
Sub-Lexical Processing of Chinese–English Bilinguals: An ERP Analysis

Abstract
:1. Introduction
1.1. Models of Bilinguals Lexical Processing
1.2. Implicit L1 Activation While Reading in a Second Language
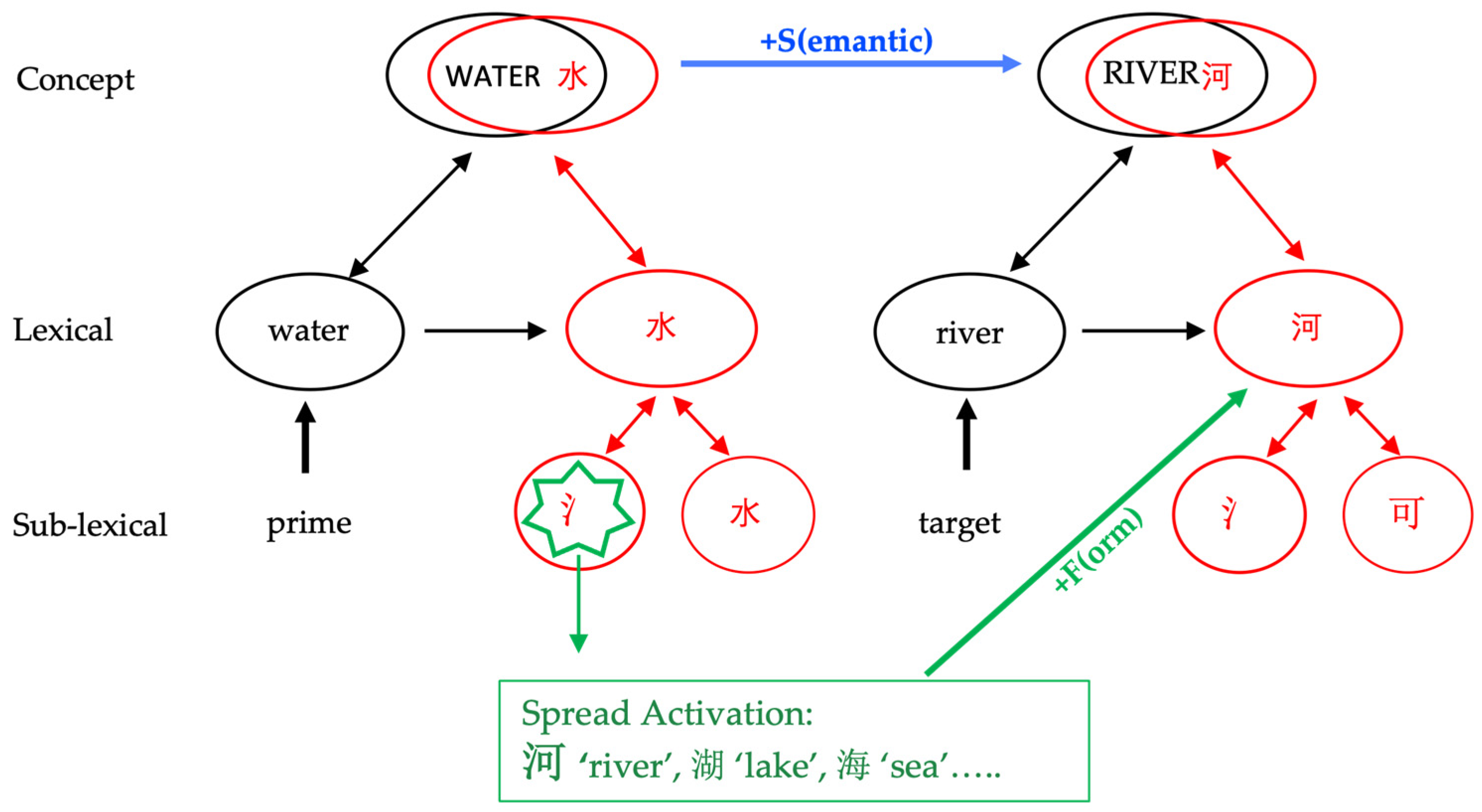
1.3. Sub-Lexical Encoding in Chinese Orthography
1.4. Current Study: Rationale and Predictions
 (狗)--狼 ‘dog-wolf’; +O−S (狗)-猜 ‘dog-guess’). They argued that less processing effort is needed for orthographically similar characters as the corresponding picture name would co-activate characters sharing the same radicals, contributing to facilitation in orthographic processing. Although the exact underlying cognitive function remains unclear, a consistent finding revealed by these studies is that a reduced P200 is associated with orthographically similar words. Based on these previous results, for the current study, we predict a reduction in the P200 for Chinese–English bilinguals when processing English word pairs whose Chinese translation equivalents share a semantic radical, compared to those without a shared semantic radical.
(狗)--狼 ‘dog-wolf’; +O−S (狗)-猜 ‘dog-guess’). They argued that less processing effort is needed for orthographically similar characters as the corresponding picture name would co-activate characters sharing the same radicals, contributing to facilitation in orthographic processing. Although the exact underlying cognitive function remains unclear, a consistent finding revealed by these studies is that a reduced P200 is associated with orthographically similar words. Based on these previous results, for the current study, we predict a reduction in the P200 for Chinese–English bilinguals when processing English word pairs whose Chinese translation equivalents share a semantic radical, compared to those without a shared semantic radical.2. Methods
2.1. Participants
2.2. Material and Design
2.2.1. Semantic Relatedness Task
2.2.2. Translation Task
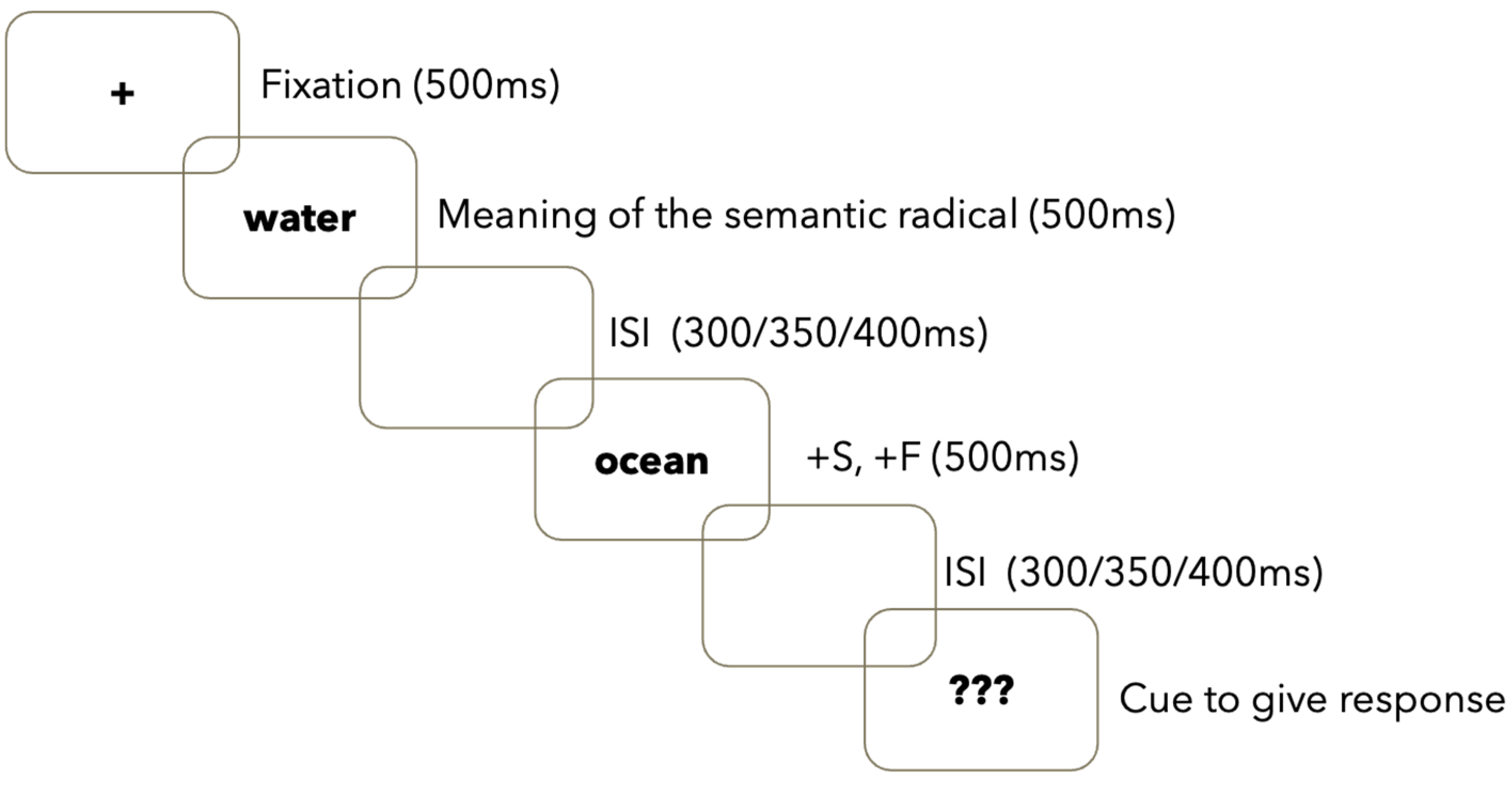
2.3. Study Procedure
2.4. EEG Recording and Preprocessing
2.5. Data Analyses
3. Results
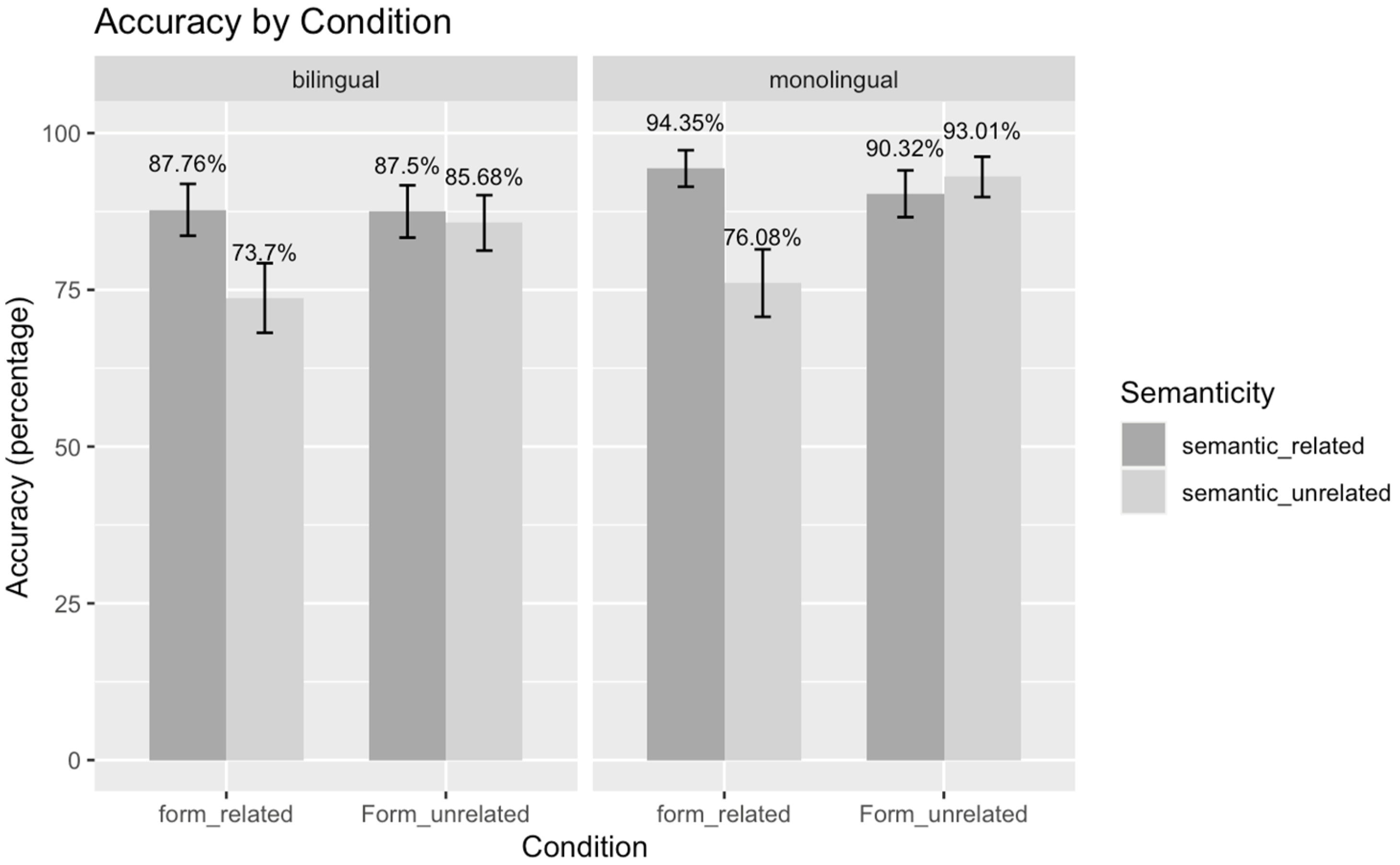
3.1. Behavioral Results
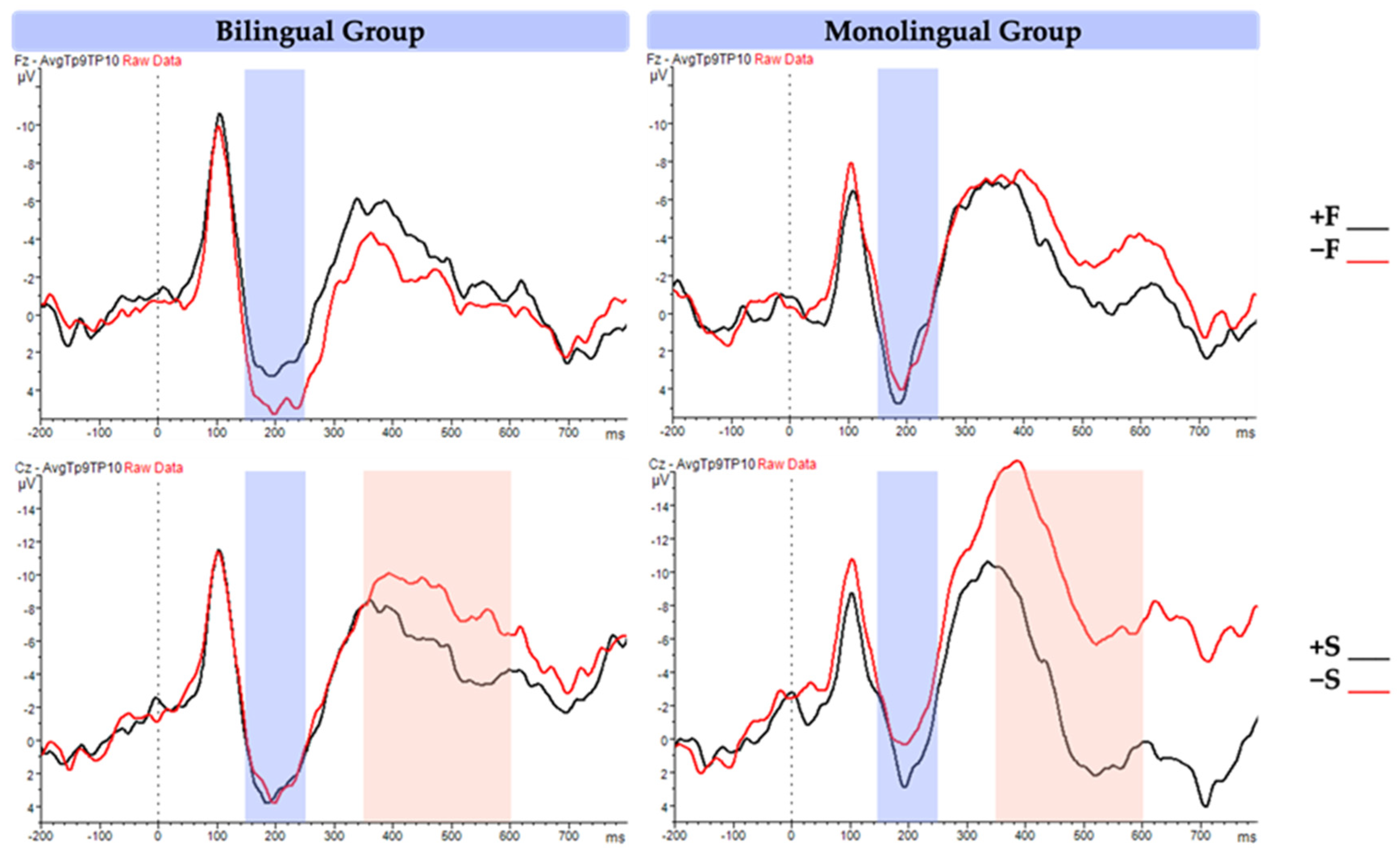
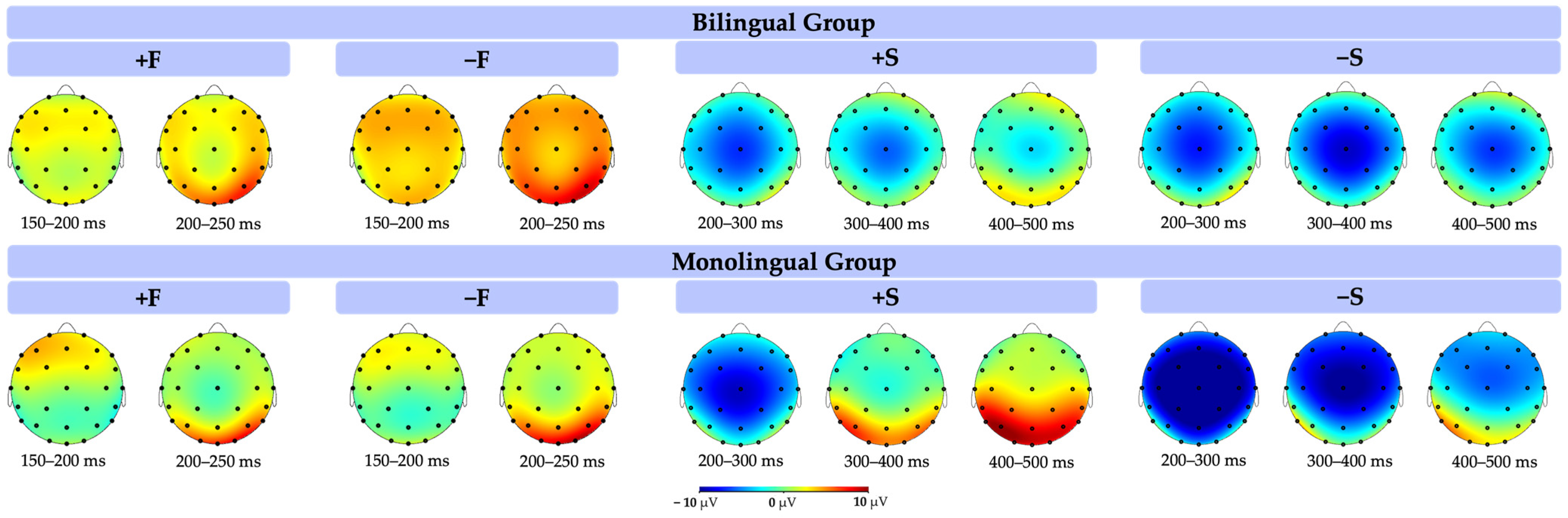
3.2. ERP Results
3.2.1. P200
3.2.2. N400
4. Discussion
4.1. Discussion of Behavioral Results
4.2. Discussion of ERP Results
4.2.1. P200 Findings and Interpretation
4.2.2. P200 Revisit for Bilingual Sub-Lexical Processing
(狗)-狼 ‘dog-wolf’; +O−S (狗)-猜 ‘dog-guess’). 4.2.3. N400 and Semantic Processing
4.3. Implications for Current Models of Bilingual Lexical Co-Activation
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Thierry, G.; Wu, Y.J. Brain Potentials Reveal Unconscious Translation during Foreign-Language Comprehension. Proc. Natl. Acad. Sci. USA 2007, 104, 12530–12535. [Google Scholar] [CrossRef] [PubMed]
- Green, D.W.; Abutalebi, J. Language Control in Bilinguals: The Adaptive Control Hypothesis. J. Cogn. Psychol. 2013, 25, 515–530. [Google Scholar] [CrossRef] [PubMed]
- Kroll, J.F.; Gullifer, J.W.; McClain, R.; Rossi, E.; Martín, M.C. Selection and Control in Bilingual Comprehension and Production. In The Cambridge Handbook of Bilingual Processing; Schwieter, J.W., Ed.; Cambridge Handbooks in Language and Linguistics; Cambridge University Press: Cambridge, UK, 2015; pp. 485–507. [Google Scholar] [CrossRef]
- Marian, V.; Blumenfeld, H.K.; Boukrina, O.V. Sensitivity to Phonological Similarity Within and Across Languages. J. Psycholinguist. Res. 2008, 37, 141–170. [Google Scholar] [CrossRef] [PubMed]
- Ju, M.; Luce, P.A. Falling on Sensitive Ears: Constraints on Bilingual Lexical Activation. Psychol. Sci. 2004, 15, 314–318. [Google Scholar] [CrossRef]
- Hoshino, N.; Thierry, G. Do Spanish-English Bilinguals Have Their Fingers in Two Pies—Or Is It Their Toes? An Electrophysiological Investigation of Semantic Access in Bilinguals. Front. Psychol. 2012, 3, 9. [Google Scholar] [CrossRef]
- Hatzidaki, A.; Branigan, H.P.; Pickering, M.J. Co-Activation of Syntax in Bilingual Language Production. Cognit. Psychol. 2011, 62, 123–150. [Google Scholar] [CrossRef]
- Vaughan-Evans, A.; Liversedge, S.P.; Fitzsimmons, G.; Jones, M.W. Syntactic Co-Activation in Natural Reading. Vis. Cogn. 2020, 28, 541–556. [Google Scholar] [CrossRef]
- Marian, V.; Spivey, M. Competing Activation in Bilingual Language Processing: Within- and between-Language Competition. Biling. Lang. Cogn. 2003, 6, 97–115. [Google Scholar] [CrossRef]
- Morford, J.P.; Wilkinson, E.; Villwock, A.; Piñar, P.; Kroll, J.F. When Deaf Signers Read English: Do Written Words Activate Their Sign Translations? Cognition 2011, 118, 286–292. [Google Scholar] [CrossRef]
- Hoshino, N.; Midgley, K.J.; Holcomb, P.J.; Grainger, J. An ERP Investigation of Masked Cross-Script Translation Priming. Brain Res. 2010, 1344, 159–172. [Google Scholar] [CrossRef]
- Van Heuven, W.J.B.; Schriefers, H.; Dijkstra, T.; Hagoort, P. Language Conflict in the Bilingual Brain. Cereb. Cortex 2008, 18, 2706–2716. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Perfetti, C.A.; Fang, X.; Chang, L.Y. Activation of L1 Orthography in L2 Word Reading: Constraints from Language and Writing System. Second Lang. Res. 2021, 37, 323–348. [Google Scholar] [CrossRef]
- Chen, S.; Fu, T.; Zhao, M.; Zhang, Y.; Peng, Y.; Yang, L.; Gu, X. Masked Translation Priming With Concreteness of Cross-Script Cognates in Visual Word Recognition by Chinese Learners of English: An ERP Study. Front. Psychol. 2022, 12, 796700. [Google Scholar] [CrossRef] [PubMed]
- Degani, T.; Prior, A.; Hajajra, W. Cross-Language Semantic Influences in Different Script Bilinguals. Bilingualism 2018, 21, 782–804. [Google Scholar] [CrossRef]
- Dijkstra, T.O.N.; Van Jaarsveld, H.; Brinke, S.T. Interlingual Homograph Recognition: Effects of Task Demands and Language Intermixing. Biling. Lang. Cogn. 1998, 1, 51–66. [Google Scholar] [CrossRef]
- Kerkhofs, R.; Dijkstra, T.; Chwilla, D.J.; De Bruijn, E.R.A. Testing a Model for Bilingual Semantic Priming with Interlingual Homographs: RT and N400 Effects. Brain Res. 2006, 1068, 170–183. [Google Scholar] [CrossRef]
- Martin, C.D.; Dering, B.; Thomas, E.M.; Thierry, G. Brain Potentials Reveal Semantic Priming in Both the “active” and the “Non-Attended” Language of Early Bilinguals. NeuroImage 2009, 47, 326–333. [Google Scholar] [CrossRef]
- Wen, Y.; van Heuven, W.J.B. Limitations of Translation Activation in Masked Priming: Behavioural Evidence from Chinese-English Bilinguals and Computational Modelling. J. Mem. Lang. 2018, 101, 84–96. [Google Scholar] [CrossRef]
- Myers, J. The Grammar of Chinese Characters|Productive Knowledge of Formal Patterns in an Orthographic System, 1st ed.; Routledge: London, UK, 2019. [Google Scholar]
- Hsu, C.H.; Wu, Y.N.; Lee, C.Y. Effects of Phonological Consistency and Semantic Radical Combinability on N170 and P200 in the Reading of Chinese Phonograms. Front. Psychol. 2021, 12, 603878. [Google Scholar] [CrossRef]
- Dijkstra, T.; van Heuven, W.J.B. The Architecture of the Bilingual Word Recognition System: From Identification to Decision. Biling. Lang. Cogn. 2002, 5, 175–197. [Google Scholar] [CrossRef]
- Kroll, J.F.; Stewart, E. Category Interference in Translation and Picture Naming: Evidence for Asymmetric Connections Between Bilinguals Memory Representation. J. Mem. Lang. 1994, 33, 149–174. [Google Scholar] [CrossRef]
- Dijkstra, T.O.N.; Wahl, A.; Buytenhuijs, F.; Van Halem, N.; Al-Jibouri, Z.; De Korte, M.; Rekké, S. Multilink: A Computational Model for Bilingual Word Recognition and Word Translation. Bilingualism 2019, 22, 657–679. [Google Scholar] [CrossRef]
- Midgley, K.J.; Holcomb, P.J.; Grainger, J. Effects of Cognate Status on Word Comprehension in Second Language Learners: An ERP Investigation. Cogn. Neurosci. 2011, 23, 1634–1647. [Google Scholar] [CrossRef] [PubMed]
- Strijkers, K.; Costa, A.; Thierry, G. Tracking Lexical Access in Speech Production: Electrophysiological Correlates of Word Frequency and Cognate Effects. Cereb. Cortex 2010, 20, 912–928. [Google Scholar] [CrossRef]
- Guo, T.; Misra, M.; Tam, J.W.; Kroll, J.F. On the Time Course of Accessing Meaning in a Second Language: An Electrophysiological and Behavioral Investigation of Translation Recognition. J. Exp. Psychol. Learn. Mem. Cogn. 2012, 38, 1165–1186. [Google Scholar] [CrossRef]
- Shen, H.H.; Ke, C. Radical Awareness and Word Acquisition Among Nonnative Learners of Chinese. Mod. Lang. J. 2007, 91, 97–111. [Google Scholar] [CrossRef]
- Shu, H.; Anderson, R.C. Learning to Read Chinese: The Development of Metalinguistic Awareness. In Reading Chinese Script; Psychology Press: London, UK, 1999. [Google Scholar]
- Su, X.; Kim, Y.-S. Semantic Radical Knowledge and Word Recognition in Chinese for Chinese as Foreign Language Learners. Read. Foreign Lang. 2014, 26, 131–152. [Google Scholar]
- Taft, M.; Zhu, X.; Peng, D. Positional Specificity of Radicals in Chinese Character Recognition. J. Mem. Lang. 1999, 40, 498–519. [Google Scholar] [CrossRef]
- Williams, C.; Bever, T. Chinese Character Decoding: A Semantic Bias? Read. Writ. 2010, 23, 589–605. [Google Scholar] [CrossRef]
- Wang, X.; Pei, M.; Wu, Y.; Su, Y. Semantic Radicals Contribute More than Phonetic Radicals to the Recognition of Chinese Phonograms: Behavioral and ERP Evidence in a Factorial Study. Front. Psychol. 2017, 8, 1–9. [Google Scholar] [CrossRef]
- Liu, Y.; Perfetti, C.A.; Hart, L. ERP Evidence for the Time Course of Graphic, Phonological, and Semantic Information in Chinese Meaning and Pronunciation Decisions. J. Exp. Psychol. Learn. Mem. Cogn. 2003, 29, 1231–1247. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Jiang, M.; Huang, Y.; Qiu, P. An ERP Study on the Role of Phonological Processing in Reading Two-Character Compound Chinese Words of High and Low Frequency. Front. Psychol. 2021, 12, 637238. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Su, I.F.; Chen, F.; Ng, M.L.; Wang, L.; Yan, N. The Time Course of Orthographic and Semantic Activation in Chinese Character Recognition: Evidence from anERP Study. Lang. Cogn. Neurosci. 2019, 35, 292–309. [Google Scholar] [CrossRef]
- Holcomb, P.J. Semantic Priming and Stimulus Degradation: Implications for the Role of the N400 in Language Processing. Psychophysiology 1993, 30, 47–61. [Google Scholar] [CrossRef] [PubMed]
- Kutas, M.; Hillyard, S.A. Brain Potentials during Reading Reflect Word Expectancy and Semantic Association. Nature 1984, 307, 161–163. [Google Scholar] [CrossRef]
- Kutas, M.; Hillyard, S.A. Reading Senseless Sentences: Brain Potentials Reflect Semantic Incongruity. Science 1980, 207, 203–205. [Google Scholar] [CrossRef]
- Nieuwland, M.S.; Van Berkum, J.J.A. When Peanuts Fall in Love: N400 Evidence for the Power of Discourse. J. Cogn. Neurosci. 2006, 18, 1098–1111. [Google Scholar] [CrossRef]
- Hagoort, P.; Hald, L.; Bastiaansen, M.; Petersson, K.M. Integration of Word Meaning and World Knowledge in Language Comprehension. Science 2004, 304, 438–441. [Google Scholar] [CrossRef]
- Kutas, M.; Van Petten, C. Event-Related Brain Potential Studies of Language. Adv. Psychophysiol. 1988, 3, 139–187. [Google Scholar] [CrossRef]
- Kutas, M.; Federmeier, K.D. Thirty Years and Counting: Finding Meaning in the N400 Component of the Event-Related Brain Potential (ERP). Annu. Rev. Psychol. 2011, 62, 621–647. [Google Scholar] [CrossRef]
- Li, P.; Zhang, F.; Yu, A.; Zhao, X. Language History Questionnaire (LHQ3): An Enhanced Tool for Assessing Multilingual Experience. Biling. Lang. Cogn. 2020, 23, 938–944. [Google Scholar] [CrossRef]
- Marian, V.; James, B.; Sarah, C.; Anthony, S. CLEARPOND: Cross-Linguistic Easy-Access Resource for Phonological and Orthographic Neighborhood Densities. PLoS ONE 2012, 7, e43230. [Google Scholar] [CrossRef] [PubMed]
- Xu, J. Torch Corpus: Texts of Recent Chinese (2013 Summer Edition); Corpus Research Group, Beijing Foreign Studies University: Beijing, China, 2013. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sevastopol, CA, USA, 2009. [Google Scholar]
- Mamoun, A.H.; Abid, A. Semantic Measures Based on WordNet Using Multiple Information Sources. In Proceedings of the International Conference on Knowledge Discovery and Information Retrieval IC3K, Valencia, Spain, 25–28 October 2010; pp. 500–503. [Google Scholar] [CrossRef]
- Feng, Y.; Bagheri, E.; Ensan, F.; Jovanovic, J. The State of the Art in Semantic Relatedness: A Framework for Comparison. Knowl. Eng. Rev. 2017, 32, e10. [Google Scholar] [CrossRef]
- Wu, Z.; Palmer, M. Verb Semantics and Lexical Selection. In Proceedings of the 32nd annual meeting on Association for Computational Linguistics, Las Cruces, New Mexico, 27–30 June 1994; pp. 133–138. [Google Scholar] [CrossRef]
- Psychology Software Tools, Inc. E-Prime 3.0; Psychology Software Tools, Inc.: Pittsburgh, PA, USA, 2016. [Google Scholar]
- Eberhardt, P. Varying Inter-Stimulus and Inter-Trial Intervals During Stimulus-Stimulus Pairing: A Translational Extension of Autoshaping. Thesis Proj. 2019, 14, 5–43. [Google Scholar]
- Brain Products GmbH. actiCHamp; Brain Products GmbH: Gilching, Germany, 2019. [Google Scholar]
- Brain Products GmbH. BrainVision Analyzer 2.2.2; Brain Products GmbH: Gilching, Germany, 2021. [Google Scholar]
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting Linear Mixed-Effects Models Using Lme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Enviorment for Statistical Computing; R Core Team: Vienna, Austria, 2021. [Google Scholar]
- Khachatryan, E.; Wittevrongel, B.; De Keyser, K.; De Letter, M.; Van Hulle, M.M. Event Related Potential Study of Language Interaction in Bilingual Aphasia Patients. Front. Hum. Neurosci. 2018, 12, 81. [Google Scholar] [CrossRef]
- van Kesteren, R.; Dijkstra, T.; de Smedt, K. Markedness Effects in Norwegian-English Bilinguals: Task-Dependent Use of Language-Specific Letters and Bigrams. Q. J. Exp. Psychol. 2012, 65, 2129–2154. [Google Scholar] [CrossRef]
- Anderson, J.R. The Architecture of Cognition; The architecture of cognition; Lawrence Erlbaum Associates, Inc.: Hillsdale, NJ, USA, 1983; p. 345. [Google Scholar]
- Collins, A.M.; Loftus, E.F. A Spreading-Activation Theory of Semantic Processing. Psychol. Rev. 1975, 82, 407–428. [Google Scholar] [CrossRef]
- McNamara, T.P. Theories of Priming: I. Associative Distance and Lag. J. Exp. Psychol. Learn. Mem. Cogn. 1992, 18, 1173–1190. [Google Scholar] [CrossRef]
- McNamara, T.P. Theories of Priming: II. Types of Primes. J. Exp. Psychol. Learn. Mem. Cogn. 1994, 20, 507–520. [Google Scholar] [CrossRef]
- Landi, N.; Perfetti, C.A. An Electrophysiological Investigation of Semantic and Phonological Processing in Skilled and Less-Skilled Comprehenders. Brain Lang. 2007, 102, 30–45. [Google Scholar] [CrossRef] [PubMed]
- Levenshtein, V. Binary Codes Capable of Correcting Deletions, Insertions, and Reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Hsu, C.H.; Tsai, J.L.; Lee, C.Y.; Tzeng, O.J.L. Orthographic Combinability and Phonological Consistency Effects in Reading Chinese Phonograms: An Event-Related Potential Study. Brain Lang. 2009, 108, 56–66. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Kang, C.; Guo, T. Brain Electrophysiological Responses to Emotion Nouns versus Emotionless Nouns. J. Neurolinguist. 2019, 49, 144–154. [Google Scholar] [CrossRef]
- Yao, Z.; Wang, Z. The Effects of the Concreteness of Differently Valenced Words on Affective Priming. Acta Psychol. 2013, 143, 269–276. [Google Scholar] [CrossRef]
- Barber, H.A.; Otten, L.J.; Kousta, S.-T.; Vigliocco, G. Concreteness in Word Processing: ERP and Behavioral Effects in a Lexical Decision Task. Brain Lang. 2013, 125, 47–53. [Google Scholar] [CrossRef]
- Kanske, P.; Kotz, S.A. Concreteness in Emotional Words: ERP Evidence from a Hemifield Study. Brain Res. 2007, 1148, 138–148. [Google Scholar] [CrossRef]
- Pauligk, S.; Kotz, S.A.; Kanske, P. Differential Impact of Emotion on Semantic Processing of Abstract and Concrete Words: ERP and fMRI Evidence. Sci. Rep. 2019, 9, 14439. [Google Scholar] [CrossRef]
- Tsang, Y.-K.; Zou, Y. An ERP Megastudy of Chinese Word Recognition. Psychophysiology 2022, 59, e14111. [Google Scholar] [CrossRef]
- Jin, Y.; Ma, Y.; Li, M.; Zheng, X. The Influence of Word Concreteness on Acquired Positive Emotion Association: An Event-Related Potential Study. Acta Psychol. 2023, 240, 104052. [Google Scholar] [CrossRef]
- Yeomans, M. A Concrete Example of Construct Construction in Natural Language. Organ. Behav. Hum. Decis. Process. 2021, 162, 81–94. [Google Scholar] [CrossRef]
- Altın, E.; Okur, N.; Yalçın, E.; Eraçıkbaş, A.F.; Aktan-Erciyes, A. Relations Between L2 Proficiency and L1 Lexical Property Evaluations. Front. Psychol. 2022, 13, 820702. [Google Scholar] [CrossRef] [PubMed]
- De Groot, A.M.B.; Keijzer, R. What Is Hard to Learn Is Easy to Forget: The Roles of Word Concreteness, Cognate Status, and Word Frequency in Foreign-Language Vocabulary Learning and Forgetting. Lang. Learn. 2000, 50, 1–56. [Google Scholar] [CrossRef]
- Walker, I.; Hulme, C. Concrete Words Are Easier to Recall than Abstract Words: Evidence for a Semantic Contribution to Short-Term Serial Recall. J. Exp. Psychol. Learn. Mem. Cogn. 1999, 25, 1256–1271. [Google Scholar] [CrossRef]
- Posner, M.I.; Snyder, C.R.R. Attention and Cognitive Control; Cognitive psychology: Key readings; Psychology Press: New York, NY, USA, 2004; p. 223. [Google Scholar]
- Perfetti, C.A.; Tan, L.H. The Time Course of Graphic, Phonological, and Semantic Activation in Chinese Character Identification. J. Exp. Psychol. Learn. Mem. Cogn. 1998, 24, 101. [Google Scholar] [CrossRef]
- Zeguers, M.H.T.; Snellings, P.; Huizenga, H.M.; van der Molen, M.W. Time Course Analyses of Orthographic and Phonological Priming Effects during Word Recognition in a Transparent Orthography. Q. J. Exp. Psychol. 2014, 67, 1925–1943. [Google Scholar] [CrossRef]
- Anurova, I.; Immonen, P. Native vs. Second Language Discrimination in the Modulation of the N400/N400m. Eur. J. Neurosci. 2017, 45, 1289–1299. [Google Scholar] [CrossRef]
- Acheson, D.J.; Ganushchak, L.Y.; Christoffels, I.K.; Hagoort, P. Conflict Monitoring in Speech Production: Physiological Evidence from Bilingual Picture Naming. Brain Lang. 2012, 123, 131–136. [Google Scholar] [CrossRef]
- Comesaña, M.; Sánchez-Casas, R.; Soares, A.P.; Pinheiro, A.P.; Rauber, A.; Frade, S.; Fraga, I. The Interplay of Phonology and Orthography in Visual Cognate Word Recognition: An ERP Study. Neurosci. Lett. 2012, 529, 75–79. [Google Scholar] [CrossRef]
- Poort, E.D.; Rodd, J.M. Towards a Distributed Connectionist Account of Cognates and Interlingual Homographs: Evidence from Semantic Relatedness Tasks. PeerJ. 2019, 7, e6725. [Google Scholar] [CrossRef]
- Jouravlev, O.; Jared, D. Reading Russian-English Homographs in Sentence Contexts: Evidence from ERPs. Bilingualism 2014, 17, 153–168. [Google Scholar] [CrossRef]
- Chen, P.; Bobb, S.C.; Hoshino, N.; Marian, V. Neural Signatures of Language Co-Activation and Control in Bilingual Spoken Word Comprehension. Brain Res. 2017, 1665, 50–64. [Google Scholar] [CrossRef] [PubMed]
- Bobb, S.C.; Von Holzen, K.; Mayor, J.; Mani, N.; Carreiras, M. Co-Activation of the L2 during L1 Auditory Processing: An ERP Cross-Modal Priming Study. Brain Lang. 2020, 203, 104739. [Google Scholar] [CrossRef] [PubMed]
- Martin, C.D.; Thierry, G.; Kuipers, J.R.; Boutonnet, B.; Foucart, A.; Costa, A. Bilinguals Reading in Their Second Language Do Not Predict Upcoming Words as Native Readers Do. J. Mem. Lang. 2013, 69, 574–588. [Google Scholar] [CrossRef]
- Peeters, D.; Dijkstra, T.; Grainger, J. The Representation and Processing of Identical Cognates by Late Bilinguals: RT and ERP Effects. J. Mem. Lang. 2013, 68, 315–332. [Google Scholar] [CrossRef]
- Khachatryan, E.; Camarrone, F.; Fias, W.; Van Hulle, M.M. ERP Response Unveils Effect of Second Language Manipulation on First Language Processing. PLoS ONE 2016, 11, e0167194. [Google Scholar] [CrossRef]
- Yum, Y.N.; Law, S.P.; Mo, K.N.; Lau, D.; Su, I.F.; Shum, M.S.K. Electrophysiological Evidence of Sublexical Phonological Access in Character Processing by L2 Chinese Learners of L1 Alphabetic Scripts. Cogn. Affect. Behav. Neurosci. 2016, 16, 339–352. [Google Scholar] [CrossRef]
- Kim, A.E.; Oines, L.; Miyake, A. Individual Differences in Verbal Working Memory Underlie a Tradeoff between Semantic and Structural Processing Difficulty during Language Comprehension: An ERP Investigation. J. Exp. Psychol. Learn. Mem. Cogn. 2018, 44, 406–420. [Google Scholar] [CrossRef]
- Midgley, K.J.; Holcomb, P.J.; Grainger, J. Language Effects in Second Language Learners and Proficient Bilinguals Investigated with Event-Related Potentials. J. Neuroinguist. 2009, 22, 281–300. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| English Monolinguals (n = 31) | Chinese–English Bilingual (n = 32) | p Value | |
|---|---|---|---|
| Gender | Male = 9 | Male = 13 | >0.1 |
| Age (years) | 19.2 (1.5) | 26.1 (4.1) | <0.001 *** |
| Native language | English | Chinese | |
| English: age of acquisition (years) | 2.0 (1.0) | 8.4 (3.5) | <0.001 *** |
| Chinese: age of acquisition (years) | NA | 2.0 (1.2) | |
| English proficiency: reading | 6.8 (0.4) | 5.2 (1.1) | <0.001 *** |
| English proficiency: listening | 6.7 (0.5) | 5.3 (1.2) | <0.001 *** |
| English proficiency: writing | 6.7 (0.7) | 5.1 (1.0) | <0.001 *** |
| English proficiency: speaking | 6.7 (0.6) | 5.1 (1.1) | <0.001 *** |
| Chinese proficiency: reading | NA | 6.5 (0.9) | |
| Chinese proficiency: listening | NA | 6.7 (0.5) | |
| Chinese proficiency: writing | NA | 6.3 (1.2) | |
| Chinese proficiency: speaking | NA | 6.6 (0.7) | |
| English daily usage (hours) | 13.7 (5.0) | 9.3 (5.3) | <0.01 ** |
| Chinese daily usage(hours) | NA | 6.0 (4.5) | |
| Verbal fluency (English) Word counts per 30 s | 13.3 (3.6) | 10.2 (1.6) | <0.001 *** |
| Verbal fluency (Chinese) Word counts per 30 s | NA | 12.9 (2.2) |
| Semantic Radical: 氵Water Related | +Semantic | −Semantic |
|---|---|---|
| +Form | lake 湖 | law 法 |
| −Form | rain 雨 | hand 手 |
| +S+F | −S+F | +S−F | −S−F | p-Value | |
|---|---|---|---|---|---|
| Word Frequency/1M (English) | 41 (68) | 110 (203) | 69 (174) | 77 (88) | p > 0.1 |
| Orthographic Length (English) | 5 (2) | 6 (2) | 6 (2) | 6 (2) | p > 0.5 |
| Phonological Length (English) | 4 (1) | 5 (2) | 5 (2) | 4 (2) | p > 0.5 |
| Num of Syllables (English) | 1.7 (0.7) | 1.8 (1.0) | 1.8 (0.9) | 1.5 (0.8) | p > 0.5 |
| Num of Morphemes (English) | 1.0 (0.2) | 1.3 (0.6) | 1.1 (0.3) | 1.2 (0.4) | p > 0.1 |
| Word Frequency/1M (Chinese Translation) | 63 (104) | 114 (211) | 88 (106) | 80 (93) | p > 0.1 |
| Num of Syllables/Characters (Chinese Translation) | 1.6 (0.5) | 1.5 (0.5) | 1.6 (0.5) | 1.8 (0.4) | p > 0.1 |
| Accuracy | Estimate | SE | p-Value |
|---|---|---|---|
| Intercept | 2.94 | 0.18 | p < 0.001 *** |
| S(emanticity) | 0.88 | 0.35 | p < 0.05 * |
| F(orm) | −0.67 | 0.30 | p < 0.05 * |
| L(anguage Group) | 1.04 | 0.28 | p < 0.001 *** |
| S×F | 1.72 | 0.57 | p < 0.01 ** |
| S×L | 0.14 | 0.53 | p > 0.05 |
| F×L | −0.10 | 0.40 | p > 0.05 |
| S×F×L | 1.74 | 0.73 | p < 0.05 * |
| RTs | Estimate | SE | p-Value |
|---|---|---|---|
| Intercept | 6.02 | 0.06 | p < 0.001 *** |
| S(emanticity) | −0.06 | 0.03 | p < 0.05 * |
| F(orm) | 0.12 | 0.04 | p < 0.01 ** |
| L(anguage Group) | 0.14 | 0.11 | p > 0.05 |
| S×F | −0.04 | 0.05 | p > 0.05 |
| S×L | 0.07 | 0.06 | p > 0.05 |
| F×L | −0.09 | 0.08 | p > 0.05 |
| S×F×L | −0.01 | 0.10 | p > 0.05 |
| P200 | Estimate | SE | p-Value |
|---|---|---|---|
| Intercept | 1.21 | 0.22 | p < 0.001 *** |
| S(emanticity) | 0.28 | 0.18 | p > 0.05 |
| F(orm) | 0.41 | 0.18 | p < 0.05 * |
| L(anguage Group) | −0.74 | 0.44 | p > 0.05 |
| S×F | 0.28 | 0.37 | p > 0.05 |
| S×L | 0.77 | 0.37 | p < 0.05 * |
| F×L | −0.44 | 0.37 | p > 0.05 |
| N400 | Estimate | SE | p-Value |
|---|---|---|---|
| Intercept | −0.75 | 0.23 | p < 0.01 ** |
| S(emanticity) | 1.40 | 0.23 | p < 0.001 *** |
| F(orm) | 0.16 | 0.23 | p > 0.05 |
| L(anguage Group) | 0.09 | 0.46 | p > 0.05 |
| S×F | 0.87 | 0.47 | p > 0.05 |
| S×L | 1.49 | 0.47 | p < 0.01 ** |
| F×L | −0.40 | 0.47 | p > 0.05 |
| S×F×L | 0.84 | 0.93 | p > 0.05 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Rossi, E. Sub-Lexical Processing of Chinese–English Bilinguals: An ERP Analysis. Brain Sci. 2024, 14, 923. https://doi.org/10.3390/brainsci14090923
Chen Y, Rossi E. Sub-Lexical Processing of Chinese–English Bilinguals: An ERP Analysis. Brain Sciences. 2024; 14(9):923. https://doi.org/10.3390/brainsci14090923
Chicago/Turabian StyleChen, Yihan, and Eleonora Rossi. 2024. "Sub-Lexical Processing of Chinese–English Bilinguals: An ERP Analysis" Brain Sciences 14, no. 9: 923. https://doi.org/10.3390/brainsci14090923
APA StyleChen, Y., & Rossi, E. (2024). Sub-Lexical Processing of Chinese–English Bilinguals: An ERP Analysis. Brain Sciences, 14(9), 923. https://doi.org/10.3390/brainsci14090923