Dependency Analysis based Approach for Virtual Machine Placement in Software-Defined Data Center



Abstract
:1. Introduction
- We propose an approach of analyzing the traffic dependency among the VMs using the PCA for an efficient VM placement strategy in a large scale SDDC hosting a number of VMs.
- We propose a new VM placement method using a gravity-based clustering and Hungarian matching methods for reducing the volume of network traffic in the SDDC.
- We build an SDDC testbed using open source solutions and verify the efficiency of the proposed VM placement method in real environment.
2. Background and Related Work
2.1. Software-Defined Data Center
- Software-Defined Networking (SDN) is a new paradigm of networking, in which a control plane is separated from the data plane on individual network devices. The network control functionalities of each network device are directly managed by a centralized SDN controller. OpenFlow is a communication protocol used by the SDN controller to communicate with the forwarding elements over the network [12]. Such technology enables solving key challenges in data centers through the abstraction of lower level functionality that removes the complexities of the underlying hardware by separating the data and control planes. Owing to its dynamic and automated network management, a network function provisioning through the programmable interfaces is much easier and faster compared to the traditional network management [13]. Since the current SDN technology assists as an essential functionality in various cloud data centers, it is expected to become a core of future network services [14].
- Software-Defined Computing (SDC) is the first step toward developing the SDDC. It is based on the use of server virtualization to efficiently exploit the system resources and make critical decisions quickly [11]. SDC enables to build computational functions among multiple hardware devices rather than be assigned to a specific hardware device. Moreover, depending on the availability of resources, the compute functions can be moved around to different pieces of virtual infrastructure. This approach enables various benefits such as hardware cost savings, operational visibility and control of the entire system, and increased agility of service management [15]. Additionally, SDC is not only the virtualization of the underlying hardware resources, it also includes APIs that used to automate the entire infrastructure for supporting flexibility in the data centers [16].
- Software-Defined Storage (SDS) is used to manage large amounts of data in the storage system by isolating the data-control layer (the software component that manages and controls the storage resources) from the data-storage layer (the underlying infrastructure of the storage assets). Such isolation enables reducing the management complexity and operation cost of the infrastructure [17]. The controller (software layer) applies various policies on different types of storage elements according to data flows. With its central control unit, it is possible to manage different storage elements in the system regardless of their vendors rather than installing the control software on each element [18]. Additionally, such technology enables designing the data storage systems in order to ensure QoS requirements of the applications [19].
- Software-Defined Security (SDSec) achieves network security enforcement by separating the security control plane from the security processing (data) plane [20]. The control plane is in charge of security decisions, and the security logic of the controller is deployed in the data plane through programmable security mechanisms [21]. Additionally, SDSec is usually implemented with network function virtualization (NFV) such as NFV-based firewall and intrusion detection systems deployed in the network. Such technologies are designed to consolidate and deliver the security components needed to support a fully virtualized infrastructure [22,23].
2.2. Virtual Machine Placement
3. Problem Definition
3.1. System Description
3.2. Problem Statement
3.3. System Model
4. Proposed VM Placement Strategy
4.1. Dependency Analysis
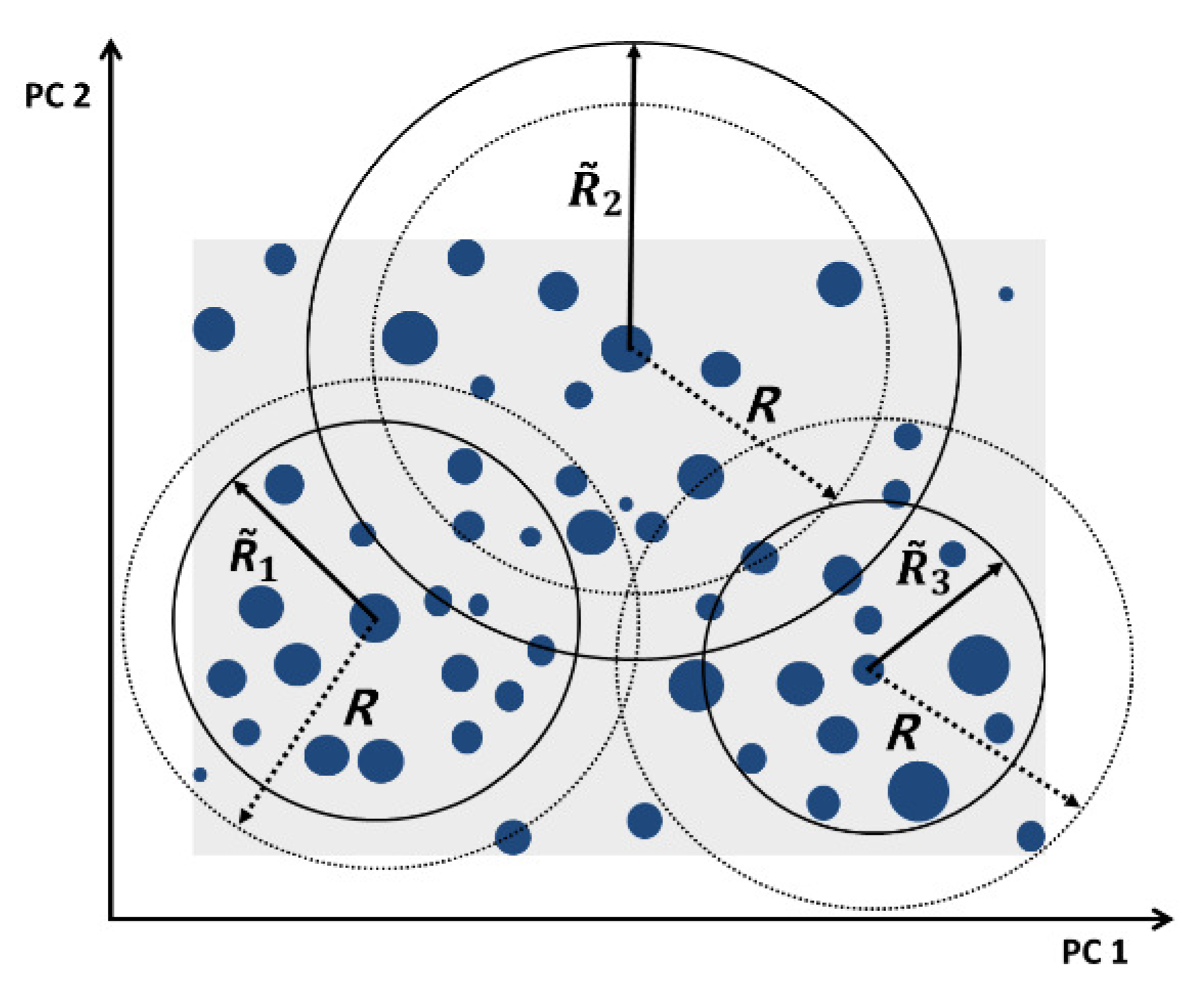
4.2. Grouping VMs
4.3. Matching Groups to PMs
4.4. Satisfying Resource Constraints
| Algorithm 1 Deciding location of VMs. |
|
5. Simulation Results and Analysis
5.1. Simulation Results of Small Network
5.2. Simulation Results of Large Network
6. Emulation Results and Analysis
6.1. Emulation Settings
6.2. Emulation Results
7. Experiment Result and Analysis
7.1. Experiment Settings
7.2. Experiment Result
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cisco. Global Data Center IP Traffic Growth. Available online: https://www.cisco.com/c/en/us/solutions/collateral/service-provider/global-cloud-index-gci/white-paper-c11-738085.html (accessed on 11 July 2019).
- Jouini, M.; Rabai, L.B.A. Design challenges of cloud computing. In IGI Global Web Services: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2019; pp. 351–376. [Google Scholar]
- Gohil, B.; Shah, S.; Golechha, Y.; Patel, D. A comparative analysis of virtual machine placement techniques in the cloud environment. Int. J. Comput. Appl. 2016, 156. [Google Scholar] [CrossRef]
- Raj, P.; Raman, A. Demystifying Software-Defined Cloud Environments. In Software-Defined Cloud Centers; Springer: Manhattan, NY, USA, 2018; pp. 13–34. [Google Scholar]
- Richard, F. The Software-Defined Data Center Is the Future of Infrastructure Architecture. Available online: https://www.vmware.com/files/include/microsite/sddc/the_software-defined_datacenter.pdf (accessed on 11 July 2019).
- SKTelecom. Evolving Telco Data Center with Software-Defined Technologies. Available online: https://manualzz.com/doc/33019990/skt-sddc-white-paper (accessed on 11 July 2019).
- Rich, M. Facebook Ops: Each Staffer Manages 20,000 Servers. Available online: http://www.datacenterknowledge.com/archives/2013/11/20/facebook-ops-staffer-manages-20000-servers/ (accessed on 11 July 2019).
- Aït-Sahalia, Y.; Xiu, D. Principal component analysis of high-frequency data. J. Am. Stat. Assoc. 2019, 114, 287–303. [Google Scholar] [CrossRef]
- Indulska, M.; Orlowska, M.E. Gravity based spatial clustering. In Proceedings of the 10th ACM International Symposium on Advances in Geographic Information Systems, McLean, VI, USA, 8–9 November 2002; pp. 125–130. [Google Scholar]
- OSDDC. Software-Defined Data Center (SDDC) Definition. Available online: https://www.dmtf.org/sites/default/files/standards/documents/DSP-IS0501_1.0.0.pdf (accessed on 11 July 2019).
- Gupta, H.; Nath, S.B.; Chakraborty, S.; Ghosh, S.K. SDFog: A Software-defined computing architecture for QoS aware service orchestration over edge devices. arXiv 2016, arXiv:1609.01190. [Google Scholar]
- McKeown, N.; Anderson, T.; Balakrishnan, H.; Parulkar, G.; Peterson, L.; Rexford, J.; Shenker, S.; Turner, J. OpenFlow: Enabling innovation in campus networks. ACM SIGCOMM Comput. Commun. Rev. 2008, 38, 69–74. [Google Scholar] [CrossRef]
- Hagos, D.H. Software-defined networking for scalable cloud-based services to improve system performance of Hadoop-based big data applications. In Web Services: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2019; pp. 1460–1484. [Google Scholar]
- Cabaj, K.; Gregorczyk, M.; Mazurczyk, W. Software-defined networking-based crypto ransomware detection using HTTP traffic characteristics. Comput. Electr. Eng. 2018, 66, 353–368. [Google Scholar] [CrossRef] [Green Version]
- SDxCentral. What Is Software-Defined Compute?—Definition. Available online: https://www.sdxcentral.com/networking/sdn/definitions/what-is-software-defined-compute/ (accessed on 11 July 2019).
- Chen, G. Software-Defined Compute. Available online: https://www.idc.com/getdoc.jsp?containerId=IDC_P10666 (accessed on 11 July 2019).
- Darabseh, A.; Al-Ayyoub, M.; Jararweh, Y.; Benkhelifa, E.; Vouk, M.; Rindos, A. SDDC: A software-defined datacenter experimental framework. In Proceedings of the IEEE International Conference on Future Internet of Things and Cloud, Rome, Italy, 24–26 August 2015; pp. 189–194. [Google Scholar]
- Karki, S.; Nguyen, B.; Zhang, X. QoS support for scientific workflows using software-defined storage resource enclaves. In Proceedings of the IEEE International Parallel and Distributed Processing Symposium (IPDPS), Vancouver, BC, Canada, 21–25 May 2018; pp. 95–104. [Google Scholar]
- Sahu, H.; Singh, N. Software-Defined Storage. In Innovations in Software-Defined Networking and Network Functions Virtualization; IGI Global: Hershey, PA, USA, 2018; pp. 268–290. [Google Scholar] [Green Version]
- SDxCentral. What Is Software-Defined Security for SDN ? Available online: https://www.sdxcentral.com/security/definitions/what-is-software-defined-security/ (accessed on 11 July 2019).
- Compastié, M.; Badonnel, R.; Festor, O.; He, R.; Kassi-Lahlou, M. Unikernel-based approach for software-defined security in cloud infrastructures. In Proceedings of the IEEE Network Operations and Management Symposium (NOMS), Taipei, Taiwan, 23–27 April 2018; pp. 1–7. [Google Scholar]
- Massonet, P.; Levin, A.; Celesti, A.; Villari, M. BEACON project: Software-defined security service function chaining in federated clouds. In Advances in Service-Oriented and Cloud Computing: Workshops of ESOCC; Springer: Berlin/Heidelberg, Germany, 2018; Volume 707, p. 305. [Google Scholar]
- Brech, B.L.; Crowder, S.W.; Franke, H.; Halim, N.; Hogstrom, M.R.; Li, C.S.; Pattnaik, P.C.; Pendarakis, D.; Rao, J.R.; Ratnaparkhi, R.P.; et al. Security within a Software-Defined Infrastructure. U.S. Patent 15/474,207, 30 March 2017. [Google Scholar]
- Khosravi, H.A.; Khayyambashi, M.R. A system for providing load-aware virtual network service in a software-defined data center network. Int. J. Netw. Manag. 2017, 27, e1989. [Google Scholar] [CrossRef]
- Xie, K.; Huang, X.; Hao, S.; Ma, M. Distributed power saving for large-scale software-defined data center networks. IEEE Access 2018, 6, 5897–5909. [Google Scholar] [CrossRef]
- Zhang, C.; Xu, H.; Liu, L.; Niu, Z.; Wang, P. Kuijia: Traffic Rescaling in Software-Defined Data Center WANs. Secur. Commun. Netw. 2018, 2018, 6361901. [Google Scholar] [CrossRef]
- Li, D.; Hong, P.; Xue, K. Virtual network function placement considering resource optimization and SFC Requests in cloud datacenter. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 1664–1677. [Google Scholar] [CrossRef]
- Kathiravelu, P.; Van Roy, P.; Veiga, L. Software-defined data services: Interoperable and network-aware big data executions. In Proceedings of the International Conference on Software Defined Systems (SDS), Barcelona, Spain, 23–26 April 2018; pp. 145–152. [Google Scholar]
- Masdari, M.; Nabavi, S.S.; Ahmadi, V. An overview of virtual machine placement schemes in cloud computing. J. Netw. Comput. Appl. 2016, 66, 106–127. [Google Scholar] [CrossRef]
- Usmani, Z.; Singh, S. A survey of virtual machine placement techniques in a cloud data center. Procedia Comput. Sci. 2016, 78, 491–498. [Google Scholar] [CrossRef]
- Wang, H.; Li, Y.; Zhang, Y.; Jin, D. Virtual machine migration planning in software-defined networks. IEEE Trans. Cloud Comput. 2017. [Google Scholar] [CrossRef]
- Meng, X.; Pappas, V.; Zhang, L. Improving the scalability of data center networks with traffic-aware virtual machine placement. In Proceedings of the IEEE INFOCOM, San Diego, CA, USA, 14–19 March 2010; pp. 1–9. [Google Scholar]
- Chen, J.; He, Q.; Ye, D.; Chen, W.; Xiang, Y.; Chiew, K.; Zhu, L. Joint affinity aware grouping and virtual machine placement. Microprocess. Microsyst. 2017, 52, 365–380. [Google Scholar] [CrossRef]
- Luo, G.; Qian, Z.; Dong, M.; Ota, K.; Lu, S. Improving performance by network-aware virtual machine clustering and consolidation. J. Supercomput. 2018, 74, 5846–5864. [Google Scholar] [CrossRef]
- Ma, W.; Beltran, J.; Pan, Z.; Pan, D.; Pissinou, N. SDN-based traffic aware placement of NFV middleboxes. IEEE Trans. Netw. Serv. Manag. 2017, 14, 528–542. [Google Scholar] [CrossRef]
- Chi, P.W.; Huang, Y.C.; Lei, C.L. In Proceedings of the Efficient NFV deployment in data center networks. In Proceedings of the IEEE International Conference on Communications (ICC), London, UK, 8–12 June 2015; pp. 5290–5295. [Google Scholar]
- Yan, J.; Zhang, H.; Xu, H.; Zhang, Z. Discrete PSO-based workload optimization in virtual machine placement. Pers. Ubiquitous Comput. 2018, 22, 589–596. [Google Scholar] [CrossRef]
- Pham, C.; Tran, N.H.; Ren, S.; Saad, W.; Hong, C.S. Traffic-aware and energy-efficient VNF placement for service chaining: Joint sampling and matching approach. IEEE Trans. Serv. Comput. 2017. [Google Scholar] [CrossRef]
- Fatima, A.; Javaid, N.; Sultana, T.; Hussain, W.; Bilal, M.; Shabbir, S.; Asim, Y.; Akbar, M.; Ilahi, M. Virtual machine placement via bin packing in cloud data centers. Electronics 2018, 7, 389. [Google Scholar] [CrossRef]
- Duong-Ba, T.H.; Nguyen, T.; Bose, B.; Tran, T.T. A Dynamic virtual machine placement and migration scheme for data centers. IEEE Trans. Serv. Comput. 2018. [Google Scholar] [CrossRef]
- López, J.; Kushik, N.; Berriri, A.; Yevtushenko, N.; Zeghlache, D. Test derivation for SDN-enabled switches: A logic circuit based approach. In IFIP International Conference on Testing Software and Systems; Springer: Cham, Switzerland, 2018; pp. 69–84. [Google Scholar]
- Walklin, S. Leaf-spine architecture for OTN switching. In Proceedings of the IEEE International Conference on Computing, Networking and Communications (ICNC), Santa Clara, CA, USA, 26–29 January 2017; pp. 95–99. [Google Scholar]
- Narantuya, J.; Zang, H.; Lim, H. Service-Aware Cloud-to-Cloud Migration of Multiple Virtual Machines. IEEE Access 2018, 6, 76663–76672. [Google Scholar] [CrossRef]
- Cerny, T.; Donahoo, M.J.; Trnka, M. Contextual understanding of microservice architecture: Current and future directions. ACM SIGAPP Appl. Comput. Rev. 2018, 17, 29–45. [Google Scholar] [CrossRef]
- Indrasiri, K. Microservices Layered Architecture. Available online: https://medium.com/microservices-in-practice/microservices-layered-architecture-88a7fc38d3f1 (accessed on 11 July 2019).
- Smith, L.I. A Tutorial on Principal Components Analysis. Available online: https://ourarchive.otago.ac.nz/bitstream/handle/10523/7534/OUCS-2002-12.pdf (accessed on 11 July 2019).
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Man, J.; Zhao, L.; Liu, M.; Peng, C.; Li, Q. A Bipartite Graph Matching Algorithm in Human-Computer Collaboration. Int. J. Perform. Eng. 2018, 14, 2384–2392. [Google Scholar] [CrossRef]
- Burns, D.M.; Whyne, C.M. Seglearn: A python package for learning sequences and time series. J. Mach. Learn. Res. 2018, 19, 3238–3244. [Google Scholar]
- ONF. ONOS. Available online: https://onosproject.org/ (accessed on 11 July 2019).
- ONF. Mininet. Available online: http://mininet.org/ (accessed on 11 July 2019 ).
- Stoer, M.; Wagner, F. A simple min-cut algorithm. J. ACM (JACM) 1997, 44, 585–591. [Google Scholar] [CrossRef]
- Wikipedia. Stoer-Wagner Algorithm. Available online: https://en.wikipedia.org/wiki/Stoer%E2%80%93Wagner_algorithm (accessed on 11 July 2019).
- OpenStack Foundation. OpenStack. Available online: https://www.openstack.org/ (accessed on 11 July 2019).
- ONF. SONA DC Network Virtualization. Available online: https://wiki.onosproject.org/display/ONOS/SONA%3A+DC+Network+Virtualization (accessed on 11 July 2019).
- Foresta, F.; Cerroni, W.; Foschini, L.; Davoli, G.; Contoli, C.; Corradi, A.; Callegati, F. Improving OpenStack networking: Advantages and performance of native SDN integration. In Proceedings of the IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CPU (Cores) | Memory (GB) | Storage (GB) | |
|---|---|---|---|
| VM1 | 3 | 5 | 100 |
| VM2 | 2 | 8 | 120 |
| VM3 | 1 | 4 | 90 |
| VM4 | 4 | 3 | 80 |
| VM5 | 2 | 1 | 70 |
| VM6 | 2 | 2 | 170 |
| VM7 | 1 | 5 | 80 |
| VM8 | 2 | 5 | 80 |
| VM9 | 2 | 3 | 150 |
| VM10 | 3 | 4 | 90 |
| CPU (Cores) | Memory (GB) | Storage (GB) | |
|---|---|---|---|
| PM1 | 10 | 20 | 700 |
| PM2 | 12 | 23 | 420 |
| PM3 | 11 | 27 | 250 |
| CPU (Cores) | Memory (GB) | Storage (TB) | |
|---|---|---|---|
| PM1 | 39 | 101 | 3.0 |
| PM2 | 31 | 70 | 2.7 |
| PM3 | 29 | 44 | 1.8 |
| PM4 | 27 | 56 | 1.2 |
| PM5 | 34 | 57 | 2.0 |
| PM6 | 39 | 91 | 3.0 |
| PM7 | 34 | 72 | 2.4 |
| PM8 | 50 | 89 | 3.0 |
| CPU (Cores) | Memory (MB) | Storage (GB) | |
|---|---|---|---|
| m1.tiny | 1 | 512 | 1 |
| m1.small | 1 | 2048 | 20 |
| m1.med | 2 | 4096 | 40 |
| m1.large | 4 | 8192 | 80 |
| m1.xlarge | 8 | 16,384 | 160 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Narantuya, J.; Ha, T.; Bae, J.; Lim, H. Dependency Analysis based Approach for Virtual Machine Placement in Software-Defined Data Center. Appl. Sci. 2019, 9, 3223. https://doi.org/10.3390/app9163223
Narantuya J, Ha T, Bae J, Lim H. Dependency Analysis based Approach for Virtual Machine Placement in Software-Defined Data Center. Applied Sciences. 2019; 9(16):3223. https://doi.org/10.3390/app9163223
Chicago/Turabian StyleNarantuya, Jargalsaikhan, Taejin Ha, Jaewon Bae, and Hyuk Lim. 2019. "Dependency Analysis based Approach for Virtual Machine Placement in Software-Defined Data Center" Applied Sciences 9, no. 16: 3223. https://doi.org/10.3390/app9163223
APA StyleNarantuya, J., Ha, T., Bae, J., & Lim, H. (2019). Dependency Analysis based Approach for Virtual Machine Placement in Software-Defined Data Center. Applied Sciences, 9(16), 3223. https://doi.org/10.3390/app9163223