
Theory-Driven Multi-Output Prognostics for Complex Systems Using Sparse Bayesian Learning


Abstract
1. Introduction
2. Problem Statement
- The state x in the mechanical system cannot be directly observed and can only be derived from the output measurement y. Then, to estimate the degradation process and predict the performance degradation, extracting the HI from y is an important step.
- When performing a state degradation prediction, an iterative process can be used to achieve a long-term prediction through a continuous single-step forward prediction. This means that at least k iterations are required to predict from time t + 1 to time t + k. If k is large, the cost of computation will increase significantly, which is not conducive to online and real-time computations.
3. Fast Multi-Output Regression with Sparse Bayesian Learning
4. Unempirical Health Index Extraction Method
4.1. Variational Mode Decomposition
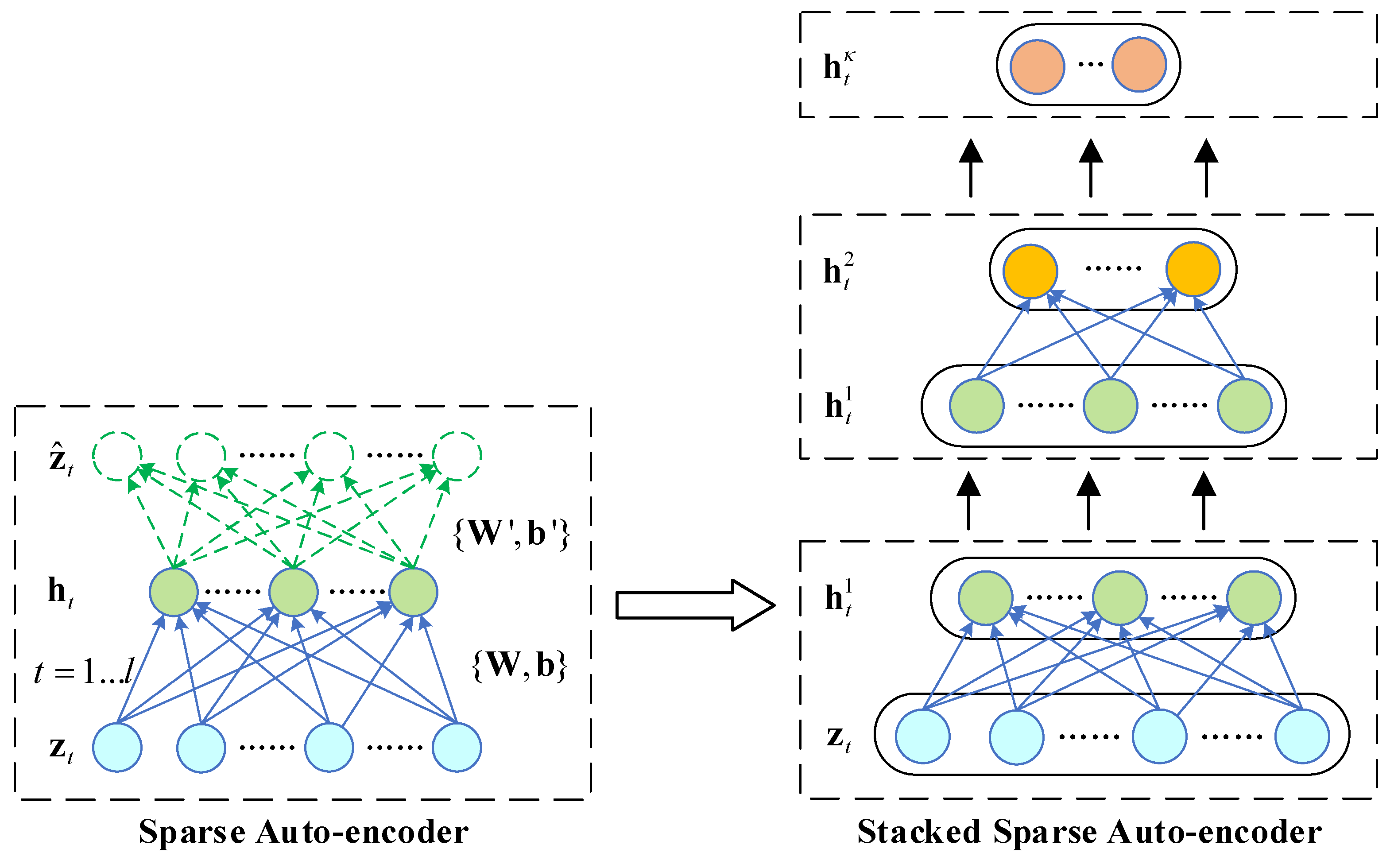
4.2. Stacked Auto-Encoder
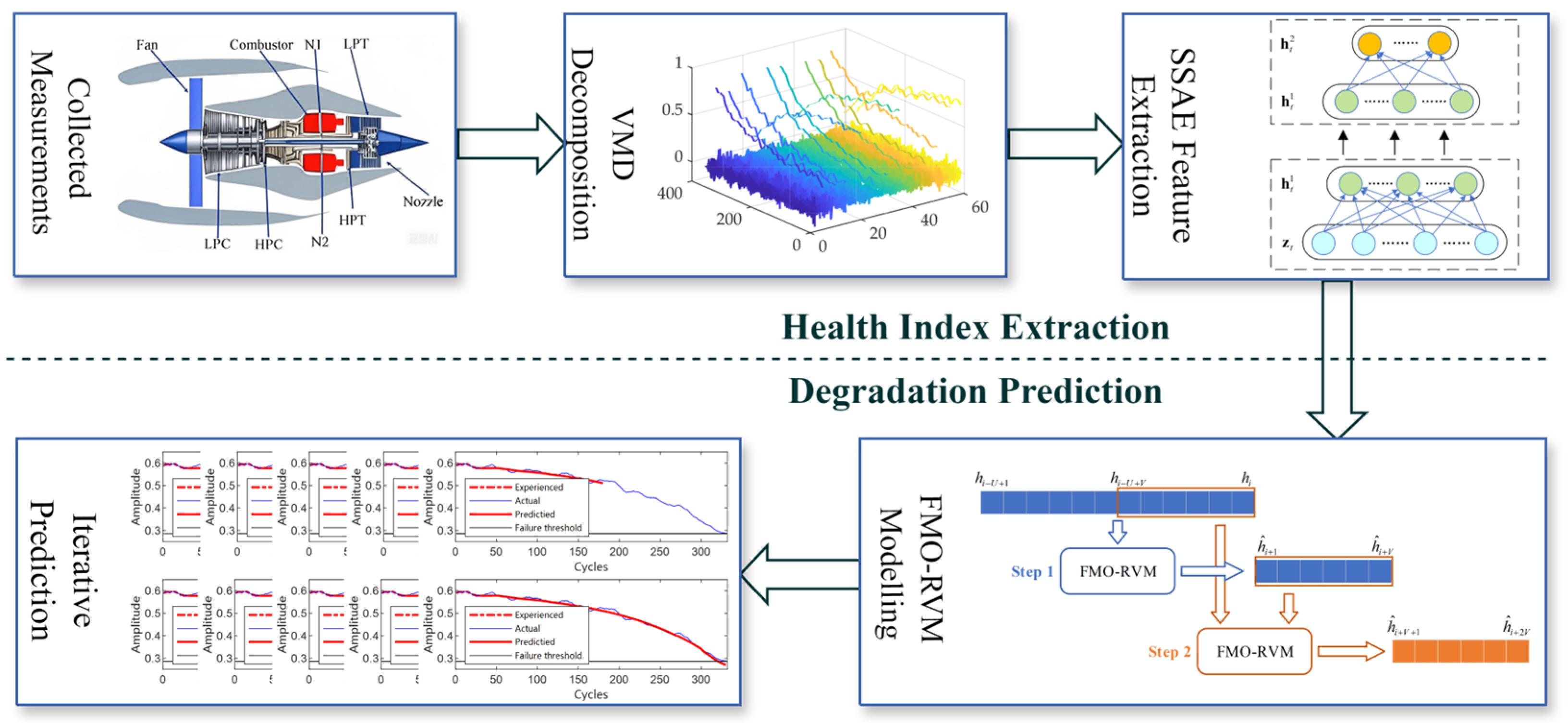
5. The Proposed Prognostic Method
5.1. Fast Prediction by Multi-Output Relevance Vector Regression
5.2. The Proposed Prognostic Structure
- Step 0. Sensor measurement data are collected.
- Step 1. The measurement data are split into training and test sets, and the training set is normalized. The normalization process uses Gaussian normalization, where each feature is scaled to have a zero mean and unit variance.
- Step 2. The features of the measurement data are decomposed by VMD.
- Step 3. The features decomposed by VMD are subjected to a data dimensionality reduction through the SSAE, and a comprehensive HI is extracted.
- Step 4. The training set is prepared and used to train the predictor based on the FMO-RVM.
- Step 5. The trained predictor based on the FMO-RVM is employed to predict the degradation trend and the remaining useful life.
6. Case Study 1
6.1. Brief Introduction of Aeroengine Performance Simulation Data (C-MAPSS)
6.2. Process and Results of Health Index Extraction Method
- (i)
- Data standardization. The formula is N(yd) = (yd − μd)/σd, where yd is the d-dimensional feature data of the training set of the measurement data sample, d = {1, 2,…, 21}, and μd and σd are the mean and standard deviation of yd, respectively. The specific sensor measurement data are shown in Table 1. These outputs contain various sensor response surfaces and operability margins, and researchers can observe the operating state of the engine by looking at these 21 sets of measurements.
- (ii)
- VMD decomposition. The 12 groups of measurements obtained from the screening were decomposed by VMD; the modal number of VMD was 5. This number was chosen after experimentation to strike a balance between effective decomposition and computational efficiency. The training data decomposed by VMD are shown in Figure 3. Modes 1–4 mainly contain noise data, and mode 5 preserves the main degradation trend.
- (iii)
- Extraction using SSAE. The comprehensive characteristic index was obtained as the predicted HI. Here, 60-dimensional data needed to be compressed to 1-dimensional data through an SSAE.
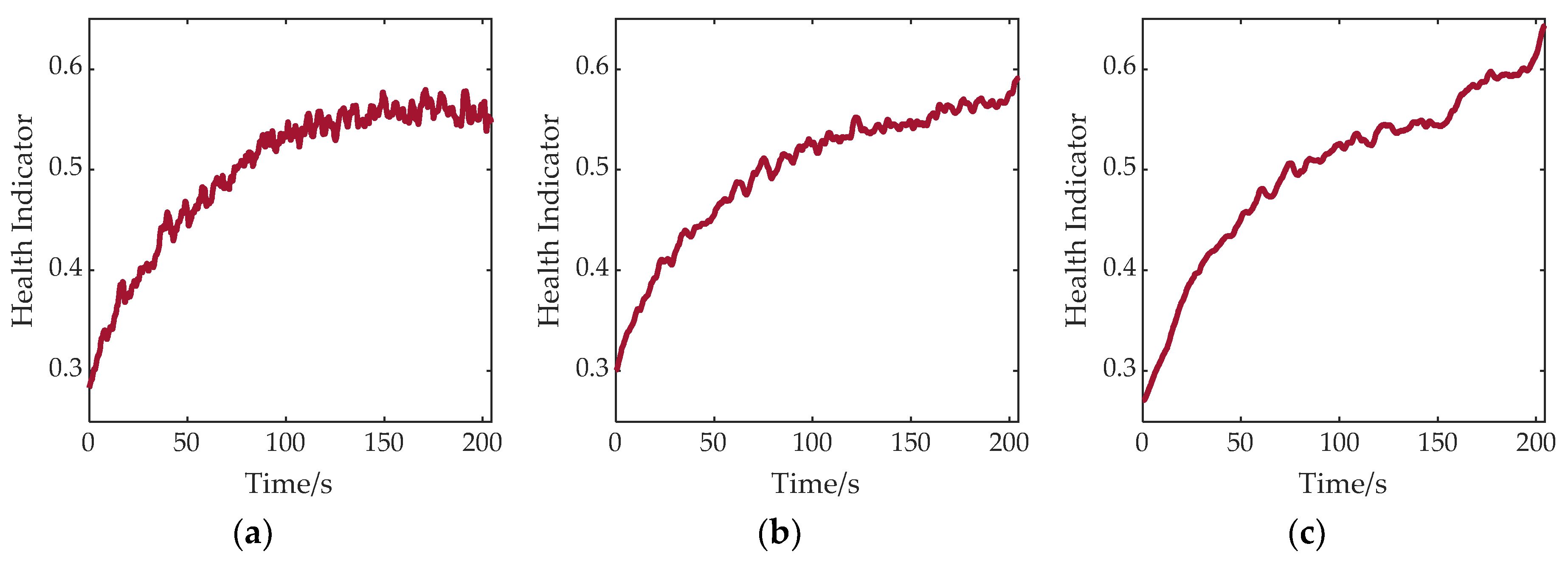
6.3. Performance Verification of Health Index Extraction Based on VMD-SSAE
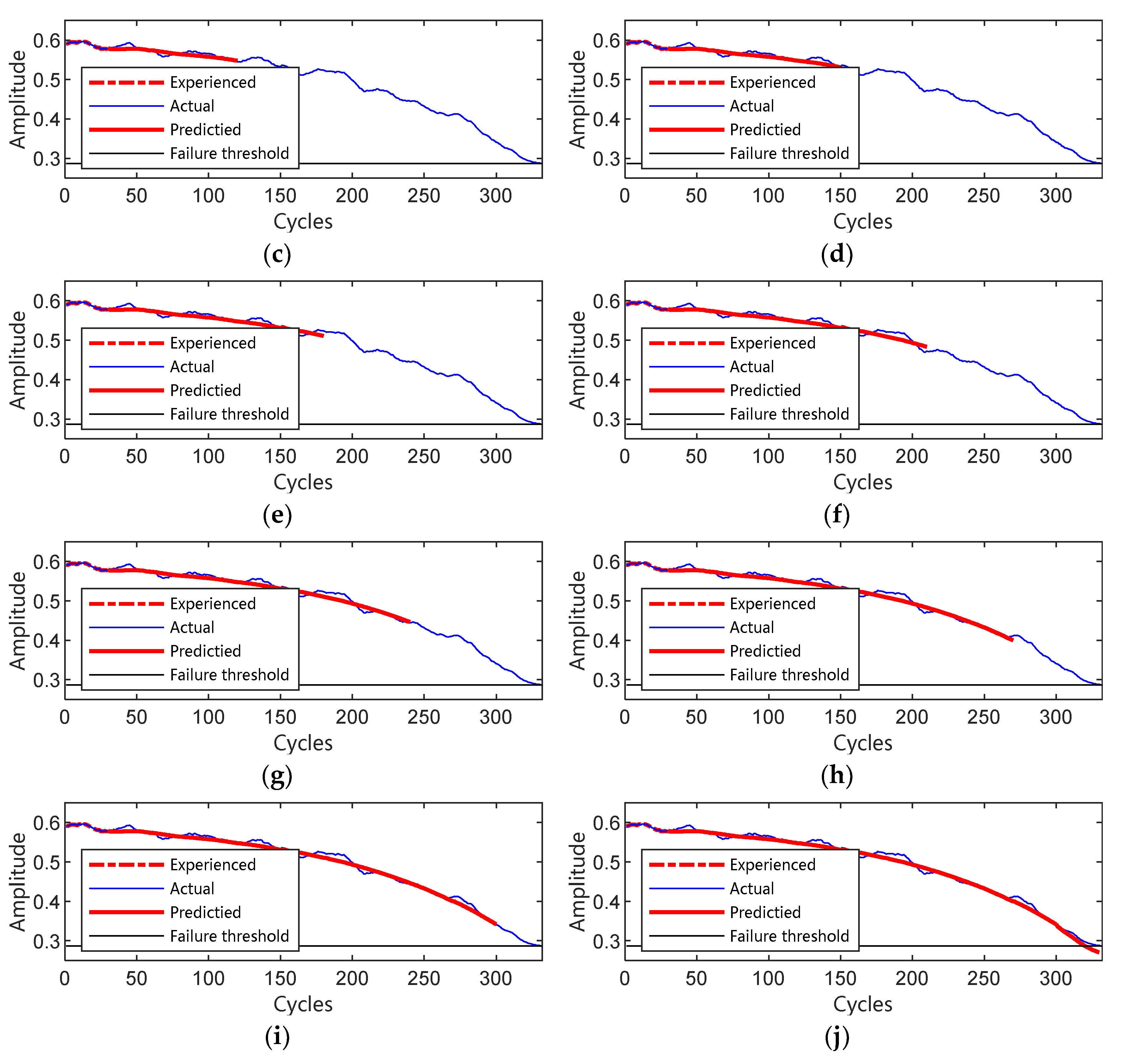
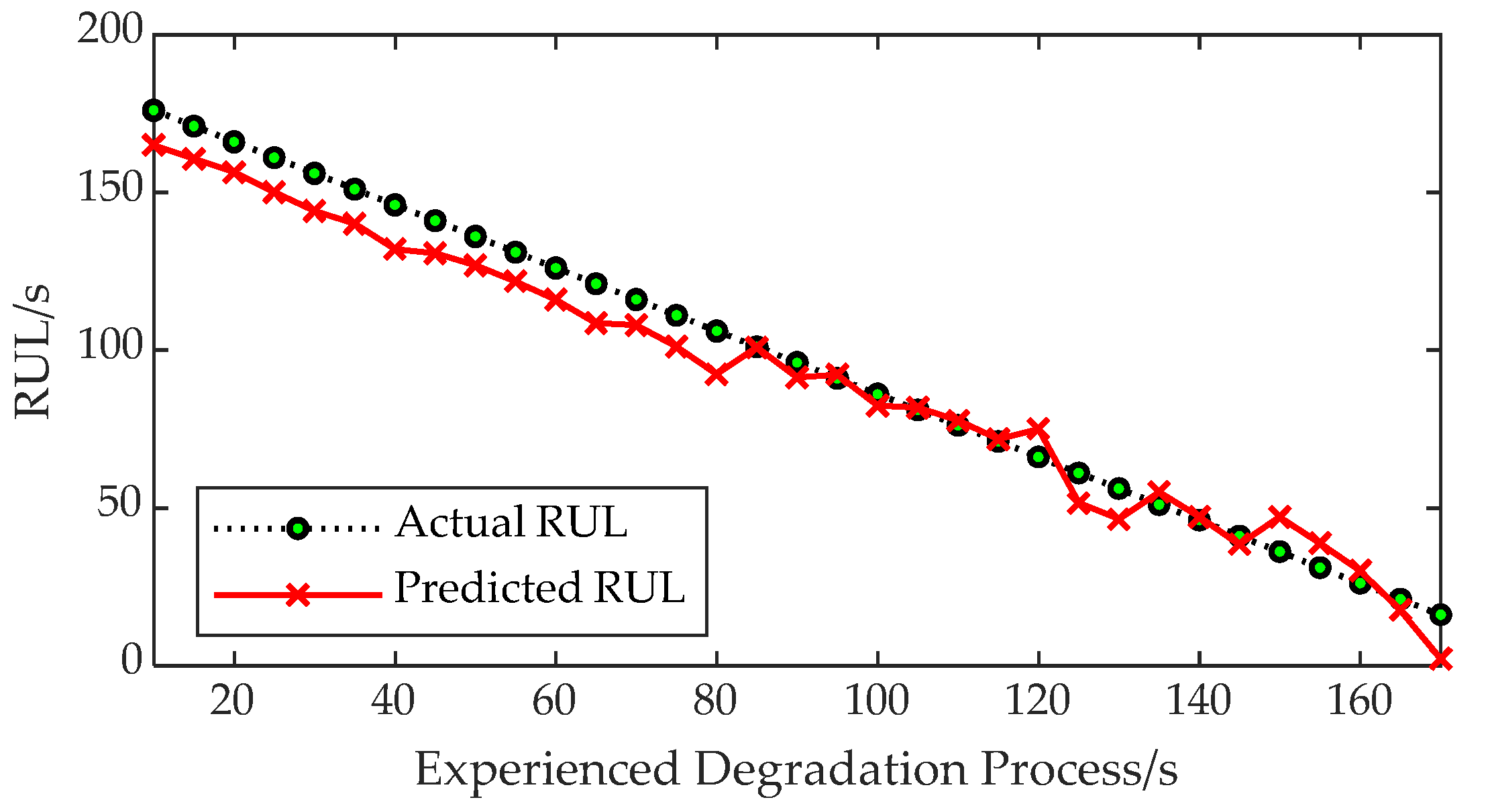
6.4. Performance Verification of Remaining Life Prediction Based on FMO-RVM
7. Case Study 2
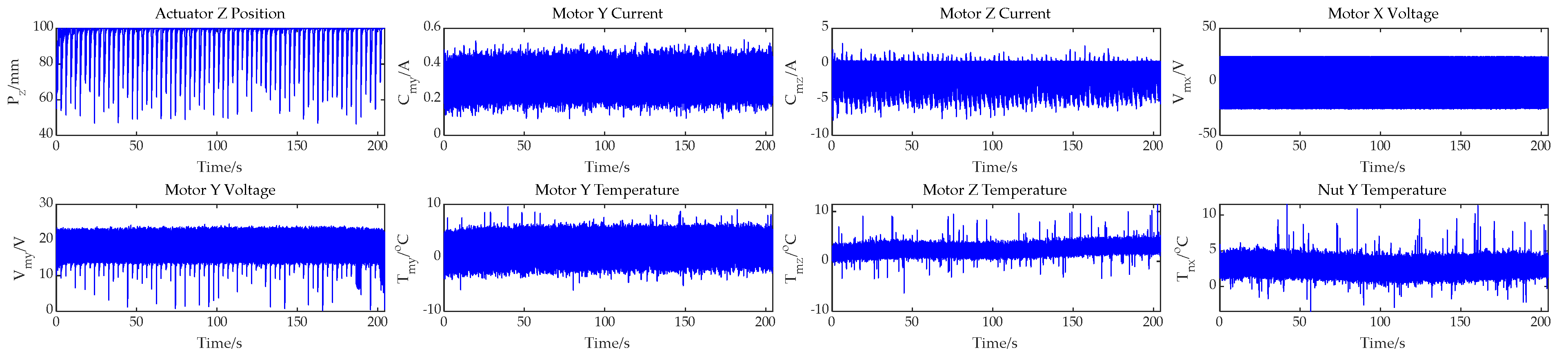
7.1. Brief Introduction of Electro-Mechanical Actuator
7.2. Prediction Performance of FMO-RVM in EMA Dataset
8. Conclusions and Discussion
- The deep sparse auto-encoder demonstrates superior feature extraction capabilities compared to the single-layer sparse auto-encoder. When combined with variational mode decomposition, it effectively extracted implicit health indicators from sensor measurements. Compared to a traditional PCA, the feature extraction ability of the deep sparse auto-encoder is significantly enhanced.
- The proposed FMO-RVM prediction method exhibited a higher accuracy than the SVM, RVM, and LSTM methods. The composite kernel structure offers a greater stability compared to single kernels. Additionally, the multi-output approach not only improves the modeling and prediction accuracy, but also significantly reduces the computational time for predictions. This provides a favorable premise for the application of the algorithm in engineering practices.
- The algorithm was applied to the NASA engine and EMA degradation simulation dataset, which has been extensively utilized and validated, demonstrating significant generalizability. The prediction method proposed in this paper is capable of quickly and accurately estimating the remaining useful life. The results validate the proposed prediction scheme’s ability to provide rapid life prediction for complex systems, indicating its potential for expanded applications to a broader range of objects in the future.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Goebel, K.; Daigle, M.J.; Saxena, A.; Roychoudhury, I.; Sankararaman, S.; Celaya, J.R. Prognostics: The science of making predictions. Prognostics 2017, 1, 1–14. [Google Scholar]
- Guo, J.; Li, Z.; Li, M. A Review on Prognostics Methods for Engineering Systems. IEEE Trans. Reliab. 2020, 69, 1110–1129. [Google Scholar] [CrossRef]
- Tahan, M.; Tsoutsanis, E.; Muhammad, M.; Abdul Karim, Z.A. Performance-Based Health Monitoring, Diagnostics and Prognostics for Condition-Based Maintenance of Gas Turbines: A Review. Appl. Energy 2017, 198, 122–144. [Google Scholar] [CrossRef]
- Qian, Y.; Yan, R.; Gao, R.X. A Multi-Time Scale Approach to Remaining Useful Life Prediction in Rolling Bearing. Mech. Syst. Signal Process. 2017, 83, 549–567. [Google Scholar] [CrossRef]
- Khelif, R.; Chebel-Morello, B.; Malinowski, S.; Laajili, E.; Fnaiech, F.; Zerhouni, N. Direct Remaining Useful Life Estimation Based on Support Vector Regression. IEEE Trans. Ind. Electron. 2017, 64, 2276–2285. [Google Scholar] [CrossRef]
- Wu, Y.; Yuan, M.; Dong, S.; Lin, L.; Liu, Y. Remaining Useful Life Estimation of Engineered Systems Using Vanilla LSTM Neural Networks. Neurocomputing 2018, 275, 167–179. [Google Scholar] [CrossRef]
- Xu, D.; Sui, S.-B.; Zhang, W.; Xing, M.; Chen, Y.; Kang, R. RUL Prediction of Electronic Controller Based on Multiscale Characteristic Analysis. Mech. Syst. Signal Process. 2018, 113, 253–273. [Google Scholar] [CrossRef]
- Li, X.; Ding, Q.; Sun, J.-Q. Remaining Useful Life Estimation in Prognostics Using Deep Convolution Neural Networks. Reliab. Eng. Syst. Saf. 2018, 172, 1–11. [Google Scholar] [CrossRef]
- Jouin, M.; Gouriveau, R.; Hisel, D.; Pééra, M.-C.; Zerhouni, N. Particle Filter-Based Prognostics: Review, Discussion and Perspectives. Mech. Syst. Signal Process. 2016, 72, 2–31. [Google Scholar] [CrossRef]
- Sankararaman, S.; Goebel, K. Uncertainty in prognostics and systems health management. Int. J. Progn. Health Manag. 2020, 6, 4. [Google Scholar] [CrossRef]
- Bender, A. A multi-model-particle filtering-based prognostic approach to con-sider uncertainties in RUL predictions. Machines 2021, 9, 210. [Google Scholar] [CrossRef]
- Park, H.; Kim, N.; Choi, J. Prognosis using bayesian method by incorporating physical constraints. In Proceedings of the Asia Pacific Conference of the PHM Society, Tokyo, Japan, 11–14 September 2023; Volume 4. [Google Scholar] [CrossRef]
- Tseremoglou, I.; Bieber, M.; Santos, B.; Verhagen, W.; Freeman, F.; Kessel, P. The impact of prognostic uncertainty on condition-based maintenance scheduling: An in-tegrated approach. In Proceedings of the AIAA AVIATION 2022 Forum, Chicago, IL, USA, 27 June–1 July 2022. [Google Scholar] [CrossRef]
- Caesarendra, W.; Widodo, A.; Thom, P.H.; Yang, B.S.; Setiawan, J.D. Combined Probability Approach and Indirect Data-Driven Method for Bearing Degradation Prognostics. IEEE Trans. Reliab. 2011, 60, 14–20. [Google Scholar] [CrossRef]
- Zhou, Y.; Huang, M.; Chen, Y.; Tao, Y. A Novel Health Indicator for On-Line Lithium-Ion Batteries Remaining Useful Life Prediction. J. Power Sources 2016, 321, 1–10. [Google Scholar] [CrossRef]
- Lin, Y.H.; Li, G.H. A Bayesian Deep Learning Framework for RUL Prediction Incorporating Uncertainty Quantification and Calibration. IEEE Trans. Ind. Inform. 2022, 18, 7274–7284. [Google Scholar] [CrossRef]
- Tang, J.; Zheng, G.H.; He, D.; Ding, X.X.; Huang, W.B.; Shao, Y.M.; Wang, L.M. Rolling bearing remaining useful life prediction via weight tracking relevance vector machine. Meas. Sci. Technol. 2021, 32, 024006. [Google Scholar] [CrossRef]
- Borchani, H.; Varando, G.; Bielza, C.; Larrañaga, P. A survey on multi-output regression. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2015, 5, 216–233. [Google Scholar] [CrossRef]
- Wang, Y.Z.; Xie, B.; E, S.Y. Adaptive relevance vector machine combined with Markov-chain-based importance sampling for reliability analysis. Reliab. Eng. Syst. Saf. 2022, 220, 108287. [Google Scholar] [CrossRef]
- Safari, M.J.S.; Rahimzadeh Arashloo, S.; Vaheddoost, B. Fast Multi-Output Relevance Vector Regression for Joint Groundwater and Lake Water Depth Modeling. Environ. Model. Softw. 2022, 154, 105425. [Google Scholar] [CrossRef]
- Cherkassky, V. The Nature of Statistical Learning Theory. IEEE Trans. Neural Netw. 1997, 8, 1564. [Google Scholar] [CrossRef]
- Tipping, M.E. The Relevance Vector Machine. In Proceedings of the 13th International Conference on Neural Information Processing Systems, Denver, CO, USA, 29 November 1999; MIT Press: Cambridge, MA, USA, 1999; pp. 652–658. [Google Scholar]
- Thayananthan, A.; Navaratnam, R.; Stenger, B.; Torr, P.H.S.; Cipolla, R. Pose Estimation and Tracking Using Multivariate Regression. Pattern Recognit. Lett. 2008, 29, 1302–1310. [Google Scholar] [CrossRef]
- Ha, Y.; Zhang, H. Fast Multi-Output Relevance Vector Regression. Econ. Model. 2019, 81, 217–230. [Google Scholar] [CrossRef]
- Tipping, M.E. Sparse Bayesian Learning and the Relevance Vector Machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar] [CrossRef]
- Vazquez, E.; Walter, E. Multi-Output Support Vector Regression. IFAC Proc. Vol. 2003, 36, 1783–1791. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational Mode Decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Bertsekas, D.P. Multiplier Methods: A Survey. IFAC Proc. Vol. 1975, 8, 351–363. [Google Scholar] [CrossRef]
- Rockafellar, R.T. A Dual Approach to Solving Nonlinear Programming Problems by Unconstrained Optimization. Math. Program. 1973, 5, 354–373. [Google Scholar] [CrossRef]
- Ng, A.Y.; Lee, H. Sparse autoencoder. In CS294A Lecture Notes; Stanford University: Stanford, CA, USA, 2011. [Google Scholar]
- Wang, Y.; Yao, H.; Zhao, S. Auto-encoder based dimensionality reduction. Neurocomputing 2016, 184, 232–242. [Google Scholar] [CrossRef]
- Xu, P.; Wei, G.; Song, K.; Chen, Y. High-Accuracy Health Prediction of Sensor Systems Using Improved Relevant Vector-Machine Ensemble Regression. Knowl.-Based Syst. 2021, 212, 106555. [Google Scholar] [CrossRef]
- Liu, Y.; Frederick, D.K.; DeCastro, J.A.; Litt, J.S.; Chan, W.W. User’s Guide for the Commercial Modular Aero-Propulsion System Simulation (C-MAPSS); NASA: Washington, DC, USA, 2012. [Google Scholar]
- Jensen, S.C.; Jenney, G.D.; Dawson, D. Flight Test Experience with An Electromechanical Actuator on the F-18 Systems Research Aircraft. In Proceedings of the Digital Avionics Systems Conference, Philadelphia, PA, USA, 7–13 October 2000; IEEE: Piscataway, NJ, USA, 2000. [Google Scholar]
- Lin, Y.; Baumann, E.; Bose, D.M.; Beck, R.; Jenney, G. Tests and Techniques for Characterizing and Modeling X-43A Electromechanical Actuators; NASA: Washington, DC, USA, 2008. [Google Scholar]
- Balaban, E.; Saxena, A.; Narasimhan, S.; Roychoudhury, I.; Goebel, K.F.; Koopmans, M.T. Airborne Electro-Mechanical Actuator Test Stand for Development of Prognostic Health Management Systems; NASA: Washington, DC, USA, 2010. [Google Scholar]
- Koopmans, M.; Mattheis, C.; Lawrence, A. Electro Mechanical Actuator Test Stand for In-Flight Experiments; NASA: Washington, DC, USA, 2009. [Google Scholar]
- Balaban, E.; Saxena, A.; Narasimhan, S.; Roychoudhury, I.; Koopmans, M.; Ott, C.; Goebel, K. Prognostic Health-Management System Development for Electromechanical Actuators. J. Aerosp. Inf. Syst. 2015, 12, 329–344. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description | Units | Variable | Description | Units |
|---|---|---|---|---|---|
| T2 | Fan inlet total temperature | °R | Phi | Ratio of fuel flow to Ps3 | pps/psi |
| T24 | Total pressure at LPC outlet | °R | NfR | Corrected fan speed | rpm |
| T30 | Total pressure at HPC outlet | °R | NcR | Corrected core speed | rpm |
| T50 | Total pressure at LPT outlet | °R | BPR | Bypass ratio | \ |
| P2 | Pressure at fan inlet | psia | farB | Burner fuel–air ratio | \ |
| P15 | Total pressure in bypass duct | psia | htBleed | Bleed enthalpy | \ |
| P30 | Total pressure at HPC outlet | psia | Nf_dmd | Demanded fan speed | rpm |
| Nf | Physical fan speed | rpm | PCNfR_dmd | Corrected fan speed demanded | % |
| Nc | Physical core speed | rpm | W31 | HPT coolant bleed | lbm/s |
| EPR | Engine pressure ratio (P50/P2) | \ | W32 | LPT coolant bleed | lbm/s |
| Ps30 | Static pressure at HPC outlet | psia |
| Test Data Number | lpast (Cycles) | lRUL (Cycles) | |
|---|---|---|---|
| Test data 1 | 303 | 21 | 93.52% |
| Test data 2 | 232 | 54 | 81.12% |
| Test data 3 | 198 | 11 | 93.52% |
| Test data 4 | 101 | 63 | 61.59% |
| Test data 5 | 97 | 137 | 41.45% |
| Test data 6 | 75 | 79 | 48.70% |
| Test data 7 | 50 | 106 | 32.05% |
| Test data 8 | 31 | 112 | 21.68% |
| Sensor | Abbr. | Unit | Sensor | Abbr. | Unit |
|---|---|---|---|---|---|
| Actuator Z Position | Pz | mm | Motor Y Voltage | Vmy | V |
| Measured Load | L | lb | Motor X Temperature | Tmx | °C |
| Motor X Current | Cmx | A | Motor Y Temperature | Tmy | °C |
| Motor Y Current | Cmy | A | Motor Z Temperature | Tmz | °C |
| Motor Z Current | Cmz | A | Nut X Temperature | Tnx | °C |
| Motor X Voltage | Vmx | V | Nut Y Temperature | Tny | °C |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Huang, G.; Liu, H.; Ke, Y.; Lin, Y.; Yuan, C. Theory-Driven Multi-Output Prognostics for Complex Systems Using Sparse Bayesian Learning. Processes 2025, 13, 1232. https://doi.org/10.3390/pr13041232
Yang J, Huang G, Liu H, Ke Y, Lin Y, Yuan C. Theory-Driven Multi-Output Prognostics for Complex Systems Using Sparse Bayesian Learning. Processes. 2025; 13(4):1232. https://doi.org/10.3390/pr13041232
Chicago/Turabian StyleYang, Jing, Gangjin Huang, Hao Liu, Yunhe Ke, Yuwei Lin, and Chengfeng Yuan. 2025. "Theory-Driven Multi-Output Prognostics for Complex Systems Using Sparse Bayesian Learning" Processes 13, no. 4: 1232. https://doi.org/10.3390/pr13041232
APA StyleYang, J., Huang, G., Liu, H., Ke, Y., Lin, Y., & Yuan, C. (2025). Theory-Driven Multi-Output Prognostics for Complex Systems Using Sparse Bayesian Learning. Processes, 13(4), 1232. https://doi.org/10.3390/pr13041232