
Forecasting and Multilevel Early Warning of Wind Speed Using an Adaptive Kernel Estimator and Optimized Gated Recurrent Units



Abstract
:1. Introduction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature | Predicting Model | Warning System | ||||
|---|---|---|---|---|---|---|
| Base Model | Decomposition Techniques | Optimization Algorithm | Data Interval | Method | Level | |
| Ref. [24] | ANN | — | — | 10 min | Deterministic | Multiple |
| Ref. [19] | ARIMA | EMD | — | 1 min | Deterministic | Multiple |
| Ref. [25] | ANN | EEMD | GA | 10 min | Deterministic | Single |
| Ref. [26] | ELM/ARIMA | ICEEMDAN | — | 10 min | Deterministic | Single |
| Ref. [27] | DBM | EEMD | — | 1 h | — | — |
| Ref. [28] | RNN | — | HNN | 15 min | Probabilistic | Single |
| Ref. [29] | ELM | — | AdaBoost | 10/20/30 min | — | — |
| Ref. [30] | RNN/ELM | EEMD | GA | 5min | — | — |
| Ref. [31] | LSTM/SVM | CEEMDAN | PSO/IWOA | 5 min | — | — |
| Ref. [22] | SVM | WD | PSO/IASO | 1 h | ||
| Ref. [32] | GRU | VMD | PSR/IWOA | 10 min | ||
| Ref. [6] | LSTM | — | — | 1/40 s | Probabilistic | Multiple |
2. Materials and Methods
2.1. Data Collection
2.2. Methodologies
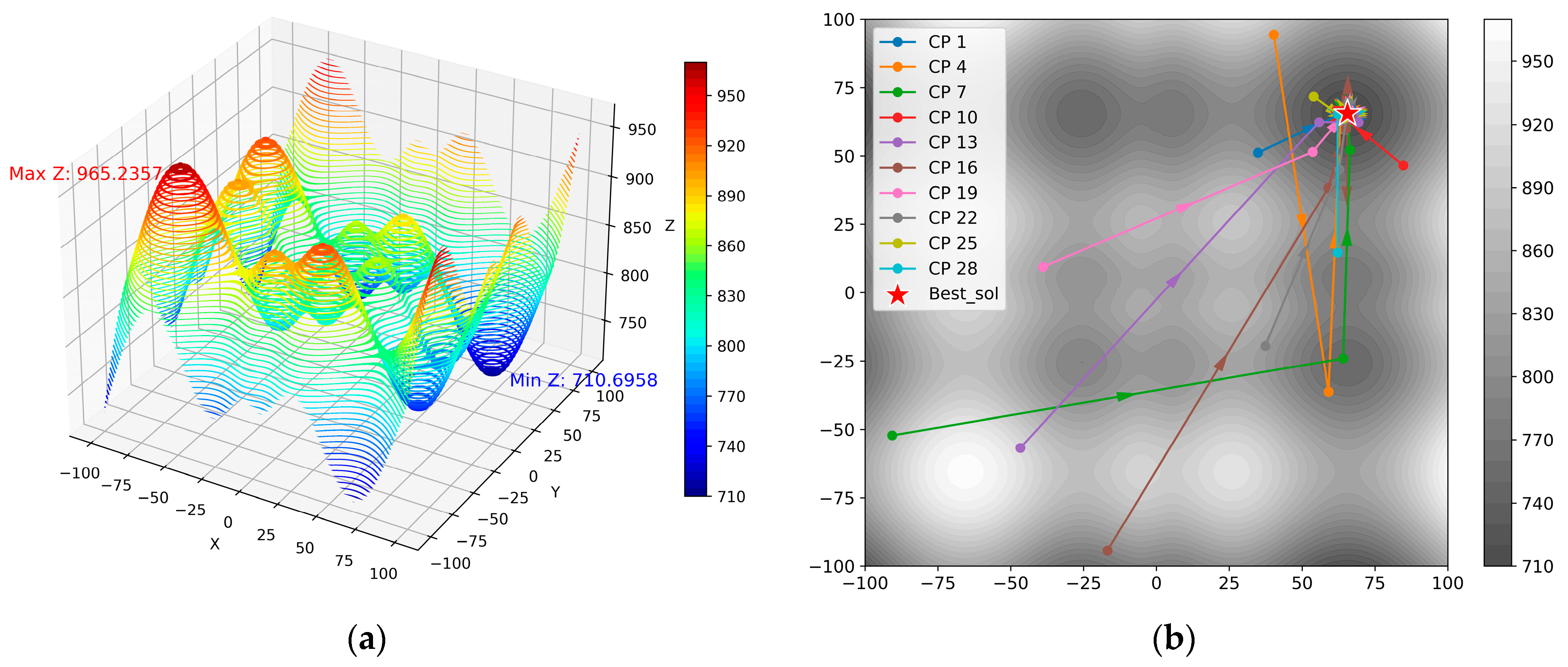
2.2.1. Crested Porcupine Optimizer
- Population and fitness initialization:
- 2.
- Four defensive strategies in CPO
- Exploration phase (strategies 1 and 2)
- Exploitation phase (strategies 3 and 4)
- 3.
- Simple case using the CPO
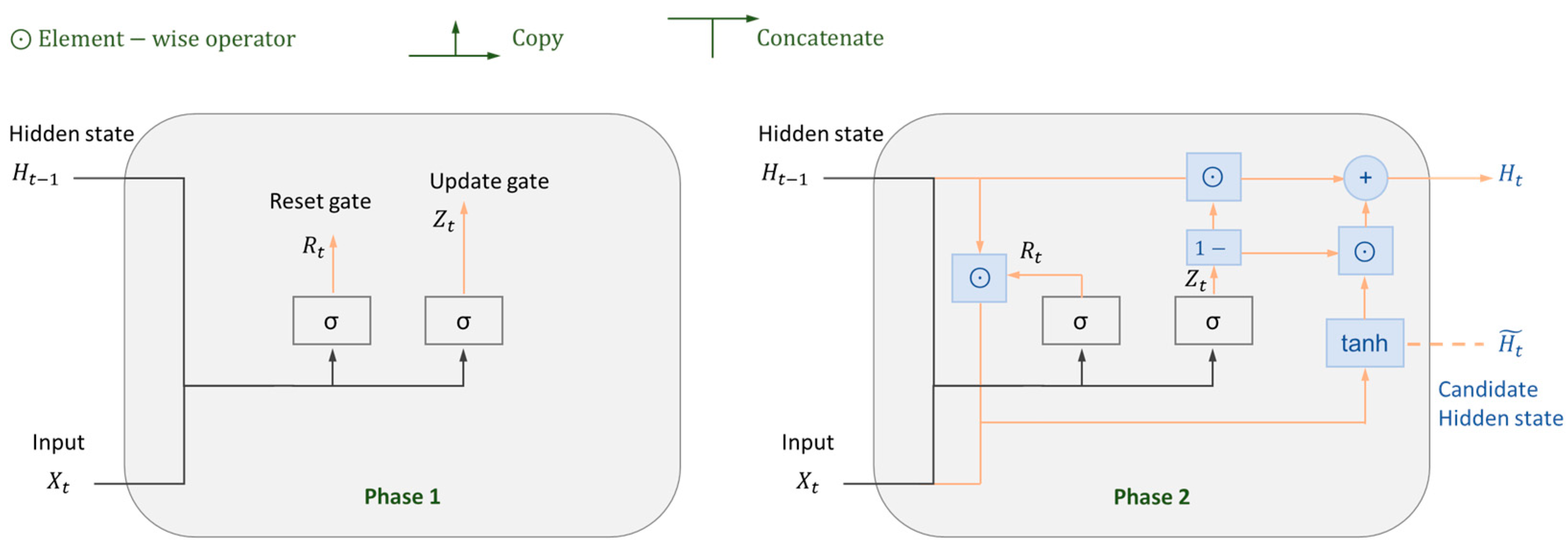
2.2.2. Gated Recurrent Unit
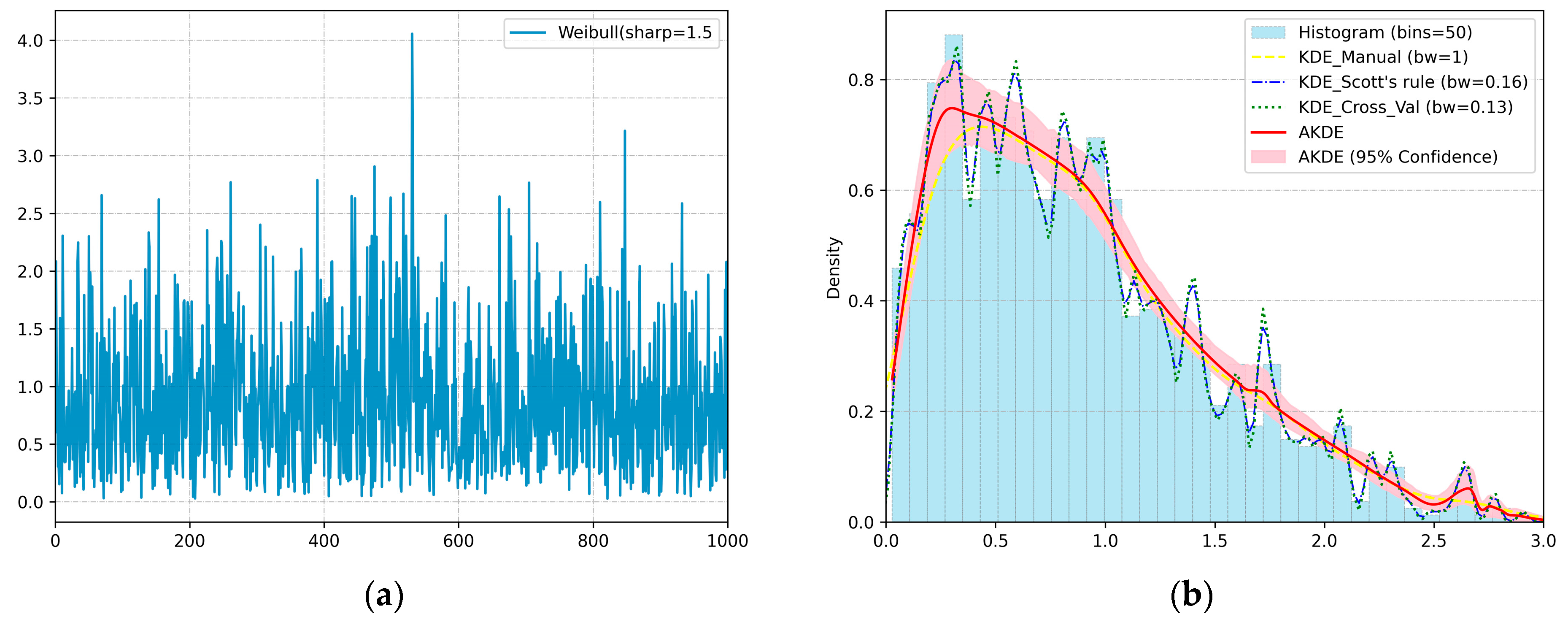
2.2.3. Interval Forecasts via Kernel Density Estimation
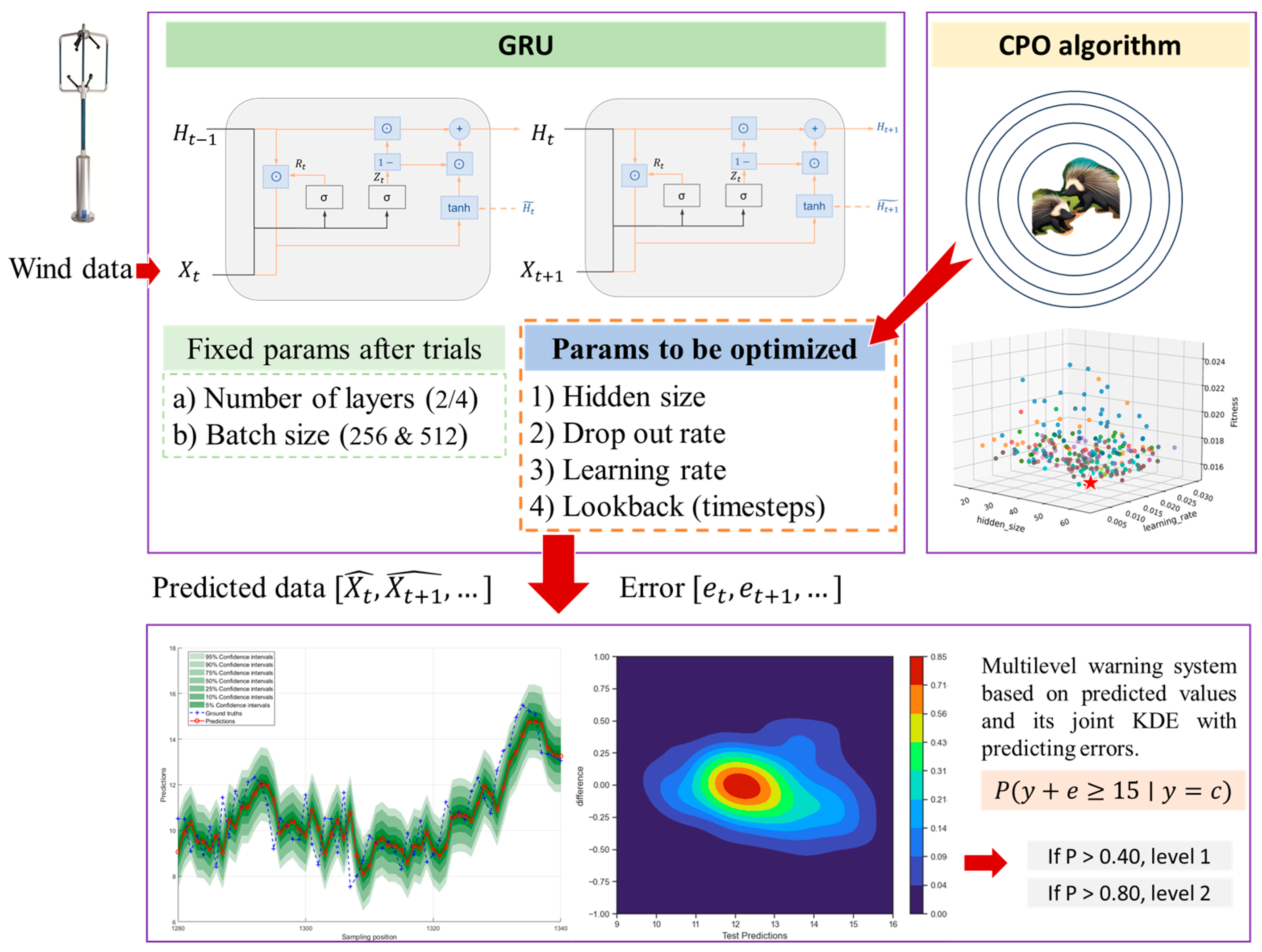
2.3. Proposed Framework
3. Results and Analysis
3.1. Performance Criteria of the Prediction Models
3.2. Results of Optimization for RNNs
3.3. Results of Various Prediction Models
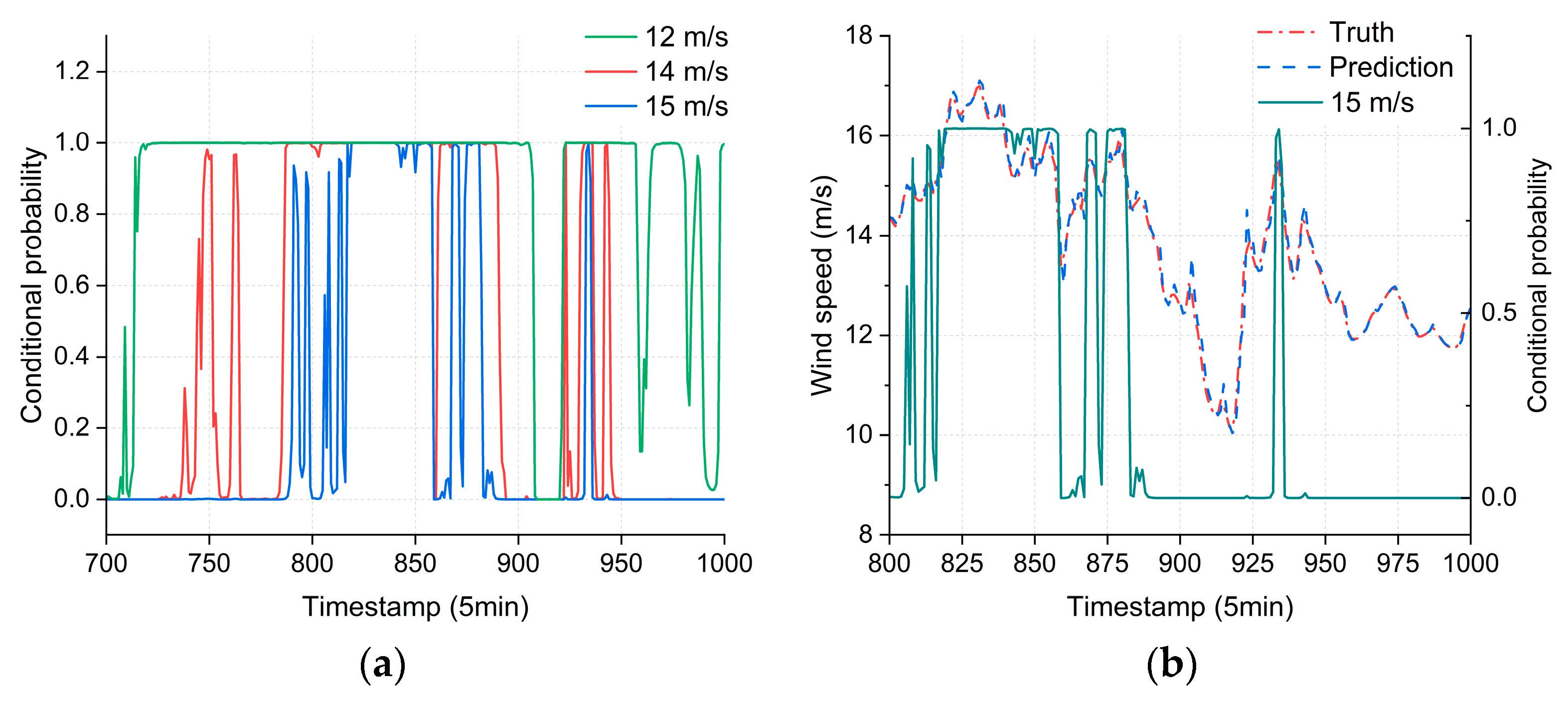
3.4. Results of Multilevel Warning
3.5. Discussions
4. Conclusions
- Recurrent networks perform well in predicting wind speeds. Nevertheless, their performance can be efficiently optimized by using a proper algorithm. A comparison of various algorithms, including ARIMA, ELM, and transformer, demonstrates that the GRU performs best on the collected database.
- The results of various optimization algorithms indicate the significance of parameter optimization. The search trace of diverse parameters can provide valuable information for model selection. For example, in the present case, the lookback size greatly affects the model performance, while the model can achieve similar performance at diverse dropout rates, learning rates, or hidden sizes.
- An analysis of the prediction results indicates that the CPO-GRU model outperforms the other combinations, with metrics of 1.28%, 0.127, 0.194, and 0.992 for the MAPE, MAE, RMSE, and R2, respectively, in the present case. In addition, it achieves similar and excellent performance on all collected databases.
- By using adaptive kernel estimators, the joint kernel density and cumulative distribution function of the predicted values and prediction errors can be obtained, thereby calculating the conditional probability at a given prediction of the wind speed. A comparison between the deterministic and probabilistic methods indicates that all methods yield high overall accuracy—due to the relatively large sample size—but also that the proposed framework can significantly address the TPR, which is valuable for practical decision making, especially when the predictions are near the critical value.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Correction Statement
References
- Liu, D.; Wang, Q.; Zhong, M.; Lu, Z.; Wang, J.; Wang, T.; Lv, S. Effect of wind speed variation on the dynamics of a high-speed train. Veh. Syst. Dyn. 2019, 57, 247–268. [Google Scholar]
- Liu, D.; Wang, T.; Liang, X.; Meng, S.; Zhong, M.; Lu, Z. High-speed train overturning safety under varying wind speed conditions. J. Wind Eng. Ind. Aerodyn. 2020, 198, 104111. [Google Scholar]
- Pan, D.; Liu, H.; Li, Y. A short-term forecast method for wind speed along Golmud-Lhasa section of Qinghai-Tibet railway. China Railw. Sci. 2008, 29, 129–133. [Google Scholar]
- Kobayashi, N.; Shimamura, M. Study of a strong wind warning system. Jr East Tech. Rev. 2003, 2, 61–65. [Google Scholar]
- Hoppmann, U.; Koenig, S.; Tielkes, T.; Matschke, G. A short-term strong wind prediction model for railway application: Design and verification. J. Wind Eng. Ind. Aerodyn. 2002, 90, 1127–1134. [Google Scholar]
- Jing, H.; Zhong, R.; He, X.; Wang, H. Multi-Level Early Warning Method for Gale Based on LSTM-GMM Model. China Railw. Sci. 2023, 44, 221–228. [Google Scholar]
- Soman, S.S.; Zareipour, H.; Malik, O.; Mandal, P. A review of wind power and wind speed forecasting methods with different time horizons. In Proceedings of the North American Power Symposium 2010, Arlington, TX, USA, 26–28 September 2010; pp. 1–8. [Google Scholar]
- Hu, J.; Heng, J.; Wen, J.; Zhao, W. Deterministic and probabilistic wind speed forecasting with de-noising-reconstruction strategy and quantile regression based algorithm. Renew. Energy 2020, 162, 1208–1226. [Google Scholar]
- Jung, J.; Broadwater, R.P. Current status and future advances for wind speed and power forecasting. Renew. Sustain. Energy Rev. 2014, 31, 762–777. [Google Scholar]
- Kavasseri, R.G.; Seetharaman, K. Day-ahead wind speed forecasting using f-ARIMA models. Renew. Energy 2009, 34, 1388–1393. [Google Scholar]
- Maatallah, O.A.; Achuthan, A.; Janoyan, K.; Marzocca, P. Recursive wind speed forecasting based on Hammerstein Auto-Regressive model. Appl. Energy 2015, 145, 191–197. [Google Scholar]
- Liu, H.; Mi, X.; Li, Y. Smart multi-step deep learning model for wind speed forecasting based on variational mode decomposition, singular spectrum analysis, LSTM network and ELM. Energy Convers. Manag. 2018, 159, 54–64. [Google Scholar]
- Cassola, F.; Burlando, M. Wind speed and wind energy forecast through Kalman filtering of Numerical Weather Prediction model output. Appl. Energy 2012, 99, 154–166. [Google Scholar]
- Song, J.; Wang, J.; Lu, H. A novel combined model based on advanced optimization algorithm for short-term wind speed forecasting. Appl. Energy 2018, 215, 643–658. [Google Scholar]
- Neshat, M.; Nezhad, M.M.; Abbasnejad, E.; Mirjalili, S.; Tjernberg, L.B.; Garcia, D.A.; Alexander, B.; Wagner, M. A deep learning-based evolutionary model for short-term wind speed forecasting: A case study of the Lillgrund offshore wind farm. Energy Convers. Manag. 2021, 236, 114002. [Google Scholar]
- Wan, J.; Liu, J.; Ren, G.; Guo, Y.; Yu, D.; Hu, Q. Day-ahead prediction of wind speed with deep feature learning. Int. J. Pattern Recognit. Artif. Intell. 2016, 30, 1650011. [Google Scholar]
- Zhang, W.; Wang, J.; Wang, J.; Zhao, Z.; Tian, M. Short-term wind speed forecasting based on a hybrid model. Appl. Soft Comput. 2013, 13, 3225–3233. [Google Scholar]
- Kiplangat, D.C.; Asokan, K.; Kumar, K.S. Improved week-ahead predictions of wind speed using simple linear models with wavelet decomposition. Renew. Energy 2016, 93, 38–44. [Google Scholar]
- Liu, H.; Tian, H.-Q.; Li, Y.-F. An EMD-recursive ARIMA method to predict wind speed for railway strong wind warning system. J. Wind Eng. Ind. Aerodyn. 2015, 141, 27–38. [Google Scholar]
- Zhang, Y.; Zhao, Y.; Kong, C.; Chen, B. A new prediction method based on VMD-PRBF-ARMA-E model considering wind speed characteristic. Energy Convers. Manag. 2020, 203, 112254. [Google Scholar]
- Xiao, L.; Shao, W.; Jin, F.; Wu, Z. A self-adaptive kernel extreme learning machine for short-term wind speed forecasting. Appl. Soft Comput. 2021, 99, 106917. [Google Scholar]
- Li, L.; Chang, Y.; Tseng, M.; Liu, J.; Lim, M.K. Wind power prediction using a novel model on wavelet decomposition-support vector machines-improved atomic search algorithm. J. Clean. Prod. 2020, 270, 121817. [Google Scholar]
- Qian, Z.; Pei, Y.; Zareipour, H.; Chen, N. A review and discussion of decomposition-based hybrid models for wind energy forecasting applications. Appl. Energy 2019, 235, 939–953. [Google Scholar]
- Marović, I.; Sušanj, I.; Ožanić, N. Development of ANN model for wind speed prediction as a support for early warning system. Complexity 2017, 2017, 3418145. [Google Scholar]
- Gou, H.; Chen, X.; Bao, Y. A wind hazard warning system for safe and efficient operation of high-speed trains. Autom. Constr. 2021, 132, 103952. [Google Scholar]
- Wang, L.; Li, X.; Bai, Y. Short-term wind speed prediction using an extreme learning machine model with error correction. Energy Convers. Manag. 2018, 162, 239–250. [Google Scholar]
- Santhosh, M.; Venkaiah, C.; Kumar, D.V. Short-term wind speed forecasting approach using ensemble empirical mode decomposition and deep Boltzmann machine. Sustain. Energy Grids Netw. 2019, 19, 100242. [Google Scholar]
- Liu, Y.; Zhang, Z.; Huang, Y.; Zhao, W.; Dai, L. Hybrid neural network-aided strong wind speed prediction along rail network. J. Wind Eng. Ind. Aerodyn. 2024, 252, 105813. [Google Scholar]
- Wang, L.; Guo, Y.; Fan, M.; Li, X. Wind speed prediction using measurements from neighboring locations and combining the extreme learning machine and the AdaBoost algorithm. Energy Rep. 2022, 8, 1508–1518. [Google Scholar]
- Chen, Y.; Dong, Z.; Wang, Y.; Su, J.; Han, Z.; Zhou, D.; Zhang, K.; Zhao, Y.; Bao, Y. Short-term wind speed predicting framework based on EEMD-GA-LSTM method under large scaled wind history. Energy Convers. Manag. 2021, 227, 113559. [Google Scholar]
- Wang, H.; Xiong, M.; Chen, H.; Liu, S. Multi-step ahead wind speed prediction based on a two-step decomposition technique and prediction model parameter optimization. Energy Rep. 2022, 8, 6086–6100. [Google Scholar]
- Zhang, C.; Ji, C.; Hua, L.; Ma, H.; Nazir, M.S.; Peng, T. Evolutionary quantile regression gated recurrent unit network based on variational mode decomposition, improved whale optimization algorithm for probabilistic short-term wind speed prediction. Renew. Energy 2022, 197, 668–682. [Google Scholar]
- Najibi, F.; Apostolopoulou, D.; Alonso, E. Enhanced performance Gaussian process regression for probabilistic short-term solar output forecast. Int. J. Electr. Power Energy Syst. 2021, 130, 106916. [Google Scholar]
- WRDB: Wind Resource Database. National Renewable Energy Laboratory. Available online: https://wrdb.nrel.gov/ (accessed on 16 August 2024).
- Kaveh, A.; Dadras, A. A novel meta-heuristic optimization algorithm: Thermal exchange optimization. Adv. Eng. Softw. 2017, 110, 69–84. [Google Scholar]
- Abdel-Basset, M.; Mohamed, R.; Abouhawwash, M. Crested Porcupine Optimizer: A new nature-inspired metaheuristic. Knowl.-Based Syst. 2024, 284, 111257. [Google Scholar]
- Liang, J.J.; Qu, B.Y.; Suganthan, P.N. Problem definitions and evaluation criteria for the CEC 2014 special session and competition on single objective real-parameter numerical optimization. Comput. Intell. Lab. Zhengzhou Univ. Zhengzhou China Tech. Rep. Nanyang Technol. Univ. Singap. 2013, 635, 2014. [Google Scholar]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar]
- Abualigah, L.; Shehab, M.; Alshinwan, M.; Alabool, H. Salp swarm algorithm: A comprehensive survey. Neural Comput. Appl. 2020, 32, 11195–11215. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Liu, X.; Lin, Z.; Feng, Z. Short-term offshore wind speed forecast by seasonal ARIMA-A comparison against GRU and LSTM. Energy 2021, 227, 120492. [Google Scholar]
- ArunKumar, K.; Kalaga, D.V.; Kumar, C.M.S.; Kawaji, M.; Brenza, T.M. Comparative analysis of Gated Recurrent Units (GRU), long Short-Term memory (LSTM) cells, autoregressive Integrated moving average (ARIMA), seasonal autoregressive Integrated moving average (SARIMA) for forecasting COVID-19 trends. Alex. Eng. J. 2022, 61, 7585–7603. [Google Scholar]
- Sheather, S.J. Density estimation. Stat. Sci. 2004, 19, 588–597. [Google Scholar]
- Scott, D.W. Multivariate Density Estimation: Theory, Practice, and Visualization; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Shimazaki, H.; Shinomoto, S. Kernel bandwidth optimization in spike rate estimation. J. Comput. Neurosci. 2010, 29, 171–182. [Google Scholar]
- Dhaker, H.; Ngom, P.; Mendy, P. New Approach for Bandwidth Selection in the Kernel Density Estimation Based on β-Divergence. 2016. Available online: https://hal.science/hal-01297034/file/articll.pdf (accessed on 16 August 2024).
- Zhou, S.; Liu, X.; Liu, Q.; Wang, S.; Zhu, C.; Yin, J. Random Fourier extreme learning machine with ℓ2, 1-norm regularization. Neurocomputing 2016, 174, 143–153. [Google Scholar]
- Wen, Q.; Zhou, T.; Zhang, C.; Chen, W.; Ma, Z.; Yan, J.; Sun, L. Transformers in time series: A survey. arXiv 2022, arXiv:2202.07125. [Google Scholar]
- Park, J.-M.; Kim, J.-H. Online recurrent extreme learning machine and its application to time-series prediction. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1983–1990. [Google Scholar]





| Term | Description | Term | Description |
|---|---|---|---|
| HSR | high-speed railway | ORELM | online recurrent extreme learning machine |
| CEC | congress on evolutionary computation | MAE | mean absolute error |
| CPO | crested porcupine optimizer | MAPE | mean absolute percentage error |
| GWO | gray wolf optimizer | RMSE | root mean square error |
| WOA | whale optimization algorithm | R2 | coefficient of determination |
| ARIMA | autoregressive integrated moving average | KDE | kernel density estimation |
| AI | artificial intelligence | AKDE | adaptive kernel density estimation |
| RNN | recurrent neural network | CDF | cumulative distribution function |
| LSTM | long short-term memory | MISE | mean integrated square error |
| BiLSTM | bidirectional LSTM | AMISE | asymptotic mean integrated square error |
| GRU | long short-term memory | T/F-P/N | true/false positive/negative |
| ELM | extreme learning machine | T/F-PR | true/false positive rate |
| Total Population = P + N | Predicted Conditions | |||
|---|---|---|---|---|
| Positive | Negative | |||
| Actual conditions | Positive | TP | FN | |
| Negative | FP | TN | ||
| Model | Parameters | Range | Initial Searching Range | Optimized Parameters | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CPO | GWO | WOA | CPO | GWO | WOA | |||||
| GRU | Learning rate | 0.001~0.03 | 0.001~0.029 | 0.001~0.029 | 0.002~0.029 | 0.007 | 0.03 | 0.020 | ||
| Dropout rate | 0~0.3 | 0.002~0.285 | 0.010~0.291 | 0.003~0.289 | 0.002 | 0.082 | 0.211 | |||
| Hidden size | 16~64 | 16~62 | 17~63 | 21~62 | 54 | 53 | 21 | |||
| Lookback | 16~128 | 18~128 | 19~120 | 24~128 | 121 | 128 | 121 | |||
| Model performance (on the test set of the entire D1-1) | MAPE: | 1.28% | 1.54% | 1.52% | ||||||
| MAE: | 0.127 | 0.145 | 0.145 | |||||||
| RMSE: | 0.194 | 0.220 | 0.222 | |||||||
| R2: | 0.992 | 0.990 | 0.990 | |||||||
| Model | Key Parameters | Metrics | ||||||
|---|---|---|---|---|---|---|---|---|
| MAPE | MAE | RMSE | R2 | |||||
| Learning rate | Dropout rate | Hidden size | Lookback | |||||
| GRU | 0.01 | 0.02 | 63 | 24 | 2.06% | 0.2108 | 0.1280 | 0.9964 |
| LSTM | 0.02 | 0.01 | 44 | 22 | 2.14% | 0.2105 | 0.1305 | 0.9964 |
| BiLSTM | 0.01 | 0.001 | 57 | 21 | 2.25% | 0.2187 | 0.1354 | 0.9961 |
| ARIMA * | p | d | q | — | ||||
| 1 | 1 | 3 | — | 2.20% | 0.2112 | 0.1350 | 0.9963 | |
| 3 | 1 | 1 | — | 2.19% | 0.2111 | 0.1345 | 0.9964 | |
| Hidden size | Reg_lambda | Forgetting factor | ||||||
| ELM | 30 | 0.001 | — | 2.50% | 0.2195 | 0.1425 | 0.9961 | |
| ORELM | 29 | 0.001 | 0.9485 | 3.81% | 0.2142 | 0.3092 | 0.9922 | |
| Layers | Dropout rate | No. of heads | FFN_dim | |||||
| Transformer * | 2 | 0.1 | 18 | 256 | 2.83% | 0.2849 | 0.2066 | 0.9928 |
| Dataset | Parameters | Metric | ||||||
|---|---|---|---|---|---|---|---|---|
| Learning Rate | Dropout Rate | Hidden Size | Lookback | R2 | MAPE | MAE | RMSE | |
| D1-1 | 0.0155 | 0.2320 | 39 | 26 | 0.9987 | 1.78% | 0.0885 | 0.1416 |
| D1-2 | 0.0149 | 0.1261 | 50 | 17 | 0.9913 | 3.84% | 0.1744 | 0.2882 |
| D1-3 | 0.0192 | 0.0030 | 45 | 16 | 0.9965 | 2.09% | 0.1043 | 0.1838 |
| D1-4 | 0.0128 | 0.0063 | 52 | 55 | 0.9917 | 1.86% | 0.1192 | 0.3060 |
| D2-1 | 0.0211 | 0.1958 | 60 | 92 | 0.9990 | 1.72% | 0.0603 | 0.1045 |
| D2-2 | 0.0145 | 0.0097 | 20 | 125 | 0.9931 | 3.58% | 0.1164 | 0.1893 |
| D2-3 | 0.0018 | 0.0483 | 60 | 128 | 0.9961 | 2.42% | 0.1192 | 0.2427 |
| D2-4 | 0.0299 | 0.0390 | 50 | 90 | 0.9982 | 0.98% | 0.0666 | 0.1384 |
| D2-1 | 0.0170 | 0.1583 | 37 | 17 | 0.9978 | 1.13% | 0.0742 | 0.1421 |
| D2-2 | 0.0129 | 0.0027 | 34 | 114 | 0.9687 | 4.34% | 0.1456 | 0.3681 |
| D2-3 | 0.0156 | 0.1093 | 33 | 22 | 0.9970 | 2.10% | 0.0809 | 0.1576 |
| D2-4 | 0.0141 | 0.0565 | 50 | 102 | 0.9969 | 0.97% | 0.0988 | 0.1925 |
| Sequence ID | Values | Ideal Decision | Deterministic | Probabilistic | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| True (m/s) | Pred. (m/s) | p * | Decisions | Y/N | Decision_1 | Y/N | Decision_2 | Y/N | ||
| 3025 | 15.01 | 14.91 | 0.1218 | 1 | 0 | N | 0 | N | 0 | N |
| 3030 | 14.99 | 15.02 | 0.5695 | 0 | 1 | N | 1 | N | 0 | Y |
| 3031 | 14.85 | 15.01 | 0.5136 | 0 | 1 | N | 1 | N | 0 | Y |
| 3505 | 15.09 | 14.97 | 0.2987 | 1 | 0 | N | 0 | N | 0 | N |
| 3508 | 14.94 | 15.08 | 0.8010 | 0 | 1 | N | 1 | N | 1 | N |
| 3514 | 15.02 | 14.94 | 0.2127 | 1 | 0 | N | 0 | N | 0 | N |
| 3547 | 14.87 | 15.08 | 0.8010 | 0 | 1 | N | 1 | N | 1 | N |
| 3612 | 14.97 | 15.01 | 0.5136 | 0 | 1 | N | 1 | N | 0 | Y |
| 4893 | 15.03 | 14.93 | 0.1773 | 1 | 0 | N | 0 | N | 0 | N |
| 4896 | 14.98 | 15.07 | 0.7637 | 0 | 1 | N | 1 | N | 0 | Y |
| Dataset | Total No. of Positive (v ≥ 15 m/s) | Total No. of TP | TPR | Overall Accuracy | |||||
|---|---|---|---|---|---|---|---|---|---|
| LSTM | CPO_GRU | CPO_GRU_KDE (CGK) | LSTM | CGK | LSTM | CGK | |||
| Level 1 | Level 2 | ||||||||
| D1-1 | 185 | 135 | 164 | 164 | 168 | 0.7297 | 0.9081 | 0.9903 | 0.9967 |
| D1-2 | 3 | 2 | 2 | 2 | 2 | 0.6667 | 0.6667 | 0.9996 | 0.9996 |
| D1-3 | 15 | 0 | 8 | 8 | 6 | 0.0000 | 0.5333 | 0.9971 | 0.9988 |
| D1-4 | 103 | 82 | 90 | 90 | 89 | 0.7961 | 0.8738 | 0.9959 | 0.9975 |
| D2-1 | 53 | 40 | 52 | 52 | 50 | 0.7547 | 0.9811 | 0.9975 | 0.9998 |
| D2-2 | 0 | 0 | 0 | 0 | 0 | — | — | 1.0000 | 1.0000 |
| D2-3 | 293 | 289 | 292 | 292 | 291 | 0.9863 | 0.9966 | 0.9965 | 0.9977 |
| D2-4 | 73 | 67 | 61 | 66 | 68 | 0.9178 | 0.9315 | 0.9977 | 0.9990 |
| D3-1 | 83 | 79 | 81 | 81 | 79 | 0.9518 | 0.9518 | 0.9990 | 0.9992 |
| D3-2 | 0 | 0 | 0 | 0 | 0 | — | — | 1.0000 | 1.0000 |
| D3-3 | 0 | 0 | 0 | 0 | 0 | — | — | 1.0000 | 1.0000 |
| D3-4 | 437 | 393 | 408 | 415 | 410 | 0.8993 | 0.9497 | 0.9910 | 0.9926 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, P.; Long, Q.; Zhang, H.; Chen, X.; Yu, R.; Guo, F. Forecasting and Multilevel Early Warning of Wind Speed Using an Adaptive Kernel Estimator and Optimized Gated Recurrent Units. Mathematics 2024, 12, 2581. https://doi.org/10.3390/math12162581
Wang P, Long Q, Zhang H, Chen X, Yu R, Guo F. Forecasting and Multilevel Early Warning of Wind Speed Using an Adaptive Kernel Estimator and Optimized Gated Recurrent Units. Mathematics. 2024; 12(16):2581. https://doi.org/10.3390/math12162581
Chicago/Turabian StyleWang, Pengjiao, Qiuliang Long, Hu Zhang, Xu Chen, Ran Yu, and Fengqi Guo. 2024. "Forecasting and Multilevel Early Warning of Wind Speed Using an Adaptive Kernel Estimator and Optimized Gated Recurrent Units" Mathematics 12, no. 16: 2581. https://doi.org/10.3390/math12162581
APA StyleWang, P., Long, Q., Zhang, H., Chen, X., Yu, R., & Guo, F. (2024). Forecasting and Multilevel Early Warning of Wind Speed Using an Adaptive Kernel Estimator and Optimized Gated Recurrent Units. Mathematics, 12(16), 2581. https://doi.org/10.3390/math12162581