



Towards an ELSA Curriculum for Data Scientists



{kind=link}
{kind=link}
Abstract
1. Introduction
2. Background
2.1. The Profile of the Data Scientist
2.2. Does the Industry Demand ELSA Skills?
2.3. What Do the Universities Teach?
2.4. What the Data Scientists Say about ELSA Challenges
2.5. Conclusions
- Data scientists come both from computer science and statistics disciplines, but a growing number of them also come from other disciplines such as social sciences, finance, and business; however, there is a considerable number that landed in data science following non- or quasi- academic ways.
- Those with an academic education did not necessarily have any ELSA-related courses, either mandatory or elective.
- The industry desires but does not require ELSA knowledge for data science employees.
- A growing number of data scientists recognise the need for awareness and action regarding the ELSA challenges in their work.
3. Curriculum Proposal
- Data science projects are multidisciplinary in the following ways: a. the application domain, for example, just examining scholar publications, at least 20 disciplines can be identified [1], b. the implementation of the project requires the cooperation of a variety of experts from many disciplines (computer scientists and engineer, statisticians, visualisation experts, etc.), and c. the impact of these projects make cooperation with other stakeholders necessary, for example legal experts, ethicists, and community representatives (such as patients in healthcare projects).
- ELSA challenges are faced throughout the data science workflow. Some of them run through more than one phase, others not; some may concern all the people involved in the project, others not so much or not to the same degree. In any case, they have to be considered part of the workflow and not as a sometimes optional task.
3.1. General Objectives and Vision
- Recognize ethical, legal, and societal aspects pertaining to their work (awareness);
- Possess a common language with the relevant domain experts in order to cooperate to find appropriate solutions (communication ability);
- Incorporate ELSA into the data science workflow. ELSA should not be seen as an impediment or a superfluous artefact but rather as an integral part of the Data Science Project Lifecycle (professional mentality building).
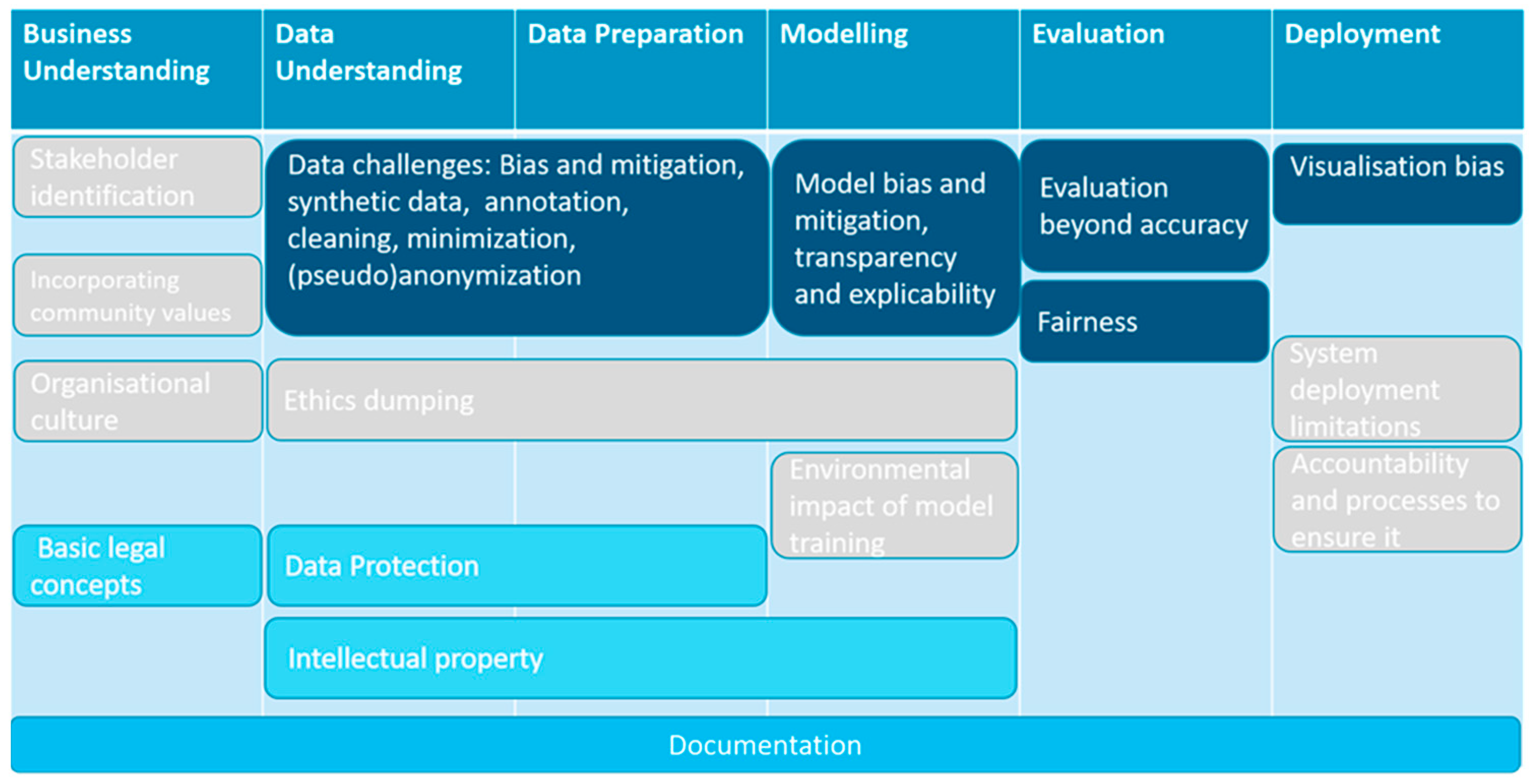
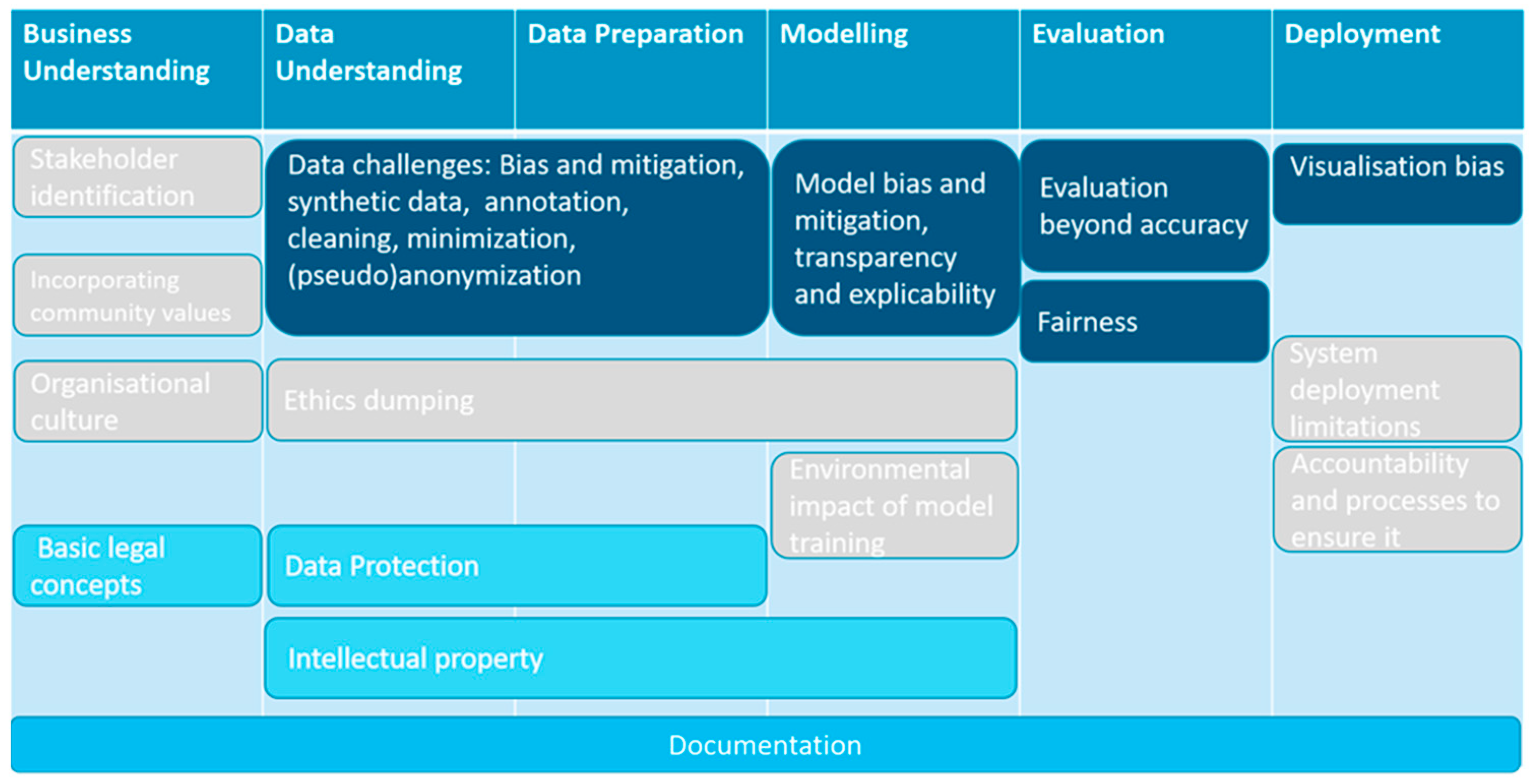
3.2. Curriculum Structure and Overview
- Ethical and Societal Knowledge Units: Ethical and societal aspects of data science range from incorporating community values into one’s work, averting discrimination against individuals or groups, taking into consideration the environmental impact of the data science applications, and assuming responsibility and being accountable for one’s decisions and actions.
- Legal Knowledge Units: The objective of these units is to help data scientists cope with legal issues they might be facing in their course of work, mainly data protection and intellectual property issues, as well as basic legal terminology and concepts.
- Technical Renderings Knowledge Units: These units deal with technical renderings of legal or ethical desiderata like privacy, data and algorithmic bias detection and mitigation strategies, incorporation of fairness, effectiveness, and explainability in the evaluation of a data science project, deployment, and monitoring outside experimental/testing environments. They illustrate the way technical solutions can be employed via use cases and do not aim to teach technical skills to data scientists since a. these might be already dealt with in specific courses during their studies or their working experience and b. vary in each application domain that might require specific techniques.
3.3. ELSA Curriculum KUs
3.3.1. Module I: Business Understanding
3.3.2. Module II: Data Understanding
3.3.3. Module III: Data Preparation
3.3.4. Module IV: Modelling
3.3.5. Module V: Evaluation
3.3.6. Module VI: Deployment
4. Discussion—Implementation Strategies and Limitations
5. Conclusions
- We tried to draw the profile of the data scientist, starting from the ideal form, as provided in the bibliography, as a multidisciplinary and multi-talented individual and augmenting the profile with the results of empirical studies and surveys as a person coming from a variety of educational and professional backgrounds. This profile reveals that while ELSA issues are considered either by organisations issuing guidelines, the industry, and the data scientists themselves as very important, there is a lack of knowledge about the respective challenges among the practitioners.
- We propose an ELSA curriculum that comprises knowledge units from three domains (ethical, legal, and technical) that belong in modules that themselves correspond to the six phases of the well-known CRISP-DM model.
- The objectives of the curriculum are to raise awareness about ELSA challenges in data science applications; enhance the communication ability of the data scientist by providing a common language with domain experts (for example, legal scholars) that they will have to cooperate in order to successfully tackle the above-mentioned challenges; and finally, to foster a professional mentality that treats ELSA issues as an integral part of the Data Science Project Lifecycle by embedding them into the Data Science Project Lifecycle.
- The implementation of such a curriculum requires a considerable number of resources, both regarding the duration of a training program and its multidisciplinary nature. We propose a flexible implementation strategy that expands, contracts, or conflates KUs in the various modules so as to fit the roles and the specific application domains of the participants. The depth of the subjects treated can vary: for novices, a more holistic but less in-depth program is proposed; for more experienced practitioners, it might be better to focus on specific areas of interest.
- Finally, we published the first version of the curriculum (see Supplementary Materials), and we welcome comments and suggestions from the community. For this purpose, we have already contacted a series of workshops, and currently, we have requested feedback via a specifically designed survey. This will lead to a second version of the curriculum. Naturally, the best way to assess the curriculum will be to actually implement and evaluate it via the experiences of both the instructors and the participants.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Emmert-Streib, F.; Dehmer, M. Defining Data Science by a Data-Driven Quantification of the Community. Mach. Learn. Knowl. Extr. 2019, 1, 235–251. [Google Scholar] [CrossRef]
- Cleveland, W.S. Data Science: An Action Plan for Expanding the Technical Areas of the Field of Statistics. Int. Stat. Rev. 2001, 69, 21–26. [Google Scholar] [CrossRef]
- O’Neil, C. Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy, 1st ed.; Crown: New York, NY, USA, 2016; ISBN 978-0-553-41881-1. [Google Scholar]
- Crawford, K. Atlas of AI: Power, Politics, and the Planetary Costs of Artificial Intelligence; Yale University Press: New Haven, CT, USA, 2021; ISBN 978-0-300-20957-0. [Google Scholar]
- European Parliament, Council of the European Union. Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the Protection of Natural Persons with Regard to the Processing of Personal Data and on the Free Movement of Such Data, and Repealing Directive 95/46/EC (General Data Protection Regulation) (Text with EEA Relevance), 119 OJ L § (2016). Available online: http://data.europa.eu/eli/reg/2016/679/oj/eng (accessed on 26 March 2024).
- European Commission, Directorate-General for Communications Networks, Content and Technology. Proposal for a Regulation of the European Parliament and of the Council Laying Down Harmonised Rules on Artificial Intelligence (Artificial Intelligence ACT) and Amending Certain Union Legislative ACTS (2021). Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:52021PC0206 (accessed on 26 March 2024).
- Jobin, A.; Ienca, M.; Vayena, E. The Global Landscape of AI Ethics Guidelines. Nat. Mach. Intell. 2019, 1, 389–399. [Google Scholar] [CrossRef]
- Fjeld, J.; Achten, N.; Hilligoss, H.; Nagy, A.; Srikumar, M. Principled Artificial Intelligence: Mapping Consensus in Ethical and Rights-Based Approaches to Principles for AI; Berkman Klein Center for Internet & Society: Rochester, NY, USA, 2020. [Google Scholar]
- AI Ethics Guidelines Global Inventory by AlgorithmWatch. Available online: https://inventory.algorithmwatch.org (accessed on 10 February 2021).
- High-Level Expert Group on AI (AI HLEG) Ethics Guidelines for Trustworthy AI; European Commission: Brussels, Belgium, 2019.
- Borenstein, J.; Howard, A. Emerging Challenges in AI and the Need for AI Ethics Education. AI Ethics 2021, 1, 61–65. [Google Scholar] [CrossRef]
- Garzcarek, U.; Steuer, D. Approaching Ethical Guidelines for Data Scientists. arXiv 2019, arXiv:1901.04824. [Google Scholar] [CrossRef]
- Mittelstadt, B. Principles Alone Cannot Guarantee Ethical AI. Nat. Mach. Intell. 2019, 1, 501–507. [Google Scholar] [CrossRef]
- FAIR Data Spaces|NFDI. Available online: https://www.nfdi.de/fair-data-spaces/ (accessed on 14 February 2024).
- Christoforaki, M. ELSA Training Curriculum for Data Scientists—Version 1.0; UzK: Cologne, Germany, 2023. [Google Scholar]
- Christoforaki, M. ELSA Training for Data Scientists-Describing the Landscape; UzK: Cologne, Germany, 2021. [Google Scholar]
- Davenport, T.H.; Patil, D.J. Data Scientist: The Sexiest Job of the 21st Century. Harv. Bus. Rev. 2012, 90, 70–76. [Google Scholar] [PubMed]
- van der Aalst, W.M.P. Data Scientist: The Engineer of the Future. In Enterprise Interoperability VI; Mertins, K., Bénaben, F., Poler, R., Bourrières, J.-P., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 13–26. ISBN 978-3-319-04947-2. [Google Scholar]
- Luna-Reyes, L.F. The Search for the Data Scientist: Creating Value from Data. ACM SIGCAS Comput. Soc. 2018, 47, 12–16. [Google Scholar] [CrossRef]
- About Anaconda. Available online: https://www.anaconda.com/about-us (accessed on 14 December 2023).
- Kaggle: Your Machine Learning and Data Science Community. Available online: https://www.kaggle.com/ (accessed on 14 December 2023).
- Anaconda|State of Data Science 2020’. Available online: https://www.anaconda.com/resources/whitepapers/state-of-data-science-2020 (accessed on 26 March 2024).
- Anaconda|State of Data Science 2021’. Available online: https://www.anaconda.com/resources/whitepapers/state-of-data-science-2021 (accessed on 26 March 2024).
- Anaconda. Anaconda|State of Data Science Report 2022. Available online: https://www.anaconda.com/resources/whitepapers/state-of-data-science-report-2022 (accessed on 26 March 2024).
- Anaconda. State of Data Science Report 2023. Available online: https://www.anaconda.com/state-of-data-science-report-2023 (accessed on 26 March 2024).
- Kaggle Kaggle’s State of Machine Learning and Data Science 2021. 2021. Available online: https://www.kaggle.com/kaggle-survey-2021 (accessed on 26 March 2024).
- Zahidi, S.; Ratcheva, V.; Hingel, G.; Brown, S. The Future of Jobs Report 2020; World Economic Forum: Geneva, Switzerland, 2020. [Google Scholar]
- Di Battista, A.; Grayling, S.; Hasselaar, E. Future of Jobs Report 2023; World Economic Forum: Geneva, Switzerland, 2023. [Google Scholar]
- Mikalef, P.; Giannakos, M.; Pappas, I.; Krogstie, J. The Human Side of Big Data: Understanding the Skills of the Data Scientist in Education and Industry. In Proceedings of the 2018 IEEE Global Engineering Education Conference (EDUCON), Santa Cruz de Tenerife, Spain, 17–20 April 2018; pp. 503–512. [Google Scholar] [CrossRef]
- Danyluk, A. Paul Leidig Computing Competencies for Undergraduate Data Science Curricula-ACM Data Science Task Force; ACM: New York, NY, USA, 2021. [Google Scholar]
- Stavrakakis, I.; Gordon, D.; Tierney, B.; Becevel, A.; Murphy, E.; Dodig-Crnkovic, G.; Dobrin, R.; Schiaffonati, V.; Pereira, C.; Tikhonenko, S.; et al. The Teaching of Computer Ethics on Computer Science and Related Degree Programmes. a European Survey. Int. J. Ethics Educ. 2022, 7, 101–129. [Google Scholar] [CrossRef]
- Shearer, C. The CRISP-DM Model: The New Blueprint for Data Mining. J. Data Warehouse. 2000, 5, 13–22. [Google Scholar]
- Fayyad, U.; Piatetsky-Shapiro, G.; Smyth, P. From Data Mining to Knowledge Discovery in Databases. AI Mag. 1996, 17, 37–54. [Google Scholar] [CrossRef]
- SAS Enterprise Miner—SEMMA. SAS Institute Introduction to SEMMA. Available online: https://documentation.sas.com/doc/en/emref/14.3/n061bzurmej4j3n1jnj8bbjjm1a2.htm (accessed on 14 February 2024).
- Azevedo, A.; Santos, M.F. KDD, SEMMA and CRISP-DM: A Parallel Overview. In IADS—DM; Weghorn, H., Abraham, A.P., Eds.; IADIS: Amsterdam, The Netherlands, 2008; pp. 182–185. Available online: https://www.iadisportal.org/digital-library/kdd-semma-and-crisp-dm-a-parallel-overview (accessed on 26 March 2024).
- Saltz, J.S.; Dewar, N. Data Science Ethical Considerations: A Systematic Literature Review and Proposed Project Framework. Ethics Inf. Technol. 2019, 21, 197–208. [Google Scholar] [CrossRef]
- Rochel, J.; Evéquoz, F. Getting into the Engine Room: A Blueprint to Investigate the Shadowy Steps of AI Ethics. AI Soc. 2021, 36, 609–622. [Google Scholar] [CrossRef]
- Morley, J.; Floridi, L.; Kinsey, L.; Elhalal, A. From What to How: An Initial Review of Publicly Available AI Ethics Tools, Methods and Research to Translate Principles into Practices. Sci. Eng. Ethics 2020, 26, 2141–2168. [Google Scholar] [CrossRef] [PubMed]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Christoforaki, M.; Beyan, O.D. Towards an ELSA Curriculum for Data Scientists. AI 2024, 5, 504-515. https://doi.org/10.3390/ai5020025
Christoforaki M, Beyan OD. Towards an ELSA Curriculum for Data Scientists. AI. 2024; 5(2):504-515. https://doi.org/10.3390/ai5020025
Chicago/Turabian StyleChristoforaki, Maria, and Oya Deniz Beyan. 2024. "Towards an ELSA Curriculum for Data Scientists" AI 5, no. 2: 504-515. https://doi.org/10.3390/ai5020025
APA StyleChristoforaki, M., & Beyan, O. D. (2024). Towards an ELSA Curriculum for Data Scientists. AI, 5(2), 504-515. https://doi.org/10.3390/ai5020025