

Analyzing Monthly Blood Test Data to Forecast 30-Day Hospital Readmissions among Maintenance Hemodialysis Patients


 ,
,
Abstract
1. Introduction
2. Preliminary
2.1. Hemodialysis Complications
2.1.1. Anemia
2.1.2. CV Disease
2.1.3. Renal Osteopathy
2.1.4. Nutrition Problem
2.1.5. Dialysis Infection
2.2. Research on Hemodialysis Prediction
2.3. Machine Learning
2.3.1. Decision Trees
- The initial value of entropy is calculated by Equation (1)
- Select the feature result, or the information obtained with minimum entropy as the root node of the decision tree
- Use the minimum entropy value to build the next layer of the decision tree
- Repeat steps 1–3 until all subtrees are of a single category and the entropy value is 0.
2.3.2. The Naive Bayes Classifier
- Gaussian Naive Bayes Classifier: Primarily used when features are continuous variables and the data follow a normal distribution
- Multinomial Naive Bayes Classifier: Mainly used when features are discrete variables
- Bernoulli Naive Bayes Classifier: Similar to the multinomial model, but differs in that Bernoulli features are binary.
2.3.3. Support Vector Machine
2.4. Ensemble Method
2.4.1. Majority Voting
- If p > 0.5, then Pmv increases monotonically in T, then
- If p < 0.5, then Pmv decreases monotonically in T, then
- If p = 0.5, then Pmv = 0.5 for any T
2.4.2. Weighted Voting
3. Materials and Methods
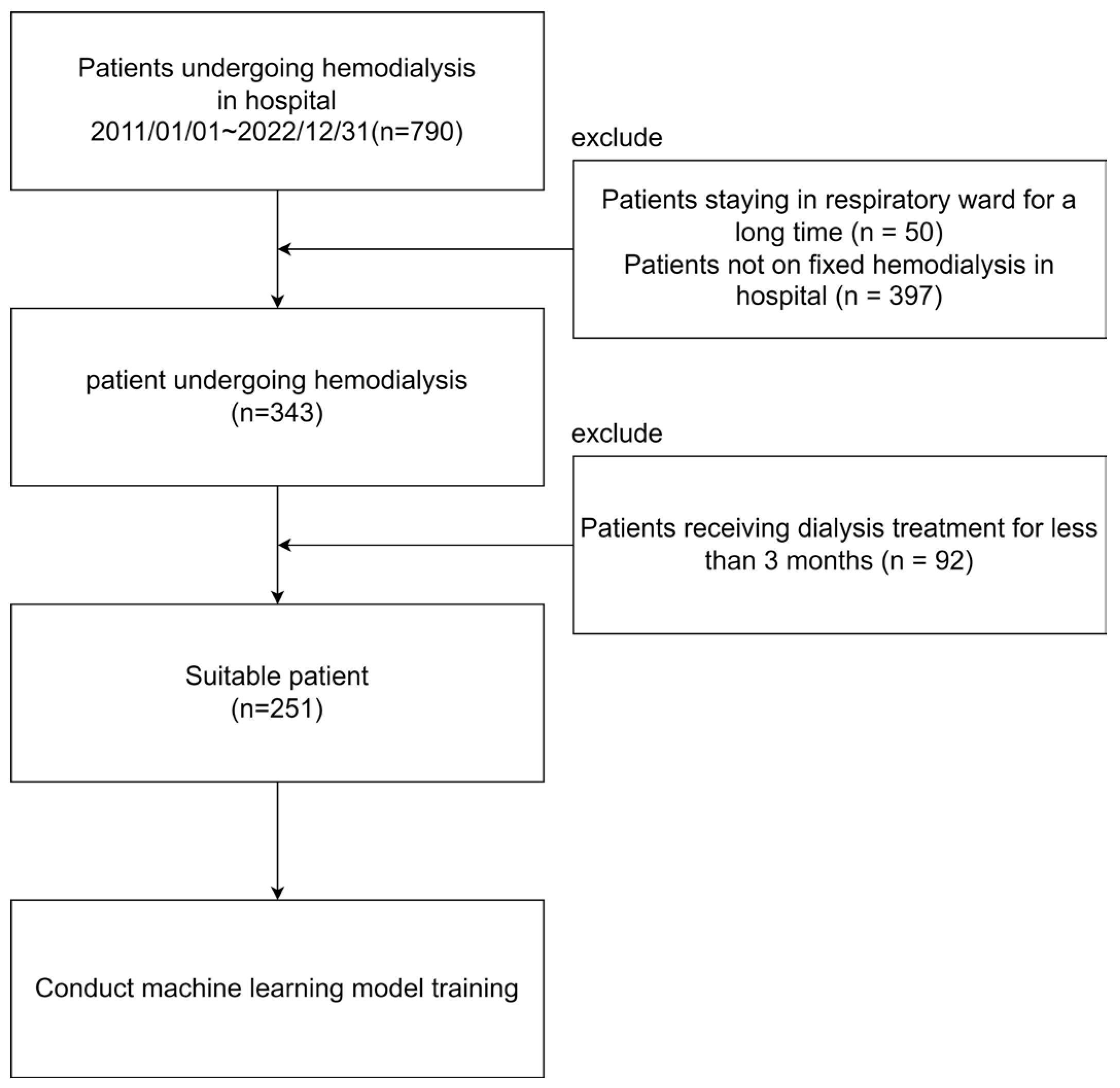
3.1. Dataset
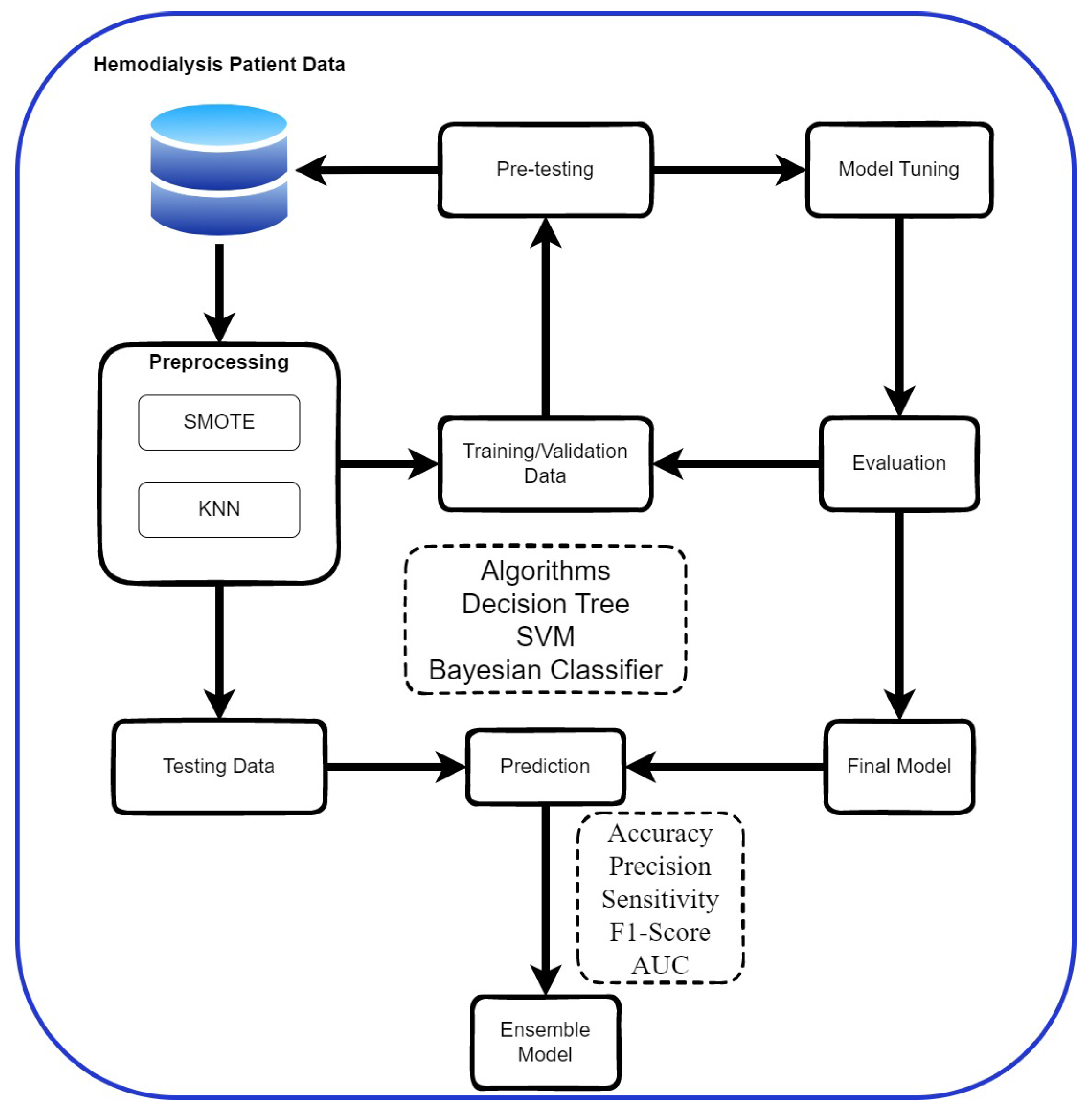
3.2. Research Process
3.3. Data Pre-Processing
3.3.1. Data Imbalance Processing
3.3.2. Missing Value Handling
3.4. Cross-Validation
3.5. Evaluation Metrics
4. Result and Discussion
4.1. Result
4.1.1. Sample Analysis
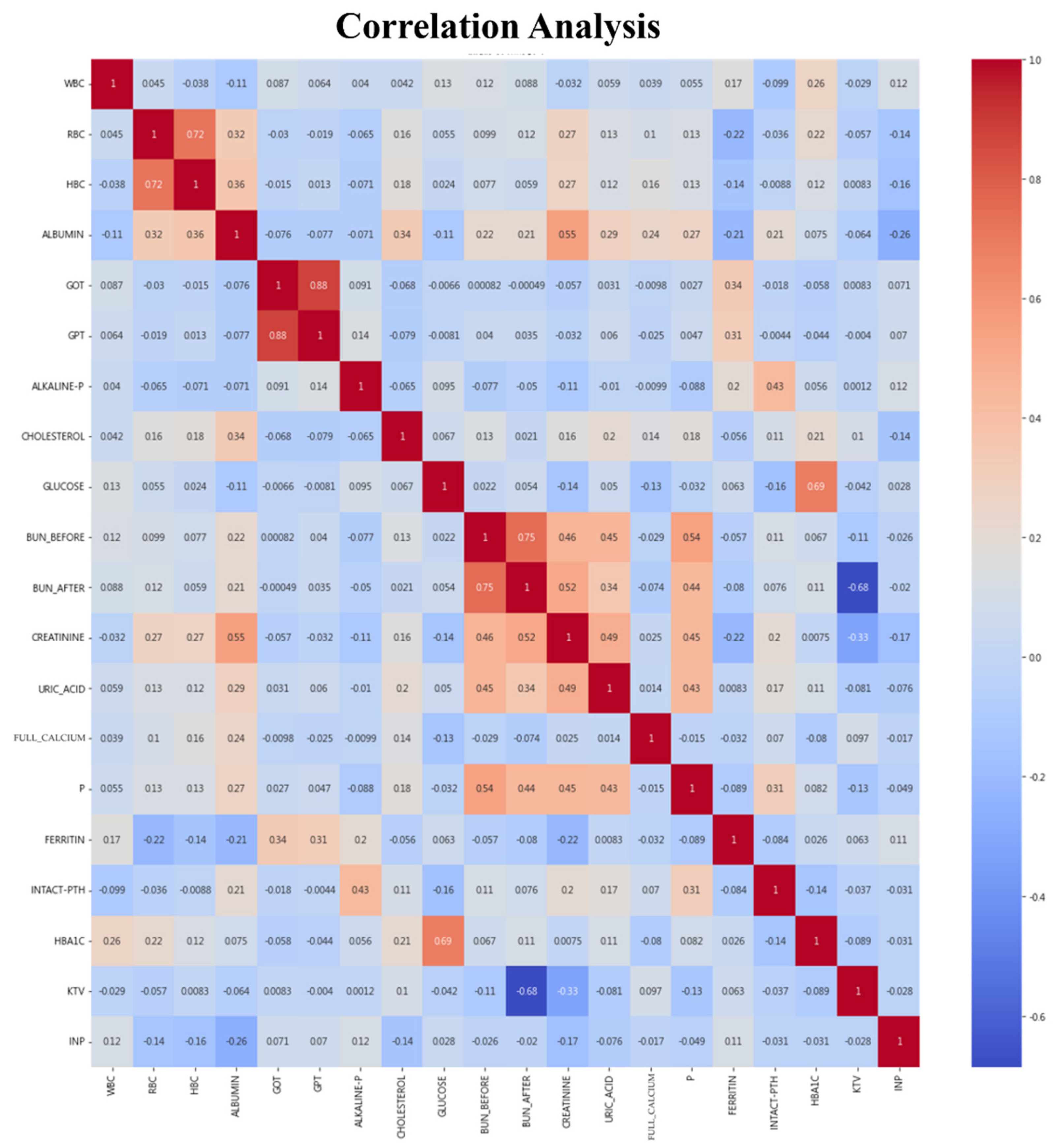
4.1.2. Data Preprocessing
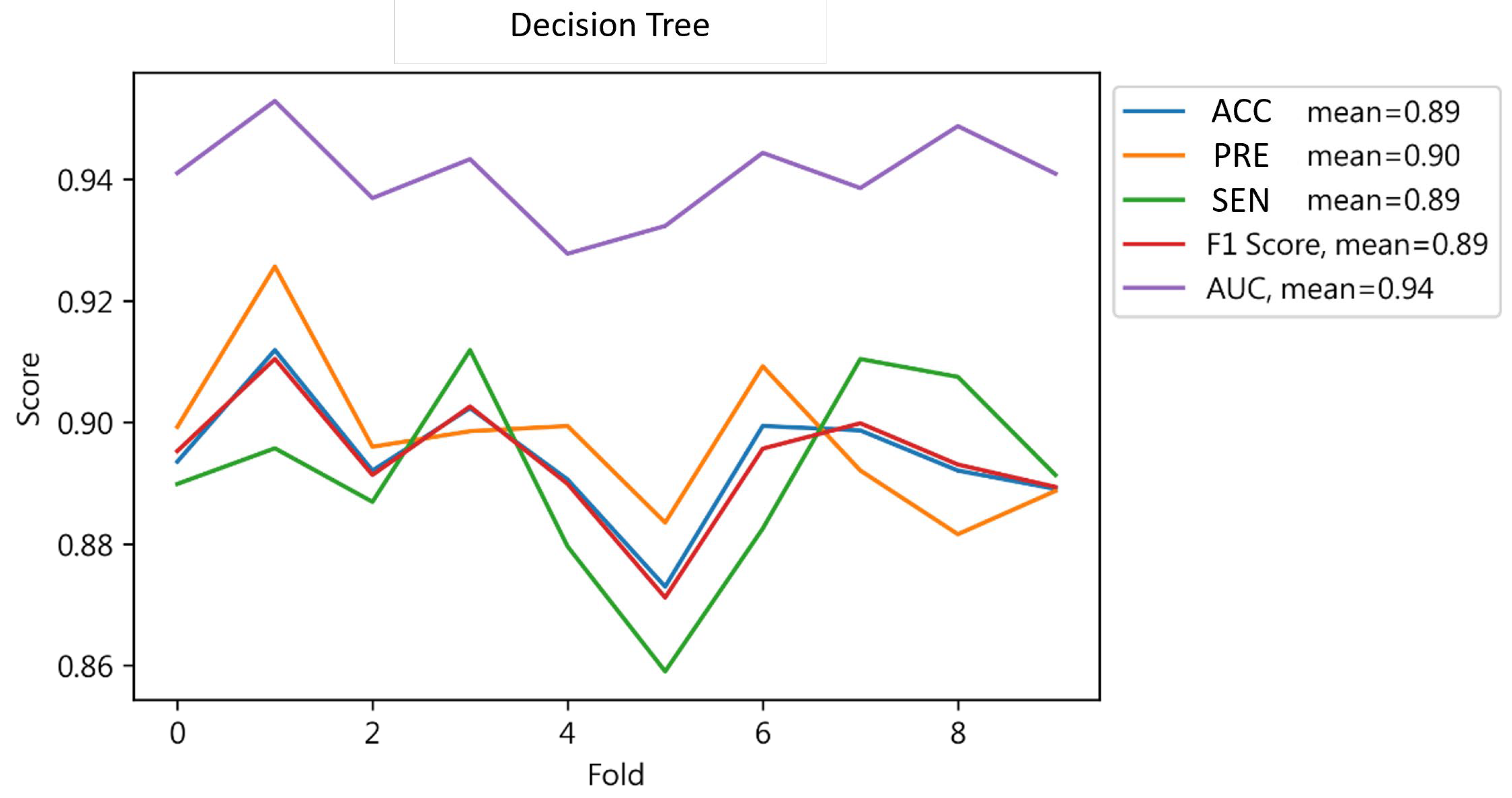
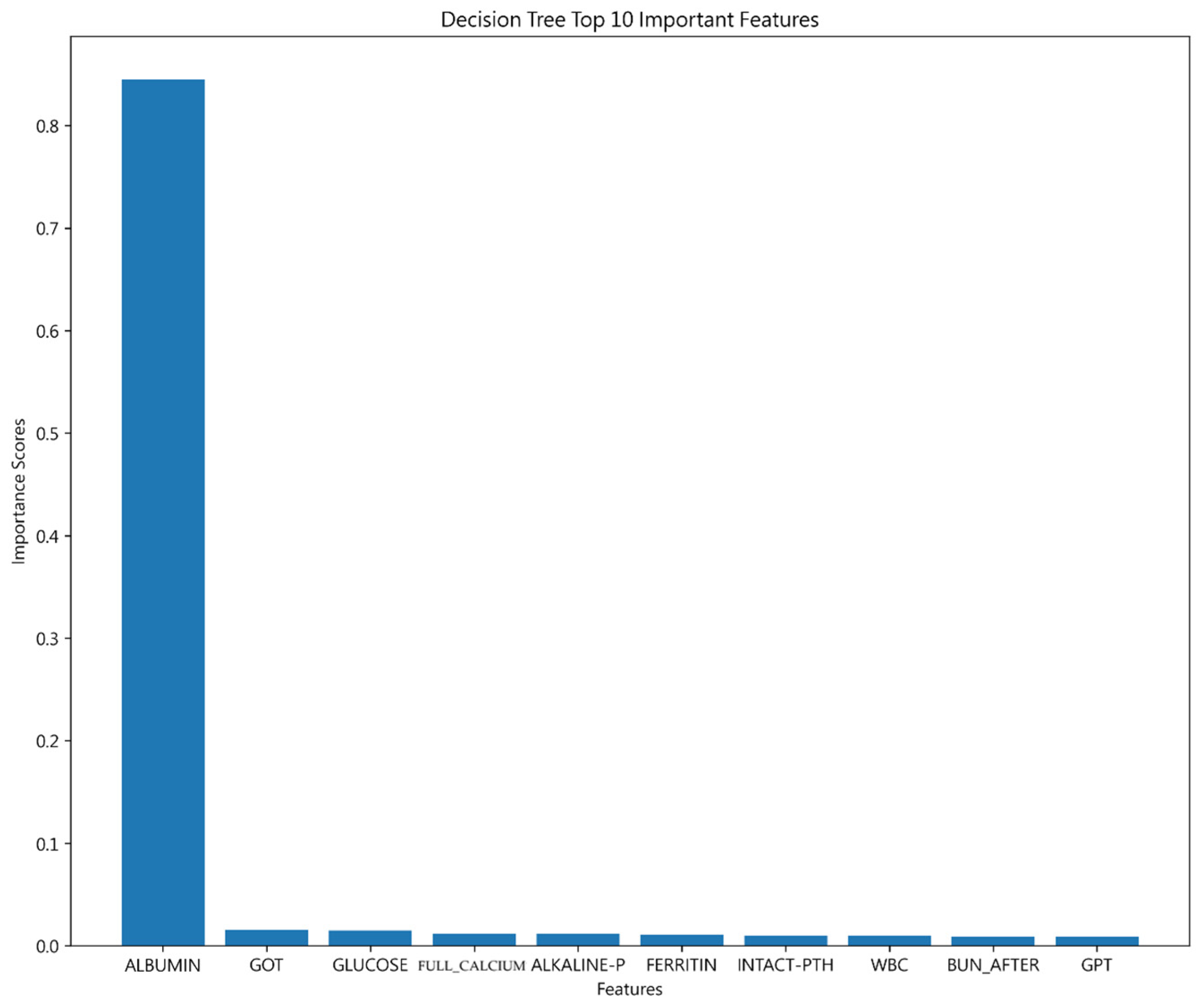
4.1.3. Decision Tree Result
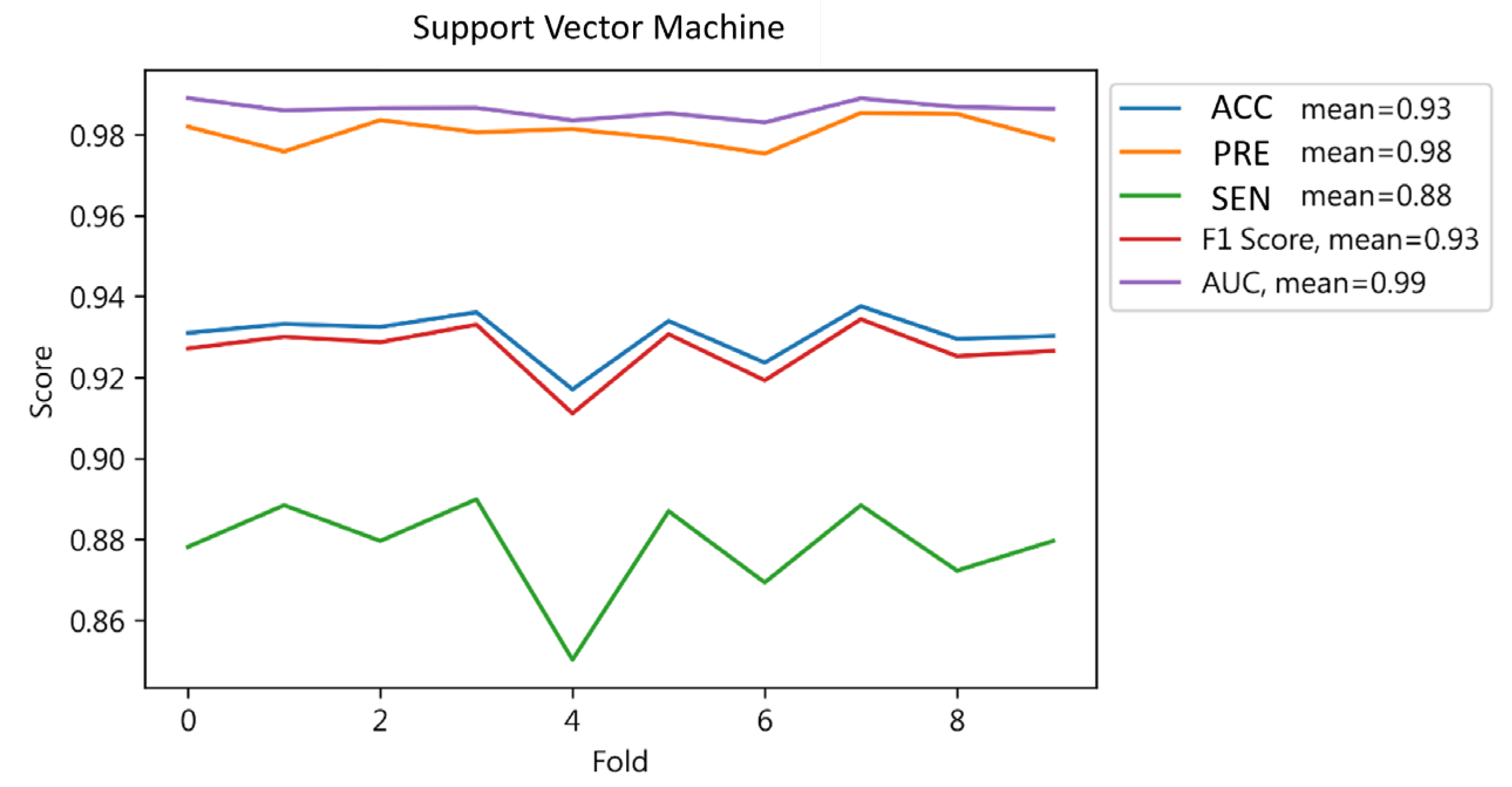
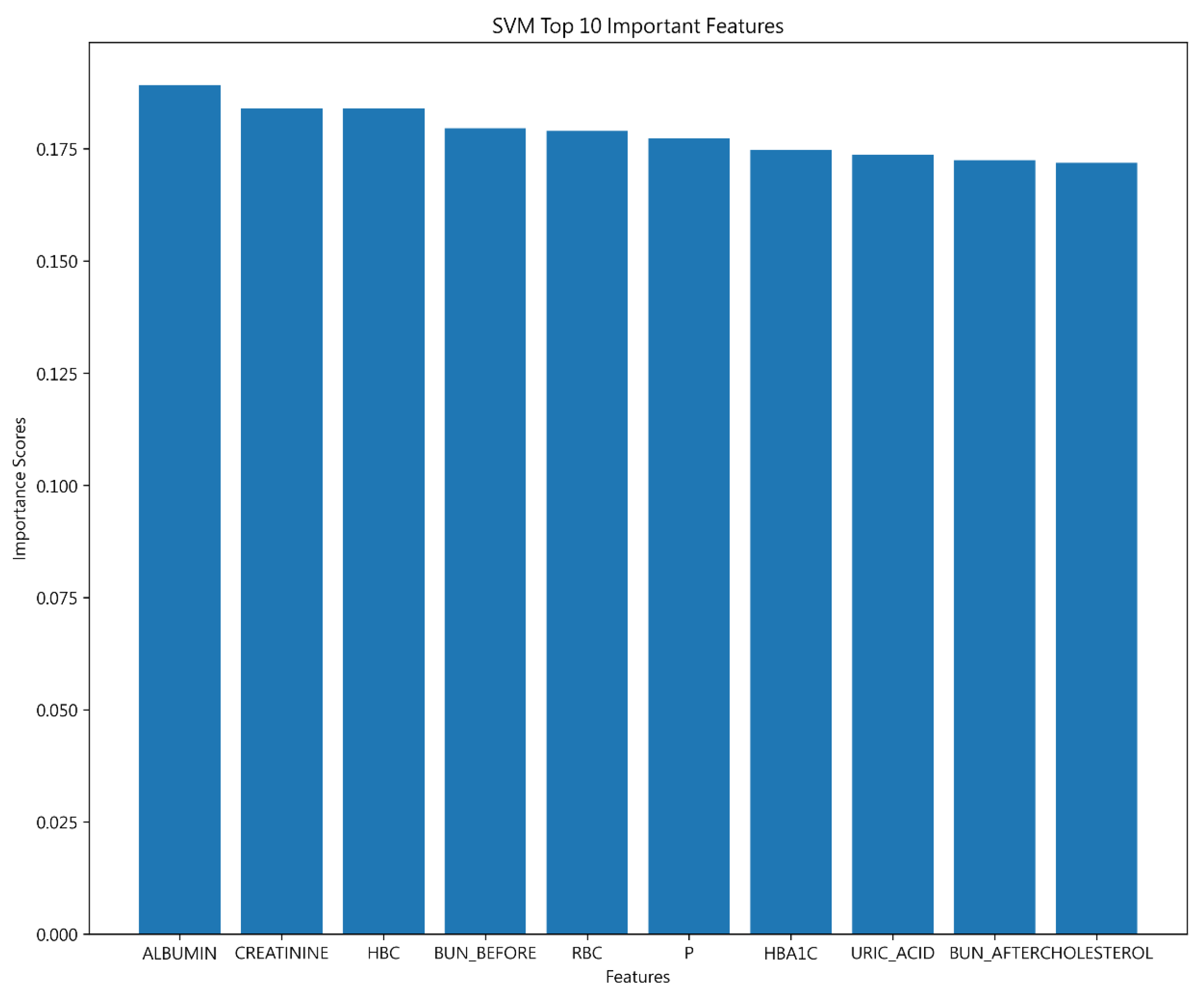
4.1.4. Support Vector Machine Results
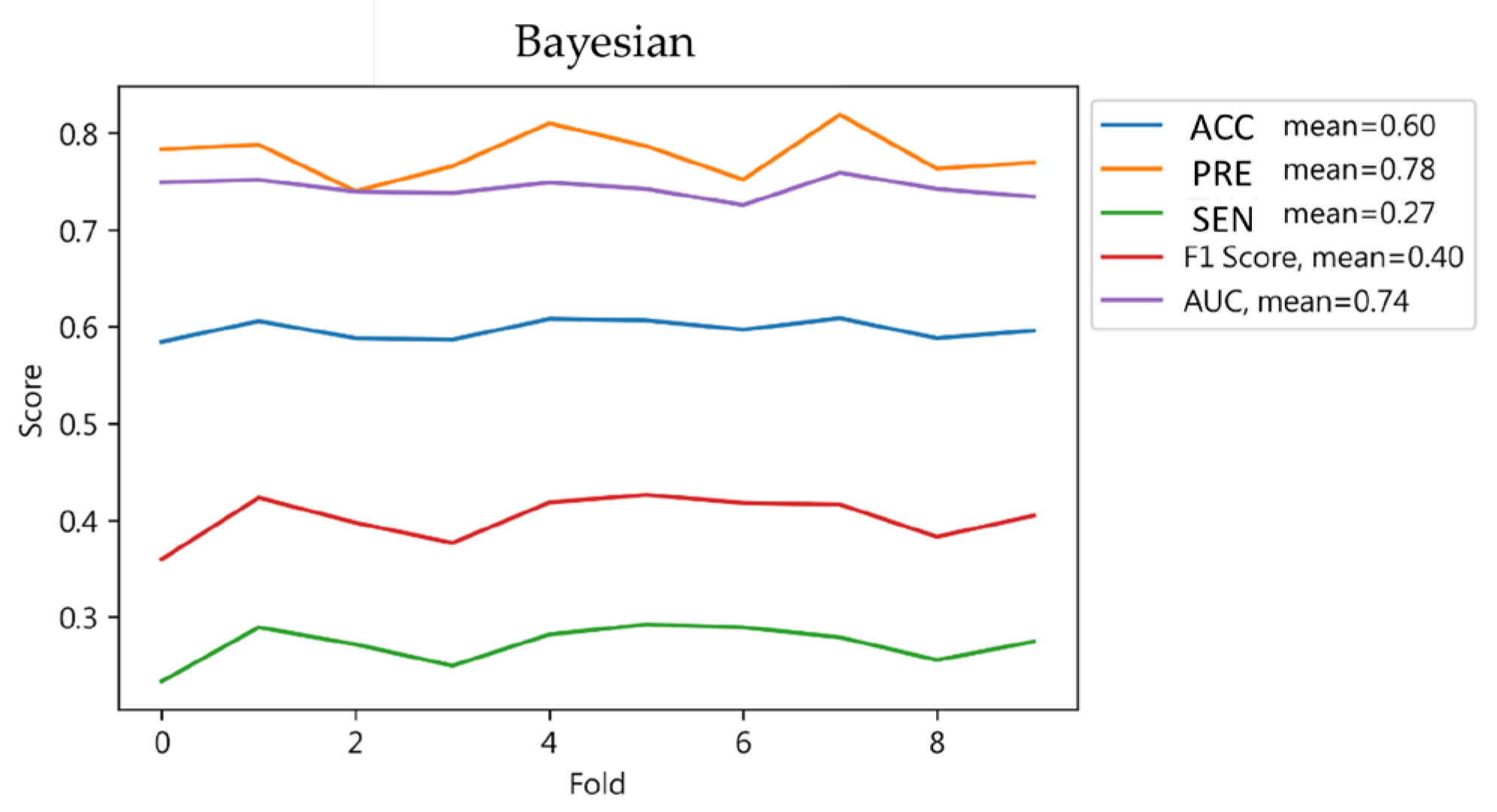
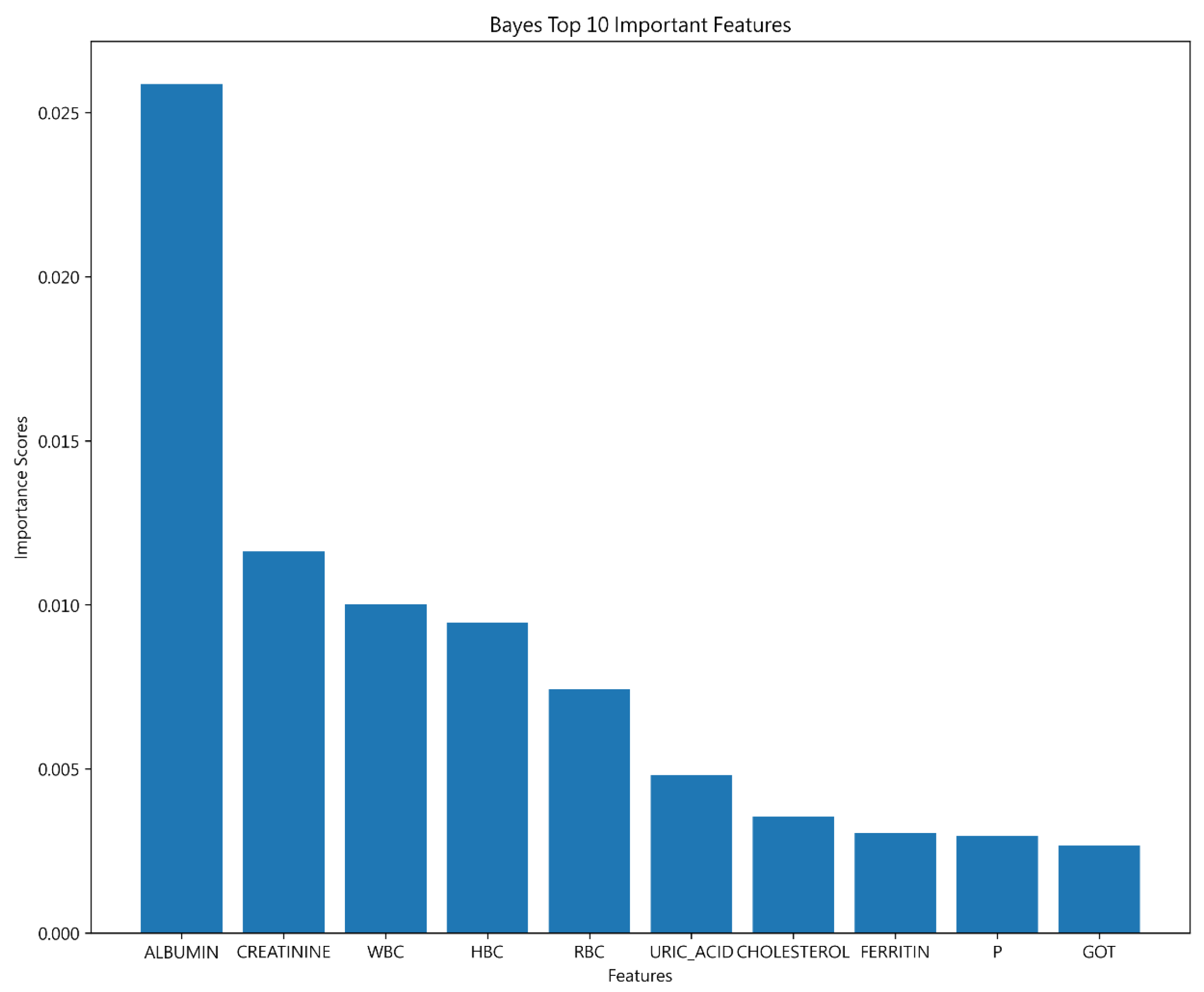
4.1.5. Bayesian Classifier Results
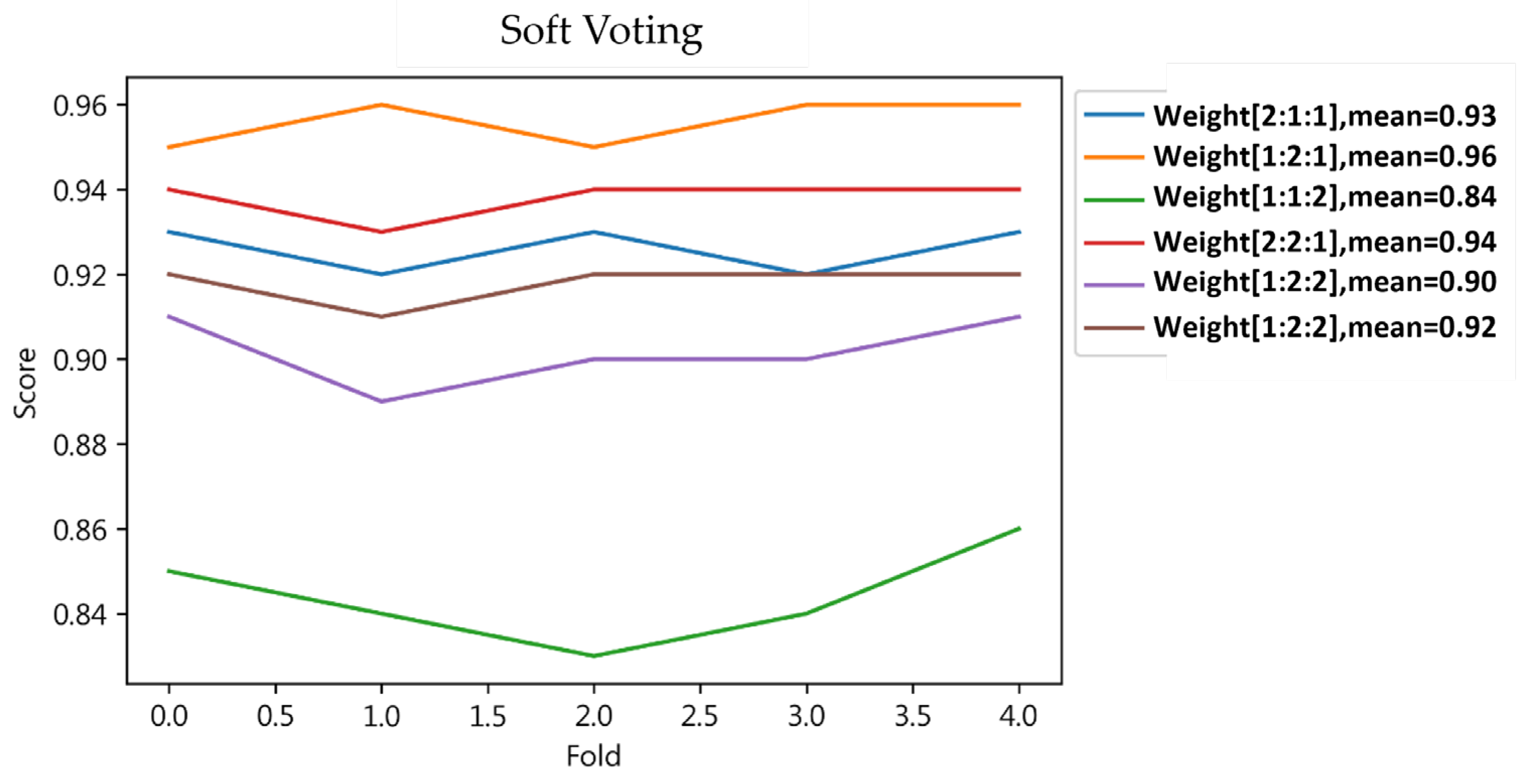
4.1.6. Result of Ensemble Learning
4.2. Discussion
4.2.1. Machine Learning and Ensemble Learning
4.2.2. Important Features of 30-Day Hospital Admissions for Hemodialysis Patients
- This study addresses a specific research gap by using monthly blood test data to predict short-term hospitalizations in hemodialysis patients. This area has previously been neglected in favor of long-term outcomes and general readmission trends.
- By analyzing routine blood tests to predict the likelihood of hospitalization within 30 days, healthcare providers can identify high-risk patients earlier. This enables the implementation of preventive measures to avoid hospitalization and potential complications associated with hemodialysis.
- Predictive analytics can help healthcare organizations better allocate resources by identifying patients at higher risk of hospitalization, ensuring interventions are directed where they are needed most.
- Early detection and prevention of potential complications can significantly improve the quality of life of hemodialysis patients and reduce the number of hospitalizations, allowing them to maintain a more stable and comfortable daily life.
- Insights from this study can inform healthcare policies and strategies, especially in improving the efficiency and effectiveness of Taiwan’s renowned health insurance system. It can serve as a model for integrating predictive analytics into daily patient care and has the potential to be adopted in similar healthcare settings around the world.
- This study contributes to the wider field of nephrology by providing a new approach to managing hemodialysis patients through the strategic use of routine clinical data, setting a precedent for future research and practice.
5. Conclusions
5.1. Limitations
5.2. Implications
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Himmelfarb, J.; Vanholder, R.; Mehrotra, R.; Tonelli, M. The current and future landscape of dialysis. Nat. Rev. Nephrol. 2020, 16, 573–585. [Google Scholar] [CrossRef] [PubMed]
- Heaf, J.; Heiro, M.; Petersons, A.; Vernere, B.; Povlsen, J.V.; Sørensen, A.B.; Clyne, N.; Bumblyte, I.; Zilinskiene, A.; Randers, E.; et al. First-year mortality in incident dialysis patients: Results of the Peridialysis study. BMC Nephrol. 2022, 23, 229. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Li, L.; Evans, M.; Xu, H.; Lindholm, B.; Carrero, J.J. Burden and causes of hospital admissions and readmissions in patients undergoing hemodialysis and peritoneal dialysis: A nationwide study. J. Nephrol. 2021, 34, 1949–1959. [Google Scholar] [CrossRef]
- Gómez-Pulido, J.A.; Gómez-Pulido, J.M.; Rodríguez-Puyol, D.; Polo-Luque, M.L.; Vargas-Lombardo, M. Predicting the appearance of hypotension during hemodialysis sessions using machine learning classifiers. Int. J. Environ. Res. Public Health 2021, 18, 2364. [Google Scholar] [CrossRef] [PubMed]
- Flythe, J.E.; Katsanos, S.L.; Hu, Y.; Kshirsagar, A.V.; Falk, R.J.; Moore, C.R. Predictors of 30-Day Hospital Readmission among Maintenance Hemodialysis Patients: A Hospital’s Perspective. Clin. J. Am. Soc. Nephrol. 2016, 11, 1005–1014. [Google Scholar] [CrossRef] [PubMed]
- Ryu, B.; Yoo, S.; Kim, S.; Choi, J. Thirty-day hospital readmission prediction model based on common data model with weather and air quality data. Sci. Rep. 2021, 11, 23313. [Google Scholar] [CrossRef] [PubMed]
- Ross, K.H.; Jaar, B.G.; Lea, J.P.; Masud, T.; Patzer, R.E.; Plantinga, L.C. Long-term outcomes among Medicare patients readmitted in the first year of hemodialysis: A retrospective cohort study. BMC Nephrol. 2019, 20, 285. [Google Scholar] [CrossRef] [PubMed]
- Decaro, C.; Montanari, G.B.; Molinari, R.; Gilberti, A.; Bagnoli, D.; Bianconi, M.; Bellanca, G. Machine learning approach for prediction of hematic parameters in hemodialysis patients. IEEE J. Transl. Eng. Health Med. 2019, 7, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Montemayor, V.; Martin-Malo, A.; Barbieri, C.; Bellocchio, F.; Soriano, S.; de Mier, V.P.-R.; Molina, I.R.; Aljama, P.; Rodriguez, M. Predicting mortality in hemodialysis patients using machine learning analysis. Clin. Kidney J. 2021, 14, 1388–1395. [Google Scholar] [CrossRef] [PubMed]
- Radović, N.; Prelević, V.; Erceg, M.; Antunović, T. Machine learning approach in mortality rate prediction for hemodialysis patients. Comput. Methods Biomech. Biomed. Eng. 2022, 25, 111–122. [Google Scholar] [CrossRef] [PubMed]
- Wong, M.M.; Thijssen, S.; Wang, Y.; Usvyat, L.A.; Xiao, Q.; Kotanko, P.; Maddux, F.W. Prediction of mortality and hospital readmissions risk using nutritional indicators and their changes over time in a large prevalent hemodialysis cohort. J. Ren. Nutr. 2020, 30, 69–78. [Google Scholar] [CrossRef] [PubMed]
- Yeh, J.Y.; Wu, T.H.; Tsao, C.W. Using data mining techniques to predict hospital readmissions of hemodialysis patients. Decis. Support Syst. 2011, 50, 439–448. [Google Scholar] [CrossRef]
- Assimon, M.M.; Flythe, J.E. Thirty-day hospital readmissions in the hemodialysis population: A problem well put, but half-solved. Clin. J. Am. Soc. Nephrol. 2017, 12, 1566–1568. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Lee, C.C.; Hsu, C.C.; Lin, M.H.; Chen, K.H.; Wu, I.W. Hospital readmissions in patients with dialysis in Taiwan: A nationwide population-based observational study. J. Formos. Med. Assoc. 2022, 121, S39–S46. [Google Scholar] [CrossRef]
- Ma, J.Z.; Ebben, J.; Xia, H.; Collins, A.J. Hematocrit level and associated mortality in hemodialysis patients. J. Am. Soc. Nephrol. 1999, 10, 610–619. [Google Scholar] [CrossRef] [PubMed]
- Ofsthun, N.; Labrecque, J.; Lacson, E.; Keen, M.; Lazarus, J.M. The effects of higher hemoglobin levels on mortality and hospital readmissions in hemodialysis patients. Kidney Int. 2003, 63, 1908–1914. [Google Scholar] [CrossRef] [PubMed]
- Hill, C.J.; Maxwell, A.P.; Cardwell, C.R.; Freedman, B.I.; Tonelli, M.; Emoto, M.; Inaba, M.; Hayashino, Y.; Fukuhara, S.; Okada, T.; et al. Glycated hemoglobin and risk of death in diabetic patients treated with hemodialysis: A meta-analysis. Am. J. Kidney Dis. 2014, 63, 84–94. [Google Scholar] [CrossRef] [PubMed]
- Block, G.A.; Klassen, P.S.; Lazarus, J.M.; Ofsthun, N.; Lowrie, E.G.; Chertow, G.M. Mineral metabolism, mortality, and morbidity in maintenance hemodialysis. J. Am. Soc. Nephrol. 2004, 15, 2208–2218. [Google Scholar] [CrossRef] [PubMed]
- de Mutsert, R.; Grootendorst, D.C.; Indemans, F.; Boeschoten, E.W.; Krediet, R.T.; Dekker, F.W.; Netherlands Cooperative Study on the Adequacy of Dialysis-II Study Group. Association between serum albumin and mortality in dialysis patients is partly explained by inflammation, and not by malnutrition. J. Ren. Nutr. 2009, 19, 127–135. [Google Scholar] [CrossRef] [PubMed]
- Lowrie, E.G.; Laird, N.M.; Parker, T.F.; Sargent, J.A. Effect of the hemodialysis prescription on patient morbidity: Report from the National Cooperative Dialysis Study. N. Engl. J. Med. 1981, 305, 1176–1181. [Google Scholar] [CrossRef] [PubMed]
- Walther, C.P.; Carter, C.W.; Low, C.L.; Williams, P.; Rifkin, D.E.; Steiner, R.W.; Ix, J.H. Interdialytic creatinine change versus predialysis creatinine as indicators of nutritional status in maintenance hemodialysis. Nephrol. Dial. Transplant. 2012, 27, 771–776. [Google Scholar] [CrossRef] [PubMed]
- Daugirdas, J.T.; Blake, P.G.; Ing, T.S. (Eds.) Handbook of Dialysis; Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2007; Volume 236. [Google Scholar]
- Uddin, S.; Khan, A.; Hossain, M.E.; Moni, M.A. Comparing different supervised machine learning algorithms for disease prediction. BMC Med. Inform. Decis. Mak. 2019, 19, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Arifuzzaman, M.; Hasan, M.R.; Toma, T.J.; Hassan, S.B.; Paul, A.K. An Advanced Decision Tree-Based Deep Neural Network in Nonlinear Data Classification. Technologies 2023, 11, 24. [Google Scholar] [CrossRef]
- Kononenko, I. Machine learning for medical diagnosis: History, state of the art and perspective. Artif. Intell. Med. 2001, 23, 89–109. [Google Scholar] [CrossRef] [PubMed]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Hansen, L.K.; Salamon, P. Neural network ensembles. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 993–1001. [Google Scholar] [CrossRef]
- Lam, L.; Suen, S.Y. Application of majority voting to pattern recognition: An analysis of its behavior and performance. IEEE Trans. Syst. Man Cybern.-Part A Syst. Hum. 1997, 27, 553–568. [Google Scholar] [CrossRef]
- Atallah, R.; Al-Mousa, A. Heart disease detection using machine learning majority voting ensemble method. In Proceedings of the 2019 2nd International Conference on New Trends in Computing Sciences (Ictcs), Amman, Jordan, 9–11 October 2019; pp. 1–6. [Google Scholar]
- Kumari, S.; Kumar, D.; Mittal, M. An ensemble approach for classification and prediction of diabetes mellitus using soft voting classifier. Int. J. Cogn. Comput. Eng. 2021, 2, 40–46. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Fotouhi, S.; Asadi, S.; Kattan, M.W. A comprehensive data level analysis for cancer diagnosis on imbalanced data. J. Biomed. Informatics 2019, 90, 103089. [Google Scholar] [CrossRef]
- Paing, M.P.; Pintavirooj, C.; Tungjitkusolmun, S.; Choomchuay, S.; Hamamoto, K. Comparison of sampling methods for imbalanced data classification in random forest. In Proceedings of the 2018 11th Biomedical Engineering International Conference (BMEiCON), Chiang Mai, Thailand, 21–24 November 2018; pp. 1–5. [Google Scholar]
- Chiang Mai, Thailand Comparison of performance of data imputation methods for numeric dataset. Appl. Artif. Intell. 2019, 33, 913–933. [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009; Volume 2, pp. 1–758. [Google Scholar]
- Rodriguez, J.D.; Perez, A.; Lozano, J.A. Sensitivity analysis of k-fold cross validation in prediction error estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 569–575. [Google Scholar] [CrossRef] [PubMed]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Hicks, S.A.; Strümke, I.; Thambawita, V.; Hammou, M.; Riegler, M.A.; Halvorsen, P.; Parasa, S. On evaluation metrics for medical applications of artificial intelligence. Sci. Rep. 2022, 12, 5979. [Google Scholar] [CrossRef] [PubMed]
- Sin, D.D.; Anthonisen, N.R.; Soriano, J.B.; Agusti, A.G. Mortality in COPD: Role of comorbidities. Eur. Respir. J. 2006, 28, 1245–1257. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Complication | Monitoring Value |
|---|---|
| Anemia | Erythrocyte, hemoglobin |
| CV disease | Uric acid, cholesterol, blood sugar, glycated hemoglobin |
| Renal osteopathy | Phosphorus ion, calcium ion, complete parathyroid hormone |
| Dialysis infection | White blood cells, transaminase glutamine phenylacetic acid, transaminase glutamine pyruvate, basic phosphoric acid, serum ferritin |
| Nutrition problem | Blood protein, urea nitrogen, creatinine |
| Subject | Method | Author |
|---|---|---|
| Hospital readmissions status | Decision Tree, MSApriori | Yeh et al. [12] |
| Hospital readmissions risk | GLM (Generalized Linear Model), GAM (Generalized Additive Model), Classification Tree, Random Forest | Wong et al. [11] |
| Hemodialysis patient mortality | Random Forest, Logistic Regression | Garcia-Montemayor et al. [9] |
| Variable Name | Variable Description | Attributes | |
|---|---|---|---|
| Basic information | CHT | Anonymous ID of patient | nonmetric |
| Inspection data | WBC (white blood cell) | White blood cell count | metric |
| RBC (red blood cell) | Red blood cell count | metric | |
| HbC | Hemoglobin | metric | |
| ALBUMIN | Albumin | metric | |
| GOT (glutamic oxaloacetic transaminase) | Serum glutamate phenylacetate transaminase | metric | |
| GPT (glutamic pyruvic transaminase) | Serum glutamate-pyruvate transaminase | metric | |
| ALKALINE-P | Alkaline phosphoric acid | metric | |
| CHOLESTEROL | Total cholesterol | metric | |
| GLUCOSE | blood sugar | metric | |
| BUN_BEFORE | Blood urea nitrogen before dialysis | metric | |
| BUN_AFTER | Blood urea nitrogen after dialysis | metric | |
| CREATININE | Creatinine | metric | |
| URIC_ACID | Uric acid | metric | |
| FULL_CALCIUM | Calcium ions | metric | |
| P | Phosphorus ions | metric | |
| FERRITIN | Ferritin | metric | |
| INTACT-PTH | Parathyroxine immunoassay | metric | |
| HBA1C | Glycated hemoglobin | metric | |
| KTV(Kt/V) | Urea nitrogen dialysis efficiency | metric | |
| Hospital readmissions | INP | Hospitalized within 30 days | non-metric |
| Character | Data (n = 251) |
|---|---|
| Sex | Male (121), female (130) |
| Age | Over 70 years old (139), under 70 years old (112) |
| Blood type | A (47), B (73), O (118), AB (13) |
| History of diabetes | Y (121), N (130) |
| History of hepatitis B | Y (18), N (233) |
| History of hepatitis C | Y (65), N (186) |
| Cardiac history | Y (72), N (179) |
| History of AH | Y (175), N (76) |
| History of stroke | Y (211), N (40) |
| History of COPD | Y (20), N (231) |
| History of cancer | Y (3), N (248) |
| MEAN | STD | MAX | MIN | |
|---|---|---|---|---|
| WBC (white blood cell) | 6.84 | 2.43 | 34.5 | 0.75 |
| RBC (red blood cell) | 3.42 | 0.56 | 6.08 | 1.58 |
| HbC | 10.19 | 1.40 | 16 | 4.9 |
| ALBUMIN | 3.86 | 0.45 | 5.3 | 1.6 |
| GOT (glutamic oxaloacetic transaminase) | 19.23 | 59.45 | 5121 | 2 |
| GPT (glutamic pyruvic transaminase) | 16.02 | 30.78 | 1976 | 2 |
| ALKALINE-P | 93.70 | 52.83 | 918 | 24 |
| CHOLESTEROL | 157.69 | 39.96 | 437 | 63 |
| GLUCOSE | 197.87 | 109.7 | 1034 | 29 |
| BUN_BEFORE | 67.01 | 19.97 | 259 | 6 |
| BUN_AFTER | 16.40 | 6.91 | 72 | 2 |
| CREATININE | 9.07 | 2.56 | 22.82 | 1.13 |
| URIC_ACID | 6.68 | 1.60 | 16.9 | 0.9 |
| TOTAL_CALCIUM | 9.16 | 0.89 | 13.5 | 3.1 |
| P | 4.99 | 1.59 | 15 | 0.4 |
| FERRITIN | 397.44 | 446.38 | 9570.25 | 4.7 |
| INTACT-PTH | 442.41 | 441.21 | 4394.6 | 3.9 |
| HBA1C (glycated hemoglobin) | 7.03 | 2.03 | 16.6 | 3.1 |
| KTV(Kt/V) | 1.46 | 0.29 | 3.71 | 0.42 |
| ACC | PRE | SEN | F1-Score | Volumn | ||
|---|---|---|---|---|---|---|
| Training | 0 | 0.93 | 0.92 | 0.92 | 6810 | |
| 1 | 0.92 | 0.93 | 0.92 | 6809 | ||
| Result | 0.92 | 0.92 | 0.92 | 0.92 | ||
| Testing | 0 | 0.91 | 0.90 | 0.90 | 1702 | |
| 1 | 0.90 | 0.91 | 0.91 | 1703 | ||
| Result | 0.91 | 0.91 | 0.91 | 0.91 | ||
| ACC | PRE | SEN | F1-Score | Volumn | ||
|---|---|---|---|---|---|---|
| Training | 0 | 1.0 | 1.0 | 1.0 | 6810 | |
| 1 | 1.0 | 1.0 | 1.0 | 6809 | ||
| Result | 1.0 | 1.0 | 1.0 | 1.0 | ||
| Testing | 0 | 0.90 | 0.98 | 0.94 | 1702 | |
| 1 | 0.98 | 0.89 | 0.93 | 1703 | ||
| Result | 0.93 | 0.94 | 0.93 | 0.93 | ||
| ACC | PRE | SEN | F1-Score | Volumn | ||
|---|---|---|---|---|---|---|
| Training | 0 | 0.56 | 0.92 | 0.70 | 6809 | |
| 1 | 0.78 | 0.27 | 0.40 | 6810 | ||
| Result | 0.60 | 0.67 | 0.60 | 0.55 | ||
| Testing | 0 | 0.57 | 0.92 | 0.70 | 1703 | |
| 1 | 0.79 | 0.29 | 0.43 | 1702 | ||
| Result | 0.61 | 0.68 | 0.61 | 0.56 | ||
| Training | Testing | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| ACC | PRE | SEN | F1 Score | ACC | PRE | SEN | F1 Score | ||
| Hard Voting | 0 | 0.94 | 0.98 | 0.96 | 0.88 | 0.97 | 0.92 | ||
| 1 | 0.98 | 0.94 | 0.96 | 0.96 | 0.86 | 0.91 | |||
| Result | 0.96 | 0.96 | 0.96 | 0.96 | 0.92 | 0.92 | 0.92 | 0.92 | |
| Soft Voting | 0 | 1.0 | 1.0 | 1.0 | 0.93 | 0.99 | 0.96 | ||
| 1 | 1.0 | 1.0 | 1.0 | 0.99 | 0.93 | 0.96 | |||
| Result | 1.0 * | 1.0 * | 1.0 * | 1.0 * | 0.96 * | 0.96 * | 0.96 * | 0.96 * | |
| Testing | |||||
|---|---|---|---|---|---|
| ACC | PRE | SEN | F1 Score | AUC | |
| DT | 0.91 | 0.91 | 0.91 | 0.91 | 0.91 |
| SVM | 0.93 | 0.94 | 0.93 | 0.93 | 0.93 |
| Bayesian | 0.61 | 0.68 | 0.61 | 0.56 | 0.61 |
| Ensemble | 0.96 * | 0.96 * | 0.96 * | 0.96 * | - |
| Decision Tree | SVM | Bayesian | |
|---|---|---|---|
| Important features | ALBUMIN | ALBUMIN | ALBUMIN |
| CREATININE | CREATININE | ||
| HBC | WBC |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsai, C.-H.; Shih, D.-H.; Tu, J.-H.; Wu, T.-W.; Tsai, M.-G.; Shih, M.-H. Analyzing Monthly Blood Test Data to Forecast 30-Day Hospital Readmissions among Maintenance Hemodialysis Patients. J. Clin. Med. 2024, 13, 2283. https://doi.org/10.3390/jcm13082283
Tsai C-H, Shih D-H, Tu J-H, Wu T-W, Tsai M-G, Shih M-H. Analyzing Monthly Blood Test Data to Forecast 30-Day Hospital Readmissions among Maintenance Hemodialysis Patients. Journal of Clinical Medicine. 2024; 13(8):2283. https://doi.org/10.3390/jcm13082283
Chicago/Turabian StyleTsai, Cheng-Han, Dong-Her Shih, Jue-Hong Tu, Ting-Wei Wu, Ming-Guei Tsai, and Ming-Hung Shih. 2024. "Analyzing Monthly Blood Test Data to Forecast 30-Day Hospital Readmissions among Maintenance Hemodialysis Patients" Journal of Clinical Medicine 13, no. 8: 2283. https://doi.org/10.3390/jcm13082283
APA StyleTsai, C.-H., Shih, D.-H., Tu, J.-H., Wu, T.-W., Tsai, M.-G., & Shih, M.-H. (2024). Analyzing Monthly Blood Test Data to Forecast 30-Day Hospital Readmissions among Maintenance Hemodialysis Patients. Journal of Clinical Medicine, 13(8), 2283. https://doi.org/10.3390/jcm13082283