

Improving Computer Vision-Based Wildfire Smoke Detection by Combining SE-ResNet with SVM



Abstract
1. Introduction
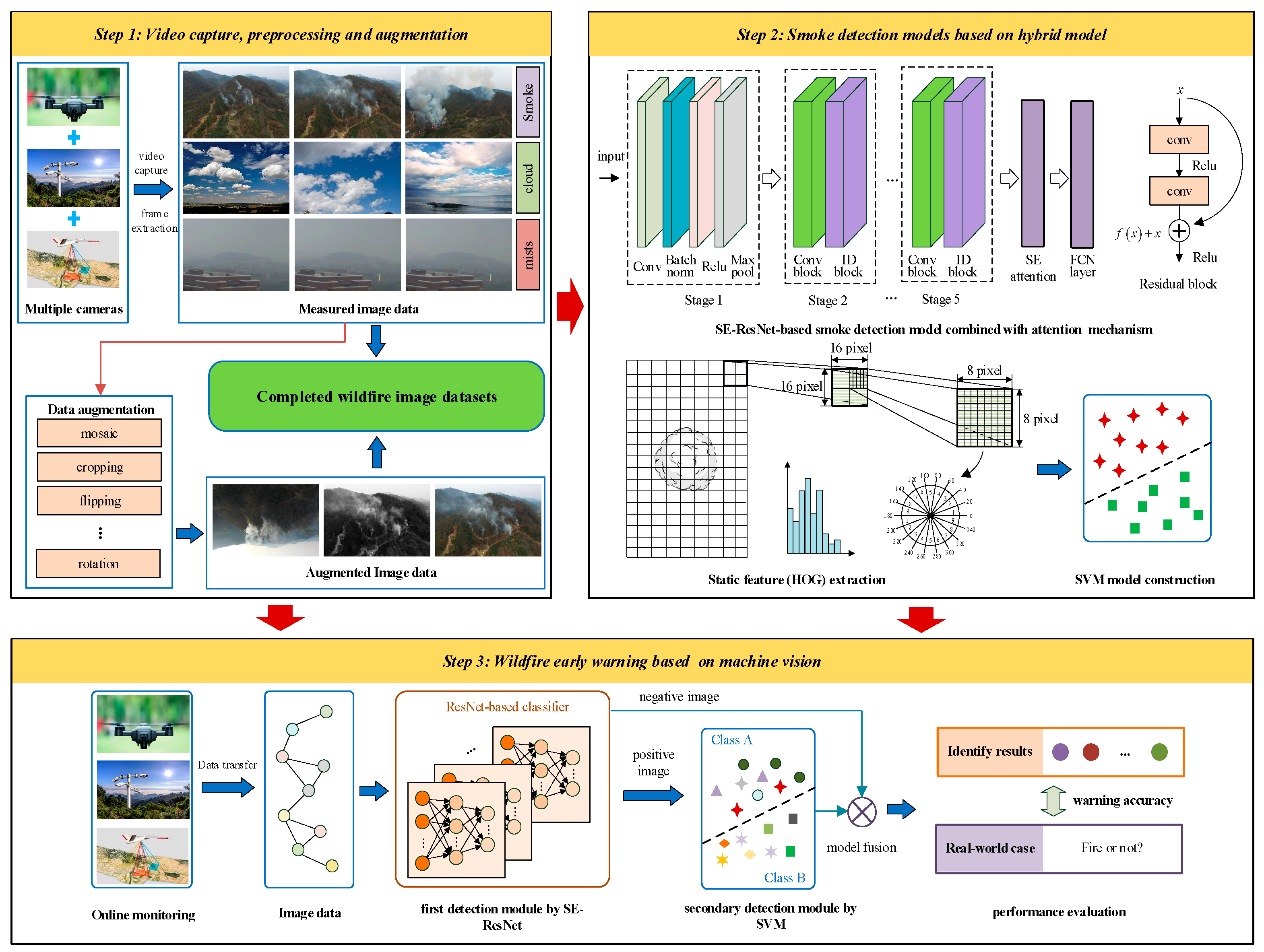
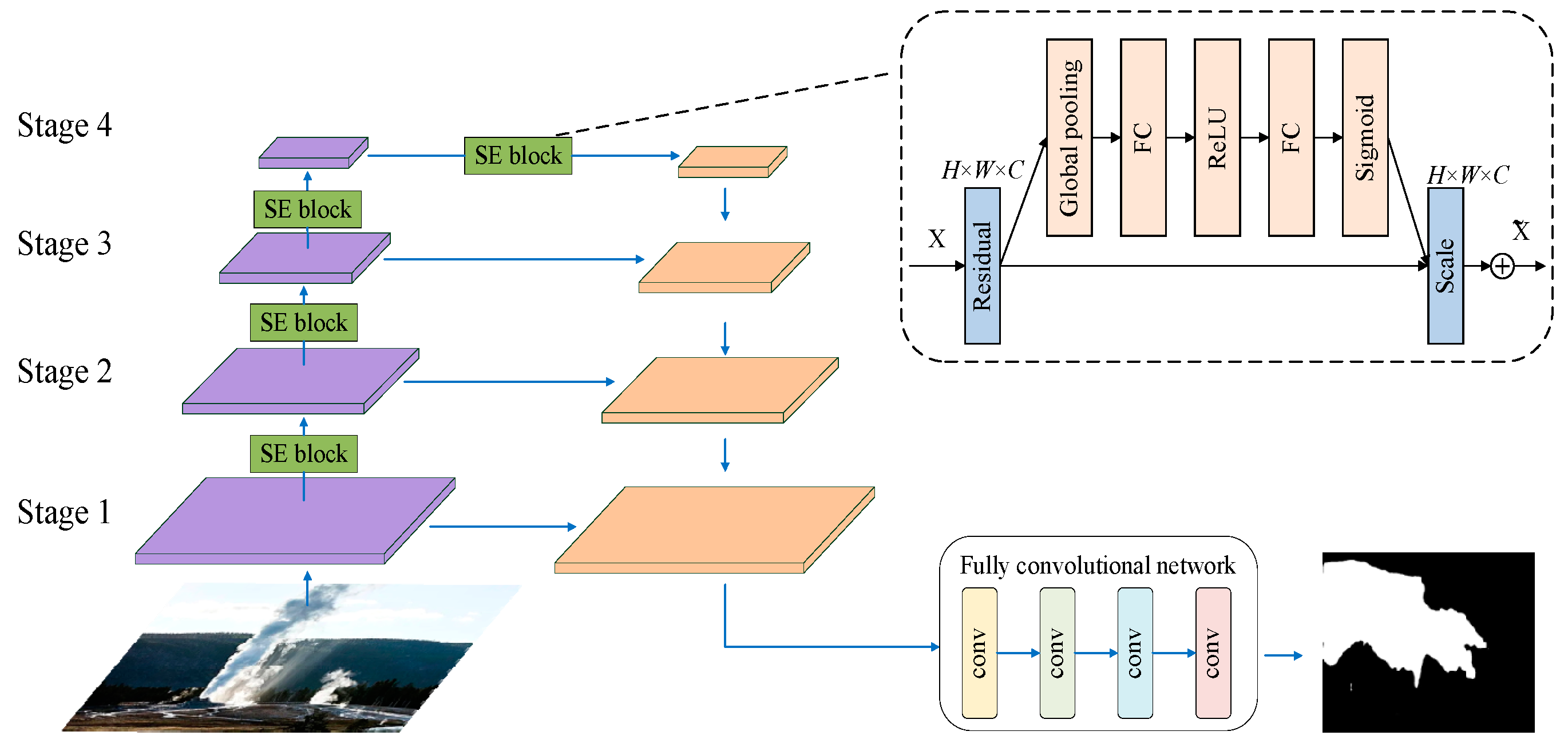
2. Framework of Proposed Approach
| Algorithm 1: Detecting wildfire smoke using a hybrid machine learning model |
| Input: online wildfire monitoring video Output: class label of each frame and early warning results Steps: 1. Extract the image frames according to time intervals . 2. For each image frame, call SE-ResNet model for smoke detection. 3. If a smoke region is labeled, then input this image frame to SVM model for secondary detection; otherwise, return the classification label as non-smoke. 4. If smoke is detected by SVM, return the classification label as smoke. 5. Issue the wildfire early warning results according to the steps above. 6. Repeat until all image frames are detected. |
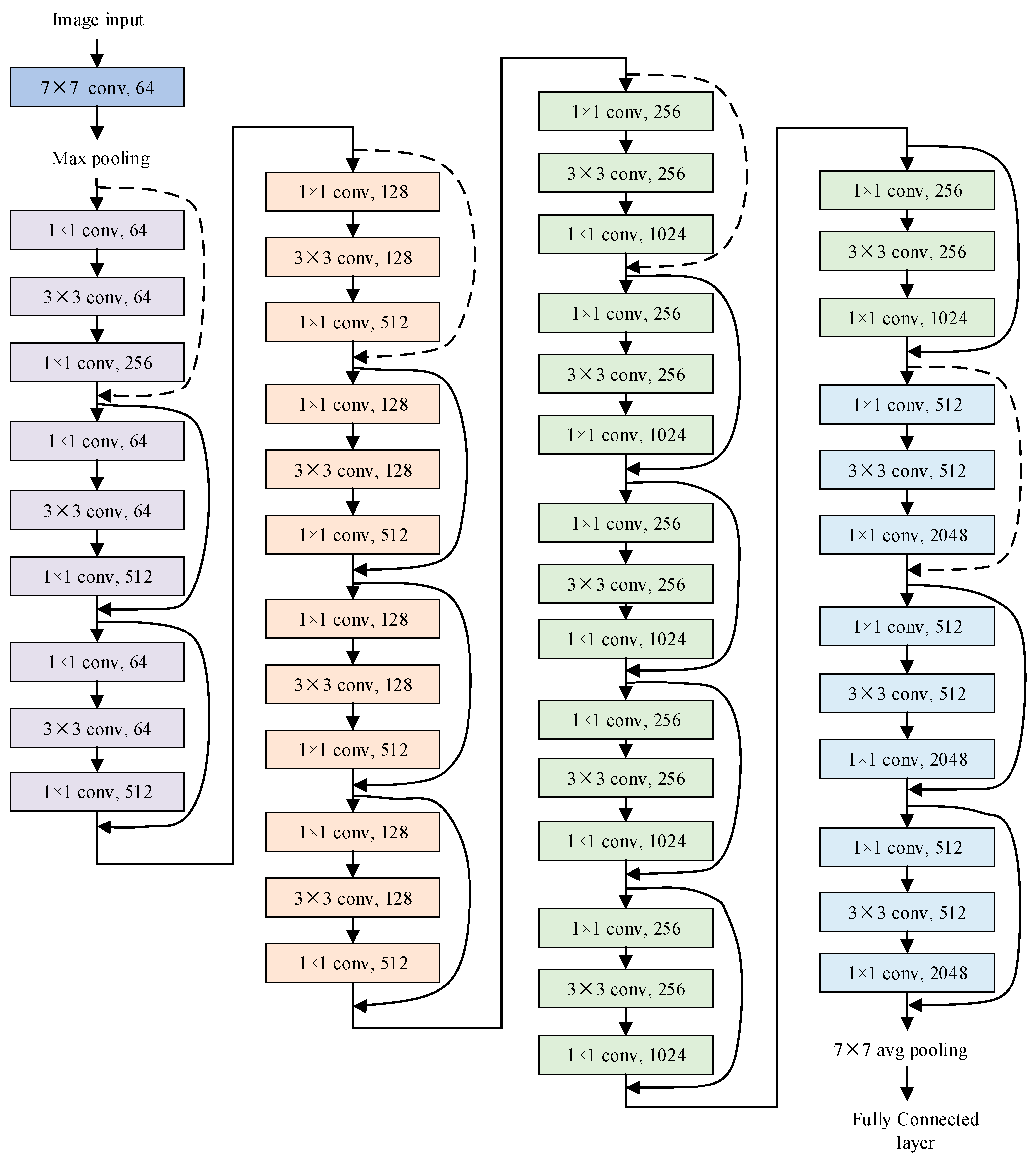
3. Wildfire Smoke Segmentation Using SE-ResNet Combined with FCN
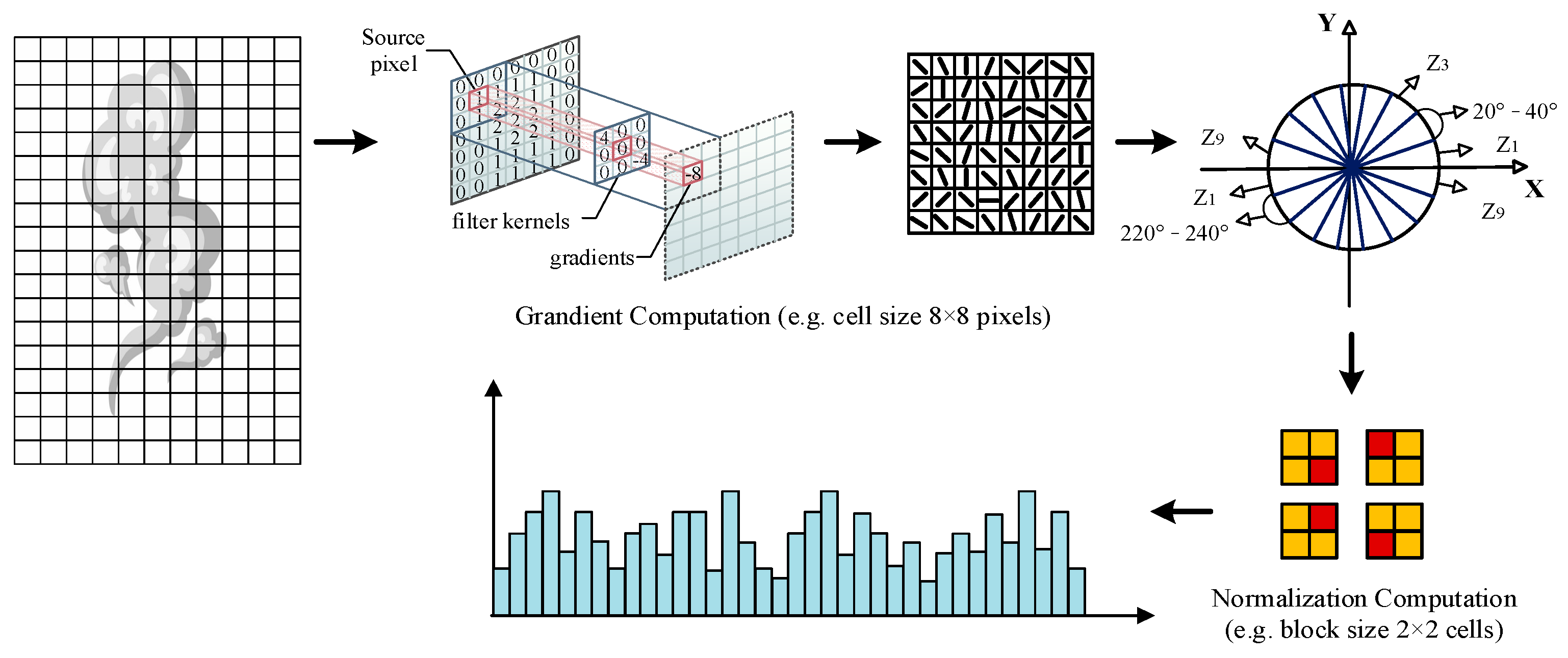
4. Secondary Smoke Detection Based on SVM Model
4.1. HOG for Wildfire Smoke Description
4.2. SVM Model for Smoke Detection
5. Case Study
5.1. Datasets
5.2. Results
5.3. Discussion
- (1)
- The hybrid model will have more accuracy if a self-attention mechanism is added, which can enable the model to capture dependencies at a distance in an image by assigning different weights to features.
- (2)
- Wildfire detection requires smaller models with faster monitoring for real-time monitoring. Methods such as quantization, weight sharing, knowledge distillation, etc., can reduce the size of the model to increase the speed of the model. This is vital for wildfire detection.
- (3)
- While some datasets are well-constructed and publicly available, they may lack the scale, richness, and unified format required for comprehensive model evaluation. This lack of standardized datasets can limit the comparability and reliability of different detection models’ performance evaluations. It is necessary to establish a standard database for smoke detection models.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chaturvedi, S.; Khanna, P.; Ojha, A. A survey on vision-based outdoor smoke detection techniques for environmental safety. ISPRS J. Photogramm. 2022, 185, 158–187. [Google Scholar] [CrossRef]
- Bouguettaya, A.; Zarzour, H.; Taberkit, A.M.; Kechid, A. A review on early wildfire detection from unmanned aerial vehicles using deep learning-based computer vision algorithms. Signal Process. 2022, 190, 108309. [Google Scholar] [CrossRef]
- Boylan, J.L.; Lawrence, C. The development and validation of the bushfire psychological preparedness scale. Int. J. Disast. Risk Re. 2020, 47, 101530. [Google Scholar] [CrossRef]
- Oliver, J.A.; Pivot, F.C.; Tan, Q.; Cantin, A.S.; Wooster, M.J.; Johnston, J.M. A machine learning approach to waterbody segmentation in thermal infrared imagery in support of tactical wildfire mapping. Remote Sens. 2022, 14, 2262. [Google Scholar] [CrossRef]
- Ghali, R.; Akhloufi, M.A.; Mseddi, W.S. Deep learning and transformer approaches for UAV-based wildfire detection and segmentation. Sensors 2022, 22, 1977. [Google Scholar] [CrossRef] [PubMed]
- Toulouse, T.; Rossi, L.; Campana, A.; Celik, T.; Akhloufi, M.A. Computer vision for wildfire research: An evolving image dataset for processing and analysis. Fire Saf. J. 2017, 92, 188–194. [Google Scholar] [CrossRef]
- Zhao, Y.Q.; Tang, G.Z.; Xu, M.M. Hierarchical detection of wildfire flame video from pixel level to semantic level. Expert Syst. Appl. 2015, 42, 4097–4104. [Google Scholar] [CrossRef]
- Ko, B.; Park, J.; Nam, J.Y. Spatiotemporal bag-of-features for early wildfire smoke detection. Image Vis. Comput. 2013, 31, 786–795. [Google Scholar] [CrossRef]
- Almeida, J.S.; Huang, C.X.; Nogueira, F.G.; Bhatia, S.; De Albuquerque, V.H.C. EdgeFireSmoke: A Novel Lightweight CNN Model for Real-Time Video Fire-Smoke Detection. IEEE Trans. Ind. Inform. 2022, 18, 7889–7898. [Google Scholar] [CrossRef]
- Pundir, A.S.; Raman, B. Deep belief network for smoke detection. Fire Technol. 2017, 53, 1943–1960. [Google Scholar] [CrossRef]
- Jakovcevic, T.; Stipanicev, D.; Krstinic, D. Visual spatial-context based wildfire smoke sensor. Mach. Vis. Appl. 2013, 24, 707–719. [Google Scholar] [CrossRef]
- Pundir, A.S.; Raman, B. Dual deep learning model for image based smoke detection. Fire Technol. 2019, 55, 2419–2442. [Google Scholar] [CrossRef]
- De Venâncio, P.V.A.B.; Campos, R.J.; Rezende, T.M.; Lisboa, A.C.; Barbosa, A.V. A hybrid method for fire detection based on spatial and temporal patterns. Neural Comput. Appl. 2023, 35, 9349–9361. [Google Scholar] [CrossRef]
- Prema, C.E.; Vinsley, S.S.; Suresh, S. Multi feature analysis of smoke in YUV color space for early forest fire detection. Fire Technol. 2016, 52, 1319–1342. [Google Scholar] [CrossRef]
- Peng, Y.S.; Wang, Y. Real-time forest smoke detection using hand-designed features and deep learning. Comput. Electron. Agric. 2019, 167, 105029. [Google Scholar] [CrossRef]
- Luo, L.; Yan, C.W.; Wu, K.L.; Zheng, J.Y. Smoke detection based on condensed image. Fire Saf. J. 2015, 75, 23–35. [Google Scholar] [CrossRef]
- Wang, Y.; Li, M.; Zhang, C.X.; Chen, H.; Lu, Y.M. Weighted-fusion feature of MB-LBPUH and HOG for facial expression recognition. Soft Comput. 2020, 24, 5859–5875. [Google Scholar] [CrossRef]
- Ko, B.; Kwak, J.Y.; Nam, J.Y. Wildfire smoke detection using temporospatial features and random forest classifiers. Opt. Eng. 2012, 51, 017208. [Google Scholar] [CrossRef]
- Li, X.Q.; Chen, Z.X.; Wu, Q.M.J.; Liu, C.Y. 3D parallel fully convolutional networks for real-time video wildfire smoke detection. IEEE Trans. Circ. Syst. Vid. 2020, 30, 89–103. [Google Scholar] [CrossRef]
- Li, J.Y.; Zhou, G.X.; Chen, A.B.; Lu, C.; Li, L.J. BCMNet: Cross-layer extraction structure and multiscale downsampling network with bidirectional transpose FPN for fast detection of wildfire smoke. IEEE Syst. J. 2023, 17, 1235–1246. [Google Scholar] [CrossRef]
- Wang, X.T.; Pan, Z.J.; Gao, H.; He, N.X.; Gao, T.G. An efficient model for real-time wildfire detection in complex scenarios based on multi-head attention mechanism. J. Real Time Image Process 2023, 20, 66. [Google Scholar] [CrossRef]
- Labati, R.D.; Genovese, A.; Piuri, V.; Scotti, F. Wildfire smoke detection using computational intelligence techniques enhanced with synthetic smoke plume generation. IEEE Trans. Syst. Man Cybern. Syst. 2013, 43, 1003–1012. [Google Scholar] [CrossRef]
- Gunay, O.; Toreyin, B.U.; Kose, K.; Cetin, A.E. Entropy-functional-based online adaptive decision fusion framework with application to wildfire detection in video. IEEE Trans. Image Process. 2012, 21, 2853–2865. [Google Scholar] [CrossRef] [PubMed]
- Bugaric, M.; Jakovcevic, T.; Stipanicev, D. Adaptive estimation of visual smoke detection parameters based on spatial data and fire risk index. Comput. Vis. Image Underst. 2014, 118, 184–196. [Google Scholar] [CrossRef]
- Fernandes, A.M.; Utkin, A.B.; Chaves, P. Automatic early detection of wildfire smoke with visible-light cameras and EfficientDet. J. Fire Sci. 2023, 41, 122–135. [Google Scholar] [CrossRef]
- Yin, Z.J.; Wan, B.Y.; Yuan, F.N.; Xia, X.; Shi, J.T. A deep normalization and convolutional neural network for image smoke detection. IEEE Access 2017, 5, 18429–18438. [Google Scholar] [CrossRef]
- Yuan, F.N.; Zhang, L.; Wan, B.Y.; Xia, X.; Shi, J.T. Convolutional neural networks based on multi-scale additive merging layers for visual smoke recognition. Mach. Vis. Appl. 2019, 30, 345–358. [Google Scholar] [CrossRef]
- Sun, X.F.; Sun, L.P.; Huang, Y.L. Forest fire smoke recognition based on convolutional neural network. J. For. Res. 2021, 32, 1921–1927. [Google Scholar] [CrossRef]
- Celik, T.; Demirel, H. Fire detection in video sequences using a generic color model. Fire Saf. J. 2009, 44, 147–158. [Google Scholar] [CrossRef]
- Yuan, F.N.; Zhang, L.; Xia, X.; Huang, Q.H.; Li, X.L. A gated recurrent network with dual classification assistance for smoke semantic segmentation. IEEE Trans. Image Process 2021, 30, 4409–4422. [Google Scholar] [CrossRef]
- Yuan, F.N.; Zhang, L.; Xia, X.; Huang, Q.H.; Li, X.L. A wave-shaped deep neural network for smoke density estimation. IEEE Trans. Image Process 2020, 29, 2301–2313. [Google Scholar] [CrossRef] [PubMed]
- Yuan, F.N. A double mapping framework for extraction of shape-invariant features based on multi-scale partitions with Adaboost for video smoke detection. Pattern Recogn. 2012, 45, 4326–4336. [Google Scholar] [CrossRef]
- Xia, X.; Yuan, F.N.; Zhang, L.; Yang, L.Z.; Shi, J.T. From traditional methods to deep ones: Review of visual smoke recognition, detection, and segmentation. J. Image Graph. 2019, 24, 1627–1647. [Google Scholar] [CrossRef]
- Zhao, Y.Q.; Li, Q.J.; Gu, Z. Early smoke detection of forest fire video using CS Adaboost algorithm. Optik 2015, 126, 2121–2124. [Google Scholar] [CrossRef]
- Calderara, S.; Piccinini, P.; Cucchiara, R. Vision based smoke detection system using image energy and color information. Mach. Vis. Appl. 2011, 22, 705–719. [Google Scholar] [CrossRef]
- Zhang, X.; Xie, J.B.; Yan, W.; Zhong, Q.Y.; Liu, T. An Algorithm for smoke ROF Detection Based on Surveillance Video. J. Circuit. Syst. Comp. 2013, 22, 1350010. [Google Scholar] [CrossRef]
- Zhang, F.; Qin, W.; Liu, Y.B.; Xiao, Z.T.; Liu, J.X.; Wang, Q.; Liu, K.H. A dual-channel convolution neural network for image smoke detection. Multimed. Tools Appl. 2020, 79, 34587–34603. [Google Scholar] [CrossRef]
- Qiang, X.H.; Zhou, G.X.; Chen, A.B.; Zhang, X.; Zhang, W.Z. Forest fire smoke detection under complex backgrounds using TRPCA and TSVB. Int. J. Wildland Fire 2021, 30, 329–350. [Google Scholar] [CrossRef]
- Khan, S.; Muhammad, K.; Mumtaz, S.; Baik, S.W.; De Albuquerque, V.H.C. Energy-efficient deep CNN for smoke detection in foggy IoT environment. IEEE Internet Things 2019, 6, 9237–9245. [Google Scholar] [CrossRef]
- Muhammad, K.; Khan, S.; Palade, V.; Mehmood, I.; De Albuquerque, V.H.C. Edge intelligence-assisted smoke detection in foggy surveillance environments. IEEE Trans. Ind. Inform. 2020, 16, 1067–1075. [Google Scholar] [CrossRef]
- Li, T.T.; Zhao, E.T.; Zhang, J.G.; Hu, C.H. Detection of wildfire smoke images based on a densely dilated convolutional network. Electronics 2019, 8, 1131. [Google Scholar] [CrossRef]
- Cheng, G.T.; Chen, X.; Gong, J.C. Deep convolutional network with pixel-aware attention for smoke recognition. Fire Technol. 2022, 58, 1839–1862. [Google Scholar] [CrossRef]
- Wang, Z.L.; Zhang, T.H.; Wu, X.Q.; Huang, X.Y. Predicting transient building fire based on external smoke images and deep learning. J. Build. Eng. 2022, 47, 103823. [Google Scholar] [CrossRef]
- Xu, G.; Zhang, Y.M.; Zhang, Q.X.; Lin, G.H.; Wang, J.J. Deep domain adaptation based video smoke detection using synthetic smoke images. Fire Saf. J. 2017, 93, 53–59. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. Available online: https://arxiv.org/pdf/1512.03385 (accessed on 22 October 2023).


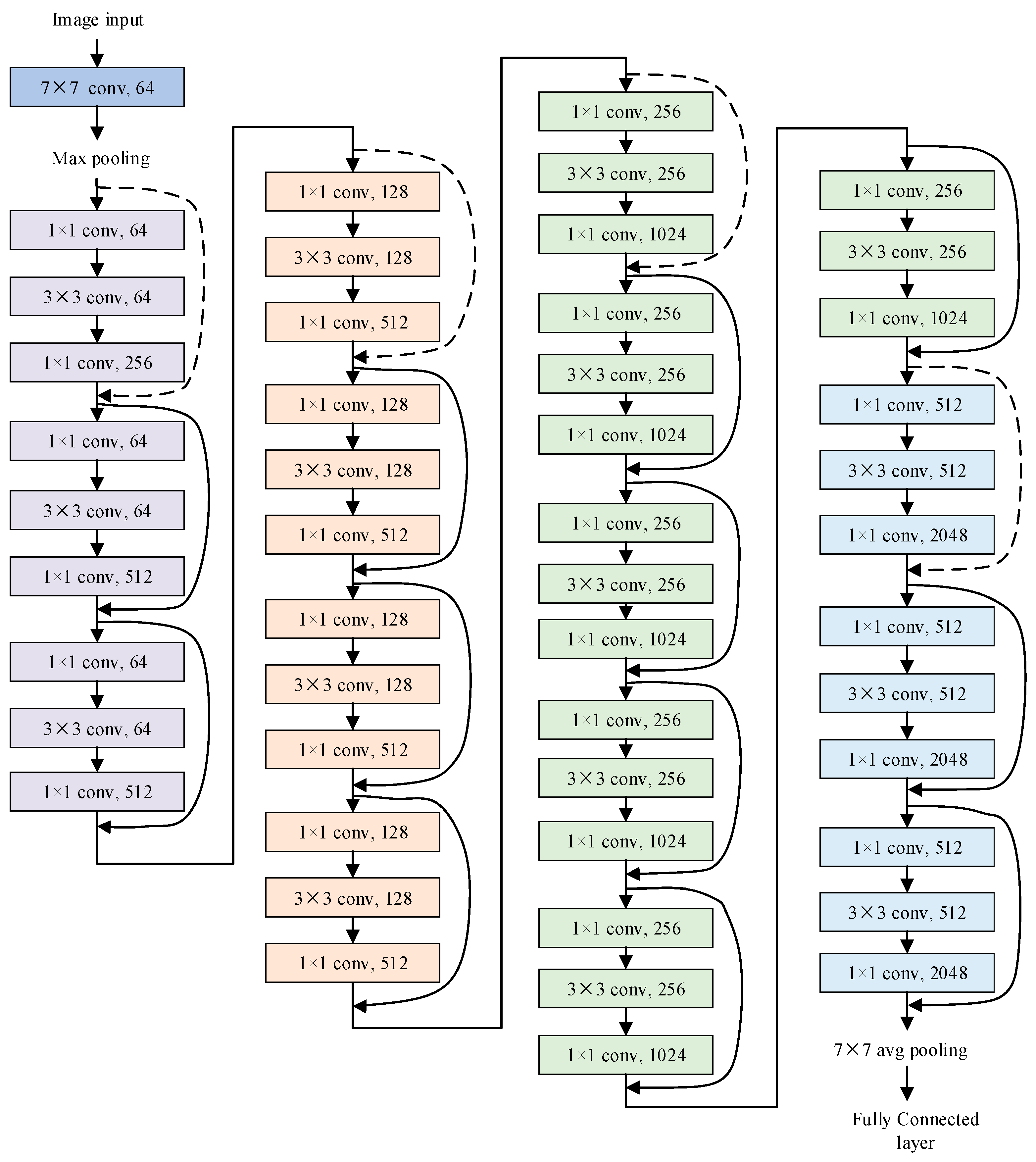





{kind=link}
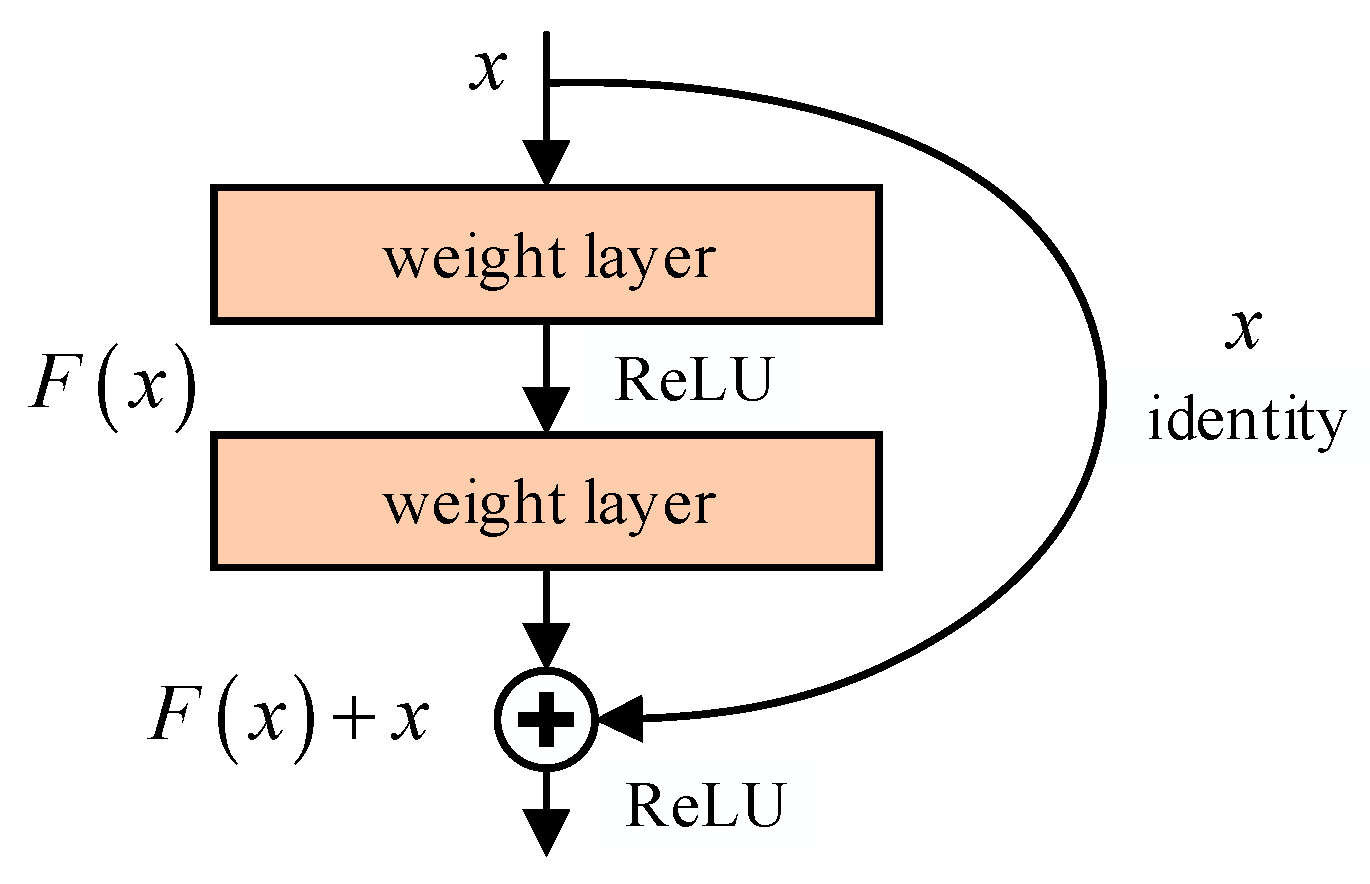{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Augmentation Operations | Horizontal Flip | Vertical Flip | Cropping | Color Dithering | Random Rotation | Gaussian Noise |
|---|---|---|---|---|---|---|
| Activation probabilities | 0.2 | 0.2 | 0.3 | 0.5 | 0.3 | 0.4 |
| HOG Parameter | Value | Hyper Parameters | Value |
|---|---|---|---|
| gradient filter | sobel | initial learning rate | 0.01 |
| cell size | 8 × 8 | epochs | 50 |
| block size | 16 × 16 | batch size | 4 |
| bin number | 9 | momentum | 0.9 |
| normalization | L2-Norm |
| Model | Accuracy | Precision | F1-Score | Running Time |
|---|---|---|---|---|
| Hybrid Model | 98.99% | 98.04% | 0.99 | 3.2779 |
| AlexNet | 87.88% | 80.65% | 0.89 | 0.0997 |
| VGG-16 | 90.91% | 85.96% | 0.92 | 0.3132 |
| GoogleNet | 94.95% | 90.91% | 0.95 | 0.1515 |
| SE-ResNet | 87.88% | 80.65% | 0.89 | 2.1495 |
| SVM | 90.91% | 84.75% | 0.92 | 1.1480 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Wang, J.; Chen, L.; Zhang, Y. Improving Computer Vision-Based Wildfire Smoke Detection by Combining SE-ResNet with SVM. Processes 2024, 12, 747. https://doi.org/10.3390/pr12040747
Wang X, Wang J, Chen L, Zhang Y. Improving Computer Vision-Based Wildfire Smoke Detection by Combining SE-ResNet with SVM. Processes. 2024; 12(4):747. https://doi.org/10.3390/pr12040747
Chicago/Turabian StyleWang, Xin, Jinxin Wang, Linlin Chen, and Yinan Zhang. 2024. "Improving Computer Vision-Based Wildfire Smoke Detection by Combining SE-ResNet with SVM" Processes 12, no. 4: 747. https://doi.org/10.3390/pr12040747
APA StyleWang, X., Wang, J., Chen, L., & Zhang, Y. (2024). Improving Computer Vision-Based Wildfire Smoke Detection by Combining SE-ResNet with SVM. Processes, 12(4), 747. https://doi.org/10.3390/pr12040747