

Vision-Based Situational Graphs Exploiting Fiducial Markers for the Integration of Semantic Entities

 ,
,  ,
, 
 , and
, and
Abstract
1. Introduction
- A novel approach to create three-layered optimizable S-Graphs based on fiducial markers and supporting RGB-D visual sensors;
- A new solution for map reconstruction with a hierarchical representation procedure able to extract structural-level (i.e., walls and doorways) and higher-level (i.e., corridors and rooms) semantic entities;
- Utilizing the potential of semantic and geometric constraints imposed by fiducial markers for improving the quality of the reconstructed map and reducing localization errors;
- Revealing the concept and potential of iMarkers for robotic situational awareness applications.
2. Related Works
2.1. SLAM and 3D Scene Graphs
2.2. Fiducial Markers and Marker-Based SLAM
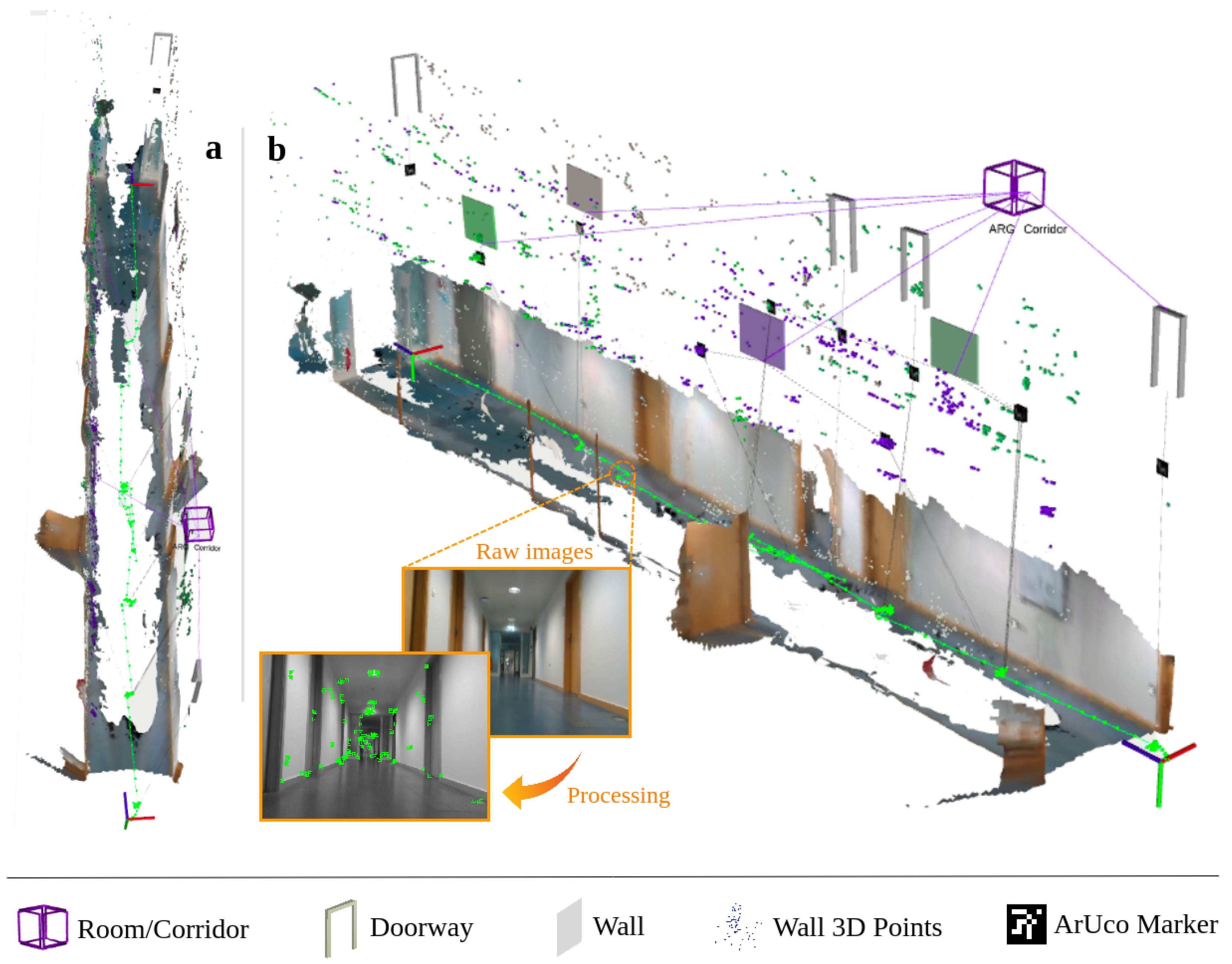
3. Proposed Method
3.1. Fundamentals
3.2. Structural-Level and Higher-Level Semantic Entities
3.3. The Final S-Graph
3.4. Inclusion of iMarkers
4. Evaluation
4.1. Evaluation Setup
4.2. Experimental Results
5. Discussions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ATE | Absolute Trajectory Error |
| CNN | Convolutional Neural Network |
| FoV | Field of View |
| IMU | Inertial Measurement Unit |
| LiDAR | Light Detection And Ranging |
| LSD | Line Segment Detector |
| ORB | Oriented FAST and Rotated BRIEF |
| ROS | Robot Operating System |
| RGB-D | Red Green Blue-Depth |
| RMSE | Root Mean Square Error |
| SLAM | Simultaneous Localization and Mapping |
| STD | Standard Deviation |
| VSLAM | Visual SLAM |
References
- Macario Barros, A.; Michel, M.; Moline, Y.; Corre, G.; Carrel, F. A comprehensive survey of visual slam algorithms. Robotics 2022, 11, 24. [Google Scholar] [CrossRef]
- Rosinol, A.; Abate, M.; Chang, Y.; Carlone, L. Kimera: An Open-Source Library for Real-Time Metric-Semantic Localization and Mapping. arXiv 2020, arXiv:cs.RO/1910.02490. [Google Scholar]
- Armeni, I.; He, Z.Y.; Gwak, J.; Zamir, A.R.; Fischer, M.; Malik, J.; Savarese, S. 3D Scene Graph: A Structure for Unified Semantics, 3D Space, and Camera. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5664–5673. [Google Scholar]
- Rosinol, A.; Gupta, A.; Abate, M.; Shi, J.; Carlone, L. 3D Dynamic Scene Graphs: Actionable Spatial Perception with Places, Objects, and Humans. arXiv 2020, arXiv:cs.RO/2002.06289. [Google Scholar]
- Hughes, N.; Chang, Y.; Carlone, L. Hydra: A Real-time Spatial Perception System for 3D Scene Graph Construction and Optimization. arXiv 2022, arXiv:cs.RO/2201.13360. [Google Scholar]
- Bavle, H.; Sanchez-Lopez, J.L.; Shaheer, M.; Civera, J.; Voos, H. S-Graphs+: Real-time Localization and Mapping leveraging Hierarchical Representations. IEEE Robot. Autom. Lett. 2023, 8, 4927–4934. [Google Scholar] [CrossRef]
- Olson, E. AprilTag: A robust and flexible visual fiducial system. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; IEEE: New York, NY, USA, 2011; pp. 3400–3407. [Google Scholar]
- Garrido-Jurado, S.; Muñoz-Salinas, R.; Madrid-Cuevas, F.J.; Marín-Jiménez, M.J. Automatic generation and detection of highly reliable fiducial markers under occlusion. Pattern Recognit. 2014, 47, 2280–2292. [Google Scholar] [CrossRef]
- Agha, H.; Geng, Y.; Ma, X.; Avşar, D.I.; Kizhakidathazhath, R.; Zhang, Y.S.; Tourani, A.; Bavle, H.; Sanchez-Lopez, J.L.; Voos, H.; et al. Unclonable human-invisible machine vision markers leveraging the omnidirectional chiral Bragg diffraction of cholesteric spherical reflectors. Light. Sci. Appl. 2022, 11, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Muñoz-Salinas, R.; Medina-Carnicer, R. UcoSLAM: Simultaneous localization and mapping by fusion of keypoints and squared planar markers. Pattern Recognit. 2020, 101, 107193. [Google Scholar] [CrossRef]
- Pfrommer, B.; Daniilidis, K. TagSLAM: Robust SLAM with Fiducial Markers. arXiv 2019, arXiv:1910.00679. [Google Scholar]
- Tourani, A.; Bavle, H.; Sanchez-Lopez, J.L.; Salinas, R.M.; Voos, H. Marker-based visual slam leveraging hierarchical representations. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023; IEEE: New York, NY, USA, 2023; pp. 3461–3467. [Google Scholar]
- Cai, D.; Li, R.; Hu, Z.; Lu, J.; Li, S.; Zhao, Y. A comprehensive overview of core modules in visual SLAM framework. Neurocomputing 2024, 590, 127760. [Google Scholar] [CrossRef]
- Al-Tawil, B.; Hempel, T.; Abdelrahman, A.; Al-Hamadi, A. A review of visual SLAM for robotics: Evolution, properties, and future applications. Front. Robot. AI 2024, 11, 1347985. [Google Scholar] [CrossRef] [PubMed]
- Bowman, S.L.; Atanasov, N.; Daniilidis, K.; Pappas, G.J. Probabilistic data association for semantic SLAM. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1722–1729. [Google Scholar] [CrossRef]
- Doherty, K.; Baxter, D.; Schneeweiss, E.; Leonard, J. Probabilistic Data Association via Mixture Models for Robust Semantic SLAM. arXiv 2019, arXiv:cs.RO/1909.11213. [Google Scholar]
- Sun, Y.; Hu, J.; Yun, J.; Liu, Y.; Bai, D.; Liu, X.; Zhao, G.; Jiang, G.; Kong, J.; Chen, B. Multi-objective location and mapping based on deep learning and visual slam. Sensors 2022, 22, 7576. [Google Scholar] [CrossRef] [PubMed]
- Yu, C.; Liu, Z.; Liu, X.J.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A semantic visual SLAM towards dynamic environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; IEEE: New York, NY, USA, 2018; pp. 1168–1174. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Yan, J.; Zheng, Y.; Yang, J.; Mihaylova, L.; Yuan, W.; Gu, F. PLPF-VSLAM: An indoor visual SLAM with adaptive fusion of point-line-plane features. J. Field Robot. 2024, 41, 50–67. [Google Scholar] [CrossRef]
- Yang, S.; Zhao, C.; Wu, Z.; Wang, Y.; Wang, G.; Li, D. Visual SLAM based on semantic segmentation and geometric constraints for dynamic indoor environments. IEEE Access 2022, 10, 69636–69649. [Google Scholar] [CrossRef]
- Wu, S.C.; Wald, J.; Tateno, K.; Navab, N.; Tombari, F. SceneGraphFusion: Incremental 3D Scene Graph Prediction from RGB-D Sequences. arXiv 2021, arXiv:cs.CV/2103.14898. [Google Scholar]
- Klokmose, C.N.; Kristensen, J.B.; Bagge, R.; Halskov, K. BullsEye: High-precision Fiducial Tracking for Table-based Tangible Interaction. In Proceedings of the Ninth ACM International Conference on Interactive Tabletops and Surfaces, Dresden, Germany, 16–19 November 2014; pp. 269–278. [Google Scholar]
- Calvet, L.; Gurdjos, P.; Charvillat, V. Camera Tracking using Concentric Circle Markers: Paradigms and Algorithms. In Proceedings of the 2012 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012; IEEE: New York, NY, USA, 2012; pp. 1361–1364. [Google Scholar]
- Lightbody, P.; Krajník, T.; Hanheide, M. A Versatile High-performance Visual Fiducial Marker Detection System with Scalable Identity Encoding. In Proceedings of the Symposium on Applied Computing, Marrakech, Morocco, 3–7 April 2017; pp. 276–282. [Google Scholar]
- Bergamasco, F.; Albarelli, A.; Torsello, A. Pi-tag: A Fast Image-space Marker Design based on Projective Invariants. Mach. Vis. Appl. 2013, 24, 1295–1310. [Google Scholar] [CrossRef]
- Uchiyama, H.; Oyamada, Y. Transparent Random Dot Markers. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; IEEE: New York, NY, USA, 2018; pp. 254–259. [Google Scholar]
- Costanza, E.; Shelley, S.B.; Robinson, J. D-touch: A consumer-grade tangible interface module and musical applications. In Proceedings of the Conference on Human-Computer Interaction (HCI03), Crete, Greece, 22–27 June 2003. [Google Scholar]
- Bencina, R.; Kaltenbrunner, M.; Jorda, S. Improved Topological Fiducial Tracking in the ReactiVision System. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05)-Workshops, San Diego, CA, USA, 20–26 June 2005; IEEE: New York, NY, USA, 2005; p. 99. [Google Scholar]
- Yu, G.; Hu, Y.; Dai, J. TopoTag: A Robust and Scalable Topological Fiducial Marker System. IEEE Trans. Vis. Comput. Graph. (TVCG) 2021, 27, 3769–3780. [Google Scholar] [CrossRef]
- Kato, H.; Billinghurst, M. Marker Tracking and HMD Calibration for a Video-based Augmented Reality Conferencing System. In Proceedings of the 2nd IEEE and ACM International Workshop on Augmented Reality (IWAR’99), San Francisco, CA, USA, 20–21 October 1999; IEEE: New York, NY, USA, 1999; pp. 85–94. [Google Scholar]
- Zhang, Z.; Hu, Y.; Yu, G.; Dai, J. DeepTag: A general framework for fiducial marker design and detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2931–2944. [Google Scholar] [CrossRef]
- Scheirer, C.; Harrison, C. DynaTags: Low-Cost Fiducial Marker Mechanisms. In Proceedings of the 2022 International Conference on Multimodal Interaction, Bengaluru (Bangalore), India, 7–11 November 2022; pp. 432–443. [Google Scholar]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual-inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | Duration | Description |
|---|---|---|
| Seq-01 | 06 min 27 s | Two rooms connected via a door |
| Seq-02 | 07 min 55 s | A corridor connected to a room and another corridor |
| Seq-03 | 12 min 32 s | Five rooms connected to a corridor |
| Seq-04 | 07 min 34 s | Two corridors connected via a landing area |
| Seq-05 | 16 min 42 s | Four corridors connected to a room, forming a loop |
| Seq-06 | 01 min 44 s | A single room connected to a corridor |
| RMSE | STD | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Seq-01 | Seq-02 | Seq-03 | Seq-04 | Seq-05 | Seq-06 | Seq-01 | Seq-02 | Seq-03 | Seq-04 | Seq-05 | Seq-06 | |
| Proposed | 0.5127 | 0.6662 | 2.3555 | 0.4479 | 2.1794 | 0.2189 | 0.2454 | 0.3332 | 0.7441 | 0.2422 | 0.7107 | 0.0796 |
| UcoSLAM [10] | 5.7996 | 3.0521 | 3.3034 | 2.1573 | 15.0184 | 1.5601 | 3.1814 | 1.3999 | 1.2332 | 1.2284 | 6.1595 | 0.8055 |
| ORB-SLAM 3.0 [34] | 0.5351 | 0.6484 | 2.5011 | 0.4895 | 2.1404 | 0.2479 | 0.2572 | 0.3334 | 0.8602 | 0.2653 | 0.7366 | 0.0815 |
| Sem. UcoSLAM [12] | 4.9437 | 2.8363 | 2.5154 | 1.9154 | 4.6672 | 1.5552 | 2.7065 | 1.3191 | 0.8582 | 1.1547 | 2.3891 | 0.8014 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tourani, A.; Bavle, H.; Avşar, D.I.; Sanchez-Lopez, J.L.; Munoz-Salinas, R.; Voos, H. Vision-Based Situational Graphs Exploiting Fiducial Markers for the Integration of Semantic Entities. Robotics 2024, 13, 106. https://doi.org/10.3390/robotics13070106
Tourani A, Bavle H, Avşar DI, Sanchez-Lopez JL, Munoz-Salinas R, Voos H. Vision-Based Situational Graphs Exploiting Fiducial Markers for the Integration of Semantic Entities. Robotics. 2024; 13(7):106. https://doi.org/10.3390/robotics13070106
Chicago/Turabian StyleTourani, Ali, Hriday Bavle, Deniz Işınsu Avşar, Jose Luis Sanchez-Lopez, Rafael Munoz-Salinas, and Holger Voos. 2024. "Vision-Based Situational Graphs Exploiting Fiducial Markers for the Integration of Semantic Entities" Robotics 13, no. 7: 106. https://doi.org/10.3390/robotics13070106
APA StyleTourani, A., Bavle, H., Avşar, D. I., Sanchez-Lopez, J. L., Munoz-Salinas, R., & Voos, H. (2024). Vision-Based Situational Graphs Exploiting Fiducial Markers for the Integration of Semantic Entities. Robotics, 13(7), 106. https://doi.org/10.3390/robotics13070106