With lightweight and low-cost RGB-D sensors, such as Microsoft Kinetic, becoming increasingly popular, RGB-D SLAM has attracted significant attention from researchers. For example, a pose graph optimization framework is proposed to realize real-time and highly accurate SLAM [
21,
22]. In addition, the conventional bundle adjustment framework is extended to incorporate the RGB-D data with inertial measurement unit to optimize mapping and pose estimation in an integrated manner [
23,
24,
25]. The inductively coupled plasma (ICP) method is used to estimate the motion between continuous frames containing dense point cloud, and is effectively applied to RGB-D SLAM [
26,
27]. it is clear that ORB SLAM2 [
28] is one of the best SLAM methods which includes most state-of-the art techniques developed in recent years, and supports single, stereo, and RGB-D cameras. Mishima, M presents a framework for incremental 3D cuboid modeling combined with RGB-D SLAM [
29]. To improve the positioning and mapping accuracy and the robustness of the system in various scenarios, various RGB-D SLAM methods are proposed correspondingly. To eliminate the influence of dynamic objects, Bescos, B presents a dynamic scene SLAM [
30] which improves the dynamic object detection using multiview geometry and deep learning, along with background inpainting. Because the line features are more stable than point features, many researchers use line features to estimate camera poses. Sun, Q. matches the plane features between two successive RGB-D scans and the scans are used to estimate the camera pose [
31] only if they can provide sufficient constraints. Zhou, Y provides Canny-VO [
32], which efficiently tracks all Canny edge features extracted from the images, to estimate the camera pose. A real-time RGB-D SLAM with points and lines [
33] is proposed. To reduce cumulative errors, a vertex-to-edge weighted closed-form algorithm [
34] is used to reduce the camera drift error for dense RGB-D SLAM, which results in significantly low trajectory error than several state-of-the-art methods; in addition, this research has received great attention for the improving real-time performance. The back-end optimization problem is decoupled into linear components (feature position) and nonlinear components (camera poses) [
35], and as a result complexity is significantly reduced without compromising accuracy; in addition, this algorithm can achieve globally consistent pose estimation in real-time via CPU computing. Thus, it is clear that, after various improvements, all of the above-mentioned RGB-D SLAM algorithms generally achieve better results in indoor environments involving small scenes. In environments involving large scenes, if prior data is not obtained, large cumulative errors are often caused by complex environments, such as by changes in illumination, motion blur, and feature mismatches. Although the global drift error can be reduced by loop closure, no loop is available in many scenarios, and computation of large loops is time-consuming. To address this problem, we intend to utilize the priori LiDAR data as the control information to guide the RGB-D SLAM operation in large indoor environments; the priori data can neglect the cumulative error problem irrespective of the tracking distance. Recently, multisource data fusion SLAM has been developed for complex indoor environments, which combines the LiDAR data and vision data; this technology mainly involves real-time fusion and postprocessing fusion. A lot of research has been conducted on real-time data acquisition fusion, by which the data acquired by the laser sensor and the camera are directly fused online for positioning and mapping. A real-time method is presented, namely V-LOAM [
36], which combines visual odometry in high frequency and LiDAR odometry in low frequency to provide localization and mapping without global map optimization. Sarvrood, Y.B combines stereo visual odometry, LiDAR odometry, and reduced inertial measurement unit (IMU) to construct a reliable and relatively accurate odometry-only system [
37]. Although both the above-mentioned methods function well, because the LiDAR data is usually obtained in real time without preprocessing, large cumulative errors may still exist after long-distance tracking. For postprocessed fusion, the LiDAR data can be utilized to obtain a priori map to enhance visual localization; however, little research exists on this technique. Fast and accurate feature landmark-based camera parameter estimation is achieved by adopting tentative camera parameter estimation and considering the local 3-D structure of a landscape using the dense depth information obtained by a laser range sensor [
38]; however, only positioning, and not map construction, is obtained by this method. A mobile platform tracks the pose of a monocular camera with respect to a given 3-D LiDAR map, achieving excellent results under changing photometric appearance of the environment [
39], because it relies only on matching geometry; however, the initialization time is long. The normalized mutual information between real camera measurements and synthetic views is utilized to the maximum extent, based on a 3D prior ground-map generated by a survey vehicle equipped with 3D LiDAR scanners to localize a single monocular camera [
40]. This method does not fully utilize the scene information of the LiDAR data map, but utilizes only that of the ground part; therefore, it has reduced robustness in special environments. A UAV platform is utilized to obtain prior LiDAR data and a stereo camera is used to map large-scale outdoor scenes without automatic initialization and real-time performance [
41]. To address the real-time map optimization problem, a multithreaded segment-based map double window optimization strategy is adopted in the method proposed in this paper, to ensure consistency and accuracy of map construction, as well as high real-time performance. The algorithm used for initial registration in the above-mentioned methods is time consuming or requires manual operation, which greatly limits its application, whereas the proposed method uses the deep learning neural network to perform automatic initialization and motion recovery, which improves the flexibility and robustness of the algorithm in difficult scenarios. In recent years, deep learning has shown great advancements and very high performance in various computer research fields because of their similar cognitive characteristics as humans. The combination of deep learning and geometric SLAM has been receiving increasing attention from researchers. Deep learning is used for closed-loop detection [
42,
43], and the results indicate that it is more suitable than conventional methods based on visual low-level features. Researches have been focused not only on addressing the conventional SLAM problems, geometric mapping, and localization, but also on semantic SLAM, which has gradually become a trend in the field of SLAM. The object detection module, realized by the deep-learning method and localization module, is integrated seamlessly into the RGB-D SLAM framework to build semantic maps with object-level entities [
44]. A robust semantic visual SLAM named DS-SLAM [
45], aimed at dynamic environments, is proposed. The absolute trajectory accuracy of this method can be improved by one order of magnitude compared with that of the ORB-SLAM2.
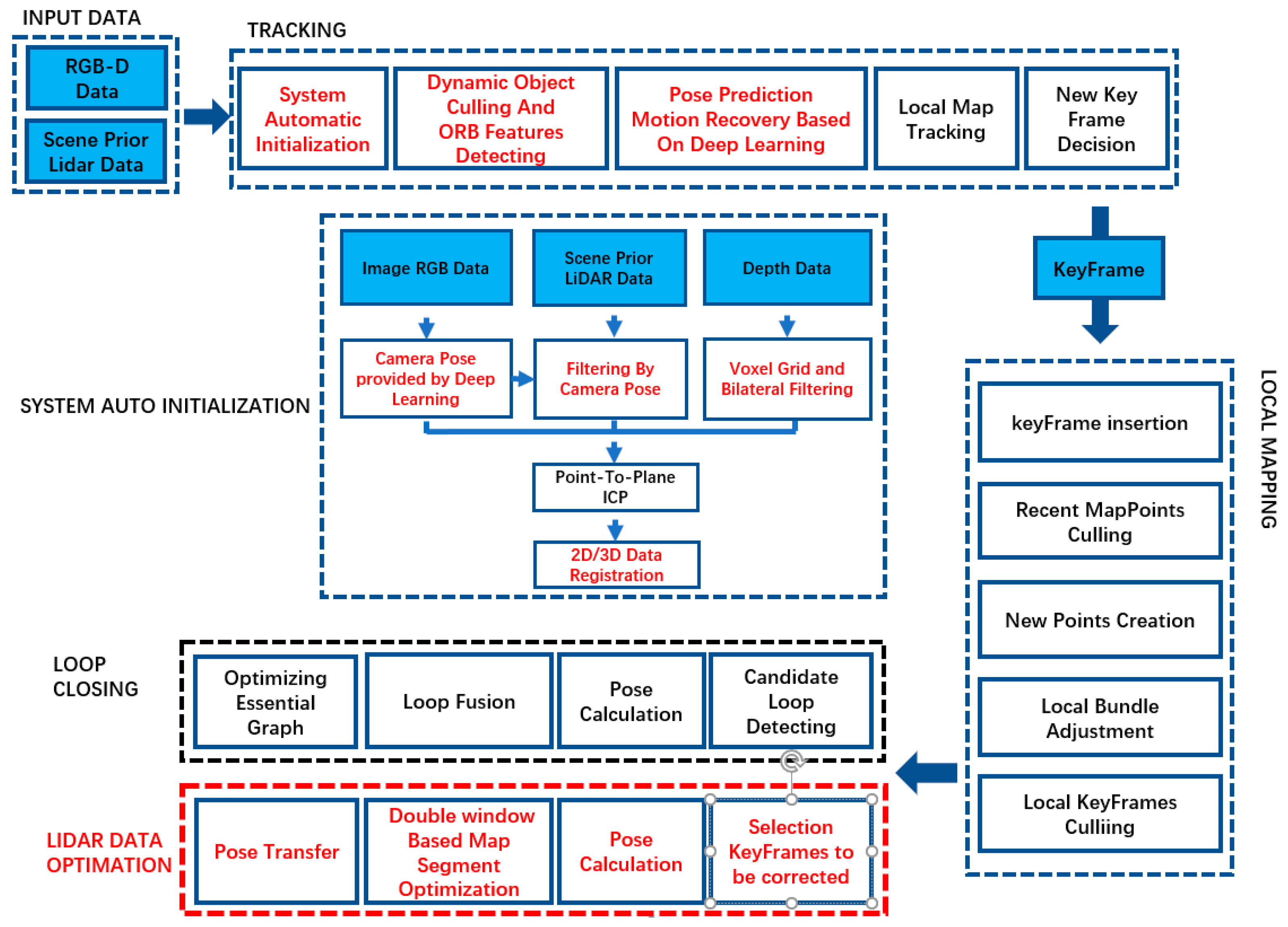
A review of literature shows that visual and RGB-D SLAM generally use the natural landscape to construct a 3-D environment and simultaneously estimate the camera pose; however, under highly variable illumination conditions and low-textured environments, without priori data, errors accumulate in long distance tracking, causing tracking failures, which may result in kidnapped-robot problem. This limitation often hinders the practicality of SLAM technology in real-life applications. Moreover, many SLAM applications such as the Google self-driving car, which is based on high definition map and indoor navigation using priori map, do not require a moving platform to navigate in unknown environments. Therefore, this research aims at proposing a novel RGB-D SLAM approach that, along with deep learning, utilizes a highly accurate priori LiDAR point cloud data as guidance for indoor 3-D scene construction and camera pose estimation. The contributions of this research can be summarized as follows.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}