1. Introduction
Artificial intelligence is crucial for detecting disinformation, which threatens democratic values worldwide. Due to the rapid growth of social media content and the rapid development of image processing and machine learning, combating disinformation has become a priority.
Distinguishing computer-generated images (CGIs) from natural images (NIs) is especially pertinent for addressing the practical challenges posed by deepfakes. Deepfakes, being advanced forms of computer-generated imagery, underscore the critical need for robust identification methods. In practical terms, the ability to differentiate between authentic and manipulated content haws become indispensable for countering the proliferation of deepfakes across diverse domains. For instance, within media and entertainment, where deepfakes can deceive audiences by depicting fabricated scenarios or altering the appearance of individuals, the capability to discern these manipulations ensures the preservation of trust between content creators and their viewers. Moreover, in a forensic analysis and cybersecurity context, the application of techniques to identify alterations plays a pivotal role in verifying the authenticity of visual evidence and mitigating the potential for false information dissemination. This practical application of distinguishing CGIs from NIs extends its significance into various industries reliant on visual representation, fortifying the credibility and reliability of presented content, which is crucial in an era where deepfakes challenge the authenticity of visual information.
Due to the perpetual and exponential growth of multimedia technologies in conjunction with the advances in the deployment of tools for CGI creation, CGIs have become so realistic that individuals are not capable of distinguishing them from NIs with their naked eyes. A plethora of image processing techniques and 3D image rendering software packages have contributed to the creation of such sophisticated content. Various high-quality galleries of CGIs exist, such as the Autodesk A360 rendering gallery [
1], the Artlantis gallery [
2], the VRay gallery [
3], and the Corona gallery [
4]. Notwithstanding the multimedia forgery outbreak, realistic CGIs have come to be added to the arsenal of fraudsters. As a countermeasure, there is an urgent need to deploy algorithms that can accurately and reliably discriminate between CGIs and NIs. Thus, multimedia forensics draws the community’s attention to methods to encounter all kinds of attacks within image forensics [
5], including approaches for universal image forensics [
6], copy–move forgery detection [
7], splice detection [
8], and face anti-spoofing detection [
9]. Many approaches have also been introduced in the context of image forgery detection that leverage gradient-based illumination [
10], decision fusion [
11], pairwise relations [
12], and transformed spaces based on image illuminant maps [
13].
Digital forensics can be useful for determining the difference between NIs and CGIs. A scenario where CGIs can cause harm is through image manipulation for political propaganda, making authenticity validation a crucial aspect. Another challenging scenario is verifying the authenticity of images, particularly when offenders attempt to manipulate child pornography photos digitally so as to appear like CGIs. In all circumstances, attesting to the validity of the photographs is a key challenge in forensics.
Distinguishing CGIs from NIs can be treated as a classification task. Until recently, many approaches have proposed hand-crafted features [
14,
15,
16,
17,
18] to cope with the aforementioned classification problem, while the majority of recent state-of-the-art methods utilize deep neural network (DNN) methods, e.g., [
19,
20,
21,
22,
23,
24]. The latter methods tend to be more efficient in discovering hidden patterns and structures in images. On top of that, the generalization ability of DNN methods allows for automation, which is crucial in real-life applications, even when large training datasets are unavailable.
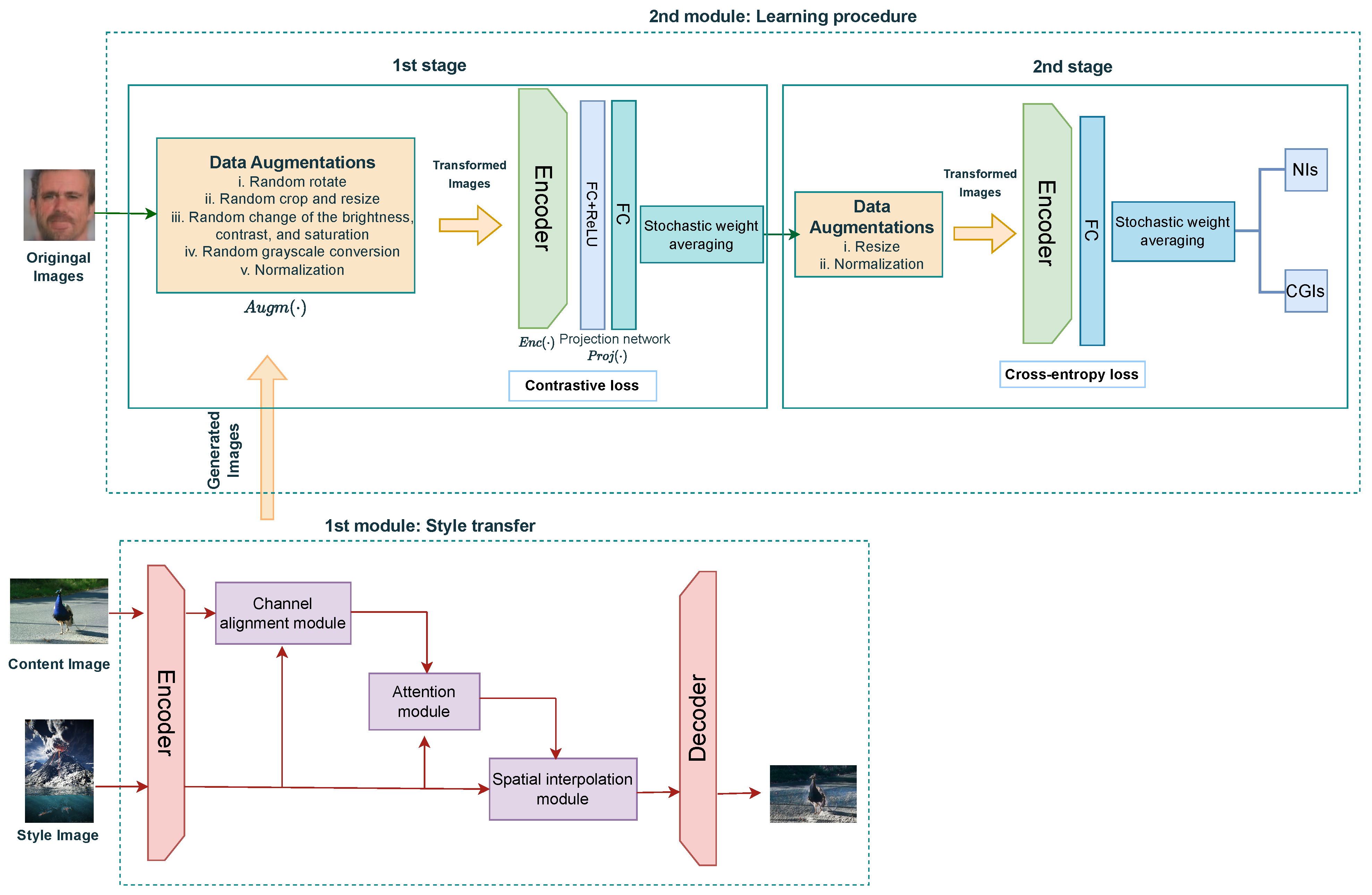
In this paper, to take full advantage of NN methods in terms of learning complex data representations and automatically deriving highly accurate decisions, an end-to-end convolutional neural network (CNN)-based framework is proposed to discriminate between CGIs and NIs. To the best of the authors’ knowledge, this is the first attempt to demonstrate the potential of supervised contrastive learning in the context of discrimination between CGIs and NIs. The proposed framework consists of two stages. First, a CNN is proposed, which is based on the ResNet-18 [
25] architecture that employs the supervised contrastive (SupCon) loss presented in [
26]. On top of this, and apart from the data augmentation, a complementary style transfer module is introduced to enhance training by enriching the network with additional negative samples to those of the original dataset. Handcrafted image augmentations (e.g., cropping, blurring, flipping) provide insufficient variation in visual features, limiting the performance of contrastive learning techniques that employ them. The style transfer module creates synthetic images (e.g., deepfakes) but they can also add artificial visual features to real images. The core idea behind integrating style transfer is to enable more accurate training by using only the original dataset, even when insufficient training samples exist. The paper demonstrates that style transfer improves the accuracy of contrastive learning. During the second stage, the trained model is fed to a linear classifier for further training using the cross-entropy loss.
Contrastive learning forces samples of the same class to stay close to each other, while samples that belong to different classes are pushed far away. Supervised contrastive learning leverages the label information, providing many positive samples to the network instead of self-supervised contrastive learning. Positive samples are fed into the classifier using data augmentation procedures. Moreover, stochastic weight averaging (SWA) is employed on the network outputs after each stage to improve robustness. The style transfer module operates in real time and takes advantage of the NIs that constitute the positive class. It introduces a progressive attentional manifold alignment. Thus, it can dynamically reposition the style features of some arbitrarily chosen CGIs by repeated attention operations to align the content manifold to the style manifold. With the contribution of the style transfer module, the training procedure is enriched with additional incoming samples, allowing models with datasets that consist of a limited number of training samples to be more robust and effective. Overall, the proposed framework aims at identifying and mitigating deceptive visuals, fortifying the trustworthiness and reliability of visual content across diverse applications and sectors.
The experimental results are disclosed on the public benchmark DSTok [
27], Rahmouni [
24], and LSCGB [
28] datasets, demonstrating that the proposed framework accurately distinguishes CGIs and NIs, outperforming the state-of-the-art approaches and motivating further research. On top of that, the generalization ability of the proposed framework trained on the DSTok dataset is tested on the publicly available Rahmouni dataset. Moreover, CoStNet is trained on the most recent state-of-the-art LSCGB dataset and tested on the challenging DSTok dataset and is compared against state-of-the-art approaches. The impact of various parameters during the training is assessed. When the test samples are infected with salt-and-pepper or Gaussian noise, an extensive evaluation of the proposed approach is performed to attest to its ability to deliver accurate results under various conditions. When insufficient training samples are available, an ablation study is undertaken to examine the impact of the style transfer module. Furthermore, hypothesis testing is performed to assess whether the improvements in detection accuracy delivered by the proposed framework against state-of-the-art approaches are statistically significant.
The main contributions of the paper are as follows:
A novel CNN-based framework is designed to discriminate between CGIs and NIs, abbreviated as CoStNet. To the best of the authors’ knowledge, this is the first attempt to conduct such discrimination based on supervised contrastive learning and style transfer in the benchmark DSTok, Rahmouni, and LSCGB datasets.
A complementary style transfer module, which operates in real-time, is employed to increase the training CGIs even when a limited number of training samples is available, thus enhancing the training procedure.
CoStNet achieves state-of-the-art accuracies in the benchmark DSTok, Rahmouni, and LSCGB datasets, underscoring its remarkable advancement in the field.
The generalization capability of CoStNet, initially trained on the LSCGB dataset, is evaluated through testing on the DSTok dataset. Additionally, CoStNet undergoes training on the DSTok dataset and is subsequently tested on the Rahmounis’ dataset to assess its broader applicability.
The proposed framework is robust against high salt-and-pepper and Gaussian noise at various corruption levels.
Multiple tests are conducted to empirically demonstrate that CoStNet is less sensitive to modifications of the training parameters, such as the number of training epochs and the batch size.
An ablation study is performed to assess the impact of the style transfer module when limited training samples are available.
Hypothesis testing confirms that the improvements in detection accuracy between CoStNet and methods reported in the literature are statistically significant.
In summary, the proposed CoStNet framework is a CNN-based novel architecture that utilizes real-time style transfer and supervised contrastive learning to discriminate CGIs from NIs. CoStNet is demonstrated to accurately discriminate CGIs and NIs across benchmark datasets such as the DSTok, the Rahmouni, and the LSCGB datasets. The incorporation of the style transfer module allows for the augmentation of CGIs based on existing image content, thus offering additional training CGIs. By doing so, the challenge of training sample scarcity for CGIs prevalent in real-world forensic scenarios is addressed. CoStNet’s robust performance in handling various noise levels and parameter settings, as well as its generalization ability in testing, further underscores its versatility and effectiveness under diverse conditions. CoStNet’s resilience to variations is also evaluated in scenarios with limited training data through an ablation study, demonstrating its capabilities in CGI discrimination.
The rest of this paper is organized as follows.
Section 2 briefly surveys the literature on the discrimination of CGIs from NIs.
Section 3 details the proposed framework. Benchmark datasets are described in
Section 4. Experimental evaluation is presented in
Section 5. Conclusions are drawn, and limitations and future work are discussed in
Section 6.
6. Conclusions, Limitations, and Future Directions
An end-to-end deep learning framework, denoted as CoStNet, has been introduced as a novel solution for the application of distinguishing NIs from CGIs. The innovation combines the principles of supervised contrastive learning, arbitrary style transfer, and the ResNet-18 architecture within a unique two-module framework. Through the integration of contrastive learning, CoStNet circumvents the necessity for hand-engineered features and adeptly captures intricate feature representations inherent in the training data, thereby enabling precise classification. Notably, the incorporation of the style transfer module extends the efficacy of training by enriching the dataset with an amplified array of negative samples beyond the confines of the original dataset. The robustness and efficacy of CoStNet are substantiated through a comprehensive series of experiments, leveraging the benchmark DSTok, Rahmouni, and LSCGB datasets. Furthermore, its prowess is evaluated in terms of both its generalization capacity and resilience through cross-dataset testing. By benchmarking CoStNet’s detection accuracy against state-of-the-art methods, its competence is reaffirmed across various parameter configurations, encompassing batch sizes and epochs. Notably, even with modest training epochs and compact batch sizes, CoStNet emerges as an adept classifier, surpassing state-of-the-art methodologies. An in-depth ablation study elucidates the pivotal role played by the style transfer module, particularly in scenarios with constrained training data availability. Empirical results corroborate CoStNet’s performance equivalence to state-of-the-art methods, while its superiority in distinguishing NIs from CGIs is underscored by a remarkable accuracy, outperforming the state-of-the-art approaches. Significantly, statistical tests substantiate the statistical significance of these performance enhancements.
While CoStNet demonstrates promising performance in distinguishing natural images NIs from CGIs in many different setups, there are some noteworthy limitations that warrant consideration. The disparities identified in Rahmouni’s dataset, which is characterized by divergent stylistic attributes, diverse content structures, and potentially distinct contextual elements compared to the DSTok dataset, extend beyond quantitative differences and significantly impact the adaptability of the CoStNet model when faced with unfamiliar data distributions. Consequently, cross-dataset testing, especially when CoStNet was trained on the DSTok dataset and tested on Rahmouni’s dataset, poses significant challenges for model generalization. Additionally, the framework is not robust in the presence of Gaussian noise during testing, leading to performance deterioration compared to scenarios involving salt-and-pepper noise. These limitations underscore the need for future research aimed at enhancing the framework’s efficacy and resilience in practical applications.
The effectiveness and efficiency demonstrated by the proposed framework chart a compelling trajectory for future research endeavors. A pursuit to enhance the robustness of the framework is evident, aiming to address inherent limitations. This could involve the development of more robust CNN architectures tailored to handle even more diverse datasets and noise conditions. Advanced noise reduction techniques or regularization methods could be explored to improve the model’s resilience to Gaussian noise. Additionally, investigating transfer learning strategies may enhance model generalization across different datasets, ultimately advancing the framework’s applicability in real-world scenarios. Moreover, there is an imperative drive towards the development and integration of lightweight models, a strategic approach poised to tackle real-world temporal constraints and to cater to applications necessitating near real-time operation.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









