1. Introduction
Tensor network algorithms [
1,
2,
3,
4,
5,
6] have been successfully employed to study the phase diagram of quantum and classical statistical models, in particular for two–dimensional systems. These algorithms are especially valuable for systems to which Monte Carlo methods are not efficient, for example, due to sign problems. This includes QCD models, but also quantum gravity models such as spin foams [
7,
8,
9,
10], which are based on complex (not Wick rotated) amplitudes. Similarly anyon systems [
11] can feature complex amplitudes.
In this work we present a tensor network renormalization algorithm applicable to three–dimensional lattice gauge systems, three-dimensional quantum gravity models [
12], as well as the study of anyon condensation.
As opposed to previous work [
5,
13,
14,
15,
16] on coarse-graining algorithms for 3D lattice gauge systems, here we introduce several new features. For more context see e.g., References [
13,
17] and the review [
16] for applications of tensor networks in the Hamiltonian descriptions of
–dimensional lattice gauge systems, and e.g., References [
10,
18,
19,
20,
21] and the review [
16] and references therein for studies of
–dimensional systems with gauge symmetry.
First, instead of working with finite groups or cut-offs of Lie groups, we work with a quantum deformation of
known as
. This allows us to work with finite systems with exact gauge symmetry, while at the same time allowing for a systematic approximation to the undeformed case
, which is reached for
. See References [
22,
23,
24] for a similar strategy employed for two–dimensional systems. In this work we test the new algorithm for three–dimensional lattice gauge systems with
symmetry and extract the critical couplings for different levels
. Although in this work we perform simulations only for systems with relatively small
, these initial investigations indicate that the critical couplings approach zero for growing
in a surprisingly fast way.
Second, the tensor network algorithm presented here employs a new (gauge invariant) basis, the fusion basis, which is ideally suited for coarse-graining [
25,
26]. The reason for this is that a fusion basis diagonalizes observables (the ribbon operators) which are only quasi-local, that is, associated to a set of regions. This set is partially ordered by the inclusion relation, which on the lattice translates into a coarse-graining scheme for the plaquettes of the lattice. Different choices for the fusion basis lead to different coarse-graining schemes.
This brings as to the third new feature: transformations between different such choices for the fusion basis will be an important part of the algorithm presented herein. These transformations reorganize the regions into which the finer degrees of freedom are blocked, and thus can be seen to function as disentanglers [
27,
28,
29]. In contrast to References [
27,
28], where the disentanglers are adjusted in each coarse-graining step through a minimization procedure, here we have pre-defined disentanglers, determined by the structure of the fusion basis.
Additionally, the use of the decorated tensor network algorithm combined with the fusion basis allows us to keep track of the coarse-graining behaviour of ribbon observables. These combine Wilson loops, which measure the magnetic flux through the region surrounded by the loop, and ‘t Hooft operators, which integrate over the electric flux through the loop, and thus are measuring the electric charge in the region surrounded by the loop. We will refer to this magnetic flux also as magnetic charge. The reason is that we will use a description which unifies magnetic flux and electric charge into a so-called dyonic charge, and we will refer to both magnetic and electric components as charge. For lattice gauge theories the Wilson loops serve as order parameters, whereas, as we will explain in more detail in the course of this paper, the electric loops allow us to monitor the appearance of electrical charges under coarse-graining.
The development of tensor network coarse-graining algorithms for three-dimensional gauge systems faces several challenges. These algorithms are much more computationally demanding for three-dimensional systems as opposed to two-dimensional systems. Therefore, for systems with gauge symmetries it is important to design algorithms which only include the gauge invariant, and therefore physical, degrees of freedom. However, these gauge invariant degrees of freedom cannot be localized to (lattice) sites, as is the case for systems described by standard tensor networks. Reference [
5], co-written by two of the current authors, introduced a generalization of tensor networks called decorated tensor networks. This generalization permits the definition of (decorated) tensor network coarse-graining algorithms for Abelian [
5] and non-Abelian [
14] lattice gauge theories and finite group analogues [
8] of 3D spin foam partition functions [
14], which were successfully tested for systems with finite gauge groups. These algorithms were based on the spin network basis, which provides a basis for the gauge invariant degrees of freedom for a lattice gauge system. Violations of gauge invariance, according to the Gauß law, lead to electrical charges. Yet, for non-Abelian gauge theories, finite regions can feature electrical charge without featuring a violation of gauge invariance. For non-Abelian lattice gauge systems we can have gauge invariance violations appearing under coarse-graining, although the initial systems are gauge invariant. Thus, the (gauge invariant) spin network basis is not closed under coarse-graining, and one is forced to truncate these electrical charges which appear without being able to check their relevance for the dynamics of the system.
In contrast, the fusion basis allows for the inclusion, but also systematic suppression, of electric charges, both on lattice scale as well as on coarser scales. This allows us to test different truncation schemes: (a) one where electric charges are allowed on lattice as well as on coarser scales, (b) one where electric charges are truncated at the lattice scale, and (c) one where electric charges are suppressed both at the lattice scale and at coarser scales. We show that the truncation (b) is justified (for the dynamics of Yang-Mills type lattice gauge systems we consider in this work), whereas (c) allows for the extraction of critical couplings but interferes considerably with the functioning of the fusion basis transformations as disentanglers, that is, short-scale entanglement filters. Indeed, suppressing electric charges at coarser scales does lead to truncations for the fusion basis transformations.
The possibility to either include or suppress the electrical charges in a scale-dependent manner is a main advantage of the fusion basis over the spin network basis. Additionally, as mentioned above, the fusion basis based algorithm does allows us to monitor the magnetic and electric charge observables, which provide order parameters for studying lattice gauge theories. As a proof of principle, we investigate this case in this work for lattice gauge theories defined for the quantum group
, which should approach the continuous group
in the limit
. Moreover a translation of this algorithm to lattice gauge theories with finite Abelian groups is straightforwardly possible. Another interesting example to study the presented algorithm for the quantum group
is 3D quantum gravity with non-vanishing cosmological constant [
30]: the level
of the quantum group is related to the value of the cosmological constant
. As
increases, the cosmological constant decreases. The question is whether one can define an effective theory that corresponds to a cosmological constant larger than the one specified by the level
, as well as study transitions between these theories [
12]. The idea is that such an effective theory would arise as a “condensation” of curvature defects (with respect the vacuum at level
). In a similar vein, we would like to apply this algorithm to anyon condensation.
The paper is organized as follows—we start with a very short review of tensor network renormalization algorithms and discuss the challenges of dealing with gauge systems in
Section 2. We continue by providing the necessary background on the fusion basis in
Section 3.
Section 4 gives both an overview as well as details of the new tensor network coarse-graining algorithm. We then apply this algorithm to lattice gauge theory with a quantum deformed structure group
in
Section 5. This includes the construction of the initial amplitudes, a description of the range of models, as well as a description of various versions of the algorithm, which either truncate or keep electric charge excitations (i.e., torsion degrees of freedom). We also discuss numerical costs and the measures we take to decrease these costs. We then describe the results of applying the various versions of the algorithms to the lattice gauge theory models. This allows us to draw first conclusions of the behaviour of the critical Yang-Mills coupling with growing level
. Furthermore, we can compare the different versions of the algorithms and thus learn whether we can truncate the electric charge excitations without affecting results. Lastly, we discuss the expectation values of (Wilson loop) observables, which can be tracked with the coarse-graining algorithm. We conclude with a discussion in
Section 6.
Appendix A and
Appendix B include the necessary background on
, as well as the definitions and proofs used for the fusion basis.
2. Tensor Network Algorithms for Lattice Gauge Theories
We are interested in approximating partition functions for physical systems in an iterative way, that is, via coarse-graining procedures. One way to proceed is to rewrite a given partition function as a contraction of a tensor network, and then to use tensor network renormalization algorithms [
1,
2,
3,
4]. However, we will advertise a generalization of tensor networks which can handle gauge systems, for instance, in a more effective way [
5,
14]. We consider physical systems, whose partition function can be understood as a gluing of amplitudes associated with building blocks. More precisely, the building blocks come with a boundary Hilbert space, and the amplitude is a functional on this boundary Hilbert space. Assuming the boundary Hilbert space admits a basis
, where
label localized or quasi-localized degrees of freedom, the amplitude is given by a function
of the labels.
Partition functions given via the contraction of a tensor network can be understood easily in this language. Consider a cubical 3D tensor network whose edges
e are labelled by indices
and whose vertices
v carry rank-six tensors
. We can define basic cubic building blocks, which each include one vertex. Each side of the elementary cubes is punctured in the middle by one edge of the network. We associate with a basic building block a boundary Hilbert space
, where
s labels the six sites (situated where the tensor network edges puncture the boundary of the building block), and the dimension of the site Hilbert space
is given by the cardinality
I of the index set
I. The site Hilbert space
can be interpreted as a space carrying the degrees of freedom associated to the site
s, which is considered completely localized. By introducing an abstract basis
in
, and by numbering the sites by
, the amplitude encoded in the tensor network is given by
. In this way, we rewrite the partition function of the system by assigning an amplitude
to each building block, identifying the shared variables and summing over them—a contraction of a tensor network:
This process of identifying and summing over shared variables can also be understood as gluing of two neighbouring building blocks, see
Figure 1. The edge of the tensor network shared between the two tensors indicates that one sums over the respective index, that is, one contracts the respective indices of both tensors. In terms of the amplitudes, we identify the basis elements (i.e., the indices) of the site Hilbert spaces that are matched to each other, and then sum them.
The resulting building block comes with a larger boundary Hilbert space given by a tensor product over ten sites.
Further iterations of the gluing procedure lead to an exponential growth of the boundary Hilbert spaces. Hence, one needs to find a way to truncate the least relevant degrees of freedom in the partition function such that the remainder fits in a boundary Hilbert space of the original (or alternatively a pre-defined) size with the same localization structure as before. This allows one to iterate the gluing and truncation procedure alternatively while keeping the size of the boundary Hilbert space finite. In this way, we can compute (approximately) the partition function depending on coarse-grained boundary data. The precise form and physical interpretation of these data depends on the truncation procedure.
We have seen that partition functions arising from tensor networks lead to a description in terms of degrees of freedom localized at sites. Yet, gauge systems might not allow for such a localization of their physical, that is, gauge invariant degrees of freedom [
31,
32,
33,
34,
35]. A complete localization (or tensor network description) in these cases can be obtained only if one introduces unphysical gauge degrees of freedom, which in a tensor network description corresponds to auxiliary tensors and degrees of freedom, see Reference [
5]. However, the introduction of auxiliary structures makes the tensor network methods much more expensive to calculate numerically, both in terms of memory and runtime.
The two basic steps in tensor network algorithms, namely, gluing and truncation, can be generalized if we consider boundary Hilbert spaces of a more general structure than the one arising from tensor networks. An example of such generalized structures which deal with lattice gauge theories are the decorated tensor networks [
5]. These encode systems with boundary Hilbert spaces of more general structures than the completely localized Hilbert space
described above.
To be more explicit, let us consider a lattice gauge theory with (finite or compact) structure group
G. The partition function for a lattice gauge theory on a cubical lattice can be rewritten as a gluing between amplitudes associated with the basic cubical building blocks, see References [
5,
9,
14]. There are different ways to cut the spacetime lattice into building blocks, and there are also two different choices for the kind of boundary Hilbert space. The first kind is supporting gauge variant amplitudes and, therefore, unphysical gauge degrees of freedom, and it is given by
, where
l denotes a link of a network
on the boundary and
is the Hilbert space of square integrable functions on the group. We will suppose links coincide with the edges of the building blocks, but other choices are possible. Thus, we can localize the degrees of freedom in this Hilbert space to the links of the network.
This boundary Hilbert space permits us to assign variables locally to building blocks, such that we can cast the partition function into tensor network form. However, this Hilbert space encodes all gauge variant information and is thus unnecessarily large for gauge invariant amplitudes. Building a coarse-graining algorithm for this gauge variant representation is less efficient, as the summations do include non-physical degrees of freedom, which thus lead to larger (effective) bond dimension. See for instance Reference [
5], which works with a gauge invariant representation vs. Reference [
36], which works with a gauge covariant representation. The gauge invariant Hilbert space is a subspace of the gauge variant Hilbert space, but it cannot be written in the form of a tensor product over localized degrees of freedom. Thus one trades redundancy for non-locality when going from the gauge variant to the gauge invariant Hilbert space. This applies to non-Abelian groups. We will see that it is possible modulo a global constraint for
-dimensional Abelian gauge systems.
To express the amplitude and to define the coarse-graining algorithm, we need a basis in this gauge invariant Hilbert space. Such a basis can be characterized by the set of commuting gauge invariant operators which is diagonalized by the basis. These operators also determine how localized the degrees of freedom described by the basis are. A candidate for the set of commuting operators are closed Wilson loops. However, for non-Abelian groups, the set of Wilson loops around the basic plaquettes are insufficient to determine a state. On the other hand, if one considers the set of all possible Wilson loops, there are complicated relations known as Mandelstam identities which have to be imposed [
37]. This makes an explicit construction of a basis difficult. In fact, we will see that in
dimensions the fusion basis does provide the diagonalization of a certain subset of Wilson loop operators, but it also includes ‘t Hooft operators measuring the electric charges.
The spin network basis [
38] is gauge invariant, and it provides a diagonalization of gauge invariant combinations of electric flux operators. A coarse-graining algorithm based on the spin network basis was developed in Reference [
5] for Abelian groups and in Reference [
14] for non-Abelian groups. The spin network basis is, however, not stable under coarse-graining—as we will discuss below, coarse-graining can lead to non-vanishing electric charges appearing as gauge invariance violations [
14,
39]. This can be dealt with by projecting to zero electric charge after each coarse-graining step [
14], but this assumes that the corresponding degrees of freedom are not relevant at larger scales. See also Reference [
40] for suggestions on how to extend the spin network basis to capture these additional degrees of freedom.
A further issue with the spin network basis is the following: after gluing two building blocks, the resulting spin network needs to be transformed into a different spin network better suited for the truncation step; see Reference [
14] for the detailed algorithm. The reason is that the choice of graph on which the spin network is defined determines the localization of the degrees of freedom, and for the coarse-graining one wishes to localize the fine-grained degrees of freedom in a certain way. The relation between the transformation and the corresponding rearrangement of the localization of degrees of freedom is not very transparent in the case of the spin network basis: it subsequently requires a transformation to a holonomy basis and back [
14]. Both issues are resolved with the fusion basis. Later we will show its structure is ideally suited for coarse-graining purposes, and that it is also applicable to systems with quantum deformed structure groups, which we employ in this work.
3. Fusion Basis in a Nutshell
The fusion basis arises in
-dimensional anyon systems [
41,
42], but it can be also constructed for
-dimensional lattice gauge theories [
26], as well as for
-dimensional gravity [
12,
25]. The associated algebraic structures, the so-called
Drinfeld Doubles, have been discussed for various physics applications [
25,
26,
43,
44,
45,
46].
In lattice gauge theory, the fusion basis provides gauge invariant states that diagonalize the set of Wilson loop operators around the lattice plaquettes. However, for non-Abelian gauge theories this set of Wilson loop operators does not provide a maximal set of commuting observables. Adding all possible Wilson loops, that is, also loops around arbitrary clusters of plaquettes, one does encounter complicated dependencies between the Wilson loop operators called Mandelstam identities. This leads to the quite involved task of constructing an independent set of (Wilson loop) observables [
37].
In
-dimensions this problem is solved by the fusion basis. The basis is most easily characterized by describing the maximal set of commuting observables, which diagonalize the basis. In the case of the fusion basis these observables are known as closed ribbon operators [
26,
42,
44,
46]. The closed ribbon operators are based on a closed path, or loop, and can be understood to measure the magnetic and electric charge contained in the region enclosed by the loop. Here we only consider non-intersecting loops. See References [
47,
48] for a discussion of the
-dimensional case with classical structure groups and Reference [
49] for the case with a quantum deformed structure group
.
In the case of lattice gauge theory with a (not quantum deformed) structure group this ribbon operator includes a Wilson loop operator, which measures the magnetic charge, and a ‘t Hooft operator which integrates the electric flux along the loop, which measures the electric charge; see Reference [
26] for a detailed description. In the case of a quantum deformed structure group such as
, the magnetic Wilson loop and the electric ‘t Hooft observables are encoded into two connection variables. These connections are non-commutative, and thus force the introduction of the notion of Wilson lines over- or under-crossing each other. The pair of connections lead to two classes of loop and open line operators, namely those which under-cross or over-cross the networks which characterize a given state. The closed ribbon operators are then given by a parallel pair of an under-crossing and an over-crossing loop operator.
Ribbon operators which cross each other generally do not commute. Hence, the fusion basis is characterized by a set of non-crossing, and therefore commuting, closed ribbon operators. Restricted to a surface with spherical topology, this set consists of ribbon operators associated with the following sets of loops: (a) those around the basic plaquettes of the lattice, and (b) those around coarse-grained plaquettes defined by the fusion procedure. Each basic step involves only the coarse-graining of two (possibly already coarse-grained) plaquettes. The second set of loops is given by those around all the coarse-grained or fused plaquettes, which arise in this manner. Note that the loops should not cross over each other.
Figure 2 gives an example for a set of loops constructed in this manner, as well as the encoding of this set into a three-valent (fusion) tree. To construct the tree, we map the basic plaquettes of the lattice to the leaves of the tree, and to each fusion of two (possibly already fused) plaquettes we associate a branch of the tree. We also choose orientations for the leaves and branches of the tree—these encode an orientation for corresponding ribbon loop operator, and in our case a choice of phase factors for the basis states. See References [
26,
41,
48] on how to generalize the basis for non-trivial topologies.
The fusion tree can describe more general structures than (regular) lattices. In the context of (extended) topological quantum field theory, one introduces so-called defect excitations by allowing topology-changing punctures in the underlying spatial manifold [
25,
41,
50]. The fusion basis provides a basis of states on such manifolds with punctures. The leaves of the fusion tree are identified with the punctures. The fusion basis diagonalizes the ribbon operators which go around single punctures as well as the operators encircling certain clusters of punctures, as encoded in the fusion tree. Thus, the basic plaquettes can be identified with punctures; see Reference [
26,
42] for constructions of explicit mappings. Hereafter, we use the terms plaquettes and punctures interchangeably.
Next, we specify the data associated with the fusion tree. These data encode the eigenvalues of the ribbon operators. As each branch of the tree is associated with an operator, each branch carries a label. These labels are given by objects in a certain fusion category—for a finite group this is the (fusion) category of representations of the Drinfeld Double of the group. For
this is the Drinfeld centre (also referred to as Drinfeld Double) of the fusion category of representations of
. (See
Appendix A for some essential basics on
.).
In physical terms, the objects in this fusion category describe the electric and magnetic charges measured by the ribbon operators. The fusion of two charges
, that is, the set of resulting charges, is described by the so-called fusion product of the corresponding objects
where
labels the charges in the fusion product.
are the fusion coefficients, which we assume to be zero or one; otherwise, we would have further degeneracy labels at the vertices of the fusion tree. Thus, we have at each vertex of the fusion tree a condition on the labels of the three adjacent branches, namely that the associated fusion coefficient should be non-vanishing,
. In this way, the labelled fusion tree encodes the closed ribbon operators which are diagonalized by the fusion basis, along with the eigenvalues of these ribbon operators.
In general, the fusion basis also describes non-gauge invariant states. The violation of gauge invariance is equivalent to the violation of the Gauß constraint and, therefore, the presence of electric charges at the plaquettes. To locate these electric charges in the middle of the plaquettes one can imagine that, for example, on a square lattice one has an open link that starts in one corner of the given plaquette and ends in the middle of the plaquette.
For such non-gauge invariant states we need to specify one additional piece of information, which is only attached to the endpoint of the leaves of the tree. For a given leaf l this is a ‘tail’ label , which denotes a basis element in the irreducible representation of the Drinfeld Double associated with the leaf. The tail labels are necessary to specify the action of open ribbon operators, which start and end at the mid-point of the plaquettes, and are in general not gauge invariant (at their endpoints).
In this work, we consider only the initial amplitudes which are gauge invariant. As we will discuss later, coarse-graining can lead to the emergence of electric charges, which would make the tail labels necessary. However, we will define a truncation in which the amplitudes have a trivial dependence on the tail labels. This allows us to neglect the tail indices in our coarse-graining algorithm, in turn leading to a significant reduction in the numerical costs of the algorithm.
To construct a fusion basis, we have to choose a fusion scheme for the plaquettes of the lattice. Different choices for this fusion scheme lead to different fusion trees and associated fusion bases. Two fusion trees can be transformed into each other via a set of basic transformation steps. Here we will need the so-called F-move,
and a transformation that we will refer to as R-move:
Note that for
the recoupling symbols
and
do not depend on the orientations of the leaves and branches. The reader can find the definitions for
and
in
Appendix B.
With a choice of fusion basis for a given building block, that is, for the associated boundary Hilbert space, we can express the amplitude associated with this building block. We can understand the amplitude as defining a state
in the boundary Hilbert space. This allows us to make the choice of fusion basis explicit: for a cubical building block with six plaquettes, we write
Here
is the amplitude associated with the building block,
are the (Drinfeld Double) representations attached to the leaves
l, and
are the (Drinfeld Double) representations attached to the branches
b. (As mentioned previously, we assume a trivial dependence on the tail indices
; therefore, we drop these indices all together.) The notation makes it obvious how the amplitudes change under a change of fusion basis. Under an F–move, we have
Remembering that the fusion tree encodes a fusion ordering for the plaquettes, we can interpret this transformation as a change of how we coarse-grain, and accordingly we can organize the degrees of freedom of the system. In fact, these F-move transformations can be seen as (dis-)entanglers [
51,
52].
In the following, we will briefly review three classes of examples—Abelian structure groups, non-Abelian structure groups, and finally the quantum deformed structure group , which we employ later in this paper.
Abelian structure group: We consider a -dimensional lattice gauge theory with finite Abelian group . As mentioned above, the ribbon operator includes a Wilson loop whose possible eigenvalues are labeled by the conjugacy classes of the structure group, that is, by . This Wilson loop measures the magnetic flux through the region surrounded by the loop, which represents the curvature of the lattice connection. The other part of the ribbon operator is given by a product of group translation operators that act on the lattice links which are crossed by the ribbon. For non-Abelian groups these translation operators need to be parallel transported, via an adjoint action, to a common reference system. This is not necessary for Abelian groups. These translation operators measure the electric charge (or the violation of the Gauß constraint). The resulting eigenvalues are again labeled by . Technically, we would have the Poincare dual of , which is . Correspondingly, the irreducible representations of the Drinfeld Double of are labeled by and are one-dimensional. Thus, tail labels do not appear for Abelian structure groups.
For an Abelian structure group, both the magnetic and electric charges satisfy very simple fusion rules. With
the fusion rules are given by
where
if
and is vanishing in all other cases.
Thus, the measurement results of coarser ribbon operators are completely determined by the measurement results of the ribbon operators around the basic plaquettes. For a spherical topology we actually need all but one of these plaquettes. It follows that the labels of the fusion tree are entirely determined by the labels associated with the leaves. We can restrict to gauge invariant states, that is, states for which the basic electrical charges associated with the plaquettes are trivial. In the Abelian case, the electrical charges associated with coarser regions are then also trivial.
Non-Abelian structure group—The situation is more involved for finite non-Abelian groups; see Reference [
26] for a detailed construction of the fusion basis and ribbon operators and Reference [
53] for a construction of the Drinfeld double representations for
. The irreducible representations of the Drinfeld Double are labelled by
where
C denotes a conjugacy class of the group and
R an irreducible representation of the stabilizer of (one of the representatives of) the conjugacy class
C. The dimension of a representation
is given by
, where
C denotes the number of group elements in
C.
The fusion rules are now more intricate—the fusion rule for the magnetic part can be deduced from the interpretation of the Wilson loop. A loop around two plaquettes with conjugacy classes and respectively, can yield all conjugacy classes of representatives of the form , where and . Thus, specifying the measurements of coarser Wilson loops provides extra information in addition to the measurements of Wilson loops around the basic plaquettes. But, we also see that if the magnetic charges around the basic plaquettes are all trivial (i.e., the conjugacy classes are given by the identity element), this will also hold for the magnetic charges associated with coarser regions.
The situation is different for the electric charge—having vanishing electric charges for the basic plaquettes (but non-vanishing magnetic charges) does not exclude non-vanishing electric charges for the coarser plaquettes. These “Cheshire charges” [
43] signify a non-trivial interaction between the magnetic and electric parts of the Drinfeld Double. It can be explained by the fact that the part of the operator which measures the electric charge involves parallel transport [
54]. In the presence of curvature (i.e., magnetic charge) the parallel transport is non-trivial and can induce an electric charge. This is an issue for coarse-graining, as one a priori needs to keep track of the electric charges, even if one starts with a gauge invariant state, that is, a state without electric charges associated with the basic plaquettes. The fusion basis provides us with such a tracking device, whereas the spin network basis is not naturally suited for this task.
Structure group —Later in this paper we work with a more abstract generalization of groups and Drinfeld Doubles of groups. Specifically, we use a quantum deformation of
, with the deformation parameter a root of unity
[
55,
56]. See
Appendix A for some basic details, and Reference [
25] for an extensive exposition, which discusses in particular the various ribbon operators and their lattice gauge theoretic interpretations.
The origin of the deformation can be understood in the following way—the Hilbert space
, which underlies lattice gauge theory, can be obtained as a quantization of the phase space
, which has a compact configuration space
, but comes with a flat non-compact momentum space
. A quantum deformation at a root of unity leads to a replacement of
with
; see Reference [
57]. Thus, both the configuration space and momentum space are now compact and curved. Therefore, the ribbon operators, which provide both configuration space and momentum space information, have discrete and bounded spectra.
The ribbon operator eigenvalues, that is, the charges measured by the ribbon operators, are described by the Drinfeld Double of , which is given by . The bar above the second factor indicates that this copy of comes with a complex conjugated braiding structure, as opposed to the first factor.
The fusion rules for the Drinfeld Double of
are indeed given by “doubling” those of the fusion category
. The fusion category
has irreducible objects (i.e., irreducible representations or charges) labelled by half integers
. The fusion rules can be seen as a deformation of the
rules, so that only representations
appear:
The sum uses integer steps, so the coupling condition holds. In addition to the usual –coupling rule , the quantum deformation leads to the coupling condition .
We denote the irreducible representations of the Drinfeld Double by
. The fusion rule for the double are given by
Furthermore, we have non-trivial tail labels s, which for a leaf with label can take values in . In other words, the tail carries a representation label which arises from the fusion product of j and .
The interpretation of the Drinfeld Double representation labels in term of charges is the following—the sum specifies the magnetic charge, whereas the difference characterizes the electric charge. States with vanishing electric charges for the basic plaquettes carry labels at their fusion tree leaves, and they have an associated tail label . However, the fusion of two charges and can lead to a charge with and, therefore, to the “Cheshire charge” phenomenon as we saw with the non-Abelian group.
In this paper, we use gauge invariant amplitudes, which are only non–vanishing for leaf labels and tail index . The coarse-graining procedure leads to non-trivial electric charges at the leaves. As mentioned above, we will use a truncation that assumes a trivial dependence on the tail indices. Thus, we will omit the tail indices hereafter.
4. The Coarse-Graining Algorithm
4.1. Sketch of the Algorithm
The first basic piece in a coarse-graining algorithm is the iterative gluing of smaller building blocks into larger ones. The gluing process implements a summation over the variables and, thus, amounts to evaluating the partition function of the system. The larger building blocks which arise from the gluing carry increasing amounts of data. The second essential piece is, therefore, a truncation of these data, or in other words, a coarse-graining process. For the gluing and truncation we must specify the following:
Gluing—Given our cubical building blocks each with six sides (hence, six plaquettes), we must specify a basis in the boundary Hilbert space in which to express the amplitudes. We then have to determine how to glue. That is, in identifying two faces of opposite cubes we need to specify which basis labels on these two cubes we need to identify with each other, and over which (identified) labels we need to sum. This defines the amplitude of the new building block, expressed in a specific basis, which is also determined by the gluing process. As this basis is associated with a building block with now ten plaquettes, it carries more data than the initial basis for the building blocks with six plaquettes.
Transformation of the fusion basis—The basis for the ten-plaquette state, which arises from the gluing, is not well-suited for the truncation step. The reason is that this basis does not diagonalize the ribbon operators around the pairs of plaquettes, which we want to coarse-grain into effective plaquettes. Therefore, we apply basis transformations, that is, unitary maps, which transform the basis arising from the gluing to a basis in which the ribbon operators around to-be-coarse-grained pairs of plaquettes are diagonalized. These transformations amount to a reorganization of the degrees of freedom in the fusion scheme, so that this scheme is adjusted to the intended coarse-graining.
The transformations can be seen as disentanglers, which also appear in the MERA algorithm for two–dimensional systems [
27,
28] (but have not been implemented yet for
-dimensional systems). Such disentanglers are supposed to minimize the entanglement between plaquettes belonging to different to-be-coarse-grained pairs. Indeed, this applies at least to the part of the entanglement entropy, which arises due to the gauge symmetry in the system [
31,
32,
34], as shown in [
34].
The difference from the disentanglers in the MERA algorithm and the transformations here is that the MERA disentanglers are dynamically determined, for example, by a minimization procedure, and thus can change from one coarse-graining step to the next. In contrast, the transformations here are defined from the outset. References [
5,
13,
14] introduce similar transformation, that reorganize the degrees of freedom in a spin network basis, where it is argued in [
13] that these transformations act as disentanglers. One can argue, however, that the fusion basis transformations have a more transparent interpretation in terms of reorganizing the regions into which the finer degrees of freedom are blocked.
We conjecture that the transformations do indeed decrease the entanglement between fine degrees of freedom located in different coarser plaquettes. We later see that this conjecture is justified—a version of our algorithm in which these transformations are restricted leads to the appearance of short-range entanglement, which is supposed to be removed by the disentanglers.
Truncation—With the ten-plaquette amplitude transformed to a fusion basis adjusted to the intended coarse-graining scheme, we can proceed now to the truncation step. The labels of the fusion basis can be sorted into two sets: those labels associated with coarse degrees of freedom (or more precisely coarse observables), which we want to keep, and those labels associated with the finer degrees of freedom, for example, the labels associated with finer plaquettes, which we wish to discard. To implement the truncation, we need to specify how to compute an amplitude that depends only on the coarse labels given the amplitude that depends on all labels. To this end, we will construct an embedding map (also known as an isometry) from the boundary Hilbert space associated with the coarser building block to the boundary Hilbert space associated with the finer building block. One can interpret this embedding map as assigning a local vacuum state to the finer degrees of freedom [
52,
58]. In the next iteration, one does not need to sum these finer degrees of freedom anymore. A key feature of tensor network algorithms is that this embedding map is defined from the amplitudes themselves, that is, the truncation is informed by the dynamics of the system.
The coarse-graining procedure proceeds by gluing two cuboids into a larger cuboid. That is, the lattice constant is only changed in one direction. After completing a coarse-graining step in one direction, we rotate the lattice to coarse-grain one of the other another directions. This rotation can be implemented by fusion tree transformations. The amplitude then appears in a fusion basis which matches the initial fusion basis after a rotation of the cube. By applying the exact same gluing, transformations, and truncations as in the previous coarse-graining step, we obtain a coarse-graining in a different direction. A complete coarse-graining in all three directions is accomplished after a round of three such coarse-graining steps.
4.2. Fusion Basis for the Cubes and Gluing Procedure
We now explain the gluing step in more detail. As mentioned above, we always glue two cubic building blocks together, which we now refer to as ‘left’ and ‘right’ building blocks. To specify the gluing procedure we first have to choose a fusion basis for each of the building blocks.
Figure 3 shows the fusion trees for both cubes and how the cubes are glued together. Since the fusion tree is defined via a planar graph, it is convenient to draw the tree on the unfolded cube. The two cubes are glued together by identifying data of punctures 6 on the left and
on the right. Note that punctures
and 6 have opposite orientations of over- and under-crossing branches to ensure that the orientation matches upon gluing. This in turn ensures the cancellation of phase factors in the respective amplitudes. After gluing; changing the orientation of a puncture gives rise to a phase factor. Gluing punctures with opposite orientation cancels out the phases. The remaining tasks are to fuse punctures
to punctures
, respectively. Note that punctures corresponding to opposite sides of the cube, for example, 1 and 3, are chosen with opposite orientation as well, in order to prepare them for gluing in subsequent iterations of the algorithm.
We express the amplitudes for each cube using the following choices for a fusion basis:
For each of the six punctures, that is, for each leaf of the fusion tree, we have a label . Moreover, we have three branches labeled by representations . Note that the state of the right cube is obtained from the state of the left cube by ‘pulling’ punctures over the pair of strands, and this is implemented by an R-move, as decribed in (5). Thus, the amplitude components of left and right cube are related by phase factors resulting from this transformation.
Gluing the left and right cube defines a new state associated with the glued building block. As shown in
Figure 3, puncture 6 of the left cube is identified with puncture
of the right cube. Hence, we identify the labels
with
. The identified representation labels
define a branch label
for the resulting fusion tree. This is accompanied by a weight factor determined by the (quantum) dimension of
. This weight for the glued state can be derived from a similar gluing procedure using a spin network basis [
14]. The resulting state (
Figure 4) is given by
Here
are the square roots of the quantum dimensions associated with the
representations appearing in
and
is the total quantum dimension of
. (See
Appendix A.). The sum is over the labels
with
,
with
,
with
, and
with
, as well as over
.
This implies the amplitude function for the glued building block amounts to
Note that in this gluing procedure we do not have a summation appearing. If the amplitudes include a non-trivial dependence on the tail indices, a summation over does appear. The reason is that the pair of identified indices are converted into a branch index for the glued state. This corresponds to the fact that one can still define a ribbon operator on the surface of the glued building block that goes around the glued (and thus bulk) plaquettes and whose measurement is encoded in the new branch index .
4.3. Fusion Basis Transformations
The glued building block has now ten instead of six plaquettes, and thus carries more data. To avoid an exponential growth in the data, we need to truncate it. We do this by using the built-in coarse-graining feature of the fusion basis—we summarize neighbouring plaquettes on the same face of the glued building block in effective plaquettes. Concretely, we need to summarize l and , with , with an effective plaquette .
However, the fusion tree resulting from the gluing (12) is not well suited for this task: the ribbon operators measuring curvature and torsion around the pairs of plaquettes are not diagonalized by this basis. As a result, we successively transform the fusion basis, and with it the underlying fusion tree, via F- and R-moves as defined in (4) and (5).
We first transform the tree for the gluing building block (12) into a new tree, so that the puncture pairs
and
, which lay on opposite faces, can be coarse-grained. The necessary transformations are split into several steps as depicted in
Figure 5,
Figure 6,
Figure 7 and
Figure 8. In the actual algorithm, some of these transformations are performed before gluing the cubes together, since they are not affected by the gluing, and they are faster to implement for the smaller fusion trees with only six punctures instead of ten.
The first step consists of moving puncture 4 over to the other side of the fusion tree and attaching it to puncture
, see
Figure 5.
Second, we move puncture
over the other punctures on its side of the tree, in particular past the fused pair of punctures 4 and
; see
Figure 6. Besides F-moves, this also requires the R-moves defined in Equation (5).
In the third step, we continue to move puncture
to the other side of the fusion tree; see
Figure 7.
The final step is to move puncture 2 past puncture 3, and then to fuse it directly to puncture
; see
Figure 8.
After this series of transformations, we reach a fusion basis (
Figure 9) which diagonalizes the ribbon operators around the pairs of punctures
and
, respectively. Using the same principle as in (7), the amplitude for the glued building block can be expressed with respect to this new basis. This allows us to truncate the amplitude by coarse-graining the pairs of punctures
and
into effective punctures
and
, respectively. We explain this truncation procedure in
Section 4.4.
The truncated amplitude is now based on a building block with eight punctures. We now perform a further truncation corresponding to a coarse-graining of the pairs of punctures
and
into effective punctures
and
, respectively. We perform the fusion tree transformations once more (
Figure 10 and
Figure 11). It saves computational time to do these transformations after the first truncation step, as the truncated amplitudes involve less data.
First, we move the effective punctures and next to punctures 5 and , respectively, in order to attach to 5 and to . These transformations are also in preparation for the next iteration of the algorithm, in which the punctures are glued.
Next, we move punctures 3 and
such that they are attached to
and 1, respectively (
Figure 11).
This allows us to further truncate the amplitude, since we fused the pairs of punctures and into effective punctures and , respectively. The resulting amplitude is now based on a building block with six punctures.
To start a new iteration of the coarse-graining algorithm we have to first bring the fusion tree back to the same form as for the original states (11). Having coarse-grained in a given direction (here the ‘left’–‘right’ horizontal direction) we next want that the next iteration step coarse grains in a different direction so that three consecutive iterations amounts to a coarse-graining in all three directions. Each of these steps can be satisfied with another round of fusion basis transformations.
We attach puncture 5 to puncture
, then
to
, and then pull
over the strands. After that, we attach the combined punctures
and
to the combined punctures 5 and
. Eventually, we attach
directly below puncture
to arrive back at the original fusion tree (
Figure 12).
We have not yet completed the iteration, as we have to bring the fusion tree back to the same form as for the original state. At the same time, we have to make sure that we coarse-grain the amplitude in all spatial directions and eventually return to an amplitude associated with a coarser cuboid.
The freedom to choose a fusion tree allows us to kill two birds with one stone. We transform the fusion tree (21) to the original form in such a way that subsequent iterations of the same algorithm automatically coarse grain punctures in all three space-time directions. This is straightforwardly achieved by ordering the punctures according to the following scheme.
First, we attach puncture 5 to puncture
, then
to
, and then pull
over the strands. After that, we attach the combined punctures
and
to the combined punctures 5 and
. Eventually, we attach
directly below puncture
to arrive back at the original fusion tree (
Figure 12).
Figure 13 shows how three consecutive iterations of the coarse-graining algorithm do indeed perform a coarse-graining in all three directions.
We started by gluing of a ‘left’ cube with punctures
to a ‘right’ cube with punctures
, that is, a gluing in the
x-direction. This gluing proceeded by identifying the puncture 6 with
. The corresponding label becomes a branch label. Furthermore, we coarse-grain the pairs of punctures
into effective punctures
, respectively. We also have the punctures 5 and
(renamed into 6) from the original cubes. These punctures appear in the second fusion tree in
Figure 13 (which coincides with the last tree appearing in
Figure 12).
We imagine that we perform this coarse-graining in a 3D cubical lattice, that is, for each row with fixed coordinates we glue a cube positioned at to the neighbouring cube at .
In the next iteration, we glue the resulting building block, with punctures and , to a neighbouring (now in the y-direction) building block . We again use primes to indicate punctures of this neighbouring building block. The gluing identifies the punctures and , and it coarse-grains the pairs of punctures and into effective punctures , respectively. Additionally, we have the punctures and (renamed into ) from the previous building blocks.
The third iteration implements a gluing in the z-direction, as we now identify the puncture with from the neighbouring building block. The (double-tilded) labels at the resulting fusion tree indicate that all punctures have undergone two coarse-grainings. Indeed, these punctures represent two-dimensional plaquettes and a coarse-graining in three spatial directions in a cubical lattice leads to a coarse-graining of quadruples of neighbouring plaquettes into one effective plaquette. Dropping the tildes from the labels, we see that after three iterations of the algorithm we regain a fusion basis of the original form and with the original labeling.
Note that these fusion tree transformations are costly, in particular for larger quantum group levels —an F-move requires us to sum over a double index , but this sum has to be computed for all possible labels of the new fusion tree. Thus, it is imperative to keep these transformations to a minimum to avoid unnecessary numerical costs, in particular for fusion trees with many punctures.
4.4. Effective Punctures from Singular Value Decompositions
We now describe the truncation procedure, which is based on replacing pairs of plaquettes, situated on the same face of the building block, with one effective plaquette. In our algorithm, this is applied first to the pairs and . These lie on opposite faces of the glued building block, and as we will see, will be dealt with by one truncation step. A second truncation coarse grains the pairs and , which also lie on opposite faces.
Let us consider the first truncation from the lattice perspective (as opposed to considering just one building block): After the first gluing we pick a building block
a from the lattice. This building block has on its front side (
Figure 3) a pair of plaquettes
, and on its back side a pair
. In the lattice, the pair
is identified with the pair
from a neighbouring building block
b. For illustration, see also
Figure 14, where we show the analogous situation for puncture pairs
and
.
The lattice partition function is defined by summing the product of the cube amplitudes over the variables. Here, variables on faces that are identified with each other also need to be identified. Note that in our case we can have variables, which are associated with a cluster of neighbouring plaquettes situated on a cluster of neighbouring faces. This applies to the labels of (non-leaf) branches in the fusion tree for the cubical building blocks. These labels encode the eigenvalues of ribbon operators encircling the given cluster of plaquettes. Let us consider the case of a pair of plaquettes on two neighbouring faces. We imagine that the two building blocks adjacent via this pair of faces are first glued, and that the resulting amplitude is expressed in a fusion basis which diagonalizes the ribbon operator going around the pair of identified plaquettes. In the summation procedure, one identifies and sums over the labels associated to the single plaquettes as well as the labels associated with the pair of plaquettes. For the identified face, this leads to the identifications
(together with
) and
(together with
). Additionally, we have
. Truncating means summing over fewer variables—we replace the sum over the two identified
–variables and the
–variable, with a sum over the
–variable only. This leaves us with the
–variables on each of the building blocks. To explain how to deal with these variables, we insert a unity
into the summation over the
–variables and split this unity into a product of
–dependent unitary maps
where we have introduced an auxiliary label
A (and an associated auxiliary Hilbert space). Isolating the two building blocks and the summation over
in the partition function, we summarize all other indices on building block
a by
and on
b by
. The summation then becomes
Here we are discussing a truncation that keeps the same amount of data as was on the original building blocks. See the end of this section for different methods to achieve higher-order truncations. The truncation consists of replacing the summation over the index
A with
Thus, a crucial ingredient which determines the quality of the truncation is the choice of the unitaries
. Before coming to this choice, let us explain what this replacement achieves for our coarse-graining algorithm. The main point is that we can do the summations over
and
locally on each building block. That is, we define the truncated amplitudes
In the lattice, each building block has a front and a back side, and thus functions both as an
a–building block and a
b–building block. That is, going back to the coarse-graining of plaquette pairs
and
into
and
, we have
where
I denotes all labels of the glued building block, excluding the set
. We have reached a truncated amplitude, which depends on fewer variables. The maps
, therefore, do define a coarse-graining. We also can read these maps the other way around by defining embeddings from a coarser (boundary) Hilbert space to a finer (boundary) Hilbert space. It assigns to the additional degrees of freedom described by
in the finer Hilbert space a localized notion of a
-dependent vacuum state [
52,
58].
We come now to the choice of the
–dependent unitary
. This choice is informed by our goal of minimizing the error made by the replacement (
16) in the summation (
15) for the partition function
. This minimization is achieved when we define
U via a singular value decomposition (SVD) of the amplitude itself:
where
and
are unitary matrices and
is a rectangular diagonal matrix with entries
. We use the
a–building block to extract
U. We could have also used the
b–building block. For a method that compares both possibilities and then chooses the one which minimizes the summation error, see Reference [
4]. To define the SVD, we understand the amplitude
as a
–dependent matrix
with left-index given by
and a right-index given by
. We apply an SVD to this matrix in order to obtain the coarse-graining map
used in (
18). The singular values
can be used to control the quality of the approximation.
After coarse-graining the pair of punctures
and
into effective punctures
and
, respectively, the truncated amplitude is expressed with respect to the following fusion tree
where we renamed
as
, since it is now an index attached to a leaf. This is the amplitude that in the coarse-graining algorithm must undergo steps five and six of the fusion basis transformations (
Figure 10 and
Figure 11).
After these fusion basis transformations, we apply a second truncation in which we coarse grain the pair of punctures
and
into effective punctures
and
. The procedure is the same as for the coarse-graining of
and
. After this second truncation we reach a building block with the original number of punctures:
This amplitude needs to be transformed to a tree of the initial form, which is described in
Figure 12.
The truncation procedure via SVD is similar to other tensor network algorithms [
1,
2,
4]. However, in our case we rewrite the amplitude as a matrix which depends on some of the variables, for example,
in (
19). The SVD needs to be performed for all allowed values of
. That is, we perform the truncation step for a fixed value of the associated observable, which is the ribbon operator going around the coarse grained pair of plaquettes. This allows us to continue interpreting these variables as the measurements of a coarse observable. Such “passive” variables appearing in the SVD were introduced for the decorated tensor network algorithm [
5,
14], where they also served as a way to maintain control over coarse observables. This allows us to compute expectation values of such coarse observables easily, and these can serve as order parameters.
We employ a truncation that brings us back to building blocks carrying the same amount of data as the initial ones. The truncation can be improved by truncating the sum on the left side of (
16) at a larger value of
A. (Note, however, that the memory requirements, outlined in
Section 5.4, grow steeply with the level
for the truncation discussed here. The growth is polynomial in
, but comes with a large power.) This introduces additional degeneracy labels on top of the fusion basis labels. To keep the observables and fusion basis structure intact it is better to permit building blocks with more plaquettes, for example, four plaquettes on each of the faces. For non-Abelian groups (or quantum groups), this replaces labels
with
, where
, and three further representation labels
, which arise from fusing the four plaquettes.
5. Application to Lattice Gauge Theories
Having described the coarse-graining algorithm, we now focus on its application to lattice gauge theory with a (quantum deformed) structure group . The fusion basis algorithm offers several advantages for lattice gauge theories. In particular, the coarse-graining scheme allows easy access to the magnetic (or curvature) and electric (or torsion) charges throughout the coarse-graining procedure. The magnetic charges provide order parameters which distinguish between the weak- and strong-coupling phase. Although there might be no electric charges excited on the lattice level, such electric charges can appear in the coarse-grained region. Employing the fusion basis allows us to test different truncations that suppress such electric charges to various degrees.
5.1. Amplitudes for Quantum Deformed Lattice Gauge Theory
In this section, we define the amplitudes for Yang-Mills lattice gauge theory with a quantum-deformed gauge group
. A popular choice in the case of undeformed Lie groups is the Wilson action, which is expressed in terms of the plaquette holonomies
, where
are the group elements associated with the cyclically ordered edges enclosing the (square) plaquette
l. But in the quantum-deformed case, we do not have access to the holonomies. We will consider instead amplitudes based on the heat kernel action [
59]. For example, for
the amplitude is defined as
The amplitude is a product of local amplitude factors associated with each of the plaquettes l. The plaquette factor is expanded into group characters , which are evaluated on the plaquette holonomy . In light of generalizing these amplitudes to the quantum-group case, we note that this character coincides with the value of the plaquette Wilson loop in the representation . The expansion coefficients are given by the product of the dimension and the exponential , where is the value of the Casimir for the representation .
The state described by the amplitude (
22) can be obtained by starting from the state
and multiplying it by a factor
for each plaquette
l. These plaquette operators are sums over insertions of Wilson loop operators with certain weights.
Here is the state describing the strong coupling limit. This state is obtained in the limit , where only the terms with survive. For , the exponential factor goes to one and the plaquette amplitude defines the –delta–function . The relation between and the usual Yang-Mills lattice coupling constant g is given by , where a is the lattice constant.
To adopt this amplitude to the quantum-group case, we also start from the state
describing the strong coupling limit. In a spin network basis (which also exist for the quantum-group case), the amplitude is only non-vanishing if all representation labels are trivial. To obtain a quantum-deformed version of (
22), we also apply local plaquette operators to this state
where
is the signed quantum dimension,
is the quantum number,
is the total quantum dimension of
(see
Appendix A), and
is an operator that inserts a Wilson loop in the representation
k around the puncture
l. The Wilson loop operator coincides with the ribbon operator
or
. A (closed) ribbon operator
inserts two parallel Wilson loops labelled with
and
into a state
, which itself may be defined via a network of labeled (spin network) strands. The loop labelled with
over-crosses all strands in
and the loop labelled with
under-crosses all strands in
. We assume
has vanishing electric charge (i.e., it is torsionless) at the punctures: there is a region around each puncture without any pre-existing strands. Thus, an over-crossing and an under-crossing Wilson loop around a puncture lead to the same action.
Going from the Lie group to the quantum group, we replace the quantum dimension with the signed quantum dimension, the exponential with and the Wilson loop operator with its quantum-deformed equivalent. With these choices (in particular by using the signed quantum dimension) we regain the strong coupling state (modulo a normalization) for and, as we will see below, the weak-coupling state for .
Now the operators
and, therefore, the operators
, are diagonalized in the fusion basis. For states without electrical charge at the leaf
l, we have a leaf label
and the Wilson loop operator
acts as
where
is the S-matrix associated with the fusion category
(see
Appendix A for its explicit definition). In particular, we have
. The S-matrix is unitary and for
has real entries, that is,
. Thus, we see that we indeed regain the vacuum state in the limit
.
Figure 15 shows plots for the eigenvalues of
for a range of
’s.
Therefore, it is easiest to define the heat kernel states
in the fusion basis. To this end, we need to express the strong coupling state
in the fusion basis. This is given by [
12]
where
denotes the number of punctures and
are local phase factors that depend on the orientation ± of the state around the puncture
l. See the end of this section for the explicit phase factors with respect to the six-puncture fusion basis that we use for the cubical building blocks. The function CoupCond is equal to one if the labels
of the fusion tree satisfies all coupling conditions and is vanishing otherwise. Thus the heat kernel amplitude is given by
Note that the phase factors cancel out if one glues two building blocks by identifying a pair of plaquettes (identified with leaves), as these have to come with opposite orientation.
Strong coupling state for the cuboid with six plaquettes: In the fusion basis appearing for the ‘left’ cubical building block in (11), the strong coupling state appears as
The leaf indices are given by with and the branch indices by with . The R-symbols are defined as if satisfy the coupling conditions (that is, if ), and they vanish if the coupling conditions are not satisfied (). Here is a pure phase. As is an entire number (due to coupling conditions) we also have . Hence, the phase factors only depend on the representation labels associated with the leaf indices , whereas the dependence on cancels out. Note that the coupling conditions for the and indices are included in the definition of the R–symbols.
5.2. On the Appearance of Electrical Charges under Coarse-Graining
We defined the heat kernel amplitudes in
Section 5.1 by applying only plaquette operators to the strong coupling state. A more elaborate possibility is to add Wilson loop operators that surround pairs or even larger clusters of plaquettes. Such more non-local constructions would appear if one tries to approximate better the vacuum state associated with a given coupling. For loops around several plaquettes or punctures one needs to specify whether one has an under-crossing or over-crossing Wilson loop or a combination of both, that is, a ribbon operator.
As we see in a moment, the heat kernel amplitudes as defined in
Section 5.1 do not feature excitations of electrical charge labels or torsion, even if we consider ribbon operators around several plaquettes. We also show the alternative definition, which employs more non-local operators, leads to such excitations. Furthermore, we show that by gluing states for larger building blocks, we might also encounter such electrical charge or torsion excitations. This is the reason why torsion excitations might appear in the coarse-graining algorithm.
The definition of the heat kernel amplitudes in (
26) includes the condition that for all fusion basis labels
and
we have
and
. As electric charge excitations are characterized by labels
with
, we see that we do not have such excitations, neither for the leaves nor for the branches. Yet, the amplitudes are specified with respect to a particular fusion tree in a way that it could happen that such excitations appear after a tree transformation. For an F-move, given by
the transformation involves the sum
To go from the first to the second line we use the expression for the Drinfeld Double
–symbol in terms of the
F-symbols (see
Appendix B). From the second to the third line we employ the condition that the initial lattice gauge theory amplitude function
takes the form
To arrive at the fourth line we use the tetrahedral symmetry properties as well as the orthogonality relation for the
F-symbols (see
Appendix A).
The transformed amplitude again has vanishing electric excitations for the leaves and branches, and also has a trivial dependence (apart from factors) on the branch indices. For the R-transformations (see Equation (5)) we note that these are trivial for states without electric charges, and thus cannot lead to the appearance of such charges. We conclude that the initial lattice gauge theory amplitudes have vanishing electric charge for all plaquettes and clusters of plaquettes.
Equation (
29) would change if the amplitudes have a more non-trivial dependence on the labels
, even if we still have the
factor. We obtain such a dependence if we glue two heat kernel amplitudes, as described in
Section 4.2. There the punctures 6 of the left cube and the puncture
of the right cube are identified with each other. That is, the corresponding labels
are set equal and now serve as a branch label for the glued tree. But, as the punctures 6 and
carry non-trivial weights
and
, these are now associated with the branch label
. Summing over
we do not only have the Kronecker-Delta
, but also a weight
. This weight renders the orthogonality relation for the
F-symbol non-applicable, and thus it may cause the appearance of electrical excitations
for the transformed tree.
Because the coarse-graining algorithm consists of iterations of gluings, tree transformations, and truncations (in which branch labels are transformed to puncture labels), we can expect the appearance of electrical charges or torsion for the effective punctures.
Electric charges do not appear in the weak coupling limit, since this describes a state where both magnetic and electric charges are suppressed. For the strong coupling limit we have all possible magnetic charges excited, but the electrical charges are suppressed. This feature is preserved under tree transformations (and gluings) as the weights are trivial in the strong coupling limit.
Note that we could have also defined initial amplitudes which do not feature electric charges at the punctures (because the initial amplitudes are gauge invariant), but do so for branches, that is, for certain clusters of plaquettes. The same argument that showed electric charges appear under coarse-graining also shows that such charges can appear after tree transformations if we include more non-local Wilson-loop operators in the construction of the amplitudes. Reference [
12] also constructs gauge invariant states that can be interpreted as being peaked on (geometrically) homogeneous curvature, but also show electrical charge excitations for clusters of plaquettes. The appearance of electrical charge or torsion excitations for coarser regions, which include magnetic or curvature excitations, can be explained with the help of a geometric interpretation of the ribbon operators, see Reference [
54].
5.3. Range of Models
Before describing the results of the coarse-graining algorithm, we summarize the parameters of the model and introduce further modifications. Choosing the heat kernel amplitudes (
26) as initial amplitudes for the coarse-graining procedure, we have two parameters:
Level of the quantum group . The level of the quantum group determines the maximal admissable representation label of the system. Thus, larger implies higher-dimensional boundary Hilbert spaces. The level can be understood as an effective (inverse) discretization length for the group manifold : the eigenvalues of the Wilson loop operator correspond to a discretization of the class angle of as .
In the limit of one regains the classical Lie group . For the minimal choice one has an Abelian fusion algebra, where only the representations and (both with quantum dimension equal to one) are allowed.
Coupling constant g—We will use
as the lattice coupling constant. The limit
describes the lattice weak coupling limit, in which all magnetic (or curvature) and electric (or torsion) excitations are suppressed. The weak coupling amplitudes coincides with the amplitudes of the Tuarev-Viro model, which describes a topological field theory [
30]. The dual state is reached in the strong coupling limit
, where all curvature charges are excited (with a constant probability distribution), but with torsion suppressed. Both the weak and strong coupling limits constitute fixed points of the coarse-graining algorithm. (In fact, both limits describe topological, that is, triangulation-invariant state sum models. However, the strong coupling limit leads to a trivial model.)
Since we work with finite systems, we expect each of these limiting cases to come with an extended phase (for fixed defined by the values of g for which the models flow under coarse-graining to the corresponding fixed point) and a phase transition separating them. Our goal is to find this phase transition (depending on and g) and study its properties using our coarse-graining algorithm. Before we discuss the results in detail, we briefly mention three different implementations of our coarse-graining algorithm.
As explained in
Section 4.1, we define new effective punctures through a singular value decomposition. We perform such a singular value decomposition for each label
that the new effective puncture can have.
We have implemented two versions of these algorithms:
Torsion: We allow the effective puncture labels to take , that is, we allow for torsion to appear. (Note that torsion also appears for the branches, and it can be measured by ribbon operators going around several plaquettes.)
No torsion at punctures (NTP): As the name suggests, we suppress torsion for the effective punctures. Note that we still allow torsion on the branch labels, so we permit branch labels . Also, we still perform an SVD for effective puncture labels with . This allows us to compare the highest singular values for these labels with those coming from labels with , and in this way lets us estimate the relevance of the torsion degrees of freedom. However, for the subsequent definition of the coarse-grained amplitude, we implement the condition for the labels associated with the effective punctures. This truncation is equivalent to projecting back to the lattice gauge theory Hilbert space of gauge invariant wave functions after each coarse-graining step.
Fully truncated torsion (FTT): One can further truncate the NTP version, by forbidding also torsion excitations on all branches, that is, by requiring for all branch labels . This truncation constitutes a restriction of the gauge invariant lattice gauge theory Hilbert space. The truncation leads to considerable simplifications of the fusion tree transformations, for example, the R-moves become trivial. Further, the number of configurations which need to be computed and saved in each step is reduced considerably, making the algorithm more economical in terms of computational time and memory usage.
These three versions of the algorithm allow us to test whether neglecting torsion degrees of freedom changes the results of the coarse-graining algorithm significantly. Although the fusion basis algorithm allows for a systematic treatment of torsion, it does naturally increase the required amount of computational resources in a very significant way. We discuss this in more detail in the next section. The algorithm presented here allows us to test various truncations, which then can lead to huge computational savings.
Furthermore, we consider a variant of the model where we allow only a restricted set of representation labels to appear. We use the condition that the set of integer representations (as opposed to half-integers) is closed under fusion. That is, an initial amplitude, which is only non-vanishing for integer labels, will keep this property under coarse-graining. Note that the representation labels here are labels of the fusion basis. Allowing only integer labels can be understood as allowing fewer values of the curvature class angle, for instance, according to .
Integer representation labels only model: We only allow for integer representation labels throughout (
and
). This lets us write a simpler code which neglects non-integer representations, which in turn reduces the total number of configurations. For the amplitude, we use the same plaquette weights as in (
26), but we allow only integer arguments
and
. Note that the sum over the representation label
appearing in (
26) still is taken over half-integers. Summing over only integer
we obtain a plaquette amplitude
, which is symmetric around
. The strong coupling limit of this model differs from the one for the general model because we have only all integer labels appearing. In the spin network basis, this strong coupling limit of the integer model describes an amplitude which is only non-vanishing for representations
and
. The appearance of
in addition to
is due to the restriction of integer representations in the fusion basis. We test the integer models with the Torsion and NTP version of the algorithm.
In the next section we briefly outline optimizations which make the coarse-graining algorithm more feasible to implement.
5.4. Remarks on the Numerical Implementation and Costs
For tensor network coarse-graining algorithms, the building blocks carrying the most data, that is, the most configurations to store, set the limiting factor in terms of memory consumption and operational costs. For our algorithm, these are the building blocks with ten punctures. Ignoring coupling conditions and allowing for the existence of tail indices, we have 20 j-labels and 10 s-labels for the punctures, as well as 14 i-labels for the branches. At value , each and s label can have values, giving combinations. Already for this would lead to the use of GB memory, which is not a feasible amount even in modern clusters.
Fortunately, there are two steps which drastically reduce these memory requirements: first, our initial amplitudes do not depend on the tail labels , and we use a truncation that does not introduce a dependence on these labels. Therefore, we can ignore these labels altogether, leading to a reduction in the number of labels from 44 to 34. A second significant reduction results from implementing the coupling rules for the fusion basis labels. Doing so, the example only requires 43 GB of memory.
Let us explain this in more detail. At each three-valent vertex of the fusion tree, the three associated pairs of labels must satisfy coupling rules. This puts restrictions on the admissible labelings of the fusion tree, and it leads to a significant reduction in the number of allowed configurations. The labels for the allowed configurations can be represented by a “super-index”. Such super-indices have been already employed in simulations of models with global and local symmetries [
14,
23,
24,
60]. There are various choices in constructing and assigning super-indices, which allows us to adjust the structure of these indices in a way best suited for the next task in the algorithm.
Using super-indices allows us to store only the admissible configurations, which we do in a vectorized format, since the contiguous data storage offers a more optimal memory access pattern compared to that for multidimensional array storage. Moreover, this allows us to write the fusion tree transformations in a single loop which is straightforwardly parallelizable. For , these steps leads to a reduction in the required memory (for the ten-puncture building block) from around GB to 43 GB.
Further steps can be taken to reduce the required computational resources, in turn allowing coarse-graining of models at larger values of
. One possibility is to truncate torsion degrees of freedom, that is, to employ the NTP or the FTT version of the algorithm. Another is to consider models where only integer labels are allowed, as we discussed in the previous section. To give an impression of how the algorithm scales for various levels
, we show the memory cost for storing the amplitude for a ten-puncture state in
Table 1.
The required runtimes scale in a similar way—for the Abelian models ( half-integer and integer) one full iteration takes a few seconds on a modern laptop. For higher levels we use HPC resources on the MP2B cluster run by Calcul Québec (Compute Canada), which provide compute nodes with up to 512 GB of memory. We run most of our simulations using a single core to keep memory cost low. 15 full iterations of the NTP algorithm for take roughly two days, and 15 full iterations of the FTP algorithm for take roughly five days. Increasing the level further leads to a significant increase of computational times, for example, a third of a full iteration in the NTP algorithm for takes more than a week. This increase is due to the increase in the number of fusion basis transformations, as well as the increase in time for singular value decompositions of larger tensors. While it is possible to accelerate the former by CPU-level multithreading, this also increases the memory costs in a prohibitive way. The largest system we studied was the NTP integer algorithm for (using . Thus, we estimate that with the current algorithms, models that use up to 1 GB of memory can be simulated realistically.
To go towards larger quantum groups in future work, we are considering a redesign of the coarse-graining algorithm which employs smaller intermediate building blocks. These require less memory, and they use a smaller number of fusion basis transformations and singular value decompositions. Moreover, we expect it to be possible to implement such an algorithm on modern multi-GPU systems, where already one can find half a terabyte of pooled GPU memory on a single compute node. Because the algorithm is built on linear algebra operations, GPUs are the optimal solution, provided that memory access can still be made efficient. Another more speculative possibility is to use deep autoencoders to extrapolate results for larger using lower-dimensional (i.e., compressed) representations of the data. This would allow one to trade memory for accuracy, but the exact tradeoff is unknown.
5.5. Phase Diagram and Phase Transitions
5.5.1. Order Parameters
Although we characterize the initial amplitudes in a given model just by the coupling constant g, the coarse-graining algorithm leads to much more general forms of the amplitude. This is a typical feature of tensor network methods, and it allows the amplitude to develop all possible kinds of correlations between the degrees of freedom associated with the basic building blocks. This makes tracking of the coarse-graining flow generally difficult.
However, as explained in
Section 4.4, we use a set-up for the SVD procedure which is similar to the one used for decorated tensor network coarse-graining [
5]. In particular, the singular value decomposition is performed for fixed values of the label that characterizes the coarse-grained degree of freedom. In our case, this is the magnetic and electric charge label
associated with the effective puncture
. In the truncation, we keep the largest of the singular values
. The set of the squared singular values
gives (after normalization) the probability distribution of the charges
according to the truncated amplitude. That is, the set of singular values encodes the expectation values for the ribbon operators around
with respect to the (cube boundary) state as defined by the coarse-grained amplitude.
Furthermore, the effective puncture represents a plaquette with double the side lengths of the previous (full) iteration. That is, one coarse-graining step is performed in each of the three spatial directions, and thus the lattice constant is doubled in all three directions. The singular values taken from subsequent coarse-graining iterations encode the expectation value of ribbon operators around larger and larger plaquettes, thus allowing us to track the behaviour of the effective amplitude at larger and larger scales.
Generically, the amplitude will flow to one of the two lattice gauge theory fixed points, either the weak coupling limit or the strong coupling limit. These are characterized by the following singular value distributions:
Weak coupling limit: All magnetic (curvature) and electric (torsion) charges are suppressed. The amplitude is only non-vanishing if all labels take trivial values. The singular values are also vanishing for all , except for .
Strong coupling limit: Here electric (torsion) charges are still suppressed, that is, the amplitude is only non-vanishing if all labels satisfy , but all purely magnetic charges are excited. The singular values are given by . For the integer-only models we have a strong coupling limit where only magnetic charges with integer labels are excited.
In summary, keeping track of the singular values allows us to conclude whether magnetic (curvature) charges are suppressed or not. Singular values with indicate the absence or presence of electric (torsion) excitations.
5.5.2. Phase Transitions
The initial amplitudes are characterized by the coupling constant g. Under coarse-graining, the models flow (eventually) to either the weak or strong coupling limit. For each fixed type of model, in particular for fixed level , there is a critical coupling , such that for the amplitudes flow to the weak coupling limit and for they flow to the strong coupling limit. The first interval of couplings defines the weak coupling (deconfined) phase and the second the strong coupling (confined) phase.
Table 2 lists the critical couplings for different models and levels
. We plot these critical values as functions of level
, both for the half-integer and integer models in
Figure 16.
We observe the values for the critical couplings decrease both for the models including half–integer labels, as well as for the models with integers only. Furthermore, at least for the models we could coarse-grain with the version of the algorithm including torsion, the critical couplings found in the Torsion and NTP versions are essentially the same. There is only a difference for the integer model in the fifth digit. Changing from the NTP to the FTT version we find also only small differences in the critical couplings in the fourth digit.
The decrease in the critical coupling with increasing level is expected: larger levels give a better approximation to the classical group , which arise in the limit . The conjecture for is that the value of the critical coupling is at . Our results show a nearly linear decrease in the critical couplings, starting at .
If this linear dependence on coupling persists for larger , it would lead to a vanishing critical coupling for surprisingly small . We estimate this occurs for the half-integer models between and and for the integer models between and . But, we would clearly need simulations for larger levels to see whether this linear decrease does indeed persist. In fact, one would expect that is approached rather in an asymptotic limit instead by a linear decrease.
5.5.3. Model
Let us consider in more detail the
model. The representation labels
j takes values
and
. Due to the computational requirements, we employed the NTP version of the algorithm. This variant still allows for torsion degrees of freedom at the branches. For this reason, we can still find (and thus plot) the singular values for labels with torsion excitations on the effective punctures. These can give an indication of the relevance of the torsion excitations. See, however, the discussion in
Section 5.5.5, which indicates that truncating torsion does not produce any significant changes.
In
Figure 17, we plot the singular values associated with the effective puncture labels
and
. The first value indicates a flow to either the weak or strong coupling limit. The second value gives an indication of the relevance of the truncated torsion degree of freedom. (Note that due to the coupling rules, charges with label
, for instance, cannot be excited if torsion is suppressed in the initial amplitude.)
We see that the singular values flow to zero for and to one for . The other singular values with show the same behaviour. Tuning the coupling towards the phase transition, the singular values first flow to some plateau; that is, after some initial convergence remain constant over a number of iterations before eventually flowing to one of the two fixed point values. This plateau indicates the appearance of an almost scale invariant amplitude, and it hints at a higher order phase transition. In this regime, one expects that the truncated singular values (i.e., the second largest singular value for each ) are significant, which is indeed the case: for the diagonal channels the second largest singular value is up to the largest one in the same channel.
The singular values show a sharp decline for non-critical couplings. However, near the critical couplings these singular values remain significant for a number of iterations. Note that in every iteration we truncate the torsion excitations at the effective punctures. Thus, the torsion is generated anew in each coarse-graining step. A similar behaviour can be observed for the model.
5.5.4. Integer-Only Models
Next, we consider the integer-only models, where we allow only labels with integer representations j. For , this constrains and , but includes a non-trivial coupling . (This fusion category is also known as “golden chain” model.)
This model can be simulated in the Torsion and the NTP versions of the algorithm. As we will comment on in more detail in the next section, there is almost no difference between the flow in these two different versions.
Considering the singular values for the
excitation, we again see a flow to the weak coupling limit value for
and a flow to the strong coupling limit for
. But, in contrast to the
model with half-integer labels, when tuning towards the critical coupling we do not see a plateau behaviour for the singular values (see
Figure 18 and
Figure 19 in different truncation schemes explained below). This suggests a first order phase transition. Correspondingly, the singular values for the torsion excitations decay relatively fast even near the critical coupling.
The
integer-only model behaves similarly (
Figure 20). Also, we do not observe a plateau behaviour around the critical coupling.
5.5.5. On Truncating Torsion
For the
integer-only model, we compare the results of the Torsion and NTP versions of the algorithm. The critical couplings show only a tiny difference in the fifth digit. The
Figure 18 and
Figure 19 show the flow of the singular values within the two different truncation schemes, and they do not show a visible difference. This does even include the singular values for the torsion excitations.
This is quite surprising, since such a close agreement is not suggested by the size of the singular values—if we compare the singular values for the punctures and in the first iteration, the latter’s size is a quarter of the former. Hence, we clearly cannot argue that these degrees of freedom are irrelevant for the dynamics, yet it does not significantly change the singular values for pure curvature excitations nor for torsion excitations. It seems that torsion is mostly generated as curvature-induced torsion, that is, mostly from recoupling between the pure curvature excitations. But, once these torsion excitations are “transported” (via fusion tree transformations) to the effective punctures, they do not significantly influence the behaviour in the next iteration.
However, truncating torsion entirely as in the FTT version of the algorithm shows quantitative and qualitative differences. While the FTT version allows us to identify a phase transition with a critical coupling
still close to those found in the torsion and NTP algorithms (
Table 2), the flow of singular values, and thus the flow of amplitudes, is significantly different: compare
Figure 17 showing the singular values for the NTP algorithm and
Figure 21 showing the singular values for the FTT one.
With the FTT algorithm we have that for
the system does not flow to the weak coupling fixed point; instead, it flows to a continuum line of fixed points. The singular values for these fixed points depend on the initial coupling
g. Moreover, with the FTT algorithm one can no longer recognize a plateau in the singular values close to the phase transition as with the NTP algorithm, see
Figure 21 and
Figure 17 respectively.
Similar features occur when tensor network coarse-graining methods, like the tensor network renormalization group [
2], are applied to models like the 2D Ising model. These algorithms possess fixed points of a particular form, dubbed “corner double line tensors.” These appear because these algorithms do not fully resolve entanglement among short scale degrees of freedom, and they promote short scale entanglement to larger scales under consecutive iterations. This caveat was addressed by entanglement filtering algorithms [
2,
28], which include measures (e.g., disentanglers in Reference [
28]) that are designed to remove short scale entanglement.
The main difference between the FTT version, where the continuum line of fixed points appear, and the NTP algorithm, where this continuum line does not appear, is that the FTT version also implements a truncation for the fusion basis transformations—in the NTP version torsion excitations are only removed at the effective punctures after the SVD procedure. In particular, the branch labels are of the more general form , allowing for a larger Hilbert space on which the fusion basis transformations can act.
This suggests to us that the fusion tree transformations do indeed act as disentangler maps, as we discussed in
Section 4.1. For the Torsion and NTP versions, the fusion tree transformation remove short scale entanglement sufficiently well for the truncation employed, that is, we keep only the largest singular value
for each channel
.
5.5.6. Abelian Models
Among the q-deformed lattice gauge theories discussed above, there are two Abelian ones: the half-integer model and the integer model. Both models permit only two representation labels, and . Therefore, the face weights (in the initial amplitude) can only take two values. Hence, we can identify our model with gauge theory by choosing parameters g and such that the face weigths in both theories match. The plaquette weights in gauge theory are given by with (up to a constant).
Translating the critical couplings
in
Table 2 to critical couplings
for the
gauge theory, we find that both critical coupling constants translate to the same
. There are slight deviations in the fourth digit of
in both models due to the limited precision of
. We also ran simulations for
gauge theory weights and found the same critical
for both models at this value. Indeed the initial plaquette weights differ only by signs resulting from quantum dimension factors, and these signs cancel out under gluing. Each puncture
l carries a dimension factor
, which is negative for half-integer representations, see (
26).
The value of deviates by only a few percent from the value found in Monte Carlo simulations, .
5.5.7. An Example of Anyon Condensation
We have encountered two different strong coupling fixed points: one in the models where half-integers allowed and another one where only integers allowed. In the fusion basis, the integer-only fixed point describes a state where all the magnetic charges with integer representation charges are excited, whereas the fixed point of the full model describes a state where all magnetic charges are excited.
The transition from the integer-only fixed point to the half-integer one can be interpreted as an anyon condensation [
11], where the charges here are identified with anyons. The fixed points are interpreted as vacuum states. Thus, including half-integer charges means that additional types of anyons condense to form a new vacuum state.
Note that these strong coupling fixed points have a very simple amplitude in the spin network basis. There, the amplitude for the half-integer strong coupling fixed point allows only the trivial representation label to appear with non-vanishing amplitude. The integer-only strong coupling fixed point allows two representation labels and . Both representations have quantum dimension equal to one, and the allowed couplings are reproducing the ones for gauge theory (in the strong coupling representation)— and as well as . Thus, we expect an Ising-type phase transition.
Here, we consider as initial amplitudes a simple superposition of the amplitudes for the integer-only and half-integer strong coupling fixed point
Varying the superposition parameter
from zero to one we expect to find a transition from the integer-only to the half-integer fixed point. We use the
example with the NTP version of the algorithm, which gives a phase transition at
.
Figure 22 shows the singular values for the magnetic charge
, whose values distinguish clearly between the two fixed points. Tuning towards the critical parameter
we find a plateau-like behaviour indicative of a higher order phase transition.
5.6. Observables
The coarse-graining algorithm presented herein tracks a certain class of observables given by the ribbon operators. These ribbon operators are generalizations of Wilson loops that measure both the electric and magnetic charges in the encircled region.
The fusion basis diagonalizes a set of ribbon operators
, where
is also a charge label, and
denotes a loop. This set always includes the ribbon operators around the single plaquettes. If the charge labels of this plaquette are given by
, the eigenvalues of the ribbon operator are given by (see e.g., Reference [
25] for details)
where
is the S-matrix of the fusion category
. For
and
we obtain
This can be compared to the eigenvalue for the k–Wilson loop in the Lie group , where is the class angle of the group element g. Thus, for torsion-free plaquettes with label , we conclude that the ribbon operators are analogous to the Wilson loop operator in the k–representation, and they probe a (discretized) version of curvature angle (i.e., magnetic charge) .
In our coarse-graining algorithm, after N full iterations, an effective plaquette is coarse-grained from initial plaquettes. Therefore, ribbon operators around such effective plaquettes, arising from subsequent iterations, represent ribbons around a larger and larger number of initial lattice plaquettes.
We now consider the expectation value of such ribbon operators as computed from the partition function. The partition function is the one associated with the 3-torus, which can be obtained by identifying the three pairs of sides of a cubical building block. is then obtained by gluing the corresponding labels with each other and summing the cube’s amplitude over all remaining free labels. Doing that for our amplitude after N iterations, our coarse-graining algorithm computes the (approximation to the) partition function for a 3-torus built from basic building blocks.
We next consider the expectation value of a normalized ribbon operator
around one of the effective
plaquettes of the torus. After normalization, this ribbon operator has eigenvalue one when applied to a puncture with label
. The expectation value is obtained by inserting the operator into the partition function, and in the notation for the left cube in
Section 4.2, is given by
where
Expectation Values in the Model
We now consider the expectation value of the ribbon operator in the half-integer model using the NTP version of the algorithm. The ribbon operator is analogous to a Wilson loop operator in the fundamental () representation.
In
Figure 23, we show the expectation value
over several iterations
N and for different initial couplings
g. We see that the expectation value is a good order parameter, since it differentiates well the two fixed points and, therefore, phases. In the weak coupling limit, the expectation value is non-vanishing, whereas, due to the averaging of the eigenvalues
over
j, it vanishes in the strong coupling limit. This is the same behaviour as we observed for Wilson loop operators in lattice gauge theory. Closer to the phase transition, we require more iterations before the expectation values converge to the fixed point values in agreement with the results for the coarse-graining flow.
The phase transition is further illustrated in
Figure 24, where we plot
as a function of the initial coupling constant
g for different
N. Around the critical value
, the graphs quickly become steeper as we increase the number of iterations
N. This reflects that for growing
N the system tends nearer and nearer to one of the two final fixed points. Moreover, the graphs intersect (almost) at the same point, where the expectation values do not change with consecutive iterations, that is, length scale. This is an indication for a higher order phase transition.
The observables also reveal properties of the system in the respective phases. In
Figure 25 we plot the logarithm of the expectation value, that is,
, as a function of the number
N of iterations for different values of the initial couplings
g in the weak coupling phase
. Note that
N determines the perimeter
of the effective plaquette around which we take the ribbon operator.
In general, we observe that for larger perimeters the values decrease, consistent with the fact that the expectation values for the Wilson loops reach the value one in the weak coupling fixed point.
As expected, the decrease is much more pronounced further away from the phase transition, for example, for the blue curve (
) in
Figure 25 the logarithm of the expectation value appears to drop off
, signalling a (hyper-) deconfining behaviour.
Similarly, we study the same expression in the strong coupling phase (
Figure 26). As expected, we observe a different behaviour:
increases linearly with the area
enclosed by the ribbon operator. This illustrates the area law
, and thus the confining behaviour for the strong coupling regime.
6. Discussion
In this article we presented a new tensor network renormalization algorithm which can be applied to
-dimensional lattice systems with (non-Abelian) gauge symmetry, and also used to study anyon condensation. This algorithm builds on the decorated tensor network algorithm [
5]. The novel input here is that the tensor networks encode the amplitudes of the system in the fusion basis. This produces an algorithm where observables which measure the magnetic and electric charges of a region are central, and they can be monitored throughout the coarse-graining process. This is quite different from standard tensor network algorithms, in which the interpretation of the coarse-grained tensor network amplitudes requires additional work [
2].
The fusion basis diagonalizes a hierarchically ordered set of these observables, and in this way it defines a coarse-graining scheme for the plaquettes of the basic and glued building blocks. Fusion basis transformation change this ordering, and thus reorganize the blocking of the degrees of freedom. The fusion basis transformations, therefore, play an essential part in the algorithm and function as pre-defined disentanglers.
A crucial advantage of employing the fusion basis, rather than the spin network basis [
5,
13,
14], is that the fusion basis explicitly controls the electric charge excitations, which on the lattice level appear as violations of gauge invariance. Thus, we have constructed different versions of the coarse-graining algorithm. A first version allows electric charge excitations (and violations of gauge invariance) to appear on the coarse-grained lattice level. A second version truncates these electric charges. Yet, this only applies to the charges of the effective plaquettes, and not to the electric charges which might appear on pairs of effective plaquettes, for instance. This version is equivalent to a truncation to the gauge invariant Hilbert space after each coarse-graining step. A third version of the algorithm does not allow for any electric charges. This truncation reduces even the gauge invariant Hilbert space.
We have seen that the first and second version lead to almost identical results for the class of lattice gauge theories considered herein. The third version led to the accumulation of short range entanglement under coarse-graining. Because this version of the algorithm restricts the fusion basis transformations, we can take this as a hint that these transformation do indeed act as pre-defined disentanglers. Furthermore, one should rather keep the degrees of freedom encoded in the electric charges associated with coarser regions. That is, for Yang-Mills lattice gauge theory, it is safe to truncate back to the gauge invariant Hilbert space after each coarse-graining step, but one should not further restrict this gauge invariant Hilbert space.
We have applied this coarse-graining algorithm to lattice gauge theory with the quantum-deformed structure group . The level in some sense determines the size of the structure group, and one regains for . Using this quantum deformation of , we can work with a finite-dimensional system—which is imperative for tensor network algorithms—and, nevertheless, keep an exact gauge symmetry. The coarse-graining algorithm allowed us to extract the critical couplings for a certain range of . Despite being able to access only a relatively small range of , we saw that the critical couplings do seem to approach zero surprisingly fast. Of course, it would be good to confirm this behaviour for larger . We have also found certain differences in the coarse-graining behaviour between the two different models, the half-integer and integer-only models, which we considered. The fusion basis algorithm allowed us to extract in a straightforward way the scaling behaviour of the Wilson loops, and to monitor the appearance and relevance of the electrical charges.
In future work, we plan to apply this algorithm to study anyon condensation [
11] as well as transitions between (weak coupling limit) vacua for different
[
12]. The latter scenario can be interpreted as a phase transition between different values of the discretized cosmological constant. Anyon condensation is much less understood than, for example, lattice gauge theory, and systems with low
already exhibit a rich structure. The algorithm is ideally suited to track whether some anyons have condensed or not. These anyons are described by the magnetic and electric charges
we employed. Condensation of an anyon type
would be indicated by the singular values for this channel
approaching a non-vanishing fixed point value. It would be also interesting to see whether there is a relation between the statistical properties of the
-dimensional systems and their
-dimensional descriptions [
22,
24].
Tensor network algorithms rely on an explicit summing procedure, so they require considerable computing resources, and much more so for higher (than two-) dimensional systems. Although the required memory and computational time scale polynomially with the system size (in our example with the level
), the power with which it scales is quite large; see the discussion in
Section 5.4. Here, we have only performed first tests of the algorithm. There are certainly a number of optimizations that can be applied, such as vectorization, multi-core parallelization on the CPU, and parallelization on multi-GPU systems.
Another possible direction to reach higher levels
is to simplify the current algorithm. One option is to use smaller building blocks, as illustrated in Reference [
5]. Another is offered by the central role observables take in our algorithm: we can aim to extract coarse-graining rules in terms of these observables. These would lead to much simpler coarse-graining descriptions, which could be compared with the results of the full algorithm, at least for small level
.
Such simpler algorithms can then be suitable to treat four-dimensional systems, for example, four-dimensional quantum gravity models, which are not amenable to Monte Carlo simulations. There are a number of long-standing open questions, for example, the understanding of the large scale limit of spin foam models, the nature of the quantum gravity vacuum [
52,
58,
61], a possible restoration of diffeomorphism symmetry [
62], and the fixing of free parameters in the models [
63,
64], which we hope can be answered by better coarse-graining algorithms.

























































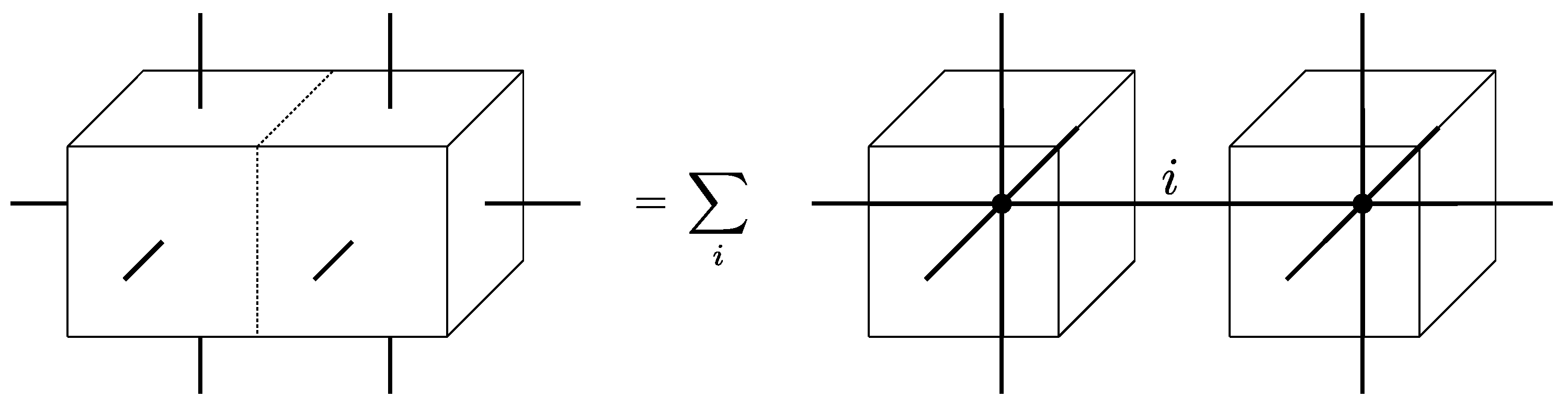{kind=link}
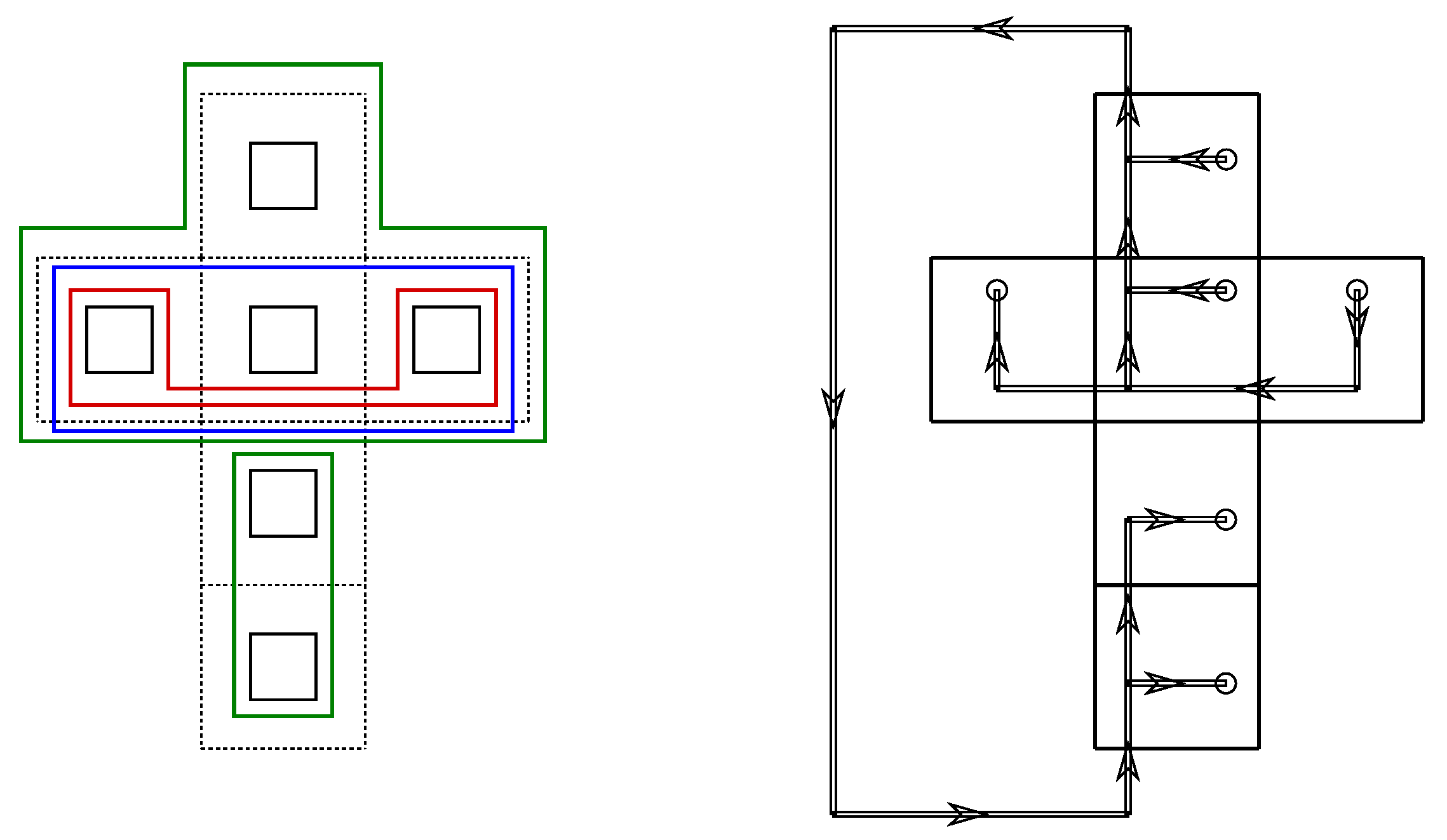{kind=link}
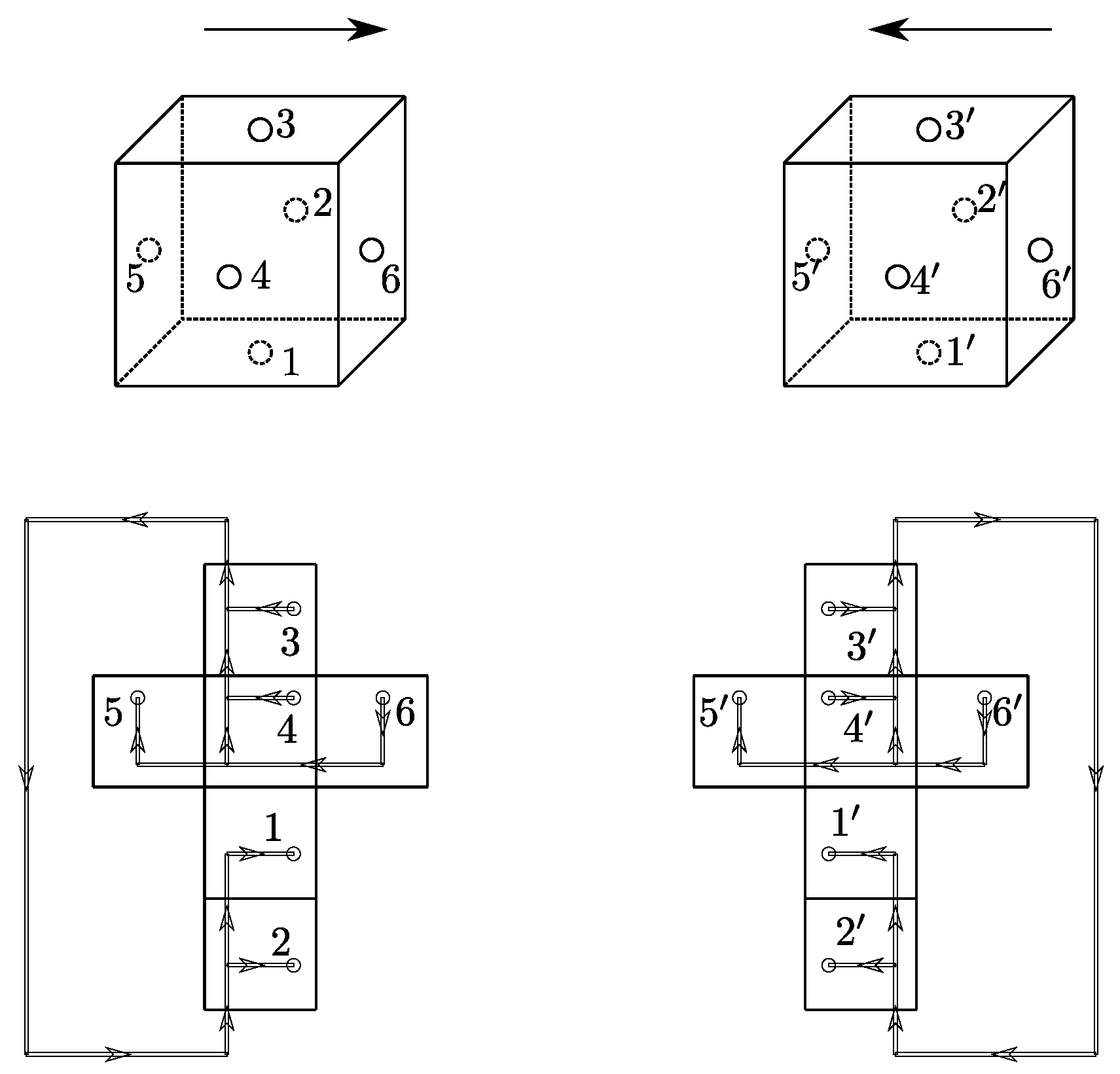{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
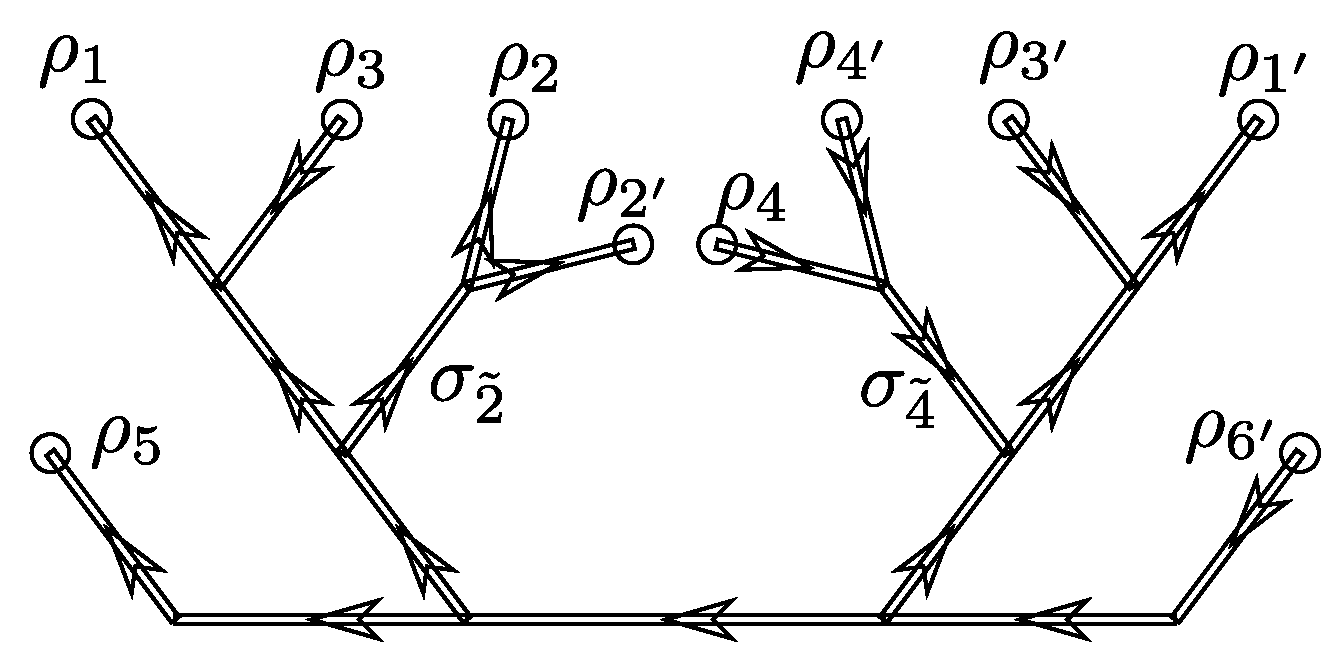{kind=link}
{kind=link}
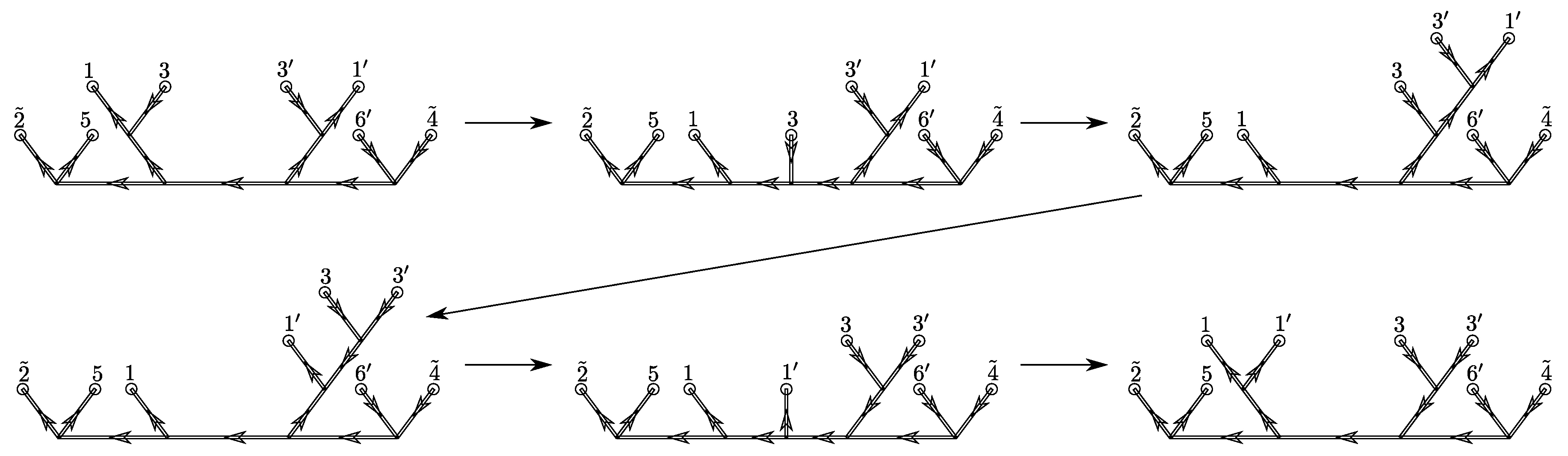{kind=link}
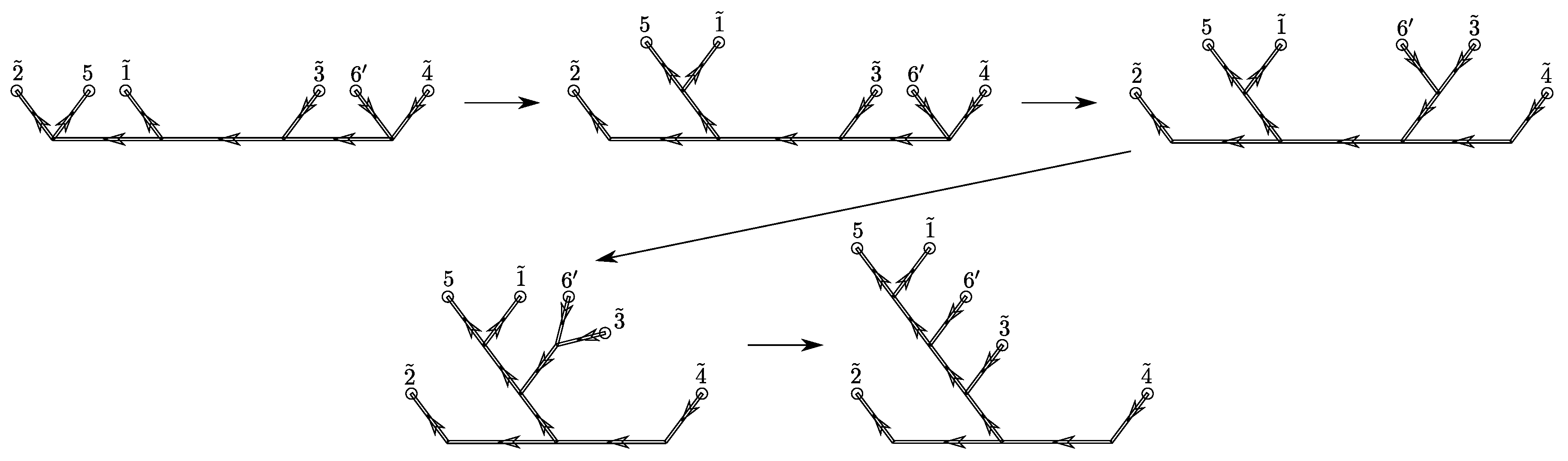{kind=link}
{kind=link}
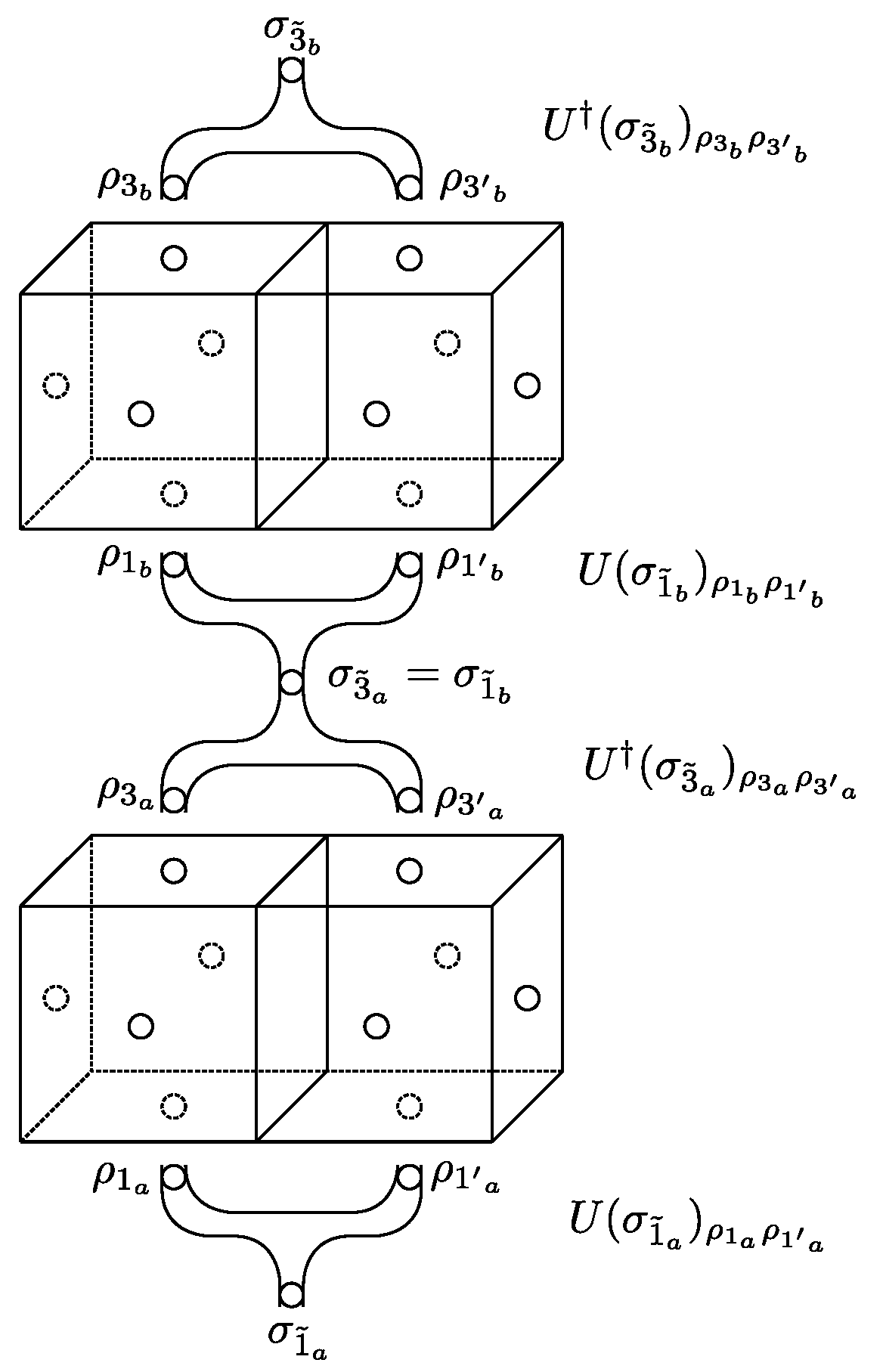{kind=link}
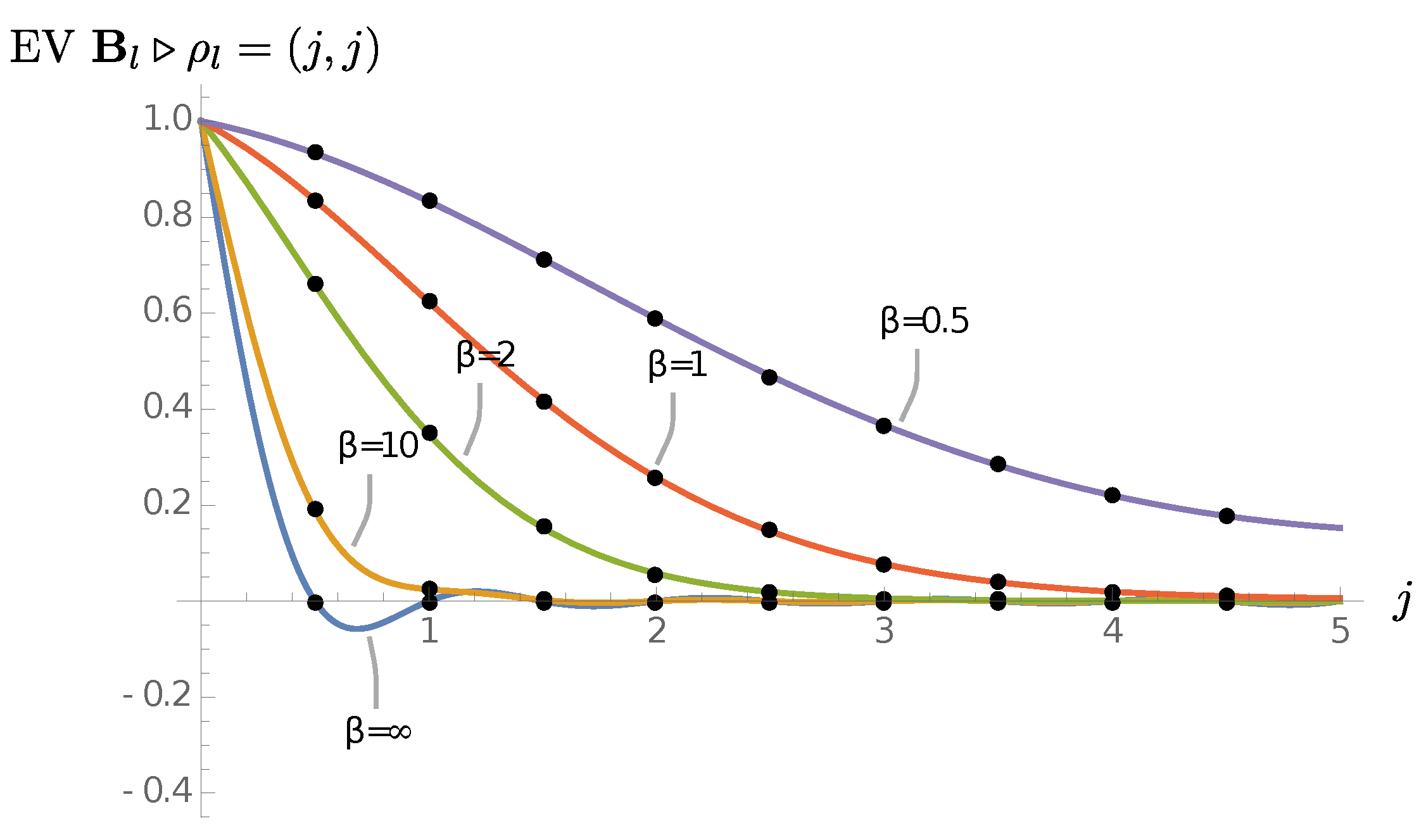{kind=link}
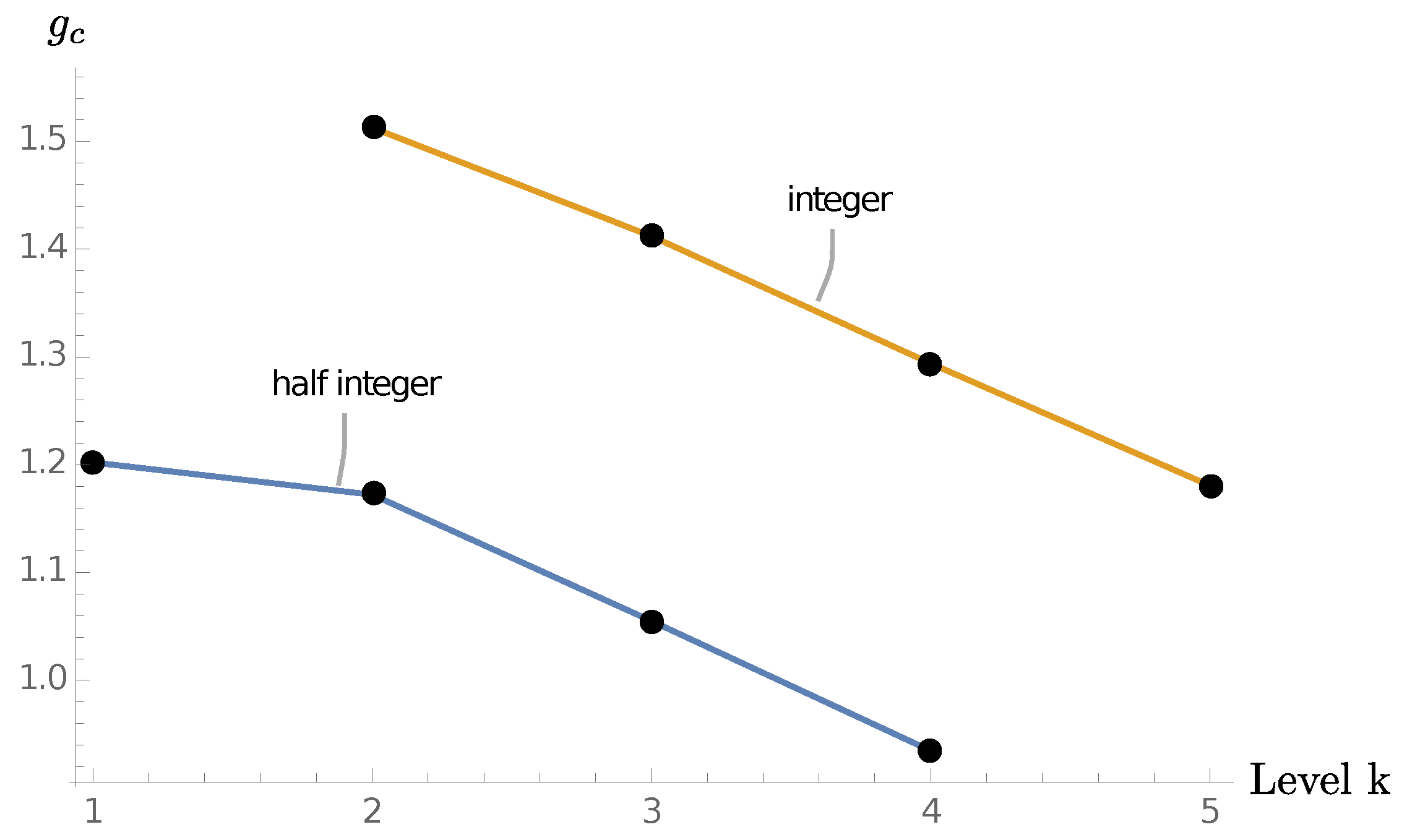{kind=link}
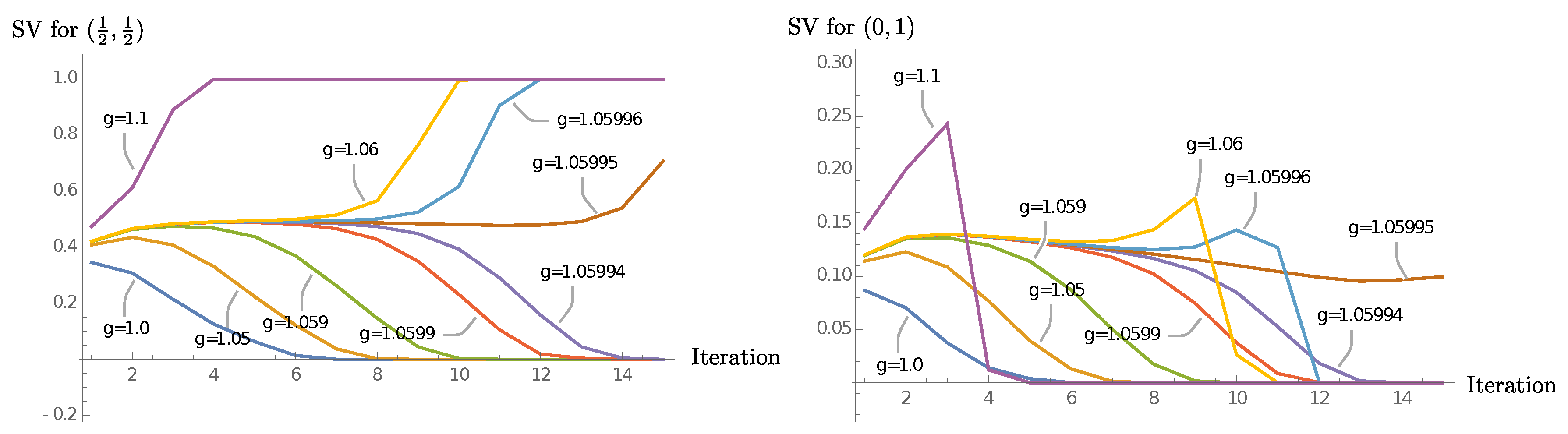{kind=link}
{kind=link}
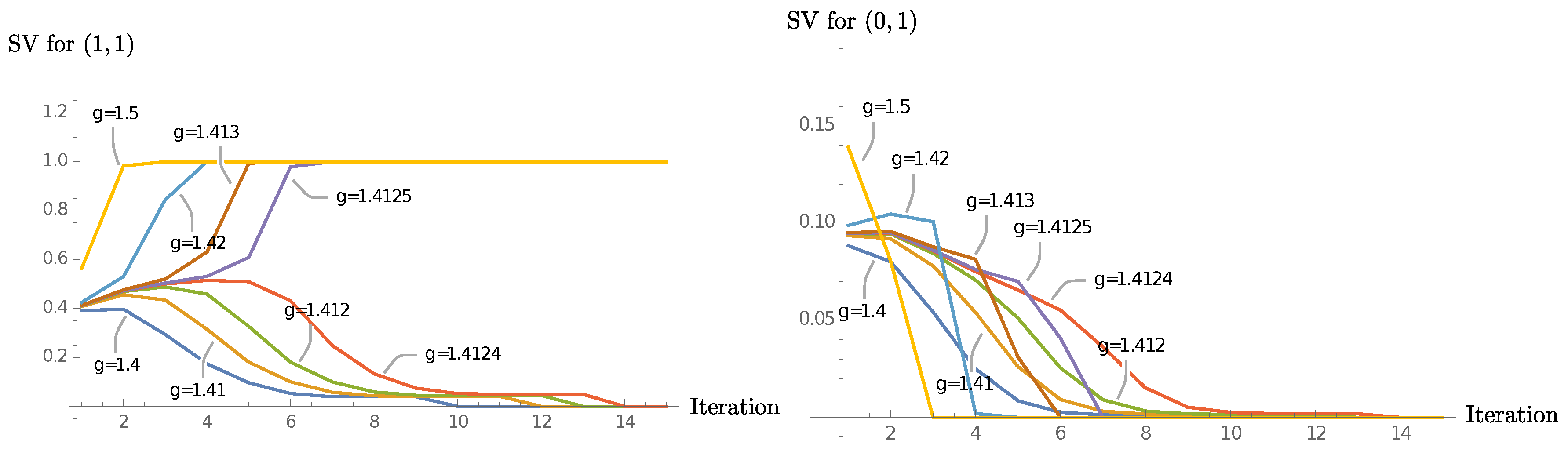{kind=link}
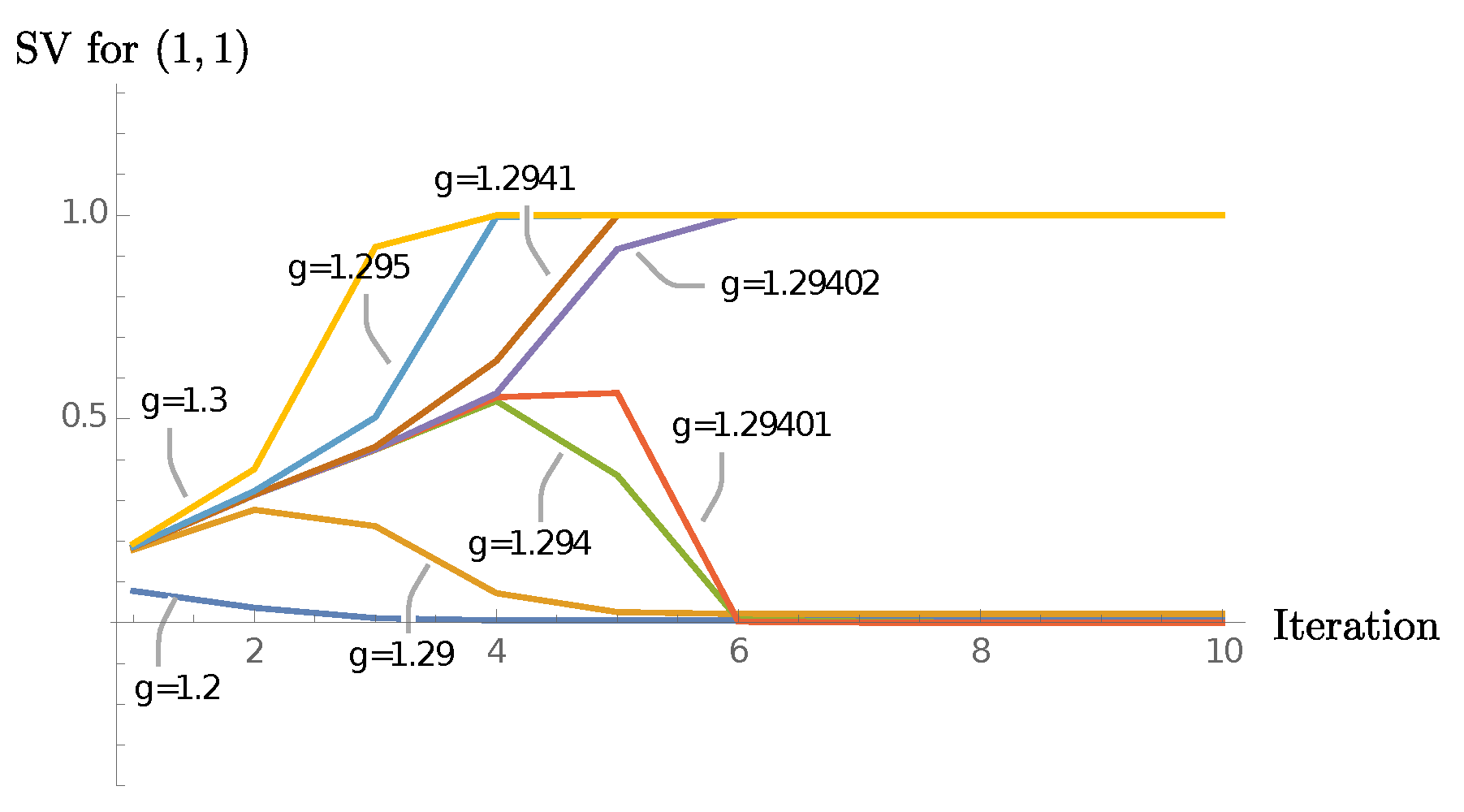{kind=link}
{kind=link}
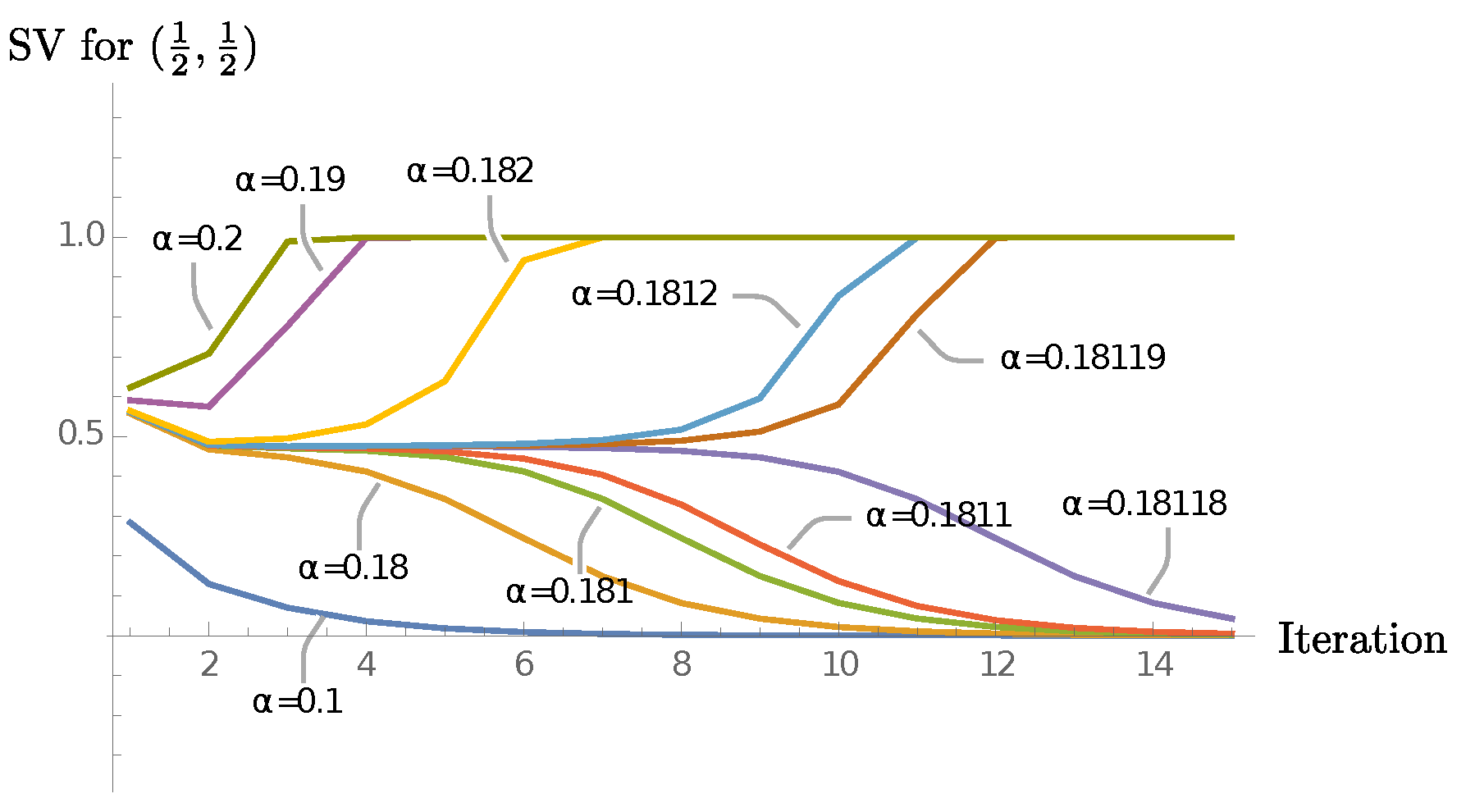{kind=link}
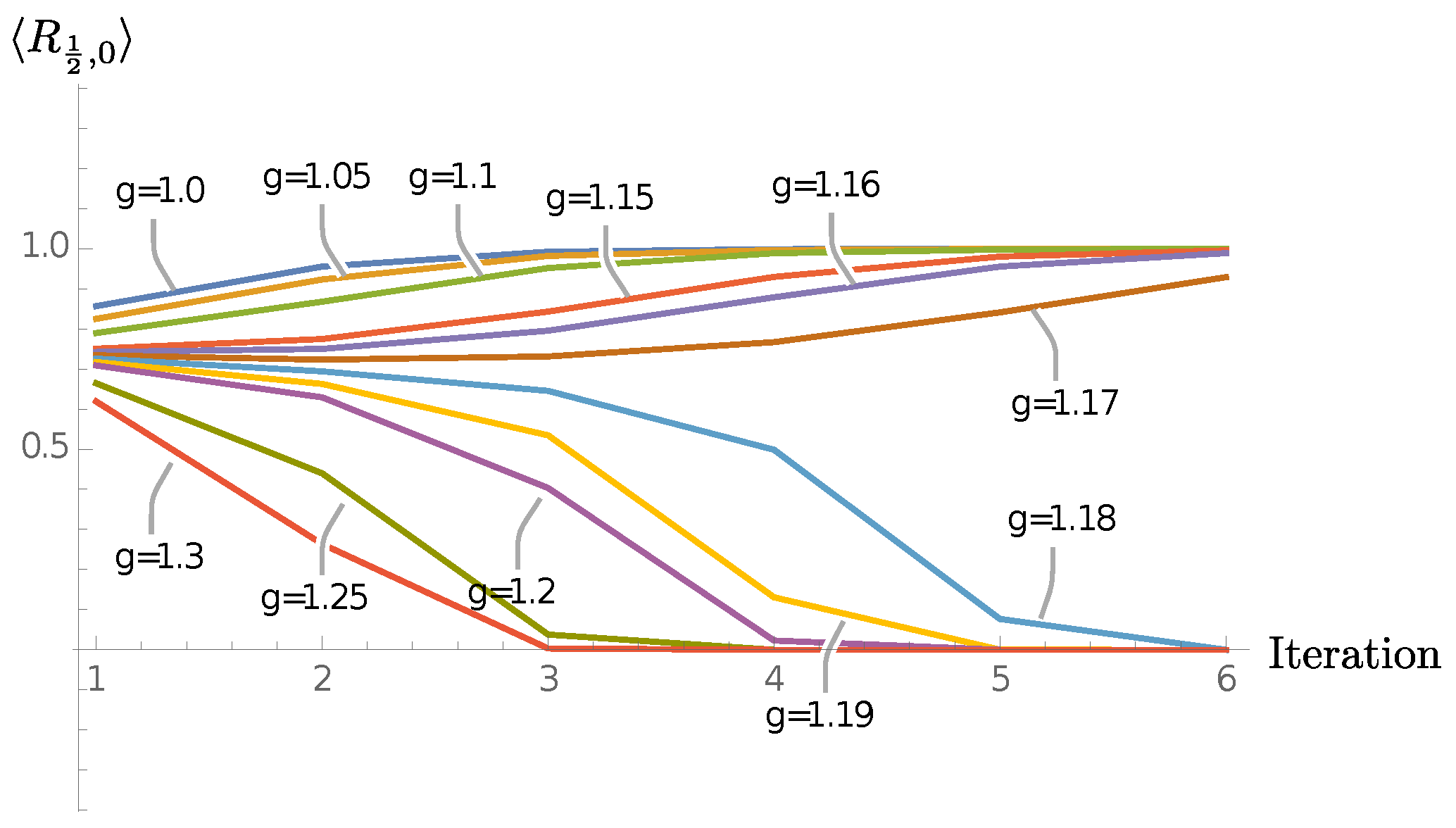{kind=link}
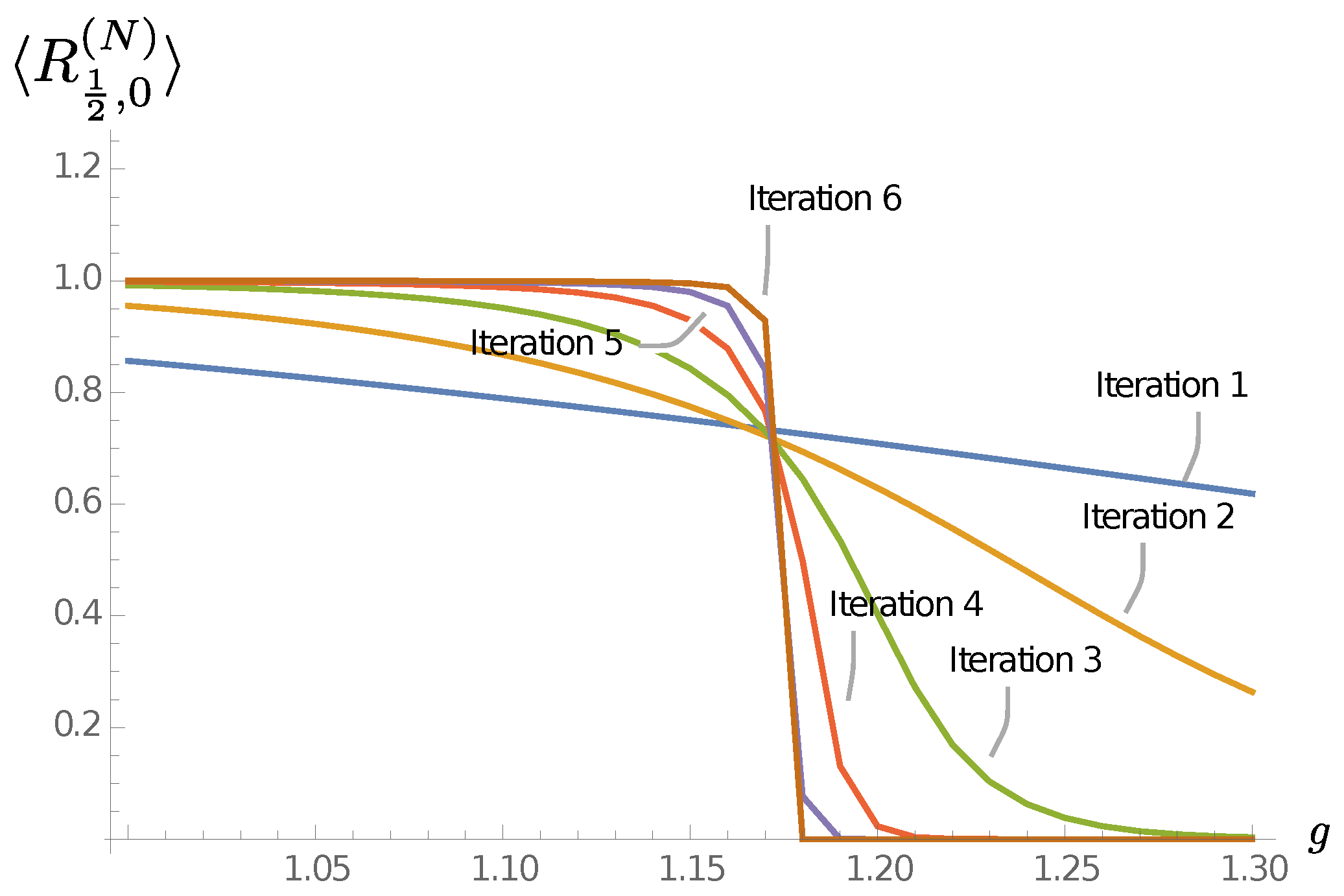{kind=link}
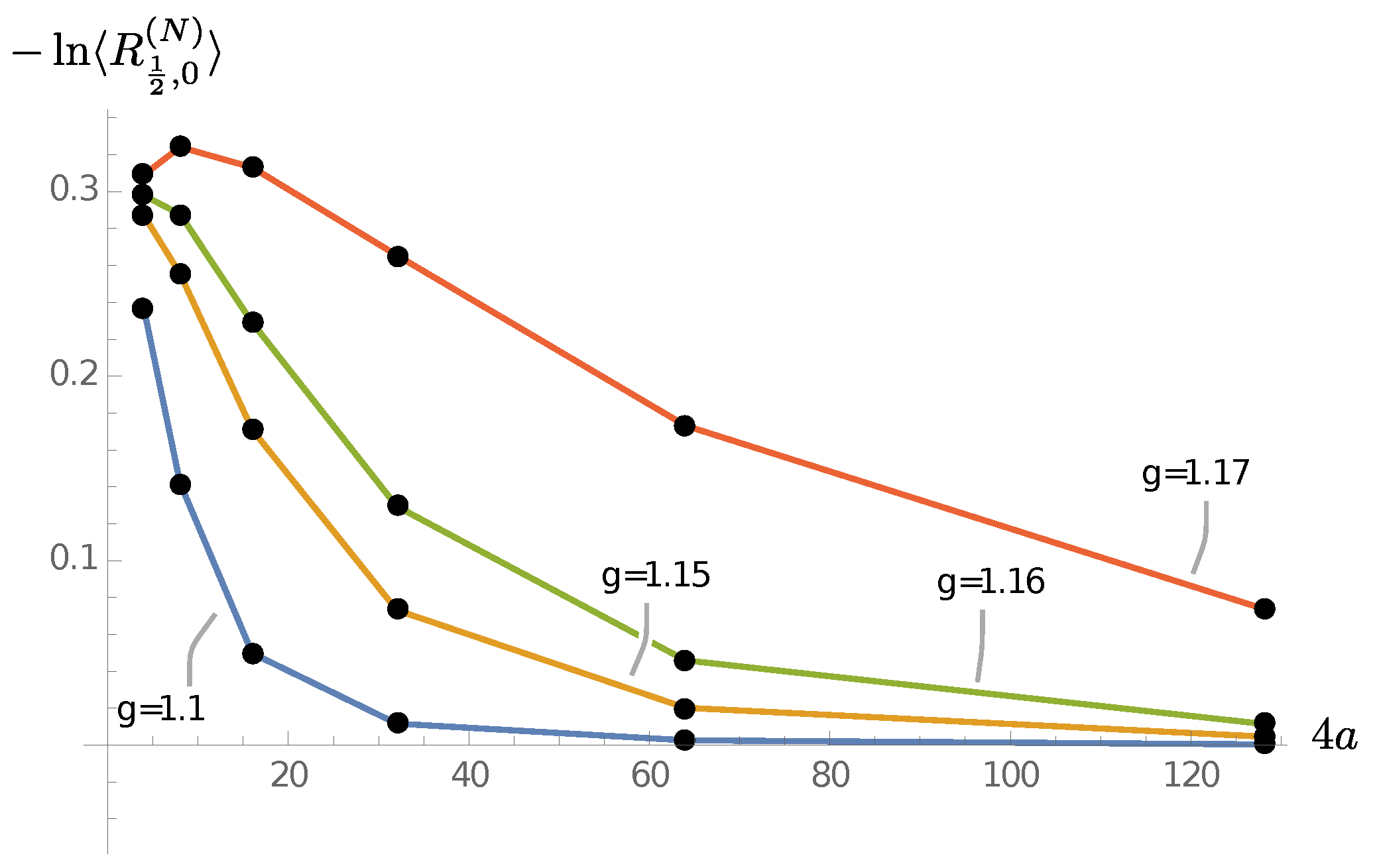{kind=link}
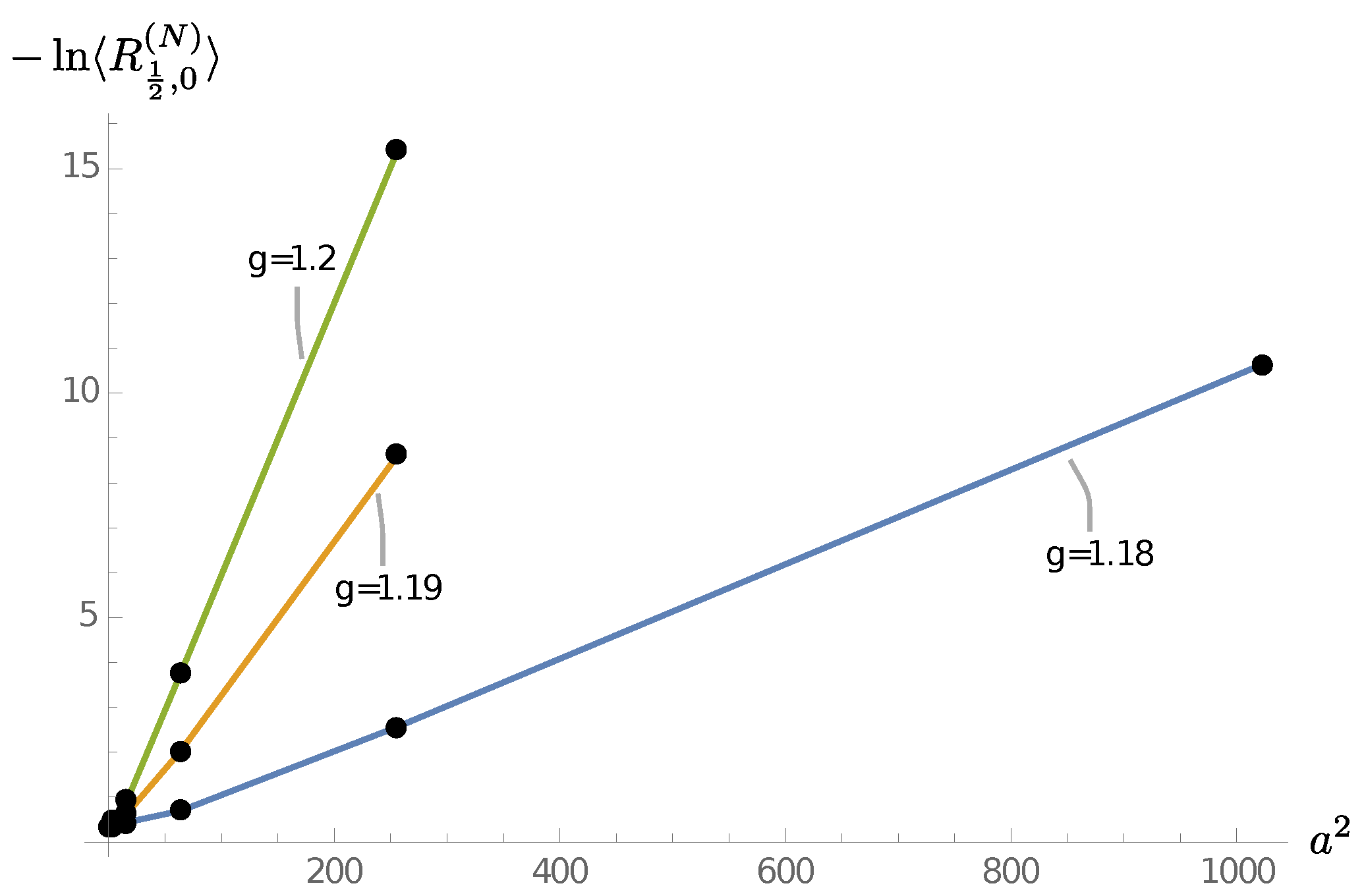{kind=link}