
Forecasting Future Research Trends in the Construction Engineering and Management Domain Using Machine Learning and Social Network Analysis

 ,
,  , ,
, ,
Abstract
:1. Introduction
2. Goal and Objectives
3. Background
4. Methodology
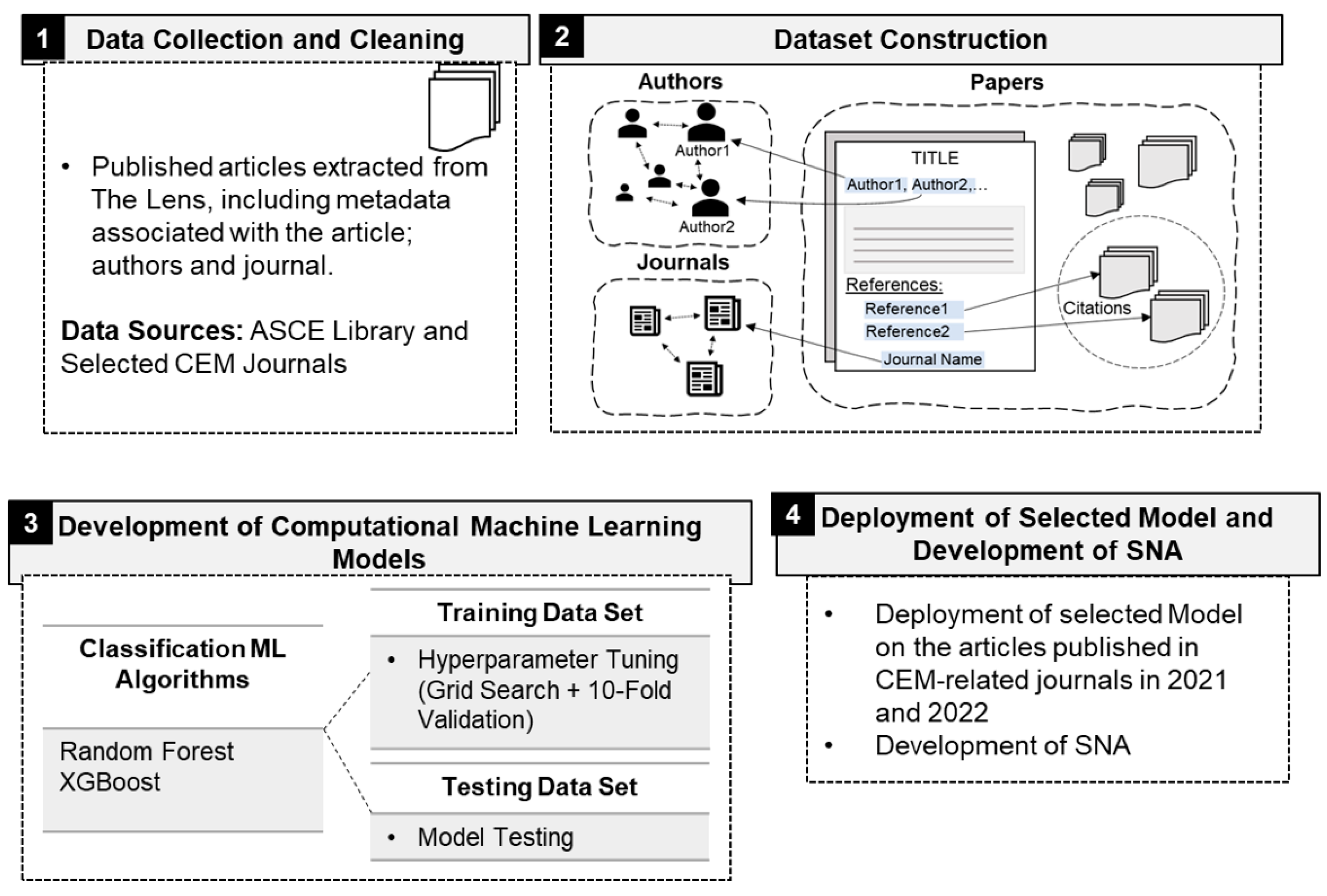
4.1. Data Collection and Cleaning
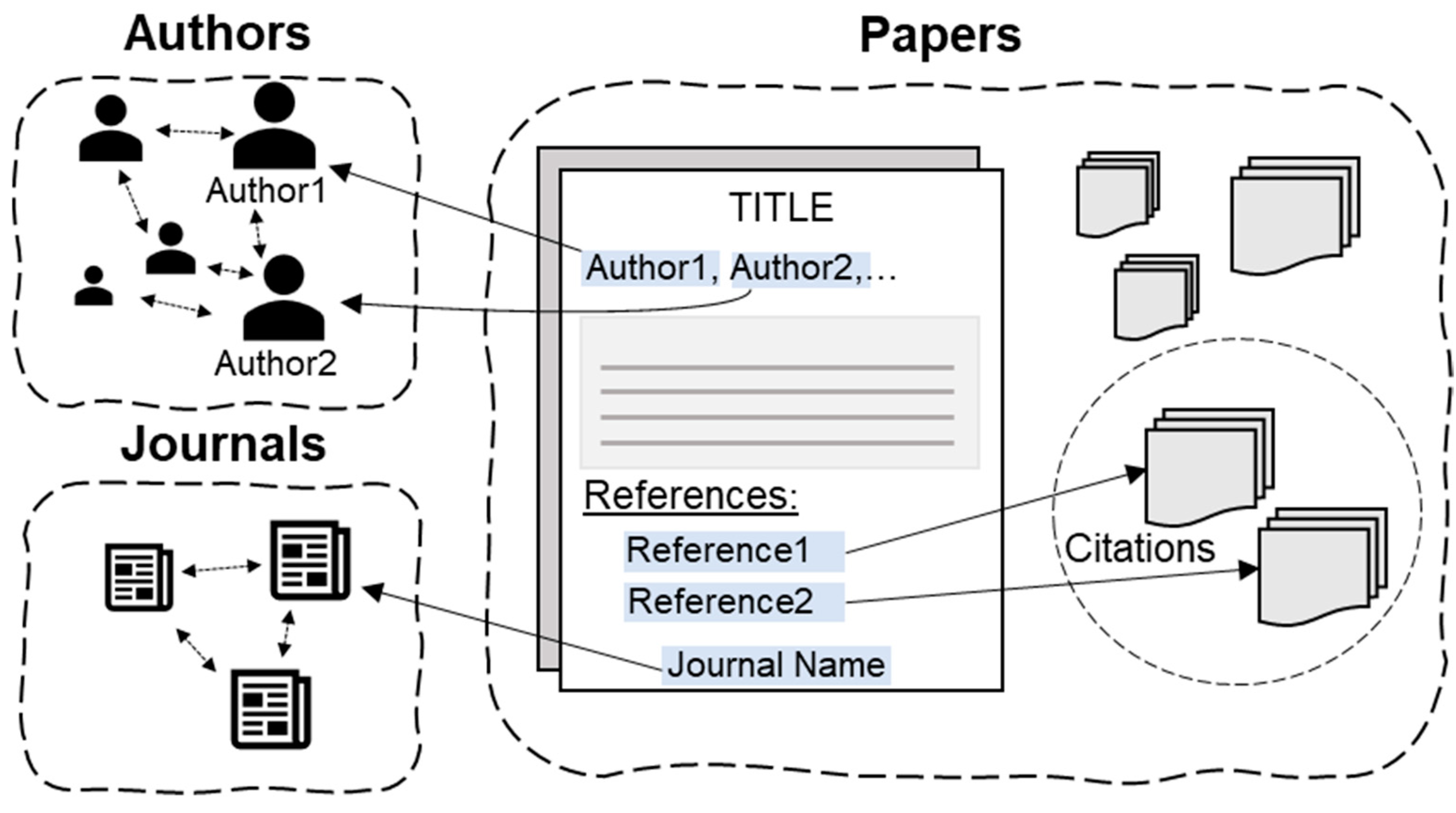
4.2. Dataset Construction
4.3. Machine Learning Models
4.3.1. RF Classifier
4.3.2. XGBoost Classifier
4.4. Resampling for Imbalanced Data
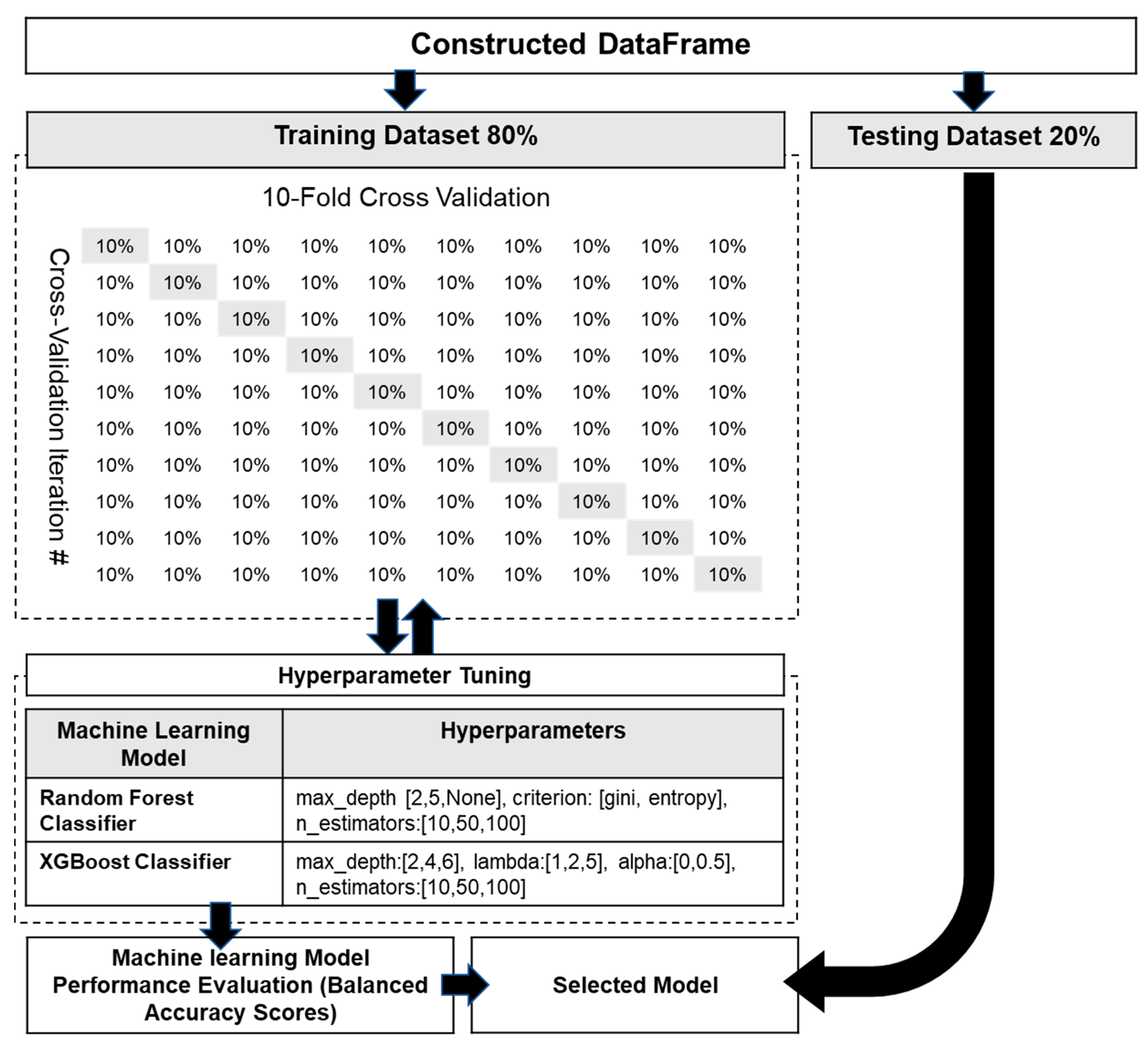
4.5. K-Fold Cross Validation, Hyperparameter Tuning, Model Performance Evaluation, and Selection
4.6. Model Deployment
4.7. SNA Development
4.8. Tools and Software Used
5. Results and Analysis
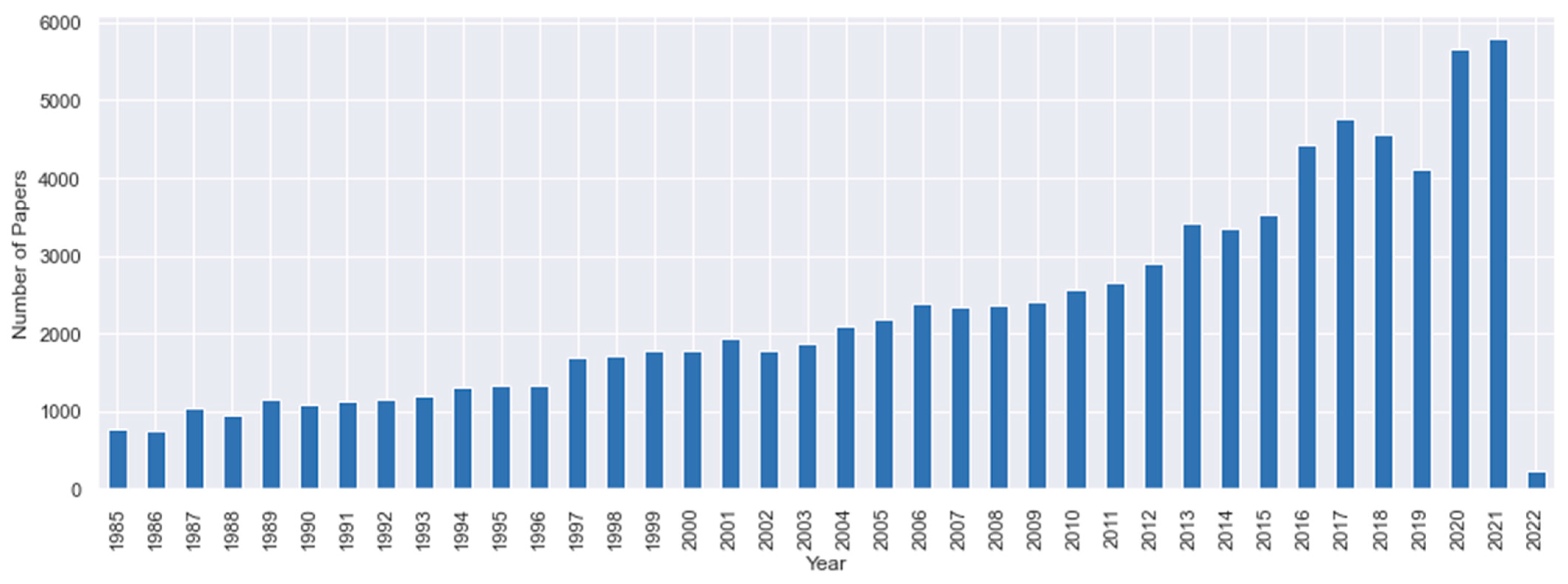
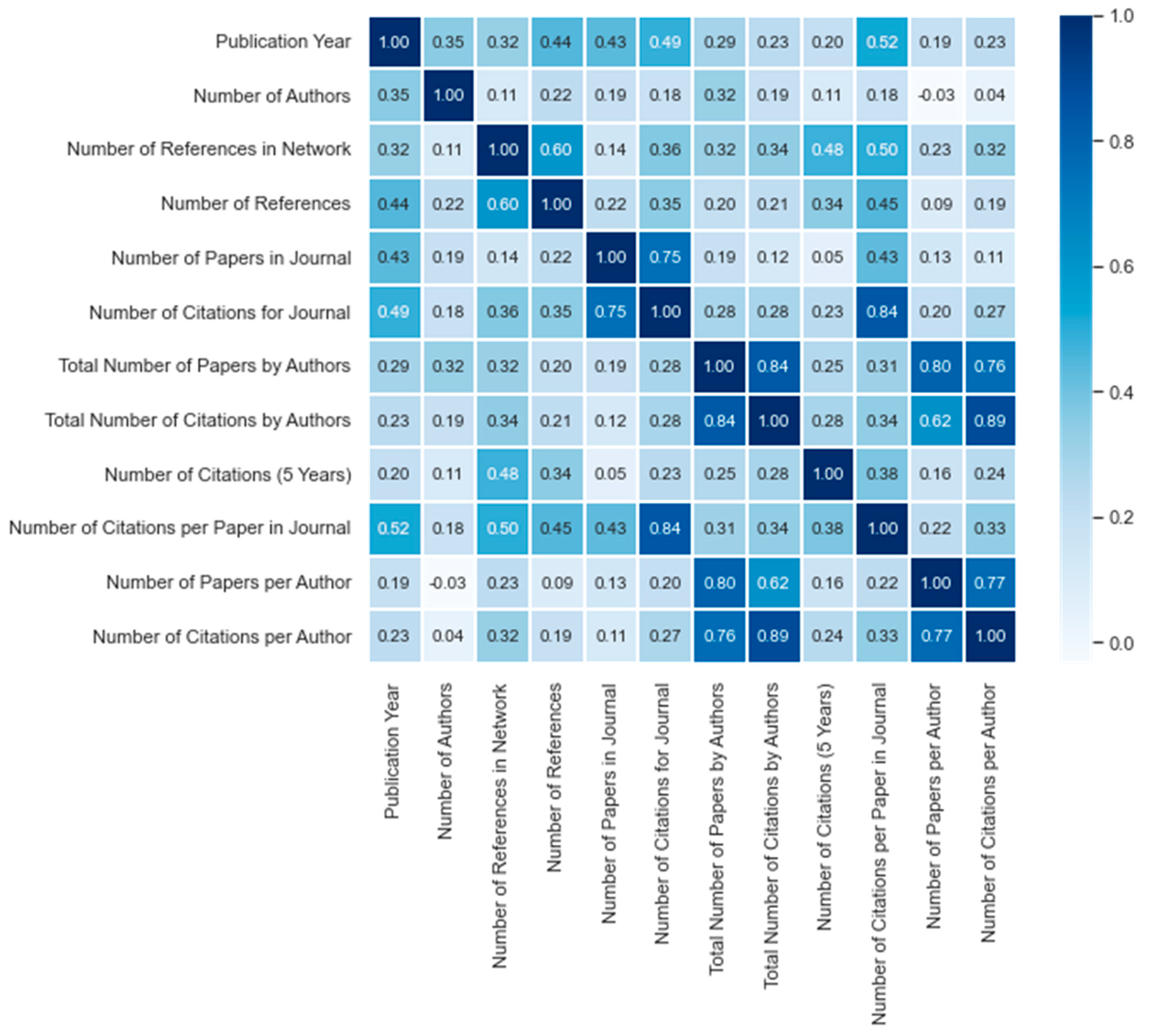
5.1. Exploratory Analysis of the Constructed Dataset
5.2. Results of the Developed Machine Learning Models
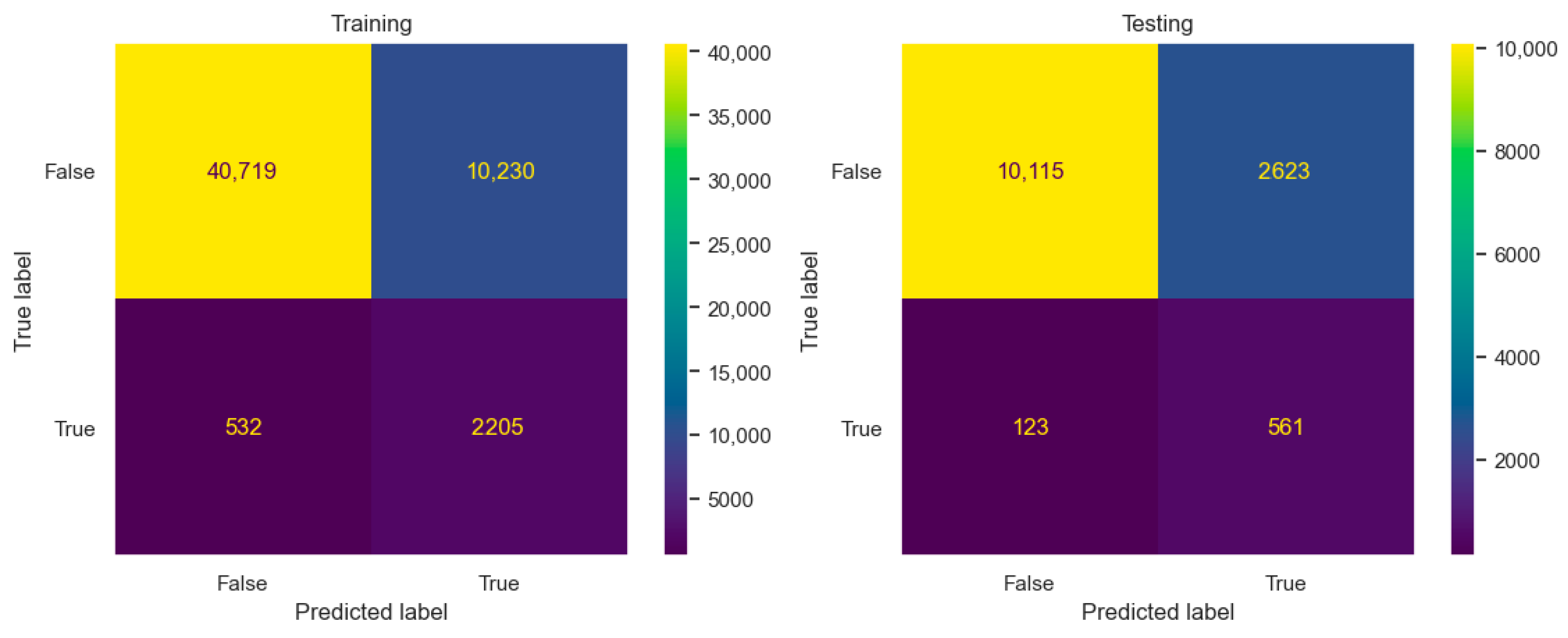
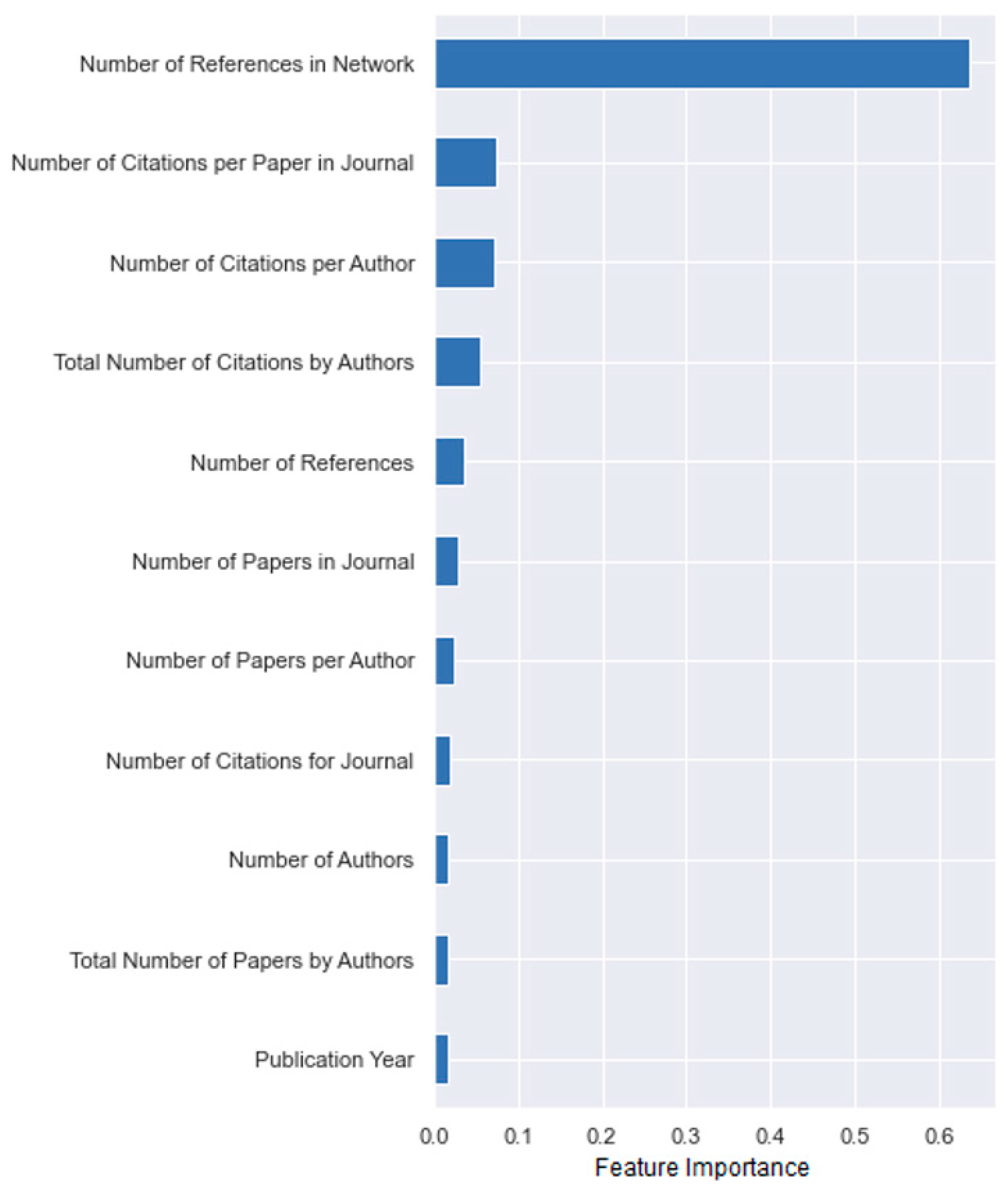
5.2.1. Selection of the Best-Performing Prediction Model
5.2.2. Evaluation of the Best-Performing Prediction Model
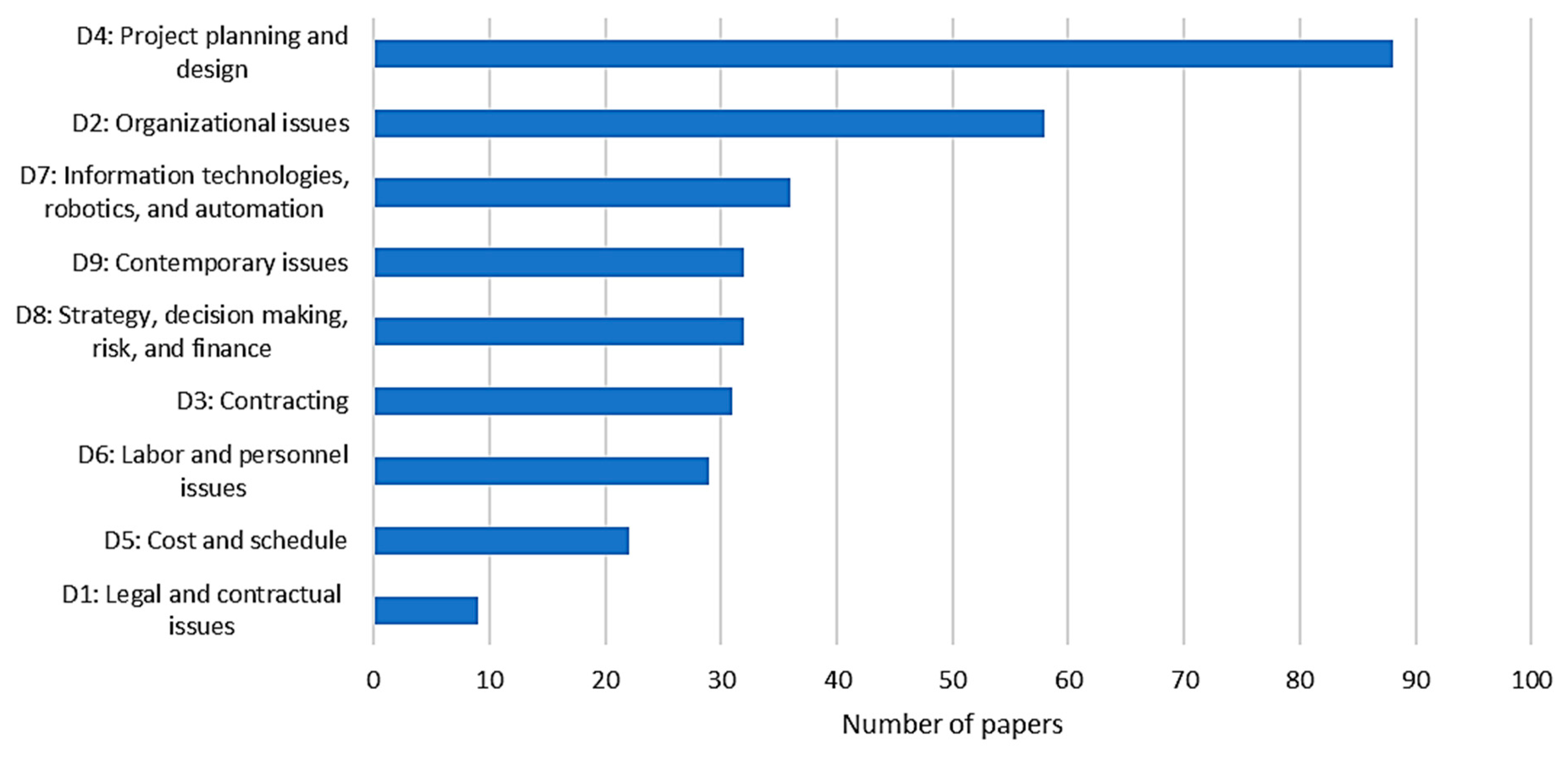
5.3. Impactful CEM Research Trends
6. Discussion
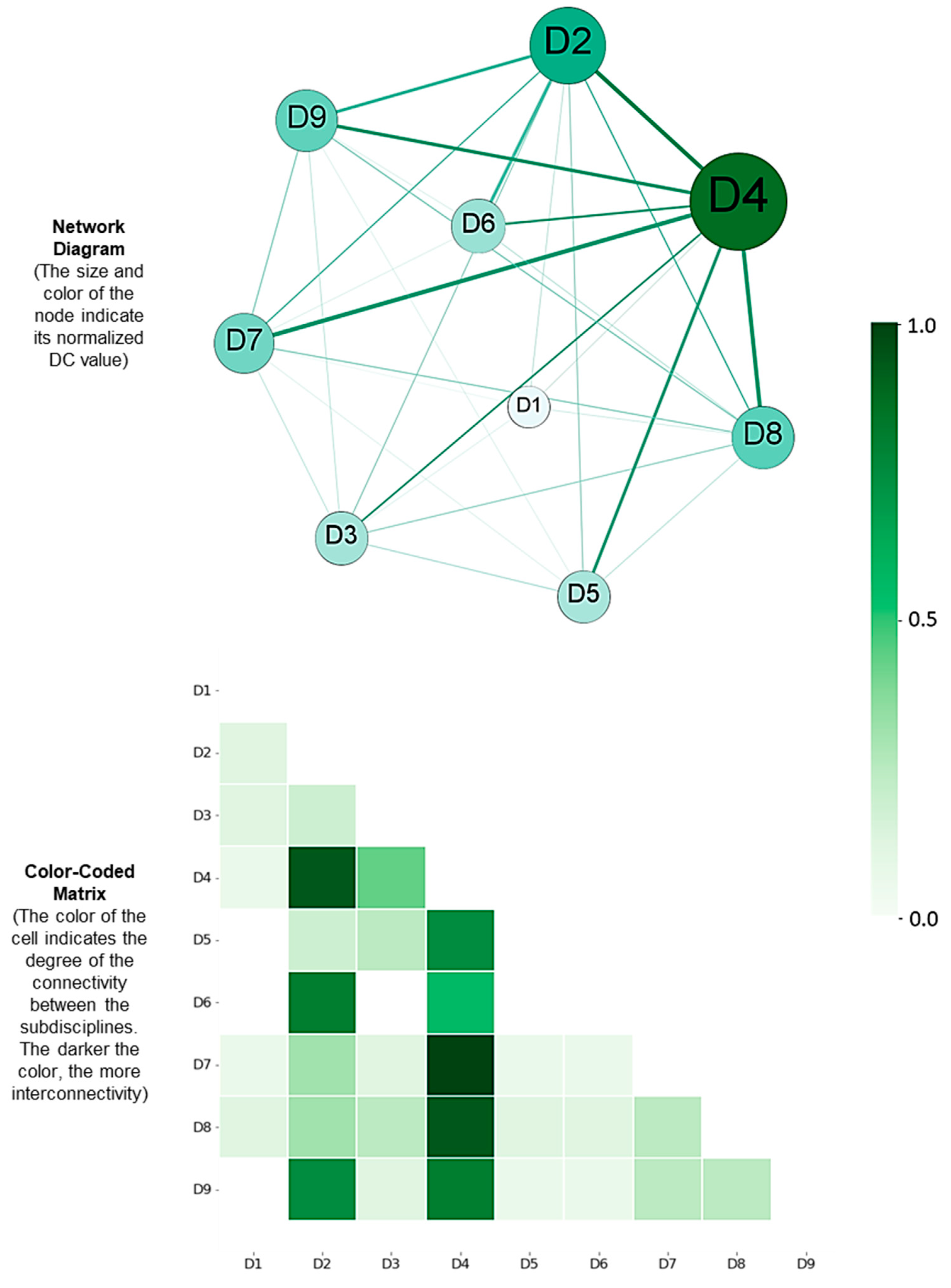
- Results show that “Project planning and design” is considered a central CEM subdiscipline topic that is strongly connected to other subdisciplines, as shown by the links in the network diagram and the cells in the color-coded matrix in Figure 10. In the study by Jin et al. [2], it was found that topics related to the “Project planning and design” subdiscipline, such as scheduling and planning, were among the top studied topics in the period from 2000 to 2018 based on a quantitative analysis of keywords. The findings in this paper imply that the growth of the “Project planning and design” subdiscipline is expected to continue to grow. The “Project planning and design” is a primary area of CEM as it covers various vital topics within the CEM domain, including project management, scheduling, engineering design, and construction methods, among others. As such, it may be considered central to the growth of CEM research.
- The “Organizational issues” subdiscipline tackles various trendy research topics in today’s construction industry including equality and diversity, human resources management, relationships between project stakeholders, and project teams, among others. Topics related to equality and diversity in the construction industry have gained substantial attention since the publication of the well-known special issue by Dainty and Bagilhole [60]. Since then, various publications investigated the needed steps to address the lack of equality and diversity within the construction sector [61,62]. In addition, various publications emphasized the strong tie between the structure and culture of project teams, the relationship between stakeholders, and the success of construction projects [63,64]. Moreover, organizational issues, such as organizational work structures, virtual teams, and organizational resilience, were identified among the anticipated future research streams as a result of the COVID-19 pandemic [65].
- The “Information technologies, robotics, and automation” subdiscipline focuses on the adoption of new technologies and automation of construction processes using various techniques, including BIM, Geographic Information System (GIS), blockchain, Internet of Things (IoT), augmented reality, and virtual reality, among others. In relation to the CEM domain, El-adaway et al. [12] found that the number of publications on the “Information technologies, robotics, and automation” subdiscipline began to spike starting from the year 2010. Nowadays, the diffusion of the “Construction 4.0” concept reflects the trendy dynamic of the utilization of technologies to reshape the way projects are designed, constructed, and operated [66]. Ghaffar et al. [67] stated that “the COVID-19 pandemic has forced many construction players to digitize to ensure safety and productivity, this dynamic will likely continue to be accelerated in the future years”. This emphasizes the anticipated significance and trendiness of this subdiscipline in the future as an assisting tool for much research subdisciplines and processes within the CEM domain.
- The “Legal and contractual issues” subdiscipline covers several topics including contractual provisions and guidelines, applied laws and regulations, jurisdiction, claims, and disputes, among others. As previously highlighted, the “Legal and contractual issues” subdiscipline possessed the least number of anticipated impactful CEM papers, as well as the least DC value in the conducted SNA. This result is in line, to some extent, with the findings of El-adaway et al. [12], which highlighted that “Legal and contractual issues” is the least cited CEM subdiscipline compared to others. This result can be ascribed to the impact of the research community size and their output on the citation metrics. A community of a smaller size is expected to have lower research output and fewer citations compared to other communities of a larger size. Moreover, according to de la Garza [68], the magnitude and quality of research output related to a specific topic depend on many factors, including funding availabilities and the interest of researchers. Overall, it is worth highlighting that possessing the least number of anticipated impactful CEM paper and/or DC value does not imply that the subdiscipline is less important compared to other CEM subdisciplines, because all subdisciplines collectively impact the CEM domain and the construction industry as a whole.
7. Recommendations
8. Limitations
9. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Aboulezz, M.A. Mapping the Construction Engineering and Management Discipline. Ph.D. Thesis, Worcester Polytechnic Institute, Worcester, MA, USA, 2003. [Google Scholar]
- Jin, R.; Zuo, J.; Hong, J. Scientometric Review of Articles Published in ASCE’s Journal of Construction Engineering and Management from 2000 to 2018. J. Constr. Eng. Manag. 2019, 145, 06019001. [Google Scholar] [CrossRef]
- Pietroforte, R.; Stefani, T.P. ASCE Journal of Construction Engineering and Management: Review of the Years 1983–2000. J. Constr. Eng. Manag. 2004, 130, 440–448. [Google Scholar] [CrossRef]
- Carpenter, C.R.; Cone, D.C.; Sarli, C.C. Using Publication Metrics to Highlight Academic Productivity and Research Impact. Acad. Emerg. Med. 2014, 21, 1160–1172. [Google Scholar] [CrossRef]
- National Science Foundation (NSF). Proposal and Award Policies and Procedures Guide (PAPPG); NSF: Alexandria, VA, USA, 2022.
- Aragón, A.M. A Measure for the Impact of Research. Sci. Rep. 2013, 3, 1649. [Google Scholar] [CrossRef]
- Wilson, L. The Academic Man: A Study in the Sociology of a Profession; Routledge: New York, NY, USA, 2017; ISBN 978-1-315-13080-4. [Google Scholar]
- Gross, P.L.K.; Gross, E.M. College Libraries and Chemical Education. Science 1927, 66, 385–389. [Google Scholar] [CrossRef]
- Lawani, S.M. Citation Analysis and the Quality of Scientific Productivity. BioScience 1977, 27, 26–31. [Google Scholar] [CrossRef]
- Fu, L.; Aliferis, C. Using Content-Based and Bibliometric Features for Machine Learning Models to Predict Citation Counts in the Biomedical Literature. Scientometrics 2010, 85, 257–270. [Google Scholar] [CrossRef]
- Yang, J.; Liu, Z. The Effect of Citation Behaviour on Knowledge Diffusion and Intellectual Structure. J. Informetr. 2022, 16, 101225. [Google Scholar] [CrossRef]
- El-adaway, I.H.; Ali, G.; Assaad, R.; Elsayegh, A.; Abotaleb, I.S. Analytic Overview of Citation Metrics in the Civil Engineering Domain with Focus on Construction Engineering and Management Specialty Area and Its Subdisciplines. J. Constr. Eng. Manag. 2019, 145, 04019060. [Google Scholar] [CrossRef]
- Chakraborty, T.; Kumar, S.; Goyal, P.; Ganguly, N.; Mukherjee, A. Towards a Stratified Learning Approach to Predict Future Citation Counts. In Proceedings of the IEEE/ACM Joint Conference on Digital Libraries, London, UK, 8–12 September 2014; pp. 351–360. [Google Scholar]
- Staszkiewicz, P. The Application of Citation Count Regression to Identify Important Papers in the Literature on Non-Audit Fees. Manag. Audit. J. 2018, 34, 96–115. [Google Scholar] [CrossRef]
- Weis, J.W.; Jacobson, J.M. Learning on Knowledge Graph Dynamics Provides an Early Warning of Impactful Research. Nat. Biotechnol. 2021, 39, 1300–1307. [Google Scholar] [CrossRef]
- Jin, R.; Zou, Y.; Gidado, K.; Ashton, P.; Painting, N. Scientometric Analysis of BIM-Based Research in Construction Engineering and Management. Eng. Constr. Archit. Manag. 2019, 26, 1750–1776. [Google Scholar] [CrossRef]
- Hammersley, M. On ‘Systematic’ Reviews of Research Literatures: A ‘Narrative’ Response to Evans & Benefield. Br. Educ. Res. J. 2001, 27, 543–554. [Google Scholar] [CrossRef]
- Pietroforte, R.; Aboulezz, M.A. ASCE Journal of Management in Engineering: Review of the Years 1985–2002. J. Manag. Eng. 2005, 21, 125–130. [Google Scholar] [CrossRef]
- Yi, W.; Chan, A.P.C. Critical Review of Labor Productivity Research in Construction Journals. J. Manag. Eng. 2014, 30, 214–225. [Google Scholar] [CrossRef]
- Larsen, J.K.; Ussing, L.F.; Brunø, T.D. Trend-Analysis and Research Direction in Construction Management Literature. In Proceedings of the ICCREM 2013: Construction and Operation in the Context of Sustainability, Karlsruhe, Germany, 10–11 October 2013; pp. 73–82. [Google Scholar] [CrossRef]
- Pan, Y.; Zhang, L. Roles of Artificial Intelligence in Construction Engineering and Management: A Critical Review and Future Trends. Autom. Constr. 2021, 122, 103517. [Google Scholar] [CrossRef]
- Bröchner, J.; Björk, B. Where to Submit? Journal Choice by Construction Management Authors. Constr. Manag. Econ. 2008, 26, 739–749. [Google Scholar] [CrossRef]
- Weihs, L.; Etzioni, O. Learning to Predict Citation-Based Impact Measures. In Proceedings of the 2017 ACM/IEEE Joint Conference on Digital Libraries (JCDL), Toronto, ON, Canada, 19 June 2017; pp. 1–10. [Google Scholar]
- The Lens. The Lens—Free & Open Patent and Scholarly Search. Available online: https://www.lens.org/lens (accessed on 15 March 2022).
- Jefferson, O.A.; Koellhofer, D.; Warren, B.; Jefferson, R. The Lens MetaRecord and LensID: An Open Identifier System for Aggregated Metadata and Versioning of Knowledge Artefacts. 2019. Available online: https://osf.io/preprints/lissa/t56yh (accessed on 15 March 2022).
- NVIDIA What Is XGBoost? Available online: https://www.nvidia.com/en-us/glossary/xgboost/ (accessed on 15 March 2022).
- Khalef, R.; El-adaway, I.H. Automated Identification of Substantial Changes in Construction Projects of Airport Improvement Program: Machine Learning and Natural Language Processing Comparative Analysis. J. Manag. Eng. 2021, 37, 04021062. [Google Scholar] [CrossRef]
- Piryonesi, S.M.; El-Diraby, T.E. Role of Data Analytics in Infrastructure Asset Management: Overcoming Data Size and Quality Problems. J. Transp. Eng. Part B Pavements 2020, 146, 04020022. [Google Scholar] [CrossRef]
- Scikit-Learn Ensembles: Gradient Boosting, Random Forests, Bagging, Voting, Stacking. Available online: https://scikit-learn.org/stable/modules/ensemble.html (accessed on 15 March 2022).
- Azeez, D.; Gan, K.B.; Ali, M.A.M.; Ismail, M.S. Secondary Triage Classification Using an Ensemble Random Forest Technique. Technol. Health Care 2015, 23, 419–428. [Google Scholar] [CrossRef]
- Wu, J.; Ma, D.; Wang, W. Leakage Identification in Water Distribution Networks Based on XGBoost Algorithm. J. Water Resour. Plan. Manag. 2022, 148, 04021107. [Google Scholar] [CrossRef]
- Wang, M.-X.; Huang, D.; Wang, G.; Li, D.-Q. SS-XGBoost: A Machine Learning Framework for Predicting Newmark Sliding Displacements of Slopes. J. Geotech. Geoenvironmental Eng. 2020, 146, 04020074. [Google Scholar] [CrossRef]
- Xu, C.; Liu, X.; Wang, E.; Wang, S. Calibration of the Microparameters of Rock Specimens by Using Various Machine Learning Algorithms. Int. J. Geomech. 2021, 21, 04021060. [Google Scholar] [CrossRef]
- IBM What Is Random Forest? Available online: https://www.ibm.com/topics/random-forest (accessed on 15 March 2022).
- Ahmed, M.O.; Khalef, R.; Ali, G.G.; El-adaway, I.H. Evaluating Deterioration of Tunnels Using Computational Machine Learning Algorithms. J. Constr. Eng. Manag. 2021, 147, 04021125. [Google Scholar] [CrossRef]
- Gupta, R.; Bruce-Konuah, A.; Howard, A. Achieving Energy Resilience through Smart Storage of Solar Electricity at Dwelling and Community Level. Energy Build. 2019, 195, 1–15. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Chawla, N.V.; Lazarevic, A.; Hall, L.O.; Bowyer, K.W. SMOTEBoost: Improving Prediction of the Minority Class in Boosting. In Proceedings of the Knowledge Discovery in Databases: PKDD 2003, Cavtat-Dubrovnik, Croatia, 22–26 September 2003; Lavrač, N., Gamberger, D., Todorovski, L., Blockeel, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 107–119. [Google Scholar]
- Brodersen, K.H.; Ong, C.S.; Stephan, K.E.; Buhmann, J.M. The Balanced Accuracy and Its Posterior Distribution. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3121–3124. [Google Scholar]
- Lemaire, C.; Rivest, L.; Boton, C.; Danjou, C.; Braesch, C.; Nyffenegger, F. Analyzing BIM Topics and Clusters through Ten Years of Scientific Publications. J. Inf. Technol. Constr. (ITcon) Spec. Issue Archit. Inform. 2019, 24, 273–298. [Google Scholar]
- Onososen, A.O.; Musonda, I. Research Focus for Construction Robotics and Human-Robot Teams towards Resilience in Construction: Scientometric Review. J. Eng. Des. Technol. 2022, 21, 502–526. [Google Scholar] [CrossRef]
- Otte, E.; Rousseau, R. Social Network Analysis: A Powerful Strategy, Also for the Information Sciences. J. Inf. Sci. 2002, 28, 441–453. [Google Scholar] [CrossRef]
- Ali, G.G.; El-adaway, I.H. Distributed Solar Generation: Current Knowledge and Future Trends. J. Infrastruct. Syst. 2024, 30, 03123002. [Google Scholar] [CrossRef]
- Elbashbishy, T.S.; Ali, G.G.; El-adaway, I.H. Blockchain Technology in the Construction Industry: Mapping Current Research Trends Using Social Network Analysis and Clustering. Constr. Manag. Econ. 2022, 40, 406–427. [Google Scholar] [CrossRef]
- Choudhury, N.; Uddin, S. Time-Aware Link Prediction to Explore Network Effects on Temporal Knowledge Evolution. Scientometrics 2016, 108, 745–776. [Google Scholar] [CrossRef]
- Freeman, L.C. Centrality in Social Networks Conceptual Clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef]
- Oliphant, T.E. Python for Scientific Computing. Comput. Sci. Eng. 2007, 9, 10–20. [Google Scholar] [CrossRef]
- Millman, K.J.; Aivazis, M. Python for Scientists and Engineers. Comput. Sci. Eng. 2011, 13, 9–12. [Google Scholar] [CrossRef]
- Oliphant, T.E. A Guide to NumPy; Trelgol Publishing: Provo, UT, USA, 2006; Volume 1. [Google Scholar]
- Van der Walt, S.; Colbert, S.C.; Varoquaux, G. The NumPy Array: A Structure for Efficient Numerical Computation. Comput. Sci. Eng. 2011, 13, 22–30. [Google Scholar] [CrossRef]
- McKinney, W. Pandas: A Foundational Python Library for Data Analysis and Statistics. Python High Perform. Sci. Comput. 2011, 14, 1–9. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-Learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. J. Mach. Learn. Res. 2017, 18, 559–563. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D Graphics Environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Waskom, M. Seaborn: Statistical Data Visualization. JOSS 2021, 6, 3021. [Google Scholar] [CrossRef]
- Bastian, M.; Heymann, S.; Jacomy, M. Gephi: An Open Source Software for Exploring and Manipulating Networks. In Proceedings of the International AAAI Conference on Web and Social Media, San Jose, CA, USA, 19 March 2009; Volume 3, pp. 361–362. [Google Scholar]
- Chakrabarti, S. Voltage Stability Monitoring by Artificial Neural Network Using a Regression-Based Feature Selection Method. Expert Syst. Appl. 2008, 35, 1802–1808. [Google Scholar] [CrossRef]
- Wang, R.; Lu, S.; Li, Q. Multi-Criteria Comprehensive Study on Predictive Algorithm of Hourly Heating Energy Consumption for Residential Buildings. Sustain. Cities Soc. 2019, 49, 101623. [Google Scholar] [CrossRef]
- Fox, C.W.; Paine, C.E.T.; Sauterey, B. Citations Increase with Manuscript Length, Author Number, and References Cited in Ecology Journals. Ecol. Evol. 2016, 6, 7717–7726. [Google Scholar] [CrossRef]
- Dainty, A.R.J.; Bagilhole, B.M. Guest Editorial. Constr. Manag. Econ. 2005, 23, 995–1000. [Google Scholar] [CrossRef]
- Baker, M.; French, E.; Ali, M. Insights into Ineffectiveness of Gender Equality and Diversity Initiatives in Project-Based Organizations. J. Manag. Eng. 2021, 37, 04021013. [Google Scholar] [CrossRef]
- Al-Bayati, A.J.; Abudayyeh, O.; Fredericks, T.; Butt, S.E. Managing Cultural Diversity at U.S. Construction Sites: Hispanic Workers’ Perspectives. J. Constr. Eng. Manag. 2017, 143, 04017064. [Google Scholar] [CrossRef]
- Chinowsky, P.S.; Rojas, E.M. Virtual Teams: Guide to Successful Implementation. J. Manag. Eng. 2003, 19, 98–106. [Google Scholar] [CrossRef]
- Albanese, R. Team-Building Process: Key to Better Project Results. J. Manag. Eng. 1994, 10, 36–44. [Google Scholar] [CrossRef]
- Assaad, R.; El-adaway, I.H. Guidelines for Responding to COVID-19 Pandemic: Best Practices, Impacts, and Future Research Directions. J. Manag. Eng. 2021, 37, 06021001. [Google Scholar] [CrossRef]
- Forcael, E.; Ferrari, I.; Opazo-Vega, A.; Pulido-Arcas, J.A. Construction 4.0: A Literature Review. Sustainability 2020, 12, 9755. [Google Scholar] [CrossRef]
- Ghaffar, S.H.; Mullett, P.; Pei, E.; Roberts, J. (Eds.) Innovation in Construction: A Practical Guide to Transforming the Construction Industry; Springer International Publishing: Cham, Switzerland, 2022; ISBN 978-3-030-95797-1. [Google Scholar]
- De La Garza, J.M. Sponsored Research and Its Impact on Universities, Faculty, and Journals. J. Constr. Eng. Manag. 2007, 133, 708–709. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domain | Journal Name |
|---|---|
| Structural | Journal of Bridge Engineering Journal of Structural Engineering Journal of Cold Regions Engineering Journal of Performance of Constructed Facilities Practice Periodical on Structural Design and Construction |
| Materials | Journal of Composites for Construction Journal of Materials in Civil Engineering Journal of Nanomechanics and Micromechanics Journal of Engineering Mechanics |
| Geotechnical | International Journal of Geomechanics Journal of Geotechnical and Geoenvironmental Engineering GEOSTRATA Magazine |
| Environmental and Water Resources | Journal of Environmental Engineering Journal of Hydraulic Engineering Journal of Hydrologic Engineering Journal of Irrigation and Drainage Engineering Journal of Pipeline Systems Engineering and Practice Journal of Sustainable Water in the Built Environment Journal of Water Resources Planning and Management Journal of Waterway, Port, Coastal, and Ocean Engineering |
| Transportation | Journal of Highway and Transportation Research and Development (English Edition) Journal of Transportation Engineering, Part A: Systems Journal of Transportation Engineering, Part B: Pavements |
| Cross-Disciplinary Civil Engineering | Journal of Infrastructure Systems Journal of Hazardous, Toxic, and Radioactive Waste Natural Hazards Review ASCE-ASME Journal of Risk and Uncertainty in Engineering Systems, Part A: Civil Engineering ASCE-ASME Journal of Risk and Uncertainty in Engineering Systems, Part B: Mechanical Engineering Journal of Architectural Engineering Journal of Urban Planning and Development Journal of Energy Engineering Journal of Computing in Civil Engineering Journal of Surveying Engineering |
| Engineering Education and Practices | Journal of Civil Engineering Education |
| Aerospace Engineering | Journal of Aerospace Engineering |
| Others | Civil Engineering Magazine Journal of Technical Topics in Civil Engineering Transactions of the American Society of Civil Engineers |
| Construction Engineering and Management | Journal of Construction Engineering and Management Leadership and Management in Engineering Journal of Legal Affairs and Dispute Resolution in Engineering and Construction Journal of Management in Engineering Automation in Construction International Journal of Project Management Engineering, Construction, and Architectural Management Construction Innovation Construction Management and Economics International Journal of Construction Management |
| Category | Variable Name |
|---|---|
| Article | Publication year |
| Number of authors | |
| Number of references | |
| Number of references in network 1 | |
| Total number of citations in network 5 years after publication 1 | |
| Author | Total number of papers by authors |
| Total number of citations for authors | |
| Number of papers per author | |
| Number of citations per author | |
| Journal | Number of papers in the journal |
| Number of citations per paper in journal | |
| Number of citations per paper in journal |
| Algorithm | Best Set of Hyperparameters | Mean Cross-Validation Balanced Accuracy (%) |
|---|---|---|
| RF | Criterion = ‘entropy’, max_depth = 5, n_estimators = 50 | 79.1% |
| XGBoost | Alpha = 0.5, Lambda = 2, max_depth = 4, n_estimators = 10 | 79.5% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, G.G.; El-adaway, I.H.; Ahmed, M.O.; Eissa, R.; Nabi, M.A.; Elbashbishy, T.; Khalef, R. Forecasting Future Research Trends in the Construction Engineering and Management Domain Using Machine Learning and Social Network Analysis. Modelling 2024, 5, 438-457. https://doi.org/10.3390/modelling5020024
Ali GG, El-adaway IH, Ahmed MO, Eissa R, Nabi MA, Elbashbishy T, Khalef R. Forecasting Future Research Trends in the Construction Engineering and Management Domain Using Machine Learning and Social Network Analysis. Modelling. 2024; 5(2):438-457. https://doi.org/10.3390/modelling5020024
Chicago/Turabian StyleAli, Gasser G., Islam H. El-adaway, Muaz O. Ahmed, Radwa Eissa, Mohamad Abdul Nabi, Tamima Elbashbishy, and Ramy Khalef. 2024. "Forecasting Future Research Trends in the Construction Engineering and Management Domain Using Machine Learning and Social Network Analysis" Modelling 5, no. 2: 438-457. https://doi.org/10.3390/modelling5020024