

Development of a Wafer Defect Pattern Classifier Using Polar Coordinate System Transformed Inputs and Convolutional Neural Networks

Abstract
:1. Introduction
2. Related Work
2.1. Single-Failure Pattern Classification
2.2. Mixed Failure Pattern Classification
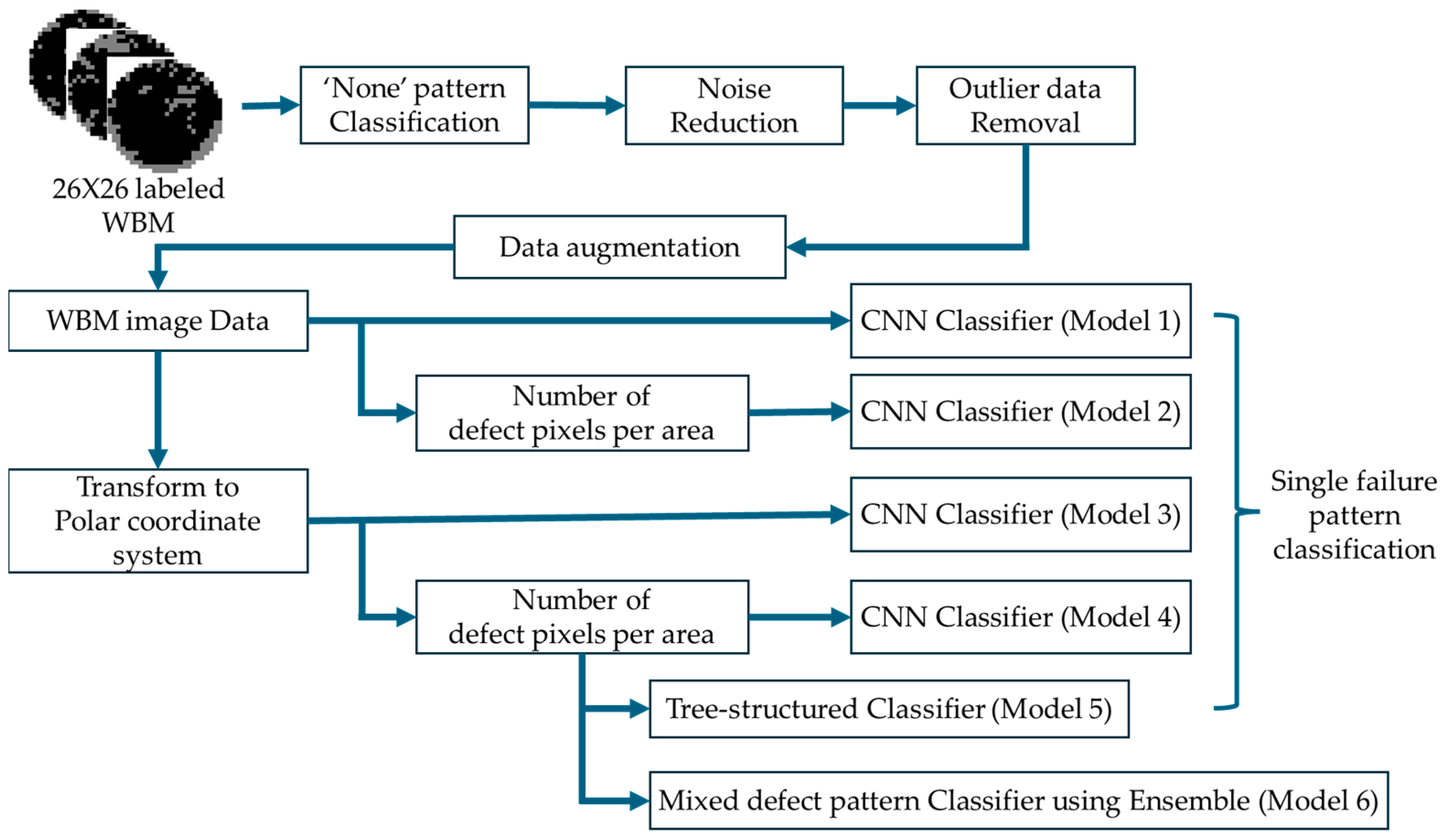
3. Materials and Methods
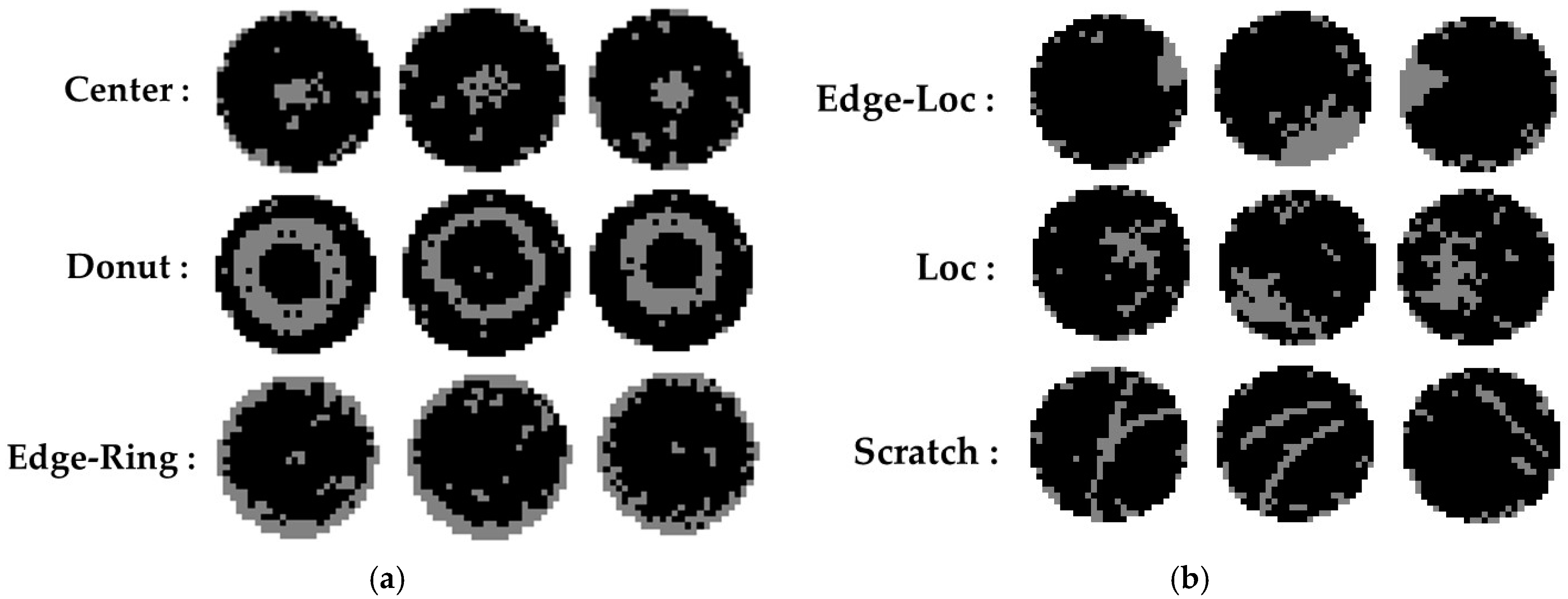
3.1. Dataset
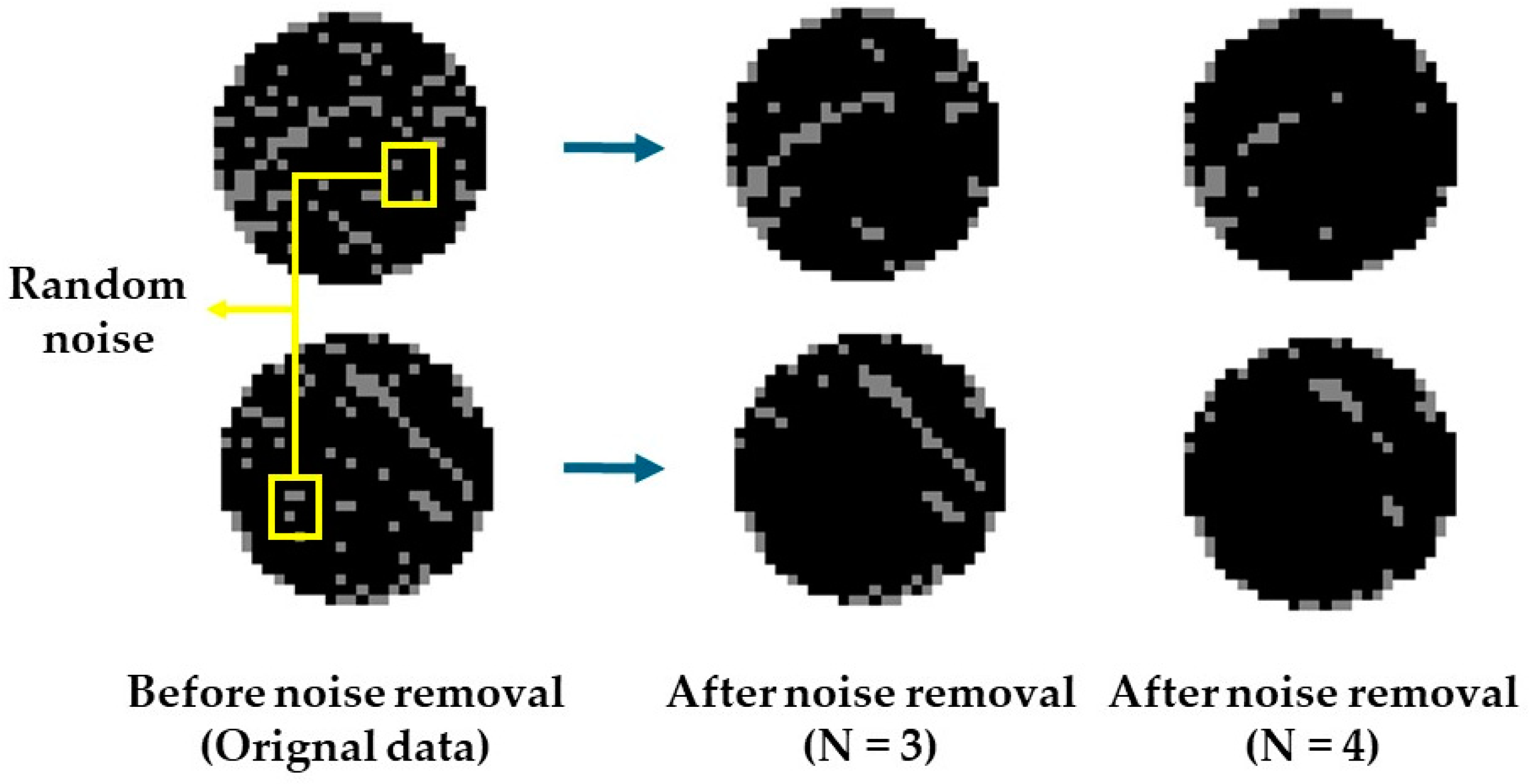
3.2. Random Noise Filtering and Data Augmentation
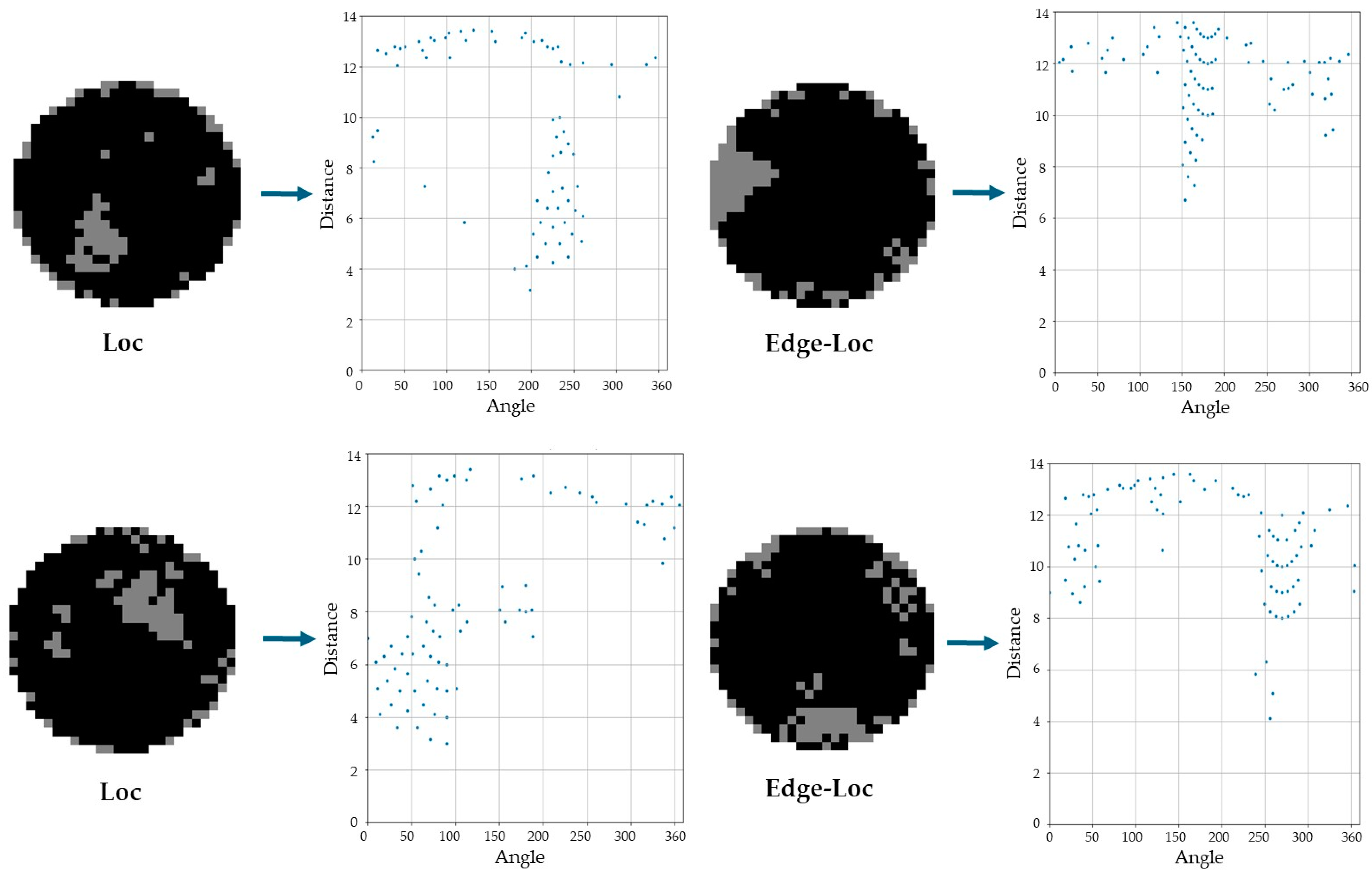
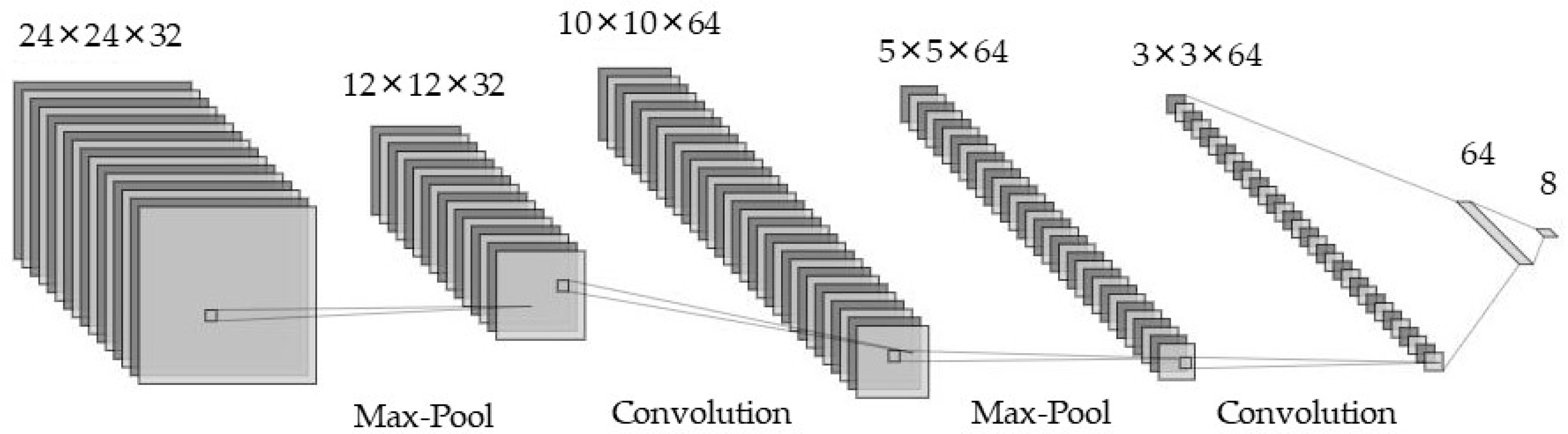
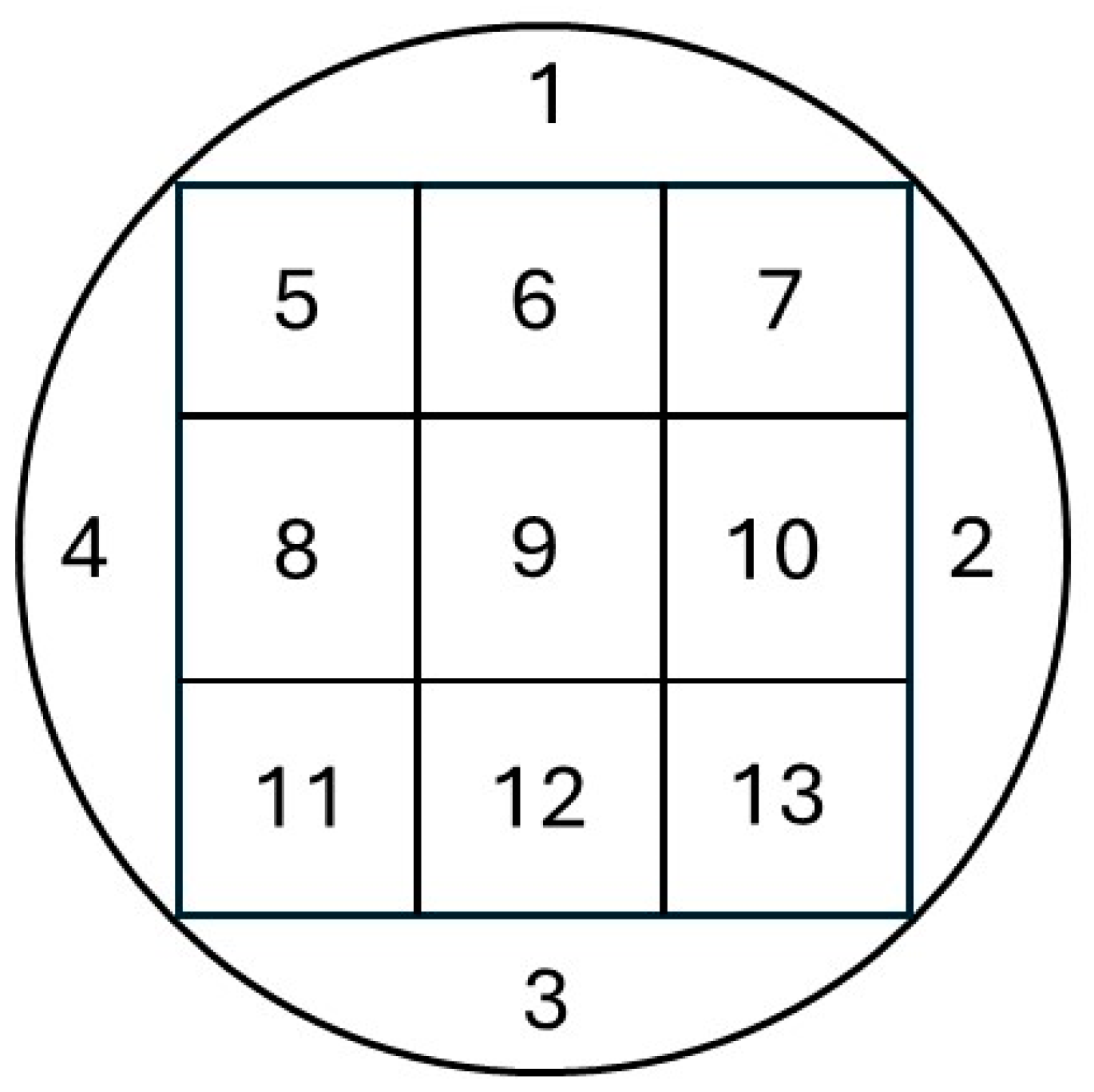
3.3. Defect Pattern Classification Using Polar Coordinate Data
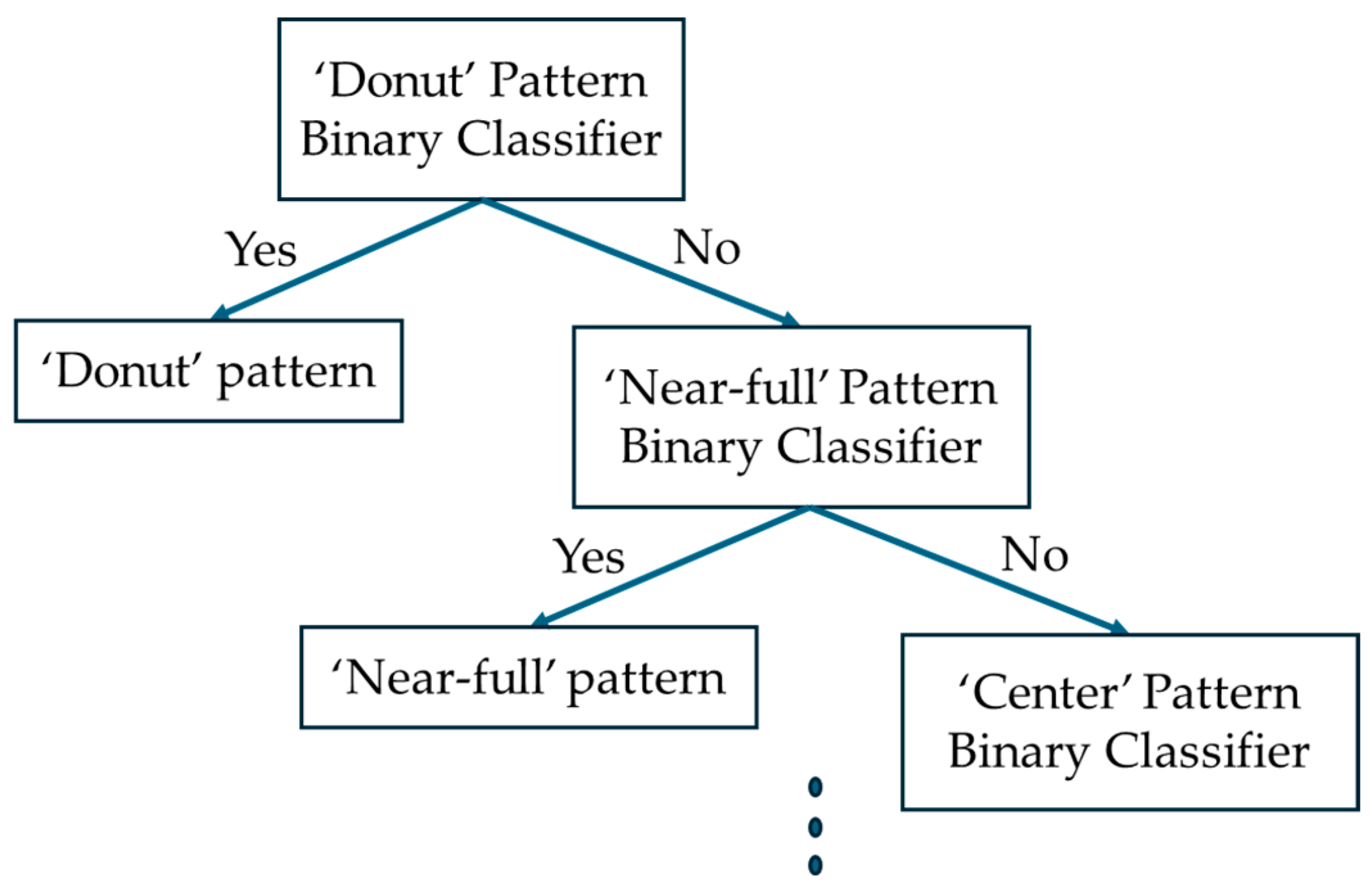
3.4. Defect Pattern Classifier Using Polar Coordinate System Data and Tree Structure
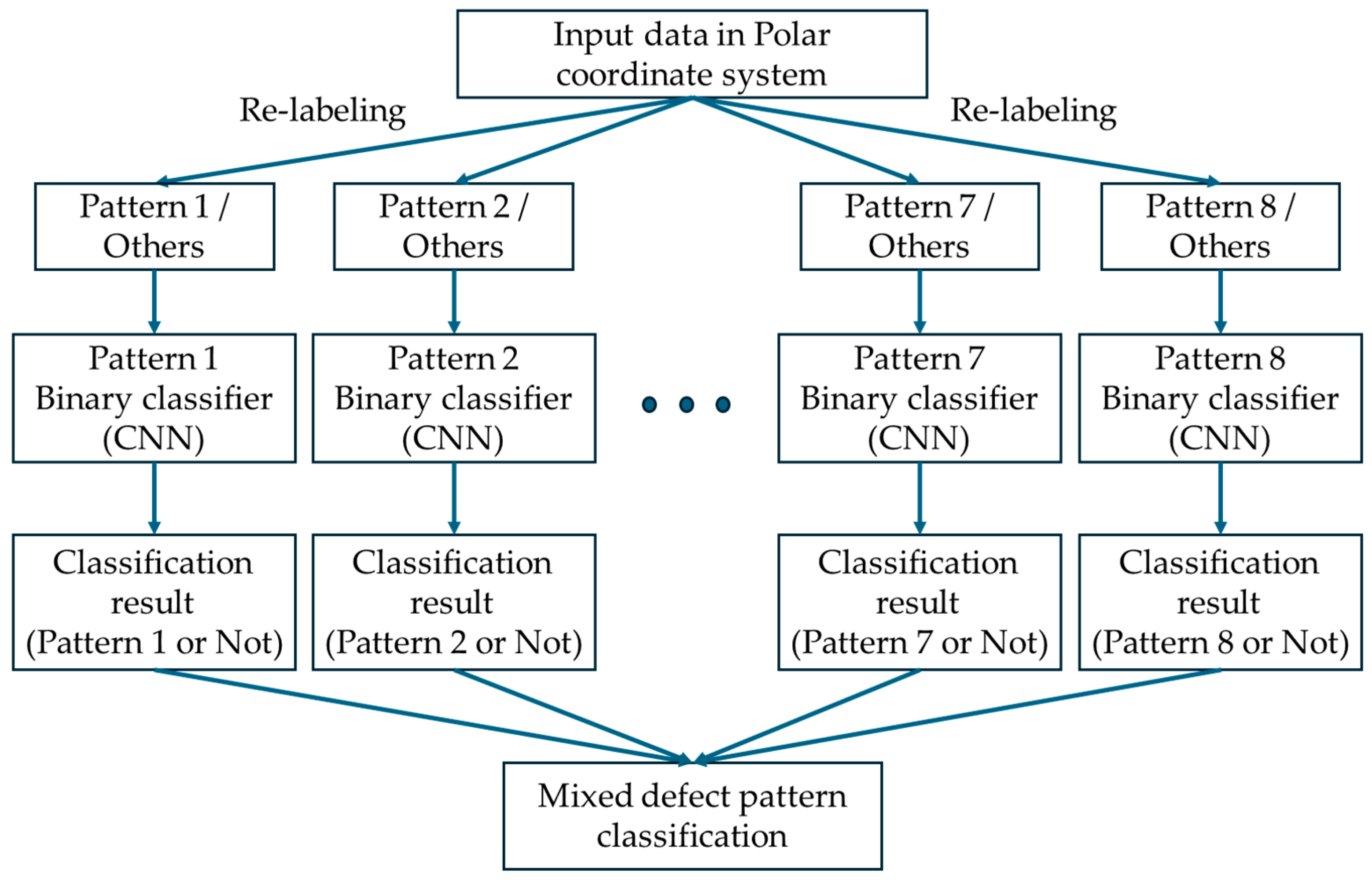
3.5. Ensemble Structure for Classifying Mixed Failure Patterns
4. Experiments and Results
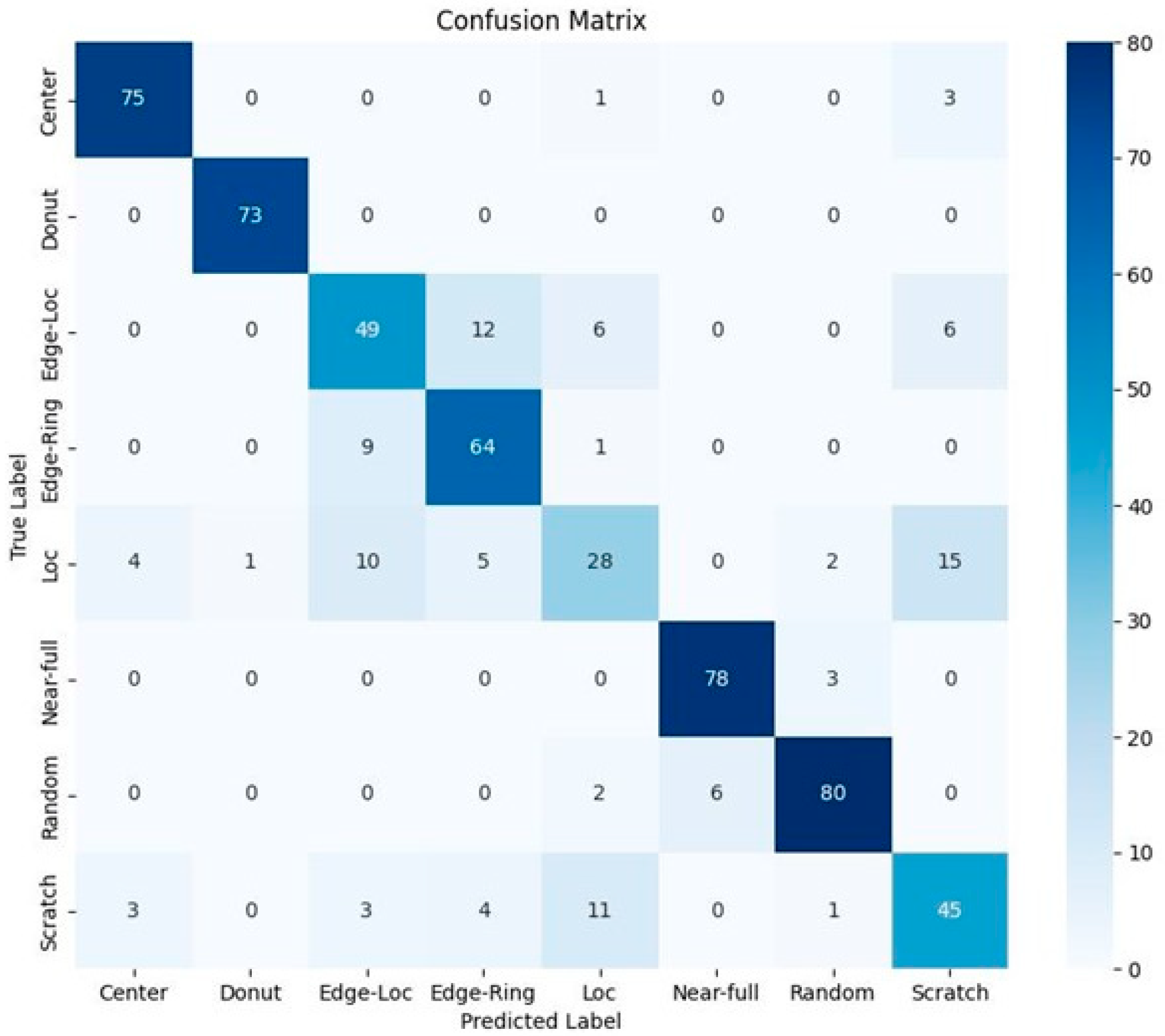
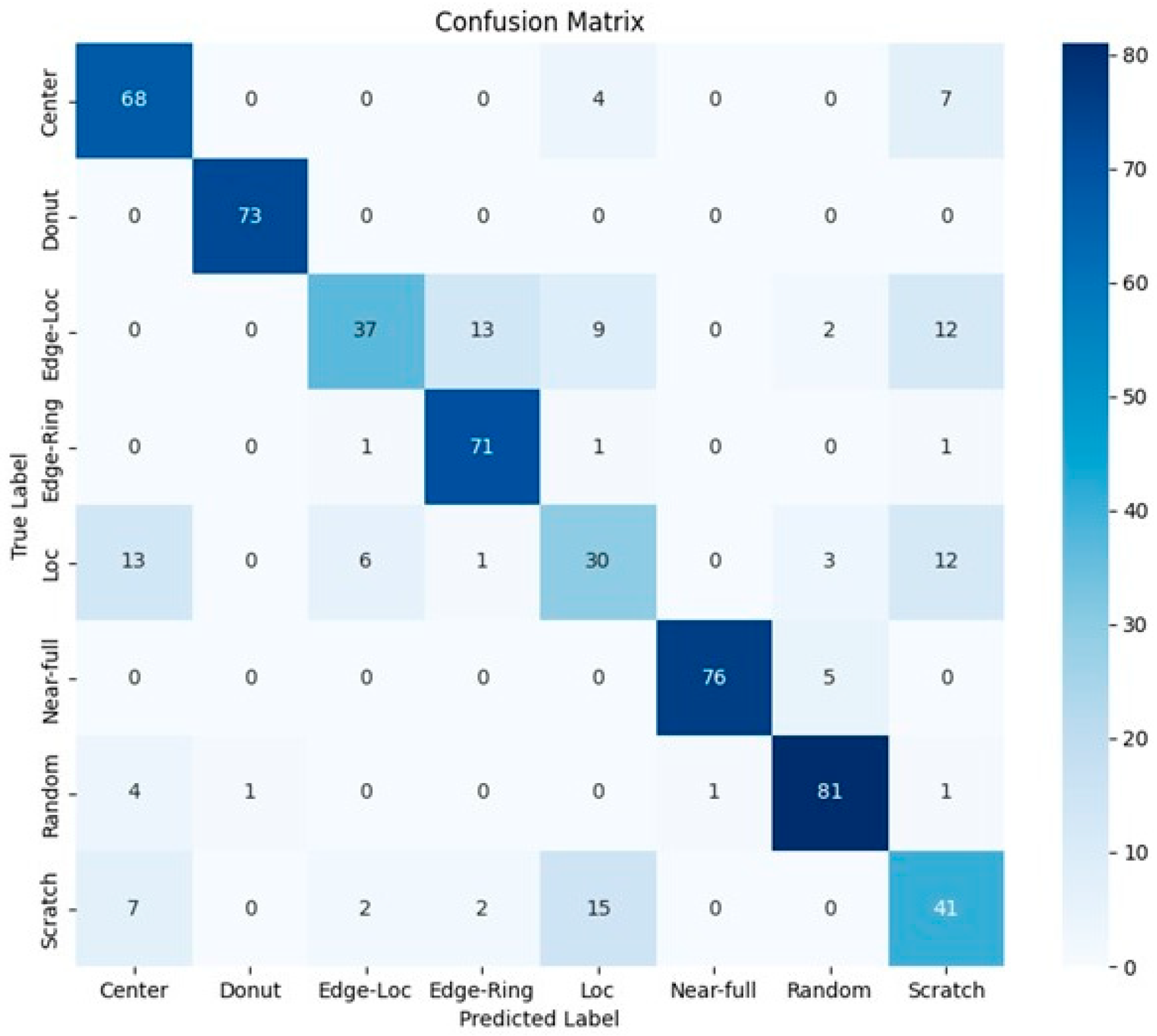
4.1. Comparison of Classifier Performance Using WBM Image Information and Polar Coordinate Information
4.1.1. Comparison of Models Using WBM Image Data as Inputs
4.1.2. Comparison of Models Using Polar Coordinate System Data as Inputs
4.1.3. Comparison of Classification Performance of WBM with Different Die Size from Training Data (Model 1 and Model 4)
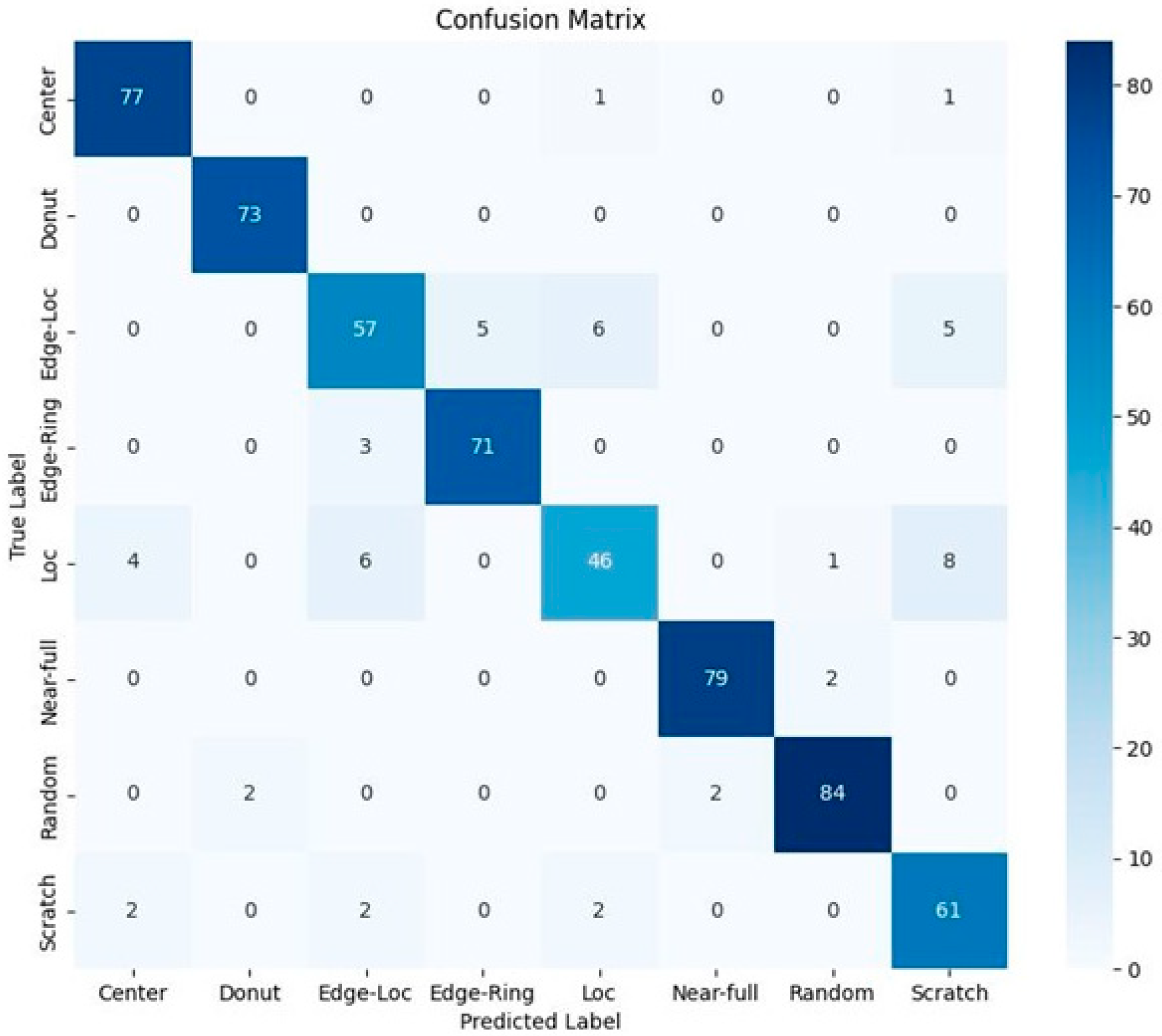
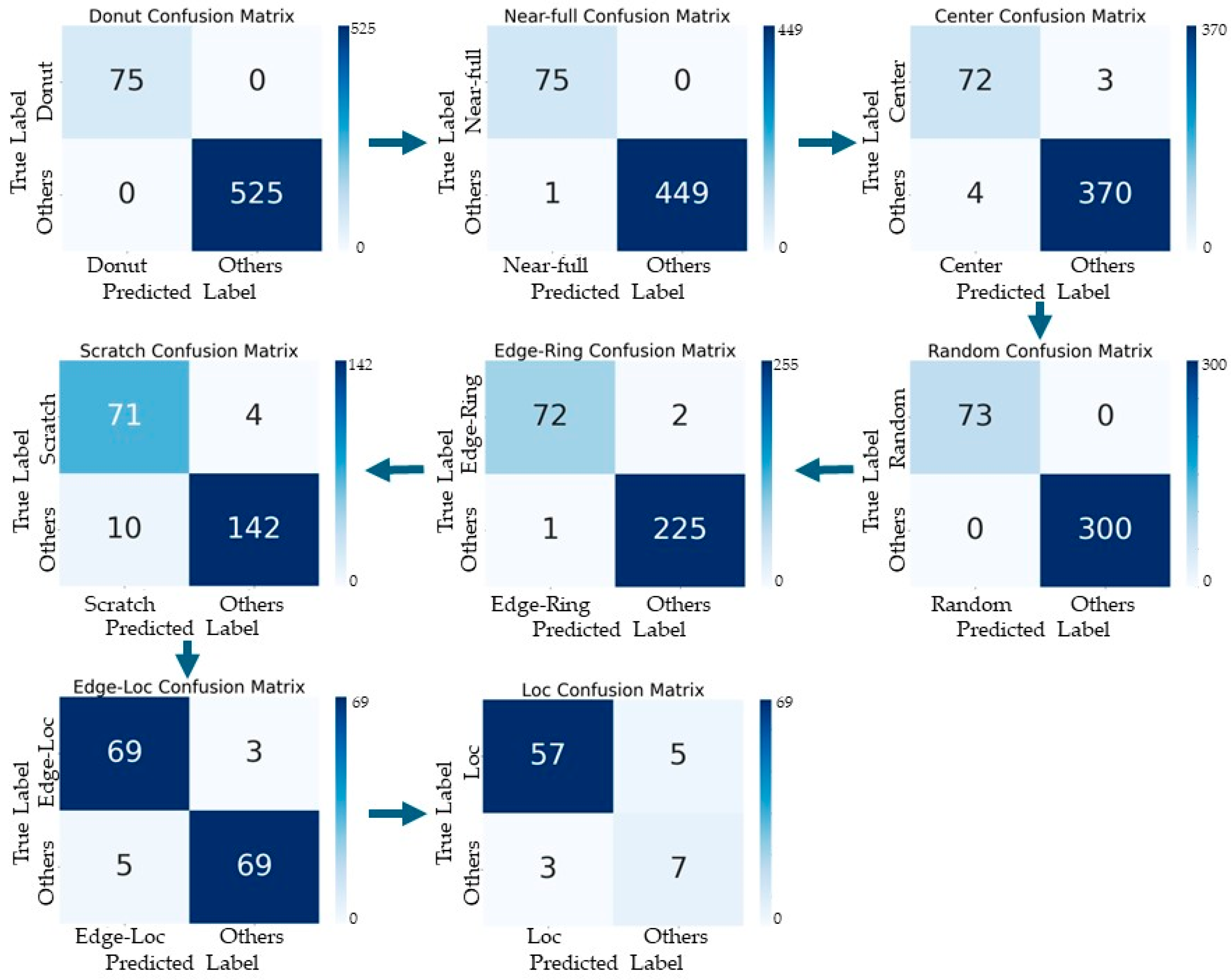
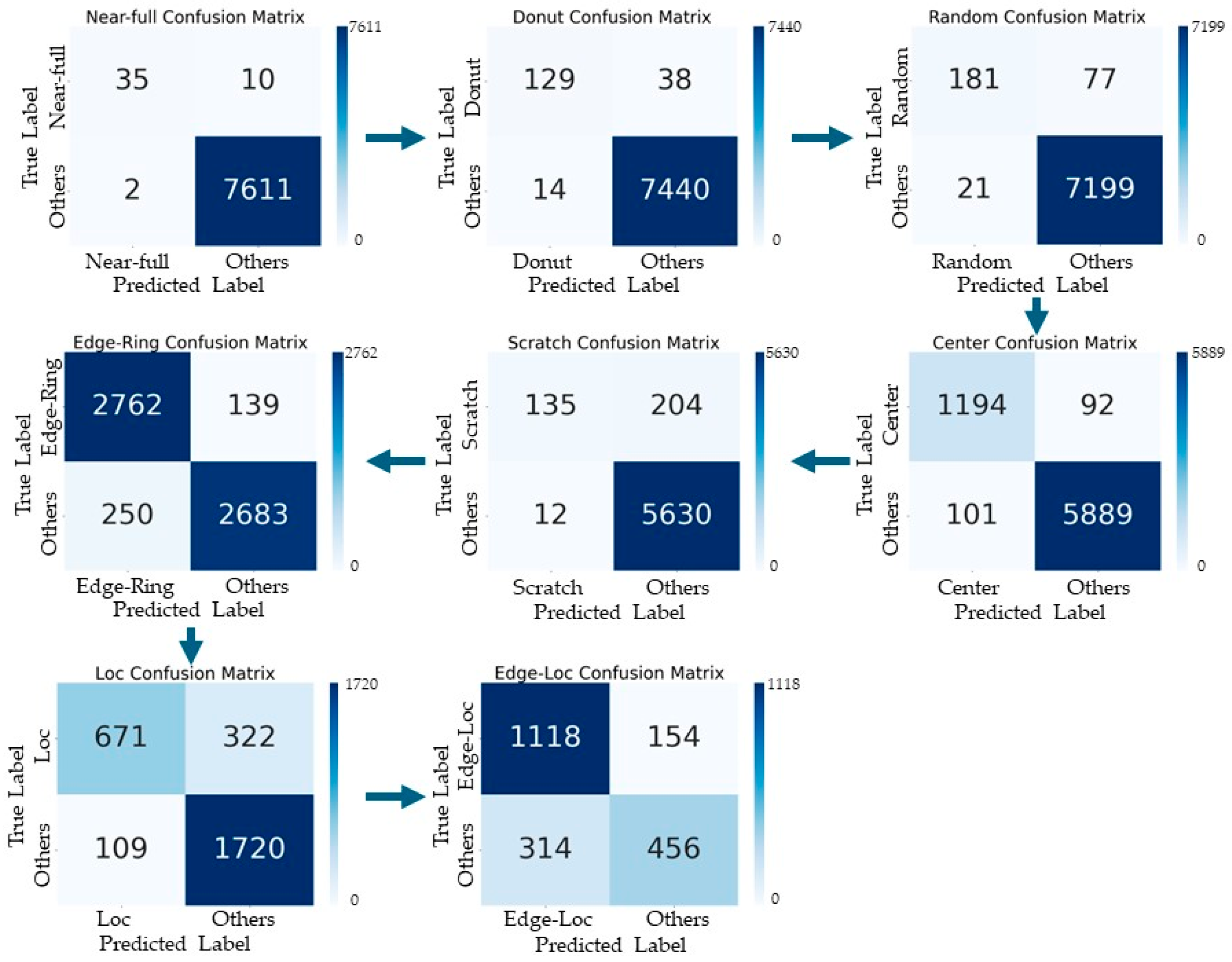
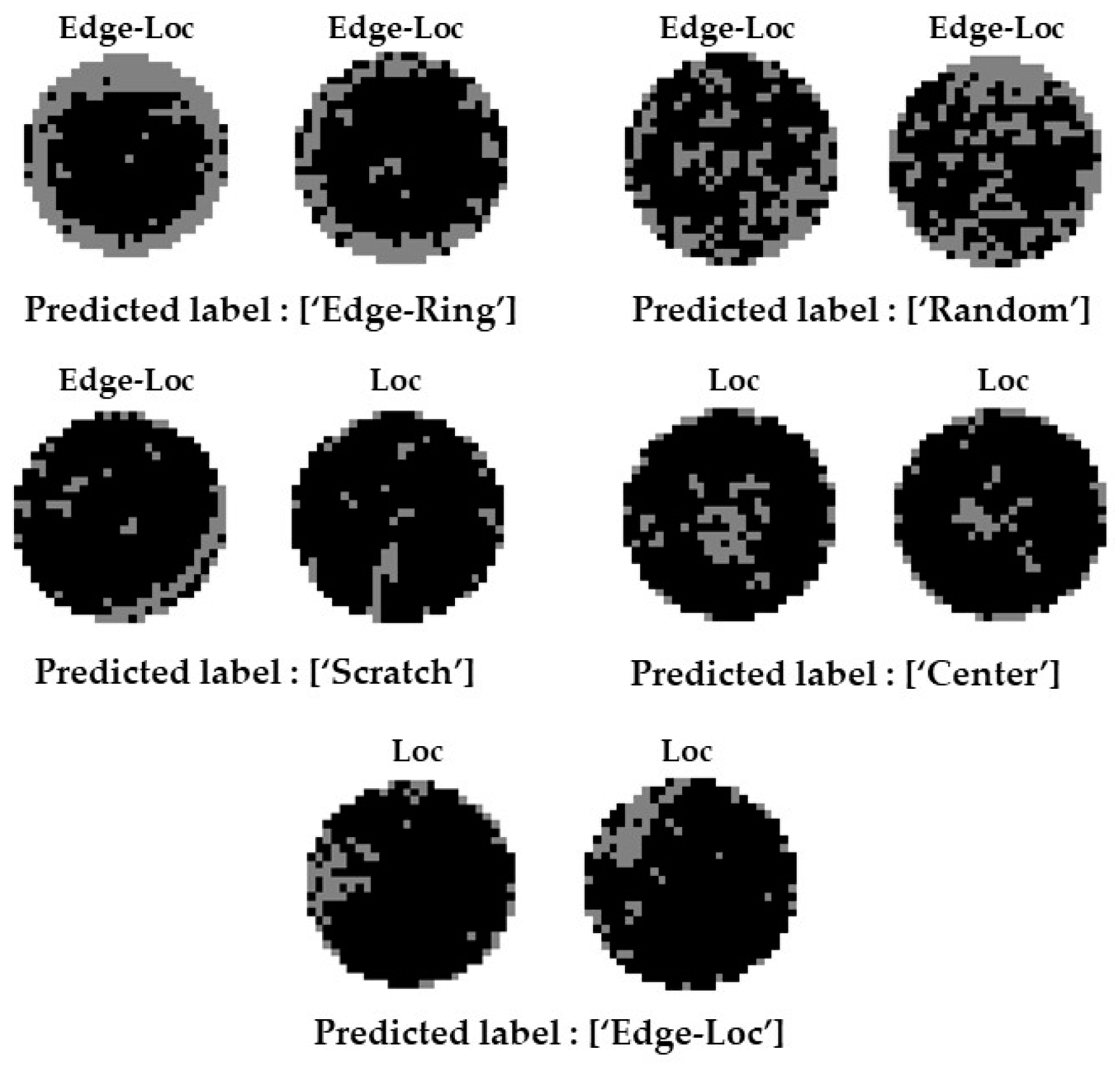
4.2. Defect Pattern Classifier Based on Polar Coordinate System Input Data and Tree Structure
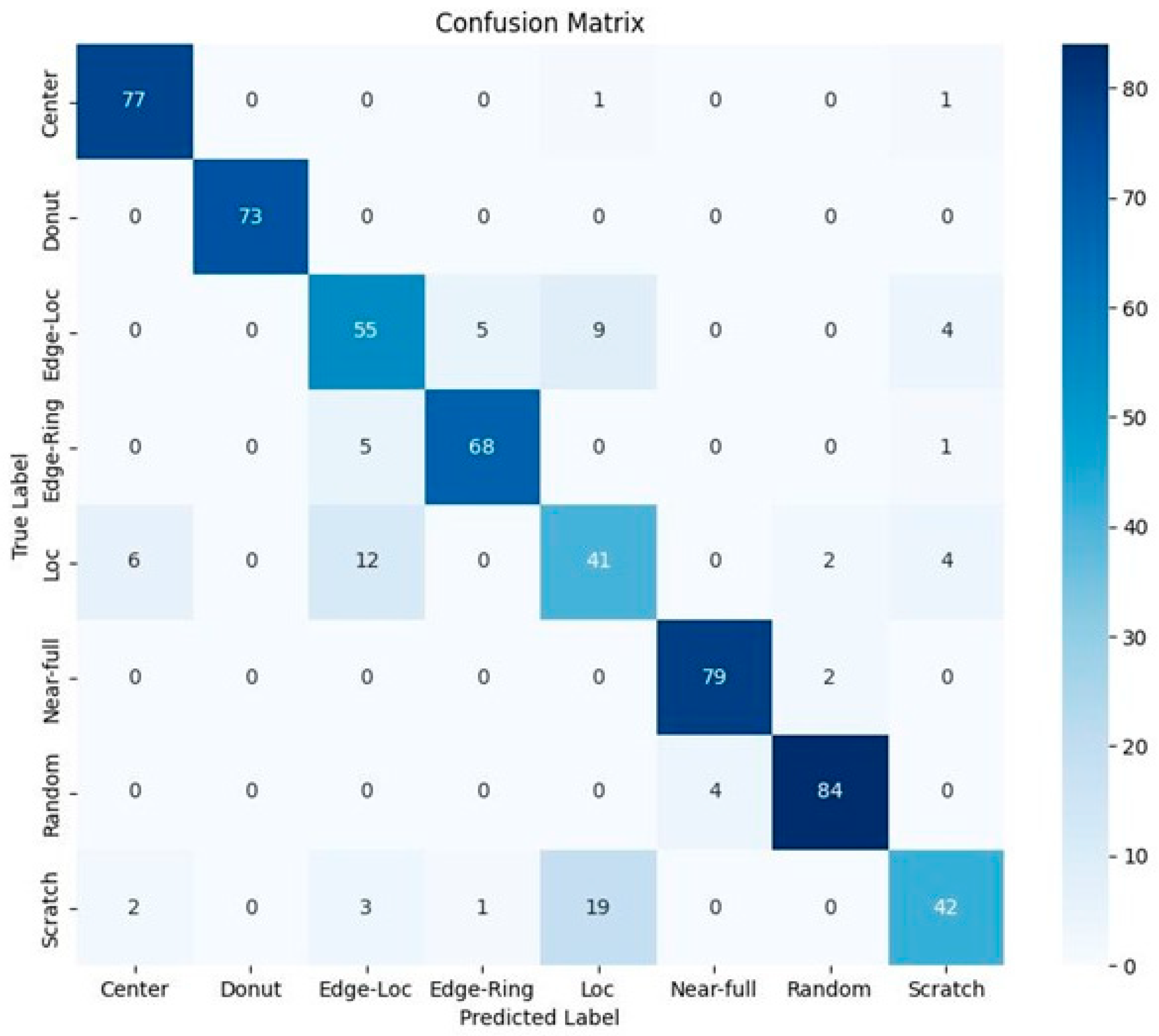
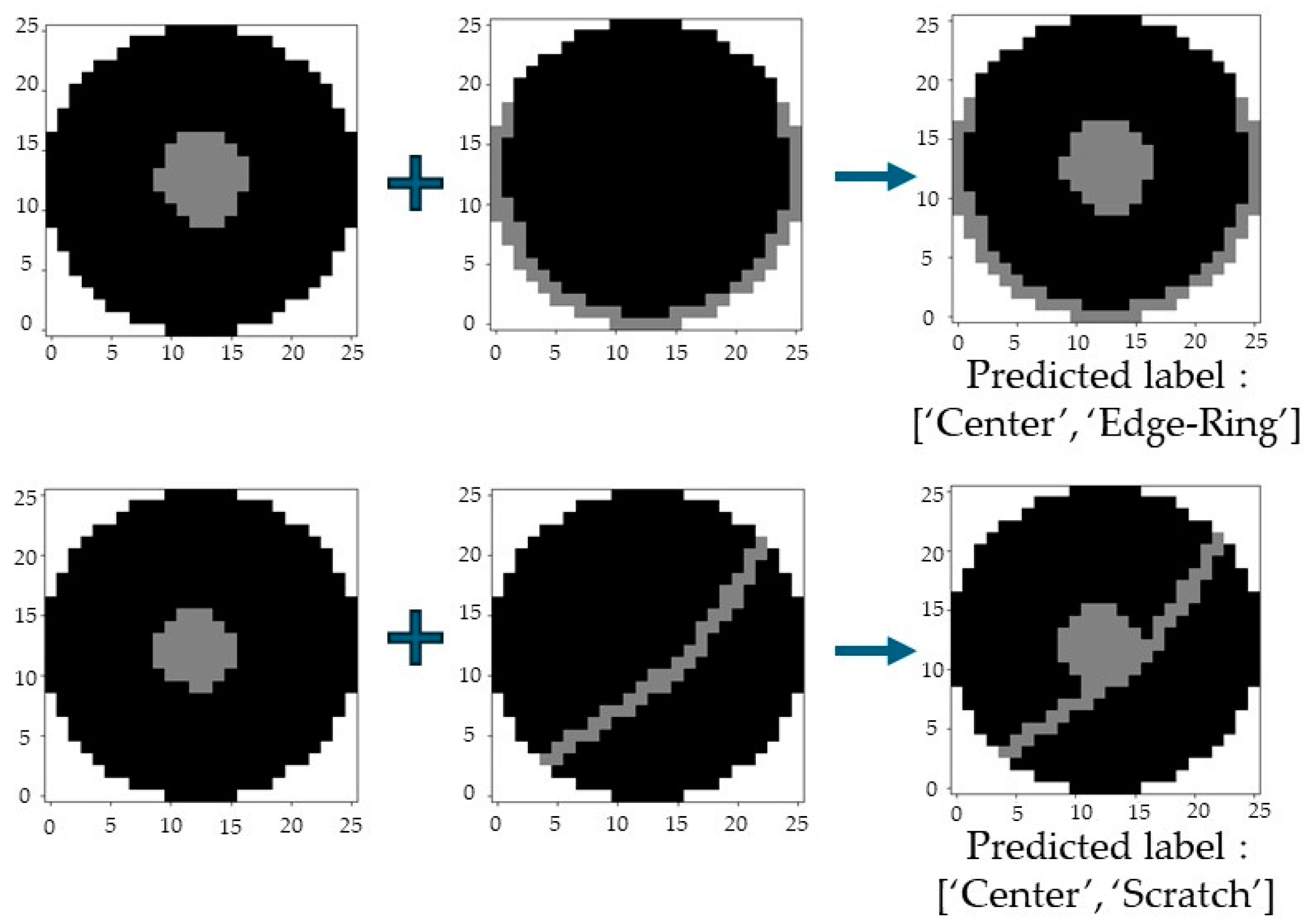
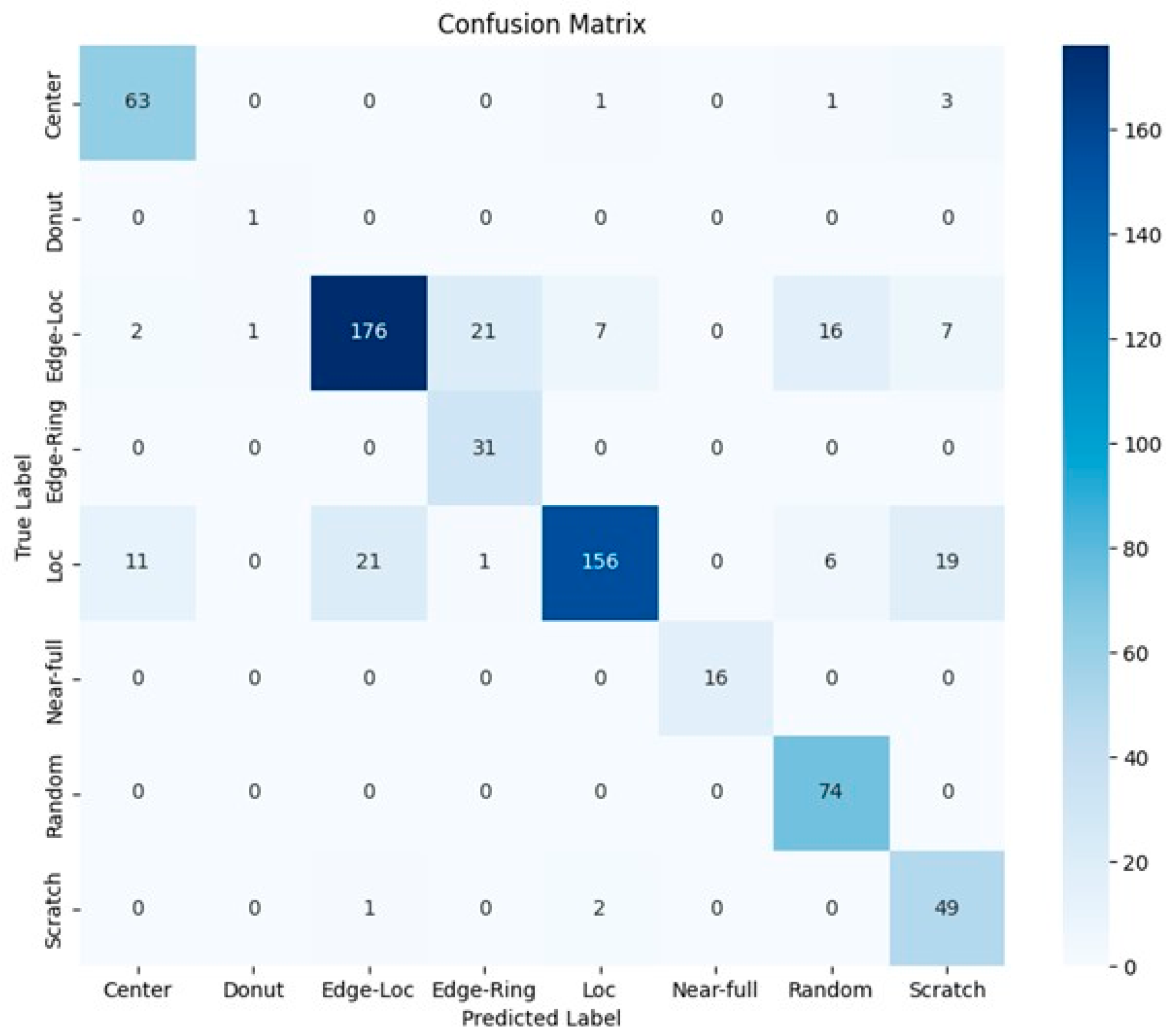
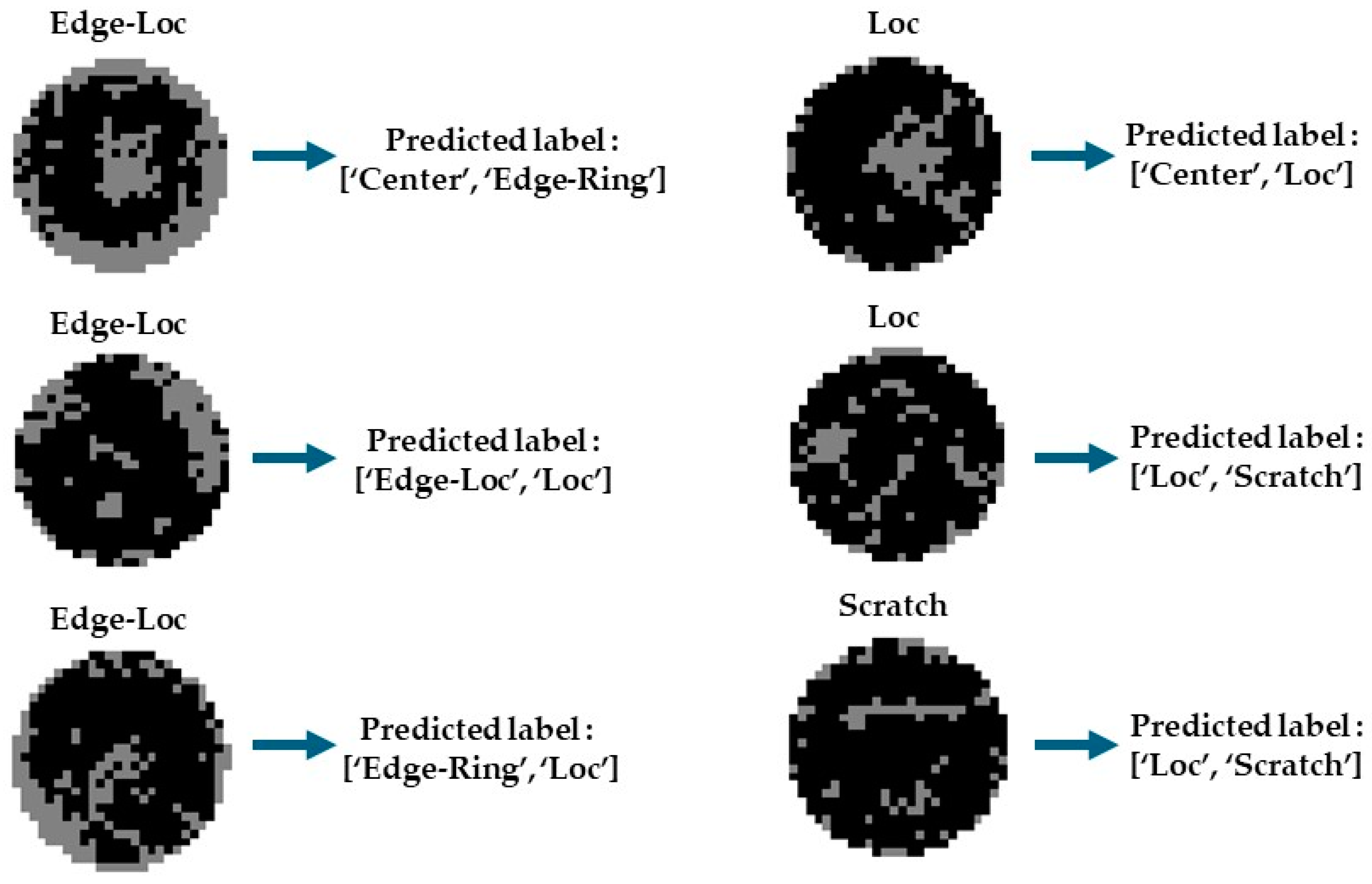
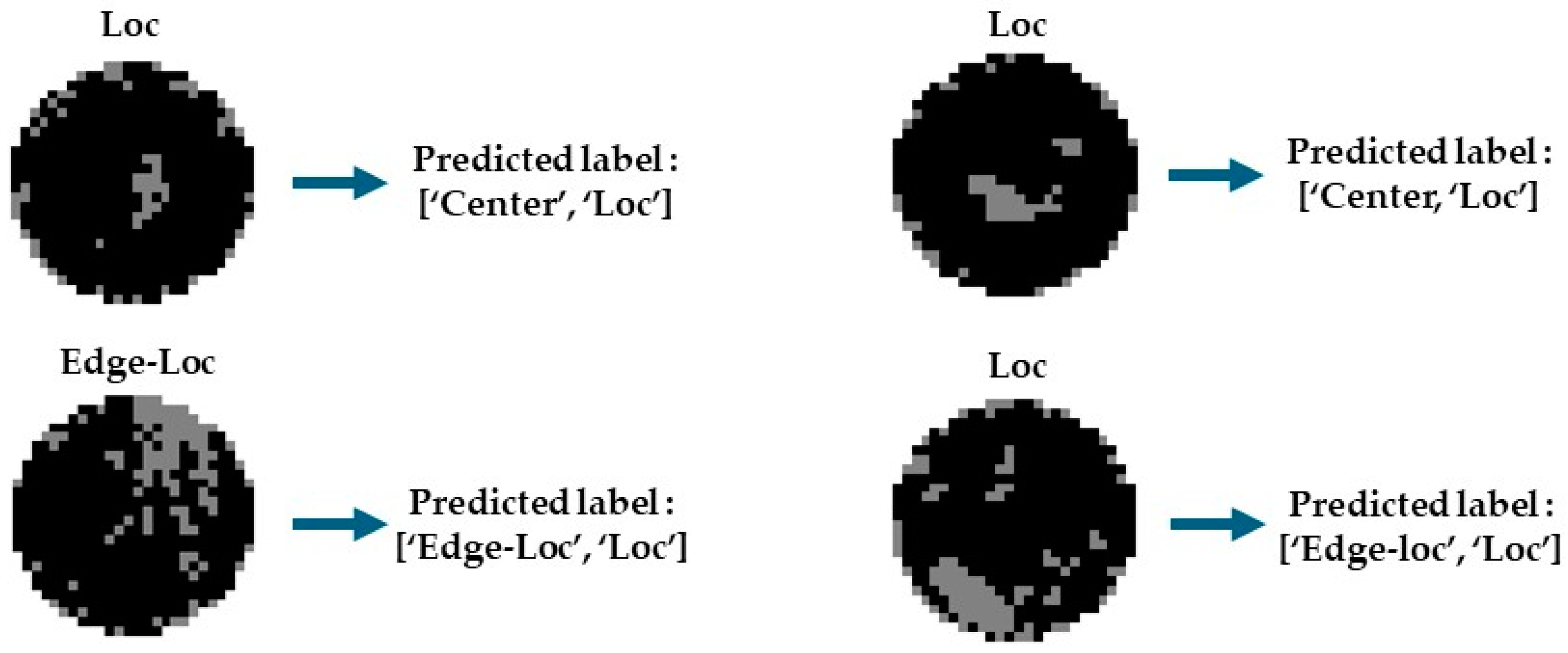
4.3. Ensemble Models for Mixed-Fault Pattern Classification
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, W.C.; Tseng, S.S.; Wang, C.Y. A novel manufacturing defect detection method using association rule mining techniques. Expert Syst. Appl. 2005, 29, 807–815. [Google Scholar] [CrossRef]
- Hsu, S.-C.; Chien, C.-F. Hybrid Data Mining Approach for Pattern Extraction from Wafer Bin Map to Improve Yield in Semiconductor Manufacturing. Int. J. Prod. Econ. 2007, 107, 88–103. [Google Scholar] [CrossRef]
- Chen, F.-L.; Liu, S.-F. A neural-network approach to recognize defect spatial pattern in semiconductor fabrication. IEEE Trans. Semicond. Manuf. 2000, 13, 366–373. [Google Scholar] [CrossRef]
- Li, K.; Liao, P.; Cheng, K.; Chen, L.; Wang, S.; Huang, A.; Chou, L.; Han, G.; Chen, J.; Liang, H.; et al. Hidden wafer scratch defects projection for diagnosis and quality enhancement. IEEE Trans. Semicond. Manuf. 2021, 34, 9–15. [Google Scholar] [CrossRef]
- Nakazawa, T.; Kulkarni, D.V. Wafer Map Defect Pattern Classification and Image Retrieval using Convolutional Neural Network. IEEE Trans. Semicond. Manuf. 2019, 31, 309–314. [Google Scholar] [CrossRef]
- Lee, K.B.; Cheon, S.; Kim, C.O. A Convolutional Neural Network for Fault Classification and Diagnosis in Semiconductor Manufacturing Processes. IEEE Trans. Semicond. Manuf. 2017, 30, 135–142. [Google Scholar] [CrossRef]
- Park, J.S. Wafer map-based defect Detection Using Convolutional Neural Networks. J. Korean Inst. Ind. Eng. 2018, 44, 249–258. [Google Scholar] [CrossRef]
- Wu, M.J.; Jang, J.S.R.; Chen, J.L. Wafer map failure pattern recognition and similarity ranking for large-scale data sets. IEEE Trans. Semicond. Manuf. 2014, 28, 1–12. [Google Scholar] [CrossRef]
- Piao, M.; Jin, C.H.; Lee, J.Y.; Byun, J.Y. Decision tree ensemble-based wafer map failure pattern recognition based on radon transform-based features. IEEE Trans. Semicond. Manuf. 2018, 31, 250–257. [Google Scholar] [CrossRef]
- Li, T.-S.; Huang, C.-L. Defect spatial pattern recognition using a hybrid SOM–SVM approach in semiconductor manufacturing. Expert Syst. Appl. 2009, 36, 374–385. [Google Scholar] [CrossRef]
- Remya, K.; Sajith, V. Machine Learning Approach for Mixed type Wafer Defect Pattern Recognition by ResNet Architecture. In Proceedings of the 2023 International Conference on Control, Communication and Computing (ICCC), Thiruvananthapuram, India, 19–21 May 2023; pp. 1–6. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Tsai, T.-H. Defect Detection on Wafer Map Using Efficient Convolutional Neural Network. In Proceedings of the IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW), Penghu, Taiwan, 15–17 September 2021; pp. 1–2. [Google Scholar] [CrossRef]
- Ko, S.; Koo, D. A novel approach for wafer defect pattern classification based on topological data analysis. Expert Syst. Appl. 2023, 30, 120765. [Google Scholar] [CrossRef]
- Shin, E.; Yoo, C.D. Efficient Convolutional Neural Networks for Semiconductor Wafer Bin Map Classification. Sensors 2023, 23, 1926. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Ni, D.; Huang, Z. A Momentum Contrastive Learning Framework for Low-Data Wafer Defect Classification in Semiconductor Manufacturing. Appl. Sci. 2023, 13, 5894. [Google Scholar] [CrossRef]
- Shim, J.; Kang, S.; Cho, S. Active learning of convolutional neural network for cost-effective wafer map pattern classification. IEEE Trans. Semicond. Manuf. 2020, 33, 258–266. [Google Scholar] [CrossRef]
- Tziolas, T.; Theodosiou, T.; Papageorgiou, K.; Rapti, A.; Dimitriou, N.; Tzovaras, D.; Papageorgiou, E. Wafer Map Defect Pattern Recognition using Imbalanced Datasets. In Proceedings of the 2022 13th International Conference on Information, Intelligence, Systems & Applications (IISA), Corfu, Greece, 18–20 July 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Ebayyeh, A.A.R.M.A.; Danishvar, S.; Mousavi, A. An Improved Capsule Network (WaferCaps) for Wafer Bin Map Classification Based on DCGAN Data Upsampling. IEEE Trans. Semicond. Manuf. 2021, 35, 50–59. [Google Scholar] [CrossRef]
- Park, S.; You, C. Deep Convolutional Generative Adversarial Networks-Based Data Augmentation Method for Classifying Class-Imbalanced Defect Patterns in Wafer Bin Map. Appl. Sci. 2023, 13, 5507. [Google Scholar] [CrossRef]
- Shon, H.S.; Batbaatar, E.; Cho, W.-S.; Choi, S.G. Unsupervised Pre-Training of Imbalanced Data for Identification of Wafer Map Defect Patterns. IEEE Access 2021, 9, 52352–52363. [Google Scholar] [CrossRef]
- Xu, Q.; Yu, N.; Essaf, F. Improved Wafer Map Inspection Using Attention Mechanism and Cosine Normalization. Machines 2022, 10, 146. [Google Scholar] [CrossRef]
- Niu, S.; Lin, H.; Niu, T.; Li, B.; Wang, X. DefectGAN: Weakly-supervised defect detection using generative adversarial network. In Proceedings of the 2019 IEEE 15th International Conference on Automation Science and Engineering (CASE), Vancouver, BC, Canada, 22–26 August 2019; pp. 127–132. [Google Scholar] [CrossRef]
- Li, K.S.M.; Jiang, X.H.; Chen, L.L.Y.; Wang, S.J.; Huang, A.Y.A.; Chen, J.E.; Liang, H.C.; Hsu, C.L. Wafer Defect Pattern Labeling and Recognition Using Semi-Supervised Learning. IEEE Trans. Semicond. Manuf. 2022, 35, 291–299. [Google Scholar] [CrossRef]
- Wang, C.H.; Kuo, W.; Bensmail, H. Detection and classification of defect patterns on semiconductor wafers. IIE Trans. 2006, 38, 1059–1068. [Google Scholar] [CrossRef]
- Kim, J.; Lee, Y.; Kim, H. Detection and clustering of mixed-type defect patterns in wafer bin maps. IISE Trans. 2018, 50, 99–111. [Google Scholar] [CrossRef]
- Jin, C.H.; Na, H.J.; Piao, M.; Pok, G.; Ryu, K.H. A novel DBSCAN-based defect pattern detection and classification framework for wafer bin map. IEEE Trans. Semicond. Manuf. 2019, 32, 286–292. [Google Scholar] [CrossRef]
- Kyeong, K.; Kim, H. Classification of mixed-type defect patterns in wafer bin maps using convolutional neural networks. IEEE Trans. Semicond. Manuf. 2018, 31, 395–402. [Google Scholar] [CrossRef]
- Liu, C.; Tang, Q. Triplet Convolutional Networks for Classifying Mixed-Type WBM Patterns with Noisy Labels. In Proceedings of the 2021 IEEE International Test Conference (ITC), Anaheim, CA, USA, 10–15 October 2021; pp. 395–402. [Google Scholar] [CrossRef]
- Wang, R.; Chen, N. Detection and Recognition of Mixed Type Defect Patterns in Wafer Bin Maps via Tensor Voting. IEEE Trans. Semicond. Manuf. 2022, 35, 485–494. [Google Scholar] [CrossRef]
- Qiu, Q. Effect of internal defects on the thermal conductivity of fiber-reinforced polymer (FRP): A numerical study based on micro-CT based computational modeling. Mater. Today Commun. 2023, 36, 106446. [Google Scholar] [CrossRef]
- Zschech, E.; Niese, S.; Löffler, M.; Wolf, M.J. Multi-scale X-ray tomography for process and quality control in 3D TSV packaging. Int. Symp. Microelectron. 2014, 2014, 184–187. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, T.; Yang, C.; Cao, Y.; Xie, L.; Tian, H.; Li, X. Review of Wafer Surface Defect Detection Methods. Electronics 2023, 12, 1787. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Defect Type | Number of Samples |
|---|---|
| Center | 90 |
| Donut | 1 |
| Edge-Loc | 296 |
| Edge-Ring | 31 |
| Loc | 290 |
| Near-Full | 16 |
| Random | 74 |
| Scratch | 72 |
| None | 13,489 |
| Defect Type | Number of Samples |
|---|---|
| Center | 46 |
| Donut | 13 |
| Edge-Loc | 160 |
| Edge-Ring | 31 |
| Loc | 108 |
| Near-Full | 13 |
| Random | 74 |
| Scratch | 35 |
| Defect Type | Number of Samples |
|---|---|
| Center | 250 |
| Donut | 250 |
| Edge-Loc | 250 |
| Edge-Ring | 250 |
| Loc | 250 |
| Near-Full | 250 |
| Random | 250 |
| Scratch | 250 |
| Layer | Kernel Size, Stride | No. of Parameters | Output Shape |
|---|---|---|---|
| Input | - | - | (26, 26, 3) |
| Convolutional | 3 × 3 × 32, 1 | 320 | (24, 24, 32) |
| Max-Pooling | 2 × 2, 2 | - | (12, 12, 32) |
| Convolutional | 3 × 3 × 64, 1 | 18,496 | (10, 10, 64) |
| Max-Pooling | 2 × 2, 2 | - | (5, 5, 64) |
| Convolutional | 3 × 3 × 64, 1 | 36,928 | (3, 3, 64) |
| Flatten | - | - | (576) |
| Fully Connected | - | 36,928 | (64) |
| Fully Connected | - | 520 | (8) |
| Model Number | Input Type | Pre-Processing | Model Type | Objective |
|---|---|---|---|---|
| 1 | WBM image | n/a | Single CNN | For classification of single-failure pattern |
| 2 | WBM image | Number of defect dies per block | Single CNN | For classification of single-failure pattern |
| 3 | Transformed data to polar coordinate representation | n/a | Single CNN | For classification of single-failure pattern |
| 4 | Transformed data to polar coordinate representation | Number of defect dies per block | Single CNN | For classification of single-failure pattern |
| 5 | Transformed data to polar coordinate representation | Number of defect dies per block | CNN-based tree structure | For classification of single-failure pattern |
| 6 | Transformed data to polar coordinate representation | Number of defect dies per block | Ensemble of CNN | For classification of mixed-failure patterns |
| Hardware Environment | Software Environment |
|---|---|
| CPU: AMD Ryzen 7 3700X 8-Core Processor, 3.59 GHz GPU: NVIDIA GeForce RTX 2070 SUPER | Window 10 TensorFlow 2.15.0 Keras 2.15.0 Python 3.10.9 |
| Defect Type | Model 1 | Model 2 | Model 3 | Model 4 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| Center | 0.91 | 0.97 | 0.94 | 0.91 | 0.95 | 0.93 | 0.74 | 0.86 | 0.8 | 0.93 | 0.97 | 0.95 |
| Donut | 1 | 1 | 1 | 0.99 | 1 | 0.99 | 0.99 | 1 | 0.99 | 0.97 | 1 | 0.99 |
| Edge-Loc | 0.73 | 0.75 | 0.74 | 0.69 | 0.67 | 0.68 | 0.8 | 0.51 | 0.62 | 0.84 | 0.78 | 0.81 |
| Edge-Ring | 0.92 | 0.92 | 0.92 | 0.75 | 0.86 | 0.81 | 0.82 | 0.96 | 0.88 | 0.93 | 0.96 | 0.95 |
| Loc | 0.59 | 0.63 | 0.61 | 0.57 | 0.43 | 0.49 | 0.51 | 0.46 | 0.48 | 0.84 | 0.71 | 0.77 |
| Near-Full | 0.95 | 0.98 | 0.96 | 0.93 | 0.96 | 0.96 | 0.99 | 0.94 | 0.96 | 0.98 | 0.98 | 0.98 |
| Random | 0.95 | 0.95 | 0.95 | 0.93 | 0.91 | 0.91 | 0.89 | 0.92 | 0.91 | 0.97 | 0.95 | 0.96 |
| Scratch | 0.81 | 0.63 | 0.71 | 0.65 | 0.67 | 0.66 | 0.55 | 0.61 | 0.58 | 0.81 | 0.91 | 0.86 |
| Average | 0.86 | 0.85 | 0.85 | 0.8 | 0.81 | 0.8 | 0.78 | 0.78 | 0.78 | 0.91 | 0.91 | 0.91 |
| Defect Type | Number of Samples |
|---|---|
| Center | 4294 |
| Donut | 555 |
| Edge-Loc | 5189 |
| Edge-Ring | 9680 |
| Loc | 3593 |
| Near-Full | 149 |
| Random | 866 |
| Scratch | 1193 |
| Defect Type | Model 1 | Model 4 | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | |
| Center | 0.93 | 0.93 | 0.93 | 0.93 | 0.95 | 0.94 | 0.99 | 0.96 |
| Donut | 0.78 | 0.78 | 0.83 | 0.83 | 0.91 | 0.97 | 0.94 | 0.95 |
| Edge-Loc | 0.8 | 0.81 | 0.79 | 0.79 | 0.79 | 0.82 | 0.84 | 0.83 |
| Edge-Ring | 0.97 | 0.97 | 0.96 | 0.96 | 0.97 | 0.94 | 0.97 | 0.95 |
| Loc | 0.72 | 0.72 | 0.71 | 0.71 | 0.74 | 0.86 | 0.79 | 0.82 |
| Near-Full | 0.87 | 0.87 | 0.87 | 0.87 | 0.92 | 0.9 | 0.95 | 0.92 |
| Random | 0.82 | 0.82 | 0.86 | 0.86 | 0.83 | 0.9 | 0.86 | 0.88 |
| Scratch | 0.36 | 0.36 | 0.41 | 0.41 | 0.54 | 0.79 | 0.58 | 0.67 |
| Average | 0.85 | 0.81 | 0.78 | 0.8 | 0.9 | 0.89 | 0.86 | 0.87 |
| Defect Type | SVM | CNN | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | |
| Center | 0.971 | 0.928 | 0.951 | 0.939 | 0.988 | 0.967 | 0.982 | 0.974 |
| Donut | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Edge-Loc | 0.891 | 0.753 | 0.661 | 0.692 | 0.948 | 0.88 | 0.876 | 0.878 |
| Edge-Ring | 0.976 | 0.955 | 0.934 | 0.944 | 0.98 | 0.953 | 0.953 | 0.953 |
| Loc | 0.855 | 0.635 | 0.648 | 0.641 | 0.926 | 0.829 | 0.756 | 0.786 |
| Near-Full | 0.996 | 0.988 | 0.998 | 0.992 | 0.99 | 0.978 | 0.978 | 0.978 |
| Random | 0.886 | 0.835 | 0.651 | 0.694 | 0.983 | 0.966 | 0.966 | 0.966 |
| Scratch | 0.905 | 0.78 | 0.659 | 0.697 | 0.961 | 0.897 | 0.913 | 0.905 |
| Average | 0.935 | 0.859 | 0.813 | 0.825 | 0.972 | 0.934 | 0.928 | 0.93 |
| Defect Type | Model 4 | Model 5 | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | |
| Center | 0.97 | 0.93 | 0.97 | 0.95 | 0.98 | 0.99 | 0.98 | 0.99 |
| Donut | 1 | 0.97 | 1 | 0.99 | 1 | 1 | 1 | 1 |
| Edge-Loc | 0.78 | 0.84 | 0.78 | 0.81 | 0.95 | 0.96 | 0.93 | 0.95 |
| Edge-Ring | 0.96 | 0.93 | 0.96 | 0.95 | 0.99 | 0.99 | 0.99 | 0.99 |
| Loc | 0.7 | 0.84 | 0.71 | 0.77 | 0.89 | 0.58 | 0.7 | 0.64 |
| Near-Full | 0.97 | 0.98 | 0.98 | 0.98 | 0.99 | 1 | 0.99 | 0.99 |
| Random | 0.95 | 0.97 | 0.95 | 0.96 | 0.98 | 0.99 | 0.99 | 0.99 |
| Scratch | 0.91 | 0.81 | 0.91 | 0.86 | 0.94 | 0.97 | 0.93 | 0.95 |
| Average | 0.91 | 0.91 | 0.91 | 0.91 | 0.97 | 0.93 | 0.94 | 0.94 |
| Defect Type | Model 5 (Using Different Sizes of WBM Data) | |||
|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | |
| Center | 0.97 | 0.92 | 0.93 | 0.93 |
| Donut | 0.99 | 0.90 | 0.77 | 0.83 |
| Edge-Loc | 0.77 | 0.78 | 0.88 | 0.83 |
| Edge-Ring | 0.93 | 0.92 | 0.95 | 0.93 |
| Loc | 0.85 | 0.86 | 0.68 | 0.76 |
| Near-Full | 0.99 | 0.95 | 0.78 | 0.85 |
| Random | 0.99 | 0.90 | 0.70 | 0.79 |
| Scratch | 0.96 | 0.92 | 0.40 | 0.56 |
| Average | 0.93 | 0.89 | 0.76 | 0.81 |
| Labeled Defect Type | No Defect Pattern | Single Defect Pattern | Two Types of Mixed-Defect Patterns | Sum |
|---|---|---|---|---|
| Center | 22 | 68 | 0 | 90 |
| Donut | 0 | 1 | 0 | 1 |
| Edge-Loc | 59 | 230 | 7 | 296 |
| Edge-Ring | 0 | 31 | 0 | 31 |
| Loc | 66 | 214 | 17 | 297 |
| Near-Full | 0 | 16 | 0 | 16 |
| Random | 0 | 74 | 0 | 74 |
| Scratch | 14 | 52 | 6 | 72 |
| Sum | 161 | 686 | 30 | 877 |
| Model | Algorithm | Data | F1-Score | Accuracy |
|---|---|---|---|---|
| C.-Y. Wang, T.-H. Tsai [13] | MobileNet V2 | Labeled WM-811K data (25,519) train: 70%, test: 30% | - | 96.56% |
| C.-Y. Wang, T.-H. Tsai [13] (lightweight model) | MobileNet V2 (simplified version) | Labeled WM-811K data (25,519) train: 70%, test: 30% | - | 93.26% |
| T. Tziolas et al. [18] | Modified CNN | Randomly select data after data augmentation using rotation train: 832 for 9 classes test: 45 for 9 classes | 0.93 | 95.3% |
| Ebayyeh et al. [19] | WaferCaps | WM-811K train: 22,137, test: 2165 | 0.77 | 78.2% |
| Ebayyeh et al. [19] | WaferCaps | Data augmentation using DCGAN train: 63,200, test: 15,600 | 0.91 | 91.4% |
| Q. Xu, N. Yu, F. Essaf [22] | Add CBAM based on ResNet-18, Cosine normalization algorithm | Labeled WM-811K data (25,519) + 10,000 ‘none’ pattern data train: 75%, test: 25% | - | 95.5% |
| Proposed Model 4 | Modified CNN | 26 × 26 data (Table 3) train: 70%, test: 30% | 0.96 | 91.33% |
| Proposed Model 4 | Modified CNN | Labeled WM-811K data (25,519) train: 70%, test: 30% | 0.87 | 89.89% |
| Proposed Model 5 | Modified CNN | 26 × 26 data (Table 3) train: 70%, test: 30% | 0.94 | 94% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.H.; Kim, T.S. Development of a Wafer Defect Pattern Classifier Using Polar Coordinate System Transformed Inputs and Convolutional Neural Networks. Electronics 2024, 13, 1360. https://doi.org/10.3390/electronics13071360
Kim MH, Kim TS. Development of a Wafer Defect Pattern Classifier Using Polar Coordinate System Transformed Inputs and Convolutional Neural Networks. Electronics. 2024; 13(7):1360. https://doi.org/10.3390/electronics13071360
Chicago/Turabian StyleKim, Moo Hyun, and Tae Seon Kim. 2024. "Development of a Wafer Defect Pattern Classifier Using Polar Coordinate System Transformed Inputs and Convolutional Neural Networks" Electronics 13, no. 7: 1360. https://doi.org/10.3390/electronics13071360