

Performance Analysis of Deep Learning Model-Compression Techniques for Audio Classification on Edge Devices



Abstract
:1. Introduction
- We compare different DL models for audio classification for raw audio and Mel spectrograms.
- We apply different model-compression techniques to the neural network and propose hybrid pruning techniques.
- We deploy DL models for audio classification in the Raspberry Pi and NVIDIA Jetson Nano.
2. Methodology
2.1. Model Architecture
2.2. Model Compression
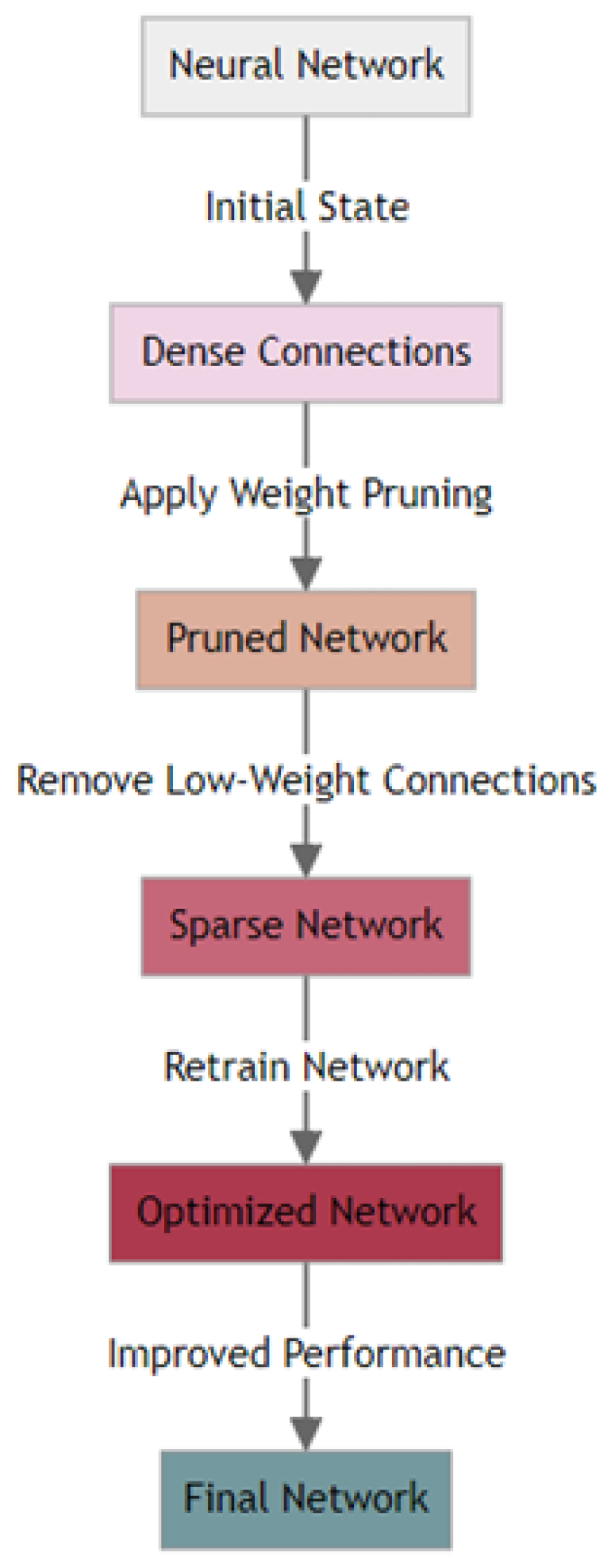
2.2.1. Pruning
2.2.2. Quantization
3. Experimental Details
3.1. Datasets
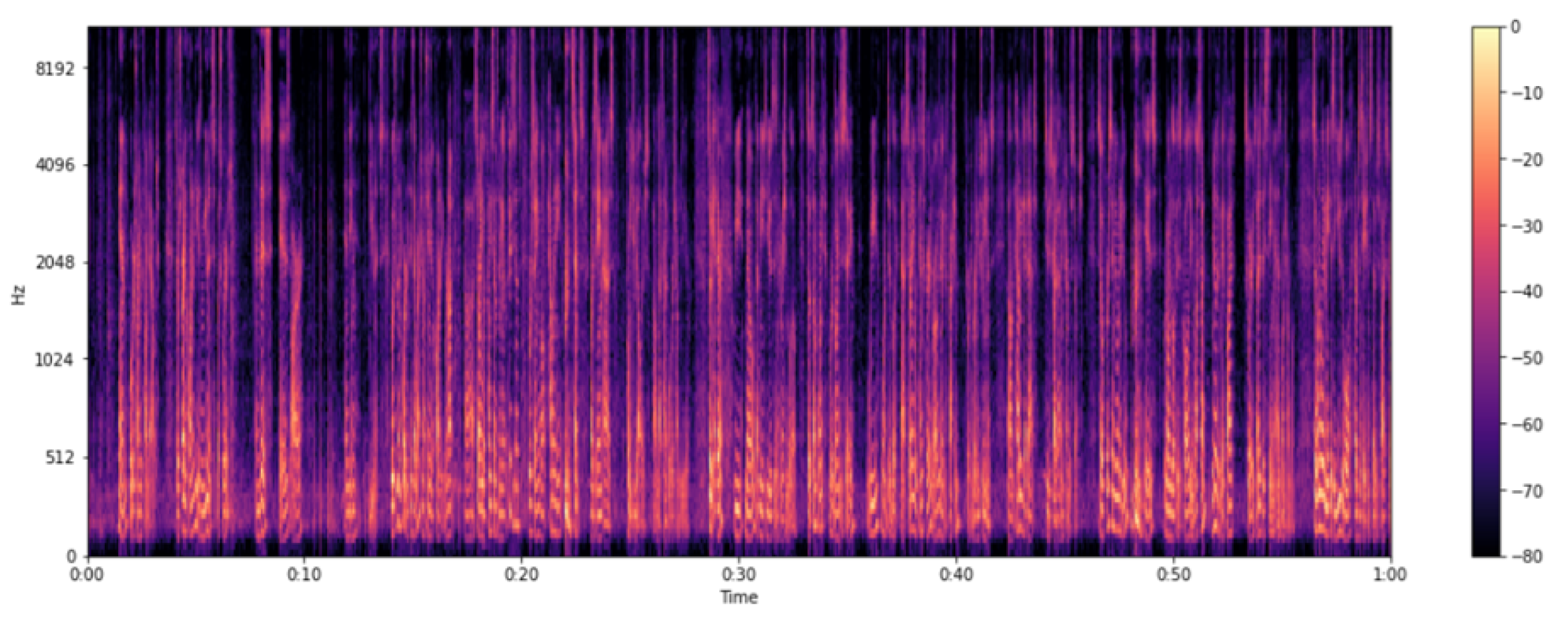
3.2. Data Preprocessing
4. Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- der Mauer, M.A.; Behrens, T.; Derakhshanmanesh, M.; Hansen, C.; Muderack, S. Applying sound-based analysis at porsche production: Towards predictive maintenance of production machines using deep learning and internet-of-things technology. In Digitalization Cases: How Organizations Rethink Their Business for the Digital Age; Springer: Berlin/Heidelberg, Germany, 2019; pp. 79–97. [Google Scholar]
- Yun, H.; Kim, H.; Kim, E.; Jun, M.B. Development of internal sound sensor using stethoscope and its applications for machine monitoring. Procedia Manuf. 2020, 48, 1072–1078. [Google Scholar] [CrossRef]
- Sharan, R.V.; Moir, T.J. An overview of applications and advancements in automatic sound recognition. Neurocomputing 2016, 200, 22–34. [Google Scholar] [CrossRef]
- Xu, W.; Zhang, X.; Yao, L.; Xue, W.; Wei, B. A multi-view CNN-based acoustic classification system for automatic animal species identification. Ad. Hoc. Netw. 2020, 102, 102115. [Google Scholar] [CrossRef]
- Stowell, D.; Petrusková, T.; Šálek, M.; Linhart, P. Automatic acoustic identification of individuals in multiple species: Improving identification across recording conditions. J. R. Soc. Interface 2019, 16, 20180940. [Google Scholar] [CrossRef] [PubMed]
- Yan, X.; Zhang, H.; Li, D.; Wu, D.; Zhou, S.; Sun, M.; Hu, H.; Liu, X.; Mou, S.; He, S.; et al. Acoustic recordings provide detailed information regarding the behavior of cryptic wildlife to support conservation translocations. Sci. Rep. 2019, 9, 5172. [Google Scholar] [CrossRef] [PubMed]
- Radhakrishnan, R.; Divakaran, A.; Smaragdis, A. Audio analysis for surveillance applications. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, NY, USA, 16–19 October 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 158–161. [Google Scholar]
- Vacher, M.; Serignat, J.F.; Chaillol, S. Sound classification in a smart room environment: An approach using GMM and HMM methods. In Proceedings of the 4th IEEE Conference on Speech Technology and Human-Computer Dialogue (SpeD 2007), Iasi, Romania, 10–12 May 2007; Publishing House of the Romanian Academy: Bucharest, Romania, 2007; Volume 1, pp. 135–146. [Google Scholar]
- Wong, P.K.; Zhong, J.; Yang, Z.; Vong, C.M. Sparse Bayesian extreme learning committee machine for engine simultaneous fault diagnosis. Neurocomputing 2016, 174, 331–343. [Google Scholar] [CrossRef]
- Guo, L.; Li, N.; Jia, F.; Lei, Y.; Lin, J. A recurrent neural network based health indicator for remaining useful life prediction of bearings. Neurocomputing 2017, 240, 98–109. [Google Scholar] [CrossRef]
- Pacheco, F.; de Oliveira, J.V.; Sánchez, R.V.; Cerrada, M.; Cabrera, D.; Li, C.; Zurita, G.; Artés, M. A statistical comparison of neuroclassifiers and feature selection methods for gearbox fault diagnosis under realistic conditions. Neurocomputing 2016, 194, 192–206. [Google Scholar] [CrossRef]
- Liu, J.; Wang, W.; Golnaraghi, F. An enhanced diagnostic scheme for bearing condition monitoring. IEEE Trans. Instrum. Meas. 2009, 59, 309–321. [Google Scholar]
- Henriquez, P.; Alonso, J.B.; Ferrer, M.A.; Travieso, C.M. Review of automatic fault diagnosis systems using audio and vibration signals. IEEE Trans. Syst. Man Cybern. Syst. 2013, 44, 642–652. [Google Scholar] [CrossRef]
- Malmberg, C. Real-Time Audio Classification onan Edge Device: Using YAMNet and TensorFlow Lite. Ph.D. Thesis, Linnaeus University, Vaxjo, Sweden, 2021. [Google Scholar]
- Sharma, G.; Umapathy, K.; Krishnan, S. Trends in audio signal feature extraction methods. Appl. Acoust. 2020, 158, 107020. [Google Scholar] [CrossRef]
- Wang, Y.; Wei-Kocsis, J.; Springer, J.A.; Matson, E.T. Deep learning in audio classification. In Proceedings of the International Conference on Information and Software Technologies, Kaunas, Lithuania, 13–15 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 64–77. [Google Scholar]
- Zaman, K.; Sah, M.; Direkoglu, C.; Unoki, M. A Survey of Audio Classification Using Deep Learning. IEEE Access 2023, 11, 106620–106649. [Google Scholar] [CrossRef]
- Maccagno, A.; Mastropietro, A.; Mazziotta, U.; Scarpiniti, M.; Lee, Y.C.; Uncini, A. A CNN approach for audio classification in construction sites. In Progresses in Artificial Intelligence and Neural Systems; Springer: Berlin/Heidelberg, Germany, 2021; pp. 371–381. [Google Scholar]
- Wang, X.; Han, Y.; Leung, V.C.M.; Niyato, D.; Yan, X.; Chen, X. Convergence of Edge Computing and Deep Learning: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2020, 22, 869–904. [Google Scholar] [CrossRef]
- Murshed, M.S.; Murphy, C.; Hou, D.; Khan, N.; Ananthanarayanan, G.; Hussain, F. Machine learning at the network edge: A survey. ACM Comput. Surv. CSUR 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Mohaimenuzzaman, M.; Bergmeir, C.; Meyer, B. Pruning vs XNOR-net: A comprehensive study of deep learning for audio classification on edge-devices. IEEE Access 2022, 10, 6696–6707. [Google Scholar] [CrossRef]
- Choudhary, T.; Mishra, V.; Goswami, A.; Sarangapani, J. A comprehensive survey on model compression and acceleration. Artif. Intell. Rev. 2020, 53, 5113–5155. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New Paltz, NY, USA, 2012; Volume 25. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Mohaimenuzzaman, M.; Bergmeir, C.; West, I.; Meyer, B. Environmental Sound Classification on the Edge: A Pipeline for Deep Acoustic Networks on Extremely Resource-Constrained Devices. Pattern Recognit. 2023, 133, 109025. [Google Scholar] [CrossRef]
- Choi, K.; Kersner, M.; Morton, J.; Chang, B. Temporal knowledge distillation for on-device audio classification. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual Conference, 7–13 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 486–490. [Google Scholar]
- Hwang, I.; Kim, K.; Kim, S. On-Device Intelligence for Real-Time Audio Classification and Enhancement. J. Audio Eng. Soc. 2023, 71, 719–728. [Google Scholar] [CrossRef]
- Kulkarni, A.; Jabade, V.; Patil, A. Audio Recognition Using Deep Learning for Edge Devices. In Proceedings of the International Conference on Advances in Computing and Data Sciences, Kumool, India, 22–23 April 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 186–198. [Google Scholar]
- Choudhary, S.; Karthik, C.; Lakshmi, P.S.; Kumar, S. LEAN: Light and Efficient Audio Classification Network. In Proceedings of the 2022 IEEE 19th India Council International Conference (INDICON), Kochi, India, 24–26 November 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Kumar, A.; Ithapu, V. A sequential self teaching approach for improving generalization in sound event recognition. In Proceedings of the International Conference on Machine Learning (PMLR), Virtual Event, 13–18 July 2020; pp. 5447–5457. [Google Scholar]
- Salamon, J.; Jacoby, C.; Bello, J.P. A dataset and taxonomy for urban sound research. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 1041–1044. [Google Scholar]
- Piczak, K.J. ESC: Dataset for environmental sound classification. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1015–1018. [Google Scholar]
- Gemmeke, J.F.; Ellis, D.P.W.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio Set: An ontology and human-labeled dataset for audio events. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 776–780. [Google Scholar] [CrossRef]
- Piczak, K.J. Environmental sound classification with convolutional neural networks. In Proceedings of the 2015 IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP), Boston, MA, USA, 17–20 September 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–6. [Google Scholar]
- Kim, J. Urban sound tagging using multi-channel audio feature with convolutional neural networks. In Proceedings of the Detection and Classification of Acoustic Scenes and Events, Tokyo, Japan, 2–3 November 2020; Volume 1. [Google Scholar]
- Boddapati, V.; Petef, A.; Rasmusson, J.; Lundberg, L. Classifying environmental sounds using image recognition networks. Procedia Comput. Sci. 2017, 112, 2048–2056. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Layer | Operation/Description |
|---|---|
| Conv2d | Input: (1, 1, 30,225) |
| Filters: 8, Kernel: (1, k); Output: (8, 1, 15,109) | |
| Batch Normalization, ReLU Activation | |
| MaxPool2d | Max Pooling, Kernel: (2, 1); Stride: (2, 1); Output: (8, 1, 7554) |
| AvgPool2d | Average Pooling, Kernel: (2, 1); Stride: (2, 1); Output: (8, 1, 3777) |
| Permute | Permute Dimension Order |
| Flatten | Flatten to 1D Vector |
| Linear | Fully Connected Layer, Output: (1, n) |
| Softmax | Softmax Activation for Classification |
| Datasets | Raw Audio | Mel Spectrograms |
|---|---|---|
| ESC-50 | 91% | 92.7% |
| UrbanSound8k | 79% | 84% |
| AudioSet | 90% | 95% |
| Networks | ESC50 | US8k |
|---|---|---|
| Pizak-CNN [34] | 64.50% | 73.70% |
| Multi-CNN [35] | 89.50% | - |
| GoogLENet [36] | 73% | 93% |
| Proposed | 92.7% | 84% |
| Pruning Methods | Accuracy |
|---|---|
| Weight | 88% |
| Taylor | 88.75% |
| Hybrid | 89.25% |
| Model Compression | Accuracy | Model Size |
|---|---|---|
| Original Model | 92% | 18.18 MB |
| Pruning | 89.25% | 528 KB |
| Quantization | 85.25% | 157 KB |
| Device | Accuracy | Inference Time | Power Consumption |
|---|---|---|---|
| Raspberry pi4 | 85% | 3.89 s/it | 7 W |
| NVIDIA Jetson Nano | 88% | 2.12 s/it | 10 W |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mou, A.; Milanova, M. Performance Analysis of Deep Learning Model-Compression Techniques for Audio Classification on Edge Devices. Sci 2024, 6, 21. https://doi.org/10.3390/sci6020021
Mou A, Milanova M. Performance Analysis of Deep Learning Model-Compression Techniques for Audio Classification on Edge Devices. Sci. 2024; 6(2):21. https://doi.org/10.3390/sci6020021
Chicago/Turabian StyleMou, Afsana, and Mariofanna Milanova. 2024. "Performance Analysis of Deep Learning Model-Compression Techniques for Audio Classification on Edge Devices" Sci 6, no. 2: 21. https://doi.org/10.3390/sci6020021
APA StyleMou, A., & Milanova, M. (2024). Performance Analysis of Deep Learning Model-Compression Techniques for Audio Classification on Edge Devices. Sci, 6(2), 21. https://doi.org/10.3390/sci6020021