A Novel Approach to Wearable Image Recognition Systems to Aid Visually Impaired People


Abstract
:1. Introduction
2. Proposed Architecture
2.1. System Overview
2.2. System Architecture
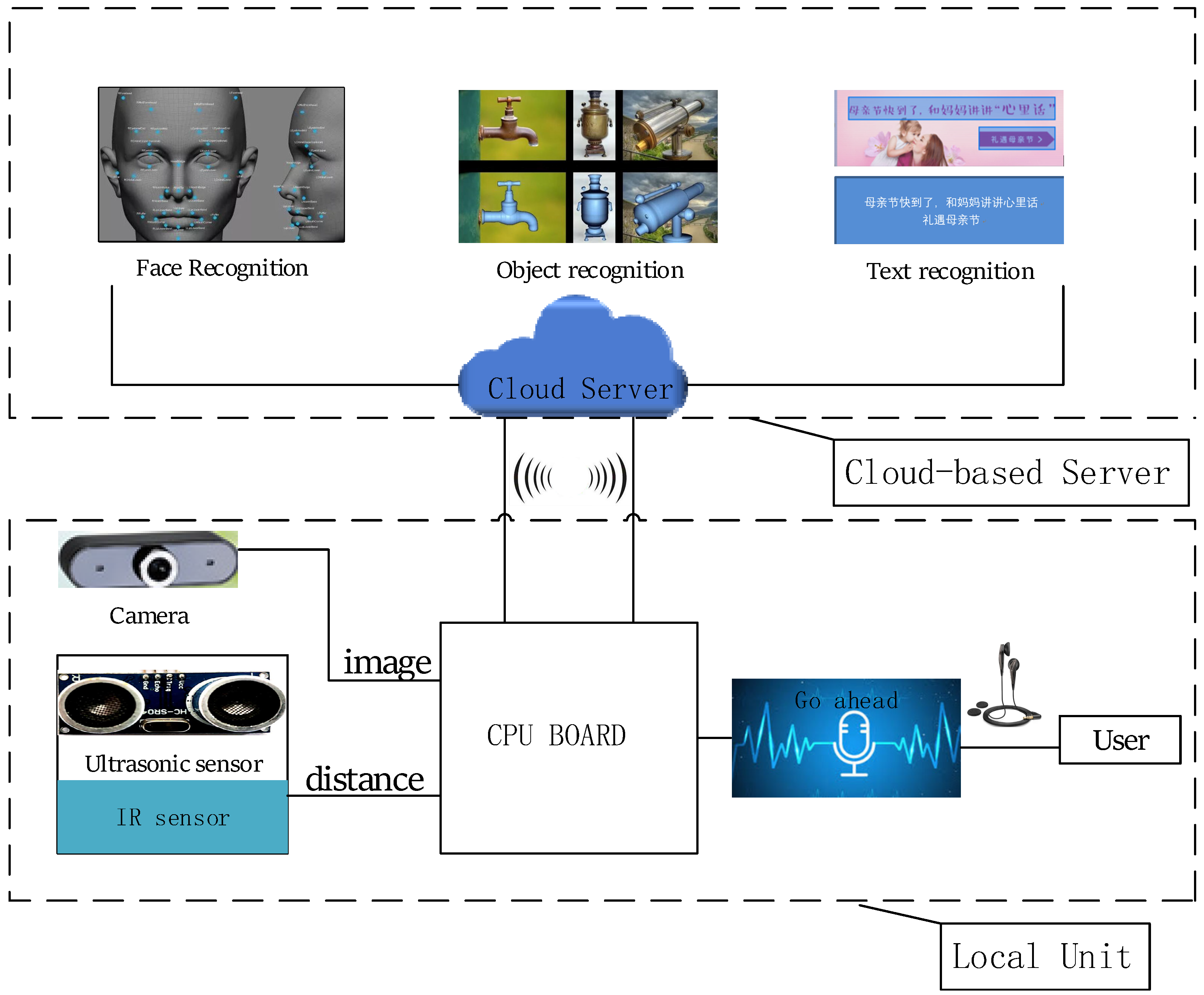
- Cloud-based Server: This unit is a cloud computing platform, integrated with intelligent algorithms such as face recognition, object recognition, optical character recognition (OCR) text recognition. The server of the system uses the Baidu Cloud Server. Running the image recognition algorithm on small embedded devices brings on excessive resource usage and overlong processing time. But for a cloud server with very high hardware configurations, these algorithms can be run in parallel at high speed while ensuring accuracy and speed. It can accept processing requests from many clients at the same time, and then return the recognition results to the client in a short time, as shown in Figure 2.
- Local Unit: it includes the control unit and the input/output unit. The structure and function of the local unit are shown in Figure 3.
- (a)
- Control unit: This unit is the brain of the whole system, which is responsible for receiving and processing visual information collected by the sensors, uploading images and analyzing the results of the server feedback. Compared to smart glasses of OrCam Myeye2, this solution has lower capability requirements for the CPU. Because the complex image recognition algorithms are run on the server instead of the local unit.
- (b)
- Input/output unit: It includes a micro camera, ultrasonic sensor, infrared sensor and headphone. The camera is the most important input part of the wearable device, serving as the “eye” of the user, which can capture the information of the surrounding environment. The ultrasonic sensor is used to measure the distance from the user to the front obstacle. Infrared sensor is mainly used to help users identify whether there is a person in front of them. It is an important input source of the multi-sensor fusion algorithm. In the choice of earphones, two options are provided: single-in-ear headphones, or Bluetooth-enabled bone conduction headphones (especially for hearing impaired people).
- Network unit: the most important problem of online identification is the networking problem. Visually impaired people cannot configure the network, so it is necessary to maintain a good Internet connection. The system supports WIFI and 4G mobile communication. Because the stability of outdoor WIFI is too poor, 4G communication Internet has become an alternative to outdoor networking.
2.3. Physical Model
3. Model and Algorithm
3.1. Image Recognition Module
3.2. Point of Interest Capture Algorithm Based on Multi-Sensor
3.3. Multithreaded Processing Algorithm
3.4. Posture Correction Mechanism Based on Error Codes
3.5. Feedback and Arbitration Mechanisms Based on Multiple Priority
4. Evaluation
4.1. Data Set Preparation
4.2. Accuracy Test
4.2.1. Face Recognition in Simulation
4.2.2. Object Recognition in Simulation
4.2.3. Crowd Counting in Simulation
4.3. Contrast Test
- (1)
- We have prepared a test set that stores two different face photos, two different object photos, and two different text photos. The file size of each image is the same, because the main control board will first encode the image before uploading the cloud server identification. Different file sizes will have different encoding times.
- (2)
- We connected the two test machines to the same router and set the IP flow control rules of the two machines as the unified priority to ensure that their network speeds are the same.
- (3)
- The test set is identified on two devices one by one, using Python’s datetime module to calculate the time required for the recognition process, and then repeating the test 10 times to obtain the average recognition time. The result is shown in Figure 12.
4.4. User-Experience Experiments
4.4.1. Face and Object Recognition
- (a)
- Each participant wore the device to start from the designated starting point, then walked forward and scanned the room information by turning the head left and right. According to the prompt of the device (when the person is scanned, there will be a ringtone), participants were asked to find the general orientation of the person, then started the recognition and spoke out the recognition result aloud.
- (b)
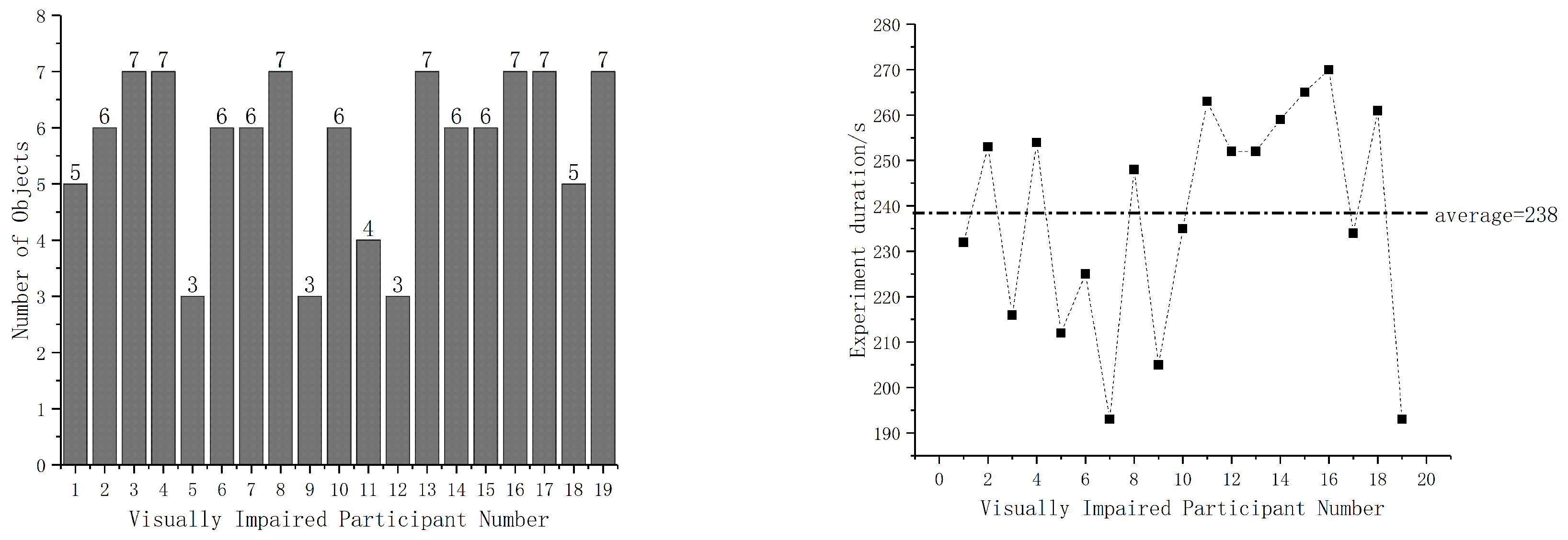
- Each participant started from the front of the table, scanned left and right to get the name of the object, and then loudly said the recognition result. There are observers around to ensure the safety of the participants. The test environment includes seven objects (cup, glasses, personal computer, stool, trash bin, potted plant). The test room is shown as Figure 14.
4.4.2. Text Recognition
4.4.3. Second Round of Experimental Evaluation
4.5. Discussion
- The visually impaired people who participated in the experiment expressed their willingness to experience this device and felt that the modular design was cool. In addition, they think the system is easy to learn because of vibrations, ring tones, and audio information. Therefore, they only need to make a corresponding judgment according to the prompt.
- A participant said that he preferred hand-held type device instead of wearing his head, especially when reading text. Because he only needs to control the vertical distance between the device and the book by hand, instead of moving the head. Six participants expressed their support for his views.
- Most participants suggested that we should choose a thinner mobile power source so that the hand-held device can be easily placed in the pocket. The weight of the head-mounted device also needs to be further reduced.
- When asked if the recognition speed can meet the daily needs, they said that the recognition time of 2–3 s is completely acceptable. Furthermore, they pay more attention to accuracy than time. They are willing to use the device at a party or at home to find their acquaintances.
- Two participants indicated that the number of vibrations was frequent when an object was detected, which affected the wearing comfort. They suggested reducing the frequency of detecting obstacles or pausing vibrations while identifying objects.
- All participants indicated that the price of $250 is acceptable. They have always believed that the price of smart assistive equipment is very high and cannot be afforded at all.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Blindness and Vision Impairment. Available online: https://www.who.int/zh/news-room/fact-sheets/detail/blindness-and-visual-impairment (accessed on 1 May 2019).
- Jafri, R.; Ali, S.A. Exploring the Potential of Eyewear-Based Wearable Display Devices for Use by the Visually Impaired. In Proceedings of the 2014 3rd International Conference on User Science and Engineering (i-USEr), Shah Alam, Malaysia, 2–5 September 2014; pp. 119–124. [Google Scholar]
- Maisto, M.; Pacchierotti, C.; Chinello, F.; Salvietti, G.; De Luca, A.; Prattichizzo, D. Evaluation of Wearable Haptic Systems for the Fingers in Augmented Reality Applications. IEEE Trans. Haptics 2017, 10, 511–522. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pissaloux, E.E.; Velázquez, R.; Maingreaud, F. A New Framework for Cognitive Mobility of Visually Impaired Users in Using Tactile Device. IEEE Trans. Hum.-Mach. Syst. 2017, 47, 1040–1051. [Google Scholar] [CrossRef]
- Andò, B.; Baglio, S.; Marletta, V.; Valastro, A. A Haptic Solution to Assist Visually Impaired in Mobility Tasks. IEEE Trans. Hum.-Mach. Syst. 2015, 45, 641–646. [Google Scholar] [CrossRef]
- Patil, K.; Jawadwala, Q.; Shu, F.C. Design and Construction of Electronic Aid for Visually Impaired People. IEEE Trans. Hum.-Mach. Syst. 2018, 48, 172–182. [Google Scholar] [CrossRef]
- Yi, Y.; Dong, L. A design of blind-guide crutch based on multi-sensors. In Proceedings of the 2015 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Zhangjiajie, China, 15–17 August 2015; pp. 2288–2292. [Google Scholar]
- Lapyko, A.N.; Tung, L.P.; Lin, B.S.P. A Cloud-based Outdoor Assistive Navigation System for the Blind and Visually Impaired. In Proceedings of the 2014 7th IFIP Wireless and Mobile Networking Conference (WMNC), Vilamoura, Portugal, 20–22 May 2014; pp. 1–8. [Google Scholar]
- Shen, C.; Zhang, Y.; Tang, J.; Cao, H.; Liu, J. Dual-optimization for a MEMS-INS/GPS system during GPS outages based on the cubature Kalman filter and neural networks. Mech. Syst. Signal Process 2019. In Press. [Google Scholar]
- Simões, W.C.S.S.; de Lucena, V.F. Blind user wearable audio assistance for indoor navigation based on visual markers and ultrasonic obstacle detection. In Proceedings of the 2016 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 9–11 January 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 60–63. [Google Scholar]
- Sammouda, R.; Alrjoub, A. Mobile blind navigation system using RFID. In Proceedings of the Computer & Information Technology, Liverpool, UK, 26–28 October 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–4. [Google Scholar]
- Yamashita, A.; Sato, K.; Sato, S.; Matsubayashi, K. Pedestrian Navigation System for Visually Impaired People Using HoloLens and RFID. In Proceedings of the 2017 Conference on Technologies and Applications of Artificial Intelligence (TAAI), Taipei, Taiwan, 1–3 December 2017. [Google Scholar]
- Owayjan, M.; Hayek, A.; Nassrallah, H.; Eldor, M. Smart Assistive Navigation System for Blind and Visually Impaired Individuals. In Proceedings of the International Conference on Advances in Biomedical Engineering, Beirut, Lebanon, 16–18 September 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 162–165. [Google Scholar]
- Krishna, S.; Little, G.; Black, J.; Panchanathan, S. A wearable face recognition system for individuals with visual impairments. In Proceedings of the International ACM SIGACCESS Conference on Computers & Accessibility, Baltimore, MD, USA, 9–12 October 2005; ACM: New York, NY, USA, 2005. [Google Scholar]
- Astler, D.; Chau, H.; Hsu, K.; Hua, A.; Zaidi, K. Increased accessibility to nonverbal communication through facial and expression recognition technologies for blind/visually impaired subjects. In Proceedings of the International ACM SIGACCESS Conference on Computers & Accessibility, Dundee, Scotland, UK, 24–26 October 2011. [Google Scholar]
- Utsumi, Y.; Kato, Y.; Kai, K.; Iwamura, M.; Kise, K. Who are you? A wearable face recognition system to support human memory. In Proceedings of the Augmented Human International Conference, Stuttgart, Germany, 7–8 March 2013. [Google Scholar]
- Neto, L.D.; Maike, V.R.; Koch, F.L. A Wearable Face Recognition System Built into a Smartwatch and Low Vision Users. In Proceedings of the International Conference on Enterprise Information Systems, Barcelona, Spain, 27–30 April 2015; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Bai, J.; Liu, D.; Su, G.; Fu, Z. A Cloud and Vision-based Navigation System Used for Blind People. In Proceedings of the International Conference on Artificial Intelligence, Cambridge, UK, 12–14 December 2017. [Google Scholar]
- Neto, L.B.; Grijalva, F.; Maike, V.R.M.L.; Martini, L.C.; Florencio, D.; Baranauskas, M.C.C.; Rocha, A.; Goldenstein, S. A Kinect-Based Wearable Face Recognition System to Aid Visually Impaired Users. IEEE Trans. Hum.-Mach. Syst. 2017, 47, 52–64. [Google Scholar] [CrossRef]
- Klatzky, R.L.; Marston, J.R.; Giudice, N.A.; Golledge, R.G.; Loomis, J.M. Cognitive load of navigating without vision when guided by virtual sound versus spatial language. J Exp. Psychol. Appl. 2006, 12, 223–232. [Google Scholar] [CrossRef] [PubMed]
- OrCam MyEye 2. Available online: https://www.orcam.com/en/myeye2/ (accessed on 1 January 2019).
- An Invention that Changes Lives. Available online: https://www.esighteyewear.com/ (accessed on 2 March 2019).
- Widen Your Outlook. Available online: https://www.oxsight.co.uk/ (accessed on 1 March 2019).
- AngelEye. Available online: http://www.sohu.com/a/146918335_736159/ (accessed on 10 July 2019).
- Shen, C.; Yang, J.; Tang, J.; Liu, J.; Cao, H. Note: Parallel processing algorithm of temperature and noise error for micro-electro-mechanical system gyroscope based on variational mode decomposition and augmented nonlinear differentiator. Rev. Sci. Instrum. 2018, 89, 076107. [Google Scholar] [CrossRef] [PubMed]
- Labeled Faces in the Wild Home. Available online: http://vis-www.cs.umass.edu/lfw/index.html (accessed on 21 May 2019).
- The PASCAL Visual Object Classes Challenge. 2007. Available online: http://host.robots.ox.ac.uk/pascal/VOC/voc2007/ (accessed on 1 March 2019).
- Wang, Z.; Zhou, J.; Wang, J.; Du, W.; Wang, J.; Han, X.; He, G. A novel Fault Diagnosis Method of Gearbox Based on Maximum Kurtosis Spectral Entropy Deconvolution. IEEE Access 2019, 7, 29520–29532. [Google Scholar] [CrossRef]
- Wang, Z.; Du, W.; Wang, J.; Zhou, J.; Han, X.; Zhang, Z.; Huang, L. Research and Application of Improved Adaptive MOMEDA Fault Diagnosis Method. Measurement 2019, 140, 63–75. [Google Scholar] [CrossRef]
- Wang, Z.; He, G.; Du, W.; Zhou, J.; Han, X.; Wang, J.; He, H.; Guo, X.; Wang, J.; Kou, Y. Application of Parameter Optimized Variational Mode Decomposition Method in Fault Diagnosis of Gearbox. IEEE Access 2019, 7, 44871–44882. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, J.; Cai, W.; Zhou, J.; Du, W.; Wang, J.; He, G.; He, H. Application of an Improved Ensemble Local Mean Decomposition Method for Gearbox Composite Fault diagnosis. Complexity 2019, 2019, 1564243. [Google Scholar] [CrossRef]
- Wang, Z.; Zheng, L.; Du, W. A novel method for intelligent fault diagnosis of bearing based on capsule neural network. Complexity 2019, 2019, 6943234. [Google Scholar] [CrossRef]
- Mocanu, B.; Tapu, R.; Zaharia, T. When Ultrasonic Sensors and Computer Vision Join Forces for Efficient Obstacle Detection and Recognition. Sensors 2016, 16, 1807. [Google Scholar] [CrossRef] [PubMed]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Equipment | Our System | OrCam MyEye2 [21] | Oxsight [23] | eSight [22] | AngleEye [24] |
|---|---|---|---|---|---|
| Appearance Description | Glasses | Glasses | Glasses+ Controller+ External power | Glasses+ Controller | glasses+ APP |
| Target user | ALL VIP | ALL VIP | Low vision people | Low vision people | ALL VIP |
| Image Recognition | Y | Y | N | N | Y |
| Obstacle avoidance | Y (defective) | N | N | N | Y (Route navigation through voice) |
| Independent | Y | Y | Y | Y | N (needs APP) |
| endurance time of the battery | by button | gesture | Continuous scanning | Continuous scanning | by button |
| endurance time of the battery and battery capacity | 5 h (1200 mAh) | Unpublished (320 mAh) | Unpublished (external power) | 2 h (unpublished) | Unpublished (external power) |
| Price ($) | 250 | 4491.9 | 377.25 | 5950 | 1191.6 |
| Error Code | Sound Prompt |
|---|---|
| 222202 | picture not have face |
| 222207 | match user is not found |
| 223113 | face is covered |
| 223114 | face is fuzzy |
| 223115 | face light is not good |
| 223116 | incomplete face |
| 223125 | right eye is occlusion |
| 216200 | empty image |
| 282102 | The target is not detected |
| 282103 | target recognize error |
| Thread | Condition | Return Result |
|---|---|---|
| Human beings in the picture () | Number of the people | |
| Image quality is unqualified () | Left/right face is occluded | |
| Blurring pictures | ||
| The light is too strong | ||
| Registered in the face database () | name | |
| Not added in the face database () | appearance information (age, expression, glasses) | |
| Object () | Object name | |
| Book or other text () | sound of the text |
| Threshold | Test_Face 1 | Test_Face 2 | Test_Face 3 |
|---|---|---|---|
| 90 | 81 | 84 | 88 |
| 85 | 77 | 79 | 86 |
| 80 | 84 | 81 | 85 |
| 75 | 87 | 85 | 88 |
| 70 | 83 | 82 | 90 |
| Participant 1 | Participant 2 | Participant 3 | Participant 4 | |
|---|---|---|---|---|
| Gender | Male | Female | Male | Female |
| Age | 20 | 25 | 35 | 33 |
| Degree of visual impairment | Slight | Slight | Low vision | Low vision |
| Experience of using other aids | Y (TapTapsee-An IOS APP) | N | N | N |
| Experiment duration (min) | 5′5″ | 5′20″ | 6′25″ | 6′42″ |
| Explain usage before experiment | Yes | Yes | Yes | Yes |
| Face number | 3 | 2 | 2 | 2 |
| Object types | Cup, glasses, PC, stool, trash bin | Cup, PC, glasses, plate, stool, potted plant | Cup, PC, glasses, plate, trash bin | Cup, PC, glasses, plate, stool, trash bin |
| Age Range (Number) | <20 (0) | 20–39 (16) | 40–60 (10) | >60 (4) |
|---|---|---|---|---|
| gender | Male (18) | Female (12) | ||
| Do you have experience with smart assistive devices? | Yes (4) | No (26) | ||
| Degree of visual impairment | Low vision (9) | Blind (21) | ||
| Would you like to experience our equipment? | Yes (19) | Maybe later (11) | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Yao, D.; Cao, H.; Shen, C. A Novel Approach to Wearable Image Recognition Systems to Aid Visually Impaired People. Appl. Sci. 2019, 9, 3350. https://doi.org/10.3390/app9163350
Chen S, Yao D, Cao H, Shen C. A Novel Approach to Wearable Image Recognition Systems to Aid Visually Impaired People. Applied Sciences. 2019; 9(16):3350. https://doi.org/10.3390/app9163350
Chicago/Turabian StyleChen, Shiwei, Dayue Yao, Huiliang Cao, and Chong Shen. 2019. "A Novel Approach to Wearable Image Recognition Systems to Aid Visually Impaired People" Applied Sciences 9, no. 16: 3350. https://doi.org/10.3390/app9163350