Abstract
In this paper, we consider a company that wishes to determine the optimal reinsurance strategy minimising the total expected discounted amount of capital injections needed to prevent the ruin. The company’s surplus process is assumed to follow a Brownian motion with drift, and the reinsurance price is modelled by a continuous-time Markov chain with two states. The presence of regime-switching substantially complicates the optimal reinsurance problem, as the surplus-independent strategies turn out to be suboptimal. We develop a recursive approach that allows to represent a solution to the corresponding Hamilton–Jacobi–Bellman (HJB) equation and the corresponding reinsurance strategy as the unique limits of the sequence of solutions to ordinary differential equations and their first- and second-order derivatives. Via Ito’s formula, we prove the constructed function to be the value function. Two examples illustrate the recursive procedure along with a numerical approach yielding the direct solution to the HJB equation.
Keywords:
reinsurance; regime-switching; Brownian motion; Markov chain; optimal control; HJB equation; ordinary differential equations; boundary value problem MSC:
60K10; 91B30; 60J65; 49K15
1. Introduction
Writing red numbers is generally considered a bad sign for the financial health of a (insurance) company. An old but also highly criticised concept to measure company’s riskiness is the ruin probability, i.e., the probability that the company’s surplus will become negative in finite time. There is a vast of literature on ruin probability in different settings and under various assumptions, see, for instance, Rolski et al. (1999); Asmussen and Albrecher (2010) and further reference therein.
As ruin probabilities do not take into account the time and the severity of ruin, the related concept of capital injections incorporating both features has been suggested in Pafumi (1998) in the discussion of Gerber and Shiu (1998). The risk is measured by the expected discounted amount of capital injections needed to keep the surplus non-negative. If the discounting rate, or rather the preference rate of the insurer, is positive, then the amount of capital injections is minimised if one injects just as much as it is necessary to shift the surplus to zero (but not above) and to inject just when the surplus becomes negative (but not before, anticipating a possible ruin), see, for instance, Eisenberg and Schmidli (2009).
A well-established way to reduce the risk of an insurance portfolio is to buy reinsurance. Finding the optimal or fair reinsurance in different settings is a popular and widely investigated topic in insurance mathematics, see, for instance, Azcue and Muler (2005); Ben Salah and Garrido (2018); Brachetta and Ceci (2020) and the references therein. However, the reinsurance premia are usually higher than the premia of the first insurer. Otherwise, it would create an arbitrage opportunity for the first insurer, who could transfer the entire risk to the reinsurer (i.e., the amount of the necessary capital injection is zero) and still receive a risk-free gain in from of the remaining premium payments. If we consider a model including both capital injections and reinsurance, the capital injection process will naturally depend on the chosen reinsurance strategy. That is, one can control the capital injections—representing the company’s riskiness—by reinsurance. In this context, the problem of finding a reinsurance strategy leading to a minimal possible value of expected discounted capital injections has been solved in Eisenberg and Schmidli (2009). There, the optimal reinsurance strategy is given by a constant, meaning that the insurance company is choosing a retention level once and forever. This result has been obtained under the assumption that the parameters describing the evolution of the insurer’s and reinsurer’s surplus never change. However, the reality offers a contrary picture. The state of economy has an enormous impact on the insurance/reinsurance companies, adding an exogeneously given source of uncertainty.
In financial literature, regime-switching models have become very popular because they take into account possible macroeconomic changes. Originally proposed by Hamilton to model stock returns, this class of models has been adopted also in insurance mathematics, see, e.g., Asmussen (1989); Bargès et al. (2013); Bäuerle and Kötter (2007); Gajek and Rudź (2020); Jiang and Pistorius (2012). In this connection, one should not forget the models containing hidden information. Reinsurance companies deciding over the price of their reinsurance products have to take into account the competition on the market and the consequences of adverse selection, see, for instance, Chiappori et al. (2006) and references therein.
In the present paper, we model the surplus of the first insurer by a Brownian motion with drift. The insurer is obligated to inject capital if the surplus becomes negative and is allowed to buy proportional reinsurance. In order to account for the macroeconomic changes that are assumed to happen in circles, we allow the price of the reinsurance—represented through a safety loading—to depend on the current regime of the economy. A continuous-time Markov chain with two states describes the length of the regimes and the switching intensity from one state into another. We target to find a reinsurance strategy that minimises the value of expected discounted capital injections where the discounting rate is a positive regime-independent constant. If the discounting rate would be assumed to be negative in one of the states, it might become optimal to inject capital even if the surplus is still positive (see, for instance, in Eisenberg and Krühner (2018)), which would substantially complicate the problem. For the same reason, we do not incorporate hidden information or moral hazard into this model
We solve the optimisation problem via the Hamilton–Jacobi–Bellman (HJB) equation, which is in this case a system of equations. Differently than it has been done in the one-regime case, we cannot guess the optimal strategy and prove the corresponding return function to solve the HJB equation. Instead, we solve the system of HJB equations recursively. First of all, the system of HJB equations is rewritten as a system of ordinary differential equations. Then, we assume that the value function, say in the second regime, is an exponential function and solve the corresponding ordinary differential equation for the first regime. The obtained solution is inserted into the ordinary differential equation for the second regime. Proceeding in this way, we obtain a monotone uniformly converging sequence of solutions, whose limit functions solve the original HJB equation. Here, it is of crucial importance to choose correctly the exponential of the starting function in the recursion. We present an equation system providing the only correct choice of the starting function.
The aim of the present paper is to develop an algorithm for finding a candidate for the value function. Like in the case with just one regime, the HJB equation is rewritten as a differential equation with boundary conditions. Here, we are facing a boundary value problem, i.e., the conditions are specified at different boundaries, with one boundary being even infinity. Therefore, using Volterra-type representations and comparison theorems, we prove the existence and uniqueness of a solution to the HJB equation. Ito’s formula allows one to show that the constructed solution is indeed the value function. We show that the optimal reinsurance strategies are increasing in one regime and decreasing in the other, depending on the parameters. This fact reflects the dependence of the strategies on the reinsurance prices along with the switching intensities. For instance, being in a regime with a low reinsurance price and a relative high switching intensity into a state with a high reinsurance price would produce a decreasing proportion of the self-insured risk.
As we do not get a closed form expressions for the value function and for the optimal strategies, we give a numerical illustration of both the algorithm and the value function. Here, we follow the approach of Auzinger et al. (2019).
The remainder of the paper is structured as follows. In Section 2, we give a mathematical formulation of the problem and present the Hamilton–Jacobi–Bellman equation. In Section 3, we shortly revise the case of constant controls and prove that those cannot be optimal except for the case when it is optimal to buy no reinsurance. In Section 4 and Section 5 we recursively construct a function solving the HJB equation and prove it to be the value function. Finally, we explore the problem numerically in Section 6 and conclude in Section 7.
2. The Model
In the following, we give a mathematical formulation of the problem and present the heuristically derived Hamilton–Jacobi–Bellman (HJB) equation. We are acting on a probability space .
In the classical risk model, the surplus process of an insurance company is given by
where is a Poisson process with intensity and the claim sizes are iid. with and and independent of . Furthermore, x denotes the initial capital and the premium rate. For further details on the classical risk model, see, e.g., Chapter 5.1 in Schmidli (2017).
The insurer can buy proportional reinsurance at a retention level , i.e., for a claim , the cedent pays , and the reinsurer pays the remaining claim . Assume the expected value principle for the calculation of the insurance and reinsurance premia with safety loadings and , respectively, where (see Chapter 1.10 in Schmidli (2017)) transforms the surplus of the insurer, denoted now by to
The new premium rate depends on the retention level and is given by , being old premia reduced for the premia paid to the reinsurer (see, e.g., Chapter 5.7 in Schmidli (2017)).
Usually, optimisation problems can be tackled more easily if the surplus is given by a Brownian motion. Therefore, diffusion approximation of the classical risk model is a popular concept in optimisation problems in insurance. A diffusion approximation to (1) by adopting a dynamic reinsurance strategy , that is, the retention level changes continuously in time, is given by
dfsuch that the first two moments of (1) and (2) remain the same; see, for instance, Appendix D.3 in Schmidli (2008) for details. In addition to buying reinsurance, the insurance company has to inject capital in order to keep the surplus non-negative. The process describing the accumulated capital injections up to time t under a reinsurance strategy B will be denoted by . The surplus process under a reinsurance strategy B and capital injections Y is given by
Further, we introduce a continuous-time Markov chain with state space . We assume that J and W are independent, and that J has a strongly irreducible generator , where for , and we consider the filtration , generated by the pair . That is, the economy can be in two different regimes, and accordingly the parameters in (2) are no longer constant, but depend on the state. In order to emphasise the dependence on the reinsurance price, we let the safety coefficient of the reinsurer depend on the current regime by letting all other variables unchanged. Thus, instead of (2), we now consider the process
The set of admissible reinsurance strategies will be denoted by and is formally defined as
We are interested in the minimal value of expected discounted capital injections by starting in state i with initial capital x over all admissible strategies, i.e., we minimise
Here, and in the following, we use the common notation .
Our target is to find an admissible reinsurance strategy such that the value function
can be written as the return function corresponding to the strategy , i.e., .
According to the theory of stochastic control, we expect the value function V is to solve the HJB equation (see Schmidli (2008) or Jiang and Pistorius (2012) for a model with Markov-switching)
The boundary condition arises from the requirement of smooth fit (-fit) at zero. As we do not allow the surplus to become negative, it is clear that the value function for fulfils , i.e., we immediately inject as much capital as it is needed to shift the surplus process to zero, meaning . The second boundary condition originates from the fact that a Brownian motion with a positive drift converges to infinity almost surely, i.e., for the amount of expected discounted capital injections converges to 0, see, for instance, Rolski et al. (1999).
The HJB equation can be formally derived as the infinitesimal version of the dynamic programming principle, upon assuming that V has the regularity needed to apply Ito’s formula for Markov-modulated diffusion processes (as in the proof of Lemma 1 below); we refer to Chapter 2 in Schmidli (2008) for a textbook treatment.
It is clear that . If , the HJB becomes for
Technically, HJB Equation (5) is a system of 2 ordinary differential equations, coupled through the transition rates of the underlying Markov chain. It is a hard task to explicitly solve these equations and show that the solutions are decreasing and convex functions of the initial capital. Therefore, we use a recursive method to obtain the value function as a limit. However, first we look at the constant strategies and investigate why none of those can be optimal in the case of more than one regime.
3. Constant Strategies
It is known (see, for instance, Eisenberg and Schmidli (2009)) that in the one-regime case the optimal reinsurance strategy is given by a constant. In this section, we show that in the two-regime case a constant strategy (other than “no reinsurance at all”) cannot be optimal.
Let , then is an admissible reinsurance strategy. Further, we let and denote the capital injection process triggered by the reinsurance strategy and the surplus process under and after capital injections, respectively. Thus, for the return function , corresponding to , it holds
Lemma 1.
If is a solution to the system of ODEs, ,
with boundary conditions , , then .
Proof.
First, we look at the Equation (6). A general solution to (6) fulfilling is given by
where . The coefficients are uniquely given by
Now, arguing like in Shreve et al. (1984), we show that . Using a generalised form of Itô’s formula, like it has been done, for instance, in Jiang and Pistorius (2012), we get
where M is a local martingale associated with the regime switching mechanism. That is, M is given by
where is a compensated random measure as defined in Jacod and Shiryaev (2003). It holds
where is the counting measure on and is the Dirac measure at the point .
Note that M is bounded because
As is bounded, we can conclude that M is a martingale with expectation zero. Because is bounded we can conclude that also the stochastic integral is a martingale with expectation zero. Further, as solves Equation (6) with , building expectations on the both sides in (9) yields
By the bounded convergence theorem, we can interchange limit and expectations and get . □
Remark 1.
Note that it holds for all . If, for example, then we have from (8) that it must also hold and simultaneously
which leads to a contradiction.
Lemma 2.
The return function corresponding to a strategy with , , does not solve HJB Equation (4).
Proof.
We proof this lemma by contradiction. Assume that there is a strategy with , , so that the corresponding return function, solves the HJB Equation (4), i.e.,
Then, it should hold that . As we assumed , for , the expression should not depend on x. Keeping in mind the boundary conditions and , we get
which contradicts (7). □
4. Recursion
In the following, we establish an algorithm that allows us to calculate the value function as a limit of a sequence of twice continuously differentiable, decreasing and convex functions. For simplicity, we let
We will see that the behaviour of the optimal reinsurance strategy will depend on the relations between , , and . As there are many possibilities to arrange the above quantities, we consider just one path, omitting considering the case of no reinsurance, in order not to complicate the explanations. However, the algorithm proposed below can be applied to any combination of parameters.
Assumption 1.
W.l.o.g. we assume that , which is equivalent to
In the case of just one regime, the problem could be solved by conjecturing that the optimal strategy is constant and the corresponding return function is an exponential function. This allowed us to verify easily that the solution, say v, to Differential Equation (5) with was strictly increasing, convex and fulfilled or, if the case maybe, the optimal strategy was not to buy reinsurance at all. In our case of two regimes, the situation changes as we have seen in Section 3. The return functions corresponding to the constant strategies do not solve the HJB equation in general.
As it is impossible to guess the optimal strategy and to subsequently check whether the return function corresponding to this strategy is the value function, we slightly change the solving procedure. At first, we look at the HJB equation in the form of Differential Equation (5), such has been done, for instance, in Eisenberg and Schmidli (2009). The next, very technical step is to solve the obtained differential equation and to check whether the solution, say f, fulfils . Then, we show that the gained solution f is indeed the return function corresponding to the reinsurance strategy . Thus, in this way we find an admissible strategy whose return function solves HJB Equation (4). Verification theorem proves this return function to be the value function.
In the following, we describe the steps of an algorithm allowing to get a strictly decreasing and convex solution to Differential Equation (5) under Assumption (11). The procedure consists in choosing a starting function, fixing, say , and replacing the unknown function in (5) by the chosen starting function. Using the method of Højgaard and Taksar (1998), we show the existence and uniqueness of a solution. In the next step, now it holds , the unknown function in (5) is replaced by the function obtained in the first step. Letting the number of steps go to infinity, we get a solution to (5). We will see that the starting value of the recursion plays a crucial role in obtaining a solution with the desired properties: convexity and monotonicity. Therefore, we start by explaining how to choose the starting function in Step 0.
4.1. Step 0
The solutions to the differential equations
with boundary conditions and are well known and given by . Note that due to Assumption (11) it holds that .
The optimal strategy in the case of two regimes is not constant, see Section 3. However, we conjecture that the value function in the case of two regimes fulfils , i.e., the ratio of the first and second derivatives converges to the same value does not matter the initial regime state. One can see it as a sort of averaging of the optimal strategies from the one-regime cases. This means, for instance, that if in one-regime case the optimal reinsurance level was low in the first state and high in the second, in the two-regime case the optimal level in the first state will go up and go down in the second.
Mathematically, the above explanations are reflected in the starting function of our algorithm:
where fulfils
It means that and are uniquely given by
Remark 2.
It is a straightforward calculation to show and using the definition of and Assumption (11).
Note that due to our assumption, it holds that .
4.2. Step 1
Assuming (11), we start investigating Differential Equation (5) and substitute the term by defined in (13), i.e., we look now at the differential equation
Although we know the function , differential Equation (16) still cannot be solved in a way that we could easily prove the solution to be strictly decreasing and convex. Therefore, we use the following technique, introduced in Højgaard and Taksar (1998).
We assume that there is a strictly increasing, bijective on function g such that the derivative of the solution f to (16) fulfils . Then, it holds
Differentiating (16) yields
Changing the variable to leads to a new differential equation for the function g
which can be further simplified by multiplying by and inserting the definition of :
As the function g should be bijective, we will prove the existence and uniqueness of a solution to (17) on with the boundary conditions guaranteeing and . In particular, the term determines the unique condition yielding and , namely, .
In order to guide the reader through the auxiliary results below, we provide a roadmap identifying the key findings of Step 1.
Note that when investigating (17) we are looking at a boundary value problem. To show the existence and uniqueness of a solution, we will translate the boundary value problem into an initial value problem, i.e., we shift the condition as to by using Volterra type representation for (17).
- First, we show that if (17) has a solution, say g, with the boundary values and , for some , then .
- In the second step, we show that there is a unique solution to (17) with the boundary conditions and .
- We prove the existence of a solution to (17) with and .
- It holds and .
- The inverse function of fulfils and .
- for all and with given in (15).
Lemma 3.
If there is a solution g to (17) with the boundary conditions , , for some , then it holds that
Proof.
We prove the claim by contradiction. Let g be a solution to (17) with the boundary conditions , .
- Assume for the moment that . Then,meaning that stays positive but below in an environment of 0. As , the function is increasing in an -environment of 0, i.e., , which means thatThus, will stay negative and will never arrive at .
- On the other hand, if , then in a similar way one concludes that stays above for all , contradicting .
- Thus, we can conclude that .
□
Lemma 4.
For every there is a unique solution to (17) on fulfilling , .
Proof.
As the proof is very technical, we postpone it to Appendix A. □
Lemma 5.
Let be the unique solution to (17) with the boundary conditions and . Then, on .
Proof.
See Appendix A. □
Proposition 1.
There exists a unique solution to (17) with the boundary conditions and , and on .
Proof.
See Appendix A. □
Remark 3.
Note that the definition of g yields . The boundary conditions imply and . Thus, letting in (17) and using (18), we get the first equation in (14). This provides the first idea and the meaning of the choice of .
Corollary 1.
There is a strictly increasing and concave inverse function of on : . Further, it holds
- fulfils , , and .
- , i.e., is strictly increasing with for .
Proof.
The function fulfils and for all , i.e., is a bijective function, which implies the existence of an inverse function . All other properties follow from the properties of . □
We can now let
i.e., . Note that is well defined due to Corollary 1 and solves Differential Equation (17) with the boundary conditions and . In particular, due to (11) it holds .
In the following second step, we construct in a similar way a function .
4.3. Step 2
In the second step, we add the term to Differential Equation (12), i.e., we are looking at the differential equation
Note that , which implies Lipschitz-continuity on compacts. The existence of a solution with the boundary conditions and can be shown similar to Step 1.
The main findings of Step 2 are as follows:
- There is a unique solution to (20) with the boundary conditions and .
- It holds that and .
- The inverse function of fulfils and .
- for all .
In the following, we prove only the results that cannot be easily transferred from Step 1.
Lemma 6.
If there is a solution to Differential Equation (20) with the boundary conditions and then .
Proof.
See Appendix A. □
Lemma 7.
Let be the unique solution to Differential Equation (20) with the boundary conditions and . Then, for all .
Proof.
Lemma 6 yields . It means (see (A1)) that . Let , then because if and then Lemma 6 gives . Further, we also have
because due to Corollary 1. Then, becomes positive, i.e., becomes increasing and stays increasing for , i.e., bounded away from , which yields a contradiction. □
Corollary 2.
Let be the inverse function of . Then, , , , .
Proof.
The proof is a direct consequence of Lemma 7. □
4.4. Step 2m+1
In this step, we are searching for the function as the inverse of the solution to the differential equation , where
The existence of a solution can be proven similarly to Step 1. The boundary conditions are and .
Our main target is to show that the obtained sequences of functions , and are monotone. We carry out the proof by induction using as the induction step on , see Corollary 2 in Step 2.
The main findings of Step are summarised in the following remark.
Remark 5.
Similar to Step 1, we get for and its inverse function that
- ;
- , ;
- and ; and
- , .
In Lemma 8 we show
- on , and on .
Lemma 8.
Assume that the functions obtained in Steps , , fulfil
- 1.
- , , , , and , and
- 2.
- for .
Then, on , and on .
Proof.
See Appendix A. □
4.5. Step
In Step , we are searching for the function as the inverse of the solution to the differential equation , where
The main findings of this Step are summarised below.
Remark 7.
Similar to Step , we get for and its inverse function :
- ;
- , ;
- and ;
- , .
- on , and on .
Remark 8.
Similar to Step , (24) we conclude by induction from that
Note that the choice of and given by (14) is the only choice leading to . In this way, one makes sure that it holds also in the -th step, implying in this way . A different choice of and would eliminate the upper boundary for , destroying the well-definiteness of the limiting function .
5. The Value Function
In this section, we first construct a candidate for the value function by letting for the sequences , , , , and . Then, we prove the candidate to be the value function via a verification theorem.
We know from Remarks 5 and 7 that the sequences , , , , and are monotone and thus pointwise convergent. In the following lemma, we show that the convergence is uniform on compacts.
Lemma 9.
The sequences , , , , , , , converge uniformly on compacts to , , , , , , , , respectively.
Proof.
Note first that Lemma 8 and Remark 7 yield the monotonicity of the sequences , , , , and . Therefore, these sequences converge pointwise implying the pointwise convergence of and .
In the following, we show that , , and converge uniformly on compacts.
Assume , , and converge pointwise to , w, u and , respectively. Note that it holds by definition of : with defined in (23). As and , see Step , it holds
Integrating both sides of the above inequality, yields
which means that the sequence is dominated by an integrable function. By Lebesgue’s convergence theorem converges pointwise to . Recall that is a continuous function of x and because of the uniqueness of the pointwise limit converges pointwise to . That is, as is a decreasing sequence, Dini’s theorem yields the uniform convergence of to w on compacts.
With the same arguments we get that converges uniformly to and it holds on compacts.
In a similar way, one can conclude that and converge uniformly on compacts to and , respectively. So that we can conclude, compare, for instance, (de Souza and Silva 2001, pp. 60, 297), that the sequence of the inverse functions converges uniformly on compacts to , the inverse of .
As a consequence of Differential Equation , also the sequence converges uniformly to on compacts. □
Lemma 10.
The limiting functions , , and fulfil on
- ;
- , ;
- , ;
- and ;
- and .
- , , and fulfil on
Proof.
From Lemma 9, one gets immediately the above inequalities with ≥ and ≤ instead of > and < along with Differential Equation (26).
The strict inequalities follow easily using the methods presented in Step 1. □
Lemma 11.
For it holds and .
Proof.
Note that is increasing and is decreasing with , , and . It means
meaning that is increasing and is decreasing. If , then contradicting . If , then leads to the contradiction .
is a direct consequence from the above. □
Corollary 3.
It holds , .
Proof.
As and and we conclude and . Therefore,
□
Definition 1.
We let for
and
Lemma 12.
- , .
- solves the system of differential equations for withwith the boundary conditions and .
- is the return function corresponding to the strategy .
Proof.
□
Proposition 2.
Proof.
The proof follows easily from Lemma 12. □
Theorem 1 (Verification Theorem).
The strategy with
is the optimal strategy, and the corresponding return function , given in (27), is the value function.
Proof.
Let be an arbitrary admissible strategy and the surplus process under B and after the capital injections. Following the steps from lemma 1 we get
where M is again a martingale with expectation 0 as M is bounded
where is the return function corresponding to the strategy “no reinsurance”, i.e., . Because is bounded we can conclude that also the stochastic integral is a martingale with expectation zero. Further, as solves the HJB equation and is convex with , it follows that
and . Thus, building expectations on the both sides in (29) yields
By the bounded convergence theorem, we can interchange limit and expectations and get . For the strategy , we get the equality. □
6. Numerical Illustrations
All numerical computations were performed on Matlab R2020b using the library bvpsuite2.01.
The package bvpsuite2.0 has been developed at the Institute for Analysis and Scientific Computing, Vienna University of Technology, and can be used—among other applications—for the numerical solution of boundary value problems in ordinary differential equations on semi-infinite intervals. The library uses collocation for the numerical solution of the underlying boundary value problems, which is a piecewise polynomial function which satisfies the given ODE at a finite number of nodes (collocation points). This approach shows advantageous convergence properties compared to other direct higher order methods.2
The subsequent example has an illustrative scope and aims solely at providing numerical evidence of the convergence of the recursive algorithm developed in the previous theoretical sections. In order to provide a clear numerical illustration of the results, the following choice of parameters turns out to be suitable: , , , , , , and .
6.1. Illustration of the Recursive Procedure
We start with illustrating the recursive procedure described in Section 4; that is, we consider the functions and and their convergence behaviour.
The fast convergence of each for results in a very badly conditioned differential equation (in this example, ). As a consequence, we had to truncate the solution interval and set the boundary conditions at , i.e., . The short horizon leads the solver to overshoot the solution at the beginning and to compensate later on, creating a characteristic initial “hump” for , which is evened out more and more with each iteration. As a matter of fact, the larger k is, the more is converging towards a concave shape. On the other hand, the convergence of is faster, as for 6 iterations the functions are already very close to each other, see Figure 1.
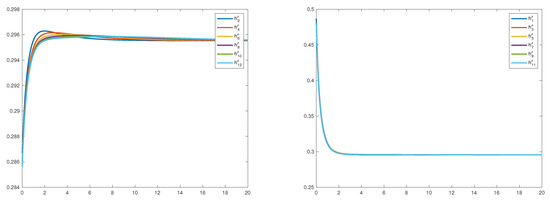
Figure 1.
The functions (left) and (right) for .
6.2. Solving the HJB Directly
Differently than in the section above, the HJB Equation (4) is now solved directly using again bvpsuite2.0. The optimal reinsurance strategy and the ratio corresponding to the limit of the sequences (for ) and (for ) are illustrated in Figure 2.
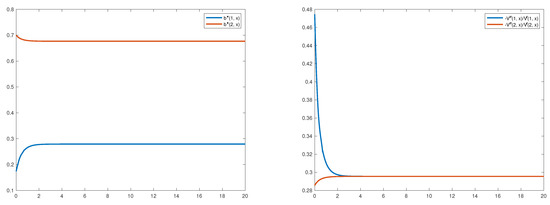
Figure 2.
The optimal reinsurance strategies (left) and the ratios (right).
In Figure 2, left picture, one sees that in both regimes the optimal reinsurance strategy is non-constant with respect to the surplus level. The red line representing the optimal strategy is decreasing and the strategy , in blue, is increasing. The reason for this behaviour is the relation , where and . The optimal strategies for the one-regime cases are
for the regime 1 and
for regime 2, respectively. Thus, due to the possibility to change into a regime with a different reinsurance price, the optimal strategy changes.
In Figure 2, right picture, we see that the ratio converges for both regimes to the level , the value towards which the sequences and converge as can be seen in Section 6.1.
Using bvpsuite optimisation, each step of the iteration takes between 30 and 40 s to compute on a single 3GHz core.
These findings confirm the validity of the iterative algorithm developed in Section 4 and illustrated numerically in Section 6.1.
7. Conclusions
In this paper, we study the problem faced by an insurance company that aims at finding the optimal proportional reinsurance strategy minimising the expected discounted capital injections. We assume that the cost of entering the proportional reinsurance contract depends on the current busyness cycle of a two-state economy, and we model this by letting the safety loading of the reinsurance be modulated by a continuous-time Markov chain. This leads to an optimal reinsurance problem under regime switching. In order to simplify our explanations, we assume a certain relation between the crucial parameters of the two regimes. Considering all possible combinations would be space-consuming with just a marginal additional value.
Differently to Eisenberg and Schmidli (2009)—where no regime switching has been considered—we find that the optimal reinsurance cannot be independent of the current value of the surplus process, but should instead be given as a feedback strategy , also depending on the current regime. However, due to the complex nature of the resulting HJB equation, determining an explicit expression for turns out to be a challenging task. For this reason, we develop a recursive algorithm that hinges on the construction of two sequences of functions converging uniformly to a classical solution to the HJB equation and simultaneously providing the optimal strategies for both regimes. The obtained optimal strategies are monotone with respect to the surplus level and converge for both regimes to the same explicitly calculated constant as the surplus goes to infinity. The algorithm is illustrated by a numerical example, where one can also see that the convergence to the solution of the HJB equation is quite fast.
The recursive scheme represents the main contribution of this paper and might also be applied (with necessary adjustments) to other optimisation problems containing regime-switching. For this reason, we retrace here the main steps and ideas of the algorithm.
The differential equation for the value function is first translated into a differential equation for an auxiliary function, transforming the derivative of the value function into an exponential function, using the method of Højgaard and Taksar (1998). In order to get a solution to the system of equations, say Equations (a) and (b), we solve the differential Equation (a) assuming that the solution to Equation (b) is given by an exponential function , which is the starting function of our algorithm. Then, we solve Equation (b) by inserting the solution to Equation (a) from the previous step. Proceeding in this manner, we obtain two sequences of uniformly converging functions whose limiting functions solve the original HJB equation system.
Note that we are facing a boundary value problem, i.e., the boundary conditions on the value function and its derivative, and are given at different boundaries, with one boundary being infinity. Therefore, the usual Picard–Lindelöf approach does not work. Instead, we use Volterra form representations and comparison theorems to show the existence and uniqueness of a solution with the desired properties.
One of the crucial points in the above considerations is the starting function of the algorithm. It turns out that there is a uniquely given constant, , allowing to obtain the desired properties of the limiting functions.
In particular, we show that the derivatives of the auxiliary functions lie in suitable intervals or , depending on the differential equation we are looking at.
Thus, we are able to show that the value function is twice continuously differentiable and the optimal strategy has a monotone character and converges for to an explicitly calculated value.
It would be interesting to implement the considerations from Chiappori et al. (2006) to extend the presented model by hidden information, for instance, by introducing a hidden Markov chain governing the reinsurance price over the parameter . This topic will be one of the directions of our future research.
Author Contributions
J.E.: Conceptualisation, methodology, formal analysis, writing—original draft preparation abs writing—review and editing; supervision abs project administration. L.F.: visualisation abs numerical results. M.D.S.: Conceptualisation, minor methodology, minor formal analysis abs writing—original draft preparation. All authors have read and agreed to the published version of the manuscript.
Funding
The research of Julia Eisenberg was funded by the Austrian Science Fund (FWF), Project number V 603-N35. Maren Diane Schmeck acknowledges financial support by the German Research Foundation (DFG) through the Collaborative Research Centre 1283 “Taming uncertainty and profiting from randomness and low regularity in analysis, stochastics and their applications”.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors would like to thank the anonymous referees for their comments and suggestions that helped to considerably improve the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Appendix A.1. Proofs of Step 1
Proof of Lemma 4.
Let and consider the differential Equation (17) on the interval with the boundary conditions and for some .
- It is straightforward to show that Equation (17) can be written in form of a Volterra integral equationNote that the functionis Lipschitz continuous in y for . Then, the Theorem on Continuous Dependence, see Walter (Walter 1998, p. 148), yields the existence of a unique solution to (17) on with and for every , where is continuous as a function of .From Lemma 3, we know that and . By the intermediate value theorem, there is a leading to a solution with and .
The Jacobi matrix is then given by
On D, the Jacobi matrix is essentially positive3 and irreducible4. We can conclude that by Hirsch’s Theorem, see Walter (Walter 1998, p. 112), for any it holds and for all . Therefore, is the unique solution to (17) with the boundary conditions and . For simplicity, we will write for this unique solution just . □
Proof of Lemma 5.
We know from Lemma 3 that . Then, it holds that and is increasing as long as . Further, deriving (17) we get
Let . Then, and consequently on . If , then
- Thus, if , then and the second derivative becomes negative, implying that stays smaller than on and contradicts .
- If , then contradicting .
- If , then implying for all . This means that is a linear function on , i.e., is a constant and on . Inserting this conjecture into Differential Equation (17) yields the contradiction.
If the claim follows with the arguments from Lemma 3. □
Proof of Proposition 1.
- First, we show that the sequences and are decreasing.As it holds for all , with Lemma 5 one gets for . This means, in particular, that .We know that . Assume now . The functionis increasing in . Letting Differential Equation (17) can be written as . Comparison Theorem, see Walter (Walter 1998, p. 139), yields then on leading to a contradiction.Thus, for all and as a direct consequence of the same Comparison Theorem: and on compacts for all .Therefore, we can conclude that the sequences and are decreasing fulfilling and . Therefore, and converge pointwise to some functions and w, respectively, and due to Differential Equation (17), the sequence converges pointwise to some function u.
- In the next step, we show that the sequences , and converge uniformly on compacts.As and , see Lemma 5, for all and all , it holds thatIntegrating both sides of the above inequality and using that , yieldswhich means that the sequence is dominated by a locally integrable function. By Lebesgue’s convergence theorem converges pointwise to . Recall that is a continuous function of x, and because of the uniqueness of the pointwise limit, converges pointwise to . That is, as is a decreasing sequence Dini’s theorem yields the uniform convergence of to w on compacts.With the same argument, we get that converges uniformly to and it holds on compacts. As a consequence of Differential Equation (17), converges uniformly to on compacts.
- Now, we are ready to show that fulfils .Note that solves Equation (17). The function fulfils due to the properties of and : , and for all . It means that . If then there is an such that for . However, for with it holds , meaning . Then, we can conclude that .If then . However, the differential equation for yieldscontradicting .Therefore, we conclude . With the arguments from Lemma (5), we can conclude on and .
□
Appendix A.2. Proofs of Step 2
Proof of Lemma 6.
- Assume for the moment that . Then,and . Therefore, on andAs , it holds that , and (22) gives and consequently . Furthermore, as long as the function is increasing giving . Thus, on ,
- Assume now . Then, and because (Corollary 1) it holdsWe conclude that and on . However, if it holds contradicting . Hence, will stay above .
- By Hirsch’s Theorem, see Walter (Walter 1998, p. 112), for it holds .
□
Appendix A.3. Proofs of Step 2m+1
Proof of Lemma 8.
Note first that and fulfil the above assumptions.
To prove the claim for a general m, we consider the difference of the differential equations :
- If , then all k-th derivatives fulfil , implying for all x. As because for , we get a contradiction.
- In this part, we show that is impossible.For that purpose, we use again the auxiliary functions introduced in Lemma 4, representing the solutions to differential equations with boundary conditions at 0 and at . We denote by the solutions to with the boundary conditions and and by the solutions to with boundary conditions and , for .Let n be arbitrary, but fixed and assume . Let further . Then, it holds and on . This means in particular, using the properties of and , that and consequentlyEquality (A2) then yields , contradicting .That is, we can conclude for all . However, this contradicts . Furthermore, we conclude leading via the uniform convergence, see Lemma 4, to . As we excluded , it must hold .
- We know already that it must hold .Let and assume that . At it holds then and which, due to (A2), meansThus, .On the other hand, from Step we know that on which is equivalent toon . As , we can conclude that and are strictly increasing. For all x with , it holds thatThus, if additionally , thenThis means in particular that and consequently for . As , we obtained a contradiction to .
□
Notes
| 1. | https://www.asc.tuwien.ac.at/~ewa/software_development5.htm (accessed on 10 February 2021). |
| 2. | https://repositum.tuwien.at/handle/20.500.12708/4782 (accessed on 10 February 2021). |
| 3. | for all . |
| 4. | cannot be transformed into a block upper triangle matrix via a permutation, i.e., there is no permutation matrix leading to . |
References
- Asmussen, Søren. 1989. Risk theory in a Markovian environment. Scandinavian Actuarial Journal 1989: 69–100. [Google Scholar] [CrossRef]
- Asmussen, Søren, and Hansjorg Albrecher. 2010. Ruin Probabilities. London: World Scientific Publishing. [Google Scholar]
- Auzinger, Winfried, Merlin Fallahpour, Othmar Koch, and Ewa Weinmüller. 2019. Implementation of a Pathfollowing Strategy with an Automatic Step-Length Control: New MATLAB Package Bvpsuite2.0. ASC Report 31/2019. Wien: Institute for Analysis and Scientific Computing, Vienna University of Technology. [Google Scholar]
- Azcue, Pablo, and Nora Muler. 2005. Optimal reinsurance and dividend distribution policies in the Cramér–Lundberg model. Mathematical Finance 15: 261–308. [Google Scholar] [CrossRef]
- Bargès, Mathieu, Stéphane Loisel, and Xavier Venel. 2013. On finite-time ruin probabilities with reinsurance cycles influenced by large claims. Scandinavian Actuarial Journal 2013: 163–85. [Google Scholar] [CrossRef]
- Bäuerle, Nicole, and Mirko Kötter. 2007. Markov-modulated diffusion risk models. Scandinavian Actuarial Journal 2007: 34–52. [Google Scholar] [CrossRef][Green Version]
- Ben Salah, Zied, and José Garrido. 2018. On fair reinsurance premiums; capital injections in a perturbed risk model. Insurance: Mathematics and Economics 82: 11–20. [Google Scholar] [CrossRef]
- Brachetta, Matteo, and Claudia Ceci. 2020. A BSDE-based approach for the optimal reinsurance problem under partial information. Insurance: Mathematics and Economics 95: 1–16. [Google Scholar] [CrossRef]
- Chiappori, Pierre-André, Bruno Jullien, Bernard Salanié, and Francois Salanie. 2006. Asymmetric information in insurance: General testable implications. RAND Journal of Economics 37: 783–98. [Google Scholar] [CrossRef]
- de Souza, Paulo Ney, and Jorge-Nuno Silva. 2001. Berkeley Problems in Mathematics. New York: Springer. [Google Scholar]
- Eisenberg, Julia, and Hanspeter Schmidli. 2009. Optimal control of capital injections by reinsurance in a diffusion approximation. Blätter DGVFM 30: 1–13. [Google Scholar] [CrossRef]
- Eisenberg, Julia, and Paul Krühner. 2018. The impact of negative interest rates on optimal capital injections. Insurance: Mathematics and Economics 82: 1–10. [Google Scholar] [CrossRef]
- Gajek, Lesław, and Marcin Rudź. 2020. General methods for bounding multidimensional ruin probabilities in regime-switching models. Stochastics, 1–16. [Google Scholar] [CrossRef]
- Gerber, Hans U., and Elias S. W. Shiu. 1998. On the time value of ruin. North American Actuarial Journal 2: 48–78. [Google Scholar] [CrossRef]
- Højgaard, Bjarne, and Michael Taksar. 1998. Optimal proportional reinsurance policies for diffusion models. Scandinavian Actuarial Journal 1998: 166–80. [Google Scholar] [CrossRef]
- Jacod, Jean, and Albert Shiryaev. 2003. Limit Theorems for Stochastic Processes, 2nd ed. Berlin: Springer. [Google Scholar]
- Jiang, Zhengjun, and Martijn Pistorius. 2012. Optimal dividend distribution under Markov regime switching. Finance and Stochastics 16: 449–76. [Google Scholar] [CrossRef]
- Pafumi, Gérard. 1998. “On the time value of ruin”, Hans U. Gerber and Elias S.W. Shiu, January 1998. North American Actuarial Journal 2: 75–76. [Google Scholar] [CrossRef]
- Rolski, Tomasz, Hanspeter Schmidli, Volker Schmidt, and Jozef L. Teugels. 1999. Stochastic Processes for Insurance & Finance. Hoboken: John Wiley & Sons Ltd. [Google Scholar]
- Schmidli, Hanspeter. 2008. Stochastic Control in Insurance. London: Springer. [Google Scholar]
- Schmidli, Hanspeter. 2017. Risk Theory. London: Springer. [Google Scholar]
- Shreve, Steven E., John P. Lehoczky, and Donald P. Gaver. 1984. Optimal consumption for general diffusions with absorbing and reflecting barriers. Siam Journal on Control and Optimization 22: 55–75. [Google Scholar] [CrossRef]
- Walter, Wolfgang. 1998. Ordinary Differential Equations. New York: Springer. [Google Scholar]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).