
On the Regularization of Recursive Least-Squares Adaptive Algorithms Using Line Search Methods
 ,
,
Abstract
:1. Introduction
2. System Model
2.1. The Widely-Linear Model
2.2. The WL-RLS-LSM Algorithm
3. The Variable Regularized WL-RLS-LSM
4. VR-WL-RLS-LSM Versions
4.1. The Conjugate Gradient LSM
4.2. The Coordinate Descent LSM
4.3. The Dichotomous Coordinate Descent LSM
5. Simulations
5.1. Practical Considerations
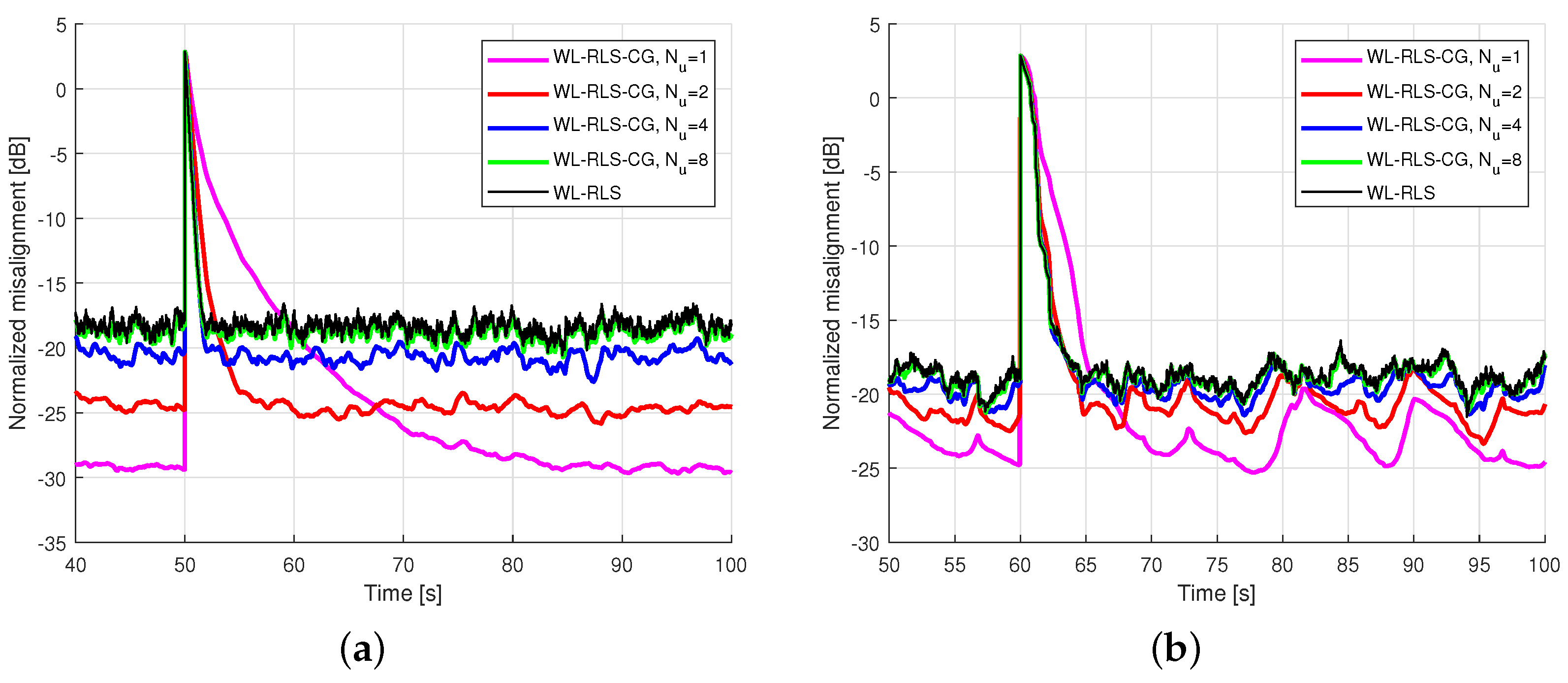
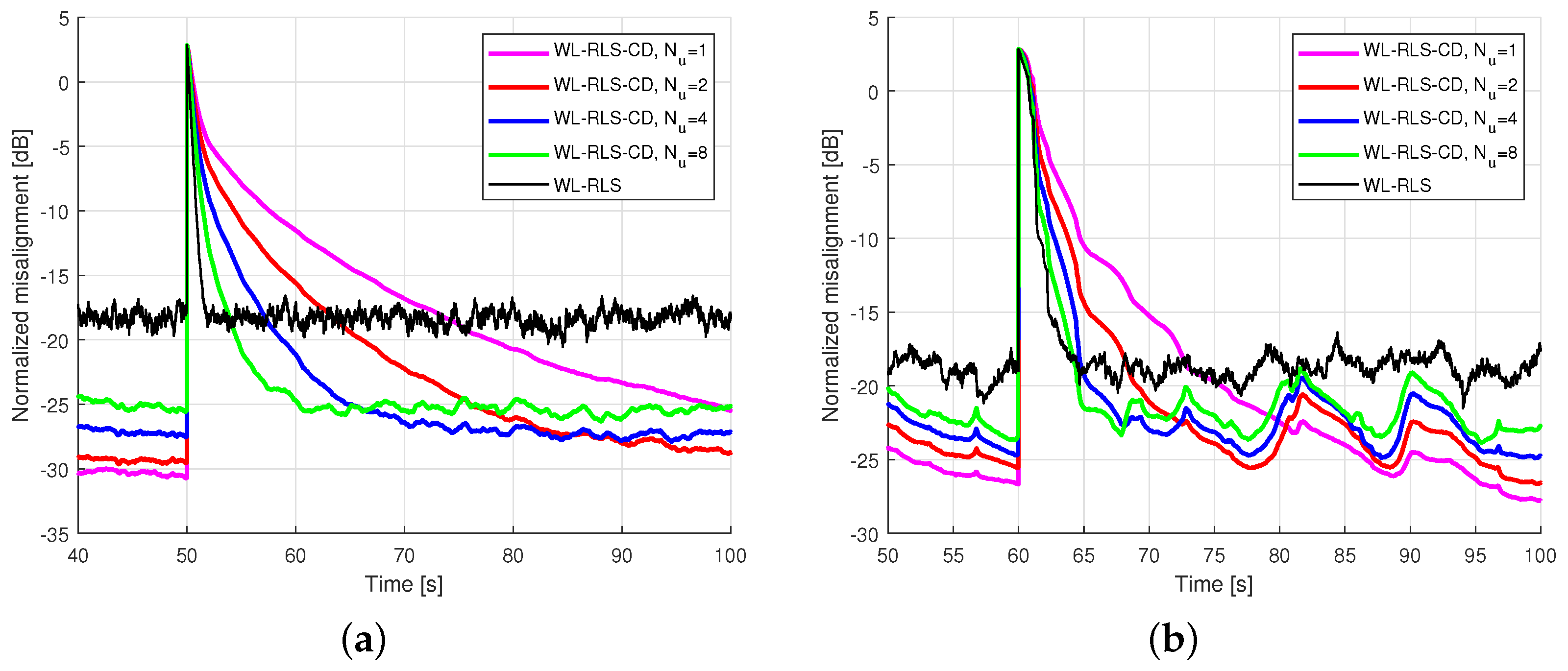
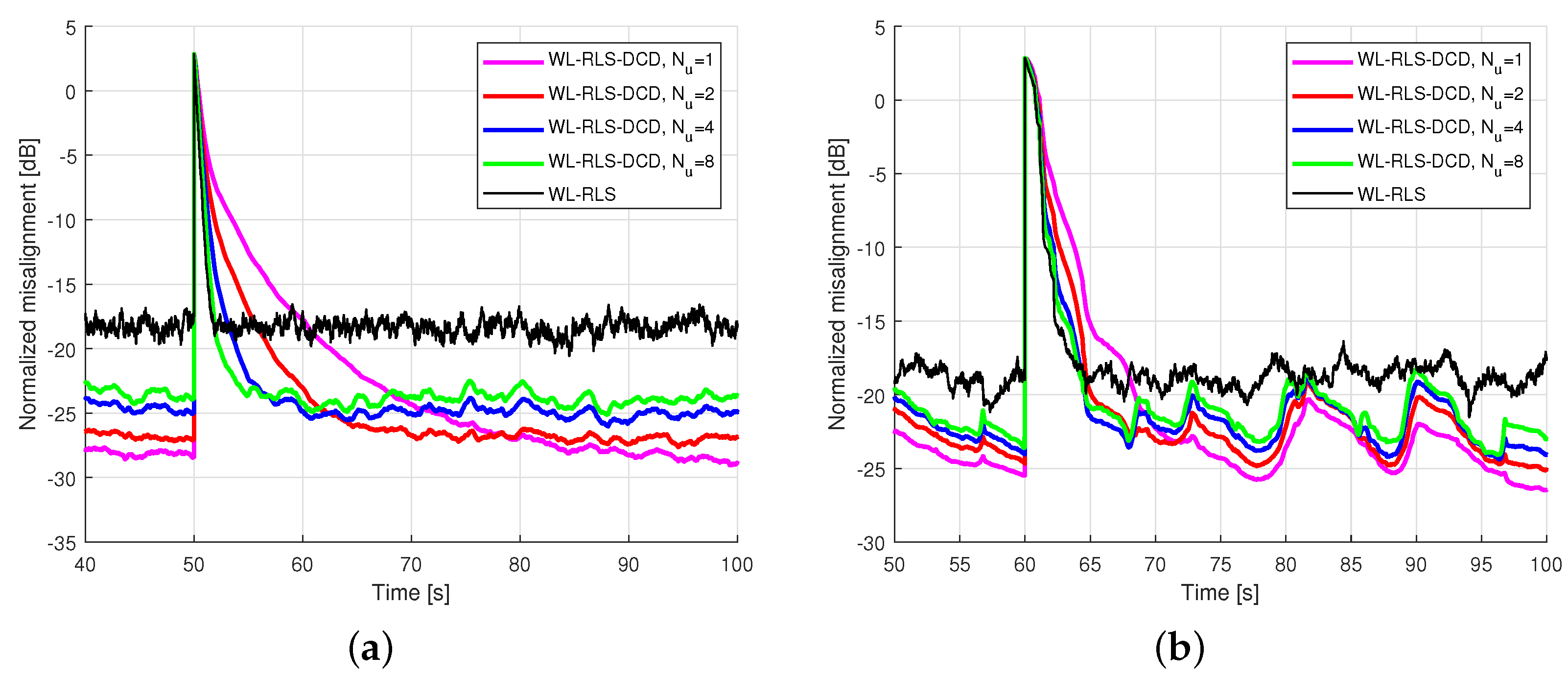
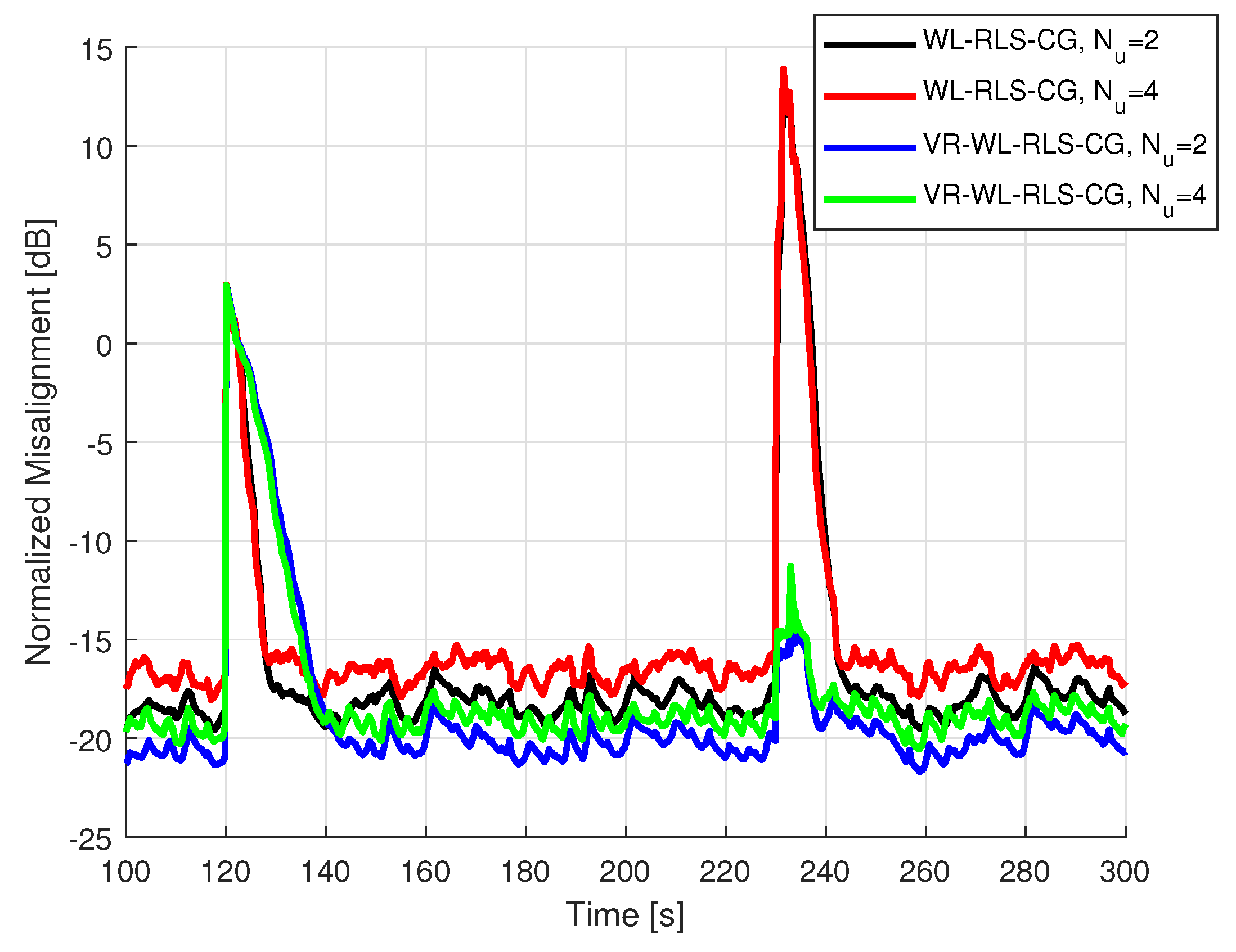
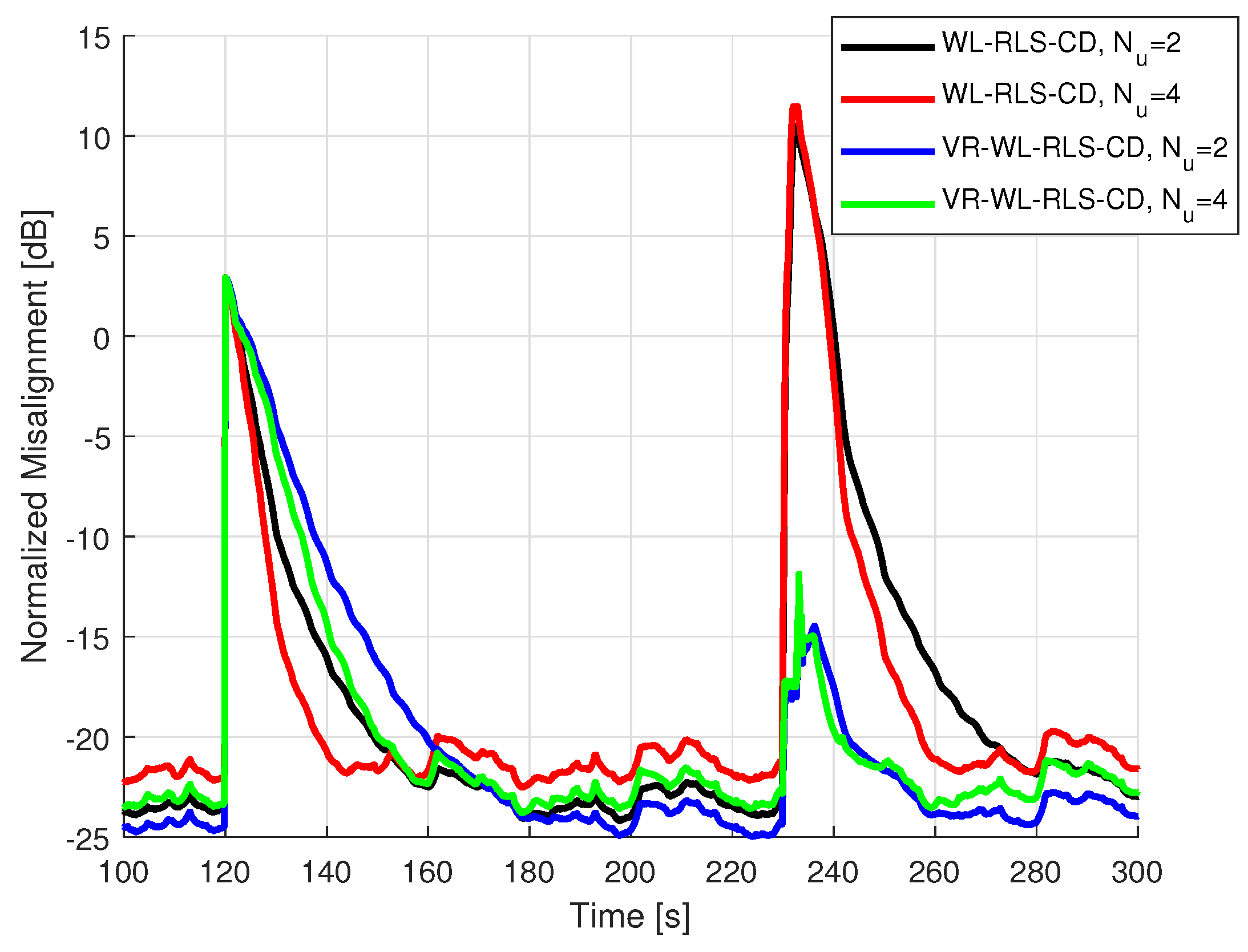
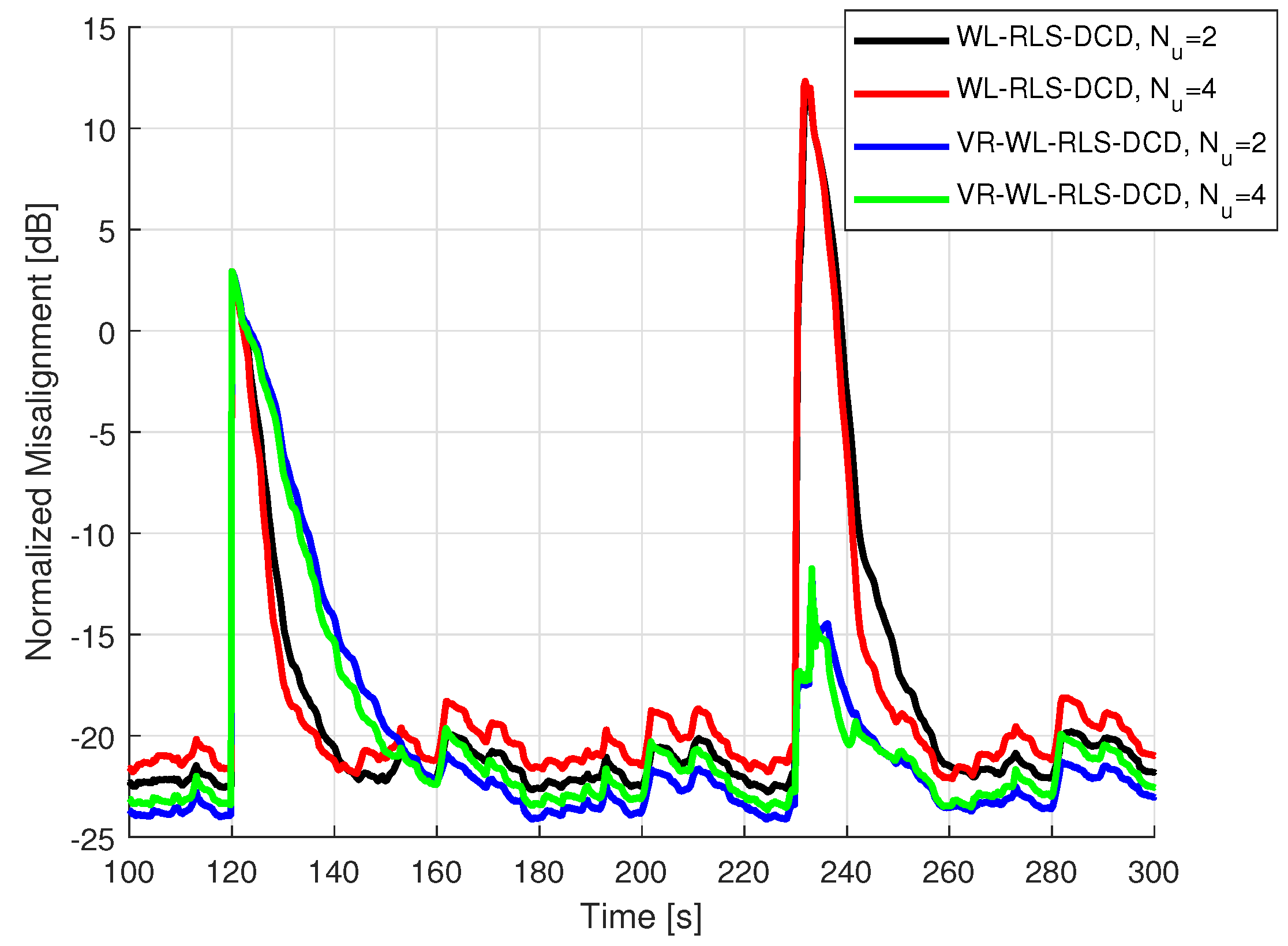
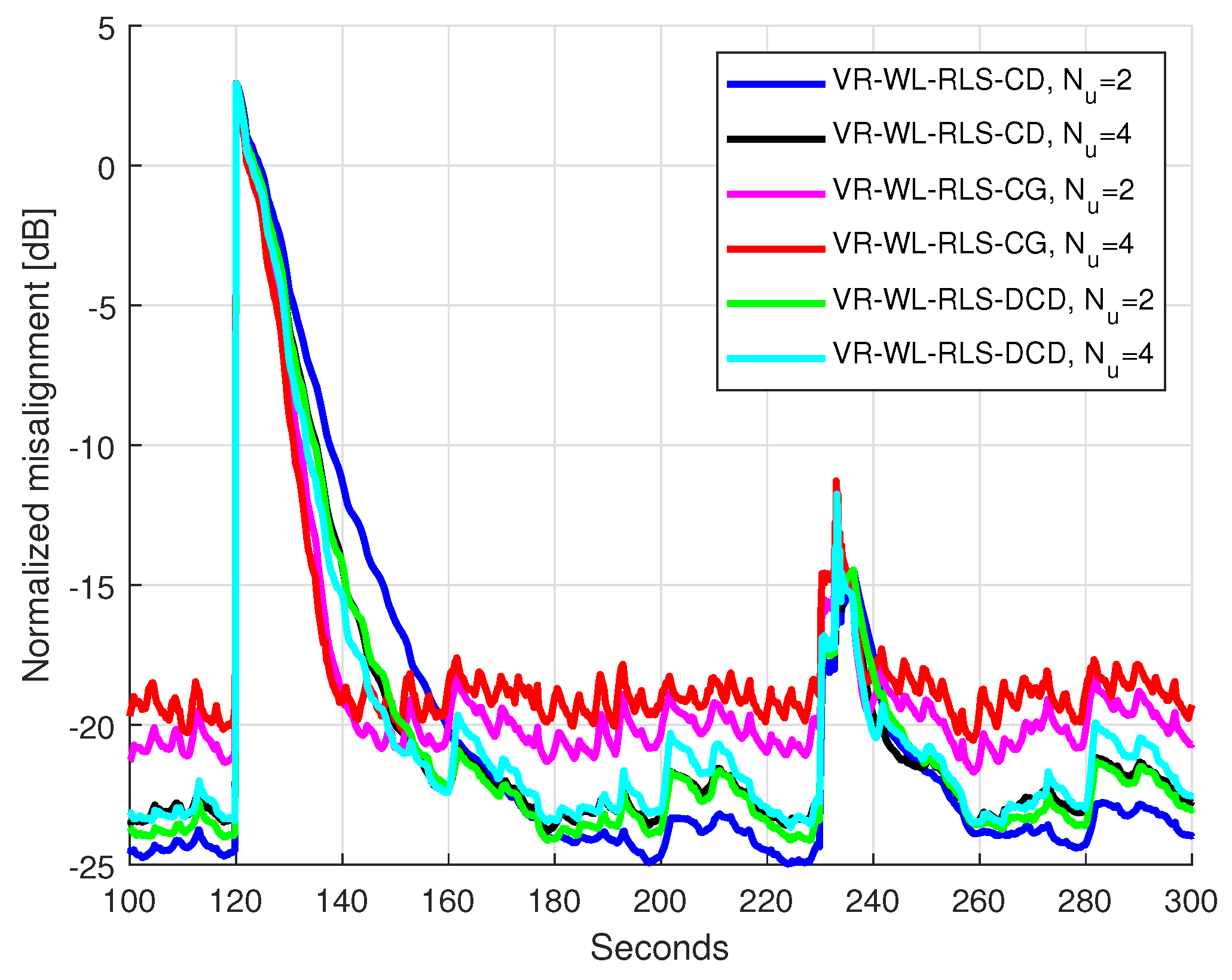
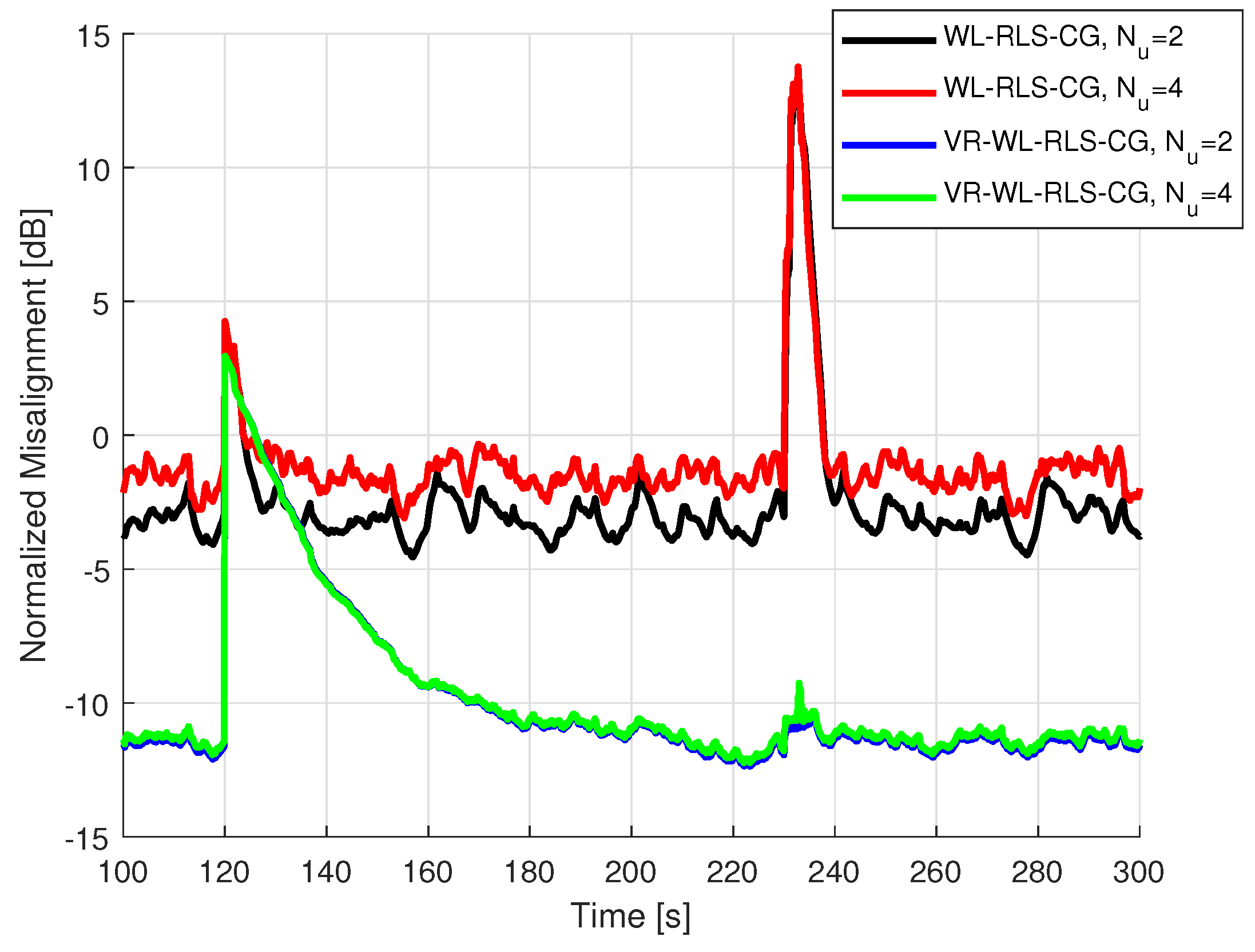
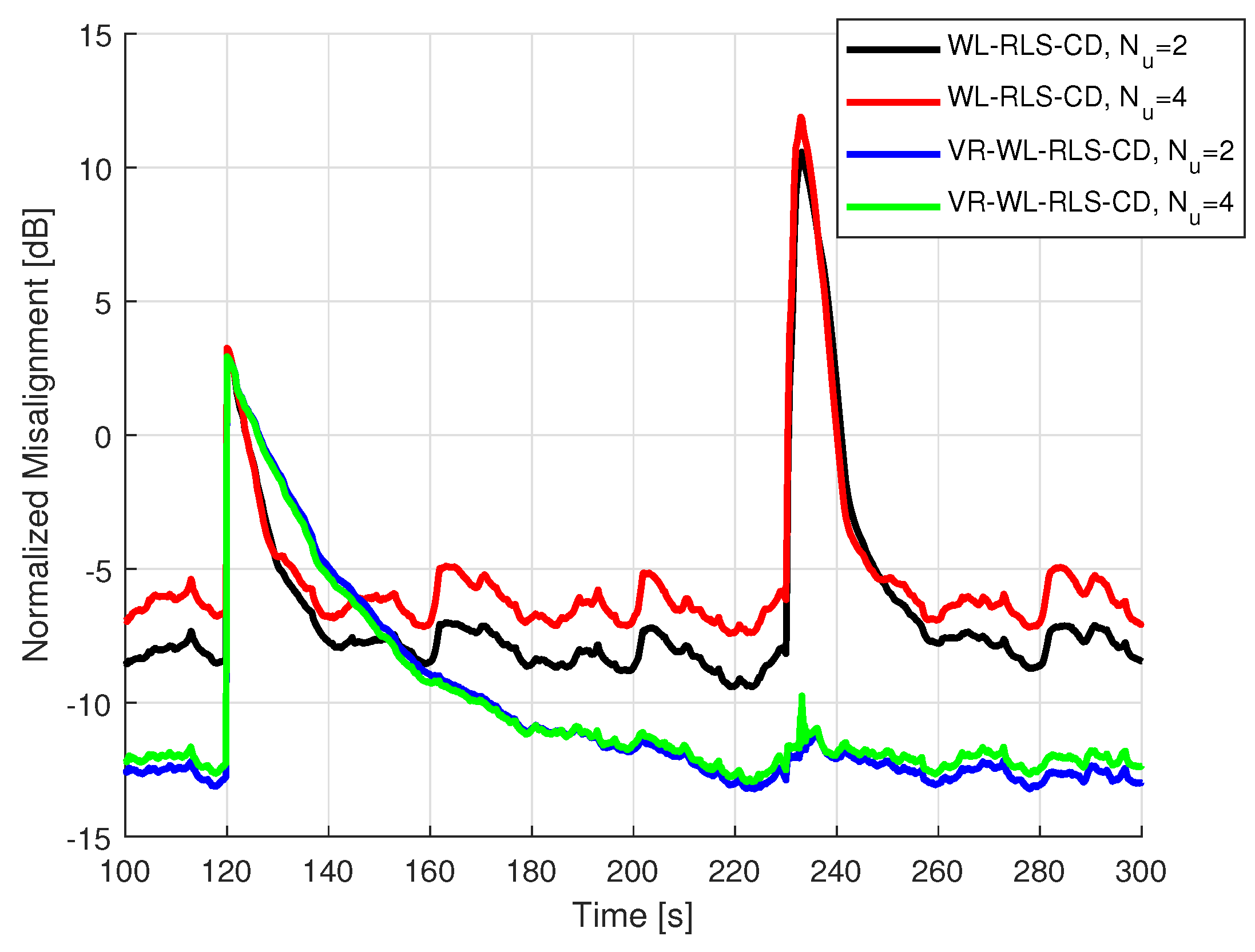
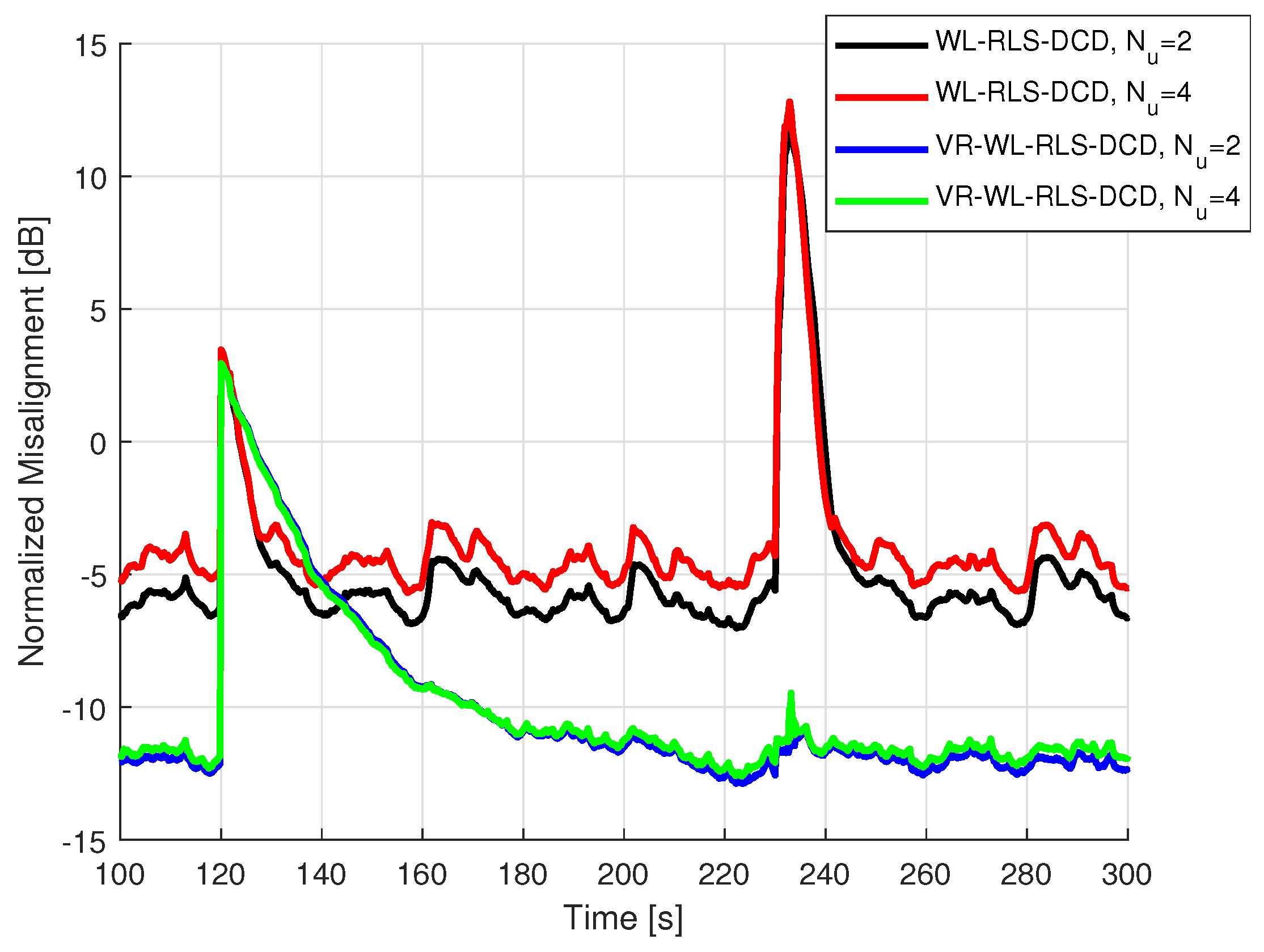
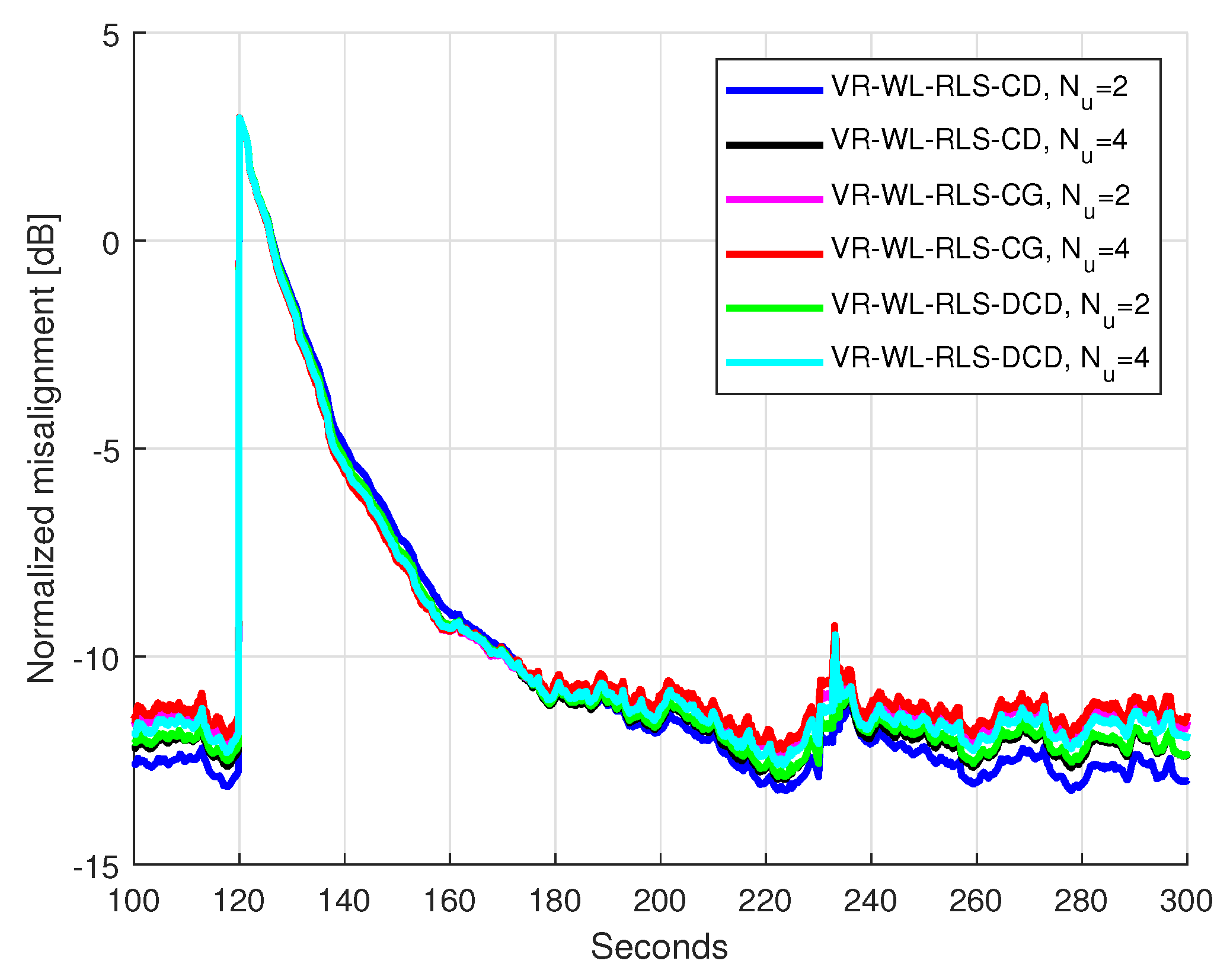
5.2. Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Benesty, J.; Huang, Y. Adaptive Signal Processing–Applications to Real-World Problems; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Stanciu, C.; Benesty, J.; Paleologu, C.; Gänsler, T.; Ciochină, S. A widely linear model for stereophonic acoustic echo cancellation. Signal Process. 2013, 93, 511–516. [Google Scholar] [CrossRef]
- Benesty, J.; Morgan, D.; Sondhi, M. A better understanding and an improved solution to the specific problems of stereophonic acoustic echo cancellation. IEEE Trans. Speech Audio Process. 1998, 6, 156–165. [Google Scholar] [CrossRef]
- Diniz, P.S.R. Adaptive Filtering: Algorithms and Practical Implementation, 4th ed.; Springer: New York, NY, USA, 2013. [Google Scholar]
- Sondhi, M.; Morgan, D.; Hall, J. Stereophonic acoustic echo cancellation-an overview of the fundamental problem. IEEE Signal Process. Lett. 1995, 2, 148–151. [Google Scholar] [CrossRef] [PubMed]
- Benesty, J.; Paleologu, C.; Gänsler, T.; Ciochină, S. A Perspective on Stereophonic Acoustic Echo Cancellation; Springer: Berlin/Heidelberg, Germany, 2011; Volume 4. [Google Scholar] [CrossRef]
- Hong, J. Stereophonic Acoustic Echo Suppression for Speech Interfaces for Intelligent TV Applications. IEEE Trans. Consum. Electron. 2018, 64, 153–161. [Google Scholar] [CrossRef]
- Cho, B.J.; Park, H.M. Stereo Acoustic Echo Cancellation Based on Maximum Likelihood Estimation with Inter-Channel-Correlated Echo Compensation. IEEE Trans. Signal Process. 2020, 68, 5188–5203. [Google Scholar] [CrossRef]
- Schneider, M.; Kellermann, W. Multichannel acoustic echo cancellation in the wave domain with increased robustness to nonuniqueness. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 518–529. [Google Scholar] [CrossRef]
- Lv, S.; Zhao, H.; Xu, W. Robust widely linear affine projection M-estimate adaptive algorithm: Performance analysis and application. IEEE Trans. Signal Process. 2023, 71, 3623–3636. [Google Scholar] [CrossRef]
- Stanciu, C.; Benesty, J.; Paleologu, C.; Gänsler, T.; Ciochină, S. A novel perspective on stereophonic acoustic echo cancellation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 25–28. [Google Scholar] [CrossRef]
- Haykin, S. Adaptive Filter Theory; Prentice-Hall Information and System Sciences Series; Prentice Hall: Hoboken, NJ, USA, 2002. [Google Scholar]
- Sayed, A. Adaptive Filters; Wiley: New York, NY, USA, 2008. [Google Scholar]
- Chu, Y.J.; Chan, S.C. A New Local Polynomial Modeling-Based Variable Forgetting Factor RLS Algorithm and Its Acoustic Applications. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 2059–2069. [Google Scholar] [CrossRef]
- Romoli, L.; Cecchi, S.; Peretti, P.; Piazza, F. A Mixed Decorrelation Approach for Stereo Acoustic Echo Cancellation Based on the Estimation of the Fundamental Frequency. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 690–698. [Google Scholar] [CrossRef]
- Romoli, L.; Cecchi, S.; Piazza, F. A novel decorrelation approach for multichannel system identification. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 6652–6656. [Google Scholar] [CrossRef]
- Paleologu, C.; Benesty, J.; Ciochină, S. Data-Reuse Recursive Least-Squares Algorithms. IEEE Signal Process. Lett. 2022, 29, 752–756. [Google Scholar] [CrossRef]
- Hänsler, E.; Schmidt, G. Acoustic Echo and Noise Control—A Practical Approach; Wiley: Hoboken, NJ, USA, 2004. [Google Scholar]
- Zakharov, Y.V.; White, G.P.; Liu, J. Low-Complexity RLS Algorithms Using Dichotomous Coordinate Descent Iterations. IEEE Trans. Signal Process. 2008, 56, 3150–3161. [Google Scholar] [CrossRef]
- Liu, J.; Zakharov, Y.V.; Weaver, B. Architecture and FPGA Design of Dichotomous Coordinate Descent Algorithms. IEEE Trans. Circuits Syst. I Regul. Pap. 2009, 56, 2425–2438. [Google Scholar] [CrossRef]
- Zakharov, Y.V.; Nascimento, V.H. DCD-RLS Adaptive Filters With Penalties for Sparse Identification. IEEE Trans. Signal Process. 2013, 61, 3198–3213. [Google Scholar] [CrossRef]
- Yu, Y.; Lu, L.; Zheng, Z.; Wang, W.; Zakharov, Y.; de Lamare, R.C. DCD-Based Recursive Adaptive Algorithms Robust Against Impulsive Noise. IEEE Trans. Circuits Syst. II Express Briefs 2020, 67, 1359–1363. [Google Scholar] [CrossRef]
- Paleologu, C.; Benesty, J.; Ciochină, S. A Robust Variable Forgetting Factor Recursive Least-Squares Algorithm for System Identification. IEEE Signal Process. Lett. 2008, 15, 597–600. [Google Scholar] [CrossRef]
- Malik, S.; Wung, J.; Atkins, J.; Naik, D. Double-Talk Robust Multichannel Acoustic Echo Cancellation Using Least-Squares MIMO Adaptive Filtering: Transversal, Array, and Lattice Forms. IEEE Trans. Signal Process. 2020, 68, 4887–4902. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, T.; Zakharov, Y.V.; Li, J. MMP-DCD-CV based sparse channel estimation algorithm for underwater acoustic transform domain communication system. Appl. Acoust. 2019, 154, 43–52. [Google Scholar] [CrossRef]
- Liao, M.; Zakharov, Y.V. DCD-based joint sparse channel estimation for OFDM in virtual angular domain. IEEE Access 2021, 9, 102081–102090. [Google Scholar] [CrossRef]
- Yu, Y.; Lu, L.; Zakharov, Y.; de Lamare, R.C.; Chen, B. Robust sparsity-aware RLS algorithms with jointly-optimized parameters against impulsive noise. IEEE Signal Process. Lett. 2022, 29, 1037–1041. [Google Scholar] [CrossRef]
- Yu, Y.; Huang, Z.; He, H.; Zakharov, Y.; de Lamare, R.C. Sparsity-aware robust normalized subband adaptive filtering algorithms with alternating optimization of parameters. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 3934–3938. [Google Scholar] [CrossRef]
- Niedźwiecki, M.; Gańcza, A.; Shen, L.; Zakharov, Y. Adaptive identification of sparse underwater acoustic channels with a mix of static and time-varying parameters. Signal Process. 2022, 200, 108664. [Google Scholar] [CrossRef]
- Yu, Y.; Ye, J.; Zakharov, Y.; He, H. Robust proportionate subband adaptive filter algorithms with optimal variable step-size. IEEE Trans. Circuits Syst. II Express Briefs 2024, in press. [CrossRef]
- Benesty, J.; Paleologu, C.; Ciochina, S. Regularization of the RLS Algorithm. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2011, E94.A, 1628–1629. [Google Scholar] [CrossRef]
- Elisei-Iliescu, C.; Stanciu, C.L.; Paleologu, C.; Benesty, J.; Anghel, C.; Ciochină, S. Robust Variable-Regularized RLS Algotihms. In Proceedings of the 2017 Hands-Free Speech Communications and Microphone Arrays (HSCMA), San Francisco, CA, USA, 1–3 March 2017. [Google Scholar] [CrossRef]
- Stanciu, C.; Anghel, C.; Stanciu, L. Efficient FPGA implementation of the DCD-RLS algorithm for stereo acoustic echo cancellation. In Proceedings of the 2015 International Symposium on Signals, Circuits and Systems (ISSCS), Iasi, Romania, 9–10 July 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Elisei-Iliescu, C.; Paleologu, C.; Benesty, J.; Stanciu, C.; Anghel, C.; Ciochină, S. Recursive Least-Squares Algorithms for the Identification of Low-Rank Systems. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 903–918. [Google Scholar] [CrossRef]
- Chang, P.S.; Willson, A.N. Analysis of Conjugate Gradient Algorithms for Adaptive Filtering. IEEE Trans. Signal Process. 2000, 48, 409–418. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step | Actions | × |
|---|---|---|
| 0 | ||
| 0 | ||
| 0 | ||
| 1 | Update using (1) and (11) | 0 |
| 2 | Update using time-shift | |
| 3 | ||
| 4 | 0 | |
| 5 | ||
| 6 | ... | |
| 7 | 0 |
| Step | Actions | × | / |
|---|---|---|---|
| 0 | 0 | ||
| 0 | 0 | ||
| 0 | 0 | ||
| 0 | 0 | ||
| 1 | Update using (1) and (11) | 0 | 0 |
| 2 | Update using time-shift | ||
| 0 | |||
| 3 | Update , using (42); | 8 | 0 |
| 4 | 0 | ||
| 5 | Update using (42) | 4 | 0 |
| 6 | 0 | 1 | |
| 7 | 1 | 1 | |
| 8 | 0 | 0 | |
| 9 | 0 | ||
| 10 | ... | ... | |
| 11 | 0 | 0 |
| Step | Actions | × | / |
|---|---|---|---|
| 1 | 1 | ||
| 2 | 0 | ||
| 3 | 1 | ||
| 4 | 0 | ||
| 5 | 0 | ||
| 6 | 0 |
| Step | Actions | × | / |
|---|---|---|---|
| 1 | |||
| , | 0 | 0 | |
| 2 | 0 | 1 | |
| 3 | 0 | 0 | |
| 4 | 0 |
| Step | Actions | + |
|---|---|---|
| ; | ||
| 1 | ||
| 2 | ||
| 3 | If → RETURN | |
| 4 | If Step 2 | 1 |
| 5 | ||
| 6 | 1 | |
| 7 | ||
| RETURN |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stanciu, C.-L.; Anghel, C.; Fîciu, I.-D.; Elisei-Iliescu, C.; Udrea, M.-R.; Stanciu, L. On the Regularization of Recursive Least-Squares Adaptive Algorithms Using Line Search Methods. Electronics 2024, 13, 1479. https://doi.org/10.3390/electronics13081479
Stanciu C-L, Anghel C, Fîciu I-D, Elisei-Iliescu C, Udrea M-R, Stanciu L. On the Regularization of Recursive Least-Squares Adaptive Algorithms Using Line Search Methods. Electronics. 2024; 13(8):1479. https://doi.org/10.3390/electronics13081479
Chicago/Turabian StyleStanciu, Cristian-Lucian, Cristian Anghel, Ionuț-Dorinel Fîciu, Camelia Elisei-Iliescu, Mihnea-Radu Udrea, and Lucian Stanciu. 2024. "On the Regularization of Recursive Least-Squares Adaptive Algorithms Using Line Search Methods" Electronics 13, no. 8: 1479. https://doi.org/10.3390/electronics13081479