
Graph Convolutional Network for Image Restoration: A Survey




Abstract
1. Introduction
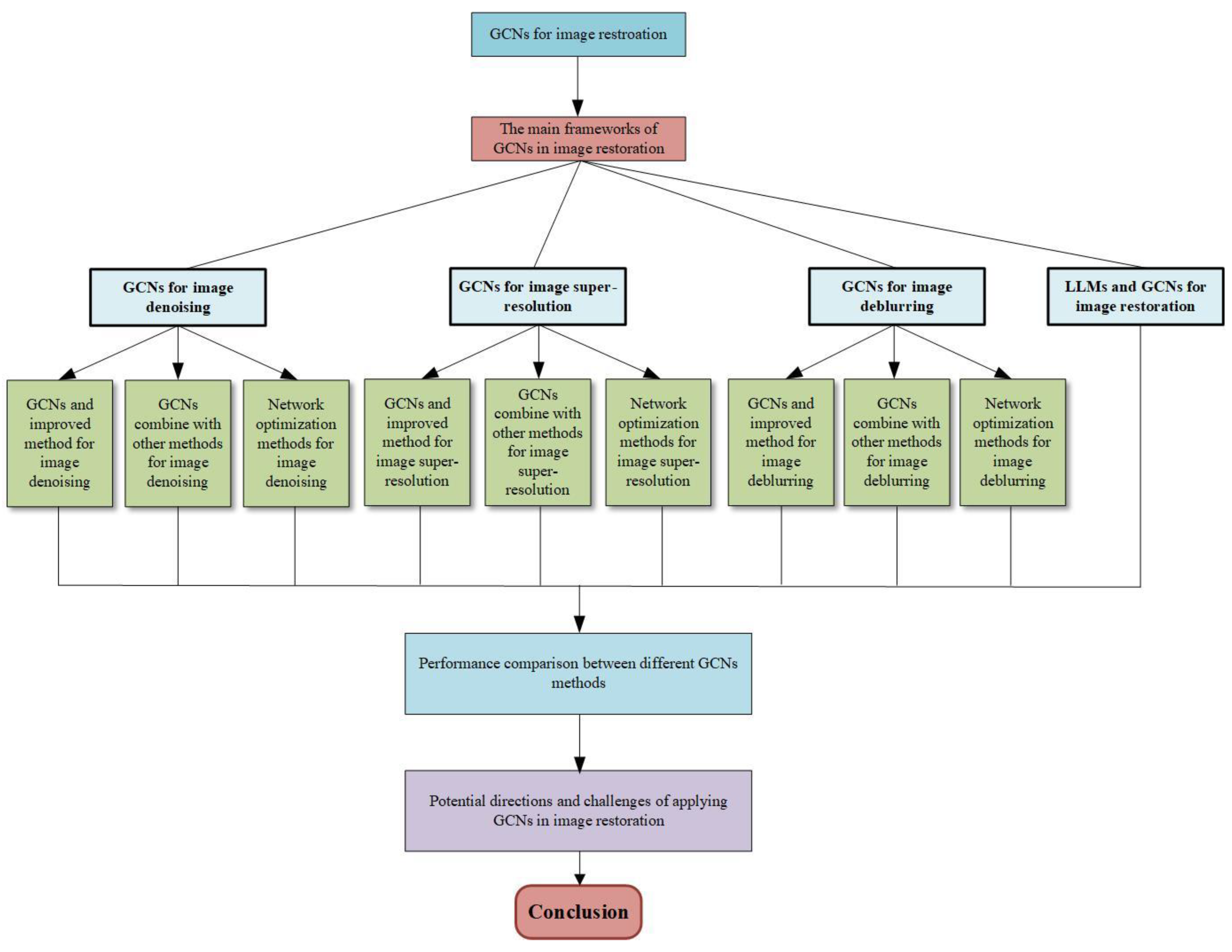
- This overview provides an overview of several common methods of GCNs for image restoration.
- This overview summarizes the solutions of GCNs in the field of image restoration (including image denoising, image super-resolution, image deblurring, LLMs, and GCNs for image restoration), and analyzes the motivation and principles of these methods in image restoration. Finally, we evaluate the graph restoration performance of these methods using both quantitative and qualitative analysis.
- This overview points out some potential applications and challenges of GCNs in the field of image restoration.
2. Development of GCNs
2.1. The Evolution of GCNs
- Spectral domain graph convolution: This approach follows graph theory and the convolution theorem, transforming data to the spectral domain for processing and then back to the original domain. Working in the spectral domain is important because it leverages a robust mathematical framework based on the graph Laplacian and Fourier transform, which facilitates more precise and theoretically grounded operations [36]. Additionally, spectral methods capture global graph structure through eigenvalues and eigenvectors, enabling effective aggregation of information from distant nodes. This method is computationally efficient, as it involves element-wise products of Fourier transforms, reducing the number of parameters by defining filters in terms of eigenvalues. Spectral domain graph convolution is also adaptable to diverse graph topologies and scales, making it particularly useful for complex or dynamic graph structures.
- Spatial domain graph convolution: This method defines the convolution operation directly in spatial space without relying on graph theory or the convolution theorem, offering greater flexibility. Spatial methods provide intuitive definitions and can be easily applied to a variety of graph structures without the need for spectral transformations.
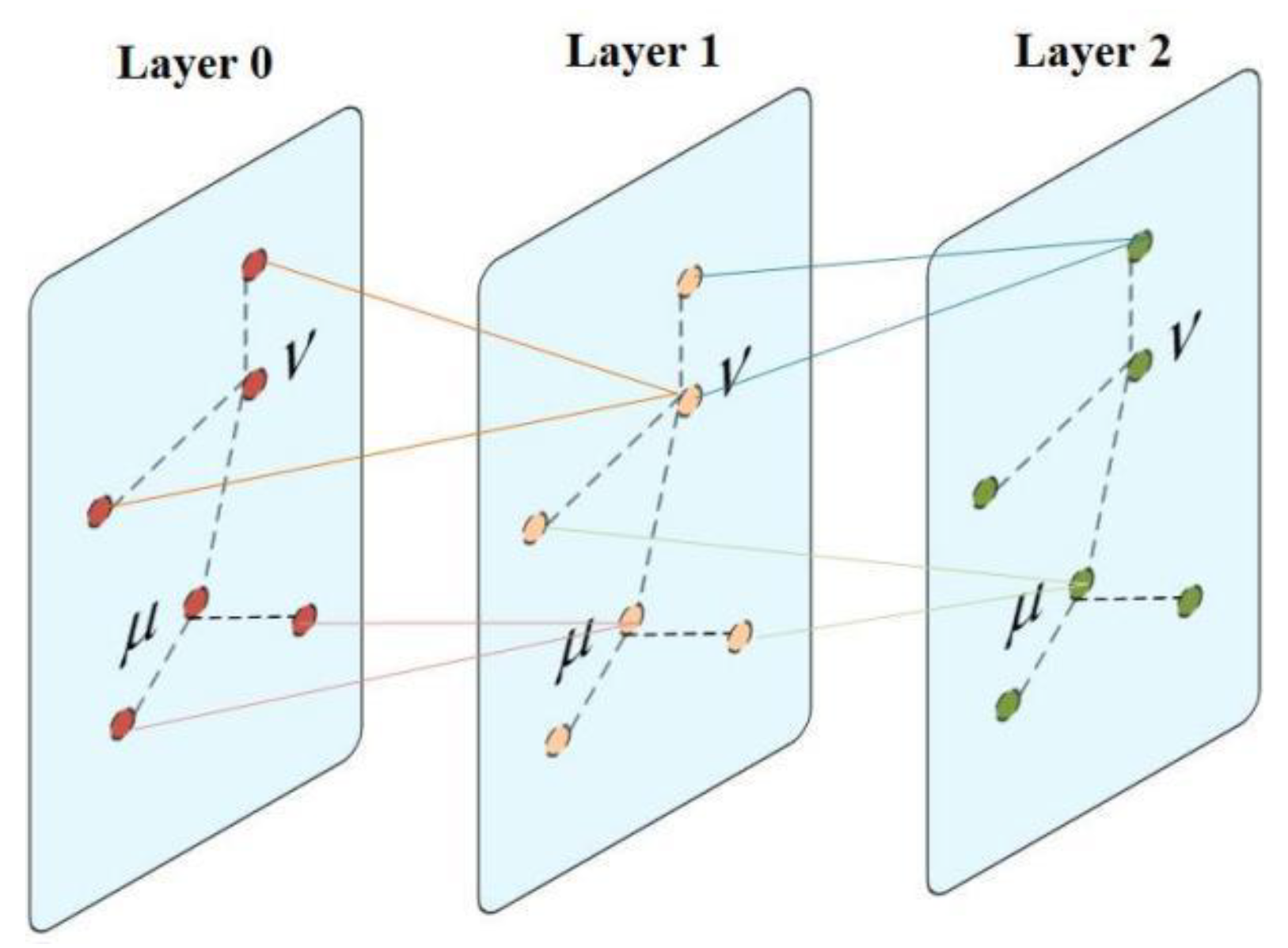
2.2. The Fundamentals of GCNs
2.2.1. Graph Data
2.2.2. Principle of GCNs
- Laplacian Operator in Graphs:
- 2.
- Message Passing Mechanism:
- 3.
- Multilayer Perceptron (MLP)-like Architecture:
- 4.
- Output Layers Tailored for Various Tasks:
2.3. Common Models
2.3.1. Graph Sample and Aggregate (GraphSAGE)
- Sampling: The first step in GraphSAGE is to sample a fixed-size neighborhood for each node in the graph. Instead of using the entire neighborhood, GraphSAGE randomly selects a subset of neighbors at each depth of the neighborhood to consider. This sampling step is crucial for making the algorithm scalable and efficient.
- Aggregation: Once the neighbors are sampled, GraphSAGE aggregates their features to generate a new feature vector for the target node. The aggregation function can be a simple mean of the neighbors’ features, a pooling operation (like max pooling), or even a more complex neural network that learns how to aggregate the features. The key idea is to create a summary of the neighborhood’s features that captures the local structural information.
- Update: The aggregated feature vector is then combined with the target node’s current feature vector (e.g., through concatenation) and passed through a neural network layer (which can include non-linear activation functions) to generate the node’s new feature vector. This step effectively updates the node’s representation based on its own features and the aggregated features of its neighbors.
- Normalization: Often, the new feature vector is normalized to ensure stable training dynamics. For example, L2 normalization can be applied to the resulting vector.
- Repeat: Steps 1 through 4 can be repeated for multiple iterations or “layers”, allowing information to propagate from increasingly distant parts of the graph. With each iteration, the node representations incorporate information from a wider neighborhood.
- Task-Specific Output: The final embeddings produced by GraphSAGE can be used for various downstream tasks such as node classification, link prediction, or even graph classification with the appropriate task-specific layers added on top of the GraphSAGE embeddings.
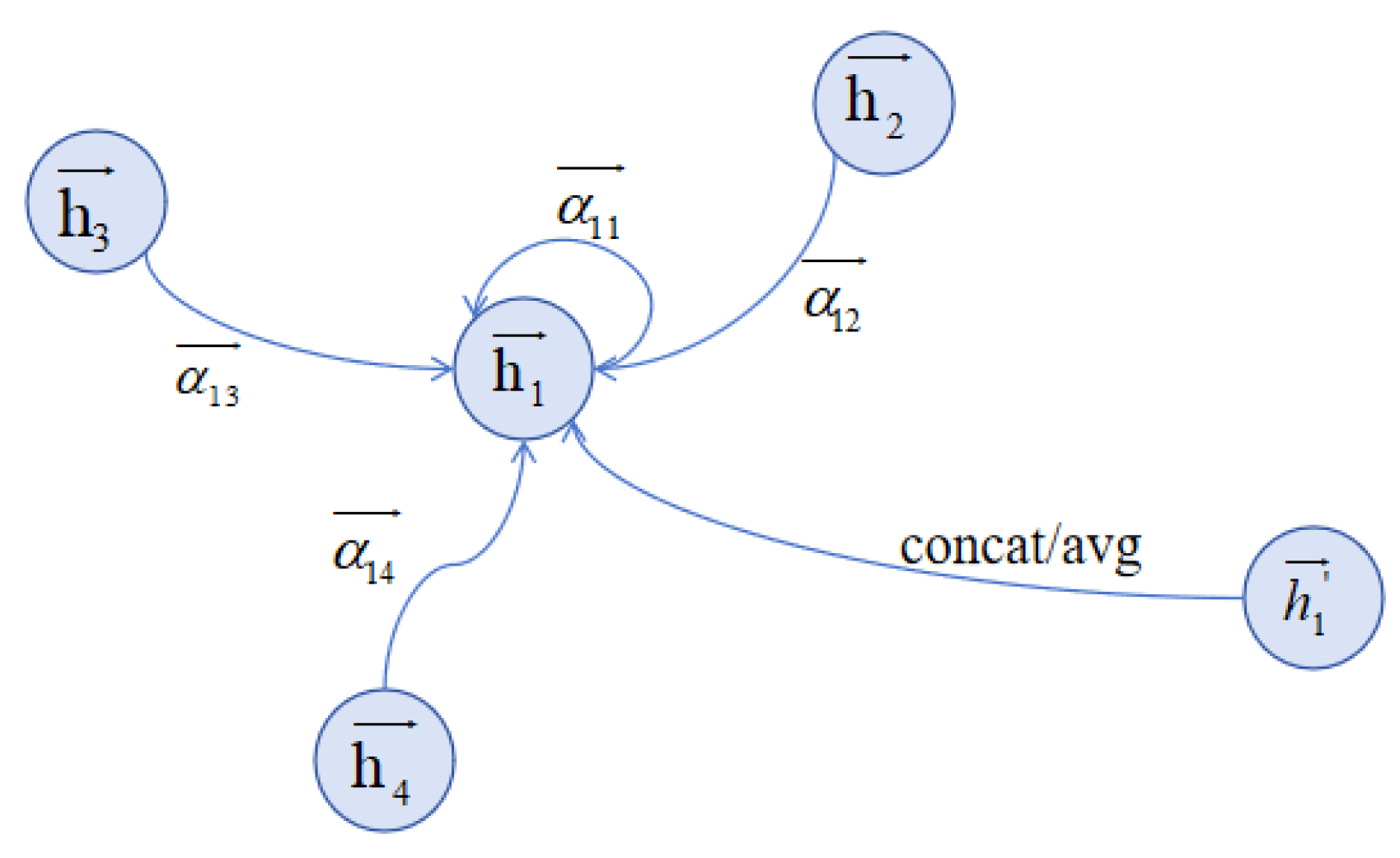
2.3.2. Graph Attention Networks (GATs)
- Node-Level Attention Mechanism: GATs leverage a self-attention strategy to compute attention coefficients that indicate the importance of each node’s features to another. This mechanism enables the model to dynamically prioritize information from different neighbors based on their feature similarity and relevance.
- Feature Aggregation with Attention: For each node, the GAT model calculates the attention coefficients for all its neighbors. These coefficients are then used to weight the neighbors’ feature vectors before aggregation. The weighted sum of the neighbors’ features, scaled by the learned attention coefficients, forms the aggregated feature representation for the node. This process ensures that features from more relevant neighbors have a greater influence on the node’s new feature representation.
- Multi-Head Attention for Stabilization: To stabilize the learning process and improve feature representation, GATs often employ multi-head attention. This involves running several independent attention mechanisms in parallel (each being a “head”), then concatenating or averaging their output feature representations. Multi-head attention allows the model to capture different aspects of feature relevance and provides a richer representation of the neighborhood’s features.
- Non-linearity and Feature Transformation: Similar to other neural network approaches, GATs incorporate non-linear transformations into the feature aggregation process. Before computing attention coefficients, features can be transformed through a learnable linear transformation (e.g., a weight matrix). Non-linear activation functions (e.g., LeakyReLU) are also applied to the attention scores to introduce non-linearity into the model.
- Normalization of Attention Coefficients: The attention coefficients for a node’s neighbors are normalized using a Softmax function, ensuring that they add up to one. This normalization step allows the model to effectively compare and contrast the importance of each neighbor within a local neighborhood context.
3. GCNs for Image Restoration
3.1. GCNs for Image Denoising
3.1.1. GCNs and Improved Methods for Image Denoising
3.1.2. GCNs Combine with Other Methods for Image Denoising
3.1.3. Network Optimization Methods for Image Denoising
3.2. GCNs for Image Super-Resolution
3.2.1. GCNs and Improved Methods for Image Super-Resolution
3.2.2. GCNs Combine with Other Methods for Image Super-Resolution
3.2.3. Network Optimization Methods for Image Super-Resolution
3.3. GCNs for Image Deblurring
3.3.1. GCNs and Improved Methods for Image Deblurring
3.3.2. GCNs Combine with Other Methods for Image Deblurring
3.3.3. Network Optimization Methods for Image Deblurring
3.4. Integration of Large Language Models (LLMs) and GCNs for Image Restoration
3.4.1. Synergistic Capabilities
- Contextual Understanding: LLMs are adept at understanding and generating complex contextual information [92]. When integrated with GCNs, LLMs can help interpret high-level contextual information about the image content, which can be used to guide the restoration process more effectively.
- Multi-Modal Learning: LLMs can facilitate multi-modal learning by bridging the gap between textual and visual data [93]. By incorporating textual descriptions or annotations associated with images, LLMs can provide additional context that GCNs can leverage to improve restoration accuracy.
- Feature Extraction: LLMs can be utilized to extract semantic features from textual data that can complement the structural features extracted by GCNs from image data [94]. This complementary feature set can enhance the overall performance of image restoration models.
3.4.2. LLMs for Image Restoration
4. Experimental Results
4.1. Datasets
4.1.1. Training Datasets
- Image denoising training datasets
- 2.
- Image super-resolution training datasets
- 3.
- Image deblurring training datasets
4.1.2. Test Datasets
- Image denoising test datasets
- 2.
- Image super-revolution test datasets
- 3.
- Image deblurring test datasets
4.2. Experimental Results
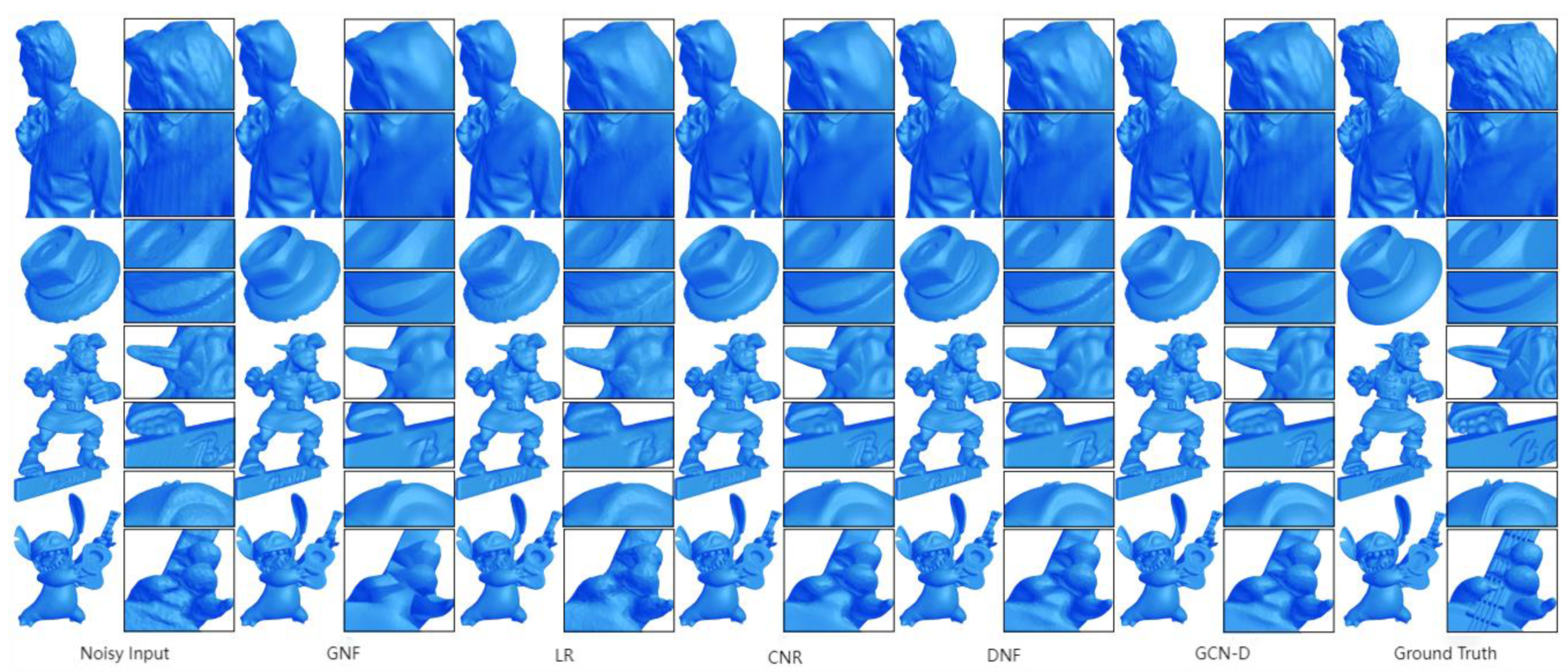
4.2.1. GCNs for Image denoising
4.2.2. GCNs for Image Super-Resolution
4.2.3. GCNs for Image Deblurring
5. Potential Research Points and Challenges
5.1. Potential Research Points
- Network Optimization: To enhance both the efficiency and effectiveness of image restoration, the structure of GCNs can be optimized. This encompasses designing deeper or wider network architectures, refining the construction method of graphs (e.g., considering more intricate relationships between pixels), adopting new activation functions, and regularization techniques to bolster learning capacity and generalization. Additionally, incorporating attention mechanisms enables GCNs to focus more keenly on critical regions in images, thereby improving restoration quality.
- Multimodal Fusion: In image restoration tasks, supplementary information can often be obtained from various modalities (such as infrared images, depth images, etc.). GCNs can integrate these disparate modalities by constructing a unified graph representation, allowing the network to consider features from all modalities simultaneously. This approach can significantly improve recovery accuracy in specific scenarios, especially in complex scenes that traditional methods struggle with.
- Applications in Complex Scenarios: GCNs are particularly adept at handling non-homogeneous and structured data in images, such as complex backgrounds or occlusions. Under such complex scenarios, adaptive graph structures can be constructed to better capture and leverage both local and global image information. For instance, in urban surveillance video restoration, GCNs can assist in recovering finer details in occluded regions by inferring obscured content based on learned environmental structural features.
- Lightweight Network Design: To make GCNs suitable for resource-constrained devices like smartphones or embedded systems, lightweight design is necessary. This involves using fewer parameters, devising more efficient graph processing algorithms, or employing knowledge distillation techniques to simplify large-scale GCN models into smaller ones. A lightweight GCN not only reduces computational and storage demands but also accelerates the image restoration process, rendering it more practical.
- Enhanced Feature Extraction Capabilities: While GCNs naturally excel at handling graph-structured data, effective feature extraction remains crucial in image restoration tasks. Integrating GCNs with other powerful feature extraction networks (like CNNs) could be considered to exploit GCNs’ ability to handle complex graph structures alongside CNNs’ efficiency in processing image data. Such a fusion can lead to further enhancements in the precision and robustness of image restoration.
- Unsupervised or Semi-Supervised Learning: In many image restoration tasks, high-quality labeled data can be challenging to obtain. The development of GCNs can explore more unsupervised or semi-supervised learning strategies that leverage unlabeled or partially labeled data, reducing dependence on copious amounts of labeled data. For example, contrastive learning or self-supervised learning methods can enable models to learn effective image restoration strategies even without explicit supervision signals.
- Cross-domain Image Restoration: GCNs can be employed in cross-domain image restoration tasks, such as restoring from one type of damage pattern (e.g., water damage) to another (e.g., cracks). Through cross-domain learning and transfer learning, GCNs can learn knowledge from one domain and apply it to another, which can dramatically boost model generalizability and practicality.
- Integration of GCNs with Large Vision Models: The integration of GCNs with large vision models presents an exciting avenue for future research and development in the field of image restoration, including super-resolution. This synergy can leverage the strengths of both GCNs and large vision models to address the complexities of high-dimensional image data more effectively.
5.2. Challenges
- Construction and Definition of Graph Structure: In GCNs, the structure of the graph is pivotal to model performance. In the context of image restoration, defining and constructing an effective graph structure poses a challenge since images are not inherently graph-structured data. Assigning pixels or image regions as nodes and determining their edges (connections) requires careful design to ensure that the graph structure accurately reflects the image content and degradation patterns.
- Computational Costs for Large-Scale Image Processing: Images often have substantial sizes, implying that the graph constructed for image restoration might involve a vast number of nodes and edges. GCNs may encounter computational and storage efficiency issues when dealing with large-scale graph data. Optimizing algorithms and implementations, as well as employing hierarchical or multi-scale graph structures, are key to enhancing GCN’s performance in large-scale image processing.
- Limitations in Feature Extraction: Although GCNs can effectively handle graph-structured data, they may have limitations in directly extracting useful features from raw image data. Compared to traditional image processing techniques such as convolutional neural networks, GCNs might be less powerful in processing pixel-level details and capturing complex texture patterns. Therefore, how to enhance GCN’s feature extraction capabilities or combine it with other techniques is a significant research direction.
- Generalization Ability and Adaptability: The generalization capability of GCN models is particularly crucial for image restoration, as the types and degrees of image degradation in practical applications can vary widely. GCN models need to adapt to different damage conditions and image types, presenting challenges in terms of model design and diversity of training data.
- Acquisition and Annotation Issues of Training Data: A substantial number of high-quality annotated data form the foundation for training effective GCN models. In the field of image restoration, obtaining ample pairs of degraded and undamaged images for training purposes can be difficult, especially for certain types of image degradation (e.g., historical document damages). Hence, how to leverage limited data or utilize unsupervised and semi-supervised learning methods to improve training effectiveness is another critical challenge for the development of GCNs.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jiao, Z.; Peng, X.; Wang, Y.; Xiao, J.; Nie, D.; Wu, X.; Wang, X.; Zhou, J.; Shen, D. TransDose: Transformer-based radiotherapy dose prediction from CT images guided by super-pixel-level GCN classification. Med. Image Anal. 2023, 89, 102902. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.; Sun, J.; Shen, J.; Luo, J.; Zhang, X.; Pan, X.; Wu, D.; Zhao, Y.; Bento, M.; Ren, Y. GCN-MIF: Graph Convolutional Network with Multi-Information Fusion for Low-dose CT Denoising. arXiv 2021, arXiv:2105.07146. [Google Scholar]
- Liang, J.; Deng, Y.; Zeng, D. A deep neural network combined CNN and GCN for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4325–4338. [Google Scholar] [CrossRef]
- Chaudhuri, U.; Banerjee, B.; Bhattacharya, A.; Datcu, M. Attention-driven graph convolution network for remote sensing image retrieval. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8019705. [Google Scholar] [CrossRef]
- Ma, C.; Zeng, S.; Li, D. Image restoration and enhancement in monitoring systems. In Proceedings of the 2020 International Conference on Intelligent Transportation, Big Data & Smart City (ICITBS), Vientiane, Laos, 11–12 January 2020; pp. 753–760. [Google Scholar]
- Ravikumar, S.; Bradley, A.; Thibos, L. Phase changes induced by optical aberrations degrade letter and face acuity. J. Vis. 2010, 10, 18. [Google Scholar] [CrossRef] [PubMed]
- Al-Hamadani, A.H.; Zainulabdeen, F.S.; Karam, G.S.; Nasir, E.Y.; Al-Saedi, A. Effects of atmospheric turbulence on the imaging performance of optical system. In Proceedings of the AIP Conference Proceedings, Beirut, Lebanon, 1–3 February 2018. [Google Scholar]
- Yang, X.; Li, S.; Cai, B.; Meng, Z.; Yan, J. MF-GCN: Motion Flow-Based Graph Network Learning Dynamics for Aerial IR Target Recognition. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 6346–6359. [Google Scholar] [CrossRef]
- Feng, R.; Li, C.; Chen, H.; Li, S.; Loy, C.C.; Gu, J. Removing diffraction image artifacts in under-display camera via dynamic skip connection network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 662–671. [Google Scholar]
- Diwakar, M.; Kumar, M. A review on CT image noise and its denoising. Biomed. Signal Process. Control 2018, 42, 73–88. [Google Scholar] [CrossRef]
- Wali, A.; Naseer, A.; Tamoor, M.; Gilani, S. Recent Progress in Digital Image Restoration Techniques: A Review. Digit. Signal Process. 2023, 141, 104187. [Google Scholar] [CrossRef]
- Zhou, Y.-T.; Chellappa, R.; Vaid, A.; Jenkins, B.K. Image restoration using a neural network. IEEE Trans. Acoust. Speech Signal Process. 1988, 36, 1141–1151. [Google Scholar] [CrossRef]
- Chang, J.-Y.; Chen, J.-L. Classifier-augmented median filters for image restoration. IEEE Trans. Instrum. Meas. 2004, 53, 351–356. [Google Scholar] [CrossRef]
- Baselice, F.; Ferraioli, G.; Ambrosanio, M.; Pascazio, V.; Schirinzi, G. Enhanced Wiener filter for ultrasound image restoration. Comput. Methods Programs Biomed. 2018, 153, 71–81. [Google Scholar] [CrossRef] [PubMed]
- Khan, M.M.R.; Sakib, S.; Arif, R.B.; Siddique, M.A.B. Digital image restoration in matlab: A case study on inverse and wiener filtering. In Proceedings of the 2018 International Conference on Innovation in Engineering and Technology (ICIET), Osaka, Japan, 6–8 January 2018; pp. 1–6. [Google Scholar]
- Zhang, B.; Wang, M.; Pan, J. Image restoration based on Kalman filter. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium-IGARSS, Melbourne, Australia, 21–26 July 2013; pp. 497–500. [Google Scholar]
- Chen, L.-Y.; Wang, C.; Xiao, X.-Y.; Ren, C.; Zhang, D.-J.; Li, Z.; Cao, D.-Z. Denoising in SVD-based ghost imaging. Opt. Express 2022, 30, 6248–6257. [Google Scholar] [CrossRef] [PubMed]
- Bian, Z.; Ma, J.; Huang, J.; Zhang, H.; Niu, S.; Feng, Q.; Liang, Z.; Chen, W. SR-NLM: A sinogram restoration induced non-local means image filtering for low-dose computed tomography. Comput. Med. Imaging Graph. 2013, 37, 293–303. [Google Scholar] [CrossRef] [PubMed]
- Eksioglu, E.M. Decoupled algorithm for MRI reconstruction using nonlocal block matching model: BM3D-MRI. J. Math. Imaging Vis. 2016, 56, 430–440. [Google Scholar] [CrossRef]
- Zha, Z.; Yuan, X.; Zhou, J.; Zhu, C.; Wen, B. Image restoration via simultaneous nonlocal self-similarity priors. IEEE Trans. Image Process. 2020, 29, 8561–8576. [Google Scholar] [CrossRef] [PubMed]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G.; Zisserman, A. Non-local sparse models for image restoration. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 2272–2279. [Google Scholar]
- Cho, T.S.; Zitnick, C.L.; Joshi, N.; Kang, S.B.; Szeliski, R.; Freeman, W.T. Image restoration by matching gradient distributions. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 683–694. [Google Scholar]
- Pleschberger, M.; Schrunner, S.; Pilz, J. An explicit solution for image restoration using Markov random fields. J. Signal Process. Syst. 2020, 92, 257–267. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning deep CNN denoiser prior for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3929–3938. [Google Scholar]
- Zhang, K.; Gao, X.; Tao, D.; Li, X. Single image super-resolution with non-local means and steering kernel regression. IEEE Trans. Image Process. 2012, 21, 4544–4556. [Google Scholar] [CrossRef] [PubMed]
- Liu, D.; Wen, B.; Fan, Y.; Loy, C.C.; Huang, T.S. Non-local recurrent network for image restoration. arXiv 2018, arXiv:1806.02919. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef] [PubMed]
- Guo, S.; Yan, Z.; Zhang, K.; Zuo, W.; Zhang, L. Toward convolutional blind denoising of real photographs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1712–1722. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. Learning a single convolutional super-resolution network for multiple degradations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3262–3271. [Google Scholar]
- Asif, N.A.; Sarker, Y.; Chakrabortty, R.K.; Ryan, M.J.; Ahamed, M.H.; Saha, D.K.; Badal, F.R.; Das, S.K.; Ali, M.F.; Moyeen, S.I. Graph neural network: A comprehensive review on non-euclidean space. IEEE Access 2021, 9, 60588–60606. [Google Scholar] [CrossRef]
- Battaglia, P.W.; Hamrick, J.B.; Bapst, V.; Sanchez-Gonzalez, A.; Zambaldi, V.; Malinowski, M.; Tacchetti, A.; Raposo, D.; Santoro, A.; Faulkner, R. Relational inductive biases, deep learning, and graph networks. arXiv 2018, arXiv:1806.01261. [Google Scholar]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral networks and locally connected networks on graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Liu, J.; Gong, M.; Miao, Q.; Wang, X.; Li, H. Structure learning for deep neural networks based on multiobjective optimization. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 2450–2463. [Google Scholar] [CrossRef]
- Coşkun, M.; Uçar, A.; Yildirim, Ö.; Demir, Y. Face recognition based on convolutional neural network. In Proceedings of the 2017 International Conference on Modern Electrical and Energy Systems (MEES), Kremenchuk, Ukraine, 15–17 November 2017; pp. 376–379. [Google Scholar]
- Zhang, S.; Tong, H.; Xu, J.; Maciejewski, R. Graph convolutional networks: A comprehensive review. Comput. Soc. Netw. 2019, 6, 11. [Google Scholar] [CrossRef]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Adv. Neural Inf. Process. Syst. 2016, 29, 3844–3852. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Yu, J.; Yin, H.; Li, J.; Gao, M.; Huang, Z.; Cui, L. Enhancing social recommendation with adversarial graph convolutional networks. IEEE Trans. Knowl. Data Eng. 2020, 34, 3727–3739. [Google Scholar] [CrossRef]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30, 1024–1034. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. Stat 2017, 1050, 10-48550. [Google Scholar]
- Jiang, B.; Lu, Y.; Chen, X.; Lu, X.; Lu, G. Graph attention in attention network for image denoising. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 7077–7088. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, M.; Lu, Z.; Xiang, T. Adargcn: Adaptive aggregation gcn for few-shot learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 3482–3491. [Google Scholar]
- Li, Y.; Fu, X.; Zha, Z.-J. Cross-patch graph convolutional network for image denoising. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 4651–4660. [Google Scholar]
- Han, W. Robust Graph Embedding via Self-Supervised Graph Denoising. In Proceedings of the 2022 19th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 16–18 December 2022; pp. 1–4. [Google Scholar]
- Mou, C.; Zhang, J. Graph attention neural network for image restoration. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Mou, C.; Zhang, J.; Wu, Z. Dynamic attentive graph learning for image restoration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 11–17 October 2021; pp. 4328–4337. [Google Scholar]
- Liu, H.; Liao, P.; Chen, H.; Zhang, Y. ERA-WGAT: Edge-enhanced residual autoencoder with a window-based graph attention convolutional network for low-dose CT denoising. Biomed. Opt. Express 2022, 13, 5775–5793. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Fu, H.; Du, Z.; Chen, X.; Burnaev, E.; Zorin, D.; Zhou, K.; Zheng, Y. GCN-denoiser: Mesh denoising with graph convolutional networks. ACM Trans. Graph. (TOG) 2022, 41, 1–14. [Google Scholar] [CrossRef]
- Armando, M.; Franco, J.-S.; Boyer, E. Mesh denoising with facet graph convolutions. IEEE Trans. Vis. Comput. Graph. 2020, 28, 2999–3012. [Google Scholar] [CrossRef] [PubMed]
- Mostafa, H.; Nassar, M. Permutohedral-gcn: Graph convolutional networks with global attention. arXiv 2020, arXiv:2003.00635. [Google Scholar]
- Tian, C.; Zheng, M.; Li, B.; Zhang, Y.; Zhang, S.; Zhang, D. Perceptive self-supervised learning network for noisy image watermark removal. IEEE Trans. Circuits Syst. Video Technol. 2024. [Google Scholar] [CrossRef]
- Zhao, Z.; Wu, W.; Liu, H.; Gong, Y. A Multi-Stream Network for Mesh Denoising Via Graph Neural Networks with Gaussian Curvature. In Proceedings of the 2023 IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 8–11 October 2023; pp. 1355–1359. [Google Scholar]
- Chen, Y.-J.; Tsai, C.-Y.; Xu, X.; Shi, Y.; Ho, T.-Y.; Huang, M.; Yuan, H.; Zhuang, J. Ct image denoising with encoder-decoder based graph convolutional networks. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; pp. 400–404. [Google Scholar]
- Chen, Z.; Li, P.; Wei, Z.; Chen, H.; Xie, H.; Wei, M.; Wang, F.L. Geogcn: Geometric Dual-Domain Graph Convolution Network For Point Cloud Denoising. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Fu, X.; Qi, Q.; Zha, Z.-J.; Ding, X.; Wu, F.; Paisley, J. Successive graph convolutional network for image de-raining. Int. J. Comput. Vis. 2021, 129, 1691–1711. [Google Scholar] [CrossRef]
- Chen, K.; Pu, X.; Ren, Y.; Qiu, H.; Li, H.; Sun, J. Low-dose ct image blind denoising with graph convolutional networks. In Proceedings of the International Conference on Neural Information Processing, Bangkok, Thailand, 18–22 November 2020; pp. 423–435. [Google Scholar]
- Liu, Q.; Xiao, L.; Yang, J.; Wei, Z. CNN-enhanced graph convolutional network with pixel-and superpixel-level feature fusion for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 8657–8671. [Google Scholar] [CrossRef]
- Tian, C.; Zheng, M.; Zuo, W.; Zhang, S.; Zhang, Y.; Lin, C.-W. A cross Transformer for image denoising. Inf. Fusion 2024, 102, 102043. [Google Scholar] [CrossRef]
- Jiang, B.; Lu, Y.; Zhang, B.; Lu, G. AGP-Net: Adaptive Graph Prior Network for Image Denoising. IEEE Trans. Ind. Inform. 2023, 20, 4753–4764. [Google Scholar] [CrossRef]
- Eliasof, M.; Haber, E.; Treister, E. Pde-gcn: Novel architectures for graph neural networks motivated by partial differential equations. Adv. Neural Inf. Process. Syst. 2021, 34, 3836–3849. [Google Scholar]
- Hattori, S.; Yatagawa, T.; Ohtake, Y.; Suzuki, H. Learning self-prior for mesh denoising using dual graph convolutional networks. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 363–379. [Google Scholar]
- Fu, X.; Qi, Q.; Zha, Z.-J.; Zhu, Y.; Ding, X. Rain streak removal via dual graph convolutional network. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; pp. 1352–1360. [Google Scholar]
- Yang, Y.; Qi, Y. Image super-resolution via channel attention and spatial graph convolutional network. Pattern Recognit. 2021, 112, 107798. [Google Scholar] [CrossRef]
- Yan, Y.; Ren, W.; Hu, X.; Li, K.; Shen, H.; Cao, X. SRGAT: Single image super-resolution with graph attention network. IEEE Trans. Image Process. 2021, 30, 4905–4918. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Qi, Y. Spatial Graph Convolutional Network for Image Super-Resolution. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Fu, Y. MR image super-resolution with squeeze and excitation reasoning attention network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13425–13434. [Google Scholar]
- Wu, H.; Zhang, J.; Huang, K. Point cloud super resolution with adversarial residual graph networks. arXiv 2019, arXiv:1908.02111. [Google Scholar]
- Chen, T.; Qiu, Z.; Zhang, C.; Bai, H. Graph Convolution Point Cloud Super-Resolution Network Based on Mixed Attention Mechanism. Electronics 2023, 12, 2196. [Google Scholar] [CrossRef]
- Liang, G.; KinTak, U.; Yin, H.; Liu, J.; Luo, H. Multi-scale hybrid attention graph convolution neural network for remote sensing images super-resolution. Signal Process. 2023, 207, 108954. [Google Scholar] [CrossRef]
- Qian, G.; Abualshour, A.; Li, G.; Thabet, A.; Ghanem, B. Pu-gcn: Point cloud upsampling using graph convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 11683–11692. [Google Scholar]
- Zhong, F.; Bai, Z. PSR-GAT: Arbitrary point cloud super-resolution using graph attention networks. Multimed. Tools Appl. 2024, 83, 26213–26232. [Google Scholar] [CrossRef]
- Cao, Q.; Tang, P.; Wang, H. Spatio-temporal Super-resolution Network: Enhance Visual Representations for Video Captioning. In Proceedings of the 2022 IEEE International Symposium on Circuits and Systems (ISCAS), Austin, TX, USA, 27 May–1 June 2022; pp. 3125–3129. [Google Scholar]
- Berlincioni, L.; Berretti, S.; Bertini, M.; Bimbo, A.D. 4DSR-GCN: 4D Video Point Cloud Upsampling using Graph Convolutional Networks. In Proceedings of the 1st International Workshop on Multimedia Content Generation and Evaluation: New Methods and Practice, Ottawa, ON, Canada, 29 October 2023; pp. 57–65. [Google Scholar]
- Yang, Y.; Qi, Y.; Qi, S. Relation-consistency graph convolutional network for image super-resolution. Vis. Comput. 2024, 40, 619–635. [Google Scholar] [CrossRef]
- Zhang, Y.; Wei, D.; Qin, C.; Wang, H.; Pfister, H.; Fu, Y. Context reasoning attention network for image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4278–4287. [Google Scholar]
- Tian, C.; Zhang, X.; Zhang, Q.; Yang, M.; Ju, Z. Image super-resolution via dynamic network. CAAI Trans. Intell. Technol. 2023. [Google Scholar] [CrossRef]
- Liu, B.; Zhao, L.; Shao, S.; Liu, W.; Tao, D.; Cao, W.; Zhou, Y. RAN: Region-Aware Network for Remote Sensing Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5408113. [Google Scholar] [CrossRef]
- You, C.; Han, L.; Feng, A.; Zhao, R.; Tang, H.; Fan, W. Megan: Memory enhanced graph attention network for space-time video super-resolution. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 1401–1411. [Google Scholar]
- Liu, Z.; Zhang, C.; Wu, Y.; Zhang, C. Joint face completion and super-resolution using multi-scale feature relation learning. J. Vis. Commun. Image Represent. 2023, 93, 103806. [Google Scholar] [CrossRef]
- Zhang, Y.; Wei, D.; Schalek, R.; Wu, Y.; Turney, S.; Lichtman, J.; Pfister, H.; Fu, Y. High-throughput microscopy image deblurring with graph reasoning attention network. In Proceedings of the 2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI), Cartagena, Colombia, 18–21 April 2023; pp. 1–5. [Google Scholar]
- Xu, B.; Yin, H. Graph convolutional networks in feature space for image deblurring and super-resolution. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Virtual, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Zhang, A.; Ren, W.; Liu, Y.; Cao, X. Lightweight Image Super-Resolution with Superpixel Token Interaction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 12728–12737. [Google Scholar]
- Li, H.; Yang, Y.; Chang, M.; Chen, S.; Feng, H.; Xu, Z.; Li, Q.; Chen, Y. Srdiff: Single image super-resolution with diffusion probabilistic models. Neurocomputing 2022, 479, 47–59. [Google Scholar] [CrossRef]
- Liu, Z.; Li, L.; Wu, Y.; Zhang, C. Facial expression restoration based on improved graph convolutional networks. In Proceedings of the MultiMedia Modeling: 26th International Conference, MMM 2020, Daejeon, Republic of Korea, 5–8 January 2020; Proceedings, Part II 26, 2020. pp. 527–539. [Google Scholar]
- Yue, Z.; Shi, M. Enhancing Space-time Video Super-resolution via Spatial-temporal Feature Interaction. arXiv 2022, arXiv:2207.08960. [Google Scholar]
- Liao, L.; Zhang, Z.; Xia, S. RAID-Net: Region-Aware Image Deblurring Network Under Guidance of the Image Blur Formulation. IEEE Access 2022, 10, 83940–83948. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, W.; Li, Z.; Wang, Y.; Zhang, B. Cloud Removal with SAR-Optical Data Fusion and Graph-Based Feature Aggregation Network. Remote Sens. 2022, 14, 3374. [Google Scholar] [CrossRef]
- Shen, H.; Jiang, M.; Li, J.; Zhou, C.; Yuan, Q.; Zhang, L. Coupling model-and data-driven methods for remote sensing image restoration and fusion: Improving physical interpretability. IEEE Geosci. Remote Sens. Mag. 2022, 10, 231–249. [Google Scholar] [CrossRef]
- Li, X.; Jin, X.; Fu, J.; Yu, X.; Tong, B.; Chen, Z. Few-Shot Real Image Super-resolution via Distortion-Relation Guided Transfer Learning. arXiv 2021, arXiv:2111.13078. [Google Scholar]
- Li, Y.; Wang, N.; Li, J.; Zhang, Y. WIG-Net: Wavelet-Based Defocus Deblurring with IFA and GCN. Appl. Sci. 2023, 13, 12513. [Google Scholar] [CrossRef]
- Yang, J.; Jin, H.; Tang, R.; Han, X.; Feng, Q.; Jiang, H.; Zhong, S.; Yin, B.; Hu, X. Harnessing the power of llms in practice: A survey on chatgpt and beyond. ACM Trans. Knowl. Discov. Data 2024, 18, 1–32. [Google Scholar] [CrossRef]
- Yin, Z.; Wang, J.; Cao, J.; Shi, Z.; Liu, D.; Li, M.; Huang, X.; Wang, Z.; Sheng, L.; Bai, L. Lamm: Language-assisted multi-modal instruction-tuning dataset, framework, and benchmark. arXiv 2024, arXiv:2306.06687. [Google Scholar]
- Chen, Z.; Mao, H.; Li, H.; Jin, W.; Wen, H.; Wei, X.; Wang, S.; Yin, D.; Fan, W.; Liu, H. Exploring the potential of large language models (llms) in learning on graphs. ACM SIGKDD Explor. Newsl. 2024, 25, 42–61. [Google Scholar] [CrossRef]
- Jin, X.; Shi, Y.; Xia, B.; Yang, W. LLMRA: Multi-modal Large Language Model based Restoration Assistant. arXiv 2024, arXiv:2401.11401. [Google Scholar]
- Wei, Y.; Zhang, Z.; Ren, J.; Xu, X.; Hong, R.; Yang, Y.; Yan, S.; Wang, M. Clarity ChatGPT: An Interactive and Adaptive Processing System for Image Restoration and Enhancement. arXiv 2023, arXiv:2311.11695. [Google Scholar]
- Fan, W.; Wang, S.; Huang, J.; Chen, Z.; Song, Y.; Tang, W.; Mao, H.; Liu, H.; Liu, X.; Yin, D. Graph Machine Learning in the Era of Large Language Models (LLMs). arXiv 2024, arXiv:2404.14928. [Google Scholar]
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 898–916. [Google Scholar] [CrossRef]
- Valsesia, D.; Fracastoro, G.; Magli, E. Deep graph-convolutional image denoising. IEEE Trans. Image Process. 2020, 29, 8226–8237. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.-B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Abdelhamed, A.; Lin, S.; Brown, M.S. A high-quality denoising dataset for smartphone cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1692–1700. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 126–135. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Proceedings Eighth IEEE International Conference on Computer Vision. ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; pp. 416–423. [Google Scholar]
- Yang, W.; Tan, R.T.; Feng, J.; Liu, J.; Guo, Z.; Yan, S. Deep joint rain detection and removal from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1357–1366. [Google Scholar]
- Zhang, H.; Sindagi, V.; Patel, V.M. Image de-raining using a conditional generative adversarial network. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3943–3956. [Google Scholar] [CrossRef]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the 23rd British Machine Vision Conference (BMVC), Surrey, UK, 3–7 September 2012. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the Curves and Surfaces: 7th International Conference, Avignon, France, 24–30 June 2010; Revised Selected Papers 7, 2012. pp. 711–730. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef]
- Cruz-Neira, C.; Sandin, D.J.; DeFanti, T.A.; Kenyon, R.V.; Hart, J.C. The CAVE: Audio visual experience automatic virtual environment. Commun. ACM 1992, 35, 64–73. [Google Scholar] [CrossRef]
- Chua, T.-S.; Tang, J.; Hong, R.; Li, H.; Luo, Z.; Zheng, Y. Nus-wide: A real-world web image database from national university of singapore. In Proceedings of the ACM International Conference on Image and Video Retrieval, Santorini, Greece, 8–10 July 2009; pp. 1–9. [Google Scholar]
- Ancuti, C.; Ancuti, C.O.; Timofte, R. Ntire 2018 challenge on image dehazing: Methods and results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 891–901. [Google Scholar]
- Visionair. Available online: https://vision-air.github.io/ (accessed on 14 November 2017).
- Cheng, S.; Liu, R.; He, Y.; Fan, X.; Luo, Z. Blind image deblurring via hybrid deep priors modeling. Neurocomputing 2020, 387, 334–345. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Yang, H.; Zhou, D.; Li, M.; Zhao, Q. A two-stage network with wavelet transformation for single-image deraining. Vis. Comput. 2023, 39, 3887–3903. [Google Scholar] [CrossRef]
- Chang, Y.; Yan, L.; Zhong, S. Transformed low-rank model for line pattern noise removal. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1726–1734. [Google Scholar]
- Wang, T.; Yang, X.; Xu, K.; Chen, S.; Zhang, Q.; Lau, R.W. Spatial attentive single-image deraining with a high quality real rain dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12270–12279. [Google Scholar]
- Wang, P.-S.; Liu, Y.; Tong, X. Mesh denoising via cascaded normal regression. ACM Trans. Graph. 2016, 35, 1–12. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. (Tog) 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Liu, P.; Zhang, H.; Zhang, K.; Lin, L.; Zuo, W. Multi-level wavelet-CNN for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 773–782. [Google Scholar]
- Devalla, S.K.; Renukanand, P.K.; Sreedhar, B.K.; Subramanian, G.; Zhang, L.; Perera, S.; Mari, J.-M.; Chin, K.S.; Tun, T.A.; Strouthidis, N.G. DRUNET: A dilated-residual U-Net deep learning network to segment optic nerve head tissues in optical coherence tomography images. Biomed. Opt. Express 2018, 9, 3244–3265. [Google Scholar] [CrossRef] [PubMed]
- Jiang, B.; Li, J.; Li, H.; Li, R.; Zhang, D.; Lu, G. Enhanced frequency fusion network with dynamic hash attention for image denoising. Inf. Fusion 2023, 92, 420–434. [Google Scholar] [CrossRef]
- Ward, C.M.; Harguess, J.; Crabb, B.; Parameswaran, S. Image quality assessment for determining efficacy and limitations of Super-Resolution Convolutional Neural Network (SRCNN). In Proceedings of the Applications of Digital Image Processing XL, San Diego, CA, USA, 7–10 August 2017; pp. 19–30. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Li, Z.; Yang, J.; Liu, Z.; Yang, X.; Jeon, G.; Wu, W. Feedback network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3867–3876. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.-T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11065–11074. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Athens, Greece, 7–10 October 2018; pp. 2472–2481. [Google Scholar]
- Zhang, K.; Gool, L.V.; Timofte, R. Deep unfolding network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3217–3226. [Google Scholar]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single image super-resolution via a holistic attention network. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XII 16, 2020. pp. 191–207. [Google Scholar]
- Zou, W.; Ye, T.; Zheng, W.; Zhang, Y.; Chen, L.; Wu, Y. Self-calibrated efficient transformer for lightweight super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 930–939. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Van Den Berg, R.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Proceedings of the The Semantic web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, 3–7 June 2018; proceedings 15, 2018. pp. 593–607. [Google Scholar]
- Lu, Z.; Li, J.; Liu, H.; Huang, C.; Zhang, L.; Zeng, T. Transformer for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 457–466. [Google Scholar]
- Gao, G.; Wang, Z.; Li, J.; Li, W.; Yu, Y.; Zeng, T. Lightweight bimodal network for single-image super-resolution via symmetric CNN and recursive transformer. arXiv 2022, arXiv:2204.13286. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. pp. 391–407. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1664–1673. [Google Scholar]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. (CSUR) 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Ren, H.; Lu, W.; Xiao, Y.; Chang, X.; Wang, X.; Dong, Z.; Fang, D. Graph convolutional networks in language and vision: A survey. Knowl.-Based Syst. 2022, 251, 109250. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
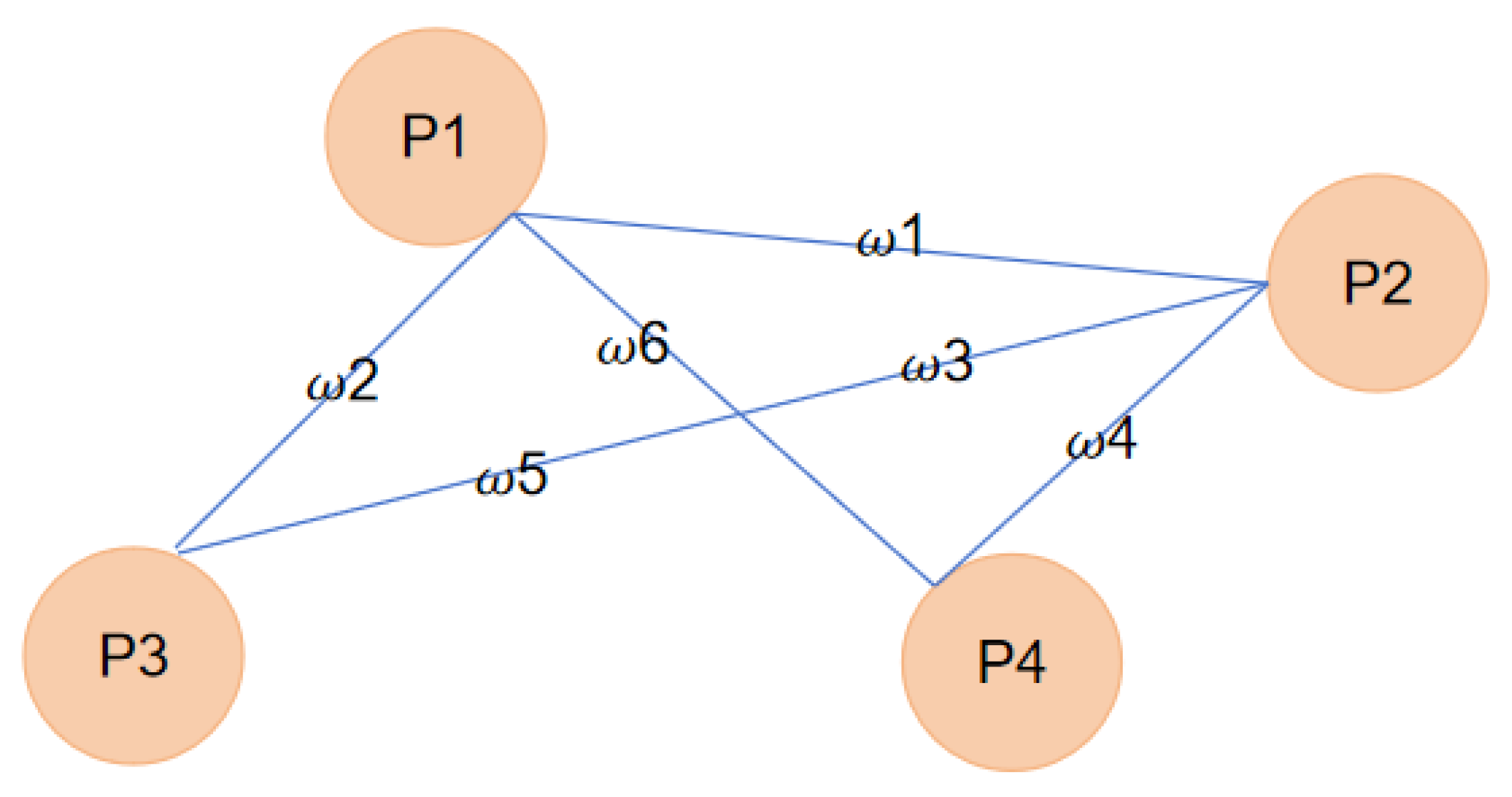
| P1 | P2 | P3 | P4 | |
|---|---|---|---|---|
| P1 | 0 | 1 | 1 | 0 |
| P2 | 1 | 0 | 0 | 1 |
| P3 | 1 | 0 | 0 | 0 |
| P4 | 0 | 1 | 0 | 0 |
| References | Methods | Applications | Key Words (Remarks) |
|---|---|---|---|
| Shen et al. (2022) [49] | GCNs | 3D mesh denoising | Mesh Geometry, Structural Features, Graph-based Filtering |
| Zhao et al. (2023) [53] | GCNs | 3D mesh denoising | Gaussian curvature-driven multi-stream networks |
| Armando et al. (2020) [50] | GCNs | 3D mesh denoising | GCNs for mesh denoising |
| Zhang et al. (2021) [43] | GCNs | Few-shot Learning tasks, image denoising | LDN method based on GCNs |
| Liu et al. (2022) [48] | GAT | Low dose CT image denoising | Edge Enhancement Module and WGAT |
| Chen et al. (2021) [54] | GCNs | CT image denoising | Encoder-decoder-based GCNs |
| Chen et al. (2021) [2] | GCNs | Low dose CT image denoising | Multi-information fusion denoising |
| Jiang et al. (2023) [42] | GAT | Graph attention denoising, synthetic noise | Pixel-level Features, Structure-level Features, Attention Mechanism |
| Mou et al. (2021) [47] | GAT | Denoising, super-resolution, compressed sensing | Dynamic Attention, Graph Learning, Image Restoration |
| Mou et al. (2021) [46] | GAT | Denoising, super-resolution, compressed sensing | Image Restoration Using Graph Attention Networks |
| Chen et al. (2023) [55] | GCNs | Denoising method for noisy point cloud | Novel geometric dual-domain GCNs for PCD |
| Han (2022) [45] | GCNs | Self-supervised Graph Denoising | Graph Embedding, Self-supervision, Robustness |
| Mostafa et al. (2020) [51] | GCNs | Graph attention denoising, synthetic noise | Attention-based Global aggregation scheme |
| Li et al. (2021) [44] | GCNs | Image denoising | Cross-patch Consistency, Long-range Dependencies, Aggregation |
| References | Methods | Applications | Key Words (Remarks) |
|---|---|---|---|
| Fu et al. (2021) [56] | GCNs CNN | GCNs for image De-raining | Global Relationship, Pixel-Channel Modeling, Fusion |
| Li et al. (2021) [44] | GCNs CNN | GCNs for image denoising | Cross-patch Consistency, Patch-based Learning, Aggregation |
| Chen et al. (2020) [57] | GCNs GAN | Low dose CT image denoising | Noise Distribution Learning, Non-local Self-similarity, GAN Integration |
| Liu et al. (2020) [58] | GCNs CNN | Processing Hyperspectral Images (HSI) | CNN-GCN Fusion, Spectral-Spatial Features, Hyperspectral Data |
| References | Methods | Applications | Key Words (Remarks) |
|---|---|---|---|
| Jiang et al. (2023) [60] | AGPNet | Image Denoising with Graph Priors | Graph Construction, Long-distance Dependencies, k-NN Algorithm |
| Eliasof et al. (2021) [61] | PDE-GCNs | GCNs for image denoising | Partial Differential Equations, Graph Neural Networks, Over-smoothing |
| Hattori et al. (2022) [62] | GCNs | GCNs for mesh denoising | Self-prior Learning, Vertex Position, Normal Vectors |
| Fu et al. (2021) [63] | GCNs | GCNs for image de-raining | Global Spatial Relationship, Inter-channel Modeling, Rain Removal |
| References | Methods | Applications | Key Words (Remarks) |
|---|---|---|---|
| Yang et al. (2021) [64] | CASGCN | Image Super-Resolution | Channel Attention, Spatial Graph Convolution, Feature Enhancement |
| Yan et al. (2021) [65] | SRGAT | Single Image Super-Resolution | Graph Attention, Multi-dataset Performance, Optimization |
| Yang et al. (2021) [66] | SGCN | Image Super-Resolution | Global Features, Residual Refinement, Spatial Graph Attention |
| Zhang et al. (2021) [67] | SERANs | MRI Super-Resolution | Magnetic Resonance, High-resolution, Medical Imaging |
| Wu et al. (2019) [68] | AR-GCNs | Point Cloud Super-Resolution | Local Similarity, Point Cloud Data, Upsampling |
| Chen et al. (2023) [69] | GCNs-MA | Point Cloud Super-Resolution | Multi-attribute, Point Cloud, Super-resolution |
| Liang et al. (2023) [70] | MAGSR | Remote Sensing Images Super-Resolution | Multi-angle, Global Features, Remote Sensing |
| Qian et al. (2021) [71] | GCNs | Point Cloud Super-Resolution | Domain Information, Feature Extraction, Point Cloud |
| Zhong et al. (2023) [72] | PSR-GAT | Point Cloud Super-Resolution | Graph Attention, Non-local Features, Point Cloud |
| Cao et al. (2022) [73] | GCNs | Video Captioning, Video Super-Resolution | Local Object Relationships, Temporal Dynamics, Video Processing |
| Berlincioni et al. (2023) [74] | 4DSR-GCNs | 4D Video Point Cloud Upsampling | 4D Video, Point Cloud, Upsampling |
| References | Methods | Applications | Key Words (Remarks) |
|---|---|---|---|
| Zhang et al. (2021) [76] | GCNs CNN | Image Super-Resolution | Context-inferring, Attention Mechanism, Feature Extraction |
| You et al. (2022) [79] | GAT CNN | Video super-resolution | Multi-scale Learning, Enhanced Attention, Temporal Dynamics |
| Liu et al. (2020) [58] | GCNs CNN | Hyperspectral Image Classification, SR | CNN-GCN Integration, Spectral-Spatial Features, Collaboration |
| Liu et al. (2023) [80] | GAN GCNs | Face Image Super-Resolution, Inpainting | GAN-GCN Synergy, Facial Features, Generative Adversarial |
| Liu et al. (2023) [78] | GCNs RAM | Remote Sensing Images Super-Resolution | Region-aware, Cross-block Self-similarity, Spatial Information |
| Zhang et al. (2023) [81] | GCNs GRAN | Electron Microscopy Image Deblurring | Fully Connected Graph, Non-local Relationships, Image Quality |
| References | Methods | Applications | Key Words (Remarks) |
|---|---|---|---|
| Xu et al. (2021) [82] | GCNs | GCNs for image super-restoration and deblurring | Feature maps are converted to graph nodes |
| Zhang et al. (2023) [83] | GCNs | GCNs for image super-restoration | Super token interaction network (SPIN) |
| Li et al. (2022) [84] | GCNs | Single Image Super-Resolution (SISR) | Single Image Super-resolution Diffusion Model |
| Liu et al. (2020) [85] | GCNs | Facial expression recovery | Facial expression restoration method based on IGCN |
| Yue et al. (2022) [86] | GCNs | Spatial-temporal Video Super-resolution | Spatial-temporal Global Refinement Module (ST-GR) |
| References | Methods | Applications | Key Words (Remarks) |
|---|---|---|---|
| Liao et al. (2022) [87] | GCNs | Different types of motion image deblurring | Attention mechanism, image deblur, image processing |
| Chen et al. (2022) [88] | GCNs | GCNs and GAT for image deblurring | Cloud removal, remote sensing image |
| Shen et al. (2022) [89] | GCNs | Deblurring of remote sensing images | Remote sensing technology, remote sensing image processing |
| Li et al. (2021) [90] | GCNs | Real Image deblurring and super-resolution | Few-shot RealSR, Distortion Relation Graph, Transfer Learning |
| References | Methods | Applications | Key Words (Remarks) |
|---|---|---|---|
| Li et al. (2023) [91] | IFA GCNs | Out-of-focus blur of the image | Wavelet transform, defocus deblurring |
| Zhang et al. (2023) [81] | GRAB GCNs | Image deblurring for Low Quality (LQ) microscopy images | Microscopy image, image deblurring |
| References | Methods | Applications | Key Words (Remarks) |
|---|---|---|---|
| Liu et al. (2020) [85] | GCNs | Facial expression restoration | Facial Expression Restoration, Generative Adversarial Network |
| Eliasof et al. (2021) [61] | GCNs | Node classification. Image deblurring | Addressing Over-smoothing in GCNs |
| Xu et al. (2021) [82] | GCNs | GCNs for image super-restoration and deblurring | Feature maps are converted to graph nodes |
| References | Methods | Applications | Key Words (Remarks) |
|---|---|---|---|
| Jin et al. [95] | LLMs | Image restoration | CEM, Transformer (DC-former) |
| Wei et al. [96] | LLMs | Image restoration | Interactive image processing |
| Model Name | Batch Size | Learning Rate | Parameters | FLOPs (G) | Framework |
|---|---|---|---|---|---|
| CASGCN | 16 | 10−4 | - | - | PyTorch |
| GRAN | 16 | 10−4 | 3.2M | 145.72 | PyTorch |
| EDSR | - | 2 × 10−4 | 38.37M | 6136.38 | PyTorch |
| RDN | - | 2 × 10−4 | 21.98M | 3514.59 | PyTorch |
| 4DSR-GCN | - | 10−4 | - | - | PyTorch |
| IGCN | 8 | 10−4 | - | - | - |
| PU-GCN | 64 | 0.001 | - | - | PyTorch |
| FG-GAN | 10 | 0.001 | - | - | TensorFlow |
| RGCN | 16 | 10−4 | 14.5M | 49.75 | PyTorch |
| STSR | - | 10−4 | 113.3M | - | PyTorch |
| SGCN | 16 | 0.01 | 14.3M | - | PyTorch |
| PSR-GAT | - | 0.003 | - | - | Torch |
| GRAN | 16 | 10−4 | 3.2M | 145.72 | PyTorch |
| EDSR | 16 | 10−4 | 38.37M | 6136.38 | PyTorch |
| RDN | 16 | 10−4 | 21.98M | 3514.59 | PyTorch |
| Pix2pix GAN | 16 | 2 × 10−4 | - | - | - |
| DSen2-CR | 16 | 7 × 10−5 | - | - | - |
| IGCN | 8 | 0.0001 | - | - | PyTorch |
| DRTL | 32 | 0.0001 | - | - | PyTorch |
| RAID-Net | 16 | 0.001 | - | - | PyTorch |
| WIG-Net | 8 | 0.9 | - | - | PyTorch |
| GCN-Denoiser | 128 | 0.001 | - | - | PyTorch |
| ERA-WGAT | 16 | 10−5 | - | - | PyTorch |
| AGP-Net | 128 | 0.01 | - | - | PyTorch |
| GeoGCN | 64 | 0.001 | - | - | PyTorch |
| DAGL | 32 | 1 × 10−4 | - | - | PyTorch |
| Permutohedral-GCN | - | - | - | - | TensorFlow |
| DGCN | 10 | 1 × 10−4 | - | - | TensorFlow |
| AdarGCN | 8 | 0.001 | - | - | PyTorch |
| Datasets | Set12 | ||
|---|---|---|---|
| Methods | σ = 15 | σ = 25 | σ = 50 |
| DnCNN [27] | 32.86 | 30.44 | 27.18 |
| FFDNet [28] | 32.75 | 30.43 | 27.32 |
| DAGL [47] | 33.28 | 30.93 | 27.81 |
| AGP-Net [60] | 33.46 | 31.15 | 28.07 |
| GCDN [49] | 33.14 | 30.78 | 27.60 |
| GAiA-Net [42] | 33.54 | 31.20 | 28.18 |
| GraphCNN [120] | 32.58 | 30.12 | 27.00 |
| MWCNN [121] | 33.15 | 30.79 | 27.74 |
| DRUNet [122] | 33.25 | 30.40 | 27.90 |
| EFF-Net [123] | 33.36 | 30.81 | 27.92 |
| Datasets | BSD68 | ||
|---|---|---|---|
| Methods | σ = 15 | σ = 25 | σ = 50 |
| DnCNN [27] | 31.73 | 29.23 | 26.23 |
| FFDNet [28] | 31.63 | 29.19 | 26.29 |
| DAGL [47] | 31.93 | 29.46 | 26.51 |
| AGP-Net [60] | 31.02 | 29.59 | 26.71 |
| GCDN [49] | 31.83 | 29.35 | 26.38 |
| GAiA-Net [42] | 32.09 | 29.67 | 26.75 |
| MWCNN [121] | 31.88 | 29.41 | 26.53 |
| DRUNet [122] | 31.91 | 29.48 | 26.59 |
| EFF-Net [123] | 31.92 | 29.49 | 26.61 |
| Datasets | Urban100 | ||
|---|---|---|---|
| Methods | σ = 15 | σ = 25 | σ = 50 |
| DnCNN [27] | 32.64 | 29.95 | 26.23 |
| FFDNet [28] | 32.40 | 29.90 | 26.50 |
| DAGL [47] | 33.79 | 31.39 | 27.97 |
| AGP-Net [60] | 33.89 | 31.51 | 28.62 |
| GCDN [49] | 33.47 | 30.95 | 27.41 |
| GAiA-Net [42] | 33.92 | 31.68 | 28.70 |
| MWCNN [121] | 33.17 | 30.66 | 27.42 |
| DRUNet [122] | 33.40 | 31.11 | 27.96 |
| EFF-Net [123] | 33.73 | 31.45 | 28.49 |
| Datasets | SysData | |||||
|---|---|---|---|---|---|---|
| Methods | Noisy Input | LR | CNR | DNF | NFN | GCN-D |
| 1st row | 28.65 | 6.52 | 2.22 | 4.5 | 5.02 | 1.86 |
| 2nd row | 33.17 | 12.17 | 8.03 | 8.34 | 8.84 | 4.39 |
| 3rd row | 31.78 | 7.56 | 8.72 | 7.98 | 6.89 | 5.25 |
| Datasets | Kinect | |||||
|---|---|---|---|---|---|---|
| Methods | Noisy Input | BNF | GNF | CNR | NFN | GCD-D |
| 1st row | 20.8 | 9.25 | 7.96 | 6.93 | 7.51 | 6.58 |
| 2nd row | 17.89 | 12.99 | 11.95 | 11.94 | 12.15 | 11.61 |
| Datasets | PrintData | |||||
|---|---|---|---|---|---|---|
| Methods | Noisy Input | GNF | LR | CNR | DNF | GCN-D |
| 1st row | 10.88 | 12.06 | 12.27 | 11.02 | 10.74 | 10.54 |
| 2nd row | 18.08 | 18.68 | 17.96 | 17.23 | 17.67 | 17.08 |
| 3rd row | 16.16 | 16.96 | 18.8 | 15.53 | 15.96 | 14.95 |
| 4th row | 8.08 | 7.5 | 7.97 | 6.11 | 6.68 | 5.84 |
| Methods | Scale | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | ||
| Bicubic | ×2 | 33.66/0.9299 | 30.24/0.8688 | 29.56/0.8431 | 26.88/0.8403 | 30.80/0.9339 |
| SRCNN [124] | ×2 | 36.66/0.9542 | 32.45/0.9067 | 31.36/0.8879 | 29.50/0.8946 | 35.60/0.9663 |
| VDSR [125] | ×2 | 37.53/0.9590 | 33.05/0.9130 | 31.90/0.8960 | 30.77/0.9140 | 37.22/0.9750 |
| EDSR [115] | ×2 | 38.11/0.9602 | 33.92/0.9195 | 32.32/0.9013 | 32.93/0.9351 | 39.10/0.9773 |
| RCAN [126] | ×2 | 38.27/0.9614 | 34.11/0.9216 | 32.41/0.9026 | 33.34/0.9385 | 39.43/0.9786 |
| NLRN [26] | ×2 | 38.00/0.9603 | 33.46/0.9159 | 32.19/0.8992 | 31.81/0.9246 | -/- |
| SRFBN [127] | ×2 | 38.11/0.9609 | 33.82/0.9196 | 32.29/0.9010 | 32.62/0.9328 | 39.08/0.9779 |
| SAN [128] | ×2 | 38.31/0.9620 | 34.07/0.9213 | 32.42/0.9028 | 33.10/0.9370 | 39.32/0.9792 |
| RDN [129] | ×2 | 38.24/0.9614 | 34.01/0.9212 | 32.34/0.9017 | 32.89/0.9353 | 39.18/0.9780 |
| USRNet [130] | ×2 | 37.77/0.9592 | 33.49/0.9156 | 32.10/0.8981 | 31.79/0.9255 | 38.37/0.9760 |
| HAN [131] | ×2 | 38.27/0.9614 | 34.16/0.9217 | 32.41/0.9027 | 33.35/0.9385 | 39.46/0.9785 |
| SRGAT [65] | ×2 | 38.20/0.9610 | 33.93/0.9201 | 32.34/0.9014 | 32.90/0.9359 | 39.30/0.9785 |
| SCET [132] | ×2 | 38.06/0.9615 | 33.78/0.9198 | 32.24/0.9006 | 32.38/0.9299 | 39.86/0.9821 |
| SwinIR [133] | ×2 | 38.35/0.9620 | 34.14/0.9215 | 32.44/0.9030 | 33.40/0.9393 | 39.60/0.9792 |
| RGCN [134] | ×2 | 38.30/0.9616 | 34.10/0.9213 | 32.44/0.9030 | 33.15/0.9377 | 39.38/0.9784 |
| Methods | Scale | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | ||
| Bicubic | ×3 | 30.39/0.8682 | 27.55/0.7742 | 27.21/0.7385 | 24.46/0.7349 | 26.95/0.8556 |
| SRCNN [124] | ×3 | 32.75/0.9090 | 29.30/0.8215 | 28.41/0.7863 | 26.24/0.7989 | 30.48/0.9117 |
| VDSR [125] | ×3 | 33.67/0.9210 | 29.78/0.8320 | 28.83/0.7990 | 27.14/0.8290 | 32.01/0.9340 |
| EDSR [115] | ×3 | 34.65/0.9280 | 30.52/0.8462 | 29.25/0.8093 | 28.80/0.8653 | 34.17/0.9476 |
| RCAN [126] | ×3 | 34.74/0.9299 | 30.65/0.8482 | 29.32/0.8111 | 29.09/0.8702 | 34.44/0.9499 |
| NLRN [26] | ×3 | 34.27/0.9266 | 30.16/0.8374 | 29.06/0.8026 | 27.93/0.8453 | -/- |
| SRFBN [127] | ×3 | 34.70/0.9292 | 30.51/0.8461 | 29.24/0.8084 | 28.73/0.8641 | 34.18/0.9481 |
| SAN [128] | ×3 | 34.75/0.9300 | 30.59/0.8476 | 29.33/0.8112 | 28.93/0.8671 | 34.30/0.9494 |
| RDN [129] | ×3 | 34.71/0.9296 | 30.57/0.8468 | 29.26/0.8093 | 28.80/0.8653 | 34.13/0.9484 |
| USRNet [130] | ×3 | 34.43/0.9279 | 30.51/0.8446 | 29.18/0.8076 | 28.38/0.8575 | 34.05/0.9466 |
| HAN [131] | ×3 | 34.75/0.9299 | 30.67/0.8483 | 29.32/0.8110 | 29.10/0.8705 | 34.48/0.9500 |
| SRGAT [65] | ×3 | 34.75/0.9297 | 30.63/0.8474 | 29.29/0.8099 | 28.90/0.8666 | 34.42/0.9495 |
| RGCN [134] | ×3 | 34.77/0.9301 | 30.67/0.8486 | 29.33/0.8114 | 28.99/0.8679 | 34.47/0.9501 |
| SCET [132] | ×3 | 34.53/0.9278 | 30.43/0.8441 | 29.17/0.8075 | 28.38/0.8559 | 34.29/0.9503 |
| ESRT [135] | ×3 | 34.42/0.9268 | 30.43/0.8433 | 29.15/0.8063 | 28.46/0.8574 | 33.95/0.9455 |
| LBNet [136] | ×3 | 34.47/0.9277 | 30.38/0.8417 | 29.13/0.8061 | 28.42/0.8559 | 33.82/0.9460 |
| SwinIR [133] | ×3 | 34.89/0.9312 | 30.77/0.8503 | 29.37/0.8124 | 29.29/0.8744 | 34.74/0.9518 |
| Methods | Scale | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | ||
| Bicubic | ×4 | 28.42/0.8104 | 26.00/0.7027 | 25.96/0.6675 | 23.14/0.6577 | 24.89/0.7866 |
| SRCNN [124] | ×4 | 30.48/0.8628 | 27.50/0.7513 | 26.90/0.7101 | 25.52/0.7221 | 27.58/0.8555 |
| VDSR [125] | ×4 | 31.35/0.8830 | 28.02/0.7680 | 27.29/0.0726 | 25.18/0.7540 | 28.83/0.8870 |
| EDSR [115] | ×4 | 32.46/0.8968 | 28.80/0.7876 | 27.71/0.7420 | 26.64/0.8033 | 31.02/0.9148 |
| RCAN [126] | ×4 | 32.63/0.9002 | 28.87/0.7889 | 27.77/0.7436 | 26.82/0.8087 | 31.22/0.9173 |
| NLRN [26] | ×4 | 31.92/0.8916 | 28.36/0.7745 | 27.48/0.7346 | 25.79/0.7729 | -/- |
| SRFBN [127] | ×4 | 32.47/0.8983 | 28.81/0.7868 | 27.72/0.7409 | 26.60/0.8015 | 31.15/0.9160 |
| SAN [128] | ×4 | 32.64/0.9003 | 28.92/0.7888 | 27.78/0.7436 | 26.79/0.8068 | 31.18/0.9169 |
| RDN [129] | ×4 | 32.47/0.8990 | 28.81/0.7871 | 27.72/0.7419 | 26.61/0.8028 | 31.00/0.9151 |
| USRNet [130] | ×4 | 32.42/0.8978 | 28.83/0.7871 | 27.69/0.7404 | 26.44/0.7976 | 31.11/0.9154 |
| HAN [131] | ×4 | 32.64/0.9002 | 28.90/0.7890 | 27.80/0.7442 | 26.85/0.8094 | 31.42/0.9177 |
| SRGAT [65] | ×4 | 32.57/0.8997 | 28.86/0.7879 | 27.77/0.7421 | 26.76/0.8052 | 31.41/0.9181 |
| RGCN [134] | ×4 | 32.65/0.9005 | 28.91/0.7892 | 27.79/0.7440 | 26.85/0.8089 | 31.24/0.9176 |
| SCET [132] | ×4 | 32.27/0.8963 | 28.72/0.7847 | 27.67/0.7390 | 26.33/0.7915 | 31.10/0.9155 |
| ESRT [135] | ×4 | 32.19/0.8947 | 28.69/0.7833 | 27.69/0.7379 | 26.39/0.7962 | 30.75/0.9100 |
| LBNet [136] | ×4 | 32.29/0.8960 | 28.68/0.7832 | 27.62/0.7382 | 26.27/0.7906 | 30.76/0.9111 |
| SwinIR [133] | ×4 | 32.72/0.9021 | 28.94/0.7914 | 27.83/0.7459 | 27.07/0.8164 | 31.67/0.9226 |
| Methods | Scale | Set5 | Set14 | Urban100 | BSD100 |
|---|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | ||
| SRCNN [124] | ×2 | 36.66/0.9542 | 32.45/0.9067 | 29.50/0.8946 | 31.36/0.8879 |
| FSRCNN [137] | ×2 | 37.05/0.9560 | 32.66/0.9090 | 29.88/0.9020 | 31.53/0.8920 |
| VDSR [125] | ×2 | 37.53/0.9590 | 33.05/0.9130 | 30.77/0.9140 | 31.90/0.8960 |
| RDN [129] | ×2 | 38.24/0.9614 | 34.01/0.9212 | 32.89/0.9353 | 32.34/0.9017 |
| D-DBPN [138] | ×2 | 38.09/0.9600 | 33.85/0.9190 | 32.55/0.9324 | 32.27/0.9000 |
| EDSR [115] | ×2 | 38.11/0.9602 | 33.92/0.9195 | 32.93/0.9351 | 32.32/0.9013 |
| GCEDSR [82] | ×2 | 38.29/0.9615 | 34.05/0.9213 | 33.12/0.9386 | 32.39/0.9023 |
| SRCNN | ×4 | 30.48/0.8628 | 27.50/0.7513 | 24.52/0.7221 | 26.90/0.7101 |
| FSRCNN | ×4 | 30.72/0.8660 | 27.61/0.7550 | 24.62/0.7280 | 26.98/0.7150 |
| VDSR | ×4 | 31.35/0.8830 | 28.02/0.7680 | 25.18/0.7540 | 27.29/0.7260 |
| RDN | ×4 | 32.47/0.8990 | 28.81/0.7871 | 26.61/0.8028 | 27.72/0.7419 |
| D-DBPN | ×4 | 32.47/0.8980 | 28.82/0.7860 | 26.38/0.7946 | 27.72/0.7400 |
| EDSR | ×4 | 32.46/0.8968 | 28.80/0.7876 | 26.64/0.8033 | 27.71/0.7420 |
| GCEDSR | ×4 | 32.61/0.9001 | 28.89/0.7885 | 26.72/0.8079 | 27.76/0.7439 |
| SRCNN | ×8 | 25.33/0.6900 | 23.76/0.5910 | 21.29/0.5440 | 24.13/0.5660 |
| FSRCNN | ×8 | 20.13/0.5520 | 19.75/0.4820 | 21.32/0.5380 | 24.21/0.5680 |
| VDSR | ×8 | 25.93/0.7240 | 24.26/0.6140 | 21.70/0.5710 | 24.49/0.5830 |
| D-DBPN | ×8 | 27.21/0.7840 | 25.13/0.6480 | 22.73/0.6312 | 24.88/0.6010 |
| EDSR | ×8 | 26.96/0.7762 | 24.91/0.6420 | 22.51/0.6221 | 24.81/0.5985 |
| GCEDSR | ×8 | 27.39/0.7876 | 25.18/0.6503 | 23.14/0.6370 | 24.92/0.6027 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, T.; Bi, T.; Ji, W.; Tian, C. Graph Convolutional Network for Image Restoration: A Survey. Mathematics 2024, 12, 2020. https://doi.org/10.3390/math12132020
Cheng T, Bi T, Ji W, Tian C. Graph Convolutional Network for Image Restoration: A Survey. Mathematics. 2024; 12(13):2020. https://doi.org/10.3390/math12132020
Chicago/Turabian StyleCheng, Tongtong, Tingting Bi, Wen Ji, and Chunwei Tian. 2024. "Graph Convolutional Network for Image Restoration: A Survey" Mathematics 12, no. 13: 2020. https://doi.org/10.3390/math12132020
APA StyleCheng, T., Bi, T., Ji, W., & Tian, C. (2024). Graph Convolutional Network for Image Restoration: A Survey. Mathematics, 12(13), 2020. https://doi.org/10.3390/math12132020