1. Introduction
The last few decades have witnessed the production and transmission of a massive amount of multimedia content in the World Wide Web. Sports videos contribute a major portion of the available multimedia content in cyberspace. Sports video content analysis has been explored heavily due to the potential commercial benefits and massive viewership around the world. The manual annotation of such an enormous video content is a challenging task. Therefore, automated methods for sports video content analysis and management are required. Humans are inclined towards meaningful concepts, while viewing and exploring interactive databases; there is a growing need for indexing and semantic video content analysis. The major goal towards video content analysis and management is to provide semantic information relevant to the user. For this purpose, researchers have proposed various automated and semi-automated techniques to analyze the sports videos for shot classification, key-events detection, and video summarization.
Shot Classification approaches are commonly applied initially for sports video summarization and content retrieval applications to provide the semantic information. Shot Classification techniques are employed to categorize the sports videos into different views, i.e., long, medium, close-up, etc. The classification makes it convenient to further process the sports videos for various applications mentioned above. The effectiveness of these applications largely depends on accurate shot classification of the sports videos. However, shot classification is very challenging in the presence of camera variations, scene change, action speeds, illumination conditions (i.e., daylight, artificial light, and shadow), etc. Therefore, there exists a need to develop an effective shot classification method that is robust to the above-mentioned limitations. The main idea is to develop a shot classification scheme that can accurately classify the frames of field sports videos in the presence of the aforementioned limitations. Soccer and Cricket field sports are selected to evaluate the effectiveness of our framework due to the massive viewership of these sports across the globe.
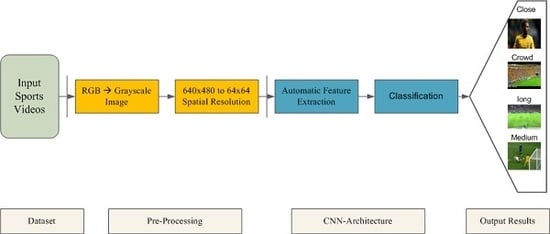
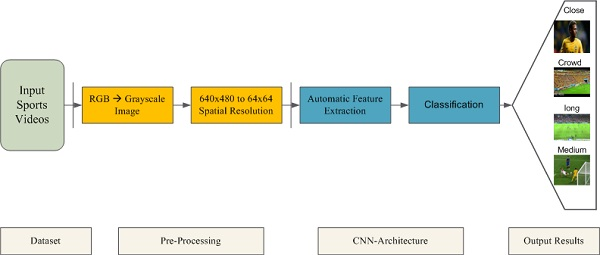
Sports videos contain different types of shots that can be categorized into following categories: (i) Long shot, (ii) medium shot, (iii) close-up shot, and (iv) crowd/out-of-the-field shots. Long shots in sports videos are considered zoomed-out shots that covers a large area or a landscape of the field, the audience and the players are presented on a small scale. Medium shots are zoomed-in shots that mostly cover a full body of the player from top head of the body to the bottom of the feet or more than one player within the playground field. Close-up shots are the most zoomed-in shots that contain the players upper body footage in the scene. Crowd shots/out-of-the-field shots consist of viewers/audience footage in the sports videos.
Most of the existing methods classify the in-field segments of sports videos, i.e., long, medium, and close-up shots as these shots are more useful to generate the highlights. After viewing massive number of sports videos, it has been observed that crowd/out-of-the-field shots also contain few exciting events that can be included in the summarized video. Therefore, we proposed an automated shot classification method of sports videos into long, medium, close-up and crowd/out-of-the-field shots. Shot classification methods have applications in various domains, i.e., sports [
1], medical [
2], news [
3], entertainment [
4], and documentaries [
5].
Existing approaches of shot classification can be categorized into (i) learning-based, and (ii) non-learning-based. Learning-based approaches employ various classifiers (i.e., Support Vector Machines (SVM), Kth Nearest Neighbor (KNN), decision trees, neural networks, etc.) to perform shot classification. Whereas, non-learning-based approaches use various statistical features, i.e., dominant grass color, histogram difference comparison, etc., to design different shot classification methods.
Existing methods [
6,
7,
8,
9,
10] have used non-learning-based approaches for shot classification of sports videos. Divya et al. [
6] proposed an effective shot classification method for basketball videos. Edge pixel ratio was used to classify the shots into two categories only: (i) Close-up view, and (ii) long view. Logo transition detection and logo sample selection were used to identify the replays. Rahul et al. [
7] proposed a method to assign the semantic information to cricket videos. The input video was segmented into shots using the scene information extracted from the text commentary. Video shots were classified into different categories, i.e., batsman action of pull shot, etc. Rodrigo et al. [
8] proposed a shot classification method for soccer videos using the Bhattacharyya distance [
9]. Murat et al. [
10] proposed a soccer video summarization method using cinematic and objects-based features. The dominant field color was used to detect the soccer field. Grass pixel ratio and color histogram comparison were used to detect the shot boundaries. Finally, statistical analysis was used to classify the shots into long, medium, and close-up shots.
In literature, approaches [
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22] also use learning-based techniques for shot classification. Learning-based approaches provide better accuracy as compared to non-learning-based approaches, but at the expense of increased computational cost. Rahul et al. [
11] presented an automated approach to identify the types of views and detection of the significant events such as goal, foul, etc, using bag of words and SVM. Sigari et al. [
12] used rule-based heuristics and SVM to classify the shots into far view/long shot, medium view, close-up view, and out-field view. Ling-Yu et al. [
13] proposed a framework for semantic shot classification in sports videos. Low-level features were derived using color, texture, and DC images in compressed domain. These low-level features were converted to mid-level features such as camera motion, action regions and field shape properties, etc. Mid-level representation was necessary to use the classifiers that do not map on low-level features. Finally, shots were classified using different supervised learning algorithms like decision trees, neural networks, support vectors machine (SVM), etc. Camera shots were classified into mid shots, long shots, and close-up shots. Matthew et al. [
14] proposed and evaluated deep neural network architectures that were able to combine image information across a video over longer time periods. They [
14] have proposed two methods for handling full length videos. Results were evaluated over previously published datasets like Sports 1 million dataset, UCF-101 Dataset. The first method explored convolutional neural networks that was used to examine the design choices needed while adapting to this framework. The second method used an ordered sequence of frames that were employed to recurrent neural network based on Long Short-Term Memory (LSTM) cells connected to the output of underlying CNN. Karmaker et al. [
15] proposed a cricket shot classification approach using motion vector detection through the optical flow method. 3D MACH filter was used for action recognition that was trained over six cricket videos to classify the different shots. Kapela et al. [
16] proposed a learning-based method that used feed-forward neural networks, ELMAN neural network, and decision trees to classify the different events in field sports videos. Konstantinos et al. [
17] presented a shot classification model using linear discriminant analysis (LDA) method to categorize the shots into full long view and player medium view. Atika et al. [
18] proposed a shot classification approach using statistical features to classify the crowd shots. Nisarg et al. [
19] proposed a multi labelled video dataset that contained over eight million videos, 500k hours of video, annotated with 4800 visual entities. The videos were labelled using Youtube vide annotation system. Each video was decoded using Deep CNN pre-trained on ImageNet to extract hidden representation immediately. Training was performed on different classification models on the dataset. The videos were classified onto different categories like vehicles, sports, concert, and animated, etc. Jungheon et al. [
20] proposed a video event classification algorithm using audio-visual features. Convolutional neural networks were applied on the frames to extract the features followed by performing the classification. In addition, Mel Frequency Cepstral Coefficients (MFCCs) were also used to train the CNN for shot classification. Loong et al. [
21] proposed a semantic shot classification algorithm for cinematography. Markov random field model based on motion segmentation was used to classify the film video into three types of shots, i.e., long, medium, and close-up. Ashok et al. [
22], proposed a hybrid classifier-based approach for activity detection of cricket videos. Low-level features (i.e., grass pixel ratio) and mid-level features (i.e., camera view, distance, etc.) were used to train a hybrid classifier comprising of Naïve bias, KNN and multi-class SVM for shot classification into field-view and non-field views.
As we already discussed that effective shot classification improves the accuracy of video content analysis applications. However, shot classification is very challenging in the presence of camera variations, scene change, action speeds, illumination conditions (i.e., daylight, artificial light, shadow), etc. To address the challenges associated with shot classification, we proposed an effective shot classification framework for field sports videos. The major contributions of the proposed research work are as follows:
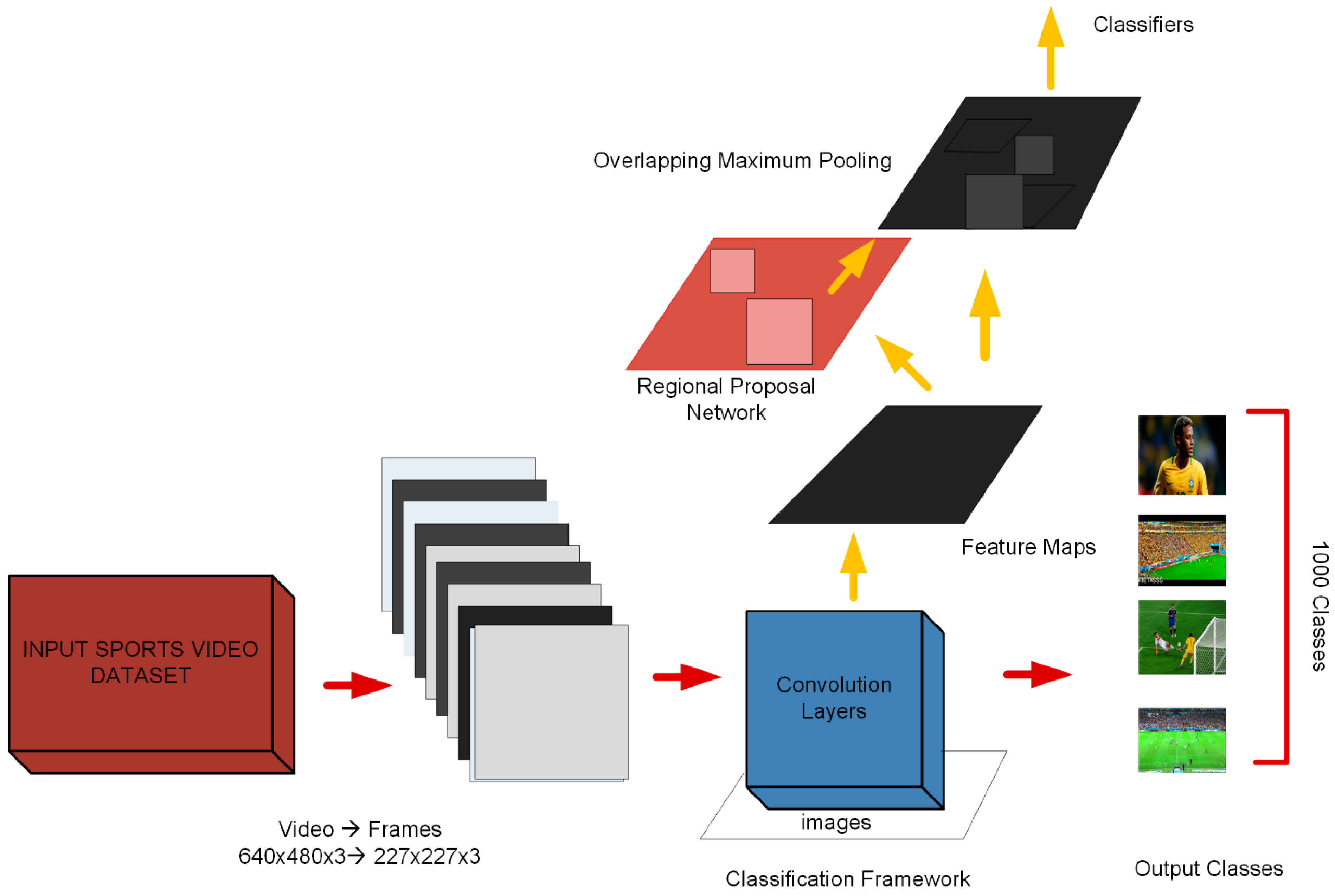
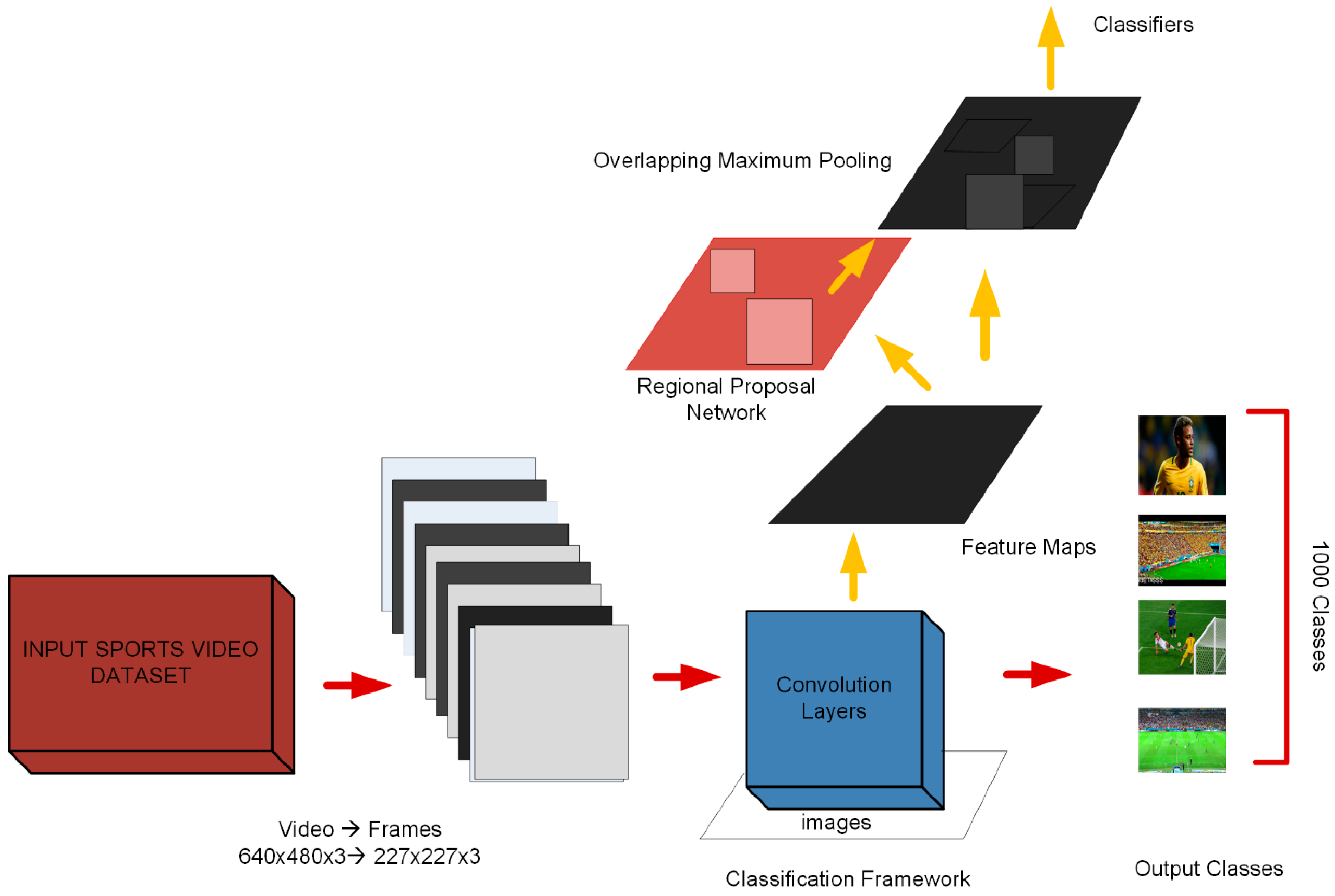
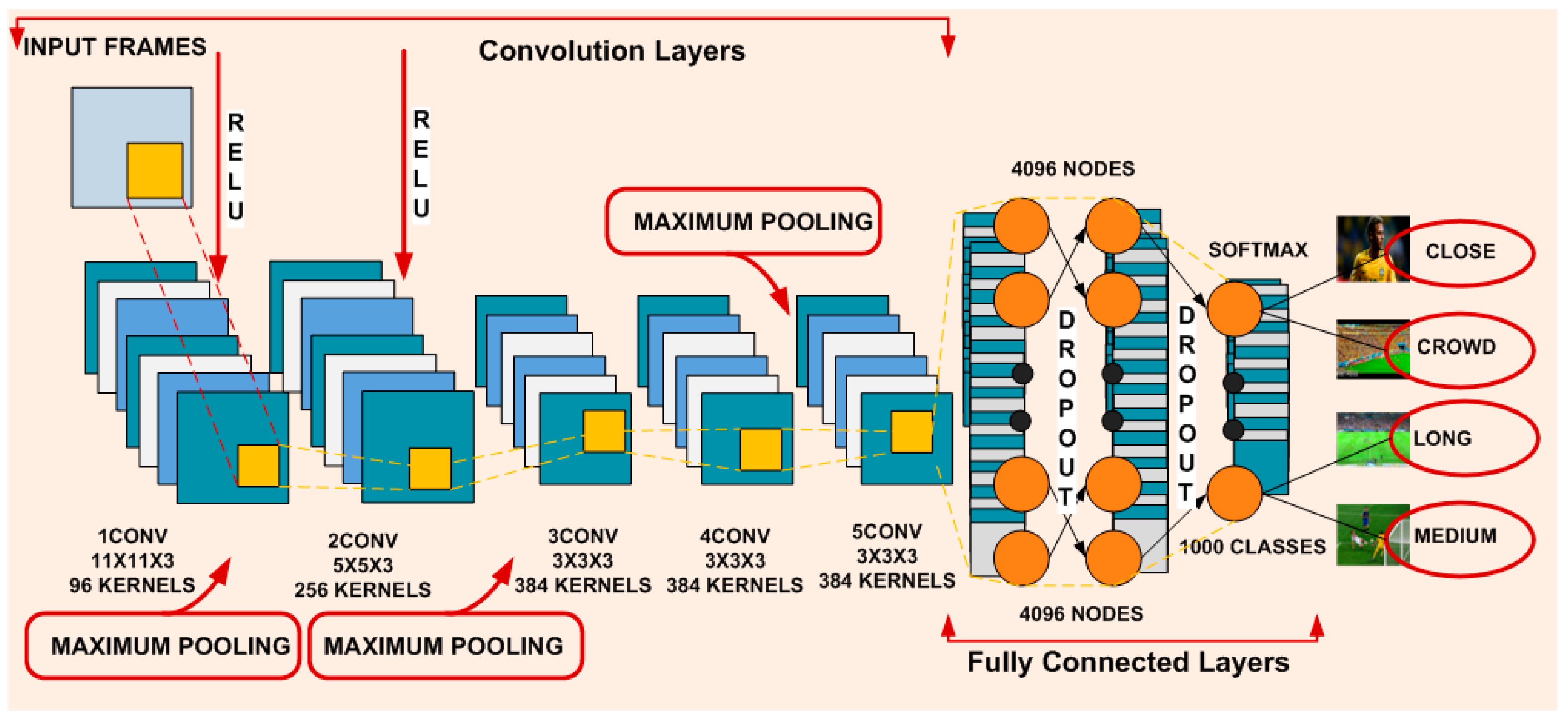
AlexNet convolution neural network is designed to effectively classify the video shots into different views (i.e., long, medium, close-up, crowd/out-of-the-field) which is promising and novel in terms of its application to shot classification.
The proposed framework is robust to camera variations, scene change, action speeds, and illumination conditions and can be reliably used for shot classification in the presence of these limitations.
Moreover, existing shot classification approaches focus on generating more classes for in-field segments (long, medium and close-up shots) because in-field segments are commonly used to generate the sports highlights. However, it has been observed after watching many sports videos that the crowd shots also contain few exciting segments that can be included in the summarized video. Therefore, the proposed research work focuses on classifying the shots of field sports videos into long, medium, close-up, and crowd/out-of-the-field shots. We categorize the crowd shots into separate class so that these shots can also be analyzed to further identify the interesting segments for video summarization. These crowd shots can also be used for different applications, i.e., activity detection, etc. The details of the proposed deep learning framework are provided in the next section.
3. Results and Discussion
This section presents the experiments designed to evaluate the performance of the proposed framework. The results of these experiments are also reported along with the discussion. Objective evaluation metrics (i.e., precision, recall, accuracy, error rate, F1-score) are employed for performance evaluation. The details of the dataset are also provided in this section.
3.1. Dataset
For performance evaluation we selected a diverse dataset comprising of soccer and cricket videos from YouTube as done by the comparative methods, i.e., [
24,
25,
26]. The dataset includes 10 videos of 13 h from six major broadcasters, i.e., ESPN, Star Sports, Ten Sports, Sky Sports, Fox Sports, and Euro Sports. In addition, we included the sports videos of different genre and tournaments in our dataset. Cricket videos consist of 2014 One Day International (ODI) tournament between South Africa and New Zealand, 2006 ODI tournament between Australia and South Africa, 2014 test series and ODI series between Australia and Pakistan, 2014 ODI series between South Africa and New Zealand, 2014 Twenty20 cricket world-cup tournament, and 2015 ODI cricket world-cup tournament. For soccer videos, we considered the 2014 FIFA world-cup and 2016 Euro-cup videos. Soccer videos consist of Brazil vs. Germany semifinal match and Argentina vs. Germany final match of 2014 FIFA world-cup, Portugal vs. France final match and France vs. Germany semifinal match of 2016 Euro-cup.
Each video has a frame resolution of 640 × 480, frame rate of 30 fps and recorded in MPEG-1 format. The videos represent different illumination conditions (i.e., daylight, artificial lights). The dataset videos are comprised of different shot types, i.e., long, medium, close-up, and crowd shots, as shown in
Figure 5. We used 70% frames of our dataset for training purpose and rest of the 30% for validation purpose. Our dataset videos can also be accessed at Reference [
27] for research purposes.
3.2. Experimental Setup
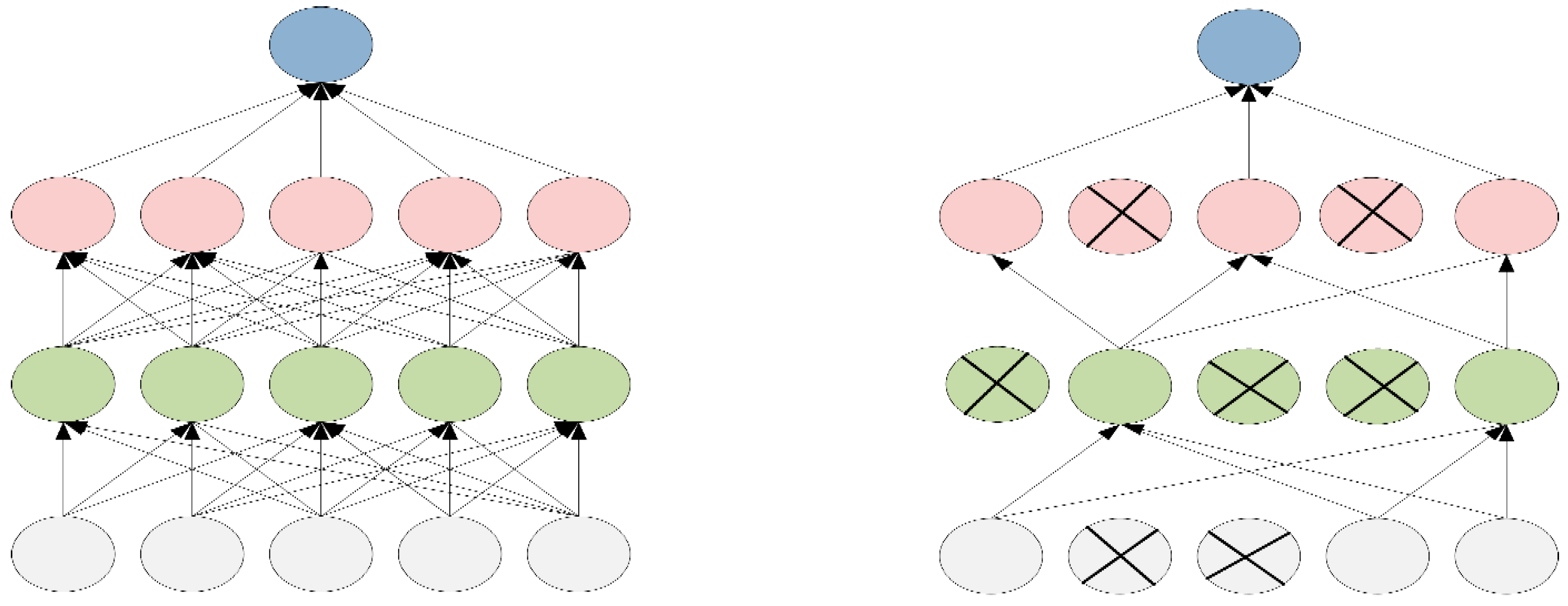
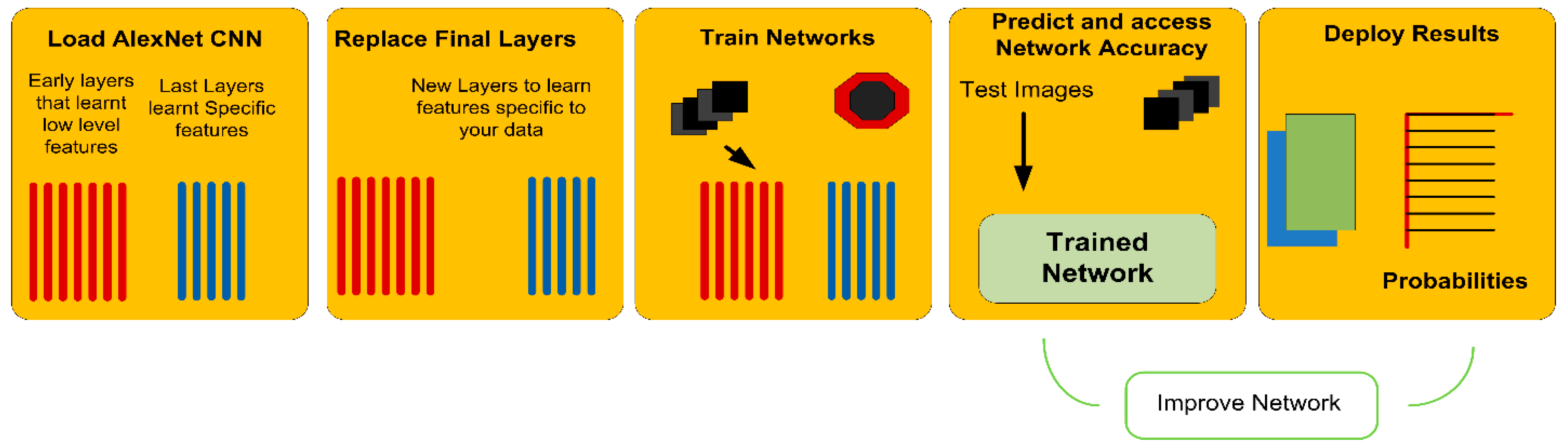
We have trained our dataset using Alexnet CNN to classify four different classes presented in our dataset. Transfer learning of a network is presented in
Figure 6.
Training
The network takes four epochs in four to five days to train on two GTX 580 Graphic Processing Units (GPU). An epoch is the number of times training vectors are used once to update the weights. In our system, each epoch has 500 iterations for our dataset. A stochastic approximation of gradient descent is used to perform training iterations on the dataset. The stochastic gradient descent (SGD) is applied with a learning rate of 0.0001, momentum of 0.9 and weight decay of 0.0005, respectively. SGD is represented in Equations (7) and (8).
where l is the iteration index, s is the momentum variable, and
is the learning rate.
is constant over the lth iteration of batch B
l of x evaluated at x
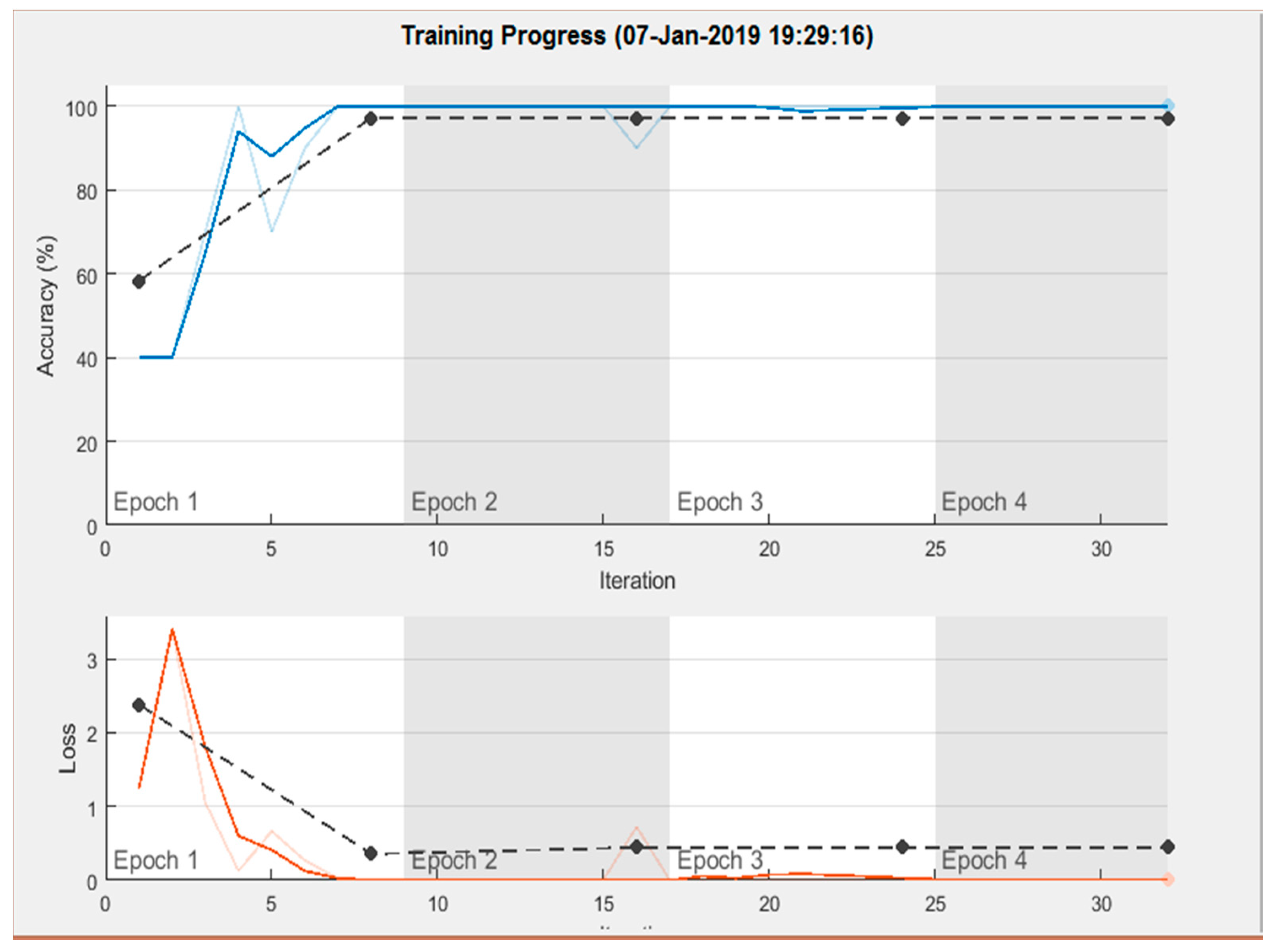
l. All the layers in our network have equal learning rate that can be adjusted during the training. Experiments have proved that, by increasing the learning features, validation set achieves better accuracy. We divided our dataset on videos level, that means we performed training on a dataset of soccer and cricket videos and tested the unique video dataset of soccer and cricket videos on the proposed network. Snapshots of the training progress are presented in
Figure 7.
3.3. Evaluation Parameters
We employed objective metrics to evaluate the performance of the proposed framework. For this purpose, we used precision (P), recall (R), accuracy (A), error rate (E), and F1-score to measure the performance. These metrics are computed in terms of correct/incorrect classification of shot types for each category. Finally, the results of all types of shots are averaged to obtain the final values.
For shot classification of sports videos, accuracy represents the ratio of correctly classified shots (True Positives and True Negatives) out of the total number of shots. Accuracy is computed as follows:
where true positives (TP) represent the correctly classified shots of a positive (P) class (i.e., long shot if we are measuring the accuracy of long shot). And, true negatives (TN) represent the correctly classified shots of negative (N) class (i.e., medium, close-up and crowd shots in case of measuring long shot accuracy).
Error rate refers to the ratio of misclassified shots (False Positives (FP) and False Negatives (FN)) to the total examined shots. Error rate is computed as:
where FP represent the N class shots misclassified as positive class shots. Additionally, FNrepresent the P class shot misclassified as the negative class shot.
Precision represents the ratio of correctly labelled shots over the total number of shots and computed as follows:
Recall is the fraction of true detection of the shots over a total number of shots in the video and computed as:
F1-score represents the harmonic mean of precision and recall. F1-score is useful metric for performance comparison in cases where some method have better precision but lower recall rate than the other method. In this scenario, precision and recall rates independently are unable to provide true comparison. Therefore, F1-score can reliably be used in such cases for performance comparison. F1-score is computed as:
3.4. Performance Evaluation
In this experiment, we computed the precision, recall, accuracy, error rate, and F-1 score against each shot category of 10 different sports videos (soccer and cricket). The results obtained for each class of shot are presented in
Table 1. The proposed method achieves an average precision of 94.8%, recall of 96.24 %, F1-score of 96.49%, accuracy of 94.07% and error rate of 5.93% on these videos. These results indicate the effectiveness of our proposed AlexNet CNN framework for shot classification of sports videos.
3.5. Performance Evaluation Using Different Classifiers
In this experiment, we compared the performance of the proposed method against different classifiers. For this purpose, we designed different experiments to test the accuracy of shot classification on standard convolutional neural networks (CNNs), SVM, KNN, Centroid displacement-based K-Nearest Neighbors (CDNN) and ELM classifiers. We also employed different feature descriptors and classifiers for shot classification and compared the classification accuracy with our framework. More specifically, we used Local Binary Patterns (LBPs) and Local Tetra Patterns (LTRPs) descriptors for feature extraction and trained them on SVM and Extreme Learning Machine (ELM) classifiers. For SVM classifier we employed different kernel functions like linear, quadratic, multi-layer perception (MLP), and radial basis functions (RBF) to analyze the classification performance. The analysis and evaluation of these experiments are presented in detail in this section.
3.5.1. Classification Using Convolutional Neural Network
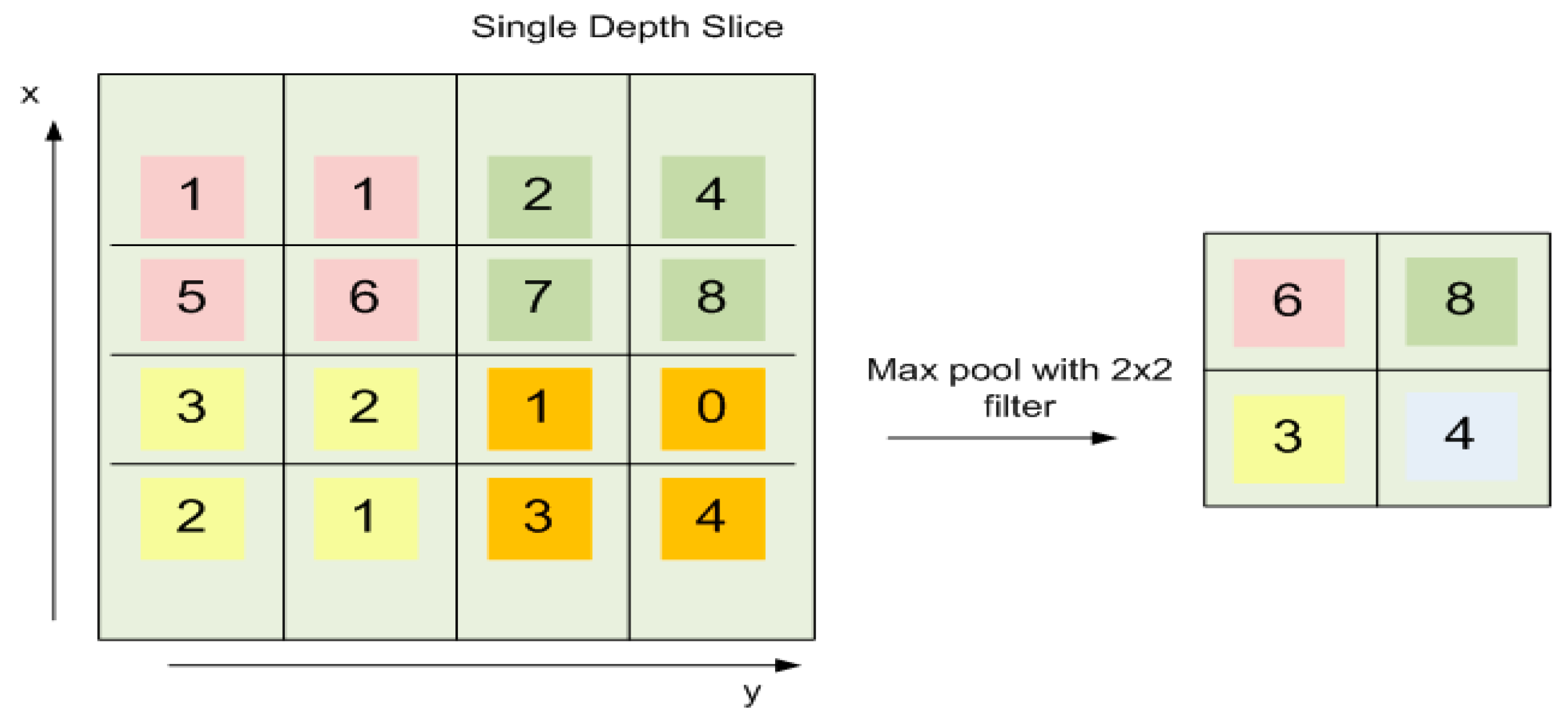
In our experiments, we used the CNN architecture having three convolutional layers followed by a batch normalization layer, a RELU layer and one fully connected layer (FC). The input video frames are transformed into grayscale and down-sampled from 640 × 480 to 64 × 64 resolution to reduce the computational cost. Each convolutional layer has a filter size of 3 × 3, and max-pooling was performed on every 2 × 2-pixel block. The output is fed to Soft-max layer for classification that helps to determine the classification probabilities used by the final classification layer. We used the learning rate of 0.01 in our experiments as we received the best results on this parameter setting. The details of each layer with the feature maps are as follows:
1st Convolutional layer (Conv1) with a kernel size of 3 × 3 and 64 feature maps.
2nd Convolutional layer (Conv2), kernel size of 3 × 3 and 96 feature maps.
3rd Convolutional layer (Conv3), kernel size of 3 × 3 and 128 feature maps.
Fully connected layer, hidden units (4000).
FC hidden units equal to several classes i.e., 4.
Soft-max layer provides the classification probabilities.
Final classification layer.
The results achieved by the standard CNN architecture for shot classification are presented in
Table 2 that shows the classification accuracy, error rate, precision, recall, and F1-score.
3.5.2. Classification Using Support Vector Machine (SVM)
For classification using SVM, we first extract features from the dataset and then performed training on the extracted features. We used Local Binary Patterns (LBPs) and Local Tetra patterns (LTrPs) for feature extraction [
28], which is discussed in detail in this section.
We computed the LBPs by comparing the grayscale values of the center pixel of the given image with its neighbor as follows:
where
represents the LBP value at the center pixel
.
Sc and
Si represents the grayscale value of the center pixel and the neighboring pixels, respectively. Q is the number of neighbors and R is the radius of the neighborhood.
For LTrPs computation, we calculated the first order derivative in the vertical and horizontal directions and encoded the relationships between the referenced pixel and its neighbors. For image
K, the first order derivative along zero and 90 degrees are calculated as:
where
Sc denotes the center pixel in
K,
Sg and
Sh represents the horizontal and vertical neighbors of S. The direction of center pixel
Sc is calculated as::
From Equation (18), four different values, i.e., 1, 2, 3, and 4 is calculated and these values are named as the direction values. The second order derivative is calculated which converts the values into three binary patterns called local ternary patterns and direction is defined using the Equation (18). Local tetra patterns are generated by calculating Euclidean distance with respect to reference direction pixels. After creating the local patterns (LBPs, LTrPs), we represented each image through the histogram as:
where
LP represents the local patterns (LBPs, LTrPs) and
M ×
N is the size of the image.
We applied a multi-class SVM classifier using different kernels for performance evaluation. We computed the SVM classifier through minimizing the following expression:
Subject to the constraints:
where C is the capacity constant, w is the vector of coefficients, b is a constant, and
depicts parameters for handling non-separable data. i is the index that labels the N training cases.
depicts the independent variable.
is the kernel that is used to transform data from input to the feature space.
The hyper-parameter for SVM classifier is the margin (C = 1) between two different classes. The largest the margin, the better will be the classifier results. Margin is the maximal width of the hyper-plane that has no interior data points. It has been observed that the larger the C, the more the error is penalized. For SVM classification, we obtained the average accuracy of 73.05% using LBP descriptor. The accuracy against each shot category is provided in
Table 3. Similarly, we obtained an average accuracy of 74.46% for LTrP descriptor with SVM classifier. The accuracy for each shot category is presented in
Table 4.
The experiments reveal that the combination of LTrP with SVM provides better accuracy as compared to LBP with the SVM. Experiments signify that crowd shots were categorized effectively in the remaining shots, which is attributed to the fact that the crowd shots contain less dominant grass field color as compared to other categories.
We also used different kernels of SVM like quadratic, Multi-layer Perception (MLP) and radial basis function (RBF) during experimentation. MLP is the most popular kernel of SVM, it is the class of feed forward neural networks and is used when response variable is categorical. RBF kernel is used when there is no prior knowledge about the data as it induces Gaussian distributions. Each point in the RBF kernel becomes a probability density function of normal distribution. It is a sort of rough distribution of data. Whereas quadratic kernel is used to induce a polynomial combinations of the features, working with bended decision boundaries. Quadratic and RBF kernel are expressed in Equations (23) and (24), respectively.
where p and q represent input space vectors that are generated from training or validation sets. Note that e ≥ 0 is a free parameter that influences higher order versus lower order terms in the polynomial.
where r(s) is the approximating function, which is expressed as a sum of N radial basis functions, s
j is the center value weighted by v
j. v
j is the estimated weight. The results obtained on LBP features with SVM using different kernel functions (quadratic, radial basis function (RBF) and MLP kernel) for shot classification are presented in
Table 5.
Similarly, the results of LTrP features with SVM using different kernel functions for shot classification are presented in
Table 6.
It has been observed from
Table 3,
Table 4,
Table 5 and
Table 6 that linear SVM provides better performance as compared to quadratic, MLP, and RBF kernels. In addition, there is a slight difference in the performance accuracy between RBF and quadratic kernels, however, we received a very low accuracy rate for MLP kernel.
3.5.3. Classification Using ELM
We also designed an experiment to measure shot classification performance using the ELM classifier. For this purpose, we extracted the LBP and LTrP features in the similar manner as discussed in
Section 3.5.2. For ELM classification, we obtained an average accuracy of 73.45%, precision of 72.67%, recall of 76.39%, and error rate of 26.55% using LBP descriptor. Similarly, an average accuracy of 75.56%, precision of 76.43%, recall of 77.89%, and error rate of 24.44% and 75.50% using LTrP descriptor was achieved. The results of LBP and LTrP descriptors with the ELM classifier are provided in
Table 7 and
Table 8, respectively.
From the results presented in
Table 7 and
Table 8, it can be clearly observed that the combination of LTrP with ELM provides better performance as compared to LBP with the ELM. This illustrates that LTrP descriptors are more effective in comparison of LBP for shot classification because it includes magnitude and direction of the neighboring pixels, whereas in case of LBP only magnitude of the vertical and horizontal neighbor is concerned. It is to be noted that crowd shots classification results are far better than the remaining types of shot classification. One significant reason is the absence of playfield in crowd shots, whereas playfield exists for all the in-field shots.
3.5.4. Classification Using KNN
We also implemented and tested the shot classification performance on our cricket and soccer video dataset using K-Nearest Neighbor (K-NN) classifier. In KNN classification, an object is classified according to majority vote of its neighbors, with the object assigned to the most common class among its k nearest neighbors. We performed this experiment on different values of k and obtained the best results with k = 5, therefore, the value for K in KNN is set to five in our experiments. Nearest neighbors are computed by calculating the Euclidean distance formula. The results obtained using the KNN are provided in
Table 9.
3.5.5. Classification Using Centroid Displacement-Based K-Nearest Neighbors (CDNN)
We also implemented and tested the shot classification performance on our cricket and soccer video dataset using centroid displacement-based K-Nearest Neighbors (CDNN) [
29] classifier. In CDNN classification, along with the distance parameter, an integral learning component that learns the weight of the view is added which helps in classifying new shots in the test dataset. The value of k for CDNN is set to five for our experiments as we obtained the optimal results on this value after checking the classifier performance on different values of k. The results obtained using the CDNN are far better than SVM and ELM classifiers, but lesser than our proposed method. The results are presented in
Table 10.
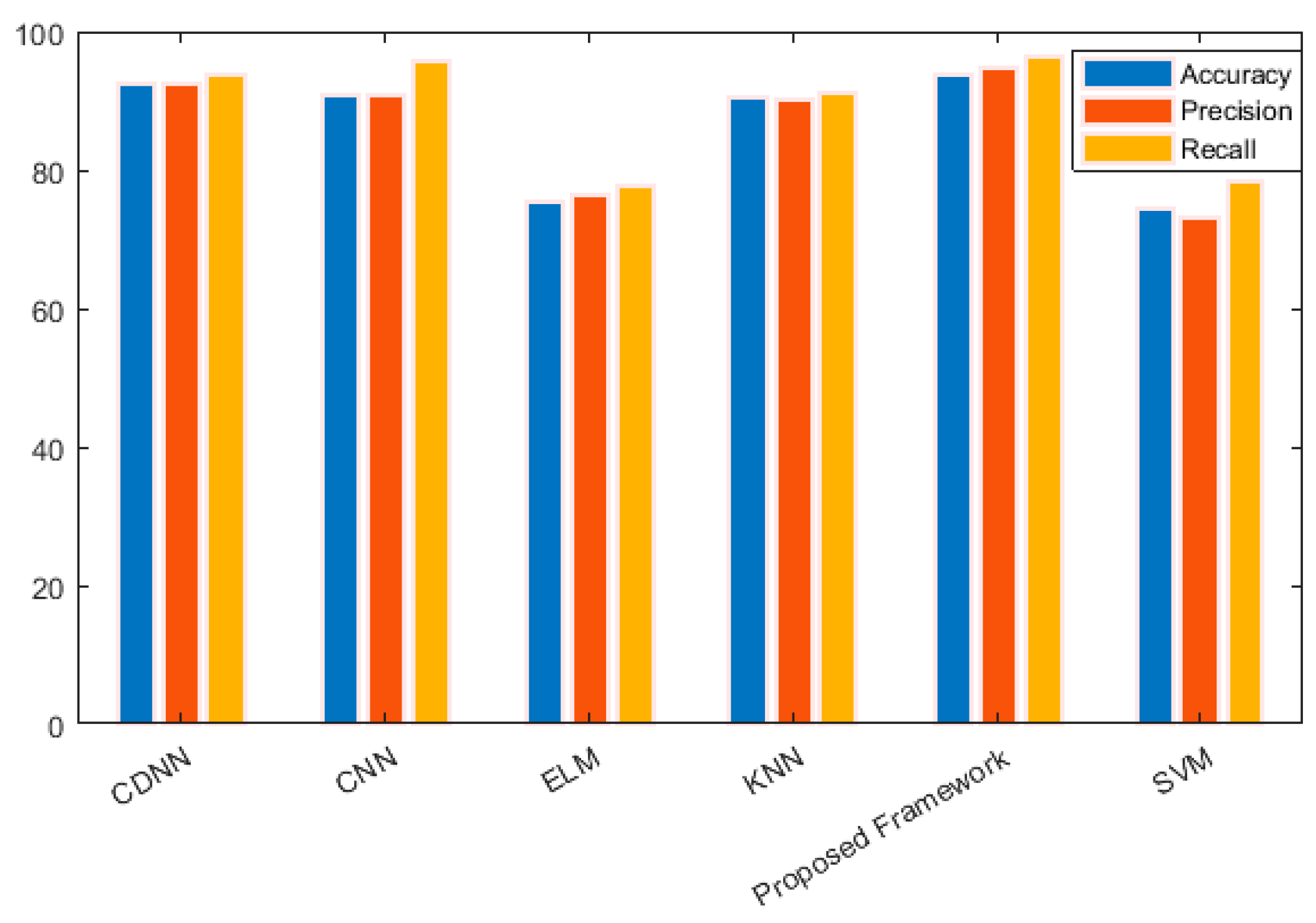
Performance comparison of the proposed method with SVM, KNN, CDNN, ELM, and standard CNN classifiers are shown in
Figure 8. The proposed method achieves an average accuracy of 94.07% in comparison with CDNN, CNN, KNN, ELM and SVM that provides 92.5%, 91.67%, 91.75%, 74.50% and 69.45%, respectively. From the results in
Figure 8, it can be clearly observed that the proposed method performs far superior, as compared to SVM, ELM, and marginally better than KNN, CDNN, and standard CNN for shot classification. Therefore, we can argue that the proposed method is very effective in terms of shot classification of sports videos.
3.6. Performance Comparison with Existing Methods
In the last experiment, we compared the performance of our method against the existing shot classification methods [
24,
25,
26] and [
30,
31,
32,
33] for sports videos.
Tavassolipour et al. [
24] proposed a Bayesian network-based model for event detection and video summarization in soccer videos. Markov model and hue histogram differences were used to detect the shot boundaries. These shots were classified as long view, medium view, and close-up view depending upon the size of the players and dominant color. Bayesian networks were applied to classify the events, i.e., goal, foul, etc. Khaligh et al. [
25] proposed a shot classification method for soccer videos. First, the in-field video frames were separated from the out-field frames. In the next stage, three features (i.e., number of connected components, shirt color in vertical and horizontal strips) were extracted from the in-field frames and fed to SVM to classify the long, medium, and close-up shots. Kapela et al. [
26] used radial basis decomposition function (RBF) and Gabor wavelets to propose a method for scene classification of sports videos. The input image was transformed into HSV color space followed by applying the Fourier transform on the image. Gabor filters were applied and trained the SVM to classify the scene into different shots. Fani et al. [
30] proposed a deep learning fused features-based framework to classify the shot types using the camera zoom and out-field information. The soft-max and fussing Bayesian layers were used to classify the shots into long, medium, close-up, and out-field shots. Chun et al. [
31] proposed a system for automatic segmentation of basketball videos based on GOP (group of pictures). Long view, medium view and full court view were classified using the dominant color feature and length of the video clips. Kolekar et al. [
32] proposed a system that generated highlights from the soccer videos. Bayesian network was employed to classify the video into replay, player, referee, spectator and playing gathering shots based on the audio features. Exciting segments from the soccer videos were detected that are assigned semantic concept labels like goals, save, yellow-cards, and kicks in sequence. Classification accuracy for the exciting segments was observed to be 86%. Raventos et al. [
33] proposed a video summarization method for soccer based on audio-visual features. Shot segmentation was performed initially to select the frames for video summarization based on the relevance. Rule-based thresholding was applied on the grass field color pixels to detect the long shots in soccer videos. The average accuracy of the proposed and existing shot classification approaches is provided in
Table 11.
From the results shown in
Table 11, we can clearly observe that the proposed method was evaluated over a diverse dataset of sports videos; and achieved the highest precision and recall values, as compared to the existing state-of-the-art shot classification methods. Although the videos used in our method and comparative methods are different but the experimental setup of our method and comparative methods is similar in terms of video source and content selection. We selected the videos from YouTube as done by the comparative methods and the selected videos represent different broadcasters, different genres, and different tournaments. The videos also represent different illumination conditions (i.e., all-day videos, day, and night videos, and night videos recorded in electric lights), and various camera shot types (i.e., long, medium, close-up and crowd/out-field shots) as selected by the comparative approaches. By testing our method on a diverse set of sports videos captured under the challenging conditions for shot-classification we ensured the fair comparison against the state-of-the-art methods. Hence, based on our results, we can say that the proposed method is a reliable approach for the shot classification of the sports videos.
3.7. Discussion
Different classification frameworks were presented using supervised and un-supervised learning-based approaches in the past. Experiments prove that convolution neural networks are effective for shot classification. We evaluated the performance of different convolution networks, and it has been observed that the proposed AlexNet convolution network performed better in classifying different shots of the sports videos. The use of response normalization rectified linear unit layer and the drop out layer on the training data makes the training much faster. In fact, once validation loss is observed to be zero, the network stops training and is ready for classification. In comparison with different classifiers like KNN++, KNN, SVM, ELM, and standard CNN, we found that the proposed system can train and validate the data by itself. It has also been brought into consideration that enhanced KNN and KNN classifiers perform significantly better than SVM and ELM classifier. The major reason is due to the integral weight factor and the distance parameters of these classifiers.
Moreover, we also observed during experimentation of the proposed method that the computers embedded with high performance Graphics Processing Unit (GPU) can further increase the speed and accuracy of the proposed framework. For fast training of dataset, AlexNet uses a Graphical Processing Unit (GPU) if its integrated on a system. It requires a parallel computing toolbox with CUDA enabled GPU, otherwise it uses Central Processing Unit (CPU) of a system. Our system is not integrated with GPU, therefore the proposed framework used CPU for training of sports videos.
It has also been observed that the proposed network stops training once it is confirmed that no validation loss is taking place, i.e., the dataset has been trained to a maximum limit. This is the advantage of our proposed network over standard CNN. Moreover, if Weight Learn Rate Factor (WLRF) and Bias Learn Rate Factor (BLRF) values of fully connected layers are increased, the leaning rate of training rises significantly. In addition, we observed during the experimentation that decreases the size of dataset to 25% increases the learning rate of the data.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}