

Improving Fire and Smoke Detection with You Only Look Once 11 and Multi-Scale Convolutional Attention

Abstract
:1. Introduction
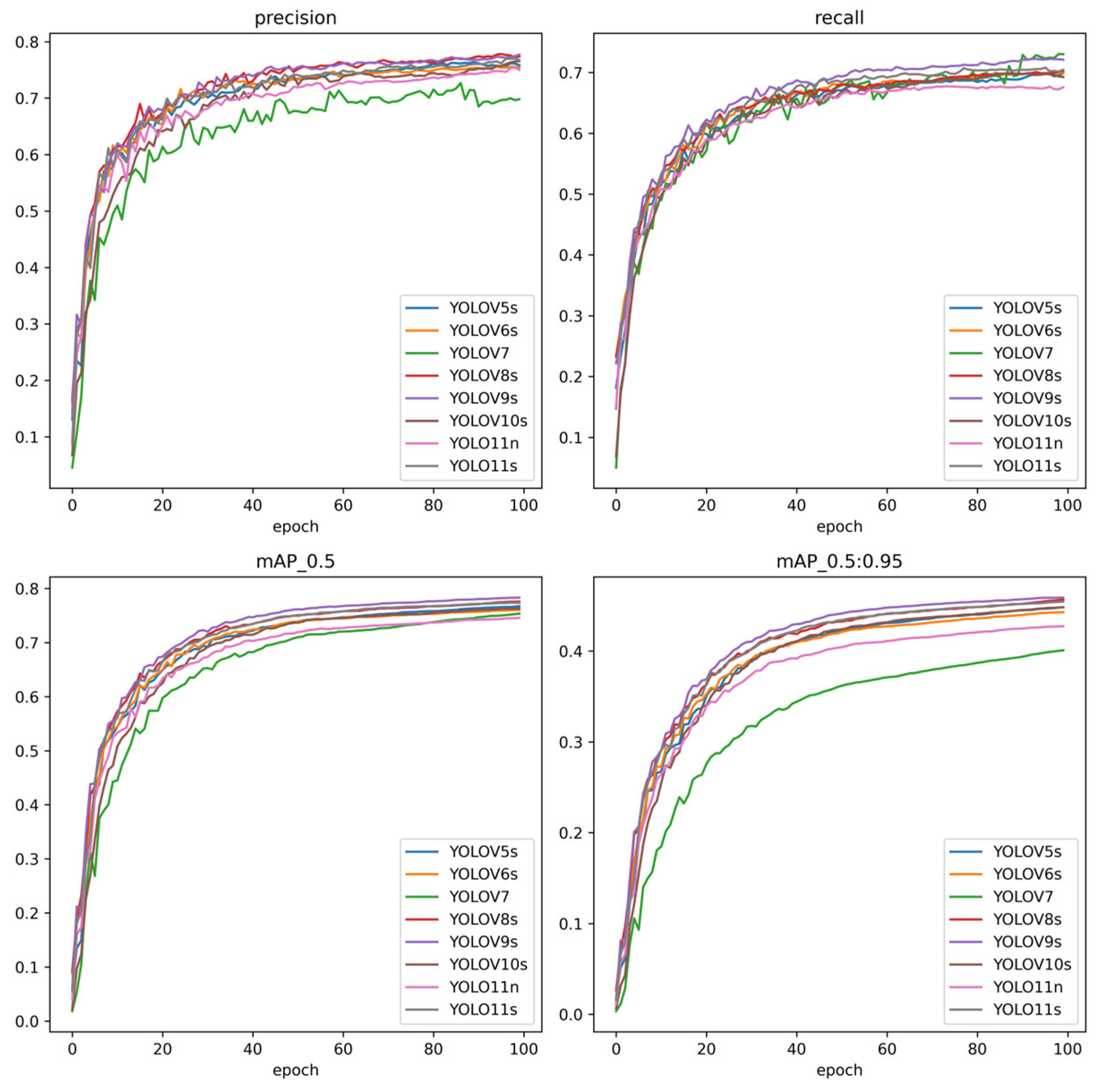
- The YOLO series has consistently played an active role in fire and smoke target detection. This study first explores the advantages of the YOLO11 network in fire and smoke target detection tasks. The result show that YOLO11 achieves the best balance between detection accuracy, detection speed, and model complexity for fire and smoke object detection tasks. Moreover, all YOLO models demonstrate higher detection accuracy for smoke than for fire, and the YOLO series can detect fires at an earlier stage. YOLO11 will be an important tool for our future fire and smoke object detection research.
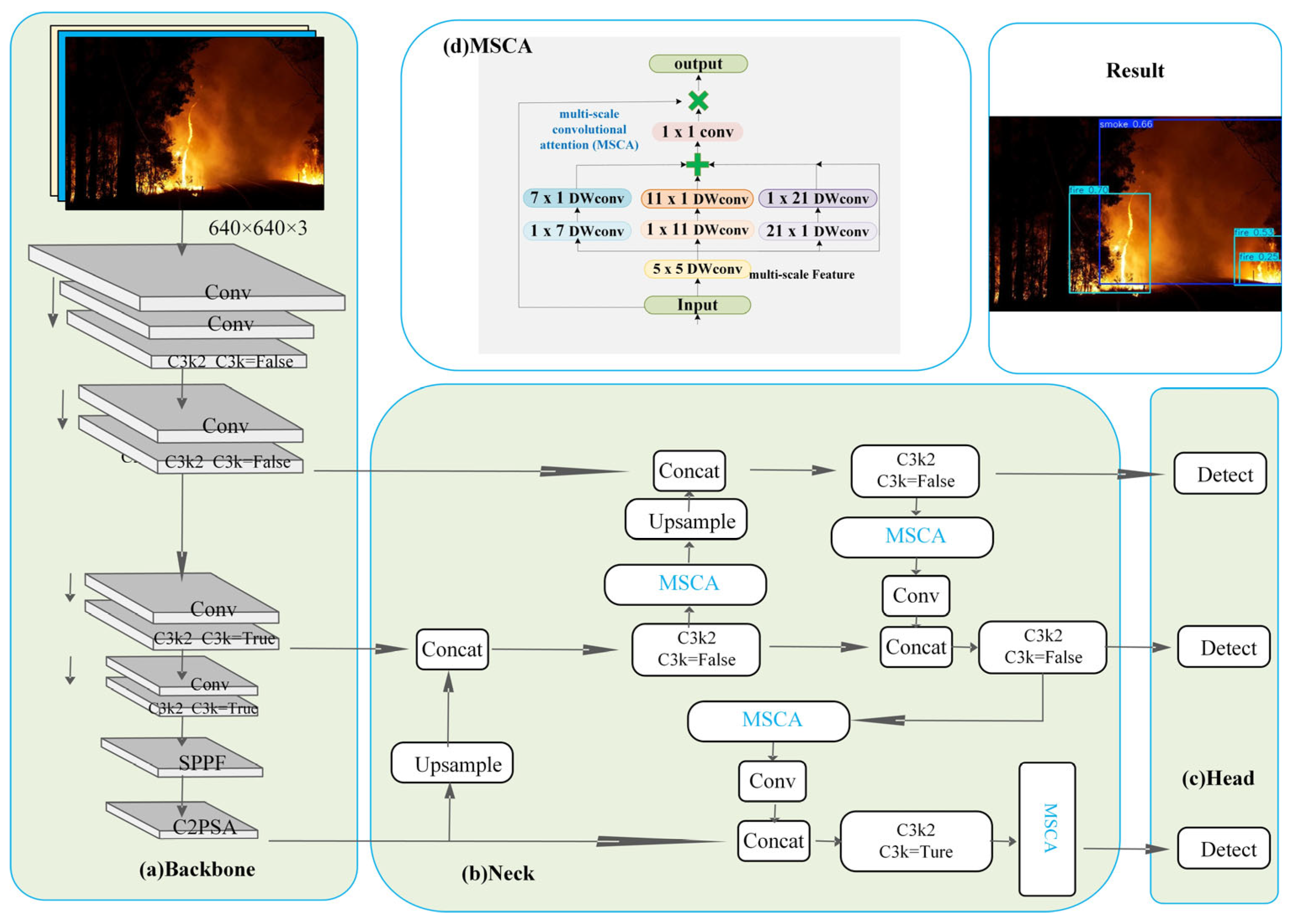
- To address the variability of smoke and fire objects across different scales and environments, this study introduces the Multi-Scale Convolutional Attention (MSCA) module to enhance YOLO11 (for simplicity, the improved YOLO11 is referred to as YOLO11s-MSCA in this paper). The components of MSCA are characterized by high efficiency, low computational cost, and minimal parameters, ensuring that the model’s detection speed and algorithm complexity do not significantly increase.
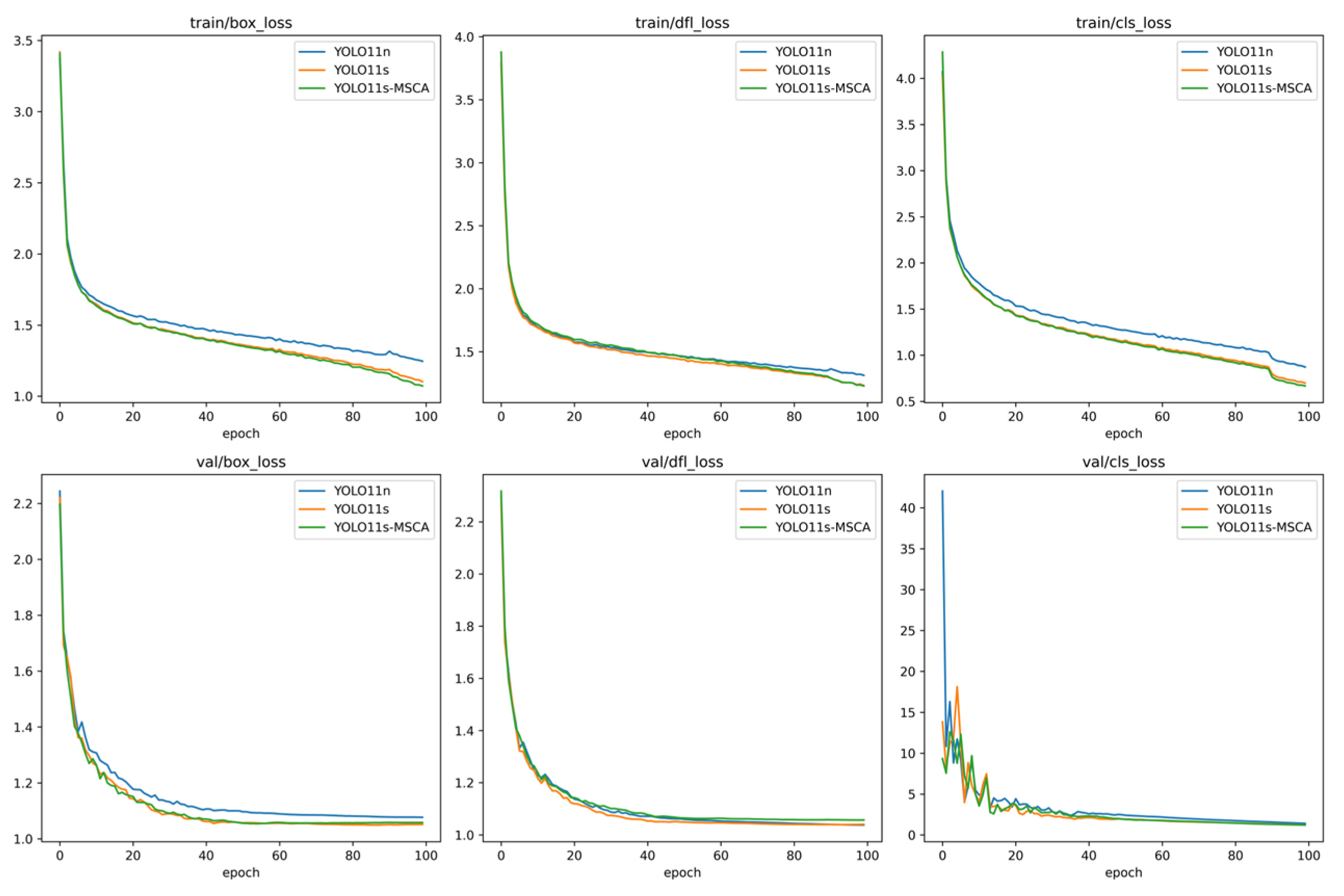
- Observations from the results of YOLO11s-MSCA on the D-Fire show that YOLO11s-MSCA improves the model’s detection accuracy without noticeably compromising detection speed or increasing model complexity. Compared to YOLO11s, the improved model detects small targets in images more accurately and demonstrates a stronger understanding of environmental contexts. However, it still struggles with identifying the occluded object, and the main sources of errors remain the complex environmental variations.
- The generalization performance of our YOLO classic model and YOLO11s-MSCA model is verified through the overall metrics and visual details on the Fire and Smoke Dataset and CBM-Fire. Even when the dataset is changed, the models maintain high accuracy and recall, confirming that the conclusions drawn from the D-Fire dataset are applicable. At the same time, different datasets of the same model are compared, and the conclusion is drawn that the construction strategy of the dataset (data volume, scene richness, classification of interference items) has a significant impact on the performance and stability of the detection model. Especially when the interference terms are clearly labeled as independent categories, the robustness and accuracy of the model can be significantly improved in complex environments.
2. Materials and Methods
2.1. Datasets
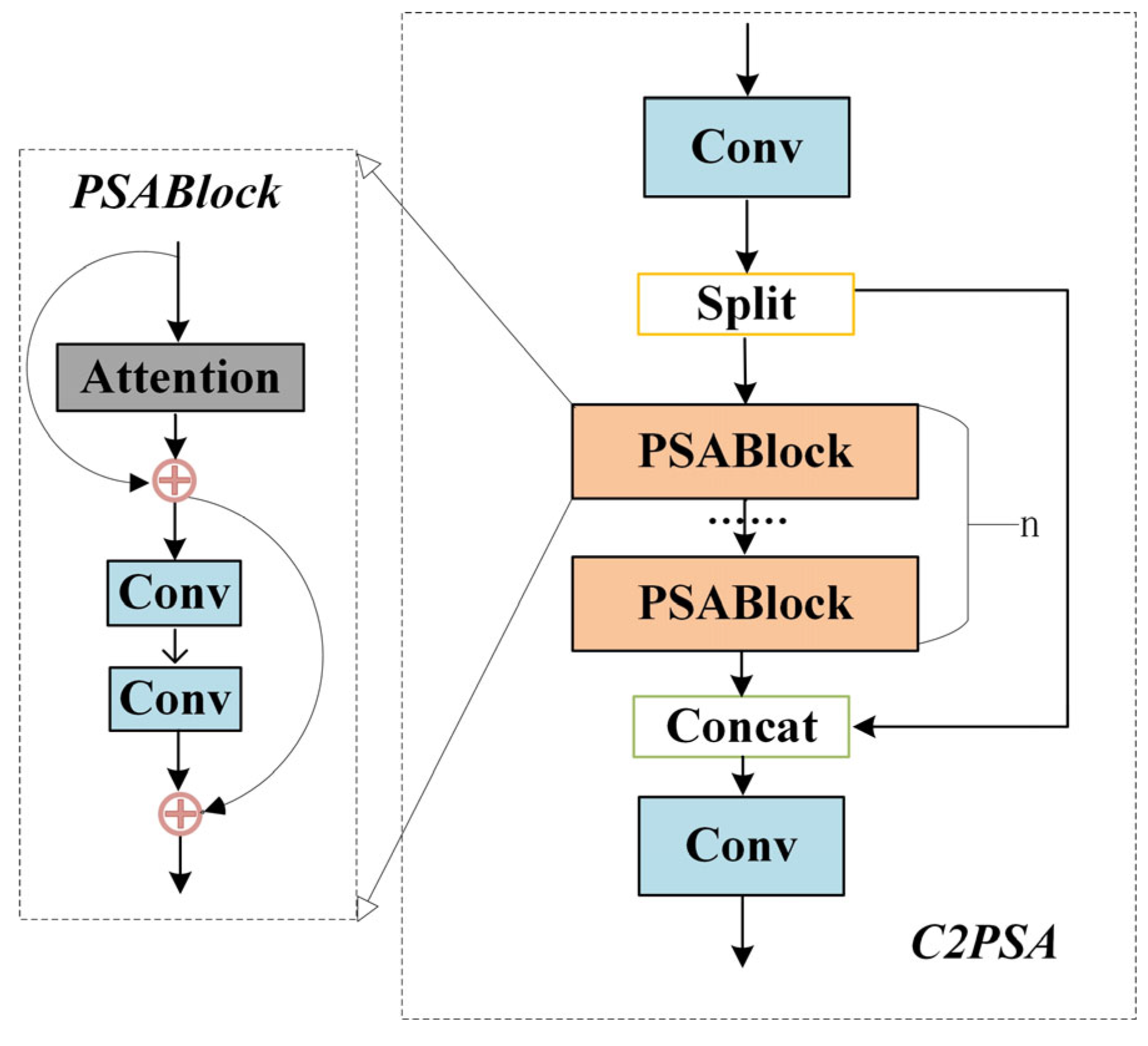
2.2. Model Overview
2.2.1. Proposed Method
2.2.2. Multi-Scale Convolutional Attention (MSCA)
3. Experiments and Analyses
3.1. Evaluation Metrics Section
- 1.
- Precision
- 2.
- Recall
- 3.
- Mean Average Precision (mAP)
- 4.
- GFLOPS
- 5.
- FPS
3.2. Experimental Configuration and Parameter Setting
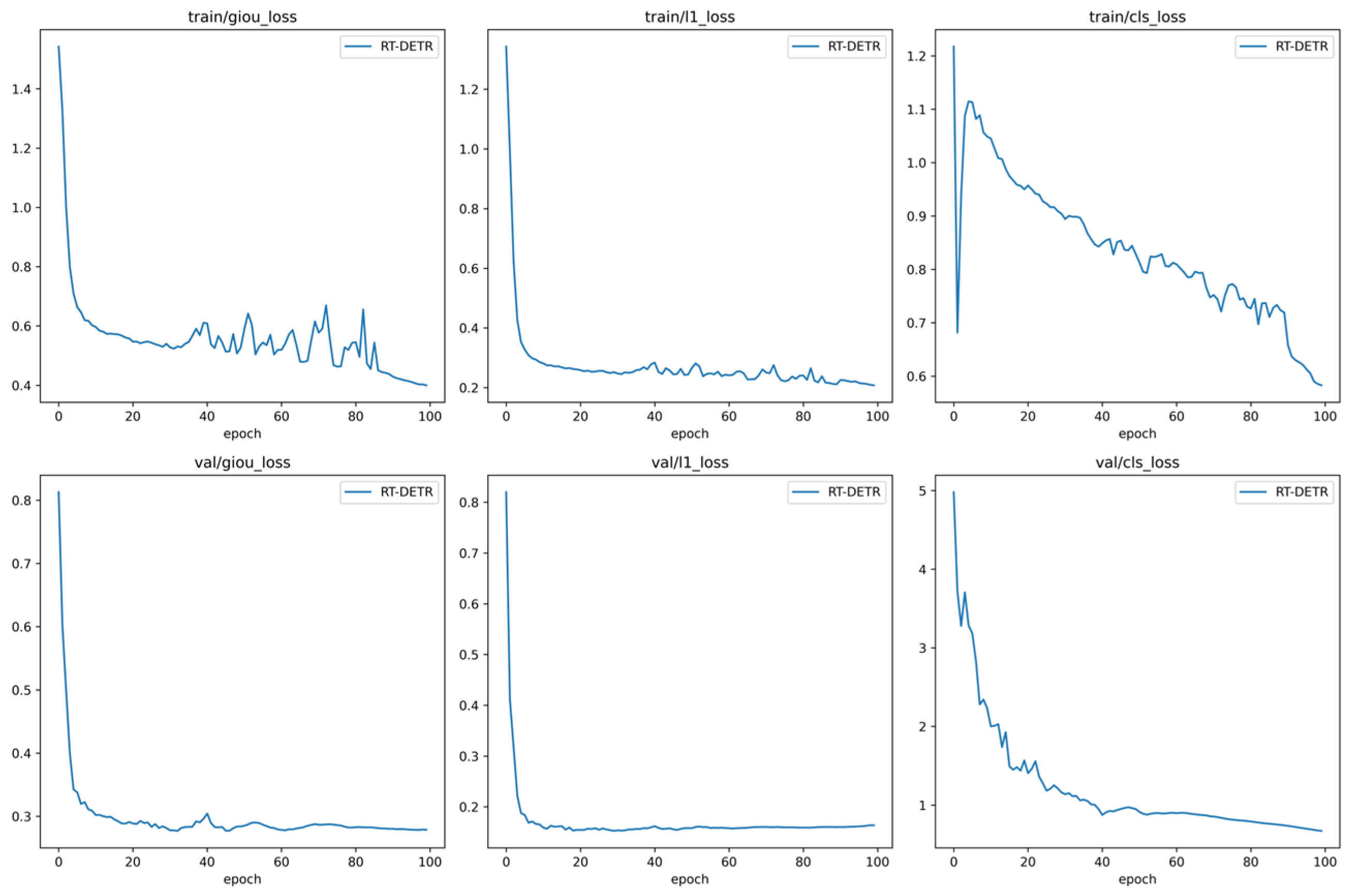
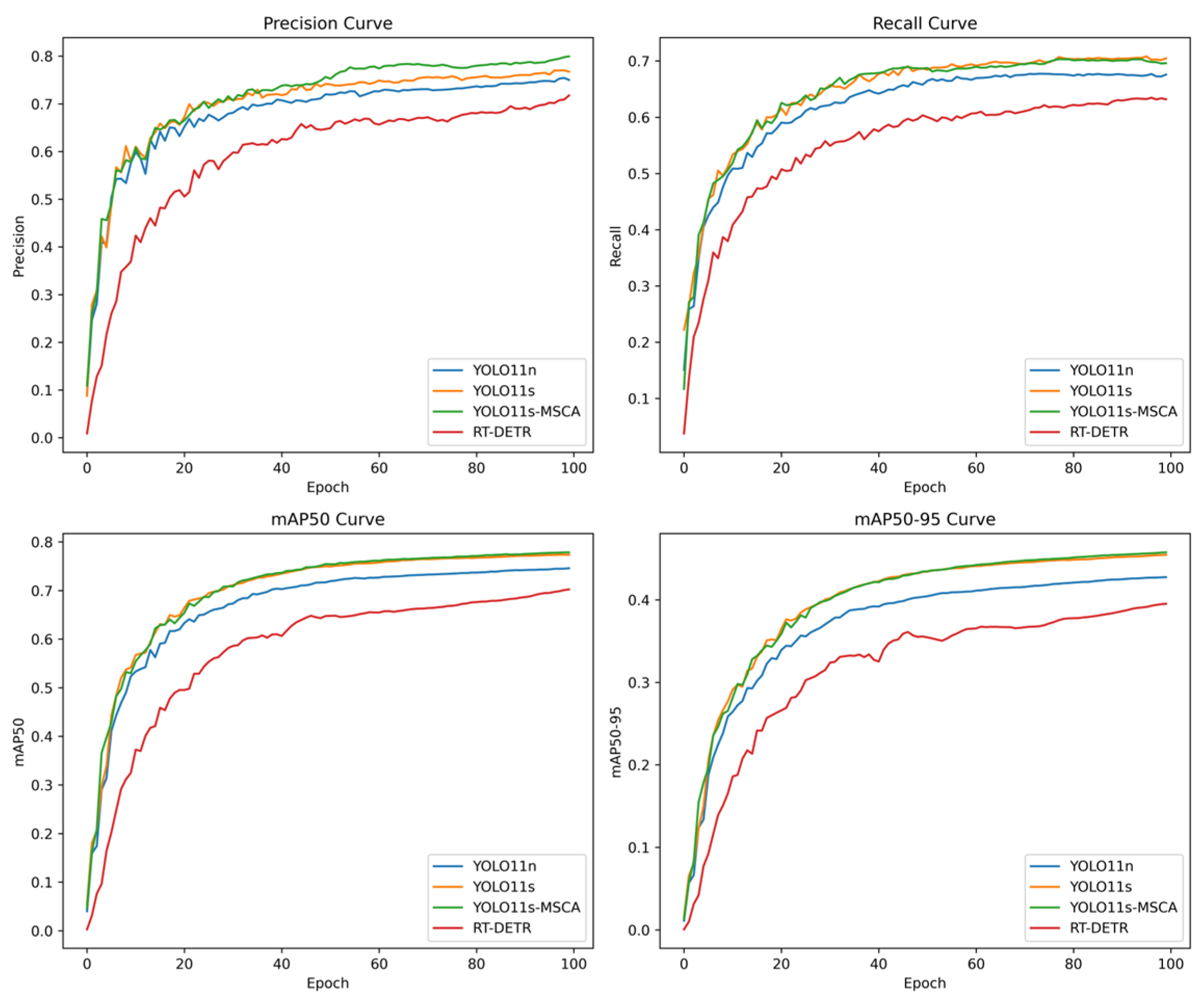
3.3. Experimental Results and Discussion Analysis
3.3.1. Comparative Analysis of the Advantages of YOLO11
3.3.2. YOLO11s-MSCA Model Performance Analysis
- As shown in Figure 11b,e, the improved method in this paper is more accurate in the detection of small objects. The small object fires that are not labeled in the label are identified accurately, which proves the effectiveness of the multi-scale spatial attention introduced in this paper. The model focuses on objects of different scales (smoke and fire objects in this paper).
- The YOLO11s-MSCA model is more accurate in locating the target frame. For example, the a in Figure 11 correctly locates the range of the smoke object and does not identify the scattering of the light as smoke. In c, the cloud of smoke object and background are correctly localized. Spatial attention makes the model focus on the correct important areas.
- The YOLO11s-MSCA model can more accurately identify the differences between fire objects and highlighted fire-like objects and can correctly classify them as in Figure 11a,c,d. The improved model in Figure 11f can correctly distinguish smoke targets at night. The advantage comes from the ability to understand the context. Smoke is a fire companion organism, and the two basically exist at the same time.
- The introduced contextual spatial attention module focuses on contextual information, which also causes some loss of accuracy in our results, e.g., our model does not detect small object white smoke in the white wall background. Small object fire in the background of a smoke, as in Figure 12g, identifies the highlight as fire, and smoke in the background of a grayish white, as in Figure 12e, does not detect smoke object.
- For occluded objects, the algorithm does not recognize them correctly, as in Figure 12e,f, occluded targets are not recognized.
- Although the improved algorithm has enhanced the detection performance for small targets, challenges remain, as illustrated in Figure 12c,d. This limitation is primarily attributed to the complexity of the environment.
- The YOLO11s-MSCA model still has the problem of misidentification for feature similarities, e.g., in Figure 12a, smoke in the distance is similar to clouds, scattered light similar to smoke (e.g., b), and sunset in red clouds (e.g., i).
- The complexity of the environment and the different performance of smoke and fire in different environments are the most important sources of error rate. The performance of smoke and fire comes from the difference in combustion material, the change in light, the change in day and night, the distance from the video sensor and so on. The processing of this variability is still an important research direction for us in the future. As in Figure 12h, the recognition accuracy of smoke and fire objects decreases at night.
3.3.3. Comparison of Model Generalization Experiments
- YOLO11s and YOLO11s-MSCA still perform well in fire and smoke object detection tasks, accurately classifying and localizing most objects in an image. Figure 13i correctly distinguishes fire objects from lights; j correctly localizes smoke objects by eliminating trees from the smoke background.
- In this dataset, YOLO11s-MSCA is still able to focus more on small objects in the model than the YOLO11s model and classify them correctly, e.g., it can focus on the candles in the pictures in Figure 13a,i, differentiating between the lights in the background of the fire and the small object flames in b, f, and k. The introduced Multi-Scale Convolutional Attention mechanism still focuses on the multi-scale information of the object in the image.
- The YOLO11s-MSCA model recognizes the sun in clouds, as shown in Figure 13d, and correctly distinguishes smoke objects in snowy landscapes, as in Figure 13c,e, and thin smoke in h. These are not small objects, their correct distinction comes from the model’s understanding of the object and the object’s surroundings. The Multi-Scale Convolutional Attention mechanism this research introduces can still focus on the object’s contextual information.
- For occluded objects, the model still fails to recognize them, as in Figure 13g. Similarly, our introduction of the MSCA module causes some small objects similar to the background to be misdistinguished, and the most important errors still originate from the variability of the environment and the diversity of fire and smoke.
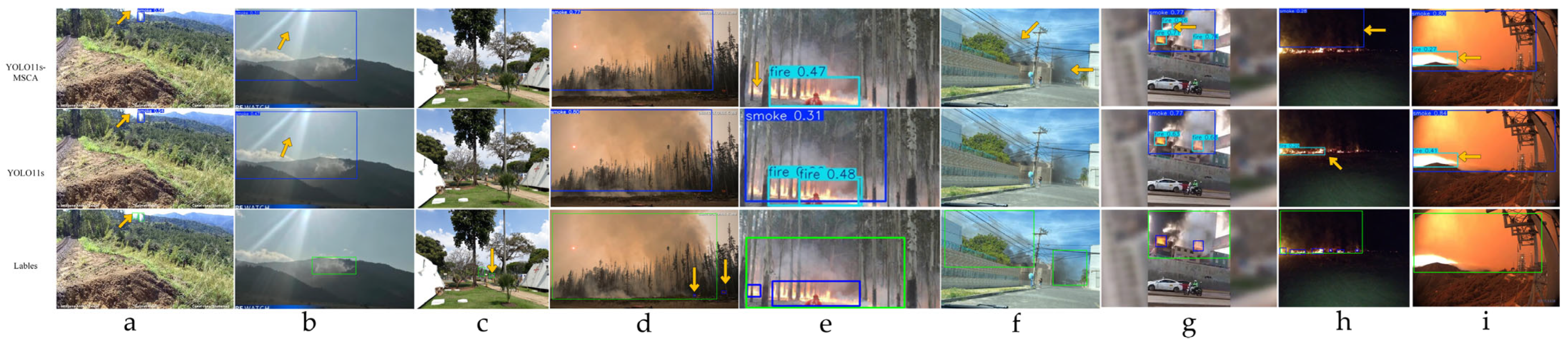
- Enhanced Confidence and Localization Accuracy: The YOLO11s-MSCA model demonstrates superior confidence scores and more precise localization capabilities. As shown in Figure 14a–c (highlighted with yellow arrows), the model accurately detects fire and smoke targets. Notably, in Figure 14b, it correctly identifies a fire instance that is absent in the ground truth annotations, and in Figure 14c, it effectively localizes a broader region of smoke. These results confirm the efficacy of the introduced attention mechanism in improving target recognition.
- Improved Detection of Small Objects: YOLO11s-MSCA exhibits enhanced sensitivity to small-scale targets, as demonstrated in Figure 14a,d, where it successfully detects small fire sources (again indicated by yellow arrows). In contrast to YOLO11s, which misclassifies a firefighter’s red uniform as fire in Figure 14a, YOLO11s-MSCA correctly identifies the actual fire target. This further supports the effectiveness of the attention mechanism in directing focus towards semantically relevant regions.
- Robustness Across Diverse Environments: Comparative experiments across three distinct datasets—each differing in source and environmental conditions—demonstrate that YOLO11s-MSCA maintains robust performance in the face of varying complexity and scene dynamics.
- Limitations in Background-Dominant Scenes: As shown in Figure 14c, although YOLO11s-MSCA captures a larger smoke area, it fails to identify smoke against a sky background. Similarly, in Figure 14e, where the entire image is engulfed in smoke, the model is unable to distinguish the smoke target. This indicates that while the MSCA module enhances environmental understanding, it may also reduce the model’s discriminability when the target blends seamlessly with the background.
- Challenges with Occlusion and Visual Similarity: In certain scenarios, such as in Figure 14f, the model struggles with occluded targets. However, the primary cause of detection errors remains the high variability of the environment. For instance, in Figure 14f, the fire color closely resembles the yellowish reflection on nearby leaves, leading to misclassification.
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Morales-Hidalgo, D.; Oswalt, S.N.; Somanathan, E. Status and Trends in Global Primary Forest, Protected Areas, and Areas Designated for Conservation of Biodiversity from the Global Forest Resources Assessment 2015. For. Ecol. Manag. 2015, 352, 68–77. [Google Scholar] [CrossRef]
- Sahoo, G.; Wani, A.; Rout, S.; Sharma, A.; Prusty, A.K. Impact and Contribution of Forest in Mitigating Global Climate Change. Des. Eng. 2021, 4, 667–682. [Google Scholar]
- Lu, N. Dark Convolutional Neural Network for Forest Smoke Detection and Localization Based on Single Image. Soft Comput. 2022, 26, 8647–8659. [Google Scholar] [CrossRef]
- Tien Bui, D.; Le, H.V.; Hoang, N.-D. GIS-Based Spatial Prediction of Tropical Forest Fire Danger Using a New Hybrid Machine Learning Method. Ecol. Inform. 2018, 48, 104–116. [Google Scholar] [CrossRef]
- Pourmohamad, Y.; Abatzoglou, J.T.; Fleishman, E.; Short, K.C.; Shuman, J.; AghaKouchak, A.; Williamson, M.; Seydi, S.T.; Sadegh, M. Inference of Wildfire Causes From Their Physical, Biological, Social and Management Attributes. Earth’s Future 2025, 13, e2024EF005187. [Google Scholar] [CrossRef]
- Wah, W.; Gelaw, A.; Glass, D.C.; Sim, M.R.; Hoy, R.F.; Berecki-Gisolf, J.; Walker-Bone, K. Systematic Review of Impacts of Occupational Exposure to Wildfire Smoke on Respiratory Function, Symptoms, Measures and Diseases. Int. J. Hyg. Environ. Health 2025, 263, 114463. [Google Scholar] [CrossRef]
- Zeng, B.; Zhou, Z.; Zhou, Y.; He, D.; Liao, Z.; Jin, Z.; Zhou, Y.; Yi, K.; Xie, Y.; Zhang, W. An Insulator Target Detection Algorithm Based on Improved YOLOv5. Sci. Rep. 2025, 15, 496. [Google Scholar] [CrossRef]
- Zhang, F.; Zhao, P.; Xu, S.; Wu, Y.; Yang, X.; Zhang, Y. Integrating Multiple Factors to Optimize Watchtower Deployment for Wildfire Detection. Sci. Total Environ. 2020, 737, 139561. [Google Scholar] [CrossRef] [PubMed]
- Hosseini, A.; Hashemzadeh, M.; Farajzadeh, N. UFS-Net: A Unified Flame and Smoke Detection Method for Early Detection of Fire in Video Surveillance Applications Using CNNs. J. Comput. Sci. 2022, 61, 101638. [Google Scholar] [CrossRef]
- Shoshe, M.A.M.S.; Rahman, M.A. Improvement of Heat and Smoke Confinement Using Air Curtains in Informal Shopping Malls. J. Build. Eng. 2022, 46, 103676. [Google Scholar] [CrossRef]
- Kuznetsov, G.V.; Volkov, R.S.; Sviridenko, A.S.; Strizhak, P.A. Fire Detection and Suppression in Rooms with Different Geometries. J. Build. Eng. 2024, 90, 109427. [Google Scholar] [CrossRef]
- Yar, H.; Khan, Z.A.; Rida, I.; Ullah, W.; Kim, M.J.; Baik, S.W. An Efficient Deep Learning Architecture for Effective Fire Detection in Smart Surveillance. Image Vis. Comput. 2024, 145, 104989. [Google Scholar] [CrossRef]
- Khan, Z.A.; Ullah, F.U.M.; Yar, H.; Ullah, W.; Khan, N.; Kim, M.J.; Baik, S.W. Optimized Cross-Module Attention Network and Medium-Scale Dataset for Effective Fire Detection. Pattern Recognit. 2025, 161, 111273. [Google Scholar] [CrossRef]
- Gaur, A.; Singh, A.; Kumar, A.; Kulkarni, K.S.; Lala, S.; Kapoor, K.; Srivastava, V.; Kumar, A.; Mukhopadhyay, S.C. Fire Sensing Technologies: A Review. IEEE Sens. J. 2019, 19, 3191–3202. [Google Scholar] [CrossRef]
- Cheng, G.; Chen, X.; Wang, C.; Li, X.; Xian, B.; Yu, H. Visual Fire Detection Using Deep Learning: A Survey. Neurocomputing 2024, 596, 127975. [Google Scholar] [CrossRef]
- Huang, P.; Chen, M.; Chen, K.; Zhang, H.; Yu, L.; Liu, C. A Combined Real-Time Intelligent Fire Detection and Forecasting Approach through Cameras Based on Computer Vision Method. Process Saf. Environ. Prot. 2022, 164, 629–638. [Google Scholar] [CrossRef]
- Boroujeni, S.P.H.; Razi, A.; Khoshdel, S.; Afghah, F.; Coen, J.L.; O’Neill, L.; Fule, P.; Watts, A.; Kokolakis, N.-M.T.; Vamvoudakis, K.G. A Comprehensive Survey of Research towards AI-Enabled Unmanned Aerial Systems in Pre-, Active-, and Post-Wildfire Management. Inf. Fusion. 2024, 108, 102369. [Google Scholar] [CrossRef]
- Han, Z.; Tian, Y.; Zheng, C.; Zhao, F. Forest Fire Smoke Detection Based on Multiple Color Spaces Deep Feature Fusion. Forests 2024, 15, 689. [Google Scholar] [CrossRef]
- Özel, B.; Alam, M.S.; Khan, M.U. Review of Modern Forest Fire Detection Techniques: Innovations in Image Processing and Deep Learning. Information 2024, 15, 538. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc., Red Hook, NY, USA; 2015; Volume 28. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Ragab, M.G.; Abdulkadir, S.J.; Muneer, A.; Alqushaibi, A.; Sumiea, E.H.; Qureshi, R.; Al-Selwi, S.M.; Alhussian, H. A Comprehensive Systematic Review of YOLO for Medical Object Detection (2018 to 2023). IEEE Access 2024, 12, 57815–57836. [Google Scholar] [CrossRef]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object Detection With Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Mamadaliev, D.; Touko, P.L.M.; Kim, J.-H.; Kim, S.-C. ESFD-YOLOv8n: Early Smoke and Fire Detection Method Based on an Improved YOLOv8n Model. Fire 2024, 7, 303. [Google Scholar] [CrossRef]
- Wang, D.; Qian, Y.; Lu, J.; Wang, P.; Yang, D.; Yan, T. Ea-Yolo: Efficient Extraction and Aggregation Mechanism of YOLO for Fire Detection. Multimed. Syst. 2024, 30, 287. [Google Scholar] [CrossRef]
- Jiao, Z.; Zhang, Y.; Xin, J.; Mu, L.; Yi, Y.; Liu, H.; Liu, D. A Deep Learning Based Forest Fire Detection Approach Using UAV and YOLOv3. In Proceedings of the 2019 1st International Conference on Industrial Artificial Intelligence (IAI), Shenyang, China, 23–27 July 2019; pp. 1–5. [Google Scholar]
- Wu, H.; Hu, Y.; Wang, W.; Mei, X.; Xian, J. Ship Fire Detection Based on an Improved YOLO Algorithm with a Lightweight Convolutional Neural Network Model. Sensors 2022, 22, 7420. [Google Scholar] [CrossRef]
- Xue, Q.; Lin, H.; Wang, F. FCDM: An Improved Forest Fire Classification and Detection Model Based on YOLOv5. Forests 2022, 13, 2129. [Google Scholar] [CrossRef]
- Chen, X.; Xue, Y.; Hou, Q.; Fu, Y.; Zhu, Y. RepVGG-YOLOv7: A Modified YOLOv7 for Fire Smoke Detection. Fire 2023, 6, 383. [Google Scholar] [CrossRef]
- Zhang, T.; Wang, F.; Wang, W.; Zhao, Q.; Ning, W.; Wu, H. Research on Fire Smoke Detection Algorithm Based on Improved YOLOv8. IEEE Access 2024, 12, 117354–117362. [Google Scholar] [CrossRef]
- Zhao, C.; Zhao, L.; Zhang, K.; Ren, Y.; Chen, H.; Sheng, Y. Smoke and Fire-You Only Look Once: A Lightweight Deep Learning Model for Video Smoke and Flame Detection in Natural Scenes. Fire 2025, 8, 104. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, F.; Xu, Y.; Wang, J.; Lu, H.; Wei, W.; Zhu, J. TFNet: Transformer-Based Multi-Scale Feature Fusion Forest Fire Image Detection Network. Fire 2025, 8, 59. [Google Scholar] [CrossRef]
- Safarov, F.; Muksimova, S.; Kamoliddin, M.; Cho, Y.I. Fire and Smoke Detection in Complex Environments. Fire 2024, 7, 389. [Google Scholar] [CrossRef]
- Alkhammash, E.H. Multi-Classification Using YOLOv11 and Hybrid YOLO11n-MobileNet Models: A Fire Classes Case Study. Fire 2025, 8, 17. [Google Scholar] [CrossRef]
- de Venâncio, P.V.A.B.; Lisboa, A.C.; Barbosa, A.V. An Automatic Fire Detection System Based on Deep Convolutional Neural Networks for Low-Power, Resource-Constrained Devices. Neural Comput. Applic 2022, 34, 15349–15368. [Google Scholar] [CrossRef]
- Catargiu, C.; Cleju, N.; Ciocoiu, I.B. A Comparative Performance Evaluation of YOLO-Type Detectors on a New Open Fire and Smoke Dataset. Sensors 2024, 24, 5597. [Google Scholar] [CrossRef] [PubMed]
- Geng, X.; Han, X.; Cao, X.; Su, Y.; Shu, D. YOLOV9-CBM: An Improved Fire Detection Algorithm Based on YOLOV9. IEEE Access 2025, 13, 19612–19623. [Google Scholar] [CrossRef]
- Terven, J.; Córdova-Esparza, D.-M.; Romero-González, J.-A. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Ali, M.L.; Zhang, Z. The YOLO Framework: A Comprehensive Review of Evolution, Applications, and Benchmarks in Object Detection. Computers 2024, 13, 336. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the Proceedings of the 32nd International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-Weighted Linear Units for Neural Network Function Approximation in Reinforcement Learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef]
- Liu, W.; Liao, S.; Ren, W.; Hu, W.; Yu, Y. High-Level Semantic Feature Detection: A New Perspective for Pedestrian Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5187–5196. [Google Scholar]
- Zhang, H.; Zu, K.; Lu, J.; Zou, Y.; Meng, D. EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network. arXiv 2021, arXiv:2105.14447. [Google Scholar]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. PANet: Few-Shot Image Semantic Segmentation With Prototype Alignment. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9197–9206. [Google Scholar]
- Zhang, D. A Yolo-based Approach for Fire and Smoke Detection in IoT Surveillance Systems|EBSCOhost. Available online: https://openurl.ebsco.com/contentitem/doi:10.14569%2Fijacsa.2024.0150109?sid=ebsco:plink:crawler&id=ebsco:doi:10.14569%2Fijacsa.2024.0150109 (accessed on 6 March 2025).
- Guo, M.-H.; Lu, C.-Z.; Hou, Q.; Liu, Z.; Cheng, M.-M.; Hu, S. SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation. Adv. Neural Inf. Process. Syst. 2022, 35, 1140–1156. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.-S. SCA-CNN: Spatial and Channel-Wise Attention in Convolutional Networks for Image Captioning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Han, Q.; Fan, Z.; Dai, Q.; Sun, L.; Cheng, M.-M.; Liu, J.; Wang, J. On the Connection between Local Attention and Dynamic Depth-Wise Convolution. arXiv 2022, arXiv:10.48550/arXiv.2106.04263. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large Kernel Matters—Improve Semantic Segmentation by Global Convolutional Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network In Network 2014. arXiv 2022, arXiv:10.48550/arXiv.1312.4400. [Google Scholar]
- Pan, W.; Wang, X.; Huan, W. EFA-YOLO: An Efficient Feature Attention Model for Fire and Flame Detection. arXiv 2024, arXiv:2409.12635. [Google Scholar]
- Jiang, K.; Xie, T.; Yan, R.; Wen, X.; Li, D.; Jiang, H.; Jiang, N.; Feng, L.; Duan, X.; Wang, J. An Attention Mechanism-Improved YOLOv7 Object Detection Algorithm for Hemp Duck Count Estimation. Agriculture 2022, 12, 1659. [Google Scholar] [CrossRef]
- Cao, L.; Shen, Z.; Xu, S. Efficient Forest Fire Detection Based on an Improved YOLO Model. Vis. Intell. 2024, 2, 20. [Google Scholar] [CrossRef]
- Jia, X.; Tong, Y.; Qiao, H.; Li, M.; Tong, J.; Liang, B. Fast and Accurate Object Detector for Autonomous Driving Based on Improved YOLOv5. Sci. Rep. 2023, 13, 9711. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Al Mudawi, N.; Qureshi, A.M.; Abdelhaq, M.; Alshahrani, A.; Alazeb, A.; Alonazi, M.; Algarni, A. Vehicle Detection and Classification via YOLOv8 and Deep Belief Network over Aerial Image Sequences. Sustainability 2023, 15, 14597. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Yeh, I.-H.; Mark Liao, H.-Y. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. In Computer Vision—ECCV 2024, Proceedings of the 18th European Conference, Milan, Italy, 29 September–4 October 2024; Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G., Eds.; Springer Nature Switzerland: Cham, Switzerland, 2025; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-Time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Boroujeni, S.P.H.; Mehrabi, N.; Afghah, F.; McGrath, C.P.; Bhatkar, D.; Biradar, M.A.; Razi, A. Fire and Smoke Datasets in 20 Years: An In-Depth Review. arXiv 2025, arXiv:2503.14552. [Google Scholar]
- Saydirasulovich, S.N.; Mukhiddinov, M.; Djuraev, O.; Abdusalomov, A.; Cho, Y.-I. An Improved Wildfire Smoke Detection Based on YOLOv8 and UAV Images. Sensors 2023, 23, 8374. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Key Contributions | Future Work |
|---|---|---|
| ESFD-YOLOv8 [26] | Develop a real-time system for early and accurate smoke and fire detection in complex environments. | Address data imbalance, misdetection in complex scenes, and real-time optimization. |
| EA-YOL [27] | Solve issues of low precision, small and dense target detection, sample imbalance, and balancing real-time performance with accuracy in existing fire detection models. | Tackle challenges in small target detection, data scarcity, and complex background interference. |
| Using UAV and YOLOv3 [28] | Provide an efficient, low-cost UAV solution for resource-constrained field environments. | Improve detection of small fires in forests. |
| I-YOLOv4-tiny + S [29] | Overcome the accuracy limitations and computational complexity of traditional fire detection methods and deep learning models in complex maritime environments. | Future work will focus on optimizing model lightweighting, improving accuracy, incorporating contextual information, and expanding applications. |
| FCD [30] | Address challenges in distinguishing forest fire types, improving detection accuracy, small target detection, real-time performance, and dataset limitations. | Future work will optimize model performance, integrate multiple detection models, design lightweight models, and expand datasets. |
| RepVGG-YOLOv7 [31] | Solve the problem of low smoke detection accuracy in complex backgrounds and small targets, while balancing model complexity with detection speed. | Future plans include expanding datasets and reducing model computation and parameters. |
| YOLOv8-FE [32] | Overcome the low detection accuracy of traditional methods in complex environments prone to false alarms and missed detections due to background interference. | Future work aims to enhance detection speed, meet higher real-time requirements, and reduce model complexity for resource-constrained devices. |
| SF-YOLO (Smoke and Fire-YOLO) [33] | Solve the insufficient detection accuracy of traditional methods in complex environments. | Future plans include incorporating environmental covariates into model training and exploring multispectral data for smoke and flame detection. |
| TFNet [34] | Effectively extract features of small targets and sparse smoke, maintaining high accuracy in complex backgrounds while reducing model parameters and computational complexity. | Future plans include expanding dataset scale and exploring more lightweight network architectures. |
| Category | Training Set | Test Set |
|---|---|---|
| Fire | 14,692 | 2869 |
| Smoke | 11,865 | 2307 |
| CBM-Fire | Training Set | Test Set | Validation Set |
|---|---|---|---|
| 2000 | 1620 | 200 | 180 |
| Parameters | Values |
|---|---|
| imgsz | 640 |
| epochs | 100 |
| batch | 20 |
| close_mosaic | 10 |
| optimizer | SGD |
| lr0 | 0.01 |
| momentum | 0.937 |
| Model | Class | Precision (%) | Recall (%) | mAP50 (%) | mAP50-95 (%) | GFLOPS | FPS |
|---|---|---|---|---|---|---|---|
| YOLOv5s | All | 76.0 | 69.6 | 76.7 | 44.8 | 23.8 | 344.8 |
| Smoke | 80.3 | 76.3 | 82.6 | 51.8 | |||
| Fire | 71.7 | 62.8 | 70.8 | 37.8 | |||
| YOLOv6s | All | 75.4 | 69.9 | 76.0 | 44.3 | 44.0 | 333.3 |
| Smoke | 80.0 | 77.3 | 82.8 | 52.0 | |||
| Fire | 70.9 | 62.5 | 69.2 | 36.6 | |||
| YOLOv7 | All | 69.0 | 73.1 | 75.2 | 39.9 | 103.2 | 117.6 |
| Smoke | 75.3 | 74.7 | 78.4 | 43.7 | |||
| Fire | 62.7 | 71.6 | 71.9 | 36.2 | |||
| YOLOv8s | All | 77.2 | 70.4 | 77.5 | 45.6 | 28.4 | 322.6 |
| Smoke | 81.4 | 77.6 | 83.7 | 52.9 | |||
| Fire | 73.0 | 63.1 | 71.3 | 38.3 | |||
| YOLOv9s | All | 77.7 | 72.1 | 78.3 | 45.9 | 26.7 | 250.0 |
| Smoke | 82.5 | 79.3 | 84.4 | 53.3 | |||
| Fire | 72.9 | 64.9 | 72.1 | 38.5 | |||
| YOLOv10s | All | 76.5 | 69.3 | 76.3 | 44.8 | 24.4 | 312.5 |
| Smoke | 79.8 | 77.6 | 82.8 | 52.2 | |||
| Fire | 73.3 | 61.0 | 69.8 | 69.8 | |||
| YOLO11n | All | 75.3 | 67.4 | 74.6 | 42.8 | 6.3 | 434.8 |
| Smoke | 79.9 | 74.2 | 80.5 | 49.7 | |||
| Fire | 70.8 | 60.5 | 68.6 | 35.9 | |||
| YOLO11s | All | 77.1 | 70.1 | 77.4 | 45.5 | 21.3 | 312.5 |
| Smoke | 81.7 | 77.3 | 83.3 | 52.7 | |||
| Fire | 72.4 | 63.0 | 71.4 | 38.2 |
| Model | Class | Precision (%) | Recall (%) | mAP50 (%) | mAP50-95 (%) | GFLOPS | FPS |
|---|---|---|---|---|---|---|---|
| RT-DETR | All | 71.5 | 63.2 | 70.2 | 39.5 | 103.4 | 68.0 |
| Smoke | 72.1 | 71.2 | 74.9 | 45.2 | |||
| Fire | 71.0 | 55.2 | 65.5 | 33.8 | |||
| YOLO11s | All | 77.1 | 70.1 | 77.4 | 45.5 | 21.3 | 312.5 |
| Smoke | 81.7 | 77.3 | 83.3 | 52.7 | |||
| Fire | 72.4 | 63.0 | 71.4 | 38.2 | |||
| YOLO11s-MSCA | All | 79.7 | 69.8 | 77.9 | 45.8 | 22.5 | 222.2 |
| Smoke | 84.5 | 76.9 | 84.0 | 53.3 | |||
| Fire | 74.9 | 62.6 | 71.8 | 38.2 |
| Model | Class | Precision (%) | Recall (%) | mAP50 (%) | mAP50-95 (%) | GFLOPS | FPS |
|---|---|---|---|---|---|---|---|
| YOLOv9s | All | 78.7 | 72.8 | 79.2 | 50.4 | 26.7 | 51.3 |
| Fire | 83.0 | 84.0 | 89.3 | 58.8 | |||
| Other | 69.0 | 56.1 | 61.6 | 33.8 | |||
| Smoke | 84.1 | 78.3 | 86.6 | 58.5 | |||
| YOLOv10s | All | 77.5 | 72.2 | 77.7 | 49.0 | 24.5 | 131.6 |
| Fire | 81.4 | 83.0 | 88.2 | 58.1 | |||
| Other | 68.6 | 55.2 | 59.0 | 31.5 | |||
| Smoke | 82.4 | 78.3 | 86.0 | 57.3 | |||
| RT-DETR | All | 79.0 | 71.2 | 76.5 | 46.9 | 103.4 | 64.9 |
| Fire | 83.7 | 83.3 | 87.7 | 56.4 | |||
| Other | 69.0 | 54.0 | 58.2 | 30.4 | |||
| Smoke | 84.2 | 76.2 | 83.5 | 54.0 | |||
| YOLO11s | All | 78.3 | 72.4 | 78.6 | 49.5 | 21.3 | 142.9 |
| Fire | 83.1 | 83.9 | 89.4 | 58.6 | |||
| Other | 67.8 | 54.5 | 31.9 | 31.9 | |||
| Smoke | 84.0 | 78.8 | 87.0 | 58.0 | |||
| YOLO11s-MSCA | All | 78.5 | 73.2 | 79.2 | 50.3 | 22.5 | 109.9 |
| Fire | 83.0 | 84.0 | 89.4 | 59.0 | |||
| Other | 68.1 | 56.2 | 60.7 | 33.4 | |||
| Smoke | 84.4 | 79.5 | 87.5 | 58.6 |
| Model | Class | Precision (%) | Recall (%) | mAP50 (%) | mAP50-95 (%) | GFLOPS | FPS |
|---|---|---|---|---|---|---|---|
| YOLOv9s | All | 82.3 | 64.4 | 76.5 | 46.9 | 26.7 | 175.4 |
| Fire | 74.8 | 65.4 | 74.9 | 40.9 | |||
| Smoke | 89.7 | 63.4 | 78.1 | 52.9 | |||
| YOLOv10s | All | 77.7 | 59.0 | 70.8 | 46.2 | 24.4 | 131.6 |
| Fire | 75.0 | 61.5 | 69.4 | 41.7 | |||
| Smoke | 80.5 | 56.5 | 72.2 | 50.7 | |||
| RT-DETR | All | 57.4 | 48.9 | 49.5 | 27.3 | 103.4 | 69.9 |
| Fire | 63.1 | 60.1 | 63.4 | 33.5 | |||
| Smoke | 51.8 | 37.7 | 35.7 | 21.0 | |||
| YOLO11s | All | 82.0 | 71.3 | 80.6 | 53.6 | 21.3 | 212.8 |
| Fire | 78.8 | 75.6 | 81.2 | 81.2 | |||
| Smoke | 85.3 | 67.0 | 80.1 | 59.2 | |||
| YOLO11s-MSCA | All | 85.0 | 70.4 | 81.9 | 52.0 | 22.5 | 151.5 |
| Fire | 80.1 | 75.5 | 84.4 | 48.1 | |||
| Smoke | 90.0 | 65.2 | 79.4 | 55.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Nie, L.; Zhou, F.; Liu, Y.; Fu, H.; Chen, N.; Dai, Q.; Wang, L. Improving Fire and Smoke Detection with You Only Look Once 11 and Multi-Scale Convolutional Attention. Fire 2025, 8, 165. https://doi.org/10.3390/fire8050165
Li Y, Nie L, Zhou F, Liu Y, Fu H, Chen N, Dai Q, Wang L. Improving Fire and Smoke Detection with You Only Look Once 11 and Multi-Scale Convolutional Attention. Fire. 2025; 8(5):165. https://doi.org/10.3390/fire8050165
Chicago/Turabian StyleLi, Yuxuan, Lisha Nie, Fangrong Zhou, Yun Liu, Haoyu Fu, Nan Chen, Qinling Dai, and Leiguang Wang. 2025. "Improving Fire and Smoke Detection with You Only Look Once 11 and Multi-Scale Convolutional Attention" Fire 8, no. 5: 165. https://doi.org/10.3390/fire8050165
APA StyleLi, Y., Nie, L., Zhou, F., Liu, Y., Fu, H., Chen, N., Dai, Q., & Wang, L. (2025). Improving Fire and Smoke Detection with You Only Look Once 11 and Multi-Scale Convolutional Attention. Fire, 8(5), 165. https://doi.org/10.3390/fire8050165