Abstract
The complexity of estimating multivariate GARCH models increases significantly with the increase in the number of asset series. To address this issue, we propose a general regularization framework for high-dimensional GARCH models with BEKK representations, and obtain a penalized quasi-maximum likelihood (PQML) estimator. Under some regularity conditions, we establish some theoretical properties, such as the sparsity and the consistency, of the PQML estimator for the BEKK representations. We then carry out simulation studies to show the performance of the proposed inference framework and the procedure for selecting tuning parameters. In addition, we apply the proposed framework to analyze volatility spillover and portfolio optimization problems, using daily prices of 18 U.S. stocks from January 2016 to January 2018, and show that the proposed framework outperforms some benchmark models.
1. Introduction
Modeling the dynamics of high-dimensional variance–covariance matrices is a challenging problem in high-dimensional time series analysis and has wide applications in financial econometrics. Classical time series models for variance–covariance matrices assume that the number of component time series is low with respect to the number of observed samples. However, many financial and economic applications these days need to model the dynamics of high-dimensional variance–covariance matrices. For example, in modern portfolio management, the number of assets can easily be more than thousands and be larger or on the same order as the observed historical prices of the assets; in analyzing the movements in the financial markets of different products in different countries, it is critical to understand the interdependence and contagion effects of price movements over thousands of markets, while the amounts of jointly observed financial data are only available in decades.
In this paper, we propose an inference procedure with regularization for high-dimensional BEKK representations and obtain a class of penalized quasi-maximum likelihood (PQML) estimators. The regularization allows us to identify important parameters and shrink the non-essential ones to zero, hence providing an estimate of sparse parameters in BEKK representations. Under some regularity conditions, we establish some theoretical properties, such as the sparsity and the consistency, of the PQML estimator for BEKK representations. The proposed procedure is a fairly general framework that can be applied to a large class of high-dimensional MGARCH models; by applying our regularization techniques, the complexity of making inferences from high-dimensional MGARCH models can be greatly reduced and the intrinsic sparse model structures can be uncovered. We carried out simulation studies to show the performance of the proposed inference framework and the procedure for selecting tuning parameters. In addition, we applied the proposed framework to analyze volatility spillover and portfolio optimization problems, using daily prices of 18 U.S. stocks from January 2016 to January 2018. In the comparison of portfolio optimization based on different MGARCH models, we show that the proposed framework outperforms three benchmark models, i.e., the constant covariance model, the factor MGARCH model, and the dynamic conditional correlation model.
The proposed framework can be viewed as an extension of the literature on regularization techniques for converting high-dimensional linear models to nonlinear time series models. Since () introduced LASSO for linear regression models, various regularization techniques concerning high-dimensional statistical inference have been studied for various problems in linear models. For example, () proposed the smoothly clipped absolute deviation (SCAD) penalty that generates sparse estimation of regression coefficients with reduced bias and explored the so-called “oracle property”, in which the estimator has asymptotic properties that are equivalent to the maximum likelihood estimator in the non-penalized model. () proposed adaptive LASSO by adding adaptive weights for different parameters in the penalty to obtain better estimator performance. () proposed a group LASSO penalty to solve the problem of selecting grouped factors in regression models. () proposed a minimax concave penalty that gives nearly unbiased variable selection in linear regression. In addition to discussions on regularized estimation in high-dimensional statistics, which relies primarily on independent and identically distributed (i.i.d.) samples and linear models, regularization techniques have also been applied to study inference problems in high-dimensional linear time-series models. For instance, () studied a class of penalty functions and showed the oracle properties for the estimators in high-dimensional vector autoregressive (VAR) models. () investigated the theoretical properties of -regularized estimates in high-dimensional stochastic regressions with serially correlated errors and transition matrix estimation in high-dimensional VAR models. () developed a regularization framework for full-factor MGARCH models (), in which the dynamics of covariance matrices are determined by the dynamics of univariate GARCH processes for orthogonal factors. Using the group LASSO technique, () studied the inference problem for MGARCH models with vine structure, an alternative to dynamic conditional correlation MGARCH models.
The proposed regularization framework is also related to the problem of estimating covariance matrices using various shrinkage and regularization methods. For instance, () proposed an optimal linear shrinkage method to estimate constant covariance matrices of p-dimensional i.i.d. vectors, and, later on, () extended the method and developed nonlinear shrinkage estimators for high-dimensional covariance matrices. () and () proposed covariance regularization procedures that are based on the thresholding of sample covariance matrices to estimate inverse covariance matrices. () studied sparsistency and rates of convergence for estimating covariance based on penalized likelihood with nonconcave penalties, and () estimated high-dimensional inverse covariance by minimizing -penalized log-determinant divergence. This method is also called graphical LASSO and was studied in () and (). We note that all these discussions focus on high-dimensional constant covariance matrices; thus, they do not involve the dynamics of covariance matrices.
The remainder of the paper is organized as follows. Section 2 provides a literature review of MGARCH models and their applications in volatility spillover. Section 3 explains the BEKK model with -penalty functions in detail. In Section 4, we provide theoretical properties and implementation procedures for the regularized BEKK model. Simulation results and real data analysis are presented in Section 5 and Section 6, respectively. Section 7 gives concluding remarks.
2. Literature Review
Inspired by the idea of univariate generalized autoregressive conditionally heteroskedastic (GARCH) models (); (); (); (), various multivariate GARCH (MGARCH) models were proposed to characterize the dynamics of covariance matrices during the last three decades. Among these MGARCH models, the Baba–Engle–Kraft–Kroner (BEKK) model () uses a general specification to describe the dynamics of covariance matrices of an n-dimensional multivariate time series. Since such a specification contains unknown parameters of order , inference on the BEKK model becomes complicated, even for not very large ns. When increases with the same order as, or larger order than, the length of the time series, inference on the MGARCH–BEKK representation becomes even more difficult due to “the curse of dimensionality”.
To reduce the complexity of inference procedures for unknown parameters in MGARCH models, other forms of MGARCH specifications were proposed to reduce the number of unknown parameters in the model. An important improvement to MGARCH models is the dynamic conditional correlation (DCC) model (; ; ; ). The DCC model allows for time-varying conditional correlations and reduces the dimensionality by factorizing the conditional covariance matrix into the product of a diagonal matrix of conditional standard deviations and a correlation matrix that evolves dynamically over time. Other forms of MGARCH specifications make more assumptions on structures and dynamics of covariance matrices and include, for example, the MGARCH in mean model (), the constant conditional correlation GARCH model (; ; ), the time-varying conditional correlation MGARCH model (), the orthogonal factor MGARCH model (; ), and so on. Although these MGARCH models provide relatively simple inference procedures, the assumptions on dynamics of covariance matrices are usually too specific to capture the complexity of dynamics of covariance matrices. Furthermore, these models still fail to address the issue of making inference on high-dimensional MGARCH models.
In addition to modeling the joint behavior of volatilities for a set of returns, another aspect of MGARCH models is to characterize volatility spillover in financial markets. Volatility spillover refers to as the process and magnitude by which the instability in one market affects other markets. Volatility spillover is widely observed in equity markets (), bond markets (), futures markets (), exchange markets (), markets of equities and exchanges (), various industries and commodities (; ), and so on. Understanding volatility spillover can provide an insight into financial vulnerabilities, as well as the source and nature of financial exposures, for academic researchers, financial practitioners, and regulatory authorities. For investors, as significant volatility spillover may increase non-systemic risk, understanding volatility spillover can help them diversify the risks associated with their investment. For financial sector regulators, understanding volatility spillover can help them formulate appropriate policies to maintain financial stability, especially when stress from a particular market is transmitted to other markets, such that the risk of systemic instability increases. MGARCH models are generally used to characterize volatility spillover in the markets, which are represented via a low-dimensional multivariate series; see (), (); (), (), and (). In particular, () used multivariate GARCH-in-mean model to study the economic spillover effect across five countries, () applied a BEKK(1,1) model to study transmission of weekly equity returns and volatility in nine Asian countries from 1988 to 2000, and () employed the BEKK(1,1) specification to study three-dimensional US sector indices. Spillover effect has also been explored recently for other financial markets, such as cryptocurrency markets () and European banks with GARCH models (). Additionally, there has been an investigation into the spillover effects using network representations derived from GARCH models in recent studies (; ).
The aforementioned studies on spillover effects rely on the foundational structures of the DCC model for analysis (; ; ). Although these MGARCH models provide relatively simple inference procedures, the assumptions on dynamics of covariance matrices are usually too specific to capture the complexity of the dynamics of covariance matrices. Moreover, these models still fail to address the issue of making inference on high-dimensional MGARCH models. Under these constraints, the performance and accuracy of these simplified MGARCH models need further investigation in real markets ().
3. The MGARCH–BEKK Representations with Regularization
We first introduce the following notations. Given a vector x and a matrix A, the ith component of x and the th elements of A are written as and , respectively. The jth column and the ith row vectors of A are denoted as and , respectively. is the Euclidean norm for vector x. is the largest element of x in the modulus. is the spectral radius of A, i.e., the largest modulus of eigenvalues of A. and are the minimum and maximum eigenvalues of A, respectively. is the spectral norm, i.e., a square root of . represents the operator norm induced by , or the largest absolute row sum. For any matrix A and vector x such that is well defined, let . We use to denote the sign of if , and otherwise.
3.1. The MGARCH–BEKK Representation
Let be the vector of returns on n assets in period t. Let be i.i.d. n-dimensional standard normal random vectors. Let be the sigma field generated by the past information from s. Then, is measurable with respect to ; the distribution of can be specified as
where is an identity matrix. Denote the conditional covariance matrix of given as , i.e., . () proposed the following BEKK model to characterize the dynamics of :
where , and are parameter matrices, C is an triangular matrix, and the summation limit K determines the generality of the process.
To illustrate the idea, we consider BEKK(1,1) in our examples with in this paper, which can be written as
in which , and C are real matrices. And, without loss of generality, we choose to be symmetric. For identification purposes, () showed the following property for the BEKK model.
Proposition 1.
Suppose that the diagonal elements in C, , and are positive. Then, there exists no other C, A, or B in Model (3) that gives an equivalent representation.
Proposition 1 is also known as the identification condition ().
Let vec and vech be the vector operators that stack the columns of a matrix and the lower triangular part of a matrix, respectively. That is, if
then
and
Then, Model (3) can be rewritten in a vector form:
in which , , and ⊗ is the Kronecker product. Since the covariance matrices are symmetric, we can also write (3) in the vector-half form:
where , , and and are matrices of dimension extracting the upper triangular parts of symmetric matrices and . Note that dim and dim. For convenience, we denote by the parameter vector in Model (3), in which , so that the matrices C, , and are functions of : . And we denote by the true parameter vector of the model.
We assume that the values of in (1) are stationary; then, the following stationary condition should be imposed for the BEKK Model (5) (see () and ()).
Condition 1 (Stationary Condition).
The p-dimensional return series in (1) is stationary if the following conditions hold for Model (3):
- (i)
- is a continuous function of , and there exists , , where represents the determinant of a matrix;
- (ii)
- For any , and are continuous functions of ;
- (iii)
- For any , , i.e., the largest modulus of eigenvalues of is less than 1.
3.2. Likelihood Function
In this section, we discuss some properties of the likelihood of the BEKK model. Assume that follows a standard n-dimensional Gaussian distribution. Ignoring constants, we can write the quasi-log-likelihood as
Taking the derivative on with respect to the ith element of , we obtain
which can be computed recursively. The derivative in (7) has the following property (the proof is given in Appendix A).
Proposition 2.
Let ; then,
where and are two constants.
Assume that is twice continuously differentiable in a neighborhood of We define the averages of the score vector and Hessian matrix as follows:
where and . Taking the derivative of (6) with respect to yields
in which represents the trace of a matrix. () showed the following property for .
Proposition 3.
Under Condition 1, the following properties hold:
- (i)
- When , for a nonrandom positive-definite matrix H;
- (ii)
- For the Fisher information matrix , ;
- (iii)
- For , is bounded for all and .
In the sparse representation, the majority elements of the true parameter vector are exactly 0. Hence, we could partition into two sub-vectors. Let be the set of indices and be the q-dimensional vector composed of the nonzero elements Similarly, we define as a -dimensional zero vector. Without loss of generality, is stacked as . For convenience, we define the average of the “score subvector” and the “Hessian sub-matrix” by and . Similarly, we define . We also denote as
Proposition 4.
Here, means that with probability 1 when and c is a constant. Proposition 4(i) shows that the fourth moment of the score function is always finite. Proposition 4(ii) indicates that is almost surely positive and bounded away from 0. Hence, when the penalty is combined with the quasi-likelihood function, the concavity around can be ensured, so that a local maximizer can be obtained. Proposition 4(iii) is trivial in linear models, but not in our case. The proof of Proposition 4 is given in Appendix A.The quasi-log-likelihood function for the BEKK(1,1) has the following properties:
- (i)
- For , , where is the ith element of ;
- (ii)
- For a sufficiently large T, is almost surely positive definite, and
- (iii)
- There exists a neighborhood of such that, for all and and some ,
3.3. Penalty Function and Penalized Quasi-Likelihood
Before discussing the consistency of the sparse estimator, we introduce the following condition, by following the strong irrepresentable condition for LASSO-regularized linear regression models in ().
Condition 2 (Irrepresentable condition).
There exists a neighborhood of , such that
for a constant c that takes its value in (0,1) almost surely.
Definition 1.
The half of the minimum signal d is defined as
Assume that is an penalty function, i.e., . We consider the following penalized quasi-likelihood (PQL):
in which is the penalty term and is the regularization parameter determining the size of the model. If maxmizes the PQL, i.e.,
we say that is a penalized quasi-maximum likelihood estimator (PQMLE).
Similar to () and (), we add some conditions on the penalty function and the half minimum signal.
Condition 3.
The penalty function satisfies the following properties:
- (i)
- for some , and large T. Here, means is bounded by a constant and means when ;
- (ii)
- for some and large T, where d is the half-minimum signal we defined before.
4. Properties of the PQML Estimator and Implementation
This section studies the sparsity and the consistency of the PQML estimator and discuss some implementation issues.
4.1. Sparsity of the PQML Estimator
First, we introduce three lemmas whose proofs are given in Appendix A. For convenience, we denote , which is a set of indices corresponding to all nonzero components of , where supp is the notation of support set and is a subvector of , formed by its restriction to . Then, represents a set of indices corresponding to all 0 components in . We also denote ⊙ as the Hadmard product.
To show the weak oracle property of the PQML estimator, we also need the following lemma.
Lemma 2.
Let be a martingale difference sequence with for all t, where and is a constant. Then, we have
Then, the weak oracle property of the PQML estimator can be established by the following theorem, whose proof is provided in Appendix A.
Theorem 1.
(-PQML estimator) Under Conditions 2 and 3, for the penalty function , in which and , if
with , and , then there exists a local maximizer for , such that the following properties are satisfied:
- (i)
- (Sparsity) with probability approaching one;
- (ii)
- (Rate of convergence)
is equivalent to when . The growth rate of p is controlled by and q is slower than with . For example, to make this growth rate of q much slower than p, we can find a set of values for , and that satisfy the conditions above. Since, in our case, , we have and, hence, it is possible for n to exceed the sample size T. Although the difference between the rates of p and n is not as large as that in (), in which and , it is enough to be applied in most cases in practice.
4.2. Implementation and Selection of
To compute the whole regularization path of -PQML estimators, we note that several algorithms have been proposed to solve penalized optimization problems. For example, () proposed the least-angle regression (LARS) algorithm to compute an efficient solution to the optimization problem for LASSO. Later on, pathwise coordinate descent methods were proposed to solve the LASSO-type problem efficiently; see () and (). For the PQML estimator, we used an algorithm inspired by the BLasso algorithm (, ) with some necessary modifications since the BLasso algorithm does not need to explicitly calculate the first derivatives and second derivatives of the likelihood function, which are complicated in our case. We note that the original BLasso algorithm uses 0 as initial values for all parameters, but the diagonal elements of A and B are positive by definition, so we make the following modification. We set 0 as the initial values for all off-diagonal elements in A, B, and C, and set the estimated values of fitting the component series into a univariate GARCH model as the initial values of the diagonal elements in parameter matrices A, B, and C.
Another issue in the implementation is to select the tuning parameter , which leads to the problem of model selection. The tuning parameter can be chosen by several criteria. For example, it is usually easy to consider the Akaike information criterion (AIC), the small-sample corrected AIC (AICC), and Bayesian information criterion (BIC) criteria to select the tuning parameter. In addition, () proposed a modified BIC criterion and () extended it for the case . () proposed using Cohen’s kappa coefficient, which measures the agreement between two sets. Another method for model selection is to use cross-validation (CV). () used CV to choose the best model among model selection procedures such as AIC and BIC. In our study, we apply the AIC and BIC criteria on the testing data and select the best tuning parameters. Note that, since our data are ordered, k-fold CV is not applicable here and the data are split in time order.
5. Simulation
In this section, we study the performance of the regularized BEKK models on some simulated examples. Consider Model (3) with and . Note that we then have parameters, as matrix C is lower triangular. We assume that the parameter matrices satisfy the stationary condition, Condition 2, and, for identification purposes, we assume that the diagonal elements in C are positive, , and . We consider two cases for matrices A, B, and C, which are summarized in Table 1. In both cases, the indices of nonzero elements in coefficient matrices A, B, and C are randomly generated. To ensure that the matrices satisfy Condition 1, values of the diagonal elements in A and B are randomly generated from a uniform distribution on U, and the off-diagonal nonzero elements in A and B are generated from U. All the nonzero elements in C are generated from U.

Table 1.
Parameter matrices in simulations.
For each case, we simulate the data with , and then use the proposed regularized procedure to make inference on the model. Since the diagonal elements in A, B, and C cannot be zero, we do not shrink the diagonal elements in A, B, and C. Additionally, we set the estimates of parameters in univariate GARCH models for each component series as the initial values of diagonal elements in A, B, and C.
To demonstrate the performance of our estimates, we consider three measurements. The first is the success rate in estimating zero and nonzero elements in or parameter matrices:
The second measure is the root of mean squared errors, which is defined as . The third measure is the Kullback–Leibler information, which is given by
where . We run simulations for each case, and present the performance measures and their standard errors (in parentheses) for different s in Table 2.
Table 2.
Performance measures in two cases.
To select the tuning parameter , we use the first 500 samples as the training data and the last 100 samples as the test data. The training data are used to estimate model parameters for a given , and the test data are used to choose the best , i.e., the one that gives the minimum AICs and BICs. That is,
in which the and are defined as
where, in this case, , , and
Figure 1 shows the histograms of selected s via BIC and AIC with CV for Cases 1 and 2. In general, we can see from Figure 1 that is favored by BIC and AIC when its value is between and 2. However, slight differences between these two cases can be found. For Case 1, s around 1 are most favored by both BIC and AIC, while, for Case 2, s around 1 and 2 are most favored by BIC and AIC, respectively.
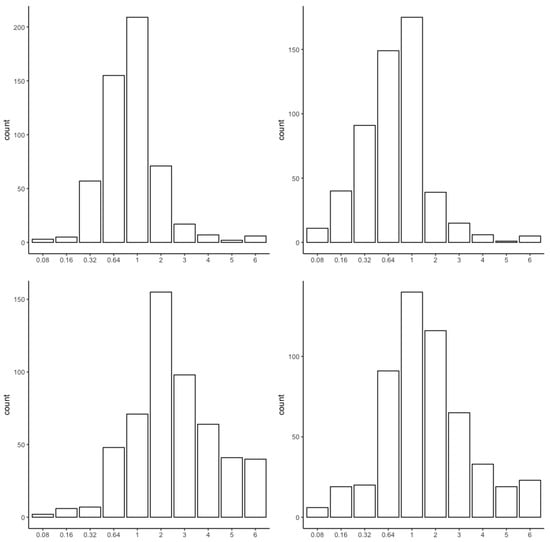
Figure 1.
Histograms of selected in Cases 1 (top) and 2 (bottom) via BIC (left) and AIC (right).
6. Real Data Applications
In this section, we use the regularized BEKK representation to study the volatility spillover effect and find optimal Markowitz’s mean–variance portfolios. The data we studied consist of daily log-returns of 18 stocks during the period 4 January 2016–31 January 2018, which are listed in Table 3 (). Figure 2 shows the time series of these 18 stocks and Table 4 summarizes the sample mean, the sample standard deviation, the sample skewness, the sample kurtosis, and the correlations of these 18 series. All the correlations are positive for every two stocks in the selected period, and, except for IPG, all the stocks have a positive mean. The sample kurtosis for some stocks is way larger than 3, which indicates that we cannot simply assume that those returns are following normal distributions individually. Hence, it is natural to employ a suitable time series model to examine the data.
Table 3.
Full names of 18 tickers.
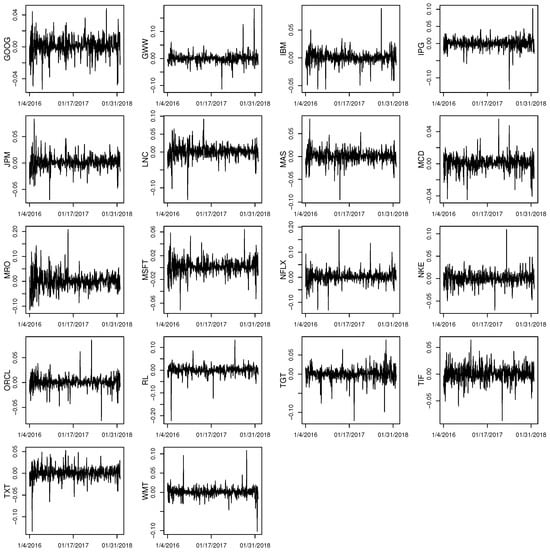
Figure 2.
Daily returns of 18 stocks from 4 January 2016 to 31 January 2018.
Table 4.
Correlation and statistical features of 18 stocks for 2016–2017.
6.1. Volatility Spillovers
To use the MGARCH–BEKK representation to analyze the market, consisting of 18 stocks, we should realize that certain types of regularization or shrinkage are necessary, due to the complexity of the volatility dynamics. In particular, we use the proposed -regularized BEKK(1,1) model and procedure to study the volatility spillover among the 18 stocks. We first compute the PQML estimates of the model for different s. Figure 3 shows the estimated structures of estimated coefficient matrices and for , in which the nonzero values of and are represented as the directional lines among stocks. Since matrices A and B in the model are not symmetric before the quadratic forms, we use the directional lines to distinguish the nonzero elements between upper-diagonal and lower-diagonal elements. Specifically, if , the directional line progresses from i to j. As the PQML estimates and tell us the significant interdependence and contagion effects of the 18 stocks, the network structures in Figure 3 provide a clear representation on volatility spillover. Furthermore, we notice that, for some moderate values of , for example, , is very sparse, whereas demonstrates more interdependence among stocks. When larger values of are used in the regularization procedure, the PQML estimates are quickly shrunk into diagonal matrices, and also become more sparse than for the case .
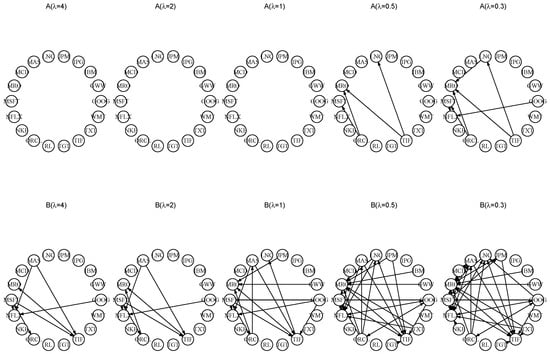
Figure 3.
The network structure of estimated matrices A (top) and B (bottom) under different s.
Using the PQML estimates of , , and and the BEKK(1, 1) representation, we compute the estimated volatilities and the dynamic correlations among 18 stocks. Figure 4 shows the volatilities estimated by the regularized BEKK(1,1) model with and univariate GARCH models. Note that most volatility series estimated by the three models are similar, except for stocks NFLX, ORCL, and TIF. We also show the estimated dynamic correlations among 18 stocks in a regularized BEKK(1,1) model with in Figure 5. We note that most correlations among the 18 stocks are positive during the sample period.
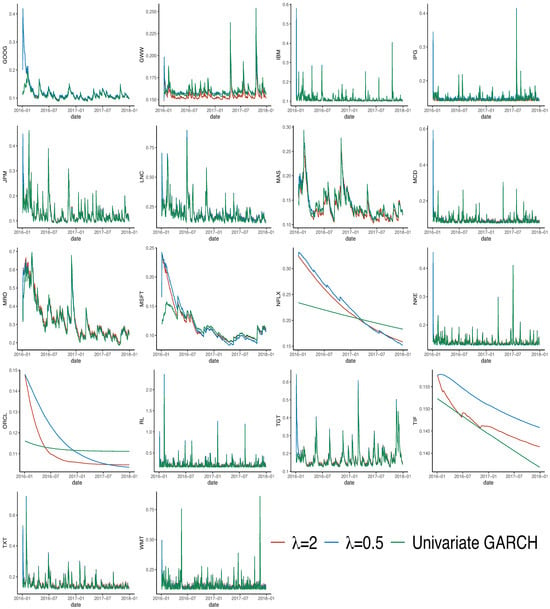
Figure 4.
Estimated volatilities by regularized BEKK(1,1) with (red lines), (blue lines), and univariate GARCH models (green lines).
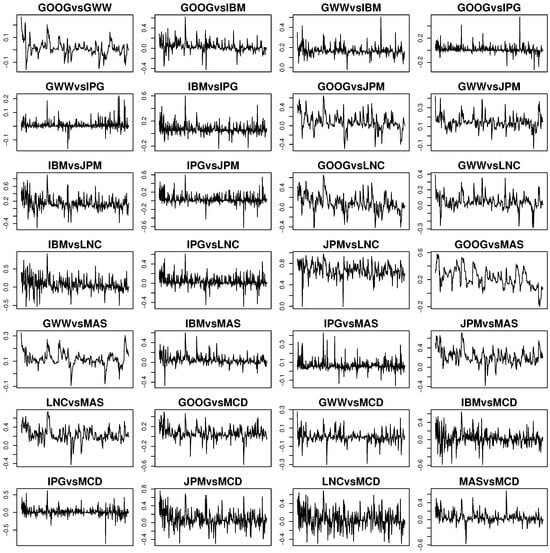
Figure 5.
Daily estimated conditional correlations when .
To show the overall volatility spillover, we extend the idea of the spillover index in (). Specifically, note that , where is the unique lower-triangular Cholesky factor of . We denote elements of by ; then, the Spillover Index is defined as
where n is the number of stocks, which is equal to 18. We plot the daily spillover indices of 18 stocks for and . The spillover indices during the sample period vary between 5% and 80%, and smaller s seem to generate more correlations among stocks. In particular, three big spikes can be found on 4 February 2016, 24 June 2016, and 9 November 2016. In addition to finding the PQML estimates for different s, we also find the whole regularization path. Note that the number of parameters in the BEKK(1,1) model for 18 stocks is , and we only show the regularized path for off-diagonal elements in , , and . And both plots are shown in Figure 6.
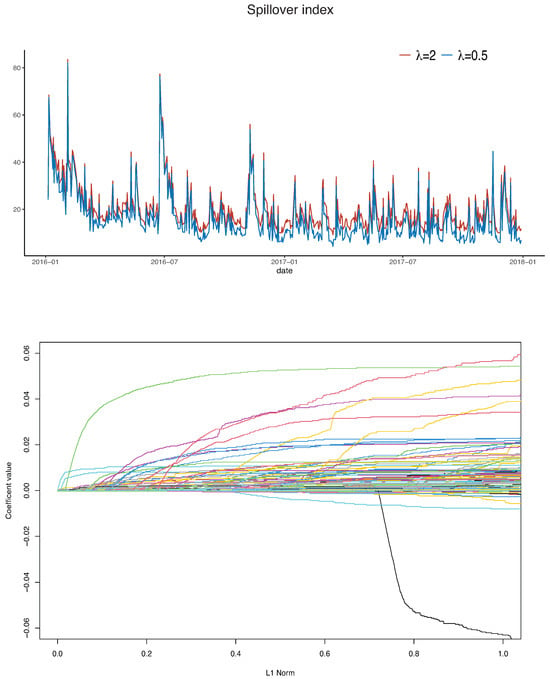
Figure 6.
Daily spillover index (top) and regularization paths of estimated off-diagonal parameters in BEKK regularization Model represented by different colors (bottom).
6.2. Portfolio Optimization
We further apply the regularized BEKK model to Markowitz mean–variance portfolio optimization (). Using portfolio variance as a measure of the risk, Markowitz portfolio optimization theory provides an optimal pay-off between the profit and the risk. Since the means and covariance matrix of assets are assumed to be known in the theory, they need to be estimated before being plugged into the framework. For high-dimensional portfolios, regularized methods are commonly used to achieve better performance. For instance, () and () used an penalty function for sparse portfolios, and () used a concave optimization-based approach to estimate the optimal portfolio. In our case, we use the regularized BEKK model to predict the covariance matrices in the next period, and then apply Markowitz portfolio theory to find the optimal portfolios.
In particular, we assume that the portfolio consists of risky assets and denote and as the mean and covariance matrix, respectively, of the n risk assets at time t. Let be an n-dimensional vector of ones. Markowtiz mean–variance portfolio theory minimizes the variance of the portfolio , subject to the constraint and , where is the target return. When short selling is allowed, the efficient portfolio can be explicitly expressed as
where , , , and . When the target return is chosen to minimize the variance of the efficient portfolio, we obtain the global minimum variance (GMV) portfolio:
For comparison purposes, we also use another three multivariate volatility models to predict the covariance matrices of stocks. The first is very simple, and it assumes a constant covariance matrix for n stocks. The second is a factor-GARCH model (; ; ; ), which assumes the following for asset return vector , factors , and volatilties of k independent factors:
where W is a lower-triangular matrix with diagonal elements equal to 1 and is a vector of k independent factors. The third covariance model is a dynamic conditional correlation GARCH (DCC–GARCH) model (), which has the form
where , , , and is the conditional correlation matrix at time t, that is, . And C is the unconditional correlation matrix, i.e., . The matrix can be interpreted as a conditional covariance matrix of devolatilized residuals. For the dynamics of the univariate volatilities, s are assumed to follow a GARCH(1,1) process:
where are GARCH(1,1) parameters.
Let 2 January 2018, ⋯, 31 January 2018; we first fit 4 covariance models to the returns of 18 stocks from 4 January 2016 to t, and then compute the 1-day-ahead prediction of covariance matrices. Using the predicted covariance matrices, we compute the efficient portfolios and for , and . Table 5 shows the means, standard deviations (SD), and the information ratios (IR, i.e., ratio of means and standard deviations) for realized portfolio returns in the month of January 2018. As argued by () and (), these statistics are good measurements of the out-of-sample performance of Markowitz portfolios. As () claimed that it is difficult to outperform equally weighted portfolios in terms of the out-of-sample mean for Markowitz portfolios, we also include the performance of equally weighted portfolios as a benchmark in Table 5. We note that all the means generated from four covariance models are smaller than that from equally weighted portfolios (0.430%), and the standard deviations of covariance models, except the factor GARCH, are smaller than that of equally weighted portfolios. Notably, the regularized BEKK model consistently maintains the second-best mean performances at 0.39%, 0.352%, 0.382%, and 0.416% for GMV, and values of 0.15%, 0.10%, and 0.05%. However, the information ratio of the regularized BEKK model surpasses that of all other portfolios. It achieves the highest values across all scenarios—0.601, 0.540, 0.654, and 0.657—for GMV and , and . These results show the robustness and efficiency of the regularized BEKK model in portfolio optimization, consistently delivering competitive mean performance and superior risk-adjusted returns compared to other covariance models.
Table 5.
Performance of portfolios using different covariance models.
7. Discussion and Conclusive Remarks
Modeling the dynamics of high-dimensional covariance matrices is an interesting and challenging problem in both financial econometrics and high-dimensional time series analysis. To address this issue, this paper proposes an inference procedure with regularization for the sparse representation of high-dimensional BEKK and to obtain a class of penalized quasi-maximum likelihood estimators. The proposed regularization allows us to find significant parameters in the BEKK representation and shrink the non-essential ones to zero, hence providing a sparse estimate of the BEKK representations. We show that the sparse BEKK representation has suitable theoretical properties and is promising for applications in portfolio optimization and volatility spillover.
The proposed sparse BEKK representation also contributes to the application of machine learning methods in time series modeling. As most discussion on applying regularization methods to time series modeling focuses on regularizing high-dimensional vector autoregressive models and their variants (; ), it seems that the sparse representation of dynamics of high-dimensional variance–covariance matrices has been ignored in the literature. While obtaining a sparse representation of the dynamics within high-dimensional variance–covariance matrices is crucial to enhance interpretability in time series modeling, our study bridges this gap by considering a basic regularization method. One obvious extension from our current study is to replace the penalty with other types of penalty for high-dimensional MGARCH models, for instance, the SCAD penalty (), the adaptive LASSO (), and the group LASSO (). With different types of penalty functions, one can regularize the assets in the model with different requirements, hence causing the estimates to have different kinds of asymptotic properties.
As the proposed sparse BEKK representation simplifies the dynamics of covariance matrices of high-dimensional time series, it has advantages over existing MGARCH models in some financial applications. In particular, the sparse BEKK representation can capture significant volatility spillover effects in high-dimensional financial time series, which usually cannot be analyzed using other MGARCH models. Since significant volatility spillover is captured, the proposed method also improves the performance of portfolio optimization based on the dynamics of high-dimensional covariance matrices. The proposed procedure can certainly be extended to incorporate more empirical aspects of financial time series. Taking the leverage effect as an example, one may modify the regularization procedure to obtain sparse representation of high-dimensional multivariate exponential or threshold GARCH models.
Although the proposed framework shows advantages in modeling dynamics of high-dimensional covariance matrices, the computational challenge is not completely resolved. The main reason is that the proposed inference procedure involves a step of computing derivatives via the Kronecker product of parameter matrices. Since the Kronecker product turns two matrices into an matrix, the requirement for computational memory resources increases significantly. Hence, the proposed procedure is suitable for problems in which the number of component time series ranges from several to 100. If the number of assets progresses beyond 200, the computational cost is still a major concern. One possible remedy for this is training a neural network to approximate the regularized likelihood of the high-dimensional model. In such a way, the proposed regularization using the high-dimensional MGARCH model can be extended to characterize the dynamics of covariance matrices of larger size.
Author Contributions
Conceptualization, H.X.; methodology, H.X., H.Z. and S.Y.; software, S.Y.; validation, S.Y., H.Z. and H.X.; formal analysis, S.Y.; investigation, S.Y., H.X. and H.Z.; resources, S.Y.; data curation, S.Y.; writing—original draft preparation, S.Y., H.X. and H.Z.; writing—review and editing, H.X.; visualization, S.Y.; supervision, H.X.; project administration, H.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available by request.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AIC | Akaike information criterion |
| BEKK | Baba–Engle–Kraft–Kroner |
| BIC | Bayesian information criterion |
| CV | Cross-validation |
| DCC | Dynamic conditional correlation |
| GARCH | Generalized autoregressive conditionally heteroskedastic |
| GMV | Global minimum variance |
| IR | Information ratio |
| LARS | Least-angle regression |
| LASSO | Least absolute shrinkage and selection operator |
| MGARCH | Multivariate GARCH |
| PQL | Penalized quasi-likelihood |
| PQML | Penalized quasi-maximum likelihood |
| SCAD | Smoothly clipped absolute deviation |
| SD | Standard deviation |
Appendix A. Proofs of Propositions, Lemmas, and Theorems
Appendix A.1. Proof of Propostion 2
Let ,, and be defined by
where , and let
with dimensions .
Define and
with convention if and if Then, the model can be written as
where L is the backshift operator . Here, is fixed and depends on but is not a function of . Then, we have
Since
we have
Applying Lemma A.3. from (), for all k, we have
in which is a fixed number, is a constant independent of , and .
To bound (A1), there are three terms to bound:
using , where is a constant that only depends on And, if this term is then easily bounded because is the nilpotent and all sums are finite. In the same way,
Finally,
Denote the first and second sums on the right-hand side of the inequality as and , respectively, we have
and
By our assumption, are all bounded. And there exists a constant w such that Hence,
where , and . □
Appendix A.2. Proof of Proposition 4
As , where denote the trace of a matrix, and , we, hence, have which means that is a martingale difference. Then, we want to prove that holds for . By Lemma 2, this proof is thus completed if we show that By Proposition 2, . Since
it is equivalent to show that
Since and is finite, there exists a constant M such that for all t. Additionally, , then
Because , there exists a constant k such that . Hence, if we let
where are constants. Since , where follow a normal distribution, , hence, admit 16 moments of order. Hence, for i from 0 to 8. Hence, ; then, .
Next, we check (c) and (d). (c) is clear, as we said before. By (III) in Lemma 1, the derivative of is bounded. By the mean-value theorem,
Hence,
where is bounded by (iii) in Proposition 3. Hence, and lies between and .
Next, we verify (e) with . For every it is sufficient to show that for a vector Using the Cauchy–Schwarz inequality and property of the norm, the left-hand side is bounded by Since, from (I) and (II) in Lemma 1, and the result follows. □
Appendix A.3. Proof of Lemma 1
First, consider the PQL , as defined in (5), in the constrained -dimensional subspace of where denotes the subvector of formed by the components in . It follows from (12) that ) is strictly concave in a ball centered at This, along with (10), entails that , as a critical point of in , is the unique maximizer of in .
Now, we show that is indeed a strict local maximizer of on the whole space Take a small ball centered at such that . We then need to show that for any Let be the projection of onto , such that . Thus, it suffices to prove that . By the mean value theorem, we have
where the vector lies between and . Note that the components of are zero for their indices in and for . Therefore, we have
where is a subvector of formed by the components in . By (10), there exists some such that, for any in a ball in centered at with radius ,
Appendix A.4. Proof of Lemma 2
A Marcinkiewicz-–Zygmund inequality for martingales () states that
holds for . Because for all t, we have
Thus, the result follows. □
Appendix A.5. Proof for Theorem 1
For notational simplicity, we write, for example, as . Consider events
where and It follows from Bonferroni’s inequality and Markov’s inequality, together with Proposition 4(i), that
where the last two terms are because of the condition Under the event we will that there exists a solution to (10)–(12) with and for some
First, we prove that, for a sufficiently large T, Equation (10) has a solution inside the hypercube , when we suppose . Define the function by
Then, (10) is equivalent to To show that the solution is in the hypercube we expand around Function (A7) is written as
where lies on the line segment that joins and . Since the matrix is invertible by Proposition 4(ii), (A8) is further written as
We now derive bounds for the last two terms in (A8). We consider first. For any ,
by Condition 3(ii), and Using Condition 3(i), we have
This, along with the property of matrix norms and Proposition 4(ii), entails that, during the event
where the last equality follows from and Next, we consider . By the property of norms and Propositions 4(ii) and (iii),
Since and with ,
with for all By (A9), (A11), and(A12), for sufficiently large T, and for all
if and
if
By the continuity of and inequalities (A13) and (A14), an application of Miranda’s existence theorem tells us that has a solution in Clearly, also solves the equation with regard to the first equality in (A8). Thus, we have shown that (10) indeed has a solution in
Second, let , with as a solution to (10), and . Next, we show that satisfies (11) for the event . By the triangle inequality and mean value theorem, we have
where lies on the line segment joining and The first term of the upper bound in (A15) is negligible, so that it suffices to show that the second term is less than Since solves the equation in (12), we obtain
with lying between and . From Proposition 4(ii),(iii) and Condition 1, the last term in (A15) can be expressed as
By Condition 3(i), the first term in the last equation of (A16) is ; hence, (A16) is eventually less than 1. This verifies (11).
Finally, (12) is guaranteed by Lemma 1: we have as a strict local maximizer of with and in the event that Thus, the proofs of Theorems 1(a) and (b) are complete, by (A6). □
References
- Aielli, Gian Piero. 2013. Dynamic conditional correlation: On properties and estimation. Jouranl of Business and Economic Statistics 31: 282–99. [Google Scholar] [CrossRef]
- Alexander, Carol. 2000. Orthogonal methods for generating large positive semi-definite covariance matrices. In ICMA Centre Discussion Papers in Finance icma-dp2000-06. London: Henley Business School, Reading University. [Google Scholar]
- Ampountolas, Apostolos. 2022. Cryptocurrencies intraday high-frequency volatility spillover effects using univariate and multivariate GARCH models. International Journal of Financial Studies 10: 51. [Google Scholar] [CrossRef]
- Apergis, Nicholas, and Anthony Rezitis. 2001. Asymmetric cross-market volatility spillovers: Evidence from daily data on equity and foreign exchange markets. The Manchester School 69: 81–96. [Google Scholar] [CrossRef]
- Apergis, Nicholas, and Anthony Rezitis. 2003. An examination of okun’s law: Evidence from regional areas in greece. Applied Economics 35: 1147–51. [Google Scholar] [CrossRef]
- Baillie, Rechard T., and Tim Bollerslev. 1990. A multivariate generalized arch approach to modeling risk premia in forward foreign exchange rate markets. Journal of International Money and Finance 9: 309–24. [Google Scholar] [CrossRef]
- Basu, Sumanta, and George Michailidis. 2015. Regularized estimation in sparse high-dimensional time series model. The Annals of Statistics 43: 1535–67. [Google Scholar] [CrossRef]
- Bauwens, Luc, and Sébastien Laurent. 2005. A new class of multivariate skew densities, with application to generalized autoregressive conditional heteroscedasticity models. Journal of Business and Economic Statistics 23: 346–54. [Google Scholar] [CrossRef]
- Bickel, Peter J., and Elizaveta Levina. 2008. Covariance regularization by thresholding. The Annals of Statistics 36: 2577–604. [Google Scholar] [CrossRef] [PubMed]
- Billio, Monica, Massimiliano Caporin, Lorenzo Frattarolo, and Loriana Pelizzon. 2023. Networks in risk spillovers: A multivariate GARCH perspective. Econometrics and Statistics 28: 1–29. [Google Scholar] [CrossRef]
- Bollerslev, Tim. 1986. Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics 31: 307–27. [Google Scholar] [CrossRef]
- Bollerslev, Tim. 1990. Comparing predictive accuracy modelling the coherence in short-run nominal exchange rates: A multivariate generalized arch model. The Review of Economics and Statistics 72: 498–05. [Google Scholar] [CrossRef]
- Bollerslev, Tim, Robert Engle, and Jeffrey Wooldridge. 1988. A capital asset pricing model with time-varying covariances. Journal of Political Economy 96: 116–31. [Google Scholar] [CrossRef]
- Boudt, Kris, Jon Danielsson, and Sébastien Laurent. 2013. Robust forecasting of dynamic conditional correlation garch models. International Journal of Forecasting 29: 244–57. [Google Scholar] [CrossRef]
- Brodie, Joshua, Ingrid Daubechies, Christine De Mol, Domenico Giannone, and Ignace Loris. 2009. Sparse and stable markowitz portfolios. Proceedings of the National Academy of Sciences of the United States of America 106: 12267–72. [Google Scholar] [CrossRef]
- Cai, Tony, and Weidong Liu. 2011. Adaptive thresholding for sparse covariance matrix estimation. Journal of the American Statistical Association 106: 672–84. [Google Scholar] [CrossRef]
- Christiansen, Charlotte. 2007. Volatility-Spillover Effects in European Bond Markets. European Financial Management 13: 923–948. [Google Scholar] [CrossRef]
- Comte, Fabienne, and Offer Lieberman. 2003. Asymptotic theory for multivariate garch processes. Journal of Multivariate Analysis 84: 61–84. [Google Scholar] [CrossRef]
- DeMiguel, Victor, Lorenzo Garlappi, and Raman Uppal. 2007. Optimal versus naive diversification: How inefficient is the 1/N portfolio strategy? The Review of Financial Studies 22: 1915–53. [Google Scholar] [CrossRef]
- Diebold, Francis X., and Kamil Yilmaz. 2009. Measuring financial asset return and volatitliy spillovers, with application to global equity markets. Economic Journal 199: 158–71. [Google Scholar] [CrossRef]
- Di Lorenzo, David, Giampalo Liuzzi, Francesco Rinaldi, Fabio Schoen, and Marco Sciandrone. 2012. A concave optimization-based approach for sparse portfolio selection. Optimization Methods and Software 27: 983–1000. [Google Scholar] [CrossRef]
- Efron, Bradley, Trevor Hastie, and Robert Tibshirani. 2004. Least angle regression. The Annals of Statistics 32: 407–99. [Google Scholar] [CrossRef]
- Engle, Rober. 1982. Autoregressive conditional heteroskedasticity with estimates of the variance of united kingdom inflation. Econometrica 50: 987–1007. [Google Scholar] [CrossRef]
- Engle, Robert. 1990. Asset pricing with a factor-arch covariance structure: Empirical estimates for treasury bills. Journal of Econometrics 45: 213–37. [Google Scholar] [CrossRef]
- Engle, Robert. 2002. Dynamic conditional correlation: A simple class of multivariate generalized autoregressive conditional heteroskedasticity models. Journal of Business and Economic Statistics 20: 339–50. [Google Scholar] [CrossRef]
- Engle, Robert, and Kenneth Kroner. 1995. Multivariate simultaneous generalized arch. Econometric Theory 11: 122–50. [Google Scholar] [CrossRef]
- Engle, Robert, and Riccardo Colacito. 2006. Testing and valuing dynamic correlations for asset allocation. Journal of Business and Economic Statistics 24: 238–53. [Google Scholar] [CrossRef]
- Engle, Robert, Olivier Ledoit, and Michael Wolf. 2019. Large dynamic covariance matrices. Journal of Business and Economic Statistics 37: 363–75. [Google Scholar] [CrossRef]
- Engle, Robert, Takatoshi Ito, and Wen-Ling Lin. 1990. Meteor showers or heat waves? Heteroskedastic intra-daily volatility in the foreign exchange market. Econometrica 58: 525–42. [Google Scholar] [CrossRef]
- Fan, Jianqing, and Jinchi Lv. 2011. Noncave penalized likelihood with np-dimensionality. IEEE Transactions on Information Theory 57: 5467–84. [Google Scholar] [CrossRef]
- Fan, Jianqing, and Runze Li. 2001. Variable selection via nonconcave penalized likelihood and its oracle properties. Journal of the American Statistical Association 96: 1348–60. [Google Scholar] [CrossRef]
- Fan, Yingying, and Cheng Yong Tang. 2013. Tuning parameter selection in high dimensional penalized likelihood. Journal of the Royal Statistical Society Series B: Statistical Methodology 75: 531–52. [Google Scholar] [CrossRef]
- Fastrich, Björn, Sandra Paterlini, and Peter Winker. 2015. Constructing optimal sparse portfolios using regularization methods. Computational Management Science 12: 417–34. [Google Scholar] [CrossRef]
- Francq, Christian, and Jean-Michel Zakoian. 2019. GARCH Models: Structure, Statistical Inference and Financial Applications. Hoboken: John Wiley & Sons. [Google Scholar]
- Friedman, Jerome, Trevor Hastie, Holger Höfling, and Robert Tibshirani. 2007. Pathwise coordinate optimization. The Annals of Applied Statistics 1: 302–32. [Google Scholar] [CrossRef]
- Giacometti, Rosella, Gabriele Torri, Kamonchai Rujirarangsan, and Michela Cameletti. 2023. Spatial Multivariate GARCH Models and Financial Spillovers. Journal of Risk and Financial Management 16: 397. [Google Scholar] [CrossRef]
- Hamao, Yasushi, Ronald W. Masulis, and Victor Ng. 1990. Correlations in price changes and volatility across international stock markets. The Review of Financial Studies 3: 281–307. [Google Scholar] [CrossRef]
- Hafner, Christian M., and Arie Preminger. 2009. Asymptotic theory for a factor GARCH model. Econometric Theory 25: 336–63. [Google Scholar] [CrossRef]
- Hafner, Christian M., Helmut Herwartz, and Simone Maxand. 2022. Identification of structural multivariate GARCH models. Journal of Econometrics 227: 212–27. [Google Scholar] [CrossRef]
- Hassan, Syed Aun, and Farooq Malik. 2007. Multivariate garch modeling of sector volatility transmission. The Quarterly Review of Economics and Finance 47: 470–80. [Google Scholar] [CrossRef]
- Hong, Junping, Yi Yan, Ercan Engin Kuruoglu, and Wai Kin Chan. 2023. Multivariate Time Series Forecasting With GARCH Models on Graphs. IEEE Transactions On Signal And Information Processing Over Networks 9: 557–68. [Google Scholar] [CrossRef]
- Kaltenhäuser, Bernd. 2002. Return and Volatility Spillovers to Industry Returns: Does EMU Play a Role? CFS Working Paper Series 2002/05. Frankfurt a. M.: Center for Financial Studies (CFS). [Google Scholar]
- Lam, Clifford, and Jianqing Fan. 2009. Sparsistency and rates of convergence in large covariance matrix estimation. The Annals of Statistics 37: 4254–78. [Google Scholar] [CrossRef] [PubMed]
- Lanne, Markku, and Pentti Saikkonen. 2007. A multivariate generalized orthogonal factor GARCH model. Journal of Business & Economic Statistics 25: 61–75. [Google Scholar]
- Ledoit, Olivier, and Michael Wolf. 2004. A well-conditioned estimator for large-dimensional covariance matrices. Journal of Multivariate Analysis 88: 365–411. [Google Scholar] [CrossRef]
- Ledoit, Olivier, and Michael Wolf. 2012. Nonlinear shrinkage estimation of large-dimensional covariance matrices. The Annals of Statistics 40: 1024–60. [Google Scholar] [CrossRef]
- Ling, Shiqing, and Michael McAleer. 2003. Asymptotic theory for a vector arma-garch model. Econometric Theory 19: 280–310. [Google Scholar] [CrossRef]
- Markowitz, Harry. 1952. Portfolio selection. The Journal of Finance 7: 77–91. [Google Scholar]
- McAleer, Michael, Suhejia Hoti, and Felix Chan. 2009. Structure and asymptotic theory for multivariate asymmetric conditional volatility. Econometric Reviews 28: 422–40. [Google Scholar] [CrossRef]
- NASDAQ Stock Symbols. n.d. Stock Symbol. Available online: https://www.nasdaq.com/market-activity/stocks/ (accessed on 24 January 2024).
- Nicholson, William B., David S. Matteson, and Jacob Bien. 2017. VARX-L: Structured regularization for large vector autoregressions with exogenous variables. International Journal of Forecasting 33: 627–51. [Google Scholar] [CrossRef]
- Pan, Ming-Shiun, and L. Paul Hsueh. 1998. Transmission of stock returns and volatility between the U.S. and Japan: Evidence from the stock index futures markets. Asia-Pacific Financial Markets 5: 211–25. [Google Scholar] [CrossRef]
- Poignard, Benjamin. 2017. New Approaches for High-Dimensional Multivariate Garch Models. General Mathematics [math.GM]. Ph.D. thesis, Université Paris Sciences et Lettres, Paris, France. [Google Scholar]
- Ravikumar, Pradeep, Martin J. Wainwright, Garvesh Raskutti, and Bin Yu. 2011. High-dimensional covariance estimation by minimizing ℓ1-penalized log-determinant divergence. Electronic Journal of Statistics 5: 935–80. [Google Scholar] [CrossRef]
- Rio, Emmanuel. 2017. Asymptotic Theory of Weakly Dependent Random Processes. Berlin: Springer Nature. [Google Scholar]
- Sánchez García, Javier, and Salvador Cruz Rambaud. 2022. Machine Learning Regularization Methods in High-Dimensional Monetary and Financial VARs. Mathematics 10: 877. [Google Scholar] [CrossRef]
- Shiferaw, Yegnanew A. 2019. Time-varying correlation between agricultural commodity and energy price dynamics with Bayesian multivariate DCC-GARCH models. Physica A: Statistical Mechanics and Its Applications 526: 120807. [Google Scholar] [CrossRef]
- Siddiqui, Taufeeque Ahmad, and Mazia Fatima Khan. 2018. Analyzing spillovers in international stock markets: A multivariate GARCH approach. IMJ 10: 57–63. [Google Scholar]
- Sun, Wei, Junhui Wang, and Yixin Fang. 2013. Consistent selection of tuning parameters via variable selection stability. Journal of Machine Learning Research 14: 3419–40. [Google Scholar]
- Sun, Yan, and Xiaodong Lin. 2011. Regularization for stationary multivariate time series. Quantitative Finance 12: 573–86. [Google Scholar] [CrossRef]
- Theodossiou, Panayiotis, and Unro Lee. 1993. Mean and volatility spillovers across major national stock markets: Further empirical evidence. The Journal of Financial Research 16: 337–50. [Google Scholar] [CrossRef]
- Tibshirani, Robert. 1996. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society. Series B (Methodological) 58: 267–88. [Google Scholar] [CrossRef]
- Tse, Yiu Kuen, and Albert K. C. Tsui. 2002. A multivariate generalized autoregressive conditional heteroscedasticity model with time-varying correlations. Journal of Business & Economic Statistics 20: 351–62. [Google Scholar]
- Uematsu, Yoshimasa. 2015. Penalized likelihood estimation in high-dimensional time series models and its application. arXiv arXiv:1504.06706. [Google Scholar]
- van der Weide, Roy. 2002. Go-garch: A multivariate generalized orthogonal garch model. Journal of Applied Econometrics 17: 549–64. [Google Scholar] [CrossRef]
- Vrontos, Ioannis, Petros Dellaportas, and Dimitris N. Politis. 2003. A full-factor multivariate garch model. The Econometrics Journal 6: 312–34. [Google Scholar] [CrossRef]
- Wang, Hansheng, Bo Li, and Chenlei Leng. 2009. Shrinkage tuning parameter selection with a diverging number of parameters. Journal of the Royal Statistical Society. Series B (Statistical Methodology) 71: 671–83. [Google Scholar] [CrossRef]
- Worthington, Andrew, and Helen Higgs. 2004. Transmission of equity returns and volatility in asian developed and emerging markets: A multivariate garch analysis. International Journal of Finance & Economics 9: 71–80. [Google Scholar]
- Wu, Tong Tong, and Kenneth Lange. 2008. Coordinate descent algorithms for lasso penalized regression. Annals of Applied Statistics 2: 224–44. [Google Scholar] [CrossRef]
- Yuan, Ming, and Yi Lin. 2006. Model selection and estimation in regression with grouped variables. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 68: 49–67. [Google Scholar] [CrossRef]
- Zhang, Cun-Hui. 2010. Nearly unbiased variable selection under minimax concave penalty. Annals of Statistics 38: 894–942. [Google Scholar] [CrossRef]
- Zhang, Yongli, and Yuhong Yang. 2015. Cross-validation for selecting a model selection procedure. Journal of Econometrics 187: 95–112. [Google Scholar] [CrossRef]
- Zhao, Peng, and Bin Yu. 2006. On model selection consistency of lasso. Journal of Machine Learning Research 7: 2541–67. [Google Scholar]
- Zhao, Peng, and Bin Yu. 2007. Stagewise lasso. Journal of Machine Learning Research 8: 2701–26. [Google Scholar]
- Zou, Hui. 2006. The adaptive lasso and its oracle properties. Journal of the American Statistical Association 101: 1418–29. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).