Abstract
The bivariate Poisson model is the most widely used model for bivariate counts, and in recent years, several bivariate Poisson regression models have been developed in order to analyse two response variables that are possibly correlated. In this paper, a particular class of bivariate Poisson model, developed from the bivariate Bernoulli model, will be presented and investigated. The proposed bivariate Poisson models use dependence parameters that can model positively and negatively correlated data, whereas more well-known models, such as Holgate’s bivariate Poisson model, can only be used for positively correlated data. As a result, the proposed model contributes to improving the properties of the more common bivariate Poisson regression models. Furthermore, some of the properties of the new bivariate Poisson model are outlined. The method of maximum likelihood and moment method were used to estimate the parameters of the proposed model. Additionally, real data from the healthcare utilization sector were used. As in the case of healthcare utilization, dependence between the two variables may be positive or negative in order to assess the performance of the proposed model, in comparison to traditional bivariate count models. All computations and graphs shown in this paper were produced using R programming language.
Keywords:
Poisson; Bernoulli; count data; maximum likelihood; moment method; regression; bivariate models MSC:
60E05; 62H10; 62H12; 62E10
1. Introduction
Bivariate count models have received increasing scholarly attention in recent years, mainly because they offer flexibility for fitting across a wide variety of random phenomena. For instance, applications based on discrete bivariate models are often used in the fields of health sciences, traffic accidents, economics, actuarial science, social sciences, environmental studies, and so forth [1]. For more information about bivariate count models, the reader is directed to [2,3,4,5,6,7,8]. The most widely used model for bivariate counts is the bivariate Poisson model, which was developed by [9]. The bivariate Poisson model, which was developed by [9], is considered the limit of a bivariate contingency table model. The literature outlines the main contributions and applications of bivariate Poisson models. For instance, the bivariate Poisson model can be used in modelling data in sports [10,11], health [12,13,14], econometrics and insurance [15,16], and so forth. Furthermore, the use of the bivariate Poisson model is not unique in its different methodological applications. One of the methods is the trivariate reduction, which was studied by [17] and developed by [18]. Bivariate Poisson models have been developed based on the method of trivariate reduction using convolutions of independent Poisson random variables. These models allow for only non-negative correlation between variables. For a comprehensive review of the bivariate Poisson model and its applications, the reader is directed to references [4,19,20,21].
More recently, researchers have developed bivariate Poisson regression models. These models analyse two response variables that are possibly correlated, and they allow the two response variables to be affected by different predictive factors. This means that bivariate Poisson regression models can be used for inference and prediction purposes. Early studies of the use of bivariate count regression models to analyse correlated count events include those by [3], who use a bivariate Poisson regression in a labour mobility study. Furthermore, using a bivariate Poisson regression model, [22] study the relationship between types of health insurance and various responses that measure the demand for health care. Only recently have bivariate regression models been compared and their application in different fields analysed in depth. A study by [13] examines bivariate and zero-inflated bivariate Poisson regression models using the conditional method, as compared with the standard method, using a joint probability distribution (j.p.d). Therefore, bivariate Poisson regression models play a vital role in modeling, analyzing, and improving the fit results when two dependent variables in a data set are highly correlated [1,12,23].
Although the bivariate Poisson regression model offers useful properties for modeling paired count data that exhibits correlations, some models have major drawbacks. One drawback is that some models can only model data with positive correlations [24]. For instance, a bivariate Poisson model based on the trivariate reduction method studied by [17] lacks generality, because it shows a positive correlation only. A few previous studies have explored and developed bivariate Poisson regression models that allow for negative correlations, including bivariate Poisson distribution as a product of Poisson marginals with a multiplicative factor [5]. In addition, [25] have proposed a bivariate Poisson distribution that allows for negative correlations by using conditional probabilities. This current paper will consider a class of bivariate Poisson models generated from the bivariate Bernoulli model, which can model positively and negatively correlated data. This is a progression on from other bivariate Poisson models already proposed in previous research, including the well-known Holgate [17] bivariate Poisson model. One of the merits of the proposed model is that its structure is relatively simple. The proposed models seek to contribute to improving the properties of commonly used bivariate Poisson models. In this paper, the statistical properties of the new model are studied, and the parameters of the proposed model are estimated using the maximum likelihood and moment methods. In this respect, a simulation study was carried out to investigate the performance of the parameter estimation ability of the proposed model using the maximum likelihood and moment method. Finally, applications of the proposed model will be presented in the healthcare sector, and the model’s performance will be compared against well-known bivariate Poisson models.
This paper is organized into sections as follows: Section 2 will detail the proposed bivariate Poisson model and the relevant estimation methods used. Section 3 will present relevant application of this model, using data drawn from different fields and will compare the results with well-known models. Finally, a conclusion will be presented in Section 4.
2. Zero-Dependent Bivariate Poisson Model (ZDBP)
Different methods have been used to construct bivariate Poisson distributions, with specified marginal distributions. Most of the well-known bivariate Poisson models use the popular reduction method [4]. However, this method has two main drawbacks. Firstly, it does not support negative correlation values and secondly, it does not cover the entire range of feasible correlations. In the current study, the construction of a developed bivariate Poisson model is presented, without the aforementioned drawbacks as follows:
If we consider that has Bernoulli marginals, then it has only four possible values , , and with the probabilities , , and which are . If the marginal probability discrete random variables are independent of , and have a probability mass function of zero-truncated Poisson distribution with the parameters and respectively, then the probability mass function can be defined as follows:
.
Here, set where . Then, has a Poisson distribution with the parameter . The j.d.f of the two random variables, and can be expressed as follows:
Then:
for where if and is otherwise.
Generally, and are dependent and therefore (1) defines a new bivariate Poisson distribution, which will be called the zero-dependent Bivariate Poisson Model (ZDBP) model. Since bivariate Bernoulli distribution is completely determined by the three parameters , and then, the above shows that the ZDBP model is completely determined by the three parameters , and . Therefore, the ZDBP ( model can be used whenever the parameters matter and as a result, (1) can be rewritten as follows:
To visualize the j.p.d for the ZDBP model in (2), the representative j.p.d plots for different parameter choices are shown in Figure 1, Figure 2 and Figure 3, where negative dependence is apparent in Figure 1 and Figure 3. The package “plot3D” in R is needed to represent the plots in Figure 1, Figure 2 and Figure 3.
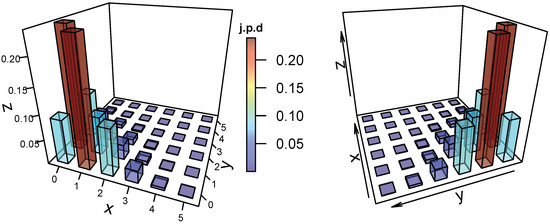
Figure 1.
The j.p.d of the ZDBP model for and with .
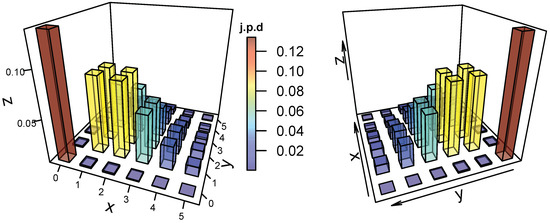
Figure 2.
The j.p.d of the ZDBP model for and with .
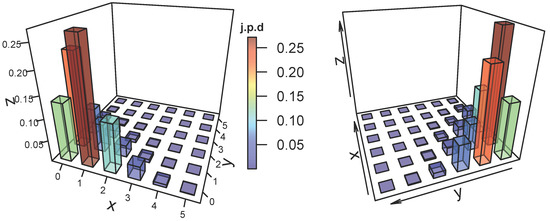
Figure 3.
The j.p.d of the ZDBP model for and with .
2.1. Statistical Properties
The ZDBP model has statistical properties that can be easily proven. These properties are shown as follows:
Theorem 1.
The conditional probability function of givenis
where,
Proof .
Dividing (2) by one gets
Therefore, for we have
In addition, for , we have
From the two cases and , we conclude that
As a result, we get
This completes the proof. □
From the above, it is clear that Theorem 1 implies that the conditional distribution of given is mixture of degenerated distribution at zero and zero-truncated Poisson distribution with mixing probabilities dependent on the value of . In other words, we can write where is the Bernoulli random variable with failure probability as independent of the zero-truncated Poisson random variable . Therefore, we have the following corollary.
Corollary 1.
Theorem 2.
The covariance ofandis
Proof .
The covariance of and according to the assumption can be defined as follows:
Since and are independent of , then
Since and therefore we get the result
□
From Corollary 1, it is clear that and will be independent variables when .
Corollary 2.
The correlation ofandis
Proof .
The correlation of and according to the assumption is defined as follows:
From Corollary 1 and since then
Since , then the equation above can be written as
□
From Corollary 2, we can conclude that the correlation of and allows the ZDBP model to be positively or negatively correlated since it depends on which can be a negative or a positive correlation.
2.2. Parameter Estimation
An estimation of the ZDBP model parameters was obtained using the maximum likelihood estimation (ML) and moment methods (MM). The ZDBP model has six parameters that can be estimated based on three parameters, which are and If we consider as the independent vectors , where the -th vector is the ZDBP model shown in (2), then the estimators can be expressed as follows:
2.2.1. Maximum Likelihood Estimation (ML)
The likelihood function of (2) is shown below as
It is worth mentioning that and are sufficient to be used with ML method in order to estimate the other parameters. This is because of the dependent relationship between the parameters. The corresponding log likelihood can be given as follows:
Furthermore, the corresponding likelihood equations are shown below:
These equations can be solved numerically to estimate the parameters and . Following on from this, other parameters were estimated using the following equations:
2.2.2. Moment Method Estimation (MM)
Using the MM, the following equations were considered in order to estimate the parameters and as follows:
Following on from this, other parameters were estimated using (4).
2.2.3. Simulation Study
A simulation study was conducted to assess the performance of the ML method and MM used for the estimation of ZDBP’s parameters. The simulation was executed according to the steps outlined below:
- A total of 1000 data sets with sizes of 20, 50, 200, and 1000, relating to each data set, were generated from the ZDBP model using four different theoretical parameters values, with varying positive and negative correlations as follows:
- (a)
- Case 1: Model ZDBP ( with 0.5;
- (b)
- Case 2: Model ZDBP ( with 0.5;
- (c)
- Case 3: Model ZDBP ( with 0.3;
- (d)
- Case 4: Model ZDBP ( with 0.7.
- Calculating the ML estimates of and and considering that , the obtained estimates by step 1 were ignored.
- The bias and mean square error (MSE) were calculated for all considered models.
In Step 1, packages “mipfp”, “VGAM”, and “actuar” in R were used in order to generate data from the ZDBP model. In addition, in Step 2, Equation (3) is solved numerically using the function “optim” in R. The method “BFGS”, a quasi-Newton method, was chosen for the optimization problem among other methods in optim function because it is relatively quick. Table 1, Table 2, Table 3 and Table 4 below show the performance of the ML method and the MM used for estimation of the ZDBP’ parameters, taking into account the MSE and bias relating to the cases shown in Step 1 of the simulation study. In general, the results revealed the superiority of the ML method for the estimation of positive and negative correlations in comparison with the MM, taking into account the MSE. In addition, the ML results of and were better than the MM results of these parameters based on the MSE for n = 20, except for the ML results of , when as shown in Table 1.

Table 1.
MSE and bias between parentheses for the different simulated data sizes: n = 20, 50, 200, 1000 for the ZDBP ( model with cor = −0.5.
Table 2.
MSE and bias between parentheses for the different simulated data sizes: n = 20, 50, 200, 1000 for the ZDBP ( model with cor = −0.5.
Table 3.
MSE and bias between parentheses for the different simulated data sizes: n = 20, 50, 200, 1000 for the ZDBP ( model with cor = 0.3.
Table 4.
MSE and bias between parentheses for the different simulated data sizes: n = 20, 50, 200, 1000 from the ZDBP ( model with cor = 0.7.
It can be seen that the performance using the ML method for the estimation of the parameters and is similar to that generated by the MM for 1000, especially for positive correlations. See Table 3.
The MSE of ML for and are the same as the MSE of MM estimates of these parameters when n = 50 for only, and when n = 200 for both parameters. Moreover, Table 4 shows that the MSE of ML for and are the same as the MSE of MM estimates of these parameters when n = 200. For n = 1000, the performance of ML in general is the same as MM for the estimation of and , according to the MSE when either the correlation is positive or negative. As a result, it can be concluded that the ML estimates of the ZDBP model’s parameters are useful for estimation, in comparison with the MM estimates, especially for small samples and for when .
Figure 4 shows the MSE results using the ML of where related to the cases is shown in Step 1 of the simulation study. It is clear from Figure 4a–d that using the MLE, as the sample size increases, the MSE for and decreases simultaneously. Using the ML method, the MSE for and is less than the MSE for in relation to the positive correlation, as shown in Figure 4c,d. On the other hand, using the ML method, the MSE for as shown in Figure 4a,b, is less than the MSE for and for the large sample sizes and for the negative correlation.
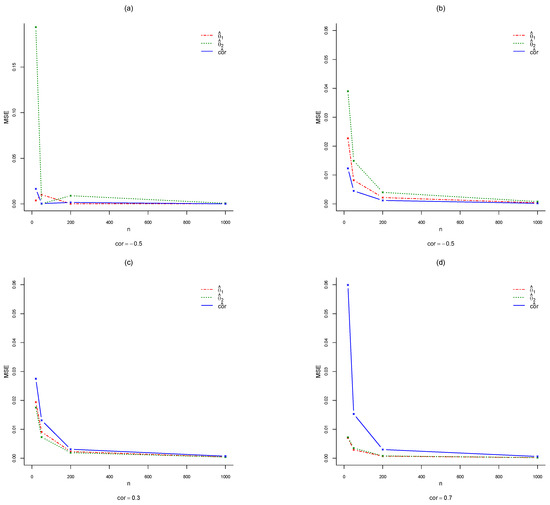
Figure 4.
Summary of the results provided by lines of MSE of the estimates and for the different simulated data sizes n = 20, 50, 200, 1000 relating to the models (a) ZDBP ( (b) ZDBP (, (c) ZDBP ( and (d) ZDBP (.
2.2.4. Applications
Real data examples were studied to investigate the performance of the ZDBP model for fitting positively and negatively correlated bivariate data compared to other models.
Health and Retirement Study (HRS) Data
The first data set used to illustrate the application of the ZDBP model was drawn from the tenth wave of the Health and Retirement Study (HRS). A summary of the descriptive statistics of dependent variables for this data are provided by Islam and Chowdhury [26]. In the same study, bivariate Poisson-Poisson (BP-P) and bivariate right-truncated Poisson-Poisson (BRTP-P) models are fitted to the data from the Health and Retirement Study. The variables comprise the number of conditions a patient has ever had, as noted by doctors, X1, and the utilization of healthcare services, where the services derive from hospitals, nursing homes, doctors, and home care assistants, X2. The sample size is 5567 and the correlation between X1 and X2 is 0.06.
For the current study, the proposed ZDBP model was fitted to the same data and compared with the models in [26]. Table 5 summarises results for the fittings for the ZDBP model, the bivariate Poisson model with independent marginals (BP), and the BP-PR and the BRTP-P models. These results are shown in terms of the number of parameters used, and according to the Akaike Information Criteria (AIC), Bayesian Information Criteria (BIC), and loglikelihood estimate (. The results show the superiority of the ZDBP model for fitting the Health and Retirement Study (HRS) data in comparison with the other models, based on AIC and BIC, show the ability of the ZDBP model to fit positively correlated data. An analysis of the ML estimates derived for the ZDBP model is presented in Table 6.
Table 5.
Comparison between models from the Health and Retirement Study data.
Table 6.
Fitting Results for the ZDBP model from the Health and Retirement Study data.
Australian Health Data (1977–1978)
The data discussed in this example comes from the Journal of Applied Econometrics 1997 Data Archive [27]. The data covers 5190 single-person households, and provides healthcare service utilization information from the 1977–1978 Australian Health Survey. A study by [28] uses this data in their analysis of various measures of health-care utilisation. A detailed summary of the statistics for the dependent and explanatory variables of this data is provided in [28]. We consider the number of consultations with doctors during the two-week period prior to the survey (Y1) and the number of prescribed medicines used in the past 2 days (Y2). The mean and the standard deviation of Y1 are 0.302 and 0.798, respectively. The corresponding values for Y2 are 0.863 and 1.415 and the correlation between Y1 and Y2 is 0.31.
The ZDBP model was fitted to the data and compared with the BP model. Table 7 presents a summary of results for the ZDBP and BP models, in terms of the number of parameters, AIC, BIC, and . The results show the superiority of the ZDBP model compared with the BP model for fitting the Australian Health data, based on AIC and BIC. An analysis of the ML parameter estimates derived for the ZDBP model is shown in Table 8. In addition, we consider the dependent variables, Y2, and the number of non-prescribed medications used in past two days, Y3. The mean and the standard deviation of Y2 are 0.863 and 1.42, the corresponding values for Y3 are 0.356 and 0.71, and the correlation between Y2 and Y3 is −0.04. Table 9 presents a summary of the results for the ZDBP and BP models, in terms of the number of parameters, AIC, BIC, and . The results show that the ZDBP model appears to be competitive with the BP model for fitting the Australian Health data in comparison with the other models, based on AIC and BIC. Therefore, this example emphasises the ability of the ZDBP model to fit positively and negatively correlated data. An analysis of the ML estimates derived for the ZDBP model is provided in Table 10.
Table 7.
Comparison between the ZDBP and BP models from the Australian Health data.
Table 8.
Fitting results for the ZDBP model from the Australian Health data.
Table 9.
Comparison between ZDBP and BP models from the Australian Health data.
Table 10.
Fitting results for the ZDBP model from the Australian Health data.
3. Zero-Dependent Bivariate Poisson Regression Model (ZDBPR)
In this section, the Bivariate Bernoulli Poisson Regression Model will be considered. In this context, , and 3 is where denotes a vector of explanatory variables of length l for the i-th observation related to the k-th parameter. This means that is the corresponding vector of regression coefficients. In this respect, the ZDBPR model can take the following form:
where , and and denotes the observation number.
The ZDBPR model uses two response variables that are positively and negatively correlated. In addition, this model can be compared with other models to show that it has identical AIC, BIC, and parameter estimates.
3.1. Applications
3.1.1. Health and Retirement Study (HRS) Data
In this example, the same dependent variables used by [26] were considered, as outlined in “Health and Retirement Study (HRS) Data” Section. A study by [26] fit this data using bivariate right-truncated Poisson-Poisson regression (BRTP-PR), and bivariate Poisson-Poisson regression (BP-PR) models. They found that the BRTP-PR model appears to be significantly better than the BP-PR model for fitting the data.
For the purpose of this research, the ZDBPR model was used to fit the data, and was compared with the model used by [26]. Furthermore, the ZDBPR model was compared with the joint bivariate Poisson regression (JBPR) model used by [13], in which the covariates are gender (1 male, 0 female), age (in years), race (1 Hispanic, 0 others), and veteran status (1 yes, 0 no). Table 11 shows the results for the ZDBPR, JBPR, BPR, BP-PR, and BRTP-PR models in terms of the number of parameters, i.e., AIC, BIC, and . The results show the superiority of the ZDBPR model for fitting the Health and Retirement Study data in comparison with the other models, based on AIC and BIC. This suggests that the ZDBPR model is able to fit positively correlated data. An analysis of the ML estimates derived for this model is provided in Table 12.
Table 11.
Comparison between models for the Health and Retirement Study data.
Table 12.
Fitting results for the ZDBPR model from the Health and Retirement Study data.
3.1.2. Australian Health Data (1977–1978)
In this example, the same dependent variables as used by [13] are used, namely Y1 and Y2. The covariates used are gender (1 female, 0 male), age in years divided by 100 (measured as midpoints of age groups), and the annual income in Australian dollars divided by 1000 (measured as midpoint of coded ranges). In the study by [13], model (A) was fitted as a JBPR model, where the covariates were gender, age, income, and age multiplied by gender, with gender as a covariate on the covariance scale. In addition, model (B) was fitted as a JBPR model, where the covariates were gender, age, and income, with a constant covariance term. A study by [13] concludes that the JBPR model performs better than the other models examined in their study. For the purposes of this current research, Model A and B have been fitted for the ZDBPR model. Table 13 shows the results for the ZDBPR and JBPR models, relating to the number of parameters, AIC, BIC, and . These results show the superiority of the ZDBPR model for fitting the Health Care Australia data in comparison with the JBPR model, based on AIC and BIC. This suggests that the ZDBPR model can positively fit the correlated data. An analysis of the ML estimates derived for this model is provided in Table 14.
Table 13.
Comparison between ZDBPR and JBPR models from the Health Care Australia data.
Table 14.
Fitting results for the ZDBPR model from the Health Care Australia data using Model A.1 and B.1.
This current study also considered the same dependent variables used by Zamani et.al. [29], which are Y2 and Y3. Furthermore, [29] fit their data using a bivariate Poisson regression model, whereby the j.p.d is proposed by [5]. The bivariate Poisson model developed by [5] is defined from the product of two Poisson marginals with a multiplicative factor parameter. For ease of notation, the current study will refer to the Zamani et al. model as BPR [29]. Table 15 shows that the ZDBPR model performs better than the BPR [29] model in terms of AIC and BIC. This suggests that the ZDBPR model can fit negatively correlated data. Table 16 provides an analysis of the ML estimates derived for this model.
Table 15.
Comparison between ZDBPR and BPR [29] models from the Health Care Australia data.
Table 16.
Results from fitting the ZDBPR model to the Health Care Australia data.
4. Conclusions
This paper has presented new bivariate Poisson models that can be fitted to bivariate and correlated count data with and without covariates. The main advantage of the ZDBP model and the ZDBPR model is their ability to fit positively and negatively correlated count data. This advantage is valuable for fitting different kinds of data in the healthcare field, as in the case of healthcare data, dependence between the two variables may be positive or negative. The statistical properties of the ZDBP model were discussed, and some properties of this model were proven, which shows that the pair of ZDBP variables can be positively or negatively correlated. Estimation for the ZDBP model was achieved using the ML and the MM methods, with different parameters, and with positive and negative correlations. In the simulation, the ML method showed good performance for estimation in comparison with the MM. Real data were used to examine the performance of the ZDBP model and the ZDBPR model for fitting positive and negative correlated count data, in comparison with other models. The applications for both models show the superiorities of these models in comparison with other models. This suggests that the ZDBP model and the ZDBPR model can allow the correlation structure to be positive or negative. Finally, although the proposed model was applied in two healthcare data sets, the model can be generalized and utilized in the other areas of research as well.
Author Contributions
Conceptualization, A.A.A.; methodology, A.A.A.; software, N.Q.; validation, A.A.A. and N.Q.; formal analysis, A.A.A. and N.Q.; investigation, A.A.A. and N.Q.; resources, A.A.A. and N.Q.; data curation, A.A.A. and N.Q.; writing—original draft preparation, A.A.A. and N.Q.; writing—review and editing, A.A.A. and N.Q.; visualization, N.Q.; supervision, A.A.A.; project administration, A.A.A.; funding acquisition, N.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This research project was funded by the Deanship of Scientific Research, Princess Nourah bint Abdulrahman University, through the Program of Research Project Funding After Publication, grant No (PRFA-P-43-1).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
We make use of publicly available data. Health and Retirement Study (HRS) data can be downloaded from R package ‘bpglm’ and Australian Health data can be downloaded from Reference [27].
Acknowledgments
The authors gratefully acknowledge Princess Nourah bint Abdulrahman University, represented by the Deanship of Scientific Research, for the financial support for this research under the number (PRFA-P-43-1).
Conflicts of Interest
The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Islam, M.A.; Chowdhury, R.I. Models for bivariate count data: Bivariate poisson distribution. In Analysis of Repeated Measures Data; Springer: Berlin/Heidelberg, Germany, 2017; pp. 97–124. [Google Scholar]
- Ghosh, I.; Marques, F.; Chakraborty, S. A new bivariate poisson distribution via conditional specification: Properties and applications. J. Appl. Stat. 2021, 48, 3025–3047. [Google Scholar] [CrossRef] [PubMed]
- Jung, R.C.; Winkelmann, R. Two aspects of labor mobility: A bivariate poisson regression approach. Empir. Econ. 1993, 18, 543–556. [Google Scholar] [CrossRef]
- Kocherlakota, S.; Kocherlakota, K. Bivariate Discrete Distributions; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Lakshminarayana, J.; Pandit, S.N.; Srinivasa Rao, K. On a bivariate poisson distribution. Commun. Stat.-Theory Methods 1999, 28, 267–276. [Google Scholar] [CrossRef]
- Marshall, A.W.; Olkin, I. A family of bivariate distributions generated by the bivariate bernoulli distribution. J. Am. Stat. Assoc. 1985, 80, 332–338. [Google Scholar] [CrossRef]
- Ma, Z.; Hanson, T.E.; Ho, Y.Y. Flexible bivariate correlated count data regression. Stat. Med. 2020, 39, 3476–3490. [Google Scholar] [CrossRef]
- Lee, H.; Cha, J.H.; Pulcini, G. Modeling discrete bivariate data with applications to failure and count data. Qual. Reliab. Eng. Int. 2017, 33, 1455–1473. [Google Scholar] [CrossRef]
- Campbell, J. The poisson correlation function. Proc. Edinb. Math. Soc. 1934, 4, 18–26. [Google Scholar] [CrossRef]
- Benz, L.S.; Lopez, M.J. Estimating the change in soccer’s home advantage during the COVID-19 pandemic using bivariate poisson regression. Adv. Stat. Anal. 2021, 1–28. [Google Scholar] [CrossRef]
- Koopman, S.J.; Lit, R. A dynamic bivariate poisson model for analysing and forecasting match results in the english premier league. J. R. Stat. Soc. Ser. A 2015, 178, 167–186. [Google Scholar] [CrossRef]
- Chou, N.-T.; Steenhard, D. Bivariate count data regression models—A sas® macro program. Stat. Data Anal. Pap. 2011, 355, 1–10. [Google Scholar]
- AlMuhayfith, F.E.; Alzaid, A.A.; Omair, M.A. On bivariate poisson regression models. J. King Saud Univ.-Sci. 2016, 28, 178–189. [Google Scholar] [CrossRef]
- Su, P.-F.; Mau, Y.-L.; Guo, Y.; Li, C.-I.; Liu, Q.; Boice, J.D.; Shyr, Y. Bivariate poisson models with varying offsets: An application to the paired mitochondrial DNA dataset. Stat. Appl. Genet. Mol. Biol. 2017, 16, 47–58. [Google Scholar] [CrossRef]
- Bermúdez, L.; Karlis, D. A posteriori ratemaking using bivariate poisson models. Scand. Actuar. J. 2015, 2017, 148–158. [Google Scholar] [CrossRef]
- I Morata, L.B. A priori ratemaking using bivariate poisson regression models. Insur. Math. Econ. 2009, 44, 135–141. [Google Scholar] [CrossRef]
- Holgate, P. Estimation for the bivariate poisson distribution. Biometrika 1964, 51, 241–287. [Google Scholar] [CrossRef]
- Mardia, K.V. Families of Bivariate Distributions; Lubrecht & Cramer Limited: Port Jervis, NY, USA, 1970. [Google Scholar]
- Johnson, N.L.; Kotz, S.; Balakrishnan, N. Discrete Multivariate Distributions; Wiley: New York, NY, USA, 1997. [Google Scholar]
- Inouye, D.I.; Yang, E.; Allen, G.I.; Ravikumar, P. A review of multivariate distributions for count data derived from the poisson distribution. Wiley Interdiscip. Rev. Comput. Stat. 2017, 9, e1398. [Google Scholar] [CrossRef]
- Weems, K.S.; Sellers, K.F.; Li, T. A flexible bivariate distribution for count data expressing data dispersion. Commun. Stat.-Theory Methods 2021, 1–27. [Google Scholar] [CrossRef]
- Cameron, A.C.; Trivedi, P.K. Regression Analysis of Count Data; Cambridge University Press: Cambridge, UK, 2013. [Google Scholar]
- Hofer, V.; Leitner, J. A bivariate sarmanov regression model for count data with generalised poisson marginals. J. Appl. Stat. 2012, 39, 2599–2617. [Google Scholar] [CrossRef]
- Famoye, F.; Consul, P. Bivariate generalized poisson distribution with some applications. Metrika 1995, 42, 127–138. [Google Scholar] [CrossRef]
- Berkhout, P.; Plug, E. A bivariate poisson count data model using conditional probabilities. Stat. Neerl. 2004, 58, 349–364. [Google Scholar] [CrossRef]
- Islam, M.A.; Chowdhury, R.I. A generalized right truncated bivariate poisson regression model with applications to health data. PLoS ONE 2017, 12, e0178153. [Google Scholar] [CrossRef] [PubMed]
- Australian Bureau of Statistics. Australian Health Survey 1977–78: Outline of Concepta; Methodology and Procedures Used (Cat. No. 4323.0); Australian Bureau of Statistics: Sydney, Australia, 1982. [Google Scholar]
- Cameron, A.C.; Trivedi, P.K.; Milne, F.; Piggott, J. A microeconometric model of the demand for health care and health insurance in Australia. Rev. Econ. Stud. 1988, 55, 85–106. [Google Scholar] [CrossRef]
- Zamani, H.; Faroughi, P.; Ismail, N. Bivariate generalized poisson regression model: Applications on health care data. Empir. Econ. 2016, 51, 1607–1621. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).