1. Introduction
Plants provide food for all living things, making them the backbone of the ecosystem [
1]. Plant species are valuable as medicine, foodstuff, and also for industrial applications. Some plants are at risk of extinction. So, it is imperative to set up a database for plant protection. Manual examination of the plant with the naked eye is the most basic or conventional technique. This procedure, involves constant supervision of a wide range of farm areas by experts [
2,
3]. This is a time-consuming and costly procedure. To achieve plant protection, the classification of the plant plays an essential role [
4]. Plants leaves are easily accessible and prominent parts, unlike flowers which are available for a shorter period. The leaves are, therefore, a good choice for automatic plant classification. The leaves are important in exploring the genetic relationship of plants and the explanation of plant development. However, given a large number of species, plant identification, even for botanists, is a relatively difficult task [
5,
6]. The leaf recognition technology was followed by botanists for classifying specific plant species. Plants generally have distinctive features that differ in many aspects, such as texture, shape, color, and size; they are different [
7]. In the last couple of years, different “Computer-Aided Detection” (CAD) methods are deployed for leaf based plant recognition owing to their high classification accuracy [
8,
9].
The interdisciplinary approach of plant classification combines botanical data, and the concept of species with computer solutions [
10]. Recent advances in science and technology allow computer vision approach to help botanists to identify plants. Computer vision researchers have used leaves to classify plants as a comparative tool [
11]. From the machine learning point of view, the classification problem can be addressed by adopting a new quick solution, which will bring experts, farmers, decision-makers, and strategists into a single chorus [
12].
In recent years, evolutionary neural networks have attracted much attention of the researchers because of their ability to give superior image classification accuracy. They combine the neural network and computation to solve any problem. Krizhevsky et al. [
13] set a record of 10.9% more classification accuracy compared to the second-best entry in ImageNet in the 2012 Large Scaled Challenge for Visual Recognition. Advances in the processing of images provided various preprocessing techniques for the extraction of images. Feature extraction is the step taken to identify discriminatory characteristics that form the basis for classification. The classification task can be performed with multiple learning technologies such as “Support Vector Machines” (SVM), Naïve Baye, “K-Nearest Neighbor” (KNN), and “Convolutional Neural Network” (CNN) [
14].
Deep learning is a subset of machine learning that consists of a set of algorithms for modeling high-level data abstractions using a deep graph with multiple processing layers that include linear and non-linear transformations [
15]. CNNs are well-suited for image classification tasks due to their close relationship between layers and spatial information, which explains their popularity in recent plant classifiers.
Several studies have found that image-based assessment methods produce more accurate and consistent results than human visual assessments [
16]. A lot of work has been completed to classify things using various techniques. Lecun et al. [
17] introduced the basic deep learning tool of CNN as an introduction to deep learning model techniques in the field of classification and detection. In recent years, deep learning models have been used to a small extent in agriculture. CNNs are a form of a dynamic model that aids classification applications. For classification, there are many CNN models, such as AlexNet [
13], GoogLeNet [
18], ResNet50, ResNet18, ResNet101 [
19], VGG16, VGG19 [
20], DenseNet [
21], SqueezeNet [
22], and others.
Mohanty et al. [
23] classified 14 different plant leaves using AlexNet and GoogLeNet, with an accuracy of 99.27% and 99.34%, respectively. The authors used different input data, such as color images, segmented images, and grayscale images separately. Dyrmann et al. [
24] classified the plant leaf data with a CNN model and achieved an accuracy of 86.2%. Barré et al. [
25] in their work for plant leaf classification, used LeafSnap, Foliage, and Flavia dataset for classification of different classes with their proposed model LeafNet. A total of 184 classes of LeafSnap were classified with an accuracy of 86.3%, and 60 classes of the Foliage dataset were classified with an accuracy of 95.8%. They achieved the performance accuracy of 97.9% for the Flavia dataset with 32 classes. A deep CNN model [
10] with “Multilayer Perceptron” (MLP) classifier achieved 97.7% accuracy and improved to 98.1% accuracy with SVM classifier for the MalayaKew dataset with 44 classes. Haque et al. [
26] have presented work for plant classification that uses geometric features in preprocessing and achieved an accuracy of 90% for the classification of 10 plant species of Flavia dataset. Gao et al. [
1] achieved an accuracy of 84.2% in a LifeCLEF Plant Identification Task with their proposed 3SN Siamese network that learns from spatial and structural features for the leaf classification task. The recognition of plant family and further identifying the plant class for the four datasets was performed with two ways attention CNN model by [
27].
In the preparation of Ayurvedic medicines, the identification and classification of medicinal plants play an essential role. In addition, it is important for farmers, botanists, practitioners, the forest department’s offices, and those involved in the preparation of Ayurvedic medicines for a correct classification of medicinal plants. Medicinal plant classification by [
28] with AlexNet model achieved an accuracy of 94.87%, and for the Ayurleaf CNN model, the accuracy is 95.06%. Duong-Trung et al. [
12] achieved 98.5% classification accuracy with the MobileNet model for 20 species of self-collected medicinal plant data.
Liu et al. [
29] proposed a ten-layer CNN model for the classification of plant leaf and achieved an accuracy of 87.92% for the 32 classes. ResNet model gave the classification accuracy of 93.09% for plant identification with LeafSnap dataset [
9]. Plant leaf classification was completed by [
5] on the images captured by Silva et al. [
30] using an Apple iPad device. The Deep Neural network (DNN) model shows 91.17% accuracy, and with the CNN model, the accuracy is improved to 95.58%. The classification of plant leaf with the complex background was completed by [
6] on the images captured through mobile phones. The classification accuracy is 91.5%, 92.4%, and 89.6% for VGG16, VGG 19, and the Inception ResNetV2 model, respectively. For the identification of the berry plants, Ref. [
14] used the AlexNet model and achieved an accuracy of 97.80% for the three classes of self-collected data of berry plants. A comparative analysis of the work related to the classification of plants is shown in
Table 1.
Once the classification of the plant is completed, further work can be extended to the classification of disease. The VGG16 model was trained with transfer learning for the apple leaf disease and yielded an overall accuracy of 90.4% [
16]. With the augmented dataset of 14828 images of tomato leaves, Ref. [
31] achieved an accuracy of 98.66% for AlexNet and 98.18% for the VGG16 model. A small CNN was proposed by [
32] for the classification of the plant into a healthy or diseased category and achieved an accuracy of 96.6%. The classification accuracy achieved by [
33] for tomato plant disease with the laboratory data is 98.50% for the VGG16 model, 98.30% for the VGG19 model, 99.40%for ResNet model, and 99.60% for the Inception V3 model. The proposed model of [
34] outperformed AlexNet and VGG16 with an accuracy of 99.45% in the classification of tomato plant leaf, with an accuracy of 90.1%.
Guava fruit diseases classification by [
35] achieved an accuracy of 99% for the Bagged Tree classifier on a set of RGB, HSV, and LBP features. Detection of Cassava plant disease by [
36] achieved an accuracy of 96.75% with the deep residual neural network model. Alli et al. [
37] used a data augmentation method to achieve an accuracy of 99.7% for cassava plant disease classification using MobileNetV2. Pearl millet disease classification with an automated method of collecting the pearl millet data from the farm and classifying the disease with a Custom-Net model with an accuracy of 98.78% [
38]. A comparative analysis of the work related to plant disease classification is shown in
Table 2.
In this work, the proposed CNN models are used for the classification of plant species for the PlantVillage (PV) and Flavia datasets. The performance of the developed models are compared with the AlexNet model with transfer learning. The proposed models have less depth as compared to AlexNet. The proposed models are compact in size and require less training time, maintaining good accuracy. The main contributions of this work are as follows:
Three highly accurate and compact models namely, N1, N2, and N3 are proposed for plant leaves classification. The proposed models show high classification accuracy, and they require less training time;
The performance of the models is validated by employing them to classify leaves from challenging PV and Flavia datasets. The models exhibit high classification accuracy;
To validate the versatility of the proposed models, they are also employed in tomato leaves disease classification using images captured from mobile phone. The disease classification accuracy shows that the proposed models are well suited for both plant leaves classification and disease classification.
3. Results and Discussion
The PV dataset with nine species of plants is shown in
Figure 3. The classes are abbreviated as follows. Apple plant with four varieties are A; Cherry with two varieties are Ch. Corn with four varieties are Co; Grape with four varieties are G. Peach with two varieties are Pch; Pepper with two varieties are Pep; potato with three varieties is Po. Strawberry with two varieties are S; tomato with nine varieties are To.
The 32 classes of the Flavia dataset are shown in
Figure 4. The classes are abbreviated as “Anhui Barberry” is AB, “Beale’s Barberry” is BB, “Big-Fruited Holly” is BFH, “Castor Aralia” is CA, “Camphortree” is Cam, “Chinese Cinnamon” is CC, “Chinese Horse Chestnut” is CHC, “Crape Myrtle” is CM, “Canadian Poplar” is CP, “Chinese Redbud’ is CR, “Chinese Toon” is CT, “Chinese Tulip Tree” is CTT, “Deodar” is D, “Ford Woodlotus” is FW, “Ginkgo Maidenhair Tree” is GMT, “Glossy Privet” is GP, “Goldenrain Tree” is GT, “Japan Arrowwood” is JA, “Japanese Cheesewood” is JC, “Japanese Flowering Cherry” is JFC, “Japanese Maple” is JM, “Nanmu” is N, “Oleander” is O, “Peach” is P, “Pubescent Bamboo” is PB, “Southern Magnolia” is SM, “Sweet Osmanthus” is SO, “Tangerine” is T, “Trident Maple” is TM, “True Indigo” is TI, “Wintersweet” is W, and “Yew Plum Pine” is YPP. All the 32 classes belong to different species here.
The pre-processing of the dataset is discussed in
Section 2.2. The dataset is augmented with augmented data 1 (ad1) and augmented data 2 (ad2) and further resized to 256 × 256 × 3 for the proposed models and 227 × 227 × 3 for the AlexNet. Some of the data augmented images are shown in
Figure 5.
Classification of leaves of plants is performed using proposed compact models N1, N2, N3, and AlexNet with transfer learning. The classification accuracy of these models on a dataset, ad1, and ad2 is shown in
Figure 6. The classification accuracy increases with the augmented dataset. More features are studied in the ad2, along with the increase in the number of images that are used for training the models. This helps in learning the model and achieving better prediction in terms of accuracy. The accuracy of the proposed N1 model is 86.58% with dataset and increased to 89.31% with ad1 and 99.45% with ad2. The accuracy of the proposed N2 model is 92.09% with the dataset and increased to 99.65% with ad2. The accuracy of the proposed N3 model is 89.61% and increases to 89.8% with ad1 and 99.55% with ad2. AlexNet shows an accuracy of 98.53% with a dataset and increases to 99.73% with ad2. The accuracy of the N1 model, N2 model, N3 model, and AlexNet is almost the same for ad2. The time for training the model increases as the number of images increase. The training time for the N1 model, N2 model, N3 model, and AlexNet model is shown in
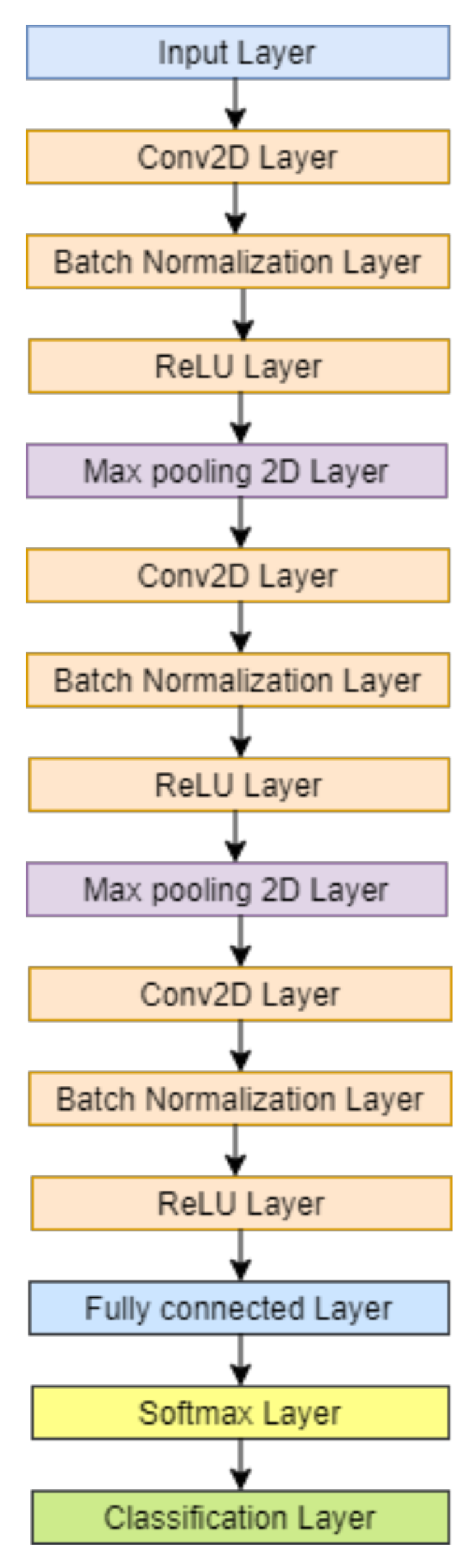
Figure 7. The proposed N1, N2, and N3 models take less training time as compared to the AlexNet model. The number of layers and the size of the filter used in the proposed CNN N1 model, N2 model, and N3 model is less than the traditional AlexNet model. There are three CNN layers in the proposed developed model, whereas there are five Convolutional layers in AlexNet. The filter size is also more in AlexNet as compared to proposed developed models. The number of CNN layers and the size of the filters used in our developed model is compact as compared to AlexNet. This reduces the complexity of the model and so the training time required for the model is less.
Overfitting occurs when your model fits well on the training data, but it does not generalize well on new, unseen data. Overfitting problem can be prevented by taking measures such as data augmentation, simplifying the models, using dropout, regularization, and early stopping [
39,
44,
45]. In this work, we have used two epochs for training the model. The learning rate for the model is 0.0001. The training accuracy and training loss, along with the validation accuracy and validation loss, is as shown in
Figure 8. The model with increasing training accuracy and validation accuracy and also decreasing training loss and validation loss shows that overfitting is prevented. The training accuracy and training loss are shown in
Figure 8, (a) N1 model, (c) N2 model, (e) N3 model, and (g) AlexNet model. The validation accuracy and validation loss are shown in
Figure 8, (b) N1 model, (d) N2 model, (f) N3 model, and (h) AlexNet model.
The comparison of models in terms of accuracy and size of the models with existing models are shown in
Table 5. Jeon and Rhee [
46] achieved an accuracy of 99.60% with GoogLeNet. Kaya et al. [
47] in their work of plant classification, used PV and Flavia dataset with AlexNet and VGG16 models. Wang and Wang [
48] classified plants with an accuracy of 84.47% with VGG16 and ResNet50 with 92.64%. For the VGG16 and VGG 19 models, the accuracy achieved by of models is 81.3% and 96.25%, respectively [
49]. The combination of pruning and post-quantization was applied to VGG16, AlexNet, and LeNet model [
50]. The pruning step was responsible for reducing the model size. The performance of models is 91.49%, 96.59%, and 95.2%, respectively. The ten-layer CNN model by [
29] achieved an accuracy of 87.92% with the Flavia dataset and 84.02% with the PV dataset. The accuracy of the proposed N1 model is 99.45%, proposed N2 model is 99.65%, proposed N3 model is 99.55%, and AlexNet with transfer learning is 99.73% with the models trained with ad2. The size of the proposed trained models is 14.8 MB, 29.7 MB, and 14.8 MB, respectively, for the N1 model, N2 model, and N3 model as compared to AlexNet, which is 202 MB. The proposed N1 model and N3 model are 92.67% more compact than AlexNet, and the N2 model is 85.29% compact than AlexNet showing the same range accuracy results. The time for training the N1 model and N2 model is also less. The N1 model takes around 34.58% less training time than AlexNet, and the N2 model takes around 18.25% less training time than AlexNet. N3 model takes 20.23% less training time than AlexNet.
The classified output images for the proposed N1 model, N2 model, N3 model, and AlexNet with transfer learning with 80% of training data for the PV dataset images are shown in
Figure 9. The models are trained with a dataset, ad1, and ad2 and their classified output is shown here. The classified output for the proposed models and AlexNet model is shown in
Figure 9, (a) N1 model with the dataset, (b) N2 model with the dataset, (c) N3 model with dataset, (d) AlexNet model with the dataset, (e) N1 model with ad1, (f) N2 model with ad1, (g) N3 model with ad1, (h) AlexNet model with ad1, (i) N1 model with ad2, (j) N2 model with ad2, (k) N3 model with ad2, (l) AlexNet with ad2. The abbreviations used for the classified output images for the PV dataset are mentioned at the start of the Results and Discussion section.
The classified output images for the proposed N1 model, N2 model, N3 model, and AlexNet with transfer learning with 80% of training data for the Flavia dataset images are shown in
Figure 10. The models are trained with a dataset, ad1, and ad2 and their classified output is shown here. The classified output for the proposed models and AlexNet model is shown in
Figure 10, (a) N1 model with the dataset, (b) N2 model with the dataset, (c) N3 model with dataset, (d) AlexNet model with the dataset, (e) N1 model with ad1, (f) N2 model with ad1, (g) N3 model with ad1, (h) AlexNet model with ad1, (i) N1 model with ad2, (j) N2 model with ad2, (k) N3 model with ad2, (l) AlexNet with ad2. The abbreviations used for the classified output images for the Flavia dataset are mentioned at the start of the Results and Discussion section.
The performance of the classification by the models trained with a dataset, ad1, and ad2, is evaluated on the PV dataset by confusion matrix as shown in
Table 6 for the proposed N1 model, N2 model, N3 model, and AlexNet. The confusion matrix shows the information about classification and misclassification by the model. The diagonal elements show the correct classification, and the non-diagonal elements show the misclassification information.
Table 6a shows the confusion matrix for the proposed N1 model trained for 80% dataset and tested for 20% of a dataset remaining. The diagonal elements show the correct classification of each class, and cells are colored in yellow.
The effect of data augmentation on the confusion matrix of N1, N2, N3, and AlexNet models with ad1 and ad2 is shown in
Table 6b. The negative number shows a decrease in classification, and a positive sign indicates an increase in classification. The cell colored in green shows the increase in classification accuracy (percentage), and the cell colored in grey shows misclassification (percentage) after data augmentation.
It is seen that the performance of the model is improved with the models trained with an augmented dataset. The accuracy of the proposed N1 model for the PV dataset is improved by 7.9% and 14.7% for the “Ch” class for the model trained with ad1 and ad2, respectively. The “Pep” class accuracy is improved by 10% and 24.3% for the model trained with ad1 and ad2, respectively. The performance of the proposed N2 model is improved by 11.3% and 21% for the “Pep” class for a model trained with ad1 and ad2, respectively. The accuracy of the N2 model is improved by 2% and 6% with a model trained with ad1 and ad2, respectively, for the “To” class. The accuracy of the proposed N3 model is improved by 8.3% and 11% for the “Po” class for the model trained with ad1 and ad2, respectively. The “Pch” class accuracy is improved by 8.9% with ad2. The performance of the AlexNet model is improved by 1.3%for the “Pch” class for a model trained with ad1. In the case of AlexNet trained with ad2, the accuracy of two classes is reduced viz. “A” and “S.” The accuracy performance for the proposed developed network N1 model, N2 model, and N3 model is seen to be improved for each of the classes with ad2.
The classification performance of the models trained with a dataset, ad1, and ad2 is evaluated on the Flavia dataset by confusion matrix as shown in
Table 7 for the proposed N1 model.
Table 7a shows the confusion matrix for the proposed N1 model trained for 80% dataset and tested for 20% of a dataset remaining. The diagonal elements show the correct classification of each class, and cells are colored in yellow. The effect of data augmentation on the confusion matrix of N1, N2, N3, and AlexNet models with ad1 and ad2 is shown in
Table 7b. The negative number shows a decrease in classification, and a positive sign indicates an increase in classification. The cell colored in green shows the increase in classification accuracy (percentage), and the cell colored in grey shows misclassification (percentage) after data augmentation.
The accuracy of the proposed N1 model for the Flavia dataset is improved by 5% and 12.4% for the “CR” class for the model trained with ad1 and ad2, respectively, and 10.8% and 16% for the proposed N2 model with ad1 and ad2. The “CT” class accuracy is improved by 7.5% with ad1 and 20.4% with ad2 for the proposed N1 model. The performance of the N2 model is improved by 7% and 13% for the “GMT” class for a model trained with ad1 and ad2, respectively. The accuracy of the proposed N3 model is improved by 19.3% for the “CC” class for the model trained with ad2. The performance of the AlexNet model is improved by 5.8% and 5.7% for the “YPP” class for a model trained with ad1 and ad2, respectively.
Data augmentation influences the average precision of the class [
53,
54]. Based on the confusion matrix, the performance parameters of macro recall, macro precision, macro F1 score, and mean accuracy are evaluated for the PV and Flavia datasets. The performance parameters of the proposed N1 model, N2 model, N3 model, and AlexNet is shown in
Table 8. The performance parameters of macro recall, macro precision, macro F1 score, and mean accuracy for the PV and Flavia dataset are compared here for data, ad1 and ad2. It is seen that the performance parameters are improved with the ad2. The proposed developed N1, N2, and N3 models have the same range performance as AlexNet. The size of these models is much more compact to AlexNet and gives great results.
For analyzing the results of the experimental designs by statistical tests, an analysis of variance (ANOVA) is developed by [
55]. The ANOVA is performed on the performance parameters for the proposed models, and AlexNet trained with the dataset, ad1, and ad2 of both the datasets is shown in
Table 9,
Table 10 and
Table 11. The parameters evaluated are Sum of Squares (SS), degree of freedom (df), mean squares (MS),
p-value, F value, and F critical value. The condition for statistical significance is evaluated based on the
p-value and if the F value is less than the F critical value. If the
p-value is between 0.0001 to 0.001, then it is extremely statistically significant when the
p-value is between 0.001 to 0.01, then it is very statistically significant when the
p-value is between 0.01 to 0.05, then it is statistically significant, and when the
p-value is greater than 0.05, then there is no statistical significance. In all three tables for ANOVA, we can see the statistical significance for the models evaluated on both datasets.
The ability of the trained model to classify new data is an important factor in decision making. The PV dataset has nine classes belonging to nine plant species. The classification of plant species for PV dataset images that were not part of the training and testing dataset is completed. The validation accuracy of the N1 model, N2 model, N3 model, and AlexNet models trained with PV dataset is shown in
Table 12. The images that were not part of the training and testing dataset are used for validation of the model into respective species. The validation performance of pepper is lower compared to other species. The proposed N2 model classifies the apple species with 92.5% accuracy, N2 model and AlexNet model classify cherry with 95% accuracy. The validation accuracy of the N2 model and AlexNet is 97.5% for the corn. The validation of grape, peach, and strawberry is good for all the models. The validation accuracy of the N3 model for tomato is 91.11%. Overall, the performance of the N2 model is more as compared to N1 and N3 models.
The classification of plant species for Flavia dataset images that were not part of the training and testing dataset is completed. In the case of the Flavia dataset, each of the 32 classes belong to different plant species. Validation accuracy of proposed N1 model, N2 model, N3 model, and AlexNet models trained with Flavia dataset is shown in
Table 13. Almost all the species are showing good classification except for the Cam class. Overall, the N2 model is performing equally well as AlexNet. N2 model achieves better performance in classification, as well as validation for PV and Flavia dataset with compact model size.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

