
Bilingual Texting in the Age of Emoji: Spanish–English Code-Switching in SMS


Abstract
1. Introduction
2. Materials and Methods
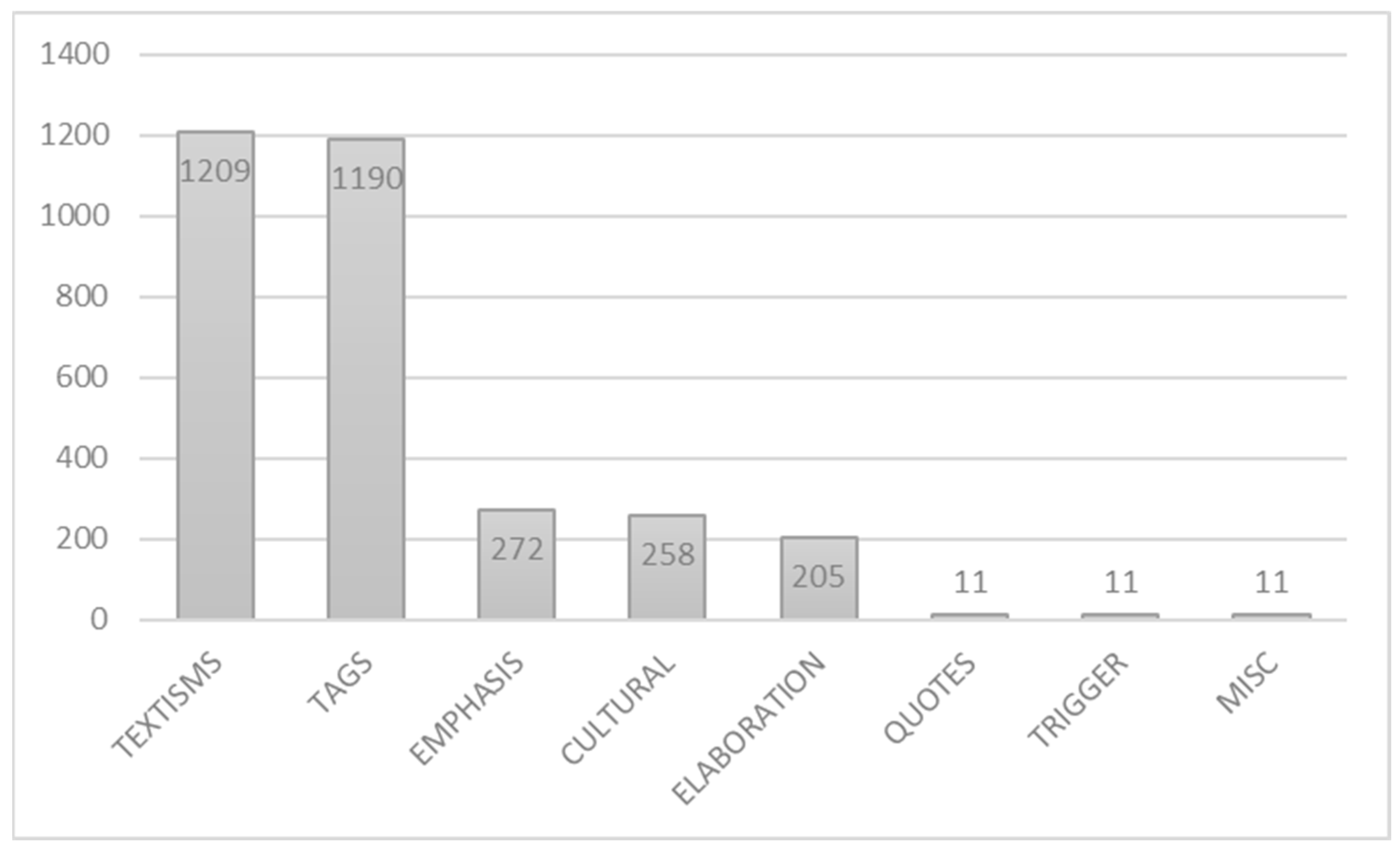
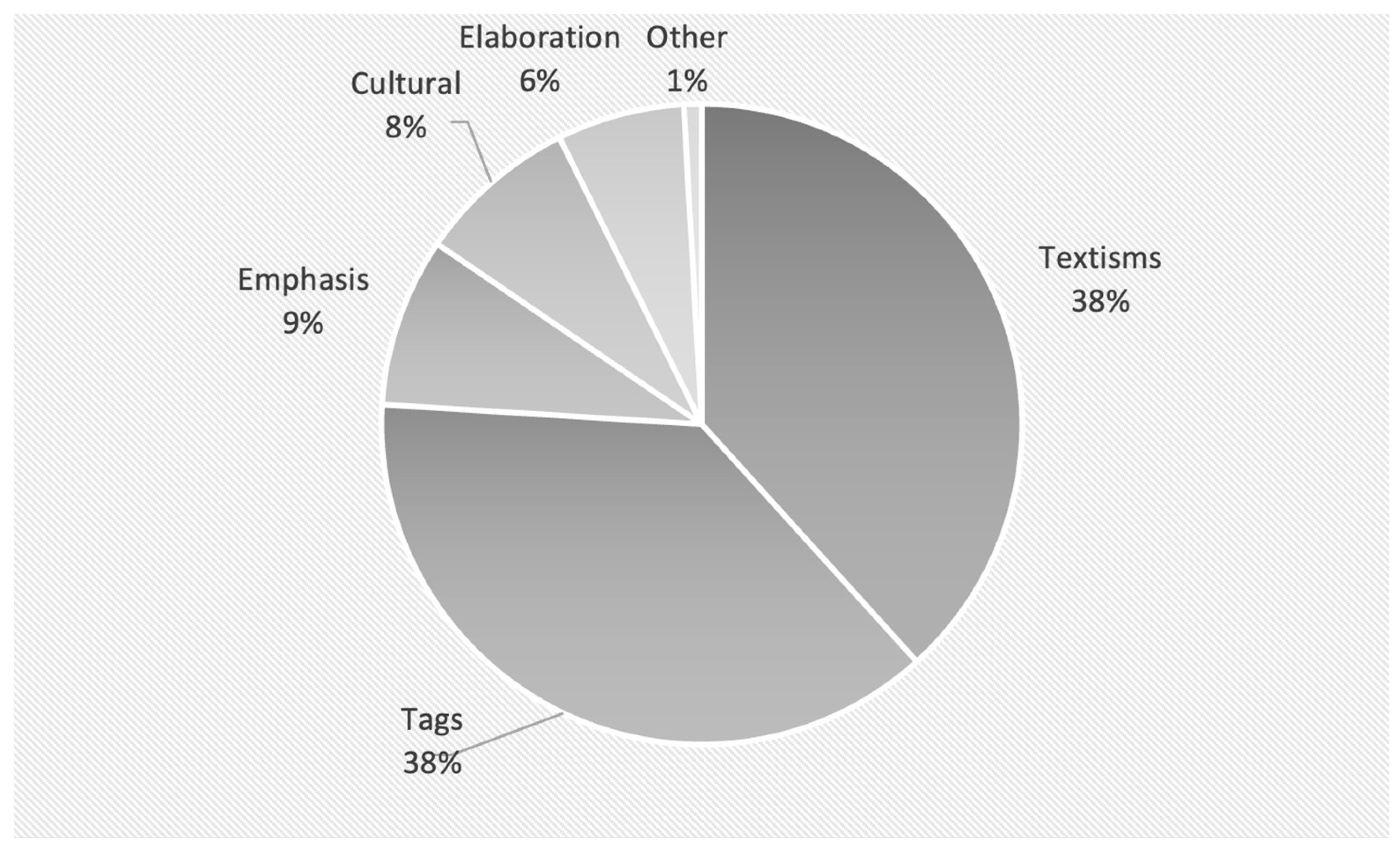
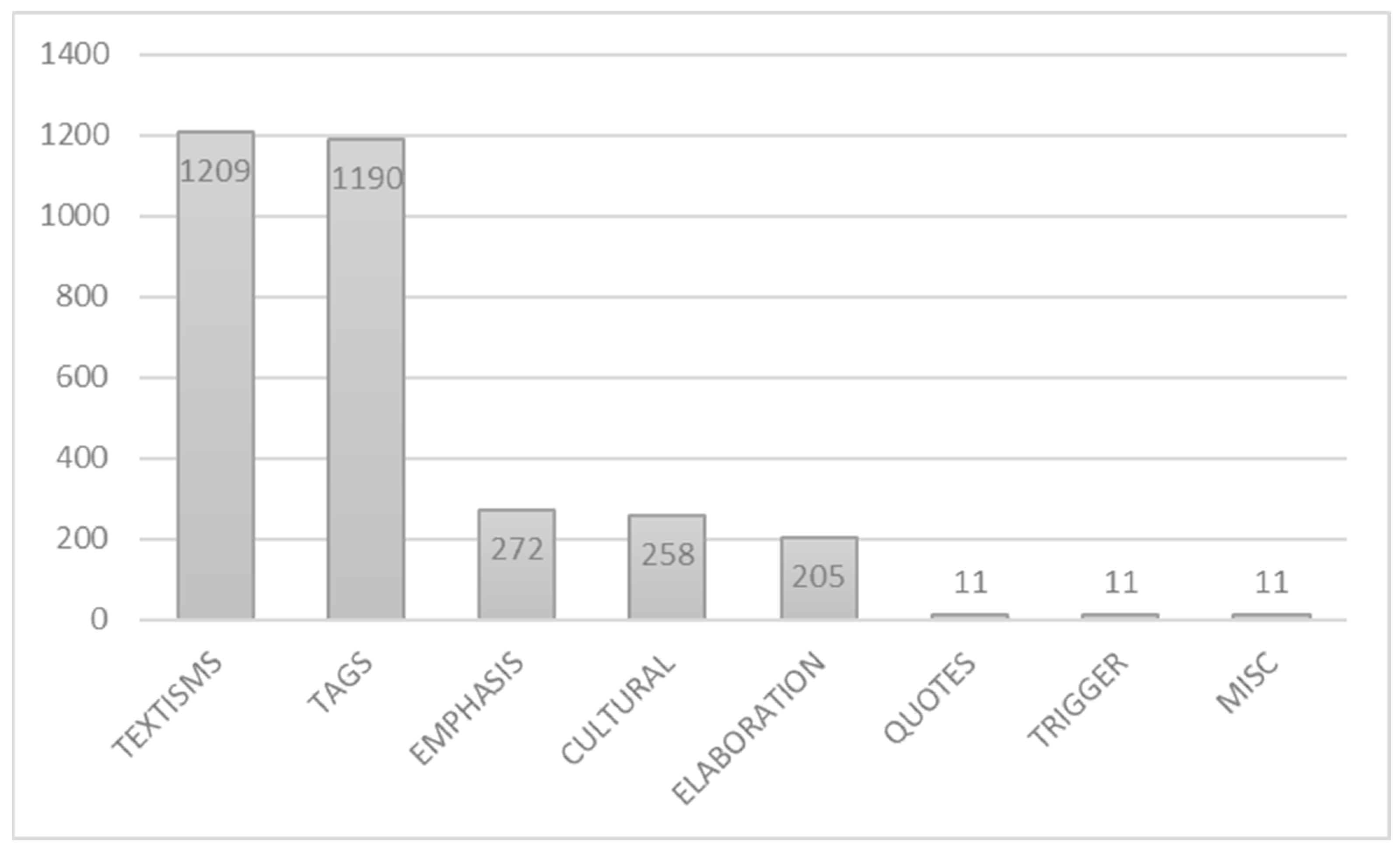
3. Results
3.1. Textisms
- Wyd ancianita 😘“Wyd (What are you doing?) little old lady?”
- Omg si que stas loco y te dolía?“Omg (oh, my God) you’re crazy, and did it hurt?”
- Babe mi telef esta en 2%. Lo voy a poner a cargar ttyl 😘“Babe my cell is at 2%. I am going to charge it ttyl” (Talk to you later)
- Idk! Dime tu“Idk! (I don’t know) You tell me”
- Asiendo brownies hbu“Making brownies hbu” (how about you?)
- Nooo baby no ahora plz“Nooo baby not now plz” (please)
- Toy muy busy ahora bby 😃“I’m very busy now bby” (bye bye)
3.2. Tag Switches
- 8.
- Voy para la casa ahora baby“I’m going to the house now baby”
- 9.
- Babe estas mirando las noticias?“Babe, are you watching the news?”
- 10.
- No hay dinero bro“There is no money bro”
- 11.
- Donde andas brother“Where are you brother?”
- 12.
- Nada men ya boy a comer y vos“Nothing man, I’m going to eat and you?”
- 13.
- Ohh so tu sigues molesto conmigo??? 😔“Oh, so are you still upset with me?”
- 14.
- Bueno, yeah by myself“Well, yeah by myself”
3.3. Emphasis
- 15.
- That’s why I don’t like cold cuz I’m always SOLITA lol‘That’s why I don’t like cold cuz I’m always ALONE lol’
- 16.
- Whatever!!! Cambiemos de tema por favor“Whatever!!! Let’s change the topic, please”
- 17.
- Que fucking novia yo tengo??“What fucking girlfriend do I have?”
- 18.
- Pendejo, we not togethherrr“Idiot, we not together”
- 19.
- Diablo no he’s my twin 😳 👌 🙏 🙈“Damn, no he’s my twin”
3.4. Cultural Switches
- 20.
- Hijita preciosa. Esta en after school?“Pretty daughter. Is she in after school?”
- 21.
- Estas haciendo tu homework?“Are you doing your homework?”
- 22.
- Yo no sabia que mi average era de 86.59 lol“I didn’t know my average was 86.59 lol”
- 23.
- Hable con ella y me dijo que necesita a alguien para full time“I talked to her and she told me that she needs someone full time”
- 24.
- Ese printer es el que mas se daña lol“That printer is the one that breaks the most lol”
- 25.
- Yeah lol!!! Hopefully I’ll see mi abuelita tomorrow 😍“Yeah lol!!! Hopefully I’ll see my grandma tomorrow”
- 26.
- I’m going to TRY to do las habichuelas today“I’m going to TRY to do the beans today”
- 27.
- Eat breakfast then babe it’ll probably be a while until the sancocho is ready“Eat breakfast then babe it’ll probably be a while until the stew is ready”
3.5. Elaboration and Clarification
- 28.
- That’s ok, pero quería que ella hablara contigo como sea“That’s ok, but I wanted her to talk to you anyhow”
- 29.
- I like night clubs porque me gusta bailar lol 💃“I like night clubs because I like to dance lol”
- 30.
- Aquí estoy! I was cleaning the bathroom“I’m here! I was cleaning the bathroom”
- 31.
- Le tengo miedo a las alturas! That’s why I don’t like planes lol“I’m scared of heights! That’s why I don’t like planes lol”
- 32.
- Not good! Peor que ayer 😔“Not good! Worse than yesterday”
- 33.
- I can’t watch tv now lol… Hay mucha bulla aquí“I can’t watch tv now lol… There is a lot of noise here”
- 34.
- I woke up to drink water! Tenia una sed“I woke up to drink water! I was so thirsty”
- 35.
- No voy a decir nada cuz I don’t wanna fight 😔 😔“I am not going to say anything because I don’t wanna fight”
3.6. Other Findings
3.6.1. Quotes
- 36.
- But then I was like:… No el no se acuerda 🙈“But then I was like: No, he does not remember”
- 37.
- And I ask her why she think that & dijo… Porque te estas riendo 😂“And I ask her why she think that and she said… because you are laughing”
- 38.
- Es que tu me dijiste que tu talk to another boy“It’s that you told me that you talk to another boy”
- 39.
- Estoy de mal humor. Y no me digas “my love”“I’m in a bad mood. And don’t tell me “my love””
3.6.2. Triggered
- 40.
- Watching Nuestra Belleza Latina con mi pai“Watching Nuestra Belleza Latina with my dad”
- 41.
- Voy en el train going down“I’m on the train going down”
- 42.
- Ohhh I thought you were in universita o algo.“Oh I thought you were in college or something”
3.6.3. Miscellaneous
- 43.
- How much valen 👀“How much are they”
- 44.
- Le puedes tomar de new la foto a la 6 7 y 8“Can you take the picture again for 6, 7 and 8”
- 45.
- Lol estoy something then“Lol I’m something then”
4. Discussion
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
| 1 | |
| 2 | See, https://www.commonsensemedia.org/press-releases/teens-are-bombarded-with-hundreds-of-notifications-a-day (accessed on 15 January 2024). |
| 3 | These authors, as many others across diverse disciplines such as translation, bilingual education, and sociolinguistics, use the term code-mixing to refer to elements from one language used in another language, when mainly the grammar of the L1 is at work, while in code-switching both grammars would be active simultaneously. Other common terms used to describe language alternation are code-meshing and translanguaging. For the sake of simplicity, I henceforth use code-switching, language switching, and language mixing interchangeably to refer to the alternative use of two or more languages in bilingual or multilingual discourse. For further discussion on terminology, see Mabule (2015). |
| 4 | See, https://www.isocfoundation.org/2023/05/what-are-the-most-used-languages-on-the-internet/ (accessed on 15 January 2024). |
| 5 | Most of the information about the corpus and participants presented here is summarized from the BYTs corpus website, with some additional details extracted from McSweeney (2018). One anonymous reviewer points out that not having enough background information about the texters poses limitations to the analysis of the data. I acknowledge such limitations and refer the reader to McSweeney (2018) for more detailed background about her project’s participants, data collection, methods, and message processing. |
| 6 | Messages are here transcribed as they originally appear in the BYTs corpus, including typos, spelling errors and emojis. I use regular font for English and italics for Spanish. All translations are my own. |
| 7 |
References
- Al-Khatib, Mahmoud A., and Enaq H. Sabbah. 2008. Language Choice in Mobile Text Messages among Jordanian University Students. SKY Journal of Linguistics 21: 37–65. [Google Scholar]
- Androutsopoulos, Jannis. 2007. Language Choice and Code Switching in German-Based Diasporic Web Forums. In The Multilingual Internet: Language, Culture, and Communication Online. Edited by Brenda Danet and Susan C. Herring. Oxford: Oxford University Press, pp. 340–61. [Google Scholar]
- Androutsopoulos, Jannis. 2013. Code-switching in computer-mediated communication. In Pragmatics of Computer-Mediated Communication. Edited by Susan C. Herring, Dieter Stein and Tuija Virtanen. Berlin and New York: Mouton de Gruyter, pp. 659–86. [Google Scholar]
- Androutsopoulos, Jannis. 2015. Networked multilingualism: Some language practices on Facebook and their implications. International Journal of Bilingualism 19: 185–205. [Google Scholar] [CrossRef]
- Barasa, Sandra Nekesa. 2016. Spoken Code-Switching in Written Form? Manifestation of Code-Switching in Computer Mediated Communication. Journal of Language Contact 9: 49–70. [Google Scholar] [CrossRef]
- Danet, Brenda, and Susan C. Herring, eds. 2007. The Multilingual Internet: Language, Culture and Communication Online. Oxford: Oxford University Press. [Google Scholar]
- Dascalu, Emanuela A. C. 1999. The Form and Function of Code-Switching in Bilingual Writing: A Comparative Analysis of English Email Messages Written by Belarusian/English, Korean/English, and Romanian/English Bilinguals. Available online: http://www.utulsa.edu/tugr/tugr99/codeswit.html (accessed on 15 January 2024).
- Dorleijn, Margreet, and Jacomine Nortier. 2009. Code-switching and the internet. In The Cambridge Handbook of Linguistic Code-Switching. Edited by Barbara Bullock and Almeida Jacqueline Toribio. Cambridge: Cambridge University Press, pp. 127–41. [Google Scholar]
- Fernández-Mallat, Víctor. 2020. Cuando me da la gana. Me AF: Washingtonian Bilingual Speakers of Spanish on Facebook. In Spanish across Domains in the United States. Edited by Francisco Salgado Robles and Edwin Lamboy. Leiden: Brill, pp. 289–311. [Google Scholar]
- Georgakopoulou, Alexandra. 1997. Self-presentation and interactional alliances in e-mail discourse: The style- and code-switches of Greek messages. International Journal of Applied Linguistics 7: 141–64. [Google Scholar] [CrossRef]
- Gumperz, John. 1982a. Conversational Code-Switching. In Discourse Strategies. Edited by John Gumperz. Cambridge: Cambridge University Press, pp. 59–99. [Google Scholar]
- Gumperz, John. 1982b. Discourse Strategies. New York: Cambridge University Press. [Google Scholar]
- Halim, Nur Syazwani, and Marlyna Maros. 2014. The Functions of Code-switching in Facebook Interactions. Procedia Social and Behavioral Sciences 118: 126–33. [Google Scholar] [CrossRef]
- Hinrichs, Lars. 2006. Codeswitching on the Web: English and Jamaican Creole in E-Mail Communication. Amsterdam and Philadelphia: John Benjamins. [Google Scholar]
- Hinrichs, Lars. 2016. Modular repertoires in English-using social networks: A study of language choice in the networks of adult Facebook users. In English in Computer—Mediated Communication. Variation, Representation, and Change. Edited by Lauren Squires. Berlin: De Gruyter Mouton, pp. 17–42. [Google Scholar]
- Jacobson, Rodolfo. 1977. The social implications of intra-sentential code-switching. New Directions in Chicano Scholarship 6: 227–56. [Google Scholar]
- Jurgens, David, Stefan Dimitrov, and Derek Ruths. 2014. Twitter Users #CodeSwitch Hashtags! #MoltoImportante #wow. Paper presented at the First Workshop on Computational Approaches to Code Switching, Doha, Qatar, October 25. [Google Scholar]
- Kytölä, Samu. 2013. Multilingual Language Use and Metapragmatic Reflexivity in Finnish Internet Football Forums: A Study in the Sociolinguistics of Globalization. Doctoral dissertation, University of Jyväskylä, Jyväskylä, Finland. [Google Scholar]
- Lanz Vallejo, Liliana. 2011. El cambio de código español-inglés como creatividad lingüística y presentación de la imagen en Tweets escritos por tijuanenses. In Memorias de las 1as. Jornadas de Lenguas en Contacto. Tepic: Universidad Autónoma de Nayarit. Available online: http://www.cucsh.uan.edu.mx/jornadas/modulos/memoria/lanz_cambio_codigo.pdf (accessed on 15 January 2024).
- Lavender, Jordan. 2017. Comparing the pragmatic function of code switching in oral conversation and in Twitter in Bilingual Speech from Valencia, Spain. Catalan Review 31: 15–39. [Google Scholar] [CrossRef]
- Lee, Carmen. 2017. Multilingualism Online. London and New York: Routledge. [Google Scholar]
- Leppänen, Sirpa, and Saija Peuronen. 2020. Multilingualism and the Internet. In The Encyclopedia of Applied Linguistics. Edited by Carol A. Chapelle. Oxford: Blackwell/Wiley, pp. 1–11. [Google Scholar]
- Leppänen, Sirpa. 2012. Linguistic and generic hybridity in web writing: The case of fan fiction. In Language Mixing and Code-Switching in Writing: Approaches to Mixed-Language Written Discourse. Edited by Mark Sebba, Shahrzad Mahootian and Carla Jonsson. New York: Routledge, pp. 233–54. [Google Scholar]
- Lienard, Fabian, and Marie-Claude Penloup. 2011. Language contacts and code-switching in electronic writing: The case of the blog. In Code-Switching, Languages in Contact and Electronic Writing. Edited by Foued Laroussi. Frankfurt and Main: Peter Lang, pp. 73–86. [Google Scholar]
- Lin, Angel. 2005. Gendered, Bilingual Communication Practices: Mobile Text Messaging among Hong Kong College Students. The Fibreculture Journal. Available online: http://six.fibreculturejournal.org/fcj-031-gendered-bilingual-communication-practices-mobile-text-messaging-among-hong-kong-college-students/ (accessed on 15 January 2024).
- Mabule, Dorah Riah. 2015. What is this? Is It Code Switching, Code Mixing or Language Alternating? Journal Of Educational And Social Research 5: 339–50. Available online: https://www.richtmann.org/journal/index.php/jesr/article/view/5628 (accessed on 15 January 2024). [CrossRef]
- Magaña, Dalia. 2013. Code-switching in Social-network Messages: A Case-study of a Bilingual Chicana. International Journal of the Linguistic Association of the Southwest 32: 43–65. [Google Scholar]
- McClure, Erica. 1981. Formal and Functional Aspects of the Codeswitched Discourse of Bilingual Children. In Latino Language and Communicative Behavior. Edited by Richard Durán. Norwood: Ablex, pp. 69–92. [Google Scholar]
- McSweeney, Michelle. 2016. The Bilingual Youth Texts Corpus. Available online: https://byts.commons.gc.cuny.edu (accessed on 15 January 2024).
- McSweeney, Michelle. 2018. The Pragmatics of Text Messaging: Making Meaning in Messages. New York: Routledge. [Google Scholar]
- Montes-Alcalá, Cecilia. 2005. Mándame un e-mail: Cambio de códigos español-inglés online. In Contactos y Contextos Lingüísticos: El Español en Los Estados Unidos y en Contacto con Otras Lenguas. Edited by Luis Ortiz López and Manel Lacorte. Madrid: Iberoamericana, pp. 173–85. [Google Scholar]
- Montes-Alcalá, Cecilia. 2007. Blogging in Two Languages: Code-Switching in Bilingual Blogs. In Selected Proceedings of the Third Workshop on Spanish Sociolinguistics. Edited by Jonathan Holmquist, Augusto Lorenzino and Lotfi Sayahi. Somerville: Cascadilla Proceedings Project, pp. 162–70. [Google Scholar]
- Montes-Alcalá, Cecilia. 2015. iSwitch: Spanish-English Mixing in Computer-Mediated Communication. Journal of Language Contact 9: 19–44. [Google Scholar] [CrossRef]
- Negrón Goldbarg, Rosalyn. 2009. Spanish-English Codeswitching in E-Mail Communication. Language@Internet 6. Available online: http://www.languageatinternet.org/articles/2009 (accessed on 15 January 2024).
- Novianti, Widya. 2013. The Use of Code Switching in Twitter (A Case Study in English Education Department). Passage 1: 1–10. Available online: https://ejournal.upi.edu/index.php/psg/article/view/532 (accessed on 15 January 2024).
- Paolillo, John C. 1996. Language Choice on Soc.Culture.Punjab. Electronic Journal of Communication/La revue Électronique de Communication 6. Available online: http://www.cios.org/www/ejc/v6n396.htm (accessed on 15 January 2024).
- Paolillo, John C. 2011. “Conversational” Codeswitching on Usenet and Internet Relay Chat. Language@Internet 8. Available online: http://www.languageatinternet.org/articles/2011/Paolillo (accessed on 15 January 2024).
- Pérez-Sabater, Carmen. 2022. Mixing Catalan, English and Spanish on WhatsApp: A case study on language choice and code-switching. Spanish in Context 19: 289–313. [Google Scholar] [CrossRef]
- Poplack, Shana. 1980. Sometimes I’ll start a sentence in Spanish y termino en español: Toward a typology of code-switching. Linguistics 18: 581–618. [Google Scholar] [CrossRef]
- Poplack, Shana. 1981. Syntactic Structure and Social Function of Codeswitching. In Latino Language and Communicative Behavior. Edited by Richard Durán. Norwood: Ablex, pp. 169–84. [Google Scholar]
- Siebenhaar, Beat. 2006. Code choice and code-switching in Swiss-German Internet Relay Chat rooms. Journal of Sociolinguistics 10: 481–506. [Google Scholar] [CrossRef]
- Ting, Su-Hie, and Kai-Liang Yeo. 2019. Code-switching Functions in Facebook Wallposts. Human Behavior, Development and Society 20: 7–18. [Google Scholar]
- Tsiplakou, Stavroula. 2009. Doing (Bi)lingualism: Language Alternation as Performative Construction of Online Identities. Pragmatics 19: 361–91. [Google Scholar] [CrossRef]
- Valdés-Fallis, Guadalupe. 1976. Social Interaction and Code-Switching Patterns: A Case Study of Spanish-English Alternation. In Bilingualism in the Bicentennial and Beyond. Edited by Gary D. Keller, Richard V. Teschner and Silvia Viera. New York: Bilingual Press, pp. 86–96. [Google Scholar]
- Verheijen, Lieke, and Roeland van Hout. 2022. Manifold code-mixing in computer-mediated communication: The use of English in Dutch youths’ informal online writing. Ampersand 9: 100091. [Google Scholar] [CrossRef]
- Verheijen, Lieke, Laura de Weger, and Roeland van Hout. 2018. Code-mixing with English in Dutch youths’ online language: OMG SUPERNICE LOL. In Proceedings of the Sixth Conference on Computer-Mediated Communication (CMC) and Social Media Corpora. Edited by Reinhild Vandekerckhove, Darja Fišer and Lisa Hilte. Antwerpen: University of Antwerp, pp. 63–67. Available online: https://hdl.handle.net/10067/1534160151162165141 (accessed on 15 January 2024).
- Verheijen, Lieke. 2018. Is Textese a Threat to Traditional Literacy? Dutch Youths’ Language Use in Written Computer-Mediated Communication and Relations with their School Writing. Doctoral dissertation, Radboud University, Netherlands Graduate School of Linguistics, LOT, Utrecht, The Netherlands. Available online: https://www.lotpublications.nl/Documents/529_fulltext.pdf (accessed on 15 January 2024).
- Warschauer, Mark, Ghada R. El Said, and Ayman G. Zohry. 2002. Language choice online: Globalization and identity in Egypt. Journal of Computer Mediated Communication 7: JCMC744. [Google Scholar] [CrossRef]
- Wentker, Michael. 2018. Code-switching and identity construction in WhatsApp: Evidence from a (digital) community of practice. In The Discursive Construction of Identities On- and Offline. Personal—Group—Collective. Edited by Birte Bös, Sonja Kleinke, Nuria Hernández and Sandra Mollin. Amsterdam: John Benjamins, pp. 109–32. [Google Scholar]
- Zentella, Ana Celia. 1997. Growing Up Bilingual: Puerto Rican Children in New York. Malden: Blackwell. [Google Scholar]


{kind=link}
{kind=link}
| User ID | Gender | Age Range | Birthplace | Age of Arrival to the US |
|---|---|---|---|---|
| U01 | F | 17–19 | Ecuador | 17 |
| U02 | F | 20–22 | Dominican Republic | 18 |
| U03 | F | 20–22 | Dominican Republic | 9 |
| U04 | M | 17–19 | Ecuador | 18 |
| U05 | F | 20–22 | Costa Rica | 18 |
| U06 | F | 20–22 | Dominican Republic | 12 |
| U07 | M | 20–22 | Dominican Republic | 5 |
| U08 | M | 20–22 | Dominican Republic | 15 |
| U09 | F | 17–19 | Dominican Republic | 16 |
| U10 | M | 17–19 | Dominican Republic | 19 |
| U11 | M | 17–19 | Guatemala | 17 |
| U12 | M | 17–19 | Dominican Republic | 14 |
| U13 | M | 17–19 | Dominican Republic | 8 |
| U14 | M | 20–22 | El Salvador | 18 |
| U15 | M | 17–19 | Ecuador | 17 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Montes-Alcalá, C. Bilingual Texting in the Age of Emoji: Spanish–English Code-Switching in SMS. Languages 2024, 9, 144. https://doi.org/10.3390/languages9040144
Montes-Alcalá C. Bilingual Texting in the Age of Emoji: Spanish–English Code-Switching in SMS. Languages. 2024; 9(4):144. https://doi.org/10.3390/languages9040144
Chicago/Turabian StyleMontes-Alcalá, Cecilia. 2024. "Bilingual Texting in the Age of Emoji: Spanish–English Code-Switching in SMS" Languages 9, no. 4: 144. https://doi.org/10.3390/languages9040144
APA StyleMontes-Alcalá, C. (2024). Bilingual Texting in the Age of Emoji: Spanish–English Code-Switching in SMS. Languages, 9(4), 144. https://doi.org/10.3390/languages9040144