A Distributed Algorithm for Fast Mining Frequent Patterns in Limited and Varying Network Bandwidth Environments

 ,
,
Abstract
:1. Introduction
2. Related Work
3. Proposed Method
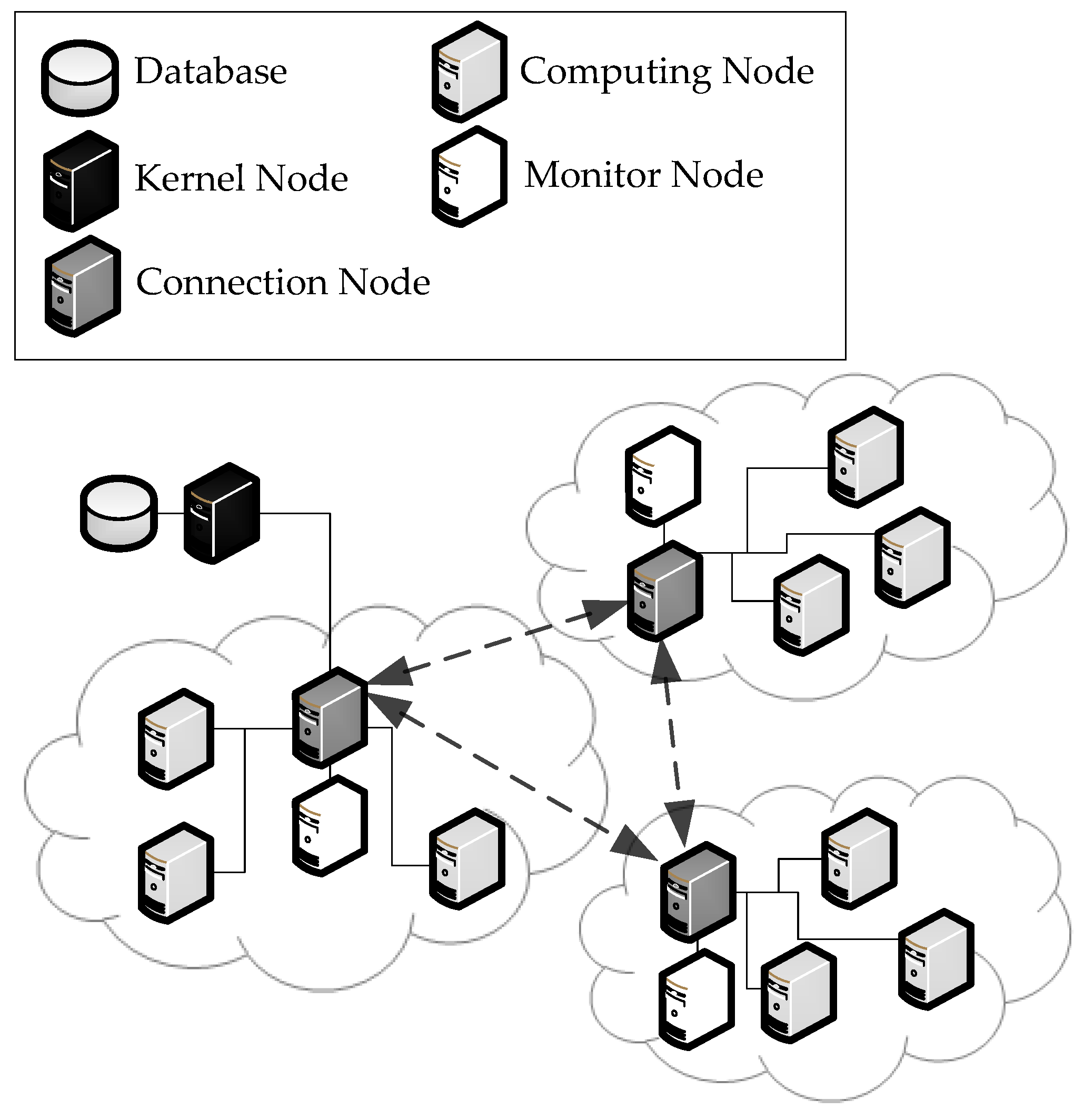
3.1. System Structure
3.2. FDCNB-MINING Algorithm
- Step 1
- Before the kernel node is activated, the monitor node must begin operation to constantly monitor the network bandwidth environment. (Line 1)
- Step 2
- When the kernel node needs to select one of the computing nodes to transmit compressed files, the monitor node provides the best computing node to the kernel node. (Line 5)
- Step 3
- If the monitor node finds the kernel node of using low bandwidth during transfer, it informs the kernel node to discontinue transmission and change into a better computing node to transfer information; otherwise, transmission is continued. FDCNB-MINING sorts computing nodes in descending order according to the performance index of bandwidth that reflects their real-time network bandwidth. A packet with size is sent to each computing node periodically from the kernel node, and the computing node acknowledges the kernel node after receiving the packet. In this way, the response time between kernel node and every computing node can be obtained. The performance index of bandwidth Bp is defined as s/t, where s is the size of transferred packet and t is the elapsed time the packet sent from the kernel node to the computing node. Paused transmitted data are saved in the computing node until the monitor node finds a recovery bandwidth. The kernel node then waits to be informed by the monitor node to mine and continue to transfer the unfinished part. (Line 7–10)
- Step 4
- This process is repeated until the kernel node does not need the computing node to help in the mining operation.
3.3. Example
| Algorithm FDCNB-MINING | |
| Input A transaction database D, minimum support S. | |
| Output Frequent Patterns FP | |
| 1 | Monitor.work (); |
| 2 | HT = getHT(D, S); |
| 3 | tree = buildFPtree(D, S); |
| 4 | WHILE (isNotEmty(HT)) |
| 5 | n = Monitor.getBestNode(); |
| 6 | transmitTree(tree, n); |
| 7 | IF(Monitor.findLowBandwidth(n)) |
| 8 | n.stopTransmitting(); |
| 9 | CONTINUE; |
| 10 | END IF |
| 11 | hi = getMiningTask(HT); |
| 12 | HT = HT − hi; |
| 13 | FLR-Mining.BeginMining(n, hi); |
| 14 | END WHILE |
| 15 | RETURN FP |
4. Experimental Results
4.1. Experiment Setup
4.2. Experiment Analysis
4.2.1. Synthetic Data
4.2.2. Real Data—Retail
4.2.3. Real Data—Accidents
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference Very Large Data Bases, VLDB, Santiago, Chile, 12–15 September 1994; pp. 487–499. [Google Scholar]
- Fournier-Viger, P.; Lin, J.C.-W.; Kiran, R.U.; Koh, Y.S.; Thomas, R. A survey of sequential pattern mining. Data Sci. Pattern Recognit. 2017, 1, 54–77. [Google Scholar]
- Gan, W.; Lin, J.C.-W.; Fournier-Viger, P.; Chao, H.C.; Philip, S.Y. HUOPM: High-Utility Occupancy Pattern Mining. IEEE Trans. Cybern. 2019. [Google Scholar] [CrossRef] [PubMed]
- Luo, P.; Lu, K.; Shi, Z.; He, Q. Distributed data mining in grid computing environments. Future Gener. Comput. Syst. 2007, 23, 84–91. [Google Scholar] [CrossRef]
- Garlasu, D.; Sandulescu, V.; Halcu, I.; Neculoiu, G.; Grigoriu, O.; Marinescu, M.; Marinescu, V. A big data implementation based on Grid computing. In Proceedings of the Roedunet International Conference (RoEduNet), Sinaia, Romania, 17–19 January 2013; pp. 1–4. [Google Scholar]
- Lin, J.C.-W.; Wu, J.M.-T.; Fournier-Viger, P.; Djenouri, Y.; Chen, C.H.; Zhang, Y. A Sanitization Approach to Secure Shared Data in an IoT Environment. IEEE Access 2017, 7, 25359–25368. [Google Scholar] [CrossRef]
- Lin, J.C.-W.; Yang, L.; Fournier-Viger, P.; Hong, T.-P. Mining of skyline patterns by considering both frequent and utility constraints. Eng. Appl. Artif. Intell. 2019, 77, 229–238. [Google Scholar] [CrossRef]
- Lin, K.W.; Lo, Y.-C. A fast parallel algorithm for discovering frequent patterns. In Proceedings of the 2009 IEEE International Conference on Granular Computing, Nanchang, China, 17–19 August 2009; pp. 398–403. [Google Scholar]
- Lin, K.W.; Lo, Y.-C. Efficient algorithms for frequent pattern mining in many-task computing environments. Knowl. Based Syst. 2013, 49, 10–21. [Google Scholar] [CrossRef]
- Lin, K.W.; Chung, S.-H. A fast and resource efficient mining algorithm for discovering frequent patterns in distributed computing environments. Future Gener. Comput. Syst. 2015, 52, 49–58. [Google Scholar] [CrossRef]
- Park, J.S.; Chen, M.-S.; Yu, P.S. Using a hash-based method with transaction trimming for mining association rules. Knowledge and Data Engineering. IEEE Trans. Knowl. Data Eng. 1997, 9, 813–825. [Google Scholar] [CrossRef]
- Ozel, S.A.; Guvenir, H. An algorithm for mining association rules using perfect hashing and database pruning. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.28.6116&rep=rep1&type=pdf (accessed on 3 May 2019).
- Agarwal, J.; Singh, A. Frequent item set generation based on transaction hashing. In Proceedings of the 2014 5th International Conference—Confluence the Next Generation Information Technology Summit (Confluence), Noida, India, 25–26 September 2014; pp. 182–187. [Google Scholar]
- Brin, S.; Motwani, R.; Ullman, J.D.; Tsur, S. Dynamic itemset counting and implication rules for market basket data. ACM Sigmod Rec. 1997, 26, 255–264. [Google Scholar] [CrossRef]
- Yang, X.Y.; Liu, Z.; Fu, Y. Mapreduce as a programming model for association rules algorithm on hadoop. In Proceedings of the 2010 3rd International Conference on Information Sciences and Interaction Sciences (ICIS), Chengdu, China, 23–25 June 2010; pp. 99–102. [Google Scholar]
- Yu, K.-M.; Zhou, J.; Hong, T.-P.; Zhou, J.-L. A load-balanced distributed parallel mining algorithm. Expert Syst. Appl. 2010, 37, 2459–2464. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Yin, Y. Mining frequent patterns without candidate generation. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000; pp. 1–12. [Google Scholar]
- Zaïane, O.R.; El-Hajj, M.; Lu, P. Fast parallel association rule mining without candidacy generation. In Proceedings of the 2001 IEEE International Conference on Data Mining, San Jose, CA, USA, 29 November–2 December 2001; pp. 665–668. [Google Scholar]
- Shang, X.; Sattler, K.U.; Geist, I. Sql based frequent pattern mining without candidate generation. In Proceedings of the 2004 ACM Symposium on Applied Computing, Nicosia, Cyprus, 14–17 March 2004; pp. 618–619. [Google Scholar]
- Schlegel, B.; Gemulla, R.; Lehner, W. Memory-efficient frequent-itemset mining. In Proceedings of the 14th International Conference on Extending Database Technology, ACM, Uppsala, Sweden, 21–24 March 2011; pp. 461–472. [Google Scholar]
- Javed, A.; Khokhar, A. Frequent Pattern Mining on Message Passing Multiprocessor Systems. Distrib. Parallel Database 2004, 16, 321–334. [Google Scholar] [CrossRef]
- Zhou, J.; Yu, K.-M. Tidset-based parallel FP-tree algorithm for the frequent pattern mining problem on PC clusters. In Advances in Grid and Pervasive Computing; Springer: Berlin/Heidelberg, Germany, 2008; pp. 18–28. [Google Scholar]
- Zhou, J.; Yu, K.-M. Balanced tidset-based parallel FP-tree algorithm for the frequent pattern mining on grid system. In Proceedings of the 2008 Fourth International Conference on Semantics, Knowledge and Grid, Kunming, China, 25–28 May 2008; pp. 103–108. [Google Scholar]
- Lai, Y.; ZhongZhi, S. An efficient data mining framework on Hadoop using Java persistence API. In Proceedings of the 2010 IEEE 10th International Conference on Computer and Information Technology (CIT), Bradford, UK, 29 June–1 July 2010; pp. 203–209. [Google Scholar]
- Yang, L.; Shi, Z.; Xu, L.D.; Liang, F.; Kirsh, I. DH-TRIE frequent pattern mining on Hadoop using JPA. In Proceedings of the 2011 IEEE International Conference on Granular Computing (GrC), Kaohsiung, Taiwan, 8–10 November 2011; pp. 875–878. [Google Scholar]
- Lin, W.-T.; Chu, C.-P. Determining the appropriate number of nodes for fast mining of frequent patterns in distributed computing environments. Int. J. Parallel Emergent Distrib. Syst. 2015, 30, 380–392. [Google Scholar] [CrossRef]
- Agrawal, R.; Srikant, R. Quest Synthetic Data Generator; IBM Almaden Research Center: San Jose, CA, USA, 1994. [Google Scholar]
- Brijs, T.; Swinnen, G.; Vanhoof, K.; Wets, G. Using association rules for product assortment decisions: A case study. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; pp. 254–260. [Google Scholar]
- Geurts, K.; Wets, G.; Brijs, T.; Vanhoof, K. Profiling of high-frequency accident locations by use of association rules. Transp. Res. Rec. 2003, 1840, 123–130. [Google Scholar] [CrossRef]
- Goethals, B.; Zaki, M.J. Frequent Itemset Mining Dataset Repository. 2003. Available online: http://fimi.ua.ac.be/data/ (accessed on 3 May 2019).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Bandwidth (Mbps) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Node | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Case 1 | Bandwidths are all 100 | |||||||||
| Case 2 | 3 | 80 | 6 | 77 | 35 | 69 | 87 | 63 | 14 | 22 |
| Case 3 | 38 | 60 | 88 | 95 | 100 | 36 | 80 | 69 | 68 | 20 |
| Case 4 | 87 | 19 | 36 | 100 | 38 | 92 | 25 | 61 | 76 | 68 |
| Case 5 | 34 | 15 | 42 | 41 | 50 | 82 | 90 | 57 | 56 | 93 |
| Case 6 | 42 | 3 | 4 | 10 | 95 | 14 | 78 | 44 | 59 | 7 |
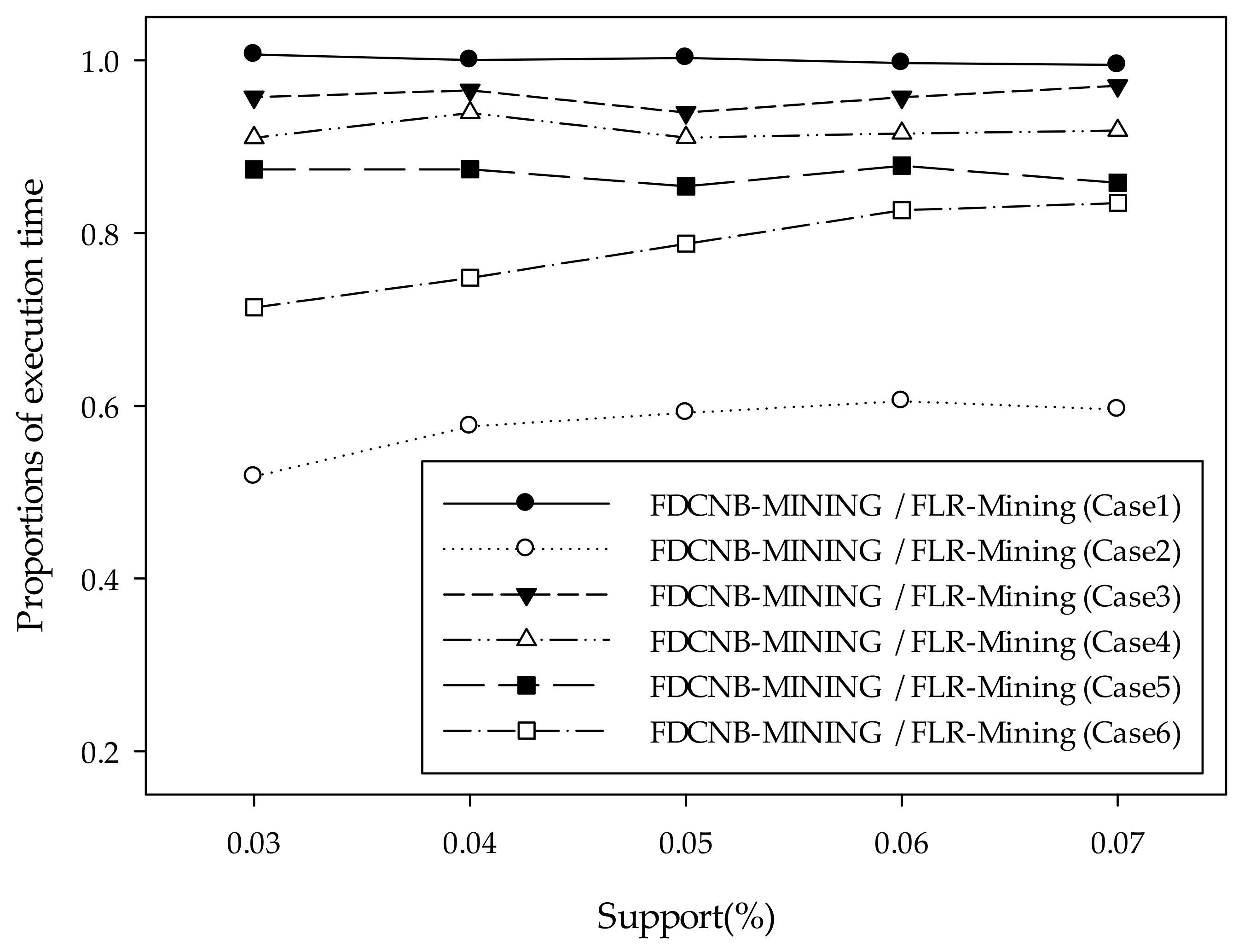
| Support (%) | 0.07 | 0.06 | 0.05 | 0.04 | 0.03 |
|---|---|---|---|---|---|
| Case1 | 0.9947 | 0.9970 | 1.0028 | 1.0002 | 1.0066 |
| Case2 | 0.5960 | 0.6056 | 0.5921 | 0.5764 | 0.5179 |
| Case3 | 0.9707 | 0.9573 | 0.9396 | 0.9656 | 0.9575 |
| Case4 | 0.9188 | 0.9154 | 0.9107 | 0.9395 | 0.9105 |
| Case5 | 0.8583 | 0.8781 | 0.8542 | 0.8742 | 0.8739 |
| Case6 | 0.8350 | 0.8265 | 0.7878 | 0.7485 | 0.7140 |
| Support (%) | 0.05 | 0.04 | 0.03 | 0.02 | 0.01 |
|---|---|---|---|---|---|
| Case 1 | 1.0013 | 1.0138 | 0.9960 | 0.9927 | 0.9904 |
| Case 2 | 0.3978 | 0.3713 | 0.3738 | 0.3957 | 0.3414 |
| Case 3 | 0.8857 | 0.8801 | 0.9093 | 0.9048 | 0.8976 |
| Case 4 | 0.8934 | 0.8720 | 0.8885 | 0.8001 | 0.8284 |
| Case 5 | 0.8163 | 0.7814 | 0.7776 | 0.8078 | 0.7255 |
| Case 6 | 0.8678 | 0.8108 | 0.7655 | 0.7668 | 0.6603 |
| Support (%) | 45 | 40 | 35 | 30 | 25 |
|---|---|---|---|---|---|
| Case1 | 0.9922 | 1.0057 | 1.0074 | 1.0117 | 0.9970 |
| Case2 | 0.3996 | 0.3643 | 0.2496 | 0.1854 | 0.1943 |
| Case3 | 0.9090 | 0.8926 | 0.9020 | 0.7831 | 0.8185 |
| Case4 | 0.9054 | 0.8746 | 0.9073 | 0.7900 | 0.6940 |
| Case5 | 0.8455 | 0.7885 | 0.7552 | 0.6538 | 0.5861 |
| Case6 | 0.8875 | 0.8110 | 0.7500 | 0.6597 | 0.6211 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, C.-C.; Li, W.-C.; Chen, J.-C.; Chung, W.-Y.; Chung, S.-H.; Lin, K.W. A Distributed Algorithm for Fast Mining Frequent Patterns in Limited and Varying Network Bandwidth Environments. Appl. Sci. 2019, 9, 1859. https://doi.org/10.3390/app9091859
Lin C-C, Li W-C, Chen J-C, Chung W-Y, Chung S-H, Lin KW. A Distributed Algorithm for Fast Mining Frequent Patterns in Limited and Varying Network Bandwidth Environments. Applied Sciences. 2019; 9(9):1859. https://doi.org/10.3390/app9091859
Chicago/Turabian StyleLin, Chun-Cheng, Wei-Ching Li, Ju-Chin Chen, Wen-Yu Chung, Sheng-Hao Chung, and Kawuu W. Lin. 2019. "A Distributed Algorithm for Fast Mining Frequent Patterns in Limited and Varying Network Bandwidth Environments" Applied Sciences 9, no. 9: 1859. https://doi.org/10.3390/app9091859