
Intelligent Low-Consumption Optimization Strategies: Economic Operation of Hydropower Stations Based on Improved LSTM and Random Forest Machine Learning Algorithm



Abstract
:1. Introduction
- (a)
- In view of the low precision of traditional curve fitting methods and the difficulty in determining mathematical formulas, based on the large amount of real machine characteristic parameter data (water head, flow, output) generated during the actual operation of the unit, and combined with the hydraulic turbine model test data, the improved particle swarm optimization algorithm is used to optimize the hyperparameters of the deep long-short term memory network to determine the network model. An improved Long Short-Term Memory neural network (I-LSTM) algorithm for fitting the flow characteristics curve of a hydraulic turbine is proposed.
- (b)
- We use the Random Forest (RF) algorithm of machine learning to perform load distribution for hydropower units. This machine learning method can train massive amounts of historical decision data, build mapping relationships between inputs and outputs, and continuously revise them over time. Solving the load-distribution problem of hydropower units to verify the effectiveness and accuracy of the algorithm.
2. Introduction Hydraulic Turbine Flow Characteristic Curve Fitting Based on I-LSTM
2.1. Hydraulic Turbine Flow Characteristic Curve Fitting Model
2.2. Data Preprocessing
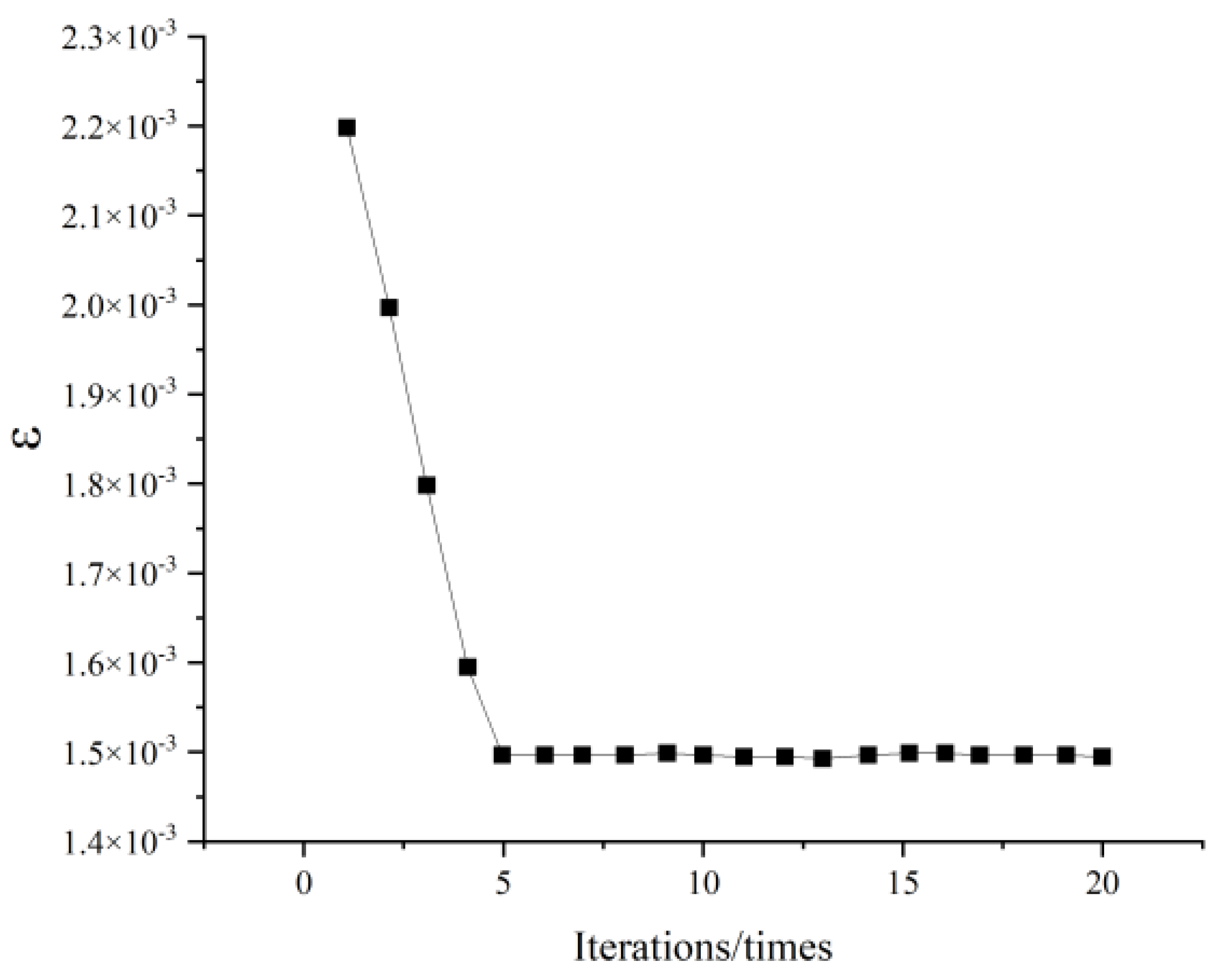
2.3. Optimization of Model Parameters
- (1)
- Initialize individual parameters, including population size, iteration count, learning factors and the range of particle velocity and position values.
- (2)
- Initialize particle position and velocity information, randomly generating a certain number of population particles , with each dimension value within the defined range.
- (3)
- Calculate the fitness value for each particle based on the established objective function, determine the global and individual extrema of the initial population and record each particle’s best position as its historical optimum.
- (4)
- In each iteration, update the velocity and position information of the particles, calculate the fitness values for the new population and determine the individual and global extrema for the current population.
- (5)
- Repeat steps (3)–(4) until the maximum number of iterations or desired accuracy is achieved, output the optimal network parameters and train the network model.

3. Load Distribution of Hydropower Units Based on Random Forest Algorithm
3.1. Data Preprocessing Based on K-Means Clustering Algorithm
- (1)
- For a set of datasets, . First, K values are randomly selected as the initial clustering centers .
- (2)
- The Euclidean distance of each sample to a cluster center is calculated, and it is classified into one category with the nearest cluster center to form K categories.
- (3)
- The average clustering centers of the K classes are recalculated, and the original clustering centers are replaced with new ones.
- (4)
- Repeat steps (2) and (3), and stop when you know that there is no change or no change in the cluster center c.
3.2. Modelling of Unit Load Distribution Based on RF
- Model building
- (1)
- Extraction of sub-training set: M samples are randomly selected from the dataset D using the Bootstrap method to form S sub-training datasets and construct M decision trees, and the samples that are not selected form M out-of-bag data.
- (2)
- Build decision tree: randomly select F features (F ≤ M) from S features at each node of the decision tree as the segmentation feature set of the node, select the optimal segmentation feature and the optimal segmentation point using certain criteria, divide the current node into two sub-nodes and divide the training set data into these two sub-nodes as well. The segmentation process is repeated until the requirements are met.
- (3)
- Build a Random Forest: repeat step (2) until all k decision trees are generated and combined into a Random Forest .
- 2.
- Data collection and preprocessing
- 3.
- Model training and prediction
4. Example Analysis
4.1. Hydraulic Turbine Flow Characteristic Curve Fitting
- (1)
- Model Parameter Optimization
- (2)
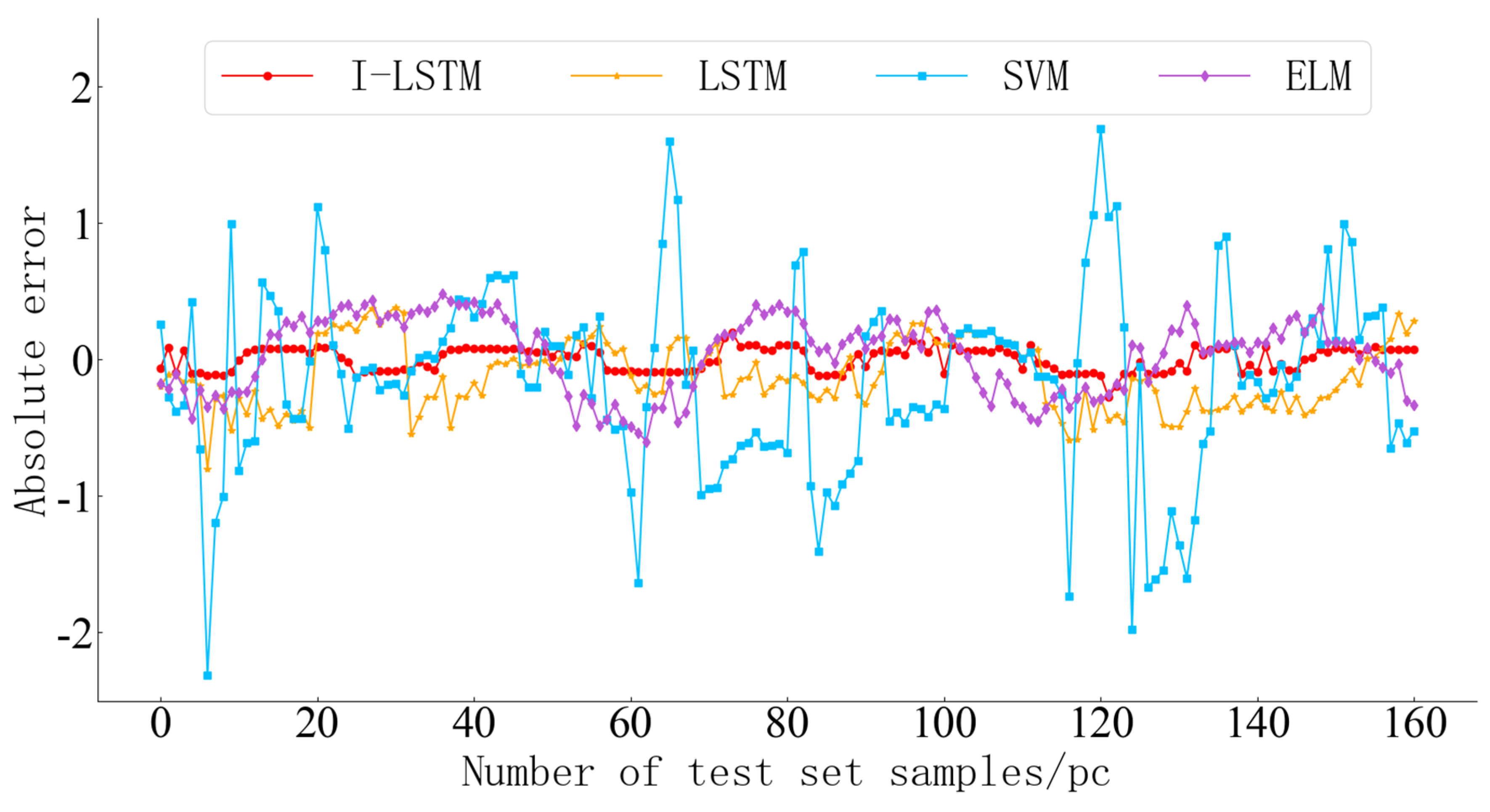
- Model Training and Prediction
4.2. Load Distribution of Hydropower Units
- (1)
- K-means Clustering
- (2)
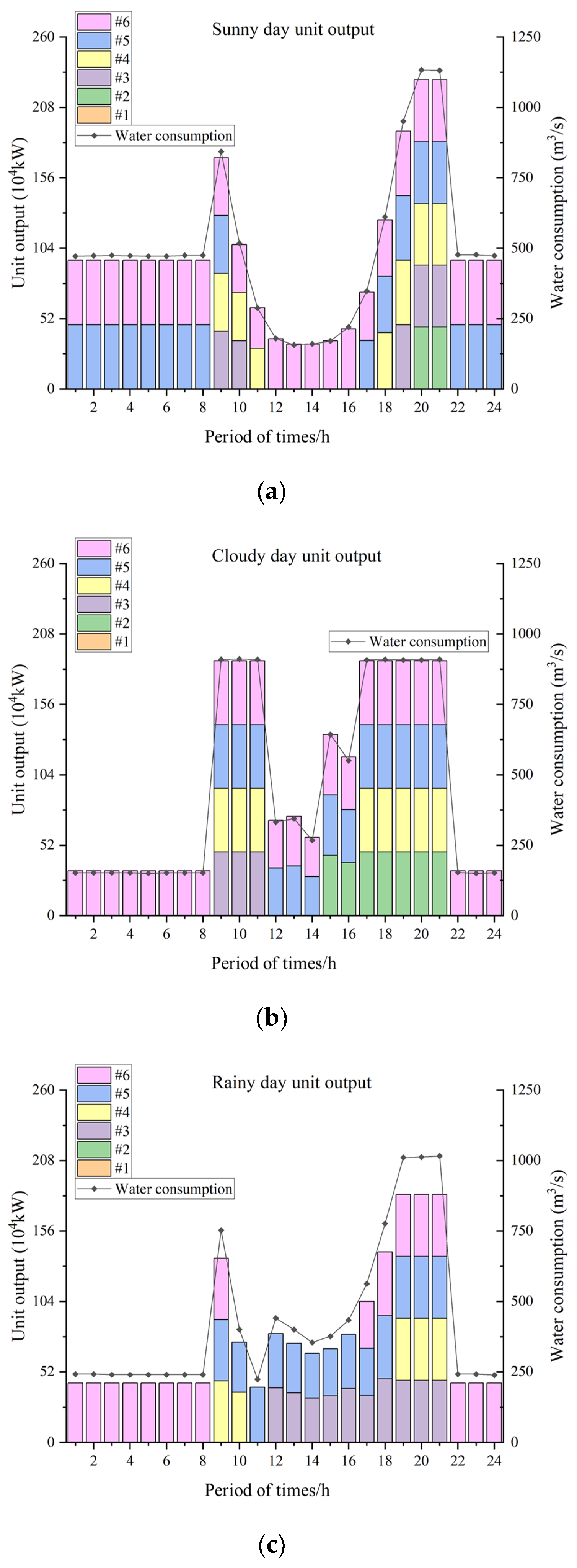
- Load Distribution of Hydropower-Unit-Based RF
5. Conclusions
- Intelligent Flow Fitting Method: This method combined the hydraulic turbine model test data and actual operational data for flow characteristic curve fitting, using an I-LSTM. The I-LSTM method is compared with SVM, ELM and LSTM. The prediction results of SVM have a large error, but compared with ELM and LSTM, MSE is reduced by about 46% and 38%, respectively. MAE is reduced by about 25% and 21%, respectively. RMSE is reduced by about 27% and 24%, respectively. The fitting model covered the operational characteristics of the hydraulic turbines under various conditions and its actual operational characteristics
- Low-consumption Load-Distribution Strategy: The RF load-distribution model was compared with the traditional dynamic programming algorithm. The total water consumption of hydropower units in each scenario is reduced by 1.24%. Start and stop no more than twice. Maximum output fluctuation rate of no more than 3.3%. The maximum value of the non-economic operating zone is only 15.43%. It significantly improved the operational efficiency and resource-utilization rate of hydropower stations, and showcased the immense potential of intelligent and low-energy consumption strategies in the field of hydropower
- In the hydro-photovoltaic complementary system, the average efficiency of the hydropower station units using the RF algorithm for load allocation is more than 93% under the three scenarios of sunny, cloudy and rainy days. The total water consumption in the three scenarios is less than based on the dynamic programming algorithm for load allocation. In the hydro-photovoltaic complementary system with more constraints, the model is trained using the real operating data, and can effectively distribute the load under the existing conditions and make corresponding predictions for some additional conditions.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shrestha, A.; Mustafa, A.A.; Htike, M.M.; You, V.; Kakinaka, M. Evolution of energy mix in emerging countries: Modern renewable energy, traditional renewable energy, and non-renewable energy. Renew. Energy 2022, 199, 419–432. [Google Scholar] [CrossRef]
- Guidi, G.; Violante, A.C.; Iuliis, S.D. Environmental Impact of Electricity Generation Technologies: A Comparison between Conventional, Nuclear, and Renewable Technologies. Energies 2023, 16, 7847. [Google Scholar] [CrossRef]
- Singh, V.K.; Signal, S.K. Operation of hydro power plants-a review. Renew. Sustain. Energy Rev. 2017, 69, 610–619. [Google Scholar] [CrossRef]
- Kumar, K.; Saini, R.P. A review on operation and maintenance of hydropower plants. Sustain. Energy Technol. Assess. 2022, 49, 101704. [Google Scholar] [CrossRef]
- Dauda, A.K.; Panda, A.; Mishra, U. Synergistic effect of complementary cleaner energy sources on controllable emission from hybrid power systems in optimal power flow framework. J. Clean. Prod. 2023, 419, 138290. [Google Scholar] [CrossRef]
- Xia, L.; Zhu, Y.; Lai, C.; Huang, W.; Chen, S.; Wang, J. Research on the Hydropower Coupling-Based Hydropower Station Scheduling Optimization Model. J. Phys. Conf. Ser. 2021, 2005, 012140. [Google Scholar]
- Gao, Y.; Xu, W.; Wang, Y.; Wen, X. Research on the Economic Operation of Large Hydropower Stations Based on Optimal Load Distribution Tables. Hydropower Energy Sci. 2023, 41, 197–201. [Google Scholar]
- Yang, K.; Chen, L.; Li, H. Overall Spatio-Temporal Economic Operation Model and Its Algorithm for Large Hydropower Stations. J. Huazhong Univ. Sci. Technol. (Nat. Sci. Ed.) 2015, 43, 117–122. [Google Scholar]
- Thaeer Hammid, A.; Awad, O.I.; Sulaiman, M.H.; Gunasekaran, S.S.; Mostafa, S.A.; Manoj Kumar, N.; Khalaf, B.A.; Al-Jawhar, Y.A.; Abdulhasan, R.A. A Review of Optimization Algorithms in Solving Hydro Generation Scheduling Problem. Energies 2020, 13, 2787. [Google Scholar] [CrossRef]
- Xu, L.; Tian, J.; Qi, P.; Sun, S.; Li, X. Curve fitting and application of the operating characteristics of a hydraulic turbine based on MEA-BP. People’s Yangtze River 2019, 50, 141–145. [Google Scholar]
- Guo, A.; Chang, J.; Yang, S.; Zhao, Y.; Wang, Y.; Fang, J. Time scale effect in dimension reduction optimal load distribution of hydropower generating units. Power Grid Technol. 2024, 1–10. [Google Scholar] [CrossRef]
- Stefanizzi, M.; Capurso, T.; Balaccco, G.; Binetti, M.; Camporeale, S.M.; Torresi, M. Selection, control and techno-economic feasibility of Pumps as Turbines in Water Distribution Network. Renew. Energy 2020, 162, 1292–1306. [Google Scholar] [CrossRef]
- Ma, W.; Yang, J.; Zhao, Z.; Yang, W.; Yang, J. Subdivision method of characteristic curve of Francis turbine under multiple boundary conditions. Trans. Chin. Soc. Agric. Eng. 2021, 37, 31–39. [Google Scholar]
- Plua, F.A.; Sanchez-Romero, F.-J.; Hidalgo, V.; Lopez-Jimenez, P.A.; Perez-Sanchez, M. New Expressions to Apply the Variation Operation Strategy in Engineering Tools Using Pumps Working as Turbines. Mathematics 2021, 9, 860. [Google Scholar] [CrossRef]
- Skjelbred, H.I.; Kong, J. A comparison of linear interpolation and spline interpolation for turbine efficiency curves in short-term hydropower scheduling problems. IOP Conf. Ser. Earth Environ. Sci. 2019, 240, 042011. [Google Scholar] [CrossRef]
- Wu, Q.; Zhang, L.; Ma, Z. Extension and Reconstruction of Turbine Comprehensive Characteristic Curves Based on Engineering Experience and RBF Neural Network. J. Basic Sci. Eng. 2022, 27, 996–1007. [Google Scholar]
- Liu, D.; Hu, X.; Zeng, Q.; Zhou, H.K.; Xiao, Z.H. Refined Model of Turbine Characteristic Curves Based on Input-Output Correction. J. Hydraul. Eng. 2019, 50, 555–564. [Google Scholar]
- Li, J.; Chen, Q.; Chen, G. Research on BP Neural Network Fitting Method for Comprehensive Characteristic Curves of Hydraulic Turbines. J. Hydroelectr. Eng. 2015, 34, 182–188. [Google Scholar]
- Li, J.; Han, C.; Yu, F. A New Processing Method Combined with BP Neural Network for Francis Turbine Synthetic Characteristic Curve Research. Int. J. Rotating Mach. 2017, 2017, 1870541. [Google Scholar] [CrossRef]
- Li, M.; Wibowo, S.; Guo, W. Nonlinear Curve Fitting Using Extreme Learning Machines and Radial Basis Function Networks. Comput. Sci. Eng. 2019, 21, 6–15. [Google Scholar] [CrossRef]
- Abritta, R.; Panoeiro, F.F.; De Aguiar, E.P.; Honorio, L.D.M.; Marcato, A.L.M.; da Silva Junior, I.C. Fuzzy system applied to a hydraulic turbine efficiency curve fitting. Electr. Eng. 2020, 102, 1361–1370. [Google Scholar] [CrossRef]
- Schonlau, M.; Zou, R.Y. The random forest algorithm for statistical learning. Stata J. Promot. Commun. Stat. Stata 2020, 20, 3–29. [Google Scholar] [CrossRef]
- Soydaner, D. A Comparison of Optimization Algorithms for Deep Learning. Int. J. Pattern Recognit. Artif. Intell. 2020, 34, 2052013. [Google Scholar] [CrossRef]
- Bao, C.; Xie, J.; Zhang, Q.; Chen, F. Deep Learning-Based Encapsulation of Hydropower Unit Consumption Characteristics and Economic Operation within Hydropower Plants. Hydropower Energy Sci. 2022, 40, 173–177. [Google Scholar]
- Alvarez, G.E. An Optimization Model for Operations of Large scale Hydro Power Plants. IEEE Lat. Am. Trans. 2020, 18, 1631–1638. [Google Scholar] [CrossRef]
- Olofintoye, O.; Otieno, F.; Adeyemo, J. Real-time optimal water allocation for daily hydropower generation from the Vanderkloof dam, South Afric. Appl. Soft Comput. 2016, 47, 119–129. [Google Scholar] [CrossRef]
- Amani, A.; Alizadeh, H. Solving Hydropower Unit Commitment Problem Using a Novel Sequential Mixed Integer Linear Programming Approach. Water Resour. Manag. 2021, 35, 1711–1729. [Google Scholar] [CrossRef]
- Paredes, M.; Martins LS, A.; Soares, S. Using Semidefinite Relaxation to Solve the Day-Ahead Hydro Unit Commitment Problem. IEEE Trans. Power Syst. 2015, 30, 2695–2705. [Google Scholar] [CrossRef]
- Finardi, E.C.; De Silva, E.L.; Sagastizábal, C. Solving the unit commitment problem of hydropower plants via Lagrangian Relaxation and Sequential Quadratic Programming. Comput. Appl. Math. 2005, 24, 317–342. [Google Scholar] [CrossRef]
- Shang, Y.; Lu, S.; Gong, J.; Liu, R.; Li, X.; Fan, Q. Improved genetic algorithm for economic load dispatch in hydropower plants and comprehensive performance comparison with dynamic programming method. J. Hydrol. 2017, 554, 306–316. [Google Scholar] [CrossRef]
- Yuan, Y.; Yuan, X. An improved PSO approach to short-term economic dispatch of cascaded hydropower plants. Kybernetes 2010, 39, 1359–1365. [Google Scholar] [CrossRef]
- Zheng, J.; Yang, K.; Lu, X. Limited adaptive genetic algorithm for inner-plant economical operation of hydropower station. Hydrol. Res. 2013, 44, 583–599. [Google Scholar] [CrossRef]
- Adarsh, B.R.; Raghunathan, T.; Jayabarathi, T.; Yang, X.-S. Economic dispatch using chaotic bat algorithm. Energy 2016, 96, 666–675. [Google Scholar] [CrossRef]
- Villeneuve, Y.; Séguin, S.; Chehri, A. AI-Based Scheduling Models, Optimization, and Prediction for Hydropower Generation: Opportunities, Issues, and Future Direction. Energies 2023, 16, 3335. [Google Scholar] [CrossRef]
- Li, P.; Liu, Y. Construction of Turbine Operating Characteristic Surface Based on Moving Least Squares Method. Hydropower Energy Sci. 2023, 41, 183–186+17. [Google Scholar]
- Landi, F.; Baraldi, L.; Cornia, M.; Cucchiara, R. Working Memory Connections for LSTM. Neural Netw. 2021, 144, 334–341. [Google Scholar] [CrossRef] [PubMed]
- Yao, L.; Pan, Z.; Ning, H. Unlabeled Short Text Similarity with LSTM Encoder. IEEE Access 2019, 7, 3430–3437. [Google Scholar] [CrossRef]
- Wang, W.; Tong, M.; Yu, M. Blood Glucose Prediction with VMD and LSTM Optimized by Improved Particle Swarm Optimization. IEEE Access 2020, 8, 217908–217916. [Google Scholar] [CrossRef]
- Biswas, T.K.; Giri, K.; Roy, S. ECKM: An improved K-means clustering based on computational geometry. Expert Syst. Appl. 2023, 212, 118862. [Google Scholar] [CrossRef]
- Zhao, X. Realization of Intelligent Power Distribution Monitoring System Based on Data Mining Technology; Nanjing University of Posts and Telecommunications: Nanjing, China, 2021. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Layers (Types) | Output Dimension |
|---|---|
| dense1 (FC) | 2 |
| lstm1 (LSTM) | |
| dropout1 (Dropout) | |
| lstm2 (LSTM) | |
| dropout2 (Dropout) | |
| dense2 (FC) | 1 |
| Methodologies | SVM | ELM | LSTM | I-LSTM | |
|---|---|---|---|---|---|
| Indicator | |||||
| MSE | 0.57100 | 0.00160 | 0.00140 | 0.00086 | |
| MAE | 0.59160 | 0.03470 | 0.03260 | 0.02590 | |
| RMSE | 0.75560 | 0.04000 | 0.03840 | 0.02930 | |
| Parameters | Value |
|---|---|
| Number of binary trees (n_estimators) | 130 |
| Maximum tree depth (max_depth) | 3 |
| Minimum number of samples of nodes (min_samples_leaf) | 1 |
| Input matrix dimensions (input_shape) | (4397*2, 4397*6) |
| Output matrix dimensions (output_shape) | 6 |
| Indicators Power | Total Water Consumption (m3) | Proportion of Non-Economic Operating Zone (%) | Number of Start–Stop Cycles | Maximum Power Output Fluctuation Rate % | Average Efficiency % | |
|---|---|---|---|---|---|---|
| Output Scenario | ||||||
| Sunny day | 69,504,958 | 0 | 2 | 1.5614 | 93.31 | |
| Cloudy day | 66,545,968 | 0 | 0 | 3.2757 | 93.15 | |
| Rainy day | 66,985,439 | 15.43 | 2 | 1.6245 | 93.54 | |
| Indicators Power | Total Water Consumption (m3) | Proportion of Non-Economic Operating Zone (%) | Number of Start–Stop Cycles | Maximum Power Output Fluctuation Rate % | Average Efficiency % | |
|---|---|---|---|---|---|---|
| Output Scenario | ||||||
| Sunny day | 70,504,958 | 0 | 2 | 1.1893 | 93.41 | |
| Cloudy day | 67,665,953 | 0 | 0 | 3.0375 | 93.05 | |
| Rainy day | 67,423,777 | 15.67 | 2 | 1.9425 | 93.84 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, H.; Yang, J.; Yu, Y.; Zheng, Y.; Zheng, X.; Hang, C. Intelligent Low-Consumption Optimization Strategies: Economic Operation of Hydropower Stations Based on Improved LSTM and Random Forest Machine Learning Algorithm. Mathematics 2024, 12, 1292. https://doi.org/10.3390/math12091292
Pan H, Yang J, Yu Y, Zheng Y, Zheng X, Hang C. Intelligent Low-Consumption Optimization Strategies: Economic Operation of Hydropower Stations Based on Improved LSTM and Random Forest Machine Learning Algorithm. Mathematics. 2024; 12(9):1292. https://doi.org/10.3390/math12091292
Chicago/Turabian StylePan, Hong, Jie Yang, Yang Yu, Yuan Zheng, Xiaonan Zheng, and Chenyang Hang. 2024. "Intelligent Low-Consumption Optimization Strategies: Economic Operation of Hydropower Stations Based on Improved LSTM and Random Forest Machine Learning Algorithm" Mathematics 12, no. 9: 1292. https://doi.org/10.3390/math12091292
APA StylePan, H., Yang, J., Yu, Y., Zheng, Y., Zheng, X., & Hang, C. (2024). Intelligent Low-Consumption Optimization Strategies: Economic Operation of Hydropower Stations Based on Improved LSTM and Random Forest Machine Learning Algorithm. Mathematics, 12(9), 1292. https://doi.org/10.3390/math12091292