
Pulse of the Nation: Observable Subjective Well-Being in Russia Inferred from Social Network Odnoklassniki


Abstract
1. Introduction
2. Related Work
2.1. Happiness and the Economy
2.2. Subjective Well-Being
2.3. Observable Subjective Well-Being
2.4. Sharing of Emotions Offline and Online
2.5. Text Analysis Methods and Traditional Surveys
2.6. Sentiment Analysis
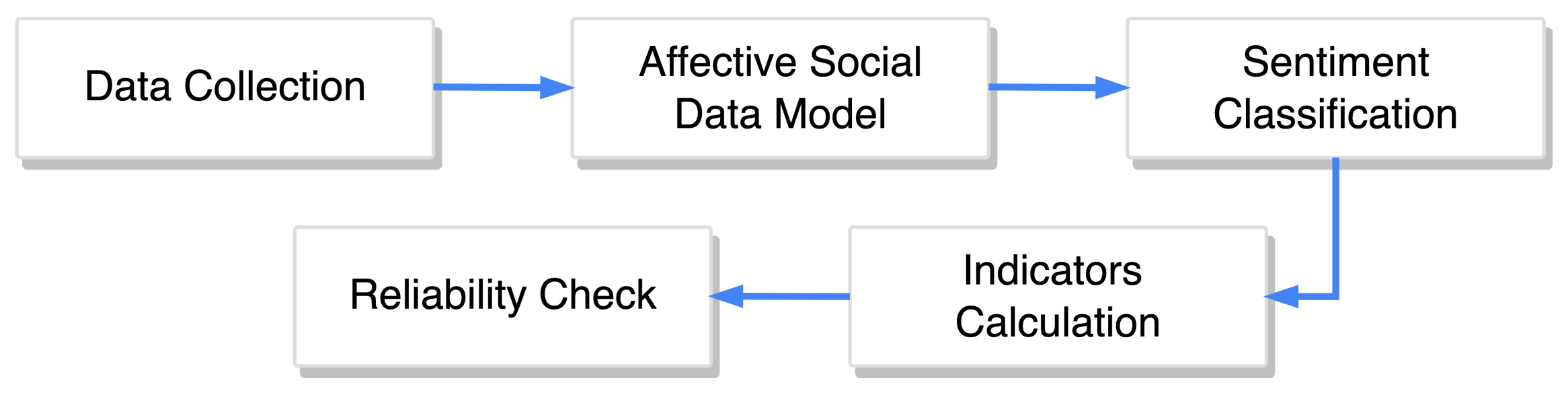
3. Measuring Observable Subjective Well-Being
- Firstly, it is necessary to calculate the minimum sample size, and collect the required amount of data.
- Secondly, it is necessary to construct the affective social data model using collected data and sentiment classification model. The proposed affective social data model is based on the theory of socio-technical interactions (STI) [114] and the phenomenon of the social sharing of emotions (SSE) [80]. Online social network platforms involve individuals interacting with technologies and other individuals, thereby representing STI. When interacting, individuals tends to share their emotions (88–96% of emotional experiences are shared and discussed [80]) regardless of emotion type, age, gender, culture, and education level, though with slight variations between them [81]. Considering that emotional communication online and offline is surprisingly similar [84,85], we assumed both to be a good source for analyzing the affective state on the individual level and then aggregated it to capture the OSWB measure on the population level.
- Thirdly, the sentiment classification model should be trained to extract sentiment from the collected data. It is recommended to train the model on the training dataset from the same source as collected data. If the training dataset from the same source of data is not available, then it is recommended to select a training dataset from the most similar data source available.
- Fourthly, it is necessary to calculate OSWB indicators of interest using the constructed affective social data model. The proposed approach for calculation takes into account demographic characteristics of selected sample of users and maps this sample to the general population of the selected country via post-stratification.
- Lastly, the reliability of calculated indices must be verified. Among various available reliability measures, comparing the obtained OSWB indicators with existing survey-based SWB indicators tends to be the most straightforward option.
3.1. Data Sampling
3.2. Affective Social Data Model
- represents a user account which was created for personal use, and
- represents a user account which was created for business use.
- represents text and (or) media posts or comments;
- represents the reactions to posted artifacts, such as likes or dislikes;
- represents digital photos, videos, and audio content.
- represents male sex, and
- represents female sex.
- represents a person who is in culturally recognized union between people called spouses;
- represents a person who is not in serious committed relationships, or is not part of a civil union;
- represents a person who is no longer married because the marriage has been dissolved;
- represents a person whose spouse has died.
- represents a family which includes only the spouses and unmarried children who are not of age;
- represents a family of one parent (The parent is either widowed, divorced (and not remarried), or never married.) together with their children;
- represents a family with mixed parents (One or both parents remarried, bringing children of the former family into the new family.);
- represents a group of people in an individual’s life that satisfies the typical role of family as a support system.
- A is the actors, representing the participants of socio-technical interactions generating UGC as defined further in Definition 11;
- I is the interactions, representing the structural aspects and UGC of as defined further in Definition 12.
- U is a finite set of users ranged over by u;
- is a finite set of user types (as defined in Definition 1) ranged over by ;
- is a finite set of users’ sexes (as defined in Definition 3) ranged over by ;
- is a set of users’ birth dates ranged over by ;
- is a set of users’ marital statuses (as defined in Definition 6) ranged over by ;
- is a set of users’ family types (as defined in Definition 7) ranged over by ;
- is the user’s numbers of children (as defined in Definition 8) ranged over by ;
- is a set of numbers of people living in the users’ households (as defined in Definition 9) ranged over by ;
- G is a set of users’ geographical information (as defined in Definition 5) ranged over by g;
- is the user type function mapping each user to the user type;
- is the sex function mapping each user to the user’s sex if defined;
- is the birth date function mapping each user to the user’s birth date if defined;
- is the marital status function mapping each user to the user’s marital status if defined;
- is the family type function mapping each user to the user’s family type if defined;
- is the number of children function mapping each user to the user’s number of children if defined;
- is the household size function mapping each user to the user’s household size if defined;
- is the geographic information function mapping each user to the user’s geographic information if defined.
- is a finite set of artifacts ranged over by ;
- is a finite set of artifact types (as defined in Definition 2) ranged over by ;
- S is a finite set of sentiment classes ranged over by s. (The list of final classes is not specified within this model, since it is expected that it may differ both depending on the final task of building the index and depending on the markup of the training dataset that is used to train the model.)
- is a function mapping the artifact and the user on whose feed it was published;
- is a function mapping the artifact and the user created it;
- is the artifact type function mapping each artifact to an artifact type;
- is a parent artifact function, which is a partial function mapping artifacts to their parent artifact if defined;
- is a relation defining mapping between artifact and sentiment;
- is a time function that keeps tracks of the timestamp of an artifact created by an user;
- is a time function that returns the age of the user on the time of the artifact creation if the user’s birthday is defined;
- is a partial function mapping users to mutually disjoint sets of their artifacts;
- is a partial function mapping users to the artifacts reacted by the users.
3.3. Sentiment Classification
3.4. OSWB Indicator Calculation
- Select content of interest for the analysis; that is, textual posts published by users on their own pages.
- Make data sample representative of the target population by applying sampling techniques.
- Calculate selected OSWB measures based on the representative data sample.
3.4.1. Data Selection
3.4.2. Data Sampling
3.4.3. Index Calculation
4. Observable Subjective Well-Being Based on Odnoklassniki Content
4.1. Odnoklassniki Data
4.2. Demographic Groups
- Gender. The array reflects the sex structure of the general population: male and female.
- Age. The array is divided into four age groups, reflecting the general population: 18–24 years old, 25–39 years old, 40–54 years old, and 55 years old and older.
4.3. Sentiment Classification
4.3.1. Training Data
- Positive Sentiment Class represents explicit and implicit positive sentiment.
- Negative Sentiment Class represents explicit and implicit negative sentiment.
- Neutral Sentiment Class represents texts without any sentiment.
- Speech Act Class represents congratulatory posts, formulaic greetings, and thank-you posts.
- Skip Class represents noisy posts, unclear cases, and texts that were likely not created by the users themselves.
4.3.2. Classification Model
- XLM-RoBERTa-Large (https://huggingface.co/xlm-roberta-large, accessed on 1 June 2022) [107] by Facebook is a multilingual RoBERTa [139] model with BERT-Large architecture trained on 100 different languages.
- RuRoBERTa-Large (https://huggingface.co/sberbank-ai/ruRoberta-large, accessed on 1 June 2022) [113] by SberDevices is a version of the RoBERTa [139] model with BERT-Large architecture and BBPE tokenizer from GPT-2 [140] trained on Russian texts.
- mBART-large-50 (https://huggingface.co/facebook/mbart-large-50, accessed on 1 June 2022) [108] by Facebook is a multilingual sequence-to-sequence model pretrained using the multilingual denoising pretraining objective [141].
- RuBERT (https://huggingface.co/DeepPavlov/rubert-base-cased, accessed on 1 June 2022) [105] by DeepPavlov is a BERT model trained on news data and the Russian-language part of Wikipedia. The authors built a custom vocabulary of Russian subtokens and took weights from the Multilingual BERT-base as initialization weights.
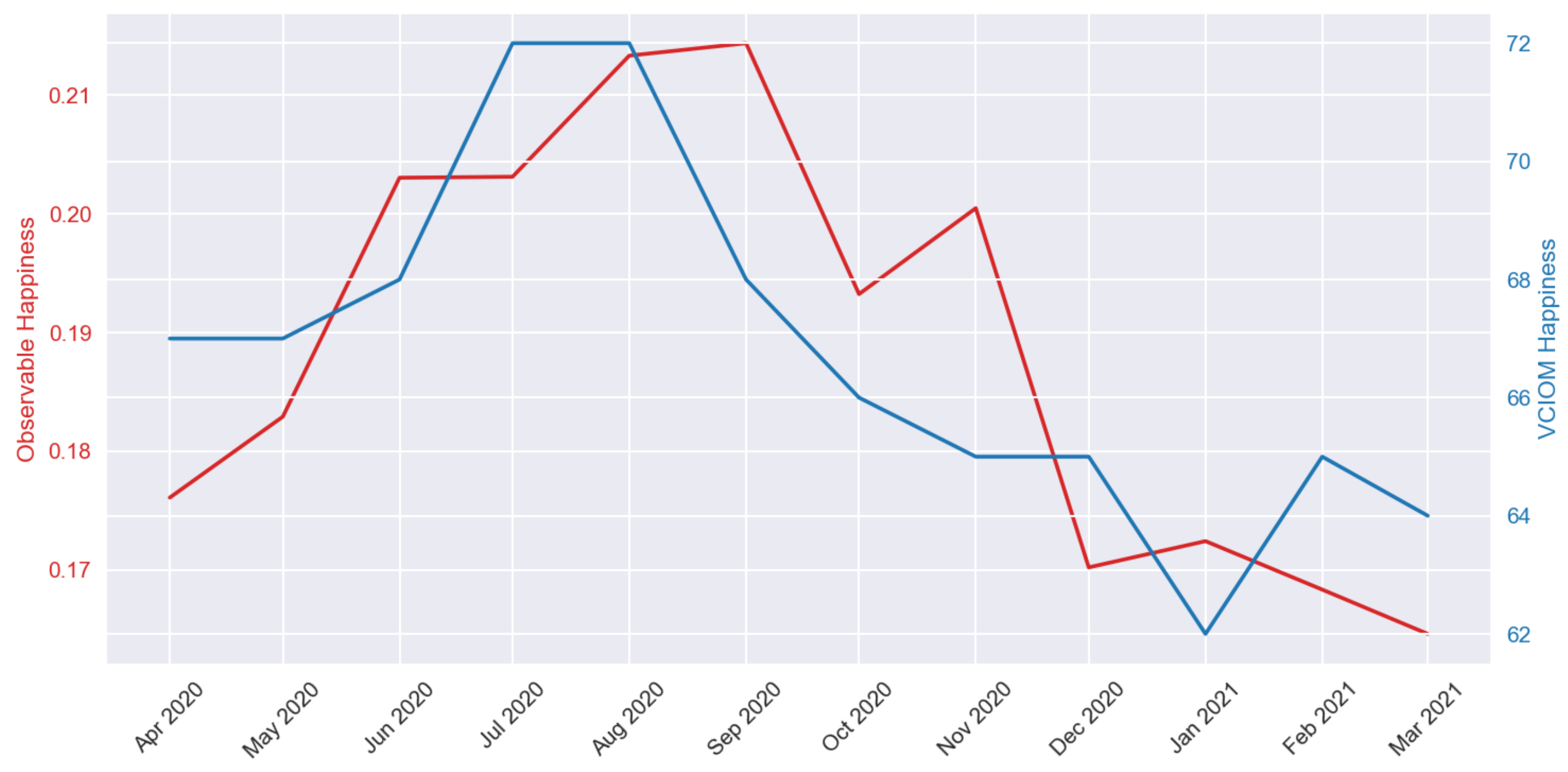
4.4. Validity Check
4.5. Indicator Formula
4.6. Misclassification Bias
5. Results
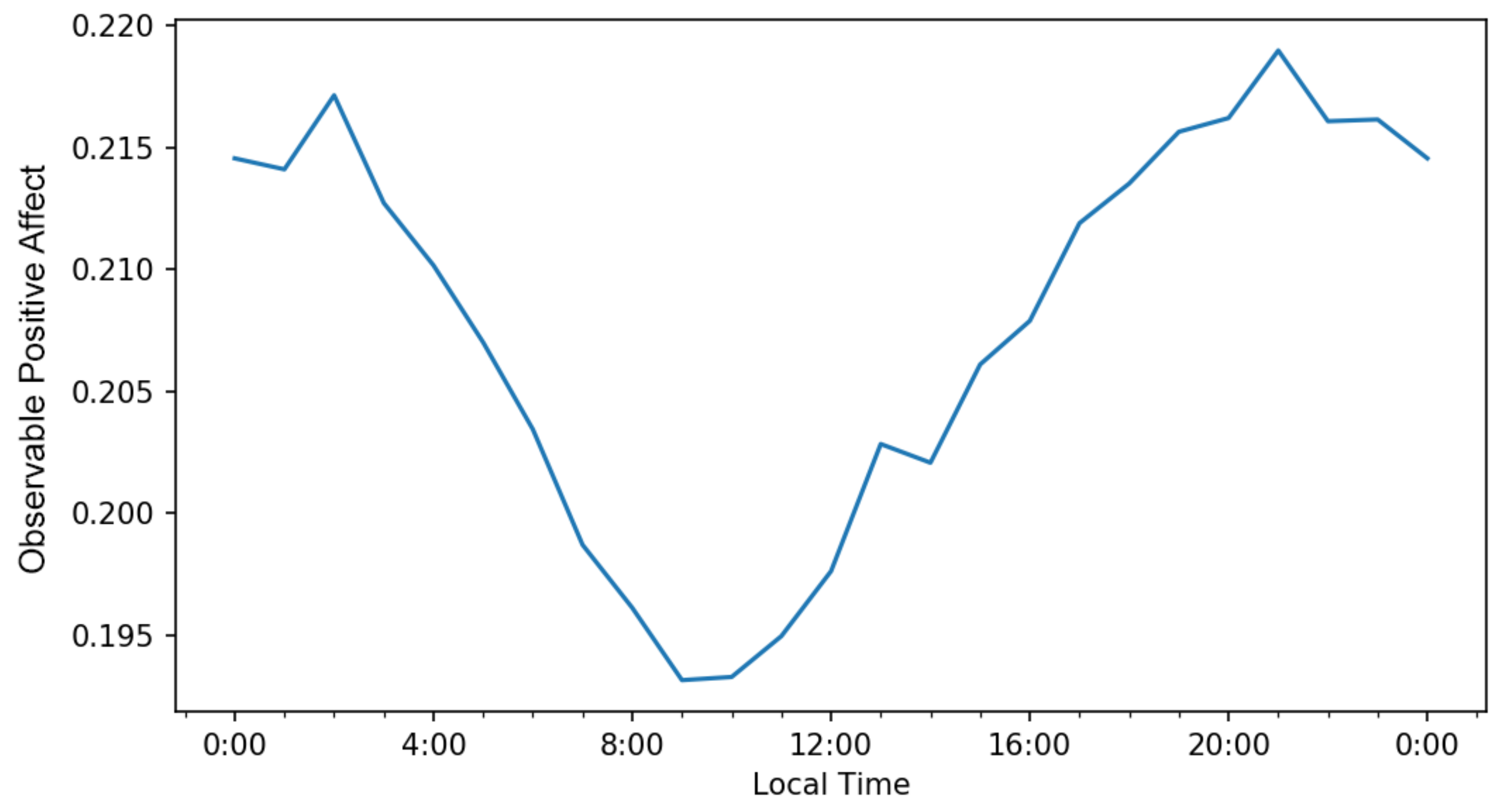
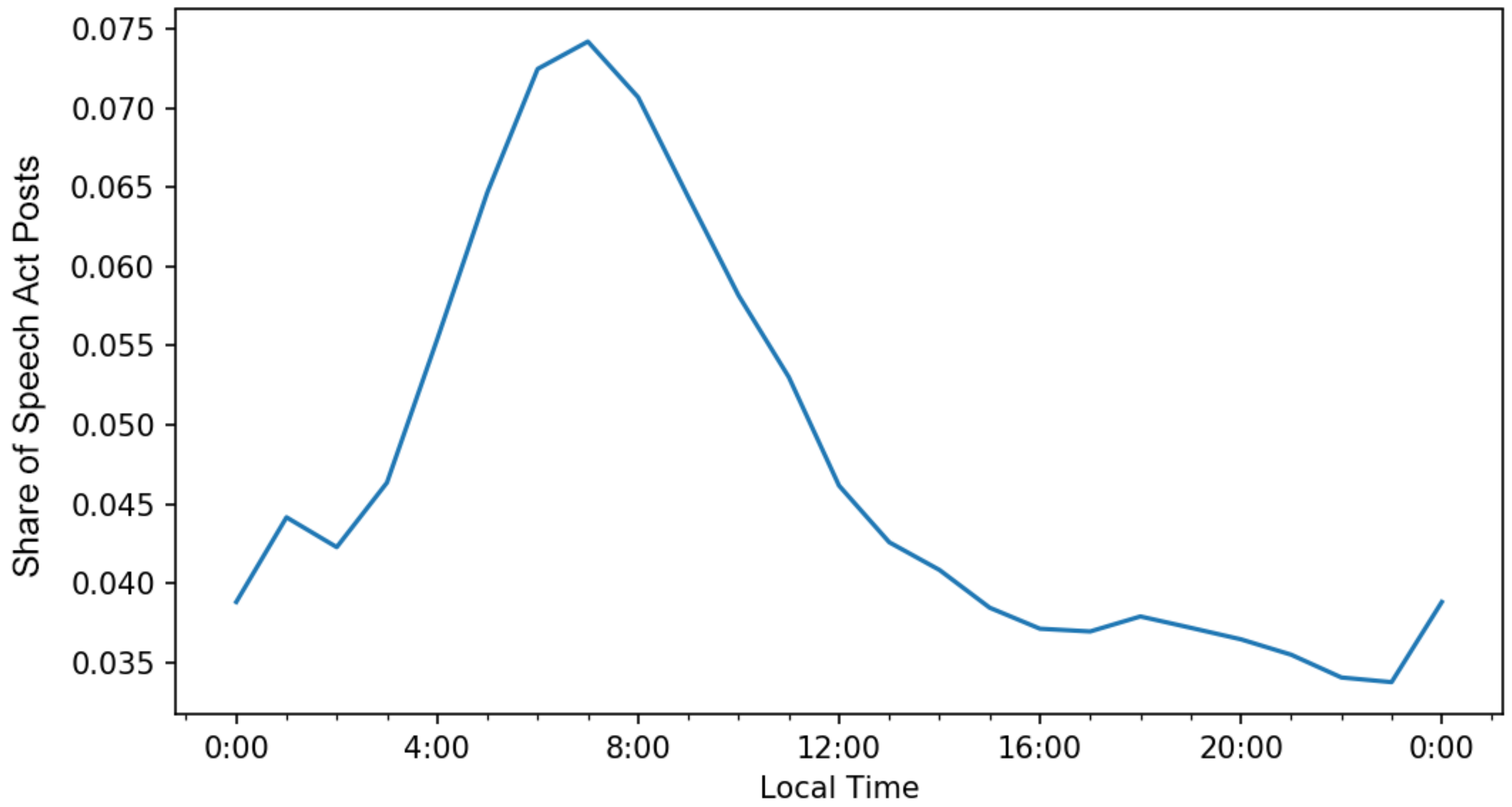
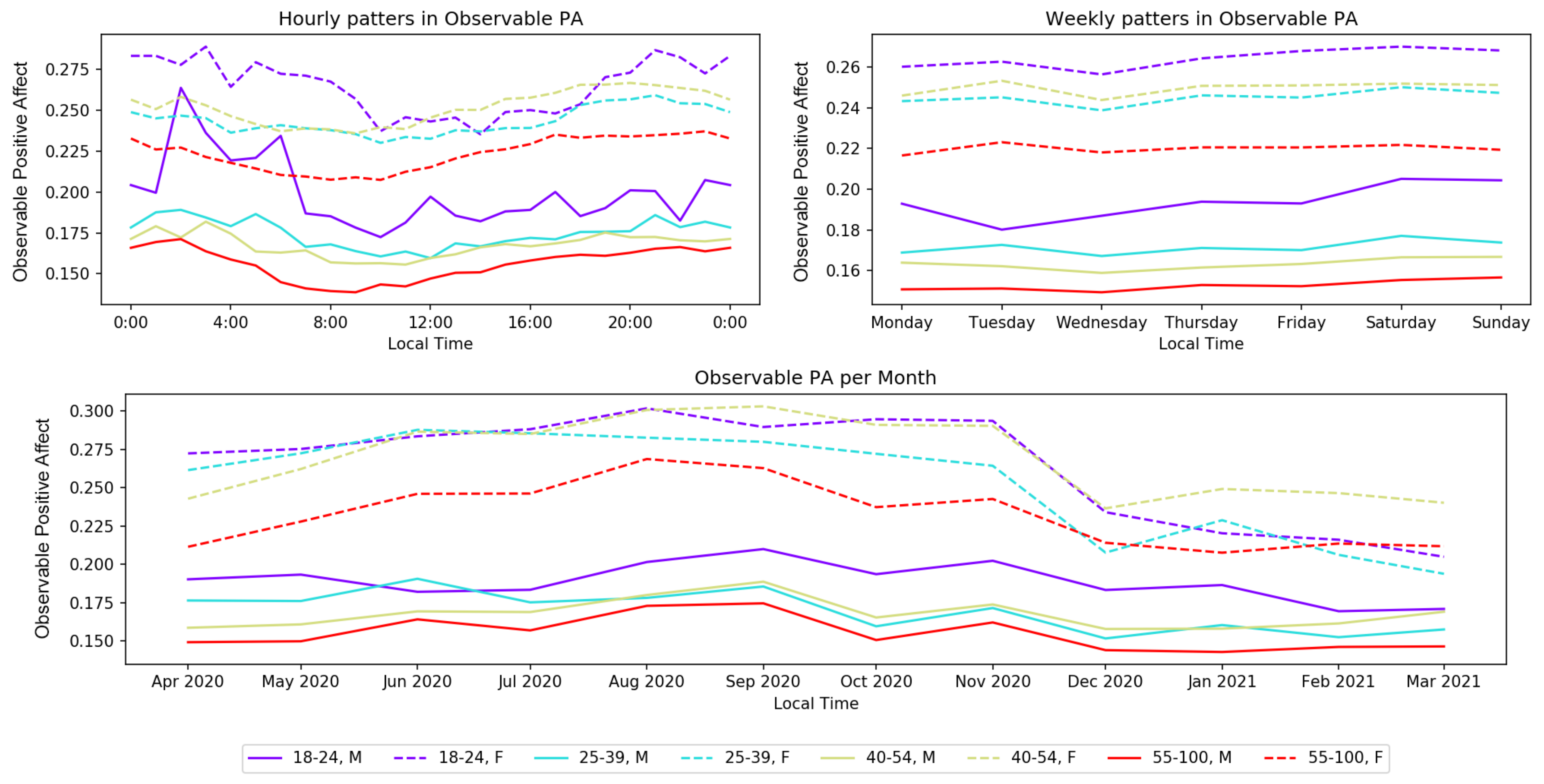
5.1. Daily Patterns
5.2. Weekly Patterns
5.3. Demographic Patterns
6. Discussion
7. Limitations
- Representativeness of a data source. The use of the internet and a certain social network in itself can affect the SWB of a particular individual. Cuihong and Chengzhi [166] found that internet use had no significant impact on the well-being of individuals compared to non-use. Although other research agrees that internet use alone does not significantly affect SWB (e.g., [166,167]), there are differing opinions about how it is affected by the intensity of internet use. For example, Cuihong and Chengzhi [166] also found frequency of internet usage significantly improved SWB, Peng et al. [168] reported that intensive internet use is significantly associated with lower levels of SWB, and Paez et al. [167] found that frequency of internet use was not associated with lower SWB. Some researchers have also studied the effects of using social network sites rather than the internet in general, and the results of these studies are also contradictory. For example, the study by Lee et al. [169] showed that although the time spent using a social network site is not related to well-being, and the amount of self-disclosure on social networks is positively related to SWB. On the contrary, Sabatini and Sarracino [170] found a significantly negative correlation between online networking and well-being. Thus, there are conflicting views in the existing literature about how the use of the internet and certain social networks affects SWB. Additionally, the proposed approach does not directly address the issue of trolls and bot accounts, which can bias the analyzed sample of accounts and their posts. Although some studies [100,101] has already been conducted to identify such accounts on Russian-language Twitter, to the best of our knowledge, the identification of such accounts on Odnoklassniki has not yet been studied and is a relevant area for further research.
- Level of internet penetration. The level of internet penetration in rural areas of Russia is commonly much lower than in urban areas [171], which is why the rural population may be underrepresented in the analyzed data. However, it should be noted that it is challenging to say whether the urban population of Russia is happier than the rural population, as there are different points of view on this issue [172,173]. In order to unequivocally confirm how much this problem affects the final result of the OSWB research, further research is needed on how strongly the SWB differs in urban and rural areas, as well as how the use of the internet in Russia, and in particular the social network Odnoklassniki, affects SWB.
- Regulation policies. In Russia, as in many other countries, there are restrictive regulation policies on the dissemination of certain information. Since negative statements may contain identity-based attacks, as well as abuse and hate speech, they may be subject to censorship under the user agreement of the analyzed social network site and the law. Thus, these policies are supposed to affect the volume of strong negative statements in both online and offline discussions [37]. Thus, it can be assumed that a certain proportion of negative comments were removed from the analyzed social network and were not taken into account in this study. However, since some of these regulation policies are also applicable to offline discussion, it cannot be unequivocally stated (at least without conducting a corresponding study) that this aspect does not also affect classical survey methods.
- Misclassification bias. As long as the classification algorithms’ predictions are not completely error-free, the estimate of the relative occurrence of a particular class may be affected by misclassification bias, thereby affecting the value of the calculated social indicator. Although our ML model for sentiment analysis achieved new SOTA results, its predictions are still far from infallible. To deal with this limitation, we estimated the impact of misclassification bias on social indicator formulae of interest using the simulation approach [121].
8. Conclusions
- Constructing a monthly OSWB indicator over a longer period of time to additionally confirm reliability of the proposed approach.
- Constructing a yearly OSWB indicator to confirm reliability of the proposed approach on the yearly scale. In this case, the OSWB indicator can be compared not only with the VCIOM Happiness indicator, but also with other international indicators such as Gallup World Poll.
- Consideration of the OSWB indicator in relation to different topics of the texts. As a high-level definition of the topics, it can be interesting to use major objectives and observable dimensions (These six dimensions were identified by Voukelatou et al. [13] based on the data of the United Nations Development Program, the Organization for Economic Co-operation and Development, and the Italian Statistics Bureau. These dimensions have already been used as topics for the analysis of toxic posts on social media in our recent study [174].) summarized by Voukelatou et al. [13] for objective well-being measurement: health, socioeconomic development, job opportunities, safety, environment, and politics.
- A more detailed consideration of the expressed emotions when constructing the OSWB indicator. For example, instead of the classic positive and negative classes, one might consider happy, sad, fear, disgust, anger, and surprise.
- Although OSWB studies based on social media posts have begun to receive considerable research attention, there are other types of data that we also believe represent great research potential. Firstly, based on user comments on news sites, one could analyze subjective attitudes toward different aspects of life. Secondly, based on the texts of blogging platforms (e.g., Reddit and Pikabu), one could analyze the subjective attitude toward different topics of posts. Finally, one could review non-textual information, such as user search queries on search engines, to determine whether there is any relationship between search behavior and SWB.
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Corpora Similarity Comparison
References
- Diener, E. Subjective Well-Being. In The Science of Well-Being; Springer Science + Business Media: Berlin, Germany, 2009; pp. 11–58. [Google Scholar] [CrossRef]
- Diener, E.; Ryan, K. Subjective Well-Being: A General Overview. S. Afr. J. Psychol. 2009, 39, 391–406. [Google Scholar] [CrossRef]
- Almakaeva, A.M.; Gashenina, N.V. Subjective Well-Being: Conceptualization, Assessment and Russian Specifics. Monit. Public Opin. Econ. Soc. Chang. 2020, 155, 4–13. [Google Scholar] [CrossRef][Green Version]
- DeNeve, K.M.; Cooper, H. The Happy Personality: A Meta-Analysis of 137 Personality Traits and Subjective Well-Being. Psychol. Bull. 1998, 124, 197–229. [Google Scholar] [CrossRef] [PubMed]
- Sandvik, E.; Diener, E.; Seidlitz, L. Subjective Well-Being: The Convergence and Stability of Self-Report and Non-Self-Report Measures. In Assessing Well-Being; Springer: Berlin, Germany, 2009; pp. 119–138. [Google Scholar] [CrossRef]
- Northrup, D.A. The Problem of the Self-Report in Survey Research; Institute for Social Research, York University: North York, ON, Canada, 1997. [Google Scholar]
- Van de Mortel, T.F. Faking It: Social Desirability Response Bias in Self-Report Research. Aust. J. Adv. Nursing 2008, 25, 40–48. [Google Scholar]
- Thau, M.; Mikkelsen, M.F.; Hjortskov, M.; Pedersen, M.J. Question Order Bias Revisited: A Split-Ballot Experiment on Satisfaction with Public Services among Experienced and Professional Users. Public Adm. 2021, 99, 189–204. [Google Scholar] [CrossRef]
- McCambridge, J.; De Bruin, M.; Witton, J. The Effects of Demand Characteristics on Research Participant Behaviours in Non-Laboratory Settings: A Systematic Review. PLoS ONE 2012, 7, e39116. [Google Scholar] [CrossRef]
- Schwarz, N.; Clore, G.L. Mood, Misattribution, and Judgments of Well-Being: Informative and Directive Functions of Affective States. J. Personal. Soc. Psychol. 1983, 45, 513–523. [Google Scholar] [CrossRef]
- Natale, M.; Hantas, M. Effect of Temporary Mood States on Selective Memory about the Self. J. Personal. Soc. Psychol. 1982, 42, 927–934. [Google Scholar] [CrossRef]
- Luhmann, M. Using Big Data to Study Subjective Well-Being. Curr. Opin. Behav. Sci. 2017, 18, 28–33. [Google Scholar] [CrossRef]
- Voukelatou, V.; Gabrielli, L.; Miliou, I.; Cresci, S.; Sharma, R.; Tesconi, M.; Pappalardo, L. Measuring Objective and Subjective Well-Being: Dimensions and Data Sources. Int. J. Data Sci. Anal. 2020, 11, 279–309. [Google Scholar] [CrossRef]
- Bogdanov, M.B.; Smirnov, I.B. Opportunities and Limitations of Digital Footprints and Machine Learning Methods in Sociology. Monit. Public Opin. Econ. Soc. Chang. 2021, 161, 304–328. [Google Scholar] [CrossRef]
- VCIOM. On the Day of Sociologist: Russians on Sociological Polls. Available online: https://wciom.ru/analytical-reviews/analiticheskii-obzor/ko-dnyu-socziologa-rossiyane-o-socziologicheskikh-oprosakh (accessed on 1 September 2021).
- FOM. About Public Opinion Polls. Available online: https://fom.ru/Nauka-i-obrazovanie/14455 (accessed on 1 January 2022).
- Krueger, A.B.; Stone, A.A. Progress in Measuring Subjective Well-Being. Science 2014, 346, 42–43. [Google Scholar] [CrossRef]
- Howison, J.; Wiggins, A.; Crowston, K. Validity Issues in the Use of Social Network Analysis with Digital Trace Data. J. Assoc. Inf. Syst. 2011, 12, 767–797. [Google Scholar] [CrossRef]
- Kuchenkova, A. Measuring Subjective Well-Being Based on Social Media Texts. Overview of Modern Practices. RSUH/RGGU Bull. Philos. Sociol. Art Stud. Ser. 2020, 11, 92–101. [Google Scholar] [CrossRef]
- Németh, R.; Koltai, J. The Potential of Automated Text Analytics in Social Knowledge Building. In Pathways Between Social Science and Computational Social Science: Theories, Methods, and Interpretations; Springer International Publishing: Cham, Switzerland, 2021; pp. 49–70. [Google Scholar] [CrossRef]
- Kapteyn, A.; Lee, J.; Tassot, C.; Vonkova, H.; Zamarro, G. Dimensions of Subjective Well-Being. Soc. Indic. Res. 2015, 123, 625–660. [Google Scholar] [CrossRef]
- Singh, S.; Kaur, P.D. Subjective Well-Being Prediction from Social Networks: A Review. In Proceedings of the 2016 Fourth International Conference on Parallel, Distributed and Grid Computing (PDGC), Waknaghat, India, 22–24 December 2016; pp. 90–95. [Google Scholar] [CrossRef]
- Zunic, A.; Corcoran, P.; Spasic, I. Sentiment Analysis in Health and Well-Being: Systematic Review. JMIR Med. Inform. 2020, 8, e16023. [Google Scholar] [CrossRef]
- Mislove, A.; Lehmann, S.; Ahn, Y.Y.; Onnela, J.P.; Rosenquist, J.N. Pulse of the Nation: US Mood throughout the Day Inferred from Twitter. Available online: http://www.ccs.neu.edu/home/amislove/twittermood/ (accessed on 1 January 2022).
- Blair, J.; Hsu, C.Y.; Qiu, L.; Huang, S.H.; Huang, T.H.K.; Abdullah, S. Using Tweets to Assess Mental Well-Being of Essential Workers during the COVID-19 Pandemic. In CHI EA ’21: Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems; Association for Computing Machinery: New York, NY, USA, 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Lampos, V.; Lansdall-Welfare, T.; Araya, R.; Cristianini, N. Analysing Mood Patterns in the United Kingdom through Twitter Content. arXiv 2013, arXiv:1304.5507. [Google Scholar]
- Lansdall-Welfare, T.; Dzogang, F.; Cristianini, N. Change-Point Analysis of the Public Mood in UK Twitter during the Brexit Referendum. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016; IEEE Computer Society: Los Alamitos, CA, USA, 2016; pp. 434–439. [Google Scholar] [CrossRef]
- Dzogang, F.; Lightman, S.; Cristianini, N. Circadian Mood Variations in Twitter Content. Brain Neurosci. Adv. 2017, 1, 2398212817744501. [Google Scholar] [CrossRef]
- Qi, J.; Fu, X.; Zhu, G. Subjective Well-Being Measurement based on Chinese Grassroots Blog Text Sentiment Analysis. Inf. Manag. 2015, 52, 859–869. [Google Scholar] [CrossRef]
- Iacus, S.M.; Porro, G.; Salini, S.; Siletti, E. How to Exploit Big Data from Social Networks: A Subjective Well-Being Indicator via Twitter. SIS 2017, 537–542. [Google Scholar]
- Wang, D.; Al-Rubaie, A.; Hirsch, B.; Pole, G.C. National Happiness Index Monitoring using Twitter for Bilanguages. Soc. Netw. Anal. Min. 2021, 11, 24. [Google Scholar] [CrossRef]
- Prata, D.N.; Soares, K.P.; Silva, M.A.; Trevisan, D.Q.; Letouze, P. Social Data Analysis of Brazilian’s Mood from Twitter. Int. J. Soc. Sci. Humanit. 2016, 6, 179–183. [Google Scholar] [CrossRef]
- Panchenko, A. Sentiment Index of the Russian Speaking Facebook. In Proceedings of the Computational Linguistics and Intellectual Technologies: Proceedings of the International Conference “Dialogue” 2014, Moscow, Russia, 4–8 June 2014; Russian State University for the Humanities: Moscow, Russia; Volume 13, pp. 506–517. [Google Scholar]
- Shchekotin, E.; Myagkov, M.; Goiko, V.; Kashpur, V.; Kovarzh, G. Subjective Measurement of Population Ill-Being/Well-Being in the Russian Regions Based on Social Media Data. Monit. Public Opin. Econ. Soc. Chang. 2020, 155, 78–116. [Google Scholar] [CrossRef]
- Kalabikhina, I.E.; Banin, E.P.; Abduselimova, I.A.; Klimenko, G.A.; Kolotusha, A.V. The Measurement of Demographic Temperature Using the Sentiment Analysis of Data from the Social Network VKontakte. Mathematics 2021, 9, 987. [Google Scholar] [CrossRef]
- Chetviorkin, I.; Loukachevitch, N. Evaluating Sentiment Analysis Systems in Russian. In Proceedings of the 4th Biennial International Workshop on Balto-Slavic Natural Language Processing, Sofia, Bulgaria, 8–9 August 2013; Association for Computational Linguistics: Sofia, Bulgaria, 2013; pp. 12–17. [Google Scholar]
- Smetanin, S. The Applications of Sentiment Analysis for Russian Language Texts: Current Challenges and Future Perspectives. IEEE Access 2020, 8, 110693–110719. [Google Scholar] [CrossRef]
- VCIOM. Russia’s Goals in the 21st Century. Available online: https://wciom.ru/analytical-reviews/analiticheskii-obzor/czeli-rossii-v-xxi-veke (accessed on 1 February 2022).
- Rogers, A.; Romanov, A.; Rumshisky, A.; Volkova, S.; Gronas, M.; Gribov, A. RuSentiment: An Enriched Sentiment Analysis Dataset for Social Media in Russian. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; Association for Computational Linguistics: Santa Fe, NM, USA, 2018; pp. 755–763. [Google Scholar]
- VCIOM. Happiness Index. Available online: https://wciom.ru/ratings/indeks-schastja (accessed on 1 February 2022).
- Stock, W.A.; Okun, M.A.; Benito, J.A.G. Subjective Well-Being Measures: Reliability and Validity among Spanish Elders. Int. J. Aging Hum. Dev. 1994, 38, 221–235. [Google Scholar] [CrossRef]
- Krueger, A.B.; Schkade, D.A. The Reliability of Subjective Well-Being Measures. J. Public Econ. 2008, 92, 1833–1845. [Google Scholar] [CrossRef]
- OECD. OECD Guidelines on Measuring Subjective Well-Being; Available online: https://doi.org/10.1787/9789264191655-en (accessed on 1 January 2022). [CrossRef]
- Levin, K.A.; Currie, C. Reliability and Validity of an Adapted Version of the Cantril Ladder for Use with Adolescent Samples. Soc. Indic. Res. 2014, 119, 1047–1063. [Google Scholar] [CrossRef]
- Lucas, R.E. Reevaluating the Strengths and Weaknesses of Self-Report Measures of Subjective Well-Being. In Handbook of Well-Being; Routledge: Abingdon, UK, 2018. [Google Scholar]
- Fleurbaey, M. Beyond GDP: The Quest for a Measure of Social Welfare. J. Econ. Lit. 2009, 47, 1029–1075. [Google Scholar] [CrossRef]
- Costanza, R.; Kubiszewski, I.; Giovannini, E.; Lovins, H.; McGlade, J.; Pickett, K.E.; Ragnarsdóttir, K.V.; Roberts, D.; De Vogli, R.; Wilkinson, R. Development: Time to Leave GDP Behind. Nat. News 2014, 505, 283–285. [Google Scholar] [CrossRef]
- Musikanski, L.; Cloutier, S.; Bejarano, E.; Briggs, D.; Colbert, J.; Strasser, G.; Russell, S. Happiness Index Methodology. J. Soc. Chang. 2017, 9, 4–31. [Google Scholar] [CrossRef]
- Yashina, M. The Economics of Happiness: Future or Reality in Russia? Stud. Commer. Bratisl. 2015, 8, 266–274. [Google Scholar] [CrossRef][Green Version]
- Rumyantseva, E.; Sheremet, A. Happiness Index as GDP Alternative. Vestn. MIRBIS 2020, 24, 92–100. [Google Scholar] [CrossRef]
- RBC. Matvienko Suggested Measuring the Impact of Government Actions on the Happiness of Russians. Available online: https://www.rbc.ru/society/05/03/2019/5c7e53f99a7947dcc6456c22 (accessed on 1 February 2022).
- Nima, A.A.; Cloninger, K.M.; Persson, B.N.; Sikström, S.; Garcia, D. Validation of Subjective Well-Being Measures Using Item Response Theory. Front. Psychol. 2020, 10, 3036. [Google Scholar] [CrossRef]
- Li, Y.; Masitah, A.; Hills, T.T. The Emotional Recall Task: Juxtaposing Recall and Recognition-Based Affect Scales. J. Exp. Psychol. Learn. Mem. Cogn. 2020, 46, 1782–1794. [Google Scholar] [CrossRef]
- ROMIR. The Dynamics of the Happiness Index in Russia and in the World. Available online: https://romir.ru/studies/dinamika-indeksa-schastya-v-rossii-i-v-mire (accessed on 1 February 2022).
- VCIOM. Happiness in the Era of a Pandemic. Available online: https://wciom.ru/analytical-reviews/analiticheskii-obzor/schaste-v-ehpokhu-pandemii (accessed on 1 February 2022).
- Gallup. Gallup World Poll Methodology. Available online: https://www.oecd.org/sdd/43017172.pdf (accessed on 1 January 2022).
- Happy Planet Index. Happy Planet Index 2016. Methods Paper. Zugriff Vom 2016, 18, 2017. [Google Scholar]
- European Social Survey. European Social Survey Round 9 Sampling Guidelines: Principles and Implementation. Available online: https://www.europeansocialsurvey.org/docs/round9/methods/ESS9_sampling_guidelines.pdf (accessed on 1 January 2022).
- Kramer, A.D. An Unobtrusive Behavioral Model of “Gross National Happiness”. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems; Association for Computing Machinery: New York, NY, USA, 2010; pp. 287–290. [Google Scholar] [CrossRef]
- Wang, N.; Kosinski, M.; Stillwell, D.; Rust, J. Can Well-Being be Measured Using Facebook Status Updates? Validation of Facebook’s Gross National Happiness Index. Soc. Indic. Res. 2014, 115, 483–491. [Google Scholar] [CrossRef]
- Shakhovskii, V. The Linguistic Theory of Emotions; Gnozis: Moscow, Russia, 2008. [Google Scholar]
- Loukachevitch, N. Automatic Sentiment Analysis of Texts: The Case of Russian. In The Palgrave Handbook of Digital Russia Studies; Palgrave Macmillan: Cham, Switzerland, 2021; pp. 501–516. [Google Scholar] [CrossRef]
- Loukachevitch, N.; Levchik, A. Creating a General Russian Sentiment Lexicon. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; European Language Resources Association (ELRA): Portorož, Slovenia, 2016; pp. 1171–1176. [Google Scholar]
- Feng, S.; Kang, J.S.; Kuznetsova, P.; Choi, Y. Connotation Lexicon: A Dash of Sentiment Beneath the Surface Meaning. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013; Association for Computational Linguistics: Sofia, Bulgaria, 2013; Volume 1, pp. 1774–1784. [Google Scholar]
- Smetanin, S.; Komarov, M. Deep Transfer Learning Baselines for Sentiment Analysis in Russian. Inf. Process. Manag. 2021, 58, 102484. [Google Scholar] [CrossRef]
- Golubev, A.; Loukachevitch, N. Improving Results on Russian Sentiment Datasets. In Proceedings of the Artificial Intelligence and Natural Language, Helsinki, Finland, 7–9 October 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 109–121. [Google Scholar] [CrossRef]
- Kotelnikova, A.V. Comparison of Deep Learning and Rule-based Method for the Sentiment Analysis Task. In Proceedings of the 2020 International Multi-Conference on Industrial Engineering and Modern Technologies (FarEastCon), Vladivostok, Russia, 6–9 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Moshkin, V.; Konstantinov, A.; Yarushkina, N. Application of the BERT Language Model for Sentiment Analysis of Social Network Posts. In Proceedings of the Artificial Intelligence, Cairo, Egypt, 8–10 April 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 274–283. [Google Scholar] [CrossRef]
- Konstantinov, A.; Moshkin, V.; Yarushkina, N. Approach to the Use of Language Models BERT and Word2Vec in Sentiment Analysis of Social Network Texts. In Recent Research in Control Engineering and Decision Making; Springer International Publishing: Cham, Switzerland, 2021; pp. 462–473. [Google Scholar] [CrossRef]
- European Social Survey. Measuring and Reporting on Europeans’ Wellbeing: Findings from the European Social Survey. Available online: https://www.europeansocialsurvey.org/docs/findings/ESS1-6_measuring_and_reporting_on_europeans_wellbeing.pdf (accessed on 1 January 2022).
- Liu, P.; Tov, W.; Kosinski, M.; Stillwell, D.J.; Qiu, L. Do Facebook Status Updates Reflect Subjective Well-Being? Cyberpsychology Behav. Soc. Netw. 2015, 18, 373–379. [Google Scholar] [CrossRef]
- Dudina, V.; Iudina, D. Mining Opinions on the Internet: Can the Text Analysis Methods Replace Public Opinion Polls? Monit. Public Opin. Econ. Soc. Chang. 2017, 141, 63–78. [Google Scholar] [CrossRef]
- Sivak, E.; Smirnov, I. Measuring Adolescents’ Well-Being: Correspondence of Naïve Digital Traces to Survey Data. In Proceedings of the International Conference on Social Informatics, Pisa, Italy, 6 October 2020; Springer: Cham, Switzerland, 2020; pp. 352–363. [Google Scholar] [CrossRef]
- Dudina, V. Digital Data Potentialities for Development of Sociological Knowledge. Sociol. Stud. 2016, 9, 21–30. [Google Scholar]
- Schober, M.F.; Pasek, J.; Guggenheim, L.; Lampe, C.; Conrad, F.G. Social Media Analyses for Social Measurement. Public Opin. Q. 2016, 80, 180–211. [Google Scholar] [CrossRef]
- Bessmertny, I.; Posevkin, R. Texts Sentiment-analysis Application for Public Opinion Assessment. Sci. Tech. J. Inf. Technol. Mech. Opt. 2015, 15, 169–171. [Google Scholar] [CrossRef][Green Version]
- Averchenkov, V.; Budylskii, D.; Podvesovskii, A.; Averchenkov, A.; Rytov, M.; Yakimov, A. Hierarchical Deep Learning: A Promising Technique for Opinion Monitoring And Sentiment Analysis in Russian-language Social Networks. In Proceedings of the Creativity in Intelligent Technologies and Data Science, Volgograd, Russia, 15–17 September 2015; Springer International Publishing: Cham, Switzerland, 2015; pp. 583–592. [Google Scholar] [CrossRef]
- Smetanin, S. The Program for Public Mood Monitoring through Twitter Content in Russia. Proc. Inst. Syst. Program. RAS 2017, 29, 315–324. [Google Scholar] [CrossRef][Green Version]
- Sydorenko, V.; Kravchenko, S.; Rychok, Y.; Zeman, K. Method of Classification of Tonal Estimations Time Series in Problems of Intellectual Analysis of Text Content. Transp. Res. Procedia 2020, 44, 102–109. [Google Scholar] [CrossRef]
- Rime, B.; Mesquita, B.; Boca, S.; Philippot, P. Beyond the Emotional Event: Six Studies on the Social Sharing of Emotion. Cogn. Emot. 1991, 5, 435–465. [Google Scholar] [CrossRef]
- Rimé, B.; Finkenauer, C.; Luminet, O.; Zech, E.; Philippot, P. Social Sharing of Emotion: New Evidence and New Questions. Eur. Rev. Soc. Psychol. 1998, 9, 145–189. [Google Scholar] [CrossRef]
- Choi, M.; Toma, C.L. Understanding Mechanisms of Media Use for The Social Sharing of Emotion: The Role of Media Affordances and Habitual Media Use. J. Media Psychol. Theor. Methods Appl. 2021, 34, 139–149. [Google Scholar] [CrossRef]
- Rodríguez-Hidalgo, C.; Tan, E.S.; Verlegh, P.W. Expressing Emotions in Blogs: The Role of Textual Paralinguistic Cues in Online Venting and Social Sharing Posts. Comput. Hum. Behav. 2017, 73, 638–649. [Google Scholar] [CrossRef]
- Derks, D.; Fischer, A.H.; Bos, A.E. The Role of Emotion in Computer-Mediated Communication: A Review. Comput. Hum. Behav. 2008, 24, 766–785. [Google Scholar] [CrossRef]
- Rimé, B.; Bouchat, P.; Paquot, L.; Giglio, L. Intrapersonal, Interpersonal, and Social Outcomes of the Social Sharing of Emotion. Curr. Opin. Psychol. 2020, 31, 127–134. [Google Scholar] [CrossRef]
- Vermeulen, A.; Vandebosch, H.; Heirman, W. #Smiling, #Venting, or Both? Adolescents’ Social Sharing of Emotions on Social Media. Comput. Hum. Behav. 2018, 84, 211–219. [Google Scholar] [CrossRef]
- Fox, J.; McEwan, B. Distinguishing Technologies for Social Interaction: The Perceived Social Affordances of Communication Channels Scale. Commun. Monogr. 2017, 84, 298–318. [Google Scholar] [CrossRef]
- Sas, C.; Dix, A.; Hart, J.; Su, R. Dramaturgical Capitalization of Positive Emotions: The Answer for Facebook Success? In Proceedings of the 23rd British HCI Group Annual Conference on People and Computers: Celebrating People and Technology, BCS-HCI ’09, Cambridge, UK, 1–5 September 2009; BCS Learning & Development Ltd.: Swindon, UK, 2009; pp. 120–129. [Google Scholar] [CrossRef]
- Bazarova, N.N.; Choi, Y.H.; Schwanda Sosik, V.; Cosley, D.; Whitlock, J. Social Sharing of Emotions on Facebook: Channel Differences, Satisfaction, and Replies. In Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing, Vancouver, BC, Canada, 14–18 March 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 154–164. [Google Scholar] [CrossRef]
- Vermeulen, A.; Heirman, W.; Vandebosch, H. “To Share or Not to Share?” Adolescents’ Motivations for (Not) Sharing Their Emotions on Facebook. In Proceedings of the Poster Session Presented at the 24 Hours of Communication Science Conference, Wageningen, The Netherlands, 3–4 February 2014. [Google Scholar]
- Hidalgo, C.R.; Tan, E.S.H.; Verlegh, P.W. The Social Sharing of Emotion (SSE) in Online Social Networks: A Case Study in Live Journal. Comput. Hum. Behav. 2015, 52, 364–372. [Google Scholar] [CrossRef]
- Stella, M.; Vitevitch, M.S.; Botta, F. Cognitive Networks Extract Insights on COVID-19 Vaccines from English and Italian Popular Tweets: Anticipation, Logistics, Conspiracy and Loss of Trust. Big Data Cogn. Comput. 2022, 6, 52. [Google Scholar] [CrossRef]
- Ferrara, E.; Yang, Z. Quantifying the Effect of Sentiment on Information Diffusion in Social Media. PeerJ Comput. Sci. 2015, 1, e26. [Google Scholar] [CrossRef]
- Cesare, N.; Lee, H.; McCormick, T.; Spiro, E.; Zagheni, E. Promises and Pitfalls of Using Digital Traces for Demographic Research. Demography 2018, 55, 1979–1999. [Google Scholar] [CrossRef]
- Pettit, B. Invisible Men: Mass Incarceration and the Myth of Black Progress; Russell Sage Foundation: New York, NY, USA, 2012. [Google Scholar] [CrossRef]
- Marwick, A.E.; Boyd, D. I Tweet Honestly, I Tweet Passionately: Twitter Users, Context Collapse, and the Imagined Audience. New Media Soc. 2011, 13, 114–133. [Google Scholar] [CrossRef]
- Hargittai, E. Potential Biases in Big Data: Omitted Voices on Social Media. Soc. Sci. Comput. Rev. 2020, 38, 10–24. [Google Scholar] [CrossRef]
- Van Deursen, A.J.; Van Dijk, J.A.; Peters, O. Rethinking Internet Skills: The Contribution of Gender, Age, Education, Internet Experience, and Hours Online to Medium-and Content-related Internet Skills. Poetics 2011, 39, 125–144. [Google Scholar] [CrossRef]
- Grishchenko, N. The Gap Not Only Closes: Resistance and Reverse Shifts in the Digital Divide in Russia. Telecommun. Policy 2020, 44, 102004. [Google Scholar] [CrossRef]
- Monakhov, S. Early Detection of Internet Trolls: Introducing an Algorithm Based on Word Pairs/Single Words Multiple Repetition Ratio. PLoS ONE 2020, 15, e0236832. [Google Scholar] [CrossRef]
- Stukal, D.; Sanovich, S.; Bonneau, R.; Tucker, J.A. Detecting Bots on Russian Political Twitter. Big Data 2017, 5, 310–324. [Google Scholar] [CrossRef] [PubMed]
- Cambria, E.; Poria, S.; Gelbukh, A.; Thelwall, M. Sentiment Analysis Is a Big Suitcase. IEEE Intell. Syst. 2017, 32, 74–80. [Google Scholar] [CrossRef]
- Tang, D.; Qin, B.; Liu, T. Deep Learning for Sentiment Analysis: Successful Approaches and Future Challenges. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2015, 5, 292–303. [Google Scholar] [CrossRef]
- Yang, Y.; Cer, D.; Ahmad, A.; Guo, M.; Law, J.; Constant, N.; Abrego, G.H.; Yuan, S.; Tar, C.; Sung, Y.H.; et al. Multilingual Universal Sentence Encoder for Semantic Retrieval. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Online, 5–10 July 2020; pp. 87–94. [Google Scholar] [CrossRef]
- Kuratov, Y.; Arkhipov, M. Adaptation of Deep Bidirectional Multilingual Transformers for Russian Language. In Computational Linguistics and Intellectual Technologies: Proceedings of the International Conference “Dialogue 2019”, Moscow, Russia, 29 May 29–1 June 2019; Russian State University for the Humanities: Moscow, Russia, 2019; Volume 18, pp. 333–340. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Long and Short Papers; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8440–8451. [Google Scholar] [CrossRef]
- Tang, Y.; Tran, C.; Li, X.; Chen, P.J.; Goyal, N.; Chaudhary, V.; Gu, J.; Fan, A. Multilingual Translation with Extensible Multilingual Pretraining and Finetuning. arXiv 2020, arXiv:cs.CL/2008.00401. [Google Scholar]
- Mishev, K.; Gjorgjevikj, A.; Vodenska, I.; Chitkushev, L.T.; Trajanov, D. Evaluation of Sentiment Analysis in Finance: From Lexicons to Transformers. IEEE Access 2020, 8, 131662–131682. [Google Scholar] [CrossRef]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained Models for Natural Language Processing: A Survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Artemova, E. Deep Learning for the Russian Language. In The Palgrave Handbook of Digital Russia Studies; Palgrave Macmillan: Cham, Switzerland, 2021; pp. 465–481. [Google Scholar] [CrossRef]
- Shavrina, T.; Fenogenova, A.; Anton, E.; Shevelev, D.; Artemova, E.; Malykh, V.; Mikhailov, V.; Tikhonova, M.; Chertok, A.; Evlampiev, A. RussianSuperGLUE: A Russian Language Understanding Evaluation Benchmark. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 4717–4726. [Google Scholar] [CrossRef]
- Sberbank. Second Only to Humans: SberDevices Language Models Best in the World at Russian Text Comprehension. Available online: https://www.sberbank.com/news-and-media/press-releases/article?newsID=db5b6ba1-f5d1-4302-ba72-18c717c650f3&blockID=7®ionID=77&lang=en&type=NEWS (accessed on 1 January 2022).
- Vatrapu, R.K. Towards a Theory of Socio-Technical Interactions. In Proceedings of the Learning in the Synergy of Multiple Disciplines, 4th European Conference on Technology Enhanced Learning, EC-TEL 2009, Nice, France, 29 September–2 October 2009; pp. 694–699. [Google Scholar] [CrossRef]
- Hox, J.J. Computational Social Science Methodology, Anyone? Methodol. Eur. J. Res. Methods Behav. Soc. Sci. 2017, 13, 3–12. [Google Scholar] [CrossRef]
- Gallup. Gallup Global Emotions 2020; Gallup, Inc.: Washington, DC, USA, 2021. [Google Scholar]
- WEAll. Happy Planet Index Methodology Paper. Available online: https://happyplanetindex.org/wp-content/themes/hpi/public/downloads/happy-planet-index-methodology-paper.pdf (accessed on 1 January 2022).
- WWS. Fieldwork and Sampling. Available online: https://www.worldvaluessurvey.org/WVSContents.jsp?CMSID=FieldworkSampling&CMSID=FieldworkSampling (accessed on 1 January 2022).
- GESIS. Population, Countries & Regions. Available online: https://www.gesis.org/en/eurobarometer-data-service/survey-series/standard-special-eb/population-countries-regions (accessed on 1 January 2022).
- FOM. Dominants. Field of Opinion. Available online: https://media.fom.ru/fom-bd/d172022.pdf (accessed on 1 January 2022).
- Smetanin, S.; Komarov, M. Misclassification Bias in Computational Social Science: A Simulation Approach for Assessing the Impact of Classification Errors on Social Indicators Research. IEEE Access 2022, 10, 18886–18898. [Google Scholar] [CrossRef]
- Mukkamala, R.R.; Hussain, A.; Vatrapu, R. Towards a Set Theoretical Approach to Big Data Analytics. In Proceedings of the 2014 IEEE International Congress on Big Data, Anchorage, AK, USA, 27 June–2 July 2014; pp. 629–636. [Google Scholar] [CrossRef]
- Vatrapu, R.; Mukkamala, R.R.; Hussain, A.; Flesch, B. Social Set Analysis: A Set Theoretical Approach to Big Data Analytics. IEEE Access 2016, 4, 2542–2571. [Google Scholar] [CrossRef]
- VCIOM. Each Age Has Its Own Networks. Available online: https://wciom.ru/analytical-reviews/analiticheskii-obzor/kazhdomu-vozrastu-svoi-seti (accessed on 1 February 2022).
- Brodovskaya, E.; Dombrovskaya, A.; Sinyakov, A. Social Media Strategies in Modern Russia: Results of Multidimensional Scaling. Monit. Public Opin. Econ. Soc. Chang. 2016, 131. [Google Scholar] [CrossRef]
- World Food Programme. Introduction to Post-Stratification. Available online: https://docs.wfp.org/api/documents/WFP-0000121326/download/ (accessed on 1 January 2022).
- Odnoklassniki. OK Mediakit 2022. Available online: https://cloud.mail.ru/public/5P13/bN2sSzrBs (accessed on 1 April 2022).
- Odnoklassniki. About Odnoklassniki. Available online: https://insideok.ru/wp-content/uploads/2021/01/o_proekte_odnoklassniki.pdf (accessed on 1 April 2022).
- VCIOM. SPUTNIK Daily All-Russian Poll. Available online: https://ok.wciom.ru/research/vciom-sputnik (accessed on 1 January 2022).
- RANEPA. Eurobarometer Methodology. Available online: https://www.ranepa.ru/nauka-i-konsalting/strategii-i-doklady/evrobarometr/metodologiya-evrobarometra/ (accessed on 1 January 2022).
- VK. About Us | VK. Available online: https://vk.com/about# (accessed on 1 September 2021).
- Lukashevich, N.; Rubtsova, Y.R. SentiRuEval-2016: Overcoming Time Gap and Data Sparsity in Tweet Sentiment Analysis. In Proceedings of the Computational Linguistics and Intellectual Technologies: Proceedings of the International Conference “Dialogue 2016”, Moscow, Russia, 1–4 June 2016; Russian State University for the Humanities: Moscow, Russia, 2016; pp. 416–426. [Google Scholar]
- Rubtsova, Y. A Method for Development and Analysis of Short Text Corpus for the Review Classification Task. In Proceedings of the Conference on Digital Libraries: Advanced Methods and Technologies, Digital Collections (RCDL’2013), Yaroslavl, Russia, 14–17 October 2013; pp. 269–275. [Google Scholar]
- Smetanin, S.; Komarov, M. Sentiment Analysis of Product Reviews in Russian using Convolutional Neural Networks. In Proceedings of the 2019 IEEE 21st Conference on Business Informatics (CBI), Moscow, Russia, 15–17 July 2019; IEEE: Moscow, Russia, 2019; Volume 1, pp. 482–486. [Google Scholar] [CrossRef]
- Smetanin, S. RuSentiTweet: A Sentiment Analysis Dataset of General Domain Tweets in Russian. PeerJ Comput. Sci. 2022, 8, e1039. [Google Scholar] [CrossRef]
- Dunn, J. Representations of Language Varieties Are Reliable Given Corpus Similarity Measures. In Proceedings of the Eighth Workshop on NLP for Similar Languages, Varieties and Dialects, Kiyv, Ukraine, 20 April 2021; Association for Computational Linguistics: Kiyv, Ukraine, 2021; pp. 28–38. [Google Scholar]
- VCIOM. Cyberbullying: The Scale of the Problem in Russia. Available online: https://wciom.ru/analytical-reviews/analiticheskii-obzor/kiberbulling-masshtab-problemy-v-rossii (accessed on 1 February 2022).
- Blinova, M. Social Media in Russia: Its Features and Business Models. In Handbook of Social Media Management; Springer: Berlin/Heidelberg, Germany, 2013; pp. 405–415. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized Bert Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Liu, Y.; Gu, J.; Goyal, N.; Li, X.; Edunov, S.; Ghazvininejad, M.; Lewis, M.; Zettlemoyer, L. Multilingual Denoising Pre-training for Neural Machine Translation. Trans. Assoc. Comput. Linguist. 2020, 8, 726–742. [Google Scholar] [CrossRef]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to Fine-tune Bert for Text Classification? In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2019; pp. 194–206. [Google Scholar] [CrossRef]
- Barriere, V.; Balahur, A. Improving Sentiment Analysis over Non-English Tweets using Multilingual Transformers and Automatic Translation for Data-Augmentation. In Proceedings of the 28th International Conference on Computational Linguistics, Online, 8–13 December 2020; International Committee on Computational Linguistics: Barcelona, Spain, 2020; pp. 266–271. [Google Scholar] [CrossRef]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020. [Google Scholar] [CrossRef]
- Baymurzina, D.; Kuznetsov, D.; Burtsev, M. Language Model Embeddings Improve Sentiment Analysis in Russian. In Proceedings of the Computational Linguistics and Intellectual Technologies: Proceedings of the International Conference “Dialogue 2019”, Moscow, Russia, 29 May–1 June 2019; Volume 18, pp. 53–63. [Google Scholar]
- Barnes, J.; Øvrelid, L.; Velldal, E. Sentiment Analysis Is Not Solved! Assessing and Probing Sentiment Classification. In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Florence, Italy, 1 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 12–23. [Google Scholar] [CrossRef]
- Chen, L.; Gong, T.; Kosinski, M.; Stillwell, D.; Davidson, R.L. Building a Profile of Subjective Well-being for Social Media Users. PLoS ONE 2017, 12, e0187278. [Google Scholar] [CrossRef]
- Iacus, S.; Porro, G.; Salini, S.; Siletti, E. An Italian Subjective Well-being Index: The Voice of Twitter Users from 2012 to 2017. Soc. Indic. Res. 2019, 161, 471–489. [Google Scholar] [CrossRef]
- Maat, J.; Malali, A.; Protopapas, P. TimeSynth: A Multipurpose Library for Synthetic Time Series in Python. Available online: https://github.com/TimeSynth/TimeSynth (accessed on 1 January 2022).
- Öztuna, D.; Elhan, A.H.; Tüccar, E. Investigation of Four Different Normality Tests in Terms of Type 1 Error Rate and Power Under Different Distributions. Turk. J. Med Sci. 2006, 36, 171–176. [Google Scholar]
- Arltová, M.; Fedorová, D. Selection of Unit Root Test on the Basis of Length of the Time Series and Value of AR (1) Parameter. Stat.-Stat. Econ. J. 2016, 96, 47–64. [Google Scholar]
- White, H. A Heteroskedasticity-Consistent Covariance Matrix Estimator and a Direct Test for Heteroskedasticity. Econom. J. Econom. Soc. 1980, 48, 817–838. [Google Scholar] [CrossRef]
- Bjørnskov, C. How Comparable Are the Gallup World Poll Life Satisfaction Data? J. Happiness Stud. 2010, 11, 41–60. [Google Scholar] [CrossRef]
- Akoglu, H. User’s Guide to Correlation Coefficients. Turk. J. Emerg. Med. 2018, 18, 91–93. [Google Scholar] [CrossRef]
- Mayor, E.; Bietti, L.M. Twitter, Time and Emotions. R. Soc. Open Sci. 2021, 8, 201900. [Google Scholar] [CrossRef]
- Dzogang, F.; Lightman, S.; Cristianini, N. Diurnal Variations of Psychometric Indicators in Twitter Content. PLoS ONE 2018, 13, e0197002. [Google Scholar] [CrossRef]
- Cornelissen, G.; Watson, D.; Mitsutake, G.; Fišer, B.; Siegelová, J.; Dušek, J.; Vohlídalová; Svaèinová, H.; Halberg, F. Mapping of Circaseptan and Circadian Changes in Mood. Scr. Med. 2005, 78, 89–98. [Google Scholar]
- Ayuso-Mateos, J.L.; Miret, M.; Caballero, F.F.; Olaya, B.; Haro, J.M.; Kowal, P.; Chatterji, S. Multi-country Evaluation of Affective Experience: Validation of an Abbreviated Version of the Day Reconstruction Method in Seven Countries. PLoS ONE 2013, 8, e61534. [Google Scholar] [CrossRef]
- Helliwell, J.F.; Wang, S. How Was the Weekend? How the Social Context Underlies Weekend Effects in Happiness and Other Emotions for US Workers. PLoS ONE 2015, 10, e0145123. [Google Scholar] [CrossRef]
- Stone, A.A.; Schneider, S.; Harter, J.K. Day-of-week Mood Patterns in the United States: On the Existence of ‘Blue Monday’, ‘Thank God It’s Friday’ and Weekend Effects. J. Posit. Psychol. 2012, 7, 306–314. [Google Scholar] [CrossRef]
- Shilova, V. Subjective Well-being as Understood by Russians: Level Assessments, Relationship With Other Indicators, Subjective Characteristics and Models. Inf. Anal. Bull. (INAB) 2020, 18–38. [Google Scholar] [CrossRef]
- Thelwall, M.; Buckley, K.; Paltoglou, G.; Cai, D.; Kappas, A. Sentiment Strength Detection in Short Informal Text. J. Am. Soc. Inf. Sci. Technol. 2010, 61, 2544–2558. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3149–3157. [Google Scholar]
- Hutto, C.; Gilbert, E. VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; AAAI Press: Palo Alto, CA, USA, 2014; Volume 8, pp. 216–225. [Google Scholar]
- Wang, D.; Al-Rubaie, A. Methods and Systems for Data Processing. U.S. Patent App. 15/092,941, 12 October 2017. [Google Scholar]
- Cuihong, L.; Chengzhi, Y. The Impact of Internet Use on Residents’ Subjective Well-being: An Empirical Analysis Based on National Data. Soc. Sci. China 2019, 40, 106–128. [Google Scholar] [CrossRef]
- Paez, D.; Delfino, G.; Vargas-Salfate, S.; Liu, J.H.; Gil de Zúñiga, H.; Khan, S.; Garaigordobil, M. A Longitudinal Study of the Effects of Internet Use on Subjective Well-being. Media Psychol. 2020, 23, 676–710. [Google Scholar] [CrossRef]
- Nie, P.; Sousa-Poza, A.; Nimrod, G. Internet Use and Subjective Well-being in China. Soc. Indic. Res. 2017, 132, 489–516. [Google Scholar] [CrossRef]
- Lee, G.; Lee, J.; Kwon, S. Use of Social-Networking Sites and Subjective Well-being: A Study in South Korea. Cyberpsychology Behav. Soc. Netw. 2011, 14, 151–155. [Google Scholar] [CrossRef]
- Sabatini, F.; Sarracino, F. Online Networks and Subjective Well-Being. Kyklos 2017, 70, 456–480. [Google Scholar] [CrossRef]
- Gladkova, A.; Ragnedda, M. Exploring Digital Inequalities in Russia: An Interregional Comparative Analysis. Online Inf. Rev. 2020, 44, 767–786. [Google Scholar] [CrossRef]
- Lastochkina, M. Factors of Satisfaction With Life: Assessment and Empirical Analysis. Stud. Russ. Econ. Dev. 2012, 23, 520–526. [Google Scholar] [CrossRef]
- Vasileva, D. Index of Happiness of the Regional Centres Republics Sakhas (Yakutia). In Innovative Potential of Youth: Information, Social and Economic Security; Ural Federal University: Yekaterinburg, Russia, 2017; pp. 109–111. [Google Scholar]
- Smetanin, S.; Komarov, M. Share of Toxic Comments among Different Topics: The Case of Russian Social Networks. In Proceedings of the 2021 IEEE 23rd Conference on Business Informatics (CBI), Bolzano, Italy, 1–3 September 2021; Volume 2, pp. 65–70. [Google Scholar] [CrossRef]
- Kostenetskiy, P.; Chulkevich, R.; Kozyrev, V. HPC Resources of the Higher School of Economics. J. Phys. Conf. Ser. Iop Publ. 2021, 1740, 012050. [Google Scholar] [CrossRef]
- Dunn, J. Corpus_Similarity: Measure the Similarity of Text Corpora for 47 Languages. Available online: https://github.com/jonathandunn/corpus_similarity (accessed on 1 January 2022).
- Kilgarriff, A. Using Word Frequency Lists to Measure Corpus Homogeneity and Similarity Between Corpora. In Proceedings of the 5th ACL Workshop on Very Large Corpora, Beijing and Hong Kong, China, 18–20 August 1997; Association for Computational Linguistics: Beijing, China; Hong Kong, China, 1997; pp. 231–245. [Google Scholar]
- Kilgarriff, A. Comparing Corpora. Int. J. Corpus Linguist. 2001, 6, 97–133. [Google Scholar] [CrossRef]
- Fothergill, R.; Cook, P.; Baldwin, T. Evaluating a Topic Modelling Approach to Measuring Corpus Similarity. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; European Language Resources Association (ELRA): Portorož, Slovenia, 2016; pp. 273–279. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Age Group | Audience | |
|---|---|---|
| Female | Male | |
| 17 | 2% | 1% |
| 18–24 | 4% | 2.8% |
| 25–34 | 11% | 8.2% |
| 35–44 | 15% | 10.8% |
| 45–54 | 12% | 7.3% |
| 55–64 | 11% | 5.3% |
| 65+ | 7% | 3.4% |
| Model | Vocabulary | Configuration | |||
|---|---|---|---|---|---|
| Tokenization | Size | Cased | Size | Parameters | |
| XLM-RoBERTa-Large | SentencePiece | 250 K | yes | large | 560 M |
| RuRoBERTa-Large | Byte-level BPE | 50 K | yes | large | 355 M |
| MBART-50-Large | SentencePiece | 250 K | yes | large | 611 M |
| RuBERT | WordPiece | 101 K | yes | base | 178 M |
| Model | Measure | |
|---|---|---|
| Macro | Weighted | |
| Random | 18.56 | 23.00 |
| Existing SOTA | 72.03 | 78.50 |
| XLM-RoBERTa-Large | 75.67 | 78.69 |
| RuRoBERTa-Large | 76.30 | 78.92 |
| mBART-large-50 | 68.63 | 72.88 |
| RuBERT | 71.91 | 75.49 |
| Study | Platform | Target Audience | Posts | Users | Demographics | Reliability Test | Sentiment Classification | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Classes | Acc | Macro | Weighted | |||||||
| Our study | Odnoklassniki | Russia | 7 M | 3.6 M | + | + | RuRoBERTa-Large [113] | 3 | n/a | 76.30 | 78.92 |
| [33] | Russian Facebook | 573 M | 3.2 M | - | - | Rule-Based | 3 | 32.16 | 26.06 | n/a | |
| [34] | Vkontakte | Russian regions | 1.7 M | n/a | - | - | LightGBM [163] | 3 | 79 | n/a | n/a |
| [73] | Vkontakte | Moscow high school students | 5.4 K | 61 | - | - | SentiStrength [162] | 2 | n/a | n/a | n/a |
| [35] | Vkontakte | Vkontakte groups | 770 K | n/a | - | - | Neural Network | 2 | 69 | n/a | n/a |
| [24] | US | 300 M | n/a | - | - | Rule-Based | 2 | n/a | n/a | n/a | |
| [25] | US Essential Workers | n/a | 4055 | - | - | VADER [164] | 3 | n/a | n/a | n/a | |
| [26] | UK Twitter | 120 M | n/a | - | - | Rule-Based | 4 | n/a | n/a | n/a | |
| [27] | UK | 10 M | n/a | - | - | Rule-Based | 5 | n/a | n/a | n/a | |
| [28] | UK Twitter | 800 M | n/a | - | - | Rule-Based | 4 | n/a | n/a | n/a | |
| [29] | Sina | China | 63.5 K | 316 | - | - | Rule-Based | n/a | n/a | n/a | n/a |
| [30] | Italian provinces | 180 M | n/a | - | + | Probabilistic Model | 3 | n/a | n/a | n/a | |
| [31] | Abu Dhabi | 800 K | n/a | - | - | LDA [165] | 4 | 54.6 (English) 54.4 (Arabic) | n/a | n/a | |
| ine [32] | Brazilian Twitter | 38 K | n/a | - | - | Naive Bayes | 2 | 79.8 | n/a | n/a | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Smetanin, S. Pulse of the Nation: Observable Subjective Well-Being in Russia Inferred from Social Network Odnoklassniki. Mathematics 2022, 10, 2947. https://doi.org/10.3390/math10162947
Smetanin S. Pulse of the Nation: Observable Subjective Well-Being in Russia Inferred from Social Network Odnoklassniki. Mathematics. 2022; 10(16):2947. https://doi.org/10.3390/math10162947
Chicago/Turabian StyleSmetanin, Sergey. 2022. "Pulse of the Nation: Observable Subjective Well-Being in Russia Inferred from Social Network Odnoklassniki" Mathematics 10, no. 16: 2947. https://doi.org/10.3390/math10162947
APA StyleSmetanin, S. (2022). Pulse of the Nation: Observable Subjective Well-Being in Russia Inferred from Social Network Odnoklassniki. Mathematics, 10(16), 2947. https://doi.org/10.3390/math10162947