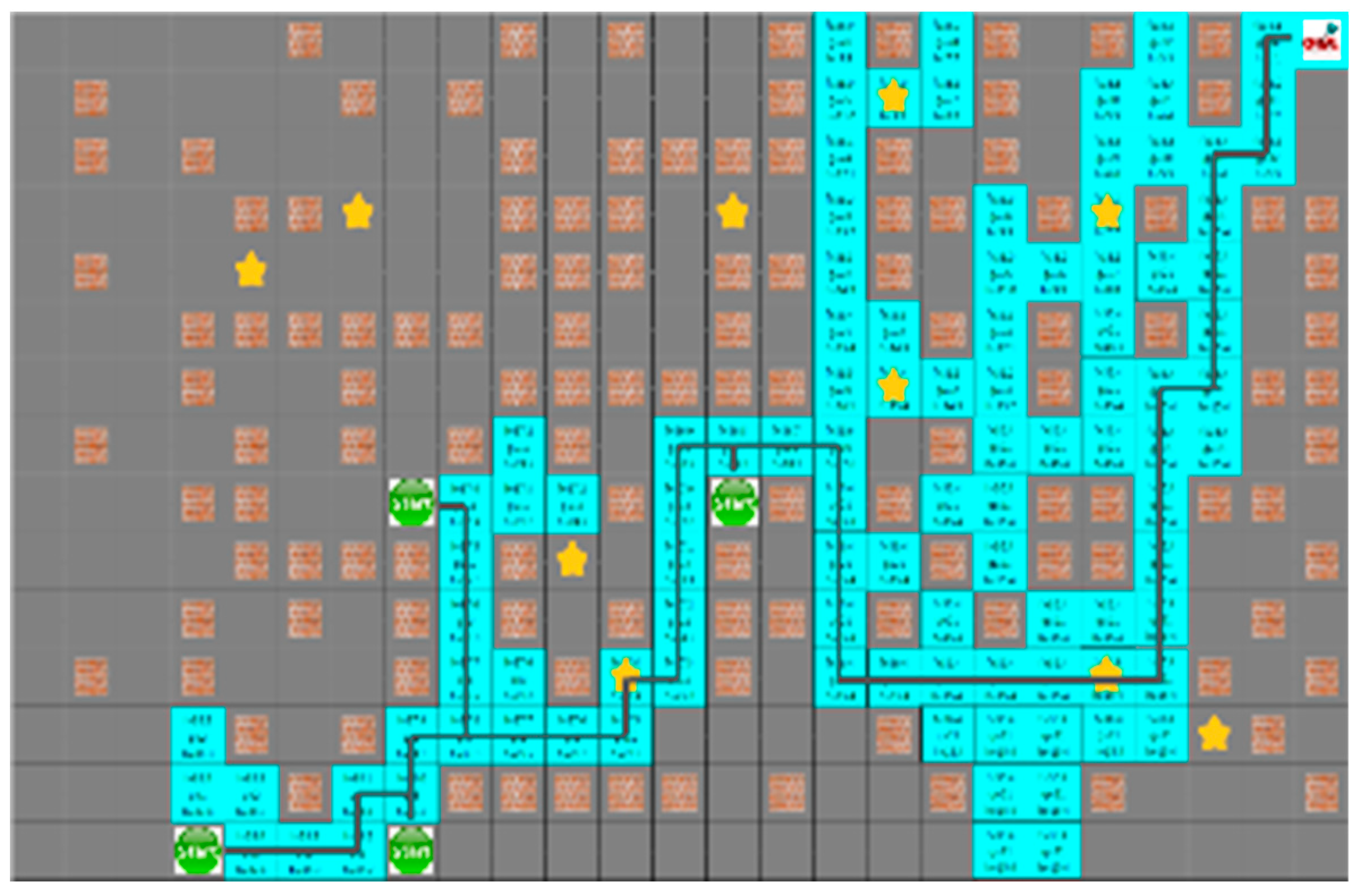
Figure 16 shows that the yellow star is a dynamic obstacle that creates the shortest path, as shown in
Figure 16, or the path to the target point rather than the shortest path, as shown in
Figure 17. This shows that the situation of the moving obstacle affects the robot’s path.
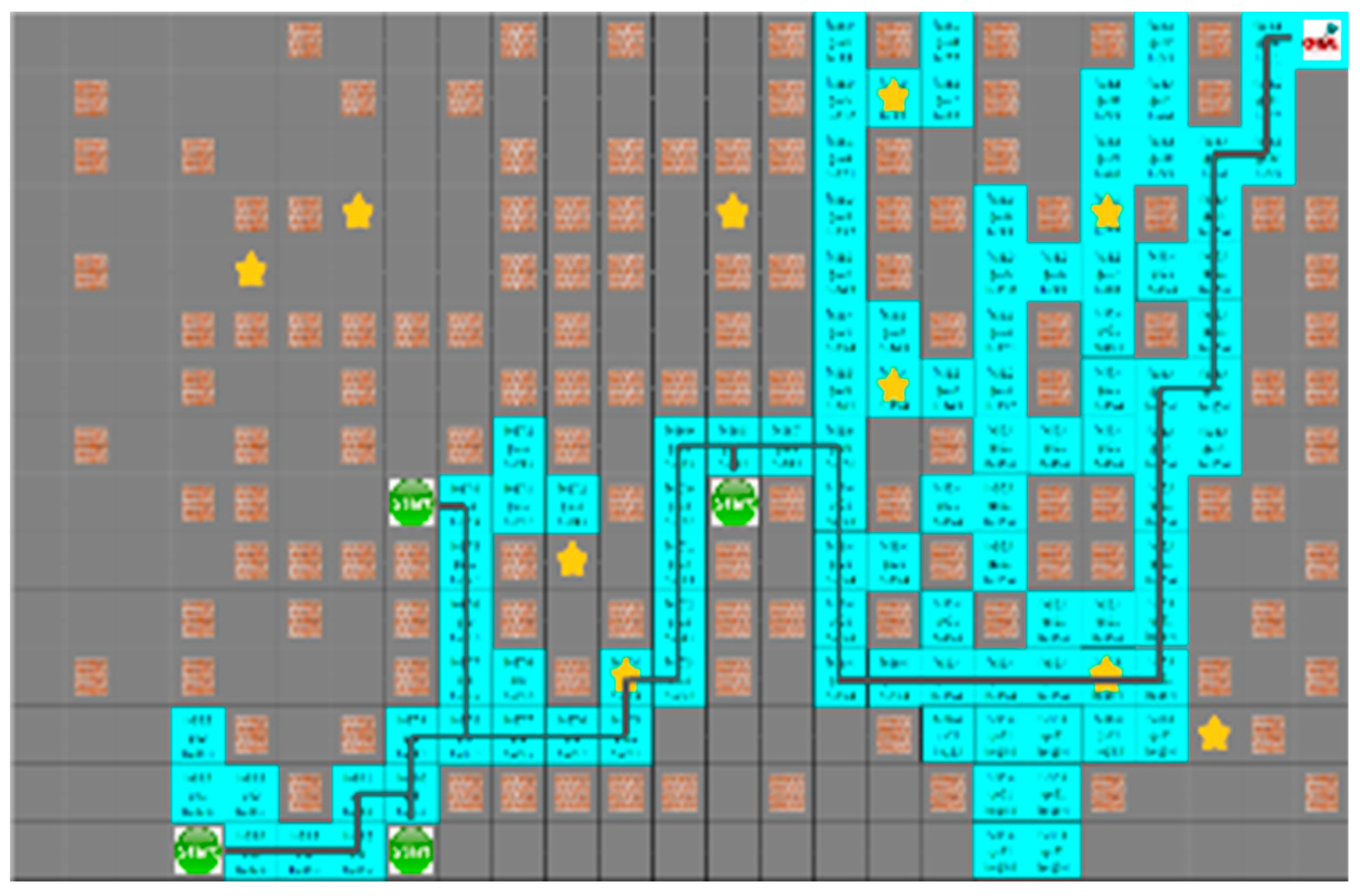
In the proposed algorithm under a dynamic environment where moving obstacles are located on the traveling path of the robot, they do not block the robot, as shown in
Figure 18. It guarantees a short traveling distance of each robot.
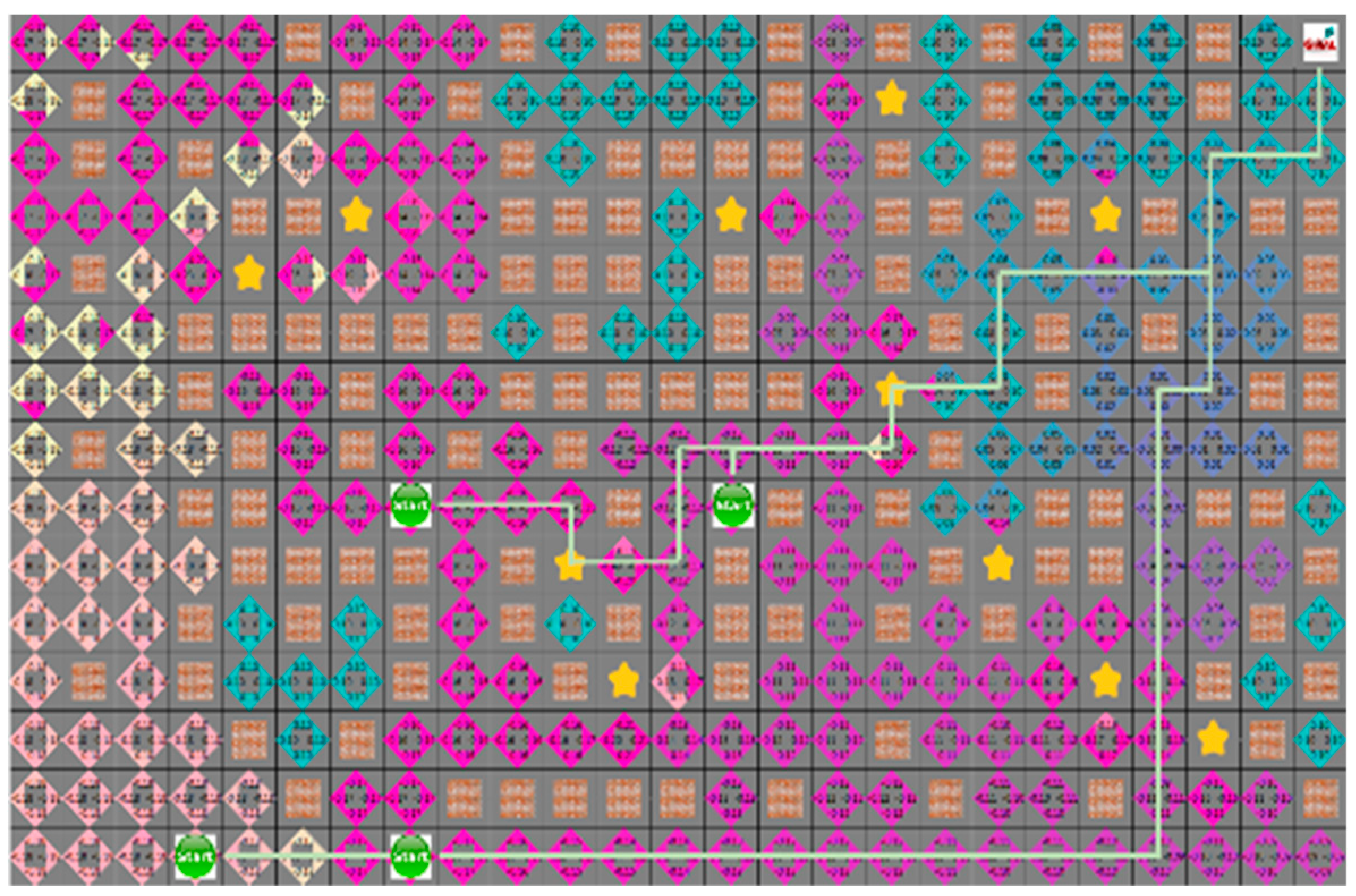
As shown in
Figure 19, the robot moves downward to avoid collision with obstacles on the path of the robot. In
Figure 19, the extent to which the path created by D* and the proposed algorithm was not moved to the existing path by the mobile yellow star and explored to generate the bypass path.
Since the robot moves actively to the next position depending on the results learned step by step, it is possible to create a path to the target point in a dynamic environment.
Table 4 shows under a dynamic environment, the first bypass path of D* and the proposed algorithm have 84 and 65 search ranges to move to the target point, respectively. In addition, for the second bypass, each method has 126 and 83 search range, respectively.
Table 5 shows the minimum search range, the maximum search range, and the average search range of the simulation for the D* algorithm and the proposed algorithm for the overall simulation results. All of the three indicators show that the search range of the proposed algorithm is no bigger than D*. Since the search range of the proposed method is small when searching for the bypass path, efficient path planning is possible to the target point. The proposed algorithm used the A* algorithm as a comparison algorithm, which is not available in a dynamic environment. The proposed algorithm was learned by comparing it with the A* algorithm, but unlike the A*, path generation is possible even in a dynamic environment.
5. Conclusions
The problem of multi-robot path planning is motivated by many practical tasks because of its efficiency for performing given missions. However, since each robot in the group operates individually or cooperatively depending on the situation, the search area of each robot is increased. Reinforcement learning in the robot’s path planning algorithm is mainly focused on moving in a fixed space where each part is interactive.
The proposed algorithm combines the reinforcement learning algorithm with the path planning algorithm of the mobile robot to compensate for the demerits of conventional methods by learning the situation where each robot has mutual influence. In most cases, existing path planning algorithms are highly depends on the environment. Although the proposed algorithm used an A* algorithm that could not be used in a dynamic environment as a comparison algorithm, it also showed that path generation is possible even in a dynamic environment. The proposed algorithm is available for use in both a static environment and in a dynamic environment. Since robots share the memory used for learning, they learn the situation by using one system. Because learning is slow and the result includes errors of each robot at the beginning of learning, each robot has the same result as using each parameter after learning progress to a certain extent. The proposed algorithm including A* for learning can be applied in real robots by minimizing the memory to store the operations and values.
A* algorithm always finds the shortest distance rather than the search time. Under the proposed algorithm, which shows diverse results, the search area of each robot is similar to A*-based learning. However, in the environment where the generated path is simple or without obstacles, an unnecessary movement occurs. To enhance the proposed algorithm, research on the potential field algorithm is undergoing. In addition, the proposed algorithm did not take into account the dynamics of robots and obstacles [
44,
45,
46] and performed simulations in situations in which robots and obstacles always made ideal movements without taking into account the dynamics of them. Based on the simulation result, the research considering the actual environment and physical engine is on the way.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}