
VerSA: Versatile Systolic Array Architecture for Sparse and Dense Matrix Multiplications


Abstract
1. Introduction
- We propose the VerSA architecture, which can be used for both dense and sparse matrix multiplications in a versatile manner;
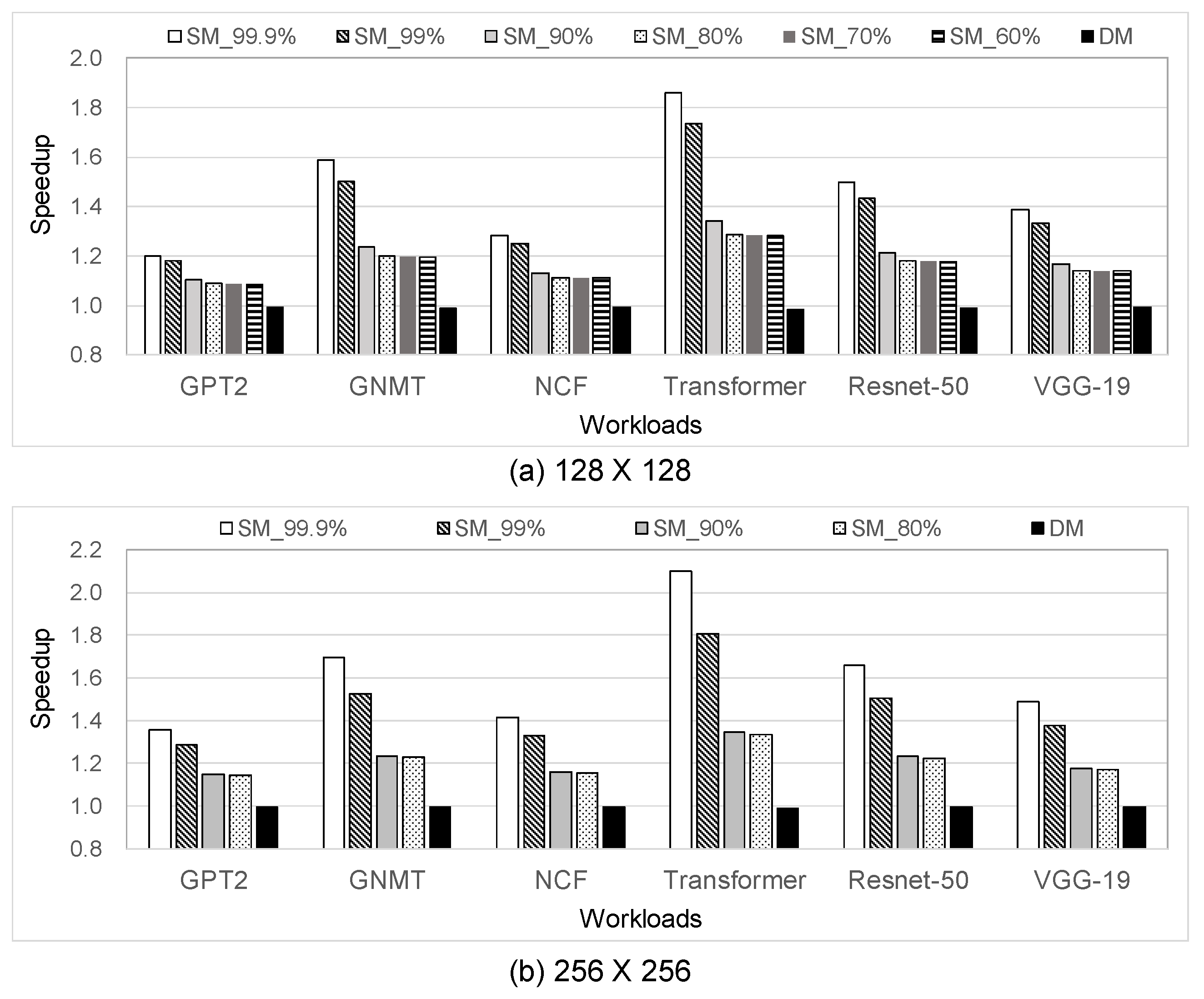
- When executing SpMM, 256 × 256 (128 × 128) VerSA results in performance improvement and energy saving by 1.21×–1.60× (1.16×–1.45×) and 7.5–30.2% (1.6–21.3%), respectively, on average, when compared to the conventional SA;
- When compared to the state-of-the-art SpMM accelerator, our 256 × 256 (128 × 128) VerSA shows a better performance by 20.1× (5.7×), on average, meaning that VerSA can be used for a broader range of MM applications;
- In terms of logic synthesis results, 256 × 256 (128 × 128) VerSA architecture can be implemented with only small hardware and power overheads when compared to the conventional SA by 12.6% (14.9%) and 11.7% (14.4%), respectively.
2. Related Works
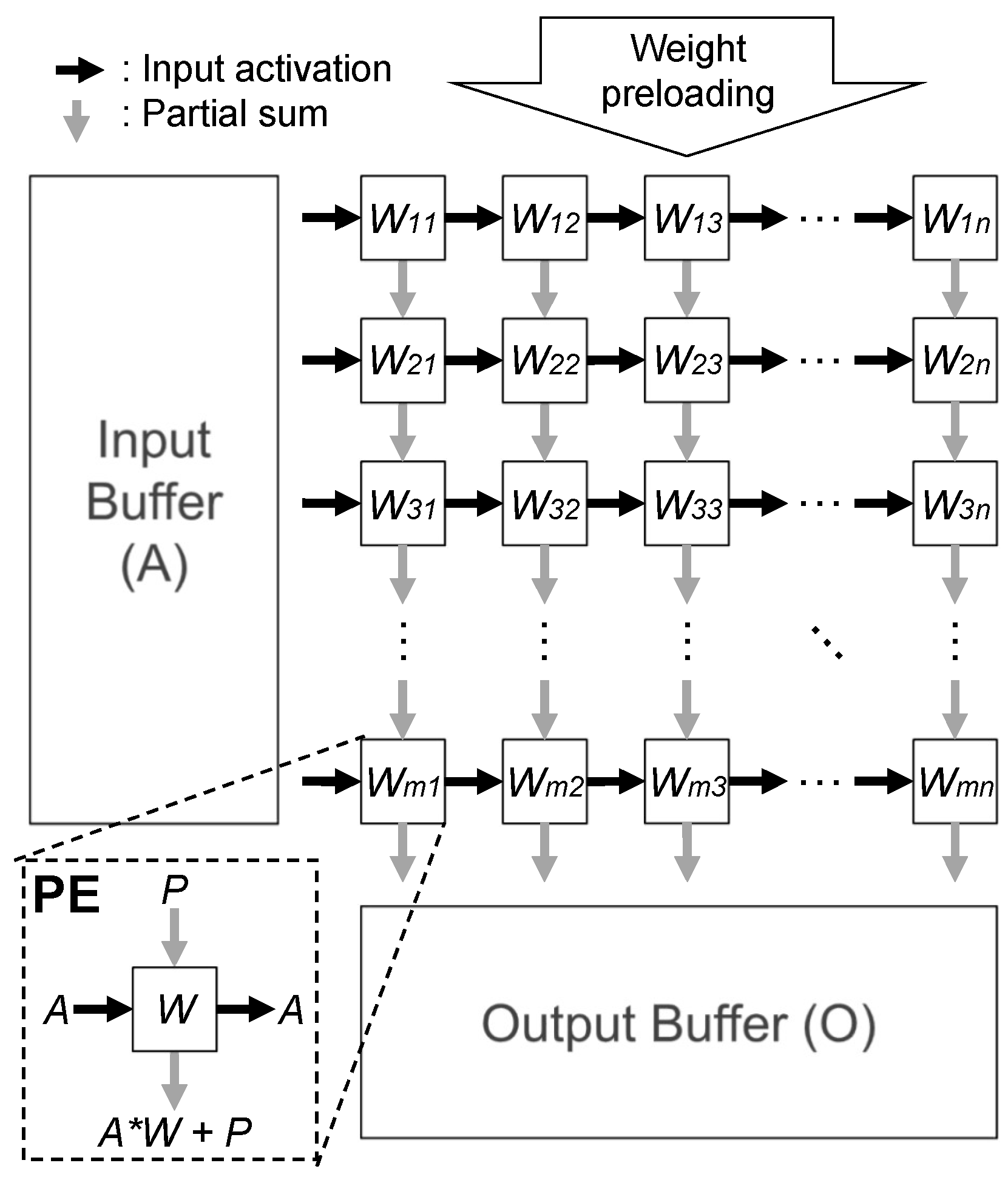
3. Background and Motivation
- We will devise a novel, unified hardware architecture for efficiently executing both sparse and dense MMs;
- For the versatility of our hardware, we will also devise appropriate hardware and software supports. We will also focus on minimizing the overhead caused from those supports.
4. VerSA Architecture
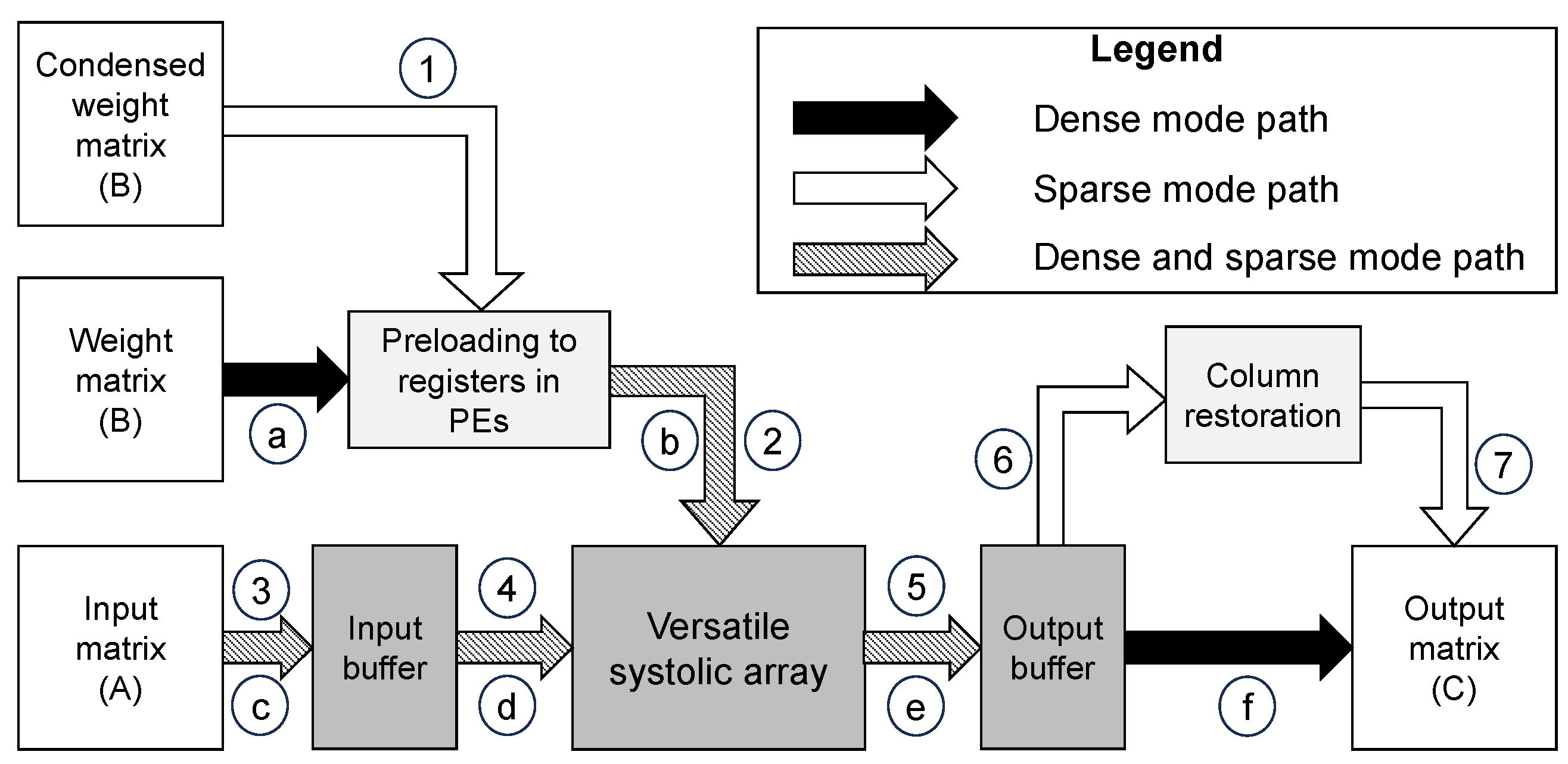
4.1. Overview
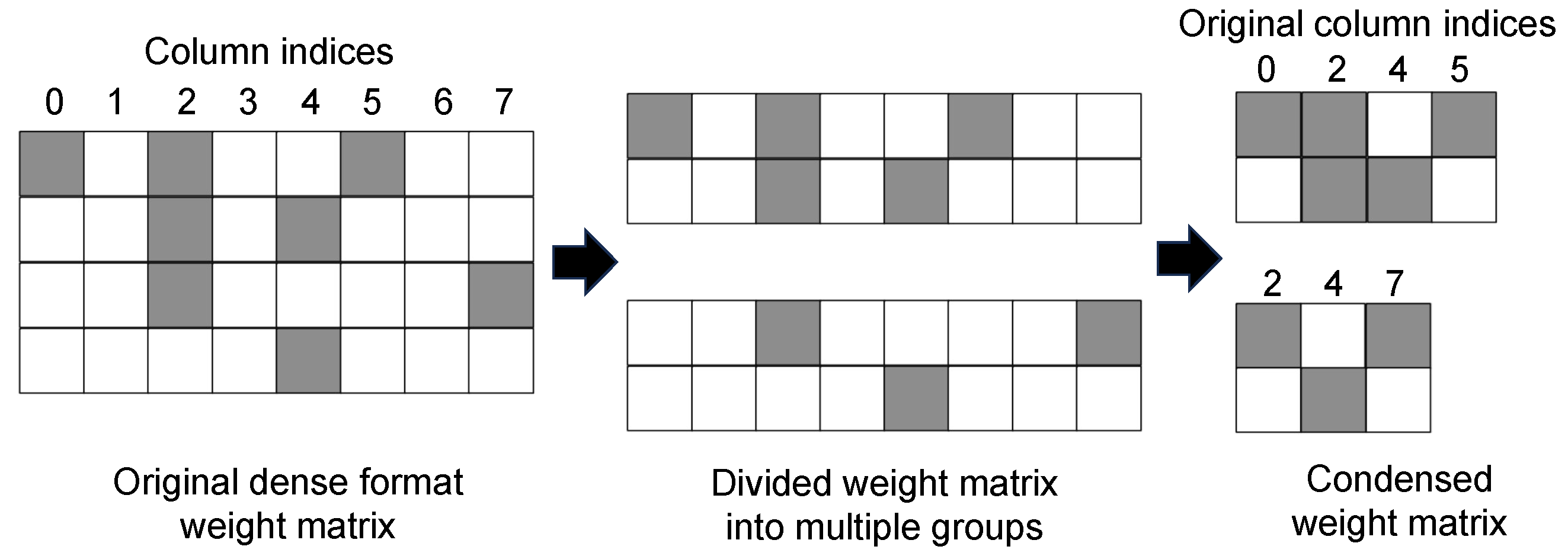
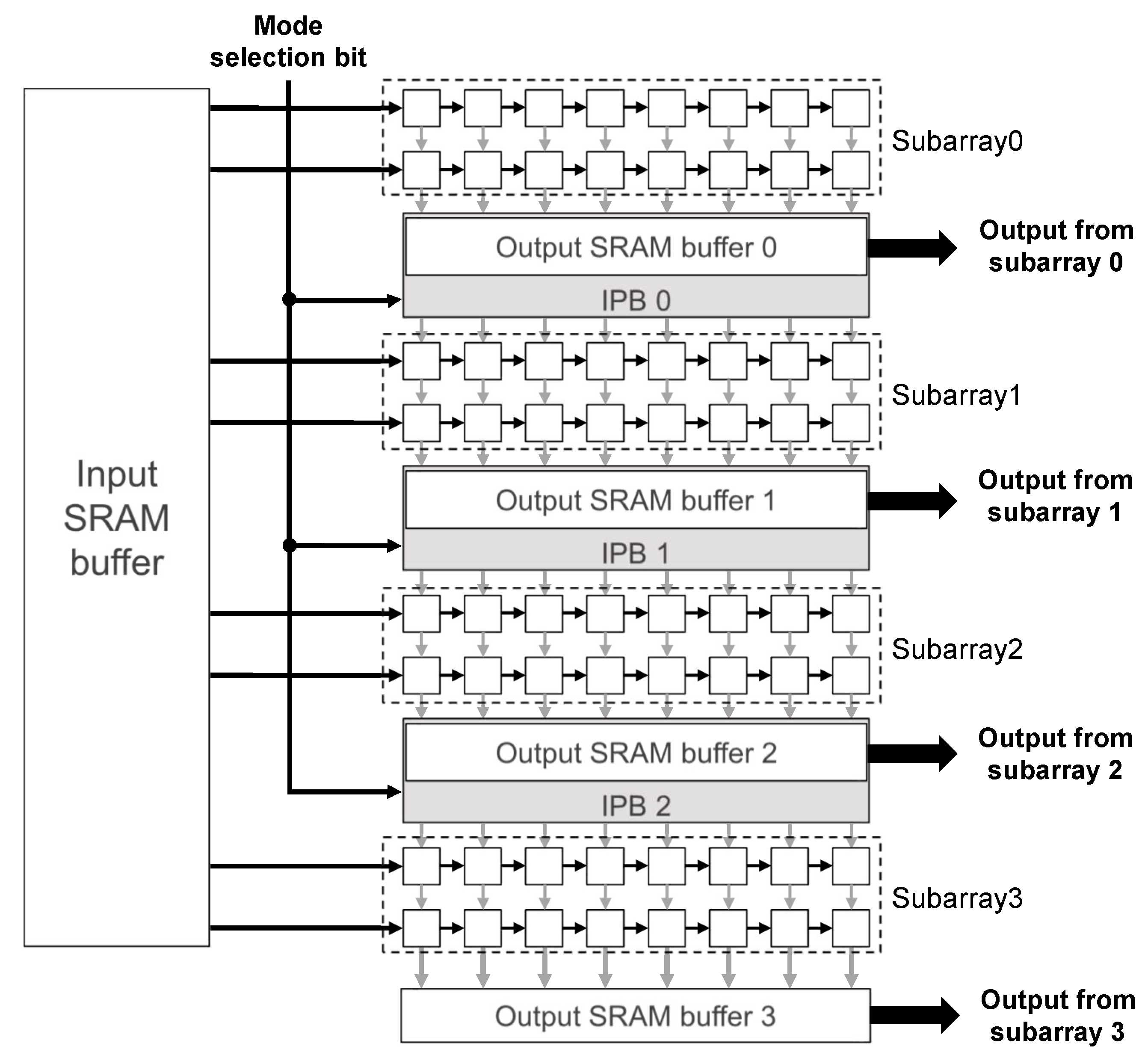
4.2. Hardware Architecture
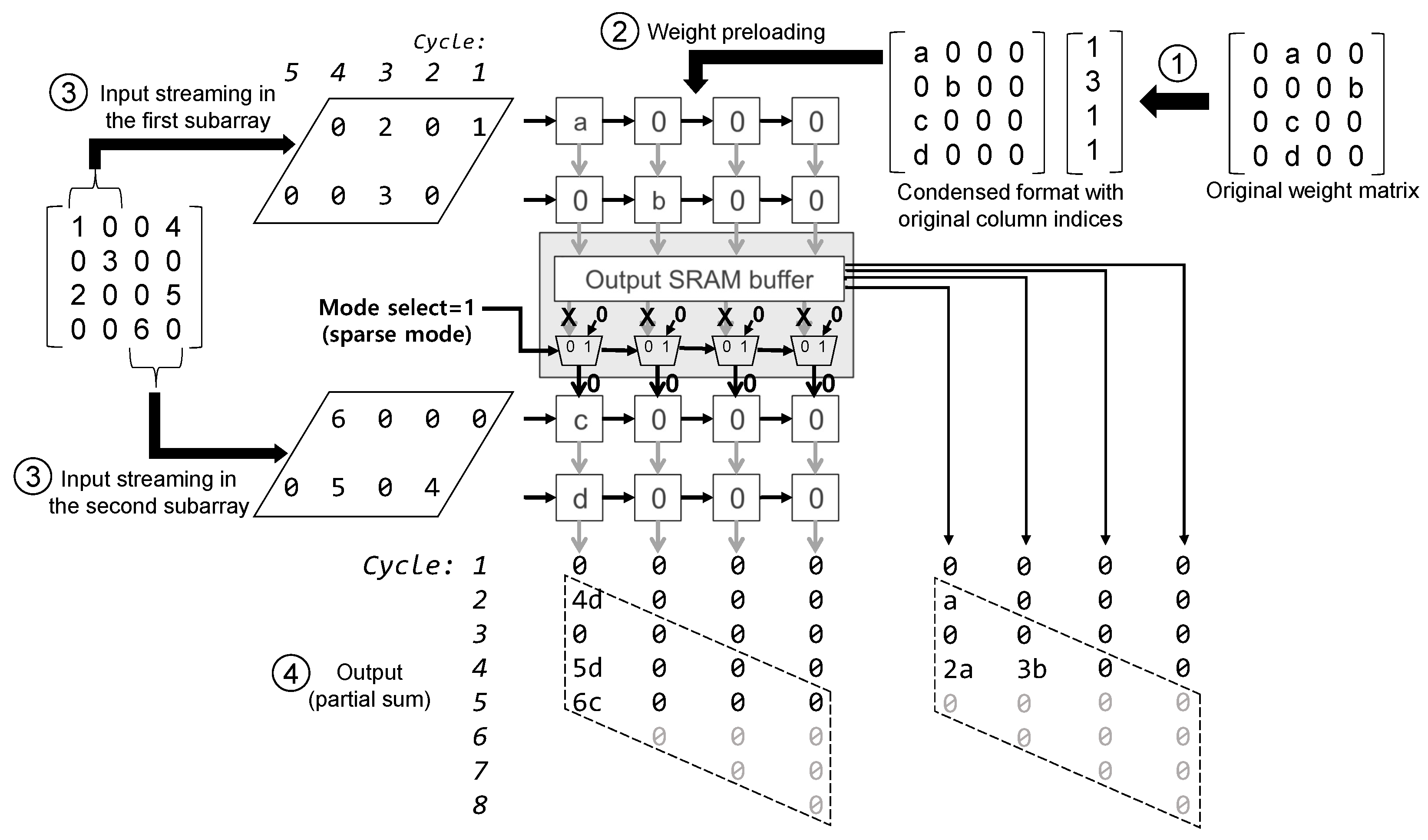
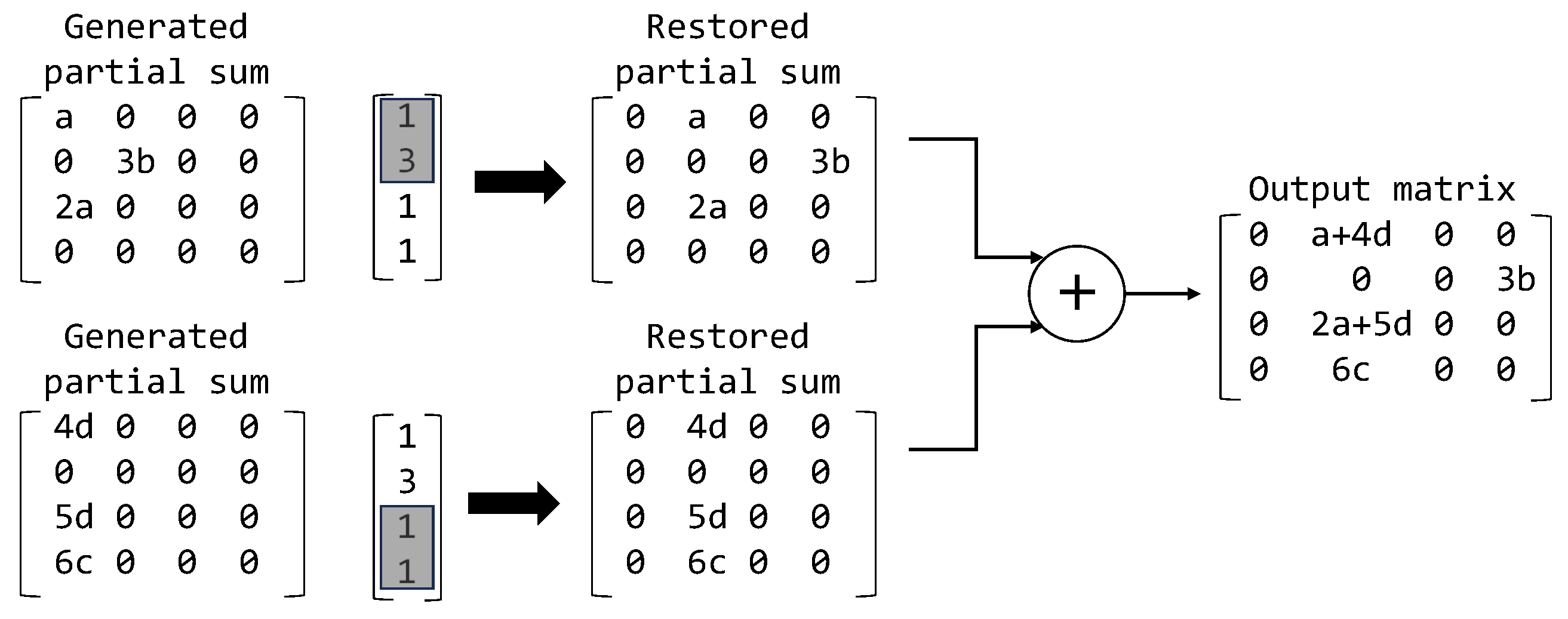
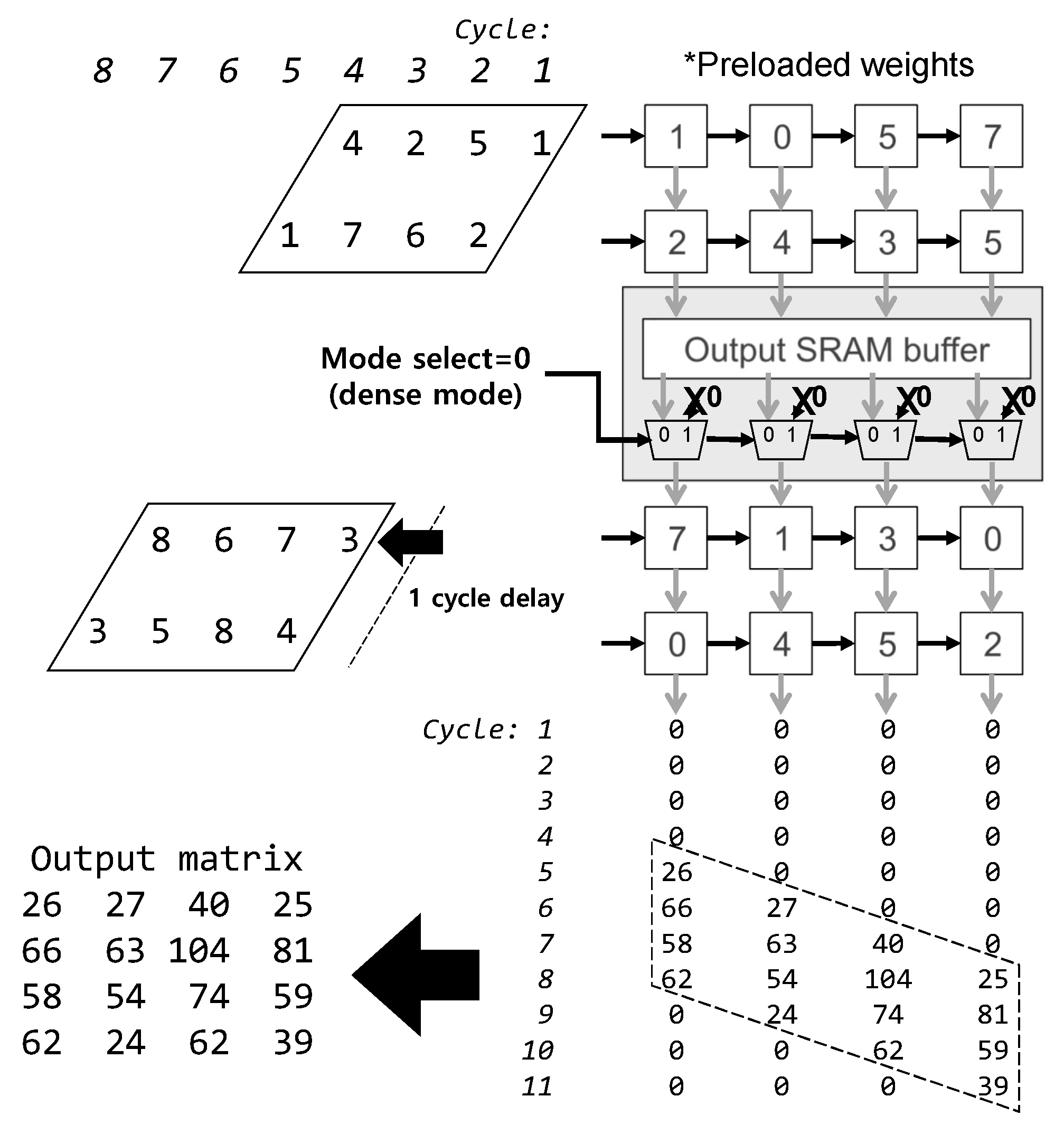
4.3. An Example of the Sparse and Dense Mode Operations
4.3.1. Sparse Mode Operations
4.3.2. Dense Mode Operations
4.4. Implementation and Logic Synthesis
5. Evaluation
5.1. Methodology
5.2. Performance
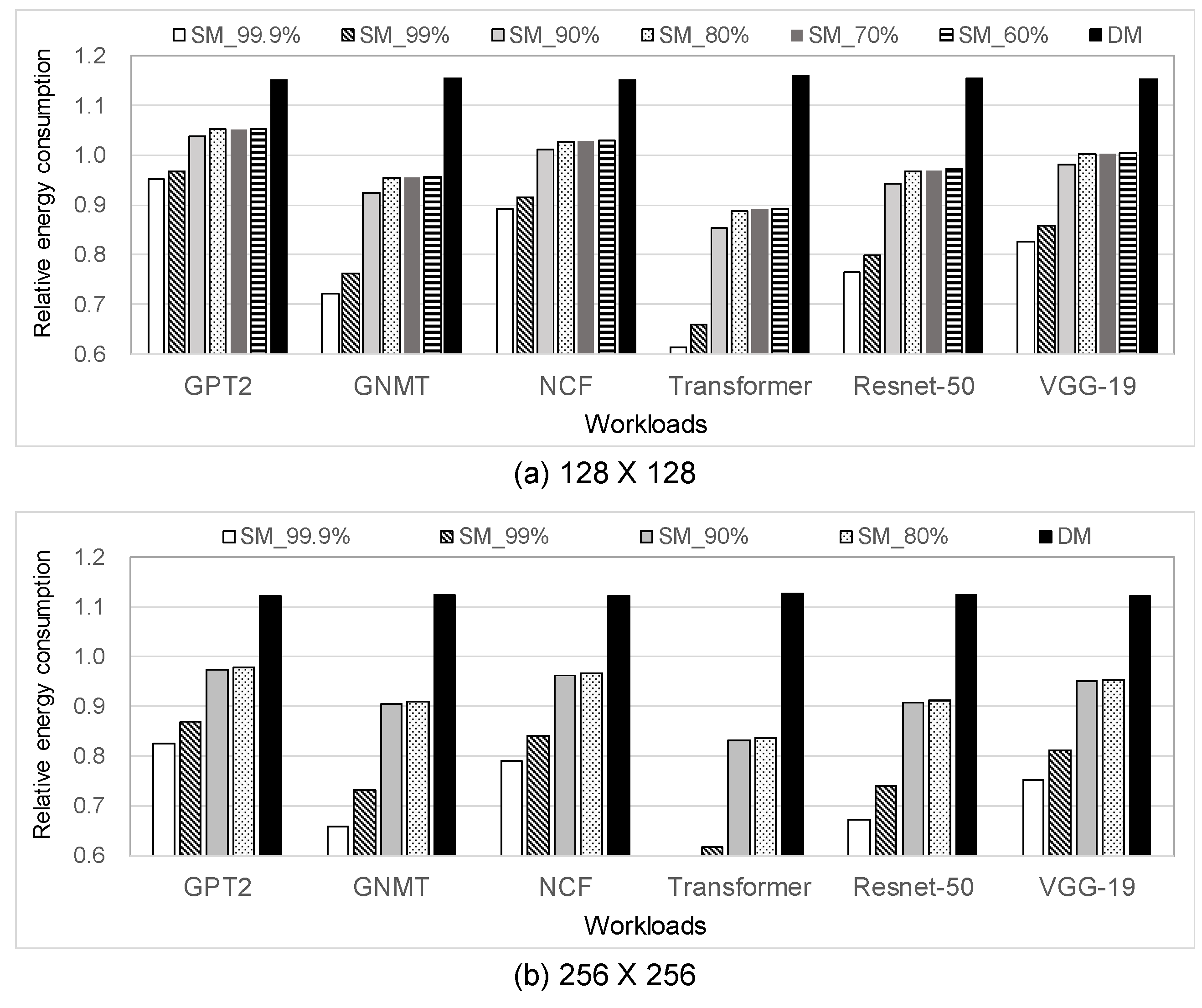
5.3. Energy
6. Discussion
6.1. Hardware Overhead
6.2. Software Overhead
6.3. Limitations of This Work
- In the evaluation results, we only considered the hardware execution time. Though the software execution time overhead could be marginal, as mentioned in Section 6.2, it would also be desirable for evaluating end-to-end performance;
- Since the main contribution of this paper is to design VerSA architecture, our evaluation is based on cycle-level simulation and logic synthesis results. A verification and evaluation with full system implementation and software supports (e.g., an implementation in field programmable gate arrays) would also be interesting;
- As presented in Section 5.2 and Section 5.3, our hardware architecture has inevitable performance and energy overheads when performing dense MM when compared to the conventional SA. This is an inherent limitation that arises from the VerSA architecture design. However, considering that the contemporary DNN models have non-negligible sparsity, our VerSA can sufficiently compensate for the performance and energy overheads of the dense MM.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-Datacenter Performance Analysis of a Tensor Processing Unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture, Toronto, ON, Canada, 24–28 June 2017; pp. 1–12. [Google Scholar] [CrossRef]
- Jouppi, N.P.; Hyun Yoon, D.; Ashcraft, M.; Gottscho, M.; Jablin, T.B.; Kurian, G.; Laudon, J.; Li, S.; Ma, P.; Ma, X.; et al. Ten Lessons From Three Generations Shaped Google’s TPUv4i: Industrial Product. In Proceedings of the 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 14–18 June 2021; pp. 1–14. [Google Scholar] [CrossRef]
- Jouppi, N.; Kurian, G.; Li, S.; Ma, P.; Nagarajan, R.; Nai, L.; Patil, N.; Subramanian, S.; Swing, A.; Towles, B.; et al. TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings. In Proceedings of the 50th Annual International Symposium on Computer Architecture, Orlando, FL, USA, 17–21 June 2023. [Google Scholar] [CrossRef]
- Pal, S.; Beaumont, J.; Park, D.H.; Amarnath, A.; Feng, S.; Chakrabarti, C.; Kim, H.S.; Blaauw, D.; Mudge, T.; Dreslinski, R. OuterSPACE: An Outer Product Based Sparse Matrix Multiplication Accelerator. In Proceedings of the 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA), Vienna, Austria, 24–28 February 2018; pp. 724–736. [Google Scholar] [CrossRef]
- Gondimalla, A.; Chesnut, N.; Thottethodi, M.; Vijaykumar, T.N. SparTen: A Sparse Tensor Accelerator for Convolutional Neural Networks. In Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, Columbus, OH, USA, 12–16 October 2019; pp. 151–165. [Google Scholar] [CrossRef]
- Qin, E.; Samajdar, A.; Kwon, H.; Nadella, V.; Srinivasan, S.; Das, D.; Kaul, B.; Krishna, T. SIGMA: A Sparse and Irregular GEMM Accelerator with Flexible Interconnects for DNN Training. In Proceedings of the 2020 IEEE International Symposium on High Performance Computer Architecture (HPCA), San Diego, CA, USA, 22–26 February 2020; pp. 58–70. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, H.; Han, S.; Dally, W.J. SpArch: Efficient Architecture for Sparse Matrix Multiplication. In Proceedings of the 2020 IEEE International Symposium on High Performance Computer Architecture (HPCA), San Diego, CA, USA, 22–26 February 2020; pp. 261–274. [Google Scholar] [CrossRef]
- Hojabr, R.; Sedaghati, A.; Sharifian, A.; Khonsari, A.; Shriraman, A. SPAGHETTI: Streaming Accelerators for Highly Sparse GEMM on FPGAs. In Proceedings of the 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Seoul, Republic of Korea, 27 February–3 March 2021; pp. 84–96. [Google Scholar] [CrossRef]
- Srivastava, N.; Jin, H.; Liu, J.; Albonesi, D.; Zhang, Z. MatRaptor: A Sparse-Sparse Matrix Multiplication Accelerator Based on Row-Wise Product. In Proceedings of the 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Athens, Greece, 17–21 October 2020; pp. 766–780. [Google Scholar] [CrossRef]
- Zhang, G.; Attaluri, N.; Emer, J.S.; Sanchez, D. Gamma: Leveraging Gustavson’s Algorithm to Accelerate Sparse Matrix Multiplication. In Proceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Virtual, 19–23 April 2021; pp. 687–701. [Google Scholar] [CrossRef]
- Kwon, J.; Kong, J.; Munir, A. Sparse convolutional neural network acceleration with lossless input feature map compression for resource-constrained systems. IET Comput. Digit. Technol. 2022, 16, 29–43. [Google Scholar] [CrossRef]
- Lee, J.H.; Park, B.; Kong, J.; Munir, A. Row-Wise Product-Based Sparse Matrix Multiplication Hardware Accelerator With Optimal Load Balancing. IEEE Access 2022, 10, 64547–64559. [Google Scholar] [CrossRef]
- Li, S.; Huai, S.; Liu, W. An Efficient Gustavson-Based Sparse Matrix–Matrix Multiplication Accelerator on Embedded FPGAs. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2023, 42, 4671–4680. [Google Scholar] [CrossRef]
- Li, Z.; Li, J.; Chen, T.; Niu, D.; Zheng, H.; Xie, Y.; Gao, M. Spada: Accelerating Sparse Matrix Multiplication with Adaptive Dataflow. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vancouver, BC, Canada, 25–29 March 2023; pp. 747–761. [Google Scholar] [CrossRef]
- Muñoz Martínez, F.; Garg, R.; Pellauer, M.; Abellán, J.L.; Acacio, M.E.; Krishna, T. Flexagon: A Multi-dataflow Sparse-Sparse Matrix Multiplication Accelerator for Efficient DNN Processing. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vancouver, BC, Canada, 25–29 March 2023; pp. 252–265. [Google Scholar] [CrossRef]
- Sze, V.; Chen, Y.H.; Yang, T.J.; Emer, J.S. Efficient Processing of Deep Neural Networks: A Tutorial and Survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]
- Samajdar, A.; Joseph, J.M.; Zhu, Y.; Whatmough, P.; Mattina, M.; Krishna, T. A systematic methodology for characterizing scalability of DNN accelerators using SCALE-sim. In Proceedings of the 2020 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Boston, MA, USA, 23–25 August 2020; pp. 58–68. [Google Scholar] [CrossRef]
- Balasubramonian, R.; Kahng, A.B.; Muralimanohar, N.; Shafiee, A.; Srinivas, V. CACTI 7: New Tools for Interconnect Exploration in Innovative Off-Chip Memories. ACM Trans. Archit. Code Optim. 2017, 14, 1–25. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Network with Pruning, Trained Quantization and Huffman Coding. In Proceedings of the 4th International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI 2019, 1, 9. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar] [CrossRef]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural Collaborative Filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Davis, T.A.; Hu, Y. The university of Florida sparse matrix collection. ACM Trans. Math. Softw. 2011, 38, 1–25. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Notation Used in the Paper |
|---|---|
| Total number of rows in the SA | |
| The number of rows in a single subarray | |
| The number of subarrays in the SA | |
| The number of IPBs | = − 1 |
| Array Size | Clock Frequency | Design Area (mm2) | Power (W) | ||
|---|---|---|---|---|---|
| Conv_SA | 128 × 128 | N/A | 250 MHz | 19.2346 | 1.4145 |
| VerSA | 8 | 22.0997 | 1.6184 | ||
| Conv_SA | 256 × 256 | N/A | 76.9042 | 5.6125 | |
| VerSA | 8 | 86.6091 | 6.2699 |
| Matrix | Dimension | Sparsity | 128 × 128 Speedup | 256 × 256 Speedup |
|---|---|---|---|---|
| web-Google | 916 k × 916 k | 99.9994% | 0.020 | 0.071 |
| mario002 | 390 k × 390 k | 99.9986% | 0.126 | 0.449 |
| amazon0312 | 401 k × 401 k | 99.9981% | 0.172 | 0.614 |
| m133-b2 | 200 k × 200 k | 99.9980% | 0.154 | 0.552 |
| cage12 | 130 k × 130 k | 99.9883% | 3.486 | 12.446 |
| 2cubes-sphere | 101 k × 101 k | 99.9843% | 5.858 | 20.908 |
| filter3D | 106 k × 106 k | 99.9766% | 9.935 | 35.460 |
| ca-CondMat | 23 k × 23 k | 99.9656% | 23.553 | 83.665 |
| wikiVote | 8.3 k × 8.3 k | 99.8529% | 206.464 | 694.082 |
| poisson3Da | 14 k × 14 k | 99.8179% | 284.415 | 1,005.949 |
| 4 k × 4 k | 98.9331% | 10,692.458 | 36,502.207 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seo, J.; Kong, J. VerSA: Versatile Systolic Array Architecture for Sparse and Dense Matrix Multiplications. Electronics 2024, 13, 1500. https://doi.org/10.3390/electronics13081500
Seo J, Kong J. VerSA: Versatile Systolic Array Architecture for Sparse and Dense Matrix Multiplications. Electronics. 2024; 13(8):1500. https://doi.org/10.3390/electronics13081500
Chicago/Turabian StyleSeo, Juwon, and Joonho Kong. 2024. "VerSA: Versatile Systolic Array Architecture for Sparse and Dense Matrix Multiplications" Electronics 13, no. 8: 1500. https://doi.org/10.3390/electronics13081500
APA StyleSeo, J., & Kong, J. (2024). VerSA: Versatile Systolic Array Architecture for Sparse and Dense Matrix Multiplications. Electronics, 13(8), 1500. https://doi.org/10.3390/electronics13081500