1. Introduction
“What people think” has historically been an important piece of information during many decision-making processes [
1]. With the rise of social media platforms, an increasing amount of information on exactly such thoughts has become available to the public [
2]. To extract meaningful information from the myriad of posts at hand, computational methods such as topic modeling [
3,
4] and sentiment analysis [
1,
2,
5] have been researched and adapted specifically for short-form textual social media data. In practice, this allows for the analysis and monitoring of a variety of real-world phenomena such as earthquakes [
6,
7], floodings [
8,
9], refugee movements [
10] or disease outbreaks [
11,
12,
13] through social media data.
Traditionally, semantic analysis in the form of topic modeling and sentiment analysis has mostly been conducted separately, resulting in sequential workflows that use the two modalities in different ways. Apart from a few joint topic-sentiment models (e.g., [
14,
15,
16]) based on the classic topic modeling technique Latent Dirichlet Allocation (LDA) [
17], the joint analysis of these two features has previously not received much attention. However, sentiments can provide additional information about semantic topics that might be helpful for critical events such as natural disasters [
18]. This situation is especially remarkable as traditional topic modeling has undergone an evolution introducing pre-trained Large Language Models (LLMs) into their working principles in recent years. Specifically, research has shown that a technique based on the clustering of embedding vectors can outperform classic topic modeling methods such as LDA [
19,
20,
21]. Yet, extensions of this framework, have hardly been considered so far.
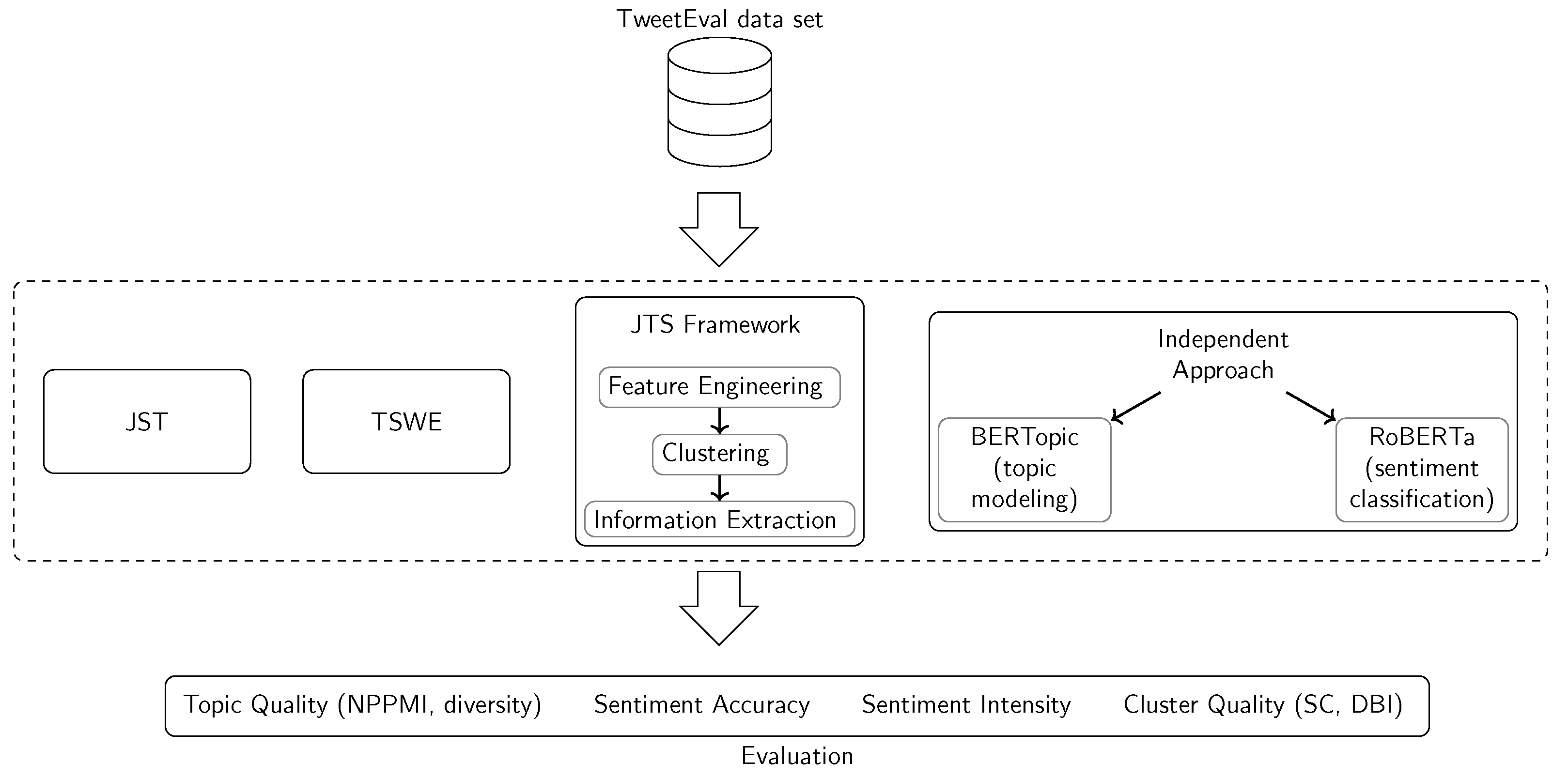
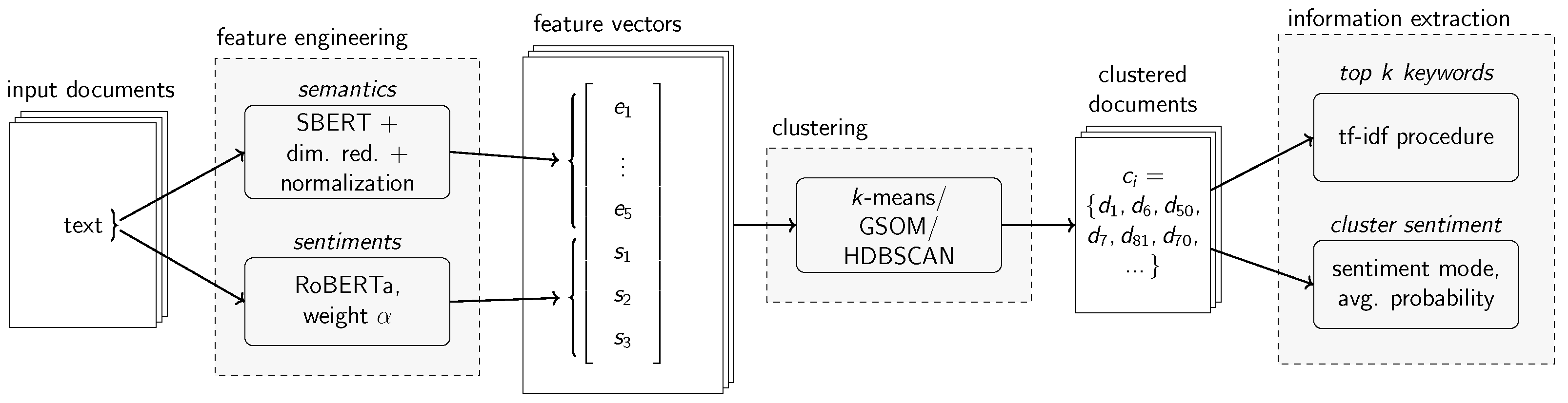
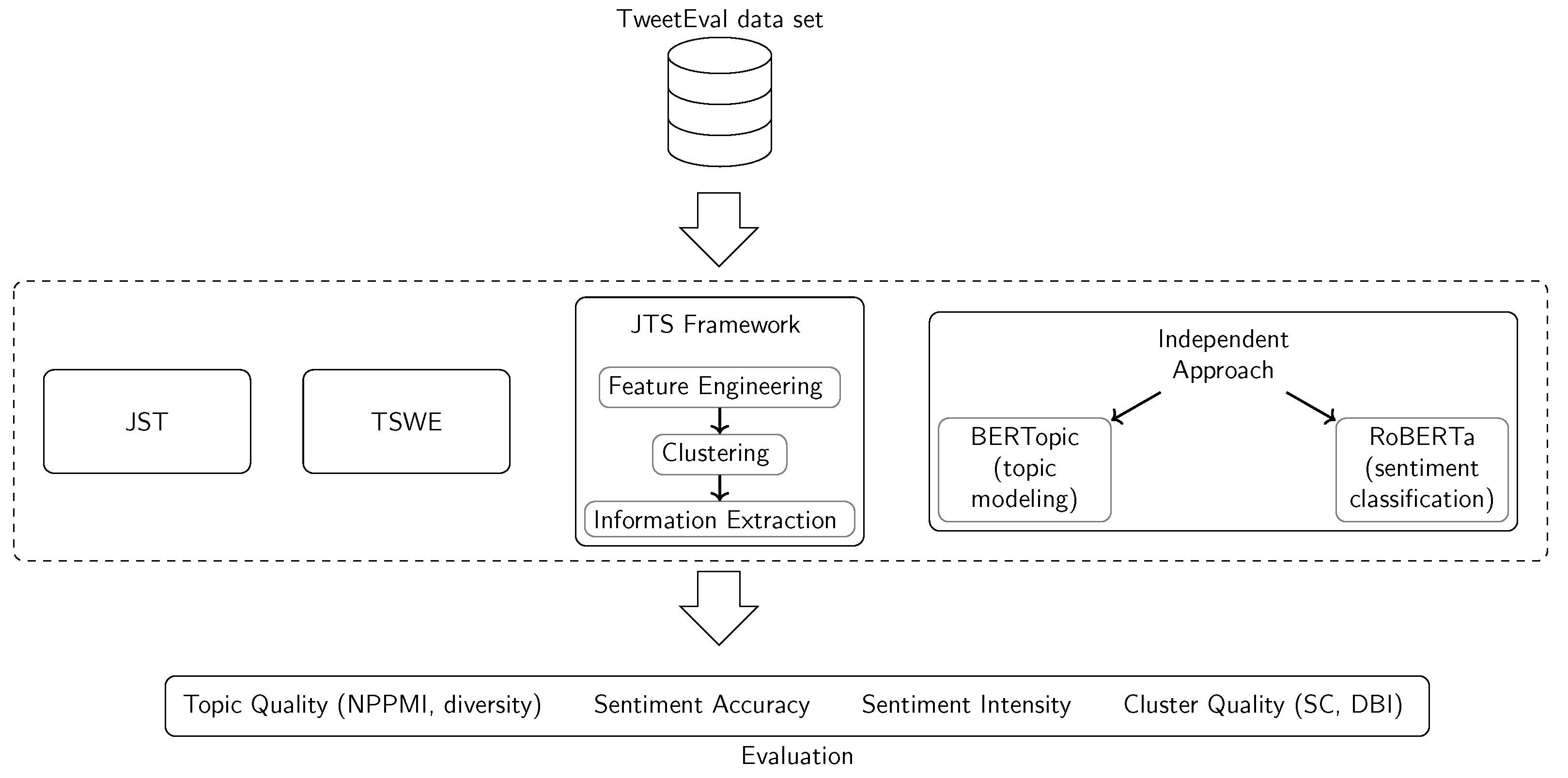
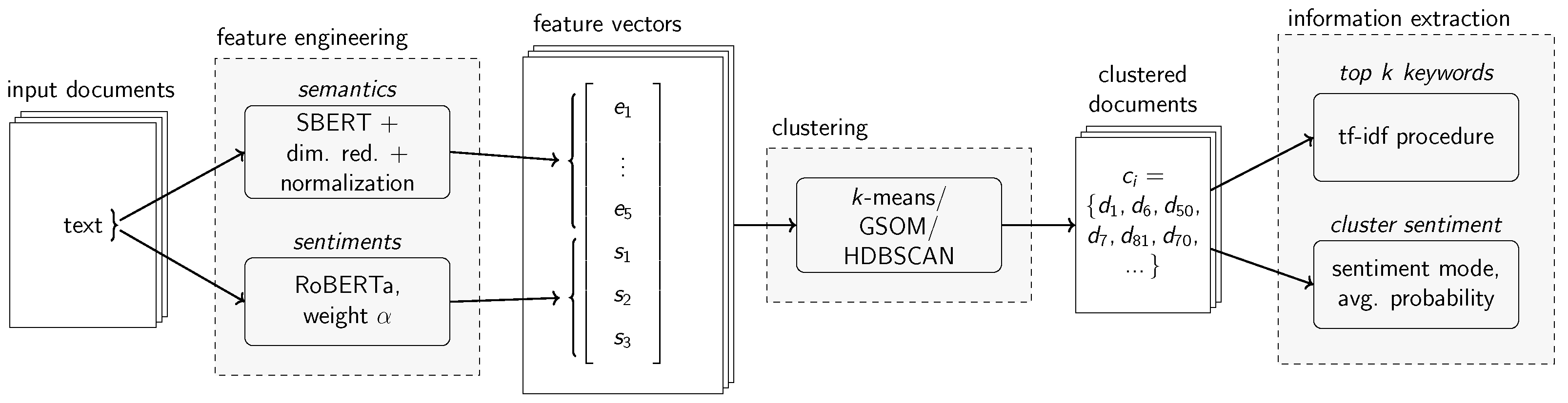
Given these developments, this research study introduces a novel approach to joint topic-sentiment modeling called the Joint Topic-Sentiment (JTS) framework. It is capable of computing semantic clusters of topics that are associated with a sentiment. The approach works by clustering joint feature vectors that represent both the semantic meaning and the sentiment of each input document. As it leverages distinct components for semantic embedding creation, dimensionality reduction, and clustering, the JTS framework itself allows for a degree of flexibility. Components can be exchanged depending on the needs of the user, e.g., if the data are multilingual or monolingual or if certain runtime requirements should be met. We realized the JTS framework using Principal Component Analysis (PCA) and Uniform Manifold Approximation and Projection (UMAP) for dimensionality reduction and
k-means, a Growing Self-Organizing Map (GSOM) and Hierarchical Density-Based Spatial Clustering of Applications with Noise (HDBSCAN) for clustering. The respective variants were compared against each other and previous approaches for joint topic-sentiment modeling. Additionally, a sequential, independent topic modeling plus sentiment classification approach using BERTopic (s.
Section 3) was considered for comparison. Our JTS framework achieved a topic coherence score of up to
and a topic diversity score of up to
whereas the highest respective scores among all other approaches were
and
. Simultaneously, the sentiment classification accuracy improved from
, which was the best value among the existing joint topic-sentiment models, to
with our approach. The uniformity of sentiments within the clusters reached up to
compared to
of the independent BERTopic plus sentiment classification approach. The key contributions of our research are therefore as follows:
We introduce the novel JTS framework for joint topic-sentiment modeling which uses LLMs and a clustering approach.
Our framework was evaluated using different configurations and compared against previous approaches as well as an independent, sequential approach.
The results indicate that the JTS framework is capable of producing more coherent clusters of social media posts both concerning semantics and sentiments while simultaneously providing the highest sentiment classification accuracy.
Going further, our study adheres to the following structure. First, in
Section 2, the related work regarding topic modeling, sentiment classification, and joint-topic-sentiment modeling is summarized. In
Section 3, we present the architecture, working principles, and implementation of our JTS framework. Moreover, the experimental setup and the evaluation metrics are explained. We then present our results in
Section 4. This is followed by a discussion of the results and the methodology in
Section 5. Finally, the contributions of our study are summarized in
Section 6.
Author Contributions
Conceptualization, D.H. and B.R.; methodology, D.H. and B.R.; software, D.H.; evaluation, D.H.; formal analysis, D.H.; investigation, D.H.; resources, B.R.; data curation, D.H.; writing—original draft preparation, D.H.; writing—review and editing, D.H. and B.R.; visualization, D.H.; supervision, B.R.; project administration, B.R.; funding acquisition, B.R. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Austrian Research Promotion Agency (FFG) through the project MUSIG (Grant Number 886355). This work has also received funding from the European Commission—European Union under HORIZON EUROPE (HORIZON Research and Innovation Actions) under grant agreement 101093003 (HORIZON-CL4-2022-DATA-01-01). Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union—European Commission. Neither the European Commission nor the European Union can be held responsible for them.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Acknowledgments
We would like to thank the anonymous reviewers for taking the time and effort to review our manuscript. We appreciate the valuable and critical comments which helped us improve the quality of our study.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Pang, B.; Lee, L. Opinion Mining and Sentiment Analysis. Found. Trends® Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef]
- Al-Qablan, T.A.; Mohd Noor, M.H.; Al-Betar, M.A.; Khader, A.T. A Survey on Sentiment Analysis and Its Applications. Neural Comput. Appl. 2023, 35, 21567–21601. [Google Scholar] [CrossRef]
- Egger, R.; Yu, J. A Topic Modeling Comparison Between LDA, NMF, Top2Vec, and BERTopic to Demystify Twitter Posts. Front. Sociol. 2022, 7, 886498. [Google Scholar] [CrossRef] [PubMed]
- Vayansky, I.; Kumar, S.A.P. A Review of Topic Modeling Methods. Inf. Syst. 2020, 94, 101582. [Google Scholar] [CrossRef]
- Yue, L.; Chen, W.; Li, X.; Zuo, W.; Yin, M. A Survey of Sentiment Analysis in Social Media. Knowl. Inf. Syst. 2019, 60, 617–663. [Google Scholar] [CrossRef]
- Crooks, A.; Croitoru, A.; Stefanidis, A.; Radzikowski, J. #Earthquake: Twitter as a Distributed Sensor System. Trans. GIS 2013, 17, 124–147. [Google Scholar] [CrossRef]
- Resch, B.; Usländer, F.; Havas, C. Combining Machine-Learning Topic Models and Spatiotemporal Analysis of Social Media Data for Disaster Footprint and Damage Assessment. Cartogr. Geogr. Inf. Sci. 2018, 45, 362–376. [Google Scholar] [CrossRef]
- Hu, B.; Jamali, M.; Ester, M. Spatio-Temporal Topic Modeling in Mobile Social Media for Location Recommendation. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining, Washington, DC, USA, 7–10 December 2013; pp. 1073–1078. [Google Scholar] [CrossRef]
- Lwin, K.K.; Zettsu, K.; Sugiura, K. Geovisualization and Correlation Analysis between Geotagged Twitter and JMA Rainfall Data: Case of Heavy Rain Disaster in Hiroshima. In Proceedings of the 2015 2nd IEEE International Conference on Spatial Data Mining and Geographical Knowledge Services (ICSDM), Fuzhou, China, 8–10 July 2015; pp. 71–76. [Google Scholar] [CrossRef]
- Havas, C.; Wendlinger, L.; Stier, J.; Julka, S.; Krieger, V.; Ferner, C.; Petutschnig, A.; Granitzer, M.; Wegenkittl, S.; Resch, B. Spatio-Temporal Machine Learning Analysis of Social Media Data and Refugee Movement Statistics. ISPRS Int. J. Geo-Inf. 2021, 10, 498. [Google Scholar] [CrossRef]
- Havas, C.; Resch, B. Portability of Semantic and Spatial–Temporal Machine Learning Methods to Analyse Social Media for near-Real-Time Disaster Monitoring. Nat. Hazards 2021, 108, 2939–2969. [Google Scholar] [CrossRef]
- Stolerman, L.M.; Clemente, L.; Poirier, C.; Parag, K.V.; Majumder, A.; Masyn, S.; Resch, B.; Santillana, M. Using Digital Traces to Build Prospective and Real-Time County-Level Early Warning Systems to Anticipate COVID-19 Outbreaks in the United States. Sci. Adv. 2023, 9, eabq0199. [Google Scholar] [CrossRef]
- Wakamiya, S.; Kawai, Y.; Aramaki, E. Twitter-Based Influenza Detection After Flu Peak via Tweets with Indirect Information: Text Mining Study. JMIR Public Health Surveill. 2018, 4, e65. [Google Scholar] [CrossRef]
- Lin, C.; He, Y. Joint Sentiment/Topic Model for Sentiment Analysis. In Proceedings of the 18th ACM Conference on Information and Knowledge Management—CIKM’09, Hong Kong, China, 2–6 November 2009; pp. 375–384. [Google Scholar] [CrossRef]
- Fu, X.; Wu, H.; Cui, L. Topic Sentiment Joint Model with Word Embeddings. In Proceedings of the DMNLP@PKDD/ECML, Riva del Garda, Italy, 19–23 September 2016. [Google Scholar]
- Dermouche, M.; Kouas, L.; Velcin, J.; Loudcher, S. A Joint Model for Topic-Sentiment Modeling from Text. In Proceedings of the 30th Annual ACM Symposium on Applied Computing—SAC’15, New York, NY, USA, 13–17 April 2015; pp. 819–824. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Neppalli, V.K.; Caragea, C.; Squicciarini, A.; Tapia, A.; Stehle, S. Sentiment Analysis during Hurricane Sandy in Emergency Response. Int. J. Disaster Risk Reduct. 2017, 21, 213–222. [Google Scholar] [CrossRef]
- Sia, S.; Dalmia, A.; Mielke, S.J. Tired of Topic Models? Clusters of Pretrained Word Embeddings Make for Fast and Good Topics Too! In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 1728–1736. [Google Scholar] [CrossRef]
- Angelov, D. Top2Vec: Distributed Representations of Topics. arXiv 2020, arXiv:2008.09470. [Google Scholar]
- Grootendorst, M. BERTopic: Neural Topic Modeling with a Class-Based TF-IDF Procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar]
- Hoyle, A.; Sarkar, R.; Goel, P.; Resnik, P. Are Neural Topic Models Broken? In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 5321–5344. [Google Scholar]
- Yau, C.K.; Porter, A.; Newman, N.; Suominen, A. Clustering Scientific Documents with Topic Modeling. Scientometrics 2014, 100, 767–786. [Google Scholar] [CrossRef]
- Suominen, A.; Toivanen, H. Map of Science with Topic Modeling: Comparison of Unsupervised Learning and Human-Assigned Subject Classification. J. Assoc. Inf. Sci. Technol. 2016, 67, 2464–2476. [Google Scholar] [CrossRef]
- Carron-Arthur, B.; Reynolds, J.; Bennett, K.; Bennett, A.; Griffiths, K.M. What is All the Talk about? Topic Modelling in a Mental Health Internet Support Group. BMC Psychiatry 2016, 16, 367. [Google Scholar] [CrossRef] [PubMed]
- Carter, D.J.; Brown, J.J.; Rahmani, A. Reading the High Court at A Distance: Topic Modelling The Legal Subject Matter and Judicial Activity of the High Court of Australia, 1903–2015. LawArXiv 2018. [Google Scholar] [CrossRef]
- Blauberger, M.; Heindlmaier, A.; Hofmarcher, P.; Assmus, J.; Mitter, B. The Differentiated Politicization of Free Movement of People in the EU. A Topic Model Analysis of Press Coverage in Austria, Germany, Poland and the UK. J. Eur. Public Policy 2023, 30, 291–314. [Google Scholar] [CrossRef]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by Latent Semantic Analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Hofmann, T. Probabilistic Latent Semantic Analysis. In Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence—UAI’99, San Francisco, CA, USA, 30 July–1 August 1999; pp. 289–296. [Google Scholar]
- Choo, J.; Lee, C.; Reddy, C.K.; Park, H. UTOPIAN: User-Driven Topic Modeling Based on Interactive Nonnegative Matrix Factorization. IEEE Trans. Vis. Comput. Graph. 2013, 19, 1992–2001. [Google Scholar] [CrossRef] [PubMed]
- Griffiths, T.L.; Steyvers, M. Finding Scientific Topics. Proc. Natl. Acad. Sci. USA 2004, 101, 5228–5235. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Zhao, W.X.; Jiang, J.; Weng, J.; He, J.; Lim, E.P.; Yan, H.; Li, X. Comparing Twitter and Traditional Media Using Topic Models. In Advances in Information Retrieval; Clough, P., Foley, C., Gurrin, C., Jones, G.J.F., Kraaij, W., Lee, H., Mudoch, V., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 338–349. [Google Scholar] [CrossRef]
- Dieng, A.B.; Ruiz, F.J.R.; Blei, D.M. The Dynamic Embedded Topic Model. arXiv 2019, arXiv:1907.05545. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar] [CrossRef]
- Le, Q.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the 31st International Conference on Machine Learning—PMLR, Beijing, China, 22–24 June 2014; pp. 1188–1196. [Google Scholar]
- Dieng, A.B.; Ruiz, F.J.R.; Blei, D.M. Topic Modeling in Embedding Spaces. Trans. Assoc. Comput. Linguist. 2020, 8, 439–453. [Google Scholar] [CrossRef]
- Lang, K. NewsWeeder: Learning to Filter Netnews. In Machine Learning Proceedings 1995; Prieditis, A., Russell, S., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 1995; pp. 331–339. [Google Scholar] [CrossRef]
- Greene, D.; Cunningham, P. Practical Solutions to the Problem of Diagonal Dominance in Kernel Document Clustering. In Proceedings of the 23rd International Conference on Machine Learning (ICML’06), Pittsburgh, PA, USA, 25–29 June 2006; ACM Press: New York, NY, USA, 2006; pp. 377–384. [Google Scholar]
- Alharbi, A.S.M.; de Doncker, E. Twitter Sentiment Analysis with a Deep Neural Network: An Enhanced Approach Using User Behavioral Information. Cogn. Syst. Res. 2019, 54, 50–61. [Google Scholar] [CrossRef]
- Wei, J.; Liao, J.; Yang, Z.; Wang, S.; Zhao, Q. BiLSTM with Multi-Polarity Orthogonal Attention for Implicit Sentiment Analysis. Neurocomputing 2020, 383, 165–173. [Google Scholar] [CrossRef]
- Barbieri, F.; Espinosa Anke, L.; Camacho-Collados, J. XLM-T: Multilingual Language Models in Twitter for Sentiment Analysis and Beyond. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022; pp. 258–266. [Google Scholar]
- Barbieri, F.; Camacho-Collados, J.; Espinosa Anke, L.; Neves, L. TweetEval: Unified Benchmark and Comparative Evaluation for Tweet Classification. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 1644–1650. [Google Scholar] [CrossRef]
- Loureiro, D.; Barbieri, F.; Neves, L.; Espinosa Anke, L.; Camacho-collados, J. TimeLMs: Diachronic Language Models from Twitter. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Dublin, Ireland, 22–27 May 2022; pp. 251–260. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J., Eds.; Association for Computational Linguistics: Seattle, WA, USA, 2020; pp. 8440–8451. [Google Scholar] [CrossRef]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Camacho, K.; Portelli, R.; Shortridge, A.; Takahashi, B. Sentiment Mapping: Point Pattern Analysis of Sentiment Classified Twitter Data. Cartogr. Geogr. Inf. Sci. 2021, 48, 241–257. [Google Scholar] [CrossRef]
- Paul, D.; Li, F.; Teja, M.K.; Yu, X.; Frost, R. Compass: Spatio Temporal Sentiment Analysis of US Election What Twitter Says! In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD’17, Halifax, NS, Canada, 13–17 August 2017; pp. 1585–1594. [Google Scholar] [CrossRef]
- Kovacs-Györi, A.; Ristea, A.; Kolcsar, R.; Resch, B.; Crivellari, A.; Blaschke, T. Beyond Spatial Proximity—Classifying Parks and Their Visitors in London Based on Spatiotemporal and Sentiment Analysis of Twitter Data. ISPRS Int. J. Geo-Inf. 2018, 7, 378. [Google Scholar] [CrossRef]
- Lin, C.; He, Y.; Everson, R.; Ruger, S. Weakly Supervised Joint Sentiment-Topic Detection from Text. IEEE Trans. Knowl. Data Eng. 2012, 24, 1134–1145. [Google Scholar] [CrossRef]
- Liang, Q.; Ranganathan, S.; Wang, K.; Deng, X. JST-RR Model: Joint Modeling of Ratings and Reviews in Sentiment-Topic Prediction. Technometrics 2023, 65, 57–69. [Google Scholar] [CrossRef]
- Alaparthi, S.; Mishra, M. BERT: A Sentiment Analysis Odyssey. J. Mark. Anal. 2021, 9, 118–126. [Google Scholar] [CrossRef]
- Kotelnikova, A.; Paschenko, D.; Bochenina, K.; Kotelnikov, E. Lexicon-Based Methods vs. BERT for Text Sentiment Analysis. In Analysis of Images, Social Networks and Texts; Burnaev, E., Ignatov, D.I., Ivanov, S., Khachay, M., Koltsova, O., Kutuzov, A., Kuznetsov, S.O., Loukachevitch, N., Napoli, A., Panchenko, A., et al., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2022; pp. 71–83. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Pota, M.; Ventura, M.; Fujita, H.; Esposito, M. Multilingual Evaluation of Pre-Processing for BERT-based Sentiment Analysis of Tweets. Expert Syst. Appl. 2021, 181, 115119. [Google Scholar] [CrossRef]
- Ek, A.; Bernardy, J.P.; Chatzikyriakidis, S. How Does Punctuation Affect Neural Models in Natural Language Inference. In Proceedings of the Probability and Meaning Conference (PaM 2020), Gothenburg, Sweden, 3–5 June 2020; pp. 109–116. [Google Scholar]
- de Barros, T.M.; Pedrini, H.; Dias, Z. Leveraging Emoji to Improve Sentiment Classification of Tweets. In Proceedings of the 36th Annual ACM Symposium on Applied Computing—SAC ’21, Virtual, 22–26 March 2021; pp. 845–852. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3980–3990. [Google Scholar] [CrossRef]
- Cer, D.; Yang, Y.; Kong, S.Y.; Hua, N.; Limtiaco, N.; John, R.S.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal Sentence Encoder. arXiv 2018, arXiv:1803.11175. [Google Scholar] [CrossRef]
- Fefferman, C.; Mitter, S.; Narayanan, H. Testing the Manifold Hypothesis. J. Am. Math. Soc. 2016, 29, 983–1049. [Google Scholar] [CrossRef]
- Strang, G. Introduction to Linear Algebra, 5th ed.; Cambridge Press: Wellesley, MA, USA, 2016. [Google Scholar]
- Lloyd, S. Least Squares Quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- MacQueen, J. Some Methods for Classification and Analysis of Multivariate Observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Statistics; University of California Press: Berkeley, CA, USA, 1967; Volume 5.1, pp. 281–298. [Google Scholar]
- Jin, X.; Han, J. K-Means Clustering. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2010; pp. 563–564. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. K-Means++: The Advantages of Careful Seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms—SODA ’07, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Alahakoon, D.; Halgamuge, S.; Srinivasan, B. Dynamic Self-Organizing Maps with Controlled Growth for Knowledge Discovery. IEEE Trans. Neural Netw. 2000, 11, 601–614. [Google Scholar] [CrossRef]
- Kohonen, T. The Hypermap Architecture. In Artificial Neural Networks; Kohonen, T., Mäkisara, K., Simula, O., Kangas, J., Eds.; North-Holland: Amsterdam, The Netherlands, 1991; pp. 1357–1360. [Google Scholar] [CrossRef]
- Campello, R.J.G.B.; Moulavi, D.; Sander, J. Density-Based Clustering Based on Hierarchical Density Estimates. In Advances in Knowledge Discovery and Data Mining; Pei, J., Tseng, V.S., Cao, L., Motoda, H., Xu, G., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Gernmay, 2013; pp. 160–172. [Google Scholar] [CrossRef]
- Malzer, C.; Baum, M. A Hybrid Approach To Hierarchical Density-based Cluster Selection. In Proceedings of the 2020 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), Virtual, 14–16 September 2020; pp. 223–228. [Google Scholar] [CrossRef]
- Salton, G. Automatic Text Processing: The Transformation, Analysis, and Retrieval of Information by Computer; Addison-Wesley Series in Computer Science; Addison-Wesley: Boston, MA, USA, 1989. [Google Scholar]
- Camacho-Collados, J.; Rezaee, K.; Riahi, T.; Ushio, A.; Loureiro, D.; Antypas, D.; Boisson, J.; Espinosa Anke, L.; Liu, F.; Martínez Cámara, E. TweetNLP: Cutting-Edge Natural Language Processing for Social Media. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 38–49. [Google Scholar]
- Rosenthal, S.; Farra, N.; Nakov, P. SemEval-2017 Task 4: Sentiment Analysis in Twitter. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 502–518. [Google Scholar] [CrossRef]
- Fellbaum, C. (Ed.) WordNet: An Electronic Lexical Database; Language, Speech, and Communication; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- van Rossum, G. Python Tutorial [Technical Report]; CWI (National Research Institute for Mathematics and Computer Science): Amsterdam, The Netherlands, 1995. [Google Scholar]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array Programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; Liu, Q., Schlangen, D., Eds.; Association for Computational Linguistics: Seattle, WA, USA, 2020; pp. 38–45. [Google Scholar] [CrossRef]
- victor7246. Victor7246/Jointtsmodel. Available online: https://github.com/victor7246/jointtsmodel (accessed on 7 March 2024).
- Chang, J.; Gerrish, S.; Wang, C.; Boyd-graber, J.; Blei, D. Reading Tea Leaves: How Humans Interpret Topic Models. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2009; Volume 22. [Google Scholar]
- Fano, R.M. Transmission of Information: A Statistical Theory of Communications, 3rd ed.; MIT Press: Cambridge, MA, USA, 1966. [Google Scholar]
- Church, K.W.; Hanks, P. Word Association Norms, Mutual Information, and Lexicography. In Proceedings of the 27th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 26–29 June 1989; pp. 76–83. [Google Scholar] [CrossRef]
- Bouma, G. Normalized (Pointwise) Mutual Information in Collocation Extraction. Proc. GSCL 2009, 30, 31–40. [Google Scholar]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing, 3rd ed. Draft. Available online: https://web.stanford.edu/~jurafsky/slp3/ (accessed on 23 May 2023).
- Niwa, Y.; Nitta, Y. Co-Occurrence Vectors from Corpora vs. Distance Vectors from Dictionaries. In Proceedings of the COLING 1994 Volume 1: The 15th International Conference on Computational Linguistics, Kyoto, Japan, 5–9 August 1994. [Google Scholar]
- Dagan, I.; Marcus, S.; Markovitch, S. Contextual Word Similarity and Estimation from Sparse Data. In Proceedings of the 31st Annual Meeting on Association for Computational Linguistics—ACL ’93, Columbus, OH, USA, 22–26 June 1993; pp. 164–171. [Google Scholar] [CrossRef]
- Terragni, S.; Fersini, E.; Galuzzi, B.G.; Tropeano, P.; Candelieri, A. OCTIS: Comparing and Optimizing Topic Models Is Simple! In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, Online, 19–23 April 2021; pp. 263–270. [Google Scholar] [CrossRef]
- Sorower, M.S. A Literature Survey on Algorithms for Multi-Label Learning. Or. State Univ. Corvallis 2010, 18, 25. [Google Scholar]
- Rousseeuw, P.J. Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Davies, D.L.; Bouldin, D.W. A Cluster Separation Measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, PAMI-1, 224–227. [Google Scholar] [CrossRef]
- McInnes, L. UMAP Documentation: Release 0.5; UMAP: Odisha, India, 2023. [Google Scholar]
- Ultsch, A.; Siemon, H.P. Kohonen’s Self Organizing Feature Maps for Exploratory Data Analysis. In Proceedings of the International Neural Network Conference (INNC-90), Paris, France, 9–13 July 1990; Widrow, B., Angeniol, B., Eds.; Springer: Dordrecht, The Netherlands, 1990; Volume 1, pp. 305–308. [Google Scholar]
- Zini, J.E.; Awad, M. On the Explainability of Natural Language Processing Deep Models. ACM Comput. Surv. 2022, 55, 103:1–103:31. [Google Scholar] [CrossRef]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. mproving Language Understanding by Generative Pre-Training [Technical Report]. OpenAI. 2018. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 15 July 2023).
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv 2023, arXiv:2307.09288. [Google Scholar] [CrossRef]
- Kheiri, K.; Karimi, H. SentimentGPT: Exploiting GPT for Advanced Sentiment Analysis and Its Departure from Current Machine Learning. arXiv 2023, arXiv:2307.10234. [Google Scholar] [CrossRef]
- Wang, Z.; Pang, Y.; Lin, Y. Large Language Models Are Zero-Shot Text Classifiers. arXiv 2023, arXiv:2312.01044. [Google Scholar] [CrossRef]
- Pham, C.M.; Hoyle, A.; Sun, S.; Iyyer, M. TopicGPT: A Prompt-based Topic Modeling Framework. arXiv 2023, arXiv:2311.01449. [Google Scholar] [CrossRef]
- Wang, H.; Prakash, N.; Hoang, N.K.; Hee, M.S.; Naseem, U.; Lee, R.K.W. Prompting Large Language Models for Topic Modeling. arXiv 2023, arXiv:2312.09693. [Google Scholar] [CrossRef]
- Stammbach, D.; Zouhar, V.; Hoyle, A.; Sachan, M.; Ash, E. Revisiting Automated Topic Model Evaluation with Large Language Models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; Bouamor, H., Pino, J., Bali, K., Eds.; Association for Computational Linguistics: Seattle, WA, USA, 2023; pp. 9348–9357. [Google Scholar] [CrossRef]
- Weidinger, L.; Mellor, J.; Rauh, M.; Griffin, C.; Uesato, J.; Huang, P.S.; Cheng, M.; Glaese, M.; Balle, B.; Kasirzadeh, A.; et al. Ethical and Social Risks of Harm from Language Models. arXiv 2021, arXiv:2112.04359. [Google Scholar] [CrossRef]
- Jiang, A.Q.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot, D.S.; de las Casas, D.; Bressand, F.; Lengyel, G.; Lample, G.; Saulnier, L.; et al. Mistral 7B. arXiv 2023, arXiv:2310.06825. [Google Scholar] [CrossRef]
- Ragini, J.R.; Anand, P.M.R.; Bhaskar, V. Big Data Analytics for Disaster Response and Recovery through Sentiment Analysis. Int. J. Inf. Manag. 2018, 42, 13–24. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}