
Auto-Machine-Learning Models for Standardized Precipitation Index Prediction in North–Central Mexico

 ,
,  , , and
, , and
Abstract
:1. Introduction
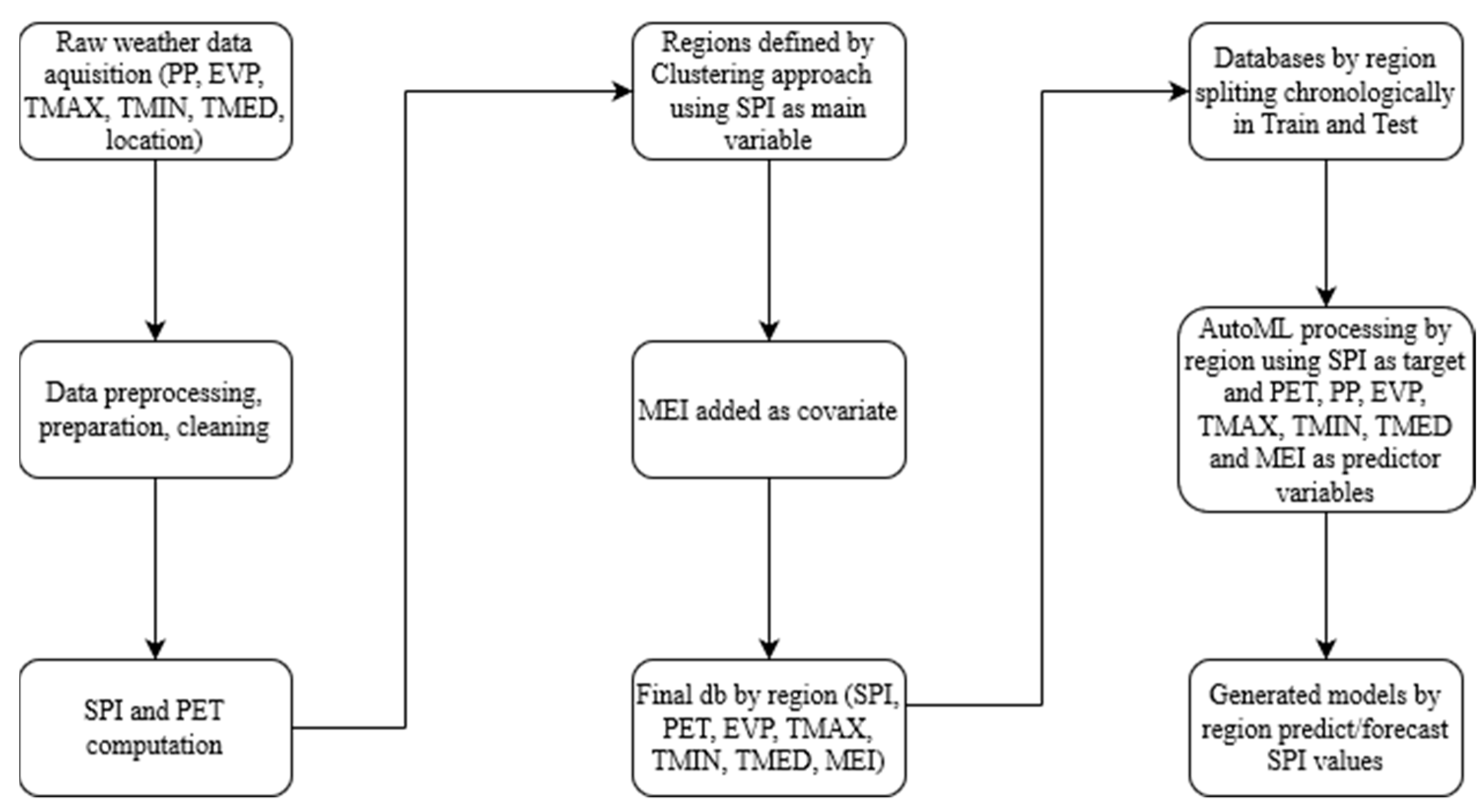
2. Materials and Methods
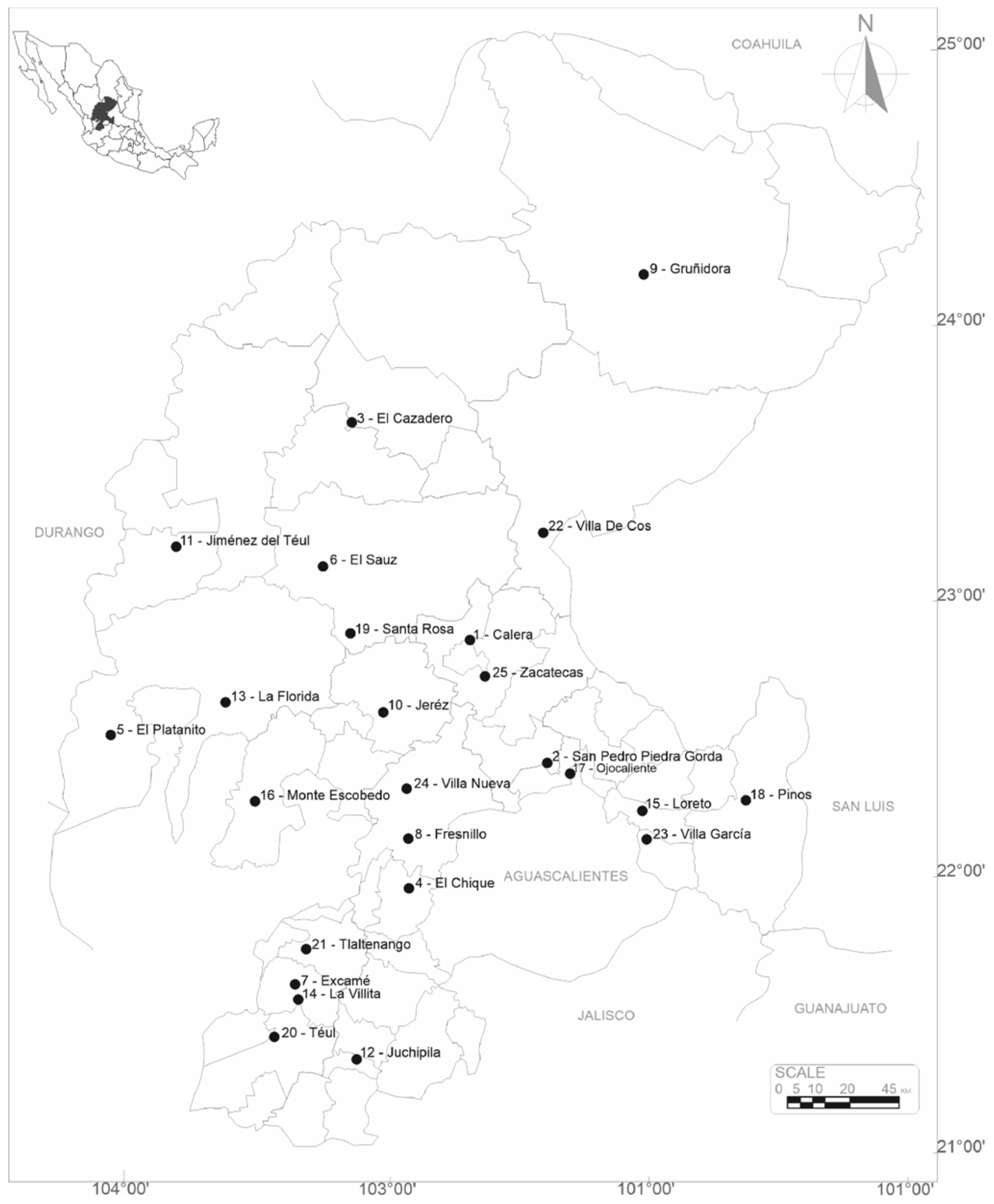
2.1. Data
2.2. Standardized Precipitation Index
2.3. Cluster Analysis
2.4. Potential Evapotranspiration Index
2.5. Multivariate ENSO Index Data
2.6. Linear Models for Time-Series Forecasting
2.7. Machine Learning for Time-Series Forecasting
2.7.1. Recurrent Neural Network
2.7.2. Long Short-Term Memory
2.7.3. Gated Recurrent Unit
2.7.4. Automated Machine Learning
- Data preprocessing: This involves cleaning and preparing the time-series data for analysis, such as handling missing values, outliers, and converting the data into a suitable format for modeling.
- Feature engineering: This step involves extracting relevant features from the time-series data to be used as input in the machine learning models.
- Model selection: In this step, prediction of the forthcoming values of the time series is achieved by evaluating and comparing different machine learning models for their performance.
- Hyperparameter tuning: This involves selecting the optimal values of hyperparameters for each machine learning model, which can significantly improve the model’s performance.
- Ensemble learning: This step involves combining multiple machine learning models to improve the prediction accuracy of the time-series data.
2.7.5. AutoML Frameworks
2.8. Performance Metrics
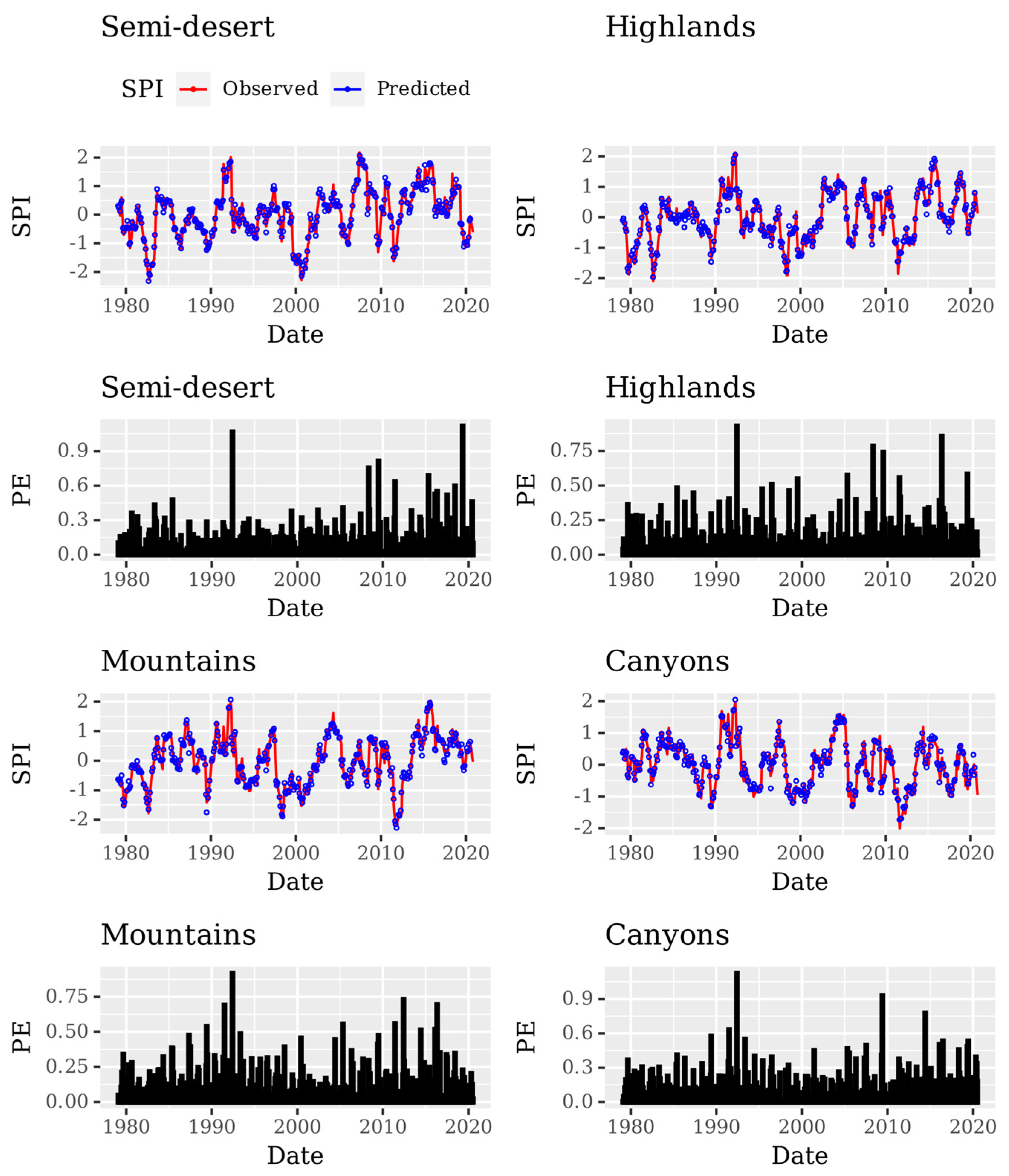
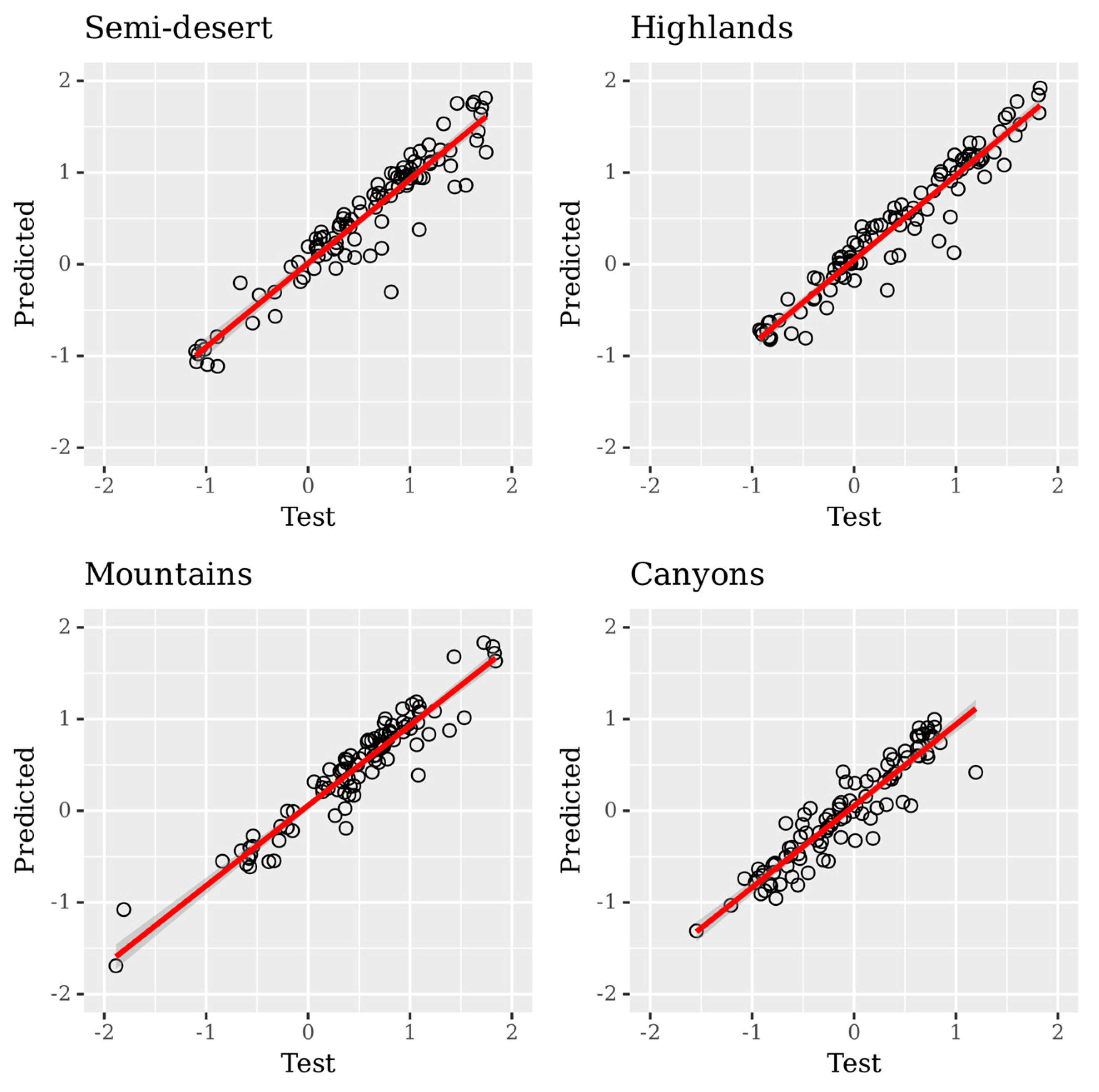
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kharin, V.V.; Zwiers, F.W.; Zhang, X.; Hegerl, G.C. Changes in Temperature and Precipitation Extremes in the IPCC Ensemble of Global Coupled Model Simulations. J. Clim. 2007, 20, 1419–1444. [Google Scholar] [CrossRef]
- Angheluță, P.S.; Badea, C.G. The Water Resources in the Context of Climate Change Produced by the Greenhouse Gases. Ann. Univ. Oradea 2015, 1, 637–643. [Google Scholar]
- Choubin, B.; Malekian, A.; Golshan, M. Application of Several Data-Driven Techniques to Predict a Standardized Precipitation Index. Atmosfera 2016, 29, 121–128. [Google Scholar] [CrossRef]
- Ali, Z.; Hussain, I.; Faisal, M.; Nazir, H.M.; Hussain, T.; Shad, M.Y.; Mohamd Shoukry, A.; Hussain Gani, S. Forecasting Drought Using Multilayer Perceptron Artificial Neural Network Model. Adv. Meteorol. 2017, 2017, 5681308. [Google Scholar] [CrossRef]
- McKee, T.B.; Doesken, N.J.; Kleist, J. The Relationship of Drought Frequency and Duration to Time Scales. In Proceedings of the 8th Conference on Applied Climatology, Anaheim, CA, USA, 17–22 January 1993; Volume 17, pp. 179–183. [Google Scholar]
- Naresh Kumar, M.; Murthy, C.S.; Sesha Sai, M.V.R.; Roy, P.S. On the Use of Standardized Precipitation Index (SPI) for Drought Intensity Assessment. Meteorol. Appl. 2009, 16, 381–389. [Google Scholar] [CrossRef]
- Mahfouz, P.; Mitri, G.; Jazi, M.; Karam, F. Investigating the Temporal Variability of the Standardized Precipitation Index in Lebanon. Climate 2016, 4, 27. [Google Scholar] [CrossRef]
- Giddings, L.; Soto, M.; Rutherford, B.M.; Maarouf, A. Standardized Precipitation Index Zones for México. Atmosfera 2005, 18, 33–56. [Google Scholar]
- Magallanes-Quintanar, R.; Blanco-Macías, F.; Galván-Tejada, E.C.; Galván-Tejada, J.; Márquez-Madrid, M.; Valdez-Cepeda, R.D. Negative Regional Standardized Precipitation Index Trends Prevail in the Mexico’s State of Zacatecas. Terra Latinoam. 2019, 37, 487–499. [Google Scholar] [CrossRef]
- Poornima, S.; Pushpalatha, M. Drought Prediction Based on SPI and SPEI with Varying Timescales Using LSTM Recurrent Neural Network. Soft Comput. 2019, 23, 8399–8412. [Google Scholar] [CrossRef]
- Chen, L.; Han, B.; Wang, X.; Zhao, J.; Yang, W.; Yang, Z. Machine Learning Methods in Weather and Climate Applications: A Survey. Appl. Sci. 2023, 13, 12019. [Google Scholar] [CrossRef]
- Ozger, M.; Mishra, A.K.; Singh, V.P. Estimating Palmer Drought Severity Index Using a Wavelet Fuzzy Logic Model Based on Meteorological Variables. Int. J. Climatol. 2011, 31, 2021–2032. [Google Scholar] [CrossRef]
- Masinde, M. Artificial Neural Networks Models for Predicting Effective Drought Index: Factoring Effects of Rainfall Variability. Mitig. Adapt. Strateg. Glob. Chang. 2014, 19, 1139–1162. [Google Scholar] [CrossRef]
- Belayneh, A.; Adamowski, J.; Khalil, B.; Ozga-Zielinski, B. Long-Term SPI Drought Forecasting in the Awash River Basin in Ethiopia Using Wavelet Neural Network and Wavelet Support Vector Regression Models. J. Hydrol. 2014, 508, 418–429. [Google Scholar] [CrossRef]
- Deo, R.C.; Şahin, M. Application of the Artificial Neural Network Model for Prediction of Monthly Standardized Precipitation and Evapotranspiration Index Using Hydrometeorological Parameters and Climate Indices in Eastern Australia. Atmos. Res. 2015, 161–162, 65–81. [Google Scholar] [CrossRef]
- Soh, Y.W.; Koo, C.H.; Huang, Y.F.; Fung, K.F. Application of Artificial Intelligence Models for the Prediction of Standardized Precipitation Evapotranspiration Index (SPEI) at Langat River Basin, Malaysia. Comput. Electron. Agric. 2018, 144, 164–173. [Google Scholar] [CrossRef]
- Magallanes-Quintanar, R.; Galván-Tejada, C.E.; Galvan-Tejada, J.I.; de Jesús Méndez-Gallegos, S.; Blanco-Macías, F.; Valdez-Cepeda, R.D. Artificial Neural Network Models for Prediction of Standardized Precipitation Index in Central Mexico. Agrociencia 2023, 57, 11–20. [Google Scholar] [CrossRef]
- LeDell, E.; Poirier, S. H2O AutoML: Scalable Automatic Machine Learning. In Proceedings of the 7th AutoML Workshop at ICML, San Diego, CA, USA, 17–18 July 2020; Volume 2020. [Google Scholar]
- Thornthwaite, C.W. An Approach toward a Rational Classification of Climate. Geogr. Rev. 1948, 38, 55–94. [Google Scholar] [CrossRef]
- Caloiero, T. Drought Analysis in New Zealand Using the Standardized Precipitation Index. Environ. Earth Sci. 2017, 76, 569. [Google Scholar] [CrossRef]
- Beguería, S.; Vicente-Serrano, S.M. SPEI: Calculation of the Standardized Precipitation-Evapotranspiration Index. In R Package Version 2017; R Foundation for Statistical Computing: Vienna, Austria, 2017; Volume 1. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013. [Google Scholar]
- Unal, Y.; Kindap, T.; Karaca, M. Redefining the Climate Zones of Turkey Using Cluster Analysis. Int. J. Climatol. 2003, 23, 1045–1055. [Google Scholar] [CrossRef]
- Karmalkar, A.V.; Bradley, R.S.; Diaz, H.F. Climate Change in Central America and Mexico: Regional Climate Model Validation and Climate Change Projections. Clim. Dyn. 2011, 37, 605–629. [Google Scholar] [CrossRef]
- Paradis, E.; Schliep, K. Ape 5.0: An Environment for Modern Phylogenetics and Evolutionary Analyses in R. Bioinformatics 2019, 35, 526–528. [Google Scholar] [CrossRef] [PubMed]
- Hanson, R.L. Evapotranspiration and Droughts. In National Water Summary 1988–89—Hydrologic Events and Floods and Droughts: US Geological Survey Water-Supply Paper; Le Haut Commissariat aux Eaux et Forêts: El Haj Kaddour, Morocco, 1991; Volume 2375. [Google Scholar]
- Vicente-Serrano, S.M.; Beguería, S.; López-Moreno, J.I. A Multiscalar Drought Index Sensitive to Global Warming: The Standardized Precipitation Evapotranspiration Index. J. Clim. 2010, 23, 1696–1718. [Google Scholar] [CrossRef]
- Wolter, K.; Timlin, M.S. Measuring the Strength of ENSO Events: How Does 1997/98 Rank? Weather 1998, 53, 315–324. [Google Scholar] [CrossRef]
- Wolter, K.; Timlin, M.S. El Niño/Southern Oscillation Behaviour since 1871 as Diagnosed in an Extended Multivariate ENSO Index (MEI.Ext). Int. J. Climatol. 2011, 31, 1074–1087. [Google Scholar] [CrossRef]
- Madsen, H. Time Series Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 2007; ISBN 0-429-19583-4. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Representations by Back-Propagating Errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.; Blum, M.; Hutter, F. Efficient and Robust Automated Machine Learning. Adv. Neural Inf. Process. Syst. 2015, 28, 2755–2763. [Google Scholar]
- Alsharef, A.; Aggarwal, K.; Kumar, M.; Mishra, A. Review of ML and AutoML Solutions to Forecast Time-Series Data. Arch. Comput. Methods Eng. 2022, 29, 5297–5311. [Google Scholar] [CrossRef]
- Olson, R.S.; Urbanowicz, R.J.; Andrews, P.C.; Lavender, N.A.; Kidd, L.C.; Moore, J.H. Automating Biomedical Data Science through Tree-Based Pipeline Optimization. In Proceedings of the 19th European Conference on the Applications of Evolutionary Computation, EvoApplications 2016, Porto, Portugal, 30 March–1 April 2016; Springer: Berlin/Heidelberg, Germany, 2016. Part I 19. pp. 123–137. [Google Scholar]
- Erickson, N.; Mueller, J.; Shirkov, A.; Zhang, H.; Larroy, P.; Li, M.; Smola, A. Autogluon-Tabular: Robust and Accurate Automl for Structured Data. arXiv 2020, arXiv:2003.06505. [Google Scholar]
- Paldino, G.M.; De Stefani, J.; De Caro, F.; Bontempi, G. Does AutoML Outperform Naive Forecasting? Eng. Proc. 2021, 5, 36. [Google Scholar] [CrossRef]
- Van Rossum, G.; Drake, F.L. Introduction to Python 3: Python Documentation Manual Part 1; CreateSpace: Scotts Valley, CA, USA, 2009; ISBN 1-4414-1270-0. [Google Scholar]
- H2O AutoML: Automatic Machine Learning. Available online: https://docs.h2o.ai/h2o/latest-stable/h2o-docs/automl.html (accessed on 28 June 2024).
- Moustris, K.P.; Larissi, I.K.; Nastos, P.T.; Paliatsos, A.G. Precipitation Forecast Using Artificial Neural Networks in Specific Regions of Greece. Water Resour. Manag. 2011, 25, 1979–1993. [Google Scholar] [CrossRef]
- Daliakopoulos, I.N.; Coulibaly, P.; Tsanis, I.K. Groundwater Level Forecasting Using Artificial Neural Networks. J. Hydrol. 2005, 309, 229–240. [Google Scholar] [CrossRef]
- Farajzadeh, J.; Fakheri Fard, A.; Lotfi, S. Modeling of Monthly Rainfall and Runoff of Urmia Lake Basin Using “Feed-Forward Neural Network” and “Time Series Analysis” Model. Water Resour. Ind. 2014, 7–8, 38–48. [Google Scholar] [CrossRef]
- Snieder, E.; Shakir, R.; Khan, U.T. A Comprehensive Comparison of Four Input Variable Selection Methods for Artificial Neural Network Flow Forecasting Models. J. Hydrol. 2020, 583, 124299. [Google Scholar] [CrossRef]
- Sharma, P.; Singh, S.; Sharma, S.D. Artificial Neural Network Approach for Hydrologic River Flow Time Series Forecasting. Agric. Res. 2022, 11, 465–476. [Google Scholar] [CrossRef]
- Bouaziz, M.; Medhioub, E.; Csaplovisc, E. A Machine Learning Model for Drought Tracking and Forecasting Using Remote Precipitation Data and a Standardized Precipitation Index from Arid Regions. J. Arid Environ. 2021, 189, 104478. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SPI Value | Category |
|---|---|
| ≥2.0 | Extremely wet |
| 1.5 to 1.99 | Severely wet |
| 1.0 to 1.49 | Moderately wet |
| −0.99 to 0.99 | Near normal |
| −1.49 to −0.99 | Moderately drought |
| −1.99 to −1.49 | Severely drought |
| ≤2.0 | Extremely drought |
| Region | Predictors | |||||
|---|---|---|---|---|---|---|
| Semi-Arid | PP (mm) | EVP (mm) | TMED (°C) | TMIN (°C) | TMAX (°C) | PET (mm) |
| Min | 0.00 | 58.00 | 10.05 | −6.00 | 21.00 | 25.19 |
| Mean | 38.89 | 160.17 | 16.37 | 4.25 | 28.41 | 63.92 |
| Max | 339.50 | 299.90 | 21.36 | 11.50 | 42.06 | 105.22 |
| SD | 45.08 | 50.79 | 2.68 | 4.14 | 2.83 | 20.96 |
| Highlands | PP (mm) | EVP (mm) | TMED (°C) | TMIN (°C) | TMAX (°C) | PET (mm) |
| Min | 0.00 | 91.91 | 9.98 | −10.91 | 23.47 | 23.656 |
| Mean | 37.63 | 167.84 | 16.67 | 3.39 | 29.24 | 66.64 |
| Max | 275.56 | 308.82 | 22.51 | 11.32 | 35.54 | 114.41 |
| SD | 42.42 | 48.13 | 3.25 | 5.02 | 2.68 | 25.42 |
| Mountains | PP (mm) | EVP (mm) | TMED (°C) | TMIN (°C) | TMAX (°C) | PET (mm) |
| Min | 0.00 | 81.27 | 11.31 | −6.42 | 25.32 | 25.29 |
| Mean | 47.22 | 166.44 | 18.18 | 4.39 | 31.57 | 74.30 |
| Max | 295.42 | 308.95 | 24.73 | 12.70 | 39.00 | 144.71 |
| SD | 54.72 | 54.54 | 3.39 | 5.18 | 2.91 | 30.78 |
| Canyons | PP (mm) | EVP (mm) | TMED (°C) | TMIN (°C) | TMAX (°C) | PET (mm) |
| Min | 0.00 | 83.28 | 11.35 | −5.43 | 24.30 | 26.54 |
| Mean | 53.55 | 156.84 | 18.50 | 4.63 | 31.74 | 72.97 |
| Max | 331.46 | 285.04 | 25.56 | 13.10 | 39.30 | 139.98 |
| SD | 62.17 | 47.83 | 3.32 | 5.13 | 2.89 | 29.02 |
| Region | T | CV | T | CV | T | CV |
|---|---|---|---|---|---|---|
| MSE | MAE | R2 | ||||
| Semi-desert | 0.0296 | 0.0615 | 0.1214 | 0.1726 | 0.9584 | 0.9136 |
| Highlands | 0.0345 | 0.0503 | 0.127 | 0.1534 | 0.9426 | 0.9163 |
| Mountains | 0.0348 | 0.0557 | 0.1277 | 0.1632 | 0.9468 | 0.9149 |
| Canyons | 0.0388 | 0.0549 | 0.1355 | 0.1637 | 0.9342 | 0.9067 |
| Region | β0 | β1 | R2 | R |
|---|---|---|---|---|
| Semi-desert | 0.046 | 0.980 | 0.897 | 0.947 |
| Highlands | −0.020 | 1.008 | 0.930 | 0.964 |
| Mountains | −0.020 | 1.050 | 0.923 | 0.961 |
| Canyons | −0.066 | 0.981 | 0.871 | 0.933 |
| Region | PE < 0 | PE > 0 |
|---|---|---|
| Semi-desert | 0.4068 | 0.5932 |
| Highlands | 0.5339 | 0.4661 |
| Mountains | 0.4900 | 0.5100 |
| Canyons | 0.6200 | 0.3800 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Magallanes-Quintanar, R.; Galván-Tejada, C.E.; Galván-Tejada, J.I.; Gamboa-Rosales, H.; Méndez-Gallegos, S.d.J.; García-Domínguez, A. Auto-Machine-Learning Models for Standardized Precipitation Index Prediction in North–Central Mexico. Climate 2024, 12, 102. https://doi.org/10.3390/cli12070102
Magallanes-Quintanar R, Galván-Tejada CE, Galván-Tejada JI, Gamboa-Rosales H, Méndez-Gallegos SdJ, García-Domínguez A. Auto-Machine-Learning Models for Standardized Precipitation Index Prediction in North–Central Mexico. Climate. 2024; 12(7):102. https://doi.org/10.3390/cli12070102
Chicago/Turabian StyleMagallanes-Quintanar, Rafael, Carlos E. Galván-Tejada, Jorge Isaac Galván-Tejada, Hamurabi Gamboa-Rosales, Santiago de Jesús Méndez-Gallegos, and Antonio García-Domínguez. 2024. "Auto-Machine-Learning Models for Standardized Precipitation Index Prediction in North–Central Mexico" Climate 12, no. 7: 102. https://doi.org/10.3390/cli12070102