

A Timestep-Adaptive-Diffusion-Model-Oriented Unsupervised Detection Method for Fabric Surface Defects


Abstract
:1. Introduction
2. Related Works
2.1. Unsupervised Detection Method
2.2. Denoising Diffusion Probabilistic Models
3. Proposed Methods
- (1)
- Surface Feature Extraction of Flawless Fabrics
- (2)
- Defect Detection with SN-DDPM
3.1. Surface Feature Extraction of Flawless Fabrics
3.1.1. Forward Diffusion
3.1.2. Simplex Noise
3.1.3. Reverse Diffusion
3.1.4. Denoising Unet
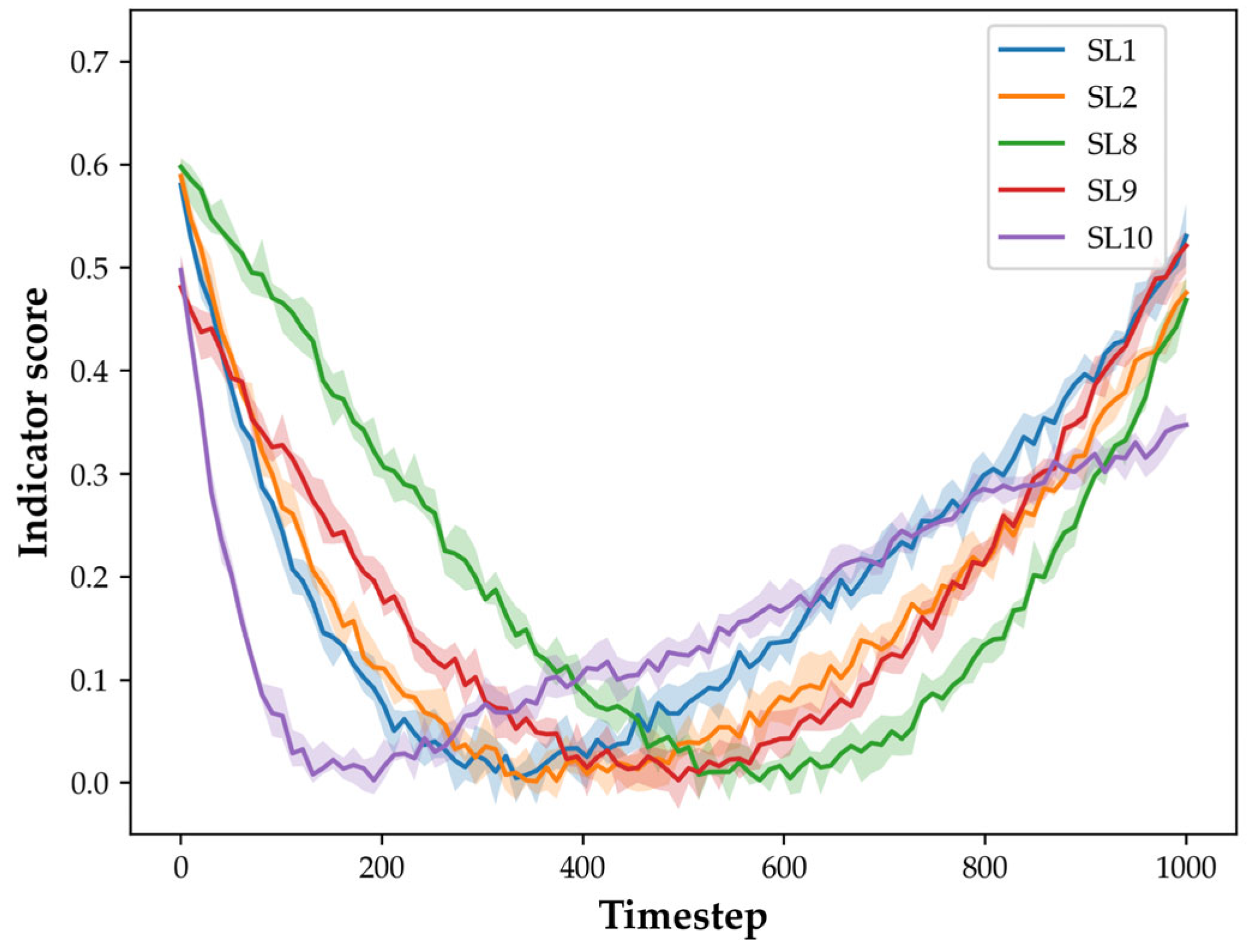
3.1.5. Timestep Adaptive Module
3.2. Defect Detection with SN-DDPM
| Algorithm 1: Defect Detection with SN-DDPM |
| Input: RGB image Output: Defect detection result 1: Step 1: Obtaining the optimal timestep and reconstructing the defect image . 2: Step 2: Processing the images as follows: 3: Converting the RGB image to grayscale: 4: Gaussian filter: 5: Step 3: Absolute difference: 6: 7: Step 4: Performing FTSD: 8: Applying the Gaussian filter to smooth the residual image 9: Converting the smoothed image to LAB color space 10: Calculating the average image feature vector 11: Calculating the pixel vector value 12: Calculating the saliency image from normalized Euclidean distance 13: Step 5: Binarization: 14: Calculating the threshold value: 15: Binarizing the saliency image: 16: Step 6: Closed operation: 17: |
4. Experimental Setup
4.1. Datasets
4.2. Training Process
4.3. Evaluation Method
4.3.1. Evaluation Indicator of Image Reconstruction Results
4.3.2. Evaluation Indicator Defect Detection Results
5. Experimental Results and Discussion
5.1. Fabric Images Reconstruction Experiments
5.2. Defect Detection Experiments
5.3. Ablation Study
5.4. Model Failure Experiment
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ngan, H.Y.; Pang, G.K.; Yung, N.H.J.I. Automated fabric defect detection—A review. Image Vis. Comput. 2011, 29, 442–458. [Google Scholar] [CrossRef]
- Wong, W.; Jiang, J. Computer vision techniques for detecting fabric defects. In Applications of Computer Vision in Fashion and Textiles; Elsevier: Amsterdam, The Netherlands, 2018; pp. 47–60. [Google Scholar]
- Rasheed, A.; Zafar, B.; Rasheed, A.; Ali, N.; Sajid, M.; Dar, S.H.; Habib, U.; Shehryar, T.; Mahmood, M.T. Fabric Defect Detection Using Computer Vision Techniques: A Comprehensive Review. Math. Probl. Eng. 2020, 2020, 8189403. [Google Scholar] [CrossRef]
- Xiang, J.; Pan, R.; Gao, W. Online Detection of Fabric Defects Based on Improved CenterNet with Deformable Convolution. Sensors 2022, 22, 4718. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Yu, L.; Zhi, C.; Sun, R.; Zhu, S.; Gao, Z.; Ke, Z.; Zhu, M.; Zhang, Y. Improved faster R-CNN for fabric defect detection based on Gabor filter with Genetic Algorithm optimization. Comput. Ind. 2022, 134, 103551. [Google Scholar] [CrossRef]
- Jing, J.F.; Zhuo, D.; Zhang, H.H.; Liang, Y.; Zheng, M. Fabric defect detection using the improved YOLOv3 model. J. Eng. Fiber. Fabr. 2020, 15, 1558925020908268. [Google Scholar] [CrossRef]
- Ren, Z.; Fang, F.; Yan, N.; Wu, Y. State of the Art in Defect Detection Based on Machine Vision. Int. J. Precis. Eng. Manuf.-Green Technol. 2021, 9, 661–691. [Google Scholar] [CrossRef]
- Szarski, M.; Chauhan, S. An unsupervised defect detection model for a dry carbon fiber textile. J. Intell. Manuf. 2022, 33, 2075–2092. [Google Scholar] [CrossRef]
- Wang, Y.Y.; Song, K.C.; Niu, M.H.; Bao, Y.Q.; Dong, H.W.; Yan, Y.H. Unsupervised defect detection with patch-aware mutual reasoning network in image data. Automat. Constr. 2022, 142, 104472. [Google Scholar] [CrossRef]
- Zhang, N.; Zhong, Y.; Dian, S.J.O. Rethinking unsupervised texture defect detection using PCA. Opt. Laser. Eng. 2023, 163, 107470. [Google Scholar] [CrossRef]
- Zhang, H.W.; Chen, X.W.; Lu, S.; Yao, L.; Chen, X. A contrastive learning-based attention generative adversarial network for defect detection in colour-patterned fabric. Color. Technol. 2023, 139, 248–264. [Google Scholar] [CrossRef]
- Zhang, H.; Qiao, G.; Lu, S.; Yao, L.; Chen, X. Attention-based Feature Fusion Generative Adversarial Network for yarn-dyed fabric defect detection. Text. Res. J. 2022, 93, 1178–1195. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Zhai, J.; Zhang, S.; Chen, J.; He, Q. Autoencoder and its various variants. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; pp. 415–419. [Google Scholar]
- Kahraman, Y.; Durmusoglu, A. Deep learning-based fabric defect detection: A review. Text. Res. J. 2023, 93, 1485–1503. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Bansal, A.; Borgnia, E.; Chu, H.-M.; Li, J.S.; Kazemi, H.; Huang, F.; Goldblum, M.; Geiping, J.; Goldstein, T.J. Cold diffusion: Inverting arbitrary image transforms without noise. arXiv 2022, arXiv:2208.09392. [Google Scholar]
- Perlin, K. Improving noise. In Proceedings of the 29th Annual Conference on Computer Graphics and Interactive Techniques, New York, NY, USA, 23–26 July 2002; pp. 681–682. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]
- Li, Y.; Zhao, W.; Pan, J. Deformable Patterned Fabric Defect Detection with Fisher Criterion-Based Deep Learning. IEEE Trans. Autom. Sci. Eng. 2017, 14, 1256–1264. [Google Scholar] [CrossRef]
- Zhang, H.W.; Liu, S.T.; Tan, Q.L.; Lu, S.; Yao, L.; Ge, Z.Q. Colour-patterned fabric defect detection based on an unsupervised multi-scale U-shaped denoising convolutional autoencoder model. Color. Technol. 2022, 138, 522–537. [Google Scholar] [CrossRef]
- Li, X.; Zheng, Y.; Chen, B.; Zheng, E. Dual Attention-Based Industrial Surface Defect Detection with Consistency Loss. Sensors 2022, 22, 5141. [Google Scholar] [CrossRef]
- Zhang, H.W.; Qiao, G.H.; Liu, S.T.; Lyu, Y.T.; Yao, L.; Ge, Z.Q. Attention-based vector quantisation variational autoencoder for colour-patterned fabrics defect detection. Color. Technol. 2023, 139, 223–238. [Google Scholar] [CrossRef]
- Wei, C.; Liang, J.; Liu, H.; Hou, Z.; Huan, Z. Multi-stage unsupervised fabric defect detection based on DCGAN. Visual Comput. 2022, 1–17. [Google Scholar] [CrossRef]
- Zhang, G.; Cui, K.; Hung, T.-Y.; Lu, S. Defect-GAN: High-fidelity defect synthesis for automated defect inspection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, Hawaii, 3–7 January 2021; pp. 2524–2534. [Google Scholar]
- Yang, L.; Zhang, Z.; Song, Y.; Hong, S.; Xu, R.; Zhao, Y.; Shao, Y.; Zhang, W.; Cui, B.; Yang, M.-H. Diffusion models: A comprehensive survey of methods and applications. arXiv 2022, arXiv:2209.00796. [Google Scholar]
- Croitoru, F.A.; Hondru, V.; Ionescu, R.T.; Shah, M. Diffusion Models in Vision: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10850–10869. [Google Scholar] [CrossRef]
- Müller-Franzes, G.; Niehues, J.M.; Khader, F.; Arasteh, S.T.; Haarburger, C.; Kuhl, C.; Wang, T.; Han, T.; Nebelung, S.; Kather, J.N.J. Diffusion Probabilistic Models beat GANs on Medical Images. arXiv 2022, arXiv:2212.07501. [Google Scholar]
- Lugmayr, A.; Danelljan, M.; Romero, A.; Yu, F.; Timofte, R.; Van Gool, L. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11461–11471. [Google Scholar]
- Li, H.; Yang, Y.; Chang, M.; Chen, S.; Feng, H.; Xu, Z.; Li, Q.; Chen, Y. SRDiff: Single image super-resolution with diffusion probabilistic models. Neurocomputing 2022, 479, 47–59. [Google Scholar] [CrossRef]
- Gedara Chaminda Bandara, W.; Gopalakrishnan Nair, N.; Patel, V.M.J. Remote Sensing Change Detection (Segmentation) using Denoising Diffusion Probabilistic Models. arXiv 2022, arXiv:2206.11892. [Google Scholar]
- Graham, M.S.; Pinaya, W.H.; Tudosiu, P.-D.; Nachev, P.; Ourselin, S.; Cardoso, J. Denoising diffusion models for out-of-distribution detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2947–2956. [Google Scholar]
- Zhang, H. Yarn-Dyed Fabric Image Dataset Version 1. 2021. Available online: http://github.com/ZHW-AI/YDFID-1 (accessed on 2 August 2023).
- Zhang, H.; Tang, W.; Zhang, L.; Li, P.; Gu, D. Defect detection of yarn-dyed shirts based on denoising convolutional self-encoder. In Proceedings of the 2019 IEEE 8th Data Driven Control and Learning Systems Conference (DDCLS), Dali, China, 24–27 May 2019; pp. 1263–1268. [Google Scholar]
- Hu, G.; Huang, J.; Wang, Q.; Li, J.; Xu, Z.; Huang, X. Unsupervised fabric defect detection based on a deep convolutional generative adversarial network. Text. Res. J. 2019, 90, 247–270. [Google Scholar] [CrossRef]
- Bansal, A.; Ma, S.; Ramanan, D.; Sheikh, Y. Recycle-gan: Unsupervised video retargeting. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 119–135. [Google Scholar]
- Mei, S.; Yang, H.; Yin, Z. An Unsupervised-Learning-Based Approach for Automated Defect Inspection on Textured Surfaces. IEEE Trans. Instrum. Meas. 2018, 67, 1266–1277. [Google Scholar] [CrossRef]
- Zhang, H.; Tan, Q.; Lu, S. Yarn-dyed shirt piece defect detection based on an unsupervised reconstruction model of the U-shaped denoising convolutional auto-encoder. J. Xidian Univ. 2021, 48, 123–130. [Google Scholar]
- Wei, W.; Deng, D.; Zeng, L.; Zhang, C. Real-time implementation of fabric defect detection based on variational automatic encoder with structure similarity. J. Real-Time Image Process. 2020, 18, 807–823. [Google Scholar] [CrossRef]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Du, C.; Li, Y.; Qiu, Z.; Xu, C. Stable Diffusion is Unstable. arXiv 2023, arXiv:2306.02583. [Google Scholar]
- Chefer, H.; Alaluf, Y.; Vinker, Y.; Wolf, L.; Cohen-Or, D. Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models. arXiv 2023, arXiv:2301.13826. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Method | SL1 | SL2 | SL5 | SL8 | SL9 | SL10 | SL11 | SL13 | Average Value |
|---|---|---|---|---|---|---|---|---|---|---|
| SSIM | DCAE | 0.9584 | 0.8035 | 0.8264 | 0.9341 | 0.6942 | 0.8907 | 0.7530 | 0.8886 | 0.8436 |
| DCGAN | 0.5477 | 0.1682 | 0.5392 | 0.0986 | 0.7462 | 0.3840 | 0.3568 | 0.0460 | 0.3608 | |
| Recycle-GAN | 0.0151 | 0.2721 | 0.1397 | 0.3643 | 0.0787 | 0.3472 | 0.1495 | 0.0330 | 0.1750 | |
| MSCDAE | 0.4084 | 0.4238 | 0.1586 | 0.3286 | 0.7645 | 0.3988 | 0.4672 | 0.4385 | 0.4236 | |
| UDCAE | 0.9558 | 0.7956 | 0.8234 | 0.8267 | 0.8564 | 0.8462 | 0.7869 | 0.7093 | 0.8250 | |
| VAE-L2SSIM | 0.5703 | 0.1699 | 0.3295 | 0.3885 | 0.4695 | 0.4629 | 0.5428 | 0.3921 | 0.4157 | |
| AFFGAN | 0.9748 | 0.8542 | 0.8594 | 0.8693 | 0.9135 | 0.9491 | 0.9446 | 0.9136 | 0.9098 | |
| SN-DDPM | 0.9646 | 0.9029 | 0.8697 | 0.8938 | 0.9396 | 0.9077 | 0.9481 | 0.9591 | 0.9232 | |
| PSNR (dB) | DCAE | 26.2641 | 26.7438 | 27.4138 | 27.1108 | 24.9037 | 28.3805 | 27.9167 | 28.6731 | 27.1758 |
| DCGAN | 14.8116 | 12.8657 | 14.5869 | 8.1876 | 14.6379 | 13.8489 | 13.2846 | 12.2010 | 13.0530 | |
| Recycle-GAN | 11.7674 | 17.5644 | 11.7564 | 18.3723 | 18.9168 | 19.0082 | 14.6736 | 11.0379 | 15.3871 | |
| MSCDAE | 19.9604 | 21.7564 | 12.4692 | 14.8990 | 24.9513 | 23.1437 | 21.2004 | 25.1333 | 20.4392 | |
| UDCAE | 25.3496 | 25.6432 | 25.3891 | 22.8675 | 26.3204 | 25.6267 | 21.9769 | 25.0596 | 24.7791 | |
| VAE-L2SSIM | 20.8485 | 10.0348 | 12.8676 | 24.6738 | 18.7857 | 22.9767 | 20.6472 | 26.1235 | 19.6197 | |
| AFFGAN | 28.1567 | 28.9947 | 27.0947 | 27.8877 | 28.9254 | 29.3189 | 30.0192 | 27.7191 | 28.5146 | |
| SN-DDPM | 28.1464 | 29.8400 | 25.4589 | 27.8956 | 29.1771 | 30.2919 | 28.3950 | 30.1329 | 28.6672 |
| Metric (%) | Method | SL1 | SL2 | SL5 | SL8 | SL9 | SL10 | SL11 | SL13 | Average Value |
|---|---|---|---|---|---|---|---|---|---|---|
| P | DCAE | 37.92 | 37.73 | 48.87 | 63.49 | 16.29 | 46.59 | 55.83 | 47.52 | 44.28 |
| DCGAN | 22.29 | 38.13 | 66.45 | 31.91 | 16.23 | 8.76 | 0.00 | 0.00 | 22.97 | |
| Recycle-GAN | 36.24 | 25.39 | 20.33 | 42.77 | 31.25 | 23.85 | 35.78 | 44.15 | 32.47 | |
| MSCDAE | 51.39 | 36.17 | 49.68 | 56.78 | 44.68 | 43.66 | 54.09 | 49.68 | 48.27 | |
| UDCAE | 54.94 | 55.55 | 87.75 | 15.53 | 59.14 | 51.14 | 15.69 | 87.75 | 53.44 | |
| VAE-L2SSIM | 0.00 | 42.69 | 25.00 | 70.13 | 14.28 | 24.48 | 2.28 | 24.06 | 25.37 | |
| AFFGAN | 62.01 | 17.02 | 21.84 | 63.26 | 35.85 | 47.69 | 34.67 | 29.86 | 39.02 | |
| SN-DDPM | 61.10 | 58.97 | 33.48 | 57.45 | 60.47 | 51.04 | 61.44 | 46.10 | 53.76 | |
| R | DCAE | 72.92 | 65.04 | 51.57 | 81.08 | 13.51 | 62.74 | 60.03 | 65.80 | 59.09 |
| DCGAN | 20.08 | 35.93 | 6.70 | 17.73 | 10.00 | 1.00 | 0.00 | 99.44 | 23.86 | |
| Recycle-GAN | 79.56 | 60.22 | 56.68 | 73.87 | 67.80 | 83.46 | 74.28 | 75.27 | 71.39 | |
| MSCDAE | 74.44 | 74.15 | 71.15 | 86.55 | 26.03 | 71.23 | 76.19 | 71.15 | 68.86 | |
| UDCAE | 82.11 | 61.61 | 35.66 | 8.08 | 78.45 | 44.20 | 15.12 | 35.66 | 45.11 | |
| VAE-L2SSIM | 0.00 | 14.14 | 0.99 | 59.60 | 22.50 | 2.81 | 11.66 | 34.10 | 18.22 | |
| AFFGAN | 75.89 | 57.42 | 69.09 | 79.30 | 80.57 | 64.41 | 38.12 | 44.79 | 63.70 | |
| SN-DDPM | 83.07 | 70.61 | 87.01 | 84.20 | 64.11 | 83.65 | 80.89 | 76.92 | 78.81 | |
| Acc | DCAE | 98.36 | 97.85 | 96.97 | 99.23 | 97.99 | 98.59 | 99.26 | 99.37 | 98.45 |
| DCGAN | 97.63 | 98.93 | 97.03 | 99.17 | 97.84 | 98.84 | 99.15 | 0.00 | 86.07 | |
| Recycle-GAN | 99.09 | 97.69 | 97.47 | 99.05 | 98.26 | 99.01 | 99.25 | 99.10 | 98.62 | |
| MSCDAE | 98.78 | 97.52 | 94.92 | 99.24 | 98.23 | 98.53 | 99.23 | 94.92 | 97.67 | |
| UDCAE | 98.94 | 98.74 | 97.84 | 99.00 | 98.67 | 98.75 | 99.21 | 97.84 | 98.62 | |
| VAE-L2SSIM | 98.68 | 98.72 | 96.90 | 99.36 | 98.27 | 98.85 | 99.53 | 99.53 | 98.73 | |
| AFFGAN | 99.16 | 97.34 | 97.97 | 99.23 | 99.82 | 98.66 | 99.17 | 99.55 | 98.86 | |
| SN-DDPM | 99.36 | 97.87 | 97.61 | 99.40 | 99.42 | 99.42 | 99.62 | 98.90 | 98.95 | |
| F1 | DCAE | 46.55 | 46.41 | 48.02 | 67.26 | 14.74 | 50.17 | 52.60 | 45.36 | 46.39 |
| DCGAN | 16.32 | 36.24 | 10.48 | 21.72 | 5.36 | 1.75 | 0.00 | 0.00 | 11.48 | |
| Recycle-GAN | 46.05 | 24.97 | 27.65 | 0.00 | 37.88 | 33.31 | 44.08 | 52.51 | 33.31 | |
| MSCDAE | 58.40 | 47.29 | 57.64 | 66.59 | 25.68 | 51.90 | 59.66 | 57.64 | 53.10 | |
| UDCAE | 63.17 | 53.36 | 46.99 | 8.63 | 60.60 | 39.22 | 13.14 | 46.99 | 41.51 | |
| VAE-L2SSIM | 0.00 | 19.34 | 1.90 | 63.68 | 15.04 | 4.86 | 22.42 | 22.42 | 18.71 | |
| AFFGAN | 65.15 | 16.41 | 31.53 | 66.57 | 49.62 | 52.57 | 32.35 | 29.93 | 43.02 | |
| SN-DDPM | 65.62 | 55.61 | 44.77 | 64.67 | 61.44 | 57.11 | 64.76 | 54.20 | 58.52 | |
| IoU | DCAE | 31.45 | 31.85 | 32.98 | 52.24 | 23.87 | 34.98 | 38.03 | 30.42 | 34.48 |
| DCGAN | 10.11 | 28.70 | 6.69 | 15.12 | 2.96 | 0.99 | 0.00 | 0.00 | 8.07 | |
| Recycle-GAN | 33.22 | 16.81 | 16.54 | 38.22 | 23.83 | 21.54 | 30.60 | 39.17 | 27.49 | |
| MSCDAE | 42.80 | 31.25 | 44.59 | 50.91 | 17.45 | 36.50 | 44.07 | 44.59 | 39.02 | |
| UDCAE | 47.31 | 39.43 | 32.49 | 6.39 | 44.06 | 26.37 | 8.62 | 32.49 | 29.65 | |
| VAE-L2SSIM | 0.00 | 13.40 | 0.99 | 48.65 | 9.44 | 2.75 | 12.76 | 12.76 | 12.59 | |
| AFFGAN | 50.09 | 9.33 | 19.18 | 51.32 | 33.00 | 37.14 | 25.48 | 20.84 | 30.80 | |
| SN-DDPM | 53.25 | 47.25 | 31.52 | 50.94 | 48.92 | 46.80 | 54.09 | 40.26 | 46.63 |
| Metric (%) | α | SL1 | SL2 | SL8 | SL9 | SL10 | Average Value |
|---|---|---|---|---|---|---|---|
| F1 | 0.1 | 32.45 | 29.17 | 29.94 | 30.17 | 30.74 | 30.49 |
| 0.3 | 58.51 | 55.56 | 56.83 | 47.00 | 52.13 | 54.01 | |
| 0.5 | 65.62 | 55.61 | 64.67 | 61.44 | 57.11 | 60.89 | |
| 0.7 | 49.00 | 46.05 | 47.95 | 43.26 | 41.46 | 45.54 | |
| 0.9 | 24.27 | 25.80 | 23.08 | 26.51 | 24.12 | 24.76 | |
| IoU | 0.1 | 19.81 | 17.11 | 17.62 | 17.77 | 18.16 | 18.09 |
| 0.3 | 41.89 | 38.93 | 40.35 | 30.71 | 35.25 | 37.43 | |
| 0.5 | 53.25 | 47.25 | 50.94 | 48.92 | 46.80 | 49.43 | |
| 0.7 | 26.10 | 33.22 | 35.01 | 29.95 | 28.19 | 30.49 | |
| 0.9 | 14.98 | 16.24 | 14.28 | 16.53 | 14.89 | 15.38 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, S.; Jin, Z.; Zhang, Y.; Lu, J.; Li, H.; Yang, J. A Timestep-Adaptive-Diffusion-Model-Oriented Unsupervised Detection Method for Fabric Surface Defects. Processes 2023, 11, 2615. https://doi.org/10.3390/pr11092615
Tang S, Jin Z, Zhang Y, Lu J, Li H, Yang J. A Timestep-Adaptive-Diffusion-Model-Oriented Unsupervised Detection Method for Fabric Surface Defects. Processes. 2023; 11(9):2615. https://doi.org/10.3390/pr11092615
Chicago/Turabian StyleTang, Shancheng, Zicheng Jin, Ying Zhang, Jianhui Lu, Heng Li, and Jiqing Yang. 2023. "A Timestep-Adaptive-Diffusion-Model-Oriented Unsupervised Detection Method for Fabric Surface Defects" Processes 11, no. 9: 2615. https://doi.org/10.3390/pr11092615
APA StyleTang, S., Jin, Z., Zhang, Y., Lu, J., Li, H., & Yang, J. (2023). A Timestep-Adaptive-Diffusion-Model-Oriented Unsupervised Detection Method for Fabric Surface Defects. Processes, 11(9), 2615. https://doi.org/10.3390/pr11092615