


Fire and Smoke Detection Using Fine-Tuned YOLOv8 and YOLOv7 Deep Models



Abstract
1. Introduction
- Presenting a fine-tuned YOLOv8 for smoke and fire detection in various locations.
- Enhancing precision: The suggested method has the potential to enhance the precision of fire and smoke detection in forests, cities, and other locations when compared to traditional methods. A possibility to achieve this is by using the features of advanced deep learning algorithms like YOLOv8. These algorithms can be trained to recognize and detect specific characteristics of fire and smoke that can be challenging to identify using traditional image-processing techniques.
- Real time: The YOLOv8 algorithm is recognized for its efficiency and accuracy in real-time object detection. The proposed method is highly suitable for fire and smoke detection applications, where the fast and timely detection of fires is crucial.
- Large dataset: Instead of using a limited number of images for fire and smoke, this study uses a large dataset that includes fire, smoke, and normal scenes. The dataset contains real-world images collected from multiple sources and includes a variety of fire and smoke scenarios, including both indoor and outdoor fires, varied in size from small to large. A deep CNN extracts important features from the large dataset in order to generate accurate predictions and avoid the problem of overfitting.
2. The Network Structure of YOLOv8
3. Experimental Results
3.1. Dataset
3.2. Metrics and Hyper-Parameters
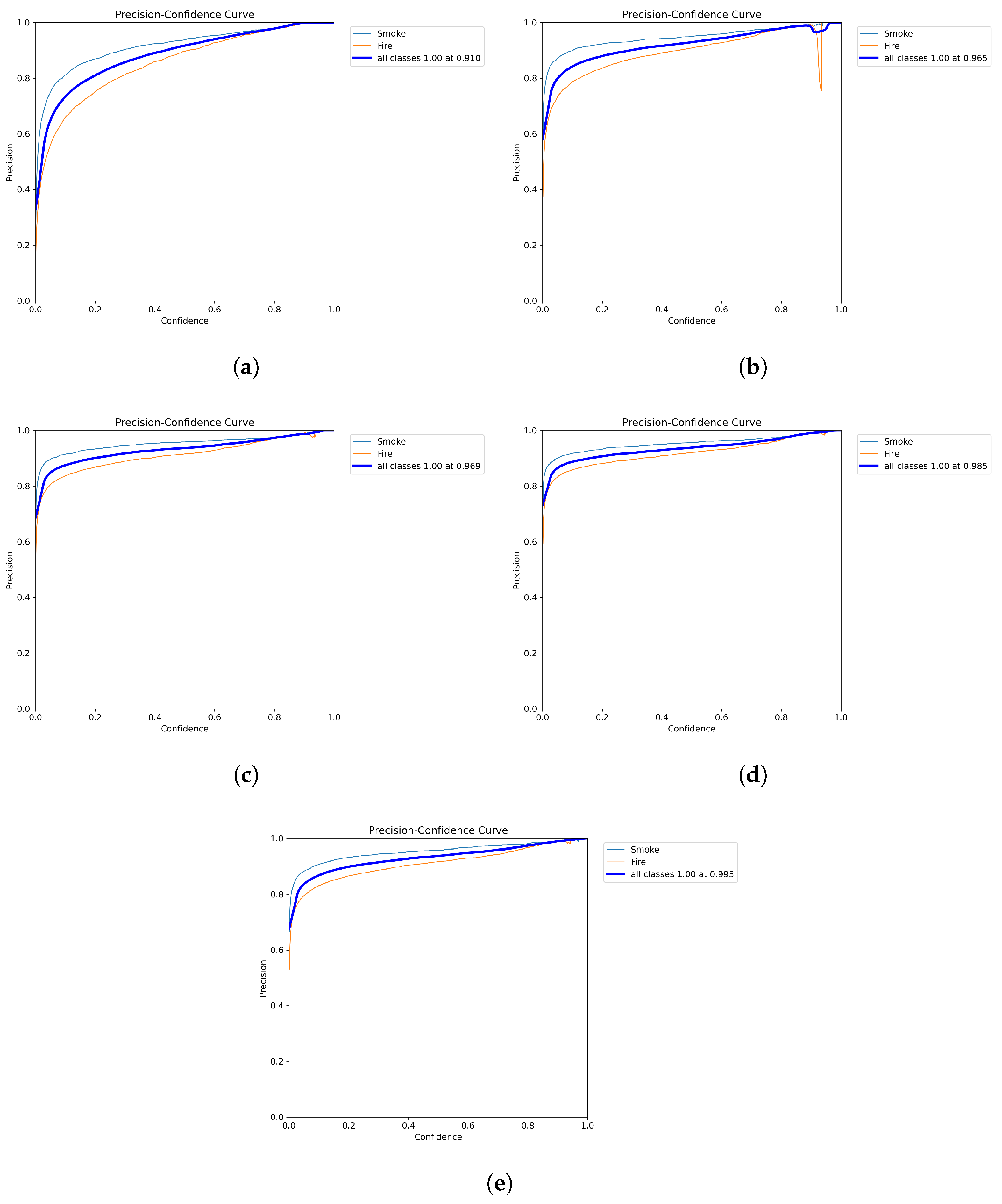
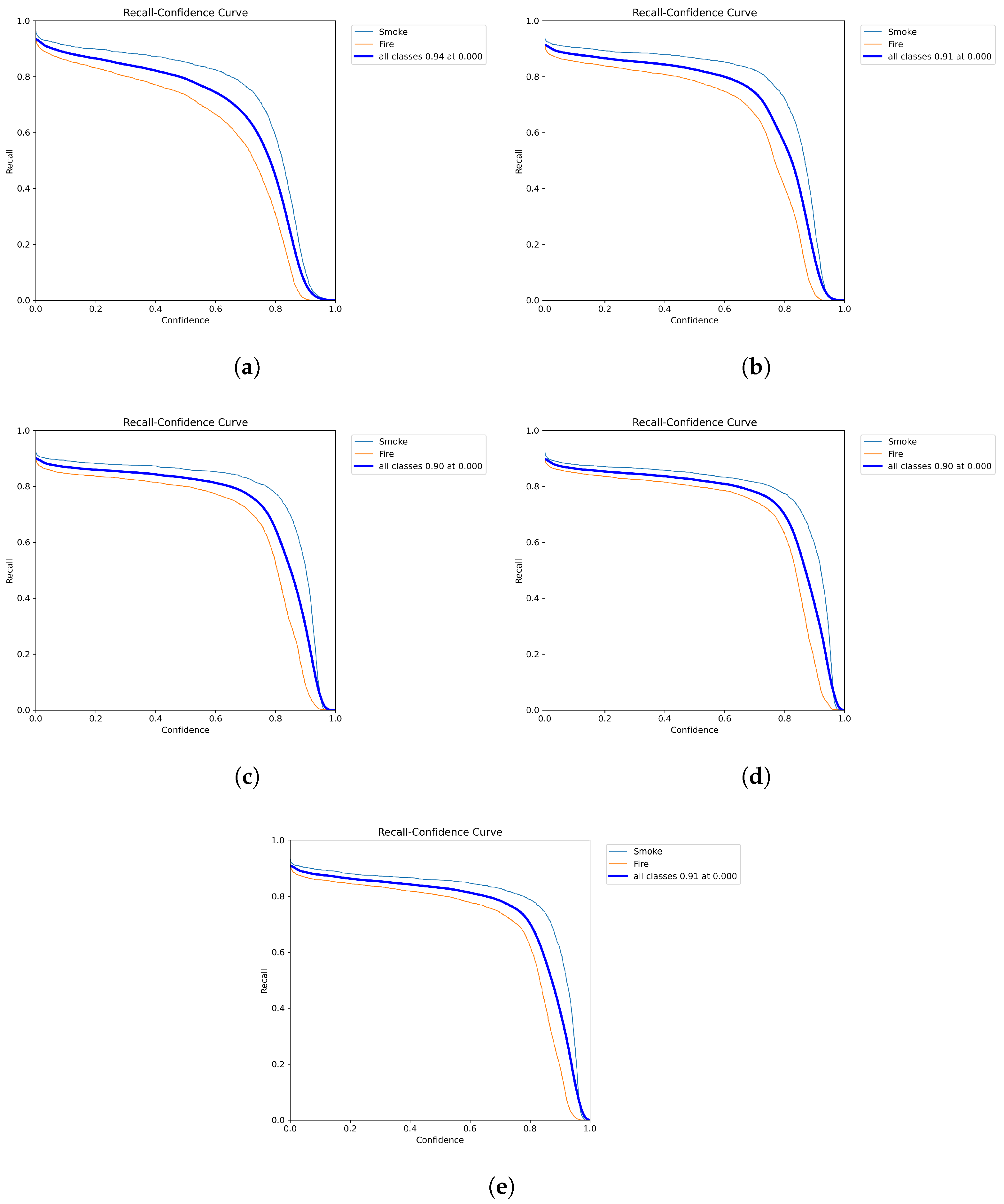
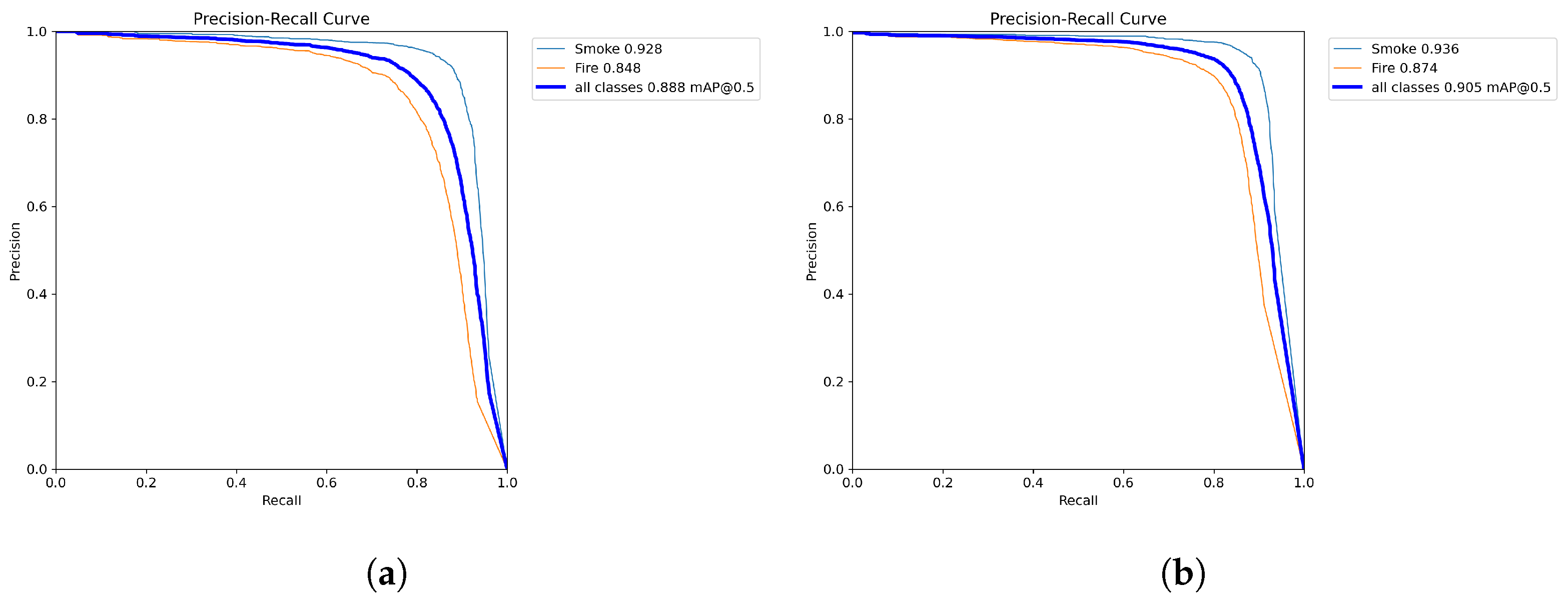
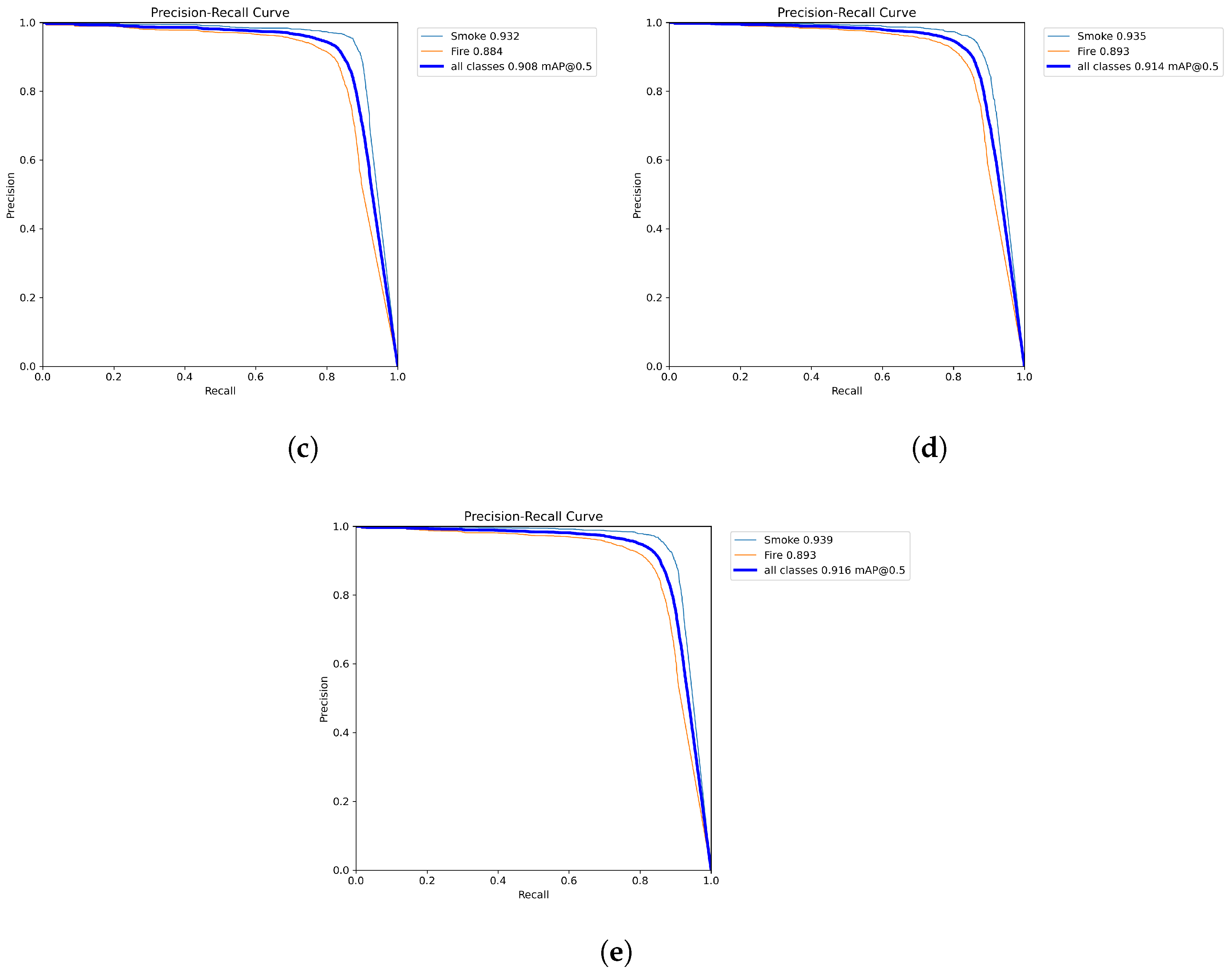
3.3. Results
4. Limitation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Belavenutti, P.; Chung, W.; Ager, A.A. The economic reality of the forest and fuel management deficit on a fire prone western US national forest. J. Environ. Manag. 2021, 293, 112825. [Google Scholar] [CrossRef]
- Martínez, J.R.M.; Machuca, M.H.; Díaz, R.Z.; y Silva, F.R.; González-Cabán, A. Economic losses to Iberian swine production from forest fires. For. Policy Econ. 2011, 13, 614–621. [Google Scholar] [CrossRef]
- Akter, S.; Grafton, R.Q. Do fires discriminate? Socio-economic disadvantage, wildfire hazard exposure and the Australian 2019–20 ‘Black Summer’fires. Clim. Chang. 2021, 165, 53. [Google Scholar] [CrossRef]
- Solórzano, A.; Fonollosa, J.; Fernández, L.; Eichmann, J.; Marco, S. Fire detection using a gas sensor array with sensor fusion algorithms. In Proceedings of the 2017 ISOCS/IEEE International Symposium on Olfaction and Electronic Nose (ISOEN), Montreal, QC, Canada, 28–31 May 2017; pp. 1–3. [Google Scholar]
- Jang, H.Y.; Hwang, C.H. Methodology for DB construction of input parameters in FDS-based prediction models of smoke detector. J. Mech. Sci. Technol. 2020, 34, 5327–5337. [Google Scholar] [CrossRef]
- Ding, X.; Gao, J. A new intelligent fire color space approach for forest fire detection. J. Intell. Fuzzy Syst. 2022, 42, 5265–5281. [Google Scholar] [CrossRef]
- Emmy Prema, C.; Vinsley, S.; Suresh, S. Efficient flame detection based on static and dynamic texture analysis in forest fire detection. Fire Technol. 2018, 54, 255–288. [Google Scholar] [CrossRef]
- Gao, Y.; Cheng, P. Forest fire smoke detection based on visual smoke root and diffusion model. Fire Technol. 2019, 55, 1801–1826. [Google Scholar] [CrossRef]
- Kim, O.; Kang, D.J. Fire detection system using random forest classification for image sequences of complex background. Opt. Eng. 2013, 52, 067202. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Jiang, H.; Learned-Miller, E. Face detection with the faster R-CNN. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 650–657. [Google Scholar]
- Kumar, A.; Srivastava, S. Object detection system based on convolution neural networks using single shot multi-box detector. Procedia Comput. Sci. 2020, 171, 2610–2617. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Choi, M.; Kim, C.; Oh, H. A video-based SlowFastMTB model for detection of small amounts of smoke from incipient forest fires. J. Comput. Des. Eng. 2022, 9, 793–804. [Google Scholar] [CrossRef]
- Xu, R.; Lin, H.; Lu, K.; Cao, L.; Liu, Y. A forest fire detection system based on ensemble learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- Ghosh, R.; Kumar, A. A hybrid deep learning model by combining convolutional neural network and recurrent neural network to detect forest fire. Multimed. Tools Appl. 2022, 81, 38643–38660. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Zhan, J.; Hu, Y.; Cai, W.; Zhou, G.; Li, L. PDAM–STPNNet: A small target detection approach for wildland fire smoke through remote sensing images. Symmetry 2021, 13, 2260. [Google Scholar] [CrossRef]
- Ghali, R.; Akhloufi, M.A.; Jmal, M.; Souidene Mseddi, W.; Attia, R. Wildfire segmentation using deep vision transformers. Remote Sens. 2021, 13, 3527. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Papaioannou, P.; Dimitropoulos, K.; Grammalidis, N. A review on early forest fire detection systems using optical remote sensing. Sensors 2020, 20, 6442. [Google Scholar] [CrossRef]
- Saleh, A.; Zulkifley, M.A.; Harun, H.H.; Gaudreault, F.; Davison, I.; Spraggon, M. Forest fire surveillance systems: A review of deep learning methods. Heliyon 2024. [Google Scholar] [CrossRef] [PubMed]
- Sathishkumar, V.E.; Cho, J.; Subramanian, M.; Naren, O.S. Forest fire and smoke detection using deep learning-based learning without forgetting. Fire Ecol. 2023, 19, 9. [Google Scholar] [CrossRef]
- Talaat, F.M.; ZainEldin, H. An improved fire detection approach based on YOLO-v8 for smart cities. Neural Comput. Appl. 2023, 35, 20939–20954. [Google Scholar] [CrossRef]
- Al-Smadi, Y.; Alauthman, M.; Al-Qerem, A.; Aldweesh, A.; Quaddoura, R.; Aburub, F.; Mansour, K.; Alhmiedat, T. Early Wildfire Smoke Detection Using Different YOLO Models. Machines 2023, 11, 246. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, L.; Li, T.; Shi, P. A smoke detection model based on improved YOLOv5. Mathematics 2022, 10, 1190. [Google Scholar] [CrossRef]
- Mukhiddinov, M.; Abdusalomov, A.B.; Cho, J. A Wildfire Smoke Detection System Using Unmanned Aerial Vehicle Images Based on the Optimized YOLOv5. Sensors 2022, 22, 9384. [Google Scholar] [CrossRef] [PubMed]
- Yazdi, A.; Qin, H.; Jordan, C.B.; Yang, L.; Yan, F. Nemo: An open-source transformer-supercharged benchmark for fine-grained wildfire smoke detection. Remote Sens. 2022, 14, 3979. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Baratov, N.; Kutlimuratov, A.; Whangbo, T.K. An Improvement of the Fire Detection and Classification Method Using YOLOv3 for Surveillance Systems. Sensors 2021, 21, 6519. [Google Scholar] [CrossRef] [PubMed]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; AAAI: Washington, DC, USA, 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3490–3499. [Google Scholar]
- Yang, J.; Zhu, W.; Sun, T.; Ren, X.; Liu, F. Lightweight forest smoke and fire detection algorithm based on improved YOLOv5. PLoS ONE 2023, 18, e0291359. [Google Scholar] [CrossRef]
- HumanSignal. LabelImg. 2015. Available online: https://github.com/HumanSignal/labelImg (accessed on 7 April 2024).
- Saydirasulovich, S.N.; Mukhiddinov, M.; Djuraev, O.; Abdusalomov, A.; Cho, Y.I. An Improved Wildfire Smoke Detection Based on YOLOv8 and UAV Images. Sensors 2023, 23, 8374. [Google Scholar] [CrossRef] [PubMed]
- Wei, Z. Fire detection of YOLOv8 model based on integrated se attention mechanism. Front. Comput. Intell. Syst. 2023, 4, 28–30. [Google Scholar] [CrossRef]
- Xu, Y.; Li, J.; Zhang, L.; Liu, H.; Zhang, F. CNTCB-YOLOv7: An Effective Forest Fire Detection Model Based on ConvNeXtV2 and CBAM. Fire 2024, 7, 54. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision | Recall | mAP:50 | mAP:50-95 |
|---|---|---|---|---|
| YOLOv8n | 0.919 | 0.793 | 0.869 | 0.658 |
| YOLOv8s | 0.929 | 0.828 | 0.891 | 0.721 |
| YOLOv8m | 0.935 | 0.831 | 0.895 | 0.745 |
| YOLOv8l | 0.949 | 0.837 | 0.901 | 0.753 |
| YOLOv8x | 0.954 | 0.848 | 0.926 | 0.772 |
| YOLOv7 | 0.881 | 0.778 | 0.854 | 0.647 |
| YOLOv7-X | 0.918 | 0.817 | 0.882 | 0.715 |
| YOLOv7-W6 | 0.922 | 0.824 | 0.887 | 0.745 |
| YOLOv7-E6 | 0.937 | 0.824 | 0.896 | 0.748 |
| YOLOv6l | 0.582 | 0.605 | 0.852 | 0.496 |
| Faster-RCNN | 0.437 | 0.374 | 0.471 | 0.348 |
| DETR | 0.443 | 0.362 | 0.413 | 0.291 |
| Study | Model | Precision | Recall | mAP:50 | # Images | Detection |
|---|---|---|---|---|---|---|
| Saydirasulovich et al. [41] | YOLOv6 | 0.934 | 0.282 | - | 4000 | Fire/Smoke |
| Talaat et al. [26] | YOLOv8 | - | - | 0.794 | 6000 | Fire/Smoke |
| Wei et al. [42] | YOLOv8 | - | 0.707 | 0.730 | 2059 | Fire |
| Xu et al. [43] | YOLOv7 | 0.861 | 0.818 | 0.883 | 2058 | Fire |
| Yang et al. [39] | YOLOv5 | 0.892 | 0.827 | 0.873 | 11,667 | Fire/Smoke |
| Proposed model | YOLOv8 | 0.837 | 0.952 | 0.890 | 11,667 | Fire/Smoke |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chetoui, M.; Akhloufi, M.A. Fire and Smoke Detection Using Fine-Tuned YOLOv8 and YOLOv7 Deep Models. Fire 2024, 7, 135. https://doi.org/10.3390/fire7040135
Chetoui M, Akhloufi MA. Fire and Smoke Detection Using Fine-Tuned YOLOv8 and YOLOv7 Deep Models. Fire. 2024; 7(4):135. https://doi.org/10.3390/fire7040135
Chicago/Turabian StyleChetoui, Mohamed, and Moulay A. Akhloufi. 2024. "Fire and Smoke Detection Using Fine-Tuned YOLOv8 and YOLOv7 Deep Models" Fire 7, no. 4: 135. https://doi.org/10.3390/fire7040135
APA StyleChetoui, M., & Akhloufi, M. A. (2024). Fire and Smoke Detection Using Fine-Tuned YOLOv8 and YOLOv7 Deep Models. Fire, 7(4), 135. https://doi.org/10.3390/fire7040135