1. Introduction
Evaluating capital requirements in a proper way is of primary importance to construct an efficient risk management system in life insurance business. In Europe, the Solvency II directive prescribes that insurers must hold eligible own funds at least equal to their Solvency Capital Requirements (SCR) defined as the value at risk (VaR) of the basic own funds with a confidence level of over a time horizon of one year. SCR may be computed according to the standard formula proposed by the regulator or according to a partial or full internal model developed by the insurer to better take into account specific aspects of the firm risk profile.
Evaluating VaR, defined in its most general form as the loss level that will not be exceeded with a certain confidence level during a specified period of time, is complicated by the fact that it must be computed at the risk horizon, implying that, if one tries to determine VaR according to a straightforward application of the Monte Carlo method, a nested simulation problem arises which is extremely time consuming. Instead of resorting to nested simulations, a possible alternative relies upon the least-squares Monte Carlo method (LSMC). LSMC was introduced in finance as a regression method to estimate optimal stopping times in American option pricing problems. The first contribution in this direction is due to
Tilley (
1993), and then generalized and extended in several ways by many authors, e.g.,
Carriere (
1996) and
Longstaff and Schwartz (
2001), just to name a few.
In a life insurance context, LSMC was firstly applied by
Andreatta and Corradin (
2003) to evaluate the option to surrender in a portfolio of guaranteed participating policies. Since then, this technique has been applied extensively to evaluate complex riders embedded in life insurance contracts. We may mention, among others, the contributions of
Bacinello et al. (
2009) and
Bacinello et al. (
2010).
In an evaluation framework described by one state variable evolving according to a geometric Brownian motion,
Feng et al. (
2016) conducted extensive numerical experiments to test the performance of nested simulations and LSMC techniques. To the best of the authors’ knowledge, no previous research has been conducted in a multidimensional setting to assess the efficiency of LSMC to determine capital requirements in a life insurance context. The present paper aims at filling this gap. For illustrative purposes, we restrict our attention to the stylized case where an insurer sells just one kind of policy: an equity-linked with a maturity guarantee. Moreover, we work in an extended Black–Scholes framework where two risk factors, the rate of return of a reference portfolio made up of equities of the same kind and the short interest rate, evolve according to a Gaussian model. This choice allows us to work in a context where a closed-form formula is readily available for the policy value and, as a consequence, a very accurate approximation of the insurer’s loss distribution at the risk horizon and a solid benchmark of the capital requirement can be obtained.
In the evaluation framework just depicted, LSMC can be applied by generating at first a certain number of outer simulations of the risk factors at the risk horizon. Then, a rough estimate of the insurer’s liabilities corresponding to each outer scenario is obtained by means of a very limited number of inner simulations along the remaining time horizon. Finally, by performing a least-squares regression an estimate of the insurer’s loss function is obtained and an empirical loss distribution is obtained by evaluating the estimated loss function in correspondence of the risk factors previously simulated at the risk horizon.
To test the accuracy of capital requirement estimates generated by LSMC, we conducted extensive numerical experiments by considering several combinations of the number of simulation runs combined with the number and the type of basis functions used in the regression function. By analyzing numerical results, it seems that, when policies with long duration are considered, the variability of the estimates obtained is non-negligible. The remainder of the paper is organized as follows. In
Section 2 we illustrate the evaluation framework in which LSMC is applied to determine SCR. In
Section 3, we illustrate the results of numerical experiments conducted to asses the efficiency of the model. In
Section 4, we draw conclusions.
2. The Evaluation Framework
Preliminarily, for ease of exposition and without loss of generality, we declare that, since SCR in Solvency II is based on VaR, from now on we consider VaR and SCR as synonyms. To test the efficiency of LSMC to compute capital requirements in life insurance, we consider a simplified setting in which there is an homogeneous cohort of insured persons who buy at time a single premium equity-linked policy with a maturity guarantee. We do not consider mortality, hence the policy is treated as a pure financial contract.
An amount
, deducted from the single premium, is invested in a reference portfolio made up of equities of the same kind. At the maturity
T, the insurer pays off the greater between the value of the reference portfolio and a minimum guarantee. We consider two different risk factors, the reference portfolio value and the short interest rate. Solvency II prescribes that SCR must be evaluated at the risk horizon,
, set equal to one year and a physical probability measure has to be used between the current date and the risk horizon while a risk-neutral market consistent probability measure has to be taken into account during the time interval from the risk horizon onward. We consider a Gaussian evaluation framework with a finite time horizon
, a probability space
, and a right-continuous filtration
We consider a Gaussian evaluation framework where the reference portfolio value dynamics is described by
where
and
are positive constants representing the drift and the volatility of the reference fund rate of return, and
is a standard Brownian motion under the real-world probability measure. The short rate dynamics is described by an Ornstein–Uhlenbeck process
where
, and
are positive constants representing the speed of mean reversion, the long-term interest rate, and the interest rate volatility, respectively, while
is a standard Brownian motion under the real-world probability measure with correlation
with
. We assume a complete market free of arbitrages that implies the existence of a unique risk-neutral probability measure under which the discounted price processes of all traded securities are martingales. The dynamics of the short interest rate is then described by the following stochastic differential equation
where
, (
is the market price of the interest rate risk) and
is a standard Brownian motion under the risk-neutral probability measure. Consequently, the dynamics of the reference fund value is
where
is a standard Brownian motion under the risk-neutral probability measure with correlation
with
.
The policy payoff at maturity is represented by the maximum between the reference fund value
and the maturity guarantee
, and can be decomposed as the face value of a zero coupon bond
plus the payoff of a European call option written on the reference fund with strike price
and maturity
T. As a consequence, the time
t-value of the policy can be obtained as follows,
where
is the time
t-value of a pure discount bond with maturity
T and
is the value at time
t of the European call above defined. The Gaussian evaluation setting allows us to obtain a closed-form formula for the policy value which is very useful to obtain a highly accurate estimate of SCR. In fact, in the extended Black–Scholes evaluation framework depicted above, we have
with
Moreover, the value of the European call option written on the reference fund with strike
is equal to
where
,
,
,
, and
Finally,
, and
is the cumulative distribution function of a standard normal random variable (see
Kim (
2002) for the details about the derivation of
).
Recalling that the insurer VaR is the maximum potential loss that can be suffered at the level of confidence
over the time interval
, we introduce at first the loss function at the risk horizon, defined, according to Solvency II, as the change in the insurer’s own fund along the risk horizon. For the sake of simplicity, and considering that the main difficulty in estimating the loss function distribution is relative to the liability side of the insurer’s own fund, we do not consider the change in the value of the firm’s assets, and, as a consequence, we consider as loss function
. While
and
are readily available through Equation (
1), being the price of a pure discount bond and the policy value at the contract inception, respectively, to determine
requires great attention; indeed, it represents the policy value at the future date
that is a random variable conditional on the realized future values of the two risk factors under the physical probability measure.
Then, VaR is defined as
where
is the cumulative distribution function of the loss. A possible way to approximate its distribution is through the empirical distribution obtained by Monte Carlo simulations. This is done, at first, by generating outer simulations of the short rate and of the reference fund at the risk horizon under the physical probability measure. Then, associated with each simulated pairs of the risk factors, the policy value under the risk-neutral probability measure has to be estimated. In this particular setting, the policy value is available in closed form but, in general, it has to be computed by resorting to inner simulations of the risk factors. With the inner simulations of the risk factors at our disposal, it is possible to obtain an estimate of the policy value at the risk horizon and, as a consequence, an approximation of the loss distribution.
The problem is that this approach, based on nested simulations, is extremely time consuming. With the aim of reducing the computational complexity of the evaluation problem, the LSMC has been proposed. It consists essentially on estimating each policy value at the risk horizon by a very limited number of inner simulations. This implies that each resulting policy value can be consistently biased. Nevertheless, the loss function may be estimated by means of a least-square regression based on a set of suitably chosen basis functions.
In particular, after having generated
N outer simulations of the risk factors at the risk horizon, each pair
, is associated with a rough estimate
of the policy value computed through a limited number,
m, of inner simulations through the time horizon
. Hence, we have at our disposal a set
which can be used to derive an approximation of the policy value
. In fact, LSMC method assumes that the time
-policy value can be approximated as
where
is the
jth basis function in the regression function, the
s represent the coefficients to be estimated, and
M is the number of basis functions. The unknown coefficients
can be estimated by a least-squares regression as
After having estimated the set
, we put these values in Equation (
2) and obtain the approximation
which can be interpreted as a random variable taking on the
N possible values
each one with probability
.
The empirical loss distribution can now be easily constructed and the requested VaR at confidence level is then determined as the corresponding th order statistic.
3. Numerical Results
In this section, we illustrate the results of extensive numerical experiments conducted to assess the goodness of the LSMC method in evaluating VaR of the equity-linked contract within the bivariate Gaussian model described in the previous section. All computations were performed on a custom-built workstation equipped with an Intel(R) Xeon(R) Silver 4116CPU 2.10 GHz processor with 64 GB of RAM and Windows 10 Pro for Workstation operating system. All source codes were written in R, version x64 3.6.0, R Development Core Team, Vienna, Austria.
The simulations were conducted under the physical probability measure from the contract inception up to the risk horizon. After having obtained
N couples
, (
), we associated with each couple a policy value computed by simulating, under the risk-neutral probability measure,
paths of the risk factors from the risk horizon until the policy maturity, with the method of antithetic variates. The next step in the evaluation process is relative to the choice of the number and the type of basis functions needed to define the regression function. We considered at first an
nth (
) degree polynomial function made up of a constant term plus all the possible monomials of order up to
n that can be obtained from the two risk factors
r and
F. Hence, with
, the regression function is made up of six terms
; with
the regression function contains
terms, i.e.,
; and so on. For each value of
n, we considered
N = 50,000, 500,000, and 1,000,000 simulation runs. For the policy with maturity
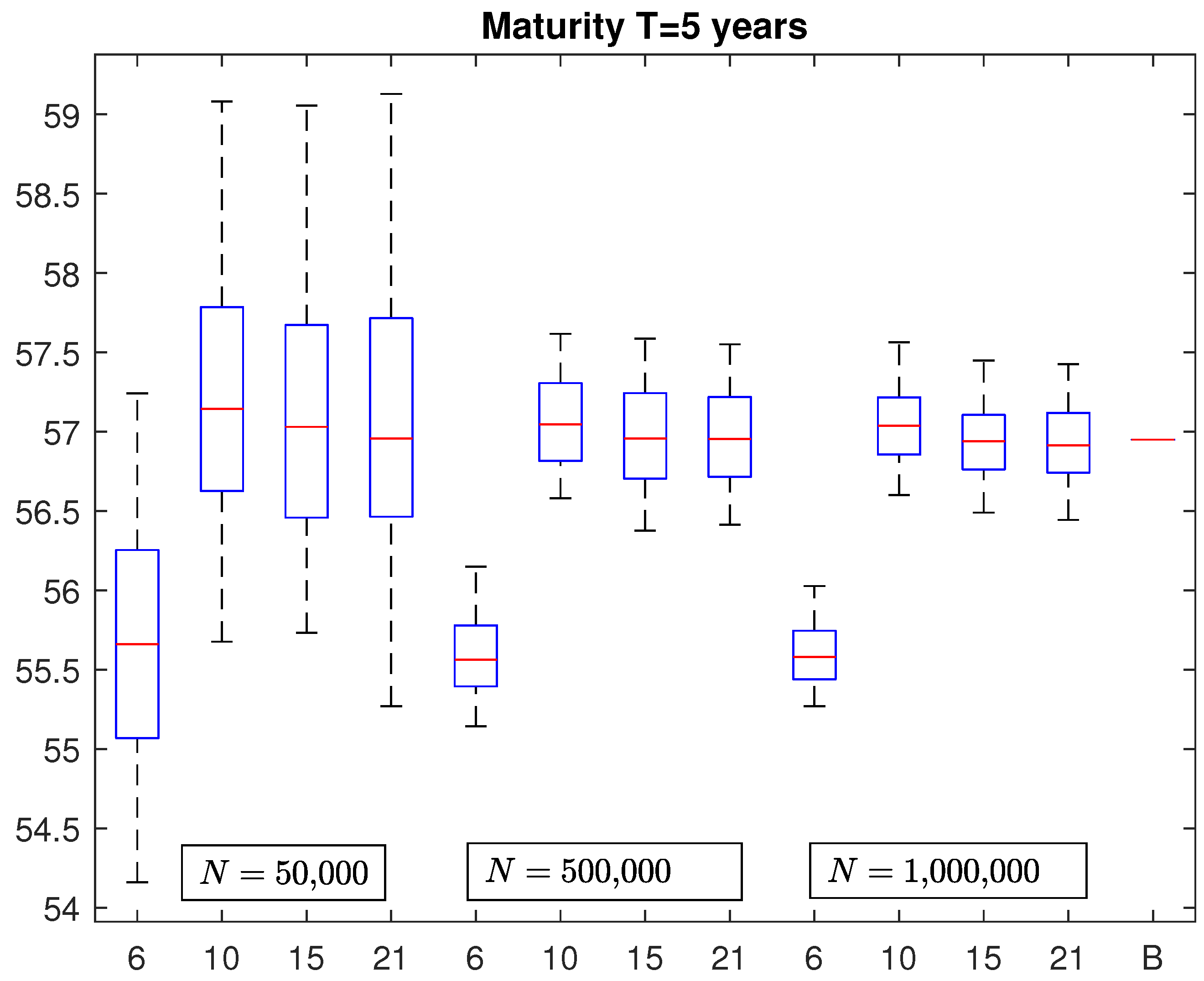
years, the corresponding results are illustrated in
Figure 1. Each box plot contains 100 VaRs estimated with
N = 50,000, 500,000, and 1,000,000 simulation runs, with
and 21 basis functions, respectively. The last segment on the right, labeled
B, represents the benchmark, equal to 56.9472. It has been obtained by averaging 100 VaRs, each one computed with
N = 10,000,000 simulations by associating with each couple
the closed-form formula of the policy value described in Equation (
1), then ordering the values from the smallest to the greatest and taking the 9,950,000th-order statistic. The parameters of the stochastic processes describing the evolution of the risk factors were set equal to
,
,
,
,
,
, and
, while
and
were set, for simplicity, equal to 0, but different values estimated on market data can be used and do not affect the precision of the evaluation model.
By looking at
Figure 1, it emerges that, if we consider in the proxy function monomials of degree up to the second (
), the resulting VaRs are consistently biased regardless of the number of simulation runs considered. When we increase the number of basis functions by including monomials of Degree 3, 4 and 5, the corresponding box plots are centered around the benchmark. Moreover, the widths of the boxes reduce as the number of simulations increases. It is interesting to observe that, given the number of simulation runs, an increment in the number of basis functions from 10 to 15 and 21 does not reduce further the variability of the estimates. This is confirmed also by looking at
Table 1 where we report the mean absolute percentage error (MAPE) of VaRs contained in each box plot. With
N = 50,000, the MAPE remains above
while for
N = 500,000 and
N = 1,000,000 we observe an MAPE around
and
, respectively. Moreover, instead of simple monomials of degree
n, we also considered alternative types of basis functions, such as Hermite or Legendre polynomials of the same degree, but we did not observe significant differences with respect to the results previously obtained by using simple polynomials.
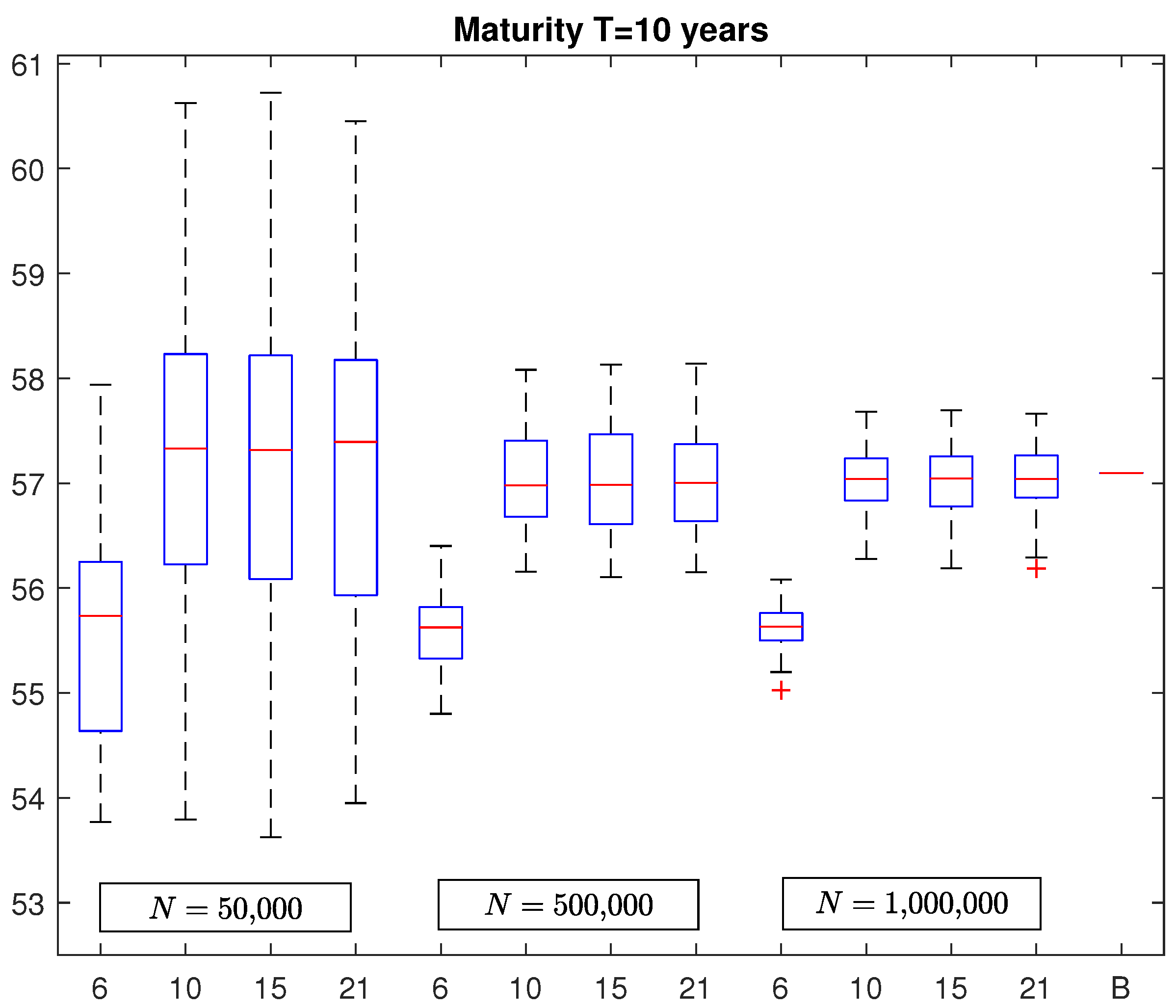
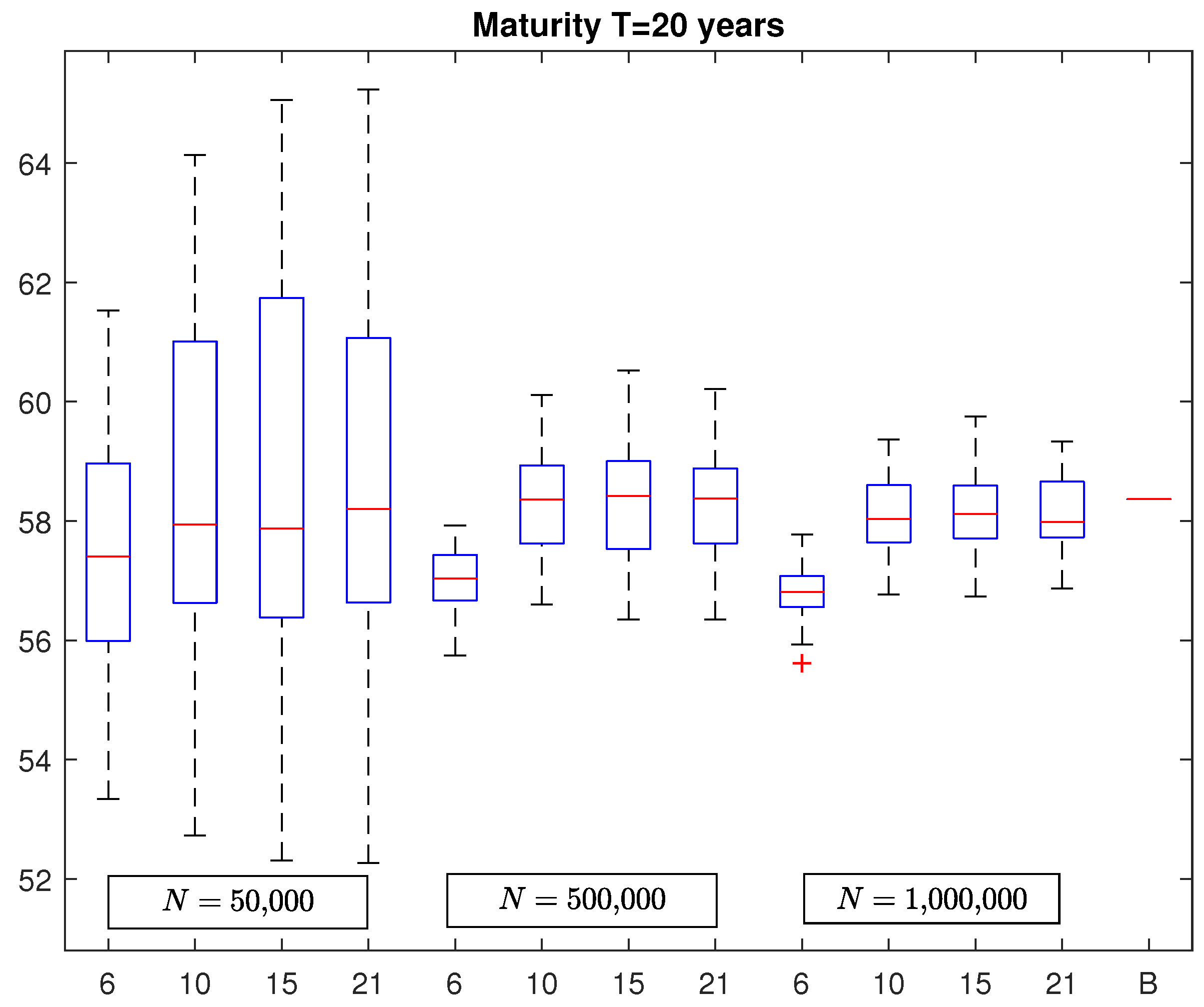
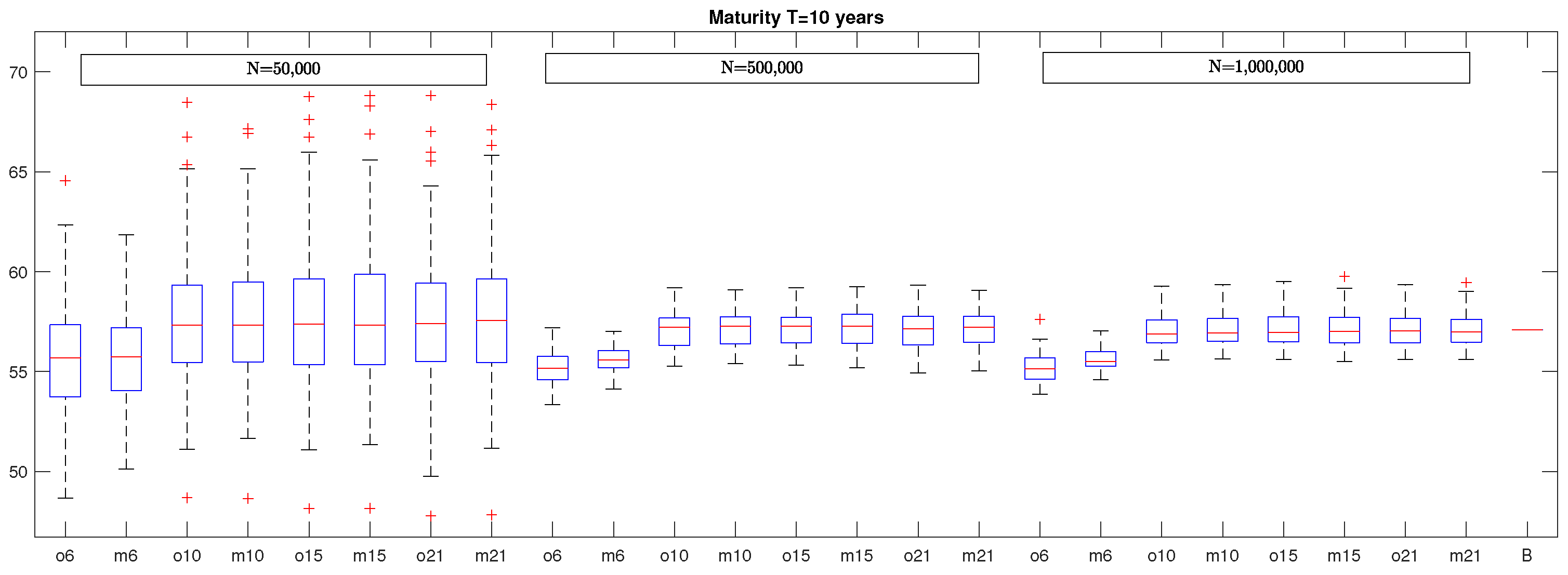
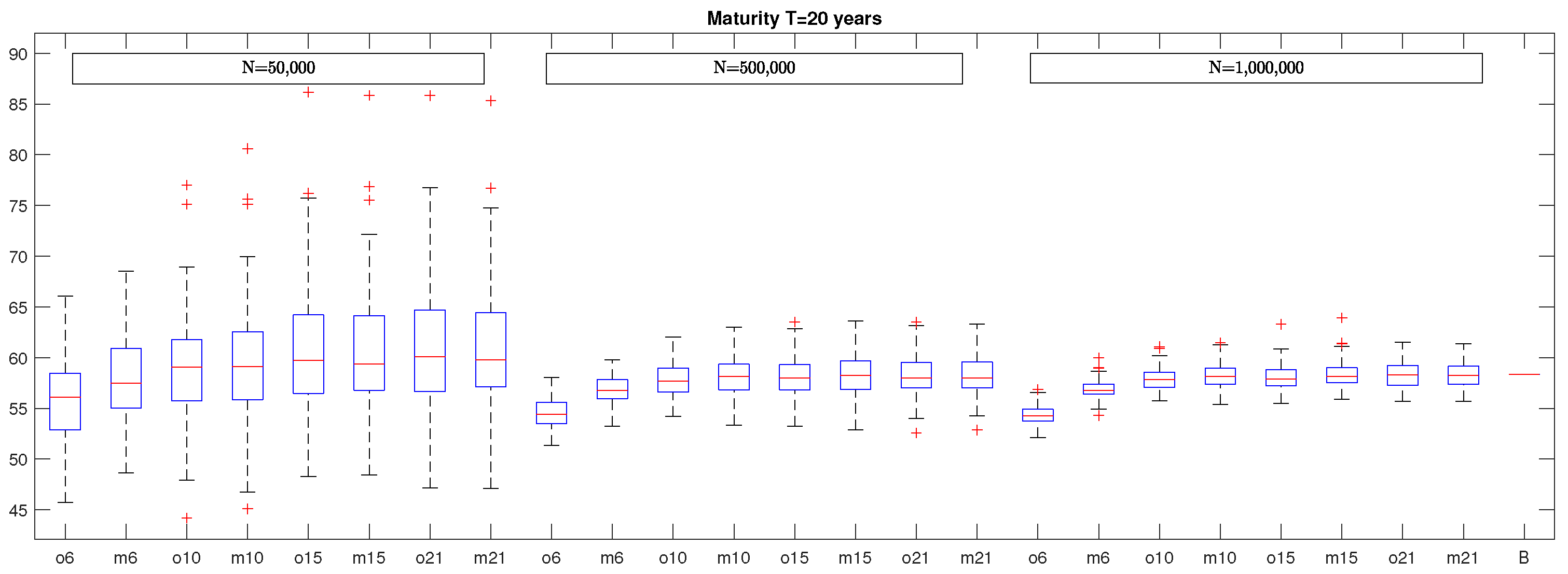
In
Figure 2 and
Figure 3, we report the box plots of VaR estimates in the case of a policy with maturity equal to
and
years, respectively. As before, the last segments represent the benchmarks which are equal to 57.1002 and 58.3666, respectively. By looking at these figures, it emerges a similar structure of the box plots already observed in the case of the five-year policy but with the obvious difference regarding to the variability of the VaR estimates that increases with the policy maturity. In fact, by considering again
Table 1, we note that the MAPE increases to around
and
for
N = 500,000 and
N = 1,000,000, respectively, for the policy with maturity
years and to
and
, for
N = 500,000 and
N = 1,000,000, respectively, for the policy with maturity
years. In addition, in this case, we observe no significant change in VaR estimates by considering polynomial basis functions of degree greater than 3.
It is also interesting to observe that the maximum absolute percentage error (ME) of VaR estimates in the most favorable case, i.e., when the number of simulation runs is equal to N = 1,000,000 and the number of basis functions is , is when the maturity is years, when the maturity is years, and when the maturity is years.
To give an idea of the computational cost of the LSMC method compared with nested simulations, we also computed the
VaR for the same policy of
Table 1 with maturity
years. As in
Floryszczack et al. (
2016) we considered 10,000 outer runs and 2500 inners for each outer. In
Table 2, we report the MAPE obtained from 100 nested evaluations with the corresponding computation time (in seconds) needed to compute each VaR and the corresponding computation times for each VaR computed by LSMC with the combination of
M and
N of
Table 1.
As shown in
Table 2, the MAPE of VaRs estimated by nested simulations is similar to those obtained by LSMC with
N = 1,000,000 and
. In contrast, running times of nested simulations are much higher than those needed with LSMC. Of course, it must be observed that alternative implementations of the nested simulation method are possible to obtain a better allocation of the computational budget between outer and inner simulations, but exploring such alternatives is beyond the scope of this work.
As a second experiment, we computed SCR with LSMC for the same policy considered before, but with basis functions chosen according to a different criterion. In fact, instead of using proxy functions made up of all monomials up to degree
n, we considered the
optimal basis functions proposed in
Bauer and Ha (
2013), which are those giving the best approximation of the
valuation operator that maps future cash flows into the conditional expectations needed to compute capital requirements. It is shown that such optimal basis functions are represented by left singular functions of this operator, which, in the case of Gaussian transition densities, are represented by Hermite polynomials of suitably transformed state variables.
1 An alternative choice of basis functions obtained according to a different optimal criterion is proposed in
Feng et al. (
2016). It is based, essentially, on the Hankel matrix approximation to determine optimal exponential functions. It has the advantage that the error bound can be easily controlled but it is less accurate when there is an unbounded functional relationship between response variables and dependent variables.
Following the approach proposed by
Bauer and Ha (
2013), we determined VaRs for the same policy described before but by considering optimal basis functions and we compared the results with those computed by LSMC with standard polynomials as proxy functions. In
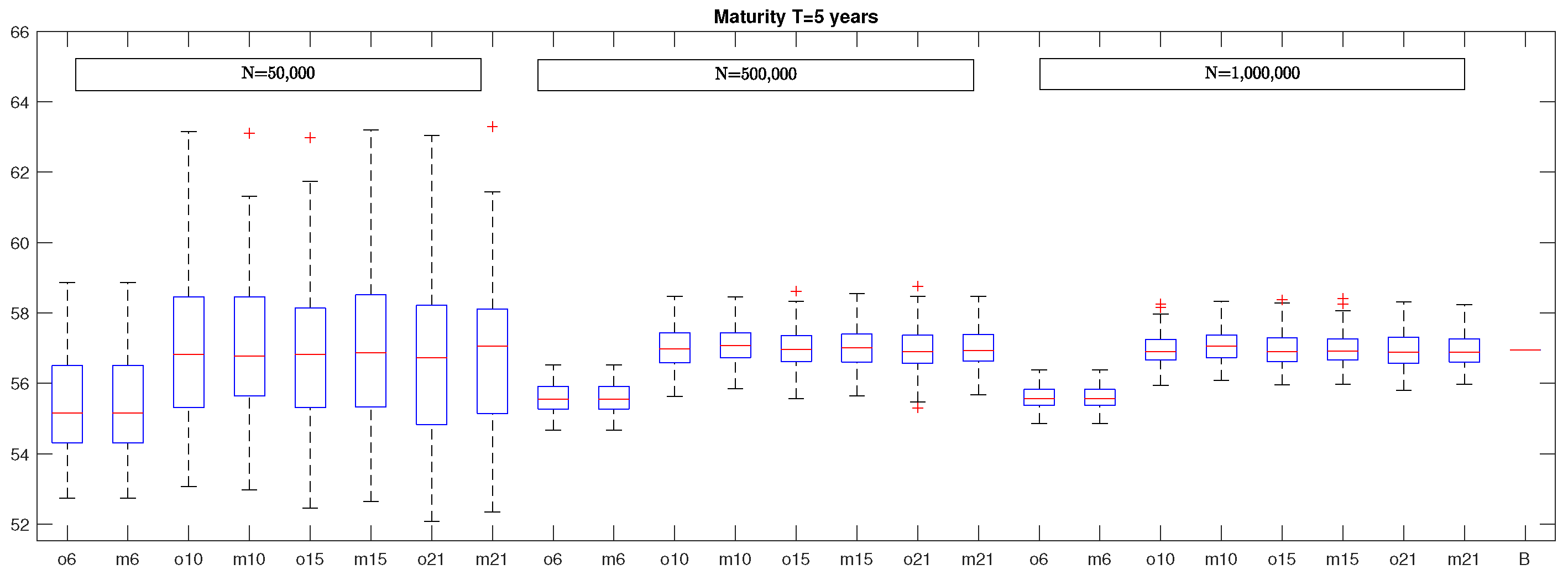
Figure 4, we report the box plots of VaR estimates computed considering different number of optimal basis functions (ox with
). Beside each box plot obtained through optimal basis functions the one containing VaRs obtained with simple polynomials of degree
x is inserted (
with
), where
means that the proxy function contains all the monomials up to second degree,
means that the proxy function contains all monomials up to third degree, and so on. The eight box plots on the left were obtained by considering
N = 50,000 simulation runs, the eight box plots in the middle were generated by considering
N = 500,000 simulations, and the eight box plots on the right were generated with
N = 1,000,000 simulations. The last segment on the right represents the benchmark.
The remaining parameters are the same as those previously considered. In all cases, each box plot was generated from 100 VaR estimates and the last segment on the right represents the benchmark. By looking at this graph, it emerges that, if we consider a number of optimal basis functions equal to six (
), the resulting VaRs are biased for all the considered number of simulation runs. Similar results are obtained by considering as basis functions the six monomials up to the second degree (
in the graph). This is also confirmed by by the results in
Table 3 where we report the MAPE of VaR estimates obtained by considering optimal basis functions and the corresponding MAPE (in brackets) obtained by using standard polynomials as proxy functions. Moreover, in
Table 3, we can see that, when we increase the number of optimal basis functions, the resulting estimates are centered around the benchmark with the variability that becomes smaller and smaller as the number of simulation runs is increased. It is worth noticing that MAPE does not reduce further by increasing the number of optimal basis functions to 15 and 21. This is also true when we use standard polynomials as proxy functions.
In
Figure 5, we report the box plots of VaR estimates in the case of a policy maturity of 10 years, while, in
Figure 6, the box plots when the maturity is 20 years are illustrated. By looking at these figures, it seems evident that the considerations already made for the policy with maturity equal to five years can be extended straightforwardly also to the cases characterized by longer maturity with the obvious caveat that the variability of VaR estimates in the different box plots increases with the policy maturity, as evidenced also in
Table 1.
For what concerns the maximum absolute percentage error, we underline that the case with optimal basis functions and N = 1,000,000 simulations is characterized by a ME equal to for years, for years, and for years. If we use the same number of monomials as basis functions and the same number of simulations, we obtain a ME equal to when years, when years, and when years.
Another aspect to be considered is that VaR estimates obtained in this second experiment seem to be affected by a greater variability than those computed in the first experiment. This is probably due to the fact that, in the first experiment, VaRs were obtained by considering policy values at the risk horizon computed with two antithetic inner simulations, while, in the second case, VaRs were obtained, as in
Bauer and Ha (
2013), by considering policy values at the risk horizon computed with just one inner simulation. In general, the lack of improvement of VaR estimates when using
optimal basis functions may be due to the fact that, when the dimension of the evaluation problem is low,
optimal basis functions and standard polynomials may generate the same span and in this case the results are equivalent.
Moreover, based on the numerical results illustrated before, it seems that the choice of the type and of the number of basis functions is not an issue in a low-dimensional setting. In fact, with a number of simulation runs up to
N = 1,000,000 a simple polynomial of degree
gives the highest explanatory power. Since the number of basis functions represents also the rank of the matrix to be inverted in the least-squares regression, the inverse matrix can be computed almost instantaneously in these cases. Of course, given the results in
Benedetti (
2017), LSMC converges when the number of simulations and the number of basis functions are sent jointly to infinity; hence, increasing further the number of simulations implies that a polynomial of higher degree is needed and
M will increase further too. Nevertheless, it is unlikely that in practical cases with path-dependent features a further increment in the number of simulation runs is possible, given the available computational budget, and even if this could be possible, it should be considered with great attention the possibility of devoting part of the computational budget to obtain better estimates of the insurer’s liabilities at the risk horizon eventually by increasing the number of inner simulations. This could produce a consistent improvement in the efficiency of the evaluation process. Things could be different when the number of risk factors increases considerably and it should be explored if polynomials including all possible monomials of up to a relatively low degree fit well the insurer’s loss distribution. When the dimension of the evaluation problem increases, selecting basis functions according to a certain
optimal criterion will, arguably, be more useful if standard polynomials of relatively low degree will not produce accurate results. This aspect deserves further research, but, when the number of risk factors is high, numerical analyses are complicated by the fact that obtaining solid benchmarks is difficult, due to large computational burden of the evaluation problem.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}