
An Approach for Plant Leaf Image Segmentation Based on YOLOV8 and the Improved DEEPLABV3+

Abstract
:1. Introduction
- Plant leaf object detection and image segmentation datasets were constructed. The original images from a public leaf segmentation dataset [27] were annotated and transformed according to the YOLO dataset format to produce a new leaf dataset for object detection. The image segmentation task was performed on this public leaf dataset. The plant leaf dataset can be accessed at https://ytt917251944.github.io/dataset_jekyll (accessed on 24 November 2022).
- To reduce the interference of the background in leaf segmentation tasks, an object detection algorithm based on YOLOv8 was proposed. The experimental results show that leaf object detection results significantly impact the second stage leaf segmentation task.
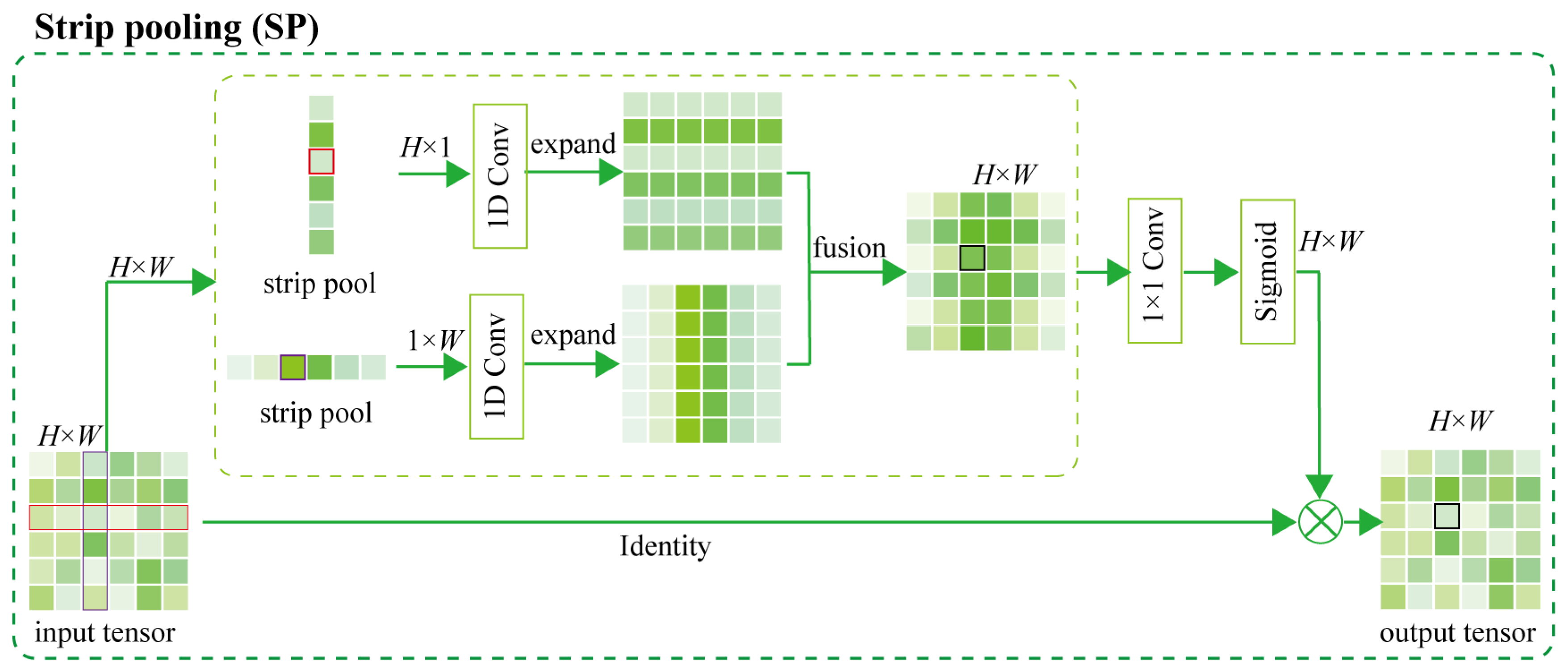
- An improved DeepLabv3+ leaf segmentation method was proposed to more efficiently capture bar leaves and slender petioles. In this paper, DenseASPP was used to replace the ASPP module, and the SP strategy was simultaneously introduced, enabling the backbone network to effectively capture long-distance dependencies.
- This new model, combined with the proposed YOLOv8 and improved DeepLabv3+, was designed to accurately segment individual leaves in various states, such as regular, curled or withered, and dorsal leaves, making the model more feasible for leaf characteristics collected in natural environments.
2. Results and Discussion
2.1. Training Environment and Evaluation Indicators
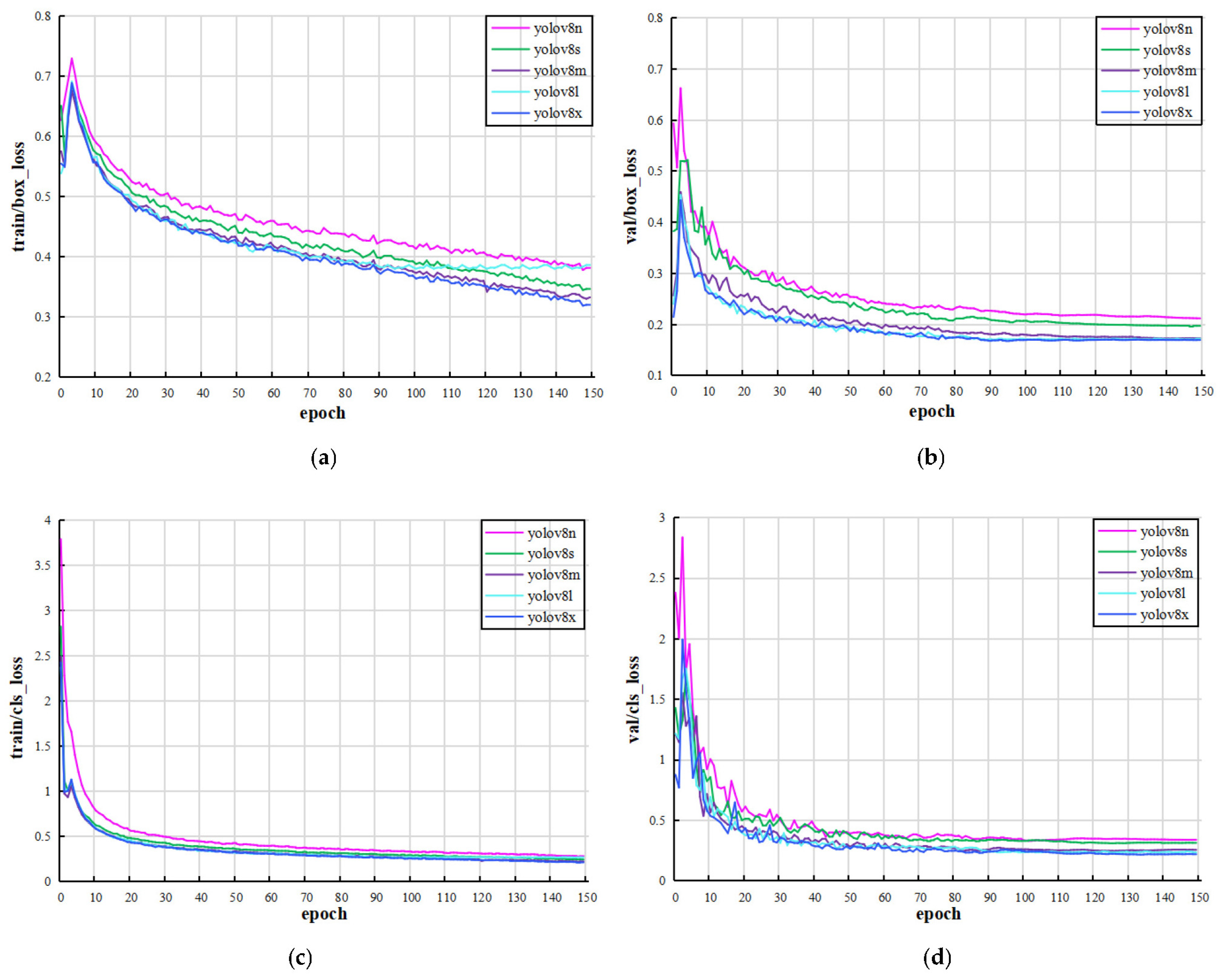
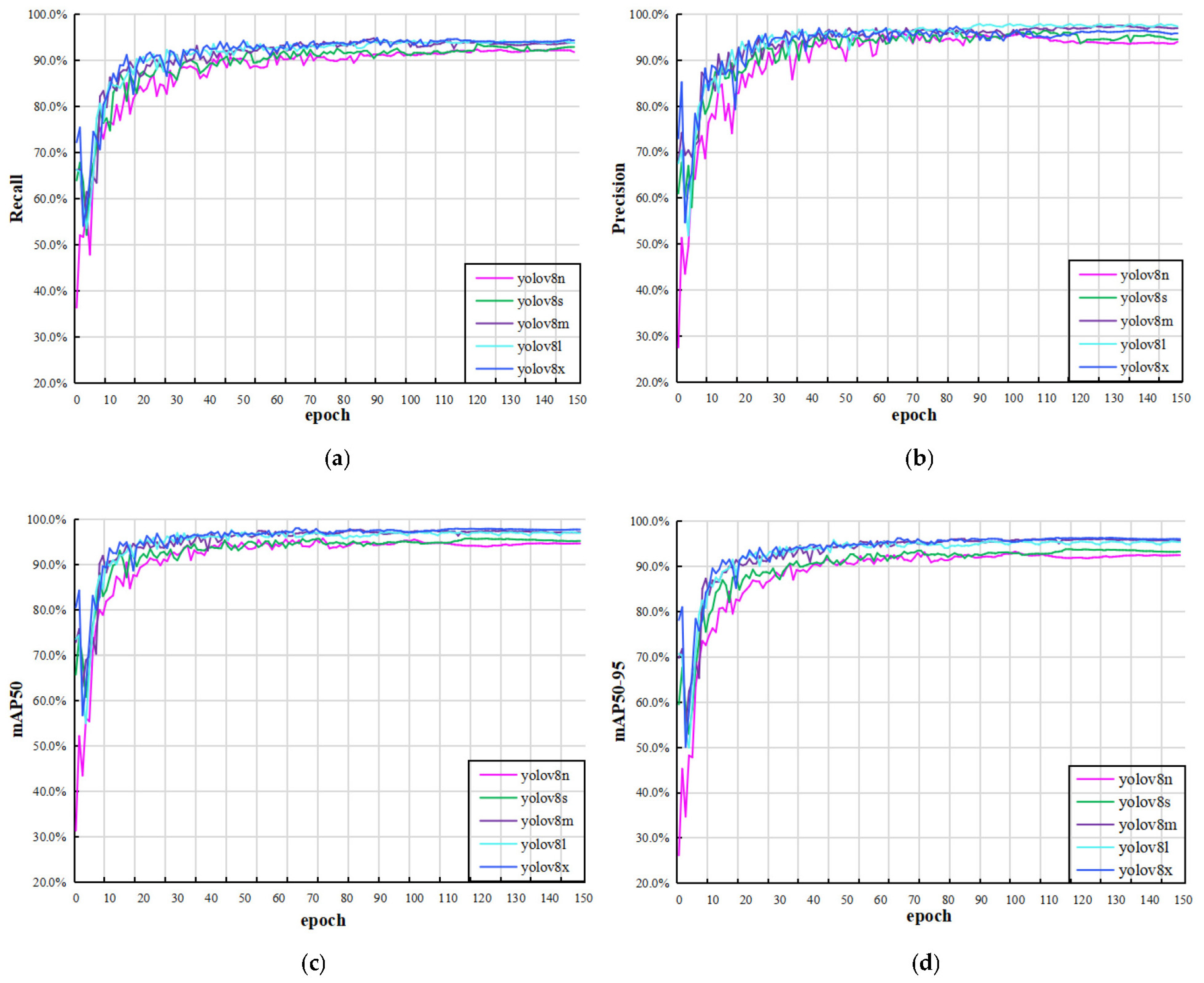
2.2. YOLOv8 Model Results and Analysis
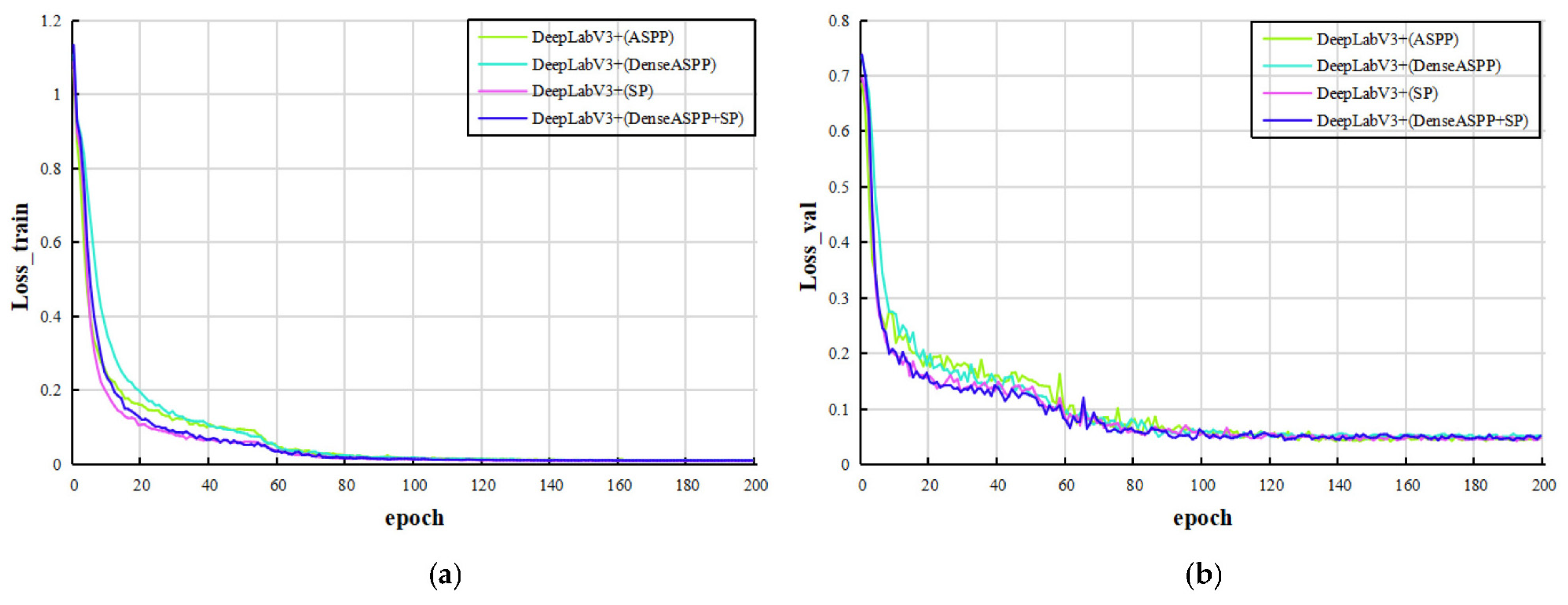
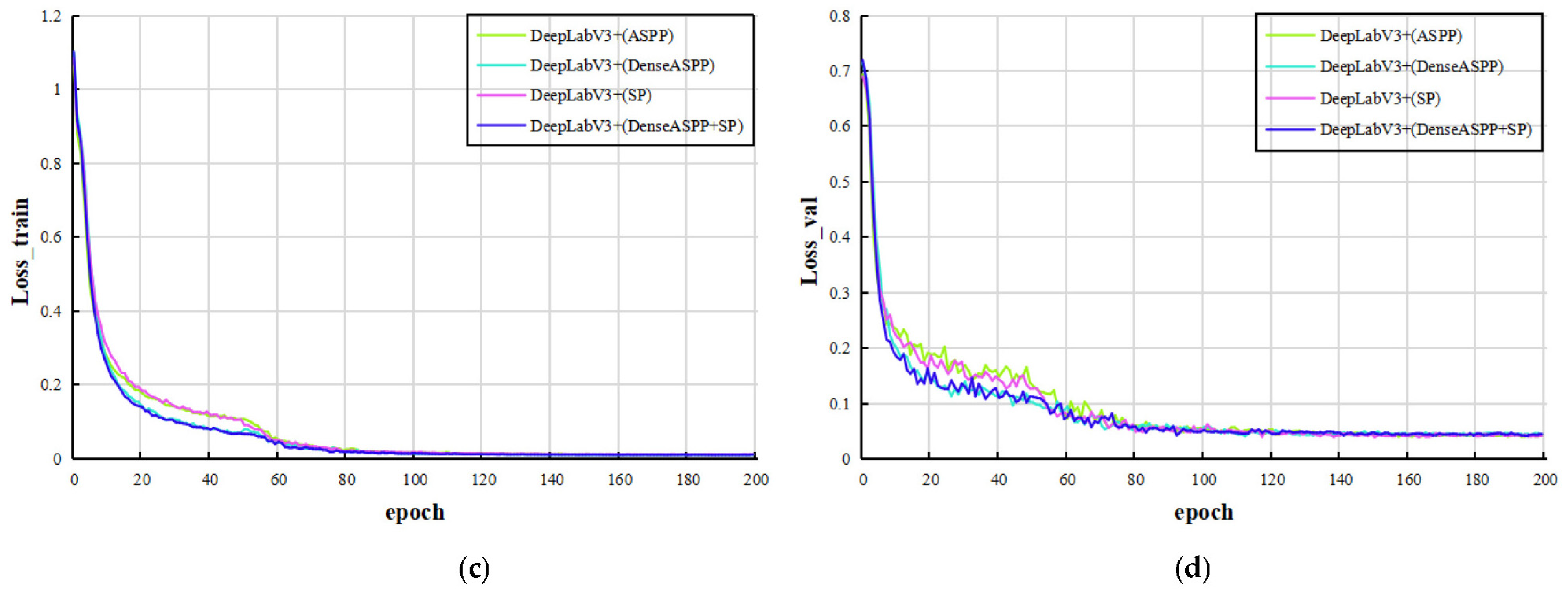
2.3. Results and Analysis of Different Segmentation Models
2.4. Discussion
3. Materials and Methods
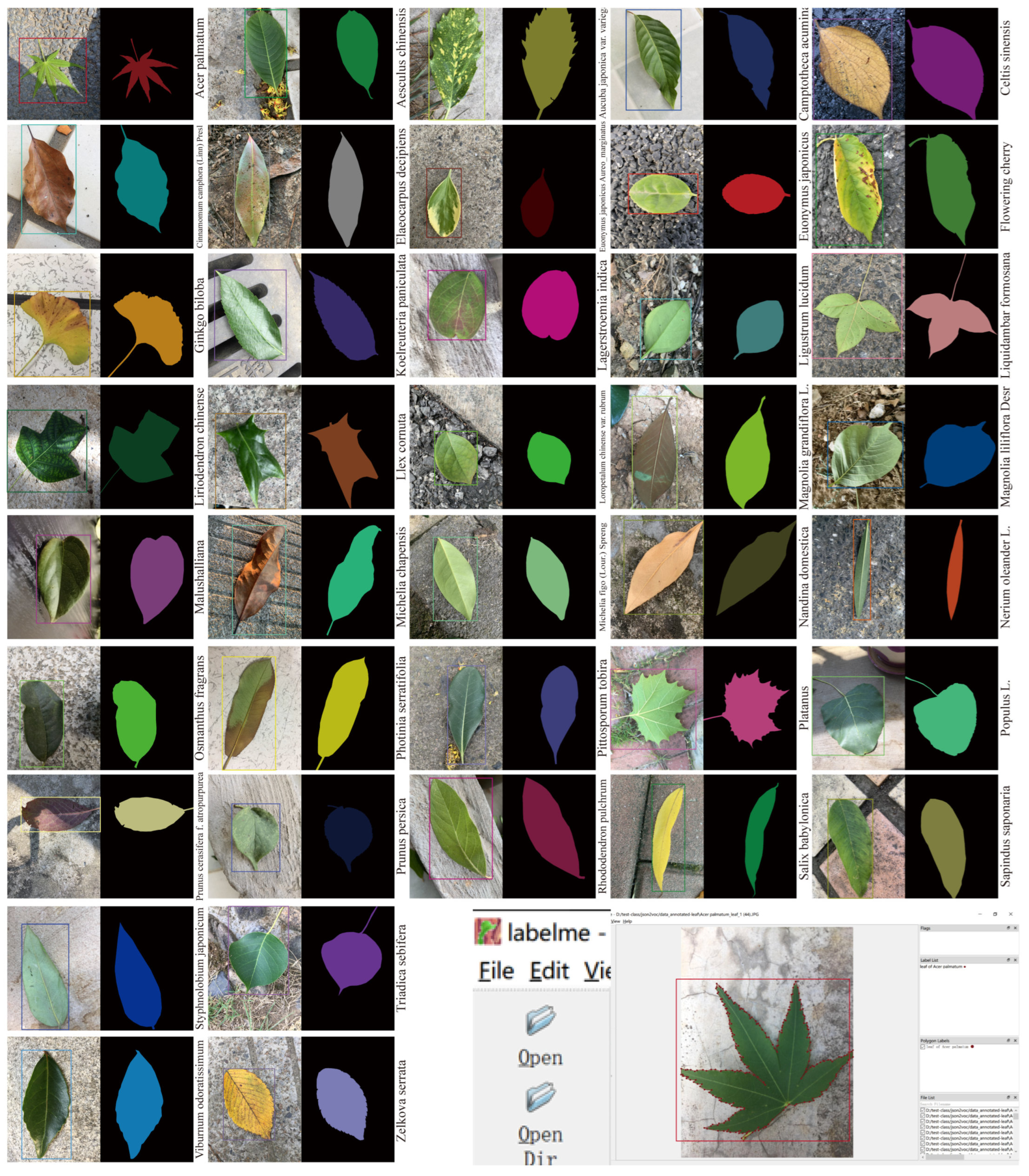
3.1. Leaf Dataset
3.1.1. Image Acquisition
- Our dataset was collected in natural environments. We, respectively, captured images of the same plant species on different city streets and under different lighting intensities, object scales, growth stages, and shooting perspectives to increase the diversity of our dataset.
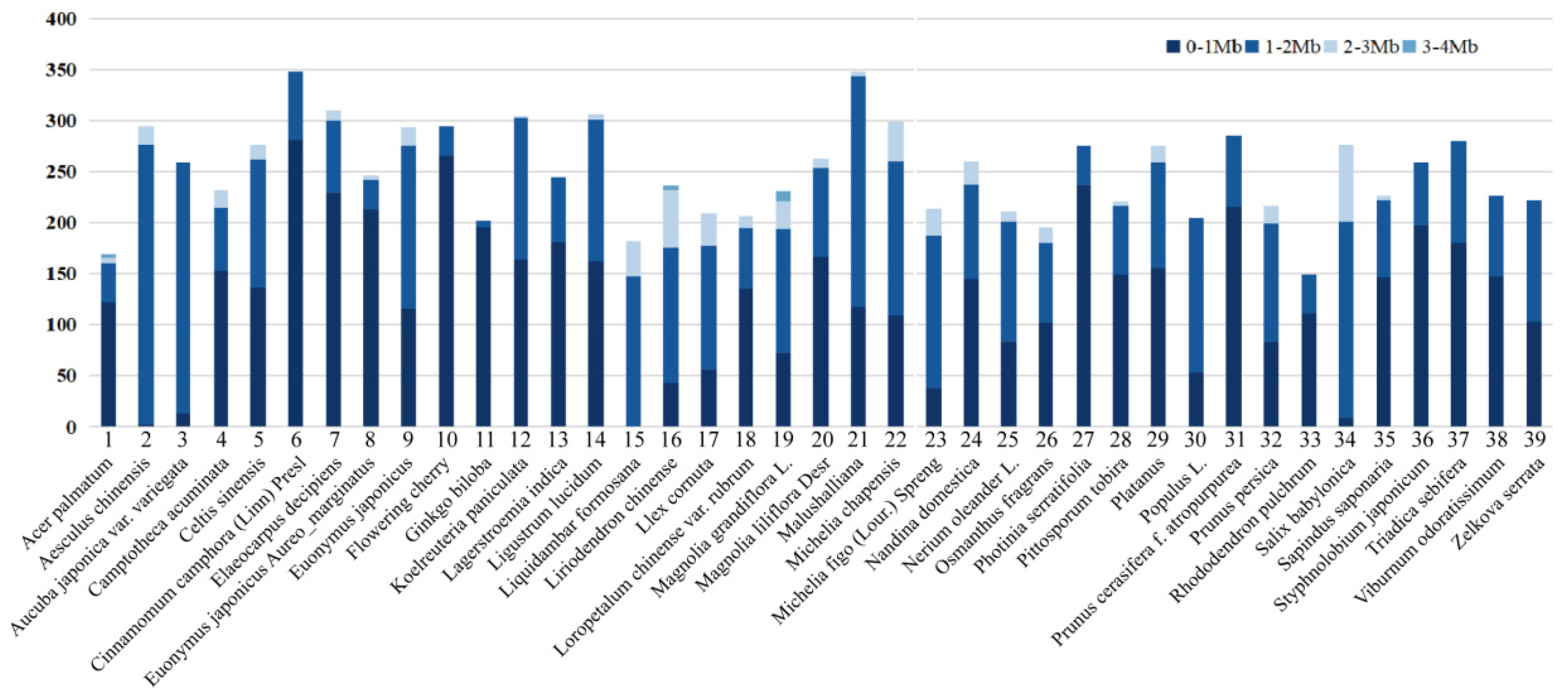
- We adopted various data augmentation techniques, such as cropping, mirroring, and rotating, to increase the magnitude of our dataset; we then performed image compression processing. A total of 9763 plant leaf images were acquired. The number of different plant species acquired is shown in Figure 7. The leaf image size was distributed from approximately 0 to 2 Mb; this range accounts for 94.7% of the total.
3.1.2. Image Annotation
3.2. Methods
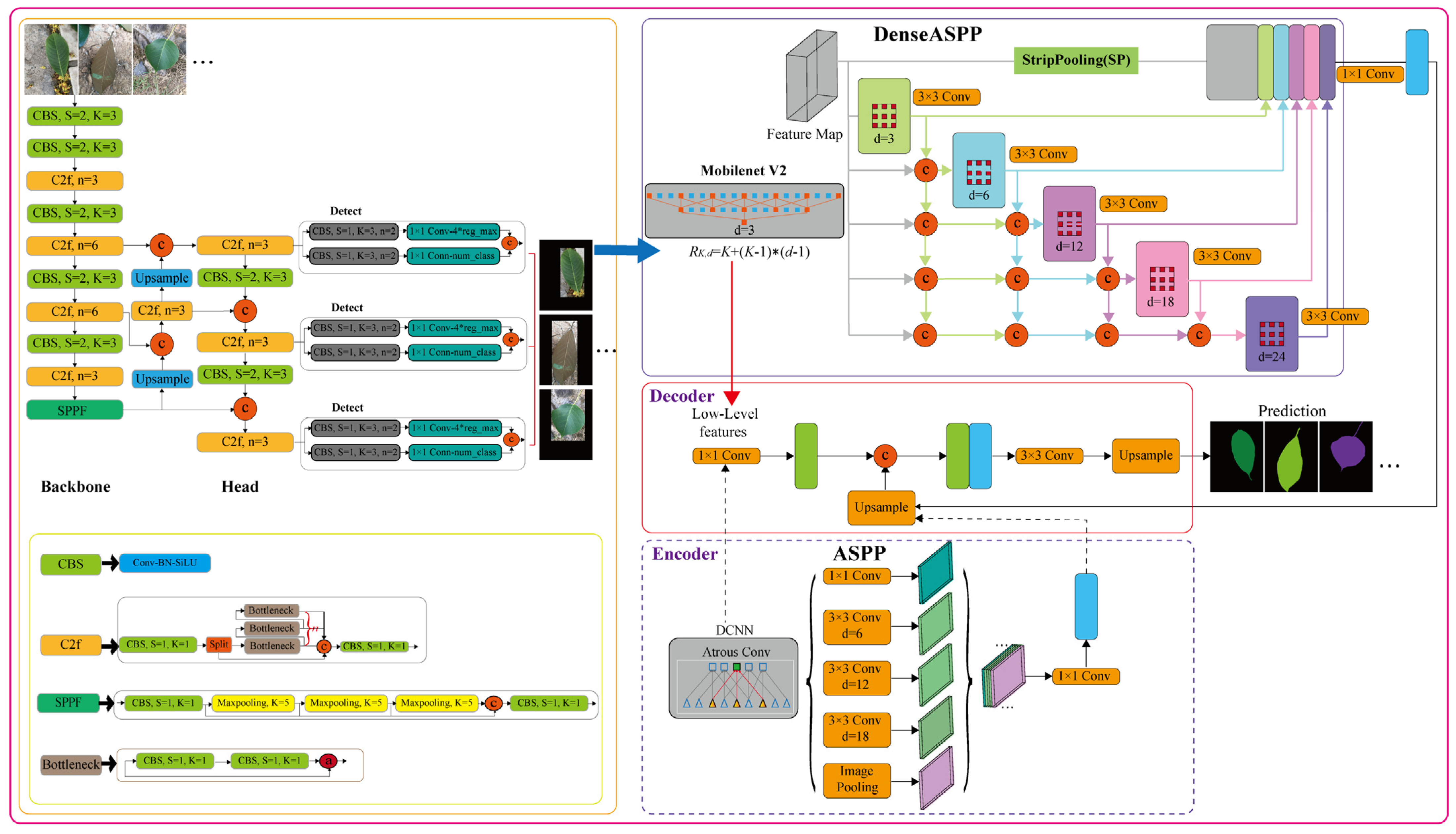
3.2.1. YOLOv8 Network
- (1)
- A new state-of-the-art model is provided. Similar to YOLOv5, different size models of the n/s/m/l/x scale are also provided based on the scaling coefficient to meet the requirements of different scenarios.
- (2)
- The backbone network and neck part may refer to the design concept of YOLOv7 ELAN, replacing the C3 structure of YOLOv5 with the C2f structure, which exhibits more abundant gradient flow and adjusts different channel numbers for different scale models, which significantly improves model performance, as shown in Figure 10.
- (3)
- Compared with YOLOv5, the head part is changed to the current mainstream decoupling head structure, separating the classification and detection heads and changing the model from anchor-based to anchor-free. The anchor-free model abandons or bypasses the anchor concept, uses a streamlined method to determine positive and negative samples, simultaneously reaches or even exceeds the accuracy of the anchor-based model, and has a faster speed than the anchor-based model.
- (4)
- The TaskAlignedAssignor positive sample allocation strategy is adopted for loss function calculation. The classification loss is the VariFocal Loss (VFL), and the regression loss is the Complete-IoU (CIoU) Loss + Distribution Focal Loss (DFL).
3.2.2. Improved DeepLabv3+
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tamvakis, P.N.; Kiourt, C.; Solomou, A.D.; Ioannakis, G.; Tsirliganis, N.C. Semantic Image Segmentation with Deep Learning for Vine Leaf Phenotyping. The 7th IFAC Conference on Sensing, Control and Automation Technologies for Agriculture. arXiv 2022, arXiv:2210.13296. [Google Scholar] [CrossRef]
- Haqqiman Radzali, M.; Nor, A.M.K.; Mat Diah, N. Measuring leaf area using otsu segmentation method (lamos). Indian J. Sci. Technol. 2016, 9, 1–6. [Google Scholar] [CrossRef]
- Yang, K.L.; Zhong, W.Z.; Li, F.G. Leaf Segmentation and Classification with a Complicated Background Using Deep Learning. Agronomy 2020, 10, 1721. [Google Scholar] [CrossRef]
- Zhu, S.S.; Ma, W.L.; Lu, J.W.; Ren, B.; Wang, C.Y.; Wang, J.L. A novel approach for apple leaf disease image segmentation in complex scenes based on two-stage DeepLabv3+ with adaptive loss. Comput. Electron. Agric. 2023, 204, 107539. [Google Scholar] [CrossRef]
- Agehara, S.; Pride, L.; Gallardo, M.; Hernandez-Monterroza, J. A Simple, Inexpensive, and Portable Image-Based Technique for Nondestructive Leaf Area Measurements. EDIS 2020, 2020. [Google Scholar] [CrossRef]
- Cao, L.; Li, H.; Yu, H.; Wang, H. Plant leaf segmentation and phenotypic analysis based on fully convolutional neural network. Appl. Eng. Agric. 2021, 2021, 37. [Google Scholar] [CrossRef]
- Praveen Kumar, J.; Domnic, S. Image based Leaf segmentation and counting in Rosette plants. Inf. Process. Agric. 2018, 6, 233–246. [Google Scholar] [CrossRef]
- Shen, P. Edge Detection of Tobacco Leaf Images Based on Fuzzy Mathematical Morphology. In Proceedings of the 1st International Conference on Information Science and Engineering (ICISE2009), Nanjing, China, 26–28 December 2009; pp. 1219–1222. [Google Scholar]
- Gao, L.W.; Lin, X.H. Fully automatic segmentation method for medicinal plant leaf images in complex background. Comput. Electron. Agric. 2019, 164, 104924. [Google Scholar] [CrossRef]
- Kalaivani, S.; Shantharajah, S.; Padma, T. Agricultural leaf blight disease segmentation using indices based histogram intensity segmentation approach. Multimed. Tools Appl. 2020, 79, 9145–9159. [Google Scholar] [CrossRef]
- Ma, J.C.; Du, K.M.; Zhang, L.X.; Zheng, F.X.; Chu, J.X.; Sun, Z.F. A segmentation method for greenhouse vegetable foliar disease spots images using color information and region growing. Comput. Electron. Agric. 2017, 142, 110–117. [Google Scholar] [CrossRef]
- Jothiaruna, N.; Joseph, A.S.K.; Ifjaz Ahmed, M. A disease spot segmentation method using comprehensive color feature with multi-resolution channel and region growing. Multimed. Tools Appl. 2021, 80, 3327–3335. [Google Scholar] [CrossRef]
- Baghel, J.; Jain, P. K-means segmentation method for automatic leaf disease detection. Int. J. Eng. Res. Appl. 2016, 6, 83–86. [Google Scholar]
- Tian, K.; Li, J.; Zeng, J.; Evans, A.; Zhang, L. Segmentation of tomato leaf images based on adaptive clustering number of K-means algorithm. Comput. Electron. Agric. 2019, 165, 104962. [Google Scholar] [CrossRef]
- Xiong, L.; Zhang, D.B.; Li, K.S.; Zhang, L.X. The extraction algorithm of color disease spot image based on Otsu and watershed. Soft Comput. 2020, 24, 7253–7263. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2016. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for mobilenetv3. arXiv 2019, arXiv:1905.02244. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar] [CrossRef]
- He, K.M.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Storey, G.; Meng, Q.G.; Li, B.H. Leaf Disease Segmentation and Detection in Apple Orchards for Precise Smart Spraying in Sustainable Agriculture. Sustainability 2022, 14, 1458. [Google Scholar] [CrossRef]
- Gonçalves, J.P.; Pinto, F.A.C.; Queiroz, D.M.; Villar, F.M.M.; Barbedo, J.G.A.; Ponte, E.M.D. Deep learning architectures for semantic segmentation and automatic estimation of severity of foliar symptoms caused by diseases or pests. Biosyst. Eng. 2021, 210, 129–142. [Google Scholar] [CrossRef]
- Lin, X.; Li, C.-T.; Adams, S.; Kouzani, A.; Jiang, R.; He, L.; Hu, Y.; Vernon, M.; Doeven, E.; Webb, L.; et al. Self-Supervised Leaf Segmentation under Complex Lighting Conditions. arXiv 2022, arXiv:2203.15943. [Google Scholar] [CrossRef]
- Khan, K.; Khan, R.U.; Albattah, W.; Qamar, A.M. End-to-End Semantic Leaf Segmentation Framework for Plants Disease Classification. Complexity 2022, 2022, 1168700. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–12 September 2018; pp. 801–818. [Google Scholar] [CrossRef]
- Yang, T.T.; Zhou, S.Y.; Huang, Z.J.; Xu, A.J.; Ye, J.H.; Yin, J.X. Urban Street Tree Dataset for Image Classification and Instance Segmentation. Comput. Electron. Agric. 2023, 209, 107852. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Laurens, V.D.M.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Hou, Q.; Zhang, L.; Cheng, M.M.; Feng, J. Strip Pooling: Rethinking Spatial Pooling for Scene Parsing. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Everingham, M.; Ali Eslami, S.M.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar] [CrossRef]
- Zhang, H.Y.; Wang, Y.; Dayoub, F.; Sünderhauf, N. VarifocalNet: An IoU-Aware Dense Object Detector. arXiv 2021, arXiv:2008.13367. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.H.; Wu, L.J.; Chen, S.; Hu, X.L.; Li, J.; Tang, J.H.; Yang, J. Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection. arXiv 2020, arXiv:2006.04388. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Size (Pixels) | Params (M) | FLOPs (B) | Layers | Recall | Precision | mAPval 50 | mAPval 50–95 |
|---|---|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 3.0 | 8.2 | 225 | 90.9 | 94.7 | 95.3 | 92.7 |
| YOLOv8s | 640 | 11.2 | 28.7 | 225 | 91.2 | 96.4 | 95.7 | 93.0 |
| YOLOv8m | 640 | 25.9 | 79.2 | 295 | 93.2 | 97.4 | 97.7 | 95.9 |
| YOLOv8l | 640 | 43.7 | 165.6 | 365 | 93.8 | 97.8 | 97.6 | 95.8 |
| YOLOv8x | 640 | 68.2 | 258.3 | 365 | 93.9 | 97.3 | 98.0 | 96.2 |
| Not Based on YOLOv8m | Based on YOLOv8m | |||
|---|---|---|---|---|
| Model | mIoU | mPA | mIoU | mPA |
| FCN (resnet50) [16] | 82.6 | - | 85.4 | - |
| LR-ASPP [19] | 82.4 | - | 85.7 | - |
| PSPnet (mobilenet) [18] | 87.1 | - | 89.7 | - |
| U-Net (resnet50) [17] | 86.2 | 93.0 | 88.1 | 93.9 |
| DeepLabv3 [20] | 86.4 | - | 89.8 | - |
| DeepLabv3+ (ASPP) [26] | 88.3 | 93.9 | 89.6 | 94.6 |
| DeepLabv3+ (DenseASPP) [28] | 87.8 | 93.7 | 89.5 | 94.5 |
| DeepLabv3+ (SP) [29] | 88.4 | 94.0 | 89.9 | 94.7 |
| Ours: DeepLabv3+ (DenseASPP + SP) | 89.0 | 94.3 | 90.8 | 95.3 |
| Not Based on YOLOv8m | Based on YOLOv8m | |||
|---|---|---|---|---|
| Model | mIoU | mPA | mIoU | mPA |
| DeepLabv3+ (ASPP) | 85.5 | 91.6 | 86.7 | 92.1 |
| DeepLabv3+ (DenseASPP) | 86.0 | 91.8 | 87.9 | 92.9 |
| DeepLabv3+ (SP) | 86.1 | 92.0 | 87.4 | 92.7 |
| Ours: DeepLabv3+ (DenseASPP + SP) | 86.7 | 92.3 | 88.1 | 93.0 |
| Leaf Dataset | Ratio | Number | Dataset Format (Object Detection) | Dataset Format (Segmentation) |
|---|---|---|---|---|
| training set | 8 | 7813 | YOLO | VOC2012 |
| validation set | 1 | 975 | ||
| test set | 1 | 975 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, T.; Zhou, S.; Xu, A.; Ye, J.; Yin, J. An Approach for Plant Leaf Image Segmentation Based on YOLOV8 and the Improved DEEPLABV3+. Plants 2023, 12, 3438. https://doi.org/10.3390/plants12193438
Yang T, Zhou S, Xu A, Ye J, Yin J. An Approach for Plant Leaf Image Segmentation Based on YOLOV8 and the Improved DEEPLABV3+. Plants. 2023; 12(19):3438. https://doi.org/10.3390/plants12193438
Chicago/Turabian StyleYang, Tingting, Suyin Zhou, Aijun Xu, Junhua Ye, and Jianxin Yin. 2023. "An Approach for Plant Leaf Image Segmentation Based on YOLOV8 and the Improved DEEPLABV3+" Plants 12, no. 19: 3438. https://doi.org/10.3390/plants12193438
APA StyleYang, T., Zhou, S., Xu, A., Ye, J., & Yin, J. (2023). An Approach for Plant Leaf Image Segmentation Based on YOLOV8 and the Improved DEEPLABV3+. Plants, 12(19), 3438. https://doi.org/10.3390/plants12193438