

Video Object Segmentation Using Multi-Scale Attention-Based Siamese Network
Abstract
:1. Introduction
- (1)
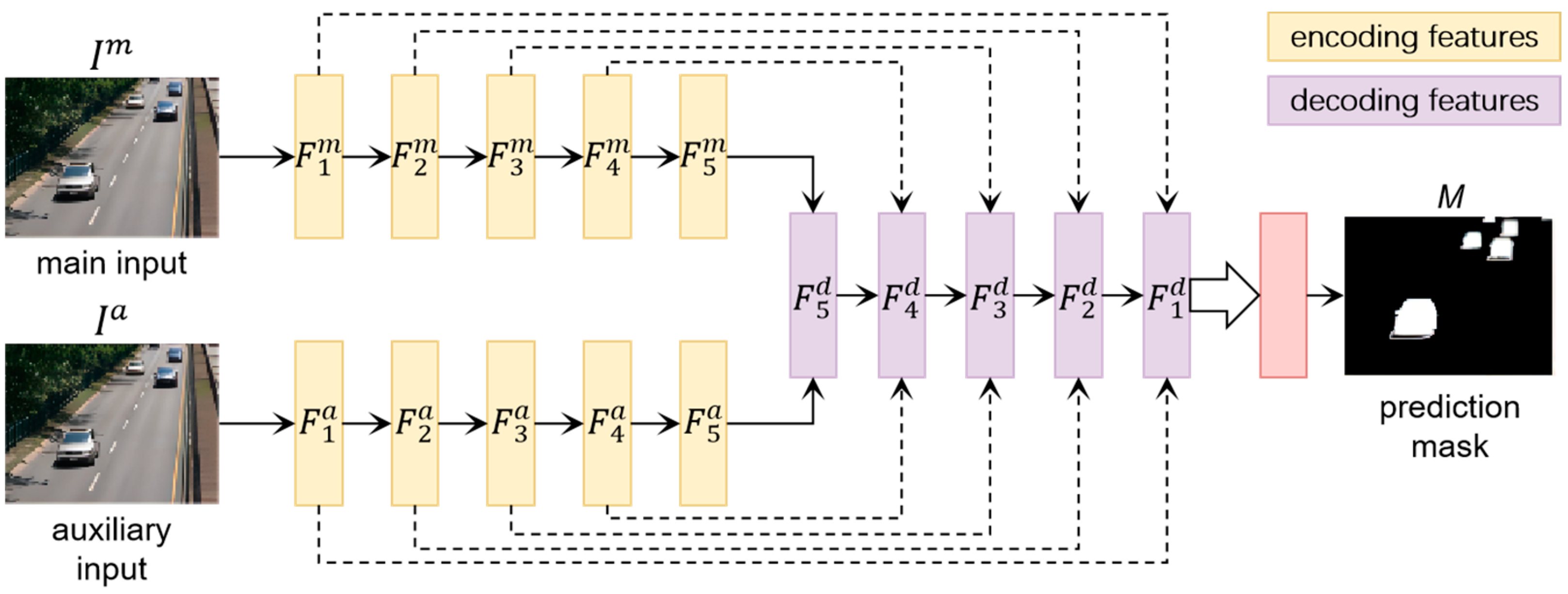
- We proposed an effective Siamese attention-based model that extracts and fuses appearance and movement features to generate foreground mask in an end-to-end manner without postprocessing steps.
- (2)
- We demonstrated that using two adjacent frames can predict the foreground mask with higher accuracy than using optical flow as auxiliary inputs.
- (3)
- We performed extensive and comprehensive experiments on the FBMS-3D dataset, and the experimental results confirm that the Siamese neural network and multiscale attention module function well. Moreover, the proposed methods can run in real time.
- (4)
- The experimental results of the FBMS-3D, CDNet2014, SegTrackV2, DAVIS2016, and DAVIS2017 datasets show that our model outperforms the state-of-the-art model on the VOS dataset, and our model is comparable with the state-of-the-art model on the VOS dataset.
2. Related Work
2.1. Language-Guided Video Object Segmentation
2.2. Optical Flow-Based Methods
2.3. Attention Mechanism
3. Proposed Model
3.1. Siamese Encoder
3.2. Multi-Scale Attention-Based Decoder
3.3. Loss Function
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Comparison with the State-of-the-Art Methods
4.4.1. Performance on SegTrackV2
4.4.2. Performance on CDNet2014
4.4.3. Performance on FBMS-3D
4.4.4. Performance on DAVIS
4.5. Ablation Study
4.5.1. Siamese Neural Network
4.5.2. Uni-Modal vs. Multi-Modal
4.5.3. Attention Experiment
4.5.4. Speed and Accuracy Trade-Off
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhou, T.F.; Porikli, F.; Crandall, D.; Gool, L.V.; Wang, W.G. A survey on deep learning technique for video segmentation. arXiv 2021, arXiv:2107.01153. [Google Scholar]
- Hou, W.J.; Qin, Z.Y.; Xi, X.M.; Lu, X.K.; Yin, Y.L. Learning disentangled representation for self-supervised video object segmentation. Neurocomputing 2022, 481, 270–280. [Google Scholar] [CrossRef]
- Gao, M.Q.; Zheng, F.; Yu, J.J.Q.; Shan, C.F.; Ding, G.G.; Han, J.G. Deep learning for video object segmentation: A review. Artif. Intell. Rev. 2023, 56, 457–531. [Google Scholar] [CrossRef]
- Farin, D.; de With, P.H.N.; Effelsberg, W.A. Video-object segmentation using multi-sprite background subtraction. In Proceedings of the IEEE International Conference on Multimedia and Expo, Taipei, Taiwan, 27–30 June 2004; pp. 343–346. [Google Scholar]
- Zhuo, T.; Cheng, Z.Y.; Zhang, P.; Wong, Y.K.; Kankanhalli, M. Unsupervised online video object segmentation with motion property understanding. IEEE Trans. Image Process. 2019, 29, 237–249. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, W.G.; Shen, J.B.; Porikli, F.; Yang, R.G. Semi-supervised video object segmentation with super-trajectories. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 985–998. [Google Scholar] [CrossRef]
- Wang, W.Y.; Tran, D.; Feiszli, M. What makes training multi-modal classification networks hard? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14—19 June 2020; pp. 12695–12705. [Google Scholar]
- Luo, Z.Y.; Xiao, Y.C.; Liu, Y.; Li, S.Y.; Wang, Y.T.; Tang, Y.S.; Li, X.; Yang, Y.J. SOC: Semantic-Assisted Object Cluster for Referring Video Object Segmentation. arXiv 2023, arXiv:2305.17011. [Google Scholar]
- Gavrilyuk, K.; Ghodrati, A.; Li, Z.Y.; Snoek, G.M.C. Actor and action video segmentation from a sentence. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5958–5966. [Google Scholar]
- Liang, C.; Wang, W.G.; Zhou, T.F.; Miao, J.X.; Luo, Y.W.; Yang, Y. Local-global context aware transformer for language-guided video segmentation. arXiv 2022, arXiv:2203.09773. [Google Scholar]
- Bellver, M.; Ventura, C.; Silberer, C.; Kazakos, I.; Torres, J.; Giro-i-Nieto, X. Refvos: A closer look at referring expressions for video object segmentation. arXiv 2020, arXiv:2010.00263. [Google Scholar]
- Seo, S.; Lee, J.Y.; Han, B. Urvos: Unified referring video object segmentation network with a large-scale benchmark. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020; pp. 208–223. [Google Scholar]
- Ye, L.W.; Rochan, M.; Liu, Z.; Zhang, X.Q.; Wang, Y. Referring segmentation in images and videos with cross-modal self-attention network. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3719–3732. [Google Scholar]
- Ding, Z.H.; Hui, T.R.; Huang, J.S.; Wei, J.Z.; Han, J.Z.; Liu, S. Language-bridged spatial-temporal interaction for referring video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 4964–4973. [Google Scholar]
- Li, D.Z.; Li, R.Q.; Wang, L.J.; Wang, Y.F.; Qi, J.Q.; Zhang, L.; Liu, T.; Xu, Q.Q.; Lu, H.C. You only infer once: Cross-modal meta-transfer for referring video object segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22 February–1 March 2022; pp. 1297–1305. [Google Scholar]
- Botach, A.; Zheltonozhskii, E.; Baskin, C. End-to-end referring video object segmentation with multimodal transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 4985–4995. [Google Scholar]
- Wu, J.N.; Jiang, Y.; Sun, P.Z.; Yuan, Z.H.; Luo, P. Language as queries for referring video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 4974–4984. [Google Scholar]
- Tokmakov, P.; Alahari, K.; Schmid, C. Learning motion patterns in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3386–3394. [Google Scholar]
- Cheng, J.C.; Tsai, Y.H.; Wang, S.J.; Yang, M.H. Segflow: Joint learning for video object segmentation and optical flow. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 686–695. [Google Scholar]
- Dutt, J.S.; Xiong, B.; Grauman, K. Fusionseg: Learning to combine motion and appearance for fully automatic segmentation of generic objects in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3664–3673. [Google Scholar]
- Xiao, H.X.; Feng, J.S.; Lin, G.S.; Liu, Y.; Zhang, M.J. Monet: Deep motion exploitation for video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1140–1148. [Google Scholar]
- Bao, L.C.; Wu, B.Y.; Liu, W. CNN in MRF: Video object segmentation via inference in a CNN-based higher-order spatio-temporal MRF. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5977–5986. [Google Scholar]
- Zhou, T.F.; Wang, S.Z.; Zhou, Y.; Yao, Y.Z.; Li, J.W.; Shao, L. Motion-attentive transition for zero-shot video object segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 13066–13073. [Google Scholar]
- de Santana Correia, A.; Colombini, E.L. Attention, please! A survey of neural attention models in deep learning. Artif. Intell. Rev. 2022, 55, 6037–6124. [Google Scholar] [CrossRef]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Qin, Z.Q.; Zhang, P.Y.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 783–792. [Google Scholar]
- Chu, X.X.; Tian, Z.; Wang, Y.Q.; Zhang, B.; Ren, H.B.; Wei, X.L.; Xia, H.X.; Shen, C.H. Twins: Revisiting the design of spatial attention in vision transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 9355–9366. [Google Scholar]
- Coull, J.T. fMRI studies of temporal attention: Allocating attention within, or towards, time. Cogn. Brain Res. 2004, 21, 216–226. [Google Scholar] [CrossRef]
- Shi, X.M.; Qi, H.; Shen, Y.M.; Wu, G.Z.; Yin, B.C. A spatial–temporal attention approach for traffic prediction. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4909–4918. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.H.; Karpahty, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.L.; Chen, B.; Kalenichenko, D.; Wang, W.J.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Li, F.X.; Kim, T.; Humayun, A.; Tsai, D.; Rehg, J.M. Video segmentation by tracking many figure-ground segments. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2192–2199. [Google Scholar]
- Wang, Y.; Jodoin, P.M.; Porikli, F.; Konrad, J.; Benezeth, Y.; Ishwar, P. CDnet 2014: An expanded change detection benchmark dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 387–394. [Google Scholar]
- Goyette, N.; Jodoin, P.M.; Porikli, F.; Konrad, J.; Ishwar, P. Changedetection. net: A new change detection benchmark dataset. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 1–8. [Google Scholar]
- Ochs, P.; Malik, J.; Brox, T. Segmentation of moving objects by long term video analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1187–1200. [Google Scholar] [CrossRef] [Green Version]
- Brox, T.; Malik, J. Object segmentation by long term analysis of point trajectories. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; pp. 282–295. [Google Scholar]
- Bideau, P.; Learned-Miller, E. It’s moving! a probabilistic model for causal motion segmentation in moving camera videos. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 10–16 October 2016; pp. 433–449. [Google Scholar]
- Bideau, P.; Learned-Miller, E. A detailed rubric for motion segmentation. arXiv 2016, arXiv:1610.10033. [Google Scholar]
- Perazzi, F.; Pont-Tuset, J.; McWilliams, B.; Gool, L.V.; Gross, M.; Sorkine-Hornung, A. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 724–732. [Google Scholar]
- Pont-Tuset, J.; Perazzi, F.; Caelles, S.; Arbelaez, P.; Sorkine-Hornung, A.; Fool, L.V. The 2017 davis challenge on video object segmentation. arXiv 2017, arXiv:1704.00675. [Google Scholar]
- Segmentation Models Pytorch. 2020. Available online: https://github.com/qubvel/segmentation_model (accessed on 16 December 2020).
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhao, H.S.; Shi, J.P.; Qi, X.J.; Wang, X.G.; Jia, J.Y. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chaurasia, A.; Culurciello, E. Linknet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the IEEE Visual Communications and Image Processing, Petersburg, VA, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Li, H.C.; Xiong, P.F.; An, J.; Wang, L.X. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Chen, L.C.; Zhu, Y.K.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Varghese, A.; Gubbi, J.; Ramaswamy, A.; Balamuralidhar, P. ChangeNet: A deep learning architecture for visual change detection. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.L.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Hui, T.W.; Tang, X.; Loy, C.C. Liteflownet: A lightweight convolutional neural network for optical flow estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8981–8989. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.J.; Li, Y.; Bao, Y.J.; Fang, Z.W.; Lu, H.Q. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Chen, L.; Zhang, H.W.; Xiao, J.; Nie, L.Q.; Shao, J.; Liu, W.; Chua, T.S. SCA-CNN: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Zhao, H.S.; Zhang, Y.; Liu, S.; Shi, J.P.; Loy, C.C.; Lin, D.H.; Jia, J.Y. Psanet: Point-wise spatial attention network for scene parsing. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 267–283. [Google Scholar]
- Liu, M.; Yin, H. Cross attention network for semantic segmentation. In Proceedings of the IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 2434–2438. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. Parsenet: Looking wider to see better. arXiv 2015, arXiv:1506.04579. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Year | #GT | #Train | #Val | Duration | #Object | Input Shape | Usage | Camera |
|---|---|---|---|---|---|---|---|---|---|
| SegTrackV2 [34] | 2013 | 947 | 9 | 5 | (21, 279) | 24 | (240 × 320, 360 × 640) | VOS | m + f |
| CDNet2014 | 2014 | 160,000 | 31 | 22 | (900, 7000) | >4 | (240 × 320, 486 × 720) | FS | f |
| FBMS-3D | 2014 | 720 | 29 | 30 | (19, 800) | >12 | (228 × 350, 540 × 960) | FS | m |
| DAVIS2016 | 2016 | 3455 | 30 | 20 | (25, 127) | 50 | (480 × 854, 480 × 1301) | VOS | m |
| DAVIS2017 | 2017 | 10,459 | 60 | 30 | (25, 127) | 376 | (480 × 854, 480 × 1301) | VOS | m |
| Network | UNet | FPN | PAN | PSPNet | LinkNet | D3+ | D3+ | ChangeNet | Ours | Ours-Attention |
|---|---|---|---|---|---|---|---|---|---|---|
| Multi-modal | √ | √ | √ | √ | ||||||
| SegTrackV2 | 55.69 | 63.00 | 58.25 | 36.91 | 37.66 | 60.55 | 39.61 * | 55.41 | 59.82 | 60.57 |
| CDNet2014 | 74.06 | 73.43 | 72.44 | 66.06 | 57.31 | 72.00 | 19.87 * | 72.51 | 72.65 | 78.36 |
| FBMS-3D | 85.14 | 83.60 | 84.21 | 73.78 | 85.33 | 85.93 | 69.02 * | 83.68 | 86.13 | 86.71 |
| DAVIS2016 | 78.98 | 80.04 | 79.86 | 65.36 | 63.83 | 81.19 | 60.59 * | 78.00 | 80.96 | 81.08 |
| DAVIS2017 | 75.45 | 75.97 | 74.77 | 63.25 | 63.29 | 76.51 | 59.81 * | 75.46 | 77.48 | 76.11 |
| Encoders | MobileNetV2 | MobileNetV2 | VGG16 | VGG16 | VGG19 | VGG19 | ResNet50 | ResNet50 |
|---|---|---|---|---|---|---|---|---|
| SNN | √ | √ | √ | √ | ||||
| F1 (%) | 79.69 | 82.00 (+2.31) | 83.61 | 82.81 (−0.80) | 84.26 | 83.72 (−0.54) | 84.47 | 86.14 (+1.67) |
| std(F1) | 1.46 | 0.31 | 1.46 | 1.38 | 1.25 | 0.80 | 1.19 | 0.29 |
| Auxiliary Encoder | MobileNetV2 | VGG11 | VGG16 | VGG19 | ResNet50 | - | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Auxiliary Input | a | o | a | o | a | o | a | o | a | o | - |
| F1 (%) | 85.62 | 85.54 | 85.78 | 85.53 | 86.49 | 86.06 | 86.59 | 86.12 | 84.47 | 85.03 | 86.34 |
| Attention Type | d [48] | S [49] | G2 [51] | n | G1 [52] | P [48] | C1 [49] | C2 [48] | C2 | C1 | C1 | C1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fusion Stage | LR | ALL | ALL | - | ALL | LR | ALL | LR | LR | ALL | LR | HR |
| Attention Feature | ALL | ALL | ALL | - | ALL | ALL | ALL | ALL | Main | Main | ALL | ALL |
| F1 (%) | 85.69 | 85.71 | 85.85 | 86.14 | 86.32 | 86.33 | 86.48 | 86.71 | 86.57 | 86.20 | 86.41 | 86.69 |
| Enc | M | M | V16 | V16 | V19 | V19 | ResNet50 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SNN | - | √ | - | √ | - | √ | - | √ | √ | √ | √ | √ | √ | √ | √ |
| Att | n | n | n | n | n | n | n | n | d | s | G1 | G2 | p | C1 | C2 |
| F1 (%) | 79.69 | 82.00 | 83.61 | 82.81 | 84.26 | 83.72 | 84.47 | 86.14 | 85.69 | 85.71 | 86.32 | 85.85 | 86.33 | 86.48 | 86.71 |
| FPS | 64 | 64 | 215 | 231 | 198 | 210 | 57 | 62 | 62 | 59 | 57 | 54 | 62 | 55 | 62 |
| #Par | 53 | 51 | 69 | 55 | 79 | 60 | 177 | 153 | 173 | 154 | 184 | 157 | 173 | 156 | 153 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Z.; Qiu, L.; Wang, J.; Xiong, J.; Peng, H. Video Object Segmentation Using Multi-Scale Attention-Based Siamese Network. Electronics 2023, 12, 2890. https://doi.org/10.3390/electronics12132890
Zhu Z, Qiu L, Wang J, Xiong J, Peng H. Video Object Segmentation Using Multi-Scale Attention-Based Siamese Network. Electronics. 2023; 12(13):2890. https://doi.org/10.3390/electronics12132890
Chicago/Turabian StyleZhu, Zhiliang, Leiningxin Qiu, Jiaxin Wang, Jinquan Xiong, and Hua Peng. 2023. "Video Object Segmentation Using Multi-Scale Attention-Based Siamese Network" Electronics 12, no. 13: 2890. https://doi.org/10.3390/electronics12132890