
A Novel Prediction Method Based on Bi-Channel Hierarchical Vision Transformer for Rolling Bearings’ Remaining Useful Life


Abstract
:1. Introduction
- (1)
- This study proposes a novelty degrading feature extraction network based on BCHViT. The improved method is more effective at identifying important depth features that characterize the degradation process from rolling bearing vibration signals’ wavelet packet coefficients.
- (2)
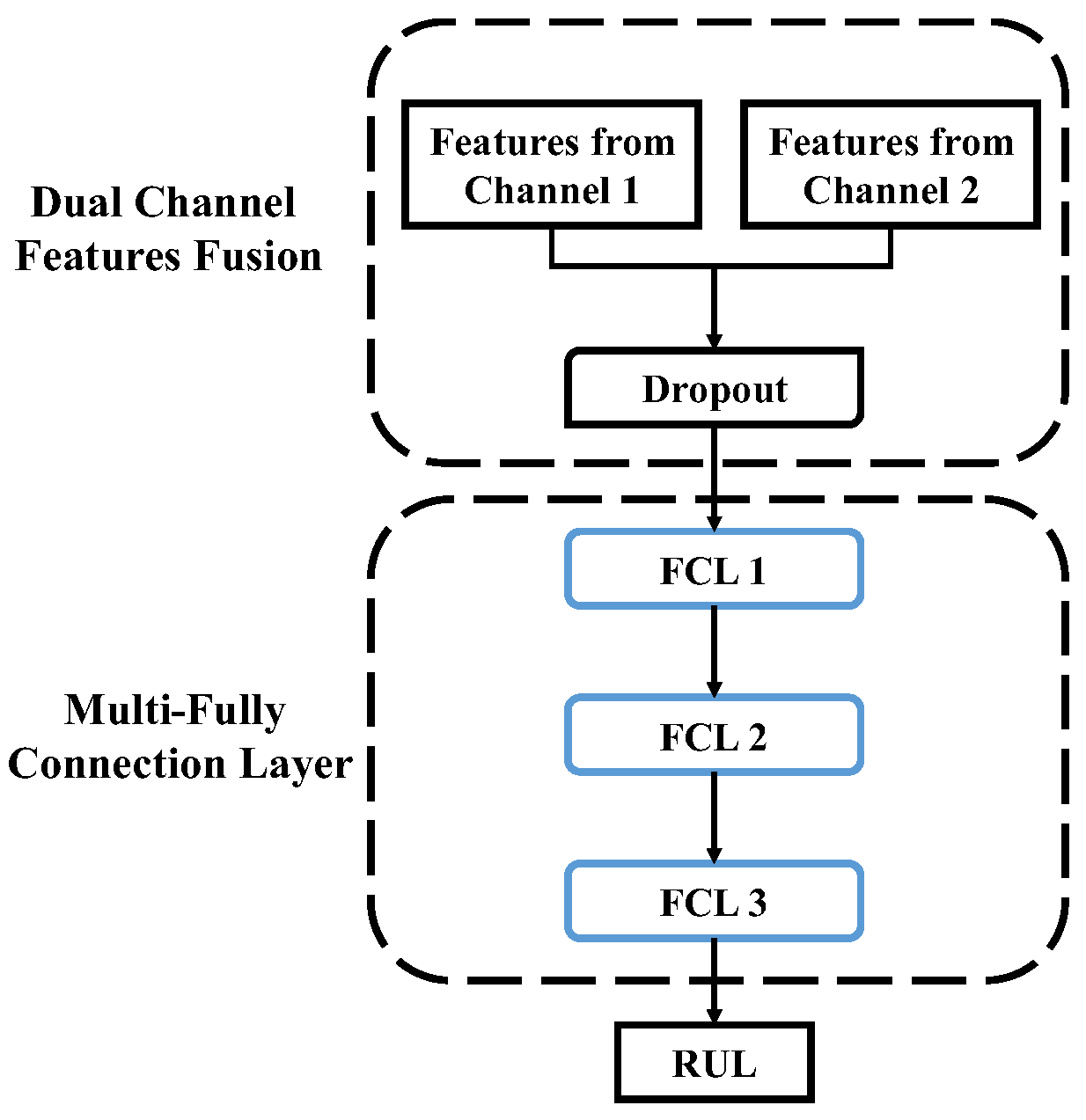
- Based on the multi-layer full connection layer, a dual-channel feature fusion technique is implemented into the RUL prediction network. This improvement contributes to guaranteeing RUL prediction accuracy at the degradation stage.
- (3)
- The experimental results show that the RUL prediction method proposed in this study can extract more common degradation information from the various rolling bearing frequency bands. It shows the guaranteed reliability and universality of RUL prediction when compared with current mainstream approaches.
2. Methods
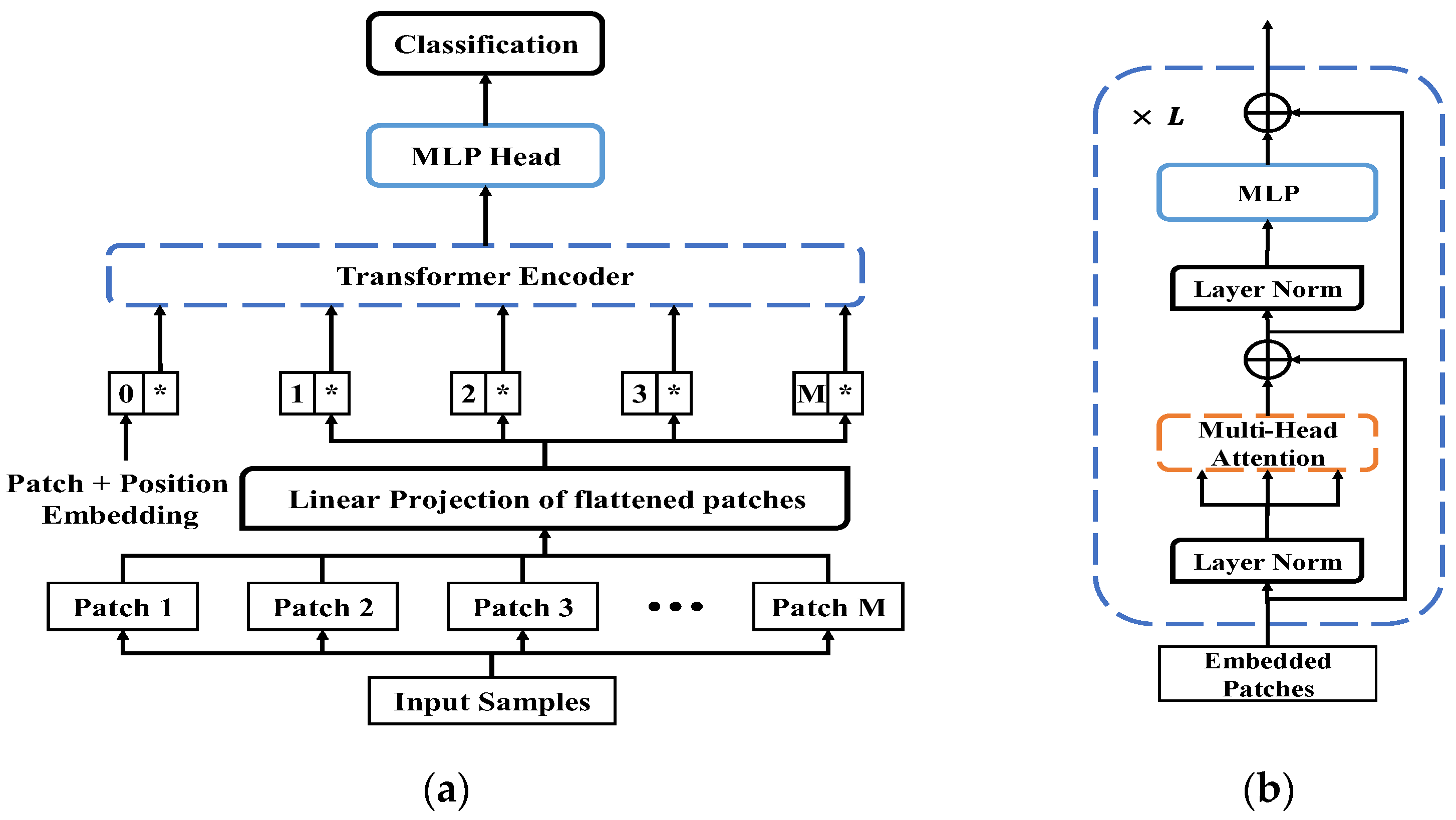
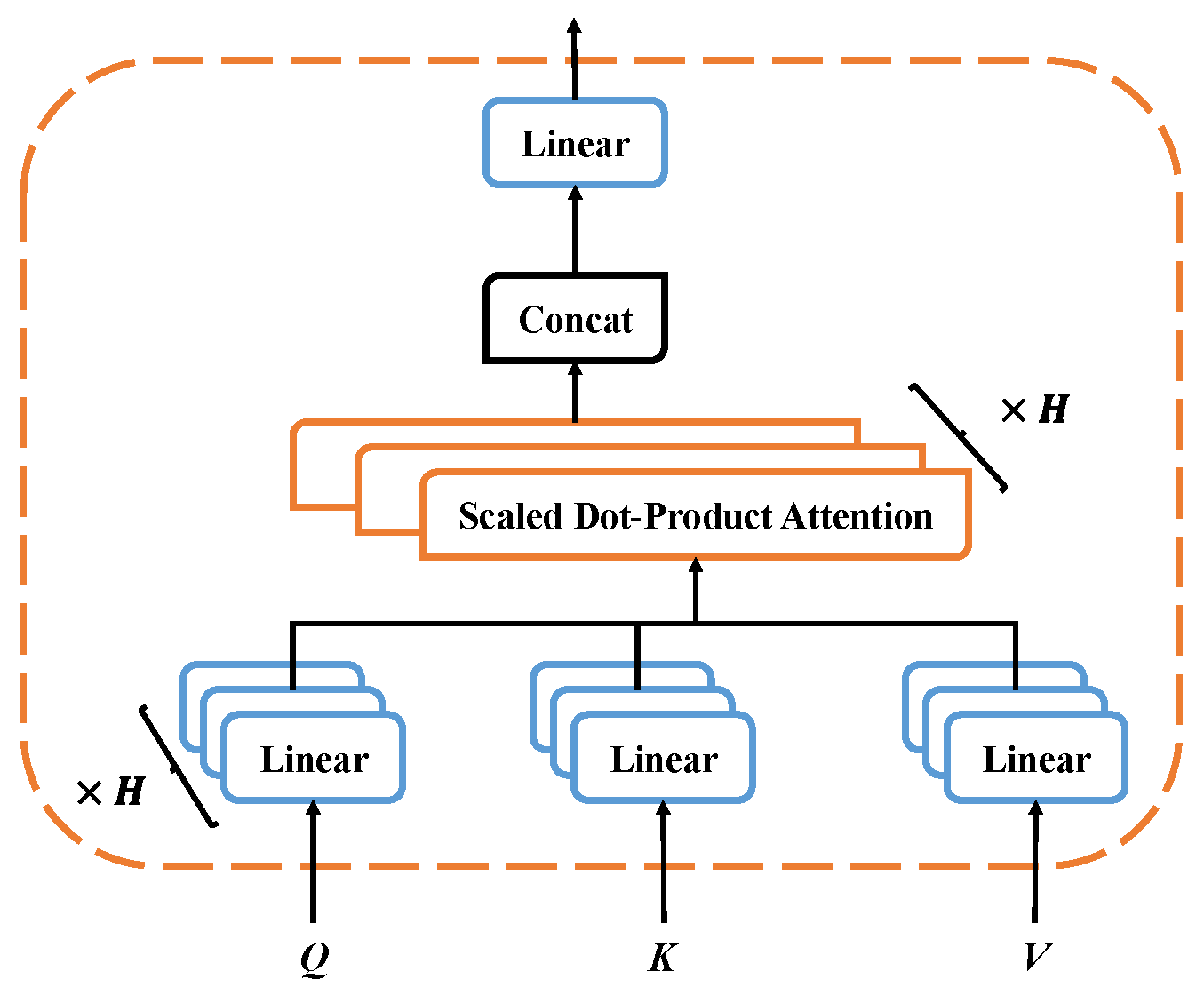
2.1. Vision Transformer
2.2. Swin Transformer
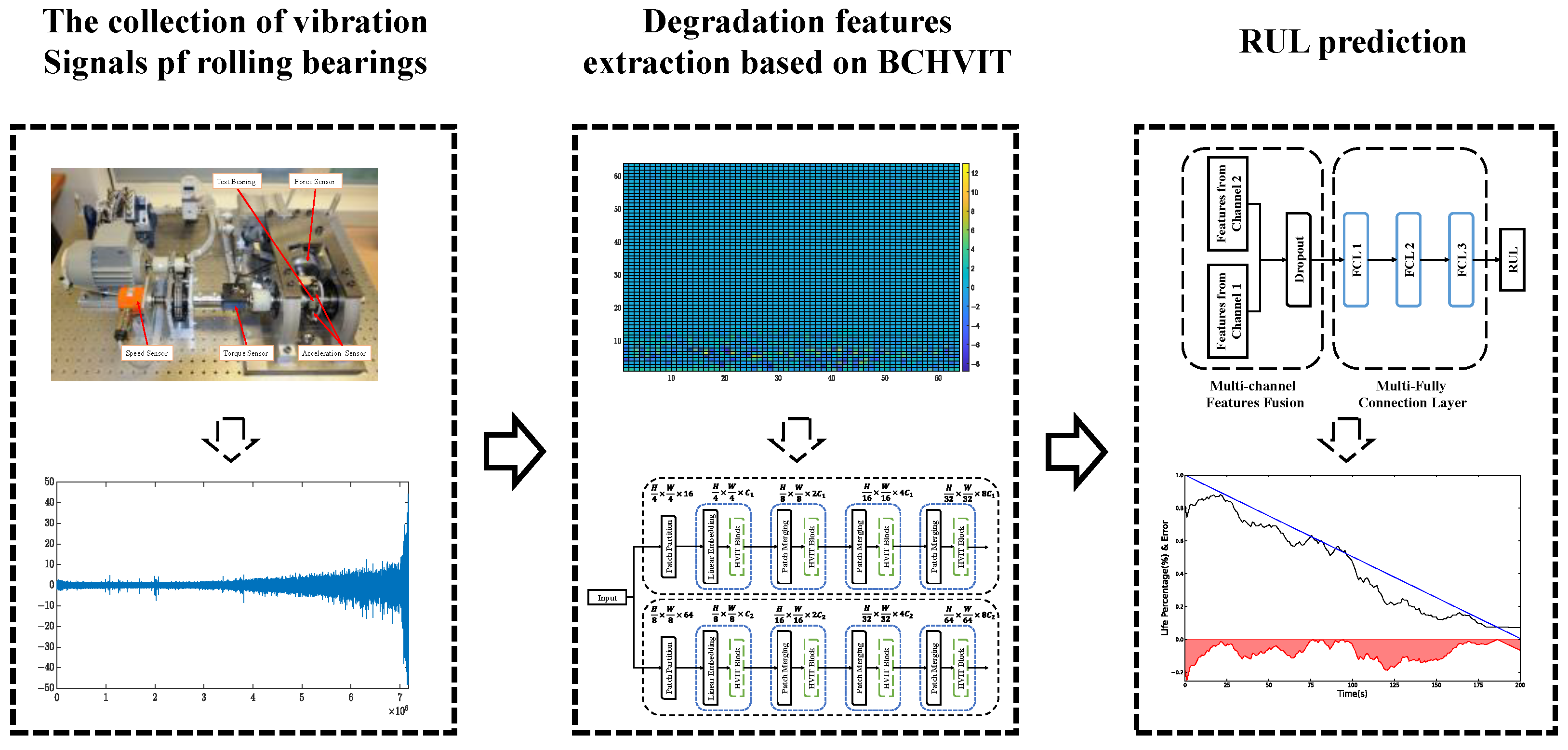
3. RUL Prediction Method Based on BCHViT
3.1. Degradation Feature Extraction Based on BCHViT
3.2. RUL Prediction Based on Dual Channel Feature Fusion
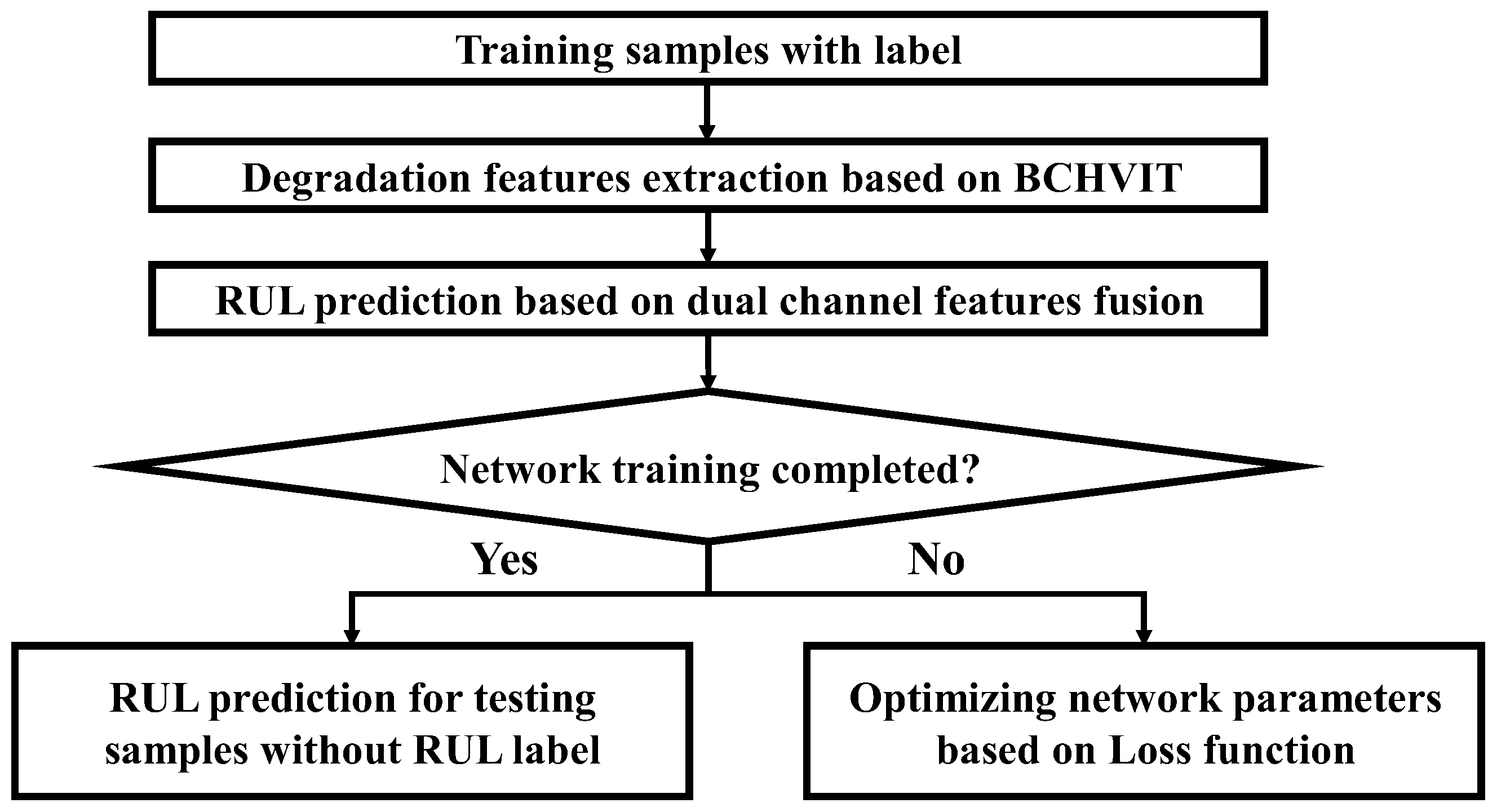
3.3. Model Optimization Objective and Training Process
| Algorithm 1. Description of algorithm flow |
| Input: sample , minimum batch 1. Initialization of parameters of networks, including and 2. do: 3. For 4. Take samples from 5. Extract degradation features based on BCHViT networks 6. Dual channel deep feature fusion ) 7. Take samples 8. Until and sum converges |
4. Experimental Verification and Analysis
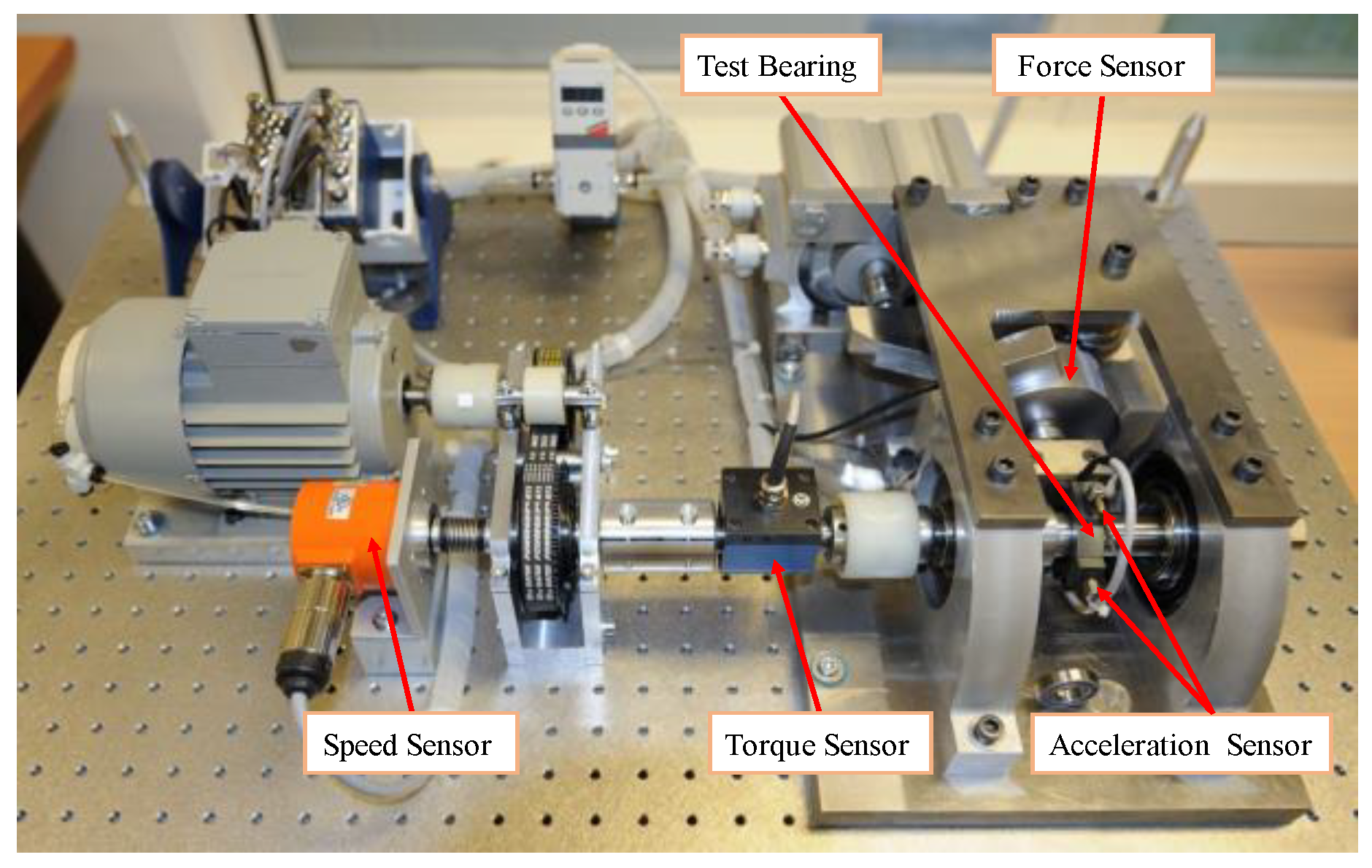
4.1. Experimental Data Introduction
4.2. Experimental Data Pre-Processing
4.3. The Experiment Designs
4.3.1. Experimental Arrangement and Evaluation Index
4.3.2. Parameter Setting
4.4. Results and Analysis
4.4.1. Ablation Experiments
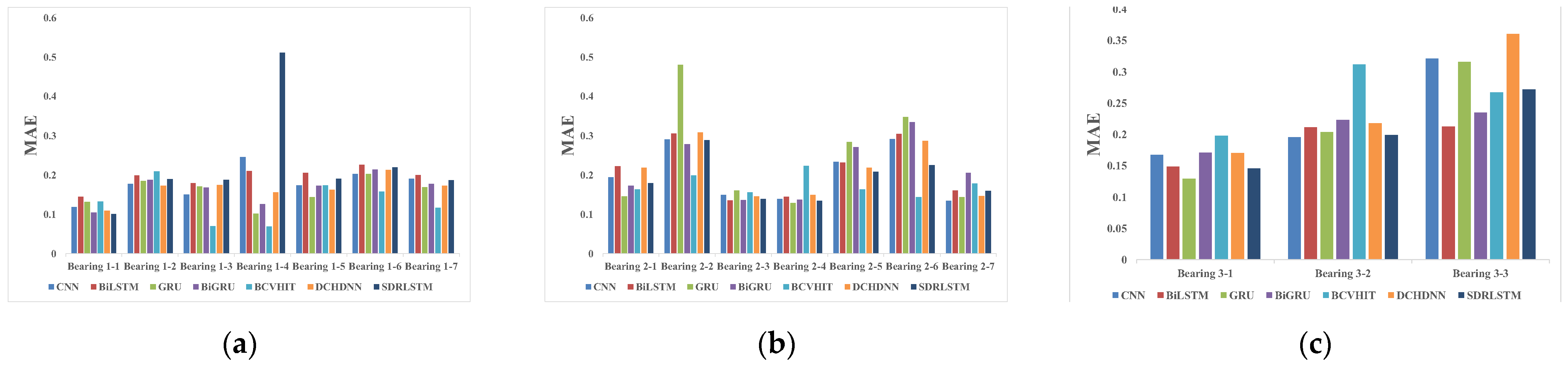
4.4.2. Comparative Analysis of Other Methods
5. Conclusions
- (1)
- Compared to the Swin transformer model, the special HViT network structure proposed in this study can better use the DL network structure to extract depth features containing more significant degradation information. This feature meets the requirements of bearing RUL prediction in practical engineering by providing a higher prediction effect of RUL in the nearing failure stage.
- (2)
- Compared with current mainstream RUL prediction methods, the proposed method can extract depth features comprising degradation process common information from different rolling bearing degradation processes. This depth feature effectively ensures that the RUL prediction method is more general and accurate.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ding, P.; Jia, M.; Zhao, X. Meta Deep Learning Based Rotating Machinery Health Prognostics toward Few-Shot Prognostics. Appl. Soft Comput. 2021, 104, 107211. [Google Scholar] [CrossRef]
- Zhou, J.; Qin, Y.; Luo, J.; Wang, S.; Zhu, T. Dual-Thread Gated Recurrent Unit for Gear Remaining Useful Life Prediction. IEEE Trans. Industr. Inform. 2022, 1–11. [Google Scholar] [CrossRef]
- Chen, M.; Shao, H.; Dou, H.; Li, W.; Liu, B. Data Augmentation and Intelligent Fault Diagnosis of Planetary Gearbox Using ILoFGAN Under Extremely Limited Samples. IEEE Trans. Reliab. 2022, 1–9. [Google Scholar] [CrossRef]
- Hao, W.; Liu, F. Imbalanced Data Fault Diagnosis Based on an Evolutionary Online Sequential Extreme Learning Machine. Symmetry 2020, 12, 1204. [Google Scholar] [CrossRef]
- Xiao, Y.; Shao, H.; Han, S.Y.; Huo, Z.; Wan, J. Novel Joint Transfer Network for Unsupervised Bearing Fault Diagnosis From Simulation Domain to Experimental Domain. IEEE/ASME Trans. Mechatron. 2022, 27, 5254–5263. [Google Scholar] [CrossRef]
- Zou, Y.; Liu, Y.; Deng, J.; Jiang, Y.; Zhang, W. A Novel Transfer Learning Method for Bearing Fault Diagnosis under Different Working Conditions. Measurement 2021, 171, 108767. [Google Scholar] [CrossRef]
- Hao, W.; Liu, F. Axle Temperature Monitoring and Neural Network Prediction Analysis for High-Speed Train under Operation. Symmetry 2020, 12, 1662. [Google Scholar] [CrossRef]
- Li, N.; Lei, Y.; Guo, L.; Yan, T.; Lin, J. Remaining Useful Life Prediction Based on a General Expression of Stochastic Process Models. IEEE Trans. Ind. Electron. 2017, 64, 119–132. [Google Scholar] [CrossRef]
- Ding, Y.; Ding, P.; Jia, M. A Novel Remaining Useful Life Prediction Method of Rolling Bearings Based on Deep Transfer Auto-Encoder. IEEE Trans. Instrum. Meas. 2021, 70, 2507812. [Google Scholar] [CrossRef]
- Cheng, H.; Kong, X.; Chen, G.; Wang, Q.; Wang, R. Transferable Convolutional Neural Network Based Remaining Useful Life Prediction of Bearing under Multiple Failure Behaviors. Measurement 2021, 168, 108286. [Google Scholar] [CrossRef]
- Wang, P.; Long, Z.; Wang, G. A Hybrid Prognostics Approach for Estimating Remaining Useful Life of Wind Turbine Bearings. IEEE Trans. Reliab. 2020, 6, 173–182. [Google Scholar] [CrossRef]
- Lei, Y.; Li, N.; Guo, L.; Li, N.; Yan, T.; Lin, J. Machinery Health Prognostics: A Systematic Review from Data Acquisition to RUL Prediction. Mech. Syst. Signal Process. 2018, 104, 799–834. [Google Scholar] [CrossRef]
- Cui, L.; Wang, X.; Wang, H.; Jiang, H. Remaining Useful Life Prediction of Rolling Element Bearings Based on Simulated Performance Degradation Dictionary. Mech. Mach. Theory 2020, 153, 103967. [Google Scholar] [CrossRef]
- Li, Y.; Huang, X.; Ding, P.; Zhao, C. Wiener-Based Remaining Useful Life Prediction of Rolling Bearings Using Improved Kalman Filtering and Adaptive Modification. Measurement 2021, 182, 109706. [Google Scholar] [CrossRef]
- Zeng, F.; Li, Y.; Jiang, Y.; Song, G. A Deep Attention Residual Neural Network-Based Remaining Useful Life Prediction of Machinery. Measurement 2021, 181, 109642. [Google Scholar] [CrossRef]
- Yan, M.; Wang, X.; Wang, B.; Chang, M.; Muhammad, I. Bearing Remaining Useful Life Prediction Using Support Vector Machine and Hybrid Degradation Tracking Model. ISA Trans. 2020, 98, 471–482. [Google Scholar] [CrossRef]
- Mishra, M.; Martinsson, J.; Goebel, K.; Rantatalo, M. Bearing Life Prediction with Informed Hyperprior Distribution: A Bayesian Hierarchical and Machine Learning Approach. IEEE Access 2021, 9, 157002–157011. [Google Scholar] [CrossRef]
- Xiahou, T.; Zeng, Z.; Liu, Y. Remaining Useful Life Prediction by Fusing Expert Knowledge and Condition Monitoring Information. IEEE Trans. Industr. Inform. 2021, 17, 2653–2663. [Google Scholar] [CrossRef]
- Zhang, K.; Tang, B.; Deng, L.; Tan, Q.; Yu, H. A Fault Diagnosis Method for Wind Turbines Gearbox Based on Adaptive Loss Weighted Meta-ResNet under Noisy Labels. Mech. Syst. Signal Process. 2021, 161, 107963. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, K.; Liu, Y.; Zou, Y.; Ding, G. A Novel Remaining Useful Life Transfer Prediction Method of Rolling Bearings Based on Working Conditions Common Benchmark. IEEE Trans. Instrum. Meas. 2022, 71, 3524909. [Google Scholar] [CrossRef]
- Li, H.; Zhao, W.; Zhang, Y.; Zio, E. Remaining Useful Life Prediction Using Multi-Scale Deep Convolutional Neural Network. Appl. Soft Comput. J. 2020, 89, 87–96. [Google Scholar] [CrossRef]
- Zou, Y.; Zhao, S.; Liu, Y.; Li, Z.; Song, X.; Ding, G. The Transfer Prediction Method of Bearing Remain Use Life Based on Dynamic Benchmark. IEEE Trans. Instrum. Meas. 2021, 70, 2516211. [Google Scholar] [CrossRef]
- Han, T.; Pang, J.; Tan, A. Remaining Useful Life Prediction of Bearing Based on Stacked Autoencoder and Recurrent Neural Network. J. Manuf. Syst. 2021, 61, 576–591. [Google Scholar] [CrossRef]
- Guo, L.; Li, N.; Jia, F.; Lei, Y.; Lin, J. A Recurrent Neural Network Based Health Indicator for Remaining Useful Life Prediction of Bearings. Neurocomputing 2017, 240, 98–109. [Google Scholar] [CrossRef]
- Zou, Y.; Li, Z.; Liu, Y.; Zhao, S.; Liu, Y.; Ding, G. A Method for Predicting the Remaining Useful Life of Rolling Bearings under Different Working Conditions Based on Multi-Domain Adversarial Networks. Measurement 2021, 188, 110393. [Google Scholar] [CrossRef]
- Fu, B.; Yuan, W.; Cui, X.; Yu, T.; Zhao, X.; Li, C. Correlation Analysis and Augmentation of Samples for a Bidirectional Gate Recurrent Unit Network for the Remaining Useful Life Prediction of Bearings. IEEE Sens. J. 2021, 21, 7989–8001. [Google Scholar] [CrossRef]
- Wang, H.; Cheng, Y.; Song, K. Remaining Useful Life Estimation of Aircraft Engines Using a Joint Deep Learning Model Based on Tcnn and Transformer. Comput. Intell. Neurosci. 2021, 2021, 5185938. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, C.; Wang, Y. Lithium-Ion Battery Capacity and Remaining Useful Life Prediction Using Board Learning System and Long Short-Term Memory Neural Network. J. Energy Storage 2022, 52, 104901. [Google Scholar] [CrossRef]
- Ren, L.; Cui, J.; Sun, Y.; Cheng, X. Multi-Bearing Remaining Useful Life Collaborative Prediction: A Deep Learning Approach. J. Manuf. Syst. 2017, 43, 248–256. [Google Scholar] [CrossRef]
- Zhang, K.; Tang, B.; Deng, L.; Liu, X. A Hybrid Attention Improved ResNet Based Fault Diagnosis Method of Wind Turbines Gearbox. Measurement 2021, 179, 109491. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, S.; He, Y. An Integrated Method of the Future Capacity and RUL Prediction for Lithium-Ion Battery Pack. IEEE Trans. Veh. Technol. 2022, 71, 2601–2613. [Google Scholar] [CrossRef]
- Su, X.; Liu, H.; Tao, L.; Lu, C.; Suo, M. An End-to-End Framework for Remaining Useful Life Prediction of Rolling Bearing Based on Feature Pre-Extraction Mechanism and Deep Adaptive Transformer Model. Comput. Ind. Eng. 2021, 161, 107531. [Google Scholar] [CrossRef]
- Ding, Y.; Jia, M.; Cao, Y. Remaining Useful Life Estimation under Multiple Operating Conditions via Deep Subdomain Adaptation. IEEE Trans. Instrum. Meas. 2021, 70, 3516711. [Google Scholar] [CrossRef]
- Cao, Y.; Ding, Y.; Jia, M.; Tian, R. A Novel Temporal Convolutional Network with Residual Self-Attention Mechanism for Remaining Useful Life Prediction of Rolling Bearings. Reliab. Eng. Syst. Saf. 2021, 215, 107813. [Google Scholar] [CrossRef]
- Zeng, D.; Yang, J.; Zou, Y.; Zhang, J.; Song, X. Bearing Life Prediction Method Based on PMCCNN-LSTM. China Mech. Eng. 2020, 31, 2454–2462. [Google Scholar]
- Zhang, C.; Zhao, S.; Yang, Z.; Chen, Y. A Reliable Data-Driven State-of-Health Estimation Model for Lithium-Ion Batteries in Electric Vehicles. Front. Energy Res. 2022, 10. [Google Scholar] [CrossRef]
- Mao, W.; He, J.; Zuo, M.J. Predicting Remaining Useful Life of Rolling Bearings Based on Deep Feature Representation and Transfer Learning. IEEE Trans. Instrum. Meas. 2020, 69, 1594–1608. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5999–6009. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Yen, G.G. Wavelet Packet Feature Extraction for Vibration Monitoring. IEEE Trans. Ind. Electron. 2000, 47, 650–667. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving Neural Networks by Preventing Co-Adaptation of Feature Detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Zhu, J.; Chen, N.; Shen, C. A New Data-Driven Transferable Remaining Useful Life Prediction Approach for Bearing under Different Working Conditions. Mech. Syst. Signal Process. 2020, 139, 106602. [Google Scholar] [CrossRef]
- Nectoux, P.; Gouriveau, R.; Medjaher, K.; Ramasso, E.; Chebel-morello, B.; Zerhouni, N.; Varnier, C.; Nectoux, P.; Gouriveau, R.; Medjaher, K.; et al. PRONOSTIA: An Experimental Platform for Bearings Accelerated Degradation Tests. To Cite This Version: HAL Id: Hal-00719503 PRONOSTIA: An Experimental Platform for Bearings Accelerated Degradation Tests. In Proceedings of the IEEE International Conference on Prognostics and Health Management, PHM’12, Denver, CO, USA, 20 June 2012; pp. 1–8. [Google Scholar]
- Yao, D.; Li, B.; Liu, H.; Yang, J.; Jia, L. Remaining Useful Life Prediction of Roller Bearings Based on Improved 1D-CNN and Simple Recurrent Unit. Measurement 2021, 175, 109166. [Google Scholar] [CrossRef]
- Xiao, L.; Liu, Z.; Zhang, Y.; Zheng, Y.; Cheng, C. Degradation Assessment of Bearings with Trend-Reconstruct-Based Features Selection and Gated Recurrent Unit Network. Measurement 2020, 165, 108064. [Google Scholar] [CrossRef]
- Zhao, C.; Huang, X.; Li, Y.; Iqbal, M.Y. A Double-Channel Hybrid Deep Neural Network Based on CNN and BiLSTM for Remaining Useful Life Prediction. Sensors 2020, 20, 7109. [Google Scholar] [CrossRef]
- Fu, S.; Zhang, Y.; Lin, L.; Zhao, M.; Zhong, S. sheng Deep Residual LSTM with Domain-Invariance for Remaining Useful Life Prediction across Domains. Reliab. Eng. Syst. Saf. 2021, 216, 108012. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Condition 1 | Condition 2 | Condition 3 |
|---|---|---|---|
| Load (N) | 4000 | 4200 | 5000 |
| Motor Speed (rpm) | 1800 | 1650 | 1500 |
| Number of Bearings | 7 | 7 | 3 |
| Name of Bearings | 1-1,1-2,1-3,1-4,1-5,1-6,1-7 | 2-1,2-2,2-3,2-4,2-5,2-6,2-7 | 3-1,3-2,3-3 |
| Testing Bearing | Training Datasets | Testing Datasets |
|---|---|---|
| Bearing 1-2 | 1-1,1-3,1-4,1-5,1-6,1-7 | 1-2 |
| Bearing 2-2 | 2-1,2-3,2-4,2-5,2-6,2-7 | 2-2 |
| Bearing 3-2 | 3-1,3-3 | 3-2 |
| Testing Bearing | Training Datasets | Testing Datasets |
|---|---|---|
| Bearing 1-1 | 1-2,1-3,1-4,1-5,1-6,1-7, 2-1,2-2,2-3,2-4,2-5,2-6, 2-7,3-1,3-2,3-3 | 1-1 |
| Bearing 1-2 | 1-1,1-3,1-4,1-5,1-6,1-7, 2-1,2-2,2-3,2-4,2-5,2-6, 2-7,3-1,3-2,3-3 | 1-2 |
| Bearing 1-3 | 1-1,1-2,1-4,1-5,1-6,1-7, 2-1,2-2,2-3,2-4,2-5,2-6, 2-7,3-1,3-2,3-3 | 1-3 |
| Bearing 1-4 | 1-1,1-2,1-3,1-5,1-6,1-7, 2-1,2-2,2-3,2-4,2-5,2-6, 2-7,3-1,3-2,3-3 | 1-4 |
| Bearing 1-5 | 1-1,1-2,1-3,1-4,1-6,1-7, 2-1,2-2,2-3,2-4,2-5,2-6, 2-7,3-1,3-2,3-3 | 1-5 |
| Bearing 1-6 | 1-1,1-2,1-3,1-4,1-5,1-7, 2-1,2-2,2-3,2-4,2-5,2-6, 2-7,3-1,3-2,3-3 | 1-6 |
| Bearing 1-7 | 1-1,1-2,1-3,1-4,1-5,1-6, 2-1,2-2,2-3,2-4,2-5,2-6, 2-7,3-1,3-2,3-3 | 1-7 |
| Parameters | Channel 1 | Channel 2 | |
|---|---|---|---|
| Patch size | 4 | 8 | |
| The dimension of patch embedding | 24 | ||
| Window size | 4 | ||
| Depth of each HViT layer | (2,2,6,2) | ||
| Number of attentions heads in different layer | (3,6,12,24) | ||
| Dropout Rate | Attention | 0.2 | |
| Stochastic | 0.1 | ||
| MLP ratio | 3 | ||
| No. | Name of layers | Units | Channel | Activation Function |
|---|---|---|---|---|
| 1 | FCL 1 | (384,192) | 1 | ReLU |
| 2 | FCL 2 | (192,64) | 1 | Leaky ReLU |
| 3 | FCL 3 | (64,1) | 1 | ReLU |
| Working Condition | Swin Transformer | HViT | BCVHiT |
|---|---|---|---|
| Condition 1 | |||
| Condition 2 | |||
| Condition 3 | |||
| Average |
| Method | Condition 1 | Condition 2 | Condition 3 | Average |
|---|---|---|---|---|
| CNN | ||||
| BiLSTM | ||||
| GRU | ||||
| BiGRU | ||||
| DCHDNN | ||||
| SRDLSTM | ||||
| BCHViT |
| Testing Bearing | CNN | Bi-LSTM | GRU | BIGRU | DCH-DNN | SRD-LSTM | BCVHIT |
|---|---|---|---|---|---|---|---|
| Bearing 1-1 | 0.1316 | 0.1670 | 0.0932 | 0.1267 | 0.1248 | 0.13405 | 0.1402 |
| Bearing 1-2 | 0.1726 | 0.1829 | 0.1640 | 0.1815 | 0.1614 | 0.1873 | 0.0697 |
| Bearing 1-3 | 0.1425 | 0.1637 | 0.1210 | 0.1281 | 0.1511 | 0.1633 | 0.1044 |
| Bearing 1-4 | 0.2977 | 0.1314 | 0.0637 | 0.1389 | 0.3145 | 0.4106 | 0.0941 |
| Bearing 1-5 | 0.1830 | 0.1976 | 0.1718 | 0.1731 | 0.1895 | 0.1855 | 0.0917 |
| Bearing 1-6 | 0.2337 | 0.2078 | 0.2307 | 0.2193 | 0.2306 | 0.2243 | 0.2453 |
| Bearing 1-7 | 0.1747 | 0.2093 | 0.1798 | 0.1798 | 0.1813 | 0.1929 | 0.1069 |
| Average | 0.1908 | 0.1800 | 0.1463 | 0.1639 | 0.1933 | 0.2140 | 0.1218 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hao, W.; Li, Z.; Qin, G.; Ding, K.; Lai, X.; Zhang, K. A Novel Prediction Method Based on Bi-Channel Hierarchical Vision Transformer for Rolling Bearings’ Remaining Useful Life. Processes 2023, 11, 1153. https://doi.org/10.3390/pr11041153
Hao W, Li Z, Qin G, Ding K, Lai X, Zhang K. A Novel Prediction Method Based on Bi-Channel Hierarchical Vision Transformer for Rolling Bearings’ Remaining Useful Life. Processes. 2023; 11(4):1153. https://doi.org/10.3390/pr11041153
Chicago/Turabian StyleHao, Wei, Zhixuan Li, Guohao Qin, Kun Ding, Xuwei Lai, and Kai Zhang. 2023. "A Novel Prediction Method Based on Bi-Channel Hierarchical Vision Transformer for Rolling Bearings’ Remaining Useful Life" Processes 11, no. 4: 1153. https://doi.org/10.3390/pr11041153