

Genome-Wide Association Study on Imputed Genotypes of 180 Eurasian Soybean Glycine max Varieties for Oil and Protein Contents in Seeds


 , ,
, ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Soybean Population
2.2. Genotype Data
2.3. Phenotype Data
2.4. Genotype Imputation
2.5. Genome-Wide Association Analysis
2.6. Phenotypic and Genetic Correlations, Heritability Estimates
2.7. The In-Silico Interpretation of GWAS Results (Post-GWAS)
2.8. Development of DNA Markers and Polymerase Chain Reaction
3. Results
3.1. Characteristics of Studied Lines
3.2. Imputation
3.3. Phenotypes
3.4. GWAS
3.5. Screening for the Presence of Genes Affecting Protein Content
4. Discussion
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rotundo, J.L.; Marshall, R.; McCormick, R.; Truong, S.K.; Styles, D.; Gerde, J.A.; Gonzalez-Escobar, E.; Carmo-Silva, E.; Janes-Bassett, V.; Logue, J.; et al. European soybean to benefit people and the environment. Sci. Rep. 2024, 14, 7612. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Mungara, P.; Jane, J.-l. Mechanical and thermal properties of extruded soy protein sheets. Polymer 2001, 42, 2569–2578. [Google Scholar] [CrossRef]
- Avinc, O.; Yavas, A. Soybean: For textile applications and its printing. In Soybean—The Basis of Yield, Biomass and Productivity; IntechOpen: London, UK, 2017. [Google Scholar]
- Milanović, T.; Popović, V.; Vučković, S.; Rakaščan, N.; Popović, S.; Petković, Z. Analysis of soybean production and biogas yield to improve eco-marketing and circular economy. Eкoнoмuкa Пoљonpuвpeдe 2020, 67, 141–156. [Google Scholar] [CrossRef]
- Shaibu, A.S.; Ibrahim, H.; Miko, Z.L.; Mohammed, I.B.; Mohammed, S.G.; Yusuf, H.L.; Kamara, A.Y.; Omoigui, L.O.; Karikari, B. Assessment of the genetic structure and diversity of soybean (Glycine max L.) germplasm using diversity array technology and single nucleotide polymorphism markers. Plants 2021, 11, 68. [Google Scholar] [CrossRef]
- Andrijanić, Z.; Nazzicari, N.; Šarčević, H.; Sudarić, A.; Annicchiarico, P.; Pejić, I. Genetic diversity and population structure of European soybean germplasm revealed by single nucleotide polymorphism. Plants 2023, 12, 1837. [Google Scholar] [CrossRef]
- Potapova, N.A.; Zlobin, A.S.; Perfil’ev, R.N.; Vasiliev, G.V.; Salina, E.A.; Tsepilov, Y.A. Population Structure and Genetic Diversity of the 175 Soybean Breeding Lines and Varieties Cultivated in West Siberia and Other Regions of Russia. Plants 2023, 12, 3490. [Google Scholar] [CrossRef]
- Dong, L.; Fang, C.; Cheng, Q.; Su, T.; Kou, K.; Kong, L.; Zhang, C.; Li, H.; Hou, Z.; Zhang, Y. Genetic basis and adaptation trajectory of soybean from its temperate origin to tropics. Nat. Commun. 2021, 12, 5445. [Google Scholar] [CrossRef]
- Lu, S.; Fang, C.; Abe, J.; Kong, F.; Liu, B. Current overview on the genetic basis of key genes involved in soybean domestication. Abiotech 2022, 3, 126–139. [Google Scholar] [CrossRef]
- Liu, L.; Wang, J.; Zhang, Q.; Sun, T.; Wang, P. Cloning of the Soybean GmNHL1 Gene and Functional Analysis under Salt Stress. Plants 2023, 12, 3869. [Google Scholar] [CrossRef]
- Fang, C.; Ma, Y.; Wu, S.; Liu, Z.; Wang, Z.; Yang, R.; Hu, G.; Zhou, Z.; Yu, H.; Zhang, M.; et al. Genome-wide association studies dissect the genetic networks underlying agronomical traits in soybean. Genome Biol. 2017, 18, 161. [Google Scholar] [CrossRef]
- Shook, J.M.; Zhang, J.; Jones, S.E.; Singh, A.; Diers, B.W.; Singh, A.K. Meta-GWAS for quantitative trait loci identification in soybean. G3 Genes|Genomes|Genet. 2021, 11, jkab117. [Google Scholar] [CrossRef]
- Priyanatha, C.; Torkamaneh, D.; Rajcan, I. Genome-wide association study of soybean germplasm derived from Canadian× Chinese crosses to mine for novel alleles to improve seed yield and seed quality traits. Front. Plant Sci. 2022, 13, 866300. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.H.; Tayade, R.; Kang, B.H.; Hahn, B.S.; Ha, B.K.; Kim, Y.H. Genome-Wide Association Studies of Seven Root Traits in Soybean (Glycine max L.) Landraces. Int. J. Mol. Sci. 2023, 24, 873. [Google Scholar] [CrossRef] [PubMed]
- Miller, M.J.; Song, Q.; Fallen, B.; Li, Z. Genomic prediction of optimal cross combinations to accelerate genetic improvement of soybean (Glycine max). Front. Plant Sci. 2023, 14, 1171135. [Google Scholar] [CrossRef] [PubMed]
- Miller, M.J.; Song, Q.; Li, Z. Genomic selection of soybean (Glycine max) for genetic improvement of yield and seed composition in a breeding context. Plant Genome 2023, 16, e20384. [Google Scholar] [CrossRef]
- Riaz, A.; Raza, Q.; Kumar, A.; Dean, D.; Chiwina, K.; Phiri, T.M.; Thomas, J.; Shi, A. GWAS and genomic selection for marker-assisted development of sucrose enriched soybean cultivars. Euphytica 2023, 219, 97. [Google Scholar] [CrossRef]
- Zhang, C.; Shao, Z.; Kong, Y.; Du, H.; Li, W.; Yang, Z.; Li, X.; Ke, H.; Sun, Z.; Shao, J.; et al. High-quality genome of a modern soybean cultivar and resequencing of 547 accessions provide insights into the role of structural variation. Nat. Genet. 2024, 56, 2247–2258. [Google Scholar] [CrossRef]
- Torkamaneh, D.; Chalifour, F.-P.; Beauchamp, C.J.; Agrama, H.; Boahen, S.; Maaroufi, H.; Rajcan, I.; Belzile, F. Genome-wide association analyses reveal the genetic basis of biomass accumulation under symbiotic nitrogen fixation in African soybean. Theor. Appl. Genet. 2020, 133, 665–676. [Google Scholar] [CrossRef]
- Rani, R.; Raza, G.; Ashfaq, H.; Rizwan, M.; Razzaq, M.K.; Waheed, M.Q.; Shimelis, H.; Babar, A.D.; Arif, M. Genome-wide association study of soybean (Glycine max [L.] Merr.) germplasm for dissecting the quantitative trait nucleotides and candidate genes underlying yield-related traits. Front. Plant Sci. 2023, 14, 1229495. [Google Scholar] [CrossRef]
- Lee, S.; Van, K.; Sung, M.; Nelson, R.; LaMantia, J.; McHale, L.K.; Mian, M.A.R. Genome-wide association study of seed protein, oil and amino acid contents in soybean from maturity groups I to IV. TAG. Theor. Appl. Genet. Theor. Angew. Genet. 2019, 132, 1639–1659. [Google Scholar] [CrossRef]
- Kim, W.J.; Kang, B.H.; Kang, S.; Shin, S.; Chowdhury, S.; Jeong, S.C.; Choi, M.S.; Park, S.K.; Moon, J.K.; Ryu, J.; et al. A Genome-Wide Association Study of Protein, Oil, and Amino Acid Content in Wild Soybean (Glycine soja). Plants 2023, 12, 1665. [Google Scholar] [CrossRef] [PubMed]
- Jin, H.; Yang, X.; Zhao, H.; Song, X.; Tsvetkov, Y.D.; Wu, Y.; Gao, Q.; Zhang, R.; Zhang, J. Genetic analysis of protein content and oil content in soybean by genome-wide association study. Front. Plant Sci. 2023, 14, 1182771. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Goettel, W.; Song, Q.; Jiang, H.; Hu, Z.; Wang, M.L.; An, Y.C. Selection of GmSWEET39 for oil and protein improvement in soybean. PLoS Genet. 2020, 16, e1009114. [Google Scholar] [CrossRef]
- Chu, J.S.; Peng, B.; Tang, K.; Yi, X.; Zhou, H.; Wang, H.; Li, G.; Leng, J.; Chen, N.; Feng, X. Eight soybean reference genome resources from varying latitudes and agronomic traits. Sci. Data 2021, 8, 164. [Google Scholar] [CrossRef]
- Yi, X.; Liu, J.; Chen, S.; Wu, H.; Liu, M.; Xu, Q.; Lei, L.; Lee, S.; Zhang, B.; Kudrna, D.; et al. Genome assembly of the JD17 soybean provides a new reference genome for comparative genomics. G3 Genes|Genomes|Genet. 2022, 12, jkac017. [Google Scholar] [CrossRef]
- Chen, L.; Yang, S.; Araya, S.; Quigley, C.; Taliercio, E.; Mian, R.; Specht, J.E.; Diers, B.W.; Song, Q. Genotype imputation for soybean nested association mapping population to improve precision of QTL detection. TAG. Theor. Appl. Genet. Theor. Angew. Genet. 2022, 135, 1797–1810. [Google Scholar] [CrossRef]
- Perfil’ev, R.; Shcherban, A.; Potapov, D.; Maksimenko, K.; Kiryukhin, S.; Gurinovich, S.; Panarina, V.; Polyudina, R.; Salina, E. Impact of Allelic Variation in Maturity Genes E1–E4 on Soybean Adaptation to Central and West Siberian Regions of Russia. Agriculture 2023, 13, 1251. [Google Scholar] [CrossRef]
- Rogers, S.O.; Bendich, A.J. Extraction of DNA from milligram amounts of fresh, herbarium and mummified plant tissues. Plant Mol. Biol. 1985, 5, 69–76. [Google Scholar] [CrossRef]
- Song, Q.; Hyten, D.L.; Jia, G.; Quigley, C.V.; Fickus, E.W.; Nelson, R.L.; Cregan, P.B. Development and evaluation of SoySNP50K, a high-density genotyping array for soybean. PLoS ONE 2013, 8, e54985. [Google Scholar] [CrossRef]
- Grant, D.; Nelson, R.T.; Cannon, S.B.; Shoemaker, R.C. SoyBase, the USDA-ARS soybean genetics and genomics database. Nucleic Acids Res. 2010, 38, D843–D846. [Google Scholar] [CrossRef]
- Perfil’ev, R. Genotypes of 180 Soybean Accessions; [Data set]; Zenodo: Geneva, Switzerland, 2024; Available online: https://doi.org/10.5281/zenodo.13879245 (accessed on 1 November 2024).
- Dekking, F.M.; Kraaikamp, C.; Lopuhaä, H.P.; Meester, L.E. A Modern Introduction to Probability and Statistics: Understanding Why and How; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Song, Q.; Hyen, D.L.; Jia, G.; Quigley, C.V.; Fickus, E.W.; Nelson, R.L.; Cregan, P.B. Fingerprinting Soybean Germplasm and Its Utility in Genomic Research. G3 Genes|Genomes|Genet. 2015, 5, 1999–2006, Erratum in G3 Genes|Genomes|Genet. 2016, 6, 495. [Google Scholar] [CrossRef] [PubMed]
- Kim, M.S.; Lozano, R.; Kim, J.H.; Bae, D.N.; Kim, S.T.; Park, J.H.; Choi, M.S.; Kim, J.; Ok, H.C.; Park, S.K.; et al. The patterns of deleterious mutations during the domestication of soybean. Nat. Commun. 2021, 12, 97. [Google Scholar] [CrossRef] [PubMed]
- Browning, B.L.; Zhou, Y.; Browning, S.R. A one-penny imputed genome from next-generation reference panels. Am. J. Hum. Genet. 2018, 103, 338–348. [Google Scholar] [CrossRef] [PubMed]
- Browning, B.L.; Tian, X.; Zhou, Y.; Browning, S.R. Fast two-stage phasing of large-scale sequence data. Am. J. Hum. Genet. 2021, 108, 1880–1890. [Google Scholar] [CrossRef]
- Zhou, Z.; Jiang, Y.; Wang, Z.; Gou, Z.; Lyu, J.; Li, W.; Yu, Y.; Shu, L.; Zhao, Y.; Ma, Y. Resequencing 302 wild and cultivated accessions identifies genes related to domestication and improvement in soybean. Nat. Biotechnol. 2015, 33, 408–414. [Google Scholar] [CrossRef]
- Zhou, X.; Stephens, M. Genome-wide efficient mixed-model analysis for association studies. Nat. Genet. 2012, 44, 821–824. [Google Scholar] [CrossRef]
- Potapova, N.A.; Timoshchuk, A.N.; Tiys, E.S.; Vinichenko, N.A.; Leonova, I.N.; Salina, E.A.; Tsepilov, Y.A. Multivariate Genome-Wide Association Study of Concentrations of Seven Elements in Seeds Reveals Four New Loci in Russian Wheat Lines. Plants 2023, 12, 3019. [Google Scholar] [CrossRef]
- VanRaden, P.M. Efficient methods to compute genomic predictions. J. Dairy Sci. 2008, 91, 4414–4423. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, Y.; Wang, J.; Zhao, X.; Li, Y.; Teng, W.; Han, Y.; Zhan, Y. GWAS and WGCNA Analysis Uncover Candidate Genes Associated with Oil Content in Soybean. Plants 2024, 13, 1351. [Google Scholar] [CrossRef]
- Sonah, H.; O’Donoughue, L.; Cober, E.; Rajcan, I.; Belzile, F. Identification of loci governing eight agronomic traits using a GBS-GWAS approach and validation by QTL mapping in soya bean. Plant Biotechnol. J. 2015, 13, 211–221. [Google Scholar] [CrossRef]
- Zhang, Q.; Sun, T.; Wang, J.; Fei, J.; Liu, Y.; Liu, L.; Wang, P. Genome-wide association study and high-quality gene mining related to soybean protein and fat. BMC Genom. 2023, 24, 596. [Google Scholar] [CrossRef]
- Duan, Z.; Zhang, M.; Zhang, Z.; Liang, S.; Fan, L.; Yang, X.; Yuan, Y.; Pan, Y.; Zhou, G.; Liu, S.; et al. Natural allelic variation of GmST05 controlling seed size and quality in soybean. Plant Biotechnol. J. 2022, 20, 1807–1818. [Google Scholar] [CrossRef] [PubMed]
- Fliege, C.E.; Ward, R.A.; Vogel, P.; Nguyen, H.; Quach, T.; Guo, M.; Viana, J.P.G.; Dos Santos, L.B.; Specht, J.E.; Clemente, T.E.; et al. Fine mapping and cloning of the major seed protein quantitative trait loci on soybean chromosome 20. Plant J. 2022, 110, 114–128. [Google Scholar] [CrossRef] [PubMed]
- Purcell, S.; Neale, B.; Todd-Brown, K.; Thomas, L.; Ferreira, M.A.; Bender, D.; Maller, J.; Sklar, P.; De Bakker, P.I.; Daly, M.J. PLINK: A tool set for whole-genome association and population-based linkage analyses. Am. J. Hum. Genet. 2007, 81, 559–575. [Google Scholar] [CrossRef] [PubMed]
- Novikova, L.Y.; Seferova, I.; Nekrasov, A.Y.; Perchuk, I.; Shelenga, T.; Samsonova, M.; Vishnyakova, M. Impact of weather and climate on seed protein and oil content of soybean in the North Caucasus. Vavilov J. Genet. Breed. 2018, 22, 708–715. [Google Scholar] [CrossRef]
- Song, W.; Yang, R.; Wu, T.; Wu, C.; Sun, S.; Zhang, S.; Jiang, B.; Tian, S.; Liu, X.; Han, T. Analyzing the Effects of Climate Factors on Soybean Protein, Oil Contents, and Composition by Extensive and High-Density Sampling in China. J. Agric. Food Chem. 2016, 64, 4121–4130. [Google Scholar] [CrossRef]
- Petibskaya, V. Soy: Chemical Composition and Use; All-Russian Research Institute of Oilseeds Named After VS Pustovoita: Krasnodar, Russia, 2012; Volume 432. [Google Scholar]
- Xu, M.; Li, H.; Liu, Z.N.; Wang, X.H.; Xu, P.; Dai, S.J.; Cao, X.; Cui, X.Y. The soybean CBL-interacting protein kinase, GmCIPK2, positively regulates drought tolerance and ABA signaling. Plant Physiol. Biochem. 2021, 167, 980–989. [Google Scholar] [CrossRef]
- Li, H.; Wang, X.H.; Li, Q.; Xu, P.; Liu, Z.N.; Xu, M.; Cui, X.Y. GmCIPK21, a CBL-interacting protein kinase confers salt tolerance in soybean (Glycine max. L). Plant Physiol. Biochem. 2022, 184, 47–55. [Google Scholar] [CrossRef]
- Ketehouli, T.; Zhou, Y.G.; Dai, S.Y.; Carther, K.F.I.; Sun, D.Q.; Li, Y.; Nguyen, Q.V.H.; Xu, H.; Wang, F.W.; Liu, W.C.; et al. A soybean calcineurin B-like protein-interacting protein kinase, GmPKS4, regulates plant responses to salt and alkali stresses. J. Plant Physiol. 2021, 256, 153331. [Google Scholar] [CrossRef]
- Montag, K.; Ivanov, R.; Bauer, P. Role of SEC14-like phosphatidylinositol transfer proteins in membrane identity and dynamics. Front. Plant Sci. 2023, 14, 1181031. [Google Scholar] [CrossRef]
- Xu, H.; Li, Y.; Yan, Y.; Wang, K.; Gao, Y.; Hu, Y. Genome-scale identification of soybean BURP domain-containing genes and their expression under stress treatments. BMC Plant Biol. 2010, 10, 197. [Google Scholar] [CrossRef] [PubMed]
- Lu, M.; Han, Y.P.; Gao, J.G.; Wang, X.J.; Li, W.B. Identification and analysis of the germin-like gene family in soybean. BMC Genom. 2010, 11, 620. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.Y.; Lu, Z.W.; Sun, Y.; Fang, Z.W.; Chen, J.; Zhou, Y.B.; Chen, M.; Ma, Y.Z.; Xu, Z.S.; Min, D.H. The Ankyrin-Repeat Gene GmANK114 Confers Drought and Salt Tolerance in Arabidopsis and Soybean. Front. Plant Sci. 2020, 11, 584167. [Google Scholar] [CrossRef] [PubMed]
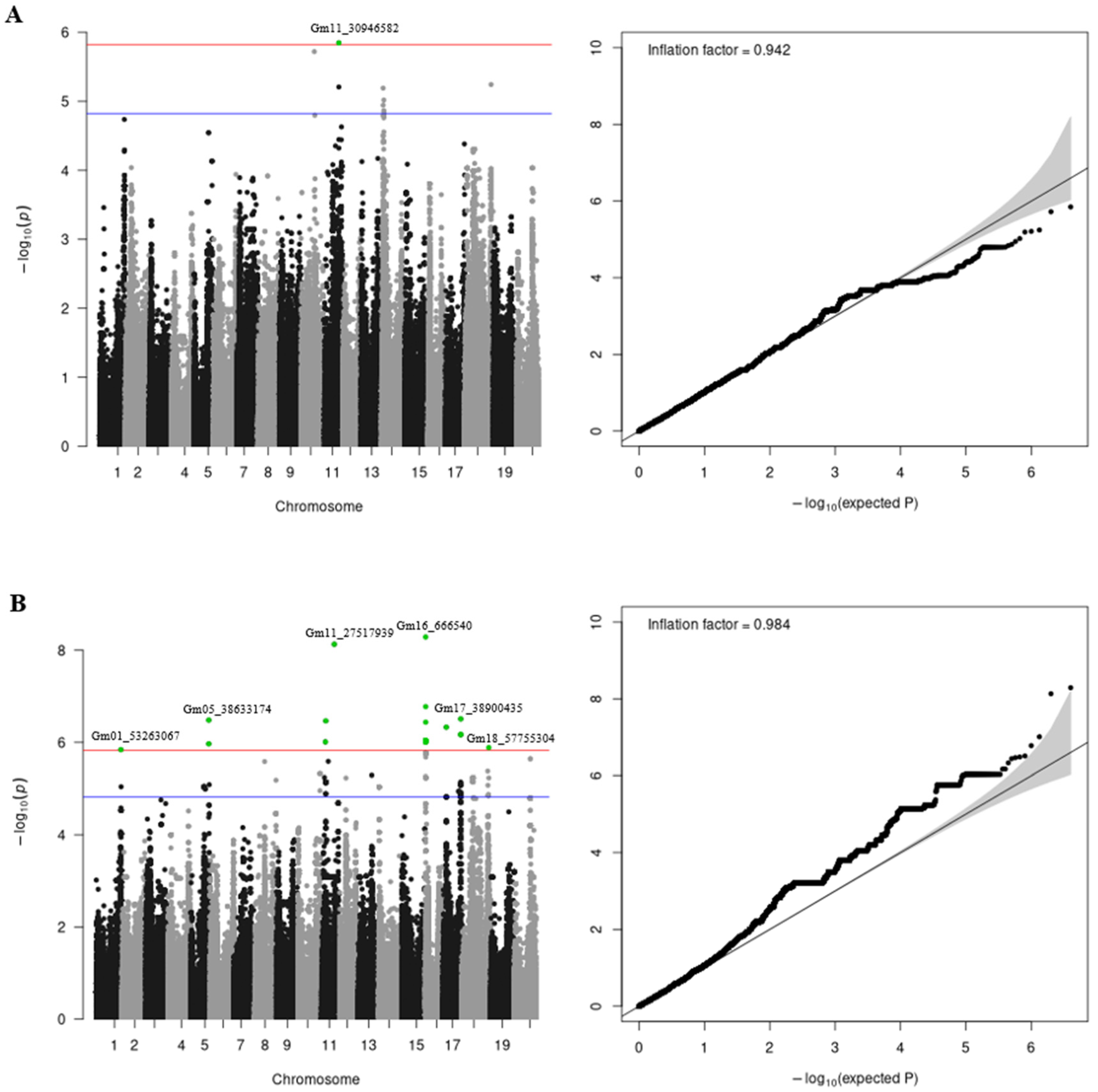

{kind=link}
| Trait | Chr | SNP | A1 | A0 | AF | Beta | SE | P* |
|---|---|---|---|---|---|---|---|---|
| Protein | 10 | glyma.Wm82.gnm1.Gm10_28857346 | T | A | 0.230 | −0.57 | 0.118 | 1.91 × 10−6 |
| Protein | 11 | glyma.Wm82.gnm1.Gm11_30946582 | G | A | 0.235 | 0.59 | 0.121 | 1.42 × 10−6 |
| Protein | 14 | glyma.Wm82.gnm1.Gm14_3287898 | T | C | 0.131 | −0.56 | 0.124 | 6.44 × 10−6 |
| Protein | 14 | glyma.Wm82.gnm1.Gm14_3289887 | T | A | 0.116 | −0.55 | 0.125 | 1.14 × 10−5 |
| Protein | 14 | glyma.Wm82.gnm1.Gm14_4736491 | C | T | 0.092 | −0.66 | 0.148 | 9.58 × 10−6 |
| Protein | 14 | glyma.Wm82.gnm1.Gm14_4745240 | T | C | 0.086 | −0.61 | 0.140 | 1.46 × 10−5 |
| Protein | 18 | glyma.Wm82.gnm1.Gm18_56804345 | A | G | 0.011 | −1.50 | 0.328 | 5.71 × 10−6 |
| Oil | 1 | glyma.Wm82.gnm1.Gm01_53263067 | G | C | 0.469 | −0.39 | 0.081 | 1.44 × 10−6 |
| Oil | 5 | glyma.Wm82.gnm1.Gm05_28366927 | A | G | 0.050 | −0.64 | 0.142 | 8.87 × 10−6 |
| Oil | 5 | glyma.Wm82.gnm1.Gm05_31043361 | T | A | 0.033 | −0.91 | 0.205 | 1.02 × 10−5 |
| Oil | 5 | glyma.Wm82.gnm1.Gm05_38633174 | C | T | 0.050 | −0.70 | 0.135 | 3.29 × 10−7 |
| Oil | 5 | glyma.Wm82.gnm1.Gm05_39499099 | A | G | 0.067 | −0.46 | 0.103 | 8.19 × 10−6 |
| Oil | 8 | glyma.Wm82.gnm1.Gm08_46435715 | G | T | 0.105 | −0.51 | 0.113 | 6.55 × 10−6 |
| Oil | 10 | glyma.Wm82.gnm1.Gm10_47564009 | A | G | 0.317 | −0.38 | 0.081 | 4.74 × 10−6 |
| Oil | 11 | glyma.Wm82.gnm1.Gm11_8270913 | A | G | 0.035 | −0.91 | 0.183 | 9.78 × 10−7 |
| Oil | 11 | glyma.Wm82.gnm1.Gm11_9120632 | C | A | 0.057 | −0.72 | 0.140 | 3.42 × 10−7 |
| Oil | 11 | glyma.Wm82.gnm1.Gm11_27517939 | A | G | 0.016 | −2.17 | 0.371 | 7.39 × 10−9 |
| Oil | 12 | glyma.Wm82.gnm1.Gm12_13640091 | A | G | 0.057 | −0.65 | 0.143 | 5.88 × 10−6 |
| Oil | 14 | glyma.Wm82.gnm1.Gm14_679279 | C | G | 0.020 | −1.05 | 0.234 | 9.21 × 10−6 |
| Oil | 16 | glyma.Wm82.gnm1.Gm16_666540 | T | C | 0.059 | −0.66 | 0.111 | 5.13 × 10−9 |
| Oil | 16 | glyma.Wm82.gnm1.Gm16_678372 | A | C | 0.050 | −0.68 | 0.137 | 9.93 × 10−7 |
| Oil | 16 | glyma.Wm82.gnm1.Gm16_708777 | A | G | 0.085 | −0.56 | 0.110 | 3.65 × 10−7 |
| Oil | 17 | glyma.Wm82.gnm1.Gm17_33884325 | A | T | 0.014 | −1.05 | 0.237 | 1.14 × 10−5 |
| Oil | 17 | glyma.Wm82.gnm1.Gm17_38648249 | G | A | 0.059 | −0.52 | 0.116 | 7.19 × 10−6 |
| Oil | 17 | glyma.Wm82.gnm1.Gm17_38677801 | C | G | 0.056 | −0.50 | 0.112 | 8.25 × 10−6 |
| Oil | 17 | glyma.Wm82.gnm1.Gm17_38900435 | C | A | 0.055 | −0.58 | 0.112 | 3.10 × 10−7 |
| Oil | 18 | glyma.Wm82.gnm1.Gm18_22353675 | A | G | 0.011 | −1.26 | 0.279 | 7.03 × 10−6 |
| Oil | 18 | glyma.Wm82.gnm1.Gm18_22813241 | T | C | 0.014 | −1.21 | 0.266 | 5.84 × 10−6 |
| Oil | 18 | glyma.Wm82.gnm1.Gm18_56821491 | G | A | 0.139 | −0.35 | 0.080 | 1.33 × 10−5 |
| Oil | 18 | glyma.Wm82.gnm1.Gm18_56862027 | A | G | 0.070 | −0.56 | 0.129 | 1.40 × 10−5 |
| Oil | 18 | glyma.Wm82.gnm1.Gm18_57755304 | G | A | 0.070 | −0.53 | 0.108 | 1.30 × 10−6 |
| Oil | 20 | glyma.Wm82.gnm1.Gm20_34390124 | G | A | 0.011 | −1.14 | 0.239 | 2.28 × 10−6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Potapova, N.A.; Zorkoltseva, I.V.; Zlobin, A.S.; Shcherban, A.B.; Fedyaeva, A.V.; Salina, E.A.; Svishcheva, G.R.; Aksenovich, T.I.; Tsepilov, Y.A. Genome-Wide Association Study on Imputed Genotypes of 180 Eurasian Soybean Glycine max Varieties for Oil and Protein Contents in Seeds. Plants 2025, 14, 255. https://doi.org/10.3390/plants14020255
Potapova NA, Zorkoltseva IV, Zlobin AS, Shcherban AB, Fedyaeva AV, Salina EA, Svishcheva GR, Aksenovich TI, Tsepilov YA. Genome-Wide Association Study on Imputed Genotypes of 180 Eurasian Soybean Glycine max Varieties for Oil and Protein Contents in Seeds. Plants. 2025; 14(2):255. https://doi.org/10.3390/plants14020255
Chicago/Turabian StylePotapova, Nadezhda A., Irina V. Zorkoltseva, Alexander S. Zlobin, Andrey B. Shcherban, Anna V. Fedyaeva, Elena A. Salina, Gulnara R. Svishcheva, Tatiana I. Aksenovich, and Yakov A. Tsepilov. 2025. "Genome-Wide Association Study on Imputed Genotypes of 180 Eurasian Soybean Glycine max Varieties for Oil and Protein Contents in Seeds" Plants 14, no. 2: 255. https://doi.org/10.3390/plants14020255
APA StylePotapova, N. A., Zorkoltseva, I. V., Zlobin, A. S., Shcherban, A. B., Fedyaeva, A. V., Salina, E. A., Svishcheva, G. R., Aksenovich, T. I., & Tsepilov, Y. A. (2025). Genome-Wide Association Study on Imputed Genotypes of 180 Eurasian Soybean Glycine max Varieties for Oil and Protein Contents in Seeds. Plants, 14(2), 255. https://doi.org/10.3390/plants14020255